
Abstract
Cellular manufacturing is a prevailing pursuit in increasing productivity and throughput and in reducing setup and lead time in production systems that are configured as clusters of machines or facilities. Although several approaches exist today to optimize the quality of cluster, they are cumbersome in terms of implementation due to high complexity and resource requirements. In this work, these issues are addressed effectively using a novel two-stage approach which integrates centre ordering of vectors on ring and an agglomerative hierarchical clustering. The centre ordering of vectors on ring–agglomerative hierarchical clustering approach is much simpler and quicker to grasp and implement in a resource-constraint environment. Problem sets retrieved from the existing literature are put to experimentation for optimality and are compared to study improvements using grouping efficacy. The proposed method has yielded significant improvement, as found from the experimental results, over earlier reported ones. This establishes the centre ordering of vectors on ring–agglomerative hierarchical clustering algorithm as an efficient approach for clustering. Furthermore, the number of iterations required to reach optimality is significantly lesser, compared to the ones obtained through existing approaches based on mathematical models and heuristics.
Keywords
Introduction
Cellular manufacturing system (CMS) is a manufacturing facility disposition designed based on the group technology (GT) approach where parts requiring similar processes are grouped into part families and the processing machines are assigned to machine cells where these part families are allocated for processing. Thus, a cell consists of dissimilar machines where a part undergoes several different processes according to the required technological sequence that warrants work-skill or people to manufacture similar products in shorter lower lead times and low work-in-process inventory (WIP), setup times and workforce. 1 However, simultaneous grouping of machines and parts into cells was studied by Srinivasan et al. 2 CMS persists as the ideal approach for organizing the manufacturing system of a company for moderate volume and variety parts. 3
A lot of work has been reported, during the past few decades, on CMS research, whereupon broad summaries and taxonomies of work dedicated to machine–part cell formation (CF) problem were studied by Kusiak 4 and Wemmerlöv and Hyer. 5 The methods of CF can be classified as design-oriented or production-oriented. In design-oriented methods, the CF takes place based on similar design features, for example, classification and coding. The production-oriented approaches involve the similarity of processing and have been further categorized into cluster analysis, graph partitioning, mathematical programming, artificial intelligence (AI)-based approaches and heuristics based on its resolutions. An optimal number of cells are determined heuristically on the basis of total inter-cell movements following the machine sequence.
A wide variety of approaches, such as mathematical programming,6,7 graph theory, 8 neural networks, 9 genetic algorithms,7,10 simulated annealing 11 and water flow–like algorithm, 12 have been reported in the literature to optimize various CF problems. The machine–part grouping problem is non-polynomial (NP) complete, and genetic algorithm (GA) has been successfully applied to minimize the total intercellular and intracellular part movement. A genetic imperialist competitive algorithm is shown to have performed successfully while applying on hypothetical numerical cellular manufacturing example data sets with different input parameters and also by a real-world case study gleaned from a glass mould company. 13 A hybrid formation solution involving six cells with several comparative scenarios have been applied, in the semiconductor manufacturing setting, using heuristic approach. 14 GA optimizer, greedy search and simulated annealing methods were applied for changing the machine facilities orientation for achieving maximum space utilization, minimizing the material handling cost related to normal and breakdown periods. A two-phase GA approach is applied to generate CF solution to minimize energy consumption and makespan from the generated independent cells. 15 Coextending, CF, operator assignment and inter-cell layout problems have been solved using a mathematical model to achieve minimum inter–intra cell transfer, machine relocation cost and problems related to operator hiring, layoff, training and salary costs. 16 A visual hierarchical clustering (HC) approach using growing hierarchical self-organizing map has been applied to solve CF problems. 17 The results of some test problems have been verified after applying an integrative combination algorithm and a heuristic algorithm. 6 A comparison has been made between the efficiency and efficacy (clustering) parameters of the CF solution obtained through firefly meta-heuristic algorithm applied on several benchmarked problems. 18 It has been reported, out of the comparative analysis, that the application of efficacy parameter is desirable if the reliance is on clustering, although the application of efficiency parameter can also lead to beneficial and economical layouts at the cost of inadvertence of cell clustering.
Most of the heuristics associated with manufacturing CF have few major disadvantages: they are unable to solve problems with considerable number of parameters as applicable in real-life conditions in reasonable computational time, and they settle for the part family formation and cell grouping problems separately. It has been observed, based on the extensive literature review, that the quality of CF can further be improved.
This work endeavours to achieve optimal CF solution through development of a new approach, namely, centre ordering of vectors on ring (COVR) and integrating it with a well-known technique called agglomerative hierarchical clustering (AHC). In the first stage, the input vectors (machines or parts) are represented as points on a plane by the COVR algorithm. In the second stage, the AHC technique is deployed in grouping these representations (points) into clusters. The principle objective is that all parts in a part family are processed in the same cell precluding intercellular transfer 6 while finding the CFs which are diagonal blocks formed from part–machine incidence matrix (PMIM). This helps to identify the machine cells and part families. The sequential centre ordering of vectors on ring–agglomerative hierarchical clustering (COVR-AHC) approach yields diagonal block formation by similarly allocating part families to machine cells. COVR-AHC is evaluated for 23 benchmarked CF problems, and the results are compared using grouping efficacy, a measure of goodness of cluster quality, proposed by Suresh Kumar and Chandrasekharan. 19
Thus, the contribution of this work is twofold. First, we propose a novel COVR-AHC to optimize CF quality in a resource-constraint scenario. Second, we compare the efficiency and robustness of COVR-AHC in achieving the optimal clustering solution for benchmarked CF problems retrieved from the literature.
The later sections of the article are structured as follows. Section ‘Proposed two-stage algorithm: state of the art and goals’ introduces the developed algorithm, COVR, and its integration with AHC. This section also typifies the performance measurement metric. Section ‘Research problem’ provides a detailed numerical explanation using problem data. Results obtained from COVR-AHC are compared with other benchmark solutions and are presented in section ‘Result and discussion’. Conclusion and future scope of research are summarized in section ‘Conclusion and future study’.
Proposed two-stage algorithm: state of the art and goals
The proposed method consists of two major steps, namely, COVR, which is developed to represent any vector, representing parts or machines, on a two-dimensional (2D) plane, and conjoining with an AHC which we have modified to group these vectors. Following is a brief overview of the proposed algorithm which is elaborated in the ensuing sections.
