
Abstract
Replication of existing research is often referred to as one of the cornerstones of modern science. In this study, I tested whether the publication of independent replication attempts affects the citation patterns of the original studies. Investigating 95 replications conducted in the context of the Reproducibility Project: Psychology, I found little evidence for an adjustment of citation patterns in response to the publication of these independent replication attempts. This finding was robust to the choice of replication criterion, various model specifications, and the composition of the contrast group. I further present some suggestive evidence that shifts in the underlying composition of supporting and disputing citations have likely been small. I conclude with a review of the evidence in favor of the remaining explanations and discuss the potential consequences of these findings for the workings of the scientific process.
Replication of existing research is often referred to as one of the cornerstones of modern science. However, direct replications, defined as the same analyses being conducted on newly collected data using original materials, have historically been published infrequently. 1 Recently, a number of systematic, large-scale replication attempts have been published in prominent scientific journals (e.g., see Camerer et al., 2016, 2018; Klein et al., 2018; Open Science Collaboration, 2015), and the question of replicability has received a substantial amount of attention in subsequent academic publications and media outlets.
The replication projects published thus far have undoubtedly succeeded in raising awareness of methodological shortcomings with regard to the power of research designs and the pitfalls of postdiction, culminating in the advent of Registered Reports (Nosek & Lakens, 2014) and a widespread adoption of preregistration of research designs in psychology (Nosek & Lindsay, 2018). However, little is known about how these replication attempts have shaped the way specific findings are perceived in the literature. In this study, I attempted to fill this gap by analyzing changes in yearly citation patterns of articles replicated in the context of the Reproducibility Project: Psychology (RP:P; Open Science Collaboration, 2015) after the publication of its results in Science in 2015.
A single replication attempt, especially if insufficiently powered, provides only limited information about whether a prior research result is robust. However, I worked under the assumption that replication attempts can shift beliefs about the validity of an existing research finding (McDiarmid et al., 2021). In particular, replications that produce evidence in line with the original findings should strengthen beliefs in their validity, whereas nonsupportive or contradicting replications should weaken these beliefs (Earp & Trafimow, 2015). This motivated my main research question: Does the publication of supportive versus nonsupportive replication attempts affect the frequency with which the underlying studies are cited? 2 I believe that the answer to this question could provide important insights into the workings of the scientific process by illuminating the extent to which new insights replace or strengthen existing knowledge and thereby shape the way new research is conducted.
I found that neither supportive nor nonsupportive replications have had a statistically significant effect on the number of times articles are cited. This null result is robust to different replication criteria and various model specifications as well as to alternative compositions of the contrast group. In investigating potential explanations for my findings, I present some suggestive evidence that shifts in the underlying composition of supporting and disputing citations have likely been small and discuss how the remaining explanations fit with the evidence.
Although I acknowledge that a number of forces are at the heart of my results, some of the contending explanations have particularly daunting consequences and therefore deserve additional attention: If researchers either were unaware of replication results or, in spite of their awareness, chose to discount them and continued to cite the original results at face value, this could considerably limit the self-corrective ability of the scientific process because it would reduce the likelihood that research results that have been called into question will be phased out and replaced by new insights. This could be particularly problematic in light of evidence by Gneezy and Serra-Garcia (2021), who report that studies that failed to replicate within three large-scale replication projects (and for which prediction markets were conducted) have higher citation counts than studies that replicated successfully.
Method
Setting
My empirical approach built on the sampling design of the RP:P (Open Science Collaboration, 2012, 2015). This project was a coordinated effort by the Center for Open Science that brought together a large and diverse group of more than 200 researchers and aimed to test the reproducibility of psychological science. Participating research teams chose studies to replicate from a predefined sampling frame and subsequently conducted independent replication attempts “using high-powered designs and original materials when available” (Open Science Collaboration, 2015, abstract). Ultimately, the results of 100 such replication attempts were included in the publication, which concluded that merely 36% of the replications had resulted in statistically significant results compared with 97% of the original studies.
Statement of Relevance
A crucial feature of the scientific process is its ability to self-correct by identifying and promoting robust results and phasing out those that fail to hold up to further scrutiny. This process ensures that through the cumulative generation of research and systematic replications, a reliable body of knowledge is created. This article provides a test of this self-corrective ability “in the medium run” by analyzing articles replicated in the context of the Reproducibility Project: Psychology. I investigated changes in citation patterns around the time the replication results were published, and my findings do not support the hypothesis that citation rates changed in response to independent replications. These results thus emphasize the need for replication on a large scale and the effective communication of replication results.
Although a number of drawbacks in the design of the RP:P have been identified, it is one of the most comprehensive attempts to study replicability and followed a strict sampling protocol designed to minimize selection effects. This particular feature made it an appealing setting to study the present research question because it allowed for the definition of a contrast group against which the effect of replications can be evaluated.
Specifically, the sample of eligible studies for the RP:P was selected from the 2008 issues of the Journal of Experimental Psychology: Learning, Memory, and Cognition (JEP), Journal of Personality and Social Psychology (JPSP), and Psychological Science (PS). Replication teams chose studies from among the first 30 articles published in each of these journals beginning with the first 2008 issue; additional articles were made available in sets of 10 in case of additional demand. 3 This sampling strategy limits concerns regarding the selection of articles on the basis of observable or unobservable characteristics, which could complicate an analysis of citation patterns if those characteristics were correlated with both the likelihood of successful replication and citation patterns. Further, I expected that if the articles included in the RP:P sampling frame had not been selected for replication, they would have had similar citation patterns over time as studies published immediately prior or shortly after in the same journals.
The resulting variation therefore lends itself to be exploited in a generalized differences-in-differences design. This design compares changes in yearly citations after the publication of the replication results between the replicated and the contrast sample. Under the assumption of parallel trends—in the absence of the RP:P replications, the different sets of studies would have followed similar citation trajectories—this allowed me to identify the effect of interest.
Sample selection
The definition of a contrast group is complicated by two notable deviations of the RP:P from its intended sampling frame. First, because of constraints regarding available instruments, samples, and knowledge among replicators, not all studies in the sampling frame could be replicated. Second, the sampling frame was not always followed, resulting in some studies being replicated despite being published in an issue that had not been made available for selection.
