
Abstract
Computer self-efficacy (CSE) continues to be an important construct in research and application. Two measures of CSE, the Brief Inventory of Technology Self-Efficacy (BITS) and the Brief Inventory of Technology Self-Efficacy – Short Form (BITS-SF) were recently developed to correct for issues in other available measures. The BITS and BITS-SF were originally written in English, and their psychometric properties assessed in samples from the United States. The current two studies translated the BITS and BITS-SF into simplified Chinese (Mainland China) and traditional Chinese (Taiwan) and assessed their psychometric properties. In Study 1, 207 adults in Mainland China completed the simplified Chinese BITS and BITS-SF, as well as measures given to assess convergent, discriminant, and concurrent validity. In Study 2, 273 adults in Taiwan did the same, except that they completed the traditional Chinese BITS and BITS-SF. In both studies, the translated BITS showed evidence of a three-factor correlated structure, and the translated BITS-SF yielded several underlying classes consistent with theory and scoring interpretation. Additionally, the translated measures’ scores showed solid evidence of convergent, discriminant, and concurrent validity. The results replicate the findings using the original BITS and BITS-SF and extend them to simplified Chinese and traditional Chinese translated versions. These versions are recommended for use in research and applied settings to assess CSE and are available for use. Both the original and translated measures are available for download at www.bitssurvey.com.
Computer skills are considered necessary for successful education and employment (Peng, 2017; Stošić, 2015). Consequently, there has been an interest in factors contributing to employees’ and students’ adoption and use of technology (Chibisa et al., 2021; Ferdousi, 2019). Of these factors, one of the most emphasized in current research is computer self-efficacy (CSE; Gupta & Bostrom, 2019). CSE is a person’s confidence in their ability to successfully engage with computers and similar technology (Compeau & Higgins, 1995). Over the past decades, a robust literature base has emerged regarding the positive predictive role of CSE on the use of technology (e.g., Chibisa et al., 2021; Compeau & Higgins, 1995). As a result, numerous measures of CSE have been developed (see Gupta & Bostrom, 2019, for a review). However, many of these measures currently suffer from conceptual or methodological issues (Howard, 2014; Marakas et al., 2007). Two CSE measures were recently developed to correct for these issues: the Brief Inventory of Technology Self-Efficacy (BITS) and the Brief Inventory of Technology Self-Efficacy – Short Form (BITS-SF; Weigold A. & Weigold I.K., 2021). Both measures are available for download at www.bitssurvey.com. Given the importance of CSE in technology research (Gupta & Bostrom, 2019), it is necessary that current measures are available for use with diverse populations. Consequently, in the current studies, we translated the BITS and BITS-SF into simplified Chinese (Mainland China) and traditional Chinese (Taiwan). This is also the second set of studies reporting on the psychometric properties of the BITS and BITS-SF, providing both a replication and extension of the original studies.
Computer Self-Efficacy
Self-efficacy is an individual’s judgment of their ability to engage in behaviors that will lead to desired outcomes. Self-efficacy influences aspects of performance, including a person’s cognitions, emotions, and behaviors. Even when a person has sufficient ability to successfully engage in a behavior, they may not do so if they have low self-efficacy (Bandura, 1982). Bandura (2006) also emphasized that self-efficacy is domain-specific such that a person might have high self-efficacy in one area (e.g., writing a paper) but not another (e.g., using computers); consequently, each self-efficacy measure should only assess a specific domain, such as CSE.
CSE research has shown extensive support for CSE’s role in computer and technology use (e.g., Chibisa et al., 2021; Hsia et al., 2014; Thongsri et al., 2020). For example, CSE mediated the relations between several predictor variables and computer use in a sample of pre-service teachers in South Africa (Chibisa et al., 2021). Additionally, CSE was a significant positive predictor of intentions toward e-learning for Chinese college students (Thongsri et al., 2020) and both perceived ease of e-learning and intentions to engage in e-learning for Taiwanese employees of high-tech companies (Hsia et al., 2014). Researchers have also recommended that CSE be considered when designing computer trainings or implementing new technology (Ferdousi, 2019; see Hsia et al., 2014), as simple exposure and access to computers and the Internet are not sufficient for skillful use (Peng, 2017).
Over the last decades, many CSE measures have been developed; however, most of them have been critiqued for issues such as outdated items, problematic operationalization, criterion contamination, and limited range (Howard, 2014; Marakas et al., 2007). Scales often contain outdated items due to the rapid development of technology; however, simply removing outdated items when administering measures can lead to construct underrepresentation (Marakas et al., 2007). Additionally, measures may not be accurate representations of the CSE construct. For example, the Computer User Self-Efficacy Scale by Cassidy and Eachus (2002) purports to assess self-efficacy, although its instructions ask participants to respond to “statements concerning how you might feel about computers” (p. 148), rather than questions about confidence (Howard, 2014). Next, many scales assess other constructs in addition to CSE. For example, the authors of the Computer Self-Efficacy Measure, which is one of the most often-used CSE scales (Howard, 2014), have stated that scores on this measure can be influenced by respondents’ ability to think about hypothetical situations and learning self-efficacy (Compeau & Higgins, 1995). Finally, almost no CSE measures assess confidence across different computer skill levels (Weigold A. & Weigold I.K., 2021). One exception is the Computer Self-Efficacy Scale (Murphy et al., 1989); however, this scale contains many outdated items (Marakas et al., 2007). Due to these issues, researchers have recently developed two measures, the BITS and BITS-SF, designed to provide those in research and applied settings with current, psychometrically strong CSE scales (Weigold & Weigold, 2021).
Brief Inventory of Technology Self-Efficacy
The BITS and BITS-SF were developed and assessed using seven studies (Weigold & Weigold, 2021). The authors’ stated goals were to create one full-length assessment (BITS) and one screening tool (BITS-SF) that evaluated confidence for novice, advanced, and expert computer skills and could be used in research and applied settings. The underlying theory was the five-stage model of adult skill acquisition (Dreyfus, 2004). In this model, learners pass through several stages: novice, advanced beginner, competence, proficiency, and expert. Weigold A. & Weigold I.K. ’s (2021) scales emphasize the novice, competence (which they called advanced), and expert stages. Novice computer skills were defined as those “required for modern daily computer use,” advanced as those needing some knowledge of appropriate use, and expert as those requiring specialized training (Weigold A. & Weigold I.K., 2021, p. 4). Within each level, Weigold and Weigold included skills from six computer use categories: hardware, software, Internet, operating system, networking, and troubleshooting. The final BITS is comprised of 18 items, with six items each (one per computer use category) on the novice, advanced, and expert subscales. Higher scores indicate higher levels of self-efficacy for computer skills of the corresponding level. The BITS-SF was developed based on the strongest items of the BITS and consists of six items, two from each of the subscales on the BITS and one from each of the computer use categories. The BITS-SF yields a total score ranging from 0 (negligible CSE) to 6 (expert skill level CSE).