The initial input to CF problem is a binary PMIM,
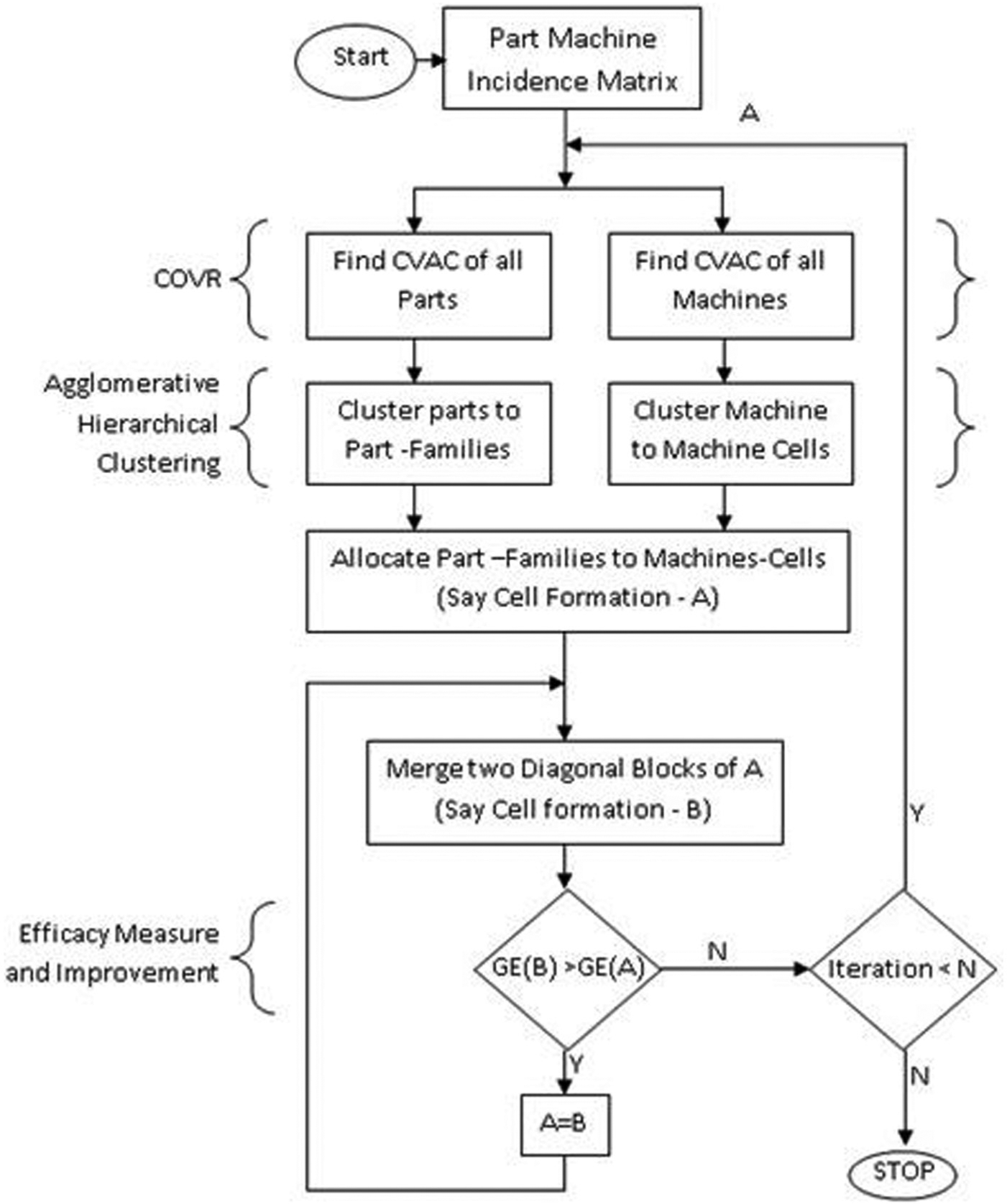
Workflow of the proposed two-stage cell formation algorithm.
COVR
COVR is a simple technique that is developed to represent any vector from higher dimension to lower dimension, on a 2D plane to be specific. This is achieved using its attributes or properties.
COVR consists of three operators – namely, Representation (R), Centre Ordering (C) and Expansion (E). These operators are used sequentially (R-C-E). However, in some cases, expansion may not be used. Using COVR, the vectors, representing parts or machines, to be grouped are positioned as centre of vector attribute circles (CVACs) inside the ring, which is also shown in Figure 1. In the second stage (as given in section ‘Modified AHC’), modified AHC clusters the CVACs into groups. COVR is illustrated in the following subsections in detail.
Representation of attributes on ring
Each row element defined as attributes, in grouping machines into cells, regarded as the interactions with parts, is represented in ring formation termed as vector attribute circle (VAC). This is used to map vector proximity for belongingness to a group. But only certain attributes stimulate vector belongingness. These attributes are active ones (i.e. =1 in PMIM). Based on cumulative stimuli of all attributes, the vectors are represented on the plane, to be grouped later. Therefore, the attributes affect the key decision with regard to belongingness of a vector to a group. It is cognizable that the maximum number of clusters which can be formed is dependent on the number of attributes.
The diameter of the ring is conceptualized to be composed of 100 units for convenience in the estimation of proportional term. Each attribute is equally spaced on the ring. The allocation of attributes for all vectors (machines) on the ring can either be clockwise or anticlockwise but never both in the same iteration. Similarly, to group parts into families, the column elements for each vector (part) are represented on the ring, that is, on VAC.
