
Abstract
Bayesian approaches for handling covariate measurement error are well established and yet arguably are still relatively little used by researchers. For some this is likely due to unfamiliarity or disagreement with the Bayesian inferential paradigm. For others a contributory factor is the inability of standard statistical packages to perform such Bayesian analyses. In this paper, we first give an overview of the Bayesian approach to handling covariate measurement error, and contrast it with regression calibration, arguably the most commonly adopted approach. We then argue why the Bayesian approach has a number of statistical advantages compared to regression calibration and demonstrate that implementing the Bayesian approach is usually quite feasible for the analyst. Next, we describe the closely related maximum likelihood and multiple imputation approaches and explain why we believe the Bayesian approach to generally be preferable. We then empirically compare the frequentist properties of regression calibration and the Bayesian approach through simulation studies. The flexibility of the Bayesian approach to handle both measurement error and missing data is then illustrated through an analysis of data from the Third National Health and Nutrition Examination Survey.
1 Introduction
Many epidemiological studies are affected by measurement error in one or more of the covariates of interest. It is well known that error in covariates results in biased estimates of true covariate(s)-outcome associations and in a loss of power to detect such associations. 1 In this paper, we focus on correcting for the effects of measurement error in continuous covariates in three models which are commonly used in epidemiological analysis; linear regression models for continuous outcomes, logistic regression models for binary outcomes, and Cox proportional hazards models for survival or time to event outcomes.
Throughout most of the paper, we will focus on the situation in which there is one main exposure of interest, which is subject to measurement error, and one or more other covariates to be adjusted for, which are assumed to be measured without error. The variable which is measured with error could equally be one of the confounders, and indeed the approaches we describe also extend to the more general case of multiple covariates measured with error. While exposure measurement error is commonly prioritized, measurement error in confounders is also a serious and highly prevalent issue, and causes estimates of exposure effects to only be partially adjusted for the poorly measured confounder. Error in continuous variables can take a number of forms. The most simple and most commonly assumed form is the classical measurement error model, under which the measured exposure is equal to the true exposure plus an independent random error term. Under this model, the measured exposure is an unbiased measure of the true exposure. The error terms are assumed to have zero mean and, typically, constant variance.
To make corrections for the effects of covariate measurement error in regression models requires some information about the relationship between the true exposure and the measured exposure, i.e. regarding the parameters of a measurement error model. One way of gaining information about the error model is to use a validation study within the main study sample, in which the true exposure is observed alongside the measured exposure. It is often not feasible or even possible, however, to obtain a validation sample and a more common alternative is to obtain one or more replicate observations of the exposure for a subset of individuals within the main study sample. We refer to this as a replication study. In this paper, we focus on replication studies.
Many methods have been described for correcting for the effects of measurement error in regression models. 1 The most widely used correction method is regression calibration (RC), which is popular due to its simplicity and applicability in different types of regression models. In RC, the true exposure, which is unobserved in the main study sample, is replaced when fitting the outcome regression model by the expected value of the true exposure, conditional on the measured exposure and the other error-free covariates for each individual. RC gives consistent estimates of the true associations between the explanatory variables and the outcome in a linear regression model, and approximately consistent estimates in non-linear models, including logistic regression models2,3 and Cox proportional hazards models. 4
RC has some drawbacks, however. First, for non-linear models estimates can have moderately large biases even when the sample size is large, particularly if the effect size (odds ratio or hazard ratio) is large. 5 Second, RC does not automatically accommodate uncertainty in the parameters indexing the measurement process. Measures of uncertainty require use of approximate methods (the ‘delta method’ approach), bootstrapping methods, which are computationally intensive, or estimating equation methods, whose validity relies on asymptotic conditions and are complex to implement in practice. Third, extending the basic RC approach to more complex situations, such as when the outcome model is assumed to depend on non-linear functions of the true covariate, 6 or when the measurement error model is more complex (e.g. heteroscedastic error 7 ), is not trivial.
