
Abstract
Uncertainty in fertility intentions is a major obstacle to understanding contemporary trends in fertility decision-making and its outcomes. Quantifying this uncertainty by structural factors such as income, ethnicity, and housing conditions is recognized as insufficient. A recently proposed framework on subjective narratives has opened up a new way to gauge factors behind fertility decision-making and uncertainty. Through surveys, such narratives can be elicited with open-ended questions (OEQs). However, analyzing answers to OEQs typically involves extensive human coding, imposing constraints on sample size. Natural Language Processing (NLP) techniques assist researchers in grasping aspects of the underlying reasoning behind responses with much less human effort. In this study, using automatic neural topic modeling methods, we identify and interpret topics and themes underlying the narratives on fertility intention uncertainty of women in the Netherlands. We used Contextualized Topic Models (CTMs), a neural topic model using pre-trained representations of Dutch language, to conduct our analyses. Our results show that nine topics dominate the narratives about fertility planning, with age and health-related issues as the most prominent ones. In addition, we found that uncertainty in fertility intentions is not homogeneous, as women who feel uncertain due to real-life constraints and those who have no fertility plans at all put their stress on vastly different narratives.
Introduction
Understanding contemporary fertility trends has been a major challenge for demographic researchers and policymakers. Many macro- and micro-level factors have been uncovered that partially explain fertility decisions and outcomes (Balbo, Billari & Mills, 2013; Mills & Rahal, 2021). Yet, current theoretical frameworks struggle to predict recent events, such as the continuous fertility downturn in many European countries (Beckert, 2016) and the temporary boosted fertility rate during the COVID-19 pandemic in Finland (Nisén et al., 2022; Rotkirch, 2020). In trying to expand insights into people’s fertility decision-making processes in the European context, people’s perception of uncertainty about the world and the short-term and long-term future is argued to be missing (Bhrolcháin & Beaujouan, 2019). Therefore, it is not enough to only analyze structural, objective indicators (e.g., age, income, and education level), as they only describe pre-existing conditions. Huinink and Kohil (2014) proposed that a life-course approach is needed to understand fertility, which involves highlighting the impact of the past and anticipation of the future. In the Narrative Framework (Vignoli et al., 2020), which incorporates individuals’ subjective narratives of their future, fertility decisions are based on a combination of “shadows of the past” and “narratives of the future.” Although the Narrative Framework originally focused on the role of economic uncertainty in influencing fertility decisions, it is arguably natural to also expand our exploration to narratives on other topics where uncertainty is observed, such as partnership status (Bolano & Vignoli, 2021; Cavalli & Klobas, 2013), health conditions (Fergus & Bardeen, 2013), and aging (Kuhnt, Minkus & Buhr, 2021).
To analyze narratives and uncertainty on fertility intentions in a systematic way, we face limitations in both our theoretical framework and methodology. While narratives about the future are proposed as the key in accounting for uncertain conditions (Vignoli et al., 2020a) and further understanding fertility intentions (Bachrach & Morgan, 2013), operationalizing the analysis of narratives and mapping them onto more formal measurements are challenging. In addition, understanding and coding what people simultaneously perceive the future will be like, as well as cleaning and analyzing the textual data through traditional qualitative methods, would be strenuous and non-scalable in large sample studies.
In this study, we use online open-ended questions (OEQs) in a survey to collect the narratives behind the uncertainty in the fertility intentions of Dutch women. We use Topic Modeling, a Natural Language Processing (NLP) method, to automatically analyze the textual data, which allows us to interpret large-scale survey qualitative data. In the following sections, we identify the major narratives on what could make people certain or uncertain about their plans to have children. Depending on respondents’ economic, partnership, or motherhood situation, their narratives may differ: therefore, we also evaluate qualitatively the topics used by different subgroups.
Our study contributes to the literature in the following ways: first, we employ text analysis techniques on free-text data, advancing empirical research based on the Narrative Framework. Second, with these techniques we provide general qualitative insights about the narratives on fertility uncertainty expressed by Dutch women, and on a scale larger than in qualitative studies on the same topic. Finally, as a technical innovation to demographic survey analysis, we introduce state-of-the-art neural topic models based on the pre-trained large language model (LLM) in the topic modeling approach.
Background
Fertility Intentions, Uncertainty, and Narratives
Fertility intentions, for example, the intentions to have a child within a set future period, are routinely recorded through close questions in many large-scale demographic surveys, including the Demographic and Health Surveys (DHS) (Corsi et al., 2012), the British General Household Survey (GHS) (Hough & Mayhew, 1983), and the Generations & Gender Surveys (GGS) (Vikat et al., 2007), which cover Europe and other high-income countries. Fertility intentions represent one’s perceived constraints in reaching their ideals, lying between the ideal family size and the actual fertility outcome (Brinton et al., 2018).
Many previous studies have identified factors that are impactful on fertility intentions, such as age, migration status (Guetto & Panichella, 2013), economic stability (Comolli & Vignoli, 2021), and union formation (Lesthaeghe, 2020). In addition, the rising economic employment instability (Gatta et al., 2021; Schneider, 2015), the changing cohabitation and marriage patterns (Sassler & Lichter, 2020), and the global COVID-19 pandemic (Guetto, Bazzani, Vignoli & others, 2020; Zhu et al., 2020) have all added uncertainty to the fertility decision-making progress, which makes understanding them a more pressing issue in fertility studies.
While researchers attempted to use responses on fertility intentions as a predictive factor for whether and when people have children (Freitas & Testa, 2017; Liefbroer, 2009; Morgan & Rackin, 2010; Trinitapoli & Yeatman, 2018), the utility of measuring fertility intentions in predicting individual (or couples’) fertility outcomes has been controversial because intentions often deviate from outcomes (Müller et al., 2022; Sennott & Yeatman, 2018). One reason for this may be the prevalent uncertainty in those intentions (Bhrolcháin & Beaujouan, 2019). People often feel uncertain about their fertility intentions (Morgan, 1982; Oakley, 1981), and this trend has changed little over time (Bhrolcháin & Beaujouan, 2011). This uncertainty may explain why fertility intentions and outcomes often do not match. Therefore, understanding uncertainty could be key to expanding our knowledge of the fertility decision-making process. Although uncertain options are increasingly offered in close-ended questions and emerge as one of the most frequently chosen options in those surveys (Bhrolcháin & Beaujouan, 2011), they are still not well-studied and often overlooked in demographic studies on fertility intentions and expectations (Agadjanian, 2005; Bhrolcháin & Beaujouan, 2019).
