
Abstract
With rapid developments in biometric recognition, a great deal of attention is being paid to robots which interact smartly with humans and communicate certain types of biometrical information. Such human–machine interaction (HMI), also well-known as human–robot interaction (HRI), will, in the future, prove an important development when it comes to automotive manufacturing applications. Currently, hand gesture recognition-based HRI designs are being practically used in various areas of automotive manufacturing, assembly lines, supply chains, and collaborative inspection. However, very few studies are focused on material-handling robot interactions combined with hand gesture communication of the operator. The current work develops a depth sensor-based dynamic hand gesture recognition scheme for continuous-time operations with material-handling robots. The proposed approach properly employs the Kinect depth sensor to extract features of Hu moment invariants from depth data, through which feature-based template match hand gesture recognition is developed. In order to construct continuous-time robot operations using dynamic hand gestures with concatenations of a series of hand gesture actions, the wake-up reminder scheme using fingertip detection calculations is established to accurately denote the starting, ending, and switching timestamps of a series of gesture actions. To be able to perform typical template match on continuous-time dynamic hand gesture recognition with the ability of real-time recognition, representative frame estimates using centroid, middle, and middle-region voting approaches are also presented and combined with template match computations. Experimental results show that, in certain continuous-time periods, the proposed complete hand gesture recognition framework can provide a smooth operation for the material-handling robot when compared with robots controlled using only extractions of full frames; presented representative frames estimated by middle-region voting will maintain fast computations and still reach the competitive recognition accuracy of 90.8%. The method proposed in this study can facilitate the smart assembly line and human–robot collaborations in automotive manufacturing.
Keywords
Introduction
Rapid developments in artificial intelligence techniques are giving rise to many smart human–machine interaction (HMI) applications and further contributing to the field of smart manufacturing nowadays.1–4 The main idea of smart HMI is to create a specific interaction between the target end-device and the person using certain types of biometric features derived from that person. It is well-known that speech communication using the speech recognition functionality is a frequently-seen and acceptable way of being interactive with a specific device, such as speech recognition performed by a smart phone or smart speaker in order to facilitate device function operations. 5 In addition to speech communication-type HMI, the HMI design using hand gesture communication has served as an alternative mode to establish fine interaction with the machine. The main purpose of human–machine interaction using hand gesture communication is to acquire the activity information of hand gesture actions made by the person, through which a specific interaction with the machine can then be carried out. Hand gesture communication with hand gesture recognition has been an extremely interesting HMI technique issue, with numerous related studies seen in recent years.6–8 As speech recognition matures, it is believed that hand gesture recognition will also become the widely-accepted HMI mode in the near future.
Among all HMI fields, human–robot interaction (HRI) is attracting much attention.9–11 HRI is an important HMI form, where the machine device which will be interactive with the human is specifically set as the “robot.” The above-mentioned speech communication with speech recognition, and hand gesture communication with hand gesture action recognition, have also been attempted in order to make fine connections with the specific robot system. In such studies,12,13 voice control-based speech recognition is effectively used for humanoid robot and ROS robot operations. Due to inevitable performance restrictions in the adverse situation where speech recognition is carried out in a noisy environment, hand gesture recognition will perhaps become a very acceptable path for HRI application system developments. 14 In fact, with the rapid growth of advanced image sensors such as three-dimension (3D) and depth sensors, there will be a significant alleviation of the performance decrease of hand gesture recognition by conventional RGB sensor-based image process calculations in the case of complicated and variant backgrounds. There has been a remarkable emergence of works related to the utilization of 3D sensor-based or depth sensor-based hand gesture recognition as an interaction interface between the robot system and the user.15–27 Studies concerning HRI via hand gesture communication can be categorized into various different applications, imitation robots,15,16 show robots, 17 sport or rehabilitation instructor expert robots,18,19 surgery robots, 20 and industrial robots.21–34
With regard to applications and developments of industrial robots, hand gesture communication-based HRI is attracting a great deal of interest. In Van den Bergh et al., 21 3D hand gesture interaction is carried out with a robot, where the robot can search the person to interact with, ask for the direction, and then carry out detection of the obtained 3D point direction. The HRI system developed in Van den Bergh et al. 21 belongs to the categorization of “reconnaissance robots.” Scene recognition, which makes it possible to plan the walking area and avoid obstacle collision by combining cloud computing and artificial intelligence techniques, is explored in the application of “clean robots.” 22 Moreover, a “mine rescue robot,” which works in the underground environment with low illumination, is presented in Shang et al., 23 while in the work of Shang et al., 23 depth sensor-based hand gesture recognition is used as the interface for creating interaction with the rescue robot. On the other hand, with the greatly increasing demand for automatic manufacturing, a substantial amount of interest is being attracted by the “collaborative robot,” sometimes also referred to as the “Cobot,” which is controlled by the hand gestures of the operator. This kind of hand gesture control-based human–robot collaboration mode is generally employed on the assembly line in automotive manufacturing. There can also be found studies on the human–robot collaborative assembly, supply chain management, or material inspections with hand gesture recognition.24–34 As can be seen in Figure 1, the operator must always stay close to the image sensor to perform specific hand gesture actions in order to create collaborative operations with the robot. Hand gesture recognition in such applications of automotive manufacturing24–34 can be primarily divided into three different categorizations of approaches, namely (1) recognition of static hand poses using only a spatial approach without involving kernel pattern recognition technique issues, detections of finger segmentations, 24 and estimations of hand joint variations observed from the 3D-(x, y, z) space of the 3D image sensor (e.g. the usage of the Leap Motion controller),25–27 (2) statistical model-based recognition techniques using the typical context-dependent statistics model, namely the hidden Markov model (HMM), for classifying continuous-time dynamic hand gestures,28–30 and (3) deep learning model-based recognition approaches by popular convolutional neural network (CNN), recurrent neural network (RNN), long short-term memory (LSTM), or integration designs of the above-mentioned models.31–34 Note that, for hand pose detection using the relatively simple spatial approach with a specific 3D image sensor, the work in developments of the recognition system is mainly designed to continually track variations of the 3D-(x, y, z) location of each hand joint defined in the specific 3D image sensing space. This kind of spatial 3D-(x, y, z) hand pose detection approach is appropriate for automotive manufacturing tasks of collaborative material inspection or collaborative assembly line without semantic cognitions of human behavior intention. On the other hand, as for the model-based categorization of recognition approaches, where dynamic hand gesture recognition is carried out using the statistical model of HMM or the deep learning model of various types of networks, it would be more suitable for this to be performed in the automotive manufacturing scenario, which requires a certain degree of cognition when it comes to recognition of the continuous-time action intentions of the operator (e.g. providing assistance to the operator). Model-based hand gesture recognition generally has fine usages in the more complex assembly line. In the development of such a model-based hand gesture recognition system, model establishments (also known as model-training) of hand gesture classification models with extremely high cost in time will be the primary technical issue.
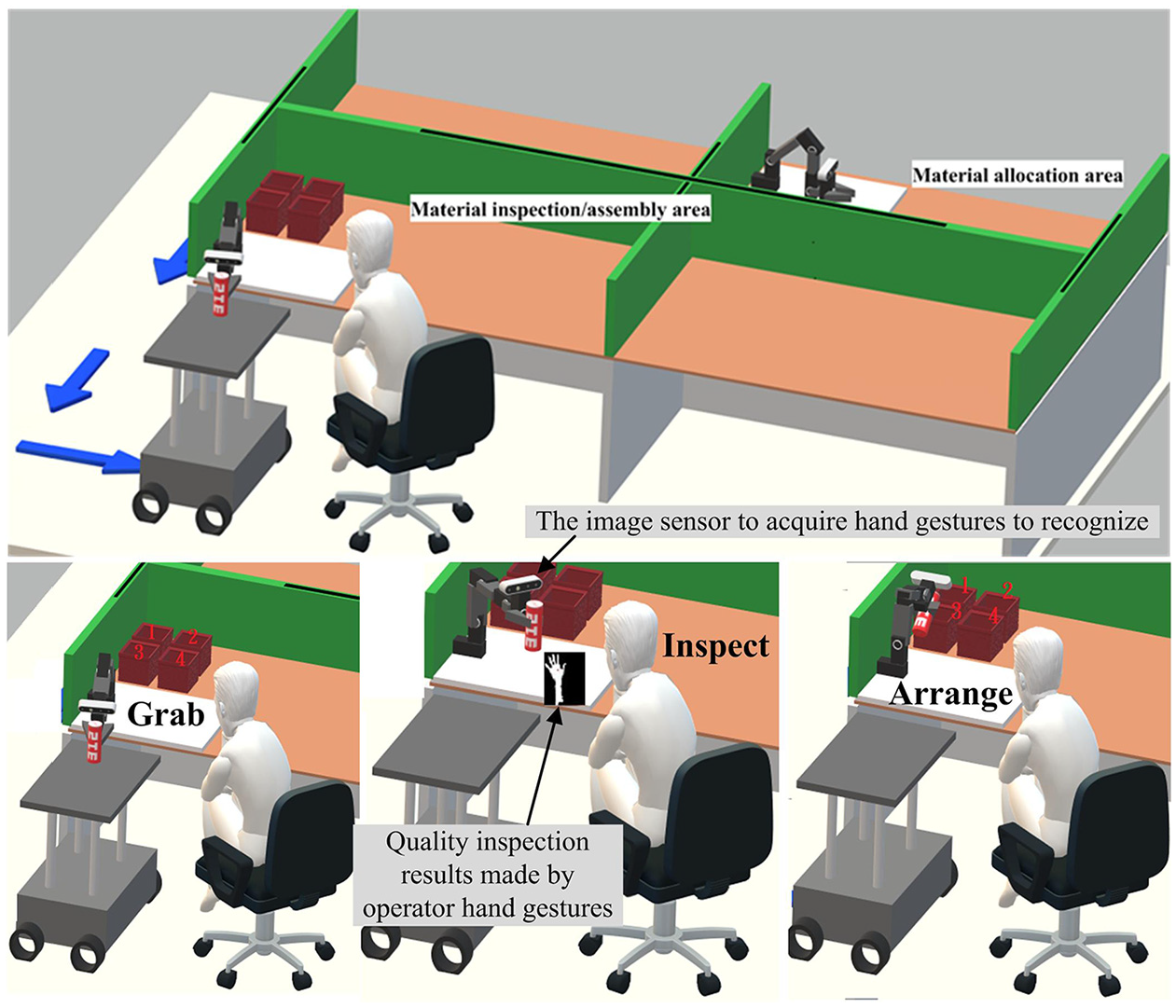
The HRI type of human-computer collaborations with hand gesture recognition of the operator employed on assembly-line, supply-chain, or material-inspection in automotive manufacturing of the new-generation.
The collaborative robot design combined with human hand gesture action interaction has been an on-going tendency in the innovative “Industry 4.0,” with the goal of completing automation in the manufacturing field. Although many studies on the developments of the human–robot collaborative system with hand gesture recognition have been seen to be used in automotive manufacturing, most of those works focus on assembly, supply chain, and material inspection. Extremely few hand gesture recognition works focus on the HRI development of the smart material-handling robot. Figure 2 depicts the operations of the typical material-handling robot, namely the automated guided vehicle (AGV), in the automotive manufacturing nowadays. The AGV robot, equipped with the handled material, is moved to the target location (assembly or inspection areas) in the factory. Conventional approaches to AGV navigations mainly include path-following and simultaneous localization and mapping (SLAM). In both of these robot navigation schemes, the human operator in the manufacture line cannot provide the path guide information to the material-handling robot. In addition, when the robot moves close to the indicated location, a robot positioning approach using the RFID tag is typically employed. However, in some situations, such navigation and positioning schemes on the material-handling robot will perhaps be unsafe, inflexible, and not collaborative. It is well-known that the “Atlas Robot,” designed by the company Boston Dynamics, has powerful material-handling ability. 35 The Atlas Robot is not categorized as a wheeled-type AGV, and instead belongs to the humanoid-type robot class. This kind of humanoid-type robot will be able to partake in further material handling with the operator in a mode of “collaborative material handling” after the robot reaches the indicated location and finishes location-positioning. To tackle this issue, a smart material-handling robot system with human–robot interactions via Kinect depth sensor-based hand gesture communication is developed in the present study. The rationale behind this design is that the operator located in the fixed position of the assembly line, performing the human–computer collaborative task via hand gesture recognition (assembly or inspection), can also use the dynamical hand gesture to achieve operations of navigation and positioning of material-handling robots of the typical AGV and the Atlas Robot-like (see Figure 3).
