
Abstract
As a component of knowledgeable manufacturing systems, the structure of flow shop–like knowledgeable manufacturing cells is similar to that of a flow shop, thus representing an NP-hard issue. Here, we propose a self-evolutionary algorithm that exhibits learning ability and is composed of learning and scheduling modules. Unlike traditional scheduling algorithms, whose performances remain unchanged when the procedure is coded, the performance of the algorithm proposed in this study gradually improves as the learning process continues. The self-evolutionary ability is realized through the training of a hybrid kernel support vector machine. The hybrid kernel support vector machine was designed to approximate the value of the Q-function to select the appropriate action for the scheduling module and thus to obtain the optimal solution. An iterative process of value based on the Q-learning was adopted to train the hybrid kernel support vector machine to gradually enhance the algorithm’s efficiency and accuracy. The extracted state features of the flow shop–like knowledgeable manufacturing cells serve as inputs to hybrid kernel support vector machine for easy generalization of the learning results. The action exerted on a feasible solution is also defined as the input of the hybrid kernel support vector machine. The computational results show that the performance of the proposed procedure improves as the learning process progresses. Data from the computation and comparisons with other algorithms verify the validity and efficiency of the proposed algorithm.
Keywords
Introduction
With increasingly customized demands and acute competition, manufacturing enterprise must adapt to new competitive environments more than ever. Several manufacturing systems, such as flexible manufacturing systems (FMSs) and agile manufacturing systems (AMSs), have been developed to meet such challenges. Yan and Liu 1 proposed knowledgeable manufacturing systems (KMSs) to account for this trend. Considering the optimal time, cost and quality as the primary goals, a KMS, as a truly intelligent manufacturing system, can be characterized by self-adaptation, self-learning, self-evolution and self-configuration. Studies that exploit knowledge in manufacturing systems have rapidly developed in recent years and have attracted significant attention.2–4 Similar to digital enterprise technology (DET) proposed by Maropoulos et al.,5–7 KMSs also emphasize on the utilization of recent technology advances in manufacturing systems. Li et al. 8 presented a review on the development of knowledge-based systems for manufacturing systems.
Various achievements have been made in recent studies that have focused on KMSs. Wan and Yan 9 proposed a heuristic algorithm for integrated assembly job shop scheduling and self-reconfiguration in knowledgeable manufacturing. Yan et al. 10 proposed a hybrid variable neighborhood search electromagnetism-like mechanism algorithm to overcome the two-stage assembly flow shop scheduling problem. Yang and Yan 11 proposed an adaptive scheduling control strategy based on B-Q learning for KMS. Yan et al. 12 proposed a new economic production lot size model for multi-cycle flexible production/inventory that incorporated an iterative learning algorithm. Unlike previous studies that focused primarily on the general frame properties of KMSs, such as knowledge presentation of KMS, 13 the aforementioned studies focus on the subsystems of KMSs, such as scheduling decision systems. Flow shop–like knowledgeable manufacturing cells (KMCFS) represent a component of the scheduling decision system of KMSs that focus on problems in the scheduling algorithm, such as flow shop problems. Compared with general scheduling algorithms, which aim to optimize the solution, the scheduling algorithm for KMCFS prioritizes self-evolutionary performance. The performance of the scheduling algorithm proposed here for KMCFS can be improved gradually through off-line learning.
The structure of KMCFS is similar to that of a flow shop, which is strongly NP-hard according to Garey et al. 14 The key module of KMCFS is the learning module rather than the scheduling module, which acts as the application of the former. Studies dedicated to flow shops have primarily focused on the design of heuristic and meta-heuristic algorithms to obtain a better solution, since flow shop problems were proved to be NP-hard in 1976. Ogbu and Smith 15 adopted a simulated annealing method to identify a better solution. Reeves and Yamada 16 applied a genetic algorithm to flow shops and obtained the best solutions of the time, which were characterized by many benchmarks. Ahmadizar 17 proposed a new mechanism to initialize the pheromone trails whose intensities are limited by bounds that changed dynamically in the ant colony algorithm. Li and Yin 18 designed composite mutation strategies in a discrete artificial bee colony algorithm. Grabowski and Wodecki 19 developed a tabu search algorithm that rapidly obtained a desirable solution in light of block properties of flow shop. Kim and Lee 20 proposed two heuristic algorithms for a re-entrant flow shop with parallel machines. Marimuthu et al. 21 proposed a simulated annealing algorithm and tabu search algorithm for a flow shop with lot sizing. Li et al. 22 used a hybrid flow shop model to schedule one-of-a-kind products, and a genetic algorithm was designed to solve the problem. Chan 23 proposed three routing policies and four dispatching rules to schedule a manufacturing system. Zobolas et al. 24 presented a hybrid meta-heuristic algorithm that consisted of a genetic algorithm and variable neighborhood. Luo et al. 25 used a genetic algorithm to solve a two-stage hybrid flow shop problem with blocking and machine availability constraints. A quantum differential evolution algorithm was developed by Zheng and Yamashiro. 26 Rao and Kalyankar 27 developed an advanced optimization algorithm for the parameter optimization during the scheduling in a laser beam welding (LBW) process. Pan et al. 28 proposed a chaotic harmony search algorithm for a flow shop with limited buffers. The heuristic algorithms discussed here seek optimal or suboptimal solutions for certain benchmarks or some specialized problems within a short period of time. However, demerits do exist with these algorithms, such as sensitivity to certain parameters, dependence on initial solutions and so on, due to the random factors in these algorithms. Moreover, these algorithms have a fixed performance and cannot improve after the procedures are coded.
Due to these limitations, the development of highly intelligent algorithms has gained significant attraction in recent years. The goal of this study was to develop an algorithm that can improve its searching performance using Q-learning to overcome the disadvantages of previously reported algorithms. Some flow shop algorithms with learning ability have been recently reported. Agarwal et al. 29 proposed an adaptive learning approach to address this issue. Lee and Michael 30 developed a method based on neural-net with two hierarchies for a real-time flow shop with sequencing knowledge learning. Solimanpur et al. 31 developed a neural-net tabu search algorithm. Li and Yin 32 developed a differential evolution algorithm with learning ability based on a memetic algorithm in which a new largest-ranked-value (LRV) rule was designed. Xie et al. 33 proposed a novel teaching-learning-based algorithm with a variable neighborhood. The idea of Q-learning based on value iteration has been widely used to solve scheduling problems as a type of reinforcement learning. Li et al. 34 modeled issues regarding the order decision making and scheduling in an order system and proposed an algorithm based on Q-learning. Xanthopoulos et al. 35 proposed a reinforcement learning–based approach for a single scheduling problem with stochastic arrivals and processing time. Aydin and Őztemel 36 adopted reinforcement learning to solve dynamic job shop problems. Stefan 37 developed a method based on reinforcement learning to solve flow shop problems. Q-learning converges markedly slower and may even be impossible for large-scale problems. Therefore, a technique to extract the state features of a flow shop is thus used here to reduce the complexity of state space, and a hybrid kernel support vector machine (HK-SVM) is proposed to approximate the Q-function through Q-learning. The proposed algorithm is composed of learning and scheduling modules. The scheduling module rapidly searches for the optimal solution using knowledge obtained from the learning module. The scheduling knowledge is generated from a process that iterates through values based on Q-learning by training the HK-SVM. More training during the off-line learning process corresponds to increased knowledge accumulation in the learning module, and thus, the algorithm’s efficiency and accuracy gradually increase as the amount of knowledge increases. Thus, the algorithm proposed in this study possesses a self-evolution feature in that the performance of searching for the optimal solution progressively improves due to the aggregate knowledge obtained through continuous off-line learning.
