
Abstract
Appropriate imputation inference requires both an unbiased imputation estimator and an unbiased variance estimator. The commonly used variance estimator, proposed by Rubin, can be biased when the imputation and analysis models are misspecified and/or incompatible. Robins and Wang proposed an alternative approach, which allows for such misspecification and incompatibility, but it is considerably more complex. It is unknown whether in practice Robins and Wang’s multiple imputation procedure is an improvement over Rubin’s multiple imputation. We conducted a critical review of these two multiple imputation approaches, a re-sampling method called full mechanism bootstrapping and our modified Rubin’s multiple imputation procedure via simulations and an application to data. We explored four common scenarios of misspecification and incompatibility. In general, for a moderate sample size (n = 1000), Robins and Wang’s multiple imputation produced the narrowest confidence intervals, with acceptable coverage. For a small sample size (n = 100) Rubin’s multiple imputation, overall, outperformed the other methods. Full mechanism bootstrapping was inefficient relative to the other methods and required modelling of the missing data mechanism under the missing at random assumption. Our proposed modification showed an improvement over Rubin’s multiple imputation in the presence of misspecification. Overall, Rubin’s multiple imputation variance estimator can fail in the presence of incompatibility and/or misspecification. For unavoidable incompatibility and/or misspecification, Robins and Wang’s multiple imputation could provide more robust inferences.
Keywords
1 Introduction
Multiple imputation (MI)
1
is the most commonly used technique for analysing incomplete data, which are frequently encountered in health-related research. Imputations are repeatedly and independently drawn from the posterior predictive distribution of the missing data given the observed data, under a Bayesian model, to generate
MI was first developed for analysing large incomplete public shared datasets, for which there may be many analysts, with a wide range of scientific questions, who may not have the specialized knowledge required to generate statistically valid inferences when data are incomplete. It was envisioned that the task of generating multiple imputed datasets would be undertaken by someone with specialized knowledge of missing data methods. 2 The analysts need only apply standard complete data statistical procedures to each imputed dataset separately and then combine the multiple estimates according to Rubin’s rules. 1
At the time of imputation, it may not be possible to anticipate all analysis procedures that will be applied to the imputed datasets. Consequently, the assumptions of a given analysis procedure may differ to those of the imputation model. We define an analysis procedure to be incompatible with an imputation model when one or more assumptions of the imputation model contradict with those made by the analysis procedure. For example, the imputer may assume that two subgroups have the same population mean of an incomplete variable (where missingness is independent of subgroup status) whilst the analyst estimates the population mean in one subgroup only.
As with any modelling or statistical procedure, the imputation model may be misspecified; that is, the imputation model’s assumptions about the missing data mechanism (MDM) or the complete data are incorrect. For example, the imputation model could incorrectly assume homoscedastic errors. Similarly, for the analysis procedure.
The MI literature has focused primarily on generating methods and guidelines for reducing the bias of the imputation estimator. However, correct imputation inference also requires an unbiased imputation variance estimator and an efficient interval estimator with at least nominal coverage. In certain settings of misspecification and incompatibility of the models, for an unbiased imputation estimator, Rubin’s variance estimator was either upwardly or downwardly biased, which led to conservative or anti-conservative confidence intervals, respectively.2–7
There are alternatives to Rubin’s MI. Robins and Wang have proposed imputing under a frequentist procedure, 5 that fixes the imputation model parameters at the observed data maximum likelihood estimate, and an imputation variance estimator that allows for misspecification and incompatibility of the imputation model and the analysis procedure, and for non- or semi-parametric analysis procedures. However, it is unclear whether the Robins and Wang MI procedure is an improvement over Rubin’s MI in situations typical of the use of imputation in practice. Also, the Robins and Wang imputation variance estimator is considerably more complex to compute than Rubin’s and importantly is more technically difficult for the analyst, although the greater burden of calculating the variance estimator is still placed on the imputer. With ever faster computers, a simpler solution could be to calculate the variance of the imputation estimator using re-sampling methods. Full mechanism bootstrapping (FMB) is a bootstrapping approach to imputation that can be applied to parametric problems.8,9
In this paper, we have conducted the first comparative evaluation of Rubin’s MI, our modified version of Rubin’s MI, Robins and Wang’s MI and FMB with respect to variance estimation and interval estimation. We have compared these four methods of imputation inference in four scenarios of incompatibility and misspecification of the imputation and analysis models that can occur in practice, via a data example (see Sections 2 and 4) and simulations (see Sections 5 and 6). In Section 2, we describe a motivating example for seeking an alternative to Rubin’s MI. Section 3 describes all four methods considered in the context of a specific example. Section 4 revisits the motivating example, applying these methods to data from the British Child and Adolescent Mental Health Study 1999 (B-CAMHS99). 10 In Sections 5 and 6, we present our simulation study and conclude with a general discussion in Section 7.