This introduces some degree of selection into the sample of replicated studies. The first deviation implies that studies with certain features were infrequently subjected to replications. This becomes an issue if these types of studies are also subject to different citation trends, thus potentially violating the common-trends assumption that underlies my identification of the effect of interest. Similarly, the second deviation suggests that some studies might have been selected by groups of researchers particularly interested in their results. Although the exact drivers of these choices are unclear, this interest might correlate with factors that affect citation trends and could therefore present a challenge to the identifying assumption.
To deal with these concerns, I implemented the following sample-selection protocol. I collected data for the 95 unique articles that had significant original findings and for which a replication was reported in the RP:P, thus excluding the three studies with insignificant original findings as well as the two duplicate replications. These data were combined with information from articles that were published in the same journals in adjacent months. This initial selection of eligible articles is detailed in Table 1. Within the sampling frame, all original research articles were considered eligible. Other material, such as editorials, commentaries, corrigenda, and book reviews, were excluded.
Sampling Frame
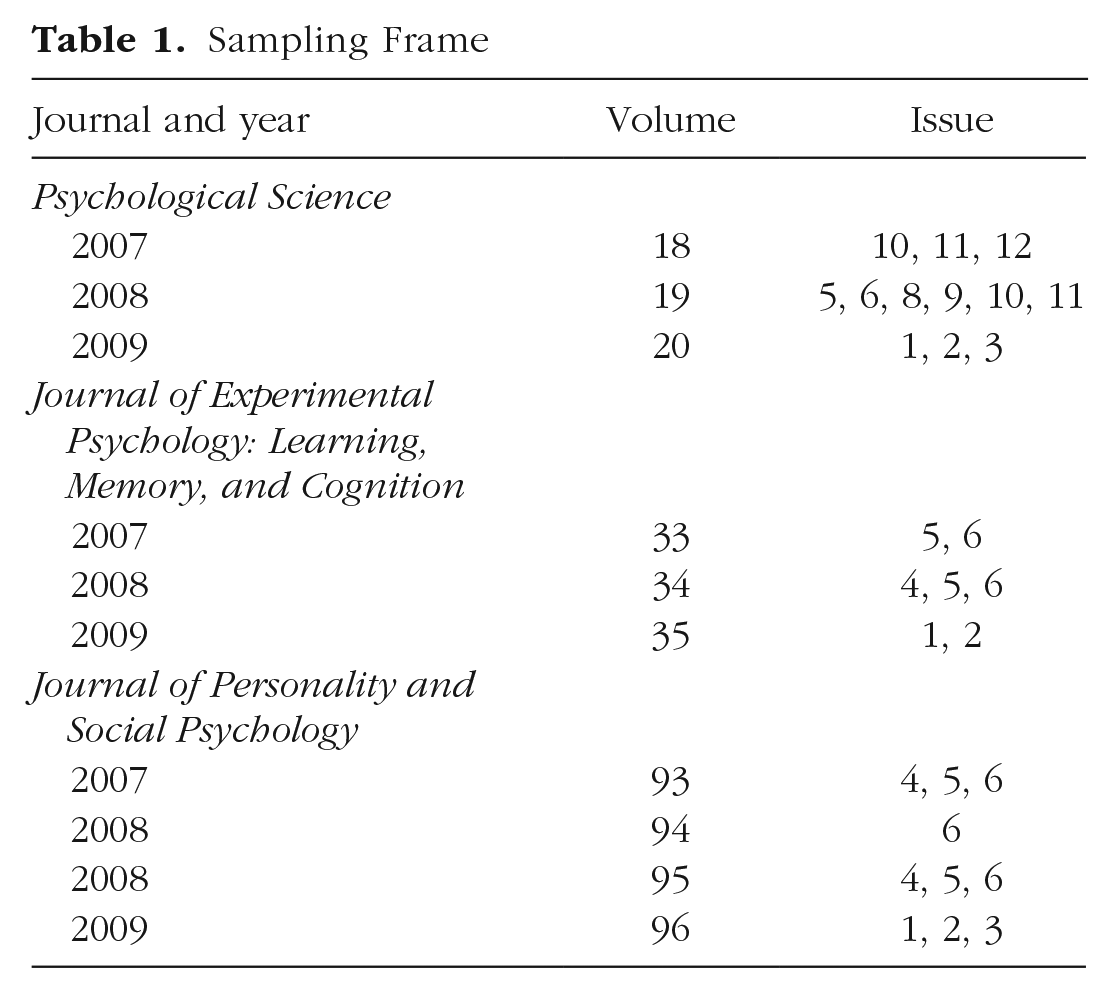
I further implemented a set of exclusion criteria intended to increase the comparability of the contrast and treatment groups. These exclusion criteria were designed to mimic the constraints faced by the replication teams in the RP:P, eliminating studies that use hard-to-access samples or that require specialized instruments that are not readily available in most laboratories. Further, I eliminated articles that did not include any experimental results that can be represented by a single statistical inference test or effect size. 4 I first coded the articles according to these criteria. To ensure the fidelity of the coding, a research assistant blind to the research question additionally coded a random subsample of 169 studies. The two classifications aligned in 97% of cases.
The sampling frame laid out in Table 1 contains a total of 476 articles, of which 202 were published in PS, 144 in JPSP, and 130 in JEP. Applying the exclusion criteria left 329 articles, of which 117 were published in PS, 112 in JPSP, and 100 in JEP. This implies journal shares ranging from 30% for JEP to 36% for PS, which closely matches the percentages of articles replicated in the RP:P (29% for JEP to 41% for PS).
Variable definitions
My main outcome variable was the number of citations that a publication received in a specific year. I collected these data from the Web of Science Core Collection between 2010 and 2019. This time range was chosen with the aim of constructing a balanced panel data set despite the fact that the sampling frame contains articles published between 2007 and 2009. The fact that the coverage of the Web of Science is limited within the social sciences (Kousha & Thelwall, 2007) was unlikely to represent a problem for my empirical strategy because there should not be any reason to expect that coverage of citing articles would have changed over time for different studies in my sample. In the main analyses, I applied an inverse hyperbolic sine (IHS) transformation to account for the nonnormality of the data. This transformation is conceptually similar to the approach of adding 1 unit to each observation and taking the natural logarithm recommended by Thelwall and Wilson (2014) but is generally considered less arbitrary (Bellemare & Wichman, 2020).
