
Abstract
Customer requirement analysis has become a primary concern for companies who compete in the global market. Kano’s model, as a customer-driven tool, has been widely used for customer requirement analysis in product improvement. Although a number of authors have improved the traditional Kano’s model, there has been a limitation of dealing with the fuzzy and uncertainty of human thought under multi-granularity linguistic environment. Furthermore, the traditional Kano’s model faces problems regarding quantitative data computation and customer requirements importance assessment. In this article, an improved fuzzy Kano’s model is proposed to analyze customer requirements under uncertain environment. A 2-tuple linguistic fuzzy Kano’s questionnaire is developed to model the uncertainty and diversity of customers’ assessments using 2-tuple linguistic variables under multi-granularity linguistic environment. Then, a comprehensive and systematic methodology is presented to prioritize customer requirements through quantitative analysis of improved fuzzy Kano’s model. This method integrates subjective judgments assigned by decision maker, objective weights based on maximizing deviation method and customer satisfaction contribution to determine the priority ratings of customer requirements. A case study of combine harvester development is presented to evaluate the proposed model.
Introduction
As competition for new markets and customers increased, customer requirements (CRs) have been widely recognized as one of the primary factors determining the success for product design and development.1,2 Manufacturing enterprises make an effort to understand and fulfill CRs to increase customer satisfaction (CS) by improving their products or services.3–5 Various methods and tools have been developed accordingly to help companies obtain a better understanding of CRs. Among them, the Kano’s model has been widely practiced in industries as an effective tool for understanding CRs and their impact on CS.6,7
Problems
In general, Kano’s model is employed to elicit customers’ preferences toward products and services through questionnaire and extract CS. The Kano’s questionnaire and Kano evaluation table are used to categorize CRs into different Kano categories. The traditional Kano’s questionnaire (TKQ) method uses binary data to model the customers’ preferences. However, customer judgments tend to be imprecise and ambiguous due to their inadequate information and experiences, 8 so binary data are insufficient to capture preference, 9 and linguistic information is needed to model and manage uncertainty. Moreover, because of the different background and discrimination ability, the customers involved in Kano’s questionnaire may prefer to express their linguistic preferences using different linguistic term sets. Therefore, an effective approach to deal with the uncertain information expressed with multi-granularity linguistic terms in Kano’s model is highly needed.
The Kano’s model is inherently customer driven, that is, it focuses exclusively on addressing the concerns of customers. 10 However, the traditional Kano diagram only provides a rough sketch of the CS in relation to the product performance level and the qualitative descriptions of various Kano categories. In such a sense, limited quantitative analysis of the CRs is discussed in the traditional Kano’s model (TKM). The ultimate goal of CRs analysis is to provide decision support to product design. Although the Kano categories may enhance designers’ understanding of CRs, they fall short as accurate quantitative estimation. In practice, without accurate quantitative estimation, such a design support seldom holds true. Hence, the TKM faces problems regarding quantitative data computation and is deemed to be inadequate to facilitate decisions in product design.
Considering the inherent deficiencies of TKM, fuzzy set theory has been used in Kano’s model to deal with the imprecision and uncertainty in CRs.9,11 Meanwhile, some quantitative analysis approaches have been incorporated into Kano’s model to prioritize CRs. The quantitative analysis approaches can be classified into two types: one approach utilizes the Kano evaluation results to adjust the raw weights of CRs,12–17 the other derives the importance weights of CRs from the Kano evaluation results.18,19 These studies make it possible to handle uncertain information or make quantitative analysis in TKM. However, they ignore the imprecision and uncertainty under multi-granularity linguistic environment and has limited quantitative analysis of the CRs. To our knowledge, there has been little work reported in the literature in which both the comprehensive quantitative analysis and the fuzzy questionnaire under multi-granularity linguistic environment in Kano’s model are addressed simultaneously.
Objectives and organization of this article
To overcome the discussed problems, this study proposes an improved fuzzy Kano’s model (IFKM) for CRs analysis. In the IFKM, a 2-tuple linguistic fuzzy Kano’s questionnaire (TL-FKQ) is developed to use 2-tuple linguistic representation model to deal with uncertainty and vagueness of human judgment under multi-granularity linguistic environment. Furthermore, subjective judgments, objective information and impacts on CS derived from IFKM have been integrated to obtain quantitative and comprehensive CRs analysis.
This article is structured as follows. The “Literature review” section briefly introduces the theoretical background of the Kano’s model, and the 2-tuple fuzzy-linguistic model. “The proposed approach for CRs analysis” section describes the proposed approach in detail. The “Case study” section illustrates a case study of combine harvester to evaluate the proposed approach. The discussion and conclusion are presented in the “Discussion” and “Conclusion” sections, respectively.
Literature review
Kano’s model
Kano et al. 20 developed a two-dimensional model to explain the different relationship between CS and the performance of a product or a service. As shown in Table 1, the Kano’s model employs functional (the feature is present) and dysfunctional (the feature is not present) questionnaires and 5 × 5 evaluation table to determine different attributes. 20 According to evaluation table, the product attribute can be classified into one of the Kano categories, including attractive, one-dimensional, must-be, indifferent, reverse and questionable. Referring to Figure 1, Kano categories are briefly explained as follows:19,21,22
Attractive (A). The functional presence of these attributes will result in high level of CS, while their absence will not affect CS.
One-dimensional (O). The functional presence of these attributes will generate CS, while their absence will result in non-satisfaction.
Must-be (M). Customers take the presence of these attributes for granted. Insufficiency of these attributes will result in extreme non-satisfaction, but the sufficiency will not increase satisfaction level.
Indifferent (I). The attributes in this category, whether present or not, will not affect satisfaction.
Reverse (R). The presence of these attributes will generate non-satisfaction, and vice versa.
Questionable (Q). This outcome indicates that either the responses do not make any logical sense, or the question is sent incorrectly.
Kano evaluation table.
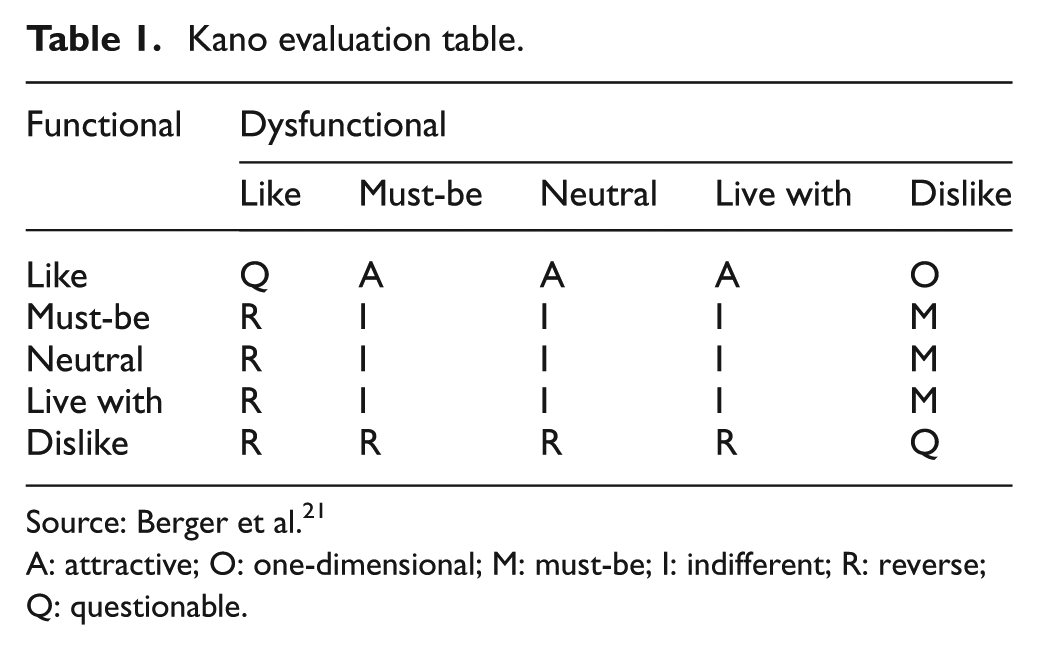
Source: Berger et al. 21
A: attractive; O: one-dimensional; M: must-be; I: indifferent; R: reverse; Q: questionable.
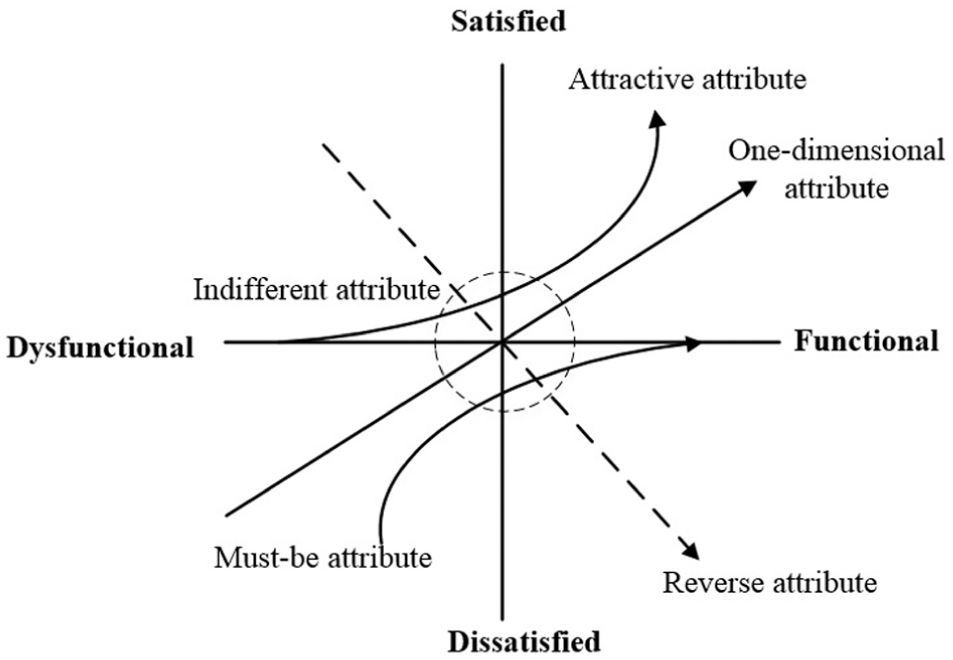
Kano’s model.
The Kano categories of product attributes are evaluated according to response frequencies.23,24 The highest frequency represents the dominant customer view. 25 The traditional Kano survey forces people to choose one answer from the survey, but it ignores the fuzzy and uncertainty factors that are related to human thinking when devising questionnaire. 9
The fuzzy set theory provides a robust way to manage the uncertainty and vagueness of human judgment. 26 Fuzzy set theory has been introduced into Kano’s model as an approach to effectively dealing with the inherent imprecision, vagueness of the human mentality and the languages.9,11,27 Lee and Huang 9 developed FKQ for respondents to express their multi-feeling in questionnaire items using membership and any numeric with their own wills. In addition, the fuzzy Kano’s model (FKM) is used for Kano evaluation to assist designers to get more and complete consumer’s real voice.9,11 However, FKQ consists of open-ended questions that require more time and effort from the respondents, and the FKM is a qualitative method. 11 Based on FKM presented by Lee and Huang, 9 Wu and Wang 11 proposed a continuous fuzzy Kano’s model (C-FKM) by introducing a modified fuzzy Kano’s questionnaire (MFKQ) and a continuous approach for fuzzy Kano evaluation. The MFKQ uses membership and numerical data to represent customer’s preference and consists of closed-ended questions that are easy and quick to answer. The continuous approach for fuzzy Kano evaluation makes it possible to prioritize CRs with quantitative analysis based on an evaluation index. However, the use of numerical data in FKQ and MFKQ to represent uncertain information is not always adequate. It is more suitable for respondents to provide their preferences by means of linguistic variables instead of numerical ones regarding the uncertain knowledge they have about the problem. 28 Moreover, because of different knowledge, background and discrimination ability, respondents may express their linguistic preferences in multi-granularity linguistic information. Furthermore, the quantitative analysis of CRs in C-FKM is basically determined by customers’ subjective evaluations and predefined influence values, which ignores the objective information, and may cause a subjective bias.
Quantitative evaluation of Kano’s model
Kano’s model has been adopted by many researchers as a useful tool to quantify customer perceptions and achieve better design. Berger introduced two quantitative CS coefficients in Kano’s model, named as satisfaction index (SI) and dissatisfaction index (DI) to reflect the average impact of a CR on CS or dissatisfaction. Then, the CS coefficients have been modified and utilized as adjustment factor for re-prioritizing CRs to achieve maximum CS.12–14 Another weight adjustment method is to use Kano parameters that are assigned according to Kano categories.15–17 For instance, Chen and Chuang
15
introduced an adjustment coefficient (K) and the raw weights were adjusted by multiplying with K. The value of K varies according to Kano category, and values of “4,”“2,”“1” and “0” were assigned to the attractive, one-dimensional, must-be and indifference categories, respectively. In addition, Chaudha et al.
29
proposed to use the combination of CS coefficients and the respective K of Kano category as an adjust factor to re-prioritize CRs. These aforementioned approaches make it possible to quantify the information provided by the Kano’s model and integrate Kano’s model to decision support for enhancing CS. However, they ignore the imprecision and uncertainty in CRs. Moreover, the use of arbitrary K values leads to the subjectivity and arbitrariness. In fact, K values may vary in different circumstances. For instance, the priority list of Kano categories for growing-period products could be
Other approaches extend Kano’s model from qualitative descriptions to quantitative analysis to derive the importance weights of product attributes.18,19 Wang and Hsueh 19 proposed to use Kano’s model to obtain the relative weight of CRs through normalizing the satisfaction range defined by SI and DI. However, this method ignores the imprecision and uncertainty in CRs. Moreover, they overlook the objective information that could be critical for the priorities of CRs. Wang 18 introduced information entropy into FKM to derive the objective important weights of product attributes, and the approach is named as entropy-based fuzzy Kano’s model (E-FKM). In their study, information entropy is applied to measure the variation of discrete probability distribution among various Kano categories. However, as described in section “Kano’s model,” it is not adequate to use numerical data in FKQ to represent uncertain information. Moreover, they overlook the subjective assessments and multi-granularity linguistic information.
The 2-tuple fuzzy-linguistic approach
As a fuzzy-linguistic approach, the 2-tuple linguistic representation model is a continuous model for linguistic evaluation information representation, combining numerical and linguistic data without information loss during the integration procedure.28,30 The 2-tuple fuzzy-linguistic representation model represents the linguistic information by a 2-tuple
This linguistic representation model defines a set of functions to facilitate linguistic computational processes:
Definition 1
Let