Centre ordering of CVACs
Now, the task is to compute centre of VAC
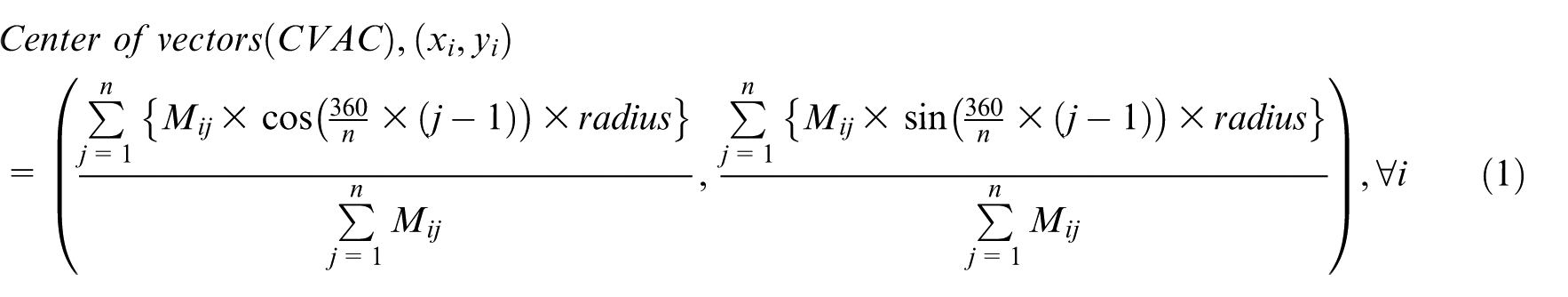
Expansion of CVACs
It is observed that for some problem matrices, CVACs are too close to form good clusters. However, if the CVACs are expanded, then better clustering could be attained. In some experiments, CVACs are expanded keeping the origin (0, 0) as centre of expansion. An appropriate value of expansion coefficient is chosen in order to achieve good clustering which is given in equation (2). This is shown in CF solution from the problem matrix (data set 1 of Table 7). It is not always, however, that CVACs will group differently on expansion. Only few data sets as shown in Table 8 require expansion where vectors have almost similar string of attributes. It is to be noted that expansion alters proximities. Thus, it is also useful when the solution does not improve over copious iterations
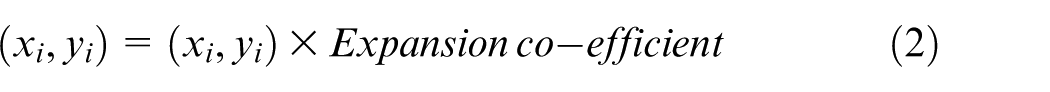
The value of expansion coefficient used is always greater than 1. However, in problem sets where expansion coefficient is not used, a ‘damp’ may be used. A ‘damp’ is a value which is the inverse of expansion coefficient, whose value is less than 1. When expansion coefficient pushes the CVACs away from origin, the damp brings the CVAC closer towards the origin. In this experiment, the minimum value of damp taken is
Modified AHC
HC uses similarities or proximities among objects, 20 obtained as measurement to classify them into homogeneous groups. Davidson and Ravi 21 in 2005 discussed AHC as a technique to improve cluster quality and reduce exceptional elements.
In this work, AHC is integrated with COVR. Prior to integration, AHC has been modified in order to accommodate COVR for grouping

The binding here is that each part must be allocated to a part family. Recursively, it implies each part family contains at least one part in the family and no part remains unallocated. The same is considered while grouping machines into machines cells. It is to be noted that this technique could produce large number of clusters (which later be merged if required).
The AHC process continues until a terminating condition is satisfied. The condition could be (1) maximum or minimum number of clusters, (2) distance threshold, (3) maximum number of members in each cluster, (4) number of iterations and (5) execution time. Here, we have used number of iterations (4) as the upper bound for optimization.
Allocation of part families to machine cells
Modified AHC groups parts into families, say
The adopted method is derived from grouping efficacy proposed by Suresh Kumar and Chandrasekharan
19
which is popular for cluster quality measurement and provided in equation (8). Comparative efficacy value, (CEV),


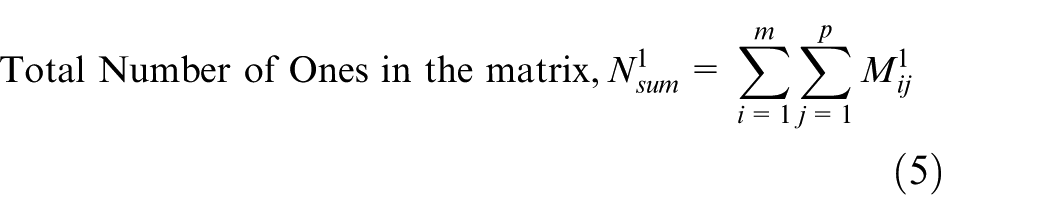

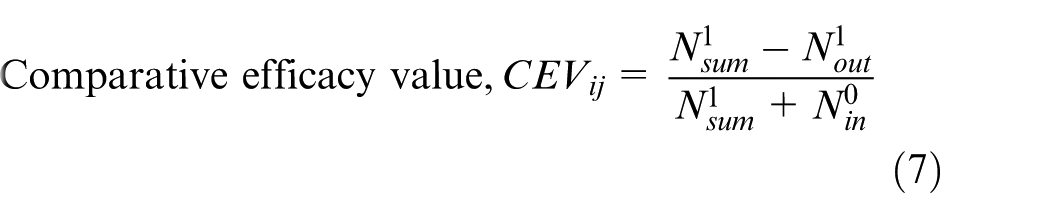
The condition is that each part family must be allocated to at least one machine cell as discussed in section ‘Allocation of part families to machine cells’. After allocation of part families to machine cells, the diagonal cell blocks are obtained. Through this, the quality of the cells (goodness of clustering) is measured using grouping efficacy.
Merging
Part family j allocated to machine cell i to form primary diagonal CF and the corresponding grouping efficacy is computed. Remaining CEVs are considered for merging, and two cells having the highest CEV merge together, as computed. Similar process is adopted for allocation. If the newly formed cell has higher efficacy, then it is saved; otherwise, previous solution is retained to continue to the next iterations.
Performance measure
The quality of cluster formed reflects the performance of a CMS. It can be evaluated using three popular metrics such as machine utilization, grouping efficiency and grouping efficacy.22,23 Machine utilization metric highly depends on the frequency of utilization of machines in the cell and a grouping efficiency has low discriminating capability, which means the inability to distinguish good clustering from bad. Both are unsuitable candidates to be considered for performance measurement in this work. Instead, we use grouping efficacy from Chandrasekharan and Rajagopalan 22 for measuring CF quality as it overcomes these shortcomings.
Grouping efficacy is the ratio of number of Ones outside (as exceptional elements) and number of Zeros inside the cells (as voids/void elements). To achieve better cluster quality, both exceptional elements and voids must be reduced as much as possible. Therefore, a cluster formation is high on grouping efficacy when the number of voids in the cell gets reduced with the number of exceptional elements outside the cells. However, if the number of void elements and exceptional elements are more, grouping efficacy will be low resulting in poor cluster quality
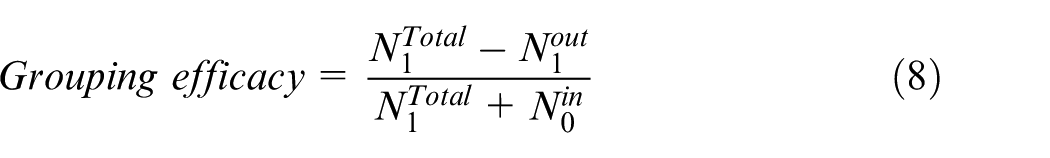
Equation (8) computes grouping efficacy, where
Research problem
Problem description
Our research problem deals with a manufacturing firm attempting to group products with similar design/manufacturing processing to maximize production throughput. Therefore, the main objective is to create machine cell and allocate part families to improve machine intercellular movement.
