
Abstract
A deep reinforcement learning application is investigated to control the emissions of a compression ignition diesel engine. The main purpose of this study is to reduce the engine-out nitrogen oxide
Keywords
Introduction
Heavy-duty and medium-duty diesel engines are commonly used for public transportation and delivering goods. The high combustion efficiency and fuel conversion efficiency advantages (especially at full-load operation) along with the long lifetime and durability of diesel engines have made their usage widespread in a wide range of transportation applications.1,2 Despite all the advantages, diesel engines contribute significantly to air pollution worldwide. Although hybridization and electrification are getting increasing market share for passenger vehicles, it is expected that this will occur more slowly for heavy-duty applications due to the limited battery range, high battery costs, and increased total cost of ownership. 3 Therefore, strategies to minimize the effect of diesel engine emissions on the environment are still needed.
Traditionally, engine control units (ECUs) use a feedforward controller that is based on two-dimensional look-up tables, also known as calibration maps, that are generated on a test bench to ensure the engine performs optimally while meeting power demand and enhancing fuel economy, and durability. Additionally, engine emissions are also evaluated during the creation of the these calibration maps making the calibration complicated and time-consuming. These tables must then be further tested in real driving conditions to meet new real driving emission legislation. 1 The use of a feedback controller, especially a model-based optimal controller, is a promising method to help solve the ever-increasing calibration efforts. Model-based methods such as linear quadratic regulator (LQR), 4 sliding mode controller (SMC),5,6 adaptive,7,8 and model predictive control (MPC)9–11 have been previously investigated for engine applications. The two main drawbacks of these model-based controllers are their sensitivity to model accuracy and the required runtime especially for online optimization. There is often a trade-off between these two as improving model accuracy requires increased model complexity and these complex models usually exhibit nonlinear behavior requiring a more complicated control law such as nonlinear model predictive controller (NMPC). 12 Instead of using a model-based controller, the alternative option is using a model-free controller. Machine reinforcement learning (RL) 13 is one of the powerful methods in generating optimal options without the requirement of the model. Another well-known model-free controller in control theory is iterative learning controller (ILC). 14 As ILC is also a model-free learning-based control strategy, it will be compared with both RL and a model-based state-of-the-art deep learning–based MPC.
Machine learning (ML) is a powerful tool that has been used to address various engineering problems and has been shown to be particularly useful in control engineering, especially when deriving an exact system model is difficult. 15 In general, supervised learning, unsupervised learning, and RL are the main categories of ML. Unlike supervised and unsupervised learning that operate using a static data set, RL works using dynamic data. 16 The main goal of RL is generating the optimal outcome by finding the best sequence of actions. Unlike classical ML, RL uses an agent to explore, interact with, and learn from the defined system environment. The RL agent learns by receiving the environment observation and reward and generating a sequence of actions to reach a specific goal. RL has a similar structure to control theory. The goal is to determine the correct inputs into a system that would generate the desired system’s behavior. The controller is called the policy, the actuator command provides the actions, and the plant is the environment in RL. As we tune the controller using a tuning algorithm or adaptation law, the RL policy updates are based on the RL algorithm. 17 The RL algorithm can be either model-free or model-based, and due to the model requirement, the model-free algorithm has been the main focus in engineering applications.16,17 One common algorithm used for model-free RL is Q-learning. In Q-learning, the value of an action for a particular state is learned and the optimal policy is found by maximizing the expected value (Q-value) of the total reward. 13
When an agent performs an action which has the highest reward without further exploring the environmental space, it is considered a greedy policy. In continuous spaces, obtaining a greedy policy to optimize the action at each time interval is extremely slow. Therefore, sometimes, it is not possible to apply Q-learning easily to continuous action systems. However, an actor-critic method based on the deterministic policy gradient (DPG) algorithm is a suitable choice for a system with a continuous space. 18 The DPG learning procedure is robust and stable because of the off-policy network training; it takes samples from the replay buffer (which is a finite size cache used to store previous samples from the environment). This allows for the reduction of the correlation between samples. 19 Off-policy learning is independent of the agent’s actions and it determines the optimal policy regardless of the agent’s motivation. It means that in contrast with on-policy learning, where the agent learns about the policy to generate the data, the off-policy estimates the reward for future actions and adds value to the new state without following any greedy policy. 13 The deep deterministic policy gradient (DDPG) agent is a model-free and off-policy RL algorithm where an actor-critic RL agent calculates an optimal policy by maximizing the long-term reward. One of the differences between DDPG and DPG is that DDPG uses a deep neural network (DNN) as an approximator in DDPG to learn for large state and action pairs. 19
Using DNN in RL is referred to as deep reinforcement learning (deep RL) and has allowed for a wide variety of complicated decision-making tasks that were previously unfeasible to be solved. 13 For example, deep RL is of interest in applications such as robotics and autonomous driving. 20 Earlier versions of RL algorithms had challenges in the design of the feature selection. In contrast, deep RL has been able to successfully overcome complicated tasks even when a limited amount of previous information is available. This is possible because of the deep RL capability to learn various levels of abstractions from data.20–23 Deep RL has also been used in computer science for many applications. 13 Utilizing deep RL in real-world applications, especially in engineering applications, has started to increase in recent years. Deep RL has been successfully used for control of an unmanned aerial vehicle, 24 quadrotor system, 25 autonomous vehicles,26,27 wind farm control, 28 torque distribution of electric vehicles, 29 and robotic applications.30,31
RL has been used for automotive powertrain control systems especially in energy management of hybrid electric vehicles32–34 and for internal combustion engines.35–40 Q-learning RL is used as idle speed control of a spark-ignition (SI) engine by controlling the spark timing and intake throttle valve position. 41 Similar studies have been carried out for diesel engine idle speed control by controlling the fuel injection timing. 36 RL has also been used for emission control of SI engines.37,38 A very limited number of studies have been carried out utilizing RL for internal combustion control, and most of the existing work has focused on SI engines. To the authors’ knowledge, deep RL algorithms have not been previously implemented for diesel engine performance and emission control. Safety concerns and constraint violations of pure learning controllers in highly complex systems such as internal combustion engines have hindered the development of these learning controllers. Fortunately, recent studies have addressed output constraint enforcement in the learning-based controller using a safe learning filter. This method enforces the output constraints and provides a method to implement safe learning RL.42–45 To implement the safety filter, a simplified version of a second optimization-based method to enforce output constraints is used. Instead of an MPC-based filter, an online optimization with a single-step optimization is used where the safe control action minimizes the deviation from the RL-generated control action subject to constraints determined using a quadratic programming (QP) solver during the training of the RL agent. Then, the RL agent must learn the constraints using the RL algorithm and prior knowledge of system constraints.
Although RL is now receiving attention from the control system community, a learning controller is not a new concept.14,46 One of the well-known learning-based controllers is ILC which is used to improve the tracking performance of a system in the presence of repetitive input or disturbances.47–49 ILC was first introduced in 1984 by Arimoto et al.
14
and since then has been used for various control problems. ILC has a simple structure and is computationally efficient for real-time applications and can have stability guarantees. Different types of ILC have been implemented for internal combustion engine control. ILC has been used in SI engine load control,50,51 a dual-fuel control of homogeneous charge compression ignition (HCCI) engine,
52
SI engine speed and air-to-fuel ratio,
53
parameter optimization in a turbocharged SI engine,
54
variable injection rate control for compression ignition (CI) engines,
55
diesel
Safe learning in the content of deep RL used to control diesel engine emissions is not available in the literature. Therefore, a deep RL with and without safety filters is designed and compared to address this gap. Then to compare RL to ILC, ILC and safe ILC are also designed. Additionally, RL is compared with a deep recurrent neural network–based nonlinear model predictive controller that has been developed in our previous study. 59 The main contributions of this article are as follows:
Design of a deep RL controller for diesel engine
Design of a safe filter that provides safe RL for diesel engine emission control;
Comparison with a classical learning-based control, ILC, and a long-short-term memory-based nonlinear model predictive controller (LSTM-NMPC 59 ).
This article is organized into five sections. The first section provides an introduction, literature review, and main contributions of this article. In the “Engine simulation model” section, the experimental setup and detailed physics-based modeling are explained. The main methodology of the safe deep RL are discussed in section “Deep RL.” Details regarding the development of the ILC are explained in section “ILC.” The “Results and discussions” section illustrates the performance of designed controllers and provides a comparison of the controllers. Finally, the main conclusions of this article are summarized in section “Summary and conclusion.”
