
Abstract
Most of our interactions with our environment involve manipulating real 3D objects. Accordingly, 3D objects seem to enjoy preferential processing compared with 2D images, for example, in capturing attention or being better remembered. But are they also more readily perceived? Thus far, the possibility of preferred detection for real 3D objects could not be empirically tested because suppression from awareness has been applied only to on-screen stimuli. Here, using a variant of continuous flash suppression (CFS) with augmented-reality goggles (“real-life” CFS), we managed to suppress both real 3D objects and their 2D representations. In 20 healthy young adults, real objects broke suppression faster than their photographs. Using 3D printing, we also showed in 50 healthy young adults that this finding held only for meaningful objects, whereas no difference was found for meaningless, novel ones (a similar trend was observed in another experiment with 20 subjects, yet it did not reach significance). This suggests that the effect might be mediated by affordances facilitating detection of 3D objects under interocular suppression.
Keywords
In our daily lives, we navigate in a world filled with objects, yet not much is known about the mechanisms by which real objects are processed. We do know that these mechanisms differ from ones evoked by 2D representations, both behaviorally (Ozana & Ganel, 2019) and neurally (Marini et al., 2019). Three-dimensional objects are also remembered better (Snow et al., 2014), valued more than pictures (Bushong et al., 2010), less easily habituated as a category than photographs during infancy (Gerhard et al., 2016), and learned earlier (DeLoache et al., 2003). Thus, it seems that 3D objects enjoy preferential processing over 2D images; this is strengthened by some cases of visual agnosia, in which recognition of objects from pictures is impaired but no impairment is found for real objects (a “real-object advantage”; Chainay & Humphreys, 2001). If so, could it be that our perceptual mechanisms are more tuned to consciously detect real objects, akin to how we prioritize other stimulus types (e.g., upright faces, socially relevant stimuli, danger-associated stimuli; for a review, see Gayet et al., 2014)? If so, this would shed light both on the underlying mechanisms of object processing and on conscious perception.
In object processing, a key concept is affordances: motor action plans activated by objects, referring to the possible uses or actions that the observer can perform on them (Gibson, 1979). Affordances are held to be automatically evoked by objects, even when either the affordances (Vainio et al., 2011) or the objects (Roche & Chainay, 2017; for a review, see Borghi & Riggio, 2015) are task irrelevant. Similarly, increased activation in areas related to functional object and tool manipulation has also been found for objects for which no action is required (for a meta-analysis, see Ishibashi et al., 2016). Such activations were even claimed to occur in response to unconsciously presented tools (Fang & He, 2005; Tettamanti et al., 2017), yet other studies challenged these claims (Rothkirch & Hesselmann, 2018). Thus, it is currently unknown whether affordances can be activated under interocular suppression (Stein et al., 2011) or whether they can facilitate detection of the afforded object.
To date, there is only suggestive evidence in that direction: One study (Gomez et al., 2018) found enhanced attentional capture by 3D-object flankers compared with photograph flankers (akin to the paradigm of Eriksen & Eriksen, 1974). Critically, this effect was not found when the real objects were positioned either out of reach or behind a transparent barrier, a common manipulation for decreasing affordance activation (Caggiano et al., 2009). Another study (Weller et al., 2019) reported shorter suppression times for useful tools compared with useless ones, for which subjects do not have motor knowledge.
Yet for real 3D objects to be more readily detected or enjoy some preferential perceptual status, they should be distinctively processed as different from 2D images even prior to being detected or reported to be detected. Until now, this possibility could not have been tested because the available methods did not allow researchers to test detection of 3D items, as opposed to their pictorial representations. Testing detection requires some method that would make it harder to detect the 3D items or even suppress them from awareness until they break suppression and are detected. Current suppression methods are all based on screen-presented psychophysical manipulations and are therefore limited to 2D, on-screen stimuli (for a review, see Breitmeyer, 2015) or, recently, to virtual objects (Suzuki et al., 2019).
Here, we used a novel variant of the continuous flash suppression (CFS) paradigm (Tsuchiya & Koch, 2005), termed “real-life” CFS (Korisky et al., 2019), to uniquely suppress real 3D objects. In CFS, conscious perception of a target stimulus presented to the nondominant eye is suppressed by a series of masks (consisting of Mondrian patterns) presented to the dominant eye (Tsuchiya & Koch, 2005) until the target stimulus emerges into awareness (for a recent review and discussion, see Stein, 2019). In the “real-life” CFS paradigm, augmented-reality goggles are used to present the series of masks directly to the subjects’ dominant eye while their nondominant eye is exposed to the real world in front of them. Any object placed in front of the subject can therefore be suppressed from awareness. We first hypothesized that 3D objects would indeed be more readily detected (i.e., reported to break suppression faster) than their 2D photographs; our second hypothesis was that this effect would be driven by affordances. Notably, reanalyzing data from a study validating the method, we already found initial support for the first hypothesis (see Fig. S1 in the supplementary online material [SOM] available on OSF at https://osf.io/9gkv4/; based on data obtained by Korisky et al., 2019).
Statement of Relevance
When it comes to visual awareness, not all stimuli are created equal. Some things are more readily perceived than others, and determining which stimuli are more easily detected and why has been an ongoing experimental challenge. Here, we highlight a new type of stimuli that seem to be perceptually favored: real 3D objects. We found that 3D objects are more readily perceived than 2D images and that this effect holds only for intact, and not scrambled, objects. Why might this be? People are able to functionally interact with 3D objects, whereas they cannot do so with 2D images or even scrambled objects. This suggests that the perceptual priority of 3D objects stems, at least in part, from prior motor knowledge of how one interacts with them. This work not only expands our understanding of the factors affecting detection of stimuli but also suggests that the possibility of functional interaction might play a crucial role in perception.
Here, the question was addressed in a series of three experiments. Experiment 1 presented 3D objects and 2D photographs at three levels of representation (color, black and white, and contours), and subjects were asked to report as soon as they detected a stimulus. Three-dimensional objects were indeed detected faster than 2D photographs, irrespective of representation level. We reasoned that this effect could be driven by three possible factors: (a) affordances, in line with the literature presented above; (b) depth, that is, 3D objects could emerge faster because of monocular depth cues or lens accommodation (Ciuffreda, 1998); or more trivially, (c) differences in reflectivity between the real 3D objects that sometimes included shiny parts and the matte-printed 2D photographs. These might induce low-level differences, known to affect interocular suppression (Tsuchiya & Koch, 2005). To arbitrate between these alternative interpretations of the results, in Experiment 2 (preregistration: https://osf.io/wa8g6/), we manipulated object familiarity as well. To do so, we prepared digital 3D models of the intact objects and of scrambled versions of them. This created novel, unfamiliar objects, for which subjects did not have prior motor knowledge, that shared some of the low-level features of the intact objects. These models were then 3D printed, and detection times for them were compared with detection times for their 2D photographs. A marginally significant trend toward faster detection of intact 3D objects, but not of scrambled ones, was found. Finally, in Experiment 3 (preregistration: https://osf.io/vb95f/), in which a bigger sample size was used and the distance between subjects and stimuli was reduced (facilitating affordances processing; Kalénine et al., 2016), a clear and strong effect in the same direction was obtained. Overall, our results suggest that real 3D objects are more readily perceived and that this might indeed be driven by the activation of affordances.
