
Abstract
The systematic literature review (SLR) is the gold standard in providing research a firm evidence foundation to support decision-making. Researchers seeking to increase the rigour, transparency, and replicability of their SLRs are provided a range of guidelines towards these ends. Artificial Intelligence (AI) and Machine Learning Techniques (MLTs) developed with computer programming languages can provide methods to increase the speed, rigour, transparency, and repeatability of SLRs. Aimed towards researchers with coding experience, and who want to utilise AI and MLTs to synthesise and abstract data obtained through a SLR, this article sets out how computer languages can be used to facilitate unsupervised machine learning for synthesising and abstracting data sets extracted during a SLR. Utilising an already known qualitative method, Deductive Qualitative Analysis, this article illustrates the supportive role that AI and MLTs can play in the coding and categorisation of extracted SLR data, and in synthesising SLR data. Using a data set extracted during a SLR as a proof of concept, this article will include the coding used to create a well-established MLT, Topic Modelling using Latent Dirichlet allocation. This technique provides a working example of how researchers can use AI and MLTs to automate the data synthesis and abstraction stage of their SLR, and aide in increasing the speed, frugality, and rigour of research projects.
Keywords
Introduction
The growth of Artificial Intelligence (AI) is changing the way that research is conducted across a variety of fields and disciplines (Longo, 2020). Not since the industrial revolution have new technologies, such as the ones provided through AI and Machine Learning Techniques (MLTs) automated what were once labour-intensive tasks (Dwivedi et al., 2021). Simultaneously, research outputs are continuing to expand exponentially, making reviews that aim to systematically gather and synthesise all pertinent information related to a phenomenon increasingly more difficult (Gusenbauer & Haddaway, 2020). There is therefore a gap where AI and MLTs can be utilised to respond to not only the increasing amount of evidence now available, but also to the demands of providing evidence in a timely, frugal, transparent, and rigorous manner. As such, it is not the purpose of this article to claim that AI and MLTs can or will produce superior research, or diminish the role of the researcher in anyway, but that they are another tool for researchers to employ; in this context, researchers with coding experience that are conducting systematic literature reviews (SLRs).
The SLR is often considered the ‘gold standard’ of evidence gathering and evidence synthesis (Pati & Lorusso, 2018; Thomé et al., 2016). This article seeks to draw attention to a novel method that researchers conducting a SLR can utilise to reduce time and money on what is otherwise a laborious and time-consuming stage in a SLR, data synthesis and data abstraction. In addition to financial and time constraints, due to the very nature of the time taken to conduct them, SLRs can quickly become out of date (Marshall & Wallace, 2019; Sundaram & Berleant, 2022). Due to this time crunch, the automation of stages of an SLR with AI and MLTs can offer researchers an opportunity to speed up their reviews. Additional benefits of this method are the reduction of researcher bias, improved transparency and repeatability, all of which are intertwined within the SLR process.
An information technology-based computer system, AI has the ability to perform tasks that normally require human intelligence (Yang & Siau, 2018). Characterised by cognitive abilities, learning, adaptability, and decision-making, human intelligence through AI has allowed for the automation of tasks that would normally take a person significant time to complete (Chen et al., 2020). A subset of AI, Machine Learning (ML) is a form of AI that allows software applications to make projections and precise outcomes and is one of the fastest growing fields within computer science (Osisanwo et al., 2017). The three main kinds of ML are: reinforced, supervised, and unsupervised learning (Mahalakshmi et al., 2022).
The method that this article advocates combines an unsupervised MLT with an already established form of qualitative analysis; Deductive Qualitative Analysis (DQA). This combination allows AI to play a supportive role in the coding and categorisation of extracted SLR data, and in synthesising then abstracting SLR data. There are other stages of an SLR that can benefit from AI and MLTs, and this article will briefly touch upon them, however, the main thrust of this work is on the data synthesis and abstraction stage. The data for this article was gathered utilising DQA methods (the process can be found and assessed in
Traditional GTMs are based on researchers collecting, and concurrently analysing data (Charmaz & Belgrave, 2007), with the aim of generating new theories based on qualitative data (Glaser et al., 1968). This has traditionally meant that researchers inductively encode data from the beginning of research, even as evidence is still being gathered (Barberis Canonico et al., 2018)
Involving the simplification of data, abstraction has been widely utilised in AI (see, Zucker (2003) for an overview). In essence, abstraction refers to the human ability to focus on simpler explanations of observation and conceptualisation, alongside reasoning (Goldstone & Barsalou, 1998). In the context of utilising MLTs for data synthesis of SLR data, abstraction involves the identification of key themes or concepts that are relevant to the deductive analysis and representing them in a more concise and organised way (Mohan & Kumar, 2022). As such, it allows for complex data sets, such as those extracted during a SLR, to be simplified to facilitate integration and analysis. This is achieved through filtering crucial elements while excluding unrelated or less significant details (Batra et al., 2020; Kallimani, 2018). Therefore, if a research project, such as this one, utilises data extraction based on preconceived templates, when combined with DQA, abstraction allows researchers to leverage the strengths of qualitative analysis methods with MLTs to synthesise and obtain meaningful insights from qualitative data in a more efficient and scalable manner. One way for researchers to achieve this is through unsupervised MLTs such as topic modelling programs utilising Latent Dirichlet allocation (LDA).