The BITS and BITS-SF items were developed based on a survey of computer experts regarding what skills novice, advanced, and expert computer users should have and a series of analyses using several independent samples (Weigold A. & Weigold I.K., 2021). Confirmatory factor analyses provided support for the three-factor correlated structure of the BITS, which was a better fit than the single-factor (ΔAIC = 1,275.82) and three-factor uncorrelated (ΔAIC = 145.62) structures. The three factors also showed strong evidence of internal consistency, with Cronbach’s alpha levels of .86 (novice), .87 (advanced), and .90 (expert). A test of multigroup invariance comparing men and women supported configural (item associations), metric (item loadings), and scalar (item intercepts) invariance for the novice and advanced subscales, and configural and metric invariance for the expert subscale. Relatedly, a latent class analysis of the BITS-SF indicated there were three underlying classes corresponding to self-efficacy for novice, advanced, and expert computer skills. Items indicating novice self-efficacy had a high likelihood of being answered affirmatively by participants in all classes; items suggesting advanced self-efficacy had a high likelihood of being answered positively by those in the advanced and expert classes; and items indicating expert self-efficacy had a moderate-to-high likelihood of being answered affirmatively by those in the expert class.
Both the BITS subscale and BITS-SF total scores generally correlated positively and significantly with 10 measures of convergent validity (e.g., measures of CSE) and generally had small correlations with 11 measures of discriminant validity (e.g., measures of personality and self-esteem). These scores also showed evidence of concurrent validity related to self-identified computer skill level (i.e., those reporting higher skill levels also had significantly higher scores on the BITS and BITS-SF than those indicating lower skill levels) and major in college (i.e., students majoring in engineering and computer science had significantly higher scores on the BITS and BITS-SF than students majoring in education and nursing). Finally, the BITS subscale scores showed strong test-retest reliability for 2- and 8-week periods (ICC range = .80 for novice to .93 for expert, both at eight weeks; Weigold A. & Weigold I.K., 2021).
Taken together, the BITS and BITS-SF evidenced solid psychometric properties related to internal consistency; test-retest reliability; convergent, discriminant, and concurrent validity; and either the factor structure (BITS) or underlying class structure (BITS-SF). However, the development article (Weigold A. & Weigold I.K., 2021) is currently the only one to report on these properties. Additionally, the BITS and BITS-SF were written in English and assessed using United States college students and Mechanical Turk workers, and it is unclear to what extent these measures can be used with other samples. Finally, although the BITS-SF total score potentially includes 0, indicating negligible CSE (Weigold, 2021), no participant in the original latent class analysis scored below 1 (Weigold A. & Weigold I.K., 2021). As a result, further studies are needed to determine the degree to which negligible CSE, as defined by the BITS-SF, exists in current populations; this might have implications for how the BITS-SF is scored. Consequently, in the current studies, we translated the BITS and BITS-SF into simplified and traditional Chinese and examined their psychometric properties in adults residing in Mainland China and Taiwan, respectively.
Relevance of CSE to Mainland China and Taiwan
Both Mainland China and Taiwan have introduced technology-related initiatives with implications for research, application, and education. For example, Mainland China recently began the 15-year China Brain Project (officially titled “Brain Science and Brain-Inspired Intelligence”) in which brain research focuses both on brain-related diseases and “brain-inspired intelligence technology,” such as artificial intelligence (Poo et al., 2016, p. 591). Mainland China has also worked toward the incorporation of information and communication technology (ICT) into education since the 1980s (Zeng, 2022). The most recent five-year plan related to the ICT for Education initiative began in 2021 and focuses on digital technologies (Cyberspace Administration of China, 2021). The goals of these plans are to provide infrastructure and related assets to facilitate students’ learning of digital technologies, and they include providing resources to millions of teachers and lessening the ICT gap between urban and rural schools (Bajpai et al., 2019).
Taiwan has also introduced initiatives related to technology. For example, Taiwan has recently made large investments into artificial intelligence and medical devices, with a focus on becoming the “Silicon Valley of Asia” and a “Hub of Biotech and Medical R&D in Asia” (Haldorai et al., 2020, p. 569). The country has also invested in e-learning and digital technologies since 2002, with the first five-year plan showing positive results for the business sector and e-learning (Chang et al., 2009). More recently, Taiwan has focused on digital education by allocating money for tablets, high-speed Internet, and smart classrooms in schools, as well as worked to reduce the urban-rural education divide through technology allocation (Hsin-fang & Tzu-hsuan, 2022).
Given the initiatives in Mainland China and Taiwan, there is a need for current measures of CSE that can be used to best tailor computer instruction in educational and business settings. For example, Tsai (2019) found that using a specific intervention to facilitate learning basic computer programming skills in Taiwanese college students was most helpful for those with low and moderate self-efficacy. Consequently, the current study focused on translating the BITS and BITS-SF into simplified and traditional Chinese and assessing their psychometric properties to make them widely available for use with Chinese-reading populations.
The Current Studies
To address the need for updated and current CSE measures, as well as replicate and extend the findings of the original BITS and BITS-SF studies (Weigold A. & Weigold I.K., 2021), we conducted two studies. The first focused on the translation of the BITS and BITS-SF into simplified Chinese (BITS-SC and BITS-SF-SC) and the examination of the translated measures’ psychometric properties in adults living in Mainland China. The second was similar to the first, except the measures were translated into traditional Chinese (BITS-TC and BITS-SF-TC) and assessed using adults in Taiwan.
We made similar hypotheses for both studies, which were based on the results described in the BITS and BITS-SF development article (Weigold A. & Weigold I.K., 2021). First, we expected the translated BITS to show evidence of a three-factor correlated structure corresponding to the novice, advanced, and expert subscales (Hypothesis 1a). We also expected this model to be a better fit than either single-factor or three-factor uncorrelated models (Hypothesis 1b).
Second, we hypothesized that the translated BITS’ subscale and translated BITS-SF’s total scores would show evidence of convergent validity by having positive, moderate-to-strong correlations with other measures of computer self-efficacy (Hypothesis 2a), as well as discriminant validity by yielding small correlations with self-esteem (Hypothesis 2b). We also expected the measures to show evidence of concurrent validity such that respondents with higher self-identified computer skill levels and occupations requiring specialized computer training would score higher on the translated BITS’ subscale and translated BITS-SF’s total scores than those with lower self-identified computer skill levels (Hypothesis 2c) and occupations requiring less computer training (Hypothesis 2d).
Finally, we hypothesized that the translated BITS-SF would show evidence of either three or four underlying classes (Hypothesis 3a). The original BITS-SF latent class analysis yielded three underlying classes corresponding to self-efficacy for novice, advanced, and expert levels. The authors reported that scores of 1 and 2 indicate novice skill level CSE, 3 indicates novice-to-advanced skill level CSE, 4 indicates advanced skill level CSE, 5 indicates advanced-to-expert skill level CSE, and 6 indicates expert skill level CSE (Weigold A. & Weigold I.K., 2021); this pattern corresponds to the five theoretical stages of the model of skill acquisition (Dreyfus, 2004). However, it is also possible that a fourth class could emerge corresponding to negligible self-efficacy. This would be consistent with the scoring and interpretation of the BITS-SF (Weigold, 2021). We also expected that the translated BITS-SF’s underlying classes would show evidence of convergent validity such that scores on the translated BITS and additional measures of CSE would be higher as class increased from negligible/novice to expert CSE.