Method
Because the methodology was shared across the three experiments, we jointly describe it below, highlighting differences between experiments where needed. The complete data, stimuli, and analysis code for all experiments are available at https://osf.io/mygt2/.
Subjects
Ninety subjects participated in three experiments for payment or course credit: 20 participants in Experiment 1 (14 female; age: M = 24.35 years, SD = 3.88; all right handed; sample size in this more exploratory experiment was chosen on the basis of a common practice for exploratory experiments in our laboratory), 20 participants in Experiment 2 (13 female; age: M = 23.35 years, SD = 1.77; all right handed; sample size was selected on the basis of a power analysis on the effect from Experiment 1; see preregistration at https://osf.io/wa8g6/), and 50 participants in Experiment 3 (29 female; age: M = 24.76 years, SD = 3.48; 47 right handed; sample size was defined by multiplying the sample size of Experiment 2 by 2.5; see Simonsohn, 2015).
Fourteen additional subjects were excluded for not completing the experiment: one in Experiment 1 (incomplete data due to fatigue), four in Experiment 2 (technical issues; discomfort in wearing the augmented-reality goggles, which prevented them from taking the experiment), and nine in Experiment 3 (discomfort, difficulty in achieving fusion, fatigue, technical issues). Their data were accordingly not collected or not observed in any way. Eleven additional subjects who completed the experiment were excluded from the statistical analyses because evidence suggested that they did not follow instructions: two in Experiment 1, one in Experiment 2 (accuracy lower than 75%), and eight in Experiment 3 (low accuracy, abundance of responses quicker than a 250-ms threshold, reporting seeing stimuli on catch trials when no such stimuli were presented). All the above exclusion criteria were preregistered for Experiments 2 and 3. And, importantly, none of these criteria pertain to assessment of awareness levels or have any bearing on the reported effects and, accordingly, should not evoke regression to the mean that might drive the reported effects (Shanks, 2017). All subjects signed a consent form and had normal vision or corrected-to-normal vision using contact lenses. They declared no past neurological, attentional, or mental disorders and no current usage of psychiatric medicines. The experiments were approved by the university’s ethics committee.
Apparatus
The apparatus included a computer-controlled “puppet theater,” in which the stimulus object was placed, and a pair of augmented-reality goggles (Epson Moverio BT200) worn by the subject. The graphics shown on the augmented-reality goggles were produced by a computer, using MATLAB (Version 2018b; The MathWorks, Natick, MA) with the Psychophysics Toolbox (Version 3; Brainard, 1997). The computer was connected wirelessly to the augmented-reality goggles.
The puppet theater (Fig. 1a) was built as a white-painted wooden wall, 1 m wide and 74.5 cm tall. A window, 20 cm wide and 15 cm tall, was cut in the middle of the wall 26 cm from the bottom of the apparatus. Behind this window was a display box, which acted as a stage. A retractable blind separated this box from the window to allow the stage to be hidden between trials. Three LED strips were used to illuminate the stage (Experiment 1: 2.75 cd/m2, Experiments 2 and 3: 10 cd/m2). The strips were covered with three layers of parchment paper to avoid highlights that might differ between the 3D and the 2D conditions. In Experiments 1 and 2, the puppet theater was placed 90 cm from the subject, and in Experiment 3, it was 60 cm away, decreasing the window size to 12 cm × 10 cm. Also, to minimize their ability to rely on irrelevant cues to detect stimulus location, we had subjects in Experiment 3 wear passive noise-cancelling headphones (Sennheiser HD 25). White noise was played between trials to prevent hearing the experimenter placing the target stimulus. In addition, to prevent cross-talk between the eyes, we placed a transparent plexiglass cover on top of the augmented-reality goggles that was opaque only in the field presenting the CFS masks. Thus, no information aside from the CFS stimulation could be perceived by the dominant eye.
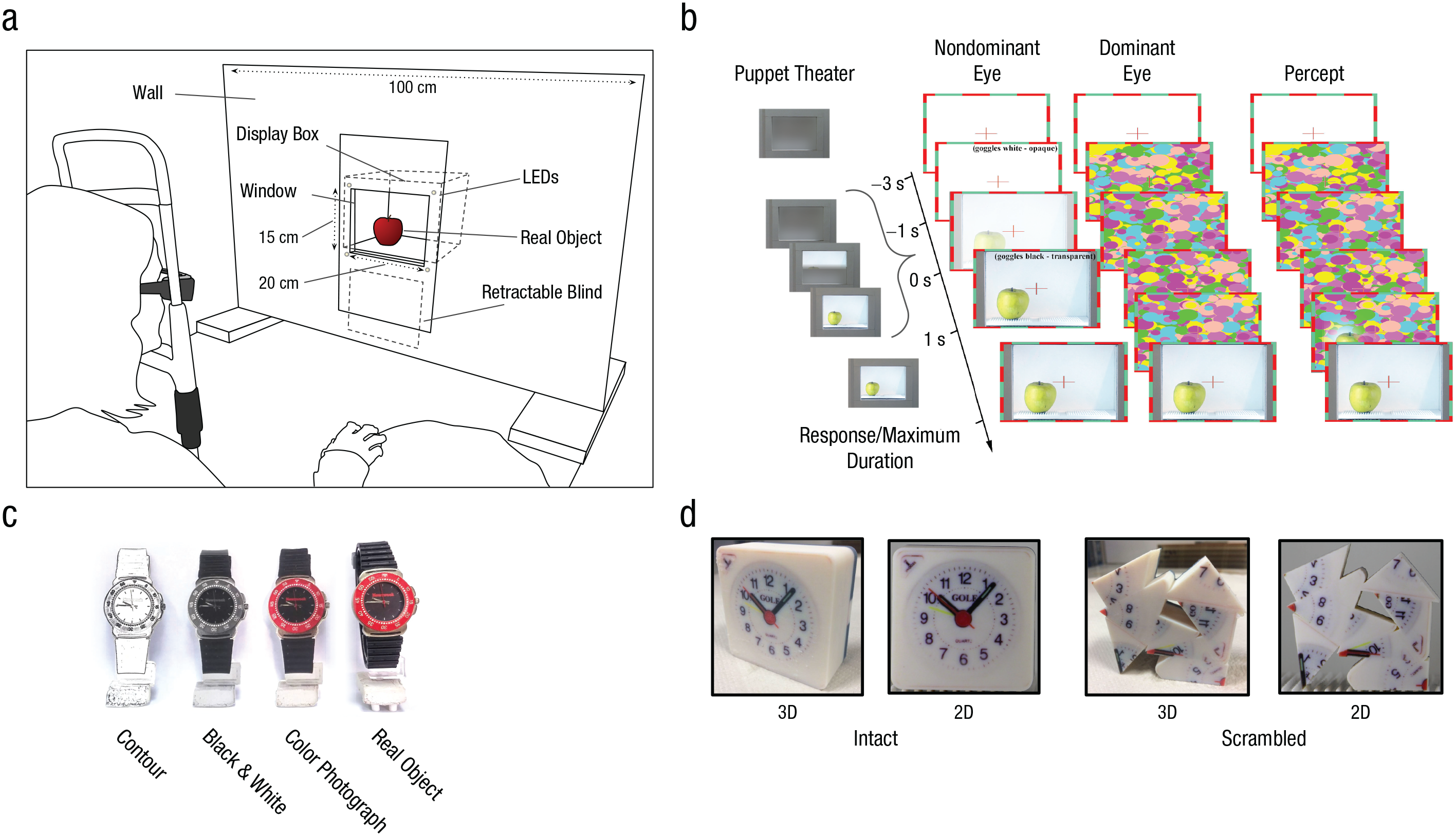
The setup, paradigm, and types of stimuli used in the experiments. Stimuli were presented to subjects in a “puppet theater” (a; schematic adapted with permission from Korisky et al., 2019). The subject laid his or her head on a chin rest, wearing the augmented-reality goggles, and responded using a mouse. The puppet theater consisted of a display box embedded within a white wall that hid the experimenter. A retractable blind was used to hide the display box between trials. In Experiments 2 and 3, an LED was placed at each corner of the display box to mark the window’s position. Across the time course of a trial in Experiments 1, 2, and 3 (b), stimuli were presented to the nondominant eye while Mondrian masks were presented to the dominant eye. The leftmost column shows the state of the puppet theater across a trial, and the rightmost column illustrates subjective perception. Example stimuli used in Experiment 1 (c) are shown from each of the four representation levels. Example stimuli used in Experiments 2 and 3 (d) are shown for levels of intactness (intact vs. scrambled) and dimensionality (2D vs. 3D).
