
Abstract
Understanding whether and how treatment effects vary across subgroups is crucial to inform clinical practice and recommendations. Accordingly, the assessment of heterogeneous treatment effects based on pre-specified potential effect modifiers has become a common goal in modern randomized trials. However, when one or more potential effect modifiers are missing, complete-case analysis may lead to bias and under-coverage. While statistical methods for handling missing data have been proposed and compared for individually randomized trials with missing effect modifier data, few guidelines exist for the cluster-randomized setting, where intracluster correlations in the effect modifiers, outcomes, or even missingness mechanisms may introduce further threats to accurate assessment of heterogeneous treatment effect. In this article, the performance of several missing data methods are compared through a simulation study of cluster-randomized trials with continuous outcome and missing binary effect modifier data, and further illustrated using real data from the Work, Family, and Health Study. Our results suggest that multilevel multiple imputation and Bayesian multilevel multiple imputation have better performance than other available methods, and that Bayesian multilevel multiple imputation has lower bias and closer to nominal coverage than standard multilevel multiple imputation when there are model specification or compatibility issues.
Keywords
Introduction
Cluster-randomized trials (CRTs) are a popular experimental design where groups of individuals are randomized to different treatment arms. 1 This design is used when the intervention is designed to be administered at the cluster level or in studies where randomization of individuals is difficult or impractical. Though methods for study design and analysis of CRTs have been developed (see, e.g. a pair of recent reviews by Turner et al.2,3), they mostly focus on studying the average treatment effect (ATE). Methods for the design and analysis of CRTs have only recently branched into identifying heterogeneous treatment effects (HTEs), where the treatment effect is hypothesized to vary across pre-specified subgroups of the trial population.4–9 In particular, there is burgeoning interest in confirmatory HTE analysis of CRTs focused on pre-specified subgroups defined by baseline demographic characteristics. A recent systematic review of 64 CRT analyses published between 2010 and 2016 found that 16 (25%) examined HTE across pre-specified demographic subgroups, and noted that guidance on design and analysis of CRTs to assess HTE needs further development. 10 Evaluation of HTE is critical to understanding treatment effects in vulnerable subpopulations and developing real-world recommendations for the administration of new treatments.
In this article, we focus on confirmatory and hypothesis-driven HTE analyses that require pre-specification. This is in contrast to exploratory HTE analyses that are often ad-hoc and used for generating hypotheses for future studies. Confirmatory HTE analyses in CRTs can be assessed using a variety of methods, including generalized estimating equations (GEE) or generalized mixed-effects models with statistical interaction terms, 4 pre-specified subgroup analyses (often also based on GEE or mixed-effects models), 11 and data-driven methods for targeting pre-specified conditional ATEs for well-defined subpopulations.12,13 Among these approaches, the statistical interaction approach is likely the most popular in practice.10,14 These interactions are often assessed one at a time, but the potential effect modifiers composing the interactions may be subject to missingness. As these modifiers are typically baseline covariates, they can be missing in a variety of common scenarios, including when electronic health record data is used to capture baseline covariates or when trial participants actively choose not to respond to questions in baseline surveys and enrollment forms. This latter scenario may occur if the questions make participants uncomfortable, if participants are not sure how to answer the questions, or if there are language barriers, among other reasons. Missing data of various forms can introduce bias in the analysis and interpretation of study results, 15 and missing modifiers in particular have been shown to introduce bias in the estimation of interaction terms in observational studies and individually randomized trials.16,17 However, the extent of this bias and appropriate methods to address missing effect modifier data are under-explored in CRTs. In the remainder of this section, we review some existing methods from two related areas of research: missing outcomes in CRTs and missing modifiers in individually randomized trials and observational studies, to provide context for our current study.
While research on missing effect modifier data in CRTs is under-developed, research on methods for missing outcome data in CRTs has grown substantially over the last two decades.3,18,19 In particular, multiple imputation (MI) has been shown to be a useful tool for reducing bias, 20 but addressing the correlations within clusters was found to be key for valid estimation and inference in CRTs. 21 One method that addresses such correlations is multilevel MI (MMI), which includes random intercepts for clusters in both imputation and outcome models. MMI has been studied for both continuous and binary outcomes in CRTs,22–24 and has also been shown to be useful for studies with missing multivariate outcomes. 25 While fixed effects for clusters are used in some imputation models, such specification may introduce model parameter estimation bias in many settings, especially when the intracluster correlations (ICCs) or cluster sizes are small. 26 Whether and how these methods can be applied to study HTE in CRTs with missing effect modifier data is comparatively less well understood; the goal of this article is, therefore, to compare existing methods such as MI and MMI in a CRT setting with a continuous outcome where a binary effect modifier (used to define pre-specified subgroup membership) is subject to missingness.
Research developing or comparing methods for addressing missing modifier data is more developed in the observational study and individually randomized trial settings. In some of this existing literature, these methods are described broadly as methods for missing covariates or missing covariates with interactions. It is worth mentioning that in the current article, all effect modifiers of interest we consider are baseline covariates, even though not all baseline covariates are effect modifiers of interest. In observational studies, MI and MMI are popular for handling missing modifiers, and much attention has been focused on whether interaction terms should be computed as the product of variables after imputation (passive imputation) or treated as their own missing variable in the process (just-another-variable imputation). 17 This issue is less important in randomized trials focused on HTE, since an interaction between treatment and a modifier will always equal 0 under placebo and equal the modifier under treatment (assuming 0-1 coding). A second key issue, which remains relevant for randomized trials, is that imputation and outcome models should be compatible. Imputation and outcome models are compatible (sometimes referred to as congenial) if there exists a joint model for the modifier and outcome which has implied conditional distributions equal to those specified by the imputation and outcome models.27,28 However, choosing a compatible imputation model may not be straightforward, especially when the outcome model contains interaction terms. Semiparametric approaches such as fractional imputation29,30 and nonparametric approaches such as imputation from Bayesian additive regression trees (BARTs)31,32 have been proposed to address missing covariates, but such methods have not yet been extended to account for the within-cluster correlations in the covariates and outcomes in the CRT setting. With independent data, Erler et al. 33 noted that nesting MI in a Bayesian approach could alleviate imputation model misspecification issues and help account for additional uncertainty in the imputation process. This procedure can be adapted for the analyses of CRTs with a random-effects specification in the imputation model to arrive at a Bayesian MMI (B-MMI) approach, which represents another useful candidate method for evaluating HTE in CRTs with missing modifiers. Thus, from prior work on (i) missing outcomes in CRTs and (ii) missing modifiers in individually randomized trials or observational studies, we can enlist a set of existing methods that may be applicable for assessing HTE in CRTs with missing modifiers, but which have not been studied specifically for that purpose. Importantly, previous methods and guidelines developed for individually randomized trials will not necessarily be applicable for CRTs because covariates and/or missingness may be correlated within clusters, and this challenge has motivated our current study.