Further, to address the research question, I required a measure to evaluate the degree to which a replication attempt supports the original finding. An intuitive criterion relies on the binary decision of whether the replication produces evidence that is statistically significant at the 5% level in the same direction as the original finding. The main point of contention in using this criterion is its inability to quantify the strength of the evidence contained in a replication coded as failed or successful. For example, a failed replication attempt might not be able to detect a true effect if it is itself underpowered, whereas a high-powered replication might uncover an effect that is orders of magnitude smaller than the original effect. The “small-telescopes” approach of Simonsohn (2015) is based on the idea of detectability in that it tests whether the effect obtained in a replication study is smaller than an effect size that the original study had only 33% power to detect. In comparison, the Bayesian approach applied by Etz (2015) is based on the calculation of Bayes factors (BFs) comparing the hypothesis of no effect with an alternative of the effect size found in the original publication, originally proposed by Verhagen and Wagenmakers (2014).
In the main specification, I employed the intuitive binary criterion, which has been used as the main replication criterion in the RP:P and has been widely communicated. In a secondary analysis, I instead used an alternative definition of failed replications based on the Bayesian approach outlined above. To ensure the comparability of my analyses across the different criteria, I collapsed the continuous BF into three categories. Specifically, I coded a replication as successful if it yielded a BF of 3 or more and as unsuccessful if it yielded a BF of one third or less; all remaining replications were coded as inconclusive. In Section S1 in the Supplemental Material available online, I further implemented similar analyses on the basis of the small-telescopes approach.
Summary statistics
The main criterion classified 35 replication attempts as successful and the remaining 60 as unsuccessful. The Bayesian criterion considered 31 replications successful, 34 unsuccessful, and 26 inconclusive. 5 The discrepancy in the number of articles coded is due to three studies missing effect-size estimates for either the original analysis or the replication attempt in the RP:P files. For one further study, the BF could not be calculated, resulting in a total of 91 replicated studies for which I had a valid classification.
Regarding the distribution of yearly citations, the average study in my estimation sample received 7.34 (SD = 7.91) citations, and the share of article years with no citations was 0.068. Further, yearly citations have been on an increasing trajectory even several years after the initial publication: On average, there were 6.46 (SD = 5.37) citations per year between 2010 and 2014 and 8.22 (SD = 8.81) yearly citations from 2015 to 2019. This reflects the fact that the articles under consideration are among the most influential in the field and thus have a long citation half-life (Walters, 2011). 6
Empirical strategy
The core of the estimation strategy lies in the assumption that in the absence of the RP:P replications, the studies included in the contrast group would have been subject to the same citation trends as those in the RP:P sample. Under this assumption, I could identify the effect of interest in a generalized differences-in-differences estimation framework by comparing changes in citation trends. I employed two closely related operationalizations: The first assumed that treatment effects are constant over time, whereas the second allowed for time-varying treatment effects.
The first model was
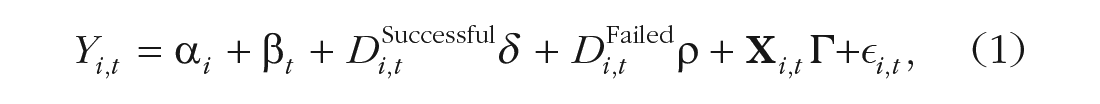
where
The two sets of fixed effects
The second model differs from the first only in that it allows for time-varying treatment coefficients. It is given by
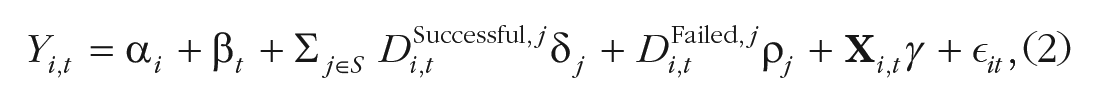
with S equal to {2010, . . ., 2019}\{2014}. The variables
This specification has two advantages. First, it allows one to gauge whether any effects of replications on citation patterns arise immediately or only with a lag as well as whether these effects persist over time. Second, the pre-2014 coefficients allow for an investigation of the identifying assumption: If the estimated coefficients prior to the publication of the RP:P results were significantly different from zero, this would call into question the assumption that replicated and nonreplicated articles would have followed similar citation trends in the absence of the RP:P.
It is important to note that the above exposition deviates from my preregistered analysis plan in a number of ways. 7 Most importantly, I specified Equation 2 as my main model and proposed to test my main hypothesis by testing for the joint significance of the post-2014 coefficients. I chose to deviate from this strategy because it did not take into account the direction of the estimated effects and depends strongly on the choice of base year. The results of this test and further explanations are provided in Section S1.