Additionally, in Experiments 2 and 3, an LED was set at each corner of the window of the puppet theater. These LEDs assisted subjects in aligning their gaze with the window despite the dim lighting.
Stimuli
On-goggles stimuli
Using the goggles, the subject was presented with a fusion frame (~9.6 × 6.4 degrees of visual angle, depending on individual eye disparity) and a fixation cross. During the trial, the “real-life” CFS method (described in detail by Korisky et al., 2019) was used by presenting the Mondrian masks at 10 Hz on the goggles, monocularly, to the dominant eye. The Mondrian masks consisted of colorful circles, randomly placed, ranging between 0.12 and 0.84 degrees of visual angle. The circles were of six different colors, all of 100% value and saturation on the hue, saturation, and value (HSV) scale.
Real-world stimuli
In Experiment 1, 11 real-life common everyday objects, smaller than 15 cm × 10 cm and easily recognizable, were used (see Fig. S4 in the SOM). The color-photograph stimuli were created by taking photographs of the objects with a Canon 700D camera from both the left and right sides of the stage of the puppet theater. Photos were taken at the same distance as they were presented in the experiment to match the two perspectives in which they appeared to the subject and to mimic as much as possible the illumination conditions and the shading within the stage that would be observed when the 3D objects were placed. The photographs were then professionally manipulated by a digital print designer and printed on matte paper (Epson enhanced) to avoid highlight reflections. The resulting cutouts closely matched the real objects in appearance (see Fig. S4). The black-and-white stimuli were created by reducing the saturation of the colored photographs to zero. The contour stimuli were created by employing a “find edges” filter on the black-and-white stimuli in Adobe Photoshop.
In Experiment 2, two sets of stimuli were used (for the creation process, see the SOM): Intact stimuli were 10 full-color real-size 3D-printed replicas of 10 objects out of the 11 used in Experiment 1, all smaller than 10 cm × 10 cm. Scrambled stimuli were 3D-printed versions of these same 10 objects that were digitally deformed in various ways to create meaningless nonobjects (for further details, see the SOM). Notably, the main motivation behind the 3D-printing in Experiments 2 and 3 was to minimize all differences in materials and reflectance between the different items and between each item and its photograph. The 3D printing was accordingly done using a uniform matte polymer, which does not reflect highlights (akin to the matte paper on which the 2D photographs were printed). The same procedure as described above was used to prepare 2D representations of all 3D printed models. In Experiment 3, eight out of the 10 stimuli were used (excluding the Rubik’s cube and camera, which were too large to fit in the smaller window).
Procedure
Experiment 1 consisted of 176 trials split evenly across two blocks. In each block, all 11 objects were shown in all possible experimental conditions in a 4 (representation level: real object, color photograph, black-and-white photograph, contours photograph) × 2 (side of stage: left, right) design. Trial order was pseudorandomly set, with the constraint that no value of one of the variables, or combination thereof, would repeat for more than three consecutive trials.
Experiment 2 consisted of 160 experimental trials split evenly across two blocks. In each block, five intact objects and five scrambled objects were shown in all possible experimental conditions in a 2 (dimensionality: real 3D object, 2D color photograph) × 2 (side of stage: left, right) design. To prevent subjects from forming associations between the scrambled and intact versions of the items, we ensured that each subject saw each item as either intact or scrambled but never both. Five catch trials, in which no stimulus was introduced, were added to each block. Although adding catch trials is less common in typical on-screen breaking-CFS paradigms, here they were needed to minimize false reports of seeing a stimulus on one side when the subject actually just saw the other, empty side of the stage (because as opposed to on-screen CFS, here we could not simply present the stimuli on a uniform gray background, and sometimes the empty stage itself broke suppression, allowing subjects to infer the location of the suppressed stimulus without seeing it). The maximum duration of catch trials was 19.6 s in Experiment 2 and 40 s in Experiment 3.
Experiment 3 was similar to Experiment 2, except for the following changes: (a) There were only one or two catch trials in each block, and (b) item assignment as intact or scrambled was counterbalanced between subjects so that each item was seen by approximately the same number of subjects in its intact or scrambled forms.
At the beginning of each block, a short calibration session was conducted to account for differences in subjects’ eye disparity (for details, see Korisky et al., 2019). All experiments started with a training block of up to 10 trials, using different stimuli from the ones in the experimental trials.