The remainder of this article is organized as follows. In section “Problem formulation,” the KMCFS is introduced and formulated. Q-learning and HK-SVM are presented and analyzed in section “Q-learning and HK-SVM.” The implementation steps of the proposed algorithm are given in section “Scheduling algorithm with evolutionary features for KMCFS.” Section “Numerical simulation” presents the numerical simulation. Section “Conclusion” presents the final conclusion.
Problem formulation
There are m processing units (PUs) to process n tasks and the function of the KMCFS is to schedule the tasks to minimize the make-span. Similar to the flow shop structure reported in Brucker, 38 the tasks to be processed and the PUs need to satisfy the following requirements: (a) the sequences of all of the tasks flowing through the PUs are identical, (b) each task can be processed by at most one PU at given time, (c) every PU can process at most one task at given time, (d) process time of each task by a PU is determined in advance and (e) the process sequences of all of the tasks for each PU are identical.
A feasible scheduling given by the KMCFS can be represented as
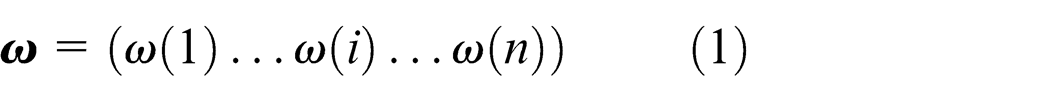
where ω(i) denotes the task to be processed in the ith position in the sequence
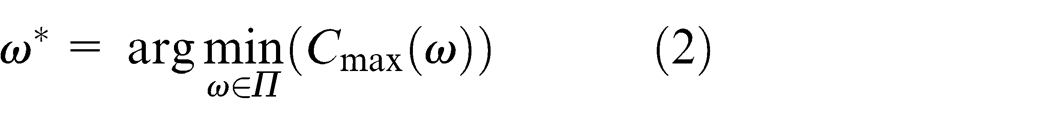
Let piω
(j) denote the processing time of the jth task in

Q-learning and HK-SVM
The evolutionary characteristics of the KMCFS are realized via a support vector machine (SVM) with a hybrid kernel that learns the value of the Q-function for the master scheduling. A brief account of Q-learning and the construction of the HK-SVM is presented below.
Q-learning
Q-learning, which is a type of reinforcement learning, is widely used for system control, and inventory control, scheduling and is an important technique in machine learning and intelligent control fields. The key principle of Q-learning is that an intelligent system can obtain knowledge from the environment by observing the feedback of the system’s action and modifying its strategy to reach the goal.
According to Mitchell,
39
the expected reward can be represented by equation (4) when a system adopts a strategy π in state
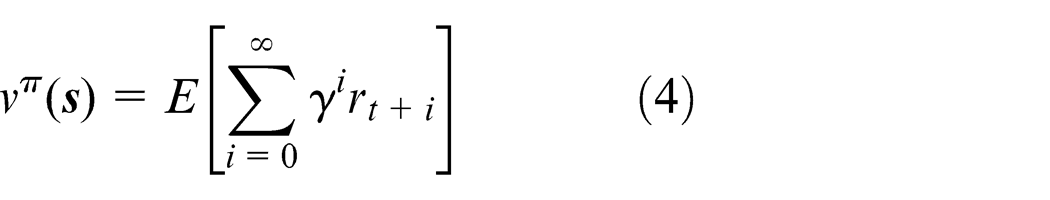
The optimal strategy
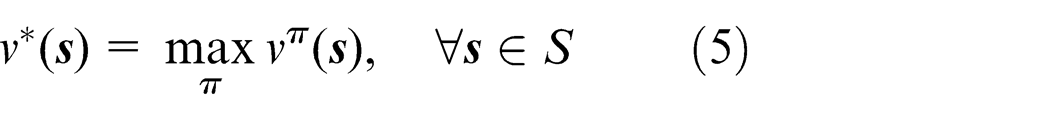
There exists the following relation between state
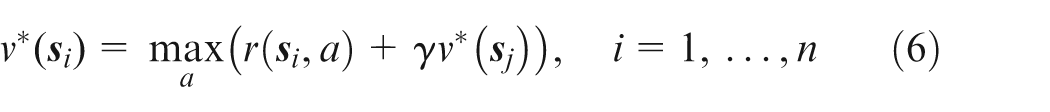
According to equation (5), the optimal strategy
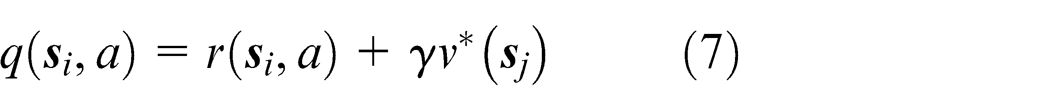
Then, equation (5) can be transformed into
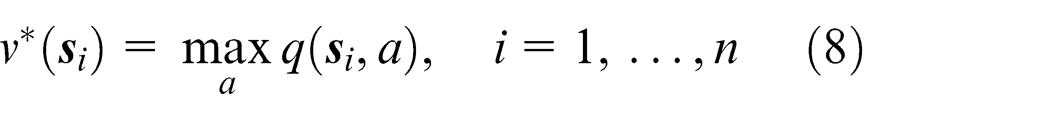
where the value of
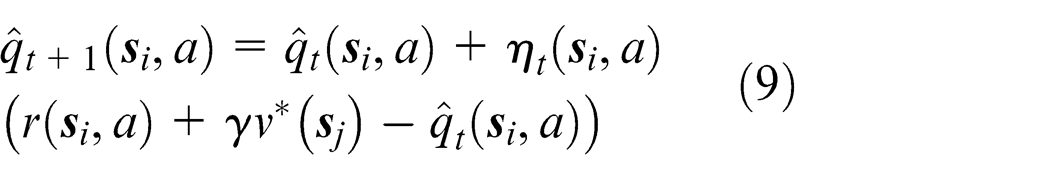
The computation process of
HK-SVM
SVMs have gained their wide applications in fields such as pattern recognition 41 and the regression of non-linear functions. The principle of SVMs is to map the input vector from a low-dimensional space into a high-dimensional linear space such that the problem can be treated as linear and solved. The results can be well generalized based on Vapnik–Chervonenkis (VC) dimension theory to minimize the structure risk.