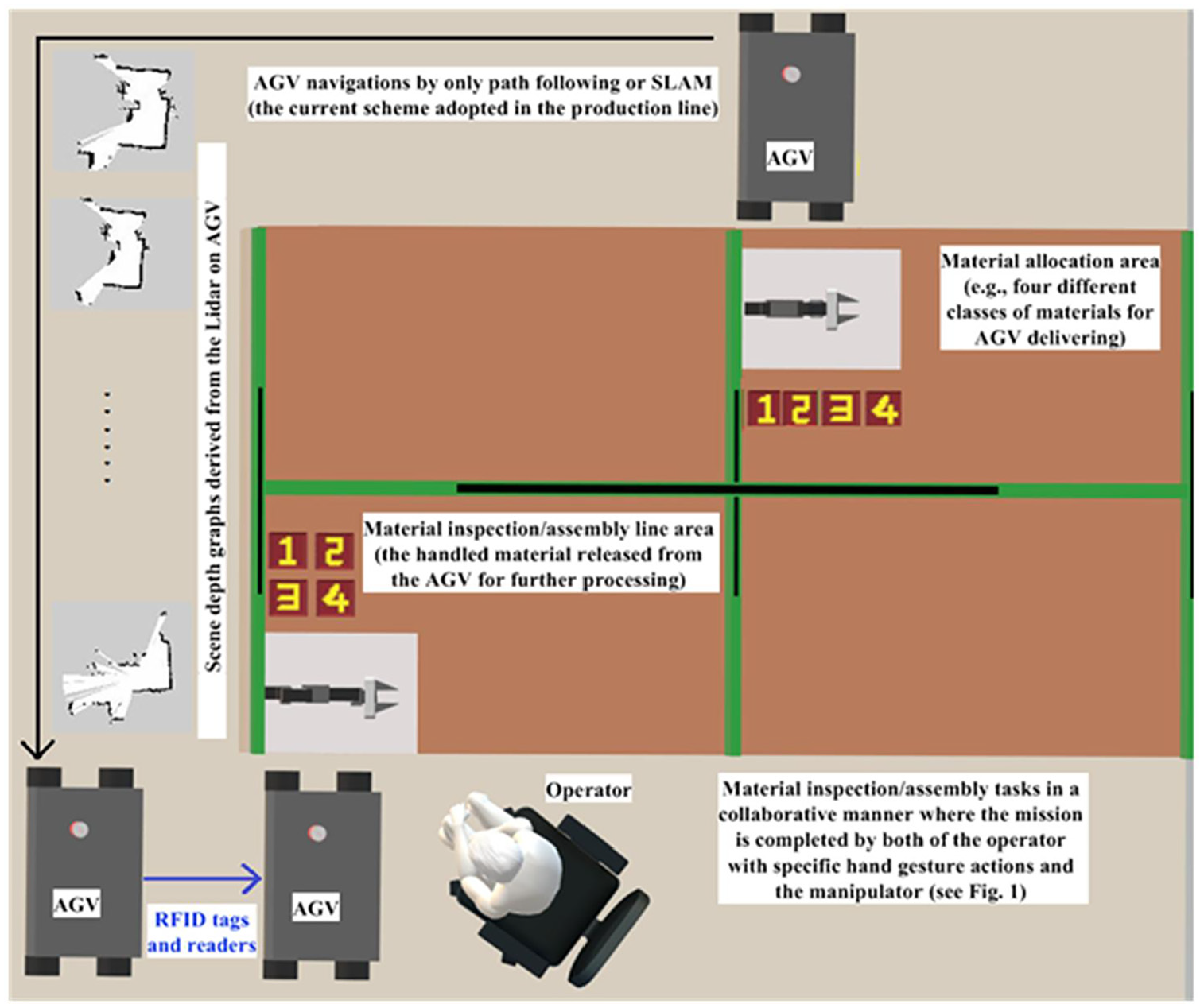
Navigating and positioning of the typical material handling robot (AGV) by simple path-following (or SLAM) and RFID tagging approaches respectively in the assembly-line of automotive manufacturing.
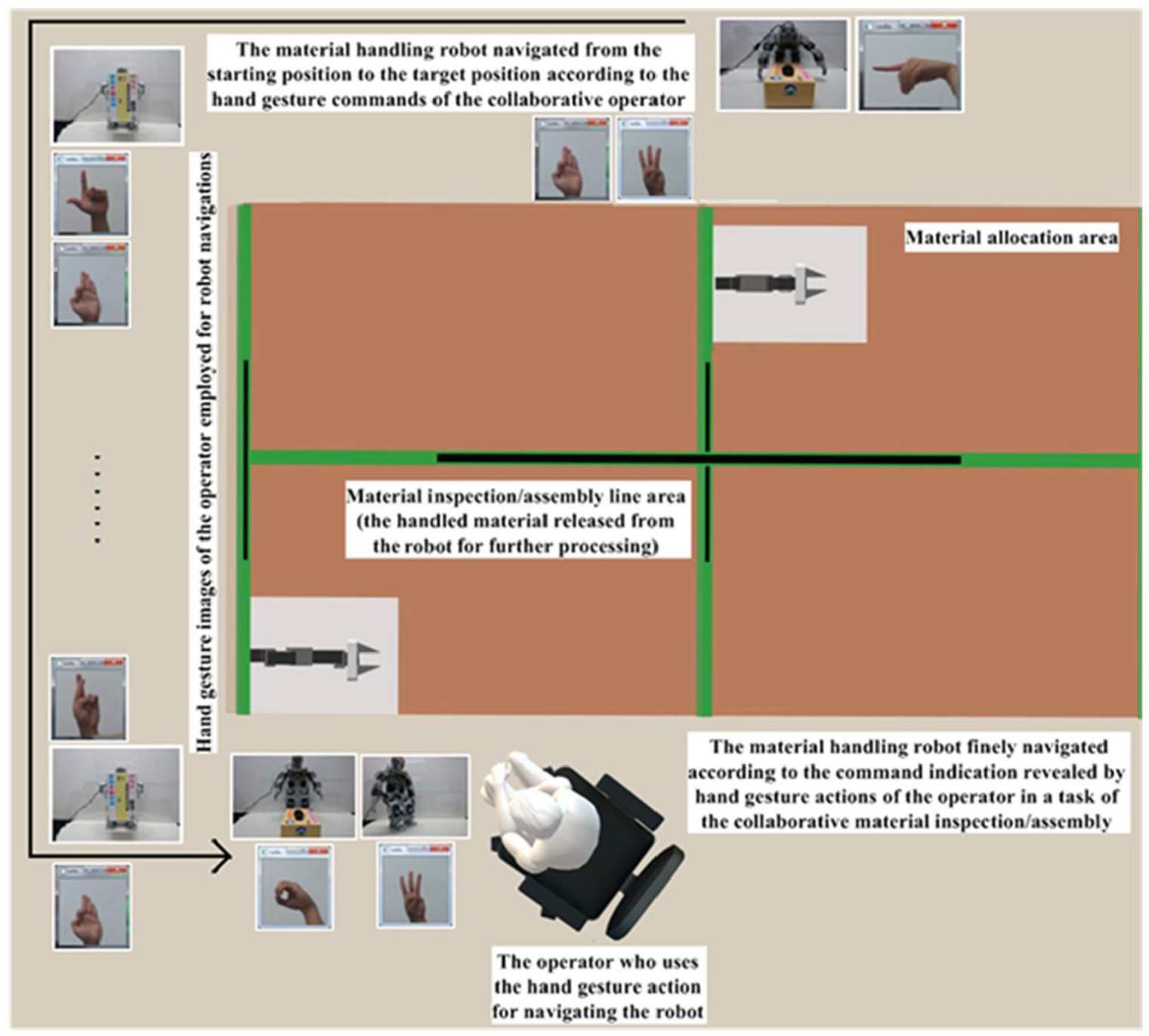
An advanced HRI design on operations of the material handling robot presented using hand gesture actions of the specific operator in the assembly-line to make semantic communication with the robot and possible material handling in a collaborative manner.
Compared with those hand gesture recognition approaches which have been explored in the field of automotive manufacturing, such as the finger segmentation detection approach, 24 the spatial 3D-(x, y, z) hand pose detection method (which involves observing hand joint variations from the specific 3D image sensor),25–27 and those model-based recognition approaches using the well-trained statistics model HMM28–30 or the deep learning neural network with iterative learning of image characteristics,31–34 the hand gesture recognition presented in this study for smart material-handling robot operations is a feature-based approach. Depth sensor images of continuous-time dynamic hand gestures are extracted from the significant feature of the Hu invariant moments and then made into classifications via template match. From the technical viewpoints of calculation cost and computational real-time, without the exhausting requirement of gesture classification model establishments in model-based hand gesture recognition, the feature-based recognition approach presented in this work maintains the competitive merit. On the other hand, compared with those static hand pose recognition approaches of finger segmentation detection and 3D-(x, y, z) hand joint variation estimates, due to the estimate of representative frames of the acquired specific HRI hand gesture actions finely incorporated into template match, the approach presented in this work can recognize continuous-time dynamic hand gesture actions, and therefore the context-dependent semantics revealed by continuous-time dynamic hand gesture actions can still be significantly extracted. Furthermore, in this work, in order to perform command recognition of a series of continuous-time dynamic hand gesture actions to smoothly interact with the robot, the wake-up reminder scheme to regulate starting, ending, and switching of meaningful gesture actions is also finely provided using fingertip detection designs.
Aimed at the ideal plan of full-line automation in next-generation manufacturing, by the proposed HRI scheme, the conventional material-handling robot can further be promoted to increase much intelligence. The presented HRI by hand gesture communication on the material-handling robot will also provide a feasible way, where the efficiency of current collaborative robot missions in the smart assembly line can be increased. Details of the proposed HRI design using depth sensor-based hand gesture communication for smart material-handling robot operations will be described in the following sections.
The main contributions of this study are summarized below:
A complete framework of advanced HRI by hand gesture communication for intelligent material-handling robot operations proposed to facilitate the smart assembly line and human–robot collaborations in automotive manufacturing.
A depth sensor feature-based hand gesture recognition approach developed using template match with estimates of representative frames for attaining real-time recognition and achieving extraction of the semantic information from the continuous-time dynamic hand gesture action, without extremely exhausting cost on model training of the model-based recognition approach.
Fingertip detection estimates of system wake-up reminders designed to be appropriately combined with hand gesture recognition in order to smoothly regulate a series of gesture communication actions on the material-handling robot.
The developed smart material-handling robot system with HRI designs of Kinect depth sensor-based hand gesture communication
Figure 4 illustrates the framework of the presented system. As shown in the said figure, the developed system contains three main technique components, namely data acquisition and preprocess of Kinect depth sensor-based hand gesture actions, HRI with hand gesture recognition using the extracted continuous-time depth sensing hand gesture data, and operations of the material-handling robot with HRI integrations of continuous-time dynamic hand gesture recognition. A series of depth sensing images containing hand gesture action information are captured by the Kinect depth sensor, following which hand detection, hand tracking, and noise removal of the extracted hand gesture depth image are orderly performed. When the fine hand gesture depth image is obtained, feature extraction and recognition of this depth image is then carried out. Finally, the classification label of the recognized hand gesture to denote the corresponding robot operation command is sent to the material-handling robot to complete robot manipulation actions. It’s noted that in this study, the robot operation command derived from hand gesture recognition is transmitted to the robot device via Bluetooth (BT) wireless transmission.
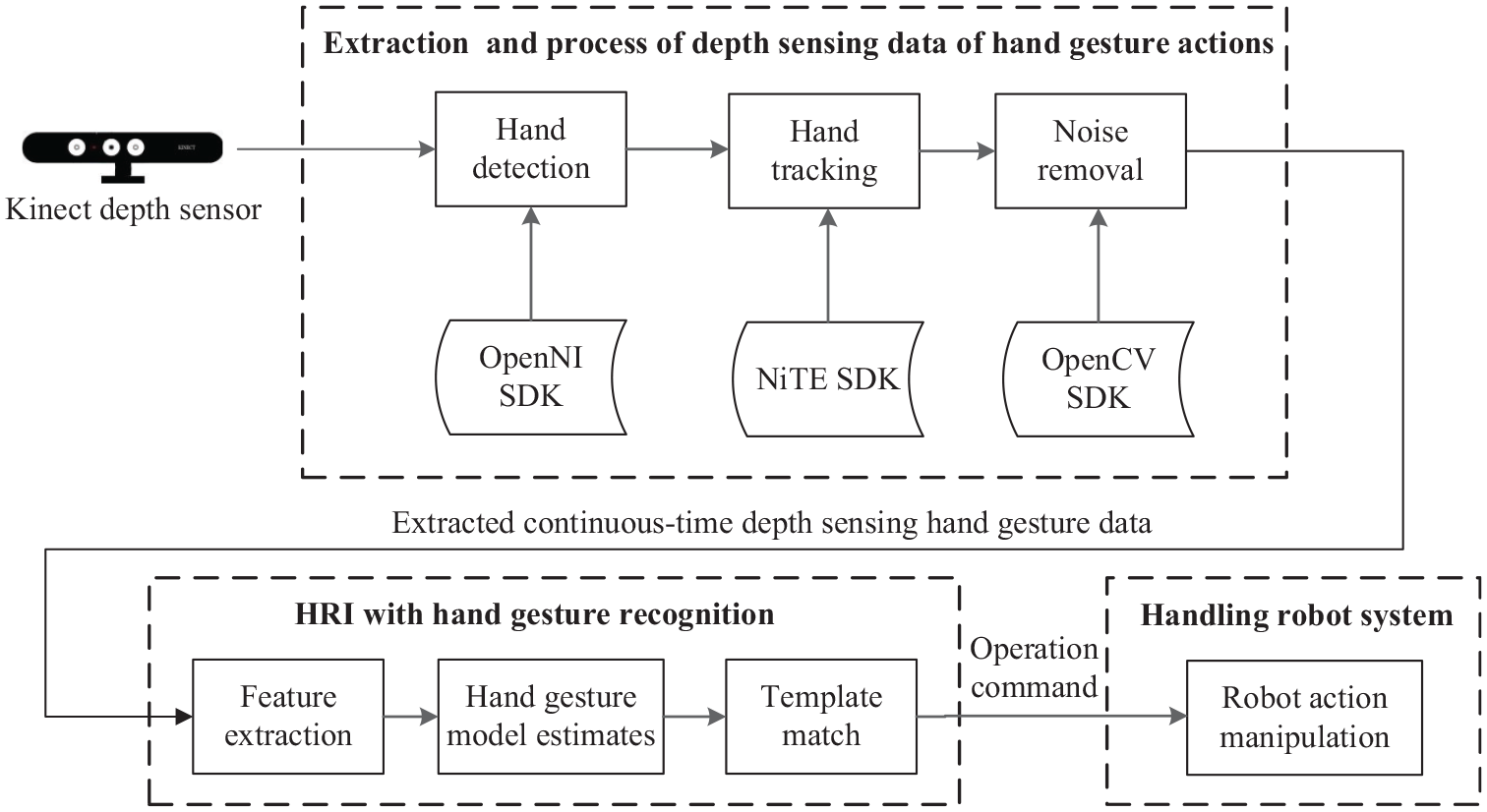
Frameworks of the presented smart material handling robot system with depth sensing-based hand gesture communication HRI designs.