Results
Table 2 presents four specifications of Equation 1 that differ in terms of which set of time-varying controls were included in the model. Row 2 presents the prespecified model equation including fixed effects for the number of years since publication. Rows 3 and 4 represent further attempts at accounting for potential deviations from the common-trends assumption by including separate year-fixed effects for each journal (Row 3) or allowing for issue-specific linear trends (Row 4). In all specifications, successful replications were positively associated with citation rates,
Differences-in-Differences Estimates of the Effect of Replications on Yearly Citations: Main Criterion
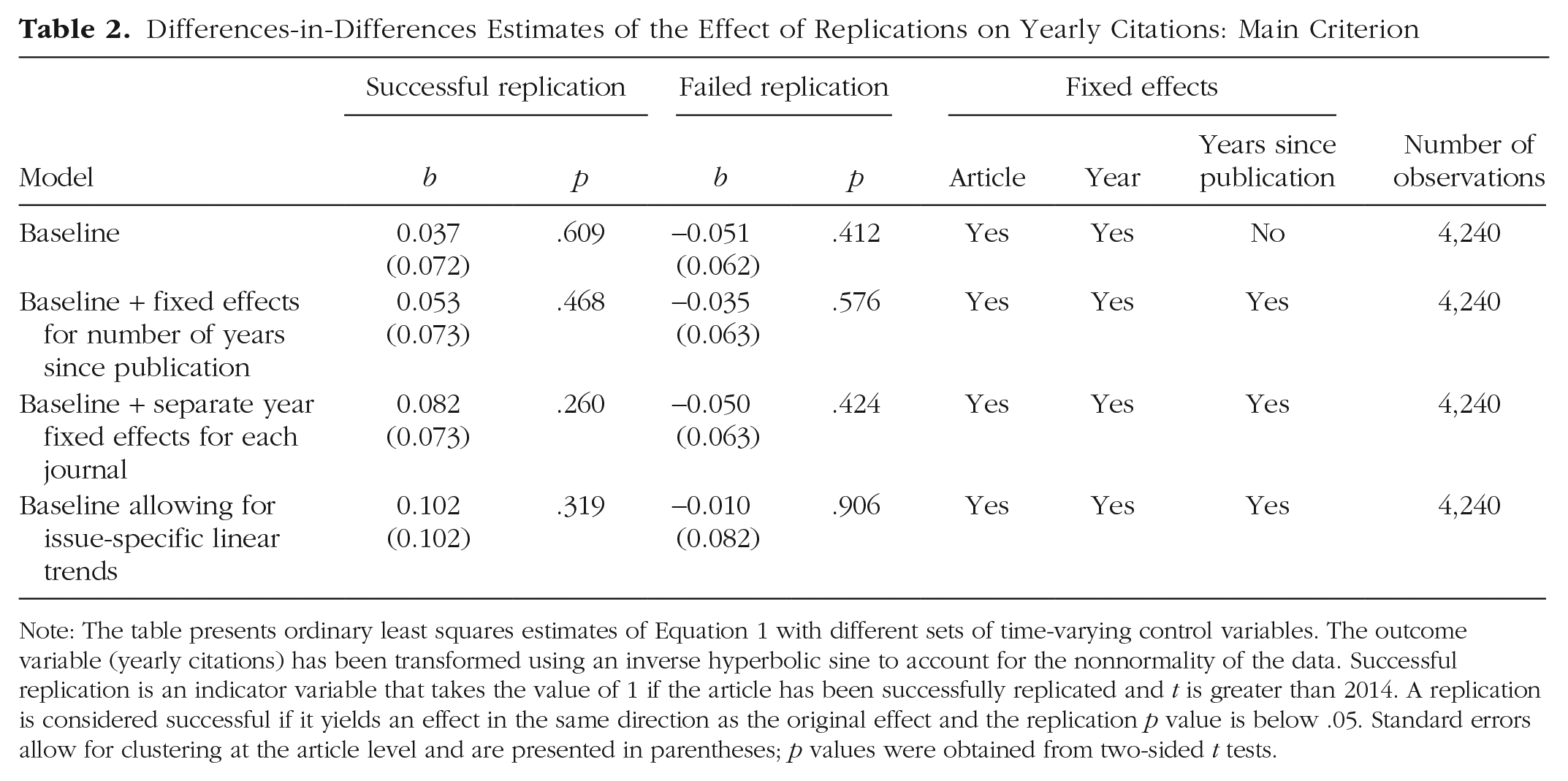
Note: The table presents ordinary least squares estimates of Equation 1 with different sets of time-varying control variables. The outcome variable (yearly citations) has been transformed using an inverse hyperbolic sine to account for the nonnormality of the data. Successful replication is an indicator variable that takes the value of 1 if the article has been successfully replicated and t is greater than 2014. A replication is considered successful if it yields an effect in the same direction as the original effect and the replication p value is below .05. Standard errors allow for clustering at the article level and are presented in parentheses; p values were obtained from two-sided t tests.
Potential explanations
An obvious question is whether my inability to reject the null hypothesis is the result of the study being inadequately powered. On the basis of the estimated standard errors in the main specification, I had 80% power to detect an effect of around 0.2 in IHS units for successful replications and around 0.18 IHS units for failed replications at an α of .05, corresponding to 0.19 and 0.17 standard deviations, respectively. I thus conclude that my results are informative about effect sizes in this range but cannot make meaningful statements about the presence or absence of subtler effects. Although this important qualification should be taken into account in interpreting my results, I nonetheless emphasize that, as of yet, the RP:P represents the largest available sample to test my main hypothesis. It is my hope that future systematic replications will allow for the effect to be analyzed in even larger samples, thus enabling the investigation of smaller effect sizes.
Another possible explanation lies in the relatively short postreplication time window I had at my disposal. The citation count in the Web of Science is largely based on articles published in peer-reviewed journals. Hence, in order to be represented in the citation count, an article has to be written and pass through peer review, two processes that take a considerable amount of time. This could call into question my assumption of time-invariant treatment effects, a violation that could bias my estimates toward zero and hence drive the null result.
To investigate this concern, I present OLS estimates of Equation 2 in Figure 1, including the additional set of fixed effects for years since publication. The plot reveals two main patterns. First, the estimated coefficients in the years up to the publication of the RP:P do not differ substantially from zero for either the successful or the unsuccessful replications, which increases confidence in the common-trends assumption underlying my previous estimation results. Second, the plot provides scant evidence for treatment effects arising in later years. Although some of the estimated yearly coefficients are significantly different from zero at the 5% level on the basis of a two-sided t test, no consistent pattern arises. Further, these effects are dependent on the normalization with regard to the base year 2014. This is reflected in the fact that already prior to 2014, all estimated coefficients for successful replications are positive, and all estimated coefficients for unsuccessful replications are negative. As a result, the coefficients would appear considerably more muted if compared with those of the average prereplication year. Overall, the figure provides little evidence that time-varying effects were driving the null result.
