
Abstract
Topic models have been widely used by researchers across disciplines to automatically analyze large textual data. However, they often fail to automate content analysis, because the algorithms cannot accurately classify individual sentences into pre-defined topics. Aiming to make topic classification more theoretically grounded and content analysis in general more topic-specific, we have developed Seeded Sequential Latent Dirichlet allocation (LDA), extending the existing LDA algorithm, and implementing it in a widely accessible open-source package. Taking a large corpus of speeches delivered by delegates at the United Nations General Assembly as an example, we explain how our algorithm differs from the original algorithm; why it can classify sentences more accurately; how it accepts pre-defined topics in deductive or semi-deductive analysis; how such ex-ante topic mapping differs from ex-post topic mapping; how it enables topic-specific framing analysis in applied research. We also offer practical guidance on how to determine the optimal number of topics and select seed words for the algorithm.
Keywords
Introduction
Researchers from various fields of social science have extensively used topic models to analyze vast amounts of textual data because their algorithms can automatically group documents with a similar content and provide a summary of the corpus with topic words. Even though existing algorithms recognize topics only as clusters of words, they can produce meaningful results because co-occurrences of words tend to reflect their semantic relationships. Among several topic models, Latent Dirichlet allocation (LDA) (Blei et al., 2003) has been arguably the most popular algorithm in social science research (Grimmer & Stewart, 2013). For example, scholars have employed it to analyze thinktank reports on climate change (Boussalis & Coan, 2016), central bank committees transcripts (Baerg & Lowe, 2018), international news about political violence (Mueller & Rauh, 2018), and patents on robotics (Savin et al., 2022).
LDA is typically applied to a corpus of documents in order to either identify known topics based on a theoretical framework (deductive approach) or to discover unknown topics in order to improve such frameworks (inductive approach). However, researchers often find it difficult to interpret and accept topics identified by the algorithm, because these topics only loosely match the theoretical concepts (Eshima et al., 2020). A common solution to this problem is to manually map topics to the target concepts after fitting a model (ex-post mapping), but another, and better, solution is to “teach” the algorithm the target concepts through seed words before fitting a model (ex-ante mapping). Such a semi-supervised approach is enabled by Seeded LDA (Jagarlamudi et al., 2012; Lu et al., 2011), but only a few researchers have to date applied the model in applied research (e.g., Curini & Vignoli, 2021).
Furthermore, researchers who attempt to perform topic-specific content analysis by correlating topics and other traits (e.g., sentiment, lexical complexity, named entities) of individual sentences often fail, because LDA struggles to identify topics in shorter documents, in which words co-occur less frequently (Yan et al., 2013). 1 The solution to this problem is to rely on topic models that associate words in a group of documents (Amoualian et al., 2016; Du et al., 2012; Gruber et al., 2007; Jiang et al., 2019; Yan et al., 2013). Among proposed algorithms, Sequential LDA (Amoualian et al., 2016; Du et al., 2012) appears to be the most useful for classification of sentences, but it has not been widely used either.
Aiming to facilitate the use of topic models in broader research applications across disciplines, we have developed Seeded Sequential LDA and implemented it in an open-source package by extending the popular LDA algorithm. 2 With the new algorithm, we contribute to making topic classification more theoretically grounded in the deductive (or semi-deductive) approach and to making content analysis in general more topic-specific with its capability to classify individual sentences more accurately.
In this article, we explain how Seeded Sequential LDA differs from the original algorithm and why it can be used to perform topic-specific content analysis of sentences. In the following sections, we first explain the key aspects of the LDA algorithms. Specifically, since Heinrich (2008) has given a detailed explanation of the original LDA algorithm, we focus on how the proposed changes affect the way the Gibbs sampler assigns topics to words. Second, we compare the new LDA algorithms (unseeded, seeded non-sequential and seeded sequential) by applying them to sentences from the United Nations General Assembly speeches. Third, we present topic-specific sentiment analysis of the sentences as an example of framing analysis that the Seeded Sequential LDA enables. 3 Finally, we conclude this article by offering the best practice in topic classification of sentences in social science research.
LDA Algorithms
LDA: Unsupervised Topic Model
We present algorithms using graphical models to help readers understand the key differences between the seeded, sequential and original algorithms. In Figure 1, gray circles are variables whose values are known, whereas white circles are latent variables whose values are unknown; rectangles around them indicate that there are many such variables. The most important variables for LDA are topics of words, Graphical model of the original LDA. 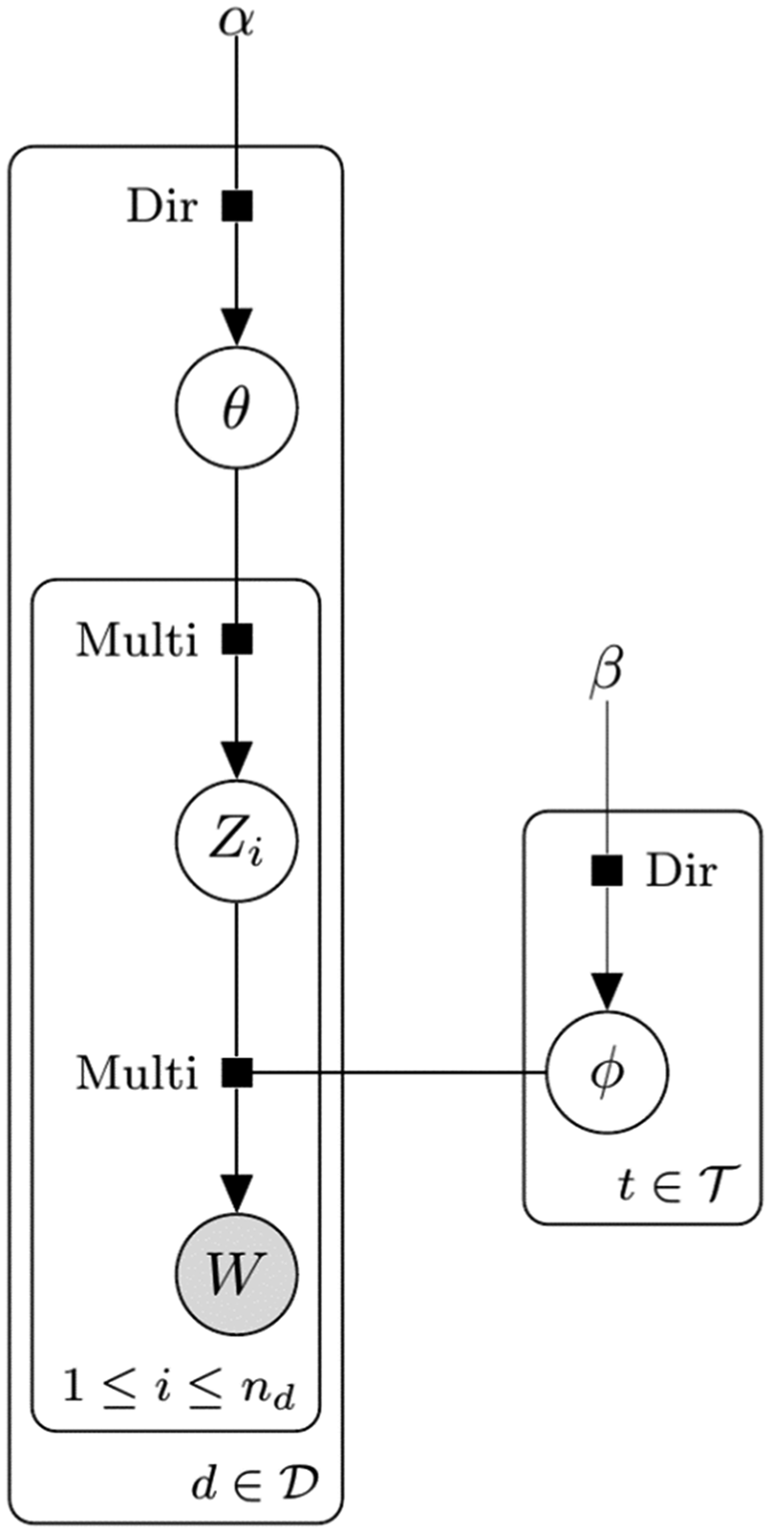
Although
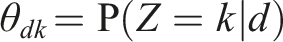




Every time a new topic is sampled,
Seeded LDA: Semi-Supervised Topic Model
In unsupervised topic models, topics and concepts match only by accident because the algorithms recognize topics as clusters of words in the corpus. Such mismatches between topics and concepts make it difficult for researchers to employ LDA when analysis is theoretically motivated (Watanabe & Zhou, 2020). However, Seeded LDA can solve this problem because it allows researchers to define topics a priori through seed words, before fitting the model.
