
Abstract
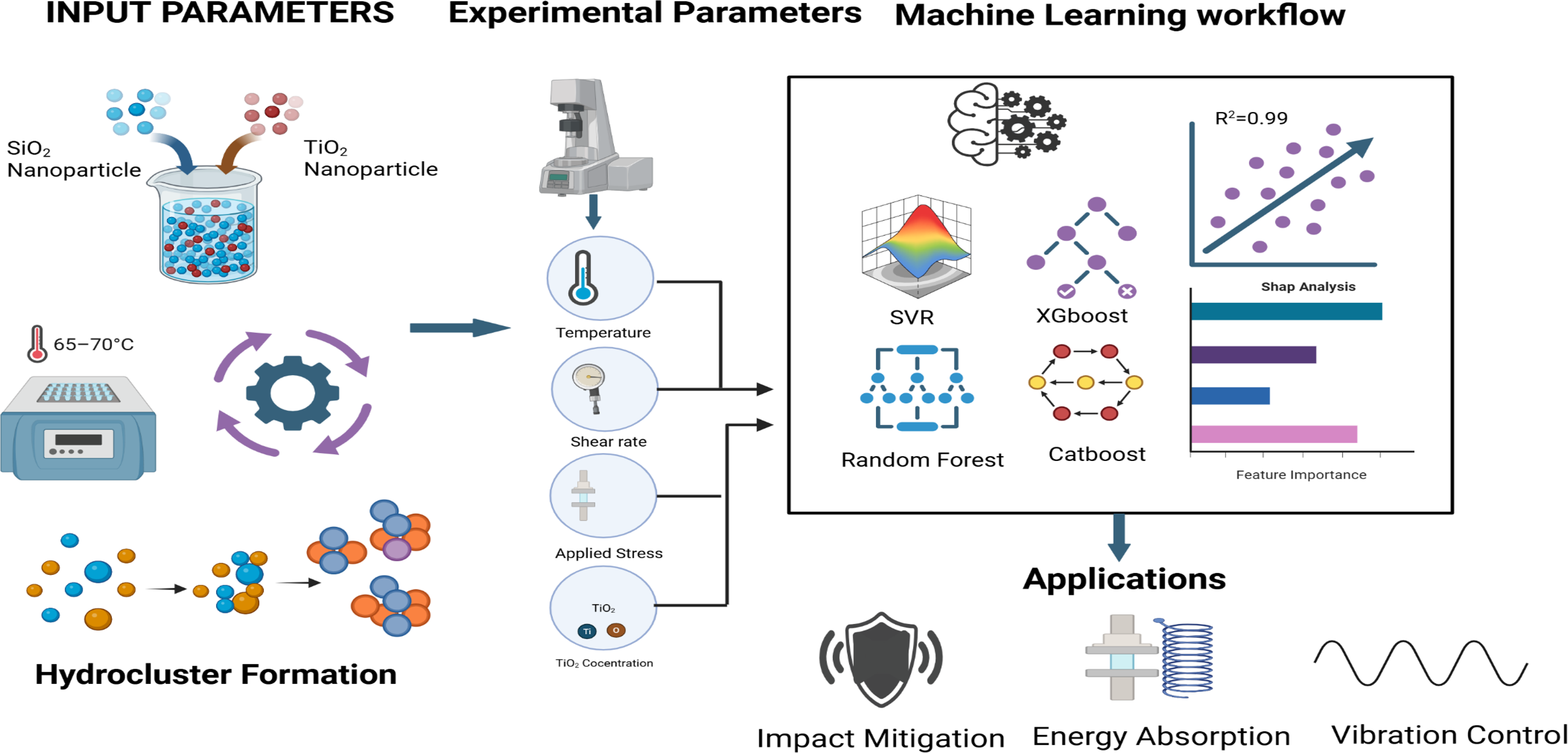
A silica-based (SiO2) shear-thickening fluid (STF) reinforced with titanium dioxide (TiO2) nanoparticles was systematically examined across a broad range of temperature, shear rate, and applied stress. The TiO2/SiO2 system showed a distinct, stress-dependent, nonlinear shear-thickening behavior, with an optimal nanoparticle concentration that maximized viscosity increase. The synergistic interaction between SiO2 and TiO2 nanoparticles promoted the formation of dense hydroclaster structures, significantly enhancing resistance to flow at high shear rates and improving rheological stability across different thermal conditions. To accurately model and predict highly nonlinear viscosity behavior, advanced machine learning (ML) models, including Support Vector Regression (SVR), Random Forest (RF), XGBoost, and CatBoost, were developed and fine-tuned using Bayesian Optimization (BO). CatBoost outperformed others, achieving a coefficient of determination (R2) of 0.9991 and 0.9906 for training and testing datasets, respectively, along with a test root mean squared error (RMSE) of 7.2553 and a mean absolute error (MAE) of 4.0291. Additional validation confirmed the model’s generalization, with an R2 of 0.9842. Moreover, Shapley additive explanation (SHAP) analysis was used to improve interpretability, revealing shear rate and shear stress as the most influential factors in viscosity changes. Meanwhile, temperature and TiO2 concentration contributed positively within an optimal range. The close match between experimental results and ML predictions demonstrates the robustness of the proposed data-driven approach. This research highlights the potential of ML-based methods for the intelligent design and optimization of high-performance STFs for advanced impact mitigation, energy absorption, and vibration control applications.