Definition 2
Let
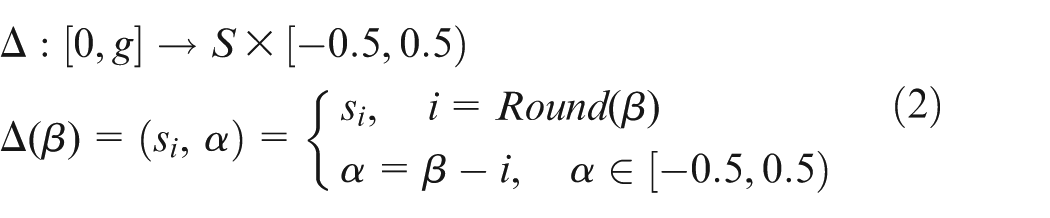
where
Definition 3
Let
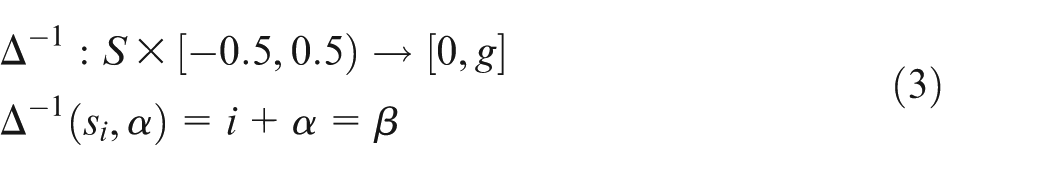
Definition 4
Let
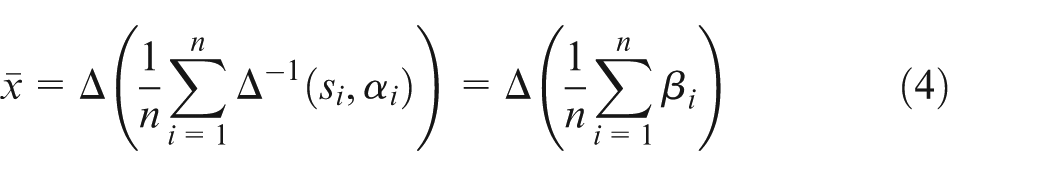
Definition 5
Let
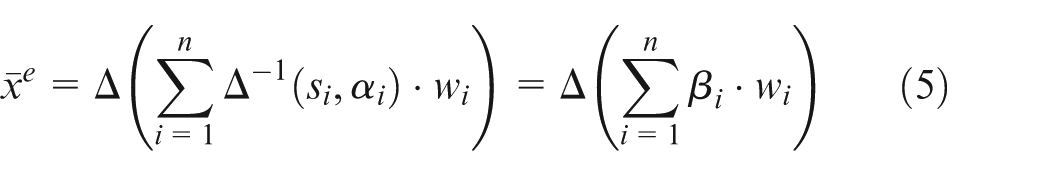
Definition 6
Let
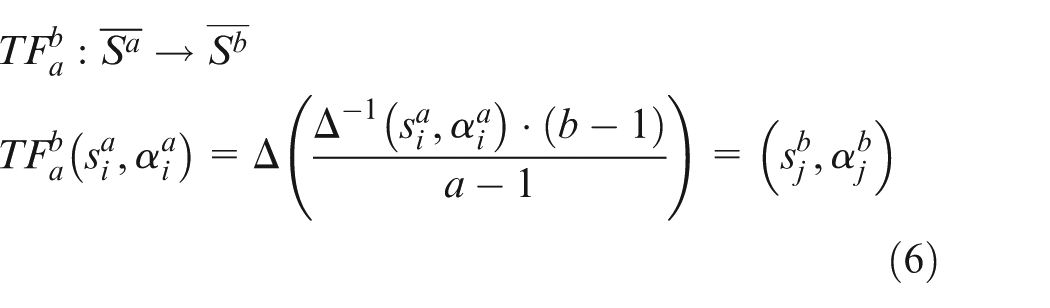
The proposed approach for CRs analysis
The objective of this research is to develop IFKM to better prioritize CRs. IFKM follows the theoretical foundation of TKM and FKM. 9 A TL-FKQ is developed in IFKM to deal with the uncertainty and diversity of customers’ assessments under multi-granularity linguistic environment. Then, a quantitative approach is proposed to analyze the data gathered through IFKM. Finally, the quantitative analysis results are integrated to determine the priority ratings of CRs.
Improved FKM
In most actual situations, many respondents are involved in the Kano’s questionnaire. Because of the different background and discrimination ability, they may prefer to express their linguistic preferences using different linguistic term sets. Therefore, this study proposes a TL-FKQ based on 2-tuple linguistic representation model under multi-granularity linguistic environment. Unlike the original FKQ and MFKQ, a respondent can freely express self-feelings using a 2-tuple
Suppose that in a product design, V respondents denoted by
Based on above assumptions or notations, the procedure of IFKM can be described as follows.
Step 1. The multi-granular linguistic information
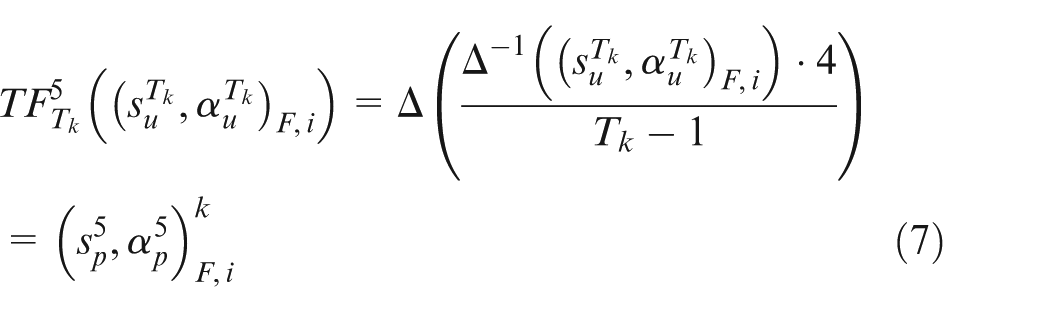
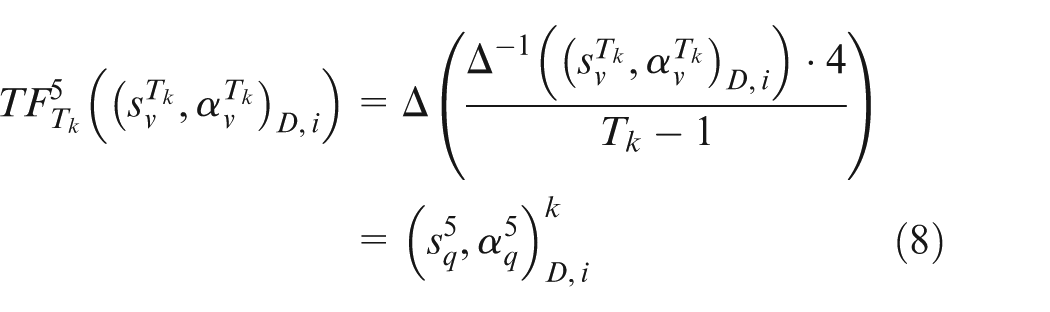
where
Step 2. Calculate the membership degrees of
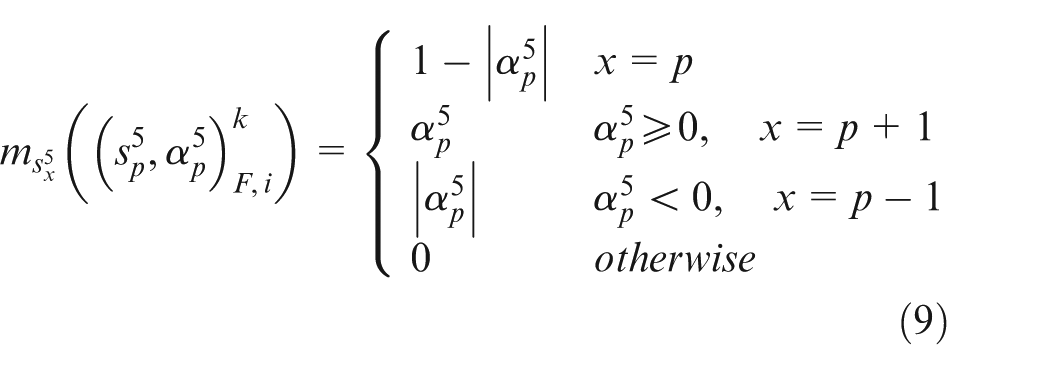
where
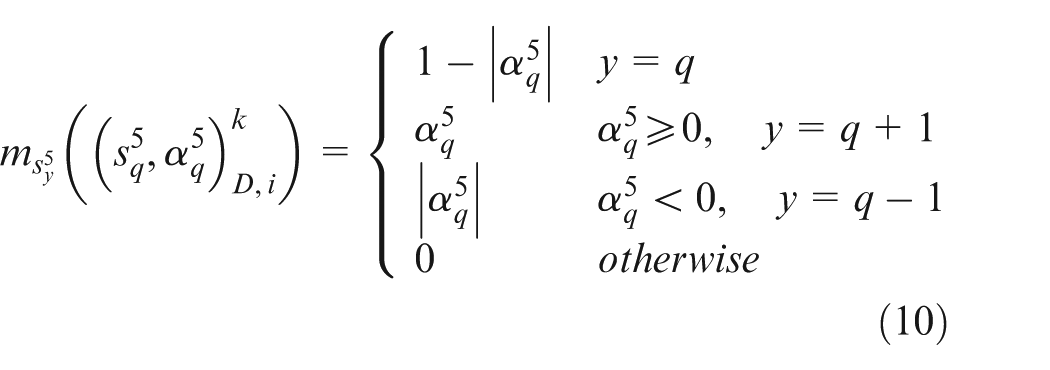
Step 3. Calculate the possibility degrees among Kano categories of
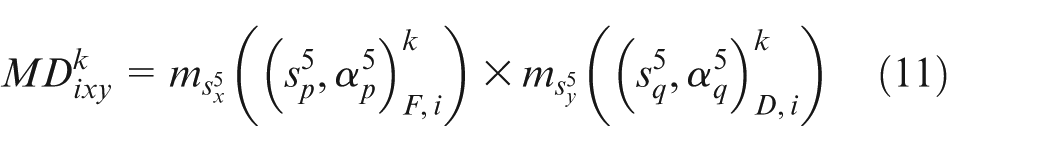
The possibility degree