In order to group machine and parts into cells and families, respectively, similarity of operations is of utmost concern. We pursue our research following the four-stage process of Burbidge 24 from 1975 for clustering. This is discussed briefly below.
In Stage 1, machines are classified based on their type, followed by Stage 2, where part lists are identified that contain essential information on machines assigned for the operations. Stage 3, also known as ‘factory flow analysis’, prepares macro-examination of component flow through machines by forming PMIM. This is vital as it represents which part is processed by which machine. Processing index 1 means true and 0 means false on part–machine interaction. Finally, in Stage 4, parts and machines are grouped using clustering algorithm, COVR-AHC, in this work to achieve cellular groups by forming diagonal block cells.
Our attempt relates to Stage 4, where the grouping of the components is performed based on their similarities. It is a sequential process which is followed for machine and parts in order, which later is assigned one to another. Therefore, we obtain a diagonal block cellular structure that minimizes inter-cell movement and improves machine utilization.
Numerical explanation
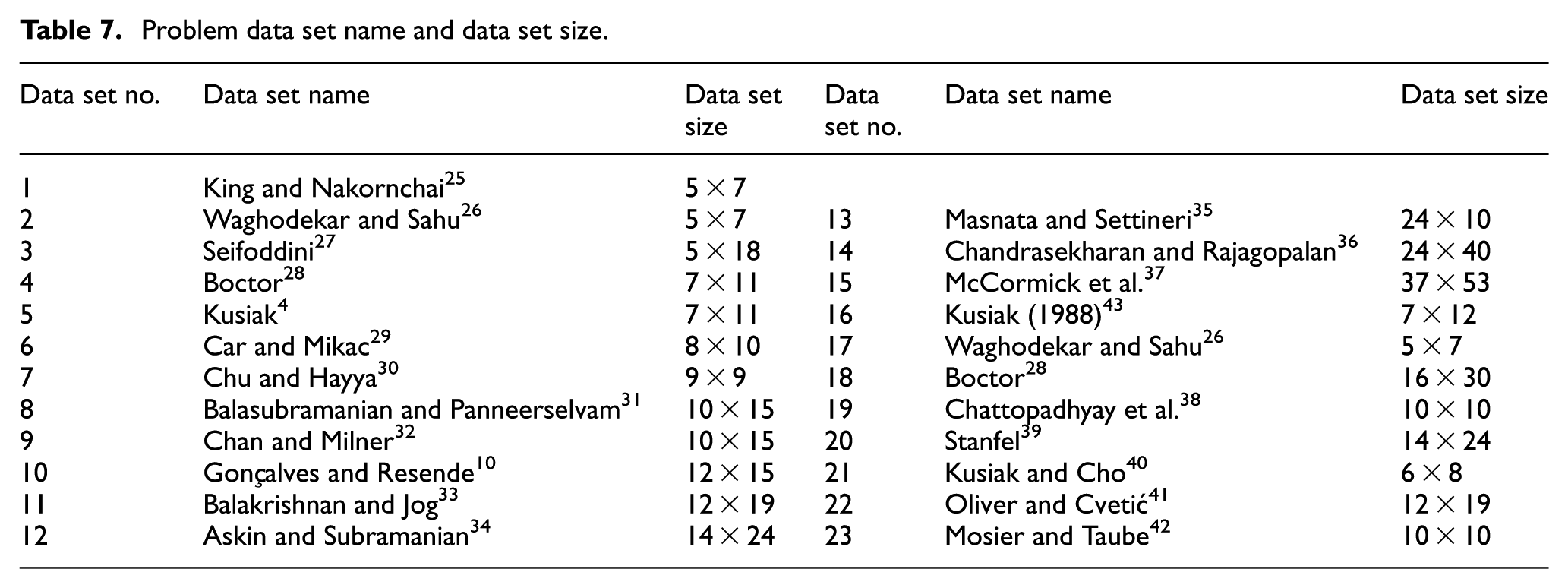
COVR-AHC algorithm which was executed on 23 data sets, collected from various literature works, is given in Table 7. Data set 1 with a dimension of 5 × 7, from Table 7, has been used for validation and numerical illustration. This is chosen due to the fact that the optimality of clustering has been attained in just two iterations.
For data set 1 (Table 7), the grouping of machines to cells and parts to families will be performed in six steps. Each of the operations is illustrated below. These operations will iterate until desired optimal result is obtained with the problem matrix as input to the algorithm to render the output solution as formed cells.
Iteration 1
Step 1. Centre ordering: To find the centres of all vectors for grouping parts into families and machines into cells. CVAC is represented as per equation (1) for both machines (as
Step 2. Expansion: The centre point(s) from previous step undergoes expansion from the origin as given in equation (2). As a result, the relative distance between the centres changes. The expansion, however, is not always necessary, but it is useful when the solution particularly remains unimproved for a given number of iterations. In problem sets where expansion is not used, a damp constant
To graphically demonstrate the mechanism of COVR, that is, the connection between machines/parts and its representation as vectors, data set 1 mentioned in Table 7 is used, which contains five machines and seven parts. This demonstration is shown in Figure 2(a) and (b). In Figure 2(a), machine M4 with part incidence {0 1 0 1 0 1 0} as attributes is used to find CVAC of M4. Similarly, CVACs of machines (M1, M2, M3, M5, M6 and M7) are found as shown in Figure 2(b) with respective coordinates.