Engine simulation model
This study uses a 4.5-L diesel engine manufactured by Cummins and is located in the advanced internal combustion engine lab at the University of Alberta, Canada. The main specifications of this engine are presented in Table 1.
Engine specifications.

To train the deep RL used in this study and to compare with NMPC and ILC, a detailed physical model (DPM) was developed in GT-Power software and validated using experimental data in our previous studies.60,61 This DPM is implemented in GT-Power and the model includes several physical and chemical sub-models for simulating the combustion phenomenond gas exchange process of diesel combustion. The DPM was calibrated using experimental in-cylinder pressure, injection timing, and intake air mass flow and temperature over the various engine operating range. Optimal parameter values are determined by means of the genetic algorithm (GA). Additional details of the DPM development and structure are presented in the authors’ previous works.60,61
The developed DPM predicts the experimental in-cylinder pressure over the entire engine cycle (see Figures 5 and 6 in the work by Shahpouri et al.
60
) with the maximum in-cylinder pressure and intake manifold pressure error of
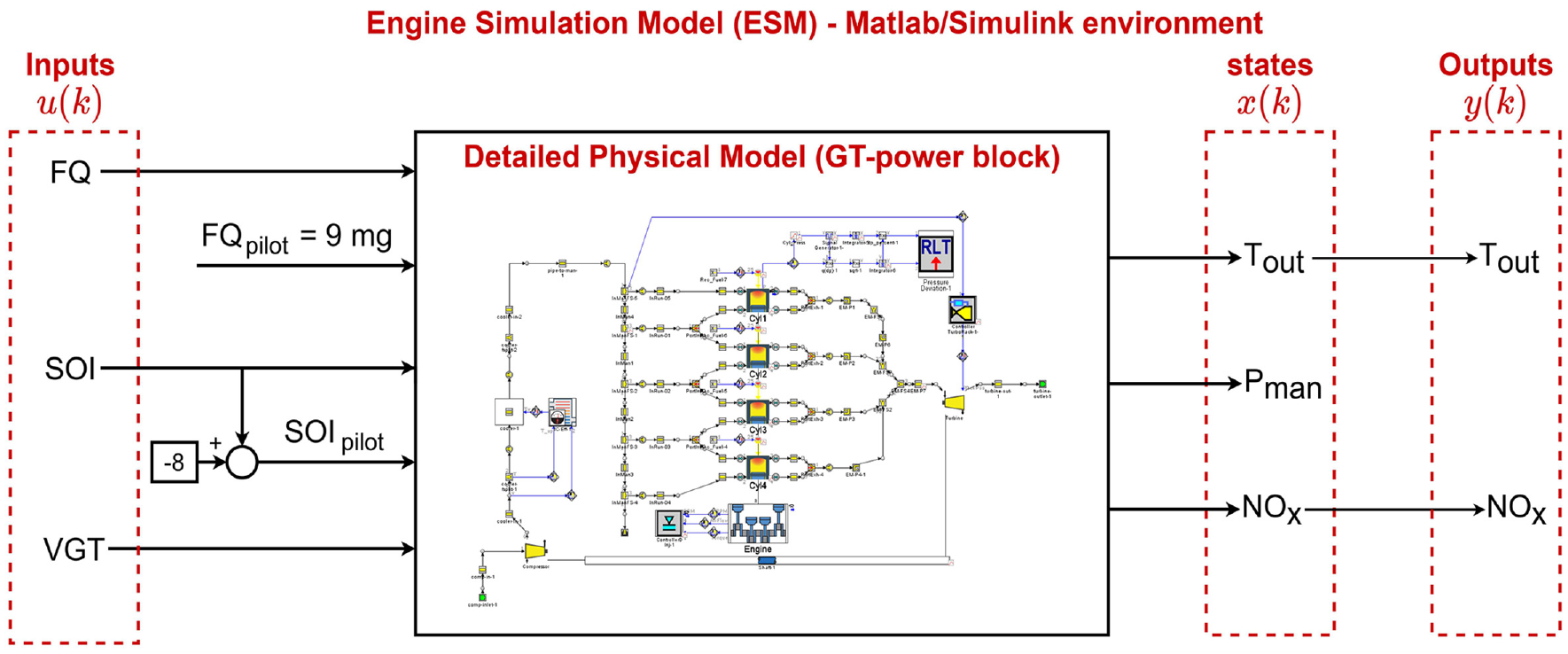
Input, output, and states of engine simulation model (ESM) to simulate engine torque
Deep RL
DDPG agents algorithm
A DDPG agents algorithm is used to minimize the engine-out emissions and fuel consumption while maintaining the same load. DDPG is a model-free and off-policy RL algorithm where an actor-critic RL agent calculates an optimal policy by maximizing the long-term reward. When a DNN is used, the DDPG algorithms are referred to deep DPG. The psudo code of DDPG is shown in Algorithm 1. 19 During training, the actor and critic are updated by the DDPG algorithm at each sample time, and the agent stores past experiences using an experience buffer. The actor and critic are then updated using a mini-batch of those experiences randomly sampled from the buffer. Also, the policy’s selected action is perturbed using a stochastic noise model at each training step. 17

In the DDPG algorithm (Algorithm 1), first, a copy of the actor
Safe DDPG
Despite all the advantages of deep RL, it relies on the experience and interaction with the environment (here ESM). To enforce output constraints, the following optimization-based filter is added to DDPG algorithm
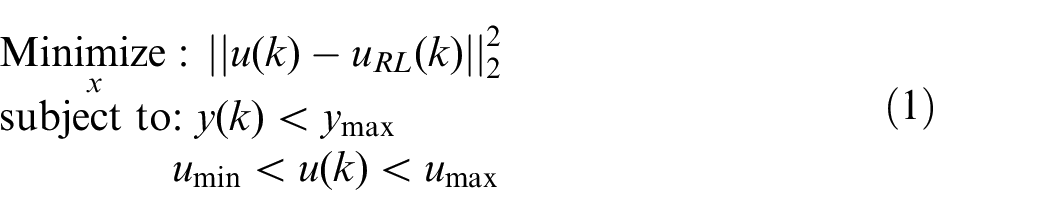
where
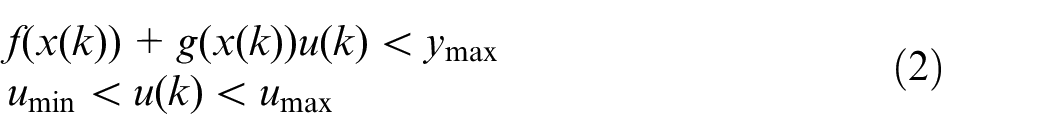
where
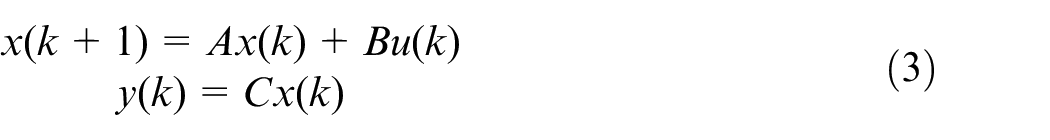
where

where the constrained output
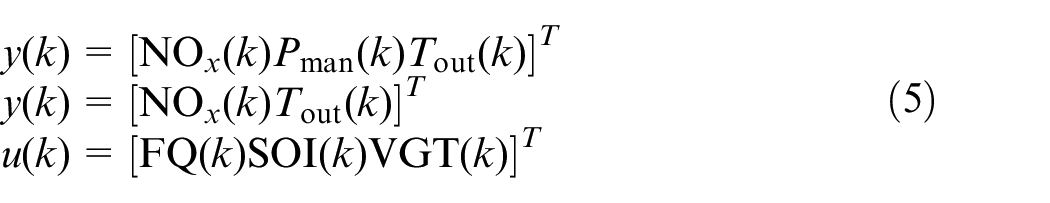
where

Substituting system matrices (equation (4)) in equation (6) results in the following

To simplify the control problem, the pre-injection is kept constant at 9 mg that is injected 8°CA before the main injection.
