
Abstract
We present Bayesian Controller Fusion (BCF): a hybrid control strategy that combines the strengths of traditional hand-crafted controllers and model-free deep reinforcement learning (RL). BCF thrives in the robotics domain, where reliable but suboptimal control priors exist for many tasks, but RL from scratch remains unsafe and data-inefficient. By fusing uncertainty-aware distributional outputs from each system, BCF arbitrates control between them, exploiting their respective strengths. We study BCF on two real-world robotics tasks involving navigation in a vast and long-horizon environment, and a complex reaching task that involves manipulability maximisation. For both these domains, simple handcrafted controllers exist that can solve the task at hand in a risk-averse manner but do not necessarily exhibit the optimal solution given limitations in analytical modelling, controller miscalibration and task variation. As exploration is naturally guided by the prior in the early stages of training, BCF accelerates learning, while substantially improving beyond the performance of the control prior, as the policy gains more experience. More importantly, given the risk-aversity of the control prior, BCF ensures safe exploration and deployment, where the control prior naturally dominates the action distribution in states unknown to the policy. We additionally show BCF’s applicability to the zero-shot sim-to-real setting and its ability to deal with out-of-distribution states in the real world. BCF is a promising approach towards combining the complementary strengths of deep RL and traditional robotic control, surpassing what either can achieve independently. The code and supplementary video material are made publicly available at https://krishanrana.github.io/bcf.
Keywords
1. Introduction
As the adoption of autonomous robotic systems increases around us, there is a need for the controllers driving them to exhibit the level of sophistication required to operate in our everyday unstructured environments. Recent advances in reinforcement learning (RL) coupled with deep neural networks as function approximators, have shown impressive results across a range of complex control tasks in robotics including dexterous in-hand manipulation (Andrychowicz et al., 2020), quadrupedal locomotion (Haarnoja et al., 2018) and targeted throwing (Ghadirzadeh et al., 2017).
Nevertheless, the widespread adoption of deep RL for robot control is bottle-necked by two key factors: sample efficiency and safety (Ibarz et al., 2021). Learning these behaviours requires large amounts of potentially unsafe interaction with the environment and the deployment of these systems in the real world comes with little to no performance guarantees. The latter can be attributed to the black-box nature of neural networks, while the sample complexity is related to the fact that RL agents tend to randomly search the solution space. This is further exacerbated by the sparse, long-horizon reward setting.
A general avenue to addressing the sample complexity in RL is the deliberate use of inductive bias or prior knowledge to aid the exploratory process. This includes reward-shaping (Andrychowicz et al., 2018; Grzes and Kudenko 2009; Schoettler et al., 2019), curriculum learning (Bengio et al., 2009), learning from demonstrations (Hester et al., 2018; Vecerik et al., 2017) and the use of behavioural priors (Jeong et al., 2020; Johannink et al., 2018; Lee et al., 2020; Rana et al., 2020). The incorporation of prior knowledge in the form of behavioural priors has been gaining increasing traction in recent years. These priors include learned policies or hand-crafted controllers that capture the core capabilities for solving a task. They, however, are not necessarily the optimal solution to solving the task at hand. We refer to this class of methods as Reinforcement Learning from Behavioural Priors (RLBP). RLBP approaches can directly query an action from the prior at any given state. This allows for a diverse range of mechanisms for introducing inductive bias during training, including regularisation (Cheng et al., 2019; Galashov et al., 2019; Tirumala et al., 2019), exploration bias (Cheng et al., 2019; Jeong et al., 2020; Rana et al., 2020) and residual learning (Johannink et al., 2018; Silver et al., 2018).
We focus on the robotics setting, where decades of research have yielded numerous behavioural priors in the form of hand-crafted controllers and algorithmic approaches for the vast majority of real-world physical systems (from mobile robots to humanoids) and tasks (Siciliano and Khatib, 2016). These include classical feedback controllers (Nise, 2020), trajectory generators (Ijspeert, 2008) and behaviour trees (Colledanchise and Ögren, 2016). While the explicit analytic nature of these controllers comes with certain performance guarantees including safety and robustness, they can be highly suboptimal with respect to variations in the task and tend to require great effort in system modelling and controller tuning to achieve higher levels of performance.
In this work, we present Bayesian Controller Fusion (BCF), a novel RLBP approach that closely couples hand-crafted robot controllers within the RL framework for accelerated learning and safety awareness during both training and deployment. BCF enables RL agents to learn substantially better behaviours than the underlying hand-crafted controllers while exploiting their risk-aversity for safe behaviours in out-of-distribution states, a limiting factor for neural network-based policies.
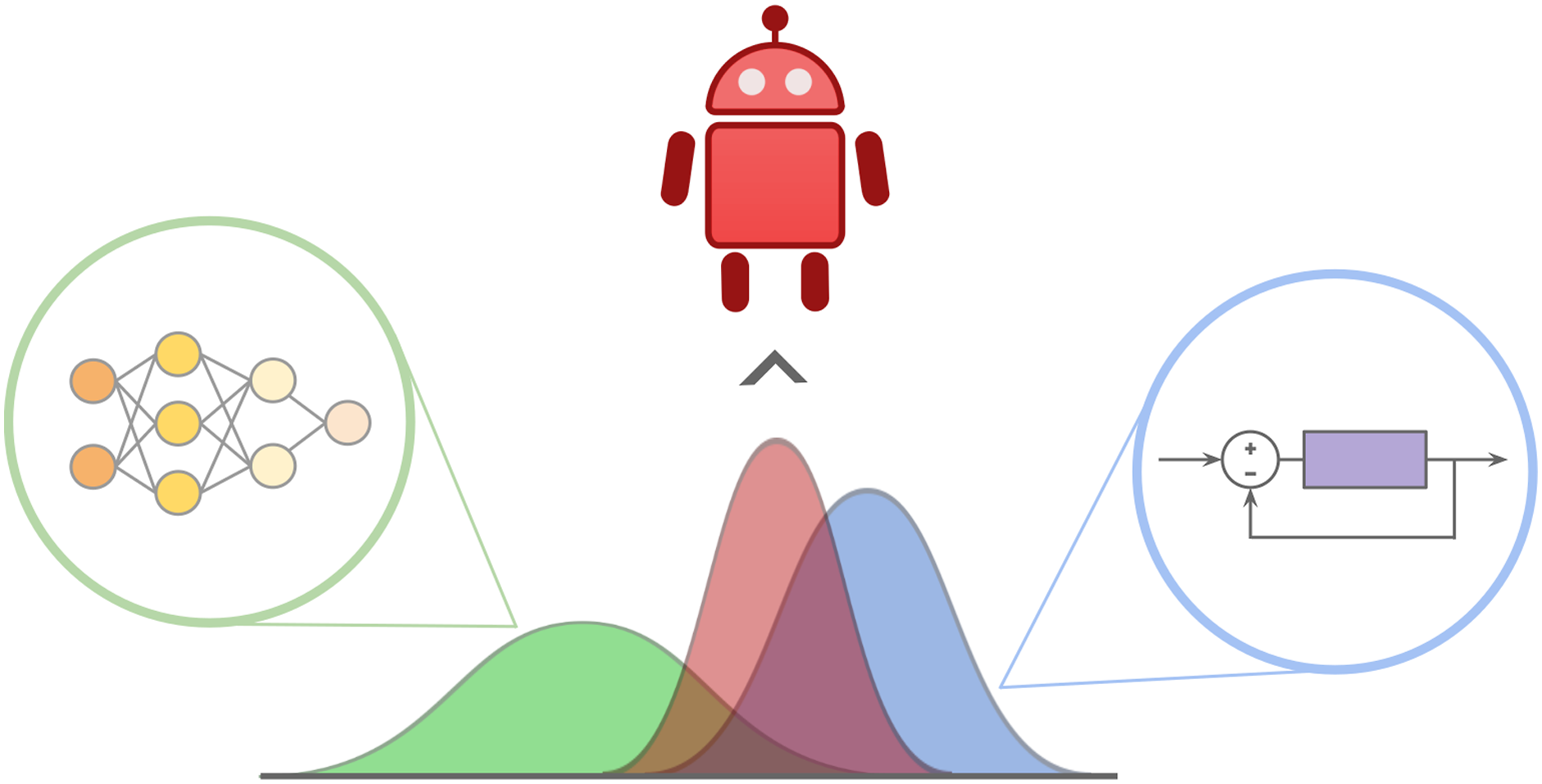
In order to exploit the respective strengths of each of these systems, we draw inspiration from the dual-process theory of decision-making, seen in the human brain. This theory suggests that the brain leverages multiple neural controllers to govern behaviours based on their confidence in a given scenario (Dayan and Daw, 2008; Daw et al., 2005; Hassabis et al., 2017). As opposed to leveraging just a single controller, this hybrid control strategy allows humans to exploit the strengths of each system when necessary in order to successfully complete a task. BCF follows this strategy, learning a compositional policy that interpolates between the behaviours specified by uncertainty-aware stochastic outputs generated by an RL policy and a hand-crafted controller as shown in Figure 1. Our Bayesian formulation allows the system exhibiting the least uncertainty to dominate control. This has important implications both during training and deployment. In states of high policy uncertainty, BCF biases the composite action distribution heavily towards the risk-averse prior, reducing the chances of catastrophic failure. In more confident states, it exploits the optimal behaviours discovered by the policy. We highlight our key contributions below: 1. A novel uncertainty-aware training strategy that accelerates learning in sparse reward, long-horizon task settings while allowing for safe exploration in unknown environments. 2. The ability to leverage a suboptimal controller to aid learning without inhibiting the final policy from identifying the optimal behaviours. 3. A novel deployment strategy for robot control that combines the strengths of classical controllers and learned policies, allowing for reliable performance even in out-of-distribution states. 4. An evaluation of our deployment strategy to transfer a simulation-trained policy directly to the real-world, for two different free-space motion robotics tasks, and its ability to act reliably in out-of-distribution states. Bayesian Controller Fusion: We learn a compositional policy (red) for robotic agents that combines an uncertainty-aware deep RL policy (green) and a classical handcrafted controller (blue). Utilising this compositional policy to govern exploration allows for accelerated learning towards an optimal policy and safe behaviours in unknown states. It additionally allows for the reliable sim-to-real transfer of RL policies.
This paper is structured as follows. In Section 2, we provide an overview of the RL concepts and algorithms used in this work and introduce the notion of control priors for robotics. Section 3 discusses related work and based on their limitations we formulate the problem in Section 4. In Section 5, we describe our algorithm, the derivation of the relevant components and BCFs applicability to both exploration and sim-to-real transfer. Section 6 describes our experimental setup, and in Section 7 and 8, we provide both qualitative and quantitative results for training and sim-to-real deployment of our system on a physical robot. In Section 9, we highlight the limitations of our strategy and avenues for future work, before concluding with Section 10.
2. Background
In this section, we provide an overview of two broad areas for robot control which we aim to combine: learned controllers based on the deep reinforcement learning framework and classical hand-crafted controllers.