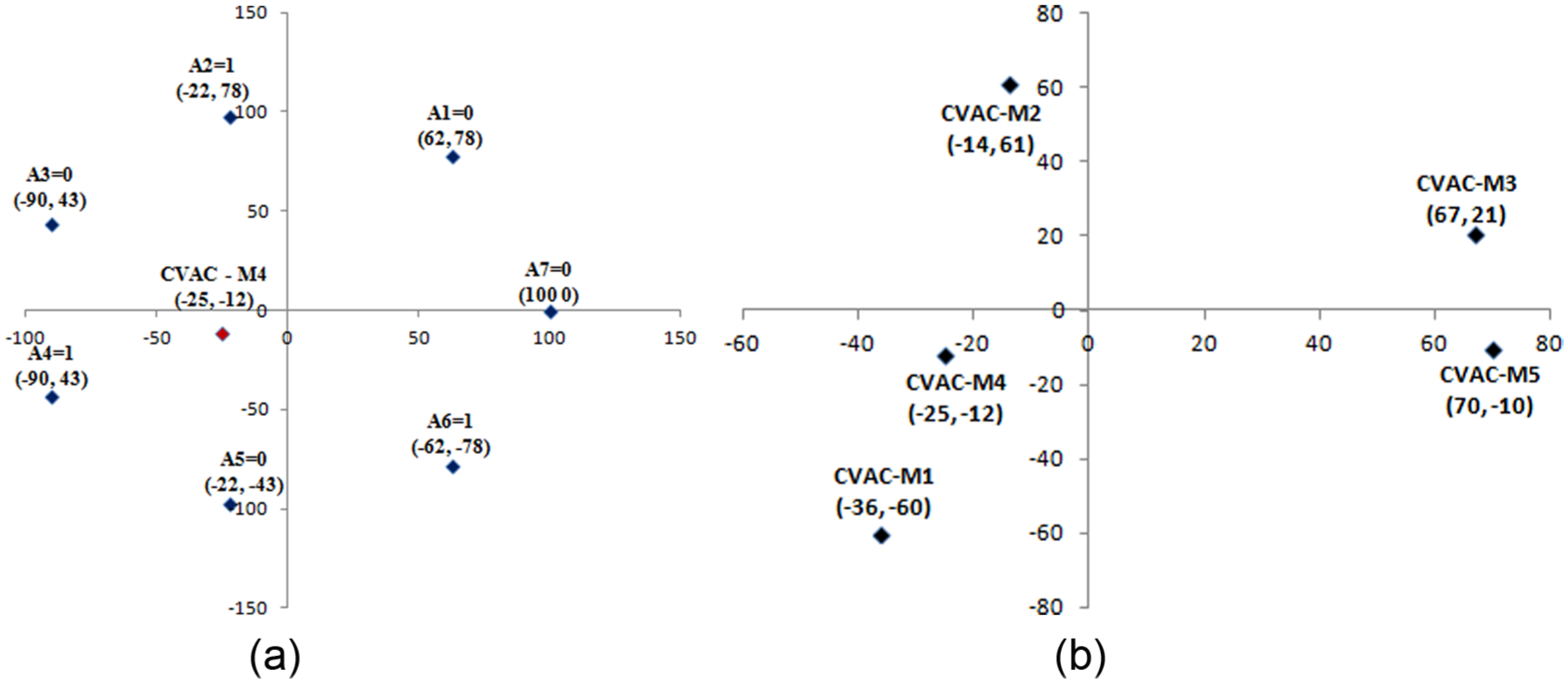
(a) Machine M4 on a 2D plane (as vector M14 with attributes {0 1 0 1 0 1 0} as {A1 A2 A3 … A7}, respectively). Attributes are distanced equally with radius 100 from the origin. M4 (−25,−12) is the CVAC of machine M1 calculated (using damp value = 2/3) as centre/mean of attributes with value = 1, that is, of A2, A4 and A6 only. (b) Extension of Figure 2(a) when CVACs of all machines (M1, M2, M3, M4 and M5) are graphically plotted on a 2D plane. M1 is closest to M4 and M3 is closest to M5. M2 is neither closer to M1–M4 nor to M3–M5.
Step 3. Distance matrix: It is the distance between the centre points, that is,
Step 4. Agglomerative hierarchal clustering: Using algorithm in subsection ‘Modified AHC’, the grouping of centre points having lesser Euclidian distance between them compared to others, for machines and parts, is computed. Machines are grouped to cells (represented as MCi) and parts into families (represented as PFi) sequentially, while N represents the number of entities in the group. Thus, MC1 = {3, 5}, MC2 = {1, 4}, MC3 = {2}, PF1 = {2, 4}, PF2 = {6, 7, 1, 3} and PF3 = {5}.
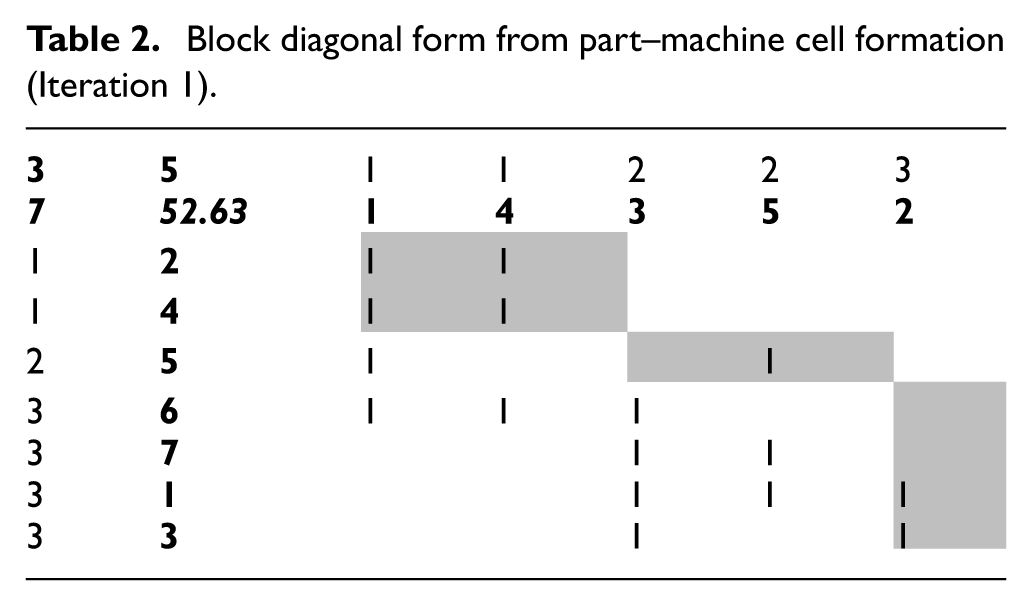
Step 5. Computing ‘CEV’ using equation (7): Allocating part families to machine cells to form diagonal blocks using CEV is shown in Table 1, forming Cells Ci, where i is the cell number. The result of the allocation is shown in Table 2.