Data acquisition and preprocess of Kinect depth sensor-based hand gesture actions
The Kinect sensor device employed in this work for capturing depth information of active hand gestures is depicted in Figure 5.36,37 As shown in the said figure, the Kinect device essentially includes a 3D depth sensor, the RGB camera, acoustic sensors of the microphone array, and the motor control module to adjust the tilt degree of the image capture. For image data acquisition by the Kinect device, both the RGB camera and the 3D depth sensor can be utilized. However, for hand gesture action data, the RGB camera-based images will inevitably encounter the problem of complex background and insignificant brightness. In contrast, the depth sensor uses the infrared receiver to obtain the sensing data emitted by the infrared transmitter in order to achieve extraction of the depth image characteristics. The depth sensor is therefore able to be much more tolerant of the environment of complex background and insignificant brightness. However, when the hand gesture action is performed, the depth image acquired from the Kinect device reveals the overall contour of the hand gesture-making person. The desired hand gesture image segment will still have to be separated from the overall depth image for further analyzing and recognizing.
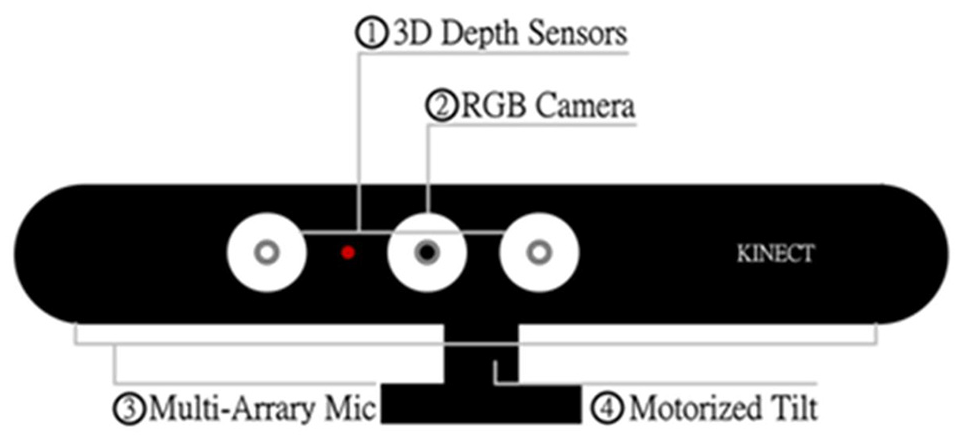
Depth sensor-based hand detection by OpenNI SDK
Since the raw parameters of the image data cannot be derived from the Kinect sensor-acquired depth image, the OpenNI SDK, developed by the organization of open natural interaction (OpenNI), is employed for data acquisition of the 3D sensor.
38
The OpenNI SDK essentially provides the efficient tool of natural user interface and human-computer interaction mode to allow the system developer to be able to acquire the required sensing raw data from various types of 3D sensor devices. With the support of the OpenNI SDK, a human–machine interaction application using 3D sensors can be quickly developed. This work employs the OpenNI SDK to obtain the depth value of the captured scene image from the infrared ray information of Kinect depth sensors. A gray scale depth image is obtained by converting numerous depth values in the captured scene to gray scale map information using equation (1). As observed from equation (1), the index

The Kinect sensor gray scale depth image obtained by the OpenNI SDK where the overall contour of the hand gesture-making person including the hand segment is covered.
Hand tracking and segmentation by NiTE SDK
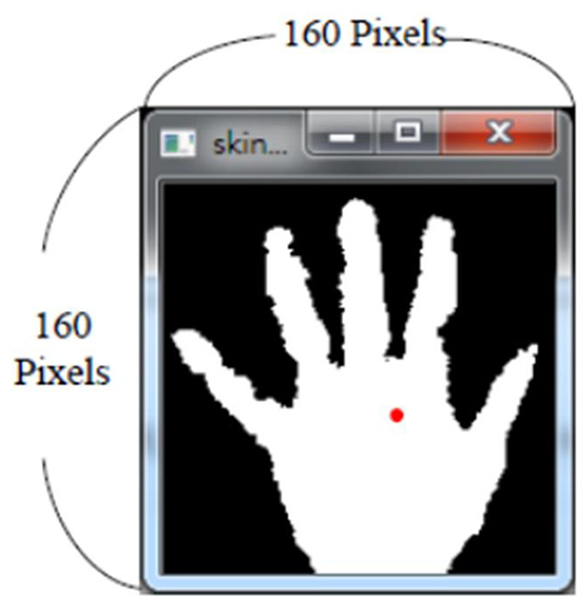
After obtaining the gray scale depth image, the significant hand part will be independently separated from the overall depth image. The purpose of such image segmentation is essentially to obtain the significant front-ground segment and emit the unnecessary back-group segment. This work properly employs the NiTE SDK to ascertain the location of the hand center point. 39 Figure 7 shows the estimated hand center point (i.e. the red point depicted in Figure 7) by the NiTE SDK.

The center point of the hand estimated by the NiTE SDK (the red point in the figure).
When the location of the NiTE SDK hand center point is derived, the gray scale depth value of this location,

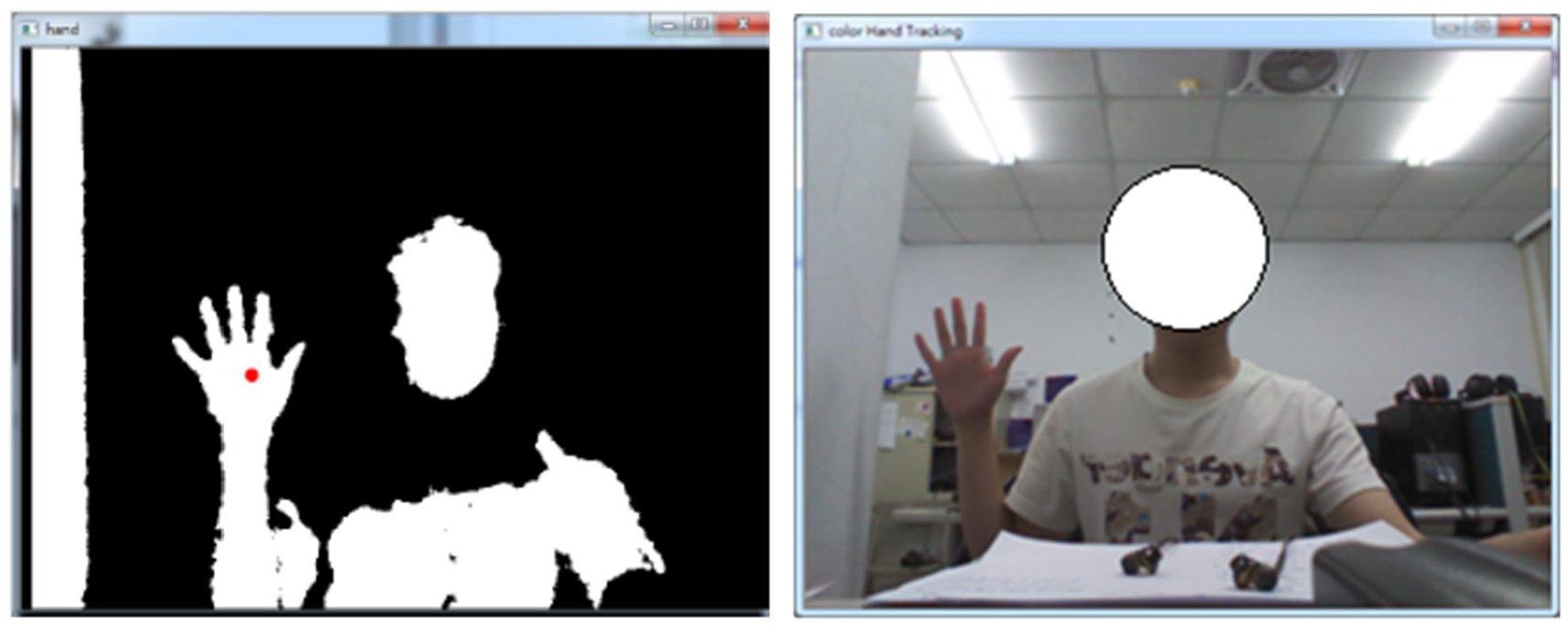
The binary image process with equation (2) calculations on the Kinect sensor gray scale depth image of Figure 6 (binary-valued and original RGB raw images in the left and right respectively).
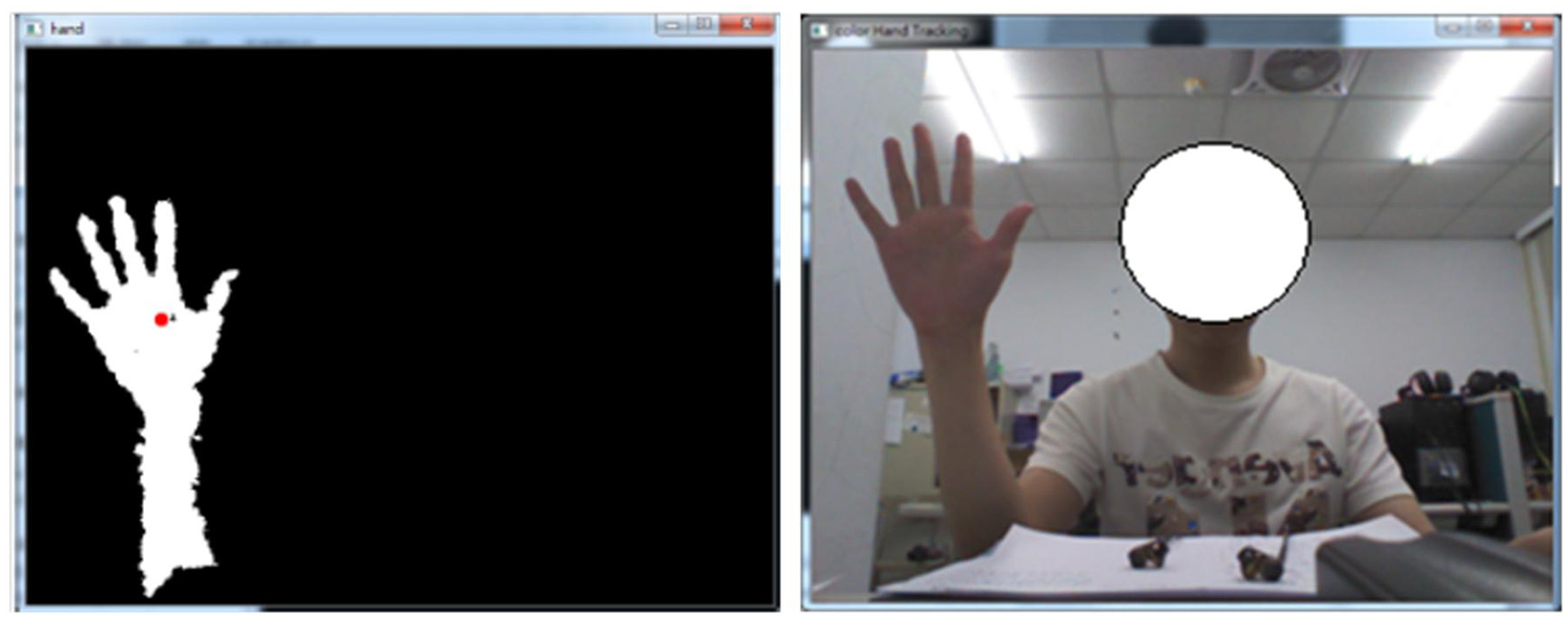
The binary image process with equation (2) calculations on the Kinect sensor gray scale depth image in the situation that the hand of the gesture-making user is much close to the sensor (binary-valued and original RGB raw images in the left and right respectively).