Before each trial, the experimenter pulled up a blind, hiding the puppet theater stage, and placed a stimulus either on the left or on the right half of the stage. A fixation frame with a white background was subsequently presented binocularly for 2 s. Then, Mondrian masks were presented to the dominant eye for 1 s while the nondominant eye’s fixation frame remained white. Within this second, the blind hiding the stage collapsed, exposing the stage to the subject. Importantly, because of the effective opaqueness of the white background and CFS masks, the subject was not yet exposed to the stimulus. Then, the white background of the fixation frame was linearly transformed to black over 1 s, exposing the nondominant eye to the stage. The Mondrian masks were presented to the dominant eye until subjects responded or for a maximum window of 18.6 s (Experiment 1), 19.6 s (Experiment 2), and 60 s (Experiment 3), including the 1 s of opaqueness ramping down. Subjects were asked to report the location of the stimulus as soon as they detected it by pressing the right or left mouse button. Then, the mask disappeared, allowing the subject to see the stage clearly. The blind was lifted by the experimenter, and a new trial began.
Statistical analysis
All results were false discovery rate (FDR) corrected (Benjamini & Hochberg, 1995), collapsed across experiments, unless otherwise specified. Overall, 16 p values were corrected using FDR. Results in the SOM were FDR corrected separately (87 p values). Because of the nonnormal nature of the detection time distributions in our experiments, randomization procedures and tests were employed (this approach was chosen following consultation that we received after the preregistration of Experiment 2; for a detailed description of the original analyses that we planned and the results obtained under these analyses, see the SOM). Each such procedure or test included 104 iterations of resampling or reshuffling of the data, respectively. In cases in which 104 iterations did not suffice to produce a p value greater than zero in a test (i.e., no permutations yielded an effect as extreme as in the real data), we reran the permutation test with more iterations (105) in an attempt to obtain a more accurate p value. If this too yielded a p value of zero, we report it as p < 10−5.
Descriptive statistics: confidence intervals (CIs)
To obtain CIs, we used a bootstrapping procedure. A resampling of trials was done in each iteration, respecting the division into subjects, items, and conditions (i.e., not shuffling across the borders defined by the values of these variables) and not including side of stage (left, right). The statistics were then calculated on the resulting resampled data. The 2.5 and 97.5 percentiles of the resulting distributions were taken as CIs.
Experiment 1
Main effect of representation level
An omnibus nonparametric permutation test was conducted. The statistic calculated on the real and permuted data was the sum of squares of the differences between the average detection time for each representation level and the overall detection time across levels. To obtain the distribution of the null hypothesis, whereby representation level has no impact on detection time, we conducted permutations in two different fashions: The first was per-subject swap, in which all trials belonging to a specific representation level were grouped, and their label was randomly shuffled, respecting the division into subjects and items (e.g., for a specific subject, all black-and-white trials in which a light bulb appeared were labeled as contour trials, and so on). The second was across-subjects swap, which was identical to the first permutation method but applied the changed label for all subjects (e.g., all black-and-white trials in which a light bulb appeared were labeled as contour trials for all subjects, and so on). This shuffling type takes into account variance that is common to subjects and items but does not allow for item-by-item analysis (see the SOM).
To make sure that the effect did not depend on specific items, we conducted a post hoc item-based analysis under the per-subject-swap approach. For each item, all trials in which other items were presented were excluded from the data, and the same omnibus test was performed. Items were considered extreme if their per-item main effect for representation level was extreme in their distribution and if this extremeness survived a local FDR correction, which included only the p values of the per-item effects of this experiment. These extreme items were then excluded, and the grand omnibus test was performed again to determine whether the effect was still obtained without them (see the SOM). For the FDR correction of the results reported in the SOM, the original, nonlocally FDR-corrected p values of each item’s effect were used.
Post hoc comparison of paired representation-level categories
To test differences between specific representation levels, we excluded all trials of other representation levels. Then, the test statistic was the difference between the mean detection time across stimuli and subjects for the two representation levels, using the same permutation procedure performed in the omnibus test.
Experiments 2 and 3
Interaction between intactness and dimensionality
A directional nonparametric test was used to assess the interaction between intactness and dimensionality. The statistic was calculated by subtracting the mean difference between the two dimensionality levels (3D – 2D) for intact items from the same difference for scrambled items, respecting the division between subjects and items. In the permutation procedure, all trials belonging to the same dimensionality level were grouped, and their labels were randomly shuffled (2D, 3D). Additionally, the labels of items as intact or scrambled were shuffled, respecting the division between subjects and the counterbalancing (or lack thereof) between them.
Simple effect of dimensionality within each intactness level
This analysis was exploratory and was conducted separately for intact and scrambled items. The statistic was the mean difference in detection time between the two dimensionality levels (3D – 2D), respecting the division between subjects and items. In the permutation procedure, it was determined with a probability of .50 whether the labeling of all the trials of each item as “3D” or “2D” should be inverted, again respecting the division between subjects and items. Here, too, we tested to see whether the simple effects for dimensionality were driven by any one specific item (see the SOM).
Main effect of dimensionality
This test was done similarly to the above test for the simple effect, except that it was done across all items, irrespective of their intactness. An additional analysis was done, in which variance common to subjects and items was taken into account (across-subjects swap). There, in each iteration, for each item, all trials belonging to a certain dimensionality, across all subjects, were treated as one group. Then, for each item, the labels of the two groups were inverted with a probability of .50.
Effect sizes
Effect-size measures (Cohen’s d, η p 2) are reported. Although the significance of the corresponding effects was calculated using nonparametric methods, we report parametric effect-size estimations to facilitate interpretation as well as comparability with other findings in the field.
Results
Trial exclusion
Following the preregistered criteria, we removed trials in which subjects’ responses were wrong (Experiment 1: 6.85% of total trials, n = 239 across all subjects; Experiment 2: 1.75%, n = 56; Experiment 3: 2.2%, n = 175) or faster than 250 ms (Experiment 1: 0.17%, n = 6; Experiment 2: 1.85%, n = 59; Experiment 3: 1.03%, n = 82). Trials in which the subject did not respond at all (no-response trials) were included in the analysis (Experiment 1: 7.22%, n = 252; Experiment 2: 4.45%, n = 142; Experiment 3: 0.98%, n = 78). No-response trials were taken as evidence that suppression lasted at least as long as the duration of the trial. We conducted additional analyses excluding these trials to make sure they did not solely drive the effect (see the SOM).
Experiment 1
Detection times in Experiment 1 were compared among four different levels of representation: real 3D objects, 2D color photographs, 2D black-and-white photographs, and 2D contour-only photographs. A nonparametric permutation analysis revealed that detection time differed between the four levels of representations (Fig. 2): Real 3D objects were detected fastest—main effect of representation level: p < .0005, η p 2 = .37 (for descriptive and inferential statistics, see Tables 1 and 2). Post hoc permutation analyses revealed that this effect stemmed solely from shorter detection times for real objects compared with each and every other representation level (all comparisons were Bonferroni-corrected for six possible comparisons between levels). No other two representation levels differed. These effects remained largely the same when we excluded no-response trials (see the SOM).