Keywords
Introduction
Shear-thickening fluids (STFs) are a distinctive category of non-Newtonian materials that exhibit a sudden, significant increase in viscosity when subjected to applied shear or impact forces. This rapid transition from a fluid-like to a solid-like state is generally attributed to the formation of transition particle clusters, often referred to as hydroclasters, which result from intensified interparticle interactions under external loading conditions. Notably, STFs exhibit reversible behaviour, enabling them to revert to their original liquid state once the applied force is removed. This variable change has established STFs as essential materials for applications that require impact resistance and energy dissipation, such as earthquake-vibration mitigation systems, isolators, and dampers.1–3
STFs generally consist of a dispersed phase alongside a dispersing medium.4,5 A typical STF is composed of nano-sized silica (SiO2) particles uniformly distributed within a liquid medium like polypropylene glycol or polyethylene glycol. These systems effectively absorb shock energy, making them appropriate for various types of dynamic situations and applications.6–8 Recent advances have focused on enhancing the performance of STFs by introducing functional groups into the dispersed phase or by utilizing chemically modified particles. Several factors, including particle size, shape, mass fraction, dispersion medium, and temperature, significantly influence the rheological behaviour of STFs.9–13
Research efforts have explored a wide array of dispersed-phase materials to optimize STF performance. For instance, Wagner and Egres demonstrated that suspensions that contain anisotropic particles like plates and rods exhibit enhanced shear thickening effects related to spherical particles due to their asymmetrical configuration. 14 Similarly, studies incorporating multiwalled carbon nanotubes and nanofibers of cellulose STFs have shown significant improvements in rheological properties, including greater shear-thickening and enhanced energy dissipation. 15 The relationship between dispersed particles and the dispersing medium has also been shown to play a pivotal role. Attalla and Osman underlined that polymer chains and functional units inside the medium greatly affect the STF’s performance, notably in terms of molecular interactions and structure stability. 16
Temperature sensitivity is another critical factor influencing STF behaviour. Wagner et al. experimentally demonstrated that the viscosity of STFs decreases with increasing temperature, driven by changes in particle interactions and fluid properties. 17 However, achieving optimal performance often requires balancing multiple constraints, as noted by Jiang et al. A new STF was developed by replacing SiO2 with polystyrene-acrylic acid (PS-AA) nanoparticles (polystyrene-acrylic acid), leading to an additional substantial shear-thickening effect with increasing nanoparticle absorption. 18 Likewise, He et al. combined silica nanoparticles with cetyltrimethylammonium bromide (CTAB) to create an STF with a remarkable shear thickening effect due to enhanced nanoparticle surface interactions. 19 Wang et al. have demonstrated that STF characteristics can be further improved by combining hybrid materials, such as halloysite nanotubes, with silica nanoparticles. 20 In a recent contribution, Khan et al. 21 investigated silica-based STFs reinforced with hexagonal boron nitride (h-BN) nanosheets, where enhanced rheological performance was primarily attributed to lubrication-dominated interactions, high thermal conductivity, and controlled hydrocluster formation. In contrast to such lubrication-based mechanisms, oxide-based nanoparticles such as titanium dioxide (TiO2) offer a distinct advantage due to their higher surface energy, which promotes stronger interparticle friction and contact interactions. This influences shear thickening through friction-driven particle clustering, particle jamming, and temperature-dependent solvation layer effects, leading to fundamentally different rheological responses. Furthermore, TiO2 exhibits distinct rheological behaviour influenced by particle size and shape22–25 and provides better thermal stability and resistance to aggregation than silica, making it a promising option for hybrid STF formulations. Therefore, the present study aims to systematically investigate TiO2-enhanced silica-based STFs and to establish a robust predictive framework to capture their nonlinear rheological behaviour.