where
Step 4. Calculate the probability distribution among Kano categories of

For convenience, the percentages among various Kano categories of

Quantitative analysis of IFKM
The importance weight of CR is a critical step for customer-oriented product development to achieve higher CS, and systematic quantitative analysis of Kano’s model should be committed to properly acquire the final importance weights of CRs in order to keep related product improvement successful. Different CRs may not be of the same importance to a particular respondent, and a certain CR may not be of the same importance to different respondents. 11 Thus, it is necessary to analyze the subjective importance weights to prioritize CRs. However, the subjective importance weights of CRs are solely determined according to the preference or judgments of decision makers and may cause a subjective bias. The objective importance weights should be utilized in CRs analysis to balance the influence of subjective factors. In addition, CRs in different kinds of the Kano’s categories affect CS in a different way. Thus, the important weights for achieving the desired CS of CRs are different and are effected by the Kano’s categories for CRs. To achieve the total CS in an economic way, the importance rating for achieving the desired CS of a CR, defined as Kano importance weights, should be taken into account. To make accurate and deep understanding of CRs, this section conducts comprehensive quantitative analysis of IFKM, including subjective importance weights analysis, objective importance weights analysis and Kano importance weights analysis. Then, the quantitative results are integrated to determine the final importance weights of CRs.
Determining the subjective importance weights of CRs
This article adopts a self-stated importance questionnaire in parallel with the TL-FKQ to determine the subjective importance weights of CRs. Respondents are asked to estimate the raw importance of each CR on a particular linguistic term set
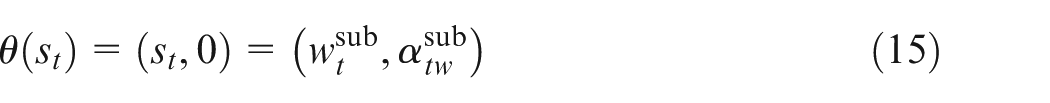
The relative frequency