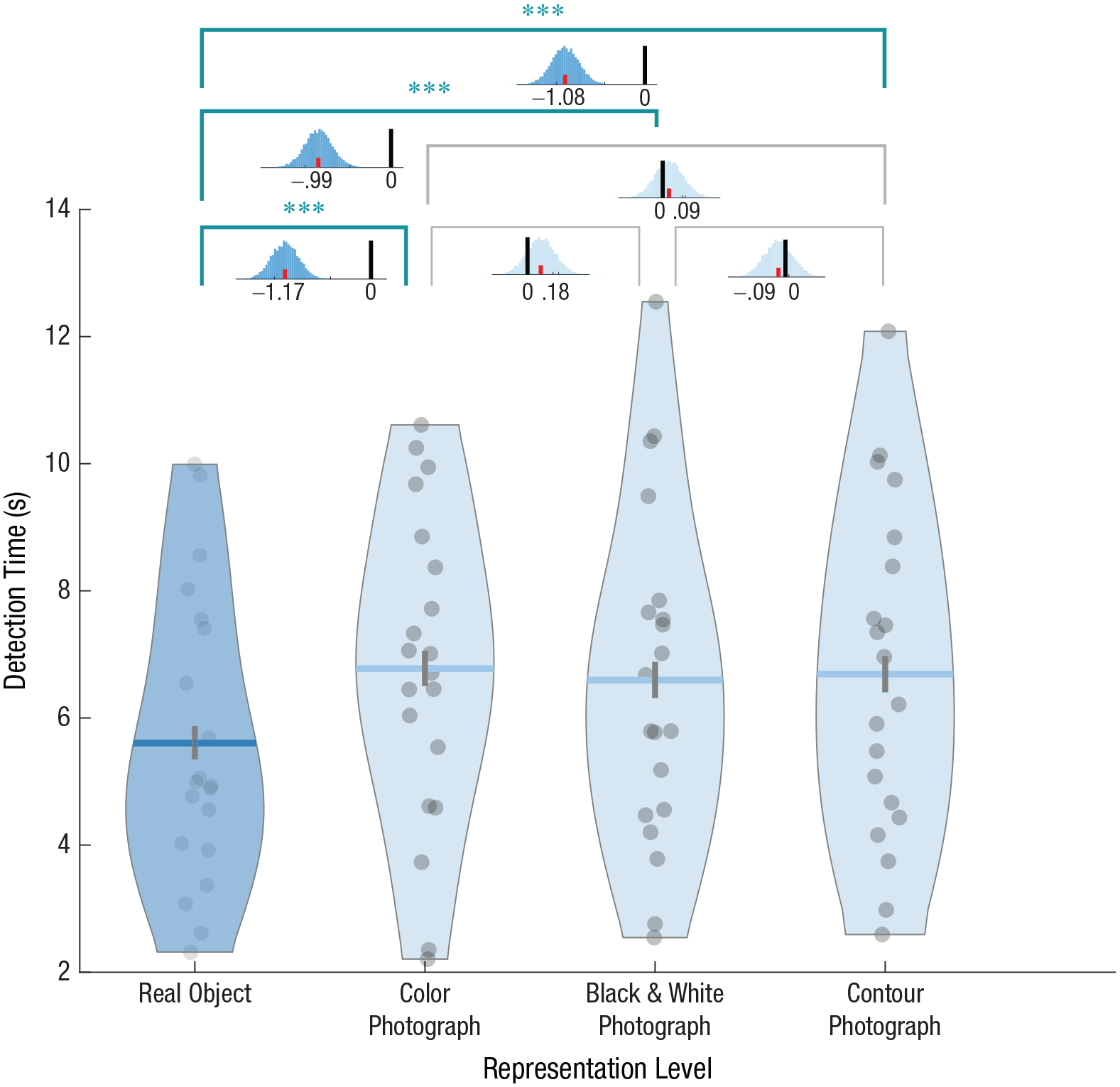
Detection time in Experiment 1. The violin plots show detection time for each representation level. Dots represent single subjects, horizontal lines show group means, and vertical lines depict 95% confidence intervals obtained by bootstrapping. The shape of each violin plot represents the distribution of its values along the y-axis. Above the plot, histograms depict distributions of pairwise differences between every two levels, obtained by bootstrapping. Red lines represent the actual differences. Asterisks mark distributions that exclude zero, which indicates a significant effect (***p < .0005).
Mean Detection Time (in Seconds) for Each Representation Level in Experiment 1
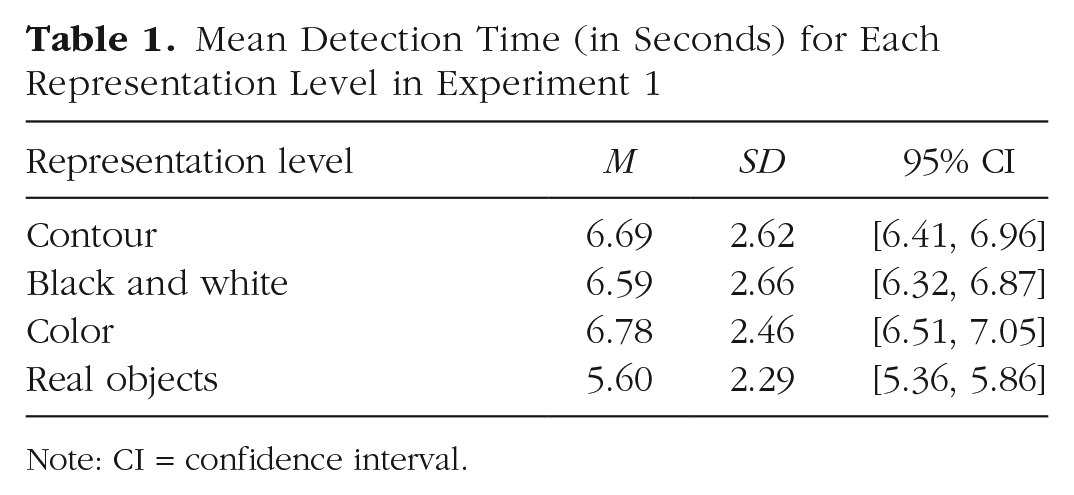
Note: CI = confidence interval.