A popular and well-established probabilistic model, LDA facilitates latent topic identification within a collection of documents, such as data uncovered during a SLR. It is commonly applied in Natural Language Programming (NLP) and text mining to identify hidden thematic structures in textual data (Jacobi et al., 2016). LDA facilitates abstraction by automatically identifying latent topics across a corpus of data. Through analysing word-pattern co-occurrence, LDA assigns probabilistic distributions to each document the degree to which they are associated within a given topic (Rahimi et al., 2022). This then allows for higher level abstraction of the content as researchers can focus on the main themes and ideas uncovered in the data (Priyadharshini & Magesh, 2021). LDA also facilitates abstraction through topic summarisation. LDA generates a set of word-topic distributions representing the probability of each word occurring in each topic (Onah et al., 2022). Through examining the most probable words that are associated within each topic, researchers can gain an understanding of the main concepts and themes that are represented by the topics. This summarisation aids in distilling key information and abstracting the data (Onah et al., 2022). This then helps to accomplish a key outcome sought throughout an SLR; the identification of gaps in the research domain under investigation through a comprehensive summary of its pertinent research (Paul et al., 2021).
The paper is structured as follows. The next section will provide an overview of the literature pertinent to creating and running a SLR. The following section will then discuss the role for AI and automation for SLRs, and briefly how AI can be applied to each stage of an SLR. It will then discuss how MLTs such as LDA topic modelling can aid in increasing the speed, frugalness, and strength of the data synthesis and abstraction stage of an SLR. Following this, the methods section will give an extensive overview of the coding used to create a well-established MLT, LDA Topic Modelling. Next, the results and discussion section will present the synthesised and abstracted data from a SLR on the resilience and sustainability of energy infrastructures (
Literature Review
SLRS
SLRs seek to gather, appraise, and synthesise evidence pertaining to a phenomenon under investigation (Petticrew & Roberts, 2008). In order to achieve this, they involve thorough searches of research databases aimed at uncovering all pertinent work in the review domain (Siddaway et al., 2019). There are a number of reasons to undertake a SLR: (1) to advertise research being undertaken and to avoid repeating research already conducted; (2) to guide the planning of new research; and (3) to underpin claims of originality when new research is contrasted against old (Paul et al., 2021).
SLRs are important because they allow for the incremental advancement of a field through building on previous research (Lame, 2019). Additionally, they provide a structured approach to gather, appraise, and synthesise evidence, they also aid in monitoring research practices in the review domain, and finally, they are important as a means to bridge different domains (Lame, 2019). Not all SLRS follow the same guidelines; however, there are certain stages that are common to all SLRs.
The process of formulating and creating a SLR can be broken down into several stages. Framing a research question is generally considered the first stage (Khan et al., 2003). The next stage is where relevant works are identified, normally through the screening of titles and abstracts, followed by sourcing full texts of included studies and performing quality assessment on the included studies (Khan et al., 2003). Following this stage is data extraction, then data synthesis and data abstraction, followed with the analysis/interpretation of results (Beller et al., 2018; Tsafnat et al., 2014).
Guidelines for SLRs.

Automating Stages of an SLR
The use of AI in SLRs is not a newfound occurrence. AI tools have been utilised in reviews and evidence synthesis since 2016 (see EPPI-Reviewer and Abstracker for examples) (Nguyen-Trung et al., 2023). Due to SLRs taking a substantial amount of time, months to years in some cases (Larsen et al., 2019; Tsafnat et al., 2014) and are becoming increasingly complicated due to the amount of published evidence that needs to be incorporated into the review (Antons et al., 2023; Beller et al., 2018), additional tools need to become available to increase their speed and frugality, while also maintaining the rigour and transparency expected in an SLR. A route to overcoming these issues is by integrating computational methods that combine the powers of human comprehension and judgement with a computers speed and effectiveness (Antons et al., 2023). These methods can be applied to individual, or multiples stages of a review. As noted earlier, the first stage of a SLR is generally research question formulation. Following this stage, AI and MLTs can increase the speed and frugality of SLRs.