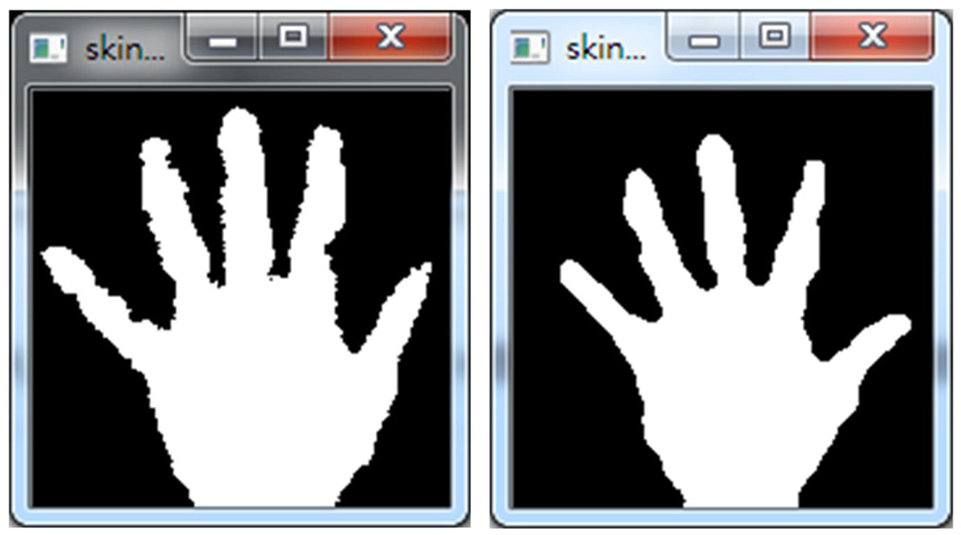
As shown in Figure 9, after the binary image process shown in equation (2), the significant front-ground part in the overall image can then clearly be seen, which includes mainly the hand and the arm part. In this work, to consider the issue of real-time calculations and the effect of responses to hand gesture communication on the operations of the material-handling robot, only the hand part (i.e. the palm and five fingers) is focused on, while feature extraction is performed to represent a specific hand gesture action. The binary-valued image segmentation, with a fixed size of
The binary-valued image segmentation with the fixed size of
Noise removal of the segmented hand gesture image by OpenCV SDK
As can be seen in Figure 10, the hand shape used to describe hand gesture variation information in the
The smooth degree significantly increased by median filtering calculations.
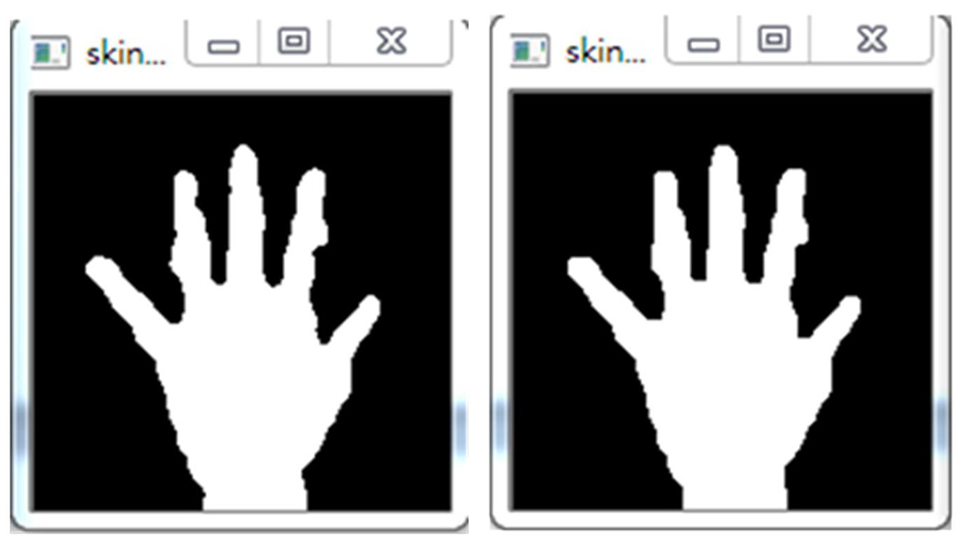
The opening operation scheme employed for further improving hand contour smooth.
Hand gesture recognition with features of HU moment invariants
The Hu moments approach is essentially the improved version of the geometric moment (GM) method.41,42 Generally, the moment invariant approach seeks to achieve a specific goal, namely for those calculated moments of the observed object in the image to still be able to maintain the invariant after image rotating, moving, zooming, or mirroring. These GM invariants presented by Hu are essentially “rotation moment invariants.” Due to the invariant characteristics of Hu moments in the case image geometric transformation is performed, the moment invariant approach earlier presented in the work of Hu
41
has been proven to be an effective and efficient feature extraction scheme. The features of the Hu moment extracted from the specific types of images have been widely used in many image-related applications, such as image analysis (shape circularity measure in Žunić et al.
43
) and visual-based pattern recognition (face recognition in Paul et al.
44
; 3D human action recognition in Al-Azzo et al.
45
). The image-extracted Hu moment belonging to the 2D geometric characteristics contains the characteristics of image translation, scaling, and rotation, and can be calculated from seven functions, which are shown in equations (5)–(11). The centroid in a 2D image is generally defined as the central moment,

in which,

In terms of the scaled central moments, a total of seven Hu moment feature parameters (


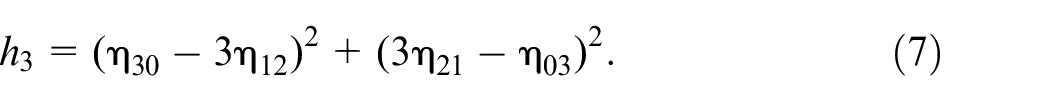
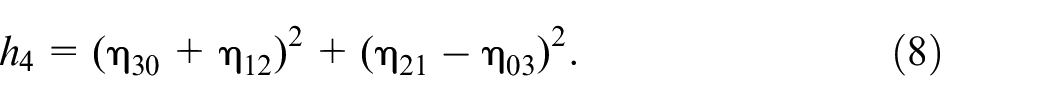
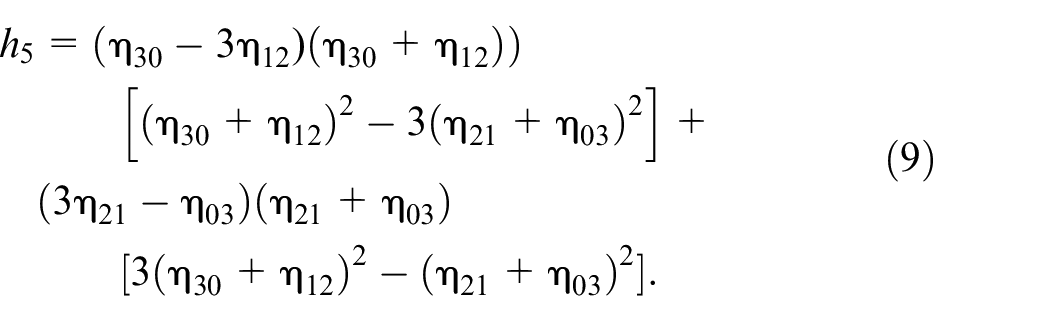
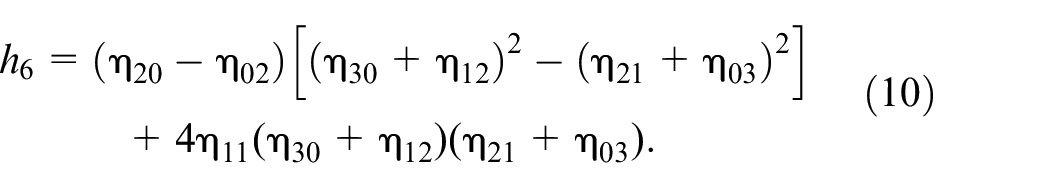
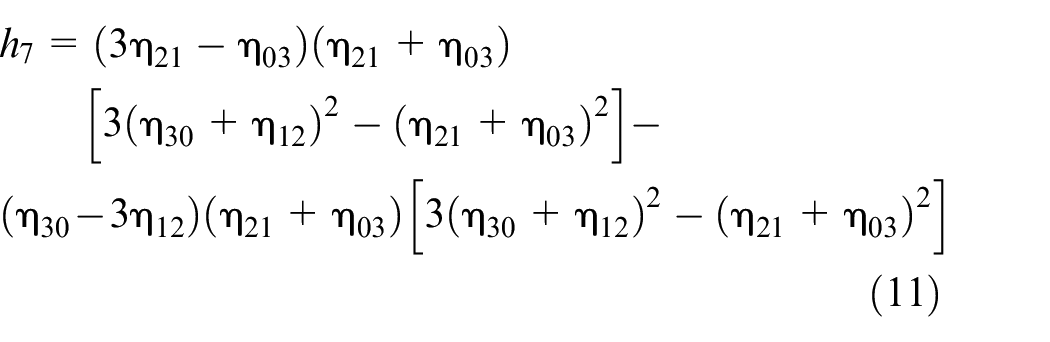
Note that these seven different parameters of Hu moments derived from equations (5) to (11) are used to describe the interesting object of the hand segment in an image in this work. These seven invariant moment parameters,
In the present work on HRI designs, in order to use hand gesture communication for operating the material-handling robot, K different specific hand gesture actions, Gesture1, Gesture2,…, and Gesture
K
, are set, each of which is used to indicate the corresponding operation of robot action behavior. Each of these set K hand gesture actions is composed of numerous frames in a certain continuous-time period. Figure 13 depicts test and training database establishments through the feature extraction of Hu moment invariants. As can be seen in Figure 13, each of the different hand gesture actions contains n continuous-time frames, Frame 1, Frame 2,…, and Frame n. Each of these n hand gesture frames includes seven different estimated Hu moments,
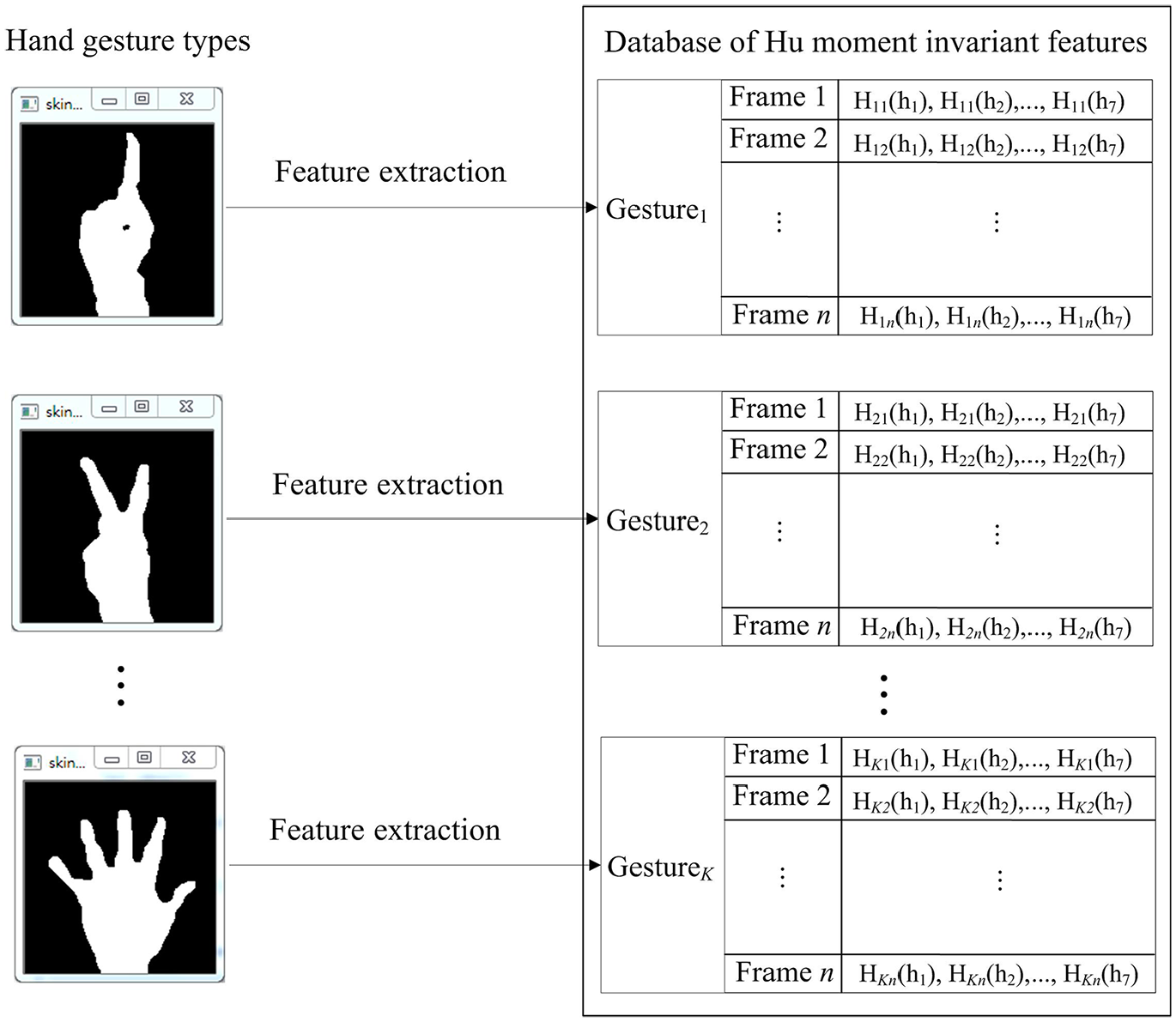
Test and training database establishments of Hu moment invariant-features by feature extraction to each
In this study, considering its simplicity and rapid computation, the template match method is adopted for recognition calculations. Equations (12) and (13) detail the calculation process of template match used in this study. When performing recognition in the test recognition phase, the test hand gesture action for classification,
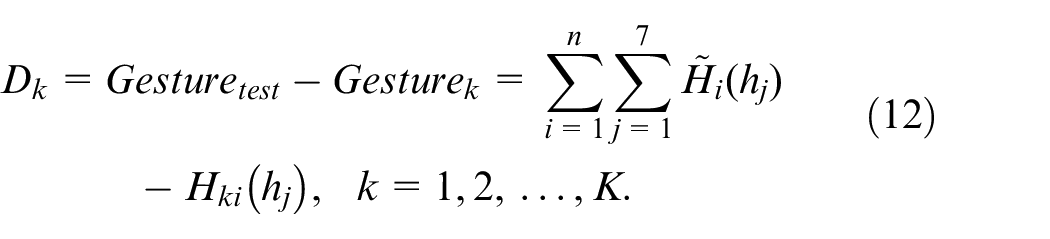
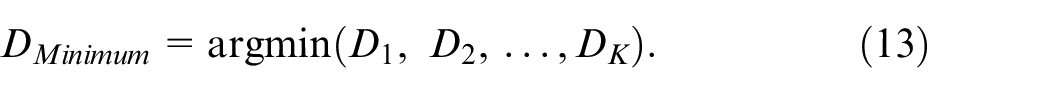
The material-handling robot system with HRI integrations of continuous-time hand gesture communication
The above-mentioned hand gesture recognition system is then integrated into a material-handling robot device to further construct a smart HRI system. Figure 14 illustrates integrations between the hand gesture recognition system and the robot device, where the Bluetooth (BT) wireless transmission scheme is employed for sending the label of the recognized hand gesture action to the robot device to provide the corresponding robot operation. It is noted that, for robot developments nowadays, the end-device of robots being equipped with a wireless transmission scheme including BT is a mainstream tendency. The HRI system presented in this work can be effectively employed in most of the robot devices with wireless transmission modules.