where
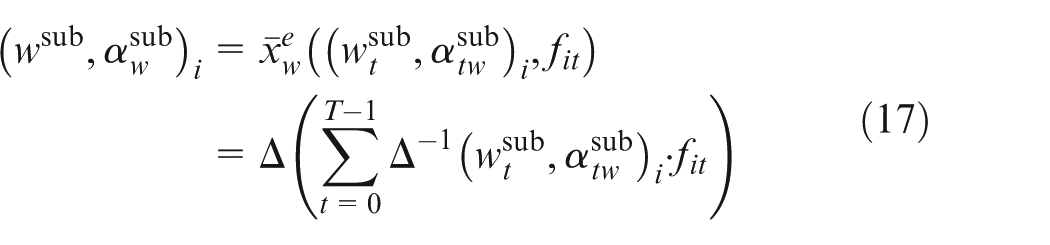
The normalized subjective importance weight of
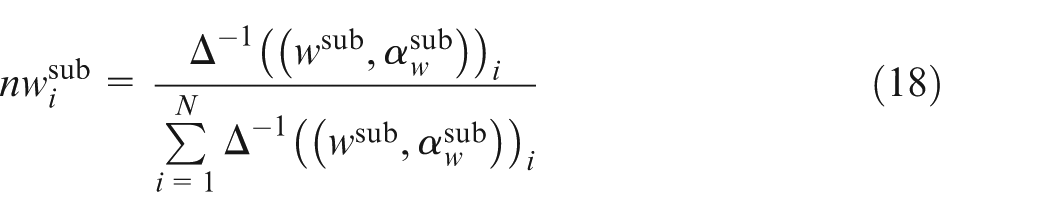
For convenience, the vector of the normalized subjective importance weights of CRs can be described as
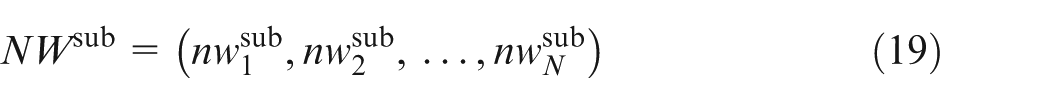
Determining the objective importance weights of CRs
The objective weights are determined by solving the mathematical models based on objective methods, including entropy method, standard deviation method, maximizing deviation method and so on.32,33 Entropy method is applied to attributes’ discrete percentages among Kano categories for deriving the objective importance weights of product attributes by Wang.
18
It assumes that when an attribute possesses small variation (i.e. balanced distribution) among Kano categories, it has lower importance weight, and vice versa. For the Kano categories evaluation results represented in equation (14), if the difference is smaller among all percentage values of all Kano categories under
The maximizing deviation method proposed by Wang
34
is used to determine the attribute weights. The deviation method is selected here to compute the difference of percentage values of Kano categories. For
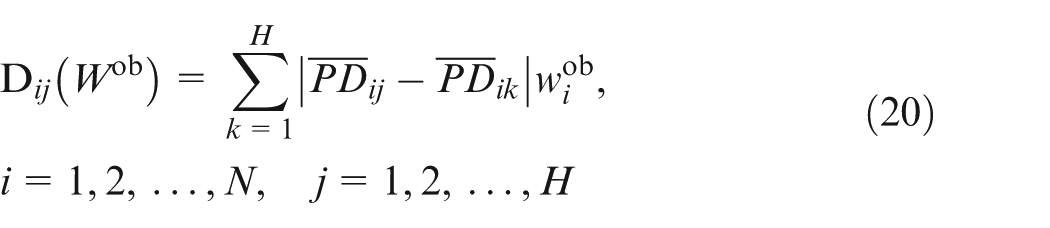
where
Let
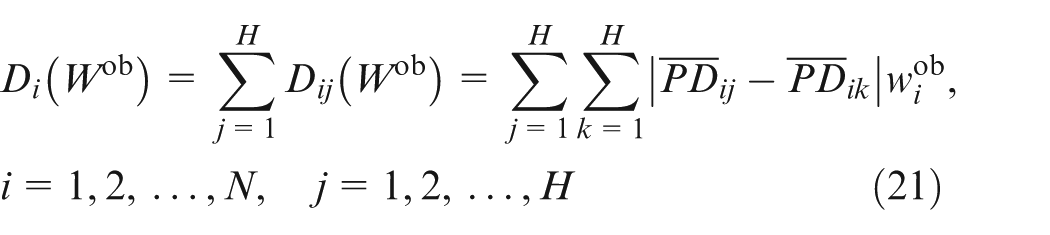
Based on above analysis, the reasonable weight vector

Therefore, the maximizing deviation model is constructed as follows
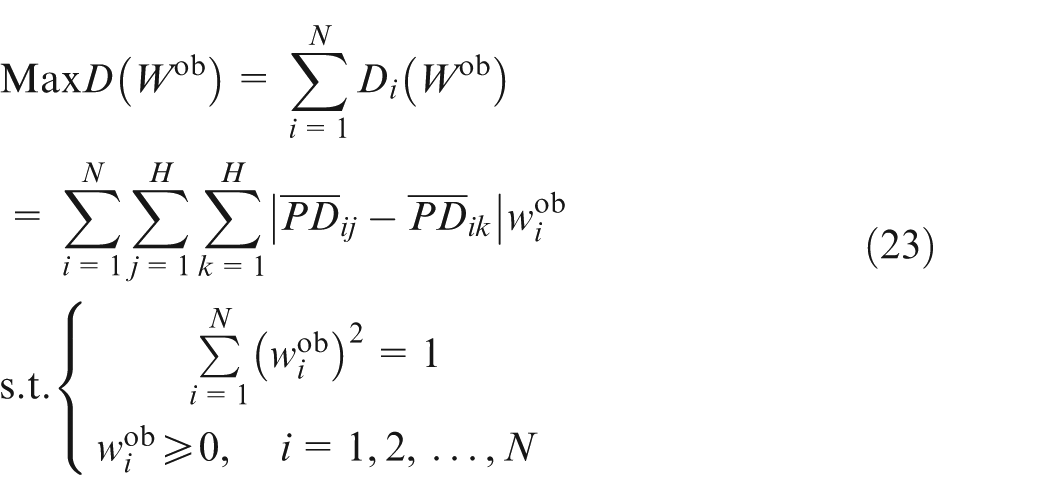
Equation (23) is a non-linear programming model. According to the proof provided by Li et al.,
35
the optimal solution
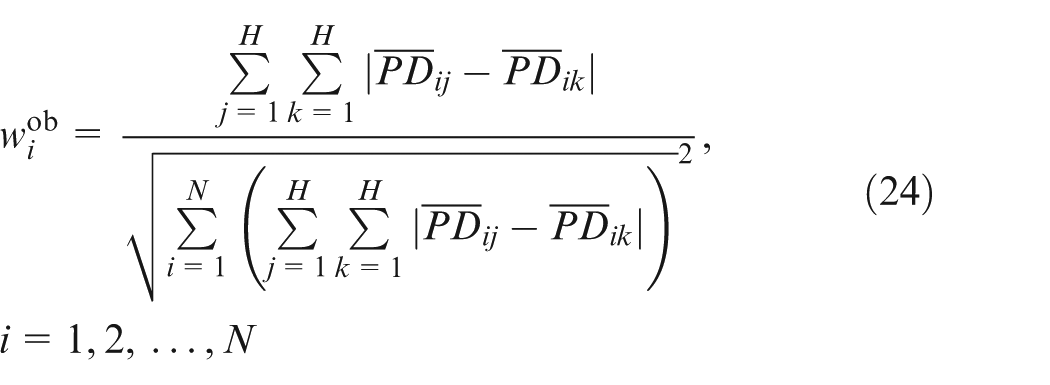
Then,
For convenience, the vector of the normalized objective importance weights of CRs can be described as
Determining the Kano importance weights of CRs
A Kano’s questionnaire helps categorize CRs related to consumer satisfaction into different types of qualities and indicates how much attention should be paid to each CR to achieve the desired CS. 15 In this section, Kano importance weight based on the Kano classification is used to re-prioritize the CRs for enhancing CS.
Let
Membership function of linguistic scale