The Bayesian approach has been often advocated as a natural route to accommodating sources of uncertainty, including measurement error, misclassification, and missing data. Early papers include those by Richardson and Gilks,8,9 who described a Bayesian approach to handling measurement error. By taking a Bayesian approach to handle covariate measurement error, uncertainty in the parameters indexing the measurement process is automatically accommodated. Like the method of maximum likelihood (ML), the posterior distributions involved typically involve intractable likelihoods, but this difficulty is obviated by Markov Chain Monte Carlo (MCMC) methods, which are now implemented in a number of standard and Bayesian-specific packages. A further strength is that these software packages allow one to define and fit quite complex user defined Bayesian models, meaning that there is great flexibility in adapting the modelling assumptions to the situation at hand. Lastly, and in contrast to methods such as ML or multiple imputation (MI), whose inferences typically rely on various large sample assumptions (e.g. to handle nuisance parameters or in deriving simple imputation combination rules), Bayesian methods do not. In the setting of covariate measurement error, estimators which allow for the error typically have skewed sampling distributions, and this is automatically accommodated in a Bayesian approach, since the entire posterior distribution is simulated.
Despite excellent book length treatments of covariate measurement error methods, 1 including one specifically focusing on Bayesian methods, 10 in our view it nevertheless continues to be underused by the epidemiological and clinical research communities. This may be for a number of reasons, but principal among them may be the apparent need to move from a frequentist to a Bayesian inferential approach, and the fact that standard statistical packages have (with exceptions) not enabled such Bayesian models to be fitted. To the first of these reasons, as has been noted by others (e.g. Little 11 ), Bayes procedures often have good frequentist properties, and indeed in small samples can have better frequentist properties than ML methods. As such, one may be able to use a Bayesian method without necessarily adopting the Bayesian inferential paradigm. To this end, we present simulation results to examine the frequentist properties of the Bayesian approach to covariate measurement error, using certain default priors. To the second reason, major steps forward have been made over the last 25 years in terms of accessible MCMC software, such that software and computational power are usually not a hinderance to using a Bayesian approach. Moreover, we make all of our code available online to facilitate increased use of the Bayesian approach.
In Section 2, we begin by describing the assumed setup and notation for the covariate measurement error problem. Next, in Section 3, we review the RC approach. In Section 4, we describe the Bayesian approach, both in terms of modelling choices and statistical properties, and its practical implementation. We contrast the Bayesian approach with ML and MI in Section 5. In Section 6, we evaluate the frequentist properties of RC and Bayesian analysis in a series of simulation studies of the most common outcome model types. In Section 7, we present results of illustrative analyses using data from the Third National Health and Nutrition Examination Survey (NHANES III). We conclude in Section 8 with a discussion.
2 Setup and notation
In this section, we describe the general setup used for the remainder of the paper.
2.1 Outcome model
We assume data are available for an i.i.d. sample of n individuals. For individual i, we let Yi, Xi, and

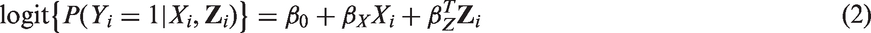
Lastly, in the case of a censored time to event outcome, the outcome
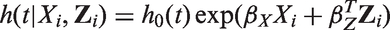
2.2 Measurement error model
We assume that for each study individual, an error-prone measurement
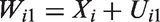
To permit estimation of the measurement error variance, we assume the existence of an internal replication sub-study. This means that for a randomly selected group of individuals a second error-prone measurement
3 Regression calibration
In the simplest version of RC, the outcome model is fitted as usual, with the unobserved Xi replaced by an estimate of
If one is willing to make additional assumptions, a somewhat more efficient version of RC can be used, in which Xi is replaced by an estimate of
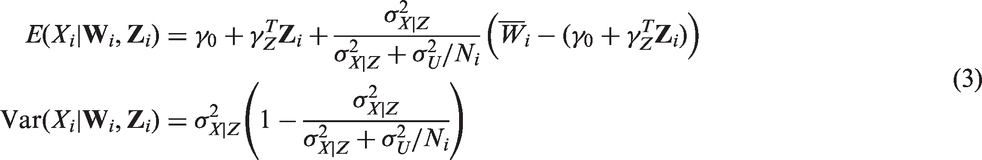
As noted in the introduction, RC gives consistent parameter estimates in the case of a linear outcome model. For logistic and Cox outcome models, RC is approximately consistent. Armstrong first gave justification for RC in generalized linear models under the assumption that
For valid inferences, the estimation of the parameters involved in
4 Bayesian approach
In this section, we describe the key elements of a Bayesian analysis of the covariate measurement error problem.