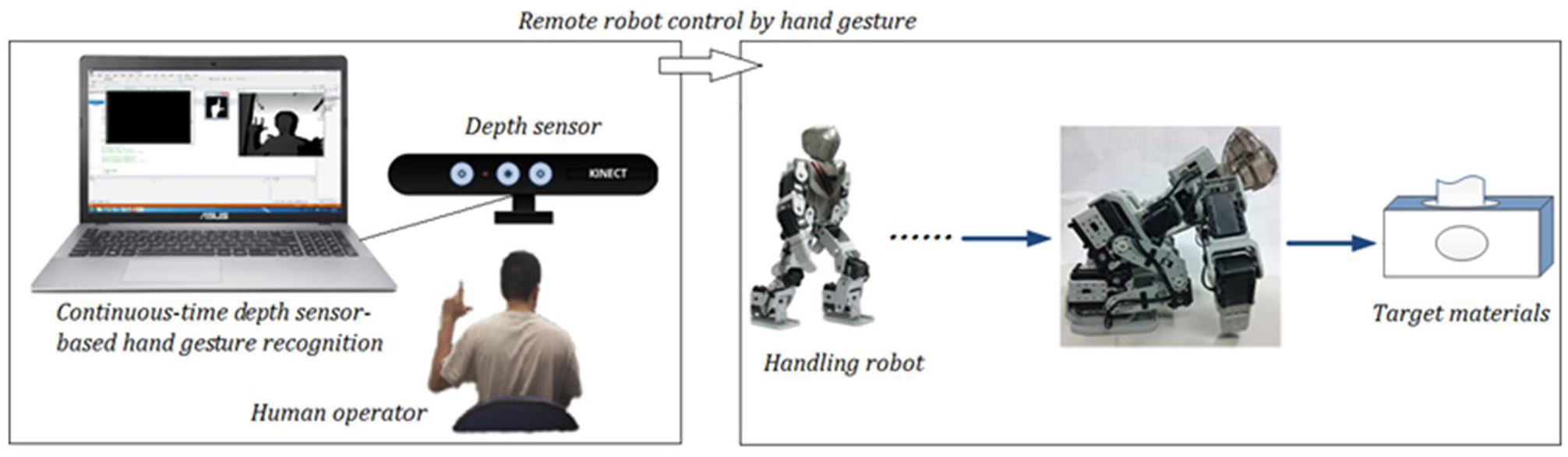
Human robot interaction by hand gesture communication where the recognized hand gesture action is sent to the robot device to denote the corresponding robot operation via Bluetooth.
Start and end time-point determination of specific HRI hand gesture action acquisitions
To be able to construct a practical hand gesture communication-based HRI system in a real-life application, real-time detection, and recognition of the specific hand gesture communication sent to the robot device will undoubtedly be crucial. In order to accurately and completely capture all hand gesture frames of the specific hand gesture robot operation action carried out by a human operator, this work presents a hand gesture detection scheme. Developed detection of the significant hand gesture action is mainly designed to provide a scheme to denote start and end time-points on hand image acquisitions. When the starting point is detected, a series of gray-scale depth hand gesture images are then acquired from the Kinect depth sensor. This hand gesture image capturing process will be repeatedly carried out before the end time-point is detected. Figure 15 depicts this detection design for the start and end of the hand gesture action. It is noted that hand gesture images acquired between the start and end time-points will then be considered for further feature extraction and hand gesture recognition. As can also be seen in Figure 15, both start and end indications of the significant hand gesture action are the hand poses of “open the hand fully.” The hand gesture action detection will then essentially become a problem of detecting the hand pose “open the hand fully.”
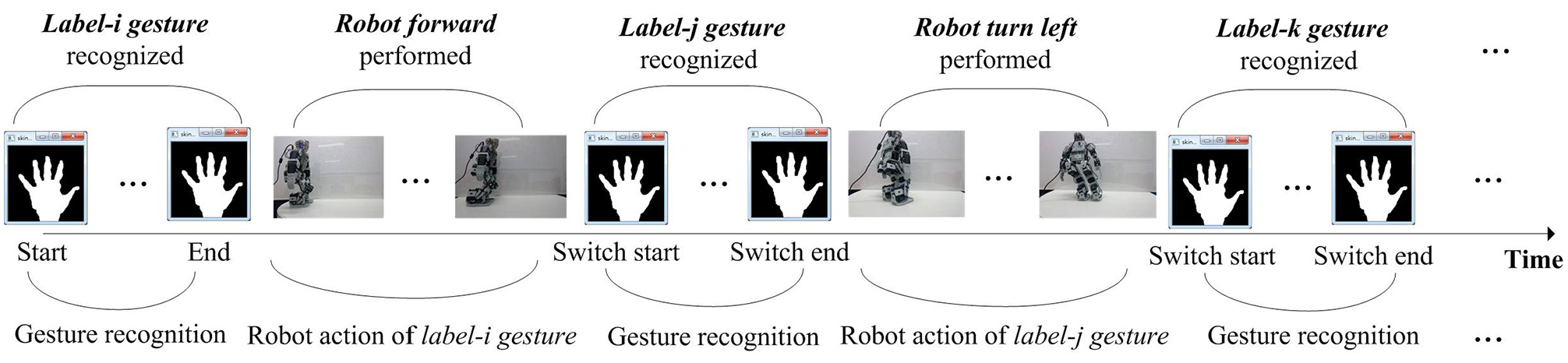
Start and end time point determination by detection of the hand pose “open the hand fully” for image acquisitions of the specific hand gesture robot operation action.
In this work, the problem of hand pose detection for the pose “open the hand fully” can essentially be viewed as the fingertip detection issue, that is, detection of the hand pose with five fingertips. In order to tackle this issue, the Douglas–Peucker algorithm, which belongs to the categorization of iterative end-point fit algorithms, is adopted.
46
As can be seen in Figure 16, when the pose “open the hand fully” is made, proper utilizations of the Douglas–Peucker algorithm can then transform the image with a curve of multiple piecewise line segments to that with a much simpler and similar curve composed of only fewer points. As observed from Figure 16, the image with the noise removal process (see Figure 12) can be transformed into the image which is represented by some hand critical points. In order to rapidly implement the Douglas–Peucker calculations mentioned herein, this work directly adopts the OpenCV SDK.
40
After performing the Douglas–Peucker algorithm, a fingertip search of the Douglas–Peucker derived simple hand curves is then carried out; all critical points distributed on the derived curve will be evaluated. The main evaluation scheme of fingertip verification in this work is that three consecutive critical points on the curve are considered using equations (14)–(17). Figure 17 illustrates the fundamental rationale of such fingertip verification. In this study, when the
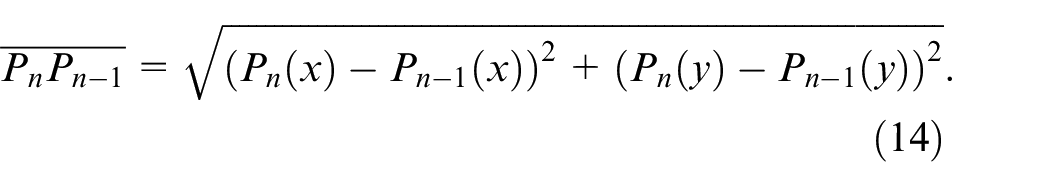
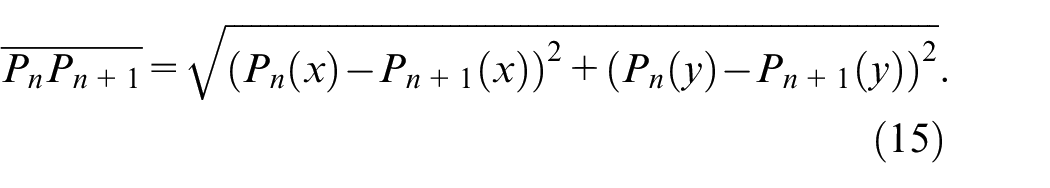
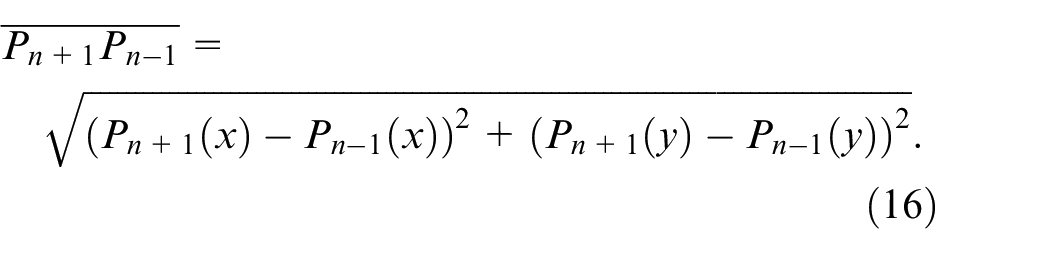
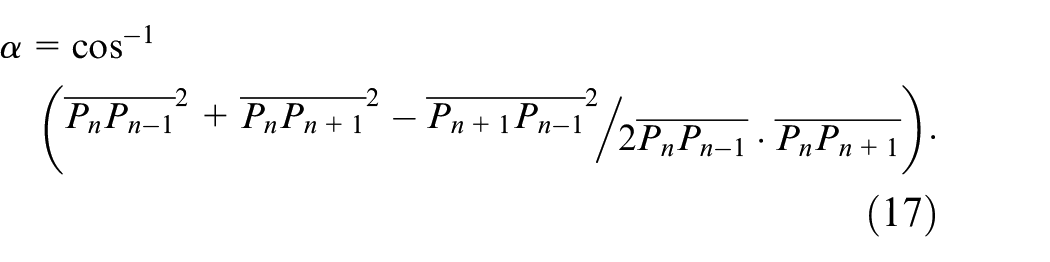

The use of the Douglas–Peucker algorithm for obtaining a simple hand curve composed of only some critical points.