2.1. Reinforcement learning
We consider the reinforcement learning framework in which an agent learns an optimal policy for a given task through environment interaction in order to solve a Markov Decision Process (Sutton and Barto, 1998). A Markov Decision Process (MDP) is described by a tuple
Using an MDP, we can generate a sequence of states and actions as follows. Given an initial state s0, iteratively select the next action a
t
∼ π(s
t
) and evolve the state by sampling
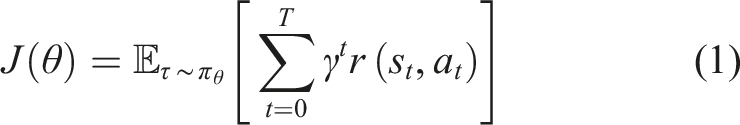
2.1.1. Soft-actor critic
SAC is an off-policy, actor-critic algorithm that has achieved state-of-the-art results in recent years for continuous control tasks (Haarnoja et al., 2019). It is based on the maximum entropy RL framework that optimises a stochastic policy to maximise a trade-off between the expected return and policy entropy,
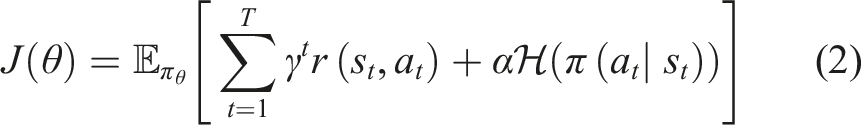
This is closely related to the exploration-exploitation trade-off (Sutton and Barto, 1998), encouraging exploration in previously unvisited states, where actions are chosen by sampling from a Gaussian distribution. While effective in exhaustively searching the solution space, the associated risk and sample inefficiency are unsuitable for robotics. In this work, we focus on leveraging priors to better inform this action selection process. SAC learns three functions: two Q-functions
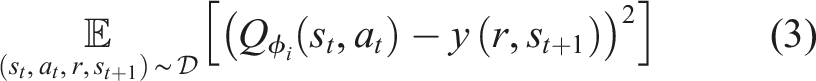
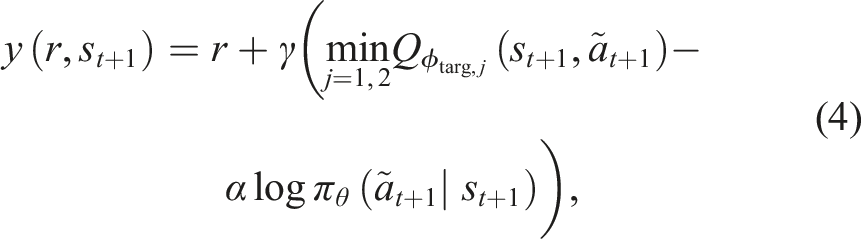
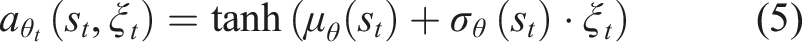
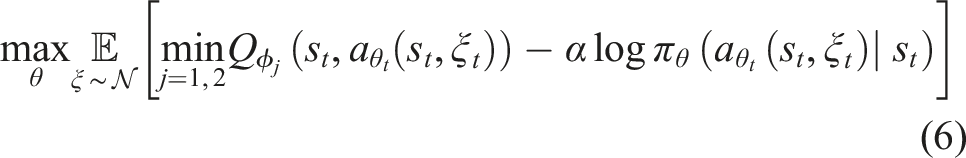
2.2. Control priors
The classical robotics community has developed a plethora of algorithms and controllers that are capable of solving various tasks or part of more complex tasks using explicit analytic derivations (Siciliano and Khatib 2016). In the context of our work, we refer to these as control priors. In their most general form, we can view these control priors as deterministic mapping functions from state to action

These methods make the assumption that a significant amount is known about the system dynamics, such as the differential equations governing state transitions. Given these explicit models, an error signal can be generated and traditional feedback approaches (e.g. optimal (Kirk 2004), model predictive (Camacho and Alba 2013) and robust control (Zhou and Doyle 1998)) can be used to control the input of the system in order to attain the desired behaviours. For more complex and long-horizon robotic tasks, these low-level control systems can be integrated within a larger decision-making framework such as a state machine (Balogh and Obdrzálek 2018) or behaviour tree (Colledanchise and Ögren 2017). Given their known explicit derivation and deterministic nature, we make the assumption that these controllers are risk-averse and ensure the safety of the robot. This is in contrast to the black-box nature of deep RL policies. Figure 2 shows examples of control priors and how we can treat them as mapping functions from states to actions. Examples of control priors in robotics include (a) traditional feedback controllers and (b) state machines. Note that despite the difference in the structure of these priors, they both can be treated as mapping functions, a = ψ(s) from state to action in their most general form.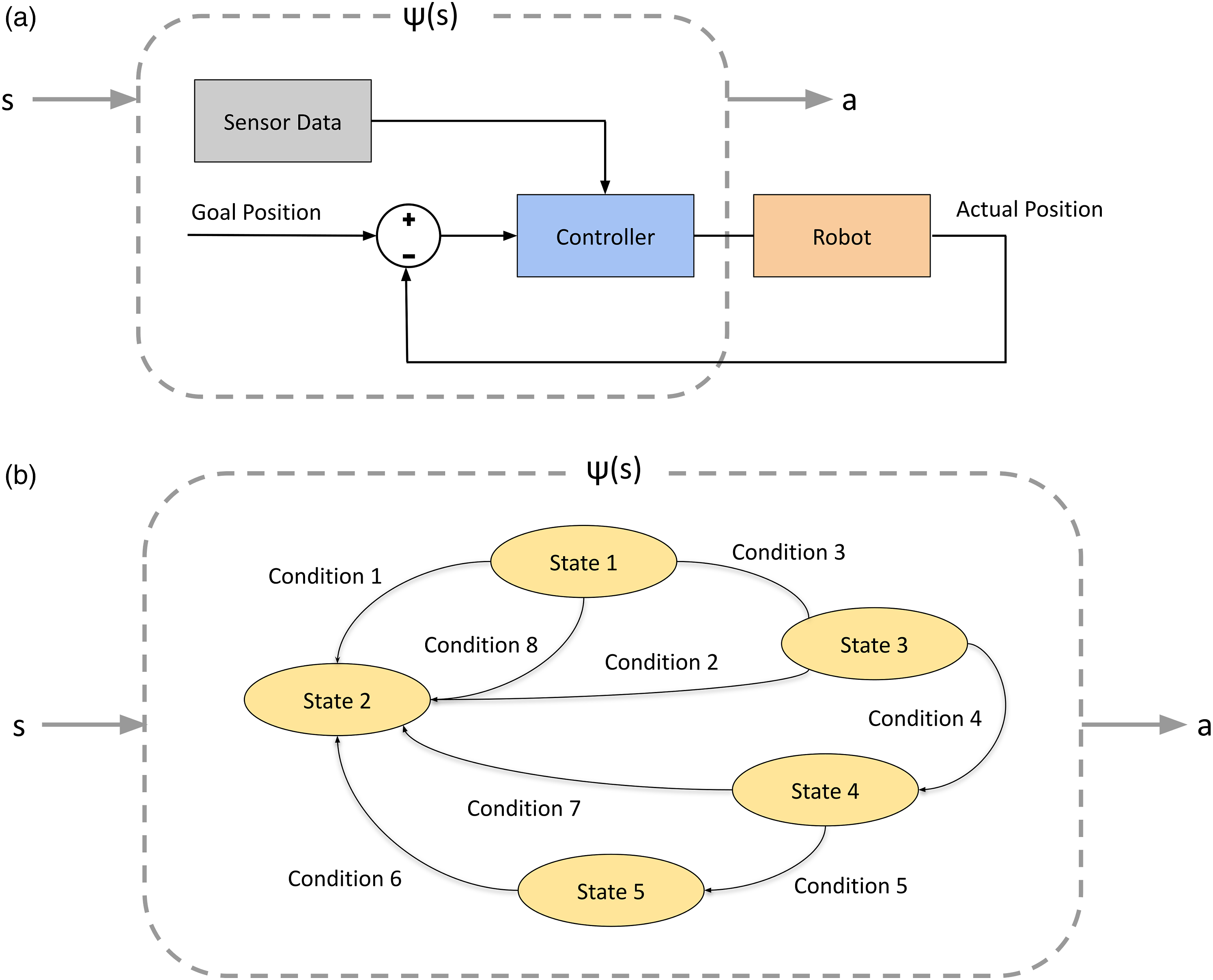
These control priors, however, tend to require significant amounts of hand engineering, linear approximations and domain knowledge instilled to ensure that they are functional and can solve the task. As the complexity of the tasks increases and the operational environment for these controllers becomes unstructured as seen in the real world, such hand-engineered solutions tend to be suboptimal. Explicitly engineering these controllers to meet the level of dexterity required becomes non-trivial and impractical amounts of modelling and calibration may be required.
3. Related work
In this section, we review some of the key RLBP methods introduced in the literature. We focus on the specific set of approaches that leverage behavioural priors in the form of control priors within the RL framework and discuss their current limitations when considering their application to robotics.
3.1. Residual reinforcement learning
The residual reinforcement learning framework (Johannink et al., 2018; Silver et al., 2018; Srouji et al., 2018) focuses on learning a corrective residual policy for a control prior. The executed action a t is generated by summing the outputs from a control prior and a learned policy, that is, a t = ψ(s t ) + π θ (s t ). The residual policy, π θ , can be learned using any off-policy RL algorithm.
Johannink et al., (2018); Silver et al., (2018) utilise this approach to learn complex manipulation tasks that involve contacts and friction that are typically hard to model analytically. They leverage conventional feedback controllers as control priors that can solve part of the task, and utilise the residual to modify its behaviour in order to learn the unmodelled contact dynamics. Although showing promise towards accelerating the learning of manipulation tasks, they only demonstrate its ability to make small changes to the underlying controller and the implications of utilising highly suboptimal controllers have not yet been explored.
Iscen et al., (2018) extend this architecture to not only learn a residual but additionally the parameters to modify the classical controller itself. They argue that this allows for a more expressive and flexible architecture, not attainable using solely a residual and shows its applicability to dexterously control a quadrupedal robot. However, allowing the policy direct access to modify the control prior, diminishes any safety guarantees the prior can provide which is a limiting factor when considering the safety of the robot. Srouji et al. (2018) attempt to maintain the guarantees of the control prior by restricting the policy to solely learning a linear policy, limiting its ability to make significant modifications to the underlying behaviours of the prior. This strict decoupling additionally allows for a better interpretation of the two controllers, an important factor when assessing the stability and robustness of the overall system. While an interesting perspective, this greatly limits the potential optimality of the final controller that the RL agent can achieve.
3.2. KL-regularised reinforcement learning
Recent algorithms directly optimise a regularised objective that trades off reward maximisation with the minimisation of the policy divergence from a behavioural prior which could be a fixed or learned reference distribution. The most common divergence measure used is the Kullback–Leibler (KL) divergence, which computes the degree of similarity (or dissimilarity) between two distributions. The KL-regularised RL objective is given by
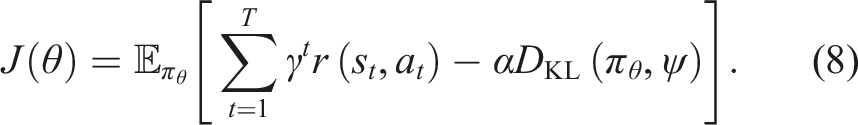
Typically this reference distribution could be a uniform distribution (Haarnoja et al., 2019), learned policy (Galashov et al., 2019; Hausman et al., 2018; Hunt et al., 2019; Pertsch et al., 2020; Teh et al., 2017; Tirumala et al., 2019), or an occupancy measure that characterises the distribution of state-action pairs when executing a policy (Jing et al., 2020; Kang et al., 2018). This approach is typically used for transfer and multi-task learning and has been shown to be effective in distilling prior knowledge into the policy during optimisation.
In the case of a uniform reference distribution, Pertsch et al. (2020) show that we recover the maximum entropy objective given in Equation (2). This is the least informative distribution when considering the incorporation of useful structure and priors to aid the learning process. A more informed distribution constitutes common behaviours (Galashov et al., 2019; Teh et al., 2017) that agents can share across multiple tasks which allows them to significantly accelerate learning. Such behavioural priors are typically learned in parallel or already trained policies that can solve simpler tasks (Pertsch et al., 2020), forming a continual learning paradigm. This is an important motivation for our work, where it makes sense to build on the vast body of work already solved by the robotics community, as opposed to learning policies from scratch.
The KL-constrained setting can be seen as a hard constraint that can severely restrict the policies from attaining optimal behaviours given the potential sub-optimality of the behavioural priors used. Pertsch et al. (2020) address this by automatically learning the weighting parameter, and show the applicability of the regularised objective to accelerate learning of complex tasks within a hierarchical framework. Recent work by Kang et al. (2018) and Jing et al. (2020) softens the constraint by gradually annealing the divergence tolerance. This allows the policy to deviate further away from the prior as training progresses in order to learn potentially better behaviours, an important factor when the prior is highly suboptimal. The choice of the annealing rate is however non-trivial and needs to be carefully selected.
While overall a promising approach to accelerate learning, the KL regularised objective provides limited safety guarantees to the agent during training. This is particularly important in the robotics case, where we additionally seek to ensure the safety of the robot during exploration. A more promising strategy would be to directly utilise the behavioural prior to influence the actions taken by the agent during exploration. We discuss these approaches below.
3.3. Exploration bias using behavioural priors
These methods can be interpreted as biasing the policy search towards the behavioural prior’s actions during exploration. This is done by utilising the prior as a source of exploration data, directly moderating the agent’s behaviours in the given environment.
The simplest approach to this method is policy reuse/intertwining proposed by (Fernández and Veloso 2006; Jeong et al., 2020), who utilise an epsilon-greedy-like approach to balance exploration and the usage of a behavioural prior. While providing an attractive solution, this method is not suitable when considering the robotics scenario. Such an approach alternates between the policy, prior and random exploration throughout training without any concern for the safety of these actions. Taking completely random actions at the start of training can result in unsafe behaviours that can be detrimental to both the robot and its surroundings.
An alternative approach is to restrict exploration to be governed by the behavioural prior only until the policy is capable of safely exploring on its own accord. Rana et al. (2020) proposed a multiplicative fusion strategy for stochastic policies and behavioural priors. This approach utilises a gating function to initially allow exploratory actions only to be sampled from the behavioural prior and gradually transition control towards the policy in order to exploit its own actions. Tuning the gating function can be tedious, and requires the correct balance, while the hard switch towards the policy has limited safety guarantees since the behavioural prior has no impact after this point. This can result in unsafe behaviours as the policy continues to explore novel regions of the solution space on its own. In this work, we build on this formulation, exploring alternatives to the hard-gating function in order to address this limitation and allow for continual safe exploration.
A better-informed strategy is to govern this transition based on the policy’s confidence. Cheng et al. (2019) utilise the temporal difference error (TD-error) to estimate how confident the policy is to act in a given state. This, in theory, should allow the control prior to dominate exploration during the early stages of training and as the TD-error reduces, the policy can gradually take over. The TD-error however tends to be noisy in practice and can yield instabilities during training. In this work, we explore the use of epistemic uncertainty estimation techniques for RL as a more stable alternative to the TD-error estimate. Xie et al. (2018) propose a separately trained critic network to govern this arbitration. While this allows for expressive compositions of the two systems, the requirement to learn a separate critic increases the sample complexity of the overall approach, with limited ability to deal with out-of-distributions states. These are core limitations we address in this work, where both accelerating training and the safety of the agent are important factors to consider for robotic systems.