Study 1: Simplified Chinese
Method
Participants
Participants were 207 adults (18 years and older) living in Mainland China. They identified primarily as women (n = 123, 59.4%), followed by men (n = 84, 40.6%). Ages ranged from 19 to 75 (M = 42.86, SD = 9.15). Half of participants reported their occupation as teachers (n = 111, 53.6%), whereas others were corporate workers (n = 28, 13.5%), IT engineers (n = 19, 9.2%), public servants (n = 8, 3.9%), workers (n = 7, 3.4%), farmers (n = 6, 2.9%), unemployed (n = 20, 9.7%), or other (n = 8, 4.4%).
Measures
Brief Inventory of Technology Self-Efficacy – Simplified Chinese. We translated the BITS-SC, BITS-SF-SC, and their instructions and scoring guides from English to simplified Chinese. Various measure adaptation approaches exist, with two of the most common being the use of translation teams, such as the one specified by the Translation, Review, Adjudication, Pretesting, and Documentation (TRAPD) model, and forward and backward translation (Harkness et al., 2010; International Test Commission, 2017). Although backward translation can detect some mistakes, its use has long been considered insufficient for the appropriate cross-cultural adaptation of measures due to the multitude of errors that it does not identify (Behr & Braun, 2022). The preferred method is team approaches involving appropriate experts, as they require collaboration and can better detect nuanced errors (Behr & Braun, 2022; Harkness et al., 2010). However, backward translation can be combined with other methods to provide an additional check (International Test Commission, 2017). Consequently, we used forward and backward translation embedded within a translation team approach.
For the first step, we employed a professional translator to perform forward translations. We contacted this translator through a large online marketplace in the United States that specifically advertises translation services. This person was a native writer of simplified Chinese and specialized in both English to simplified Chinese translations and ICT content. After agreeing to provide the service, the translator completed the translations of the BITS and BITS-SF into simplified Chinese, then sent us the translated files.
Upon receiving the translations, we reviewed both the English and simplified Chinese versions as a five-member team. One team member has a doctorate in education, expertise in CSE, and lives in Mainland China. Two other team members are international doctoral students studying psychology in the United States whose home countries are Taiwan and Singapore. All three are fluent in both simplified Chinese and English; they also have relevant knowledge of self-report surveys, although they do not have prior translation experience. The other two team members have doctorates in psychology, live in the United States, are fluent in English, and are experts in CSE and measure development. These two team members have prior experience in both developing and translating measures, and one has worked as a professional translator.
Following the suggestions of the International Testing Commission (2017), the stated goal for the team was to critically examine the translations “consider[ing] linguistic, psychological, and cultural differences” so that the final measures would be accurate, read fluently, and appear indigenous (p. 11). First, the three team members fluent in both English and simplified Chinese, who were also familiar with the target cultures, separately reviewed both the original English and simplified Chinese measures. Each of these team members provided comments about the translation to the full five-person team, such as suggesting different word choices and flagging inaccurately translated terms. The full team then discussed and reached consensus on all comments, as well as agreed on tentative simplified Chinese versions of the BITS and BITS-SF.
After reaching a consensus, we sent the simplified Chinese versions to a different professional translator, also contacted through the translation marketplace, for backward translation. This person had English as their native language, as well as specialized in translations from simplified Chinese to English and ICT content. The translator completed backward translations of the measures into English and sent the files to the authors. The full team compared the original and backward-translated BITS and BITS-SF, and the three team members fluent in both English and simplified Chinese also compared the simplified Chinese BITS and BITS-SF to the backward-translated versions. The backward translations were very close to the original English versions. As answering questions about translations was included in the translation service, we contacted the translator who had performed the backward translation with minor questions about wording choice and received feedback. The full team then discussed and reconciled any discrepancies between the original and backward-translated versions, and there was full consensus on the final BITS-SC and BITS-SC-SF.
The BITS-SC used the same six-point Likert scale response options as the English version, which range from 1 (毫无信心/Not at all confident) to 6 (信心十足/Completely confident). Cronbach’s alpha levels were strong: novice α = .87, advanced α = .91, and expert α = .95. Relatedly, the BITS-SF-SC used the same dichotomous response options as the English version: 是/Yes and 否/No.
The second measure was a four-item ICT self-efficacy scale written in simplified Chinese (Dong et al., 2020). This measure assesses CSE for general computer tasks. Respondents use a five-point Likert scale ranging from 1 (强烈反对/Strongly disagree) to 5 (非常同意/Strongly agree). A sample item is, “当我在使用信息与通讯技术遇到问题时, 我总能找到几种解决方法”/“When I am confronted with a problem when using ICT, I can usually find several solutions” (Dong et al., 2020, p. 155). Items were averaged, with higher scores indicating higher CSE. Support has been shown for the unidimensional structure, and the measure’s score has shown evidence of concurrent and discriminant validity (Dong et al., 2020). Cronbach’s alpha for the current study was .92.
Procedure
The study was approved by the Institutional Review Boards (IRBs) at the first two authors’ institutions. Participants were recruited through WeChat, a popular social media platform and messaging app in Mainland China. Data were collected using the Wenjuanxing survey platform, which encrypts data and can be integrated with WeChat; this approach is recommended for collecting data in Mainland China (Mei & Brown, 2018). Interested participants were presented with a QR code. Upon scanning the code, they were sent to the survey, which consisted of a study introduction, demographics form, and the measures of interest. There were no incentives for participating.
Results
To assess model fit, we used several recommended indices: the robust χ2, the Comparative Fit Index (CFI), the Root Mean Square Error of Approximation (RMSEA), and the Standardized Root Mean Square Residual (SRMR). The robust χ2 should be nonsignificant, although this is unlikely to occur in practice. CFIs >.900 and >.950 show evidence of adequate and strong fit, respectively. RMSEAs <.100, <.080, and <.060 indicate marginal, adequate, and strong fit, respectively (see Byrne, 2012, for a review). SRMRs <.100 suggest adequate fit (Kline, 2016), and SRMRs <.050 indicate strong fit (Byrne, 2012). We compared the three models using the Akaike Information Criterion (AIC), which is appropriate for both non-nested and nested models. Lower AICs indicate better fit, such that an AIC difference of >10 shows no support for the model with the higher AIC (Burnham & Anderson, 2004).
Item Loadings and Descriptive Information for the BITS Confirmatory Factor Analyses for Simplified Chinese/Traditional Chinese Translations.