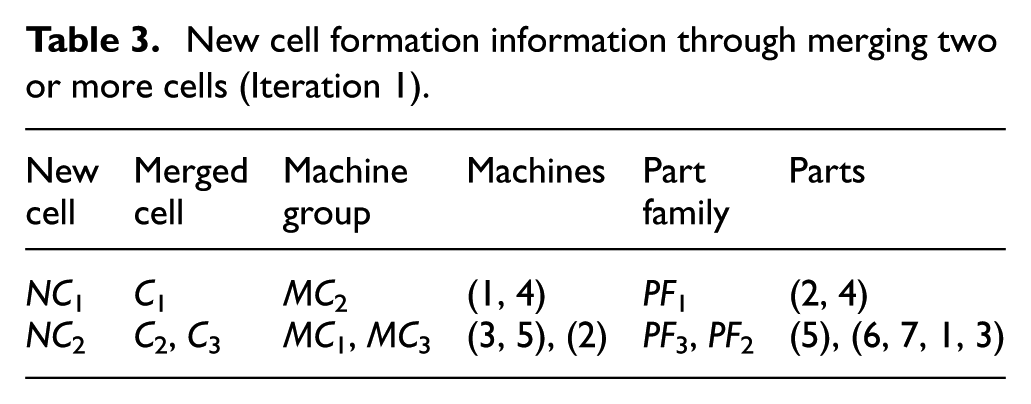
Step 6. Merging: Two or more cells can be merged together to decrease the number of voids in the cell and the number of exceptional elements outside the cell. After merging, the formation is brought about and presented in Table 3, accomplished by merging cells
Allocation of each part family to corresponding machine groups (Iteration 1).

Block diagonal form from part–machine cell formation (Iteration 1).
New cell formation information through merging two or more cells (Iteration 1).
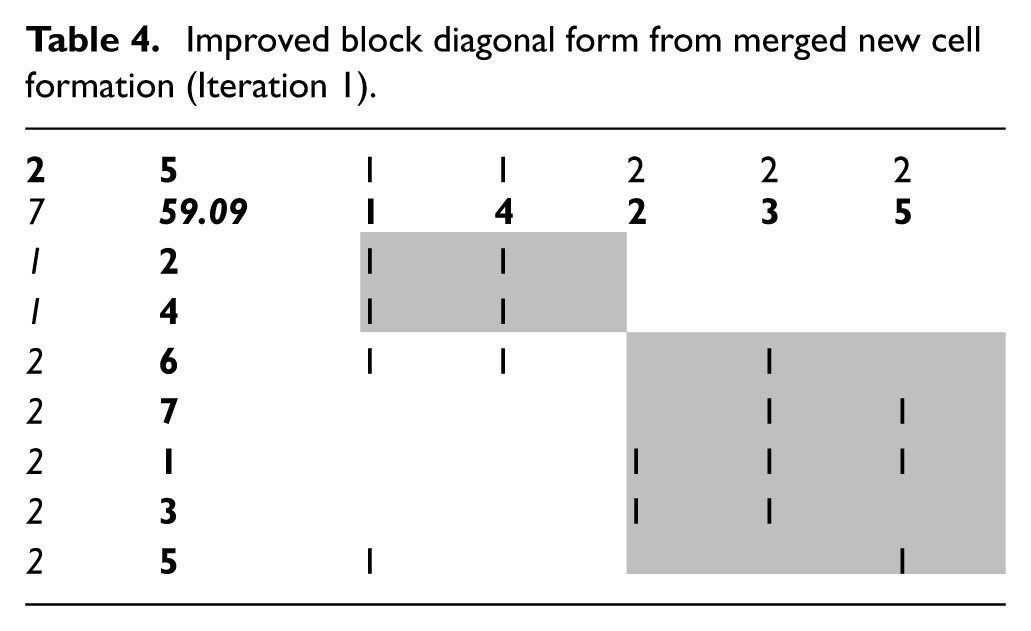
Improved block diagonal form from merged new cell formation (Iteration 1).
Iteration 2
The output from previous iteration, that is, from Table 4, is taken as input to its successive iteration. Following steps 1 through 6 as shown in Iteration 1, Tables 5 and 6 are gleaned showing machine–part grouping and allocation (with information on merging) and CF, respectively.
New cell formation information through merging two or more cells (Iteration 2).

Final block diagonal form from merged new cell formation (Iteration 2).
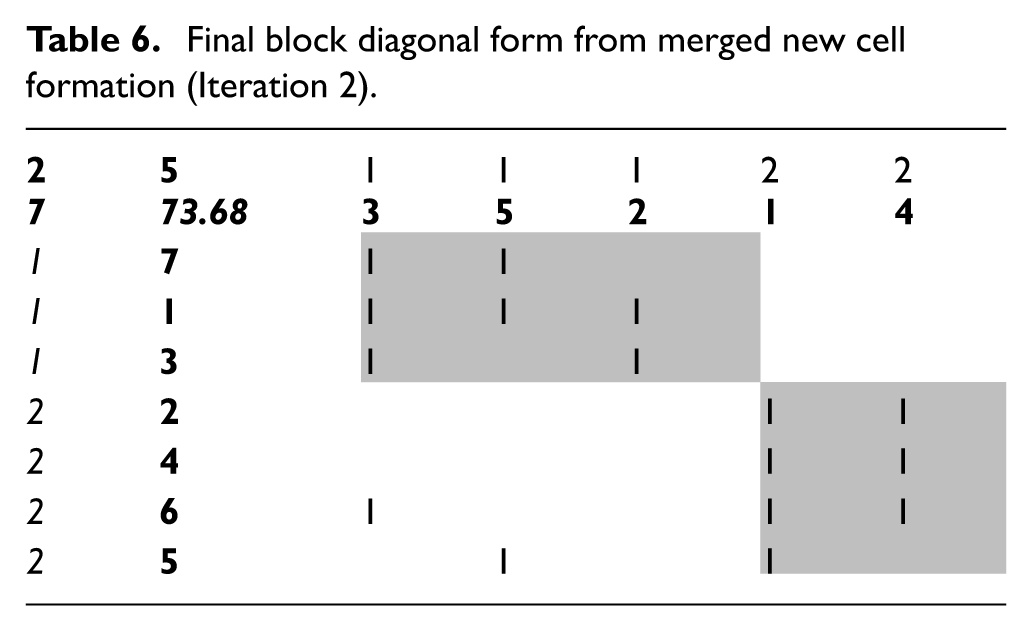
The desired grouping efficacy of 73.68 (Table 6) is achieved at the end of Iteration 2.
Thus, the result obtained matches with the highest grouping efficacy achieved, found in benchmarked results from literature works. There will be no further improvement even if more iterations are performed, and in the same way, execution on more data sets has been performed; the optimized CF is shown in Supplementary Appendix A.