Assume the
where
Then the normalized triangular fuzzy weight vector of KC, which is expressed as

The detailed formulation process and meanings of the objective and associated constraints for the optimization model of FLLSM are not discussed here and can be referred in reference of Wang et al.
36
Equation (28) is a constrained non-linear optimization model, whose constraints are all linear and can be solved without difficulty by Microsoft Excel Solver or professional optimization software packages such as LINGO or MATLAB.
36
The optimum solution to the above model directly forms normalized fuzzy triangular weight
Then, Kano importance weights
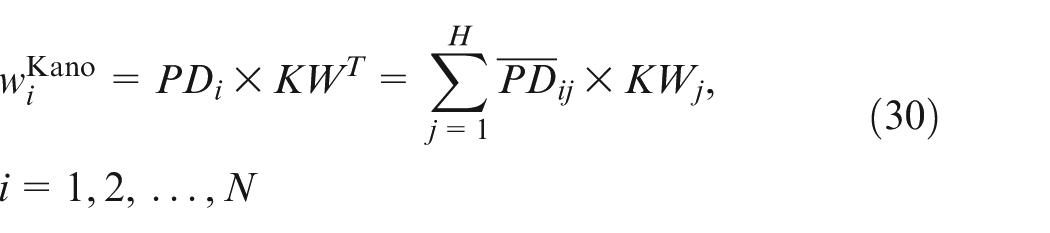
The normalized Kano importance weight

For convenience, the normalized Kano importance ratings of CRs can be described as a vector

Determining the final importance weights of CRs
The subjective importance weight represents the respondents’ preference or judgments, the objective importance weight can effectively balance the influence of subjective factors, while Kano importance weight represents the impact on desired CS. CR with larger subjective importance weight, larger objective importance weight and larger Kano importance weight should receive higher attention. Therefore,
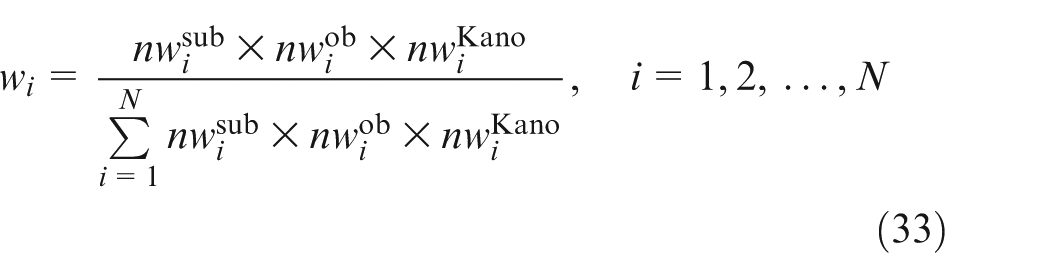
Of course, a weighted sum of

Case study
To demonstrate the applicability performance of the proposed methodology, a case study of CRs analysis in combine harvester development is described in this section. W company is a manufacturer that designs combine harvester. According to the attributes which W company currently provides, this case study focuses on nine major CRs which are identified to represent the biggest concerns of the customers. They are “good operating flexibility”
Step 1: Kano survey
TL-FKQs were designed and distributed to various customers and engineers. In this research, 160 effective samples were collected. Each respondent was required to use 2-tuples to answer the functional and dysfunctional questions with respect to each CR in the TL-FKQ. In addition to BLTS


Linguistic labels for TL-FKQ

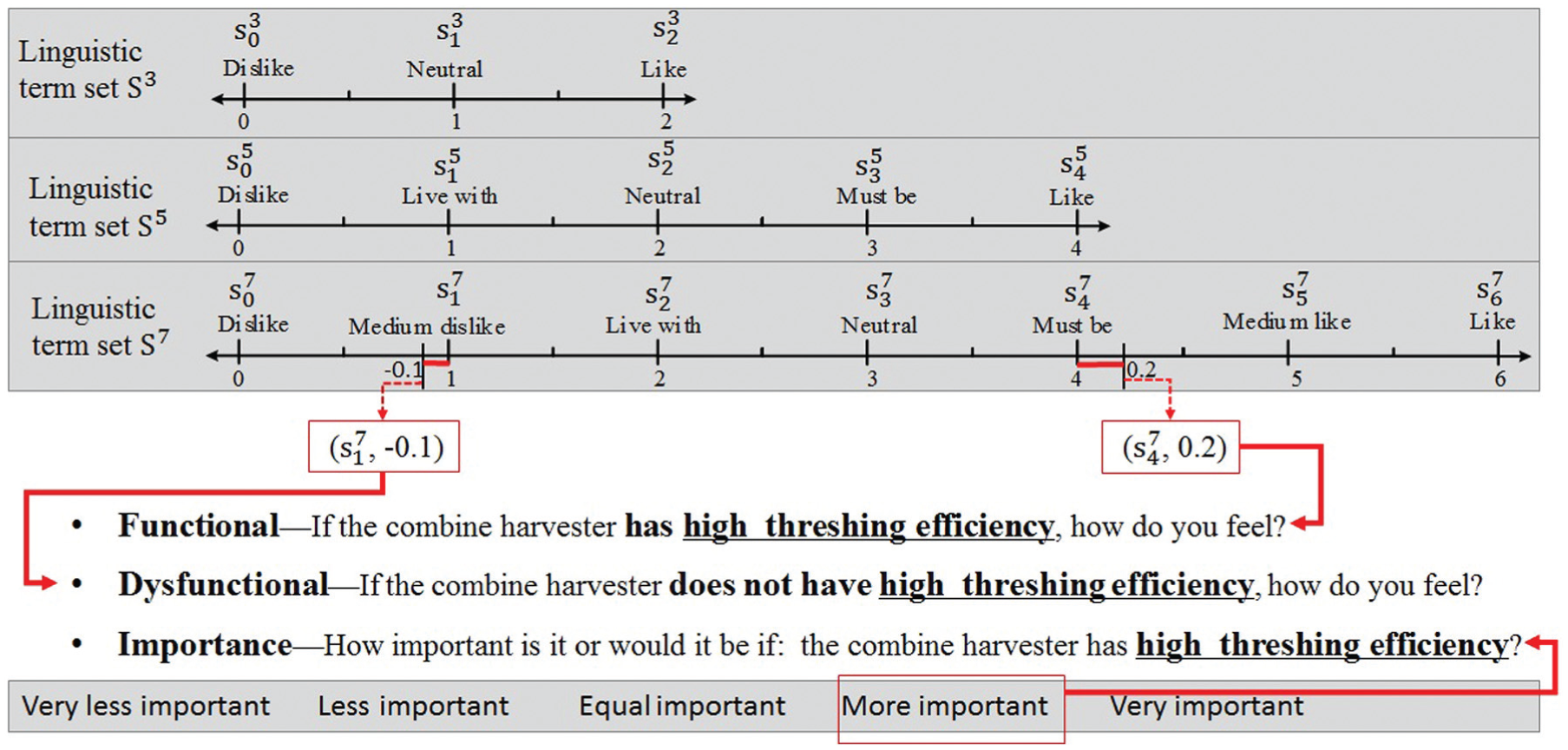
A part of the TL-FKQ used in the survey on combine harvester.
Using