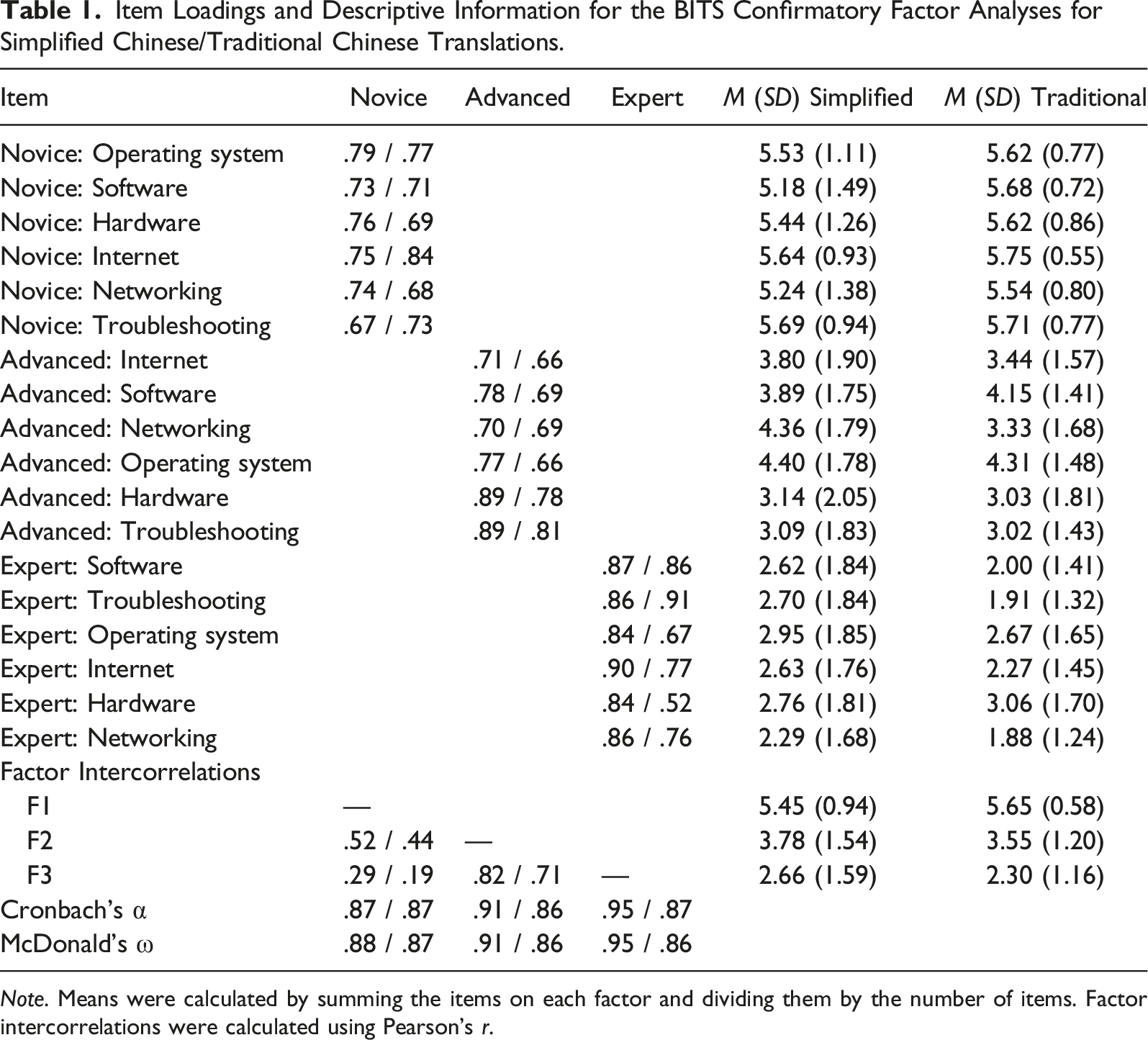
Note. Means were calculated by summing the items on each factor and dividing them by the number of items. Factor intercorrelations were calculated using Pearson’s r.
Correlations of the BITS Subscale and BITS-SF Total Scores with Measures Used to Assess Aspects of Validity.
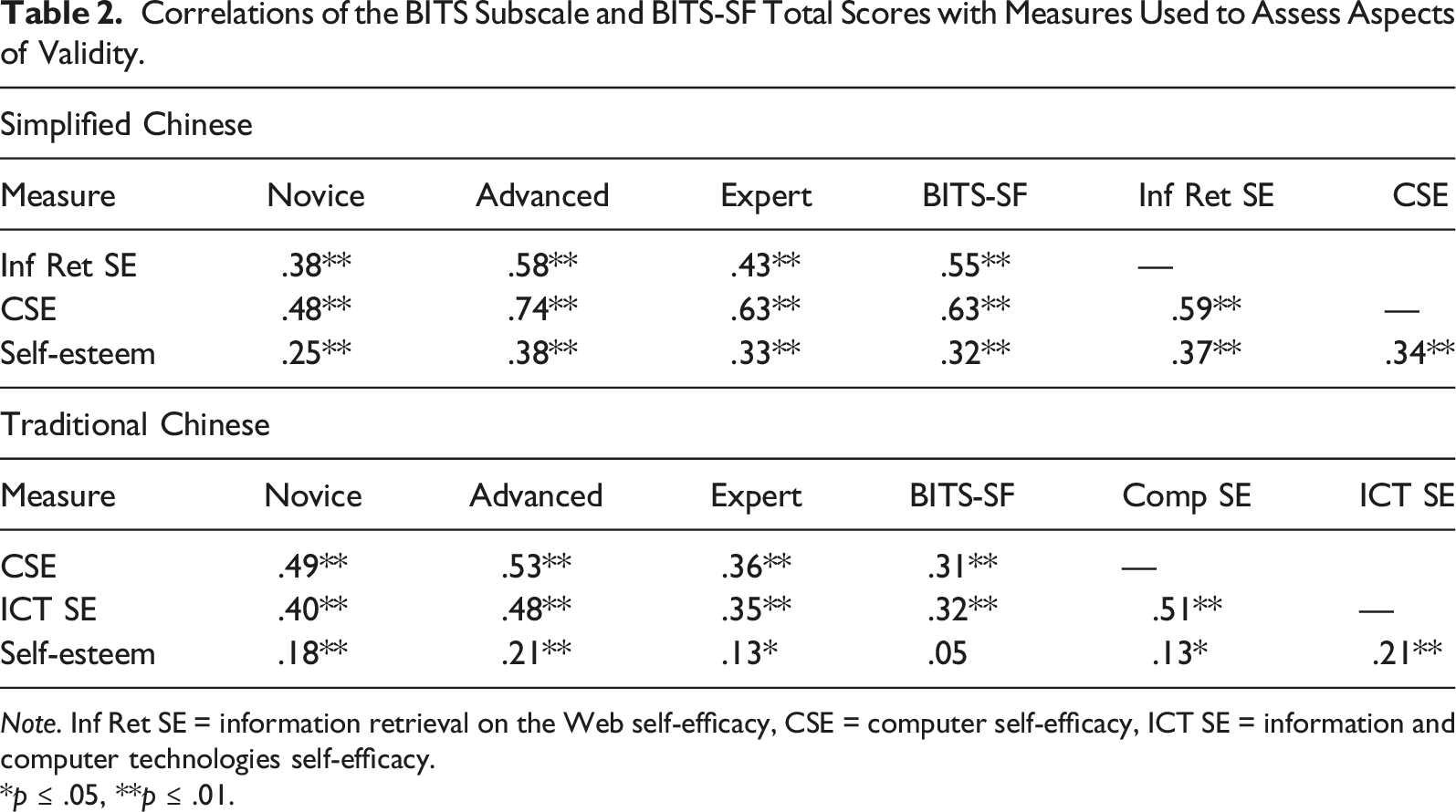
Note. Inf Ret SE = information retrieval on the Web self-efficacy, CSE = computer self-efficacy, ICT SE = information and computer technologies self-efficacy.