2 Motivating example
There are several examples in the literature, where observations used for estimation at the imputation stage of MI are not used or available at the analysis stage. For example, confidential information may be used to improve estimation of the imputation model but cannot be disseminated to the analysts. Or, when external data are used to account for measurement error using MI and the external data are not included at the analysis stage because it may not be representative of the target sample. 11 We briefly describe a case study where external data were used to impute measurements, which were not collected for any of the subjects of the target study.
The B-CAMHS99 measured conduct, hyperactive and emotional problems in 15 year olds using the strengths and difficulties questionnaire (SDQ). 12 Researchers wished to compare the results of this study to previous UK population studies, which had used the Rutter A scale. 13 A calibration study was undertaken, which measured both the Rutter A scale and the SDQ scale on an independent sample of adolescents. 10 These external data were used to impute the Rutter A subscales (for conduct, hyperactive and emotional problems) in the B-CAMHS99 study, but were not included at the analysis stage.
In this scenario, the imputations were generated using extra information that was not utilized by the analyst; i.e. that the target and external data were assumed to be identically distributed. Rubin calls such imputation superefficient from the analyst’s perspective. 2 Superefficient imputations can cause Rubin’s MI variance estimator to be positively biased.3,5
3 Methods for imputation inference
We describe Rubin’s MI and its modified version, Robins and Wang’s MI and FMB. Robins and Wang have described their complex method for a general missing data setting. 5 To aid further understanding of this method we restrict ourselves to a more simplified setting, which we describe in Section 3.1. The description of Rubin’s MI and FMB remains the same for a more general missing data setting.
3.1 Notation and setup
Suppose g random variables
Let,
Let,
The analysis procedure is the normal linear regression model
3.2 Rubin’s MI inference
Missing values are imputed independently m times, to generate m imputed datasets. Imputations are drawn independently from the posterior predictive distribution of the missing data given the observed data under a Bayesian model. For
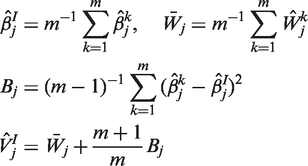