Such uncertainty can arise from a variety of factors, including ambivalence, lack of information, and competing life goals. Bachrach and Morgan (2013) and Bhrolcháin and Beaujouan (2019) all argue that, instead of concrete plans, fertility preferences expressed in surveys are constructed “at the scene” and are therefore dependent on contextual information and subject to framing effects. It is thus important to get a grasp on people’s considerations and perspectives when asking about fertility intentions. Vignoli et al. (2020a) have tried to improve our understanding of intentions by proposing the Narrative Framework, where the “narratives of the future” are included as a basis of fertility decisions. Narratives can both reflect and reinforce these factors, either by validating individuals’ uncertainty or by providing a sense of clarity and meaning around their experiences. This means that respondents consider their own subjective perspectives on their future, in addition to their other personal characteristics. Therefore, despite having similar personal situations (e.g., age, partnership, and employment), people may have a lower or more uncertain fertility intention due to a more pessimistic outlook on future conditions. The Narrative Framework reflects on empirical evidence that shows the link between expectations of the future and fertility intentions (Dantis & Rizzi, 2020; Gatta et al., 2021; Schneider, 2015).
The theoretical claims that (uncertain) fertility intentions are contextual and narrative present a challenge to the current conceptualization and empirical examination of the fertility decision-making process. While empirical works concerning narratives have been quickly expanding, the majority of them focus on a single narrative, such as on economic and employment uncertainty, measured by pre-defined categories (Lappegård et al., 2022; van Wijk, de Valk & Liefbroer, 2021). More recent contributions have also been made to capture narratives with qualitative methods. Lebano and Jamieson (2020) interviewed women on childbearing postponement in Italy and Spain, and Bazzani and Vignoli (2022) identified enabling (e.g., children as a means and family) and hindering (e.g., desire for freedom, responsibility, and prerequisites) conversion factors of fertility plans in Italy by manually coding open answers. Here, we aim to expand our object of study to a more general data-driven concept of uncertainty that covers more aspects of real-life conditions and fertility planning, in fertility intentions and related narratives.
Open-Ended Questions and Topic Modeling
In trying to frame and operationalize uncertainty that people are concerned with, open-ended questions (OEQs) are useful tools in obtaining “top-of-the-head” answers from respondents (Fernandez et al., 2016), which allows researchers to capture spontaneous narratives in place of pre-defined categories. In addition, the significance of written information has also been recently acknowledged by Trinitapoli (2021), who argues that discussions pertaining to demographic occurrences, referred to as “population chatters,” require attention in future demographic research. Demographers have employed mixed methods combining close-ended questionnaires and supplementary qualitative studies (Schatz & Williams, 2012; Staveteig et al., 2017); these studies applied small-scale in-depth interviews as follow-up studies to a subsample of survey respondents. These qualitative studies have been insightful in showing, for instance, that men’s social networks and communication affect gender ideology and contraception usage (Agadjanian, 2002). However, one drawback of this approach is that it includes costly and time-consuming analysis (e.g., long interviews and the analyses of transcripts). Moreover, when the goal is to make overall generalizations about fertility behavior to the general population (Queirós, Faria & Almeida, 2017), qualitative samples are often not sufficient. Ideally, we would acquire narratives from a large and representative sample of individuals and use all of this data.
Natural Language Processing (NLP) can help in this case. NLP is a rapidly developing field that interacts between computer science and human language, and aims to make a computer capable of “understanding” the contents of textual data. Recent advances in NLP techniques have made large-scale automatic analysis of responses to OEQs possible (He & Schonlau, 2020; Schonlau & Couper, 2016; Züll, 2016). These novel techniques can help researchers get more insights into people’s (un)certainty in their fertility preferences, which inspired us to incorporate OEQs in a larger-scale survey and apply these new techniques. Topic Modeling (Blei & Jordan, 2003) is a popular method to automatically discover narrative themes from textual data and has been widely used in processing responses to OEQs in other disciplines such as social media study and marketing (Roberts et al., 2013, 2014; Pietsch & Lessmann, 2018). The model discovers frequently mentioned topics from the answers of respondents. The results, combined with expert interpretation, are used to examine how people under different conditions utilize their narratives in varied ways. In demographic research, topic models have previously been applied in identifying research trends and directions in literature bodies (Marshall, 2013; Mills & Rahal, 2021).
This Study
In this study, we are interested in the (un)certainty of fertility intentions of a sample of women in the Netherlands. The Netherlands has maintained a stable, below-replacement level fertility rate in recent years, consistently higher than the EU average (Mills, 2015). The total fertility rate was 1.79 in 2010 and 1.70 in 2022 (United Nations, 2022). This is lower than the ideal family size of two children in major Western European countries, including in the Netherlands (Sobotka & Beaujouan, 2014).
Family policies in the Netherlands are often described as neo-liberal or conservative (Mills, 2015). Maternal leaves are fairly short, and parental leave was limited to five days before 2022, when the experiments in this study were carried out. The Netherlands is also known for the “one-and-a-half-earner” model, where the mother is expected to spend more time on caregiving and working part-time: Dutch women have the highest rate of being part-time workers in the European Union (Morgan, 2006). The use of childcare services by hours per week is also quite low compared to other EU countries (Mills et al., 2014). Same-sex marriage and parenthood are legalized, and fertility treatments are covered by healthcare in the Netherlands (Geerts & Evertsson, 2022).
Our aim in this study is to provide empirical evidence on uncertainty and fertility intentions to help advance relevant theories and to summarize the narratives used by respondents regarding their fertility decision-making process. Using topic models, we recognize topics mentioned in responses and their main content. Thus, the first research question in this work is as follows: • Which narrative themes can we find through automatic topic modeling from textual responses regarding uncertainty in fertility intention?