For a sample set
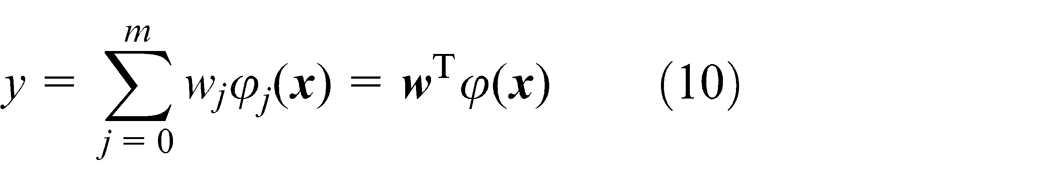
The function regression in equation (10) can be transited to a pattern classification problem using non-negative slack variables
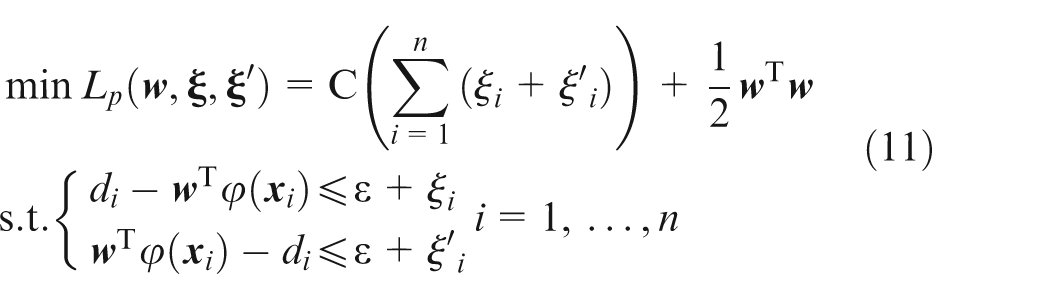
where C and ε are given constants. The optimization in equation (11) can be solved using the Lagrange function to construct its dual problem, and the approximation function of d (denoted as y(
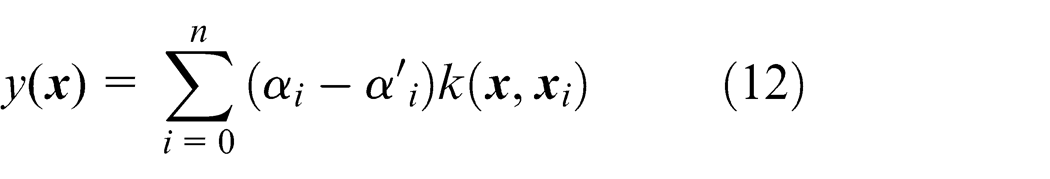
where
The performance of an SVM depends heavily on the selection of the kernel functions. Among the most commonly used are polynomial functions, Gaussian functions and Sigmoid functions. A hybrid kernel function is proposed here to guarantee full performance of the SVM
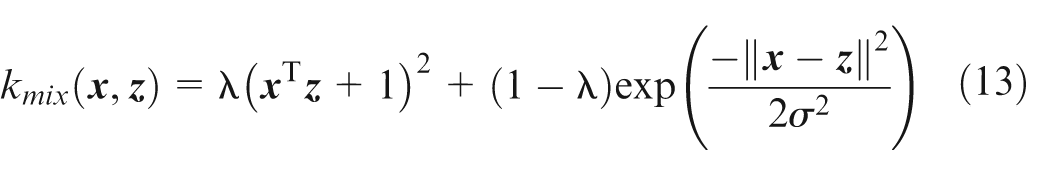
where λ denotes the optimal hybrid coefficient,
Now, let us prove that the function
Lemma 1
Let X be a finite input space with
Property 1
The function
Proof
If the function
For
Similarly, if the function denoted as
For
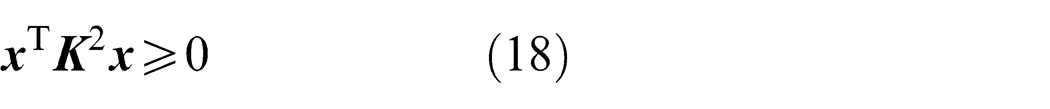
Therefore, matrix
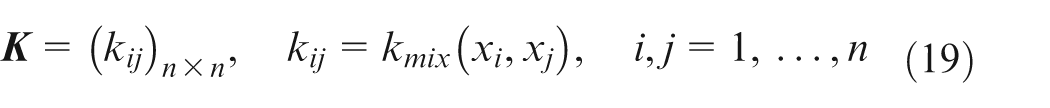
where

Then, for matrix

For
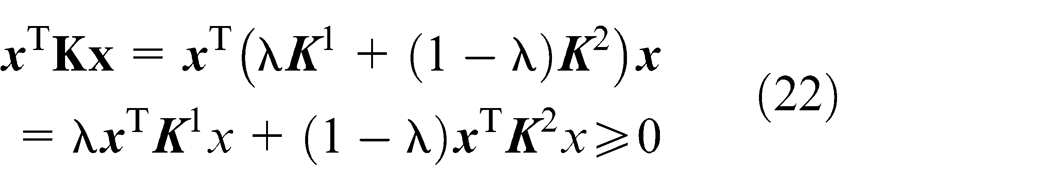
Thus, matrix

That is to say, the function
Scheduling algorithm with evolutionary features for KMCFS
The difference in our scheduling algorithm for the KMCFS (denoted as KMCFSSAEF) from other general scheduling algorithms is that the KMCFSSAEF can rapidly obtain the solution to the current problem based on the knowledge contained in the HK-SVM by which the off-line Q-learning is performed. Various techniques were employed to realize the algorithm regarding the representation of state and action. The details and full procedure of the algorithm are given in the following sections.
State representation
For a specific KMCFS problem, its state information can be precisely represented by its feasible scheduling ω and time process matrix
1. Make the time process matrix
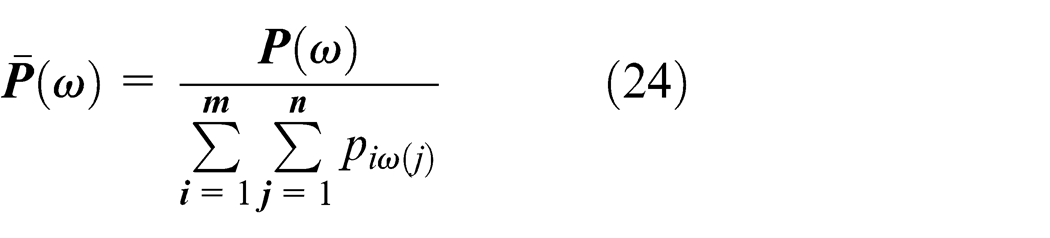
2. Extract the KMCFS state features. The parameters representing the state features are acquired as follows:
The column index
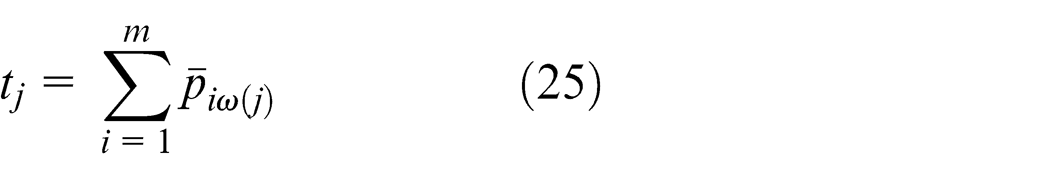
Denoting the end time of the ith PU as
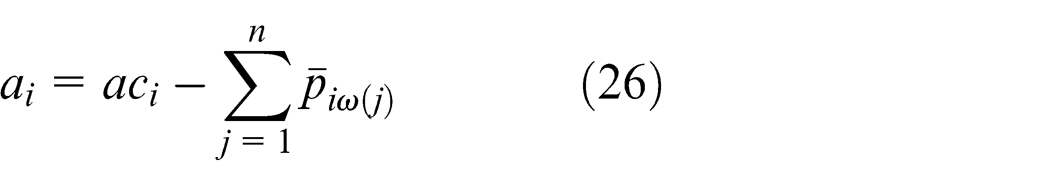
The average slack
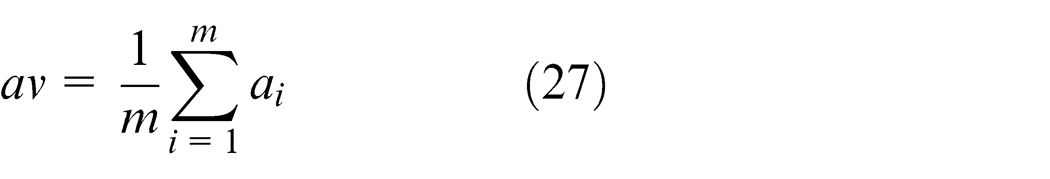
In addition, we obtain the variance of slack
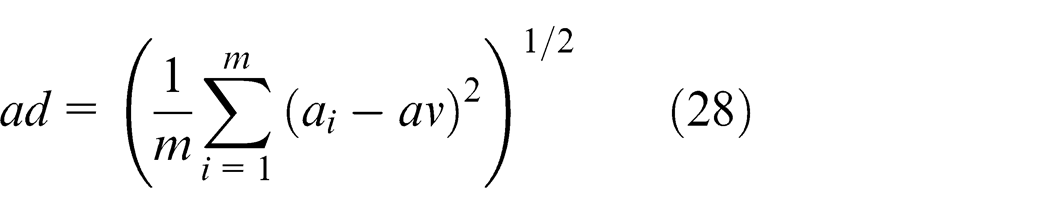
Denoting the end time of the jth task as