Confidence intervals are based on the Student’s t-distribution. When n is small a modified degrees of freedom formula is recommended.
15
The modified degrees of freedom
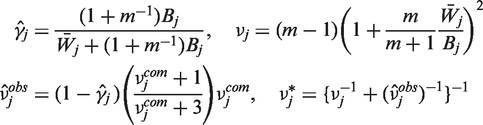
We shall also consider a modification in which the within imputation variances,
3.3 Robins and Wang’s imputation inference
The Robins and Wang variance estimator for imputation does not require multiply imputed datasets, although it may be more efficient when a dataset is multiply imputed.
5
To our knowledge, there does not exist any commercial or freely available software that calculates this variance estimator. All derivatives involving scalars, vectors and matrices are defined as in,
18
e.g. for n × 1 vectors
The m sets of imputations are drawn independently from the predictive distribution of the missing data given the observed data under the imputation model evaluated at
The analysis procedure is applied to the stack of imputed datasets
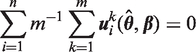
To calculate the Robins and Wang variance estimator, both the imputer and analyst must generate additional information. The imputer supplies two further datasets based on the score function of the imputation model. The analyst must generate a dataset and a matrix, which are both based on the estimating equation of the analysis procedure evaluated at
The score function of the imputation model is the derivative, with respect to
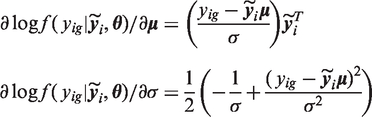
For subject i, when
For the second dataset based on the score function of the imputation model, first calculate the derivative of column vector
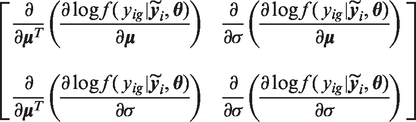
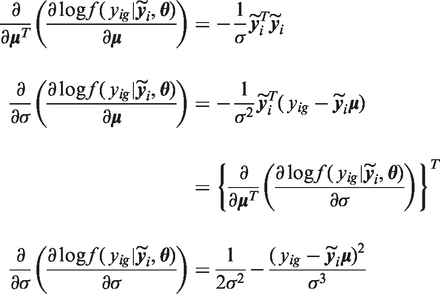
For subject i with observed yig define
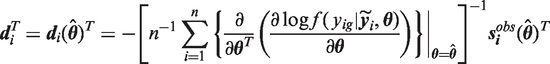
When yig is incompletely observed
Evaluating
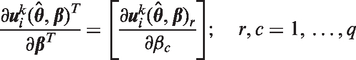
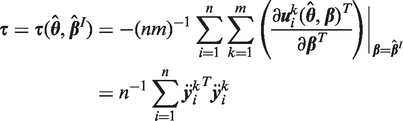
The analyst now inputs datasets
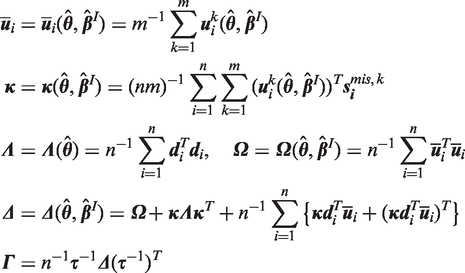
Finally, for
3.4 Full mechanism bootstrapping
FMB can be applied to parametric and non-parametric problems, 8 and under all three MDM assumptions. 19 Unless, the MDM is assumed to be missing completely at random (MCAR) then FMB requires modelling of the MDM. In Efron’s worked example of the procedure a deterministic imputation model was used. Shao and Sitter 9 describe FMB with a random regression imputation method.
FMB is implemented as follows:
8