Given the distribution mismatch between the current policy and the behavioural prior, an important factor to consider with these approaches is the exploration-exploitation trade-off between the two sources of information. Excessive reliance on the behavioural prior for experience collection, without adequately exploiting the policy’s behaviours can result in unstable learning due to extrapolation error (Fujimoto et al., 2018; Kumar et al., 2019; Van Hasselt et al., 2016). Extrapolation error tends to occur as a result of the target Q value estimate,
Given the range of RLPB approaches discussed above and their respective limitations towards applicability in the robotics setting, we formulate the problem in Section 4 before presenting our approach to address these limitations in Section 5.
4. Problem formulation
Decades of research and development have resulted in algorithmic solutions for a number of problems in robotics, distilling analytical approaches, domain knowledge and human intuition (Siciliano and Khatib, 2016). Instead of ignoring this vast resource and learning robotic tasks from scratch, we present a control strategy that seamlessly combines a learned policy π with an existing hand-crafted algorithm ψ, during both training and deployment. We refer to ψ as a control prior. We assume that ψ is suboptimal, but has a reasonable degree of task competence and is risk-averse. We define risk aversion as the tendency of these controllers to avoid unsafe behaviours that could be detrimental to both the safety of the robot and its surroundings.
We consider learning a policy π(a|s) for a robotics task. Using the formalism of an MDP, we leverage off-policy model-free RL to learn this policy. However, in contrast to most existing RL approaches, we exploit the knowledge and structure encoded in an existing prior ψ(a|s) during both training and deployment for accelerated learning and safer behaviours.
Our goals are to (1) use the control prior ψ to guide exploration during the early phases of the learning process, thereby accelerating training and improving sample efficiency; (2) naturally let the learned policy π dominate control as it gains more knowledge, ensuring it can improve beyond the performance of the existing solution ψ and (3) monitor the uncertainty of π during deployment and smoothly transfer control to ψ as a safe-but-suboptimal fall-back in situations where the learned policy cannot be trusted. In Section 5, we explain how a Bayesian combination of π and ψ can achieve the above goals.
5. Bayesian controller fusion
We introduce Bayesian Controller Fusion (BCF), a hybrid control strategy that composes stochastic action outputs from two separate control mechanisms: an RL policy π(a|s), and a control prior ψ(a|s). These outputs are formulated as distributions over actions, where each distribution captures the uncertainty over the selected action in any given state. The Bayesian composition of these two outputs forms our hybrid policy ϕ(a|s). We show that governing the agent’s behaviours in the environment using ϕ(a|s), significantly accelerates learning towards an optimal policy while allowing for safer exploration and operation in unknown environments. We describe the intuition behind BCF in more detail below.
5.1. Accelerated learning
As the action distribution generated by each system captures the uncertainty over the selected action in a given state, our Bayesian fusion strategy allows the composite distribution ϕ(a|s) to naturally bias towards the system exhibiting the least amount of uncertainty. Figure 3 shows the evolution of our exploration strategy throughout training. During the early stages of training, the policy π(a|s) exhibits high uncertainty across all states, biasing the composite distribution towards the control prior ψ(a|s). As opposed to random exploration, sampling actions from this distribution allows the control prior to strongly influence exploration at this stage. This quickly biases the agent towards the reward-yielding trajectories, while exploring the surrounding state-action space for potential improvements beyond the sub-optimality of the control prior. As the policy becomes more certain about its environment it gradually dominates control, allowing the agent to exploit its learned behaviours and stabilise training. Evolution of the composite BCF sampling distribution over the course of training. During the early stages, note the strong bias towards the control prior which provides the exploration guidance.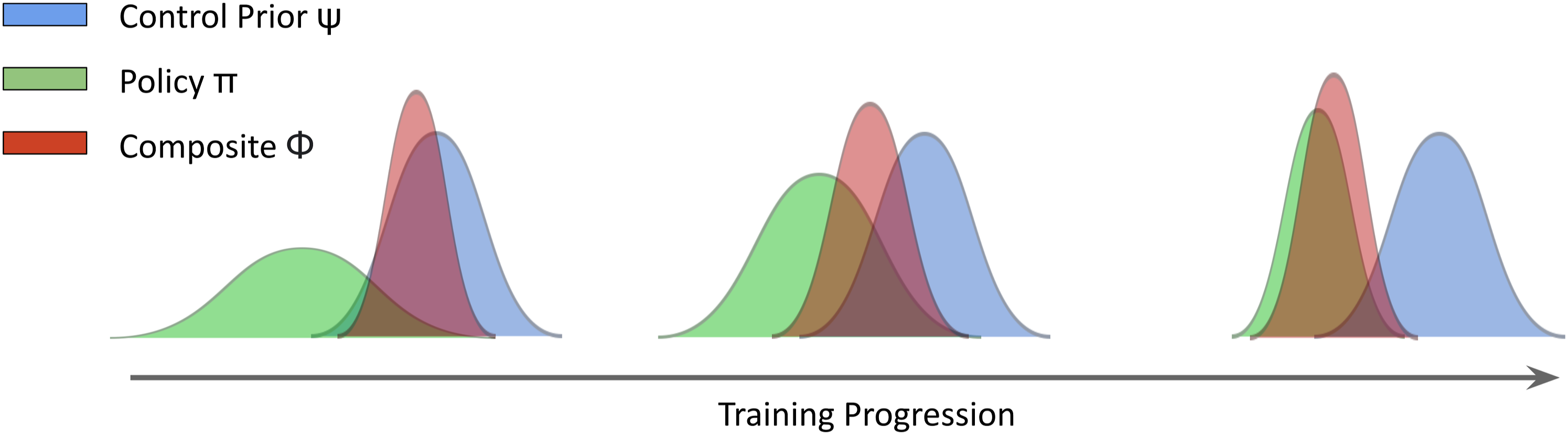
5.2. Safe exploration and deployment
Figure 4 illustrates our hybrid control strategy that composes the outputs from the learned policy π(a|s) and control prior ψ(a|s). The uncertainty-aware compositional policy ϕ(a|s) allows for the safe exploration and deployment of RL agents. In states of high uncertainty, the compositional distribution naturally biases towards the reliable, risk-averse and potentially suboptimal behaviours suggested by the control prior. In states of lower uncertainty, it biases towards the policy, allowing the agent to exploit the optimal behaviours discovered by it. This is reminiscent of the arbitration mechanism suggested by (Lee et al., 2014) for behavioural control in the human brain, where the most reliable controller influences control in a given situation. This dual-control perspective provides a reliable strategy for bringing RL to real-world robotics, where generalisation to all states is near impossible and the presence of risk-averse control priors serves as reliable fallback systems. BCF hybrid control strategy for safe deployment on real robotic systems. We derive uncertainty-aware action outputs for each controller and compose these outputs to better inform the action selection process.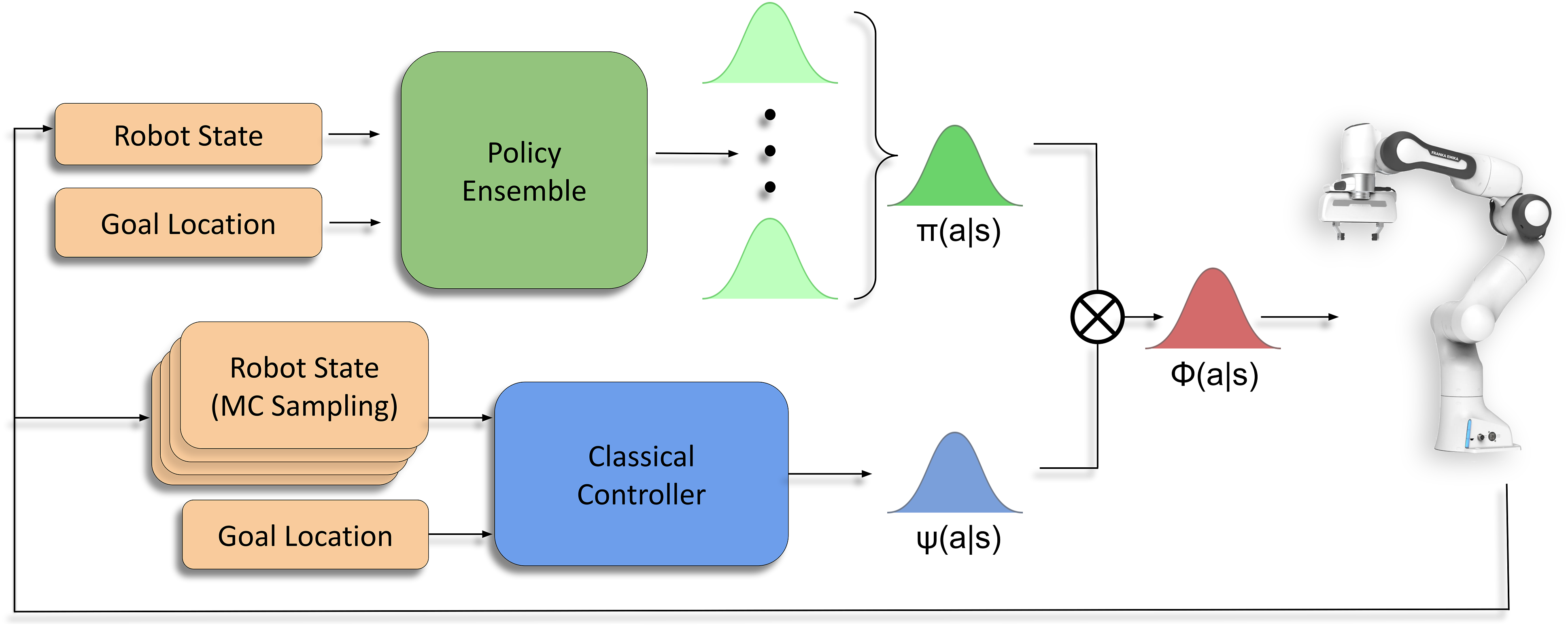
5.3. Method
Given a policy, π and control prior, ψ, we can obtain two independent estimates of an executable action, a conditioned on both a given state s and the task T. In a Bayesian context, we can utilise the normalised product to fuse these estimates under the assumption of a uniform prior, p(a)
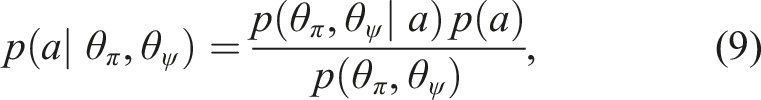
Assuming statistical independence of
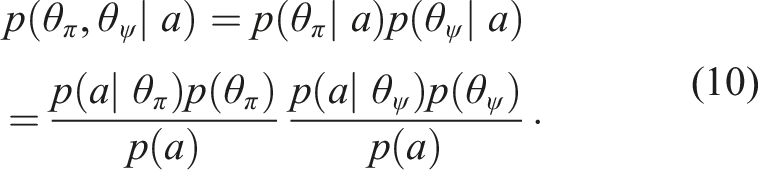
Substituting this result back into (9), we can simplify the fusion as a normalised product of the respective action distributions from each control mechanism
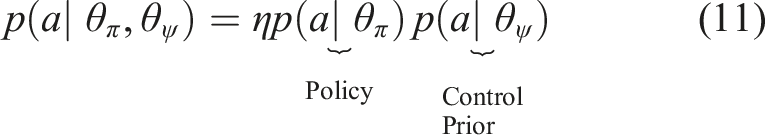
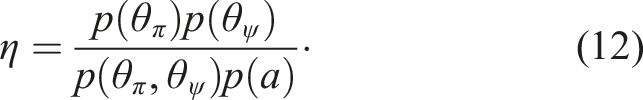
The composite distribution
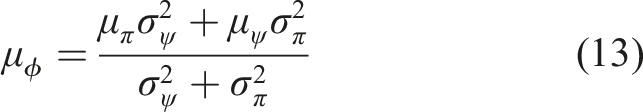

5.4. Components
In order to leverage our proposed approach in practice, we describe the derivation of the distributional action outputs for each system below and provide the complete BCF algorithm for combining these systems in Algorithm 1.