The upper bound of
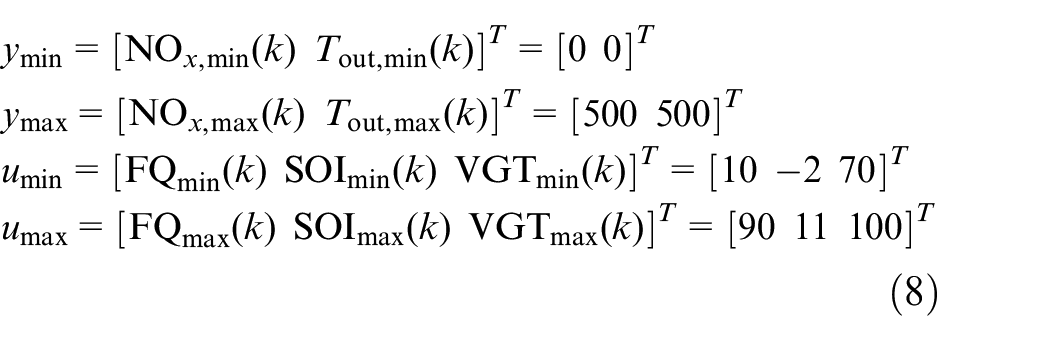
A schematic of safe DDPG for minimizing diesel engine emissions and fuel consumption while maintaining load is shown in Figure 2. The states of the system for the DDPG algorithm are defined as follows
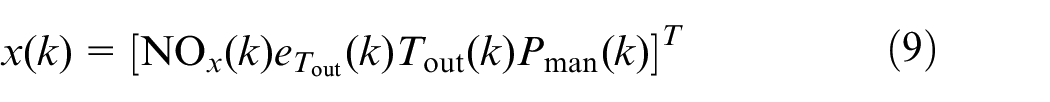
where
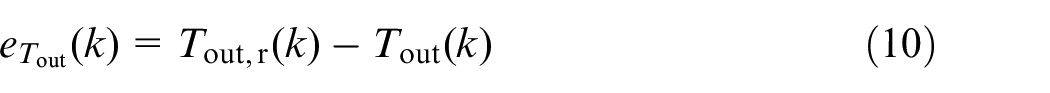
where
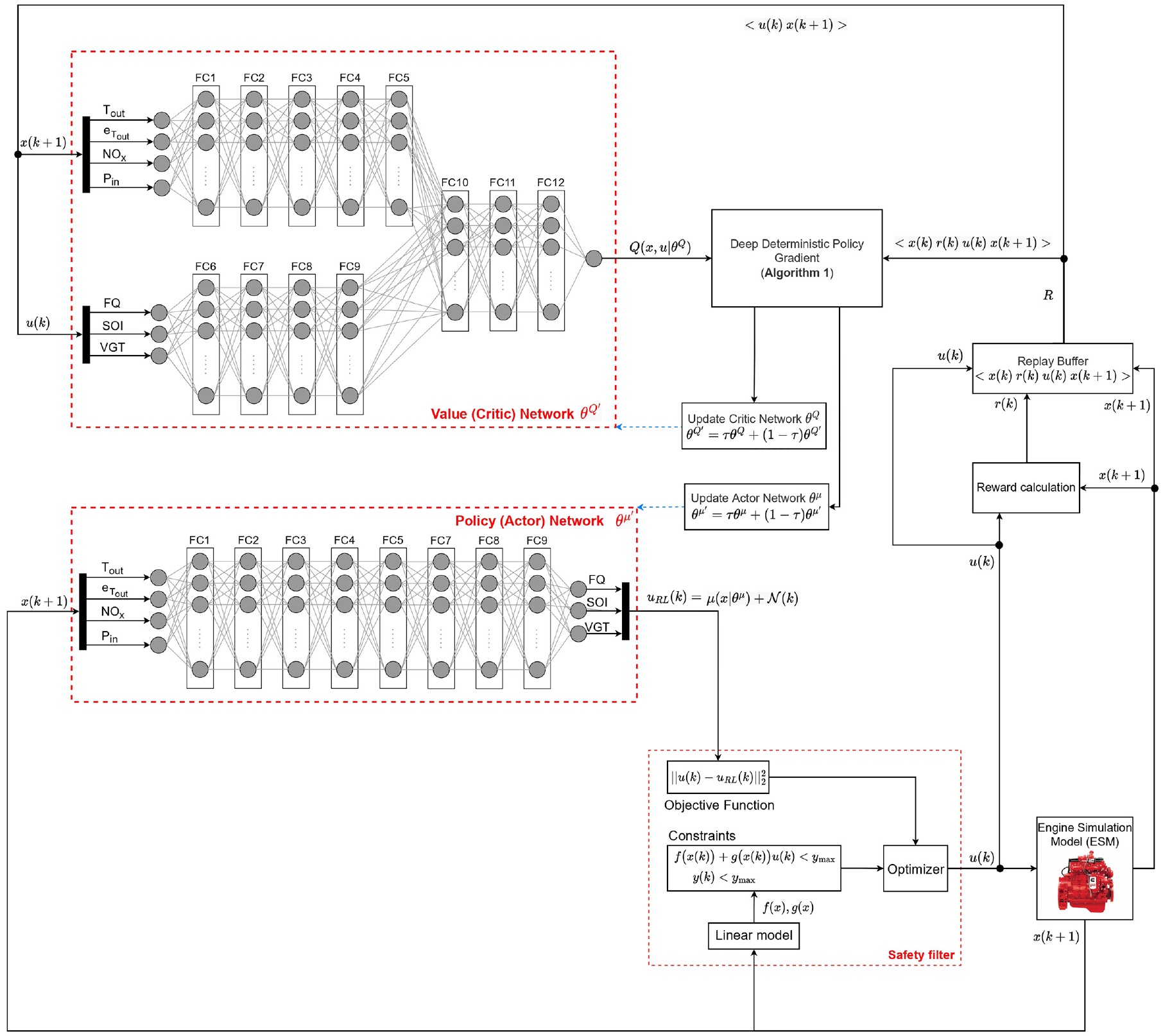
Safe deep deterministic policy gradient schematic to minimize diesel engine fuel consumption and reducing
To achieve the control objective, and output torque error, its derivatives, the FQ and
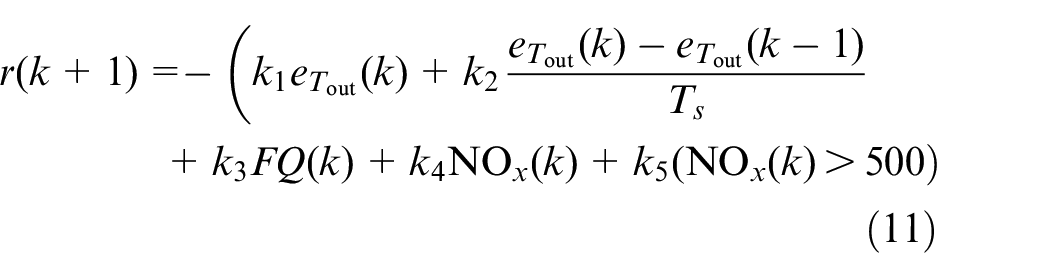
where
Figure 2 shows the network structure where the actor has nine fully connected layers (FCs) with a layer size of 64. The critic has 12 FCs with the same layer size (64) as the actor in each layer. The activation function of both the critic and actor FCs is rectified linear unit (ReLU) other than the output layers (FC12 in critic and FC9 in actor). The scaling layer is used in the output layers to standardize the output values. To train both the DDPG and safe DDPG, a mini-batch size of 64 and a smoothing factor of 0.001 are used. For training RL, the Adam optimizer with a learn rate of 0.0001 is used. A noise model has been implemented with a variance of 5.66, 0.42, and 0.01 for
Safe RL versus RL
In this study, two agents have been developed, a traditional DDPG implementation, called RL, and a DDPG with a safety filter to constrain the output, called safe RL. In both agents, the structure of actor and critic are kept same. The episodic reward that the agent receives versus the episode number is shown in Figure 3. A 40 s simulation (500 engine cycles) with a random load request,
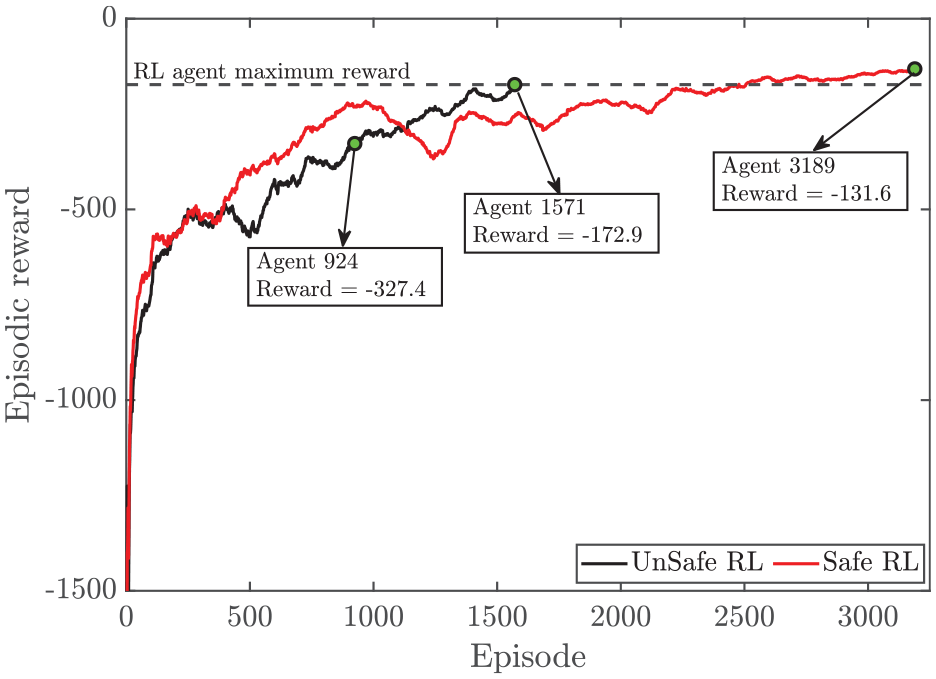
Episodic reward versus episode for safe RL and RL.