In addition, personal characteristics are likely to have an impact on the narratives one may use. For instance, a university student is expected to discuss more uncertainty about study life and career and less likely about aging and retirement. At the same time, people with similar background characteristics may vary considerably in their narratives of the future. Therefore, our second research question is as follows: • How do the themes mentioned in responses differ across subgroups with different fertility plans and personal conditions?
Analytical Strategies
Data
The data used in this study is collected through LISS (Longitudinal Internet Studies for the Social sciences) panel administered by CentERdata at Tilburg University, the Netherlands. 1 The panel covers a representative sample of Dutch individuals who participate in monthly Internet surveys, drawn from the registered data by Statistics Netherlands (CBS). The representativeness of the LISS panel was shown to be comparable to probability sampling surveys, and the selection and attrition bias are corrected through refreshment (Scherpenzeel, 2018). Only households in which at least one household member spoke Dutch are included.
The study is based on the second wave of the module Social networks and fertility (in Dutch: Sociale relaties en kinderkeuzes onderzoek) which was included in the LISS panel in 2021 (as a follow-up to a similar module fielded in 2018). The module’s objective was to investigate fertility intentions and attitudes in relation to people’s personal networks. 2 For this second wave, 596 female participants were invited, and 464 women between the ages of 21 and 44 completed the questionnaire. The survey was conducted in Dutch. Each respondent received ***7.50 for completing the questionnaire, which on average takes 15 minutes to finish. This compensation rate is twice as high as the standard rate of LISS panel ( ∼***2.50 per 10 minutes). The OEQs regarding fertility intentions are presented to respondents that are not currently pregnant (N = 433). After removing six answers that were without information (e.g., “niets,” nothing, or not in Dutch), there were in total 423 responses available. The final response rate is 71.1%.
Among the respondents, 285 (67.4%) had a partner at the moment of the survey while 138 (32.6%) did not; 189 (44.7%) had at least a child while 234 (55.3%) never had one. Seventy (16.5%) respondents were younger than 24, 177 (41.8%) between 25 and 34, and 176 (41.6%) older than 35 years. Seventy-seven (18.2%) of them had a low income according to the low-income threshold set by Statistics Netherlands (CBS).
Ethical permission for the study was obtained from the Ethical Committee of Sociology at the University of Groningen (ECS-201123). The dataset can be accessed at dataarchive.lissdata.nl.
Open-Ended Question
Since the usage of online OEQs and automatic analysis of responses is innovative in demographic research, we conducted a separate study on evaluating data quality before this study (Xu et al., 2022) (anonymized), which indicated that the quality of responses was satisfactory.
The OEQ was placed directly after a set of closed questions on fertility intentions derived from the Generations & Gender Surveys (GGS) (Gauthier, Cabaço & Emery, 2018). Two versions of the OEQ were tested: • •
The answers contain 31 words on average, and the median length is 21 words. We found that the average response length is higher by only 0.1 words for the original version of the question compared to the one with an adaptive reminder (and this effect was non-significant). Since answers to these two questions were similar on a suite of characteristics (e.g., sentence length and number of nouns), we did not differentiate between these two questions in the subsequent analyses.
Topic Modeling
In topic models, each response to an open question is seen as being generated by a distribution of latent topics. In turn, topics are probabilistic distributions of words that co-occur across responses in the dataset and are therefore considered to be generated from a single latent topic. In the context of open-ended survey data, a response to an open question can therefore be seen as being generated by a distribution of topics that are each responsible for specific words occurring in the response; in one response, typically, only a limited number of topics will appear.
Conventional topic modeling algorithms, such as the Latent Dirichlet Allocation (LDA) (Blei, Ng & Jordan, 2003), treat documents as unordered “bags of words” and ignore the syntactic and semantic structures between words. The training process also does not use any prior information on the meaning of words and learns the relation between words relying on co-occurrences in the corpus (i.e., all the answers of the respondents combined). For example, a set of responses that involved discussions on housing concerns may contain terms such as rent, mortgage, and apartment. Their frequent co-occurrences would be recognized by the model, and the words would be identified to appear in the same topic with high probability. The results can then be interpreted by researchers and identified as relevant to the topic of housing. With all responses analyzed and the number of topics determined by the researcher, the model typically outputs a list of the most representative words for each topic, as well as a proportional distribution of topics for each document (e.g., an answer of a respondent could 95% likely to be in the topic “housing” and 5% in the topic “partnership”). These results can then be interpreted by researchers to characterize latent topics present throughout the corpus and surfacing in individual responses.
A limitation of LDA is that it does not make use of word order in the documents. This can be problematic when using short texts such as survey responses (Phan et al., 2010) because they ignore the relation between words and lead to the problem of data sparsity (Rao et al., 2016). We also tested the LDA model on our data and found the results unsatisfactory (Xu et al., 2022) (anonymized). Although we tested LDA models with different numbers of topics (K), none of them were able to produce interpretable results, possibly due to the relatively small dataset of short texts (Phan et al., 2010). In recent years, pre-trained neural language models have been increasingly used in Natural Language Processing (NLP) tasks. Instead of representing documents as “bags of words,” they treat documents as a continuous sequence of tokens and produce contextualized representations that contain implicit information of semantic and order relationships among words. These language models are increasingly used in topic modeling tasks, as they are able to capture, albeit in an implicit way, more of the syntactic structures and semantic relations in texts and incorporate prior knowledge of the specific language through embedding into the model. Novel methods that integrated deep neural networks and embeddings include Top2Vec (Angelov, 2020), Embedded Topic Model (Dieng, Ruiz & Blei, 2019), SCHOLAR (Card, Tan & Smith, 2017), and Contextualized Topic Models (Bianchi, Terragni & Hovy, 2020), all of which show superior performance on various quantitative metrics compared to LDA (Zhao et al., 2021). We used a specific implementation of Contextualized Topic Models (Bianchi et al., 2021) in this study. All of these models incorporate Bidirectional Encoder Representations from Transformers (BERT) (Devlin et al., 2018), one of the most prominent language models, and Neural ProdLDA (Srivastava & Sutton, 2017), a neural topic model that is an improved approximation of LDA and is capable of including contextualized representations. This family of models has outperformed LDA in comparative experiments (Bianchi et al., 2021). To incorporate prior knowledge of the Dutch language, we use RobBERT (Delobelle, Winters & Berendt, 2020), a Dutch BERT model pre-trained on over 126 million lines of Dutch text.