Impute the incomplete dataset Sample with replacement n rows from Set observations in Singly impute the incomplete dataset from step 3, using the same imputation model as in step 1, to generate the bootstrapped imputed dataset Apply the analysis procedure to dataset Repeat steps 2–5 T times to obtain T bootstrap replicates.
Standard bootstrap formulae
20
can be applied to the bootstrap replicates
4 Return to motivating example
We applied the methods of Section 3 to data from the B-CAMHS99 study discussed in Section 2. The data (from the B-CAMHS99 study) consisted of fully observed measurements for sex and the SDQ subscales in 855 (433 boys and 422 girls) adolescents aged 15. The external data consisted of fully observed measurements for sex, the SDQ subscales and Rutter A subscales in 380 (203 boys and 177 girls) adolescents with median age 15 years (interquartile range 13–15 years).
For the purposes of this case study, each Rutter A subscale was imputed separately under an ordinal logistic regression model, with the three SDQ subscales (for conduct, hyperactive and emotional problems) and sex as covariates. The analysis of interest was a linear regression of the Rutter A subscale, with sex and the constant term as covariates, estimated in the B-CAMHS99 study only. We generated 50 imputed datasets for Rubin’s MI, robust Rubin’s MI and Robins and Wang’s MI, and 2500 bootstrap replications for FMB.
Analysis results of the B-CAMHS99 study using Rubin’s MI (Rubin), robust Rubin’s MI (Rubin R), Robins and Wang’s MI (RW) and full mechanism bootstrapping (FMB).
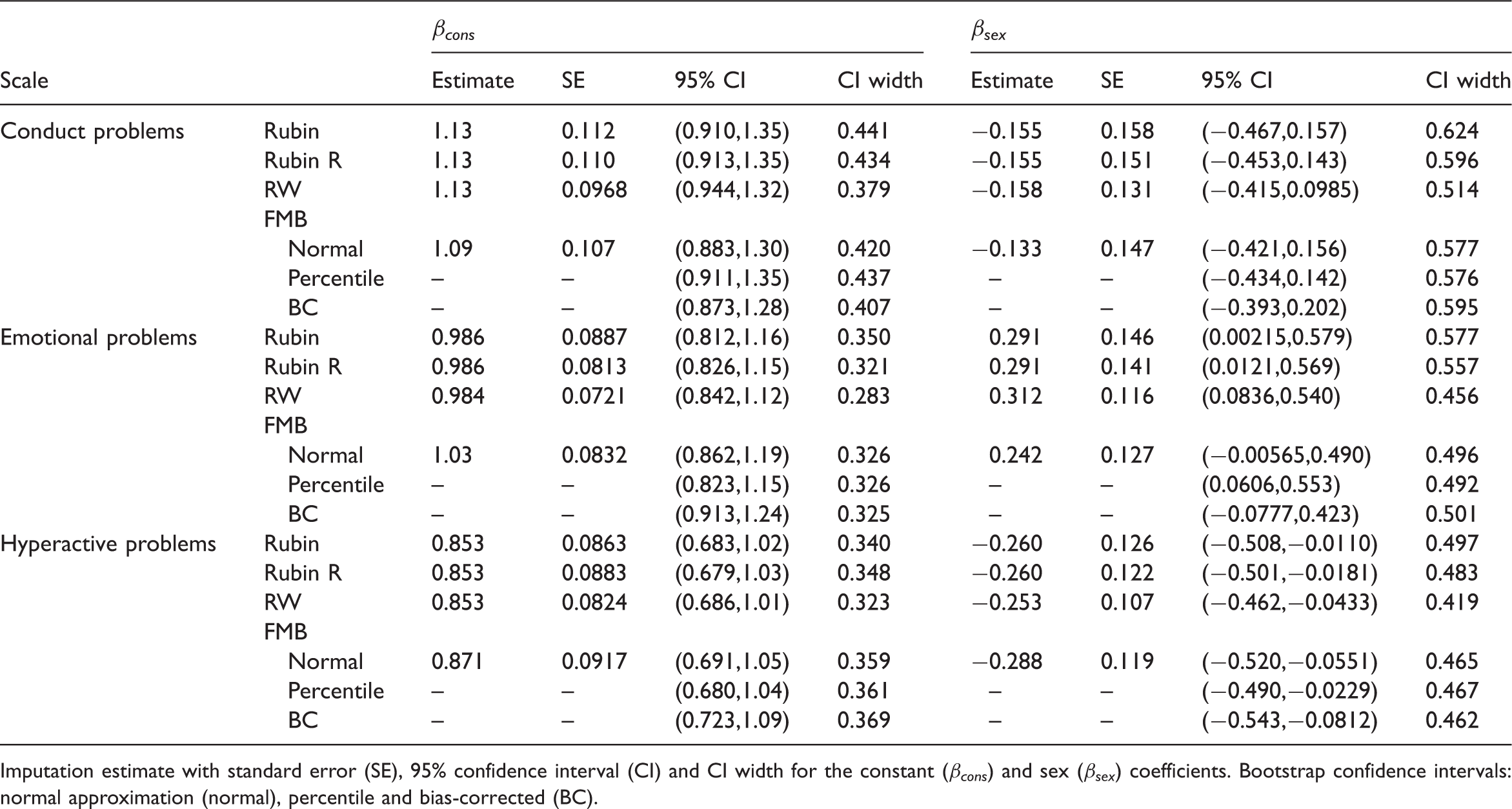
Imputation estimate with standard error (SE), 95% confidence interval (CI) and CI width for the constant (βcons) and sex (βsex) coefficients. Bootstrap confidence intervals: normal approximation (normal), percentile and bias-corrected (BC).
5 Simulation study methods
We compared the methods described in Section 3 in four scenarios of incompatibility and misspecification of the imputation and analysis models. The simulation study was based on a hypothetical dataset of one binary variable, sex (0 denoting male and 1 denoting female), and four continuous variables, age, height, weight and natural log of insulin index (hereafter referred to as loginsindex). The data were generated under the following model
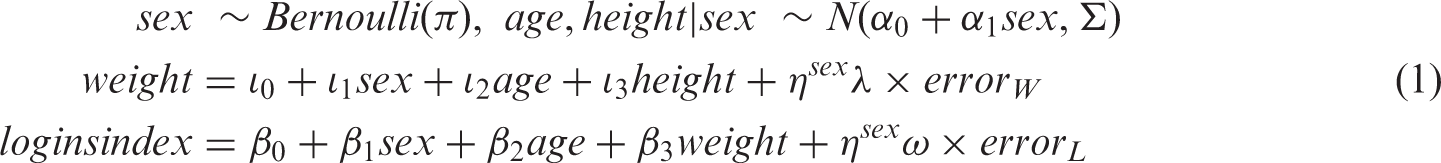
Model (equation (1)) was based on a dataset of standard anthropometric measurements of 951 young adults enrolled in the Barry Caerphilly Growth study.