Detection Time Differences Between Representation Levels in Experiment 1
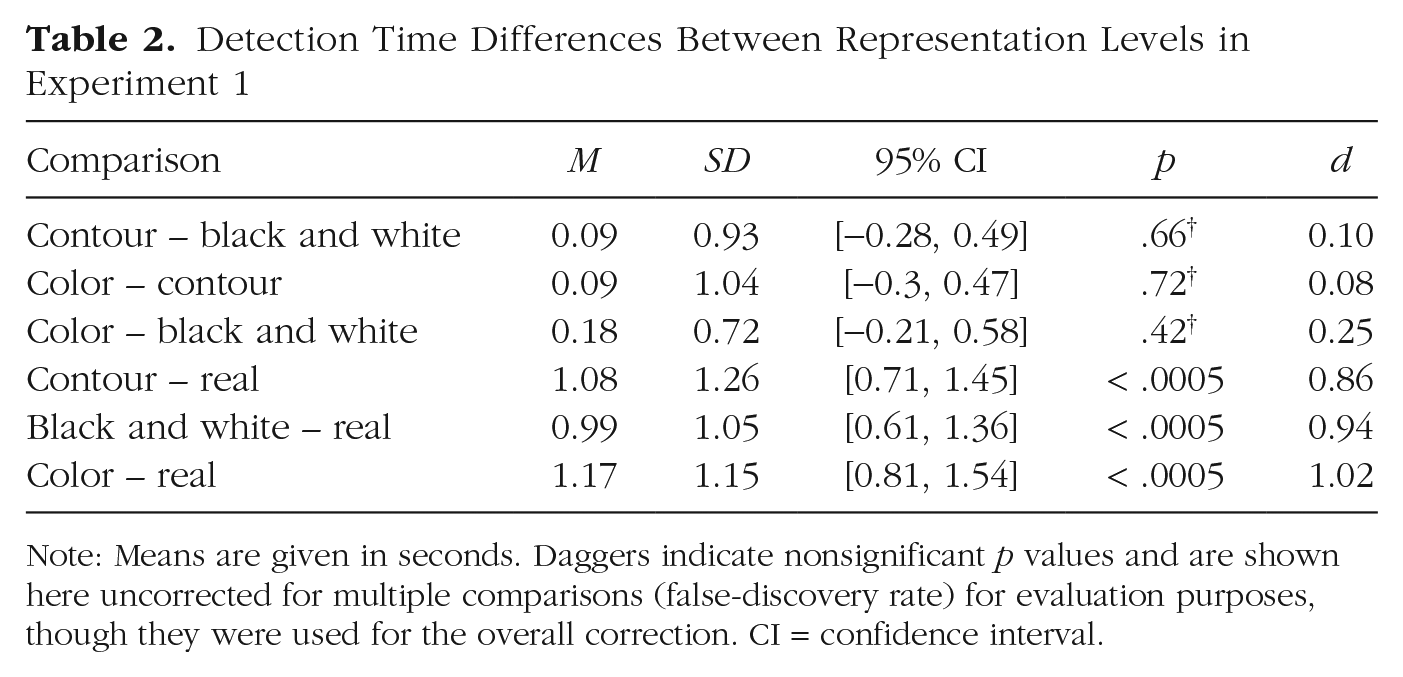
Note: Means are given in seconds. Daggers indicate nonsignificant p values and are shown here uncorrected for multiple comparisons (false-discovery rate) for evaluation purposes, though they were used for the overall correction. CI = confidence interval.
Experiment 2
On a descriptive level, the results suggested that the difference between 3D and 2D stimuli might be restricted to intact stimuli (Table 3 and Fig. 3a; see also Fig. S4a), yet this trend was only marginally significant and did not survive FDR correction. Post hoc examination of the interaction did not show a significant simple effect of dimensionality for intact items (Table 3; 3D – 2D: ΔM = −0.33 s, SD = 0.73, 95% CI = [−0.74, 0.07], uncorrected p = .11, FDR q = 0.23, Cohen’s d = 0.45) or for scrambled items (3D – 2D: ΔM = 0.2 s, SD = 0.89, 95% CI = [−0.18, 0.59], uncorrected p = .32, d = 0.23). A main effect of dimensionality was not found (3D – 2D: ΔM = −0.07 s, SD = 0.66, 95% CI = [−0.34, 0.22], per-subjects-swap analysis: uncorrected p = .65, across-subjects-swap analysis: uncorrected p = .68, d = 0.1). Excluding no-response trials yielded similar findings (see the SOM).
Means for Scrambled and Intact 2D and 3D Stimuli in Experiments 2 and 3
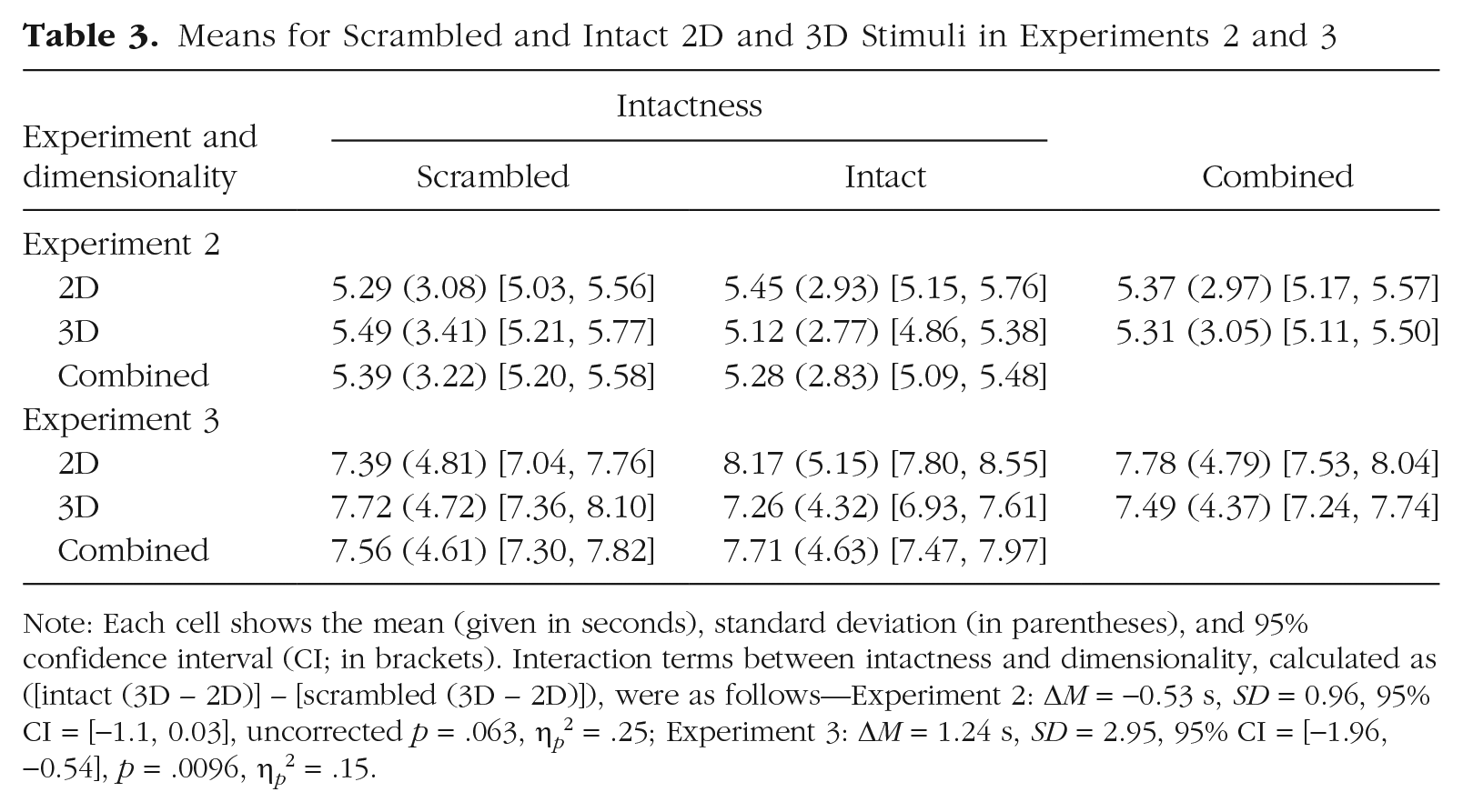
Note: Each cell shows the mean (given in seconds), standard deviation (in parentheses), and 95% confidence interval (CI; in brackets). Interaction terms between intactness and dimensionality, calculated as ([intact (3D – 2D)] – [scrambled (3D – 2D)]), were as follows—Experiment 2: ΔM = −0.53 s, SD = 0.96, 95% CI = [−1.1, 0.03], uncorrected p = .063, η p 2 = .25; Experiment 3: ΔM = 1.24 s, SD = 2.95, 95% CI = [−1.96, −0.54], p = .0096, η p 2 = .15.