The comparison between the selected agents for both the safe RL and RL is presented in Figure 4. As shown, regardless of the training process, both agents are capable of maintaining load and minimizing
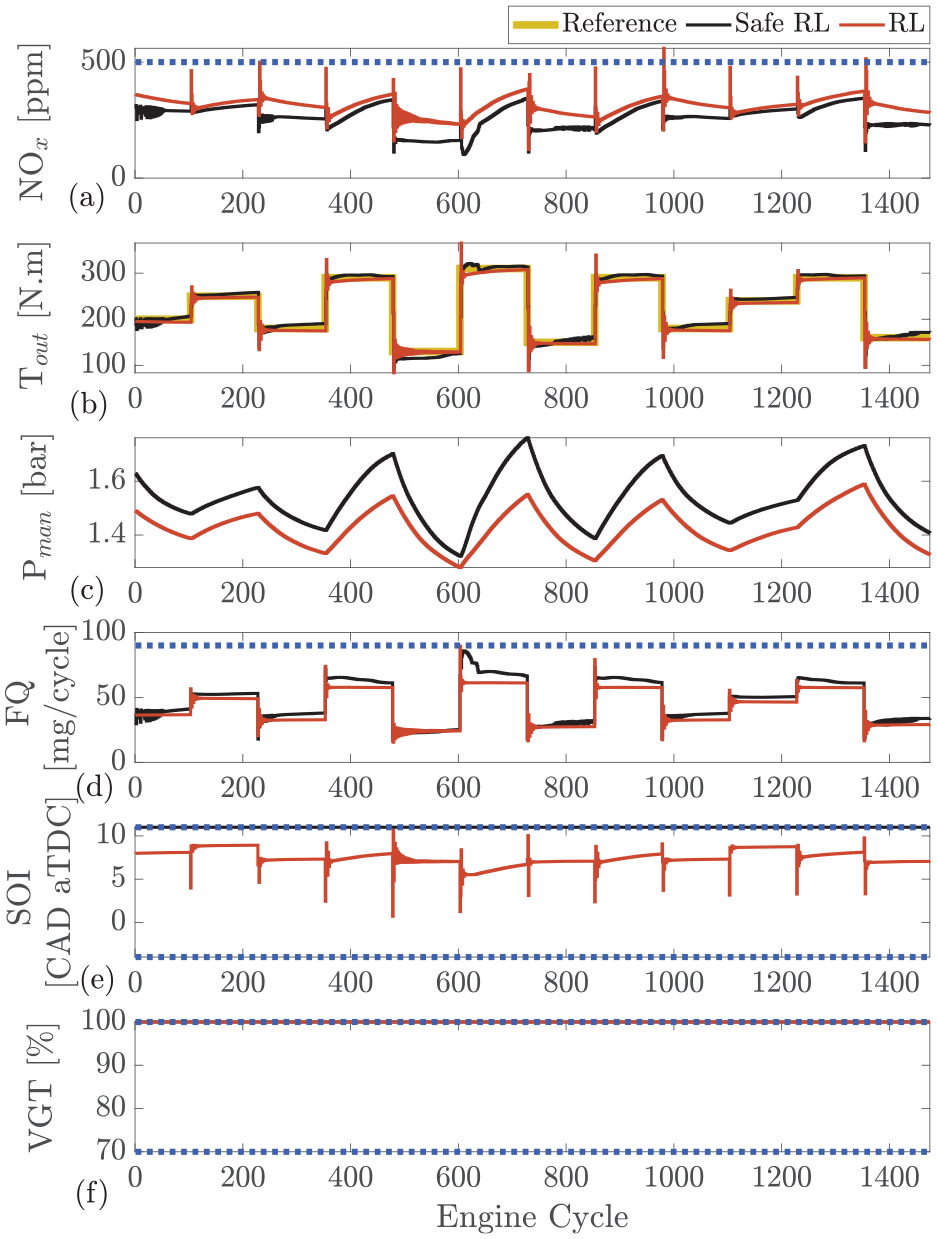
Safe RL versus RL: comparison between two agents that reach to maximum reward for safe RL (agent 3189 in Figure 3) and RL (agent 1571 in Figure 3) at engine speed of 1500 r/min. (a) engine-out
As shown in Figures 4 and 5, the NOx emissions spike following each step. This is a result of SOI oscillating at the beginning of each cycle and jumping to advance combustion for a couple of engine cycles. Therefore, in those engine cycles, an increased amount of NOx is formed.
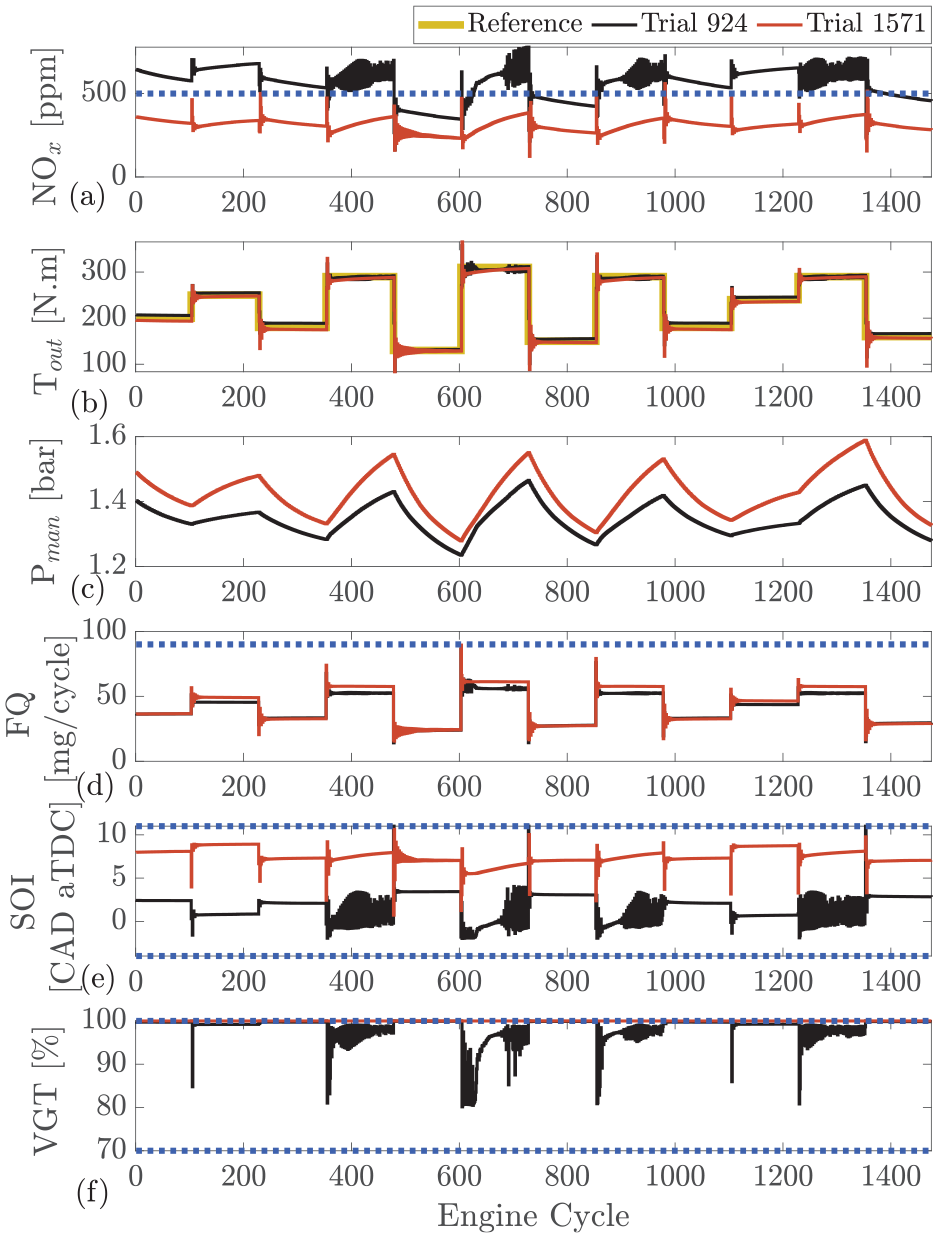
RL during training: comparison between agent in middle of training (agent 947 in Figure 3) and agent that reaches to maximum reward (agent 1571 in Figure 3) at engine speed of 1500 r/min. (a) engine-out
The two final selected agents perform well; however, a more interesting comparison can be made during the training of the agents. Figure 5 shows the two agents of the RL during training. These agents are also presented in Figure 3. One agent is in the middle of the training process at episode 924 and the other is the final