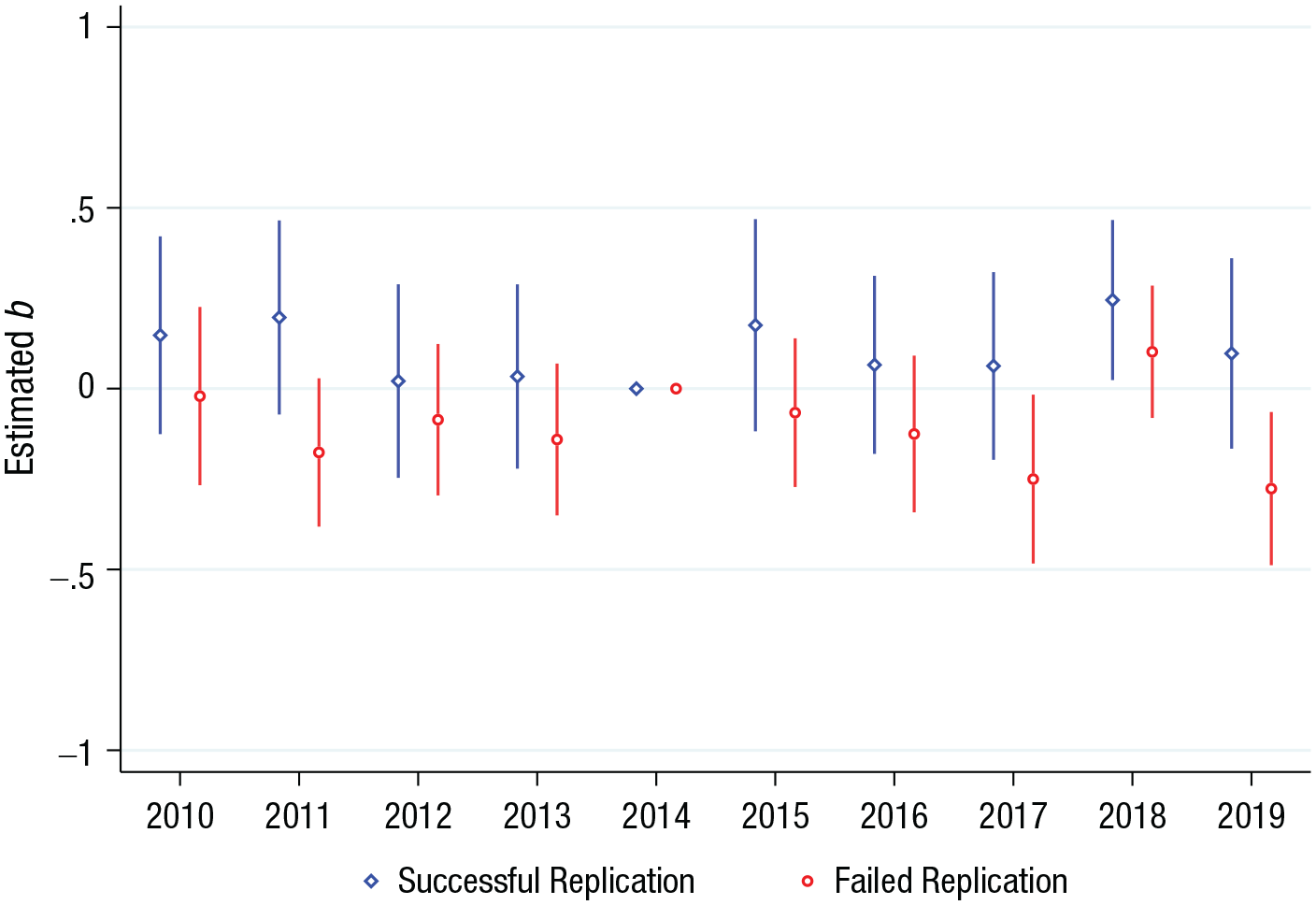
Estimated coefficients for successful and failed replications across time. A replication is considered successful if it yields an effect in the same direction as the original and the replication p value is below .05. Error bars indicate 95% confidence intervals. Estimates were obtained from an ordinary least squares regression of Equation 2, in which the dependent variable is the inverse hyperbolic sine of yearly citations. The regression includes fixed effects for article, calendar year, and years since publication. Standard errors are clustered at the article level.
A third candidate explanation for the absence of a statistically significant effect is that the replication criterion did not account for the strength of the evidence obtained in the replication. This issue is particularly important because the power calculations underlying the RP:P replications were based on the original effect sizes. In the presence of a type-M error (Gelman & Carlin, 2014), this practice is likely to result in replication attempts that are themselves not sufficiently powered to detect the effects of interest and hence could render some of the evidence too weak to shift researchers’ beliefs. In line with this argument, the Bayesian analysis by Etz and Vandekerckhove (2016) suggests that many original studies and their replications did not provide strong evidence for either the null or the alternative hypothesis, implying a limited need for belief updating in many cases. Thus, my measure of the effects of failed replications represents a weighted average of inconclusive and refuting information, which might shift the estimated coefficient toward zero.