Computer scientists have developed algorithms to guide LDA to discover user-defined a priori topics with a small number of seed words. Lu et al. (2011) proposed an LDA algorithm that clusters words around seed words by inducing bias in Gibbs sampling. Jagarlamudi et al. (2012) created an LDA algorithm that allows both seeded and unseeded topics to coexist. Eshima et al. (2020) further extended Jagarlamudi’s algorithm to incorporate document-level meta data into topic identification.
Lu’s algorithm only requires adding pseudo-count, Graphical model of Seeded LDA. The topic distribution for words, 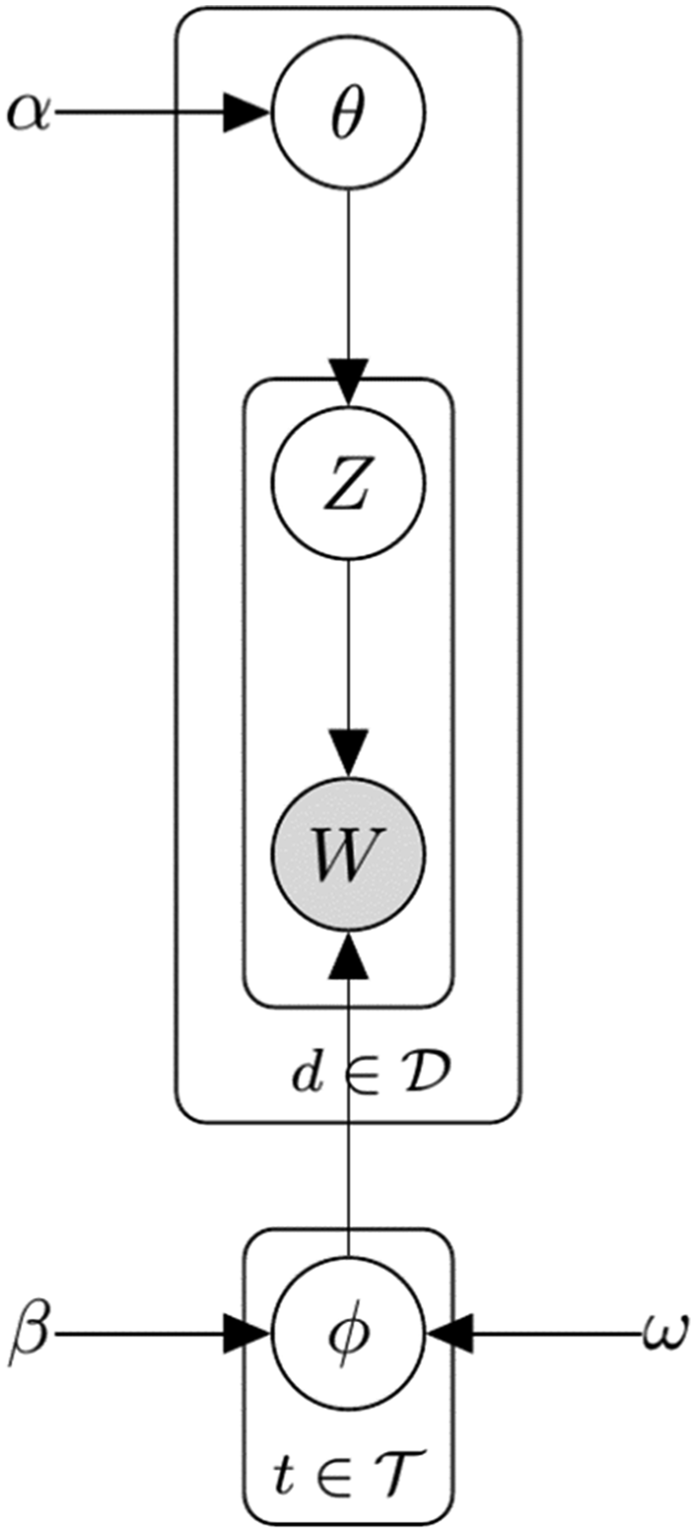


The authors suggested that the size of pseudo-count is about 1% of the total number of words in the corpus,
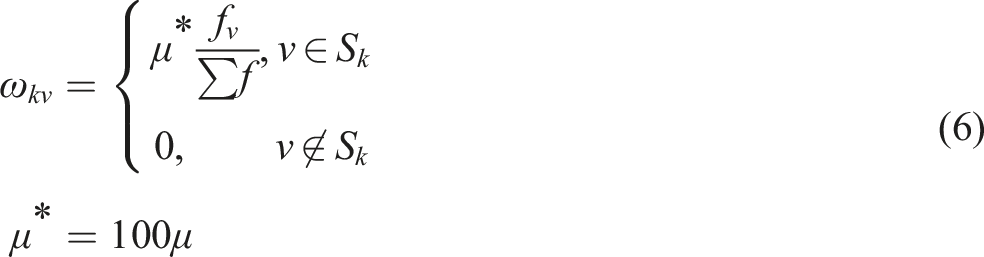
We also allow
Sequential LDA: Unsupervised Topic Model for Sentences
The original LDA ignores the order of documents like many other topic models because the content of a document is assumed to be unrelated to that of other other documents (Blei et al., 2003). The inability of LDA to consider the positions of documents in the corpus makes it unsuitable for classification of sentences because topics in the current sentence usually depend on those in the earlier sentences. However, Sequential LDA explicitly models such relationship between the current and the preceding sentencesto identify topics more accurately.
Computer scientists have proposed several algorithms that can be employed to classify sentences. Gruber et al. (2007) applied the hidden Markov model to detect changes in topics between sentences; Du et al. (2012) adopted the Poisson–Dirichlet process to model the relationship between the current and previous topics; Amoualian et al. (2016) proposed several variants of LDA to classify topics of sequentially structured documents; Jiang et al. (2019) developed a variant of LDA that considers topics of both previous and following sentences.