21
The parameters of the data model were set to the estimates from an analysis of this dataset. The values, to four significant figures, of these parameters were:
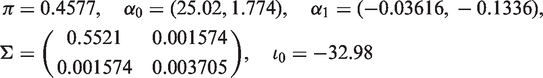
The analysis model was the normal linear regression of loginsindex on weight, with adjustment for other variables. The aim of the simulation study was to evaluate the methods with respect to the imputation variance estimator when the imputation estimator was unbiased. To avoid bias in the imputation estimator due to the MDM we set weight to be missing, for a subset of subjects, under an MCAR mechanism. The missing weight measurements were imputed under a normal linear regression model. Both imputation and analysis models included a constant term and assumed that the variance of the error terms was constant for all values of the outcome variable (i.e. homoscedasticity). Unless otherwise stated, error distributions errorW and errorL were normal, weight measurements were missing in men and women and the imputation and analysis models were fitted to the entire sample. The scenarios considered were as follows:
Scenario 1: Subgroup analysis. We set the true conditional distributions of age, height, weight and loginsindex to be the same in men and women; i.e. Scenario 2: Heteroscedastic errors. We set the true conditional distributions of age, height, weight and loginsindex to have different means in men and women; i.e. Scenario 3: Omitted interaction. We set the true conditional distributions of age, height, weight and loginsindex to have different means in men and women. The variances of weight and loginsindex were set to be the same in men and women; i.e. η = 1. The covariates of the imputation model were sex, age, height and loginsindex, and the covariates of the analysis model were sex, age, weight and the interaction between weight and sex. The imputation model was correctly specified but because the analysis model included an unnecessary interaction term the imputation and analysis models were incompatible. Scenario 4: Moderate and severe non-normality. This scenario was motivated by a simulation study that investigated the performance of MI methods with non-normal distributions.
22
Unlike these authors, we were only interested in the effect of the shape of the error distribution, not the size of the error variances. The true conditional distributions of age, height, weight and loginsindex were set to be the same in men and women, i.e.
For all scenarios, we repeated the simulation study for sample sizes n = 100 and n = 1000 and probabilities 0.6 and 0.4 that weight was observed. For the subgroup analysis scenario only, the probability that weight was observed was one among women and 0.6 or 0.4 among men. For each combination of scenario, parameter specification, sample size and observation probability we generated 2500 independent simulated datasets. Based on 2500 simulations the Monte Carlo standard error for the true coverage probability of 0.95 is