Search Strategy and Inclusion/Exclusion Criteria using Chat GPT
Normally a labour-intensive stage, formulating a comprehensive search strategy to answer a research question and then determining inclusion and exclusion criteria is a stage that can benefit from AI. A public tool created by OpenAI, Chat GPT is based on the Generative Pre-Trained language model (Kirmani, 2022). Chat GPT is a sophisticated chatbot capable of completing an array of text-based tasks that range from answering questions, to generating letters (Lund & Wang, 2023). By prompting Chat GPT with a research question, the tool can then aid in developing preliminary search strategies for researchers to examine. Wang et al. (2023) provide a comprehensive guide on how to prompt Chat GPT to formulate search strategies to be utilised in SLRs. The tool can then be prompted to suggest possible inclusion and exclusion criteria within the context of the research to be undertaken.
Title/Abstract Screening using ASReview
When conducting a SLR, researchers can face hundreds, if not thousands, of studies to screen by titles and abstracts for inclusion/exclusion in their reviews. This is traditionally a labour-intensive critical stage of a review that needs to be conducted as efficiently and as transparently as possible. A program that can drastically speed up this process is ASReview.
ASReview utilises machine learning techniques to overcome the manual and time-consuming process of screening titles and abstracts for systematic reviews. An open source and free tool, the source code of ASReview is available under an Apache 2.0 license and includes the relevant documentation (van de Schoot et al., 2021).
The process of using ASReview is simple; (1) researchers upload a file containing the metadata of articles identified in their literature searches; (2) the researcher trains the model. As the screening process is binary in nature, a researcher must select at a minimum one article that corresponds to their inclusion criteria and one that does not. The more articles selected for inclusion/exclusion at the beginning, the increase in efficiency of the active learning process utilised in ASReview; (3) the binary label of (1 for relevant vs. 0 for irrelevant) is then used to train a new model, following this a new article is presented to the researcher based on the previous articles inclusion or exclusion (van de Schoot et al., 2021). This process continues until a certain user specified number is reached. The researcher then has a file of articles labelled relevant or irrelevant (van de Schoot et al., 2021). It is important to highlight that ASReview is not a bias-free tool and is only effective when inclusion/exclusion criteria and a stopping rule are predefined (Warren & Moustafa, 2023).
Data Extraction using ChatPDF
Utilising GPT 3.5, ChatPDF allows the user to converse with PDF files. Once the application is opened, PDF files can be uploaded, and the user can begin asking the article questions using the built-in interface. The application and how to set it up can be found at https://github.com/dotvignesh/PDFChat. This program allows researcher to scrape and extract data from PDF files using targeted questions. This can significantly increase the speed that data is extracted at, greatly reducing researcher time and speeding up the process of a review. The novelty and benefits of this method of data extraction is currently the subject of another methods paper.
As can be seen, each stage of a review provides an opportunity for automation. MLTs are being increasingly employed to analyse and automate steps in the SLR process. Outside of the tools already outlined, Sundaram and Berleant (2022) and Tsafnat et al. (2014) provide an overview of AI tools that can be used for steps in the review process, and Antons et al. (2023) provide a comprehensive review method for the creation of standalone computational literature reviews.
Data Synthesis and Abstraction: Machine Learning Techniques
As the focus of this article is on the data synthesis and abstraction stage, it is this stage that will be unpacked. According to Sundaram and Berleant (2022) there is a need for SLRs focusing on automation on data synthesis. Indeed, due to the amount of unstructured data uncovered during a review, new synthesis methods, or the integration of methods from other disciplines, have the ability to expand the understanding of the emergent world of data (Abram et al., 2020).
Automating Data Synthesis
Data synthesis is the approach to interpreting extracted data to satisfy a SLRs question(s) or hypothesis/hypotheses (Sundaram & Berleant, 2022). It is the organisation of the raw data obtained during a review into a format that is simple to comprehend and then examine. All researchers employ a coding scheme to synthesise and then abstract data; index cards, highlighters, glue and scissors, or programs such as Nvivo (Perrin, 2001). Data synthesis and abstraction has been identified as one of the most time-consuming components of conducting a SLR, but one that can be improved through automation (Sundaram & Berleant, 2022; Tsafnat et al., 2014). It is also in this stage where the subjective biases that researchers hold may pose several problems with respect to a SLRs validity. A lack of clear processes and techniques during synthesis can threaten result legitimacy (Evans, 2002). Also, owing to subjective decisions made by researchers, it is difficult to delineate a researchers own beliefs and world views, and that of the subject matter (Evans, 2002). Furthermore, due to missing procedures and techniques, there is unlikely to be a trail of the decisions made for others to judge their worth (Evans, 2002). A way to address these issues is using AI and MLTs created with computer programming languages.