*p ≤ .05, **p ≤ .01.
BITS and BITS-SF Scores for Computer Skill Level and Occupation.
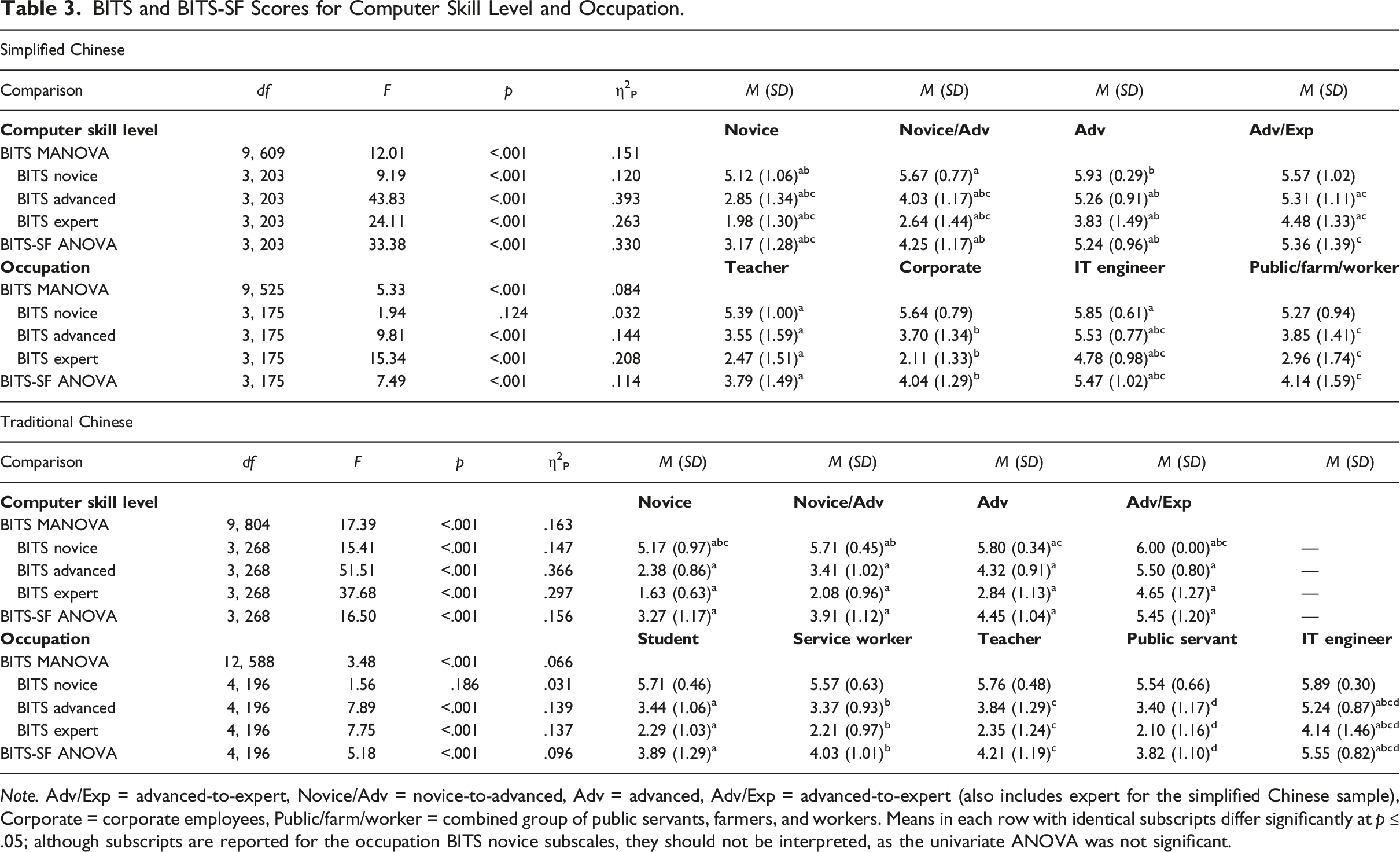
Note. Adv/Exp = advanced-to-expert, Novice/Adv = novice-to-advanced, Adv = advanced, Adv/Exp = advanced-to-expert (also includes expert for the simplified Chinese sample), Corporate = corporate employees, Public/farm/worker = combined group of public servants, farmers, and workers. Means in each row with identical subscripts differ significantly at p ≤ .05; although subscripts are reported for the occupation BITS novice subscales, they should not be interpreted, as the univariate ANOVA was not significant.
For occupation, we compared teachers (n = 111, 53.6%), corporate employees (n = 28, 13.5%), IT engineers (n = 19, 9.2%), and a combined group of public servants, workers, and farmers (n = 21, 10.2%). We ran one MANOVA on the BITS-SC subscale scores and one ANOVA on the BITS-SF-SC total score. All analyses were significant at p < .001, except the follow-up novice ANOVA (p = .124). For the advanced and expert subscales of the BITS-SC, as well as the BITS-SF-SC, IT engineers scored significantly higher than teachers, corporate employees, and public servants/workers/farmers. Detailed results are shown in Table 3. These findings support the convergent, discriminant, and concurrent validity of the BITS-SC’s subscale and BITS-SF-SC’s total scores.
Class comparisons yielded a best-fitting four-class solution. Four classes provided significantly better fit than three (BLRT p = .003) and did not show significantly worse fit than five (BLRT p = 1.000). Additionally, both the four-factor solution’s AIC (967.04) and BICadj (971.48) were lower than those for the other solutions, with the next lowest being for the three-factor solution (AIC = 973.09; BICadj = 976.37). The four underlying classes corresponded to self-efficacy for novice (n = 76, 36.7%), advanced (n = 62, 30.0%), and expert (n = 64, 30.9%) levels, as well as negligible self-efficacy (n = 5, 2.4%). Participants in the negligible class had a low probability of responding to any item with Yes (p range = .000 to .256). Those in the novice class had a high probability of responding to both novice items affirmatively (p = 1.000 for both), a low-to-moderate probability of doing so for the advanced items (p = .202 and .375), and a low probability of doing so for the expert items (p = .020 and .099). Participants in the advanced class had a high probability of responding Yes to the novice (p = .948 and 1.000) and advanced (p = .975 and 1.000) items, as well as a low probability of doing so for the expert items (p = .000 and .282). Finally, those in the expert class had a high probability of responding Yes to the novice and advanced items (p = 1.000 for all) and a moderate-to-high probability of doing so for the expert items (p = .717 and .958).