The model used in this study was implemented in Python 3.8 and deployed on the cloud development platform of Google Colaboratory (Ekaba, 2019). The pre-processing and fine-tuning in total took 369 seconds to run on the Google Colaboratory platform.
Identifying Topics
The specific implementation from the Contextualized Topic Models family we used is called Combined Topic Model (CombinedTM, by Bianchi, Terragni, and Hovy (2020)). CombinedTM is a composition of two parts: the neural topic model ProdLDA (Srivastava & Sutton, 2017) and SBERT contextualized embeddings (Reimers & Gurevych, 2019). The latter extracts information from responses and produces latent representations, which are then feed into the ProdLDA and used to reconstruct “bag of words” of those responses, generating the topics in the process.
In topic modeling, each document i in N (in our case, i refers to a response by one respondent among all N respondents) is represented as a distribution over topics θ i . Each topic k is in turn also represented as a distribution β k over the vocabulary of the corpus, which shows how prevalent each word is in the topic. The matrix θ = (θ1…θ N ) is denoted as the Document-Topic distribution matrix and β = (β1…β K ) the Topic-Word distribution matrix.
Under a generative LDA model, we draw a topic distribution θ for each document from a Dirichlet distribution given the concentration parameter α. For each word at position n in a document, we first draw a topic z
n
from θ, and then also draw the word w
n
from the word distribution of the chosen topic. In the actual implementation of ProdLDA, z is collapsed, and w
n
is directly drawn from a multinomial distribution of βθ. The marginal likelihood of each document i is as follows:
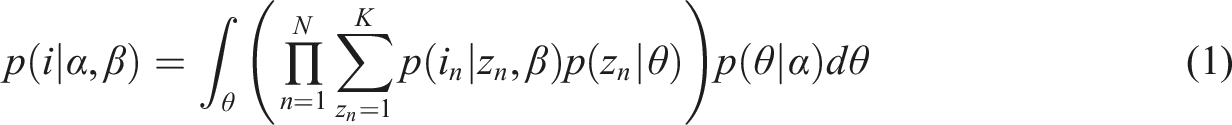
ProdLDA uses Autoencoding Variational Bayes (AEVB) (Kingma & Welling, 2013) for the inference of variable θ and i, since the two are coupled and intractable. Free variational parameters γ and ϕ are introduced over θ and i, resulting in an approximate variational posterior q(θ, i|γ, ϕ) = q
γ
(θ)∏
n
q
θ
(i
n
) over the true posterior p(θ, z∣i, α, β). The evidence lower bound (ELBO) to the marginal log likelihood can be written as follows, where the first term attempts to match the posterior over latent variables to the priors, and the second term favors the latent variables that explain the data well:
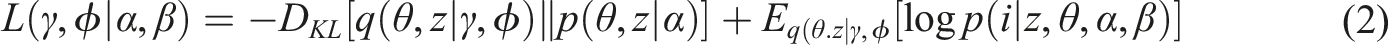
We calculate the variational parameters using neural networks, which are also called inference networks in AEVB. The corpus, combined with contextualized information provided by SBERT, is used to train the network and optimize the ELBO in (2). Once the variational parameters γ and ϕ are chosen, the expectations of q in (2) are approximated using a Monte Carlo estimator.
Based on the Document-Topic distribution matrix of the trained model, we infer the label for each topic based on the top 20 most relevant words. Since the responses are a combination of several topics instead of one, and the prevalence of common words in our comparatively small corpus, we also analyzed the 10 most representative responses for a particular topic from the Topic-Word distribution matrix before assigning labels.
Model Selection
An important decision in any topic modeling approach is deciding on the number of topics (K) that the algorithm should produce. This decision is typically done jointly through quantitative metrics and qualitative human interpretation approaches. While multiple metrics have been developed to evaluate the performance of topic models, the unsupervised nature (the absence of human-labeled, “correct” results for verification) entails that there is no gold standard for the correctness of results. Although we strive for the reproducibility of experiments, quantitative metrics, such as topic perplexity, are not always in line with human interpretability of topics (Chang et al., 2009). Therefore, a combined evaluation method of automatic and human judgment is needed.
Here, we first automatically determine the topic coherence and topic diversity to determine the optimal number of topics, after which we assessed those topics on whether they offered clear, interpretable results for researchers. Often-used quantitative metrics to assess the quality of the entire topic modeling approach include topic coherence (measured by non-negative point-wise mutual information, Newman et al. (2010)) and topic diversity (measured by inversed rank-biased overlap, Terragni et al. (2021)). Topic coherence measures how close the top n words (typically, n = 10) from a topic are to each other: if the words always co-occur in documents, they are considered “close” and the topic is considered coherent. Topic coherence correlates well with human judgments (Newman et al., 2010). Topic diversity, conversely, measures how different the top ten words from all topics are, that is, if topics share the same words. Both high topic coherence and high topic diversity suggest a high quality of topic results.
The calculation of topic coherence requires an external test corpus for calculating how frequently words in the topic occur together in real language usage (Blair, Bi & Mulvenna, 2020). The external corpus was crawled from the Viva forum, 4 a Dutch online discussion board mainly aimed at women. We prepared two corpora for cross validation: first the “Child wish” corpus, which contains 436 threads and replies including the keyword “child wish 5 ”; second the “Pregnancy” corpus, containing 5507 comments under the “Pregnancy 6 ” board. Coherence scores were calculated on both corpora.