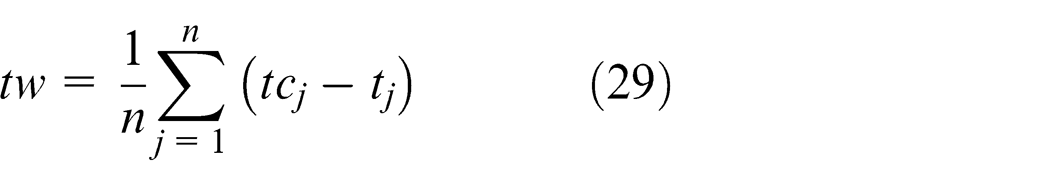
The corresponding variance
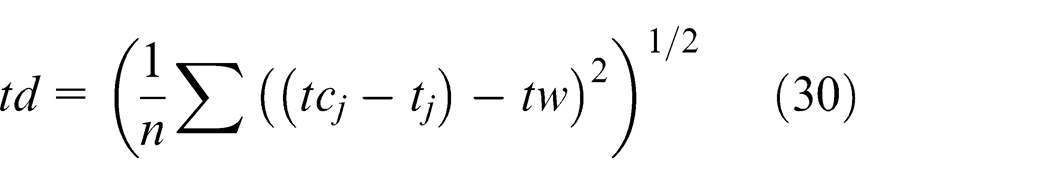
With the above parameters, the state features of the KMCFS with a scale of m × n can be represented by the following vector
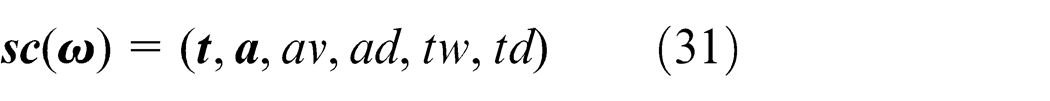
Action representation
The definitions and computation steps of the actions performed for the feasible scheduling ω of the KMCFS are presented below.
Definition 1
An action is defined as one performed on sequence ω to swap the task ω(f) at the fth position with the task ω(g) at the gth position when ω is a feasible scheduling of the KMCFS. This action is denoted as
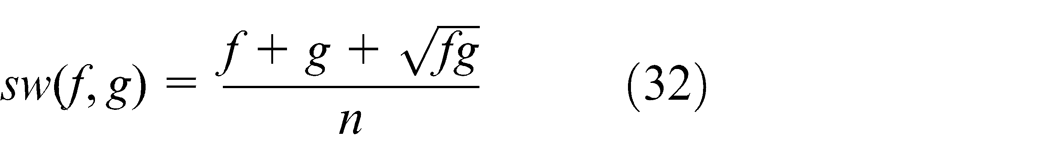
When the action
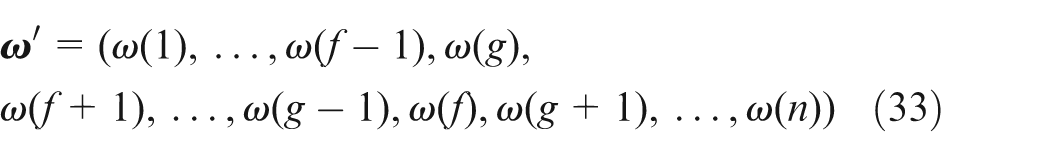
Algorithmic steps
The algorithm is composed of a training-based learning module and a scheduling module. The former module plays a key role in the entire procedure, and the latter module acts as the application. The purpose of the learning module is to ensure that the approximation degree of the Q-function gradually enhances through the training of the HK-SVM weight parameters. The value of
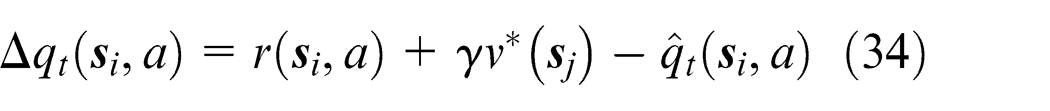
where
In equation (34),
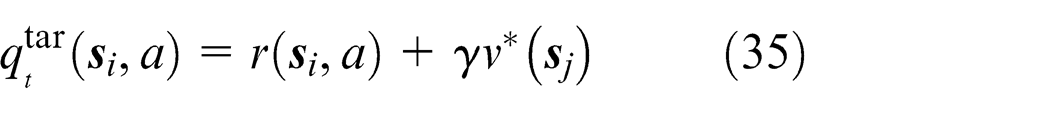
States
Step 1: Initialization. Set the initial vector
Step 2: Extract the features of state
Step 3: Calculate
Step 4: If the number of iterations is greater than the upper bound N1, then end the learning procedure; otherwise, add (
Step 5: Renew the current state
Step 6: If the number of iterations is greater than the lower bound N2, then end the procedure; otherwise, go to step 5.
In contrast to the learning procedure, the scheduling process is implemented briefly, thus exploiting the achievements of the first module after a sufficient amount of learning of the HK-SVM. The implementation proceeds as follows:
Step 1: Initialize a new problem. Choose
Step 2: Compute the vectors
Step 3: Compute the outputs of the HK-SVM
Step 4: Compute the reward r(
Step 5: Compute r(
Numerical simulation
The numerical simulation is implemented to evaluate both the influence on the performance of the procedure with varying off-line learning parameters and the procedure’s scheduling performance by comparing with other algorithms. The procedure is coded using MATLAB7.0 and run on a PC equipped with a Celeron M (1.6 GHz) CPU and 504 MB of RAM.