4.1 Model specification
First, we specify a joint parametric model for
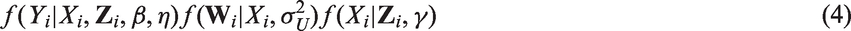
The first component is the outcome model, which contains regression parameters of primary interest
4.2 Prior specification
In the Bayesian approach, we must specify priors for the model parameters. The first ‘Bayesian’ analyses made use of flat or constant priors, based on the notion that these represent a priori ignorance regarding the value(s) of the model parameter(s). 16 The key issue with such priors is that while a flat prior expresses ignorance on one scale, a transformation of the parameter implies a non-flat prior on the transformed parameter. The latter half of the 20th century witnessed the growth of the subjective Bayesian approach, in which the analyst carefully choose the priors to represent their beliefs about the model parameters in advance of seeing the data. Arguably the majority of Bayesian analyses which are now performed by researchers make use of so called non-informative or reference priors. 17 Such priors do not (and cannot) represent total ignorance about the model parameters, but can be viewed as default priors that one might use when subjective prior information is either not available, or one does not want to use such information in the analysis. The intention of such priors is usually that they have minimal impact on inferences.
For the joint model in equation (4), prior independence is typically assumed for the parameters in the three sub-models. For the outcome model regression coefficients β and the coefficients in γ, a common default prior is a very diffuse normal prior centred at zero. For the variance parameters, the conjugate inverse Gamma distribution has traditionally been advocated. In the context of adjustment for covariate measurement error, Gustafson has proposed using a
Bayesian analysis of the Cox model requires specification of a prior for the baseline cumulative hazard process
4.3 Posterior inference and simulation
Given specification of the model and priors, Bayesian inference is then based on the posterior distributions of the model parameters. For the purposes of point estimation, the posterior mean is commonly used. To form a 95% credible interval for a particular parameter, we take the 2.5% and 97.5% centiles of the posterior distribution. An advantage of this in the present context of adjustment for covariate measurement error is that asymmetry in the posterior distribution, which typically occurs when adjusting for covariate measurement error, is automatically accounted for in credible intervals.
Except for very specific choices of model and prior, in general the posteriors are not available analytically. Instead, we can utilize MCMC methods to simulate draws from the posteriors distributions (see e.g. part III of Gelman et al. 20 ). The most common approach is the method of Gibbs sampling, in which taking each parameter in turn, a new value is drawn from its full conditional distribution given all other quantities. Often these conditional distributions do not belong to standard parametric families, necessitating the use of more sophisticated sampling techniques (see Robert 17 and Gelman et al. 20 for further details). However, these are implemented in the software packages we describe in the following, such that the analyst need not generally concern themselves with the details.
4.4 Frequentist properties
Under certain regularity conditions, as the sample size tends to infinity, the choice of prior has no impact on the posterior distribution, since the latter is then dominated by the likelihood function. Consequently, Bayes estimators and uncertainty intervals enjoy the same large sample properties as maximum likelihood methods: the Bayes posterior mean estimator is consistent, asymptotically normal, and efficient. 20 . In reality of course, all samples are finite, and the choice of prior can sometimes have a material affect on inferences. Importantly, however, in small samples or sparse data situations, Bayesian methods can have better frequentist properties than ML procedures, particularly if sensible priors are adopted. 21
4.5 Software
The explosion of Bayesian data analyses being performed over the last few decades is largely thanks to both the MCMC methods developed and their implementation in accessible software. Chief among these is the WinBUGS software package, developed in the 1990s. 22 It allows the user to define, using a simple language syntax or graphical interface, the model and priors. MCMC methods are then automatically chosen by the package, depending on the specified model and priors. One can then run the MCMC sampler, and after a sufficient number of burn-in iterations, draws can be saved as draws from the respective posterior distributions. More recently, new packages have been developed, with developments in various directions. These include the OpenBUGS project (www.openbugs.net) and Stan (mc-stan.org). In the simulations described later, we make use of the Just Another Gibbs Sampler (JAGS) program, 23 whose model language is very similar to the BUGS language used by WinBUGS, and which can be easily called from R.