We propose a Sequential LDA algorithm for sentence classification with minimal changes to preserve the well-understood behavior of the original algorithm. Its algorithm partially resembles those proposed by Du et al. (2012) and Amoualian et al., (2016), but it is much simpler to implement. Keeping all the variables in the original LDA intact, we add a hyperparameter, Graphical model of Sequential LDA. The topics of current sentence 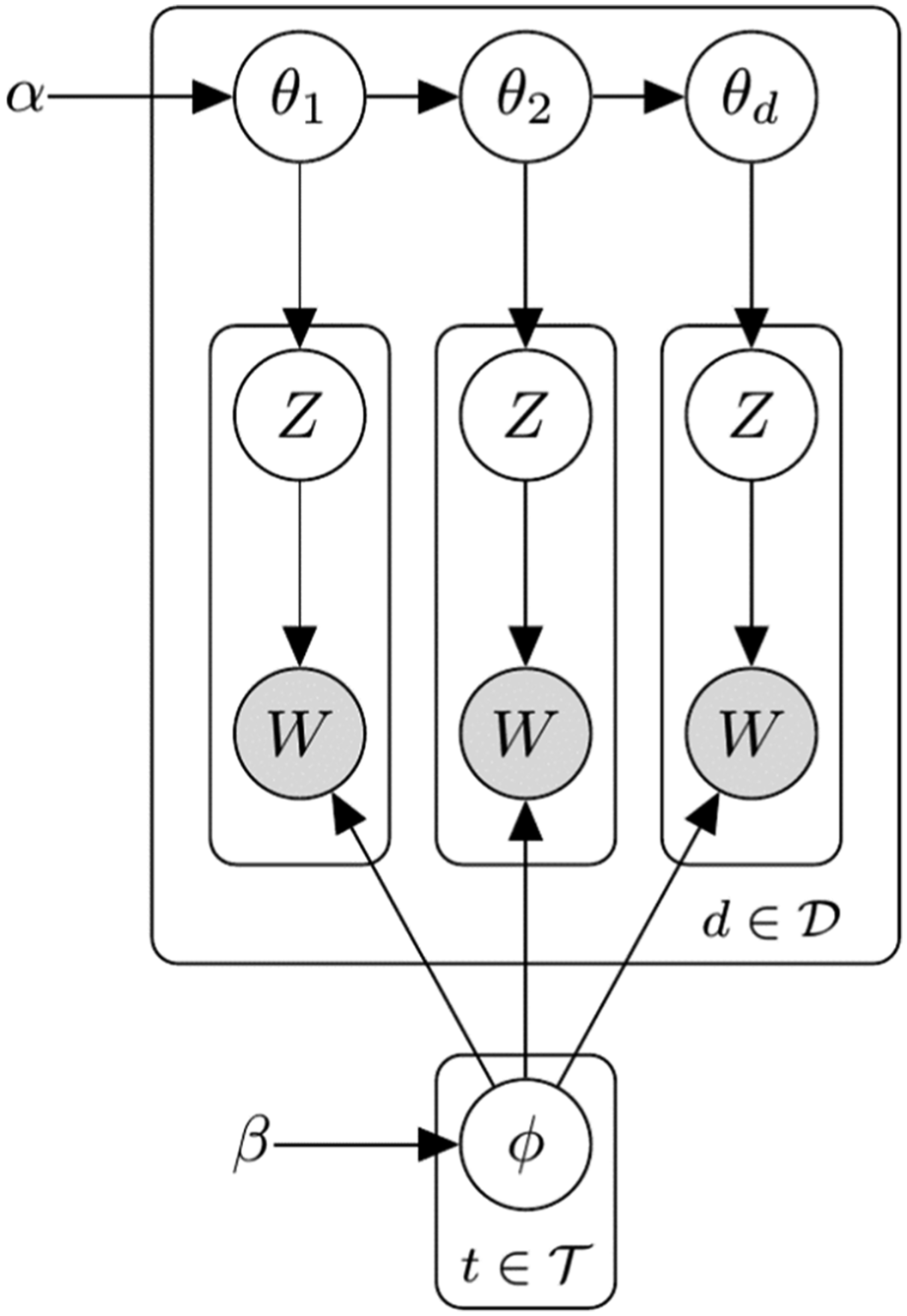
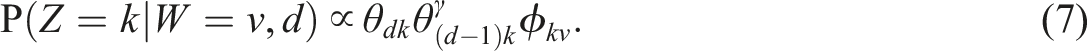
Sequential LDA can classify sentences more accurately than the original LDA because (1) it alleviates the data sparsity problem due to the short lengths of the documents; (2) it makes the transition of topics between sentences smoother; (3) it can identify topics of sentences that lack strong features based on the context.
Seeded Sequential LDA: Semi-supervised Topic Model for Sentences
It is easy to combine Sequential LDA and Seeded LDA because they affect different parts of the LDA algorithm. By merging Equations 5 and 7, we yield the sampling distribution for Seeded Sequential LDA
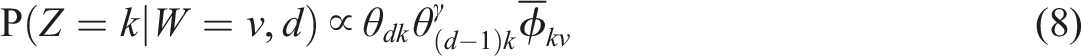
Hyperparameter Optimization
We have added two hyperparameters,
Regularized Topic Divergence
There are several methods for optimizing
According to Deveaud et al. (2014), the number of topics,
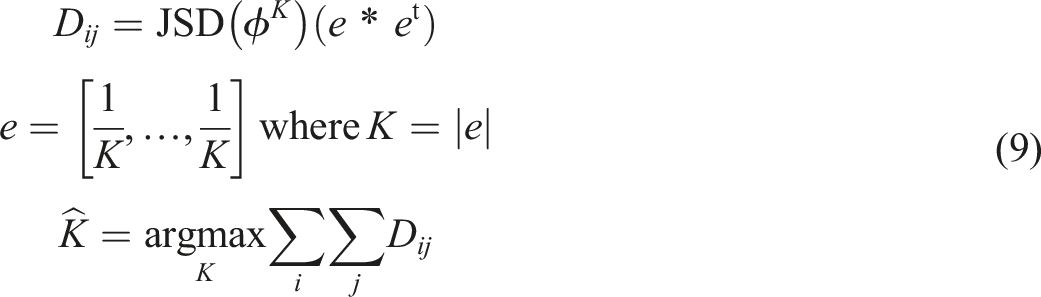
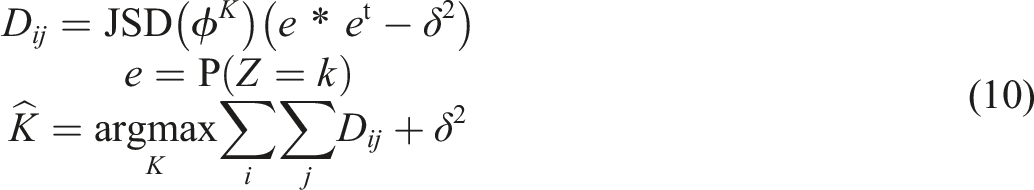
The biased weights regularize
Evaluation of the Algorithms
We evaluate the Seeded Sequential LDA algorithm and the regularized topic divergence measure on a corpus of speeches at the United Nations General Assembly (Baturo et al., 2017). 8 At the introductory General Debate meeting, delegates from the member states express their opinions on various topics in speeches (between 70 and180 sentences each in length. The speeches often start with diplomatic greetings to the audience and contain literary quotes or verbiage.
In an earlier study, Watanabe and Zhou (2020) sampled speeches delivered by delegates from 27 countries between 1991 and 2017 and had sentences manually labeled (n = 2507) into one of six general topics: “greeting” (5.7%), “UN” (18.3%), “security” (43.3%), “human rights” (6.8%), “democracy” (3.6%) or “development” (28.0%). They also compiled a list of seed words to identify topics of sentences using two semi-supervised machine learning algorithms, Seeded LDA and Newsmap. 9 They reported that Newsmap outperformed Seeded LDA, but that the overall F1 scores were only 0.57 and 0.40, respectively; both algorithms struggled to classify sentences about “human rights and “democracy” (0.14 ≤ F1 ≤0.36) because of the abstract nature of the concepts.
In this section, first, we determine the optimal number of topics for the corpus using the regularized divergence measure; second, we apply Seeded LDA and Seeded Sequential LDA to compare their classification accuracy; third, we test the sensitivity of classification accuracy to the amount of weight given to seed words; finally, we assess the impact of the residual topics on classification accuracy.
In our evaluation of the algorithms, we pre-processed the textual data using the Quanteda package in R (Benoit et al., 2018): we tokenized the texts based on the rules defined by the Unicode; we removed punctuation marks, numbers and infrequent (fewer than 10 times in the corpus) or grammatical words; we compounded collocations that are statistically significantly (p < 0.001) associated with each other.
Optimal Number of Topics
Researchers in international relations have identified different numbers of topics in speeches in the General Assembly, either manually or automatically. The chosen number reflected their varying research interests and ranged from around five (Bailey & Voeten, 2018; Finke, 2021; Kim et al., 2020; Watanabe & Zhou, 2020) to as large as 20 (Brun-Mercer, 2018) and 23 (Gray & Baturo, 2021).