Overall, the contribution of this article is to develop and report on a series of comparison studies in order to determine which readily available methods may be most suitable for assessing HTE in CRTs with missing effect modifier data. The rest of the article is structured as follows. First, we define notation and describe the GEE, 34 which will be used for all outcome models throughout the article for final outcome analyses. Then, we describe each of the missing data methods that will be compared. Next, we compare the methods in an extensive simulation study using the ADEMP framework. 35 Then, we apply each of the methods to real data from the Work, Family, and Health Study, where we impose controlled missing data scenarios on complete data where the true values are known. Finally, we conclude with a discussion of the results and offer some recommendations for practitioners.
Notation and outcome model for CRTs
We consider the setting of a two-arm CRT with intervention assignment for cluster
We first describe the data and analytic model in cases where the effect modifier is fully observed. We will focus on a GEE approach with correctly specified mean model for testing HTE to streamline our discussion. We consider the GEE approach because (i) the estimation and inference for treatment effect parameters can be robust to misspecification of the within-cluster correlation structure under correct specification of the marginal mean model,
34
and (ii) the population-averaged interpretation of the marginal mean model may be preferable for the analysis of CRTs.
36
We acknowledge, however, that GEE is not the only possible outcome modeling choice for CRTs, and mixed-effects regression may provide a more efficient estimator when both the conditional mean model and the random-effects structure are correctly specified. Suppose that the outcome follows a generalized linear marginal model of the form
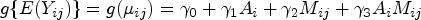
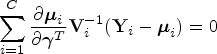
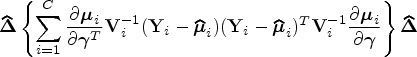
Next, five missing data methods associated with fitting the GEE outcome model when
Statistical methods for addressing a missing binary effect modifier in CRTs
Complete-case analysis (CCA)
CCA entails fitting a model based on only individuals for whom complete data is available. Thus, any individuals with missing effect modifiers will be excluded from the analysis data set. While this is usually a valid strategy in MCAR settings, it may lead to biased inference in MAR settings where the outcome and missingness of the modifier are both dependent on one or more baseline covariates. In addition, CCA may have lower power than other methods which utilize the full data. Performing CCA is equivalent to solving the GEE estimating equations weighted by the indicator that the modifier is observed
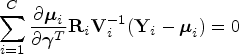
Single imputation
When the data are not MCAR, it is often reasonable to relax this assumption and assume the data are MAR. This assumption underlies each of the imputation methods described in this article. Single imputation (SI) entails imputing a single, fixed value for each of the missing effect modifiers and then fitting the GEE outcome model. Imputation can be achieved in many ways, but is typically performed using parametric models. As stated in Section 1, the distribution of
Once the imputation model is specified and fit, missing values of
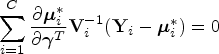
Multiple imputation
MI extends the idea of SI by imputing multiple values for each missing effect modifier and then combining results across imputed data sets in order to account for variability in the imputation procedure. In particular,
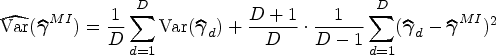
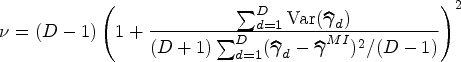
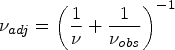
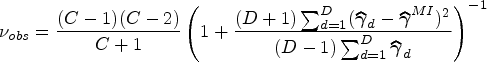
Multilevel MI
While the above imputation approaches each use GEE to account for ICC in the outcome variable when analyzing complete data, they assume in the imputation process that
Bayesian MMI
B-MMI implements MMI within a Bayesian framework to account for uncertainty in imputation model parameter estimation. This can be accomplished using Markov Chain Monte Carlo methods such as Gibbs sampling.
47
For a fully Bayesian approach that integrates the imputation model and outcome model in a single procedure, the general algorithm can be summarized as follows: (i) specify priors for all parameters; (ii) draw posterior samples of the imputation model parameters and impute values for all missing modifiers; (iii) draw posterior samples of the outcome model parameters using the imputed data; and (iv) iterate between steps (ii) and (iii) until convergence, and summarize the posterior distribution of the outcome model parameter estimator. Although this fully Bayesian approach is attractive, it often does not separate the imputation step and the outcome data analysis step, and may constrain the flexibility on choice of outcome model for data analysis. In practice, to separate the imputation and outcome data analysis steps, one often implements Bayesian MI by only omitting step (iii), and then sampling
In this article, scenarios with a binary effect modifier will be considered. A natural choice for an imputation model would be a logistic mixed-effects model, with a random intercept corresponding to cluster membership. Leveraging Pólya-Gamma random variables for Bayesian inference of logistic regression models was proposed by Polson et al.
48
, who also described expanding the procedure to logistic mixed-effects models. The essence of this approach is to recognize that the binomial likelihood parameterized by log-odds can be written as a Gaussian mixture of Pólya-Gamma densities, namely
Set initial values for the imputation model parameters Set initial values for random intercepts Define a prior Impute missing values of Update the imputation model parameters and random effects as follows.
Let Generate Update Covariance parameter equal to Mean parameter equal to Update random effects Covariance parameter equal to Mean parameter equal to Generate Iterate between Steps 4 and 5 until desired Monte Carlo Markov Chain (MCMC) chain length is reached (or parameter estimates have sufficiently converged).