5 Maximum likelihood and multiple imputation
5.1 Maximum likelihood
ML estimation and inference is based on the likelihood function, but unlike the Bayesian approach, does not involve specification of prior distributions for parameters. ML methods enjoy many favourable frequentist properties – assuming correct model specification the ML estimator is consistent, asymptotically normal, and efficient. In the specific context of adjustment for covariate measurement error, a drawback of ML is that the likelihood function typically involves intractable integrals, 1 such that numerical methods such as numerical integration are required in order to obtain estimates. The same obstacle is overcome in the Bayesian approach through the use of MCMC methods. A further drawback of ML in the present context is that in small samples inference based on symmetric Wald based confidence intervals may perform poorly due to the lack of regularity of the likelihood function. Software to fit user defined models which allow for covariate measurement error is also somewhat limited. Lastly, the absence of prior distributions prevents the incorporation of external information which may sometimes be available regarding the measurement process.
5.2 Multiple imputation
MI has become an extremely popular approach for handling missing data and has also been advocated as an approach for handling measurement error, in which Xi is multiply imputed.24–27 There is a very close connection between MI and ‘direct’ Bayesian inference. In its originally devised form, MI is based on repeatedly drawing imputations of missing values from their posterior distribution based on a Bayesian imputation model. The analysis model of interest is then fitted, typically using ML, to each of the complete datasets. The resulting estimates and standard errors are then pooled using rules developed by Rubin. 28 MI can most directly be viewed as an approximation to a full Bayesian analysis, 29 although its frequentist properties can of course also be evaluated. 30 From the Bayesian perspective, application of MI and Rubin’s rules can be viewed as a particular route to performing a Bayesian analysis, in which one effectively assumes that the posterior distributions for the parameters are normally distributed.
As described by Carpenter and Kenward 29 in the context of missing data, there are a number of settings where use of MI may be preferable to a direct Bayesian analysis. However, in the context of covariate measurement error we argue that the advantages of a direct Bayesian approach far outweigh the disadvantages, relative to MI. First, when only replicate error-prone measurements are available, standard software for performing MI cannot be applied, since Xi is missing for all individuals. Second, standard parametric imputation models which might be used to impute Xi in general may not be compatible with the assumed outcome model. 31 This will in particular occur when the outcome model is itself non-linear, or the imprecisely measured covariate is assumed to have a non-linear effect on the outcome. Third, when allowance is made for covariate measurement error, as noted earlier, the posterior distributions for the outcome model parameters are typically skewed in small to moderate sample sizes, such that symmetric credible/confidence intervals constructed using Rubin’s rules may perform poorly, either from a subjective Bayesian perspective or in a frequentist evaluation. Lastly, we note that software for performing Bayesian inference will typically also permit saving of the imputed values of Xi as a by-product, such that if the analyst really wants imputed datasets they can still be obtained.
6 Simulations
In this section, we present simulation results for the cases of a linear, logistic, and Cox proportional hazards outcome model, comparing the popular RC approach with the Bayesian approach. We adopt the standard frequentist type simulation setup, in which datasets are repeatedly generated using fixed population parameter values.
6.1 Linear regression
We first present simulation results for a simple linear regression outcome model. Datasets of size n = 1000 were simulated, with covariates Xi and Zi drawn from a bivariate normal distribution with means 0, variances 1, and covariance 0.25. Continuous outcomes Yi were generated from the linear regression model given in equation (1), with
We first estimated the outcome model parameters using RC, by fitting a random-intercepts model for the error-prone measurements, with Zi entering as a fixed effect, as described in Section 3. Next, we fitted a Bayesian model, calling JAGS from R using the rjags package. We adopted non-informative priors for all model parameters, following those proposed by Gustafson.
10
Specifically, we assumed independent normal priors for
Linear regression results.