We fitted LDA models with Changes in topic divergence scores for unseeded and seeded LDA models. The black line is the average divergence (AD), while others are the regularized divergence (RD) with different levels of granularity ( Top 20 Topic Words Identified By Non-Sequential Unseeded LDA With 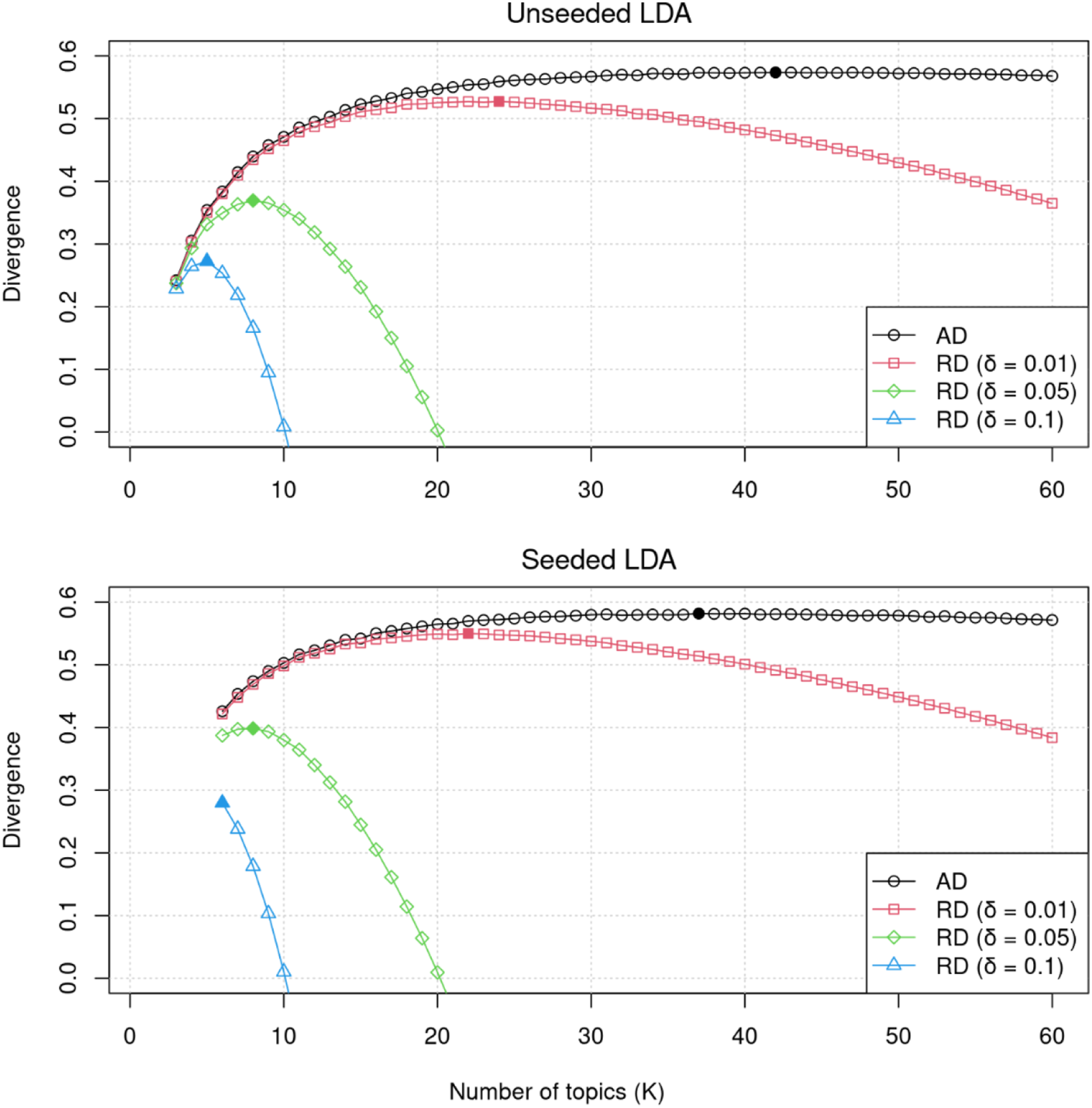

Seed Word Selection
Seed words Selected From the Top 100 Topic Words of A Non-Sequential Unseeded LDA Model.

Classification Accuracy
We evaluate the ability of Seeded Sequential LDA to identify topics of sentences accurately by fitting it on a sample of speeches with different hyperparameters. We set the number of residual topics,
We also compare the classification accuracy between ex-ante topic mapping with Seeded LDA and ex-post topic mapping with unseeded LDA. For ex-post mapping, we fit unseeded LDA with
Sequential Classification
We found that the overall F1 score of non-sequential models with two residual topics is only 0.47 (Figure 5). The poor performance of the non-sequential model is mainly due to very low F1 scores in ' “democracy” (0.12) and “human rights” (0.29). The algorithm struggles with these “difficult topics” because they usually relate to other topics but occur only infrequently.
13