Finally, one can fit the GEE outcome model on each of
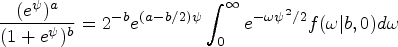
Aims
The aim of the simulation study is to compare the missing data methods described in Section 4.4 under plausible data-generating mechanisms for CRTs. The key study objectives are to (i) study which of the methods perform best in practice when imputation models are correctly specified and (ii) evaluate how robust each approach is to imputation model misspecification and/or lack of compatibility between the imputation and outcome models. We will evaluate these questions under several specific data-generating processes described below.
Data-generating mechanisms
Simulations were separated into two scenarios according to the data-generating mechanisms. The initial setup was identical in each scenario. First, a set of
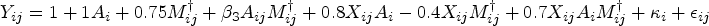
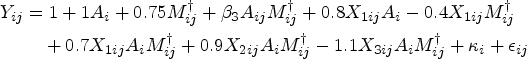
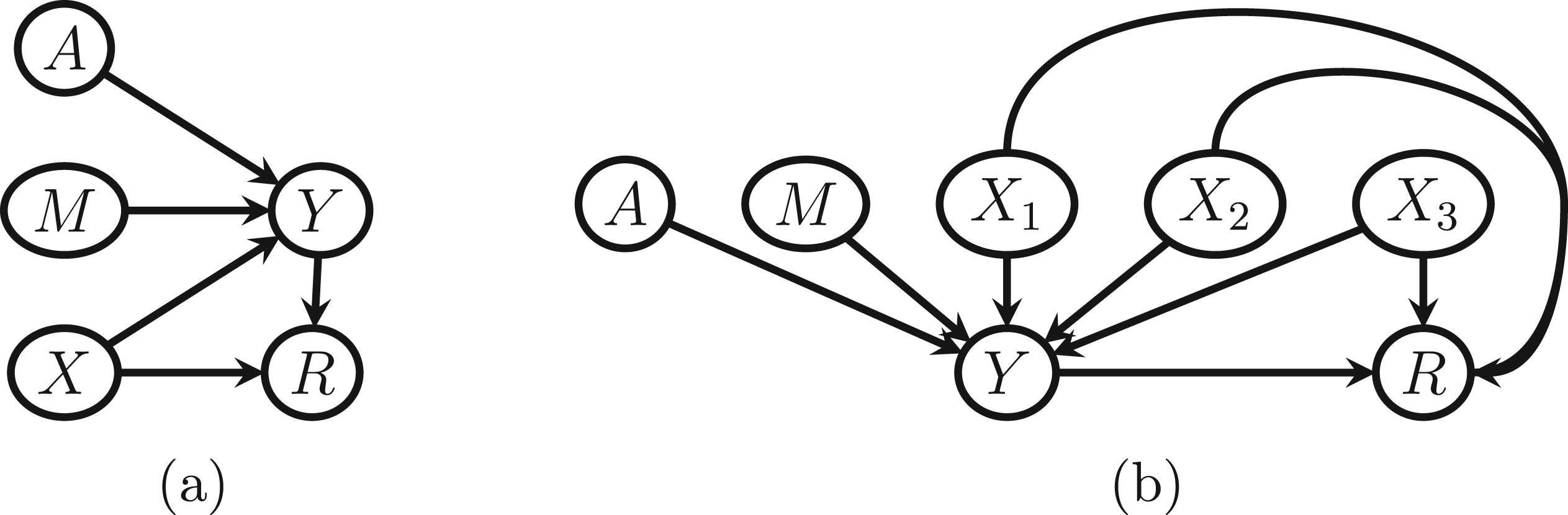
Directed acyclic graphs (DAGs) corresponding to the simulation scenarios considered. (a) Simulation Scenario 1 and (b) simulation Scenario 2.
Note that in each scenario, the modifier is generated independently of the baseline covariates. This may seem unusual given the stated goal to compare imputation methods. However, this choice helps illustrate model compatibility in this setting. The modifier
Two estimands were considered for each simulation study. First, we consider the implied marginal model after integrating out additional covariates, for example, for the first scenario,
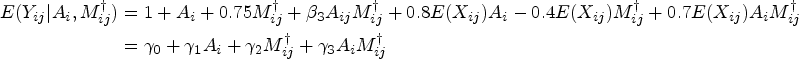
Methods
Each of the missing data methods described earlier were used to analyze the data generated under each scenario. In particular, data were analyzed using CCA, SI, MI, MMI, and B-MMI. For each method, the final outcome data analysis model was a correct GEE specification for the marginal mean model (integrating out baseline covariates) with the identity link function. Thus the estimator of the HTE estimand
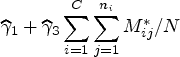
The general imputation model used had the form
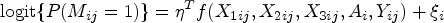
Possible imputation model specifications considered in the simulation studies, as well as abbreviations used in communicating simulation results.

Possible imputation model specifications considered in the simulation studies, as well as abbreviations used in communicating simulation results.
Specification 1 (2) is the model used for simulation scenario 1 (2). For MMI and B-MMI methods, a random intercept was added to each of the specifications in the table.