Format used for Tables 2, 4 and 6
The cells in all the respective tables shown in grey represent the diagonal blocks of CF. In position, (1, 2) is the number of machines, (2, 1) is the number of parts and (2, 2) is the grouping efficacy value. Values (in italics) in first row and first column represent cell number. Values (in bold) in second row and second column represent machines and parts, respectively.
Result and discussion
Experimental setup
This experiment is conducted on 23 data sets to measure and confirm the effectiveness of COVR-AHC. Numerous research studies have been carried out over the decades to optimize CF quality. Although a vast pool of data set could be found exhausting these published works, not all could be accommodated in this work. Among the articles, only those data sets that are found suitable are chosen for the experiment.
These data sets are collected from a wide range of literature works where authors have pursued similar objectives, that is, improving CF quality. Data set 1, which is used for validation in the previous section (as numerical analysis), is accompanied by 22 other data sets for verification here. Various problem sets of different sizes were chosen to this end, as shown in Table 7.
Problem data set name and data set size.
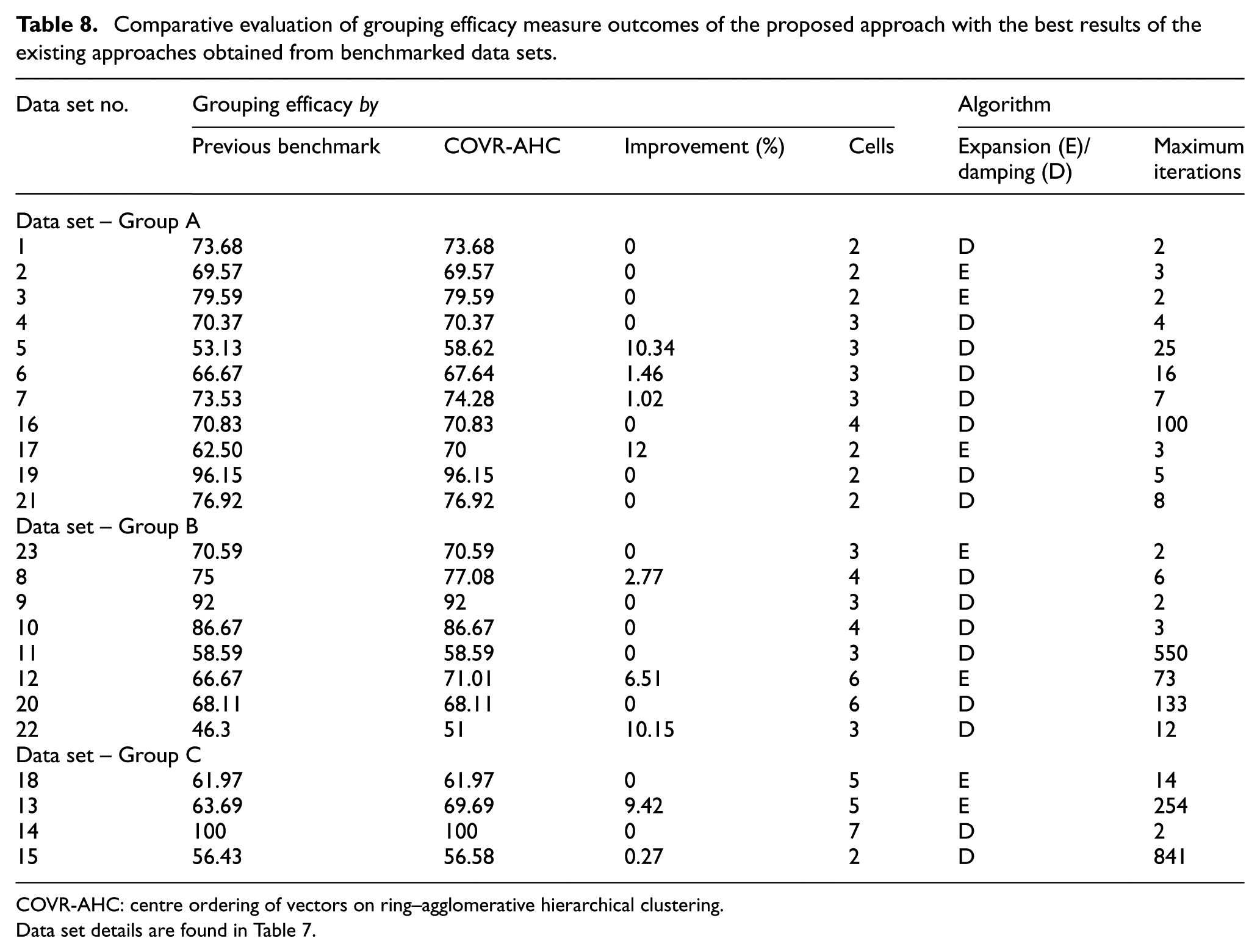
In accordance with the existing literature, we chose grouping efficacy as the performance measurement tool which is used for binary data set and computed using equation (8). Grouping efficacy obtained from the problem sources using COVR-AHC is compared with other previous study as presented in Table 8. The experimental output is represented in detail as diagonal blocks, that is, final CF, and is provided in Supplementary Appendix A.
Comparative evaluation of grouping efficacy measure outcomes of the proposed approach with the best results of the existing approaches obtained from benchmarked data sets.
COVR-AHC: centre ordering of vectors on ring–agglomerative hierarchical clustering.
Data set details are found in Table 7.
COVR-AHC was programmed in MATLAB version 7.9.0.529 (R20009b) for testing, validation and verification. The problem was executed on a personal computer with the given configuration: HP Pavilion dv4 Notebook PC of Intel(R) Core(TM)2 Duo CPU T6500 @2.10GHz with 4 GB RAM, Microsoft Windows Vista™ Home Premium(32-bit operating system).
Discussion
The results obtained from the execution are shown in Table 8. From Table 8, it is observed that 9 of 23 data set solutions were found to be better than previous benchmarks. This accounts for more than 40% improvements over all data sets that are used in this experiment. Rest of the solution obtained stands with equal grouping efficacy. With this record, a rational deduction can be reached easily. COVR-AHC efficiency is as better as other approaches pursued in previous studies towards improving quality of CF. In few cases, it even excels existing benchmarks.