Natural Language Processing
As a broad field within AI, NLP is a MLT that straddles the spaces of computational linguistics, AI, and computer science, and covers the manipulation and computer understanding of human language (Millstein, 2020). At its simplest, NLP is a computer/systems ‘ability for a computer/system to truly understand human language and process it in the same way that a human does’ (Goyal et al., 2018, p. 16). NLP has become increasingly prevalent in society. Predictive text and handwriting recognition, web search engines, and machine translation are all based on NLP technologies (Bird et al., 2009). It is also being increasingly adopted in the social sciences (Ungless et al., 2023). The use of MLTs in NLP is useful for researchers as it allows for the automation of tasks, making them more cost and time efficient (Le Glaz et al., 2021).
Topic Modelling
A statistical form of NLP, topic modelling utilises algorithms to summarise large quantities of texts into a range of topics (Leeson et al., 2019). A common way to model topics is using LDA. As a three level Bayesian model, LDA is a generative probabilistic model utilised in compiling data, such as text corporas (Blei et al., 2003). The central thrust of the model is that texts are signified as random mixtures over latent topics, where each topic is distinguished by a distribution over words (Blei et al., 2003). This means that each text is a collection of topics or themes, and that the existence of each word can be assigned to one of the texts topics or themes. It should be noted that LDA is not the only form of topic modelling available to researchers. Other topic models include; Non Negative Matrix Factorization, developed by Liu et al. (2006); Latent Semantic Analysis, developed by Landauer et al. (1998); Parallel Latent Dirichlet allocation, developed by Wang et al. (2009); and Pachinko Allocation Model, developed by Li and McCallum (2006).
Synthesising and Abstracting With Topic Modelling
Topic Modelling using MLTs such as LDA can be employed to leverage data gathered during a SLR for synthesis. This is accomplished through the creation of visualisations of topic clusters from a corpus of extracted text. Indeed, Rahgozar and Inkpen (2019) have illustrated how such techniques can be utilised to produce useful results through LDA topic modelling, including most relevant terms within topics and through mapping intertopic distances. The identification of latent topics within the synthesised text also provides strong abstraction of the data. As the LDA tool generates a set of topics that provide a representation of the included texts through topic scoring (counting the number of times a word appears within a topic cluster), the text is reduced down to simpler subset of the original text (Priyadharshini & Magesh, 2021). This text abstraction allows for easier analysis. It is also a tool that can be utilised across different reviews, or research projects. Considering the time and money saved in employing a versatile tool that, once written, can be used repeatedly for reliable results, the benefits for researchers are justified significantly. Furthermore, employing this tool also adds to the transparency of the research being conducted as questions can be asked of the coding utilised in this process.
The methods section will illustrate the code utilised for this article and for future works. As mentioned earlier on, there is an expectation that those who will utilise this tool will have a certain level of experience in coding. This is not to say that with some time and effort less knowable researchers will be able to utilise this method, however, there is unfortunately insignificant space to tailor the approach to novices. There are many blogs and articles that explain the code, or variants of code, used to create an LDA topic model. The time has been taken to include it in this article due to the important position that SLRs have within research.
Methods
Python Libraries and Versions.

Each library was installed with Pip3 using PowerShell. The code was written in a Jupyter Notebook using Microsoft Visual Studio Code. As Python is an open source and free program, there exists an extensive amount of online material to help create codes. Acquired by Microsoft in 2018, GitHub is a code hosting platform for version control and collaboration (GitHub, 2022b). If there is a particular topic of interest, GitHub facilitates browsing via topics (GitHub, 2022a). For example, ‘machine learning’ is a searchable topic in GitHub, as is ‘Topic Modelling’.
Code can be a challenge to cite as traditional bibliographic information is not always supplied by its creator. The use of online pseudonyms also makes this task difficult. To make it easier for researchers to cite codes from the GitHub repository, GitHub has facilitated built-in support for CITATION.cff files. This feature allows academics and researchers to let people know how to correctly cite their work (Smith, 2021). Unfortunately, non-academics do not share the same bibliographic views regarding correct citations. This makes it difficult to provide comprehensive bibliographic data for codes used. Indeed, at the International Collaboration for the Automation of Systematic Reviews and as noted by O’Connor et al. (2018), there is a lack of transparency with respect to ML systems. The solution, according to Beller et al. (2018), is that every technique used for automation should be shared, in particular, by making code evaluation data and corporas available. In line with this, the following section contains the coding used to create LDA Topic Modelling for this concept paper. The corpora will also be made available alongside the article.