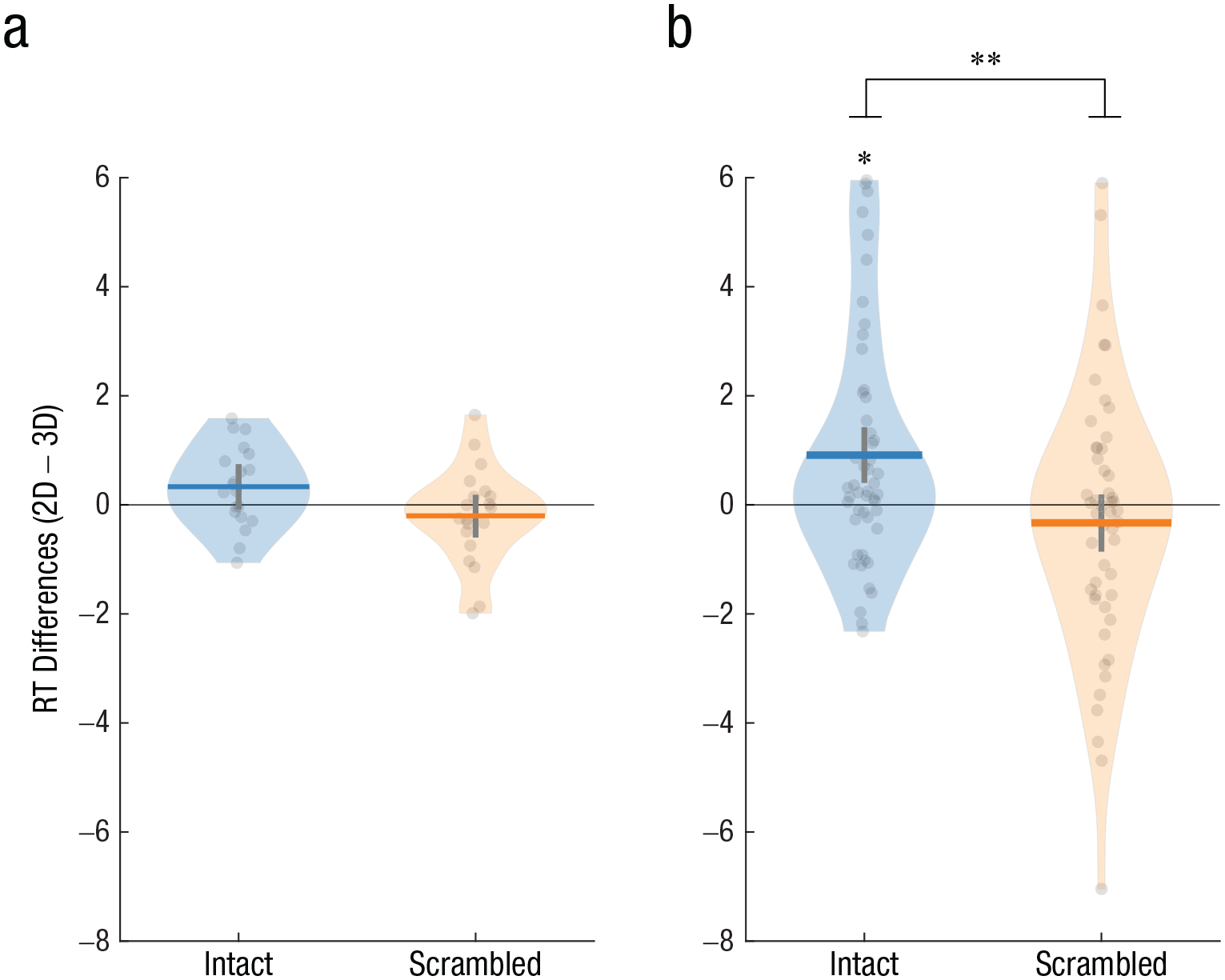
Reaction time (RT) difference between 3D and 2D representations (2D – 3D), separately for intact and scrambled objects in (a) Experiment 2 and (b) Experiment 3. Dots represent single subjects, horizontal lines show group means, and vertical lines depict 95% confidence intervals obtained by bootstrapping. The shape of each violin plot represents the distribution of its values along the y-axis. Asterisks indicate a significant difference from zero (*p < .01) or a significant difference between RT differences (2D – 3D) for intact and scrambled objects (**p < .001).
Experiment 3
A confirmatory permutation analysis revealed a clear interaction between intactness and dimensionality (Table 3 and Fig. 3b; see also Fig. S4b). Post hoc permutation analyses confirmed that the interaction stemmed from a difference between 3D and 2D stimuli for intact items; detection times for intact 3D items were shorter than for their 2D photographs (3D – 2D: ΔM = −0.91 s, SD = 2.15, 95% CI = [−1.42, −0.41], uncorrected p < .005, FDR q < 0.01, d = 0.42). This difference was not found for scrambled stimuli; detection times were similar for scrambled 3D objects and their 2D photographs (3D – 2D: ΔM = 0.33 s, SD = 2.4, 95% CI = [−0.18, 0.85], uncorrected p = .275, d = 0.14). No main effect of dimensionality was found (3D – 2D: ΔM = −0.29 s, SD = 1.74, 95% CI = [−0.65, 0.06], d = 0.17) in the two confirmatory analyses that were preregistered (permuting familiarity of items per subject, per-subject-swap, uncorrected p = .35, or across all subjects, across-subjects-swap, uncorrected p = .89; see the Method section; these two comparisons were Bonferroni corrected in line with the preregistration). Excluding no-response trials yielded similar findings (see the SOM).