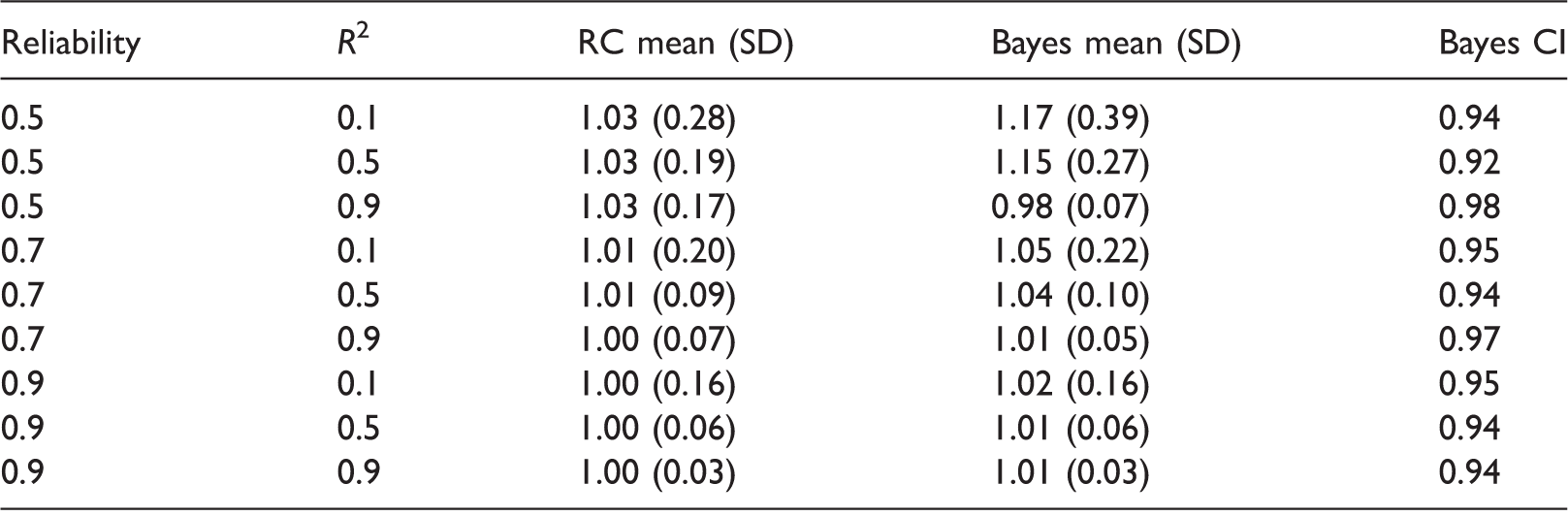
1000 simulations per scenario. Empirical means and SDs for estimates of βX, and coverage of 95% Bayesian credible intervals. RC: regression calibration; SD: standard deviation.
We emphasize that the performance of the Bayesian estimator depends on the choice of priors. In particular, the use of more informative priors for the measurement error variance and the variance for
Linear regression results with small sample size.

1000 simulations per scenario. Empirical means and SDs for estimates of βX, and coverage of 95% Bayesian credible intervals. RC: regression calibration; SD: standard deviation.
Bayes 1:
Bayes 2:
Bayes 2
6.2 Logistic regression
Next, we performed simulations with a logistic regression outcome model. The covariates Xi and Zi, and error-prone measurements were generated as described previously. The binary outcome Yi was then generated according to a logistic regression model (2). The intercept β0 was chosen so that
RC was implemented as described previously. For the Bayesian approach, we again used independent normal priors for each of β0, βX, and βZ. For β0 we used, as before, the non-informative prior
Logistic regression outcome model simulation results, with 1000 simulations per scenario.