The following sections have been delineated into separate parts. Part A is the importing of the libraries required for the model; Part B sets out how the data was cleaned; Part C creates the dictionary to be used; and finally part D covers the creation of the LDA model. The references that are provided alongside the coding go into more detail than is provided here. There reader is advised to go to the original coding sources should they desire more information.
LDA Topic Modelling Code
A. Importing the libraries and file required for the LDA tool i. Import Libraries. The libraries and their versions can be seen in in Table 2.
import spacy, nltk, gensim, pickle, random2, sklearn
import pandas as pd
import re
import en_core_web_sm
import nltk
from nltk.corpus import stopwords
nltk.download(‘wordnet’)
nlp = spacy.load(“en_core_web_sm”)(Tavora, 2018). ii. Load file.
df = pd.read_csv(r“Paste CSV file path here”, header = None)
df.shape
df.head()(Tavora, 2018). iii. Create to.list.
doc_set = df.values.T.tolist()[0]
print(doc_set[:200]) (Tavora, 2018). B. Data Cleaning. iv. Tokenise
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r‘\w+’)
tokenined_docs = []
for doc in doc_set:
tokens = tokenizer.tokenize(doc.lower())
tokenined_docs.append(tokens)
print(tokenined_docs[0][0:10]) (Tavora, 2018). v. Lemmatisation
lemmatized_tokens = []
for lst in tokenined_docs:
tokens_lemma = [lemmatizer.lemmatize(i) for i in lst]
lemmatized_tokens.append(tokens_lemma)
print(lemmatized_tokens[0][0:10]) (Tavora, 2018). vi. Stopwords
from nltk.corpus import stopwords
origional_stopwords = nltk.corpus.stopwords.words(‘english’)
print (origional_stopwords) (Tavora, 2018). vii. Custom Stopwords list
custom_stop_word_list = []
print (custom_stop_word_list)
final_stopword_list = custom_stop_word_list + origional_stopwords
print(“Total numbers of final stop words are ”)
print(len(final_stopword_list)) viii. Pass cleaned data, and apply word length limit (optional)
n = 2
cleaned_tokens = []
for lst in lemmatized_tokens:
cleaned_tokens.append([i for i in lst if not i in final_stopword_list if len(i) > n])
print(cleaned_tokens[:][0][:200])(Tavora, 2018). ix. Bi and Trigrams
bigram = gensim.models.Phrases(cleaned_tokens, min_count = 1, threshold = 1)
trigram = gensim.models.Phrases(bigram[cleaned_tokens], threshold = 1)
bigram_mod = gensim.models.phrases.FrozenPhrases(bigram)
trigram_mod = gensim.models.phrases.FrozenPhrases(trigram) (Prabhakaran, 2018).
def make_bigrams(cleaned_tokens):
return [bigram_mod[doc] for doc in cleaned_tokens]
def make_trigrams(texts):
return [trigram_mod[bigram_mod[doc]] for doc in cleaned_tokens] (Prabhakaran, 2018). x. Pass Bi and Trigrams through cleaned list
tokens_bigrams = make_bigrams(trigram_mod[bigram_mod[cleaned_tokens]])
print(tokens_bigrams[:][0][:200]) (Prabhakaran, 2018). C. Create dictionary. xi. Build dictionary.
from gensim import corpora, models
dictionary = corpora.Dictionary(tokens_bigrams) (Tavora, 2018). xii. Tokenize documents into document-term matrix.
corpus = [dictionary.doc2bow(text) for text in tokens_bigrams]
import pickle
pickle.dump(corpus, open(‘corpus.pkl’, ‘wb’))
dictionary.save(‘dictionary.gensim’)
corpus[:][0][:10] (Tavora, 2018). D. Creating the LDA model. xiii. Create model.
ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics = 5, id2word = dictionary, passes = 20, alpha = ‘auto’, per_word_topics = True)
ldamodel.save(‘model.gensim’) (Prabhakaran, 2018; Tavora, 2018).
for el in ldamodel.print_topics(num_topics = 5, num_words = 10):
print(el,‘\n’) (Tavora, 2018). xiv. Pass dictionary through model.
dictionary = gensim.corpora.Dictionary.load(‘dictionary.gensim’)
corpus = pickle.load(open(‘corpus.pkl’, ‘rb’))
lda = gensim.models.ldamodel.LdaModel.load(‘model.gensim’) (Tavora, 2018). xv. Create visual display.
lda = gensim.models.ldamodel.LdaModel.load(‘model.gensim’)
import pyLDAvis.gensim_models
lda_display = pyLDAvis.gensim_models.prepare(lda, corpus, dictionary, sort_topics = False)
pyLDAvis.display(lda_display) (Tavora, 2018).