I addressed this concern by classifying replication attempts according to the Bayesian criterion, thereby introducing an explicit distinction between failed and inconclusive replication attempts (see Table 3). The results were largely in line with those obtained previously: Neither successful,
Differences-in-Differences Estimates of the Effect of Replications on Yearly Citations: Bayesian Criterion
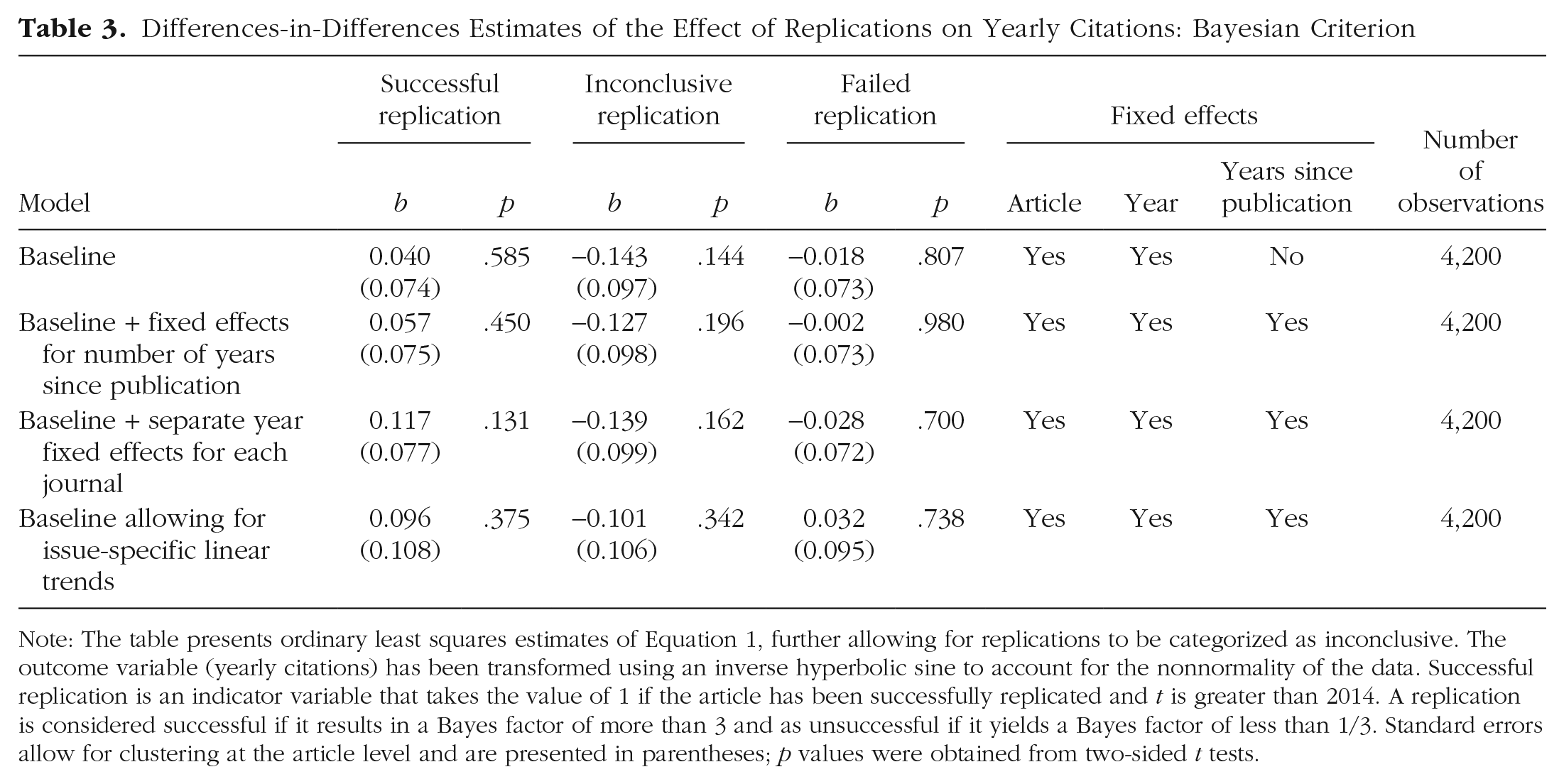
Note: The table presents ordinary least squares estimates of Equation 1, further allowing for replications to be categorized as inconclusive. The outcome variable (yearly citations) has been transformed using an inverse hyperbolic sine to account for the nonnormality of the data. Successful replication is an indicator variable that takes the value of 1 if the article has been successfully replicated and t is greater than 2014. A replication is considered successful if it results in a Bayes factor of more than 3 and as unsuccessful if it yields a Bayes factor of less than 1/3. Standard errors allow for clustering at the article level and are presented in parentheses; p values were obtained from two-sided t tests.
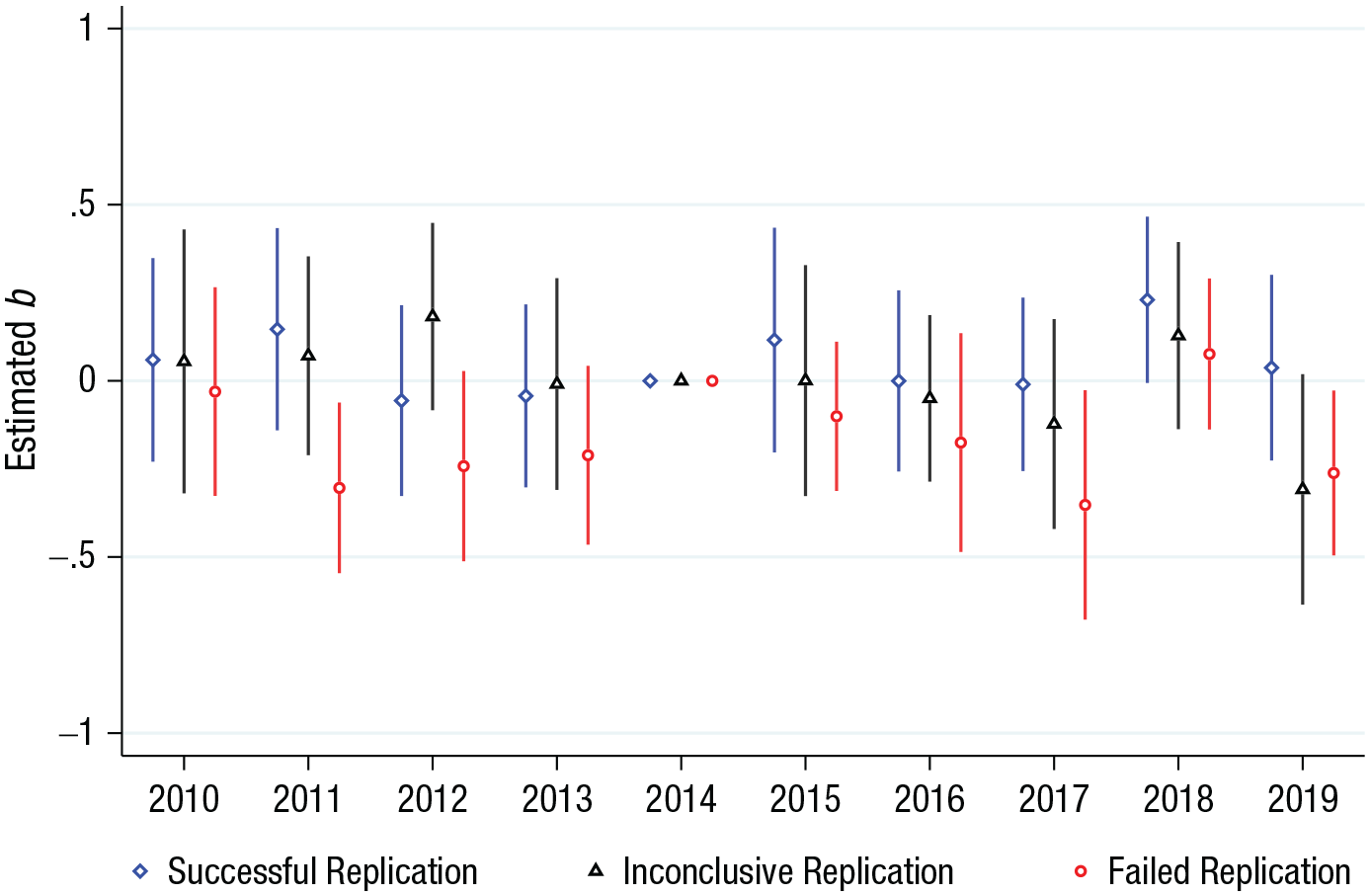
Estimated coefficients for successful, inconclusive, and failed replications across time. A replication is considered successful if it results in a Bayes factor of more than 3 and as unsuccessful if it yields a Bayes factor of less than 1/3. Error bars indicate 95% confidence intervals. Estimates were obtained from an ordinary least squares regression of Equation 2, in which the dependent variable is the inverse hyperbolic sine of yearly citations. The regression includes fixed effects for article, calendar year, and years since publication. Standard errors are clustered at the article level.