However, the sequential algorithm improves the overall score from 0.47 to 0.62 with the higher classification accuracy in all the topics by between 0.09 and 0.18. The resulting median F1 scores are 0.60 in “greeting,” 0.62 in “UN,” 0.65 in “security,” 0.38 in “human rights,” 0.31 in “democracy,” and 0.70 in “development.” The scores vary around the median mainly due to the different values of hyperparameters as discussed below. Classification accuracy (F1) of non-sequential (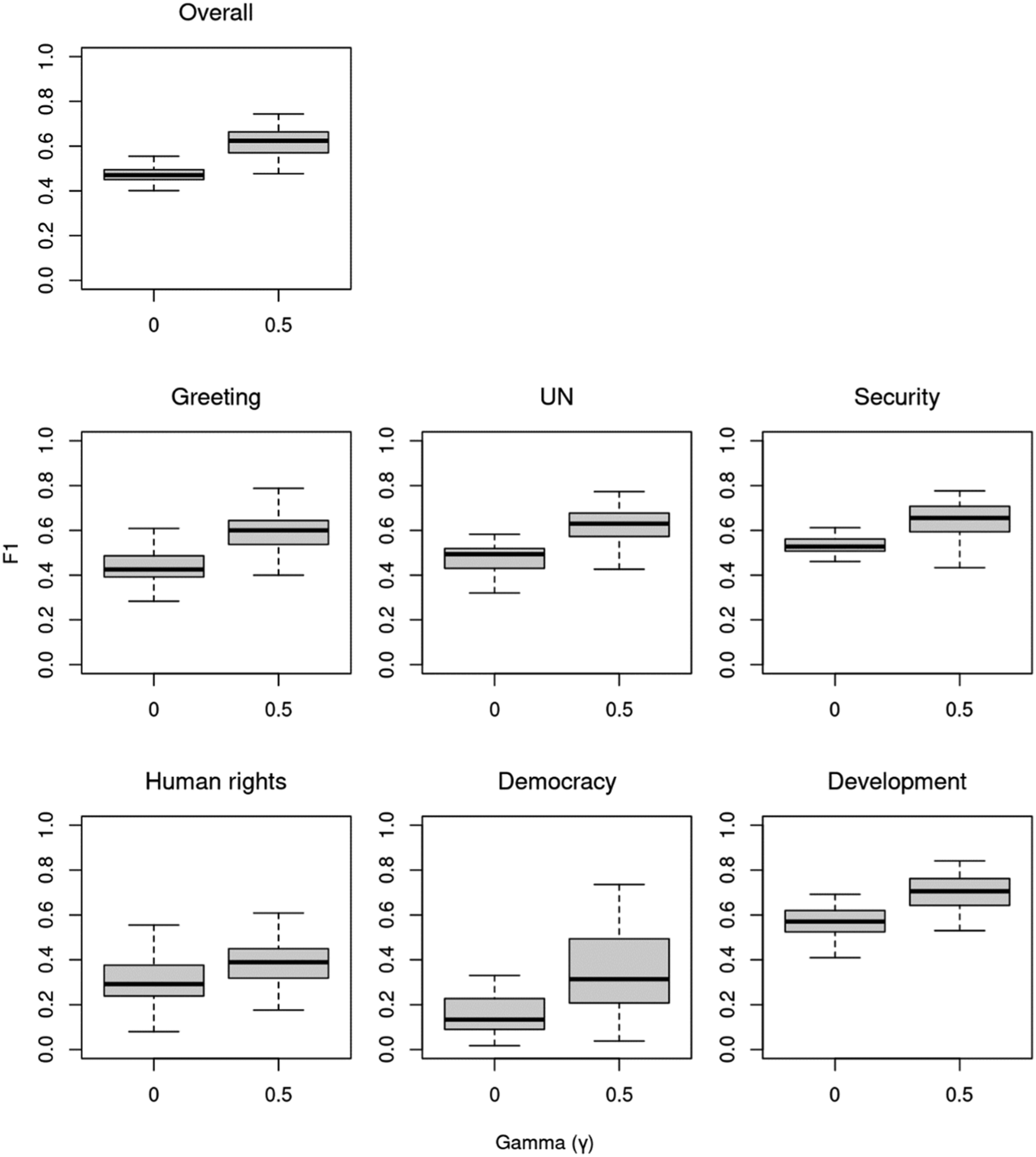
The sequential model can classify sentences more accurately than the non-sequential model because it recognizes transitions of topics in speeches. Figure 6 shows that the probability of topics estimated by the sequential model ( Probability of topics of sentences in a speech non-sequential (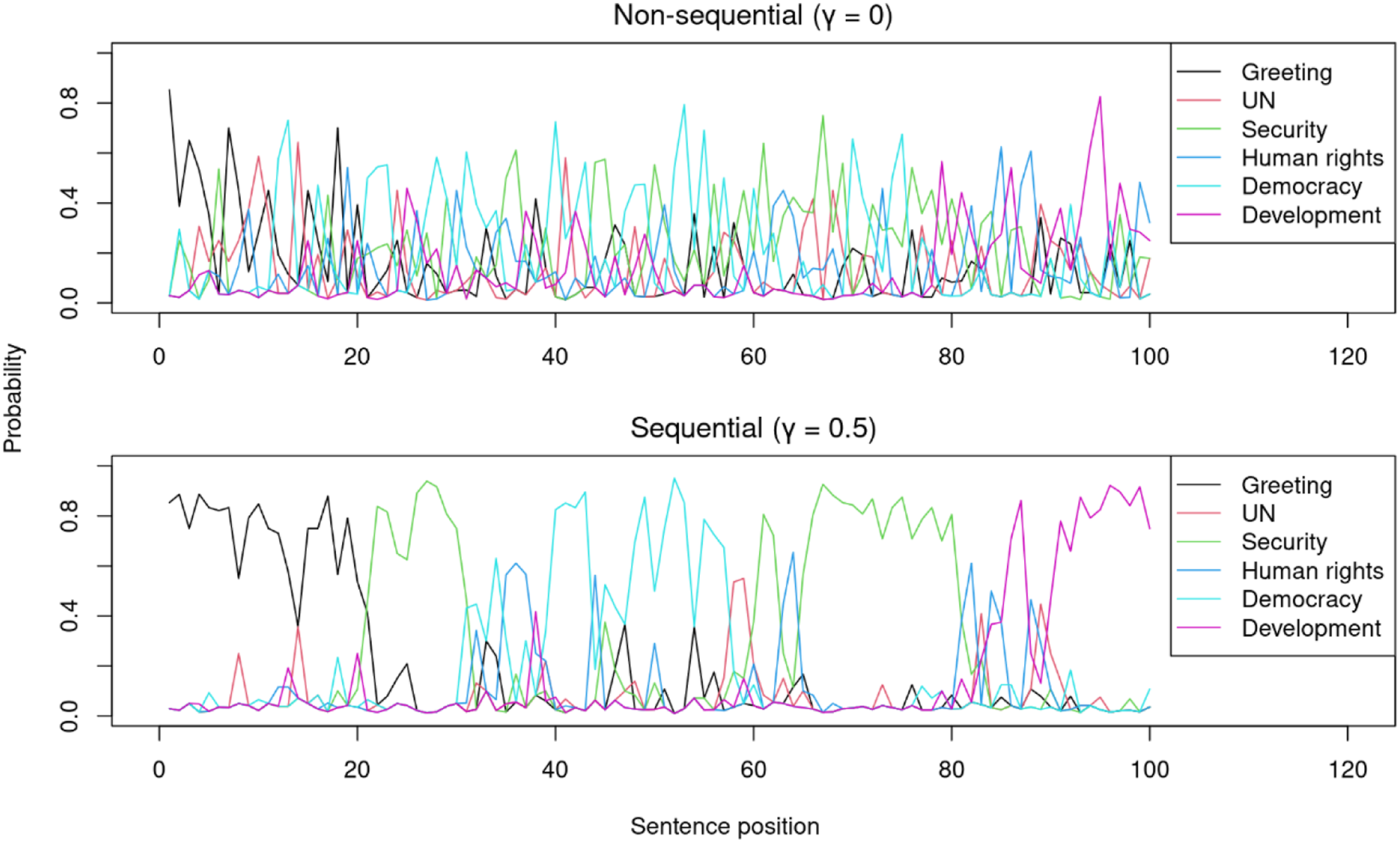
Residual Topics and Seed Word Weights
We also discovered that the non-sequential and sequential algorithms work differently under the same hyperparameters (Figure 7): while the non-sequential model works similarly with different sizes of the seed weight, the sequential model performs slightly better when the weights are 0.02 or larger. Further, whereas the scores of the non-sequential model slowly increase as more residual topics are added, the scores of the sequential model decrease visibly as two or more residual topics are added. Classification accuracy (F1) of the non-sequential (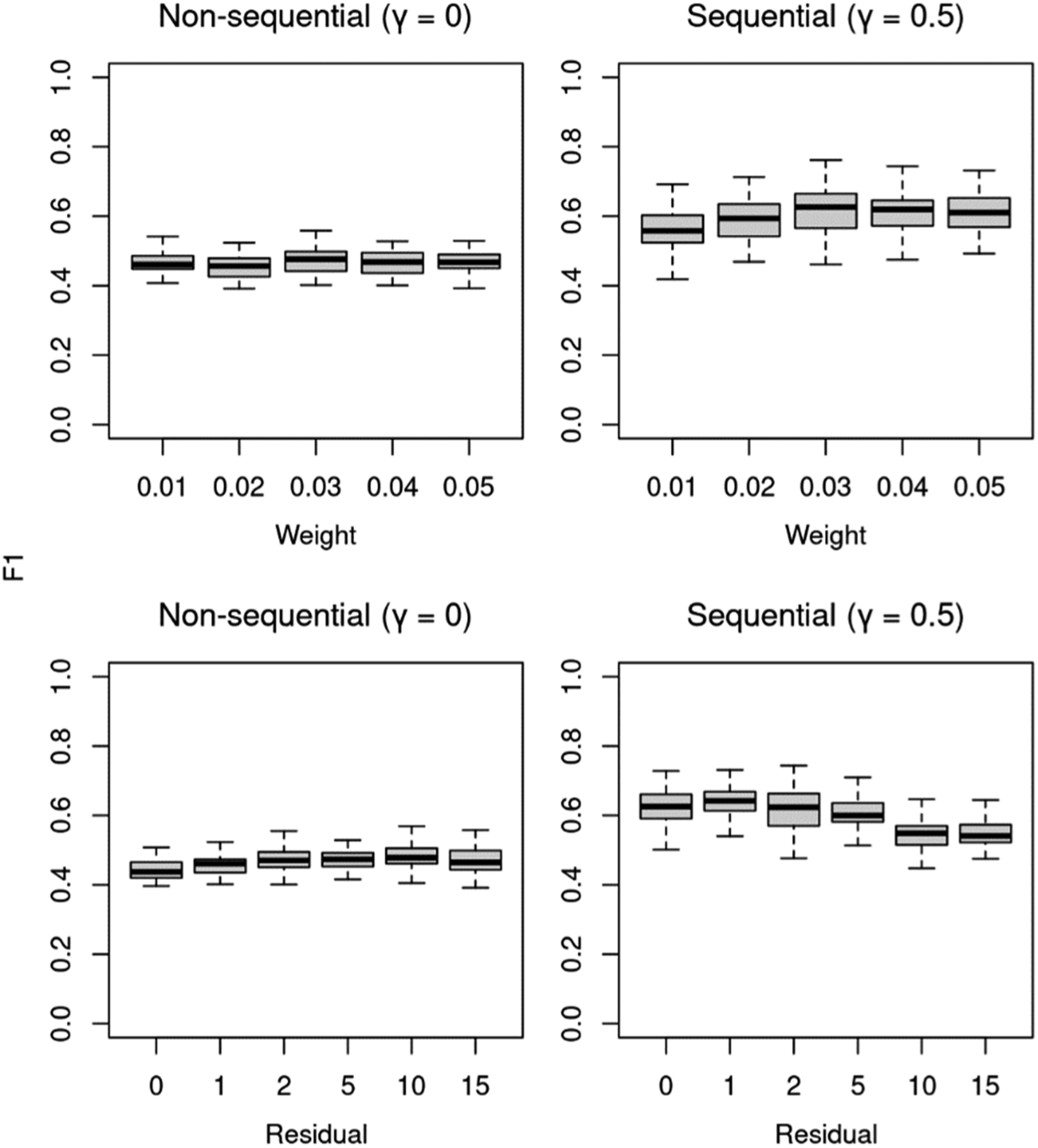
Top 10 Topic Words Identified by Seeded Sequential LDA.