Discussion
Here, we showed that intact, familiar 3D objects are detected faster than their 2D pictorial representations. This was found in both Experiments 1 and 3, alongside an insignificant trend in the same direction in Experiment 2. This confirms our first hypothesis that 3D objects are more readily detected and might be perceptually favored over 2D images. Critically, the advantage of 3D stimuli was not found for scrambled, unfamiliar objects that do not elicit stored motor programs for functional use—in line with our second hypothesis.
Our results thus suggest that affordances might grant real objects higher perceptual priority (Weller et al., 2019). Because 3D objects are held to more strongly activate affordances than 2D objects (Marini et al., 2019) and because intact objects have more affordances than scrambled ones (specifically, stable affordances; Borghi & Riggio, 2015; see further discussion below), the finding that intact 3D objects, but not scrambled ones, were detected faster implies that affordances could have indeed mediated this effect. Notably, we went to great lengths to ensure that reflectivity, shine, color, shading, or highlights would not provide cues for subjects to differentiate between the conditions; this was done to minimize differences that were not related to affordances (although naturally, there might be additional differences that were still unaccounted for; e.g., features of intact 3D objects could be easier to discern from shadows given prior knowledge about these objects). If indeed affordances drove the effects, this would put them together with other high-level, semantic properties that were claimed to influence detection (for a review and criticism, see Gayet et al., 2014), alongside low-level, physical ones (Levelt, 1965). Arguably, affordances might increase the relevance of the stimuli, making them more readily detected. This supports the claim that interaction with our environment is one of the key organizing principles of our visual system (Gibson, 1979).
More specifically, the perceptual advantage of real objects seems to be driven by stable affordances rather than by variable affordances. Stable affordances represent prior motor knowledge about possible functional interactions with a specific object (Borghi & Riggio, 2015; Osiurak et al., 2017) and were accordingly more likely to be activated by intact objects than scrambled ones in our experiments. Variable affordances, conversely, solely rely on the physical properties of the object and on the body schema of the observer (Osiurak et al., 2017), irrespective of the function of the objects (Borghi & Riggio, 2015). Accordingly, they are evoked by novel, unfamiliar objects (Weller et al., 2019), which showed no effect in our experiments. Because stable affordances are inherently confounded by familiarity, which also affects detection under interocular suppression (Yuan et al., 2019), one could claim that it was familiarity, rather than affordances, that affected detection times. Yet this is less likely because our critical comparison was between 3D and 2D versions of the very same stimuli (that were accordingly just as familiar). Taken together, our results thus suggest that a general activation of the motor system, which would be evoked by both stable and variable affordances (for a review, see Sakreida et al., 2016), is not enough to facilitate detection; rather, stored knowledge about the specific usages of the objects, involving related semantic associations (Osiurak et al., 2017), is needed to boost detection. The difference between intact and scrambled objects further mitigates concerns about a possible motor explanation of our results, at least to some extent. It could be claimed that the observed effects stem from general motor effects evoked by affordances in a manner that is not specific to the representation of these objects. Under this account, subjects’ responses would be faster for real objects not because they were actually detected faster but, rather, because processing a real object in one side evoked its affordances, and these in turn activated the respective motor area, leading to a faster response for that side (Azaad et al., 2019). Although the current design does not allow us to exclude this explanation, the fact that the effect seemed to rely on specific motor knowledge that was related to the identity of the object, rather than on variable affordances that activated the motor system in a more general manner, renders it less plausible.
Can our results serve as evidence for unconscious processing of affordances without awareness? This is indeed a common interpretation for breaking-CFS studies, according to which a difference in detection times reflects differential unconscious processing (Gayet et al., 2014). Thus, one might be tempted to interpret our results as reflecting unconscious processing of affordances. Such an interpretation, supporting claims for the automaticity of affordance processing (Binkofski & Buxbaum, 2013; Borghi & Riggio, 2015), would accord with findings of enhanced attentional capture by 3D object flankers compared with photographs flankers (Gomez et al., 2018), as well as with the shorter suppression times reported for useful tools compared with useless tools (Weller et al., 2019). Although this is admittedly a possible interpretation of the results, the current design does not allow us to make such a claim. Breaking-CFS studies simply do not allow disentangling unconscious processing from postperceptual processing (Gayet et al., 2014; Stein, 2019; Stein et al., 2011). A recently published work clearly demonstrated how breaking-CFS measures might be conflated between conscious and unconscious processes, reflecting general differences in detectability rather than unconsciously driven processes (Stein & Peelen, 2021). Accordingly, the results of this study cannot be used as the basis for claims of unconscious processing of affordances (nor was the study designed to test such claims). However, they do imply that such unconscious processing is at least possible, calling for future experiments to directly test this option using the “real-life” CFS method (Korisky et al., 2019). Such a study could then present real objects as primes while keeping their visibility at zero throughout the experiment and measure their effect on congruent and incongruent subsequent targets. A convincing control condition in such an experiment would be placing a transparent barrier between the subject and the prime, as has been done in other experiments to manipulate affordances (Caggiano et al., 2009; Gomez et al., 2018). Our study further opens the gate to two additional research questions. First, what could be the underlying mechanism that drives the effect, given that information is arriving only monocularly during CFS? This could, potentially, rest on monocular depth cues—for example, blur cues (Ciuffreda, 1998) or eye-movement-induced parallax. Second, to what extent do our results depend on the specific stimulus set we used (i.e., can they be obtained using different and possibly larger stimulus sets)?
Going beyond the specific results obtained here and their possible interpretation, this study joins other works in the cognitive sciences in using more ecological, lifelike stimuli and tasks. Such realism has been claimed to evoke more prominent, and sometimes even different, processing than the one evoked by well-controlled representations (Shamay-Tsoory & Mendelsohn, 2019). Thus far, using such stimuli in the study of consciousness was a great challenge given the limitations of current methods. Yet the “real-life” CFS methodology provides a compelling and easy way to do so with practically no adjustment of the properties of the real stimuli used, except for luminosity or contrast.
In conclusion, we present evidence that real objects enjoy a perceptual advantage over realistic photographs, having facilitated access to awareness. However, this prioritization occurs only when these objects are familiar to the observer. We therefore suggest that it is stored motor representations, or stable affordances, that drive the effect by granting real objects priority in detection, emphasizing the importance of action in perception. The use of “real-life” CFS for suppressing real 3D objects from conscious perception further paves the way for future studies to explore the limits of conscious and unconscious processing of the external world.
Footnotes
Acknowledgements
The research was generously aided by Stratasys, who printed all the 3D models used in the study. We thank David Steinberg for providing statistical consultation and Nitzan Censor, Shlomit Yuval-Greenberg, and Roy Mukamel for their feedback on earlier versions of the manuscript. We also thank Itay Lazarovitch and Alexander Kolominsky for their help in photographing the objects.
Transparency
Action Editor: Krishnankutty Sathian
Editor: Patricia J. Bauer
Author Contributions
Both authors designed the research. U. Korisky conducted the research and analyzed the data. Both authors wrote the manuscript and approved the final version for submission.