After evaluating these quantitative metrics (Figure 1), the decision of choosing K (the number of topics) was made by researchers. The four authors, two of whom are experts in the field of the demographic study of fertility intentions, first briefly read the responses and provided insights on the themes that were present in the responses. Before labels were given to the topics, all authors were familiarized with recent fertility trends and events in the Netherlands. We then read the output of all topic models and made recommendations for interpretations individually. Evaluation metrics of models, with the number of topics between 4 and 10.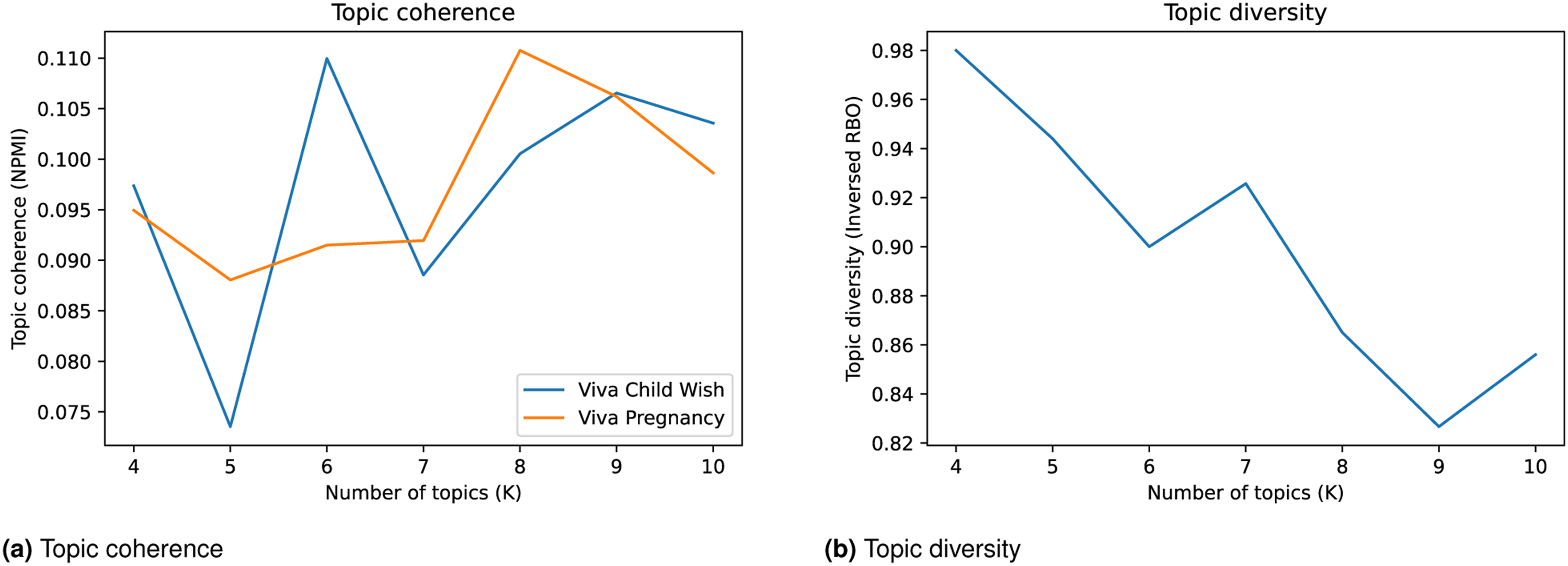
For this study, we tested models with K between 4 and 10. The authors read through the dataset to develop qualitative insights of the responses and iteratively suggested topics based on top words for each generated topic. We selected the final model based on the joint performance on topic coherence, topic diversity, and comparison to human insights. Models with high topic coherence and high topic diversity were reviewed by the researchers; the list with topics was produced that included the 20 most salient words (i.e., words with the highest likelihood of being generated by the topic) and the 10 best matching responses (i.e., documents from which the likelihood of the particular topic being generated is the highest) in the data to these topics. Researchers then assessed the coherence of these topics and word combinations iteratively. Although it is possible to select the optimal K sorely through quantitative metrics, they often conflict with the human interpretability of results, which is proven to be more important for social science purposes (Jacobi, Van Atteveldt & Welbers, 2018; Zhang, Wang & Hu, 2023). In the due process, models with K of 6, 8, and 9 were selected and reviewed, and the authors concluded that when K = 9, the results matched the best with human interpretations, while also performing decently on topic coherence and diversity. After our thorough reading and discussion, the authors have together agreed the optimal number of topics. A more detailed description of the model selection process can be found in our previous work (Xu et al., 2022) (anonymized).
Comparing Groups
In order to identify topics that are more or less salient depending on respondents’ conditions, such as economic status, partnership status, or motherhood, we compare the relevance of topics between subgroups across these different conditions, which were known from answers to close-ended questions. Since the topics are generated without human input, comparing results from subgroups could also serve as an additional robustness check of the meaning of topics. Therefore, we divide the corpus by these covariates and assess the prevalence of topics across the groups. In particular, we used the following groups: higher/lower income than full-time minimum wage in the Netherlands; highly/non-highly educated according to the International Standard Classification of Education (ISCED) 7 ; with/without a partner; and having/not having children.
This is important for two reasons. First, some topics must be more prevalent depending on personal characteristics of the respondent (e.g., age with the topic of being a student), serving as a robustness check of our data-driven method of determining topics. Second, if most topics do not vary across personal characteristics, this suggests that people with similar backgrounds may have very different uncertainties about their fertility and intentions and different narratives of the future.
Results
Topic Summary
Topic Summary: For Each Topic, an Expert-Suggested Label is Given, and the 10 Most Representative Words. Groupings of Topics are Indicated by Horizontal Separator Rules. Please Note That These are Translations From Dutch Text.

Theme 1: Health and Pregnancy (Topics 1 and 2)
Two topics express health-related concerns. We calculated the weight of each theme and found the most important theme in every response. For 103 (24.3%) respondents, health-related issues are their top concerns reflected in the answers. Topic 1 covered illness, postnatal complications, and risks during giving birth. This is made evident not only from the keywords but also from the following examples (note that all examples are translated from Dutch to English and include the Dutch original). See the following example, which, according to the model, is 88.5% related to this topic: My health. The risk of complications for myself is quite high. In addition, I take medicines that cannot be combined with a pregnancy. The fear that my partner will be left alone with a baby is very grave for both of us.
8
And the other example, which is on medically assisted reproduction: (94.8% relevant to the topic) We have 2 healthy boys. We were able to receive the 2nd through a medical process. This process was very difficult for my body due to multiple miscarriages, operations and hormone injections, and more than weekly ultrasound scans. It is also a difficult process emotionally and the relationship with the dad is not getting any better. The desire for a second one was very strong, but now our family is complete. No doubt about a 3rd one.