Top 10 Topic Words Identified by Seeded Sequential LDA With Two Residual Topics (“Other1” and “Other2”).
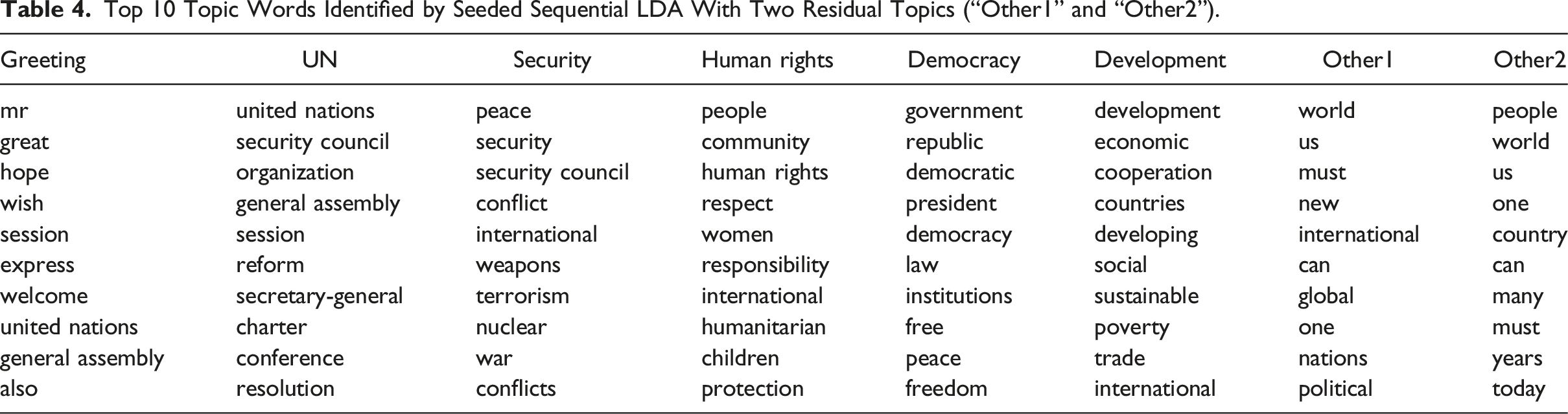
Top 10 Topic Words Identified by Seeded Sequential LDA With Two Seeded Topics (“Greeting” and “UN”) and Four Residual Topics.

Ex-post Topic Mapping
We found that the overall F1 scores are highest when Classification accuracy (F1) of the unseeded non-sequential (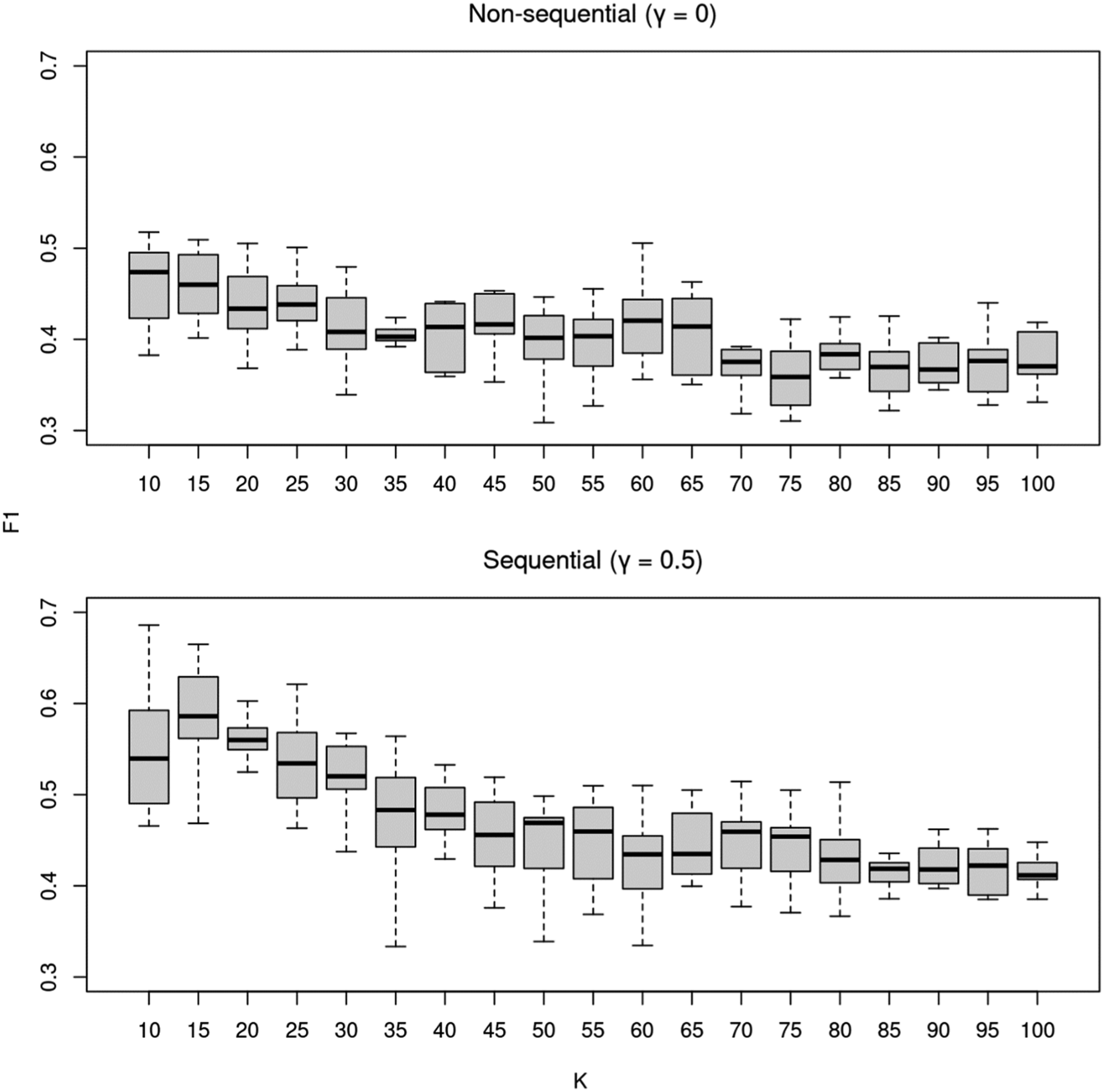
While we achieved the ex-post topic mapping based on the total count of the topic words regardless of their ranks, researchers usually perform topic mapping based only on highest-rank topic terms. To simulate this, we counted the number of topics that have at least one seed word among the top 10 or 50 topic terms from the non-sequential and the sequential algorithms (Figure 9). The number of such topics are consistently higher in the latter than in the former by about 2% if words are the top 50 topic terms; the difference between them expands to 4% if words are limited to the top 10 topic terms. The number of topics in the unseeded non-sequential (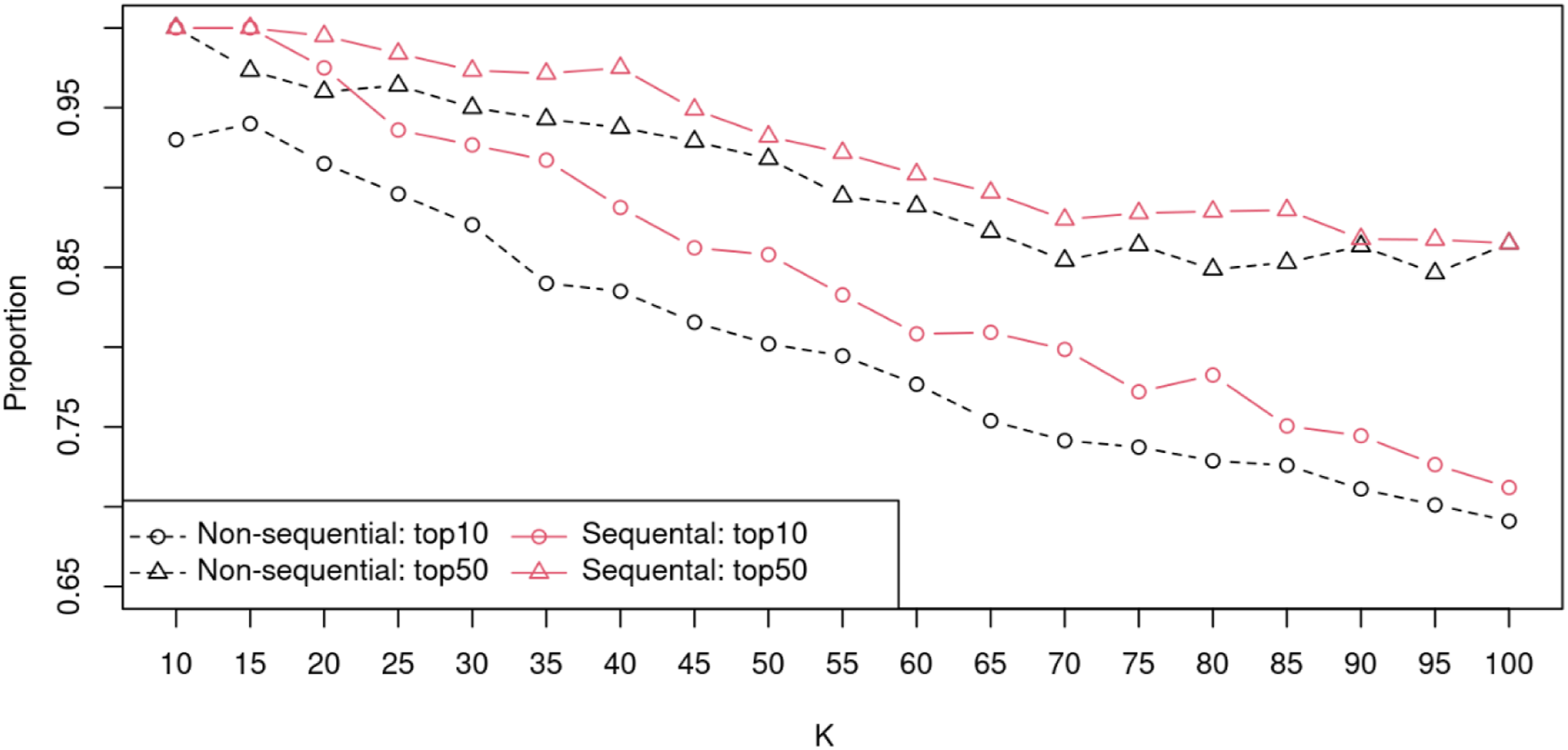
Example: Topic-Specific Sentiment Analysis
As an illustration of how the new algorithm can be successfully applied in empirical research, we present the results of topic-specific sentiment analysis. We classified all the sentences in the corpus into the six topics using a Seeded Sequential LDA model (
Figure 10 plots the average sentiment of sentences classified as about “security” and “development” by Seeded Sequential LDA, where lower scores indicate a more negative sentiment about the topics. The upper subplot for “security” reveals that the Kosovo crisis in 1998 as well as the 9/11 attacks triggered strong negative reactions of speakers from all the regions. Similarity, positive sentiment in 2011 at the onset of the Arab Spring turned very negative in the following years because of the Syrian civil war, which led to the rise of Islamic extremists. We can also observe some regional patterns, such as a more negative sentiment among Eastern European speakers during the 2008 Russo-Georgian and the 2014 Russo-Ukrainian wars. Likewise, while representatives of Latin America in general tend to express a more negative sentiment than others, there is a clear spike in a more positive sentiment in 2015, when the Colombia peace agreement was reached.