Impact of the variance of the learning parameters
Unlike traditional scheduling algorithms, the performance of the proposed KMCFSSAEF algorithm improves as the learning progresses. In this section, the simulation is performed to test the solution’s accuracy and efficiency with the varying numbers of learning iterations and training samples and the optimal hybrid coefficient λ. The variance in the solution accuracy upon changing the number of learning iterations and the number of 100 × 20 training samples is given in Table 1. The training samples are produced randomly using the method proposed by Taillard. 43 The data in Table 1 show that the make-span of the same problem solved decreases as the number of training samples and the number of iterations increase, indicating that the solution accuracy is improved when the learning process is sufficiently long.
Make-span with different number of training samples and iterations.
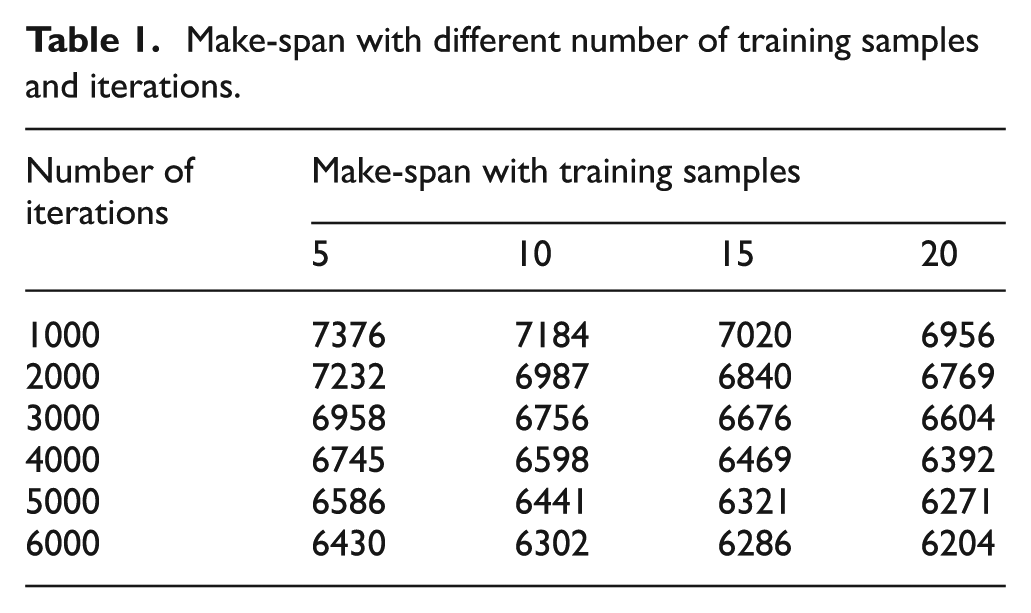
Figure 1 illustrates the trend in the time needed to search for solutions with an increasing number of learning iterations and 200 × 20 training samples. Overall, a decreasing trend is observed with increasing numbers of iterations and training samples, except for a few of the points. Figure 1 illustrates that the time needed to find the solution will decrease with fewer waves, as the learning process is sufficient. In the figure, the horizontal axis represents the number of iterations, and the vertical axis represents the average time needed to find the solution using the procedure.
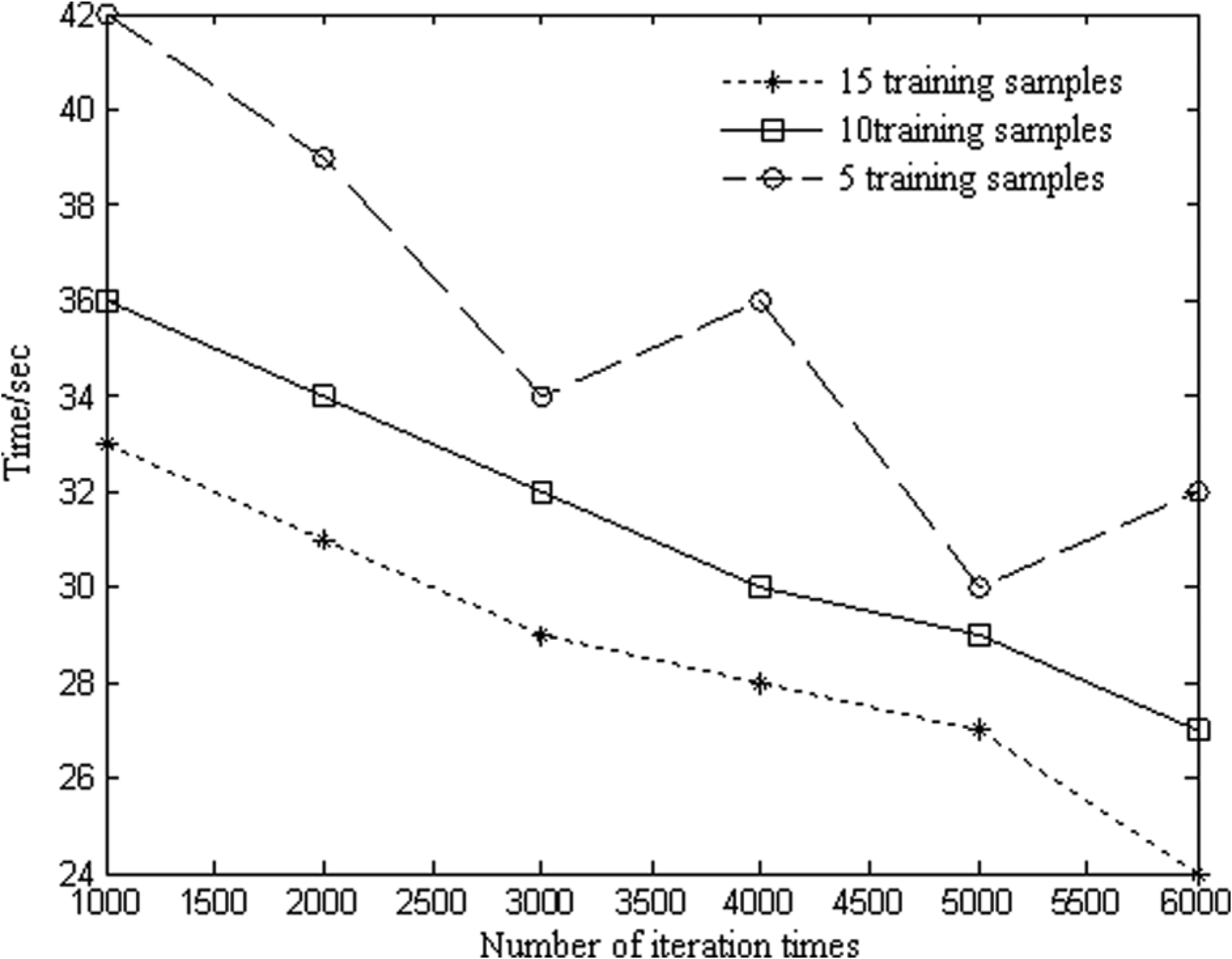
Time for solution search with the variance of iteration times.