agent that has reached the maximum reward at episode 1571. The oscillation observed from the controller during the early stages of training (episode 924) is due to the white noise used to excite the system to allow for increased learning. When compared to agent 924, the fully trained agent 1571 is significantly better at observing all constraints. For the
ILC
One of the fast learning–based controllers that has common elements with RL is ILC. ILC has a simpler structure than RL as its control law update includes two main filters and can be defined as follows
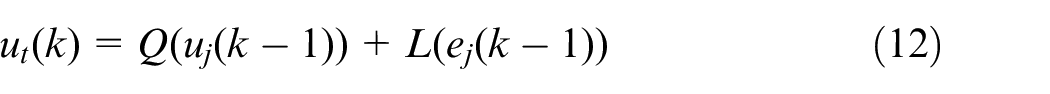
where
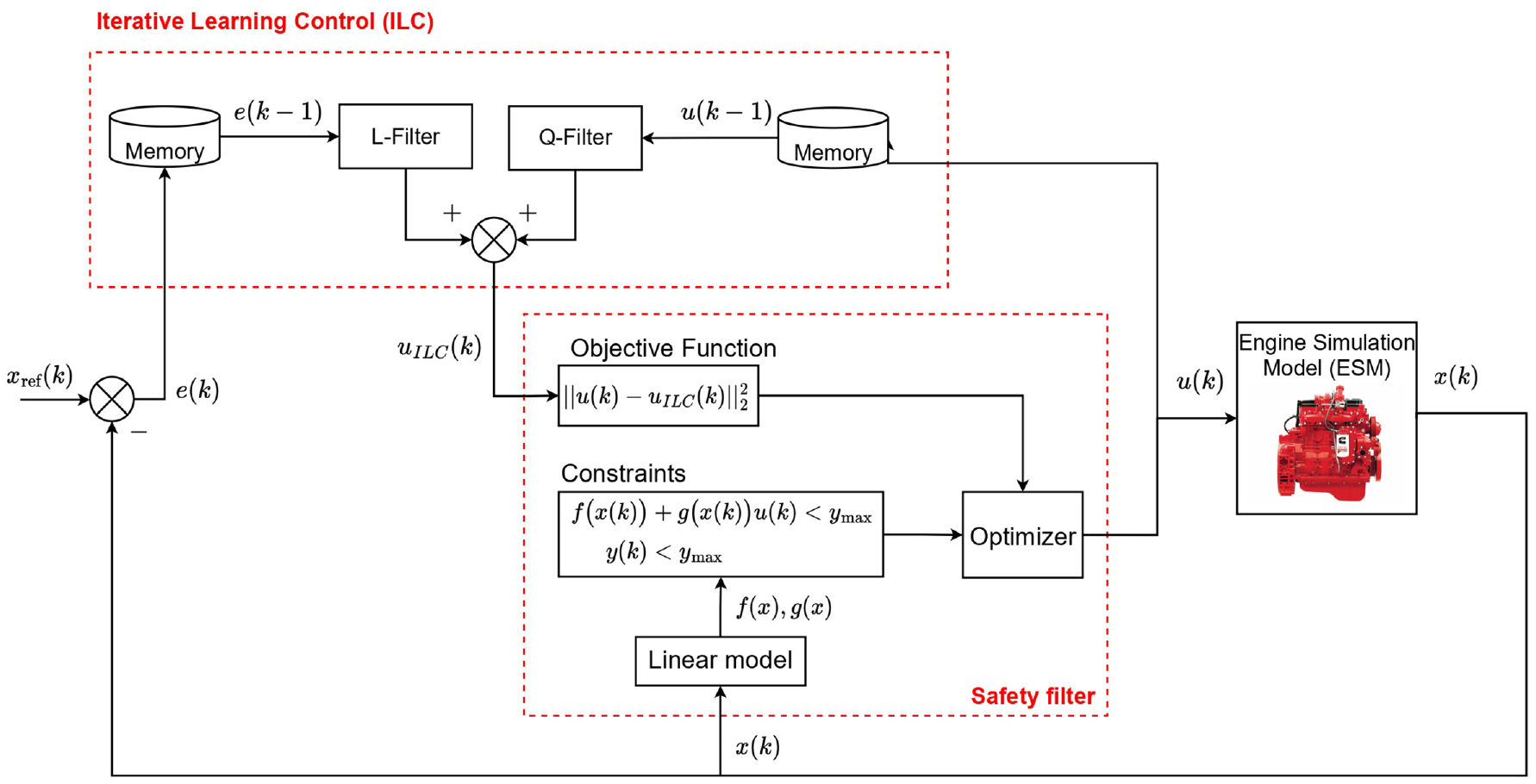
Safe iterative learning control block diagram.
For implementation purposes, this is slightly different compared to RL. Because of the nature of repetitive input requirements, a repetitive reference has been implemented and the error between the actual state and reference is provided to the ILC. The error can be defined as follows
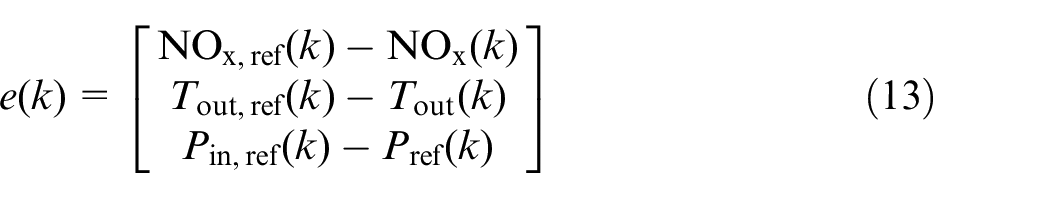
where
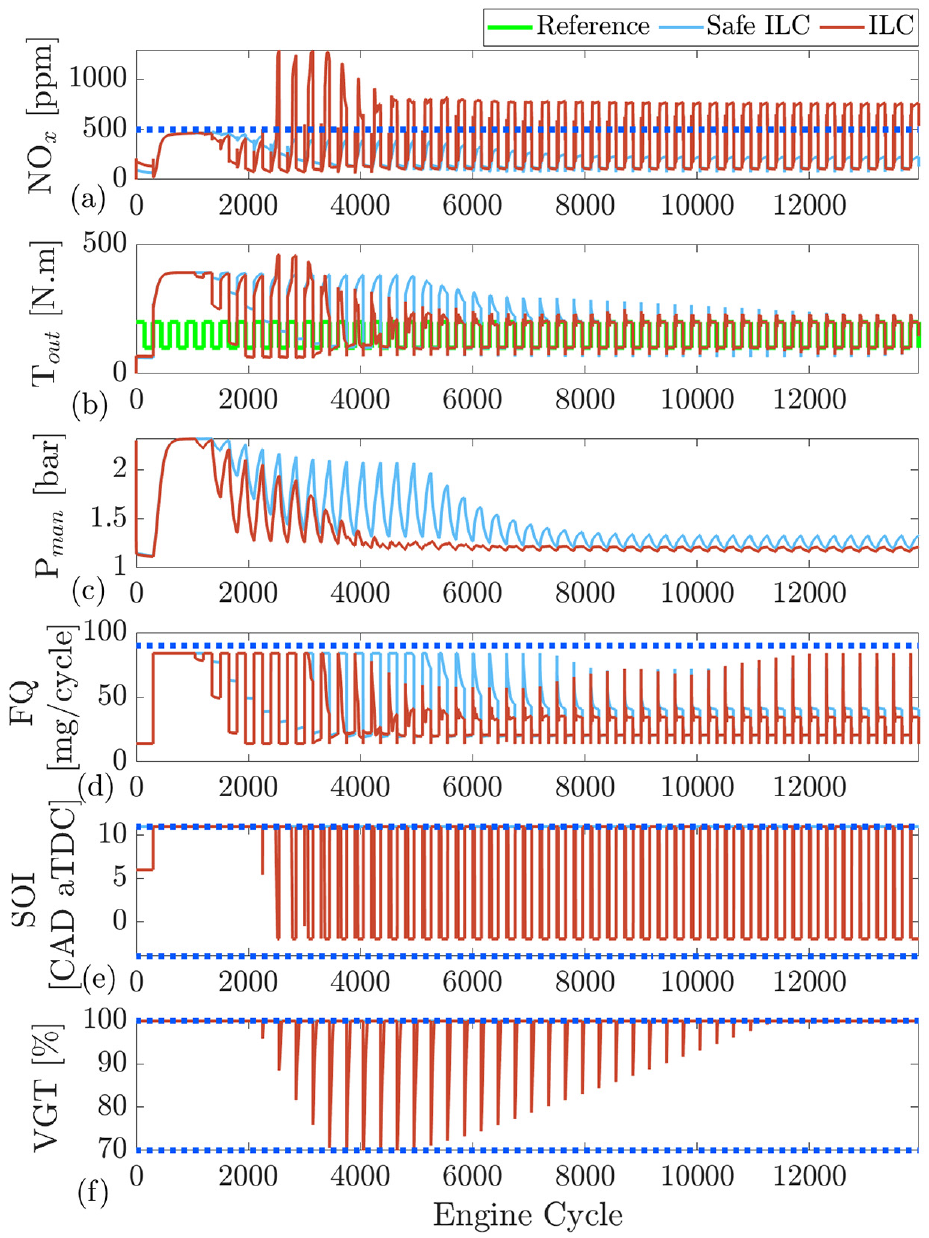
Training ILC and safe ILC at engine speed of 1500 r/min: reference is repeated every 300 cycles and 46 ILC iterations are shown: (a) engine-out
Results and discussions