6 Simulation study results
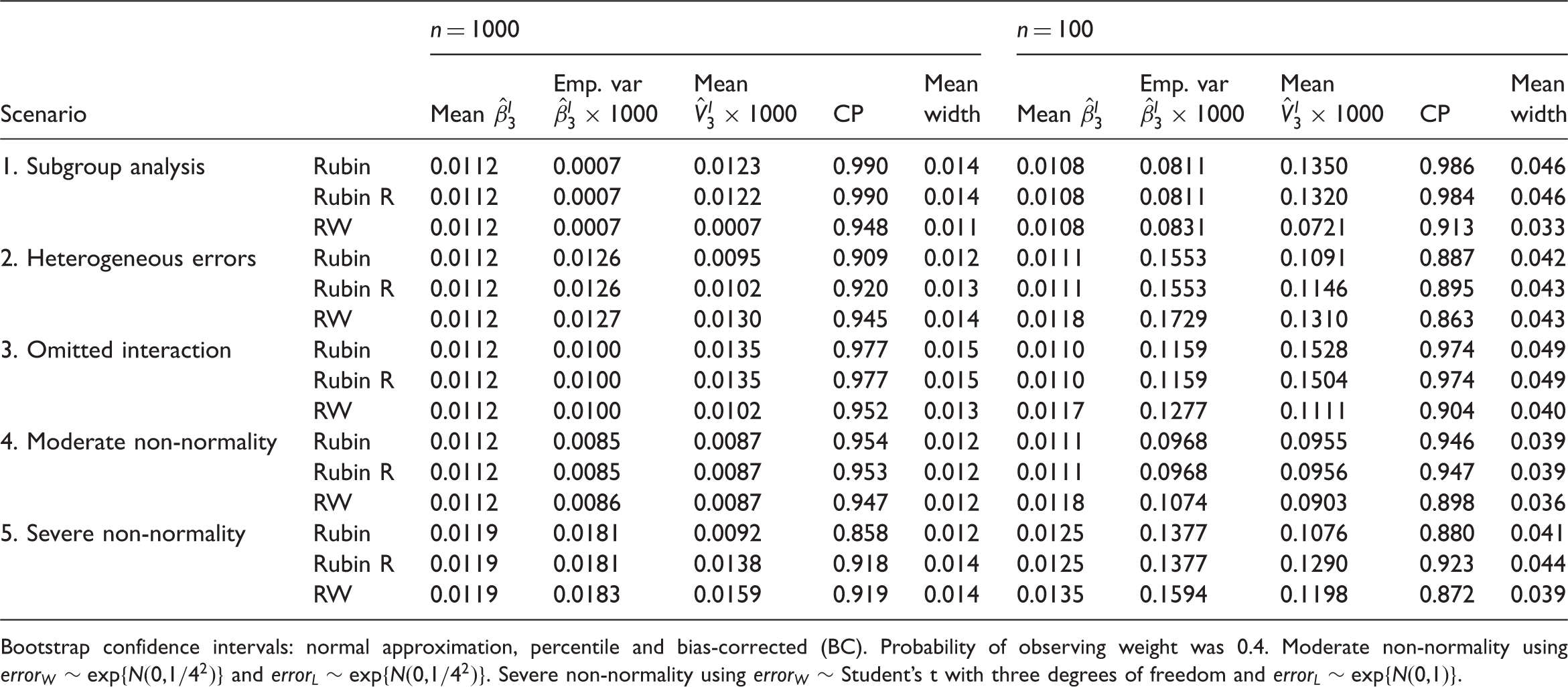
Summary of the simulation results for Rubin’s MI (Rubin), robust Rubin’s MI (Rubin R) and Robins and Wang’s MI (RW) for the weight coefficient: mean bias and empirical variance (Emp. var) of the imputation estimate
Bootstrap confidence intervals: normal approximation, percentile and bias-corrected (BC). Probability of observing weight was 0.4. Moderate non-normality using
First consider the left-hand side of Table 2, corresponding to sample size 1000. The imputation estimates,
For the moderate non-normality scenario, the imputation estimate was unbiased and the confidence interval coverage probability was close to the nominal level for all three methods. However, for the severe non-normality scenario, the imputation estimates were upwardly biased for all three methods and for both sample sizes. Robins and Wang MI under-estimated the sampling variance of
Now consider the right-hand side of Table 2, corresponding to sample size 100. The results for Rubin’s MI and robust Rubin’s MI followed the same patterns as noted for sample size 1000. There was a deterioration in the performance of Robins and Wang’s MI when applied to a dataset of sample size 100. Firstly, the imputation estimates for all but the subgroup analysis scenario were (slightly) upwardly biased. Secondly, the Robins and Wang variance estimates were downwardly biased for all scenarios, resulting in confidence interval coverage probabilities that were at least 3% below the nominal level.
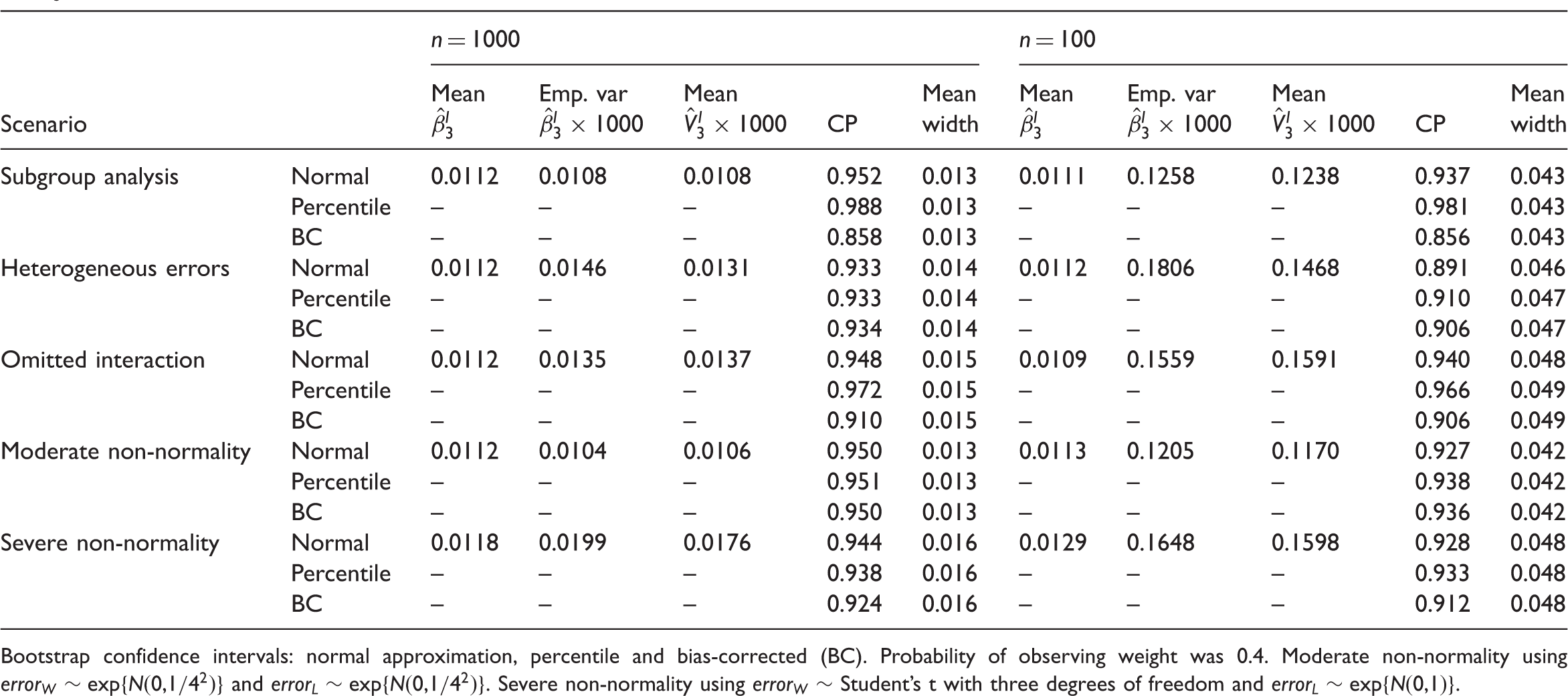
Summary of the full mechanism bootstrapping simulation results for the weight coefficient: mean and empirical variance (Emp. var) of the imputation estimate
Bootstrap confidence intervals: normal approximation, percentile and bias-corrected (BC). Probability of observing weight was 0.4. Moderate non-normality using
For the subgroup analysis, heterogeneous errors, omitted interaction and moderate non-normality, when the sample size was 1000 Robins and Wang MI outperformed FMB; i.e. had the narrowest average confidence interval and at least nominal coverage. When the sample size was 100, for the subgroup analysis and omitted interaction scenarios FMB with the percentile confidence interval was marginally better than Rubin’s MI because (for comparable coverage probabilities) the bootstrap confidence intervals were narrower on average than those of Rubin’s MI. The relative inefficiency of FMB to Rubin’s MI was outweighed by the upward bias of Rubin’s variance estimates. For the heterogeneous errors scenario, sample size 100, FMB with the percentile confidence interval had the highest coverage probability, although still outside the expected range (0.941–0.960). For the moderate non-normality scenario, Rubin’s MI was the best method for sample size 100, with close to nominal coverage and the narrowest mean confidence interval width. For the severe non-normality scenario, and for both sample sizes, FMB had the highest coverage probabilities, although still below 0.941.