There were different ranges of scores within each class: negligible 0 to 1, novice 2 to 4, advanced 3 to 5, and expert 5 to 6. However, only six (7.9%) of the novice users scored a 4 and two (3.2%) of the advanced users scored a 3; consequently, ranges for the classes were negligible 0 to 1, novice 2 to 3, advanced 4 to 5, and expert 5 to 6, with a score of 5 representing self-efficacy for advanced-to-expert levels.
Mean Differences Across BITS-SF Classes for Related Variables.
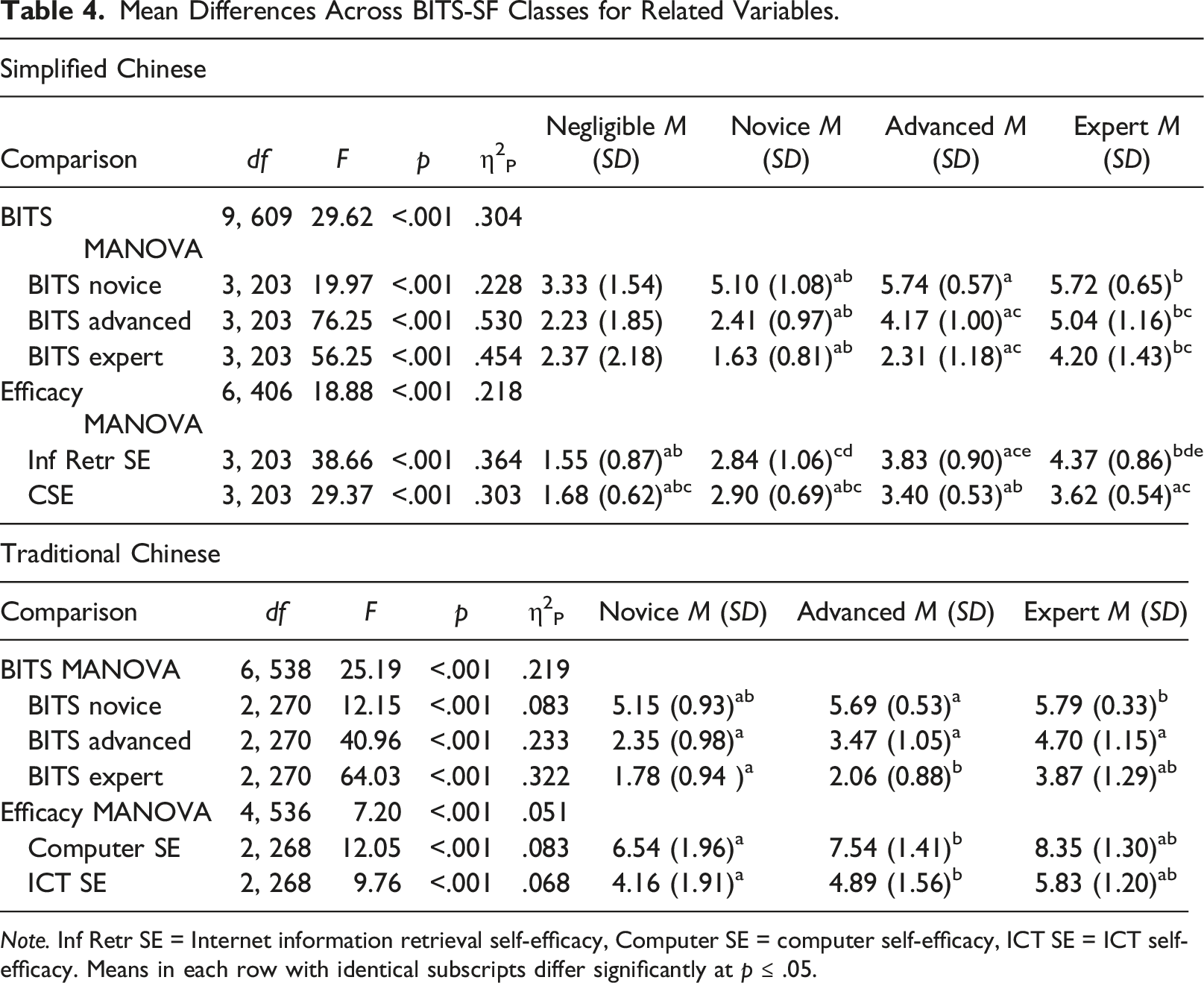
Note. Inf Retr SE = Internet information retrieval self-efficacy, Computer SE = computer self-efficacy, ICT SE = ICT self-efficacy. Means in each row with identical subscripts differ significantly at p ≤ .05.
Discussion
This study examined the psychometric properties of the translated simplified Chinese versions of the BITS and BITS-SF. The BITS-SC showed evidence of a three-factor correlated structure (novice, advanced, and expert) that mirrored the results of the original BITS (Weigold A. & Weigold I. K., 2021). The BITS-SF-SC evidenced four underlying classes (negligible, novice, advanced, and expert self-efficacy). Although the original BITS-SF only showed the latter three classes (Weigold A. & Weigold I. K., 2021), the addition of a negligible category is theoretically plausible. One reason this category may have emerged is that participants primarily accessed the study using a QR code, therefore likely completing the study on a smartphone. Conversely, the original BITS study recruited participants using a Web link (Weigold A. & Weigold I. K., 2021). It should be noted, however, that there were only five participants showing negligible self-efficacy.
We also found good evidence of convergent, discriminant, and concurrent validity. Both the three BITS-SC subscale and BITS-SF-SC total scores correlated as expected with Internet information retrieval self-efficacy and ICT self-efficacy. These scales also correlated significantly with self-esteem; however, the correlations were smaller and similar to those of the convergent validity scales with self-esteem. Finally, participants with higher self-identified computer skill levels had higher BITS-SC subscale and BITS-SF-SC total scores than those with lower computer skill levels, as did IT engineers compared to occupations in which strong computer skills are not as critical. The only exception was that the novice subscale scores were high across occupations and did not significantly differ across groups, indicating that self-efficacy for novice computer skills is generally high for those in the occupations assessed. These findings all align with those of the original BITS and BITS-SF (Weigold A. & Weigold I. K., 2021).
Taken together, our results suggest that the BITS-SC and BITS-SF-SC are viable for use with adults in Mainland China. Given the country’s strong focus on ICT infrastructure, education, and teacher training (Bajpai et al., 2019; Zeng, 2022), these measures provide a useful tool for assessing CSE at several levels to assist in identifying training needs, changes in confidence as a result of trainings, and differences associated with the ICT gap between urban and rural systems.