The two-dimensional attribute classification with respect to
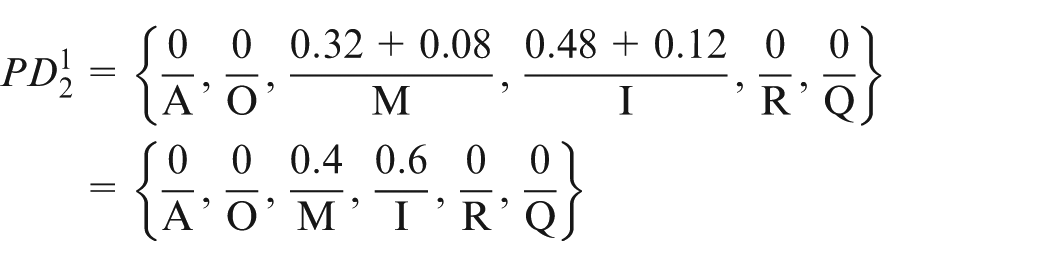
Once all respondents have completed their surveys on CRs, the results are aggregated and displayed in Table 4. For instance,
Experimental results through IFKM.
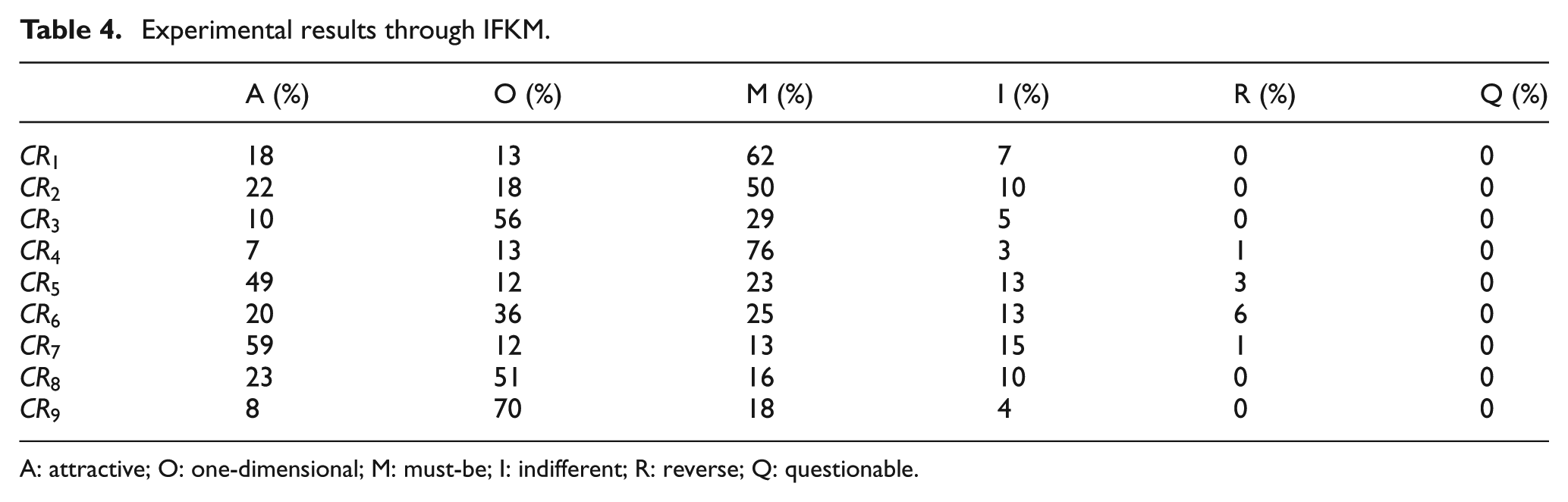
A: attractive; O: one-dimensional; M: must-be; I: indifferent; R: reverse; Q: questionable.
Step 2: Determining the subjective importance weights of CRs
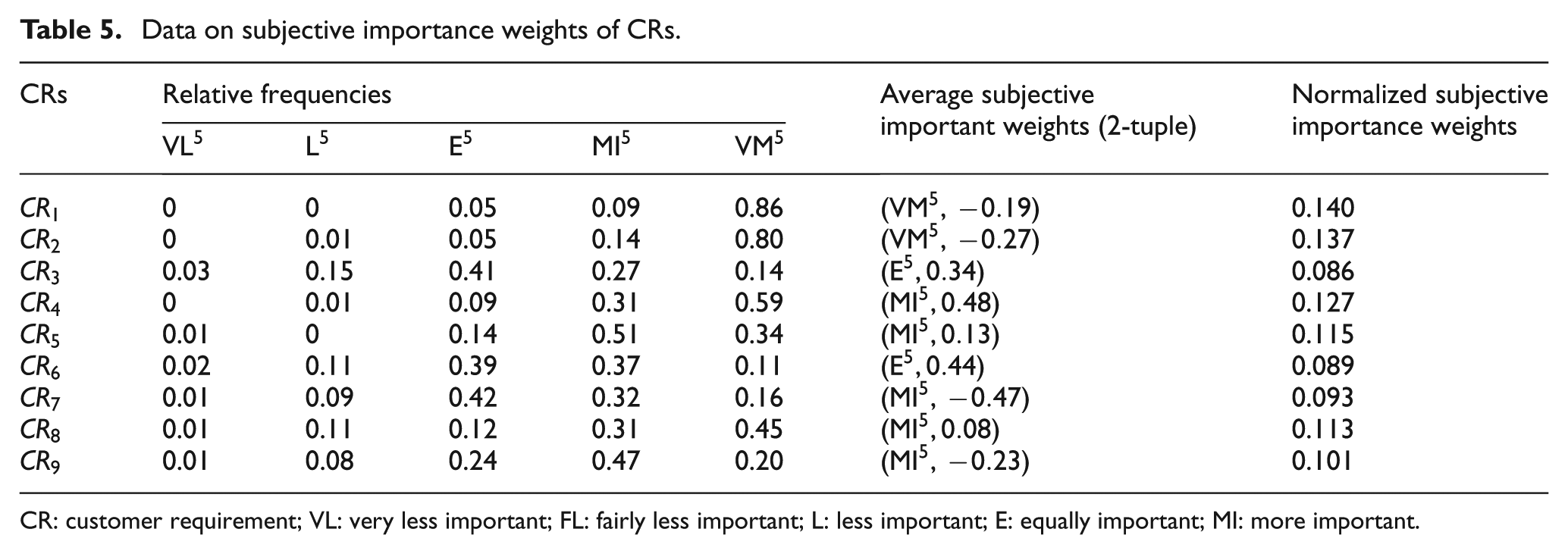
In parallel with TL-FKQ, customers were asked to assess the raw importance of each CR with linguistic term set T5 (Table 2), as shown in Figure 2. Table 5 shows the relative frequencies of these linguistic terms for nine CRs. According to equation (17), a 2-tuple weighted average is calculated to infer the subjective importance of each CR. Using equation (18), the vector of the normalized subjective importance weights for nine CRs is obtained as
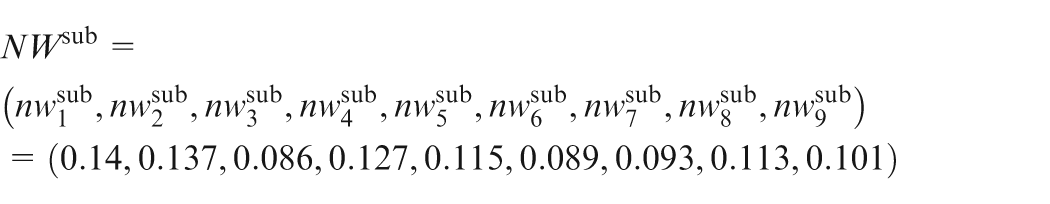
Data on subjective importance weights of CRs.
CR: customer requirement; VL: very less important; FL: fairly less important; L: less important; E: equally important; MI: more important
Step 3: Determining the objective importance weight of CRs
Subsequently, based on the percentages among discrete Kano categories in Table 4, the objective importance weights of CRs are derived using maximizing deviation method (MDA). Using equations (23) and (24), the vector of the normalized objective importance weights of these nine CRs is obtained as

Step 4: Determining Kano importance weights of CRs
In this step, the fuzzy pairwise comparison approach is used to achieve the important weights of the Kano categories. The “Questionable” category is not considered in determining the importance weight of the CRs since it can be revised by changing the Kano’s questionnaire. The product development strategy is the main factor considered in this evaluation. There are eight DMs (product designers and development experts) that were invited to evaluate the relative importance of five Kano categories (A, O, M, I, R) with linguistic term set
The fuzzy pairwise comparison matrix