Since both scenarios used binary effect modifiers, all imputation procedures were specified under the umbrella of logistic regression procedures, that is, SI and MI used logistic regression, while the MMI and B-MMI methods used logistic mixed-effects models with a random intercept at the cluster level (B-MMI using estimates from such models as initial values). For the B-MMI method, each MCMC chain included 1000 burn-in iterations and used thinning to draw one set of posterior samples every 100 iterations after burn-in until
Four performance measures were considered for each simulation scenario and estimand. First, the bias for each method was calculated as the mean difference of estimates across simulation iterations and the corresponding true estimand value described in Section 4.3. As a second measure, the coverage was calculated as the proportion of simulations for which the estimated confidence interval contained the corresponding true estimand value. Third, the power was calculated as the proportion of simulations which would reject the null hypothesis (that the corresponding estimand is equal to 0). This is equivalent to Type I error when simulating under the null. Finally, the mean squared error (MSE) was calculated as the average squared difference of estimates from each simulation and the corresponding true estimand value. The number of simulations run for each data-generating mechanism was chosen to ensure a reasonably low Monte Carlo standard error for the coverage estimates. In particular, supposing that the true coverage for a method is
Results
The results for the HTE estimand when setting
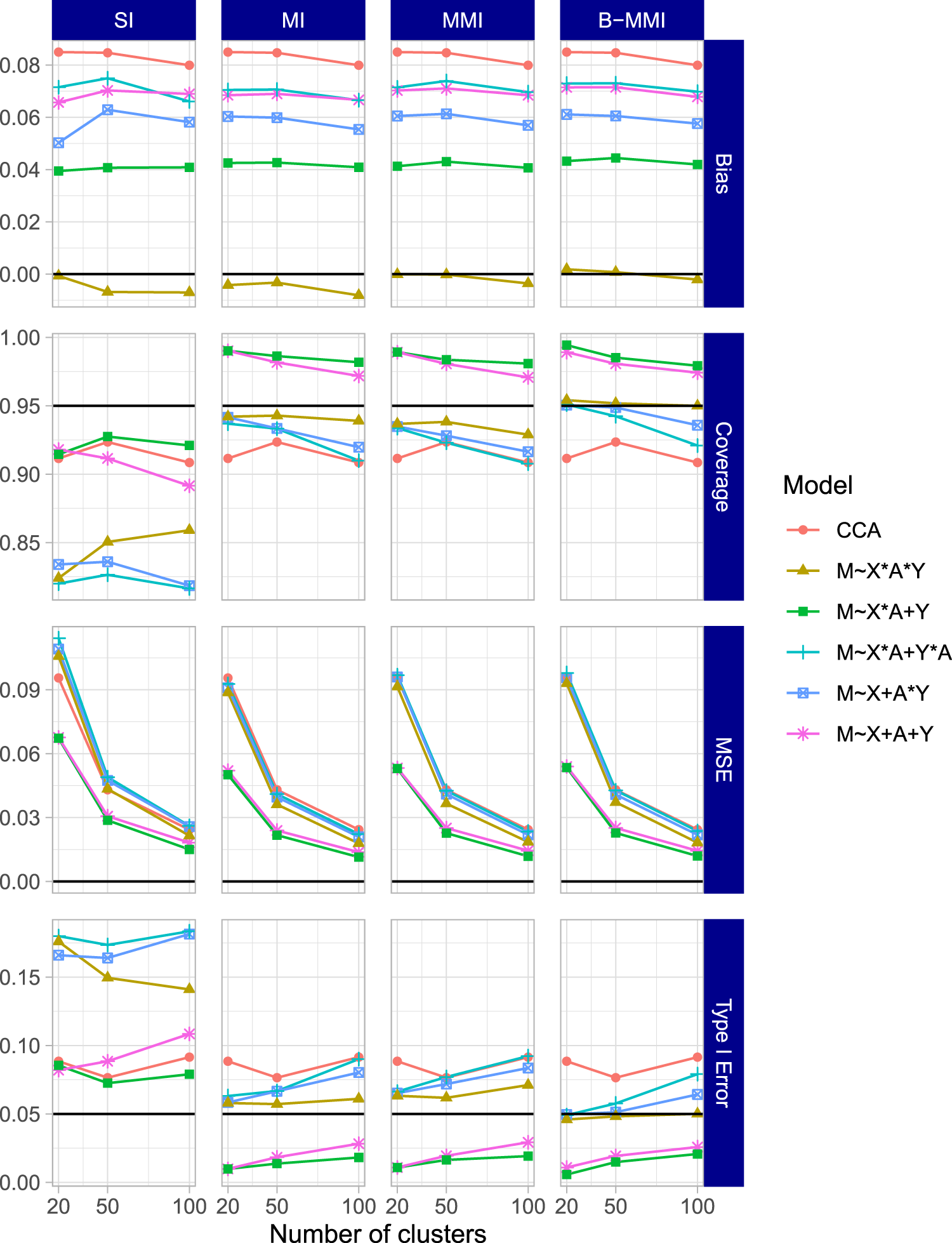
Simulation results for the HTE estimand (interaction effect estimand
Results for the HTE estimand and ATE estimand when setting
The results of the second simulation scenario were largely in agreement with the first scenario. The results for the HTE estimand
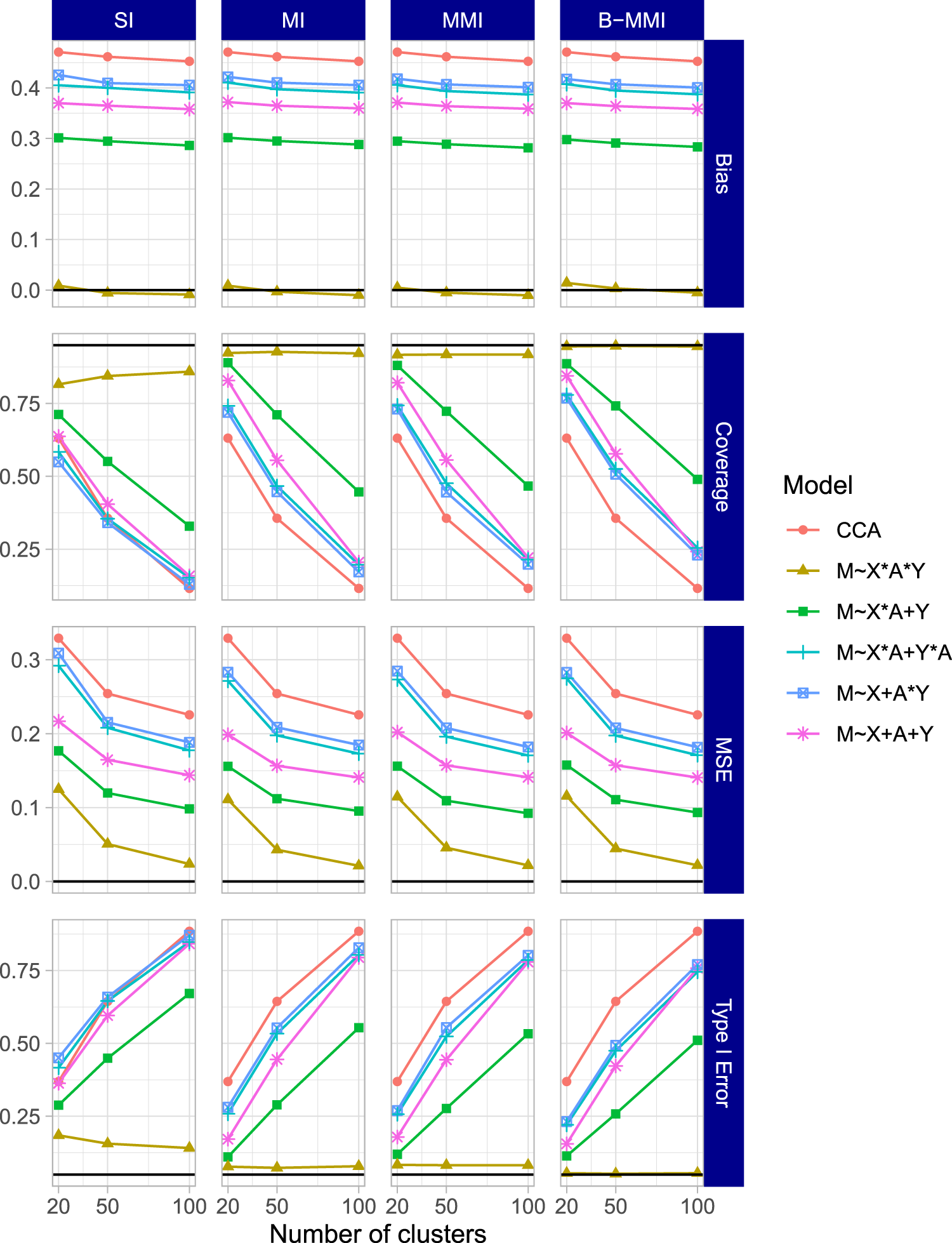
Simulation results for the HTE estimand (interaction effect estimand
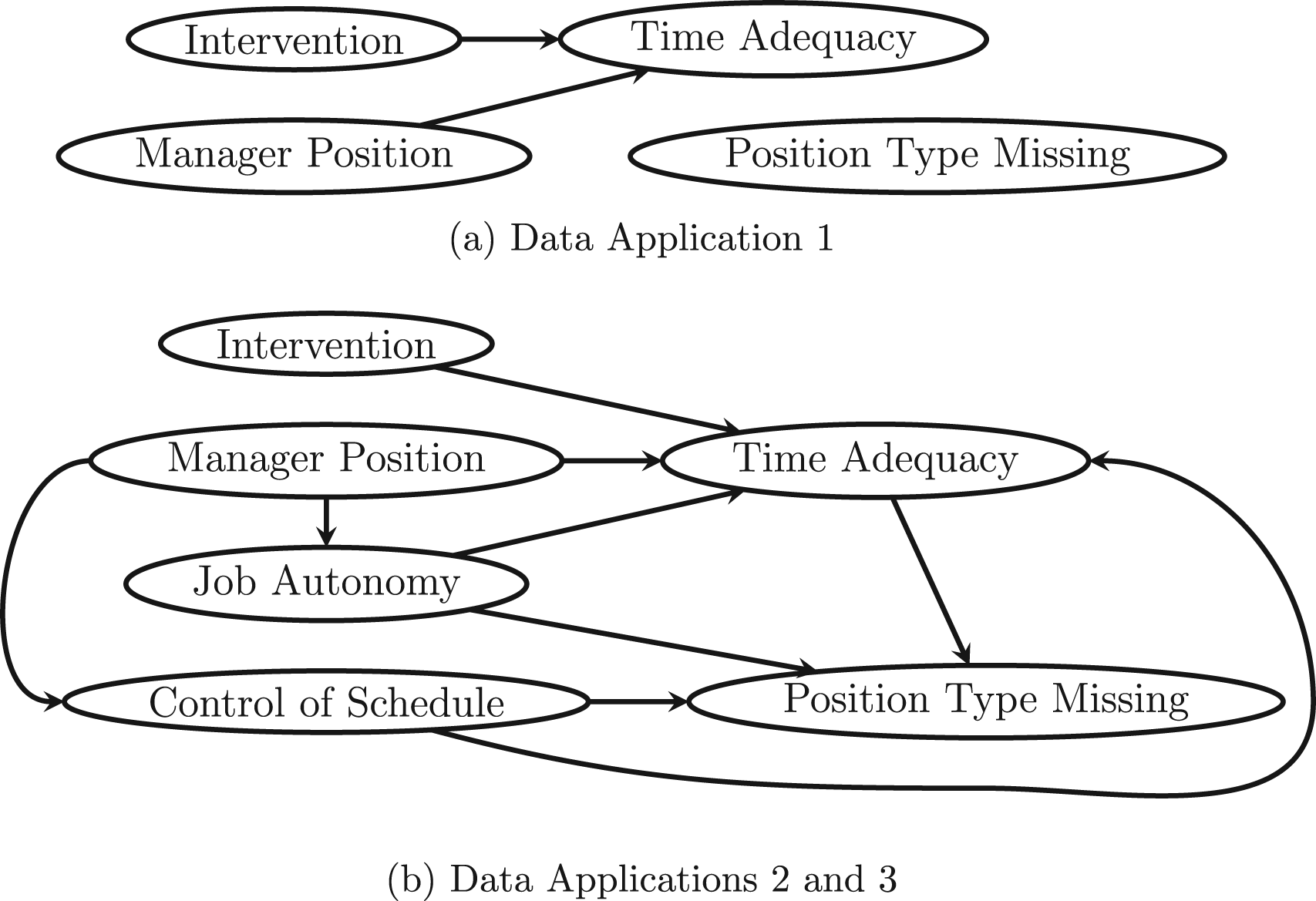
Directed acyclic graphs (DAGs) corresponding to the work, family, and health study data application scenarios that were considered.