In the lower subplot for “development,” speakers from all the regions expressed a more negative sentiment about development during the 1998 Asian financial crisis and the 2008–2009 global financial crisis. Speakers from East Europe were particularly negative during their transition to the market economy in the early 1990s, while those from Western and East European were negative during the European sovereign debt crisis in 2011. Speakers from Africa and Latin America are consistently most negative about development, but the former is less negative than the latter because arguably they must appeal to foreign donors through more positive language. 15
In short, these patterns reflect the primary function of the United Nations: maintaining peace and security. With the topic-specific sentiment analysis of the speeches, the scholars of international relations can account for the role of emotions in the discursive maintenance of power in global politics. Sentiment about “security” and “development” by geopolitical groups of countries. The vertical axis shows the average sentiment scores for the topics. Higher scores indicate a more positive sentiment.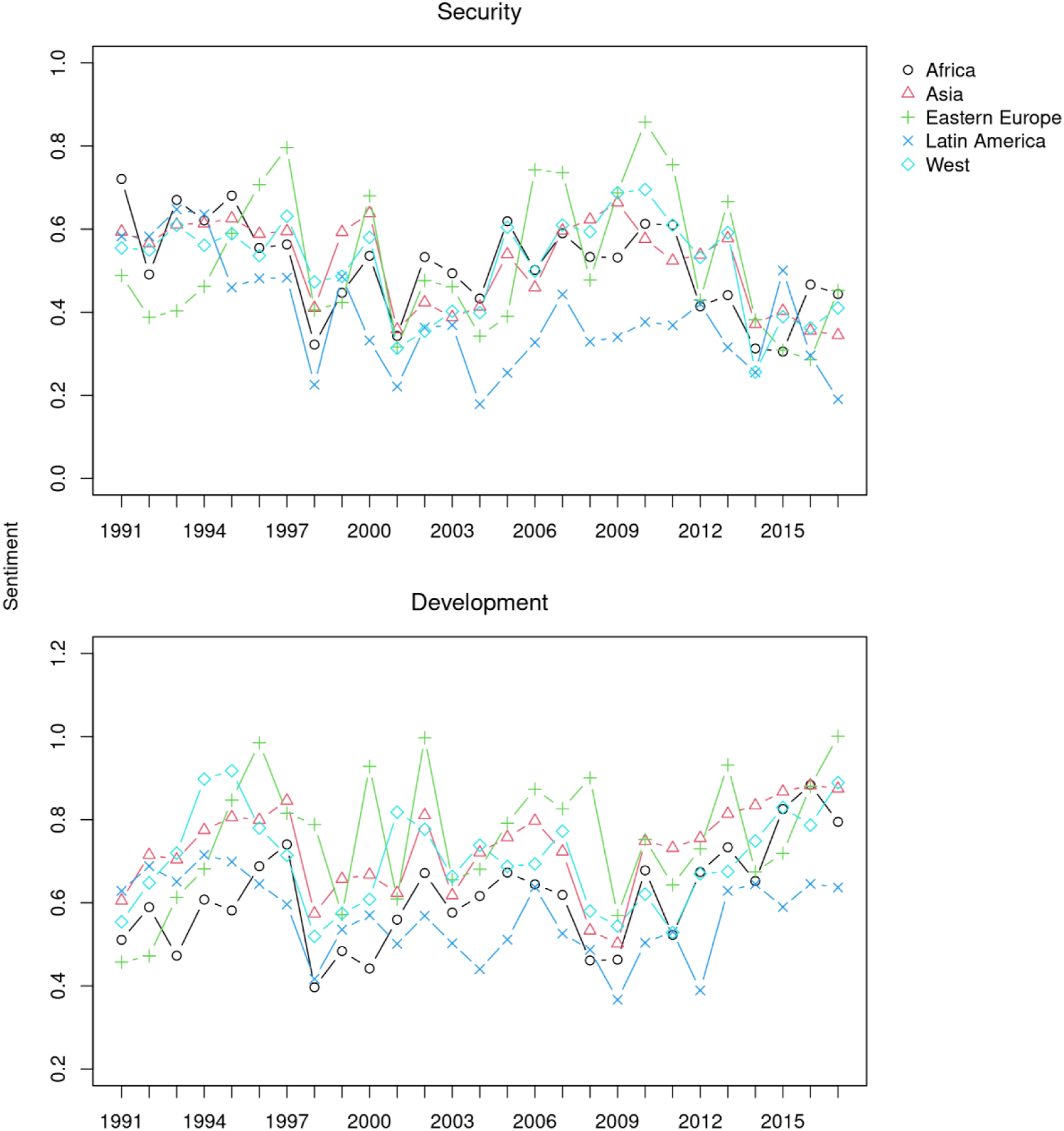
Discussion
Our evaluation of the algorithms and the illustrative example has clearly demonstrated that users can match algorithmic topics to theoretical concepts with only a small number of seed words. The classification accuracy of Seeded LDA is poor because of the short lengths of the documents, but Seeded Sequential LDA has improved the accuracy significantly. Its accuracy was lower for complex concepts such as “democracy” and “human rights,” but it performed reasonably well in other topics. The sequential algorithm achieved a higher accuracy with more stable transition of topics between sentences in the same speech.