Once eight DMs have completed their linguistic evaluations on KCs, the five fuzzy weights are achieved using equation (28). According to equation (29), these fuzzy weights are converted into crisp measures, and importance weights of KCs are obtained as
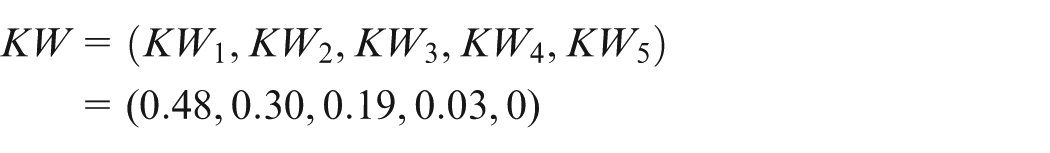
Then, according to the percentages among discrete Kano categories (Table 4) and the importance weights of KCs, the vector of the normalized Kano importance weights of CRs can be obtained using equations (31) and (32) as
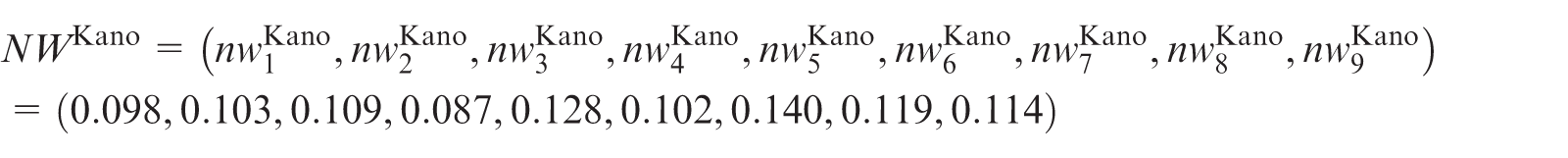
Step 5: Determining the final importance ratings of CRs
The final importance rating of each CR is decided by its subjective importance weight, objective importance weight and Kano importance weight. Using equation (33), the vector of the final importance weights of CRs is determined as
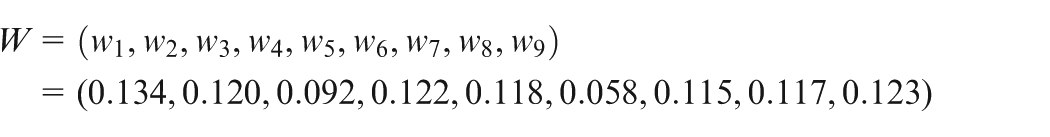
As show in Figure 3, CR with larger subjective importance weight, larger objective importance weight and larger Kano importance weight gets larger final importance weights and should receive higher attention. Specially, the top four priorities present an order of
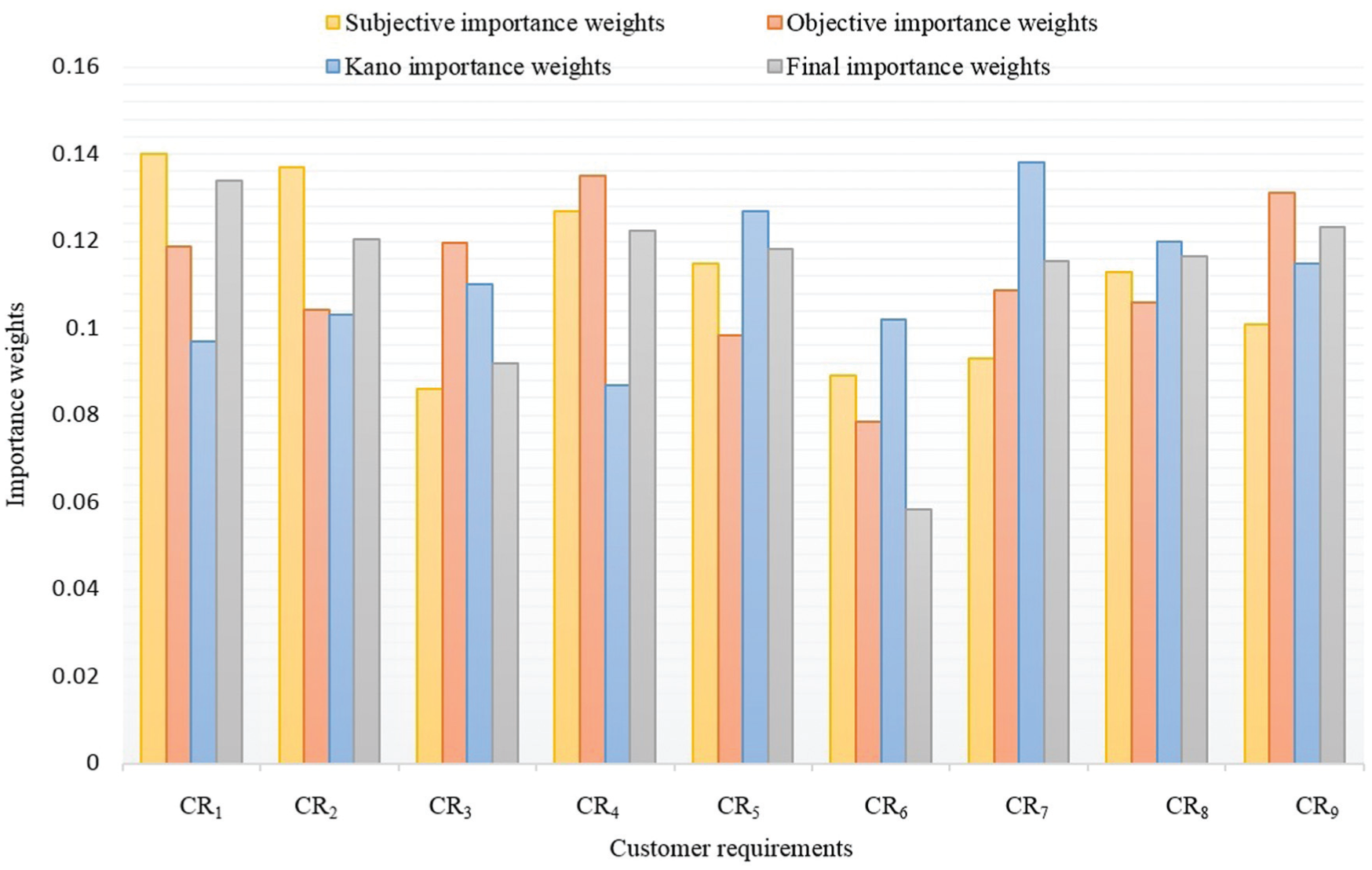
Results of the quantitative analysis.
Discussion
To validate the effectiveness of the IFKM method, three typical Kano’s model of the published researches are selected to conduct a comparative study. They are TKM, 21 E-FKM 18 and C-FKM. 11 Details of the three published models are not discussed here and can be referred in the literature.11,18,21 In section “Literature review,” TKM is mentioned as a qualitative method without fuzzy information; C-FKM and E-FKM are mentioned to incorporate fuzzy set theory and quantitative evaluation into Kano’s model simultaneously for CR analysis. To signify the difference of TKM, E-FKM, C-FKM and IFKM, further comparisons of these four approaches on Kano questionnaires and analysis results are provided.
First, the comparison of TKQ used in TKM, FKQ used in E-FKM, MFKQ proposed in C-FKM and TL-FKQ developed in this study is conducted. In TKQ, respondents are forced to choose one answer from the survey. In FKQ, respondents express their feelings about each question by assigning a percentage to each answer. In MFKQ, the five standard answers (dislike, live with, neutral, expect and enjoy) in Kano’s questionnaire are presented on “1 to 5” scale, and respondents express their feelings by choosing a numerical value ranged in [1, 5]. The answers of five respondents to the issue of “If the combine harvester has or does not have high threshing efficiency, how do you feel?” are listed in Table 6. In comparison of Table 6, it is found that the binary logic questionnaire of TKQ only considers crisp descriptions and cannot handle uncertainty of human thinking. FKQ and MFKQ use numerical data to represent the uncertainty and ambiguity in Kano’s questionnaire. However, the use of numerical-based modeling to represent uncertain information is not always adequate, and it is more suitable for respondents to provide their preferences by means of linguistic variables under multi-granularity linguistic environment. 20 As a fuzzy-linguistic approach, the 2-tuple representation model used in TL-FKQ assists respondents to express their feelings using different linguistic term sets, which can improve the accuracy and understanding of the results.
Answers for TFQ, FKQ, MFKQ and TL-FKQ.
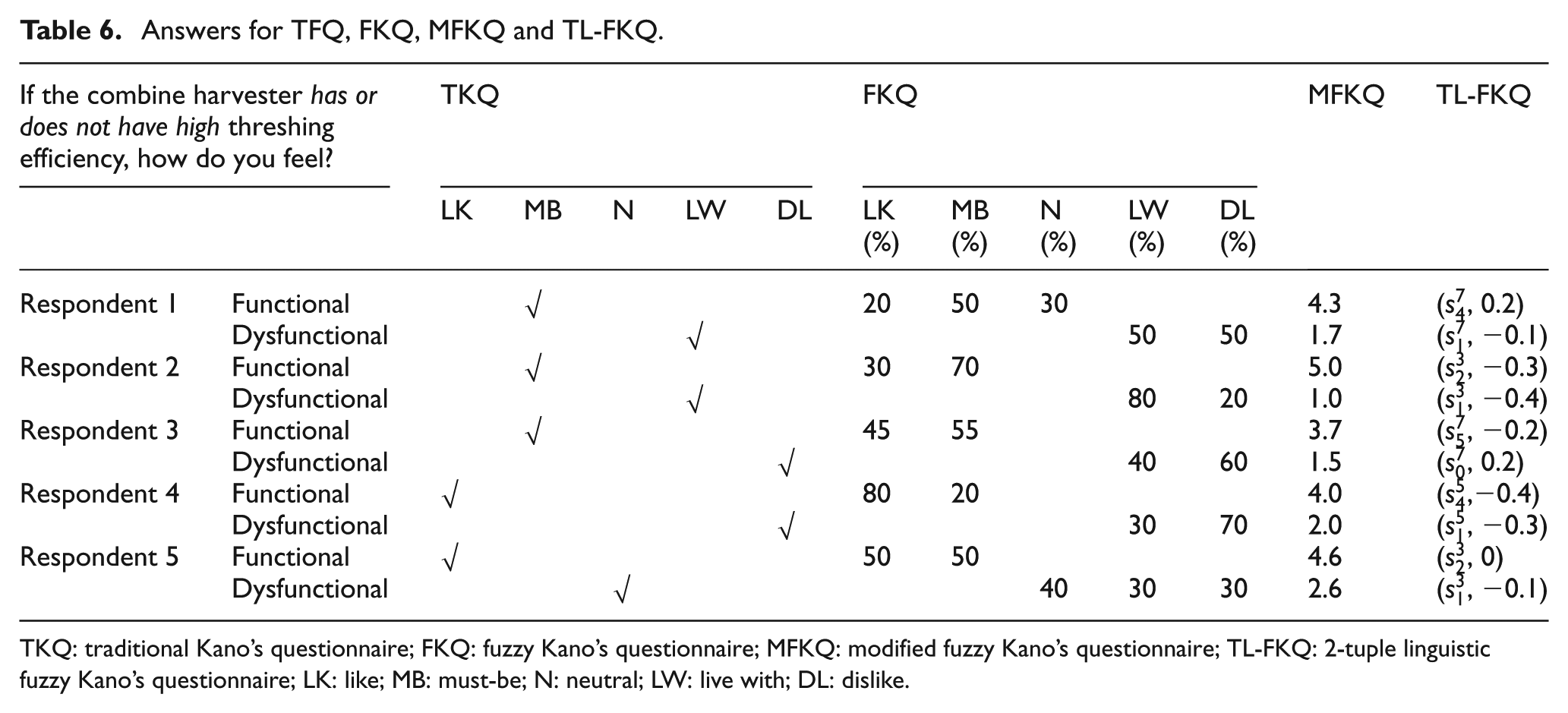
TKQ: traditional Kano’s questionnaire; FKQ: fuzzy Kano’s questionnaire; MFKQ: modified fuzzy Kano’s questionnaire; TL-FKQ: 2-tuple linguistic fuzzy Kano’s questionnaire; LK: like; MB: must-be; N: neutral; LW: live with; DL: dislike.