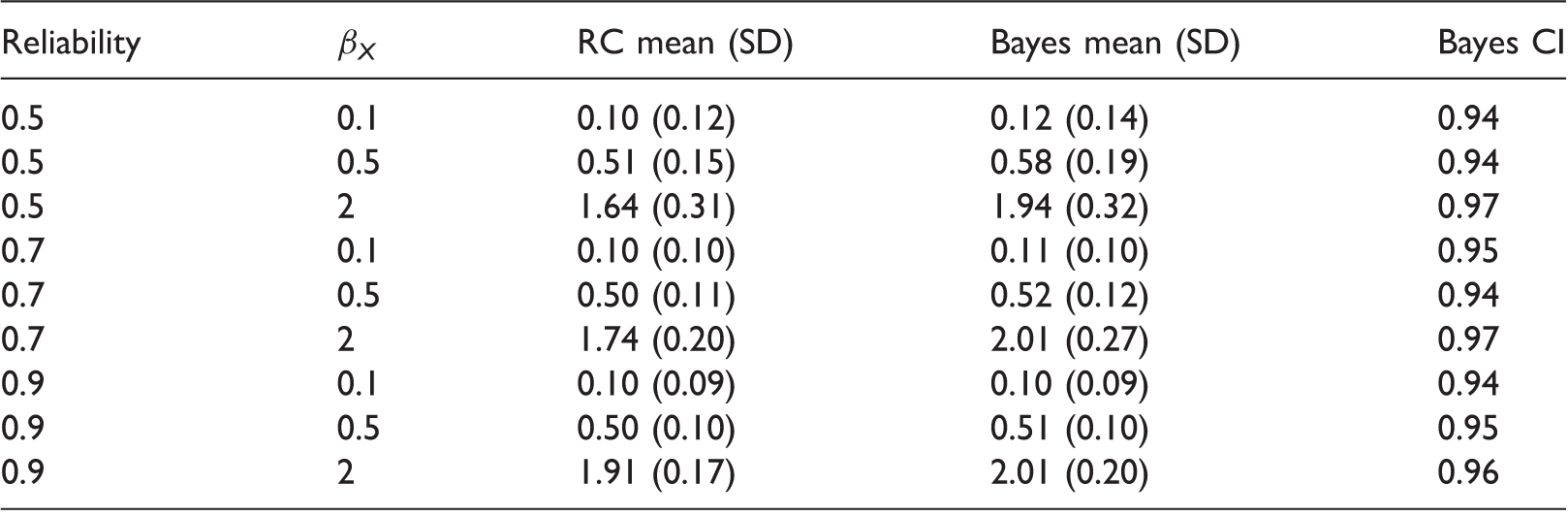
Monte-Carlo means and SDs for estimates of βX from regression calibration (RC) and Bayes, and empirical coverage of 95% Bayesian credible intervals. SD: standard deviation.
6.3 Cox proportional hazards regression
Lastly, we performed simulations for time-to-event data based on a Cox proportional hazard model. The covariates Xi and Zi were generated as described for linear regression. Event times Ti were generated according to the Weibull hazard model
RC was performed as described previously. For the Bayesian approach, we used independent normal priors for βX and βZ, and we chose the
Cox regression outcome model simulation results, with 100 simulations per scenario.
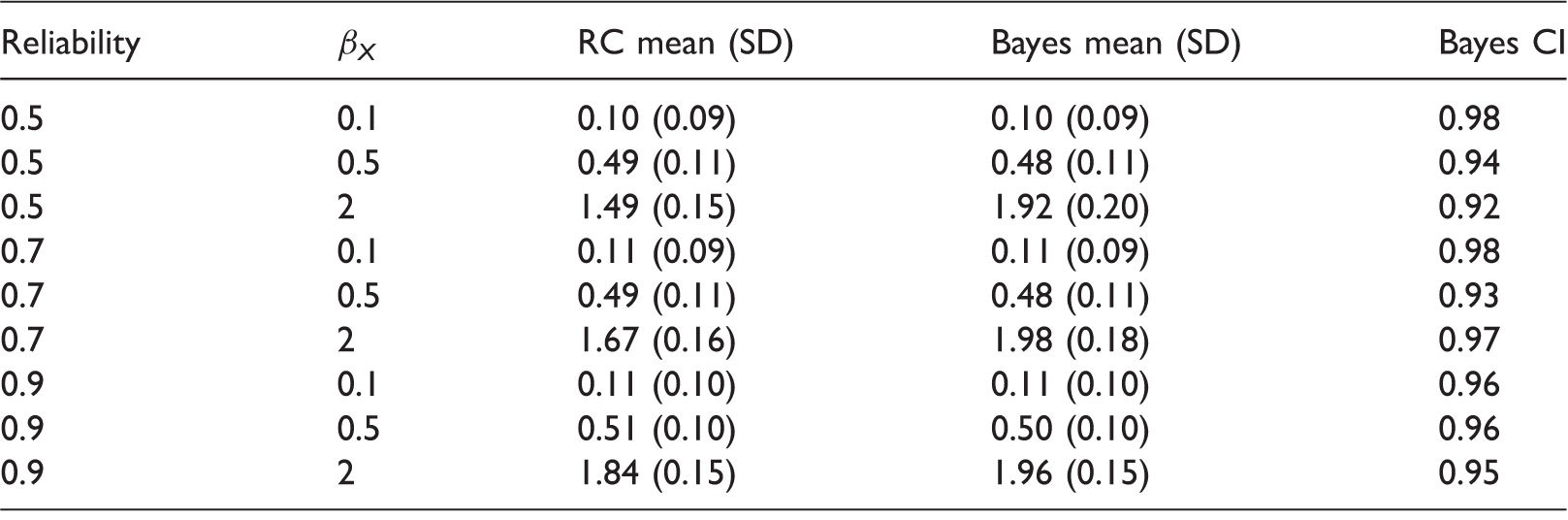
Monte-Carlo means and SDs for estimates of βX from regression calibration (RC) and Bayes, and empirical coverage of 95% Bayesian credible intervals. SD: standard deviation.
7 Illustrative example
To illustrate the potential flexibility and advantages of the Bayesian approach, we consider data from the NHANES III. NHANES III was a survey conducted in the US between 1988 and 1994 in 33,994 individuals aged two months and older. We consider a model relating known risk factors for cardiovascular disease (CVD) measured at the original survey to subsequent hazard of CVD. Mortality status at the end of 2011 is available through linkage to the US National Death Index, with cause of death classified using the ICD-10 system.
Here, we consider illustrative analyses of the data available on those aged 60 years and above at the time of the original survey. Fitting Cox models to large datasets is very slow using JAGS, particularly for large datasets. We therefore considered inference for a Weibull regression model for hazard for death due to CVD, with age, sex, smoking status, diabetes status, and systolic blood pressure (SBP) at the time of the survey as covariates
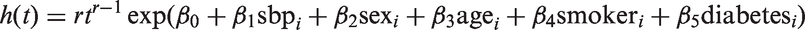