5.4.1. Uncertainty-aware policy
We leverage stochastic RL algorithms that output each action as an independent Gaussian
We train an ensemble of M agents to form a uniformly weighted Gaussian mixture model, and combine these predictions into a single univariate Gaussian whose mean and variance are, respectively, the mean, μ
π
(s) and variance,
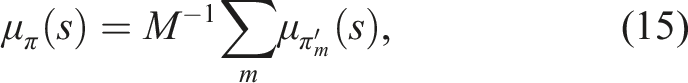
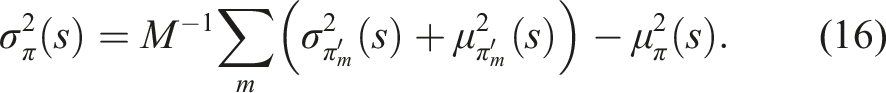
The empirical variance,
5.4.2 Control prior
In order to incorporate the inherently deterministic control priors developed by the robotics community within our stochastic RL framework, we require a distributional action output that captures its uncertainty over actions in a given state. We empirically derive this action distribution by propagating noise (provided by the known sensor model variance,
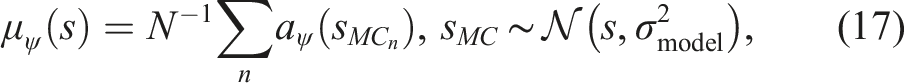
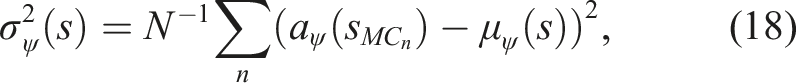
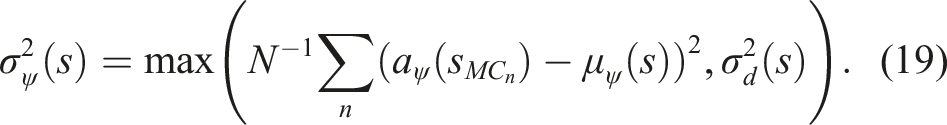
The choice of σ
d
is left as a hyper-parameter for the user to set based on the specific controller used and its optimality towards solving the task. Figure 5 provides some intuition into the choice of σ
d
and its relation to exploration. The explorable region of the state space is denoted by the set Illustration of optimal trajectory versus control prior trajectory with the explorable set 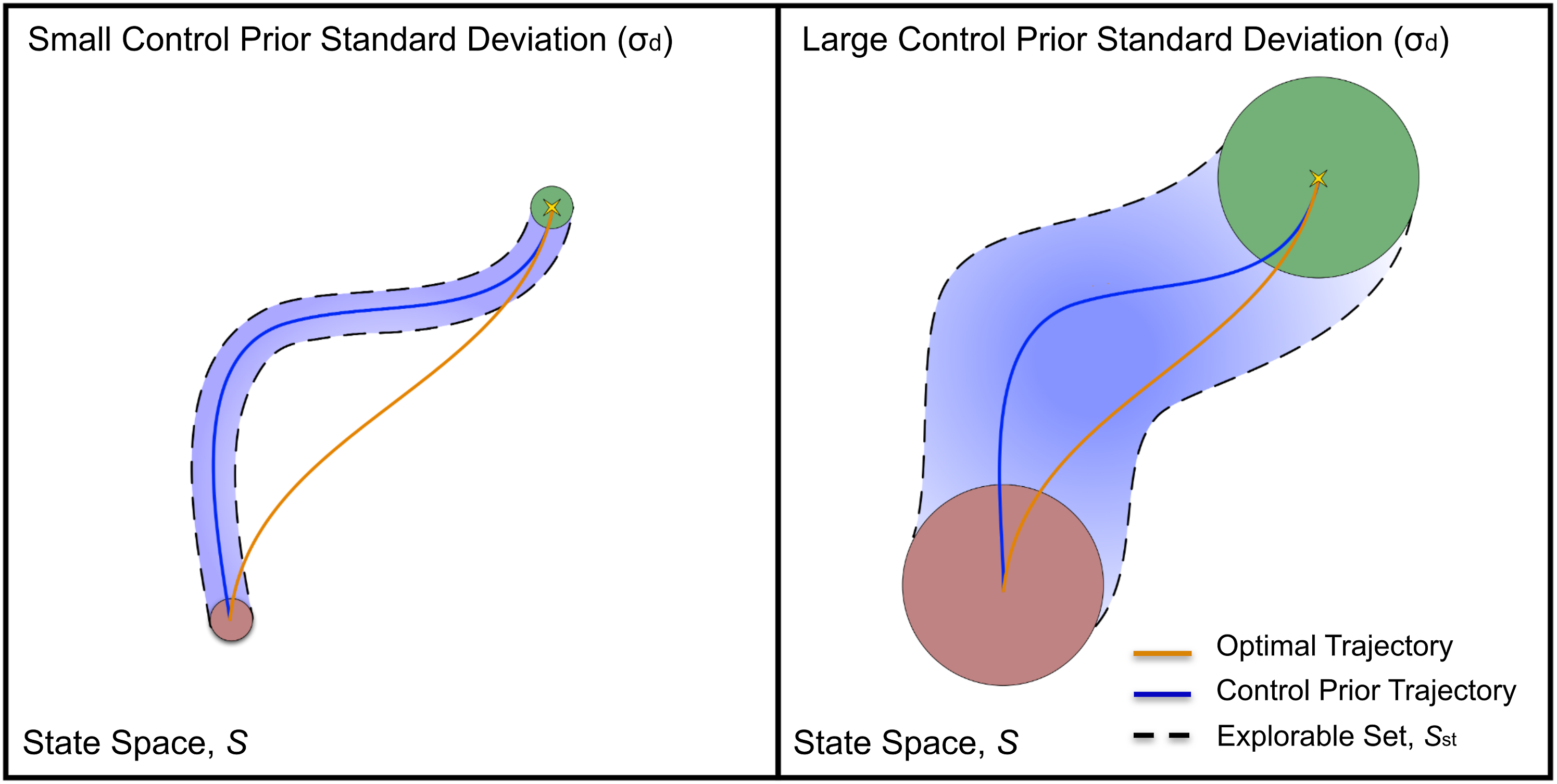
Given the formulation for the distributional outputs from each system, we present the complete BCF algorithm for governing action selection both during training and deployment in Algorithm 1.
6. Experimental setup
In this section, we describe the two different robotics tasks that we evaluate BCF on and detail the analytic derivation of the control priors we use for these tasks and their respective limitations. We additionally provide specific implementation details pertaining to our training method. We note here that the control priors used are just one particular example of existing hand-crafted solutions to the tasks, and alternative approaches could also be used.
6.1. Tasks


Simulation training environments and real-world deployment environments for (a) PointGoal Navigation and (b) Maximum Manipulability Reacher tasks. Note the stark discrepancy in obstacle profiles for the navigation task between the simulation environment and real-world environments.
6.1.1. PointGoal navigation
The objective of this task is to navigate a robot from a start location to a goal location in the shortest time possible while avoiding obstacles along the way. We utilise the training environment provided by Rana et al. (2019), which consists of five arenas with different configurations of obstacles. The goal and start location of the robot are randomised at the start of every episode, each placed on the extreme opposite ends of the arena (see Figure 6(a)). This sets the long-horizon nature of the task. As we focus on the sparse reward setting, we define r(s
t
, a
t
, st+1) = 1 if dtarget < dthreshold and r(s
t
, a
t
, st+1) = 0 otherwise, where dtarget is the distance between the agent and the goal and dthreshold is a set threshold. The action a
t
consists of two continuous values: linear velocity νnav ∈ [−1, 1] and angular velocity ωnav ∈ [−1, 1]. We assume that the robot can localise itself within a global map in order to determine its relative position to a goal location. The 180° laser scan range data is divided into 15 bins and concatenated to the robot’s angle. The overall state s
t
of the environment is comprised of: 1. The binned laser scan data 2. The polar pose error between the robot’s pose and the goal location 3. The previous executed linear and angular velocity
6.1.2. Reaching with maximum manipulability
The objective of this task is to actuate each joint of a manipulator within a closed-loop velocity controller such that the end-effector moves towards and reaches the goal point, while the manipulability of the manipulator is maximised. The manipulability index describes how easily the manipulator can achieve any arbitrary velocity. The ability of the manipulator to achieve an arbitrary end-effector velocity is a function of the manipulator Jacobian. While there are many methods that seek to summarise this, the manipulability index proposed by Yoshikawa (1985) is the most used and accepted within the robotics community (Patel and Sobh 2015). Utilising Jacobian-based indices in existing controllers have several limitations, requiring greater engineering effort than simple inverse kinematics-based reaching systems, and precise tuning in order to ensure the system is operational (Haviland and Corke 2021). We explore the use of RL to learn the desired behaviours by leveraging simple reaching controllers as priors. We utilise the PyRep simulation environment (James et al., 2019), with the Franka Emika Panda as our manipulator as shown in Figure 6(b). For this task, we generate a random initial joint configuration and random end-effector goal pose. We use a sparse goal reward, r(s
t
, a
t
, st+1) = 1 if e
t
< ethreshold and r(s
t
, a
t
, st+1) = m otherwise, where e
t
is the spatial translational error between the end-effector and the goal, ethreshold is a set threshold and 1. The joint coordinate vector 2. The joint velocity vector 3. The translation error between the manipulator’s end-effector and the goal 4. The end-effector translation vector 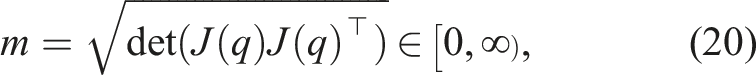
6.2. Control prior derivation
For each of the above tasks, we utilise existing classical controllers and algorithms already developed by the robotics community for solving the task at hand. They however are not necessarily optimal, due to limitations in analytical modelling, controller miscalibration and task variations. We note here that each controller was calibrated, and scripted conditions were implemented to ensure they exhibited safe and risk-averse behaviours across the state space. We describe each of these controllers in more detail below.
6.2.1. Artificial potential fields
Assuming the availability of global localisation and map information for our robot, PointGoal Navigation can mostly be solved using classical reactive navigation techniques. These systems rely on the immediate perception of their surrounding environment which allows them to handle dynamic objects and those unaccounted for in the global map. In this work, we focus on the Artificial Potential Fields (APF) family of algorithms (Warren 1989; Koren and Borenstein 1991) which compute a local attractive potential 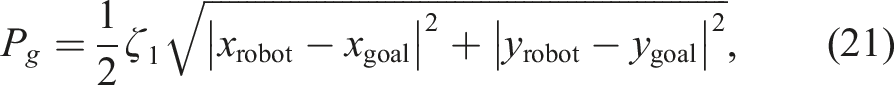
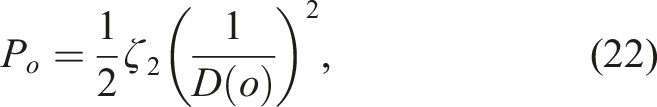

By taking the gradient of the resultant potential function, we can determine the best direction to move within the environment that avoids obstacles while heading towards the goal.
For a detailed derivation, we refer the reader to (Koren and Borenstein, 1991). This direction is used to generate an error signal e
p
with which we derive a linear feedback controller u = Knave
p
to determine the suitable velocities u to control the robot, where
A key problem faced by most classical solutions to reactive navigation, including APF, is the need for extensive tuning and hand engineering to achieve good performance, and a tendency to deteriorate in performance when overfit to a particular region (Khatib, 1986; Koren and Borenstein, 1991). This makes them susceptible to oscillations, seizure in local minima and suboptimal path efficiency.
6.2.2. Resolved rate motion control
This controller allows for direct control of a robotic manipulator’s end-effector, without expensive path planning. It serves as a simple prior for a reaching task. For a given goal pose, Resolved Rate Motion Control (RRMC) provides the robot with suitable joint velocity commands to move the end-effector in a straight line towards the goal.
For a given manipulator joint configuration 


(27) can only be solved when J(q) is square and non-singular. For redundant robots (where n > 6), J(q) is not square and therefore no unique solution exists for (27). Consequently, the most common solution is to use the Moore-Penrose pseudo-inverse in (27) as follows
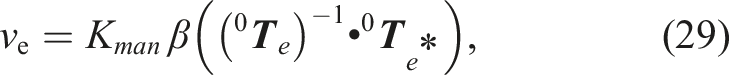
While this controller can reach arbitrary goals within the robot’s workspace, it tends to result in poor manipulability performance across the trajectory. This reduces the robustness of the robot’s behaviours and increases the chances of it hitting a singularity. Additionally, the robot’s final pose tends to be ill-conditioned for the completion of a consecutive task. This renders it suboptimal with respect to the manipulability-based reaching task evaluated in this work.
6.3. Training details
We leverage SAC as the underlying RL algorithm for BCF using the implementation provided by SpinningUp (Achiam, 2018) with a discount factor γ = 0.99, learning rate of 1e − 3, replay buffer capacity of 1e6 and batch size 100. We train an ensemble of 10 RL agents, each initialised randomly and updated using their own batch of experience sampled from a shared replay buffer. We found that this simple strategy together with the discrepancies in the target networks provided enough variation across the ensemble members over the course of training.
With the given experimental setup, we investigate to what extent BCF learns faster and safer than model-free RL alone, improves upon the given control prior, and its ability to safely deploy RL policies in the real world.