Robustness
In this subsection, I address some remaining concerns regarding the validity of my estimates along two dimensions.
First, as described in more detail in Section S2 in the Supplemental Material, I acknowledge that the inclusion criteria at best resulted in a rough approximation of the selection process of studies to be replicated in the RP:P. To ensure that my sample selection did not drive the results, I included all nonretracted studies in the contrast group in Row 1 of Table 4. This expansion of my estimation sample resulted in small gains in the precision of estimates and both successful,
Robustness Checks: Sample and Outcome Variables
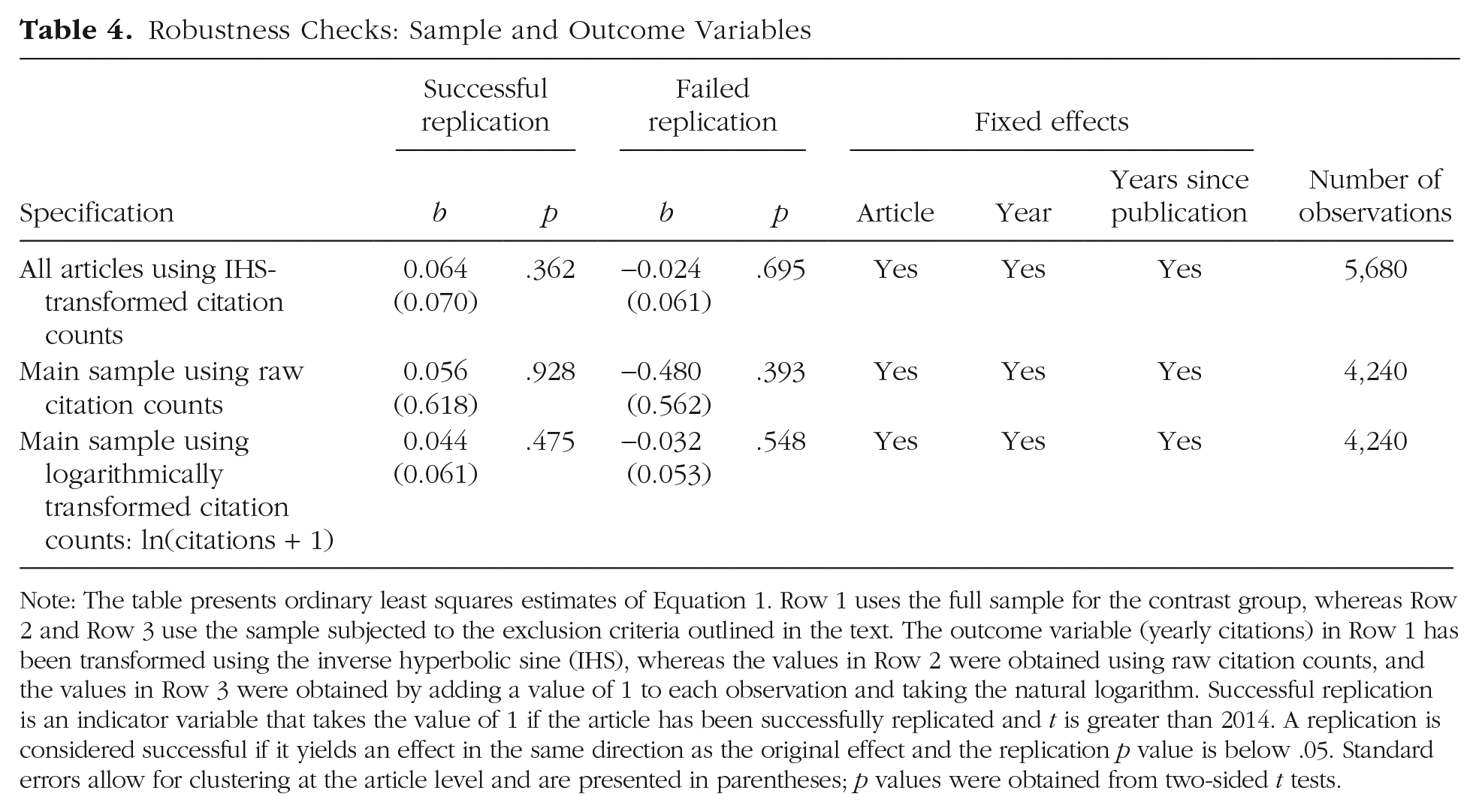
Note: The table presents ordinary least squares estimates of Equation 1. Row 1 uses the full sample for the contrast group, whereas Row 2 and Row 3 use the sample subjected to the exclusion criteria outlined in the text. The outcome variable (yearly citations) in Row 1 has been transformed using the inverse hyperbolic sine (IHS), whereas the values in Row 2 were obtained using raw citation counts, and the values in Row 3 were obtained by adding a value of 1 to each observation and taking the natural logarithm. Successful replication is an indicator variable that takes the value of 1 if the article has been successfully replicated and t is greater than 2014. A replication is considered successful if it yields an effect in the same direction as the original effect and the replication p value is below .05. Standard errors allow for clustering at the article level and are presented in parentheses; p values were obtained from two-sided t tests.