Finally, the results for the HTE and the ATE estimands when setting
In this section, we illustrate each of the methods described earlier by analyzing data from the WFHS. WFHS consisted of two CRTs conducted at two employers; here, we focus only on the experiment conducted at one employer, an extended-care company. 53 The trial included 30 work sites of 30–89 employees each. The work sites were randomly assigned to a comprehensive work–family intervention or usual practice conditions. The intervention consisted of two main components, one to increase managers’ support for their employees’ family and personal lives, and one to improve employees’ control over their schedule. As managers already have more control over their schedule and would be both giving and receiving the first component of the intervention, it’s possible that the intervention effect on various outcomes varies by employee type (manager vs. non-manager).
We specifically focus on this effect modification problem even though the employee type variable is completely observed, such that we can simulate missing data scenarios while comparing to results from the known full data. In particular, we will study employee type as a potential modifier of the effect of the intervention on the outcome of time adequacy (TA), measured for each individual employee. TA was a composite variable averaging the individual survey responses to several questions of the form “To what extent is there enough time to…” followed by a familial activity or responsibility. TA ranged from 1 to 5 with 5 signifying always having adequate time for family. Thus, TA acts as a proxy variable for the desirable but unmeasurable outcome of “good work–life balance.” Our outcome specification was the difference between TA at 12 months post-intervention and TA at baseline. This research question largely falls under Aim 4 of the selected sub-study of WFHS, to “test whether employee, mid-level manager, and work-group characteristics moderate the effect of the intervention on work–family conflict and health outcomes.”
Although the employee type variable is fully observed, we considered three hypothetical missing data scenarios for this effect modifier. In the first scenario (Figure 4(a)), about 20% of the values of employee type were set to be missing completely at random. In the second scenario (Figure 4(b)), about 20% of the values of employee type were set to be MAR as a simple function of the outcome and two additional covariates: self-reported job autonomy and a self-reported assessment of control of schedule, each of which was reported on a Likert scale of 1 to 5, with 5 indicating more control/autonomy. In particular
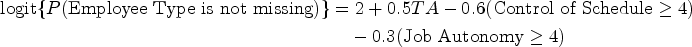

In each scenario, the five methods are compared by calculating the point estimates and confidence intervals for the two estimands described earlier—the coefficient for interaction between intervention and employee type (the HTE) and the ATE. As we mentioned earlier, we assume the absence of informative cluster size and a correct specification of the GEE marginal mean model for data analysis; therefore, the ATE and the interaction effect can be mapped to the corresponding regression coefficients and interpreted without ambiguity. For the MAR scenarios, each imputation method specified an imputation model that included the outcome, the two baseline covariates (dichotomized as in the missing data generation), the treatment, and all possible two-way interactions between them. Models with higher-order interaction terms did not always converge due to the limited sample size and nontrivial number of parameters, and were thus excluded. The missing data simulation procedure and corresponding estimation under each method was repeated for a comparison across 500 replications.
Key results are presented in Figure 5, which shows the average point estimate and average 95% confidence (upper and lower) limits across the 500 replications for each method. For these results, 13 iterations were removed in Scenario 2 for MMI due to the non-convergence of the imputation model; these were resolved for B-MMI by using alternative initial values informed by the SI/MI imputation model. For the ATE estimand (top row of the figure), all methods seem to perform similarly but with slight variation in average confidence interval width. For the HTE estimand (bottom row of the figure), CCA yielded similar results to each of the imputation methods under all scenarios, and produced narrower confidence intervals on average than MI, MMI, or B-MMI. This is in slight contrast to the results from the simulation studies, and may be due to a lack of explanatory power of the assumed imputation model with the available auxiliary data. Alternatively, this phenomenon can arise as a result of increased uncertainty in the imputation procedure. That is, whereas CCA uses less data, the MI methods can introduce nontrivial uncertainty around the imputed values and, therefore, increase the width of the confidence interval. Finally, although SI had similar confidence limits to the complete data on average, SI was also the only method for which the averaged confidence intervals did not fully cover the range of the complete data confidence interval in Scenarios 2 and 3. MI, MMI, and B-MMI performed similarly, but had noticeably wider average confidence intervals than CCA or SI. Although there is no ground truth to compare to, this may indicate that the set of MI procedures are more faithfully accounting for the uncertainty due to missing effect modifier data.