7. Evaluation of training performance
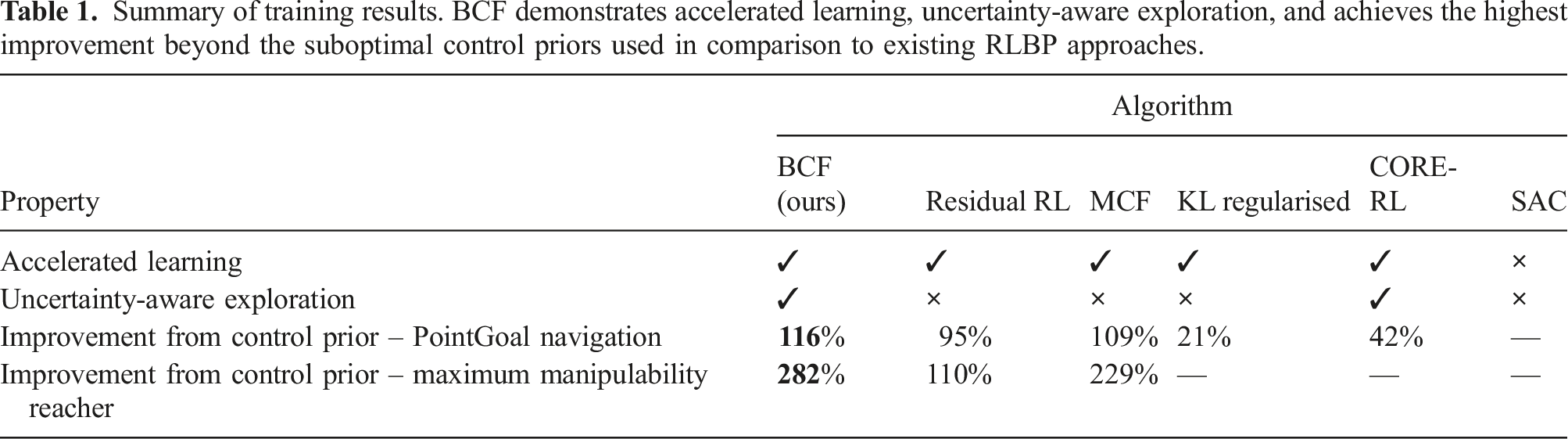
We provide an evaluation of training performance when compared to four different RLBP baselines that have been proposed in related work. We additionally compare training curves for vanilla end-to-end trained policies and indicate the average performance of the control prior used. For all baselines, we utilise SAC as the underlying RL algorithm and train each system across 10 random seeds. We present the training curves for both tasks in Figure 7 and a summary of the key characteristics demonstrated by each approach in Table 1. We note here that the BCF training curves illustrate the evaluation of the performance of the standalone RL policy component in order to better depict how BCF can be used as a framework for accelerated RL policy training without being reliant on the presence of the control prior once the agent has converged. Learning curves of BCF and existing RLBP baselines for PointGoal Navigation and Reaching with Maximum Manipulability tasks. Note the faster convergence and lower variance across 10 seeds exhibited by our proposed approach. Summary of training results. BCF demonstrates accelerated learning, uncertainty-aware exploration, and achieves the highest improvement beyond the suboptimal control priors used in comparison to existing RLBP approaches.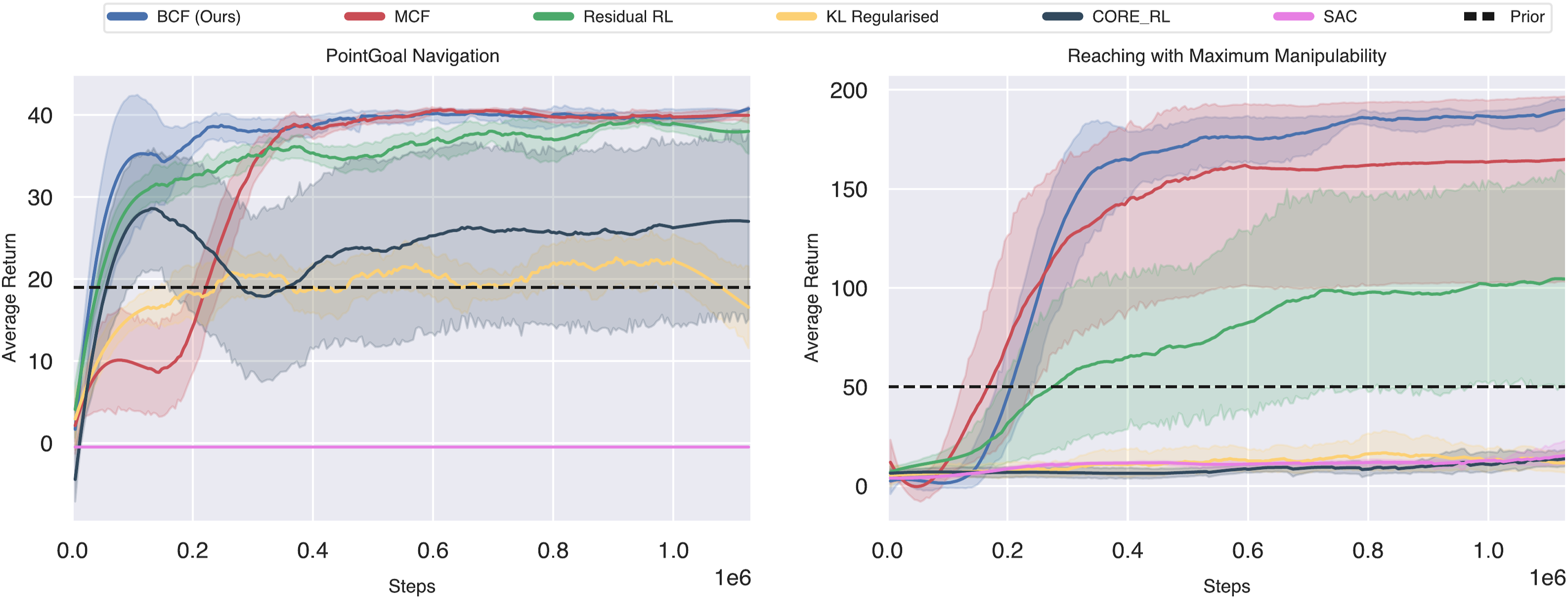
7.1. Baselines
1. Residual Reinforcement Learning: Implementation of the residual reinforcement learning algorithm proposed by Johannink et al. (2018). 2. KL Regularised RL: Modified SAC algorithm which utilises a KL regularised objective towards a prior behaviour as proposed by Pertsch et al. (2020). This method utilises an auto temperature adjustment for the KL objective. 3. CORE-RL: Implementation of the TD-error-based exploration strategy to balance exploration between a control prior and the policy as proposed by Cheng et al. (2019). 4. MCF: Our prior work that leverages a fixed gating function to switch between the control prior and policy over the course of training (Rana et al., 2020). 5. SAC: Vanilla SAC algorithm using maximum entropy based Gaussian exploration (Haarnoja et al., 2019). 6. Control Prior: Classical controller based on the algorithms described in Section 6.2.
7.2. Accelerated learning
Across both tasks, BCF consistently demonstrates its ability to substantially accelerate training and achieve significantly higher final returns than the baselines. While all the RLBP baselines show the ability to accelerate learning when compared to vanilla SAC alone, it is also important to note their ability to improve beyond the control prior used. We quantify this improvement by computing the greatest change in performance attained by the approach as a fraction of the control prior’s performance. The results are summarised in Table 1.
For the navigation task, both KL-regularised RL and CORE-RL converge towards a final policy that exhibits suboptimal performance, while failing to learn at all in the reaching task. Residual RL and MCF both yield improvements beyond the control prior similar to that attained by BCF in the navigation task, attaining a 95% and 109% increase in performance, respectively. However, in the reacher task, both approaches yield a substantially lower improvement when compared to that attained by BCF. We can speculate that this significant drop in performance between the two tasks is related to the performance gap between the control prior and the optimal policy for that task. For the Residual RL case, we can speculate that for highly suboptimal control priors, the residual’s ability to express the required modifications to achieve the optimal behaviours is limited. The performance drop across MCF, KL regularised RL and CORE-RL may be related to the significant distribution mismatch between the control prior’s behaviours and that of the current policy, where the current policy’s behaviours are inadequately exploited. This can cause instabilities in the Q-value updates as seen in the offline RL setting (Fujimoto et al., 2018; Kumar et al., 2019). BCF on the other hand covers a broad distribution across both the control prior and its own behaviours, mitigating this phenomenon and achieving the best final performance.
To gain a better intuition into the success of BCF and the limitations of the existing RLBP approaches, we conducted a focused experiment in the navigation domain for a fixed start and goal location. Figure 8 shows the state-space coverage of the agent over the course of training for each of the RLBP approaches. The dashed line in the figure indicates the deterministic trajectory taken by the control prior, and the coloured regions indicate the states visited by the agent. The figure illustrates a key attribute across all RLBP approaches to bias the search space during exploration towards the most relevant regions for solving the task. This allows them to significantly accelerate training, particularly in the sparse, long-horizon reward setting. This is in stark contrast to the exhaustive exploration carried out by vanilla SAC, which hardly progresses beyond a third of the arena over the course of training, limiting its ability to learn at all. State space coverage during exploration. The dashed line illustrates the deterministic path taken by the control prior. Note how our formulation explores regions of the state space that are likely to lead to a meaningful progression to the goal, while still exploring a diverse region around the deterministic control prior for potential improvements. The yellow crosses indicate collisions with an obstacle that resulted in a failed episode.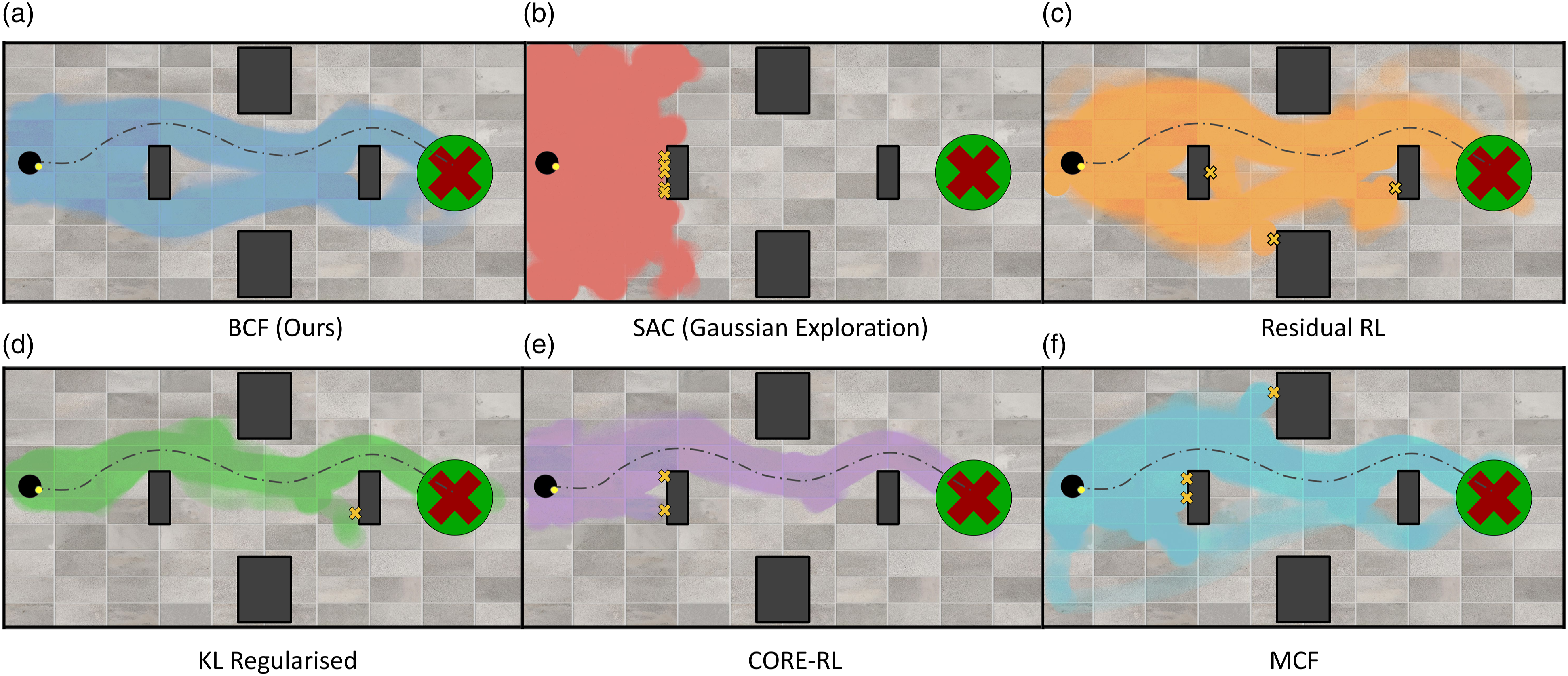
As shown in Figures 8(d) and 8(e), the KL regularised and CORE-RL approaches both heavily constrain the behaviour of the policy towards that of the control prior used. This limits their ability to learn new behaviours. The stochastic nature of BCF on the other hand allows for a broader search space around the control prior’s behaviours, allowing it to identify potentially optimal behaviours, while still biasing the agent towards the most relevant regions of the search space to accelerate learning.
7.3. Uncertainty-aware exploration
We additionally investigate the ability of our uncertainty-aware exploration strategy to allow for safer exploratory behaviours when compared to existing RLBP approaches. This is a less explored area in existing RLBP literature that can have significant benefits as we gradually transition towards training these systems in the real world. Particularly in the case of robotics, we exploit the risk-aversity of the control priors developed and leverage these traits to allow for safer exploratory behaviours. As shown in Figure 8, we additionally indicate obstacle collisions experienced by the agent that results in an overall failed episode during training. We mark the mean location for the collisions as yellow crosses in the figure. BCF completes training in this experiment without any collisions. We can attribute this to the uncertainty-aware formulation of the composite policy, which allows the risk-averse control prior to dominate control in states that the agent has never experienced before. This allows the agent to steer clear of these unsafe states throughout training, safely guiding the agent towards the goal. In contrast, all the baseline RLBP, while successfully constraining the search space, experience multiple collisions throughout training. It is important to note that while the KL regularised and CORE-RL approaches do exhibit a lower number of collisions on average, this comes at the expense of a significant drop to the overall optimality of the final policy, as they over-constrain exploration. BCF on the other hand is able to balance these two characteristics naturally.