In this section, the two developed controllers, safe RL and safe ILC, will be compared to a previously developed LSTM-NMPC. The NMPC controller previously developed in the work by Norouzi et al. 59 is used to compare the RL controllers here with MPC controller. All developed controllers are compared to a Cummins-calibrated ECU which modeled the simulation environment with the DPM and denoted “Benchmark (BM).”
The comparison between the RL, LSTM-NMPC, and BM controllers is presented in Figure 8. Both controllers solve a similar optimization problem but the reward function in RL has a slightly different cost function compared to the LSTM-NMPC. The cost function of LSTM-NMPC is defined as follows
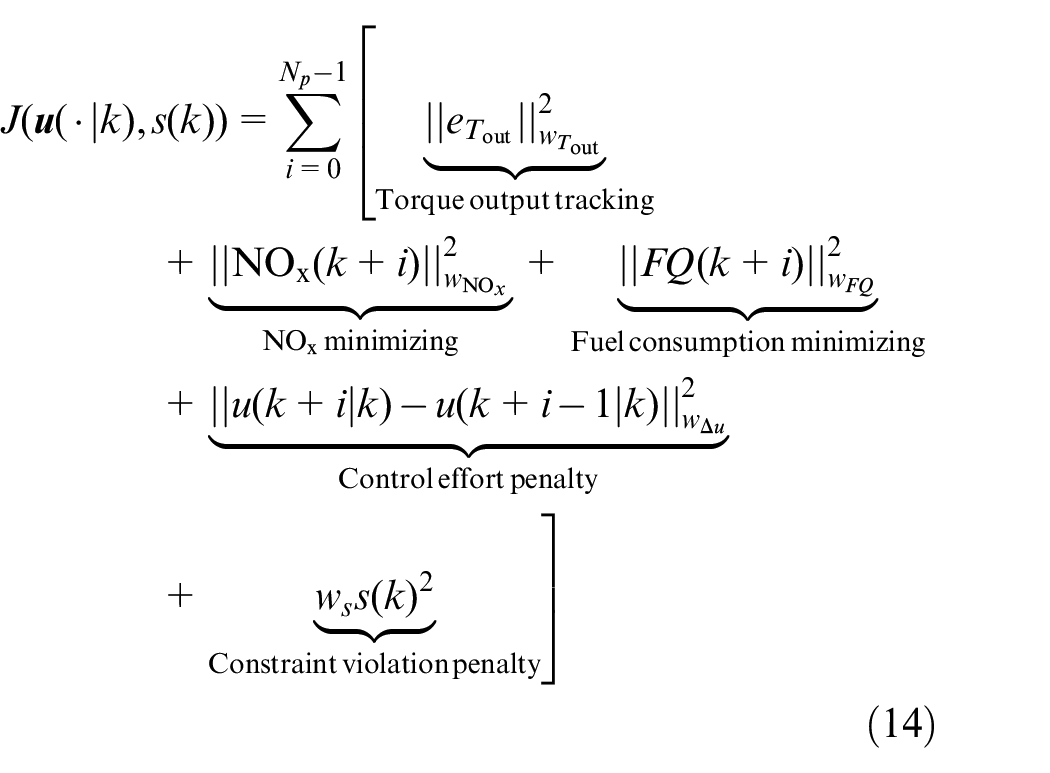
where

where
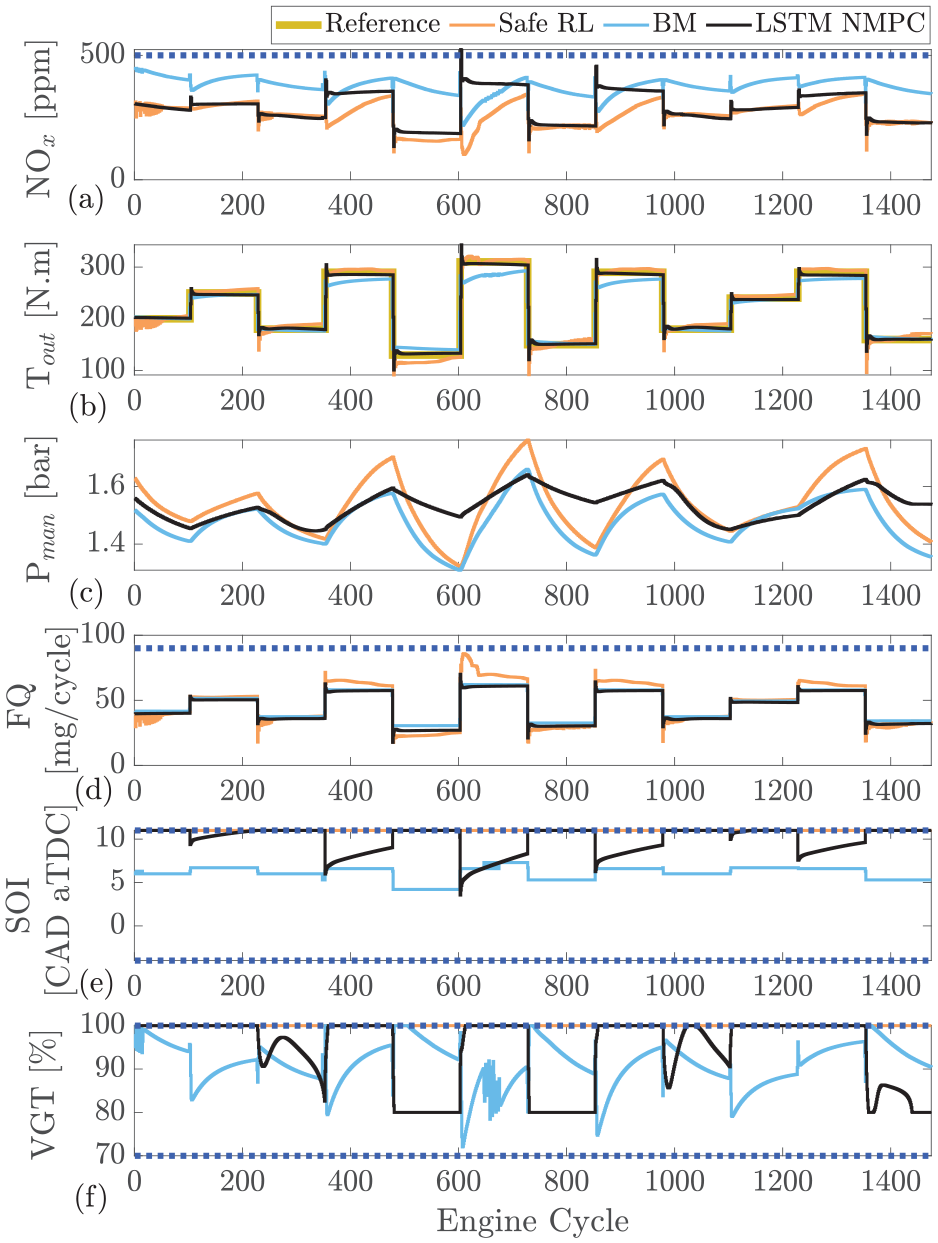
Safe reinforcement learning compared with long-short-term memory based nonlinear model predictive controller (LSTM-NMPC)
59
and Cummins-calibrated ECU which is modeled in GT-Power at engine speed of 1500 r/min: (a) engine-out
As shown in Figure 8, the safe RL is capable of accurately tracking the output torque with similar performance to the LSTM-NMPC. Both controllers outperform the BM feedforward production controller. Here the safe RL controller suffers from slightly increased overshoot when compared to the NMPC.