Then, comparison of CR analysis based on the corresponding Kano’s models is conducted and the results are shown in Table 7. In TKM, CRs are classified into different Kano categories according to the Kano evaluation table in Table 1. Designers rank CRs based on the Kano categories in the following order: must-be > one-dimensional > attractive > indifferent. 21 However, such approaches cannot distinguish CRs within the same category. Hence, the qualitative analysis of TKM is deemed to be inadequate to facilitate decisions in product design. Compared with the TKM, E-FKM, C-FKM and IFKM can help designers prioritize CRs based on the quantitative analysis. As can be seen from Table 7, the three models lead to different Kano evaluation results and ranking orders. One reason for this is because they tackle uncertain information of Kano’s questionnaire in different manners, which has been discussed above. Another reason lies in the different quantitative analysis methods adopted by these models. E-FKM derives the objective important weights of CRs using information entropy, which cannot consider the subjective judgment and the impact of each CR on desired CS. C-FKM prioritizes CRs using an evaluation index, which is determined by the subjective importance weights and the influence values considering the contribution of CS based on Kano evaluation results. However, this approach ignores to compensate the subjective factors with objective information. While IFKM determines the priority ratings of CRs by integration of the subjective judgment with self-stated importance questionnaire, the objective importance weights are acquired using MDA and the importance ratings of achieving the desired CS obtained with fuzzy pairwise comparison and FLLSM. Thus, the IFKM allows quantitative analysis of CRs in a thorough and comprehensive manner and prioritizes CRs more accurately than TKM, E-FKM and C-FKM.
CRs analysis results of TFM, E-FKM, C-FKM and IFKM.
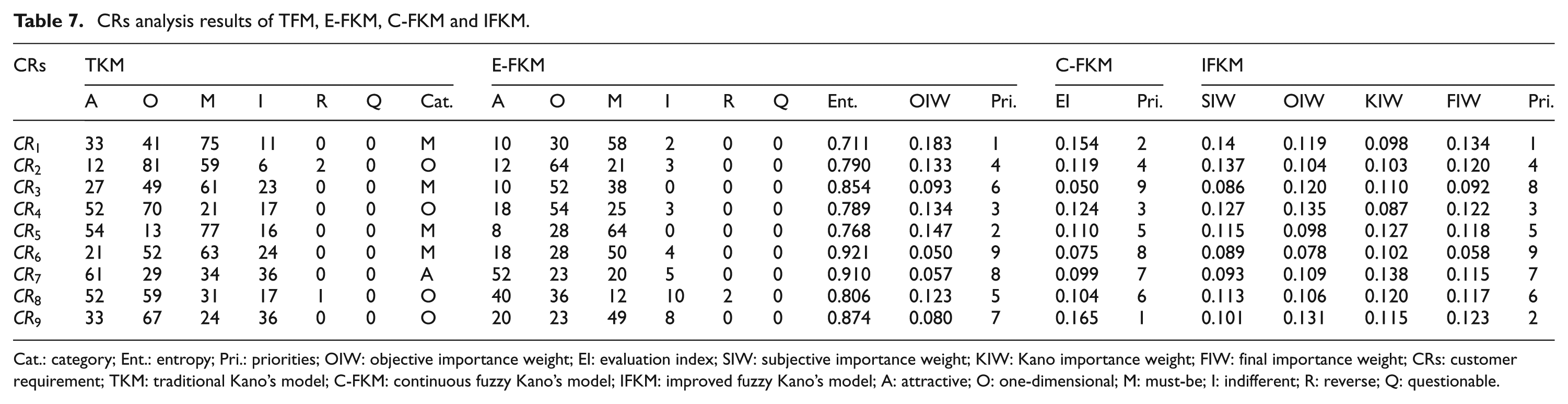
Cat.: category; Ent.: entropy; Pri.: priorities; OIW: objective importance weight; EI: evaluation index; SIW: subjective importance weight; KIW: Kano importance weight; FIW: final importance weight; CRs: customer requirement; TKM: traditional Kano’s model; C-FKM: continuous fuzzy Kano’s model; IFKM: improved fuzzy Kano’s model; A: attractive; O: one-dimensional; M: must-be; I: indifferent; R: reverse; Q: questionable.
Overall, the IFKM can improve the Kano’s model by developing a TL-FKQ to deal with the uncertainty under multi-granularity linguistic environment and presenting a systematic and comprehensive approach to make quantitative analysis of CRs to rate the final importance of CRs.
Conclusion
Determining the final importance weights of CRs is a fundamental problem in product development. In this article, a systematic and operational approach is proposed to get a better understanding of CRs through quantitative analysis of IFKM. The IFKM develops a TL-FKQ to deal with the imprecision and uncertainty in CRs effectively based on 2-tuple linguistic representation model under multi-granularity linguistic environment. With TL-FKQ, linguistic assessment information is managed as a continuous range, without information loss during the integration procedure. Meanwhile, the IFKM-based quantitative analysis method is proposed to determine the final importance weights of CRs. The proposed methodology is a comprehensive weighting mechanism with the integration of subjective judgments, objective information and the importance weights of achieving desired CS of CRs. It provides a way for Kano’s model to be integrated with other mathematical models or tools for exploiting data gathered through IFKM in a systematic and comprehensive way. To fully illustrate the proposed approach, a case study of combine harvester development is provided. With the proposed method, decision makers can understand CRs in a more accurate way and make more subtle decisions.
Finally, the future research potentials of the proposed approach are pointed out: in addition to the Kano survey results, more factors that affect the priorities of CRs may be considered; more accurate methods for determining the importance weights for achieving the desired CS of a CR may be developed; the self-stated importance questionnaire and fuzzy pairwise comparison method may be improved under multi-granularity linguistic environment.
Footnotes
Acknowledgements
The author would like to thank Shanghai Research Center for Industrial Informatics for the funding support to this research.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.