In Figure 9 we take a closer look at how the uncertainty-aware BCF formulation operates at the distributional output level when presented with unknown states during training. We explore its ability to balance the guided exploration provided by the control prior and the exploitation of the policy. We conduct the experiment in another focused PointGoal Navigation setting, where we expose the agent to different arenas over the course of training. We train the agent within the first arena until convergence and switch to a novel unknown environment after 390k steps, indicated by the dashed line in Figure 9. We indicate the performance of the agent over the course of training, as well as the empirical uncertainty of the policy. Directly below this graph, we illustrate a qualitative depiction of the distributional composition from BCF for the linear velocity component of the mobile robot at three key locations. As shown in the figure, once the agent has converged to the optimal policy, and the policy is highly certain of its surroundings, the policy component π is predominantly governing the exploratory behaviours of the agent. Upon switching to the unknown environment, we see a significant increase in the uncertainty of the policy and the transition of the composite distribution ϕ towards the behaviours suggested by the control prior ψ. While we see a significant drop in performance towards that of the control prior, it is important to note that its risk-averse behaviours help guide exploration, allowing for safer exploratory behaviours than the highly uncertain black-box policy outputs. As the agent becomes more certain with its surrounding states, we see BCF transition control to the policy, allowing it to exploit its newly found behaviours. This additionally enables it to further explore surrounding state-action pairs allowing for improvements beyond the performance of the control prior. Uncertainty-aware exploration induced by BCF during training allows for safer behaviours when presented with unseen states. As the policy’s uncertainty rises, BCF naturally relies more on the prior controller to guide exploration, while transitioning back to the policy once it gains more confidence. The accompanying plot at the bottom serves as a qualitative depiction of the BCF composition of the two distributions based on their relative uncertainty at the different stages of training.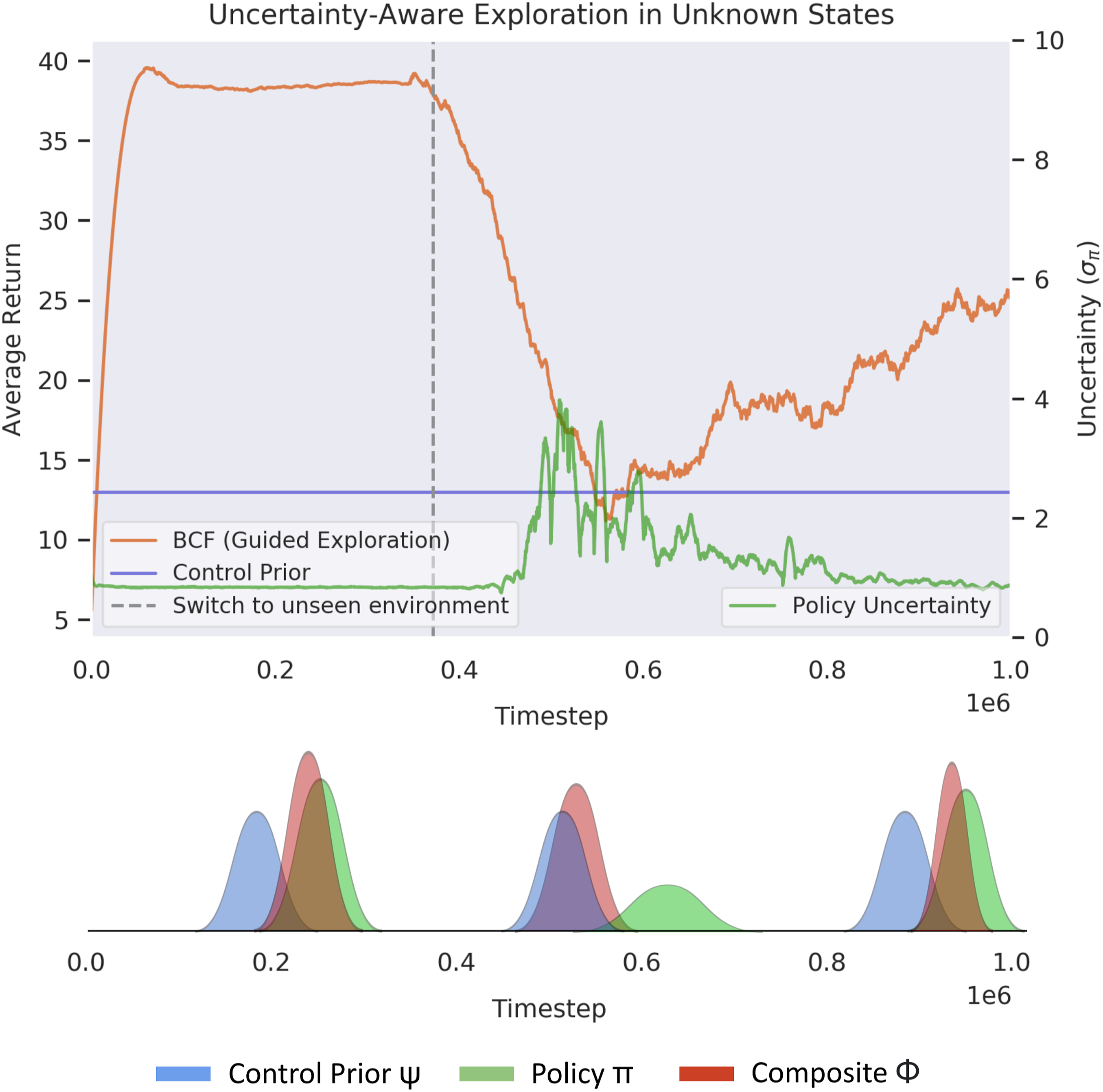
7.4. Impact of control prior performance
In this study, we analyse the impact that the competency of the control prior has on the overall training process. We seek to identify if too much structure from the control prior strongly biases the policy to a particular solution or if the control prior should solely serve as hints to guide the policy in a general direction. Figure 10 shows the range of control priors we evaluated with BCF in the PointGoal navigation environment. On the least competent end of the spectrum, we test a random prior which is a naïve controller that represents a system with no knowledge towards solving the task at hand. At the mid-range, we utilise a proportional (P) controller which is a simple controller based on the Euclidean distance to the goal. It provides basic structural knowledge towards reaching the goal, however, is incapable of avoiding any obstacles. For the more competent prior, we utilise the standard APF controller used throughout this work that can head to the goal while avoiding obstacles. Control prior competency spectrum for the PointGoal Navigation task.
The training curves for each of these controllers are given in Figure 11. The random prior does not provide any additional benefit to exploration and the policy is incapable of learning within the given number of training steps. The controller exhibiting the most competency towards the task (APF) yielded the best performance in terms of sample efficiency and low variance. For the P-controller experiment, it is interesting to note that despite being a severely limited control prior, the agent still benefits from the exploration bias provided by it and is capable of attaining a higher-performing policy as training progresses. These results indicate that BCF is capable of leveraging a control prior to assist learning, and is not crippled from attaining a better policy regardless of the level of the initial performance of the control prior. This support the results observed for the reaching task as shown in Table 1. It also suggests that control priors provide a useful form of positive bias to guide exploration as opposed to random exploration alone. It is important to note that despite their ability to accelerate learning, the competency of the control prior does play an important role when it comes to the safety of the agent. In such cases, the P-controller is not risk-averse and is prone to obstacle collisions. This makes it unsuitable when considering the application of BCF to safely train real-world systems. Training curves exploring the impact of the control prior’s performance on the ability for BCF to accelerate learning in the PointGoal navigation task. The corresponding dashed lines indicate the average return each control prior could achieve in the given environment.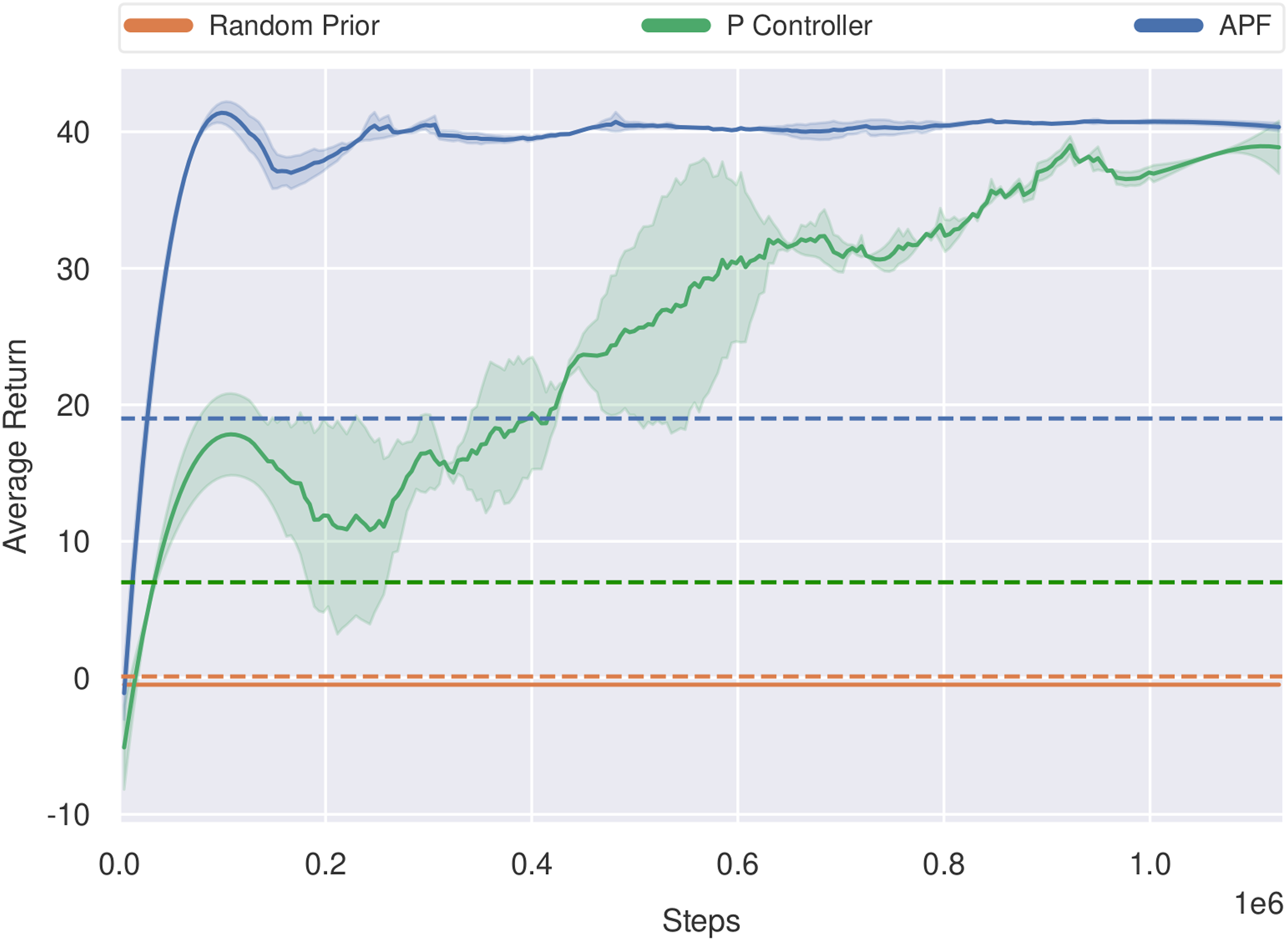
7.5. Impact of control prior variance
A key component of BCF is the distributional nature of the policy and the control prior. As most control priors are deterministic by nature, we approximate a Gaussian distribution by propagating any noise from the state inputs through to the action outputs using Monte Carlo sampling. We additionally set a default standard deviation σ d to allow for adequate exploration during training and to prevent the collapse of the distribution towards a deterministic value. In such a case, the control prior would always dominate and the impact of the policy would be rendered ineffective. In practice, we found that this default value tended to dominate over the empirical distribution derived using MC sampling, given the inherent robustness to noise of the control priors used in this work. As the value of σ d is left as a hyper-parameter that needs to be carefully selected, we study its impact on the overall training performance of BCF by sweeping across a range of fixed standard deviation values. Note that the choice of σ d is dependent on the particular action type and its corresponding unit of measurement.