9
Topic 2 focuses on obstacles in getting pregnant, which is shown in the following examples: (85.3% relevant to the topic) Two unwanted pregnancies followed by abortion have unintentionally changed my view of motherhood.
10
(79.6% relevant) after much research with both my partner and myself, no major abnormalities were found, but still no baby.
11
(77.9% relevant) I have been diagnosed with a medical condition that makes me less fertile.
12
Theme 2: Different Stages of Life (Topics 3, 4, and 5)
The three topics from this group focus on different stages in an individual’s life course. Life stage topics are the most commonly mentioned theme among all responses, with 194 (45.9%) responses. For example, Topic 3 covers many respondents in the stage of life in which they already have children and are satisfied with their current family size. (89.3% relevant) After three children it’s fine for us. Our family is complete.
13
(84.9% relevant) currently the family is complete with 2 children more children is not our wish; would be too busy, asking too much of us, don’t want to go through the trouble of childbirth again, etc. taking care of young children takes a lot of time and energy.
14
Topics 4 and 5, in contrast, focus on those in life stages prior to have children. For example, Topic 4 concerns students or young adults. In the most relevant responses, it is frequently raised that the respondent is still studying, in her 20 s, or not ready to settle down and get married: (87.5% relevant) Currently I am 25 and still studying. I want to make a career and earn money. Maybe also travel and I don’t want to combine that with children. Then I hope to marry my boyfriend in late 20’s and have children only once after that. Then we can save money in the meantime, because now we can’t afford it and we live in a student house so it’s not possible.
15
Similarly, Topic 5 focuses on being too young and not being certain about the lifestyle. (66.9% relevant) I think I’m still too young to have children. I still enjoy my freedom too much to study, work and travel, but also to spontaneously go out. In addition, there is currently no one in my life with whom I would want a child. But if this person comes within the next 3 years, I think I wouldn’t want a child because the above is still too heavy at the moment.
16
Theme 3: “It Just Happens” (Topic 6)
This topic reflects a nonchalant, not strictly planned attitude towards fertility plans, which is also found in qualitative studies (Borrero et al., 2015). Twenty (4.73%) responses have this uncertainty as their main talking point. Common words in this topic include “lukt” (work out), “weet …nooit” (never know), and “gegund” (“it’s in the stars”). This is also evident from the following examples: (93.1% relevant) The wish certainly exists, but there is also a chance that it will not succeed. Or that because of my career I no longer have a desire for it.
17
(92.5% relevant) the wish is certainly there, but of course you never know how quickly it will succeed and whether it will succeed at all.
18
(83.5% relevant) It’s not on the schedule right now. Think it’s rather grand to say never.
19
(78.9% relevant) I hope that is granted to us. It is not always self-evident.
20
(78.5% relevant) Within 3 years I think it might be too early, but I don’t rule out that it might happen.
21
Theme 4: Positive and Negative Attitudes (Topics 7 and 8)
Various types of dissatisfaction are observed in Topic 7, including but not limited to disliking children, climate change, fear of social media, “the world is too full,” and religious reasons which is the top theme in 21 (4.97%) cases. For example, (99.0% relevant) I really hate children. I just find them boring at best; I couldn’t imagine spending a whole day with a child…I tolerate children of friends and family, I can’t think of another word for it, it’s really hard for me to enjoy the presence of children…
22
(82.4% relevant) I think wanting to have children is the same feeling as not wanting to have children. I don’t want to carry and take responsibility for another life. In addition, I find it quite intense that my father and mother have determined that I live on this earth. And the world is already way too full, the future doesn’t really look very bright. So, I don’t want those responsibilities. And I don’t think it’s fun either: bad nights, it costs a lot of good, quarrels…
23
In contrast, Topic 8 mostly consists of positive responses on the enjoyment of and willingness to have children, while also mentioning other concerns. It dominates 29 (6.86%) responses. (68.7% relevant) I would very much like to have children if I am allowed. My partner and I talk about this from time to time. I think it would be great to be able to give my love to my children. What makes me insecure is also the fear that comes with parenting, the worry whether it will go well and whether nothing will happen to him/her…
24
Theme 5: General Discussion About Age and Miscellaneous (Topic 9)
Not all open answers contain complete paragraphs or sentences. In fact, many respondents only typed in a few words, such as “age” or “no child wish.” Examples where this pattern was captured include the following: (62.6% relevant) age
25
(53.2% relevant) No desire to have children and age.
26
In addition, some answers contain rarely discussed themes that are not frequent enough to be recognized. For example, one respondent mentioned that her partner was a woman: (53.2% relevant) I like women so the way of having children is a bit more complicated.
27
It is therefore hard to assign an encompassing label to this topic, as it partly functioned as a “catch-all” topic (a phenomenon that is commonly found in topic modeling output), with words and responses that were not clustered in topics above. This theme is the most significant one for 56 (13.2%) responses we received. However, the prevalence of age in this topic indicates that age may be of special relevance to uncertainty (Kuhnt et al., 2021).