Study 2: Traditional Chinese
Method
Participants
Participants were 273 adults (20 years and older) located in Taiwan. They identified primarily as women (n = 185, 67.8%), followed by men (n = 84, 30.8%) and identity not listed (n = 3, 1.1%). Their ages ranged from 20 to 67 (M = 30.01, SD = 10.57). A third of participants reported that they were students (n = 100, 36.6%), followed by service workers (n = 35, 12.8%), teachers (n = 33, 12.1%), public servants (n = 22, 8.1%), IT engineers (n = 11, 4.0%), health professionals (n = 10, 3.7%), unemployed (n = 8, 2.9%), and other (n = 54, 19.8%).
Measures
The BITS-TC again used the six-point Likert scale response options, which ranged from 1 (毫無信心/Not at all confident) to 6 (信心十足/Completely confident). Cronbach’s alpha levels were all good: Novice α = .87, advanced α = .86, and expert α = .87. The BITS-SF-TC again used the dichotomous response options of 是/Yes and 否/No.
The second measure was a 3-item scale written in traditional Chinese to assess ICT self-efficacy (Hsu et al., 2014). Participants respond to items using a seven-point Likert scale ranging from 1 (非常不同意/Strongly disagree) to 7 (非常同意/Strongly agree). A sample item is “我自己能夠順暢地使用ICT來進行工作”/“I can smoothly use ICT accomplishing works by myself” (Hsu et al., 2014, pp. 75 and 115). Items were averaged, with higher scores indicating higher ICT self-efficacy. The three items loaded together onto one factor when examined as part of a larger set of items. This factor has shown evidence of convergent validity (Hsu et al., 2014). Cronbach’s alpha for the current study was .96.
Procedures
The study was approved by the IRBs at the first two authors’ institutions, and National Taiwan University accepted the United States IRB approval. Participants were primarily recruited through the National Taiwan Normal University’s Dcard, an anonymous online communication platform open to those with an email account associated with the university. Data were also collected using social media, such as through Facebook groups for graduate students completing survey research in Taiwan. Participants clicked on a Web link, which allowed them to access the survey introduction, demographics form, and measures. Upon completion, participants had the option of being included in a raffle for one of six $500 New Taiwan dollars (approximately $17.21 USD) gift cards to 7–11 in Taiwan.
Results
Models showed a similar pattern of fit to those in Study 1. The single-factor model was a poor fit: robust χ2(135) = 1005.06, p < .001; CFI = .625; RMSEA = .154 (90% CI = .145 to .163); and SRMR = .148. The three-factor uncorrelated model also evidenced poor fit: robust χ2(135) = 601.26, p < .001; CFI = .799; RMSEA = .112 (90% CI = .103 to .122); and SRMR = .235. Finally, the three-factor correlated model showed generally adequate fit: robust χ2(132) = 327.00, p < .001; CFI = .916; RMSEA = .074 (90% CI = .064 to .084); and SRMR = .057. The three-factor correlated model had a meaningfully lower AIC (13,149.35) than both the single-factor (ΔAIC = 811.39) and three-factor uncorrelated (ΔAIC = 244.61) models. Taken together, the three-factor correlated model appeared to be the best fit. Standardized parameter estimates and descriptive information for this model are shown in Table 1.
We next assessed the two aspects of concurrent validity examined in Study 1: self-identified computer skill level and occupation. For computer skill level, participants self-identified as novice (n = 44, 16.1%), novice-to-advanced (n = 153, 56.0%), advanced (n = 64, 23.4%), and advanced-to-expert (n = 11, 4.0%); none self-identified as expert. We compared these groups on the BITS-TC subscale scores using MANOVA and the BITS-SF-TC total score using ANOVA. All main analyses were significant at p < .001. Regarding post hoc group analyses, participants self-identifying at lower computer skill levels mostly scored significantly lower on the BITS-TC and BITS-SF-TC than those self-identifying at higher levels. Detailed results are found in Table 3.
We next examined whether scores on the BITS-TC and BITS-SF-TC differed by occupation. As there were not enough participants in each occupation, we only included students (n = 100, 36.6%), service workers (n = 35, 12.8%), teachers (n = 33, 12.1%), public servants (n = 22, 8.1%), and IT engineers (n = 11, 4.0). Most main analyses were significant at p < .001, except for the novice subscale univariate ANOVA (p = .186). For the significant ANOVAs, the IT engineers had significantly higher scores than all other groups. Detailed results are shown in Table 3. Taken together, these findings show support for the convergent, discriminant, and concurrent validity of the BITS-TC’s subscale and BITS-SF-TC’s total scores.
Comparisons yielded a best-fitting three-class underlying solution. Three classes were a significantly better fit than two (BLRT p < .001) and not a significantly worse fit than four (BLRT p = .500). Additionally, the three-class AIC (1,205.11) and BICadj (1213.88) were both lower than those of the other solutions, with the next-lowest being the four-class AIC (1,211.47) and two-class BICadj (1,217.31). The three classes corresponded to self-efficacy for novice (n = 27, 9.9%), advanced (n = 206, 75.5%), and expert (n = 40, 14.7%) computer skills. Those in the novice class had a high probability of responding Yes to both novice items (p = .868 and .939), a low-to-moderate probability of doing so for the advanced items (p = .000 and .372), and a low probability of doing so for the expert items (p = .111 and .123). Participants in the advanced class had a high probability of replying affirmatively to the novice items (p = 1.000 and .991), a moderate-to-high probability of doing so for the advanced items (p = .414 and .970), and a low probability of doing so for the expert items (p = .093 and .296). Finally, those in the expert class had a high probability of replying Yes to the novice (p = 1.000 for both) and advanced (p = .999 and 1.000) items, and a moderate-to-high probability of doing so for the expert items (p = .687 and .995).
There were different score ranges in each class: novice 0 to 4, advanced 3 to 5, and expert 6. However, only one person in the novice class (4.0%) had a score of 4, indicating the actual ranges were novice 0 to 3, advanced 3 to 5, and expert 6; scores of 3 corresponded to self-efficacy for novice-to-advanced computer skills. Only one participant had a score of 0.
Finally, we used two MANOVAs to compare the three underlying classes on the three BITS-TC subscales and the CSE and ICT self-efficacy measures. All multivariate and follow-up univariate analyses were significant at p < .001. Group means generally significantly differed, with those in the novice class scoring the lowest and those in the expert class scoring the highest. Detailed results of these analyses are shown in Table 4. Taken together, these findings provide evidence of convergent validity for the three underlying classes of the BITS-SF-TC.
Discussion
This study examined the psychometric properties of the traditional Chinese versions of the BITS and BITS-SF. As expected, the three-factor correlated model (novice, advanced, and expert) was the best-fitting structure for the BITS, compared to single-factor and three-factor uncorrelated models. Relatedly, the LCA of the BITS-SF-TC showed evidence of three underlying classes corresponding to self-efficacy for novice, advanced, and expert computer skills. Both results replicate those found for the original English versions of the BITS and BITS-SF (Weigold A. & Weigold I. K., 2021).