We conducted these experiments in the PointGoal navigation environment utilising the APF controller as the underlying control prior. The resulting learning curves are provided in Figure 12. The chosen standard deviation was fixed for both the linear and angular velocity components. With low standard deviation values, the agent fails to learn at all. In this setting, the control prior exhibits high confidence and hence strongly biases the composite sampling distribution towards its own behaviours. This limits the ability of the policy to exploit its own actions during exploration which results in it failing to learn. Such a setting is reminiscent of the offline RL setting, where the agent is solely trained on data not pertaining to its own behaviours, resulting in compounding errors due to overestimation bias. Standard deviation values set in the range of 0.5–1 exhibit the best performance. Such distributions provide a softer constraint on exploration allowing the agent to balance exploration and exploitation. Larger standard deviation values, greater than 1, resulted in the agent not learning at all. This is a result of the BCF formulation constantly rendering the policy as the more confident system and hence limiting the impact the control prior could have on the overall system. This is equivalent to the agent learning without any guidance from the control prior, similar to vanilla SAC. Learning curves for BCF using different default control prior standard deviations, σ
d
. The dashed line indicates the average performance of the control prior in the environment.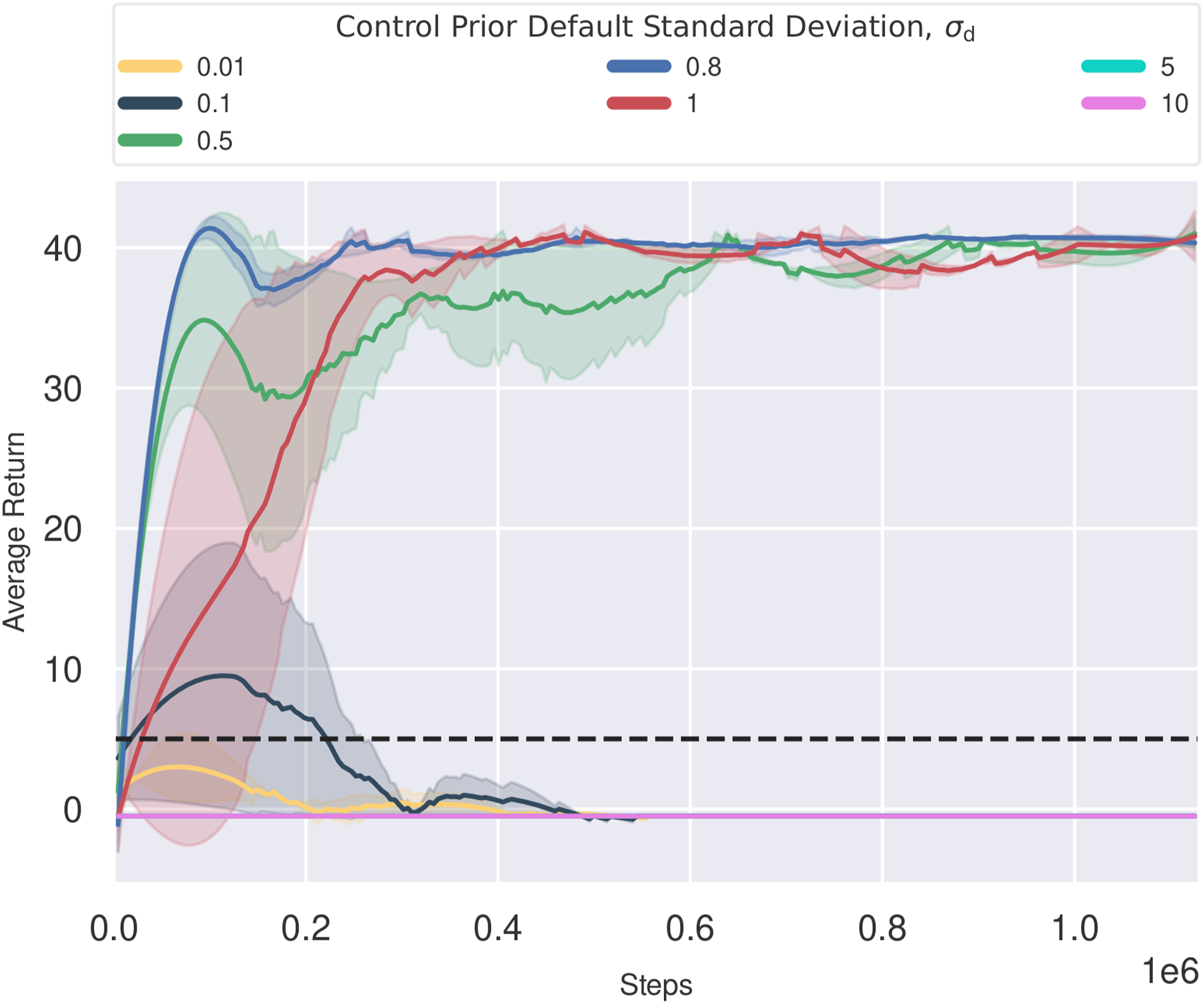
8. Evaluation of deployed system
An important motivation for this work is to leverage RL policies as a reliable strategy to control robots. In this section, we assess the ability of BCF to attain this during deployment and address the current limitations of both RL and classical robotics. As shown in Figure 9, BCF thrives in out-of-distribution states, a common occurrence when considering the sim-to-real setting. As opposed to a neural network-based policy catastrophically failing in these states, BCF has the ability to naturally transfer control to the risk-averse control prior which dominates control until a more suitable state is presented to the policy. In this setting, we gain the optimality of the learned policy in less uncertain states and the safety of the hand-crafted control prior otherwise. We thoroughly evaluate this control strategy for the two robotics tasks in both simulation and the real world. To better understand how the compositional nature of BCF can take advantage of the strengths of each individual component, we evaluate the individual components in isolation against our compositional BCF formulation. We provide details of the evaluated systems below. 1. Control Prior: The deterministic classical controller derived using analytic methods. 2. Policy Only: SAC agent, trained to convergence using BCF, and deployed as a standalone policy. 3. BCF: Our proposed hybrid control strategy that combines uncertainty-aware action outputs from the control prior and trained RL policy.
Note that all the policies used in this evaluation were trained to convergence in the simulation environments and directly deployed in the real world, without any fine-tuning. We provide a detailed account of each task in the following sections.
8.1. PointGoal navigation
In this experiment, we examine whether BCF could overcome the limitations of an existing reactive navigation controller, in this case, APF while leveraging this control prior to safely deal with out-of-distribution states that the policy could fail in. The APF controller exhibited suboptimal oscillatory behaviours particularly in between obstacles and tended to stagnate within local minima.
8.1.1. Simulation environment evaluation
For this task, we report the Success weighted by (normalised inverse) Path Length (SPL) metric proposed by (Anderson et al., 2018). SPL weighs success by how efficiently the agent navigated to the goal relative to the shortest path. The metric requires a measure of the shortest path to the goal which we approximate using the path found by an A-Star search across a 2000 × 1000 grid. An episode is deemed successful when the robot arrives within 0.2 m of the goal. The episode is timed out after 500 steps and is considered unsuccessful thereafter. We additionally report the average actuation time it takes for the agent to reach the goal.
Evaluation of PointGoal navigation in the simulation environment.

8.1.2. Real-world evaluation
We utilise a GuiaBot mobile robot which is equipped with a 180° laser scanner, matching that used in the simulation environment. The velocity outputs from the policies are scaled to a maximum of 0.25 m/s before execution on the robot at a rate of 100 Hz. The system was deployed in a cluttered indoor office space that was previously mapped using the laser scanner. We utilise the ROS AMCL package to localise the robot within this map and extract the necessary state inputs for the policy network and control prior. Despite having a global map, the agent is only provided with global pose information with no additional information about its operational space. The environment also contained clutter which was unaccounted for in the mapping process. To enable large traversals through the office space, we utilise a global planner to generate target sub-goals, for our reactive agents to navigate towards. We do not report the SPL metric for the real robot experiments as we did not have access to an optimal path. We do, however, provide the distance travelled along each path and compare them to the distance travelled by a fine-tuned ROS move_base controller. This controller is not necessarily the optimal solution but serves as a practical example of a commonly used controller on the Guiabot.
The evaluation was conducted on two different trajectories indicated as Trajectory 1 and 2 in Figure 13 and Table 3. Trajectory 1 consisted of lab space with multiple obstacles, tight turns and dynamic human subjects along the trajectory, while Trajectory 2 consisted of narrow corridors never seen by the robot during training. We terminated a trajectory once a collision occurred and marked the run as a failed attempt. We summarise the results in Table 3. Trajectories taken by the real robot for the different start (orange) and goal locations in a cluttered office environment with long narrow corridors. The trajectory was considered unsuccessful if a collision occurred. The trajectory taken by BCF is colour coded to represent the uncertainty in the linear velocity of the trained policy. We illustrate the behaviour of the fused distributions at key areas along the trajectory. The symbols Evaluation of PointGoal navigation in the real-world.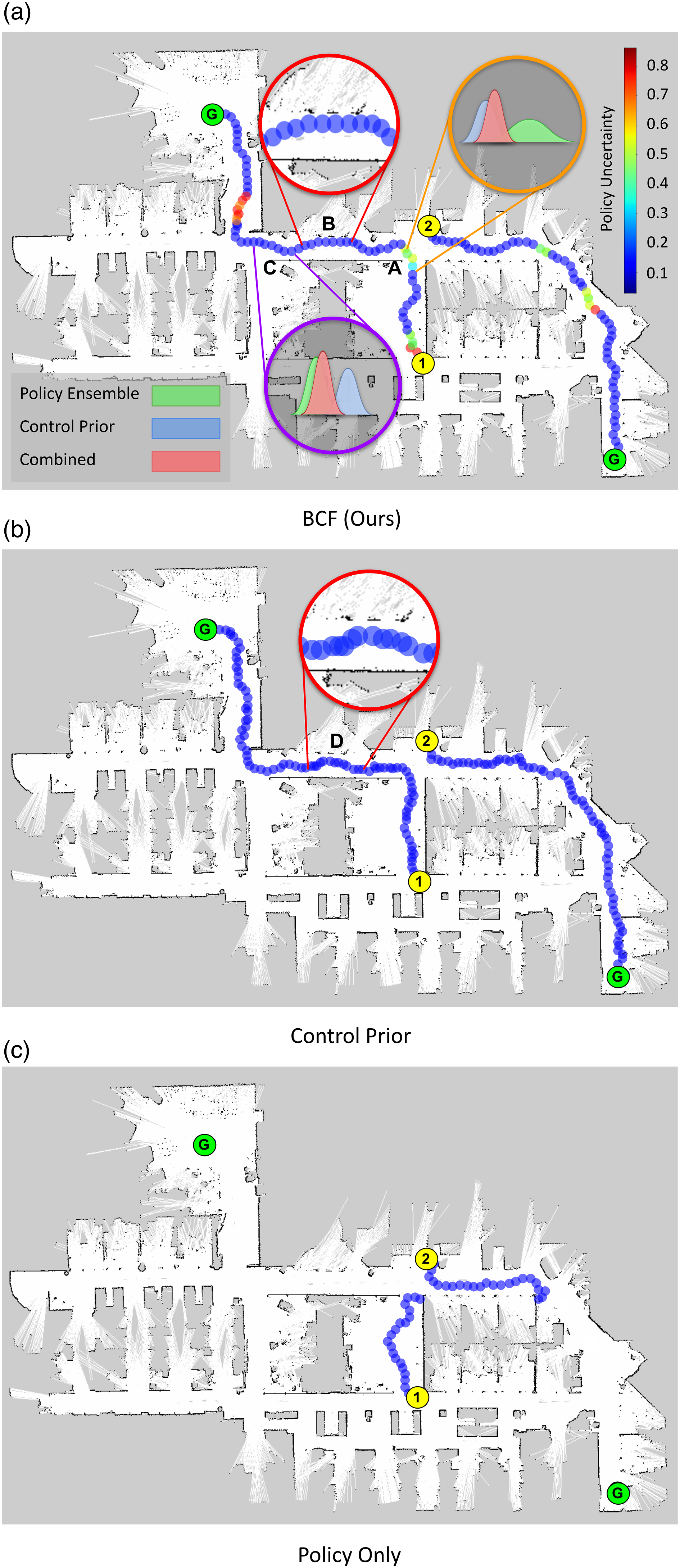

Across both trajectories, the standalone policy failed to complete a trajectory without any collisions, exhibiting erratic reversing behaviours in out-of-distribution states. We can attribute this behaviour to its poor generalisation in such states, given the discrepancies in obstacle profiles seen during training in simulation and those encountered in the real world as shown in Figure 6(a). The control prior was capable of completing all trajectories however required significantly long actuation times. We can attribute this to its inefficient oscillatory motion when moving through passageways and in between obstacles. BCF was successful across both trajectories exhibiting the lowest actuation times across all methods. This indicates its ability to exploit the optimal behaviours learned by the agent while ensuring it did not act erratically when presented with out-of-distribution states. It also demonstrates superior results when compared with the fine-tuned ROS move_base controller.
To gain a better understanding of the reasons for BCF’s success when compared to the control prior and the standalone policy acting in isolation, we examine the trajectories taken by these systems as shown in Figure 13. The trajectory attained using BCF is colour-coded to illustrate the uncertainty of the policy’s actions as given by the outputs of the ensemble. We draw the reader’s attention to the region marked
8.2. Maximum manipulability reacher
Evaluation of maximum manipulability reacher in the simulation environment.

8.2.1. Simulation environment evaluation
For this task, we report the average manipulability across an entire trajectory and the success rate of the agent out of 10 trials. We summarise the results of the experiments in Table 4. The robot was trained with a subset of goals randomly sampled from the positive x-axis region of its workspace frame as shown in Figure 6. We classify goal states sampled from outside this region as out-of-distribution states during evaluation. Similar to the navigation task, BCF attains the best performance in both settings, improving the manipulability of the control prior by 34.9% without any failure cases. While the standalone policy agent successfully attained optimal behaviours in goal states within the training distribution, it exhibited erratic and unsafe behaviours when presented with out-of-distribution goal states. In these cases, the robot was seen to constantly crash into the countertop or hit its joint limits.
8.2.2. Real-world evaluation
To ensure that the simulation-trained policies could be transferred directly to a real robot, we matched the coordinate frames of the PyRep simulator with the real Franka Emika Panda robot setup shown in Figure 6. The state and action space were matched with that used in the training environment, with the actions all scaled down to a maximum of 1.74 rad s−1 before publishing them to the robot at a rate of 100 Hz.
Evaluation of maximum manipulability reacher in the real-world.