When the probability of observing weight was 0.6, the pattern of results was the same as in Tables 2 and 3, although the differences between the methods were less marked. Across the nine different error distributions investigated for the moderate non-normality scenario, and for the severe non-normality specifications
For the subgroup analysis and interaction scenarios in several instances, the Robins and Wang variance estimate was smaller than the corresponding variance estimate that resulted from analysing the fully observed data, i.e. data without missing observations (data not shown). This is due to the fact that the imputations are superefficient with respect to the analysis procedure; i.e. the imputations contain extra information that is not contained in the true data. 2
We conducted a second simulation study to assess the robustness of FMB when data were missing at random (MAR) and the MDM (for simulating missingness in a bootstrapped dataset) was not modelled; that is, missingness was simulated using the observed MDP as above. The design of this simulation study was based on the simulation study described above, with three modifications. There were three changes. First, data were simulated to be missing dependent upon the outcome variable of the analysis model (loginsindex), thus ensuring the complete case analysis produced biased estimates. Second, the imputation and analysis models were compatible and correctly specified. Third, we conducted two FMB methods: FMB with the MDM correctly modelled (which we shall call FMB correct MDM) and FMB with missingness simulated using the observed MDP (which we shall call FMB observed MDP). For both sample sizes, when data were MAR, omitting to model the MDM for FMB resulted in downwardly biased variance estimates, which led to under-coverage of the confidence intervals. Variance estimates were not downwardly biased when the MDM was correctly modelled (FMB correct MDM). For sample size 1000, any differences in the performances of Rubin’s MI, robust Rubin’s MI, Robins and Wang’s MI and FMB correct MDM were very small. For sample size 100, the Robins and Wang method outperformed the other methods with respect to point estimation but its variance estimates were again downwardly biased. For interval estimation only FMB correct MDM with the percentile confidence interval provided coverage probabilities greater than 0.941 for all coefficients. (Results of this simulation study are available upon request from the authors.)