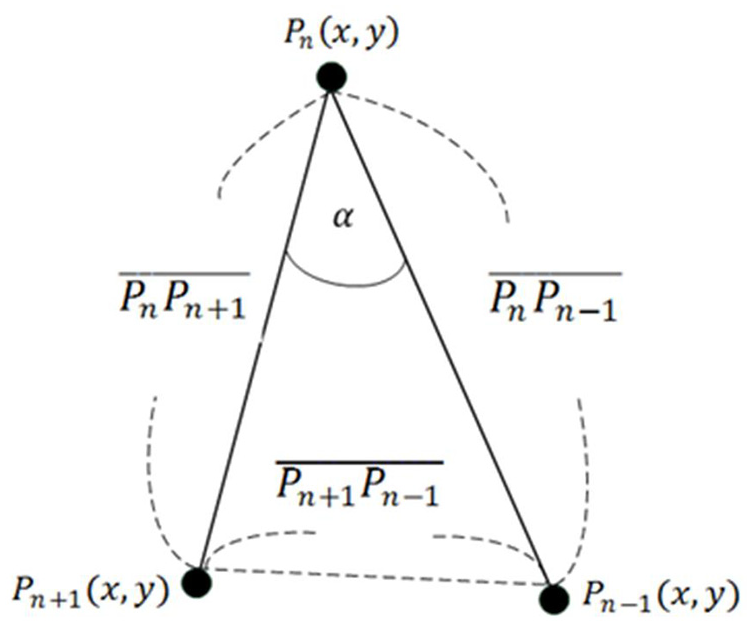
Fingertip verification by evaluations of three consecutive hand critical points.
Estimate of the representative frame of the acquired specific HRI hand gesture action
It is worth noting that all the captured hand gesture frames occurring between the start and end detection points considered for feature extraction and recognition will perhaps not be a most satisfactory strategy from the viewpoint of both issues of recognition accuracy and real-time computation. Figure 18 depicts that a series of hand gesture images (i.e. hand gesture frames) contained in the specific HRI hand gesture action denoting a certain gesture classification label can be acquired by the detected action start and end time-point. To tackle this problem and construct a hand gesture communication-based HRI system with both high recognition accuracy and low computation cost, this work presents three different strategies to effectively determine the representative frame of the specific HRI hand gesture action acquired from the detection scheme of the hand pose “open the hand fully” presented in Section 2.3.1. Note that only the representative frame of the specific HRI hand gesture action is employed for extraction of Hu moment invariant features and determination of action classification labels. Excluding the extraction of full frames without estimate of the representative frame, in order to reduce calculation cost and achieve real-time recognition, those frames that are not related to the estimated representative frame will not be considered in the recognition calculation process and will thus be neglected directly. Additionally, in the situation where the extracted Hu moment invariant features of two (or more than two) adjacent gesture frames are invariantly the same, all of these seemingly-the-same frames will still be required to be taken into account in hand gesture action recognition in this design. From the technical viewpoint of dynamical visual human action recognition with context sensitivity in certain continuous-time periods, those consecutive and invariant frames generally denote the starting or ending timestamps of a significant action. The three different strategies presented for determining the representative frame of the specific HRI hand gesture action in this study are the centroid representative frame estimate, the middle representative frame estimate, and the representative frame estimate by middle-region voting.

Estimate of the representative frame from all hand gesture images between the action start and end time-point of the specific HRI hand gesture action with certain classification label.
Extraction of full frames without estimate of the representative frame
Without real-time computation considerations of recognition, full frames of the specific hand gesture action are used for recognition, which is a simple and direct approach. This approach, without calculations of representative frames, will use all n gesture action frames of the specific hand gesture action to make one template match computation, that is,
The centroid representative frame estimate
The estimate of the centroid frame that is set as the representative frame for recognition calculations is a simple averaged determination among all n gesture action frames of the specific hand gesture action. Equation (16) details the estimate of the centroid representative frame as follows:
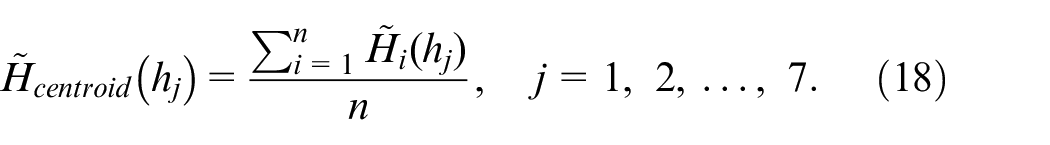
Compared with extraction of complete n frames for recognition, the centroid representative frame estimate approach employs only one estimated centroid frame derived from equation (18) for recognition.
The middle representative frame estimate
When performing a specific HRI hand gesture action in a certain continuous-time period, the most significant frames inside the gesture action will be located around the middle frame. This is because the beginning and finishing segments of each specific hand gesture action are similar to each other. The main action data that can be used to distinguish each different gesture action will be concentrated on the neighbored region of the middle frame. Equations (19) and (20) show the determination of the middle representative frame.
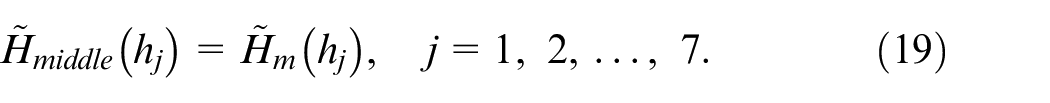

Note that, in the situation where all n frames are acquired in the specific hand gesture action, the middle frame value can be derived from equation (20). Similarly, with the centroid representative frame estimate, the middle representative frame estimate is also a computationally-rapid approach, with only one estimated middle frame for template match recognition.
The representative frame estimate by middle-region voting
The approach of middle-region voting is designed to facilitate voting among various different action classification labels on recognition determination using the hand gesture frame region of
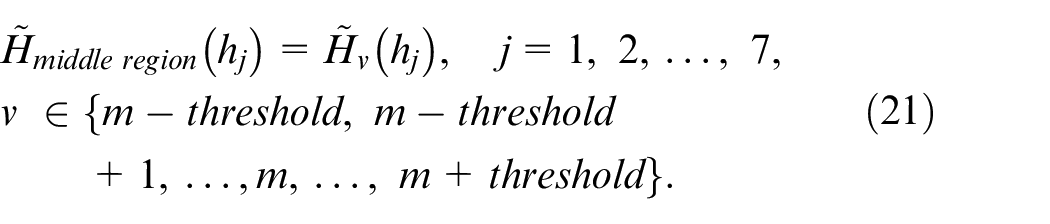
Compared with the middle representative frame estimate approach, the middle-region voting scheme will inevitably have a slightly higher computation cost due to more action frames considered for recognition evaluations. However, by accumulating more recognition decisions of template match, each of which is separately made by one of these frames in the middle-region, the recognition result of the constructed HRI hand gesture action classification system will be much more reliable.
Experiments and results
Experiments on the presented smart material-handling robot operation system with HRI designs of depth sensor-based hand gesture communication are made in an environment of the laboratory office. Related experiment settings, the established hand gesture database for performance evaluations of the developed system, and experimental results will be detailed in the following sections.
Experimental settings and establishments of the HRI hand gesture action database
In order to make it so that the constructed material-handling robot with HRI operations of hand gesture communication is able to be practically used in real-life applications, the Microsoft Windows OS with the coding environments of Visual Studio C++ is used as the system development platform. The Kinect device with Kinect software development kit version-1.8.0, employed for acquiring depth gray images of hand gesture actions, is properly deployed in the laboratory office. When capturing hand gesture actions, the sampling rate of the Kinect device is set at 30 Hz. A tilt angle of 21° is set for Kinect. In addition, the distance between Kinect and the ground is approximately 1.2 meters, while the distance between Kinect and the hand gesture-making user is set in the region of 0.7–1.2 m.
In the selection of material-handling robot devices, the “Robotis Bioloid” robot, manufactured by the Robotis company in Korea, is adopted. 47 The Bioloid robot, belonging to the humanoid robot type, has a total of 18 modular servomechanisms, that is, 18 degrees of freedom (DOF), each of which represents one robot joint and is made by an AI motor called a “Dynamixel.” In addition, three types of mechanical robot designs, to denote different function complexities, namely Type-A, Type-B, and Type-C, are contained in the Bioloid-series robot device, and this work uses the class of Type-A Bioloid for hand gesture communication HRI system developments. In addition, through motion editors of the RoBoPlus software, 48 each of the different robot operation actions denoted by the corresponding hand gesture action can be implemented on the Bioloid humanoid robot. Note that the adopted robot for material handling in this study is specifically equipped with the wireless Bluetooth module 47 so that command-based HRI applications will be easy to be constructed. In this work, for achieving efficient gesture command communication via Bluetooth, only the index value (numbered 1–6) of gesture actions is “sent” to the robot device (from the Bluetooth transmitter in the computer with developed depth sensor-based hand gesture recognition applications to the Bluetooth receiver in the Bioloid robot device). When the robot “receives” the action command index, according to the indication of this received index, the specific robot operation action with the corresponding number (finely regulated by the RoBoPlus motion editor, as mentioned) is then triggered and performed.
For HRI hand gesture action collections, there are a total of six different hand gesture actions to be designed for remotely operating the behavior of the material-handling robot. If these six designed hand gesture actions are implemented in the proper order, the robot will complete an object handling task, picking up the indicated object in the initial location, walking (i.e. handling and moving), and finally putting the object down in the destination location. In this work, these six hand gesture actions for robot operations are “Forward,”“Left,”“Right,”“Whirl,”“Pick,” and “Open,” to represent the robot actions of “robot goes forward,”“robot turns left,”“robot turns right,”“robot makes whirl,”“robot picks up the indicated target object,” and “robot opens both arms to put down the target object,” respectively. The rationale behind such hand gesture action designs is that standard hand gestures to denote 26 English letters (A–Z) are finely defined in the dictionary of American sign language (ASL). 49 Six different ASL-based hand gesture actions, which represent the six English letters of “F,”“L,”“R,”“W,”“P,” and “O,” are therefore designed for representing “Forward,”“Left,”“Right,”“Whirl,”“Pick,” and “Open,” respectively. Table 1 shows the six designed ASL-based hand gesture actions and the robot action behavior after receiving the recognized hand gesture communication. In the part of ASL-based hand gesture action collection, two different databases of “F,”“L,”“R,”“W,”“P,” and “O” actions are established; one is established by only static hand poses, and the other is built up using continuous-time hand gestures. The database of static hand poses is used for comparative evaluations of six different kinds of ASL-alphabet hand pose recognition, and the collected continuous-time hand gesture database is employed in the real robot action operation, where start and end time-point determination and representative frame estimate of the significant HRI hand gesture action, as mentioned before, will be considered. A total of 300 hand poses are contained in the database of static hand poses – 50 acquired for each of “F,”“L,”“R,”“W,”“P,” and “O.” In the part of the continuous-time robot operation hand gesture action database, there are a total of 120 gesture actions collected – 20 obtained for each of these six different indicated ASL alphabet gestures. As mentioned, the hand pose “open the hand fully” is employed as the mark to denote the start and end time-points of the required HRI hand gesture action. In the aspect of collection of the data of timestamp-marked hand poses, in order to thoroughly evaluate the performances of the presented fingertip detection method, two different categorizations of hand pose data are taken into account, namely hand poses with different fingertip numbers and hand poses of opening the hand with different degrees of openness. In establishments of the database of hand poses with different fingertip numbers, hand pose data with one, two, three, four, and five fingertips is collected, which can be seen in Table 2. For hand poses with five different types of fingertip numbers, a total of 250 hand poses are acquired (50 obtained for each of these five different hand pose types). In data collection for hand poses of opening the hand with different openness degrees, three types of open hand poses, namely “slightly open,”“half open,” and “totally open,” are considered, where 50 hand poses are collected for each of these three different types (see Table 3).
The designed six different ASL-based hand gesture actions, each of which denotes the specific robot action operation for completing a specific task of object handling.

Database establishments by collecting hand pose data with different fingertip numbers.

Database establishments by collecting hand pose data with different degrees of open hand (the action “open hand” used to denote start and end time-points of the specific HRI action with certain classification label; also see Table 6, effects of different degrees of open hand on performances of Douglas–Peucker fingertip detection).
Experimental results
Performance evaluation works on the proposed human robot interaction system with depth sensor-based hand gesture communication for smart material-handling robot operations include recognition performance evaluations of static poses of ASL-hand gesture actions, recognition performance comparisons of hand detection using different fingertip numbers, recognition accuracy measurements of hand poses with different open hand degrees, and recognition rate comparisons of four estimation approaches to derive the representative frame of the acquired specific HRI hand gesture action.