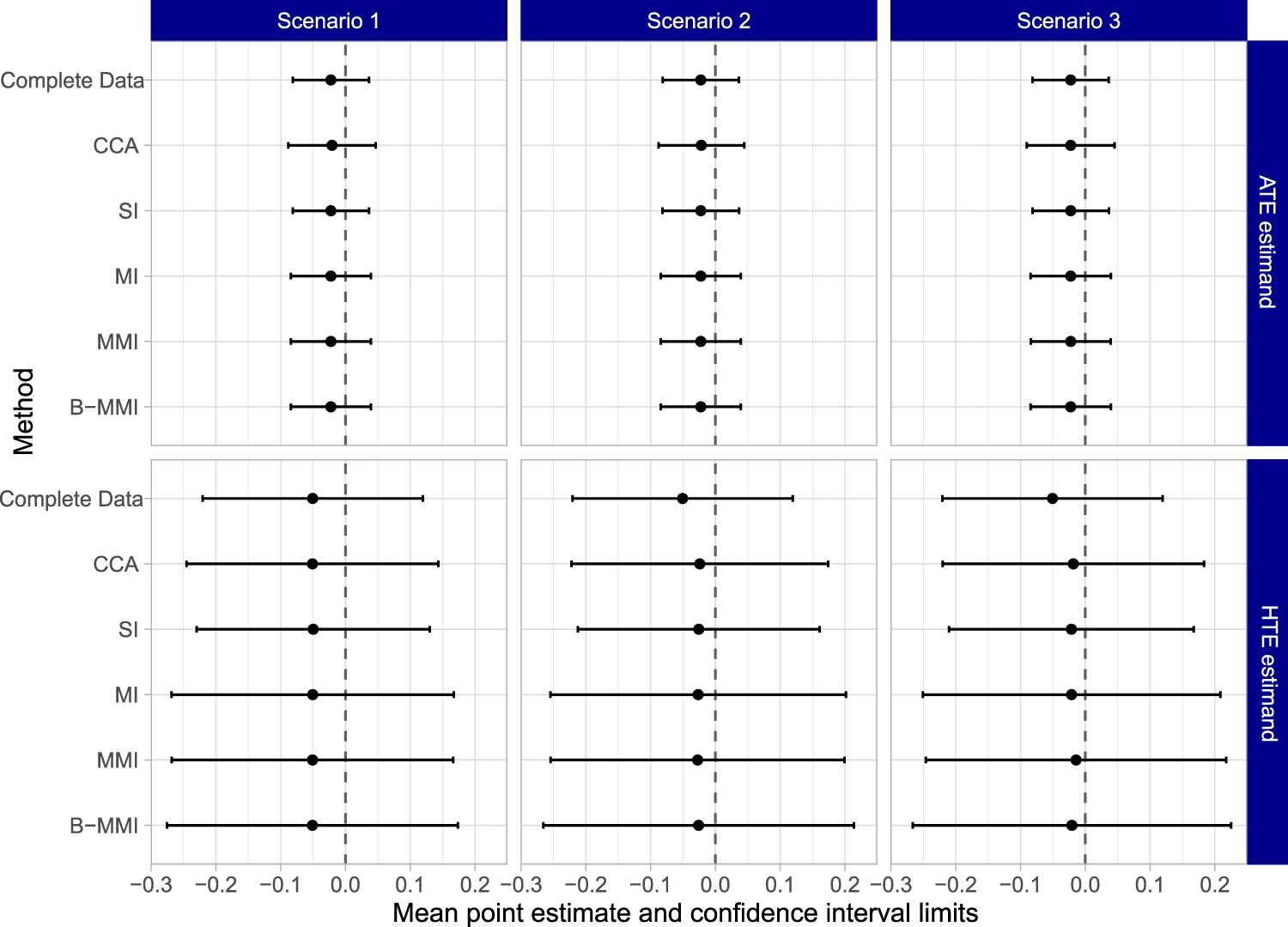
Results for the work, family, and health study data application. The top row shows the average point estimate and average confidence interval limits for each method across 500 replications of the simulation procedure for the ATE estimand. The bottom row shows the parallel results for the HTE estimand. HTE: heterogeneous treatment effect; ATE: average treatment effect.
Supplemental Tables 1 and 2 report the percentage of iterations where each methods’ confidence intervals were narrower than the corresponding complete data confidence interval, for the ATE and the HTE estimands, respectively. Notably, MI, MMI, and B-MMI almost never produced a narrower confidence interval compared to the complete data confidence interval, except for at most two iterations in a given scenario. In contrast, CCA yielded a narrower confidence interval compared to the complete data counterpart between 9.0% and 16.2% of the time, depending on the scenario. Furthermore, SI reported a narrower confidence interval than the complete data counterpart between 22.2% and 48.6% of iterations across all scenarios. This adds evidence to our Section 4 results that SI often yields overly narrow confidence intervals. Supplemental Tables 3 and 4 report a related metric, the percentage of iterations where each methods’ 95% confidence interval completely covered the complete data 95% confidence interval. A very low value of this metric could indicate that an approach is frequently excluding plausible parameter values. For the ATE estimand, MI, MMI, and B-MMI almost always covered the complete data interval, while CCA and SI tended to cover the complete data interval only around a third of the time. For the HTE estimand in Scenario 2, CCA, SI, MI, MMI, and B-MMI reported covering the complete data confidence interval 34.0%, 19.4%, 60.6%, 63.2%, and 69.4% of the time, respectively. Results for other scenarios were similar, and collectively indicate that SI likely did not appropriately account for uncertainty, while B-MMI appropriately accounts for more uncertainty on average than other approaches.
Finally, to further investigate the variability of the point estimates across replications, we provide box plots of the point estimates in Supplemental Figure 7. The complete data point estimate and 95% confidence interval are presented on the left of each panel for a reference. The top row displays results for the ATE estimand, where CCA exhibited much higher variability than the other approaches. SI exhibited slightly higher variability than the other imputation approaches. All methods’ median point estimates were close to the complete data estimate. The bottom row of the figure displays results for the HTE estimand, and suggests that no method had a median point estimate equal to the complete data point estimate in Scenario 2 or 3. While all methods tended to report point estimates within the complete data confidence interval, each had point estimates outside this range in either Scenario 2 or 3. As expected, SI has highly variable point estimates, with several point estimates outside of the complete data confidence interval. MMI reports a bias-variance tradeoff in Scenario 3, with its median point estimate being the furthest from the complete data point estimate, but also having less variable estimates overall.
We acknowledge that there is no known truth in this single data application, and the complete data results are themselves subject to variability. Thus, whether or not confidence intervals “match” those for the complete data should only be interpreted with caution. However, when considering all metrics together, this application provides strong evidence that CCA and SI are likely overly confident, and that MMI and B-MMI may be most faithful in capturing uncertainty. For the complete data, both the ATE and the HTE estimates were close to null with relatively wide confidence intervals, indicating no ATE and no effect heterogeneity. Although it is difficult to define the scale of meaningful treatment effects when the outcome is an average of Likert variables, the confidence intervals exclude treatment effects of an absolute value larger than 0.1, which would correspond to a very minor difference between groups.
In this article, we compared several methods to address missing effect modifier data for assessing HTE (and for assessing ATE as a direct product of the analysis model) in CRTs using simulation studies and then used a completed CRT where we imposed selected missing data patterns to compare their performance using real data. The key findings of our work are as follows. First, MMI and B-MMI had the lowest bias and highest coverage across the settings we investigated, with B-MMI being the only method to achieve nominal coverage rates across several scenarios considered when the imputation models were approximately correct. However, when imputation models were strongly misspecified, imputation approaches performed poorly, and could even be worse than CCA in several scenarios. Second, using an imputation model with only main effects for the outcome, treatment, and covariates resulted in especially poor performance when targeting a non-null HTE estimand. This could have important implications in practice as imputation models with only main effects are the default specification in many software packages, such as the popular
Summary of findings from the simulation and data application comparisons and recommendations for practitioners.