As shown in Figure 2, the approximation performance of the HK-SVM is affected by the optimal hybrid coefficient λ. The horizontal axis represents the value of λ, and the vertical axis denotes the relative error of the HK-SVM approximation (REA), which is defined as follows:
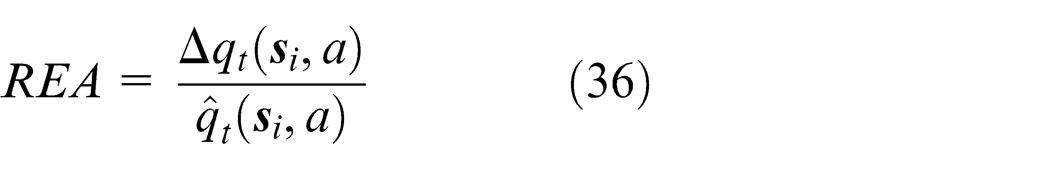
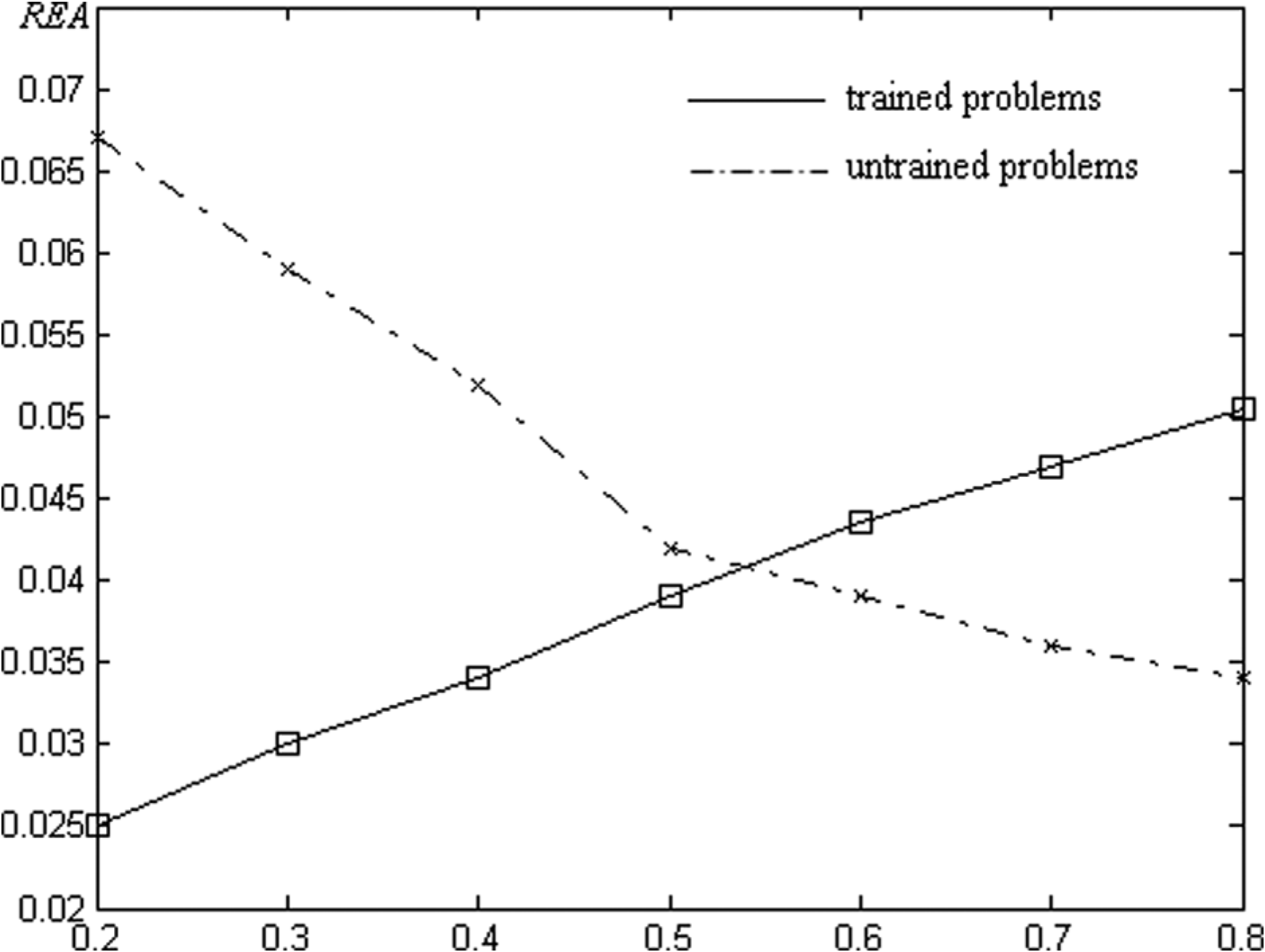
REA with the optimal hybrid coefficient λ.
The REA for problems never trained using the HK-SVM gradually decreases with increasing λ, whereas the REA for those that have been trained gradually increases. This phenomenon occurs because the polynomial kernel function exhibits good global generalization, and thus, the REA is smaller for untrained problems with a greater lambda. However, the local generalization ability of the polynomial kernel function is weaker than that of a Gaussian kernel function, and thus, the REA is larger for the trained problems. Therefore, we adopted the hybrid kennel function. The HK-SVM possesses the advantages of both the polynomial kernel function and Gaussian kernel function and can simultaneously compensate for each of their disadvantages. The scale of the problems in Figure 2 is equal to that in Figure 1.
Comparison of algorithms
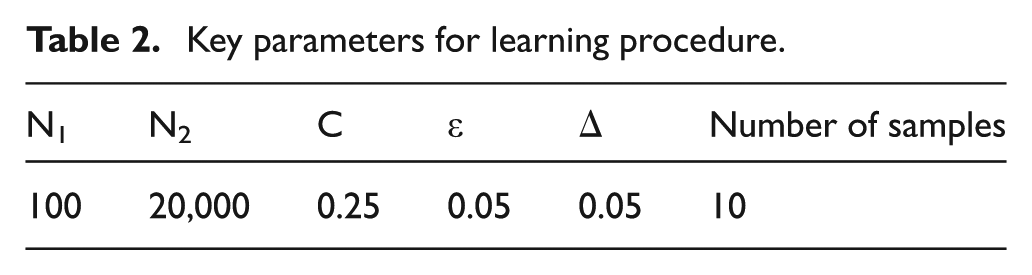
In this section, the accuracy and efficiency of the KMCFSSAEF algorithm are compared with those of the TSGW 19 (Grabowski and Wodecki), RY 16 (Reeves and Yamada), ODDE 32 (Li and Yin) and HTLBO 33 (Xie et al.) algorithms for the benchmarks of Taillard 43 on the scales of 20 × 20, 50 × 10, 50 × 20, 100 × 10, 100 × 20, 200 × 20 and 500 × 20, respectively, and then with those of the QDEA 26 (Zheng and Yamashiro), CDABC 18 (Li and Yin) and ODDE 32 (Li and Yin) algorithms for the benchmarks of Carlier, 44 Reeves and Yamada. 16 Off-line learning was completed before the comparison was made. The key parameters of learning process set are listed in Table 2.
Key parameters for learning procedure.
A comparison of the accuracies of the five algorithms is shown in Figure 3, where the horizontal axis represents the benchmarks for different scales, that is, T1: 20 × 20; T2: 50 × 10; T3: 50 × 20; T4: 100 × 10; T5: 100 × 20; T6: 200 × 20; and T7: 500 × 20, and the vertical axis represents the make-span. As can be seen from the figure, the solution accuracy obtained by our algorithm is slightly lower than that of the other four algorithms when the problem scale is small, but that gap is narrowed gradually with increasing scale, particularly in terms of some specific benchmarks. For the scale 500 × 20, the accuracy of KMCFSSAEF reaches that of TSGW, HTLBO and RY.