After deleting seven individuals who were missing diabetes status, data were available on 6519 individuals. Of these, by the end of 2011 1469 (22.5%) had died due to CVD, 3641 had died from other causes, and 1409 were still alive. In the Weibull model for hazard for CVD, we treat deaths from causes other than CVD as censorings; 5033 (77.2%) had an SBP measurement available from the first examination. An SBP measurement at the second examination was available in 401 (6.2%) of individuals. Unfortunately, smoking status was only recorded in 3433 (52.3%) of individuals. The analysis thus required handling of both the measurement error in the SBP measurements and the substantial missingness in the smoking and SBP variables.
7.1 Naive analyses
Log hazard ratios estimates and 95% confidence/credible intervals for the NHANES III data.

CCA: complete case analysis performed using 2667 individuals, full analysis performed using 6519 individuals; RC: regression calibration; naïve: ignoring measurement error; adj.: adjusting for measurement error in SBP; SBP: systolic blood pressure.
Next, we fitted the same Weibull model to the complete cases, again ignoring measurement error, using the Bayesian approach. We assumed an exponential prior for the shape parameter r with parameter 0.001. Rather than placing a prior on the log hazard ratios, we placed independent
7.2 Regression calibration
We then applied RC to the complete cases. To do this, we fitted a linear mixed model to the available SBP measurements, with a random effect for individual and fixed effects of sex, age, smoking, and diabetes. We also included a fixed effect to allow for a systematic shift in mean between the first and second exams. The resulting predicted true SBP values at exam one were then used as a covariate to fit the Weibull regression model. We used 2000 non-parametric bootstrap samples to obtain percentile 95% confidence intervals for the estimates, in order to take into account the two stage estimation process. Based on the mixed model fit to the complete cases, the estimated reliability (conditional on the error-free covariates) was 0.75. Adjusting for measurement error using RC led to the estimated log hazard ratio for SBP increasing, from 0.085 to 0.115, as expected by approximately 4/3 (1 divided by the reliability 0.75). Estimates for the other covariates did not materially change.