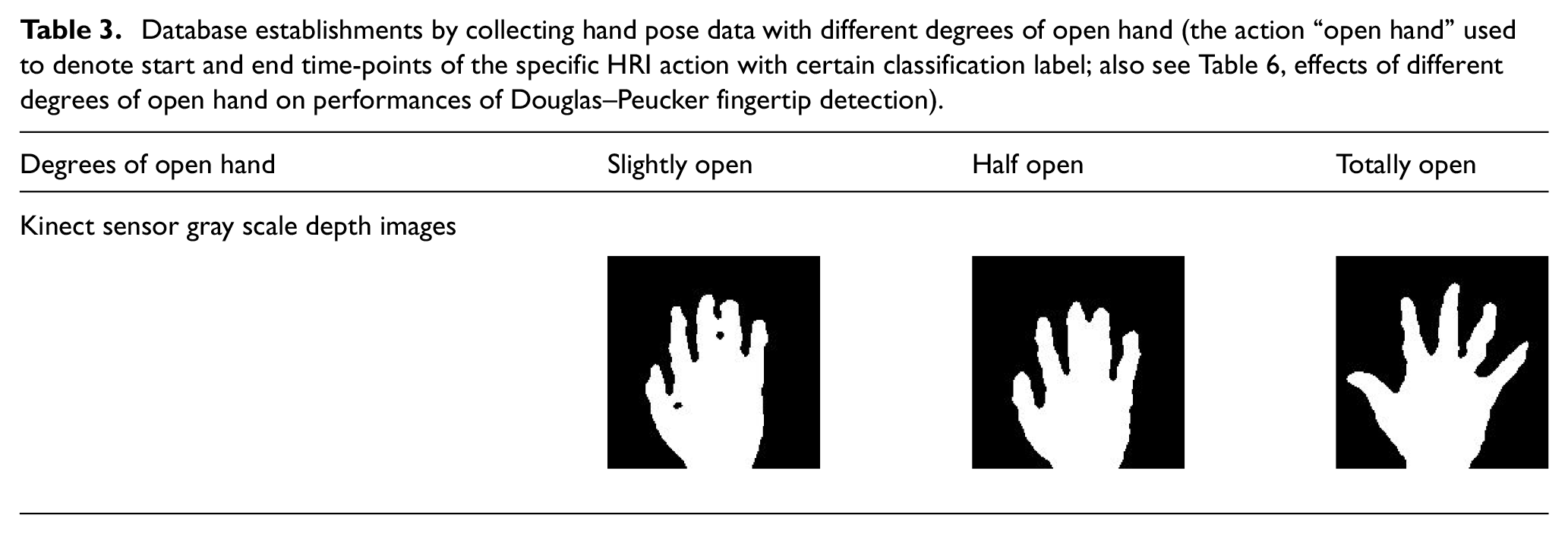
In the recognition experiment, in order to classify static poses of ASL hand gesture actions, six different static poses, representing the English letters of “F,”“L,”“R,”“W,”“P,” and “O,” are compared via pre-processing of the hand data (see Section 2.1), feature extraction of HU moment invariants, and then template match calculations (see Section 2.2). Table 4 lists the recognition performance of these six different static poses of ASL hand gesture actions. As observed from Table 4, each of these “F,”“L,”“R,”“W,”“P,” and “O,” static hand poses has satisfactory performance. The three static hand poses of “F,”“R,” and “W” achieve complete recognition (i.e. recognition accuracy of 100%). The average recognition rate of these six static ASL hand poses is 97%. Without consideration of continuous-time hand gesture HRI operations on robot control, static ASL hand poses of six English letters can almost be categorized completely.
Recognition performances of six different static poses of ASL-hand gesture actions.
In the part of smart material-handling robot control by continuous-time HRI hand gesture communication, as mentioned previously, technique issues of start and end time-point determination for image acquisitions of the specific hand gesture robot operation action (see Section 2.3.1) and the representative frame estimate to represent the acquired robot operation action (see Section 2.3.2) are additionally required to be taken into account. For start and end time-point determination, hand pose recognition of “open the hand fully” by the presented fingertip detection scheme is used. Table 5 lists the recognition rate comparison results of five different hand pose detection situations, that is, the hand pose with one to five fingers (see Table 2). It can be clearly seen in Table 5 that the condition of the hand pose with completely five fingers has an excellent performance when it comes to hand detection, achieving recognition accuracy of 98%. The average recognition accuracy of hand detection among these five different fingertip numbers is 96%. Note that, in Table 5, although the situation of the hand pose with one or two fingertips has the best hand detection performance (perfect 100%), with the concern of easy memorization and specific robot operation action continuousness, the hand pose “open the hand fully” with five complete fingertips is still chosen as the reminder action to denote the switch start or end of the HRI hand gesture robot operation action. Table 6 illustrates the recognition accuracy comparison of three hand poses with different degrees of open hand (also see Table 3). As can be seen in Table 6, in all conditions, presented hand detection performs best in the totally open type of open hand action, achieving a satisfactory 98%. The slightly open type of hand pose will be the most disadvantageous when it comes to hand detection, with only an uncompetitive 16% achieved.
Recognition rate comparisons of five hand poses with different fingertip numbers.

Recognition accuracy of three hand poses with different degrees of the open hand gesture.

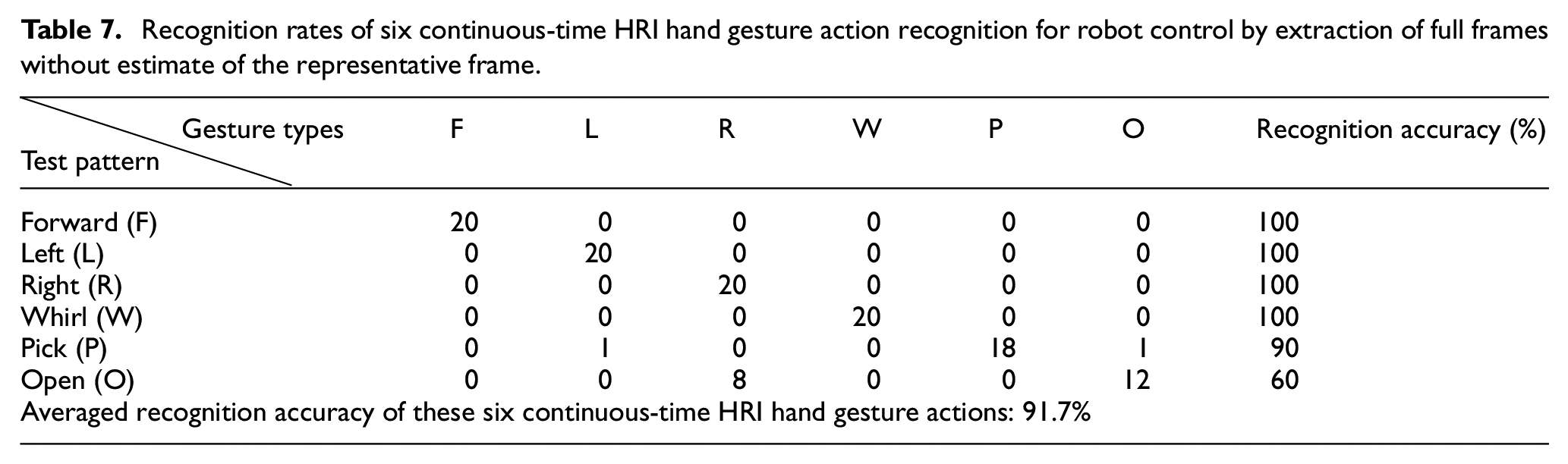
Tables 7 to 10 show the recognition performance results of six continuous-time HRI robot operation hand gesture actions by extraction of full frames without estimate of the representative frame, the centroid representative frame estimate, the middle representative frame estimate, and the representative frame estimate by middle-region voting, respectively. Among all these approaches, without consideration of the representative frame estimate, full frames of the continuous-time HRI hand gesture action employed for recognition have the highest average recognition rate, achieving 91.7%, as can be seen in Table 7. For presented representative frame estimate approaches on continuous-time HRI hand gesture action recognition, the representative frame estimate by middle-region voting is apparently the best method, reaching an average recognition accuracy of 90.8% (see Table 10); the middle representative frame estimate method, with an average recognition rate of 86.7%, follows (see Table 9). The centroid representative frame estimate approach performs worst on classifications of these six continuous-time HRI hand gesture actions, attaining only 62.5% (see Table 8). Note that, from the viewpoint of simultaneous considerations on both recognition accuracy and real-time computation, the presented representative frame estimate by middle-region voting will be the most competitive approach to be used in the practical application of hand gesture communication-based human–robot interaction.
Recognition rates of six continuous-time HRI hand gesture action recognition for robot control by extraction of full frames without estimate of the representative frame.
Recognition rates of six continuous-time HRI hand gesture action recognition for robot control by the centroid representative frame estimate.
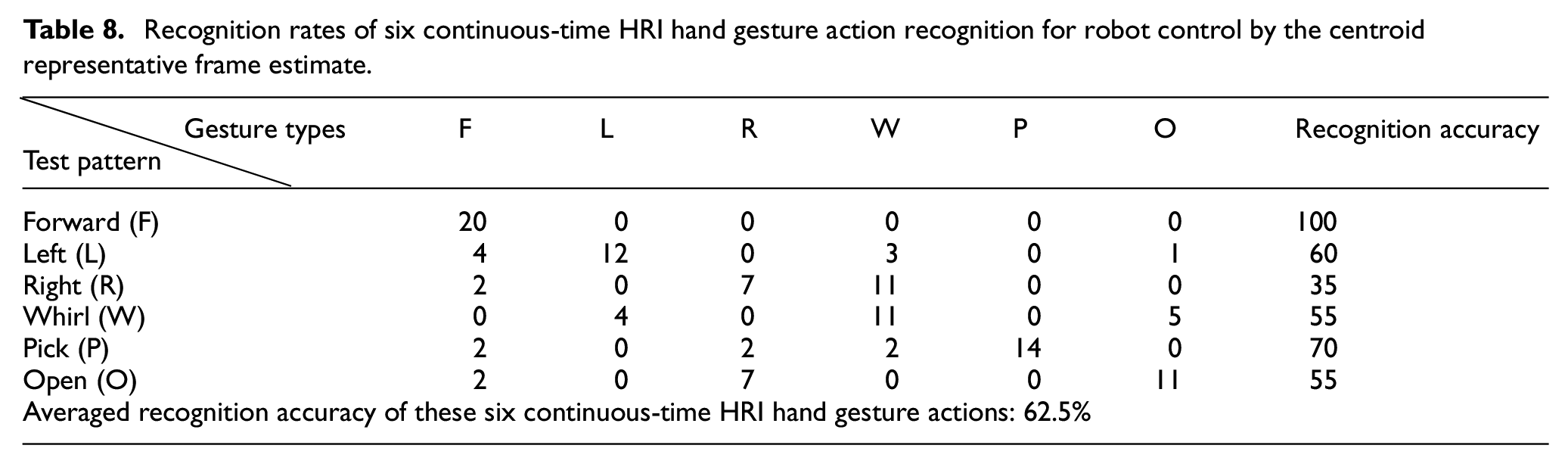
Recognition rates of six continuous-time HRI hand gesture action recognition for robot control by the middle representative frame estimate.
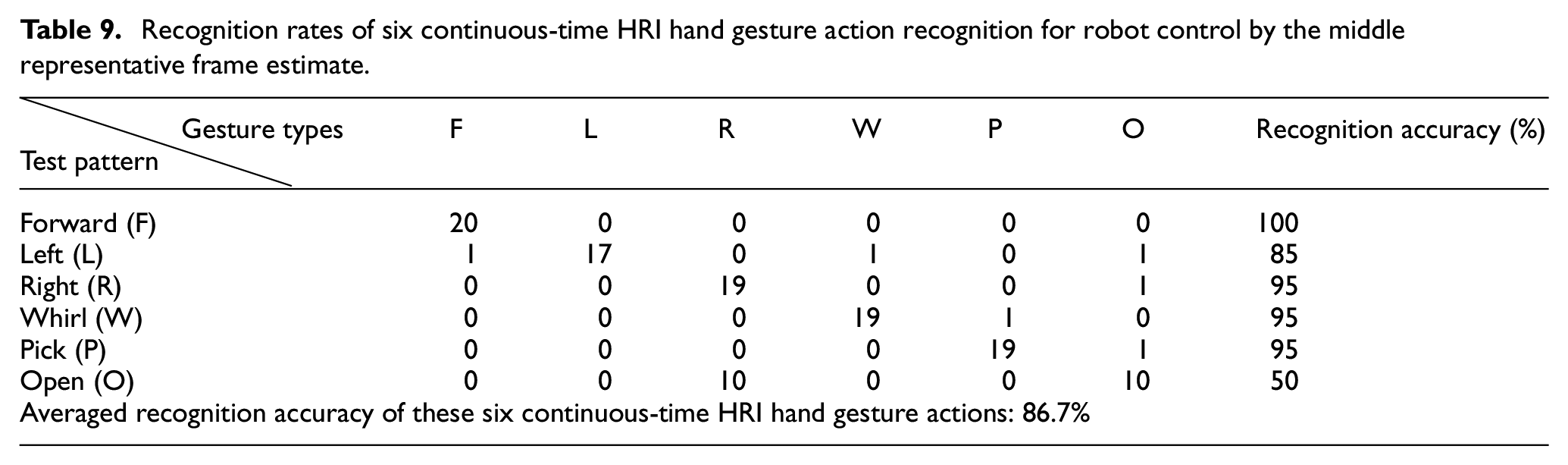
Recognition rates of six continuous-time HRI hand gesture action recognition for robot control using the representative frame estimate by middle-region voting.