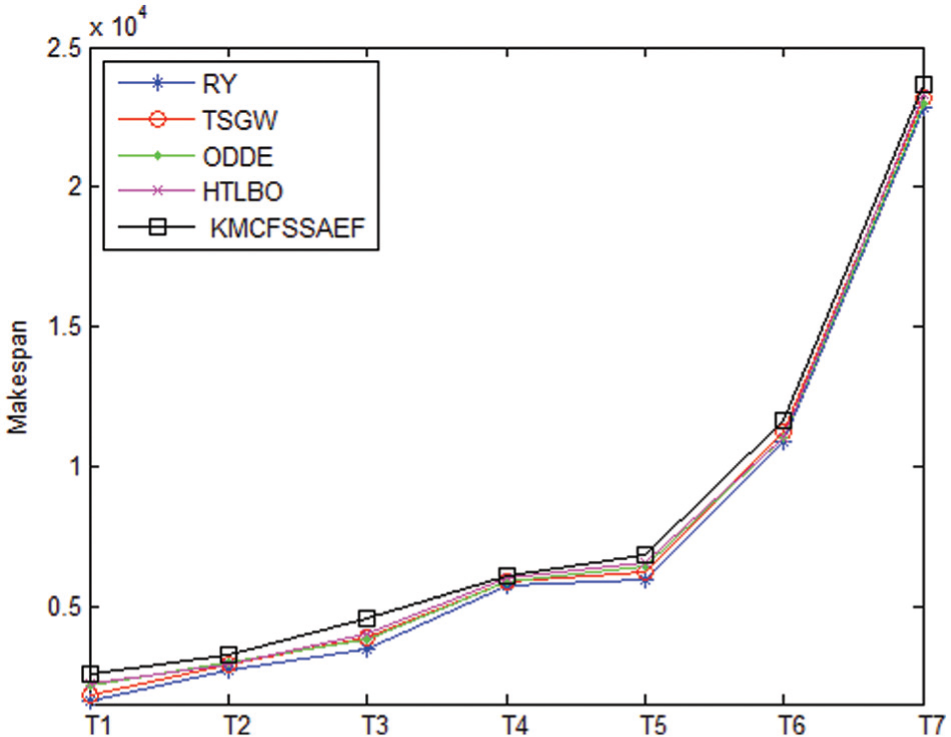
Comparison of the accuracies of the five algorithms.
Table 3 presents a comparison of the efficiencies of the five algorithms. The time required by KMCFSSAEF to find the solution is less than that required by TSGW, RY, ODDE and HTLBO. In addition, the former efficiency becomes even more conspicuous as the scale of a problem increases because its time spent increases slowly and nearly linearly with increases in the problem scale.
Comparison of the efficiencies of the five algorithms.
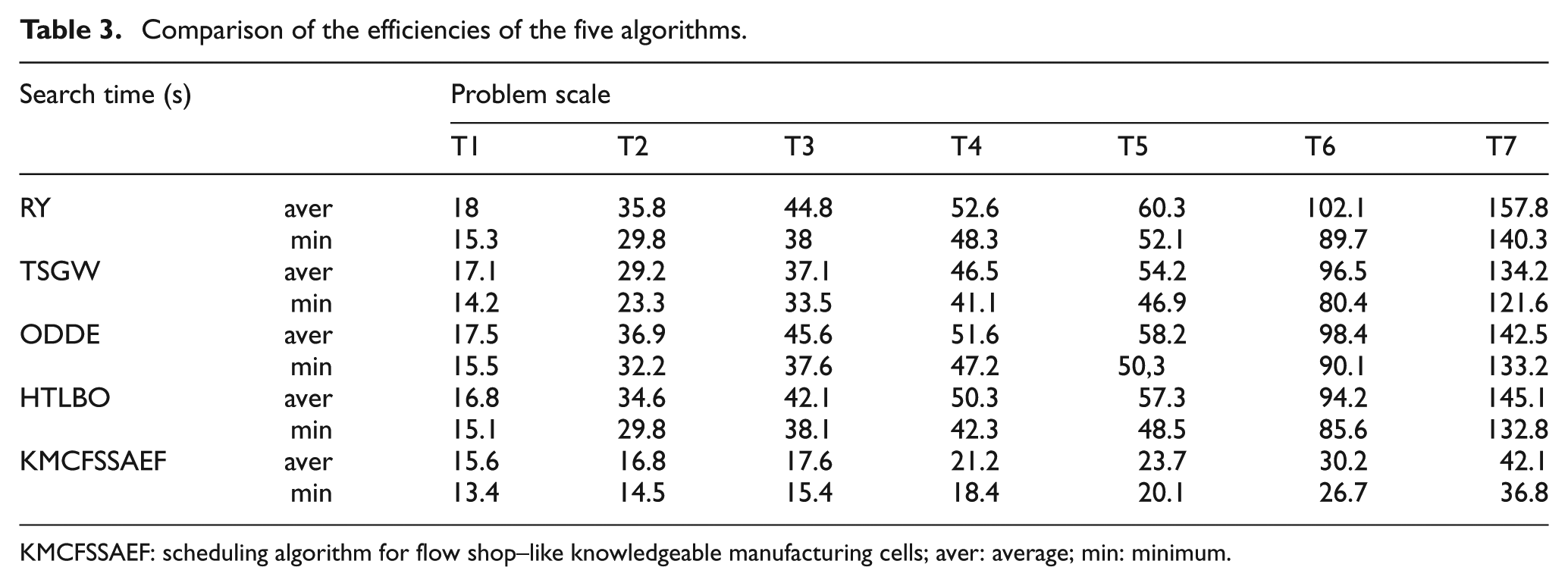
KMCFSSAEF: scheduling algorithm for flow shop–like knowledgeable manufacturing cells; aver: average; min: minimum.
The accuracy performance of the KMCFSSAEF algorithm was also compared with three other algorithms, QDEA, CDABC and ODDE. The results are listed in Table 4. In Table 4, M * denotes the lower bound value or the optimal make-span known thus far. The best relative error to M * is denoted as b re, and the average relative error to M * is denoted as a re, which can be computed according to equations (37) and (38), respectively. In Table 4, each instance is run 20 times. The data in Table 4 show that our KMCFSSAEF algorithm is slightly better than the QDEA and CDABC algorithms, but is not as good as the ODDE algorithm for obtaining the optimal make-span of each instance. However, the KMCFSSAEF algorithm exceeds the other three algorithms regarding the average searching performance after repeated runs, indicating that KMCFSSAEF is more robust than the other three algorithms in terms of searching performance.