Seeded LDA enables researchers to perform not only deductive topic analysis through user-provided seed words but also semi-deductive topics analysis with the assistance of unseeded residual topics. Unseeded LDA allows users to conduct inductive topic analysis by discovering topics and their seed words from the corpus. Nevertheless, the number of topics in unseeded LDA must be small enough (thus, the sizes of topics are large enough) to identify relevant frequent seed words from the corpus; scholars must also choose seed words based on external resources to avoid over-fitting to the current corpus.
The optimal number of topics for LDA has been determined based solely on their divergence in earlier studies, but the regularized divergence measure can incorporate users’ preferred granularity of the analysis defined as the expected minimum sizes of topics. The granularity can be any value between the
The larger seed word weights have improved the classification accuracy of Seeded Sequential LDA, but they had little or no effect on Seeded LDA. Larger weights improve the classification accuracy only in the sequential algorithm because large weights are necessary to increase the probability of both current and following sentences (small weights are sufficient to affect current sentences). This also demonstrates the robustness of the seeded algorithms, suggesting that users can give large weights (
The comparison of the LDA models has revealed significant differences in the behavior of non-sequential and sequential algorithms with respect to the number of topics. The differences originate primarily from the amended definition of what constitutes a topic: these are not only words that frequently occur in the same sentences, but also words that occur in neighboring sentences in the sequential model. This makes the algorithm susceptible to unseeded topics that interrupt a sequence of seeded topics, especially when small unseeded topics accidentally receive high probabilities.
The ex-post mapping (unseeded LDA) of topics has appeared comparable to the ex-ante mapping (Seeded LDA) with the non-sequential and sequential algorithms. This is comforting because ex-post mapping is a common practice in applied research. Still, the lower F1 scores with large
The sharp fall in the F1 and the number of topics with topic terms can be explained by the sparsity of words in small topics that makes Gibbs sampling less accurate. The average frequency of topic terms decreases rapidly as the
To summarize, we propose the following four-step procedure for topic classification of sentences based on the strength and weaknesses of the LDA algorithms: (1) Optimization: Estimate the optimal number of topics, (2) Seed Word Selection: Select seed words for the target concepts from the most important topic words identified by the unseeded non-sequential model. The number of seeded topics is (3) Estimation: Fit a Seeded Sequential LDA model with the seed words with the chosen number of residual topics to absorb junk words. The seed word weight should be (4) Prediction: Compute the probability of sentences using the fitted Seeded Sequential LDA model and classify them into topics with the highest values, ignoring those for residual topics.
Finally, classification of sentences into topics allows users to interpret the results in the same way as the traditional content analysis. They can also combine topic classification with additional analyses of the sentences (e.g., measuring positive-negative sentiment, lexical complexity or detecting named entities). Combined results will show not only which topics, but also how such topics, are discussed, enabling the users to study how speakers framed issues in a particular light.
Conclusions
With Seeded Sequential LDA, we have proposed a new approach to topic-specific content analysis of sentences. The sequential classification algorithm is relatively simple, but it significantly improves the accuracy of sentence classification across all topics. With the assistance of this algorithm, researchers can perform highly accurate topic-specific content analysis whether in a deductive, semi-deductive, or inductive approach: in a deductive analysis, scholars must provide seed words a priori; in a semi-deductive analysis they should do so only for some of the topics; and there is no need for seed words in an inductive analysis.
The ability of our algorithm to classify individual sentences allows researchers to correlate topics with other traits as demonstrated in our example. If topics and sentiment are combined in each sentence, researchers can show not only which topics, but also how such topics, are discussed, enabling the users to study how speakers framed issues in a particular light. 16 Although we chose dictionary-based sentiment analysis for simplicity, more complex traits of sentences could be captured and analyzed along with topics if other types of semi-supervised algorithms are employed (e.g., Trubowitz & Watanabe, 2021).
In our evaluation, ex-post topic mapping with unseeded LDA appeared as good as ex-ante mapping with Seeded LDA as long as
There are a lot of potential applications of Seeded Sequential LDA beyond topic-specific analysis of sentences. Seeded LDA could also be used to identify topics whose words change over time by applying it to subsets of a historical corpus with the same seed words. 17 Such dynamic topic analysis is hard to implement using unseeded algorithms unless the relationship between topics from different time windows is explicitly modeled (Blei & Lafferty, 2006), but it is easy using the seeded algorithm because topics are pre-defined. 18
Sequential LDA can be applied not only to the sentences of a long speech by the same person but also to the short comments in a conversation by a group of people, because speakers usually discuss the same topic, responding to earlier speakers’ comments. Even if they refer to the subject of the discussion only with pronouns in informal fora (e.g., social media), the sequential algorithm can identify the topic of the current comment based on the previous comment. This, in turn, allows researchers to detect points at which the topics of the conversation changed and split it into sub-conversations for further analysis.
We hope this article, along with the R package that implements the Seeded Sequential LDA algorithm, will make deductive topic classification more accessible in applied research. The algorithm already allows researchers to perform types of analysis that are otherwise hard to achieve, but there are unanswered questions for future research. First, we believe that the algorithm can classify the multifaceted difficult topics (“democracy” and “human rights”) more accurately with better seed words, but we do not have a way to easily distinguish between “good” and “bad” seed words. To make seed word selection easier, we must devise a method to detect seed words that are causing false matches in the corpus. Second, we found the sparsity of topic words is an important factor affecting the performance of the algorithms, but we have assessed its impact only in the classification of very short documents (i.e., sentences). To identify the best practice in topic modeling, especially the reliability of ex-post topic mapping, we must conduct similar evaluations of the LDA algorithms with longer documents. Finally, we discovered the performance of Sequential LDA deteriorates when many residual topics are added. We believe it is also related to the sparsity of topic words, but we do not know how to address the issue yet.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.