Second, I considered whether my results were sensitive to the choice of transformation applied to the outcome variable. Thus far, all regressions employed the IHS transformation. An alternative approach that has frequently been implemented when working with count data is adding a value of 1 to each observation and subsequently taking the logarithm. Although this approach has been criticized by some researchers for being inherently arbitrary (Burbidge et al., 1988; Campbell & Mau, 2020), in Table 4, I present estimates of Equation 1 for both untransformed citation counts (Row 2) and the logarithmic transformation (Row 3). Although the coefficients are not directly comparable across models, the broad patterns are very similar, with both successful and unsuccessful replications resulting in small and statistically insignificant coefficient estimates—succesful untransformed:
Discussion
The failure of my analyses to reject the null hypothesis that there was no effect of RP:P replications on yearly citation counts ran counter to my hypothesis that citation patterns should change as researchers adjust their beliefs about the validity of an existing research result. In the following, I outline a number of contending explanations for this null result and discuss the extent to which they are in line with the data.
First, a necessary condition for belief updating in response to replication attempts is researchers’ awareness of the replication results. Previous findings of Simkin and Roychowdhury (2005) suggest that a large number of citations are merely copied from existing reference lists and not actually read by the citing authors, making it likely that at least some researchers remain unaware of existing replications for the studies they cite.
Such inattention is likely exacerbated by the general difficulty of acquiring information about replication results. Unpublished replications are often difficult to find, but even if replication results are published, finding and evaluating them requires a substantial time investment from citing researchers. This concern carries particular weight in my setting because the RP:P was designed with the intention to draw conclusions about replicability on an aggregate level rather than to scrutinize individual research results. As a consequence, the outcomes of individual replication attempts were neither discussed in detail by the Open Science Collaboration (2015), nor were citations to the original studies included in their article, requiring researchers interested in the results of individual replication attempts to delve into the supplemental materials.
This factor substantially qualifies the external validity of my findings because other replication studies might discuss individual replication outcomes in more detail and are more easily picked up by search engines if they are similar in title and include direct references to the original study. This increased visibility has the potential to alter the citation impact of a replication attempt compared with the effects that I uncovered in the context of the RP:P; indeed, the case studies by Hardwicke et al. (2021) suggest that somewhat more marked effects might arise in other settings.
Second, even among researchers aware of the replication attempts, belief updating might have been limited. Although McDiarmid et al. (2021) show that researchers updated their beliefs about the strength of a research finding in reaction to replications conducted in a number of large-scale replication projects (not including the RP:P), it is unclear to what extent these findings can be extrapolated to my setting. In particular, the authors note the possibility that experimenter demand and observer effects could have resulted in inflated estimates of researchers’ true belief updating. Moreover, some authors of original studies that were replicated in the RP:P voiced concerns regarding the fidelity of the replication attempts (e.g., Bressan, 2019; Gilbert et al., 2016; and replies to the RP:P published on OSF by the original authors). Although Ebersole et al. (2020) show that the results of the RP:P replications were not sensitive to using peer-reviewed protocols, if citing researchers were nonetheless convinced that the replication attempts were not true to the original study, this might have weakened belief updating.
Other potential explanations could lie in articles gaining additional citations by being cited in the context of replications rather than for their content or in the citation count not taking into account citation content. Regarding the first argument, if this factor were to play a large role, one would expect to find an increase in citation rates for successful and inconclusive replications. In particular, because inconclusive replications were largely considered failures by the main criterion, these replications were likely among the most controversial and thus should have received the largest number of citations through this channel, a hypothesis that is not borne out by the present results.
Further, the second concern suggests that even if one cannot detect changes in total citation counts, the composition of supporting and disputing citations might have shifted. The analyses above are unable to directly shed light on the importance of this explanation because I am missing a reliable measure of citation content. Recently, a large-scale source of citation content classifications has become available through the website scite.ai, which uses deep learning to determine whether a citation supports, disputes, or merely mentions an existing research result. However, at the time of writing, the service is still in its beta stage and has only limited coverage. Hence, rather than subjecting these noisy measures to a formal statistical analysis, I present some suggestive evidence on the role of this channel.
According to the scite.ai classifications, only a small minority of citations are disputing or supporting existing findings. In the 10 years between 2010 and 2019, the average article in the RP:P sample has been subject to merely 0.83 disputing and 4.39 supporting citations, and 46% of the sample was never disputed. Moreover, investigating the timing of citations, I found little evidence that the frequency of disputing citations has been affected by the replication results. When the main replication criterion was used, studies that were replicated successfully received on average 0.4 disputing citations between 2015 and 2019, compared with 0.66 in the 5 years prior to replication, and studies that were replicated unsuccessfully received on average 0.38 disputing citations between 2015 and 2019, compared with 0.32 in the 5 years prior to replication. These numbers suggest that even if the RP:P replications shifted citation content, the size of these effects would likely be small.
In conclusion, my analyses fail to support the hypothesis that citation patterns adjust in response to the release of replication results. Among the potential reasons underlying these findings, a lack of attention to and the limited communication of replication results stand out as particularly important. These factors therefore have the potential to slow down the self-corrective ability of the scientific process and addressing them could represent an important step in maximizing the impact of recent advances to improve the quality and reliability of academic research. I am hopeful that technological advances such as scite.ai, with their potential to greatly improve the accessibility of the body of knowledge, can help to alleviate these issues in the future.
Supplemental Material
sj-pdf-1-pss-10.1177_09567976211005767 – Supplemental material for The Effect of Replications on Citation Patterns: Evidence From a Large-Scale Reproducibility Project
Supplemental material, sj-pdf-1-pss-10.1177_09567976211005767 for The Effect of Replications on Citation Patterns: Evidence From a Large-Scale Reproducibility Project by Felix Schafmeister in Psychological Science
Footnotes
Acknowledgements
I am thankful to Anna Dreber Almenberg, Oliver Engist, Magnus Johannesson, Brian Nosek, Robert Östling, Joakim Semb, and Domenico Viganola for their helpful comments. Vera Wellander Lindén provided excellent research assistance.
Transparency
Action Editor: Marc J. Buehner
Editor: Patricia J. Bauer
Author Contributions
F. Schafmeister is the sole author of this article and is responsible for its content.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.