This section has set out the codes used to create an LDA topic model. The next section will present the results from this section and will include a discussion.
Results
This section presents the results from the above code used to create LDA Topic Models with Python. Synthesising and abstracting all the extracted data from the SLR under the preidentified theme ‘Tier One Policy Problems’, or the policy problems most common to each included study, helps to illustrate the largest issues impacting the resilience and sustainability of energy infrastructures in the investigated research domain. Due to space constraints, this article will only discuss the two first topics. The common ten most themes for each topic are presented in table three.
LDA Topic Modelling Topics and Themes.

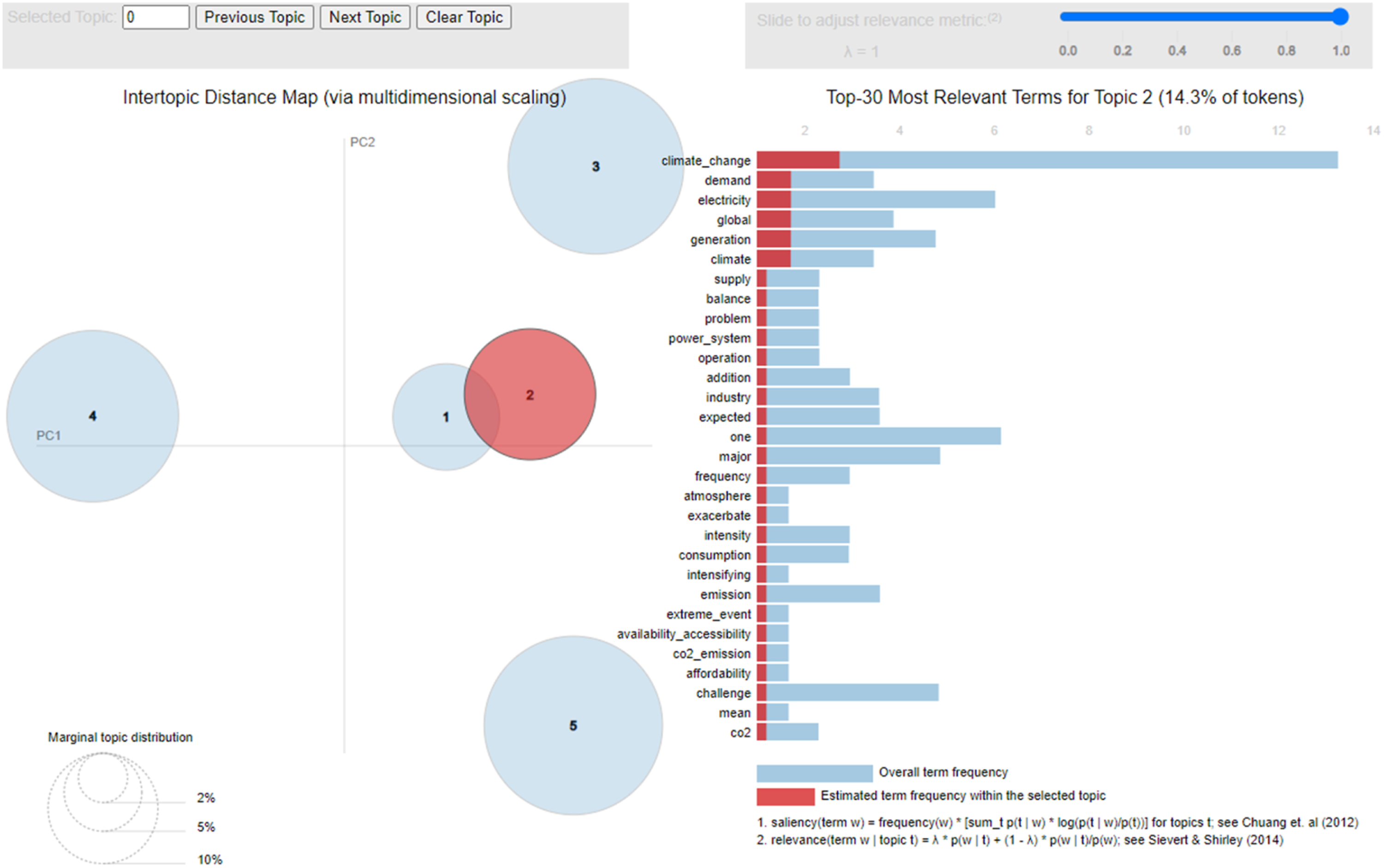
The abstracted data seen in Topic two, in Table 3, has the themes of climate change and fossil fuel, the infrastructure sector, local energy system, and potential for reliable electricity. What is identified here is that the local energy system has potential for reliable energy generation; it could be assumed that this would address climate change by transitioning away from fossil fuels. Again, to support this statement, there has been considerable research devoted to investigating this topic. For example, Hori et al. (2020) have conducted research on how local energy systems that include participatory approaches have the potential to produce reliable and sustainable renewable energy and aid in mitigating the effects of climate change. Similarly, Dobravec et al. (2021) provide evidence on how a shift from top-down federal approaches towards increasing the involvement of local and regional areas can aid in achieving climate change related goals. The proposed multi-level governance framework will aid in the push towards a transition to low-carbon and 100% renewable energy systems (Dobravec et al., 2021).