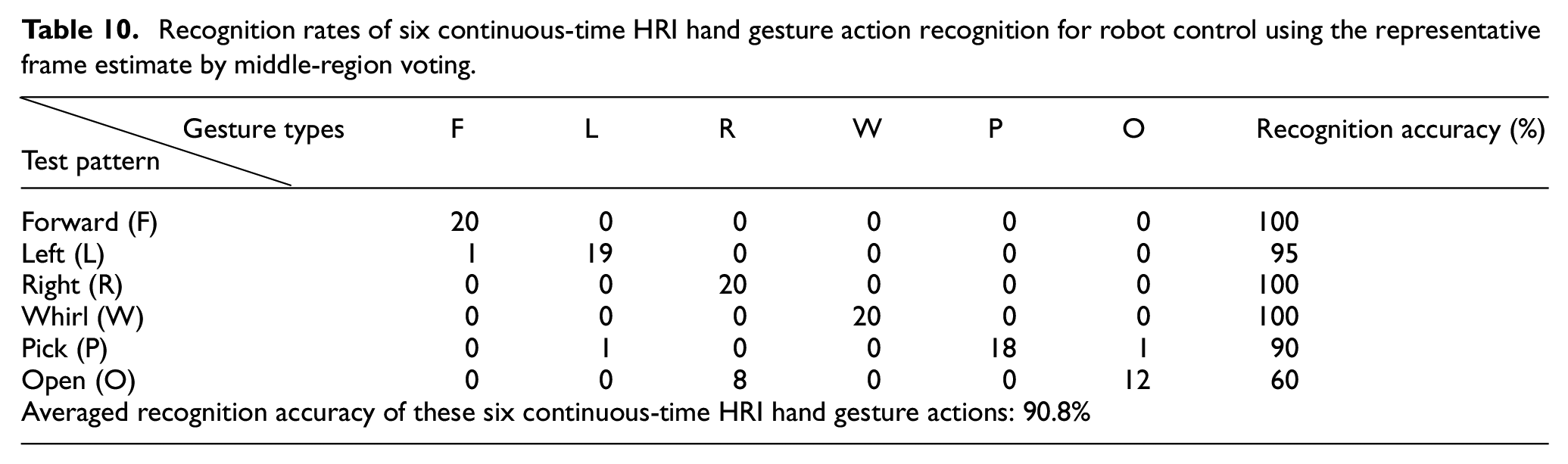
As observed from all of the above-mentioned experiment results compiled in this work, a primary remark can be made in relation to three different aspects, which are (1) performance comparisons between static (see Table 4) and various kinds of dynamic hand gesture action recognition (Tables 7–10), (2) performance analysis of presented fingertip detection for providing system wake-up reminders on appearances of a significant dynamic hand gesture action (Tables 5 and 6), and (3) recognition accuracy comparisons of continuous-time dynamic hand gesture action recognition by only extracting full frames (Table 7) and three representative frame estimate approaches (Tables 8–10).
Static hand gesture recognition performs better than dynamic hand gesture action when it comes to recognition performances due to the fact that only the unique gesture frame is determined, without consideration of these issues of context sensitivity and performances of system wake-up reminders in dynamic hand gesture action recognition. However, regarding the practical issue of continuous-time interactions with the material-handling robot in this study, dynamic hand gesture action recognition with relatively better cognition will be more feasible.
The hand pose with one or two fingertips can be verified in perfect recognition, achieving 100% on accuracy; however, these two hand poses will be very ambiguous compared with other popular hand gesture actions employed in the assembly line (e.g. the quality of materials made by the hand gesture-making inspection operator). With consideration of both detection performances and practical applications of material-handling robot operations, the hand pose with five fingertips (i.e. “open the hand fully”), achieving a competitive 98% on accuracy, will inevitably be a fine choice.
Recognition by extraction of full frames without estimate of the representative frame exhibits the best recognition performance (reaching 91.7%) when it comes to continuous-time dynamic hand gesture recognition. However, the use of full frames of a hand gesture action for recognition will bring with it much greater computation costs, which largely reduces the performance of real-time responses of the recognition system and is not proper for automotive manufacturing applications. Taking into consideration both real-time computation and high recognition accuracy, the representative frame estimate by middle-region voting (achieving a competitive 90.8%) will probably be a more appropriate approach for performing hand gesture communication with the material-handling robot in a smart factory.
Discussions
In this study, the Microsoft Kinect device with the depth sensor is employed for developing depth sensor-based hand gesture recognition. For the specification of the Kinect sensor device, the maximum distance needed to be able to capture depth images is 4 m, and such a specification is essentially effective in many practical applications, including the assembly line, where hand gesture recognition is used to create interactions with the collaborative robot. Besides the Kinect device, there are other types of depth sensors which can be used to develop the hand gesture recognition presented in this work, such as the well-known Intel real-sensor depth sensor. No matter which type of depth sensor is used, the setting of 1 m distance between the hand and the depth sensor will be general and appropriate for most applications of the smart assembly line with collaborative robots24–34 (also see Figures 1–3). In these applications of automotive manufacturing,24–34 the operator who uses hand gesture communication to achieve cooperation with the collaborative robot is generally located in a fixed location (sitting or standing near the deployed depth sensor without frequent movements), and therefore the sensitive factor of the image sensing distance between the operator and the depth sensor can be effectively regulated, thus meaning that fine recognition performances are maintained.
With regard to the aspect of handling robot operations by wireless communication, this work uses the BT wireless transmissions for sending the intention label of the hand gesture action to the robot. Due to the fine property of peer-to-peer connections of BT, the specified handling robot matched with the developed hand gesture recognition system can always obtain fine regulations without interferences from other robots or related devices. Recently, works on the utilization of a group with numerous collaborative robots to complete a specific task have been explored. When presented hand gesture recognition is employed in the scenario of operations of multiple handling robots, the Wi-Fi-wireless transmission will be alternative, in order to establish the master-client operation scheme.
In this work, focused on the developments of dynamic hand gesture recognition, designs of indicated actions on operations of the handling robot are based on the dictionary of ASL. Recently, studies on ASL-based recognition have been seen.50,51 Most ASL-based recognition works aim to develop the recognition calculation model, such as through the design of a deep learning model by 3D CNN in Sharma and Kumar 50 and the establishment of the statistical model HMM in Starner and Pentland 51 ; moreover, a translation scheme for communication between the specific disabled group and the normal group is the main purpose of these presented ASL recognition systems. ASL recognition has also been seen to be employed in robot interaction applications.52,53 Most of these studies concerning human–robot interaction by ASL recognition use just classifications of various static ASL hand poses without consideration of context-dependency, which are apparently different to the continuous-time dynamic hand gesture recognition developed in this paper. On the other hand, with regard to the issue of ease of system utilizations, ASL may perhaps not finally be accepted by all people. Some people (or operators in the assembly line) are not familiar with ASL and will cause additional loading because of having to learn operated hand gestures. In reference to this problem, the dictionary of hand gestures cannot be designed completely according to the standard ASL dictionary. For example, without consideration of ASL finger-spelling, the letter “S,” denoting “Stop movements,” can be designed as the action of “making a fist,” which will be easy to understand without exhausting memorization. It is also noted that the indicated gesture action “Open,” operated according to the symbol “O” defined in the ASL dictionary, does not have ideal performance when it comes to recognition accuracy (see Tables 7–10), with the symbol “O” often being recognized as “R,” due to similar actions on these two symbols. This classification error phenomenon of ASL-based recognition has been a challenging issue, which can be significantly alleviated via an action design without completely following the ASL definition.
Finally, regarding the issue of the interaction latency (the system response) between the human and the handling robot, the time duration of each recognized hand gesture action for operating the robot will be extremely small and will not cause great loading on real-time responses. In this work, as mentioned previously, three different representative frame estimate approaches are designed in order to extract only a few significant gesture frames from a hand gesture action with full gesture frames to make calculations of template match. Assuming that a dynamic hand gesture action is operated in durations of 2 s, a total of 60 depth images in this action will be obtained from the Kinect depth sensor (with a general specification of the frame rate of 30 in Kinect). In this case, for each of the representative frame estimate approaches presented in this study, the derived frame numbers to represent this gesture action will become very small, restricted to a size of around only 10 (millisecond levels or much less on recognition). Furthermore, each frame extracts only seven parameters of Hu invariant moments for further calculations of template match (features with much more than seven parameters are employed in the current 3D image sensor-based hand gesture tasks). Unlike all frames utilizations without estimates of representative frames or other model-based recognition approaches, calculations made using the presented approach with template match of five classification labels will achieve great competitiveness in terms of computations cost. On the other hand, although the typical approach of robot control via an operational joystick (or panel) has also been frequently seen to be used in the factory, such an approach will perhaps be inconvenient and encounter many limitations in a scenario of task “collaborative handling” carried out by both the operator and the robot. As can be seen in Figure 19, when the operator makes a specific hand gesture action to take over the material from the robot or handle the material with the robot in a cooperation mode, traditional methods of joystick or panel control will not be carried out smoothly. Advanced hand gesture recognition with collaborative HRI will be explored in future work.
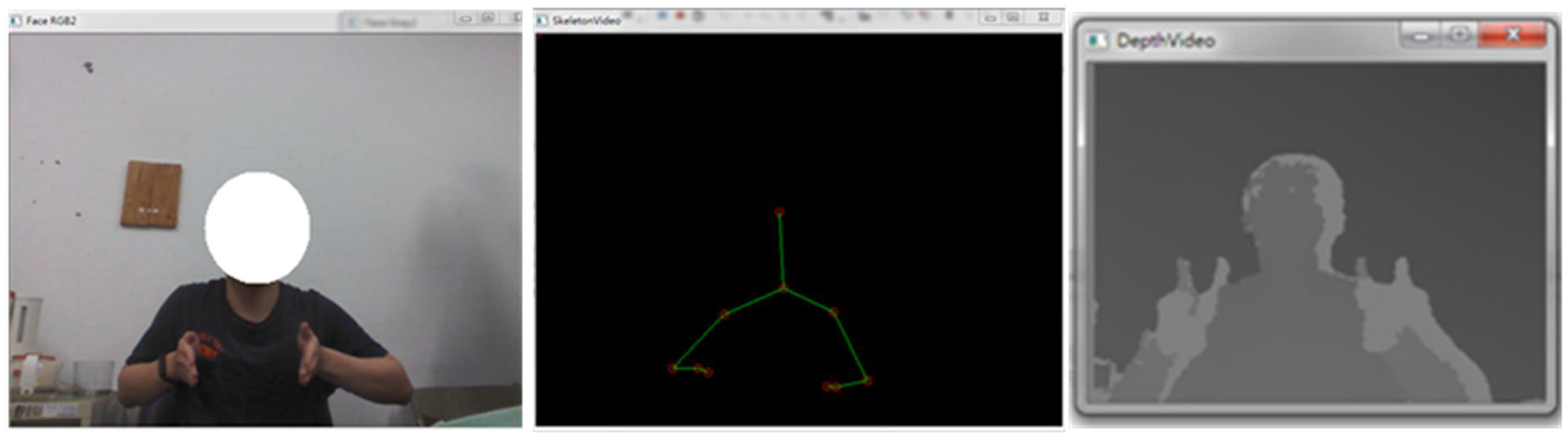
A collaborative operator-robot way to complete a material handling task cooperatively using hand gesture communication to interact with the material handling robot in the future works.
Conclusions
This work develops a smart human–robot interaction scheme by depth sensor-based hand gesture communication for continuous-time material-handling robot operations. The Kinect depth sensor-based hand gesture recognition system is presented for achieving smart remote robot control via recognized hand gesture action. In order to achieve the goal of performing continuous-time robot operations with efficiency and effectiveness, this paper also investigates detection of start and end time-points of each different type of hand gesture action and the representative frame estimate of the hand gesture action with multiple gesture frames. The presented smart material-handling robot control via hand gesture communication is very competitive when it comes to real-time recognition and human–robot interaction.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is partially supported by the Ministry of Science and Technology (MOST) in Taiwan under Grant MOST 109-2221-E-150-034-MY2.