The controllers maintain
Comparing the controllers, the values of cumulative
Comparison between safe RL, Benchmark (BM), and nonlinear model predictive control. 59
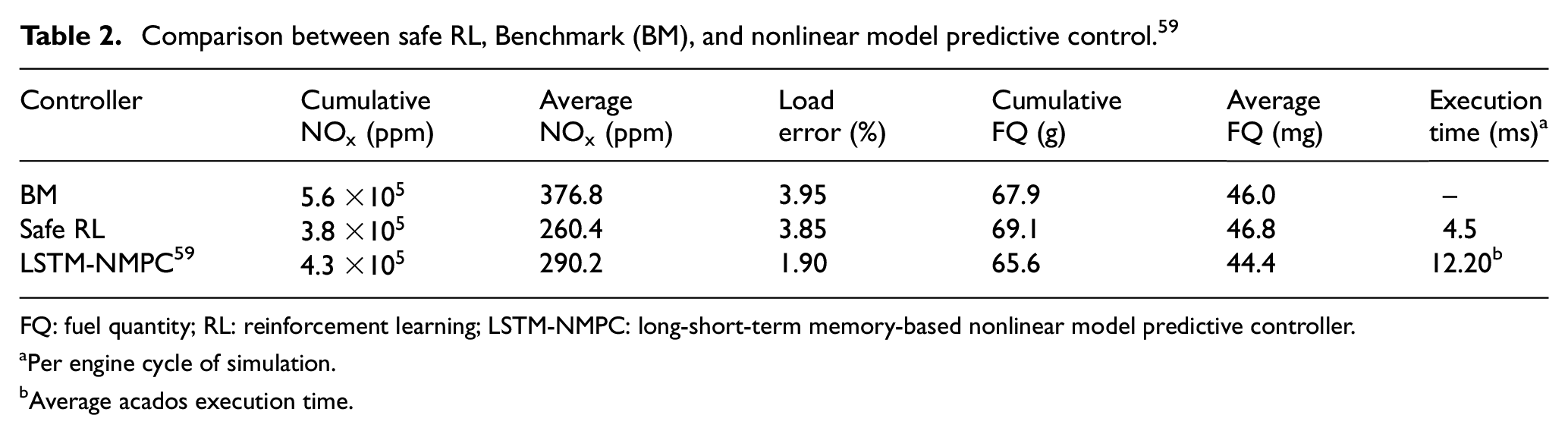
FQ: fuel quantity; RL: reinforcement learning; LSTM-NMPC: long-short-term memory-based nonlinear model predictive controller.
Per engine cycle of simulation.
Average acados execution time.
As shown, RL has significantly lower
The safe RL controller performs comparably to the NMPC; however, it is also of interest to compare with another learning control strategy such as ILC. The developed safe RL controller is compared to safe ILC and the BM in Figure 9. As shown, both learning controllers are capable of tracking the desired output torque with similar performance to the BM. ILC tracks the reference more closely than safe RL control. The ILC tracking performance is almost perfect with very little overshoot which is one of the benefits of ILC since the repetitive input requirements allow the ILC learn by repetition. The RL controller suffers from slight torque overshoot but the performance is still acceptable.
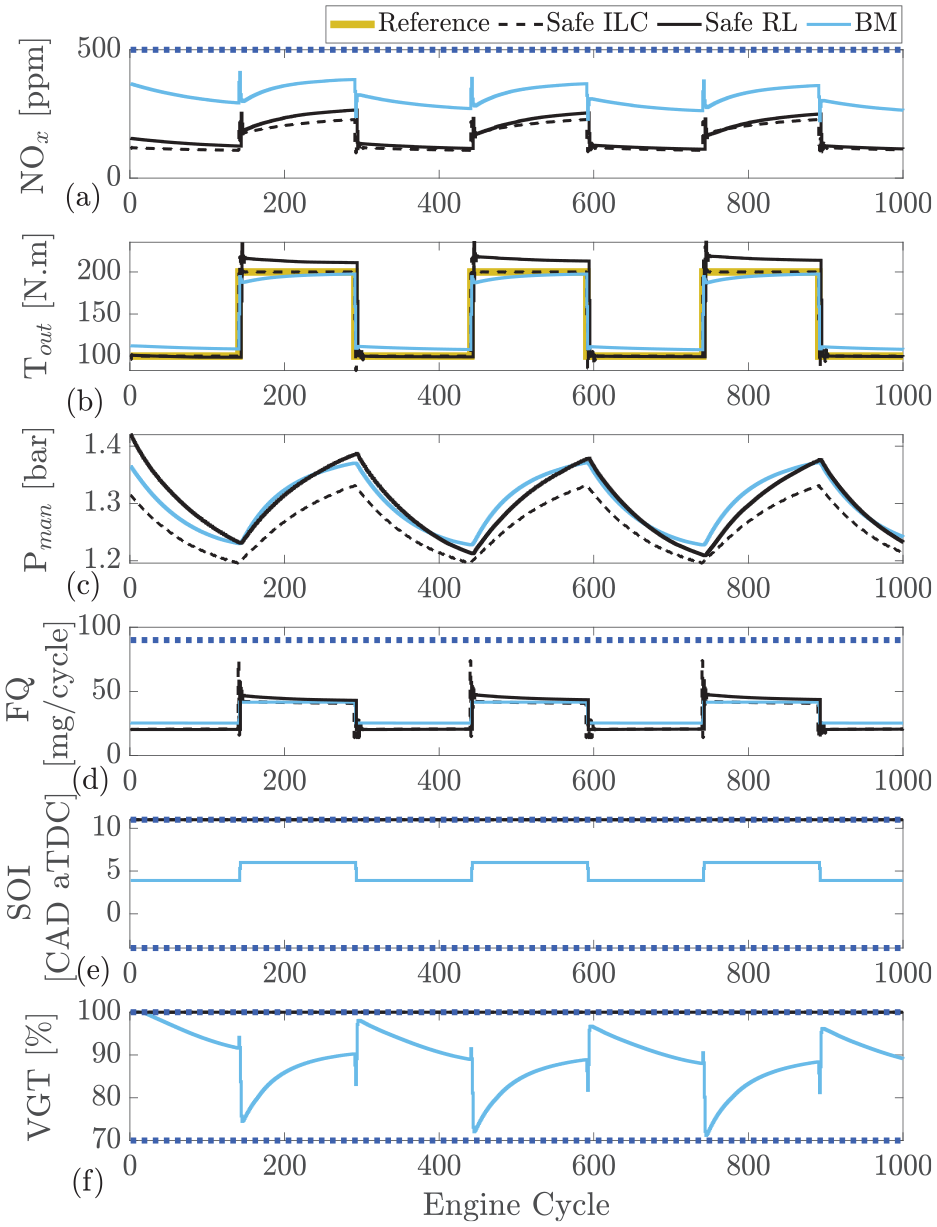
Safe reinforcement learning compared with safe ILC and Cummins-calibrated ECU which is modeled in GT-Power at engine speed of 1500 rpm: (a) engine-out
All the controllers tested were able to remain below the defined 500 ppm
The controller performance results and the values of cumulative
Comparison between safe RL, BM, and ILC.