As noted earlier, the LDA Topic Model also provides an Intertopic Distance Map. This map allows users to view the distances between topics uncovered through the process set out in the methods section. Figures 1 and 2 provide the Intertopic Distance Maps for topics one and two. When looking at the Intertopic Distance Maps in Figures 1 and 2, there is an overlap between both topics. This suggests the closeness of Topic 1 regarding climate change and how it relates to the problem of balancing global energy operations regarding the supply and demand of electricity is to the second topic on how the local energy system has potential for reliable energy generation, reducing the reliance on fossil fuels and mitigating the effects of climate change. Intertopic distance map for topic 1. Intertopic distance map for topic 2.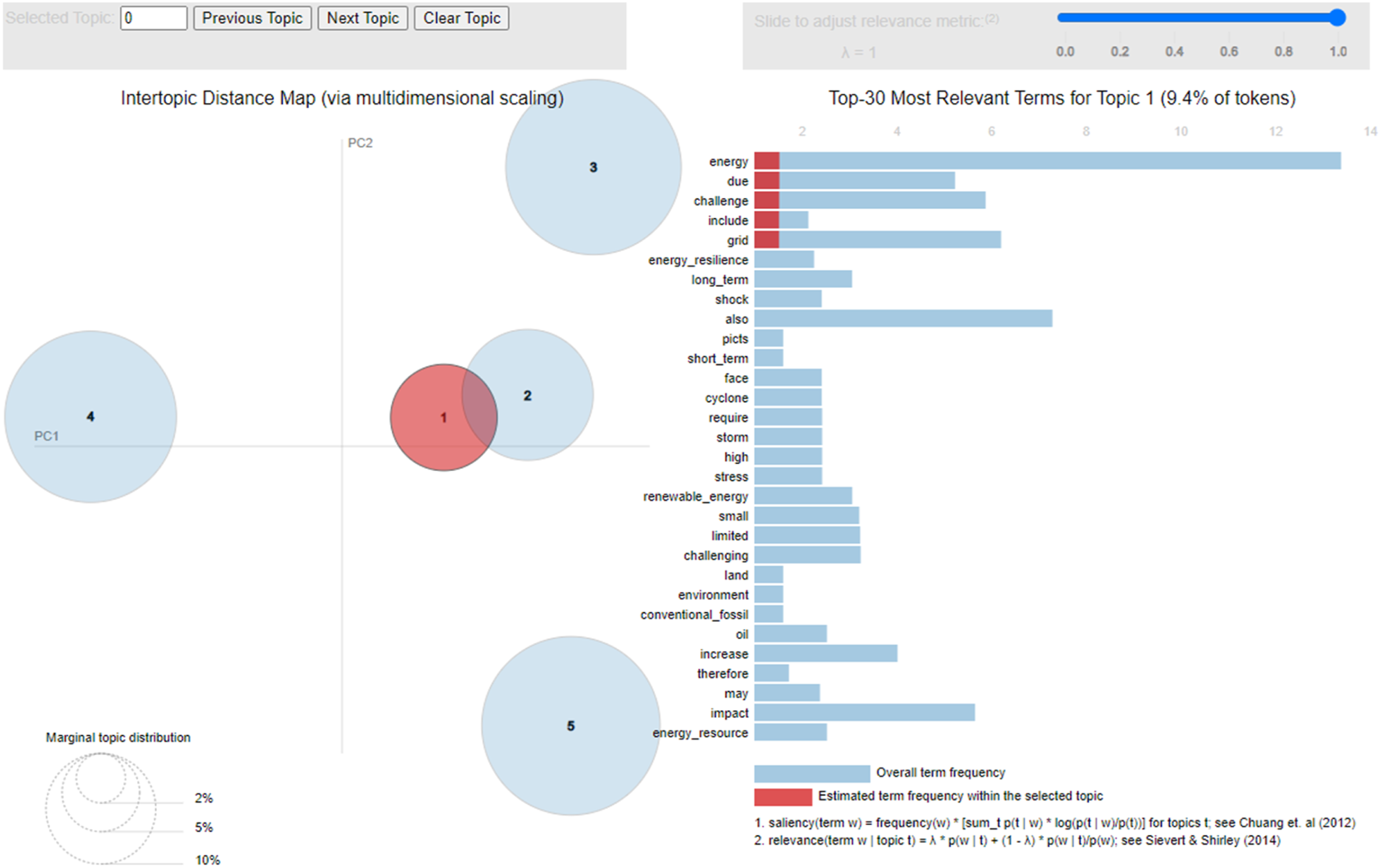
Discussion
The use of AI and MLTs in the SLR automation process is witnessing a surge of growth. Such automation tools are making SLRs more efficient, timely, and require fewer researchers and effort (Beller et al., 2018). Furthermore, they have the positive effects of lessening researcher biases and mistakes made during the review process (Beller et al., 2018). As can be seen in the presented coding above, value decisions regarding the number of topics to present, whether to include bi or trigrams, how data is cleaned, and even how many times a word must appear before it is included, are all decisions which researchers will have to make when utilising this process. However, when codes are presented alongside results, as they are here, there is a trail for other researchers to follow. Decisions can then be questioned, codes can be changed to see what would occur differently, and researchers can better understand and defend their results. For researchers conducting SLRs, this method serves to make the process more rigorous, transparent, and importantly, repeatable.
Limitations and Future Research
MLTs and AI are another tool that researchers can employ during their SLRs. However, it is important to highlight that both AI and MLTs are limited by what is input. If data is input that is noisy, incomplete, or has been extracted through processes that have introduced selective biases, then the results themselves may be erroneous (Le Glaz et al., 2021). Domingos (2012) points out that algorithms themselves may introduce biases. Importantly, although the subjective decisions of the researcher are made visible, this only shifts biases from subjective to systematic. Furthermore, care needs to be taken with using topic modelling, as unsupervised learning can produce inconsistent results (Watanabe & Zhou, 2020). However, this is a step forwards, because subjective decisions that are made visible, are decisions that can be questioned/defended/or further explained.