HTE: heterogeneous treatment effect; MSE: mean squared error; SI: single imputation; MI: multiple imputation; MMI: multilevel multiple imputation; B-MMI: Bayesian multilevel multiple imputation; CCA: complete-case analysis; ATE: average treatment effect.
A summary of findings and recommendations for practitioners reflecting our observations is provided in Table 2. As always, assessing the plausibility of MCAR and MAR assumptions should be the first step in addressing missingness. Then one should consider the assumptions of different methods and model specifications, noting that while each imputation method assumes MAR, they are distinguished by whether they account for partial or more complete uncertainty in the imputation process. These distinctions were informed by the simulations and real data analysis, where some methods were more robust to specifying imputation models which were incompatible with the substantive model. Overall, B-MMI has been shown to be a promising approach for handling missing effect modifier data in CRTs, and generally had the strongest performance among the methods that we considered. To facilitate implementation, all simulation and data application code are available at https://github.com/bblette1/CRT-miss-mod. For practitioners that do not perform, or prefer, analysis under the Bayesian paradigm, approximate (frequentist) MMI also exhibited acceptable performance for missing modifier data in CRTs in several scenarios. However, there may be bias or non-nominal coverage when using MMI or B-MMI in similar ways that we have in this article, for example, when the imputation models are not truly compatible with the outcome model. This was seen for the ATE estimand, where no method achieved nominal coverage or preserved the Type I error rate in Scenario 1 of the simulation study. Although using three-way interactions in the imputation models was often sufficient for good performance, there does not exist a joint model for which the implied conditional outcome model is a linear model with random intercept and the implied conditional modifier model is a logistic model with random intercept. This highlights the importance of and potential challenge in the imputation model specification in CRTs when the interest lies in assessing HTE (and ATE after effect modifier adjustment) with a single binary effect modifier. These recommendations will not necessarily be generalizable to other settings such as scenarios with continuous effect modifiers or binary outcomes, and future work in necessary to expand our studies to those settings.
There are several paths forward that have been illuminated by these comparison studies. First, “substantive-model compatible” approaches defined for individually randomized trials or observational studies28,56–59 could be compared and may be valuable tools in the CRT setting. These often entail deriving the correct imputation model once an outcome model is specified, and (as the correct model will likely have a non-standard form) sampling from this derived model using MCMC. Joint modeling methods for individually randomized trials and observational studies60–62 may be similarly useful. Some of these are likely adaptable to the CRT setting, while others may require extension as they are either not designed for a multilevel setting, do not have off-the-shelf software, and/or are dependent on specific outcome model forms. Second, the use of non-parametric imputation approaches that are flexible enough to be compatible with a large range of outcome models also merit deeper examination. One procedure that may be especially useful for this is imputation via BART.63,31,64 Not only would such methodology be useful for handling missing modifiers in CRTs, but it is also under-explored in individually randomized trial and observational study settings where studying HTE introduces similar model compatibility issues. If such an approach can perform well without requiring the expertise to both derive an implied imputation model and code an appropriate sampling procedure, it would be practical for assessing HTE with missing modifier data. We plan to pursue this methodological extension in a separate report.
Our studies have several limitations. First, although we considered a wide range of data-generating mechanisms, there are inevitably many possible data structures that were not included in the simulation studies. For example, all data generating mechanisms generated modifier data independently of the baseline covariates. While this still implies a complex imputation model, as described in the Section 4, it leaves out plausible scenarios where auxiliary covariates have a direct impact on the modifier. Previous work indicates that such correlations may not greatly impact simulation results, 17 but this still may be an interesting area for future exploration. Furthermore, we restricted our comparisons to scenarios with one individual-level binary effect modifier, which are common in practice when assessing subgroup-specific treatment effects or HTE. 11 Future work should consider method performance when modifiers are categorical or continuous variables, when effect modifiers are measured at the cluster level, or when there are multiple effect modifiers that are subject to missingness. In addition, for an individual-level effect modifier, varying the ICC of the effect modifier may be useful in assessing the operating characteristics of the MMI and B-MMI methods. To address data with multiple missing variables in CRTs, imputation via joint modeling and imputation via fully conditional specification should also be compared in future research; see Audigier et al. 65 for such a comparison in the observational study setting. In general, the biases found should only amplify in scenarios with more than one effect modifier, such that our results are still informative and reflective of the recommended practice and caveats in that setting. Second, only MCAR and MAR scenarios were considered across the simulations and data illustration. Imputation-based approaches may not perform as well on data where modifiers are MNAR, and sensitivity methods that account for the multilevel feature of the CRT data may be useful to address MNAR. Third, in the simulation study, standard robust standard errors were used for all GEE outcome models. However, previous research has shown that bias-corrected standard error estimates are often needed when there are fewer than 30 clusters, especially for estimating a cluster-level effect parameter with missing outcomes.66,67 In our simulation results with missing effect modifier data, the standard robust standard error estimator seemed adequate for as few as 20 clusters, but using bias-corrected standard errors may improve the slight undercoverage for the ATE estimand in a few settings. Finally, while this article focused on imputation approaches, other methods for handling missing data in CRTs such as weighting-based methods 24 may be useful and require further developments to address missing effect modifier data in the CRT setting.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802241242323 - Supplemental material for Assessing treatment effect heterogeneity in the presence of missing effect modifier data in cluster-randomized trials
Supplemental material, sj-pdf-1-smm-10.1177_09622802241242323 for Assessing treatment effect heterogeneity in the presence of missing effect modifier data in cluster-randomized trials by Bryan S Blette, Scott D Halpern, Fan Li and Michael O Harhay in Statistical Methods in Medical Research
Footnotes
Acknowledgements
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Research in this article was partially supported by the Patient-Centered Outcomes Research Institute® (PCORI® Awards ME-2020C1-19220 to Michael O Harhay and ME-2020C3-21072 to Fan Li). Michael O Harhay and Fan Li are also funded by the United States National Institutes of Health (NIH), National Heart, Lung, and Blood Institute (grant number R01-HL168202). All statements in this report, including its findings and conclusions, are solely those of the authors and do not necessarily represent the views of the NIH or PCORI® or its Board of Governors or Methodology Committee.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.