Most of the data sets were obtained from Gonçalves and Resende 10 which also provides the optimal CF. Few other data sets were collected from the original source (as provided in the reference). Execution results from Gonçalves and Resende 10 were already compared against different approaches, such as Zero-One DaTA: Ideal seed Algorithm for Clustering (ZODIAC), GRouping using Assignment method For Initial Cluster Seeds (GRAFICS), Minimum Spanning Tree (MST), Genetic Algorithm for Travelling Salesman Problem (GATSP), genetic programming and genetic algorithm. Therefore, it serves as a basis for our comparison. In addition to this, the results were also compared with other well-known techniques such as artificial neural network. Therefore, our comparison encompasses evolutionary algorithms from Gonçalves and Resende, 10 artificial neural network from Chattopadhyay et al. 38 and also includes other heuristic approaches such as water flow–like algorithm. 12
The result in Table 8 is split into 3 groups – Group A, Group B and Group C – based on problem sizes. Group ‘A’ contains part–machines incidence ‘less than 100’, and Group ‘C’ contains part–machine incidence ‘above 480’. Group ‘B’ lies in between Groups ‘A’ and ‘C’. The attempt is to reflect the impact of problem size on execution output. Observing the solution of problem data sets 1, 10 and 15 from Table 8 which belongs to different groups and reaches optimality in just two iterations, it can be inferred that COVR-AHC is independent of problem size – small, medium or large. Some problems were found to iterate longer, such as data sets 11, 13 and 15, than its group data sets. This is due to complex part–machine incidence data that incur more exceptional elements and voids.
The most significant benefit of using COVR-AHC over any other tool or technique is its computational efficiency. Among the data sets used in the experiment, the largest problem (data set 14) contains at most 960 incidences (0 or 1) with 24 machines and 40 parts which run only for 254 iterations. From the past literature, it is observed that to reach optimality, those algorithms perform numerous computations which take longer execution time. Due to the sophisticated design of COVR-AHC, the same is reached with minimal number of iterations as shown in Table 8. The maximum number of iteration is found to be 841 for problem set 16. This saves not only computational resources but also computational time. The issue with a much larger problem is the exponential increase in computational time. COVR-AHC could be implemented in such scenarios. This is one of our key contributions towards accelerated clustering.
Table 8 shows the maximum number of iterations taken to reach optimal CF in the rightmost column. However, a number of iterations are not sufficient to ascertain the novelty of our work. We have to consider all computations performed to reach optimality. Based on this, we can deduce with certainty the superiority of COVR-AHC. To analyse, the methodology of the articles from which we have compiled the grouping efficacy value is considered. The work of Gonçalves and Resende 10 which contains the minimum iteration count is used. If we simply compare the iteration count, it infers COVR-AHC runs for more iteration. Instead by evaluating the number of computations performed by respective methods, we confirm COVR-AHC as a better candidate for clustering. To explain, we consider the parameter setting used in the genetic algorithm by Gonçalves and Resende 10 for data set 1. The number of generations, that is, iteration, is equal to 1. But at each generation, 30 candidate solutions exist (which is the population size) that search the solution space for optimality. Therefore, for each generation, at least 30 operations are performed to filter elite solutions, thereby making the effective computation to be more than 30 evaluations. COVR-AHC, however, has only one candidate solution searching the solution space which reduces the number of evaluations significantly, saving a lot of computations. This is highly evident with large problems that run for longer generations and requires multiple populations in each generation. However, this issue stretches from genetic algorithm to other heuristics as well. Although the number of iteration for COVR-AHC is higher in some cases, it is fairly low for most part–machine incidence matrices. Therefore, COVR-AHC excels as an alternative for clustering, especially in a computationally resource-constraint environment.
COVR represents the vectors based on their attributes or properties on a plane as explained in section ‘Proposed two-stage algorithm: state of the art and goals’. In few data sets, it has been observed that relative distance among the vector CVACs is not significant. This is evident when two vector shares almost same attributes, making it very difficult to distinguish. In this case, expansion comes in very handy, by exploding the relative distance among CVACs allowing to capture properties which otherwise would not be possible. The value of expansion factor set for the above problems is set within the range from 3.5 to 12.
Managerial insights
In this research work, our focus is on the manufacturing firm which reorganizes its existing structure to boost productivity through improvement in manufacturing system design, leading to optimized engineering, manufacturing and production planning. This is attained by grouping similar or recurring task together.
Through the prism of this research, we study a vital problem within the spectrum of GT. This has led to the formation of a new approach COVR-AHC. As our main contribution is the fourth stage of Burbidge from 1985, 24 the provided insights pertains to the mentioned approach.
COVR-AHC is the simplest in terms of application when compared to other research works published. Through part–machine results obtained for managers especially, it becomes relatively easier to make decision on exceptional parts for subcontracting or rather be assigned to another machine. Furthermore, bottleneck parts that require high utilization of machine can now be tackled or simply eliminated with respective families.
Important additional information for managers is the proximity of a machine towards to-be-processed parts/part families. The proximity is determined by COVR operators, and the resultant CVAC (if machine) denotes the processing information of respective part families. This aids managers to understand and design the CMS layout as well as reduction in void elements inside the cell.
Another of the most critical insights gained is to perceive inter-cell movement. This deduction can be easily reached using COVR-AHC to obtain diagonal block formation for improving machine utilization and material flow.
Conclusion and future study
This research explores a new approach, namely, COVR-AHC, for obtaining machine cells and part families and has been presented in this article. Out of 23 tested data set matrices, 9 have shown improvement, which is nearly 40% of tested data set, while same grouping efficacy could be achieved for 22 other data sets. Based on the findings it is easy to deduce that (1) solutions obtained through the developed algorithm proved to be at least as good as the ones found in the literature, and (2) it produces better results than previous benchmarks achieved using heuristic techniques. Thus, COVR stands to be a competitive approach for grouping part-machines into cells.
The research work presented above has the aroma of newness in its application in the following areas:
Proposed algorithm is simple and easy to implement to any size of problem.
It can provide the scope to observe the intermediate stages and analyse it. Thus, managers are able to comprehend and analyse huge data, and based on the insights gained, they can make useful decisions out of several alternatives available during the intermediate stages.
Unlike the other approaches, no initial prior cluster information is required for obtaining optimal solution.
This study encompasses binary data sets of PMIM only. Researchers can address ordinal data set comprising sequence and cell load variation. COVR-AHC sequentially groups parts into families and machine into cells. This article creates scope for further study to develop method for clustering in combined manner, besides sequential approach. The study to incorporate multiple instances of solutions in COVR-AHC, in each iteration, to further accelerate search in solution space opens new direction for investigation as well. It would be interesting to combine COVR with popular clustering tools like k-means, graphical approach and other heuristics to study its integration. The efficiency and integration capability of COVR with AHC unfold scope of application in new areas besides GT which researchers and academician might find useful.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.