This article is intended only as a proof of concept. The results provided are limited to the space available. Future work in this space will utilise this method to provide a comprehensive synthesis and abstraction of the data extracted from two SLRs investigating how governance settings can enhance the resilience and sustainability of energy and water infrastructures. This will provide further proof of the importance of the method set out in this article. Other than SLRs, another research project that may benefit from this method are datasets obtained from semi-structured interviews. Should researchers wish to use MLTs on interview datasets then there are additional biases, such as language, that need to be taken into consideration (Ungless et al., 2023). Utilising the other AI and MLTs outlined in this article, two automated SLRs are currently being conducted on how governance settings can improve the resilience and sustainability of transport and communication infrastructures.
Conclusion
The significant increase in the amount of published research has made conducting SLRs more time-consuming and costly. Additionally, the demand for rigorous and transparent research further increases the costs of conducting an SLR, both monetarily and in time. This article has put forward a method for researchers, who have coding experience, to utilise AI and MLTs to reduce both the time and cost of synthesising and abstracting the data obtained through a SLR. In combining MLTs with DQA, this article has also provided a proof of concept regarding the utilisation of MLTs such as LDA Topic Modelling and researchers can synthesise and then perform abstraction on the data obtained during a SLR. Utilising this method the data uncovered during a SLR on how governance settings can enhance the resilience and sustainability of energy infrastructures, specifically the extracted data regarding the ‘Tier One Policy Problems’ has been synthesised, abstracted, and then briefly analysed.
Supplemental Material
Supplemental Material - Cheap, Quick, and Rigorous: Artificial Intelligence and the Systematic Literature Review
Supplemental Material for Cheap, Quick, and Rigorous: Artificial Intelligence and the Systematic Literature Review by Cameron F. Atkinson in Social Science Computer Review
Footnotes
Acknowledgements
I would like to acknowledge that this research was made possible through the College of Arts, Law and Education Research Training Program Stipend provided by the Australian Federal Government and a top-up scholarship provided by the Australian Natural Hazards Research Australia.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Natural Hazards Research Australia (Stipend scholarship).
Data Accessibility
Supplemental Material
Supplemental material for this article is available online.
Author Biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.