In order to apply RC to the full dataset, we contemplated use of its use in combination with MI. This is problematic, however. First, one could use MI to impute the missing smoking,
7.3 Bayesian analyses adjusting for covariate measurement error
Next, we modified the Bayesian CCA to accommodate measurement error. We assumed that each individual’s true underlying SBP around the time at which the first measurement was obtained, 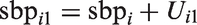
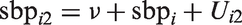
A strength of the Bayesian approach is its flexibility to simultaneously handle missing data and measurement error. To accommodate missingness in the smoking and SBP variables under a missing at random assumption, we assumed a model for the distribution of smoking, conditional on the fully observed error-free covariates sex, age, and diabetes. In our analysis, we assumed a logistic model for this conditional distribution
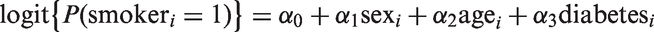
8 Discussion
In this paper, we have empirically compared the frequentist properties of RC and Bayesian approaches to handling covariate measurement error. Our simulations demonstrate that for what might be considered a fairly typical epidemiological study setup, the methods often perform very similarly. As such, we believe that the Bayesian approach for measurement error adjustment may be as useful for the frequentist as for the Bayesian statistician. When the reliability of error-prone measurements was low, the Bayes estimator performed somewhat worse than RC. However, for larger effect sizes, RC was biased for logistic and Cox regression, while the Bayes estimator showed much less bias. A critical point to bear in mind is that there are infinitely many Bayes estimators, corresponding to the different choices of prior distributions – use of different priors could lead to, depending on the true data generating mechanism, better or worse performance. While some analysts dislike the Bayesian approach because of the requirement to specify priors, they give the analyst the opportunity to exploit external information about model parameters, potentially leading to more precise estimates.
We have highlighted the fact that Bayesian estimators enjoy the same large sample frequentist properties as the method of ML, and also described the relationships between these approaches and the popular MI approach. Software for MI cannot be directly applied to handle covariate measurement error when replication data are available. Moreover, even when validation data are available, the covariate imputation models included in MI implementations may not be compatible with the analyst’s outcome model. 31 A further strength of the Bayesian approach is that uncertainty intervals automatically allow for the skewness typically found in covariate measurement error adjusted estimators.
As has been noted by many authors before, a key strength of the Bayesian approach is its flexibility to handle more complicated models and data structures. As we have demonstrated in Section 7, the Bayesian approach can readily accommodate both covariate measurement error and missing data. Moreover, more complex measurement error models can in principle be used, for example, to allow for heteroscedastic error, systematically biased measurements, or more flexible modelling of the true covariate’s distribution. 1 The flexibility of the Bayesian approach also lends itself to the problem of adjusting for covariate measurement error when the true covariate is assumed to have a complex non-linear association with the outcome. 36 In this paper, we have focused on the setting whereby internal replication data are available; the Bayesian approach readily handles the situation where validation data are instead available.
Nonetheless, the Bayesian approach has a number of drawbacks. As a fully parametric approach, a natural concern is sensitivity of inferences to distributional assumptions, particularly those about the unobserved true covariate and measurement errors. In this regard, the Bayesian approach can utilize more flexible model specifications, for example, by modelling the unobserved true covariate using a normal mixture model. 37 An important practical issue is that although the software available for fitting complex analyst defined models using the Bayesian approach has seen dramatic developments over the last 25 years, 22 fitting certain models (e.g. Cox proportional hazards models) can still take tremendously long. Although this concern will be progressively mitigated by increasing computational power, it is arguably still a material drawback. Further research and effort are therefore warranted to develop software implementations of the Bayesian approach which mitigate this.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This paper was written while JWB was a member of the Department of Medical Statistics, London School of Hygiene and Tropical Medicine and was supported by a Medical Research Council Fellowship [MR/K02180X/1]. RHK was supported by a Medical Research Council Fellowship [MR/M014827/1].