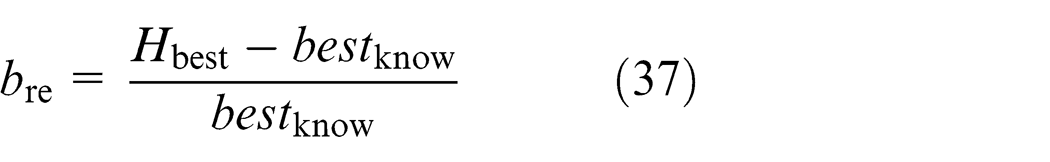
where H best denotes the best make-span obtained by algorithm H (H refers to QDEA, CDABC, ODDE and KMCFSSAEF) and best know denotes the optimal make-span, or the lower bound value known thus far
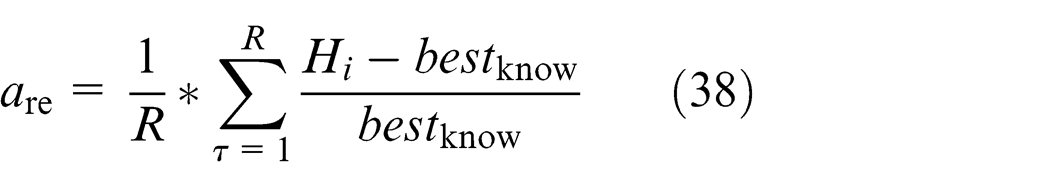
Comparisons of the QDEA, CDABC, ODDE and KMCFSSAEF algorithms in terms of make-span.
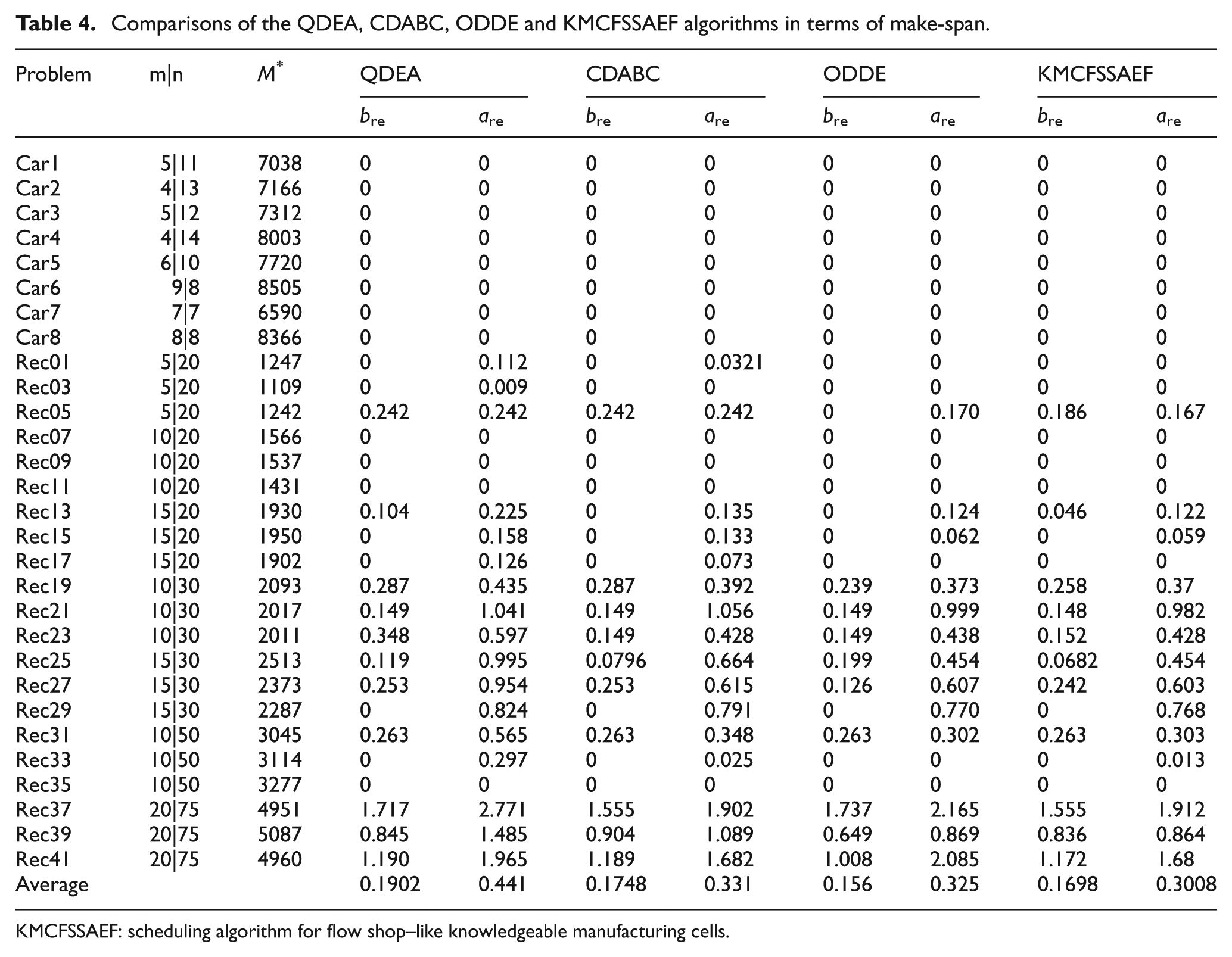
KMCFSSAEF: scheduling algorithm for flow shop–like knowledgeable manufacturing cells.
where Hi denotes the make-span obtained by algorithm H in the ith running. R denotes the total number of times that the algorithm is run.
Conclusion
In this study, we propose a scheduling algorithm referred to as KMCFSSAEF that is characterized by self-evolutionary features for KMCFS, and consists of a learning module and a scheduling module.
The self-evolutionary ability of KMCFSSAEF is realized through the trained HK-SVM for approximating the value of the Q-function, which is then used to choose the suitable action in the scheduling module to obtain the optimal solution. The training process for the HK-SVM is an iterative process based on Q-learning. The scheduling performance of KMCFSSAEF gradually improves based on the knowledge obtained during the learning process, and this feature offsets the static performance while searching for a common optimization algorithm.
The numerical simulations showed that KMCFSSAEF corresponds to an apparent improvement upon completion of the learning process due to the off-line training. When training samples are increased from 5 to 20, the accuracy of the solution can be increased 5.12% on average, and the accuracy is an average of 11.25% higher for 6000 iterations compared to 1000 iterations. The time spent searching for the optimal solution can be reduced by 24.43% upon increasing the number of iterations from 1000 to 6000 and increasing the training samples from 5 to 15. Although the KMCFSSAEF may seldom exceed a traditional scheduling algorithm, such as TSGW or RY, the efficiency far surpasses its peers, especially for large-scale problems. Our algorithm’s linear increase in the time spent on searching leads to a conspicuous advantage compared to other algorithms, thus making the proposed algorithm feasible and effective for engineering applications, especially in situations that involve real scheduling, rescheduling and on-line scheduling.
Further studies should focus on improving the evolutionary capacity of the proposed KMCFSSAEF algorithm by adopting a more suitable representation method of the system states that affect the learning quality. Another interesting issue is to study evolution algorithms of other extended types of flow shop problems, such as re-entrant flow and no-wait flow shop, based on the algorithm proposed in this article.
Footnotes
Appendix 1
Acknowledgements
The authors thank the Editor-in-Chief and Professor P. G. Maropoulos, the Associate Editor, and Mr Martin McDonald, the three anonymous reviewers and Professor Li Lu for their valuable comments and suggestions.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a key program of the National Natural Science Foundation of China under grant 60934008, the Fundamental Research Funds for the Central Universities of China under grant 2242014K10031, a Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions and the Jiangsu Province University Natural Science Research Project under grant 13KJB460005.