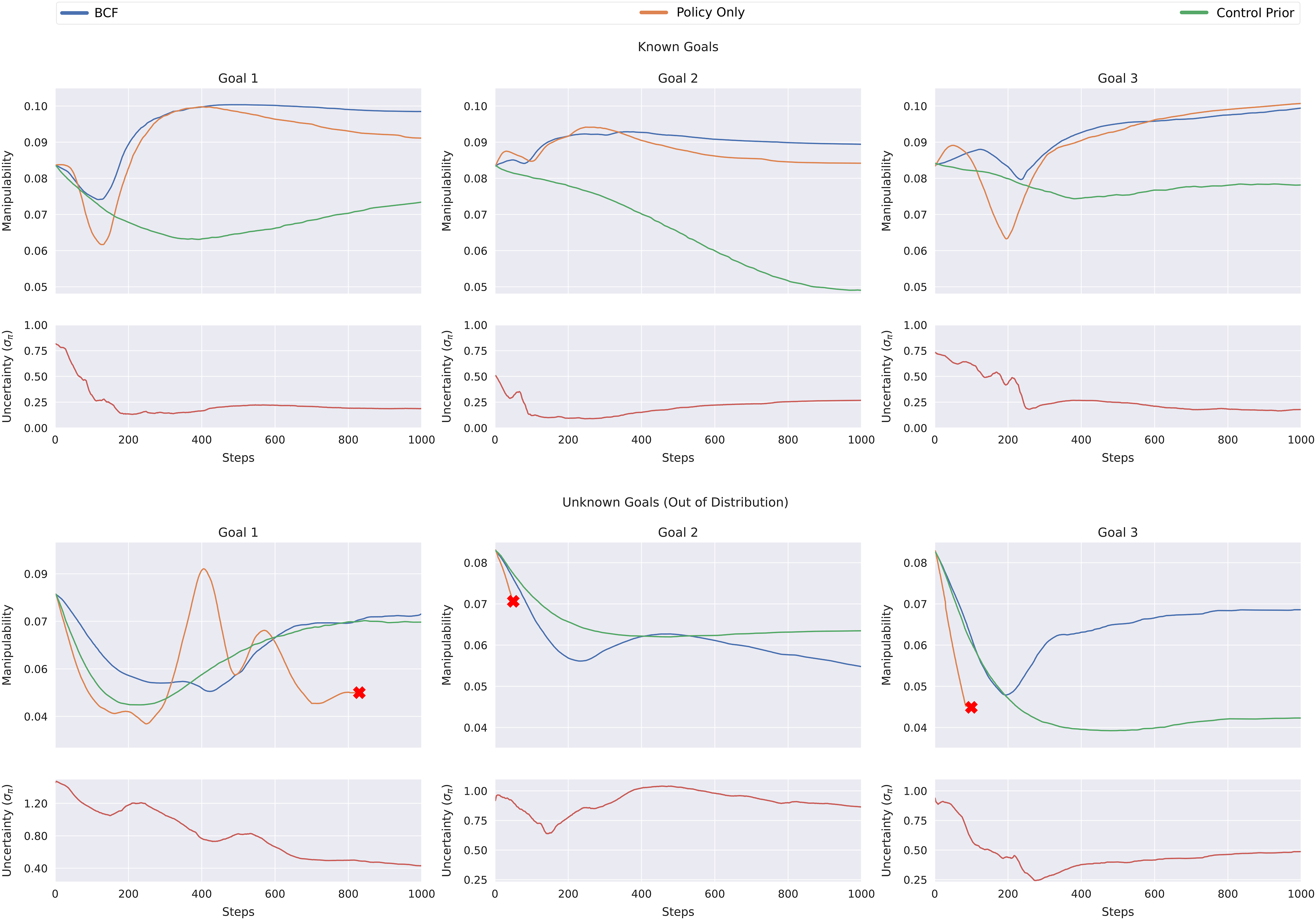
Manipulability and uncertainty curves for known and out-of-distribution goals for the reacher task, deployed on a real robot. The red cross indicates a failed trajectory.
In the case of the known goals, BCF and the standalone RL policy both attain similar performances, maximising the manipulability of the agent across the trajectory. This is in stark contrast to the control prior which exhibits significantly poor performance across the trajectory. Note here that while the control prior exhibits poor performance with regard to manipulability, it is still successful in completing the reaching task at hand without any failures. It is interesting to note the high uncertainty of the ensemble at the start of a trajectory which quickly drops to a significantly lower value. The high uncertainty could be a result of the multiple possible trajectories that the robot could take at the start, which quickly narrows down once the robot begins to move. Note that once the policy ensemble exhibits a lower uncertainty, the performance of BCF closely resembles that of the standalone RL policy, indicating that BCF does not significantly impact the optimality of the learned behaviours.
When evaluating the agents on out-of-distribution goals, BCF plays an important role in ensuring that the robot can successfully and safely complete the task. Note the higher levels of uncertainty across these trajectories when compared to the case of the known goals. In all these cases, the standalone policy fails to successfully complete a trajectory, frequently self-colliding or exhibiting random erratic behaviours. We indicate these failed trajectories with a red cross in Figure 14. BCF is seen to closely follow the behaviours of the control prior in states of high uncertainty, averting it from such catastrophic failures. While the composite control strategy works well to ensure the safety of the robot, the higher reliance of the system on the control prior results in suboptimal behaviour with regard to manipulability. The trade-off between task optimality versus the safety of the robot is an interesting dilemma that BCF attempts to balance naturally. The fixed standard deviation chosen for the control prior could serve as a tuning parameter to allow the user to better control this trade-off at deployment. A smaller standard deviation would bias the resulting distribution more strongly towards the control prior yielding more conservative and suboptimal actions; whereas a larger standard deviation would allow the agent to exploit the learned behaviours for potentially better performance, however at the expense of the robot’s safety when in out-of-distribution states. We leave the further exploration of this idea to future work.
We provide videos illustrating the behaviours of the real robot on our project page. 1
9. Limitations
While we demonstrate BCF’s ability to address some of the critical challenges faced by RL for robotics in both the training and deployment settings, there are a few limitations of our method that future work should consider. Firstly, BCF was primarily evaluated on tasks that involve free space motion which do not require any complex interaction between the robot and the environment. While BCF should naturally extend to these scenarios given the presence of a competent handcrafted control prior a thorough evaluation of the approach on these tasks is still to be made.
Secondly, the uncertainty estimation technique using an ensemble of policies occasionally tended to underestimate the variance of the resulting distribution during the early stages of training. This was due to all the networks in the ensemble producing small values close to zero (Osband et al., 2017). This poses a limit on the guidance that the control prior can provide to the agent within the BCF formulation. We did find in practice however that the ensemble members were able to quickly diversify after only a few gradient updates. We illustrate this phenomenon in the ensemble uncertainty estimate over the course of training in Figure 15. One potential avenue future work could explore is the use of Randomized Prior Functions (RPFs) suggested by (Osband et al., 2017) who show that we can enforce this diversity from the start of training by pairing each network with a fixed, untrained network, which adds its predictions to the output. RPFs ensure a high variance at regions of the input space that are not explored, and a lower variance when the trained networks have learned to compensate for their respective priors and converge to the same output. Progression of ensemble epistemic uncertainty estimates over the course of training. Note how it estimates relatively low uncertainties at the early stages of training before the ensemble members diverge.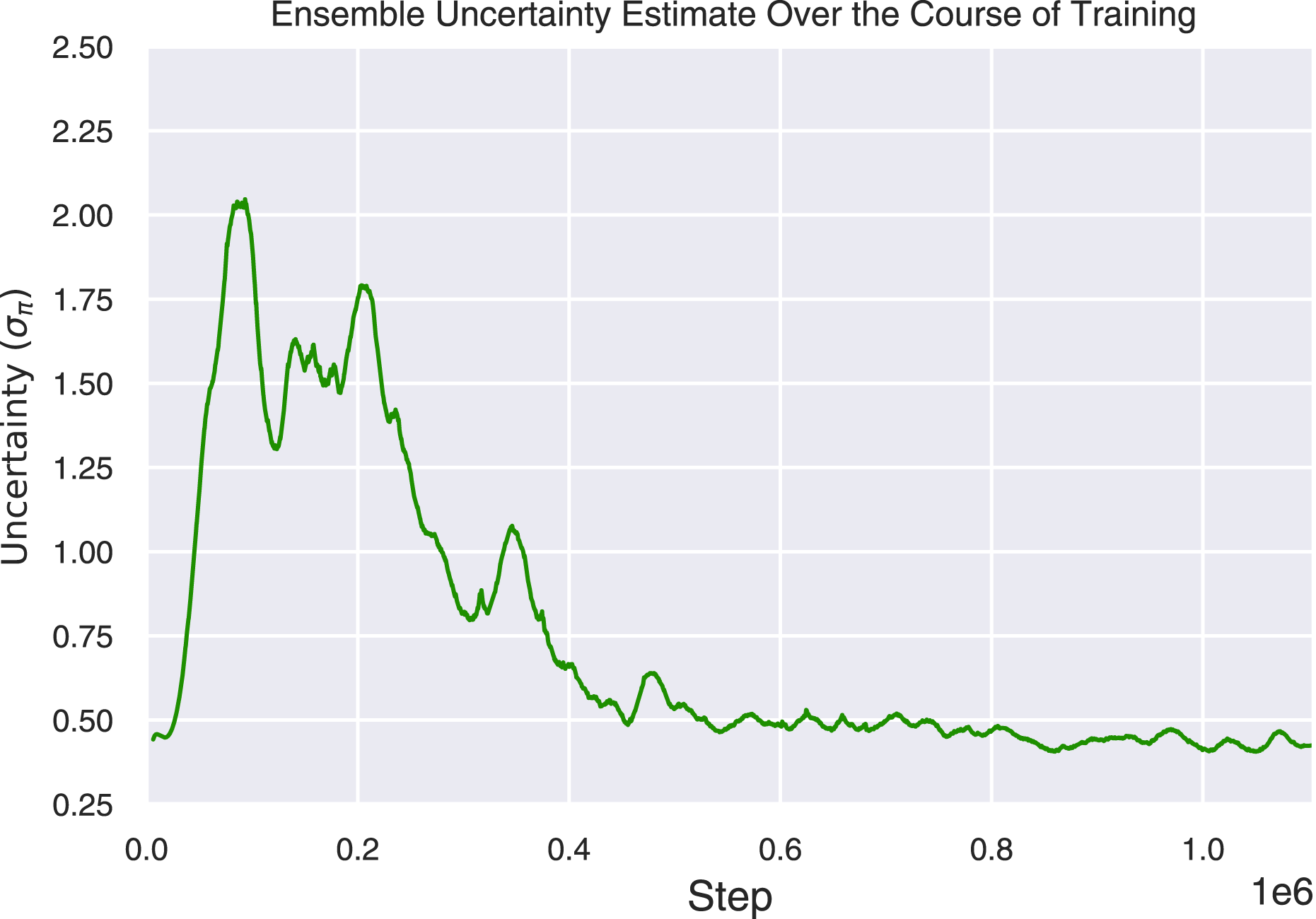
Another limitation we identified in this work is that the BCF formulation reduces the individual distribution outputs from the control prior and RL policy to a single univariate Gaussian for each actuator which limits the overall expressivity of the agent when presented with complex multi-modal scenarios. In such a case, each controller would be highly confident with opposing action distributions resulting in BCF averaging the two outputs which could produce highly unsuitable or unsafe behaviours. This calls for a more expressive representation of the resulting composition such as a Gaussian Mixture Modal.
Finally, our particular formulation is restricted to leveraging only a single control prior for guiding an RL agent. This could be restrictive in cases where multiple control priors exist, each exhibiting strengths that we would like the RL agent to capture. Future work could explore how we could incorporate these systems into a single learning framework for accelerated and safe learning. One avenue would be to incorporate the systems within a hierarchical RL setting. In such a case, the high-level agent would be pre-trained to learn an effective exploration-exploitation arbitration strategy to govern the choice among the different controllers and policies based on their uncertainty over actions and a given state.
10. Conclusion
Building on the large body of work already developed by the robotics community can greatly help accelerate the use of RL-based systems, allowing us to develop better controllers for robots as they move towards solving more complex tasks. The ideas presented in this paper demonstrate a strategy that closely couples traditional controllers with learned systems, exploiting the strengths of each approach in order to attain more reliable and robust behaviours. We see this as a promising step towards bringing reinforcement learning to real-world robotics.
Our Bayesian Controller Fusion (BCF) approach combines uncertainty-aware outputs from the two control modalities. In doing this, we show that we not only accelerate training but additionally learn a final policy that can substantially improve beyond the performance of the handcrafted controller, regardless of its degree of sub-optimality. We show results across both a navigation and reaching task where BCF attains a final policy exhibiting a 116% and 282% improvement beyond the initial performance of the control prior used, respectively, substantially higher than that attained by existing approaches. More importantly, we show that our approach can exploit the risk-aversity provided by these classical controllers to allow for safe exploratory behaviours when presented with unknown states.
At deployment, we show that forming a hybrid controller with BCF allows us to exploit the respective strengths of each controller, enabling the reliable performance of RL policies in the real world. Across two real-world tasks for navigation and reaching, we show that BCF can safely deal with out-of-distribution states in the sim-to-real setting, succeeding where a typical standalone policy would fail, while attaining the optimality of the learned behaviours in known states. In the navigation domain, we overcome the inefficient oscillatory motion of an existing reactive navigation controller, decreasing the overall actuation time during real-world navigation runs by 50.7%. For the reaching task, we show that our hybrid controller achieves the highest success rate, and improves the manipulability of an existing reaching controller by 34.9%, a system typically difficult to attain using analytical approaches.
Footnotes
Acknowledgements
We acknowledge continued support from the Queensland University of Technology (QUT) through the Centre for Robotics. This research was supported by the Australian Research Council Centre of Excellence for Robotic Vision (project number CE140100016). This work was partially supported by an Australian Research Council Discovery Project (project number DP220102398). The authors would like to thank Jake Bruce, Robert Lee, Mingda Xu, Dimity Miller, Thomas Coppin and Jordan Erskine for their valuable and insightful discussions towards this contribution.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Queensland University of Technology (QUT) through the Centre for Robotics and Australian Research Council Centre of Excellence for Robotic Vision (project number CE140100016). This work was partially supported by an Australian Research Council Discovery Project (project number DP220102398).