Topic Differences in Subgroups
Given the topic distribution on each response from the Document-Topic distribution matrix, there is further opportunity of investigating how people under different personal and socio-economic conditions express their concerns through narrative topics. Figure 2 present the shifting of popularity of each topic across different subgroups. The dots represent the median prevalence (θ
k
for topic k), and the two edges of the lines represent the first and third quantile (25% and 75%). We use Wilcoxon rank sum test to compare topic prevalence in subgroups. Topic prevalence from people with different characteristics, including age, partnership status, with or without children, income, educational level, and housing type. ****p < .0001, ***p < .001, **p < .01, *p < .05, and p < .01.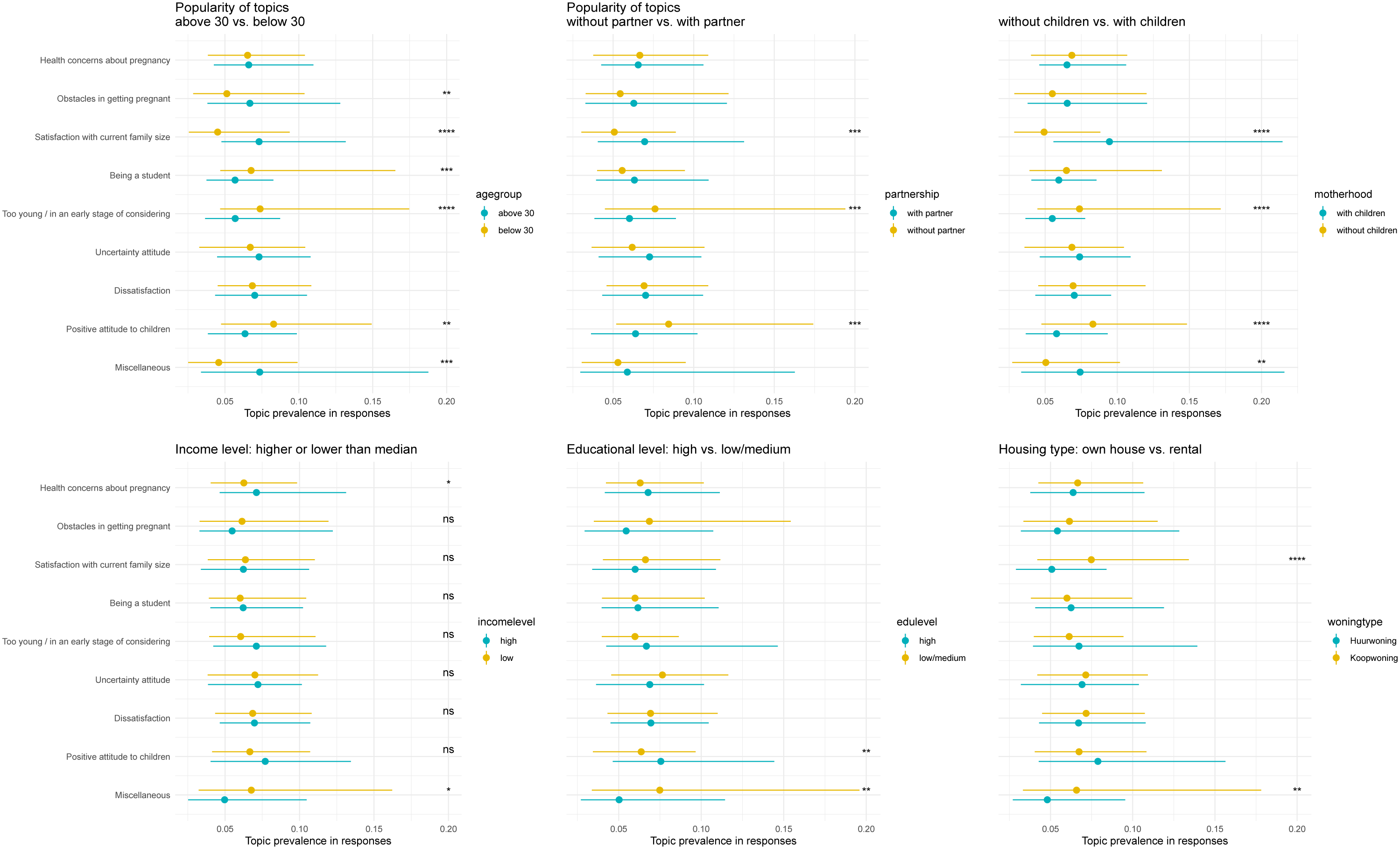
Overall, the topics are quite similar across subgroups, and statistical differences are observed in only a few instances. It is shown in Figure 2 that a person’s age and socioeconomic status are directly reflected in the narratives of women. In particular, age plays an important role in people’s narratives, as older respondents talk much more about obstacles in getting pregnant and being satisfied with the current family size. In contrast, younger people are more concerned about being a student and wanting to explore more opportunities in life. They also expressed a more positive attitude towards children. Similarly, when comparing respondents’ partnership and motherhood status, it is those who did not yet have a partner or children that more commonly discuss being fond of children, while those who were in a relationship or had children talked more about being satisfied with their current family.
We also noticed that health concerns are more prevalent among respondents with a higher-than-median income, and more positive attitudes towards children among the highly educated group. Meanwhile, the narratives used by low-income, low-education respondents are more frequently classified into the “miscellaneous” group. This might be linked to the finding that education and income levels are positively linked to response quality (Scholz & Zuell, 2012), which could lead to shorter answers. Finally, we found that people living in owned properties are more likely to express being satisfied with their current family size.
Discussion
In this study, we addressed Dutch women’s narratives about their certainty and uncertainty regarding fertility intentions. Participants were presented with an online open-ended question asking for reasons that made them feel certain or uncertain about their fertility plans. The answers were analyzed by a state-of-the-art neural topic model that has not been applied to demographic research previously, with the results being jointly interpreted by the machine and the experts. This experiment allows for the identification of topics from spontaneous answers from more than 400 respondents and offers new insights into the uncertainty and its origin in people’s fertility decision-making process.
Based on the textual evidence from our participants, we found that the uncertainty reported in fertility intentions is supported by many different constraints and arguments, which echoes the theory by Bhrolcháin and Beaujouan (2019) that uncertainty is a genuine and rational choice to the respondents. Many respondents have well-defined arguments based on real-life conditions for their uncertainty in whether they would like to have more children or no children at all. There are many narratives pertaining to future outlooks, including aspects such as aging, health conditions, being a student, and economic status. Furthermore, these narratives frequently incorporate discussions about uncertain conditions in these areas in addition to their present circumstances. The wide usage of these narratives is in line with the idea that narratives of the future play an important role in contemporary fertility dynamics (Vignoli et al., 2020a). These results also provided empirical evidence for uncertainty beyond perceived economic uncertainty alone (Vignoli et al., 2020b) in the fertility decision-making process, such as uncertain feeling about partnership or society as a whole. In addition, some respondents showed an indifferent attitude towards having children, and some reported on other (less-frequent) themes, such as LGBT and religion, which are covered in the “catch-all” topic for miscellaneous.