7 Discussion
We have conducted the first comparative evaluation of Rubin’s MI, a modified version of Rubin’s MI, Robins and Wang’s MI and FMB. Our simulation study shows that Rubin’s MI variance estimator failed in four common scenarios of misspecification of the imputation and analysis models, and of incompatibility between them. The variance estimates were substantially upwardly or downwardly biased, resulting in confidence intervals that over- and under-covered, respectively. For moderate sample size (n=1000) and all scenarios apart from severe non-normality, Robins and Wang’s MI produced the narrowest confidence intervals on average, with close to nominal coverage. When the imputation and analysis models were both misspecified due to severe non-normality all methods had the same biased imputation estimate, but the larger imputation variance estimate of FMB resulted in confidence intervals with coverage probabilities closest to the nominal level.
A key feature of Rubin’s MI is the separation of the imputation procedure from the substantive analysis. This has the advantage that the more technical process of imputation can be done by a specialist, following which multiple analyses can be done on the imputed datasets by non-specialists using standard software. However, this separation may also lead to incompatibility between the imputation and analysis models, when assumptions made during imputation are not carried forward to the analysis stage. For example, estimation for domains (i.e. subgroups or subpopulations) is common for the analysis of survey data and, in particular for large surveys analysed by many users, imputations can be generated ignoring the domain indicator. 24 In some situations, such as the subgroup analysis and omitted interaction scenarios of our simulation study, incompatibility can in principle be avoided, if the imputer provides sufficient documentation of the imputation model to future users. However, in some instances incompatibility may be unavoidable; e.g. for confidentiality reasons the provider of the imputed data may only disseminate to the users a subset of the observations (or records) used during the imputation stage.11,25
Misspecification of imputation and analysis models is a more general problem, which will arise whenever model assumptions are not justified. We investigated two scenarios, in which misspecification was due to heteroscedastic errors and non-normality. Our results suggest that when misspecification arises from heteroscedastic errors, there has to be a sizable difference between the subgroup variances in order for Rubin’s imputation variance estimator to materially under-estimate the sampling variance of the imputation estimator. In this case, heteroscedastic errors in the imputation and analysis models could have been accommodated by conducting separate MI analyses in men and women.
A limitation of the Robins and Wang MI method is that it makes large sample assumptions, which led to downwardly biased variance estimates and confidence interval coverage when applied to small datasets. A major disadvantage of the Robins and Wang method is that calculation of the imputation variance estimate is considerably more complicated than for Rubin’s MI and FMB, with a greater burden placed on both the imputer and the analyst. To our knowledge, there is no generally available software implementing the Robins and Wang method. The analyst must make available derivatives of the estimating equations for use in calculation of variance estimates, and these become harder to calculate as the complexity of the analysis procedure increases. Also, the complexity of the calculations conducted by the imputer increases when there is multiple incomplete variables with a general MDP. For this reason, our simulation scenarios were restricted to data missing in a single variable, as were the scenarios considered in the papers proposing the approach. The Robins and Wang method requires the data to be imputed under a single imputation model. Therefore, currently, it cannot be applied if imputation is conducted using chained equations imputation, 26 a flexible and commonly used method of imputation that imputes under two or more imputation models. In contrast, calculation of the variance of an imputation estimator by Rubin’s MI method and FMB is straightforward for more complex MDPs and analysis procedures, and can be applied when data are imputed using chained equations imputation.
A limitation of FMB was its inefficiency relative to the other imputation inference methods. Furthermore, FMB requires modelling of the MDM when data are MAR, which is not required by the MI methods of Rubin or Robins and Wang. A further simulation study we conducted showed that FMB required modelling of the MDM when data were MAR. Further work is needed to compare Rubin’s MI with FMB when data are MAR and the missing data model assumed by FMB is incorrectly specified.
In summary, accurate inference requires an unbiased estimator and variance estimator. Rubin’s MI variance estimator may be biased in the presence of incompatibility between the imputation and analysis models and model misspecification. This can lead to over- or under-coverage of confidence intervals. These limitations should be noted in guidelines on the appropriate use of Rubin’s MI, 27 which should emphasize how incompatibility can be avoided, and the pitfalls that can arise because of model misspecification. The simplicity and flexibility of Rubin’s MI mean that it is likely to remain the method of choice to deal with data that are MAR. However, where these problems of incompatibility and misspecification cannot be avoided, Robins and Wang MI has the potential to provide more robust inferences, should the considerable challenges in provision of software implementing the procedure be overcome.
Footnotes
Acknowledgements
The authors acknowledge Professor Andrew Pickles from the Biostatistics Department of the Institute of Psychiatry, King’s College London for granting access to data from the British Child and Adolescent Mental Health Study 1999 and the corresponding calibration study.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Medical Research Council grant [G0900724].