The results also showed good evidence for aspects of convergent, discriminant, and concurrent validity for the BITS-TC subscale and BITS-SF-TC total scores. All scores had positive, moderate correlations with measures of CSE and ICT self-efficacy, as well as small correlations with self-esteem. These scores also significantly differed across self-identified computer skill levels such that those with higher skill levels generally showed higher levels of CSE. Additionally, IT engineers had significantly higher self-efficacy for advanced and expert computer skills, as well as for the BITS-SF-TC, compared to students, service workers, teachers, and public servants. However, the differences across occupations in self-efficacy for novice computer skills was not significant, suggesting that people in these fields generally felt confident using computers at a basic level. These results were nearly identical to those found for the original English versions of the BITS and BITS-SF (Weigold A. & Weigold I. K., 2021).
Taken together, the findings indicate that the BITS-TC and BITS-SF-TC are viable measures of CSE in Taiwan. Taiwan has a strong focus on artificial intelligence, ICT, and ICT education (Haldorai et al., 2020), and tailoring related instructional interventions based on self-efficacy can be useful (see Tsai, 2019). The BITS-TC and BITS-SF-TC can be used to assist in adapting technology trainings, understanding their outcomes, and refining them for different sectors, such as education and business.
General Discussion
We translated the BITS and BITS-SF into simplified and traditional Chinese, as well as conducted two studies examining their psychometric properties. The results replicate and extend previous findings related to the BITS and BITS-SF. Both translated measures evidenced a three-factor correlated structure corresponding to the novice, advanced, and expert subscales; the subscale scores also related as expected to other measures of CSE, a measure of self-esteem, self-identified computer skill level, and occupation. Regarding the BITS-SF, the simplified Chinese version yielded four underlying classes of CSE (negligible, novice, advanced, and expert), whereas the traditional Chinese version showed three classes (novice, advanced, and expert). Both are consistent with underlying theory, the original development of the BITS-SF, and BITS-SF scoring (Dreyfus, 2004; Weigold, 2021; Weigold A. & Weigold I. K., 2021); additionally, in both studies, the underlying classes showed evidence of convergent validity.
It is possible that the different number of classes found for the BITS-SF-SC and the BITS-SF-TC are due to how data were collected. Since participants accessed the simplified Chinese study using a QR code, it is likely that most participants completing it used a smartphone and did not need basic computer skills. Conversely, the traditional Chinese study was accessed using a Web link. There are over one billion Internet users in Mainland China; 99.6% of users access the Internet through smartphones, with fewer accessing it through desktop computers (33.3%), laptops (32.6%), TVs (32.6%), and tablets (27.6%; China Internet Network Information Center, 2022). However, only six participants across both studies had a score of 0. It could be that people who have negligible self-efficacy are not likely to complete studies using technology. Alternatively, there may be few people with negligible self-efficacy in populations with easy access to computers and the Internet. If so, the results of the current studies indicate the BITS-SF can capture this in its scoring.
Implications
Given the focus on e-learning and digital technology in Mainland China and Taiwan (Bajpai et al., 2019; Hsin-fang & Tzu-hsuan, 2022), the translated BITS and BITS-SF can be used to assess which individuals are most likely to benefit from different types of technology training. For example, the three subscales of the BITS allow administrators and instructors to determine the degree of self-efficacy for different computer skill levels that employees and students might have. Additionally, the BITS-SF can be used as a CSE screening tool with large samples, such as an entire school (Weigold A. & Weigold I. K., 2021). Given that smartphones are used more frequently than computers in Mainland China to access the Internet (China Internet Network Information Center, 2022), the BITS and BITS-SF may be especially relevant in settings where computers are used, such as business and education, in this country.
Relatedly, both Mainland China and Taiwan are invested in decreasing the urban and rural educational divide through technology (Bajpai et al., 2019; Hsin-fang & Tzu-hsuan, 2022). Rural students have reported lower scores for digital self-efficacy in Mainland China and online learning self-efficacy in Taiwan compared to their urban counterparts (Li et al., 2022; Liao et al., 2016). As a result, CSE may be an important construct to consider when implementing and assessing technological initiatives. For example, the translated BITS may provide valuable information not only about major changes in CSE (e.g., moving from novice to advanced), but also about minor increases within the different subscales as individuals learn new techniques (e.g., lower scores within the advanced subscale to higher scores within the same subscale), which can then be compared across urban and rural areas. Additionally, the translated BITS-SF might be used with large samples of trainees or educators to provide population estimates of CSE across time.
The findings of the current study also have implications for future research on the BITS and BITS-SF. For example, researchers should examine potential within-country differences, such as across Mainland Chinese provinces (Rodon & Chevalier, 2017) and racial and ethnic groups living in both countries. Additionally, studies examining the BITS and BITS-SF in samples using traditional data collection methods (e.g., paper-and-pencil) would allow for a stronger estimation of the people who have CSE for different computer skill levels. The findings of the current and original studies indicate that the expert scale does not have a ceiling effect, even with IT engineers; however, it is unclear if there would be floor effects for the novice subscale in people who seldom use computers.
Relatedly, the findings of the LCAs have implications for the BITS-SF’s scoring. When combining the patterns of scores of the LCAs in the current and original studies, there is support for a score of 1 indicating negligible-to-novice CSE, rather than novice CSE. This would be consistent with the scores of 3 and 5 indicating CSE between two skill levels (Weigold, 2021). Further studies, particularly with samples expected to be low in CSE, are needed to determine the most accurate interpretation of BITS-SF low scores.
Finally, since both Mainland China and Taiwan invest in technology for education (Hsin-fang & Tzu-hsuan, 2022; Zeng, 2022), it would be helpful to examine the psychometric properties of the translated BITS and BITS-SF for use with students at different ages and levels of school so that they can potentially be used with younger samples. Relatedly, although the samples in the current study had large numbers of teachers (Study 1) and students (Study 2), the translated measures should be assessed in multiple samples of teachers and students to provide normative data for these populations.
Limitations
The results of the current studies should be understood in the context of their limitations. First, all data were collected cross-sectionally, so conclusions cannot be drawn about the longitudinal stability of the translated BITS and BITS-SF. Second, all measures were self-report surveys, which could have led to mono-method bias. Third, participants were recruited online and required to use electronic devices to complete the study. This might have resulted in biased sampling, as those without access to technology or the recruiting methods were not included. Relatedly, we only recruited one sample per study, which did not allow for an internal replication of the findings.
Conclusion
We conducted two studies assessing the psychometric properties of the simplified and traditional Chinese BITS and BITS-SF. Both measures’ scores showed evidence of a three-factor structure (BITS); underlying classes corresponding to relevant levels of CSE (BITS-SF); internal consistency; and convergent, discriminant, and concurrent validity. These replicate and extend the findings of the original English BITS and BITS-SF, indicating that they are strong measures for assessing CSE in both simplified and traditional Chinese. As the BITS and BITS-SF are modern questionnaires that correct for issues in previous CSE measures (Weigold A. & Weigold I. K., 2021), the current studies provide a strong foundation for their use in Mainland China and Taiwan. Both the BITS and BITS-SF measures are available for download at www.bitssurvey.com and free for non-commercial use.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data Availability
The data that support the findings of this study are available on request from the corresponding author. The data are not publicly available due to privacy or ethical restrictions.