Since the labels for the topics were given by the researchers and are not objective truth, as a robustness check, we verified whether our interpretations co-varied with demographic characteristics of respondents logically (e.g., the topic labeled as “being a student” should be less prevalent among older people). Most of these differences between groups are consistent with common sense and existing literature (Comolli & Vignoli, 2021; Guetto & Panichella, 2013; Sassler & Lichter, 2020), and support our interpretations. Also insightful is the finding that many topics do not vary across women with particular personal characteristics, particularly those topics concerning general attitudes towards society, studying, and health issues. This suggests that our open-ended question was successful in gathering information that was not captured by those personal characteristics and covered narratives that were out of scope of those static factors.
Some topics varied predictably across respondents with different personal characteristics. For example, topics concerning age (e.g., too old, too young, and being a student) were indeed associated with the age of the respondents. Perhaps more insightful was the finding that most topics were not associated with the background variables that we studied. This means, for instance, the education or income of the respondent was not informative about the topics that she would mention in her answers. This clearly indicates that people with similar personal characteristics may have very different concerns about the future. This, in turn, may explain why we observed relatively little variance in topic usage among respondents in different socioeconomic groups.
Regarding conditions and narratives that may determine the uncertainty in fertility intentions, our results largely confirmed findings from previous research. For example, with increasing age, the likelihood of having uncertain fertility intentions also rises (Hayford, 2009; Kuhnt et al., 2021). Age was indeed recognized as an important topic central to a group of short responses (Group 5 in Table 1). The stage of life the respondents was further uncovered by our approach: some respondents mention that they are students living a highly uncertain lifestyle, not ready to settle down; some said that they are still too young and not in a stable partnership; and also some already had a stable family and did not want to change the status quo (so they are certain instead of uncertain). All these scenarios point out the importance of context and perspective in framing fertility intentions.
While Kuhnt et al. (2021) studied fertility decision-making from a life course perspective, the life course markers are based on fixed variables such as age and partnership status. With the narratives extracted in Group 2, we found that people’s perspectives on their own stage in life course also mattered. Instead of an exact number of ages, it is often mentioned by the respondents that they feel that they are still too young and not ready for a life with children, or their family is complete and they do not want children anymore.
Our approach also highlighted topics that are less well-explored in the literature on fertility uncertainty. There is evidence that people with health issues tend to desire fewer children than healthy people (Cvancarova et al., 2009) and that women could be concerned about the potential effect of their health conditions or illness on pregnancy, motherhood, and the health of their babies (Drew, 2002; Dow & Kuhn, 1969). Although demographic studies tend to disregard the link between health and fertility in high-income countries due to higher health standards (Alderotti & Trappolini, 2021), its psychological impact on individual narratives may be underestimated. This impact is captured in narratives but is hard to gauge in conventional health measures. The keywords and examples from the group of topic on health and pregnancy (Group 5) show that, in addition to “hard” medical restrictions, the psychological impact of past failed, unwanted, or unhappy pregnancy experiences is also a common talking point. Infertility, postnatal illness, and depression are mentioned as reasons for not being certain in fertility plans, and the topic is prevalent in all subgroups regardless of age, income, and motherhood. Particularly, we see examples where women suffered from unpleasant medically assisted reproduction care experiences and became reluctant to achieve their original fertility intentions. Therefore, we argue that, while the impact of health has been recognized as a factor in fertility intentions (Shandra, Hogan & Short, 2014), further attention should be paid to women’s past pregnancy experience and their perspectives on future post-natal conditions.
In contrast to the well-defined concerns mentioned above, there are also many answers that only contain a vague concept of the intention to have a child and a lack of plans, and this is reflected as a topic by the model as well (Group 3). The examples reflect an “it just happens” attitude and indicate a lack of explicit fertility plans. This topic resembles the phenomenon of pregnancy ambivalence/indifference (Bernardi, Mynarska & Rossier, 2014). Although the two concepts are often discussed together, this attitude, according to us, may be better described as “indifferent” instead of “ambivalent,” as answers tend to show a weak positive/negative intention rather than contradicting ones (Miller, Jones & Pasta, 2016). This result matches the fact that more than 20% percent of births are unplanned in high-income countries (Singh, Sedgh & Hussain, 2010) and the phenomenon of childbearing ambivalence/indifference (Miller, 2011; Sennott & Yeatman, 2018). However, this factor was too often treated as a form of “uncertainty” and yet to be treated as an independent factor alongside personal conditions. As such, we propose that the indifference level be a new dimension in explaining fertility intention uncertainty. Distinguishing the two helps us to have a better grasp of to which extent can we realistically and reliably explain and predict future fertility trends.
While our results contribute to the body of literature on uncertainty in fertility intentions, they also raise new questions for further research. The indifference/ambivalence dimension in fertility intention is a new concept, and there’s no precedence for its measurement. Although similar studies have been carried out in studies of pregnancy ambivalence (Miller et al., 2016), incorporating this dimension in future data collection processes should be given more attention. Furthermore, the classification of ambivalence is controversial: Gómez et al. (2019) found that almost all ambivalent participants’ interview responses could be clustered into sub-themes such as acceptability of an undesired pregnancy and perceived lack of control regarding pregnancy and were not actually ambivalent. It would therefore be a renewed challenge to explore narratives and themes used by respondents who expressed an indifferent/ambivalent attitude toward fertility intentions.
More generally, the trade-off between depth and breadth in data collection and analysis has been a key challenge for empirical research in various social science disciplines, including but not limited to demography. Pretrained Large Language Models (RoBERTa in our case), exposed to a large amount of real-life textual data, incorporate prior knowledge in its billions of parameters and can be applied to a wide range of NLP tasks, including topic modeling. This development offers demographers an incentive to collect and utilize textual data without reservations, where this has been generally avoided (although Cesare et al. (2018) and Merli et al. (2023) are notable exceptions). As the latest Large Language Models, such as GPT-4 and LaMDA, become increasingly powerful, zero-shot learning (i.e., completing a task without any training on our own sample) is becoming viable, providing immense future research opportunities. We therefore argue that, to further investigation into the potential of narratives and uncertainty, it is necessary to continue advancing NLP techniques for demographic research.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Nederlandse Organisatie voor Wetenschappelijk Onderzoek (451-15-034).