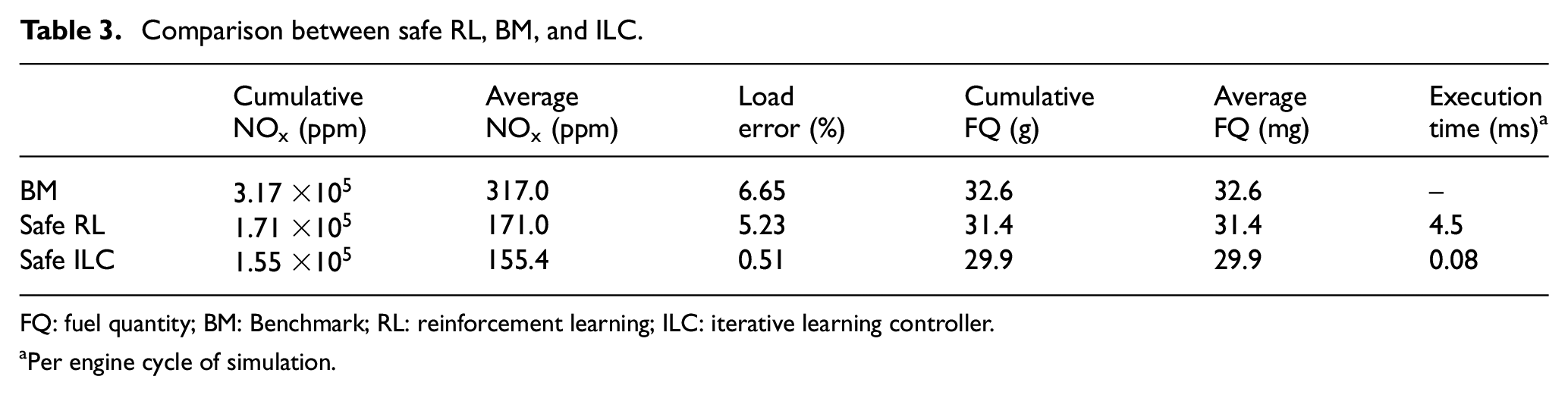
FQ: fuel quantity; BM: Benchmark; RL: reinforcement learning; ILC: iterative learning controller.
Per engine cycle of simulation.
As shown, both RL and ILC are able to reduce
Summary and conclusion
A deep RL–based controller is developed to minimize the
The learning-based controllers with safety filter are compared to their standard versions to better understand the effect of adding a safety filter. It was found that for deep RL, both the safe and standard controllers result in almost the same controller performance once training is completed. Even the standard RL is able to learn to enforce the output constraints. However, during training, there are large violations of the constraints suggesting that using safe learning is crucial when working with a real engineering system for real-time learning. For ILC, the safety filter implementation shows a significant effect during both training and final controller performance. This suggests that ILC requires a safety filter to enforce output constraints.
The safe RL is then compared to safe ILC to evaluate which controller has better performance as they both share a similar learning-based controller approach. This comparison shows that the deployment time of ILC is two orders of magnitude faster than RL and ILC has the ability to take advantage of online learning. Although ILC has a 4% better torque tracking and 16 ppm lower average
To compare the safe RL to a state-of-the-art controller, a comparison is made to a model-based LSTM-NMPC.
59
This comparison shows that the deep RL is capable of reducing the average
Summary of comparison for developed controllers.
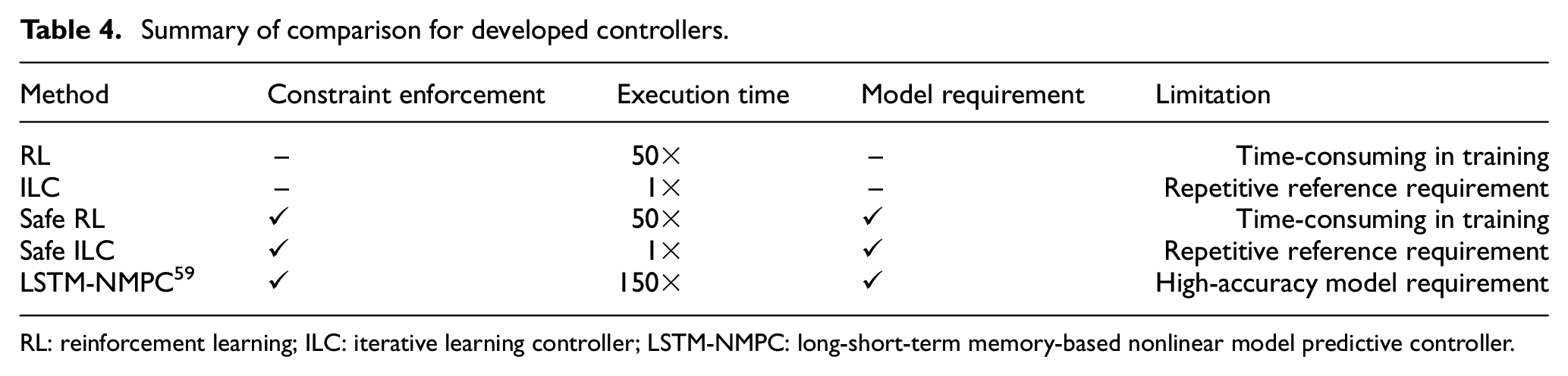
RL: reinforcement learning; ILC: iterative learning controller; LSTM-NMPC: long-short-term memory-based nonlinear model predictive controller.
Summary of comparison for developed controllers—controller performance compared to Benchmark.
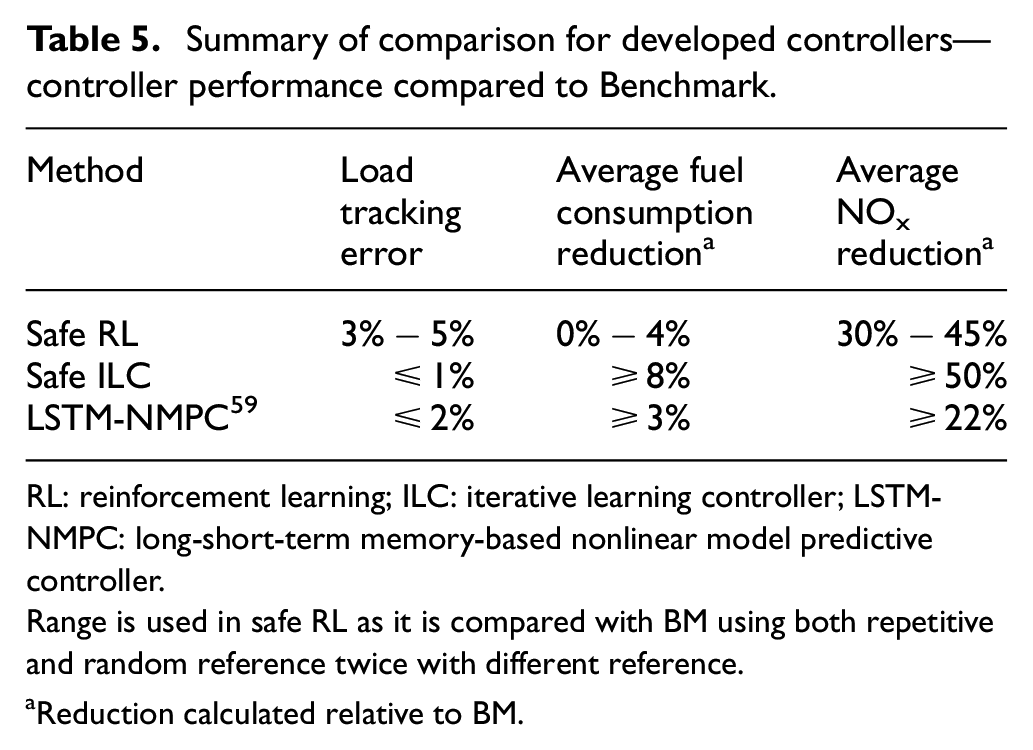
RL: reinforcement learning; ILC: iterative learning controller; LSTM-NMPC: long-short-term memory-based nonlinear model predictive controller.
Range is used in safe RL as it is compared with BM using both repetitive and random reference twice with different reference.
Reduction calculated relative to BM.
The application of using a safe learning–based control is demonstrated in simulation; however, for next-generation AI-powered engine controllers, these methods require extensive real-time data. Implementing either of these model-free learning-based controllers in real-time requires detailed testing on real hardware. Future work includes testing these methods on the engine in real time.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by Natural Sciences and Engineering Research Council of Canada (NSERC) grant numbers 2016-04646, and 2020-04403, and Canada First Research Excellence Fund (CFREF) grant number T01-P04.