The viscosity of STFs and nanofluids can be quantified utilizing rheometric instruments; however, such procedures are expensive, labour-intensive, and necessitate extensive repetitions to effectively characterize viscosity over wide parameter ranges. 26 Conventional empirical models assume a continuous relationship between viscosity and shear rate, which limits their relevance for STFs that exhibit non-linear and discontinuous responses, including abrupt shear thickening. Only a limited number of studies have attempted to construct computational or analytical models capable of reproducing the complete viscosity profile, encompassing both the shear-thinning regimes and the discontinuous thickening zone. Galindo-Rosales et al. proposed an apparent viscosity expression that aligned with several experimental datasets, and a subsequent work extended this formulation to incorporate temperature and concentration effects. 27 Shende et al. introduced an empirical relation based on free-volume theory that identifies threshold parameters and characterizes STF rheology using measurable quantities. 28
Although these phenomenological models facilitate the generalization of experimental observations, they rely on simplifying assumptions and do not fully capture the physical mechanisms governing non-Newtonian behaviour. The need for numerous auxiliary parameters and repeated computations further restricts their applicability. Only a limited number of studies have explored predictive or hybrid modelling strategies that integrate rheological measurements with data-driven approaches to describe the nonlinear and discontinuous characteristics of STFs.29,30 Furthermore despite the increasing incorporation of functional nanoparticles, such as TiO2, to tailor STF performance, the specific influence of these additives on shear-thickening intensity, thermal stability, and the underlying interparticle interactions remains insufficiently characterized.
These limitations collectively define a critical research gap: the absence of a robust, interpretable framework that can simultaneously capture the nonlinear rheological response of nanoparticle-enhanced STFs, particularly those incorporating TiO2, while overcoming the structural constraints of conventional phenomenological models. Although machine learning (ML) methods offer a promising alternative by providing improved predictive accuracy relative to empirical formulations,31–33 their application in this domain has been largely exploratory and lacks mechanistic interpretability. For instance, Potnuri et al. applied support vector regression (SVR) to estimate product distributions in microwave-assisted co-pyrolysis demonstrating the model’s capability to incorporate catalyst characteristics, process conditions, and feedstock properties. 34 Similarly Sun et al. employed SVR to predict crude-oil viscosity based on compositional and physicochemical parameters illustrating the utility of data-driven models for reservoir-fluid characterization under varying thermodynamic conditions. 35 However analogous methodologies have yet to be systematically applied to predict the viscosity of TiO2- and SiO2-based STFs, while maintaining transparency and physical coherence.
The present study addresses these gaps by systematically investigating the rheological behaviour of STFs formulated with SiO2 and TiO2 particles across varying mass fractions. The experimental work encompasses shear-thickening response, temperature dependence, and viscoelastic properties through steady-state and dynamic rheological tests. To complement this experimental foundation, advanced ML models, including SVR, random forest (RF), extreme gradient boosting regression (XGBoost), and categorical boosting regression (CatBoost), are optimized using Bayesian optimization with Gaussian process surrogates (BO_GP) to predict STFs’ viscosity as a function of key experimental variables. Shapley additive explanations (SHAP) is further employed to interpret model outputs and quantify the contribution of each input feature, enabling a transparent, physically coherent understanding of the ML-based viscosity predictions. Collectively, these findings provide critical insights into integrating STF systems into composite materials for advanced impact-resistance and vibration-control applications.
Experimental methods
The selected materials
The study utilized SiO2, which was purchased from Shanghai, China’s Aladdin Biochemical Technology Co., Ltd. 22 The SiO2 particles supplied by Usolf Chemical Technology Cooperation Limited (Shandong Province, China) had an average particle size of approximately 15 nm. Their relative densities ranged from 2.338 to 2.655, and the measured pH values ranged from 3.88 to 4.77. Polypropylene glycol (PPG200) was a clear, stable fluid at ambient temperature. The hydroxyl group value ranged from 511 to 624 mg KOH/g, and TiO2, with a molecular weight of approximately 80, was purchased from China Shanghai. 22
Shear thickening fluid (STF) preparation
STF has been prepared in multiple phases to guarantee optimal rheological performance and dispersion. Before testing, TiO2 and SiO2 were heated in a vacuum oven at 70°C for 15 hours to remove any remaining moisture.
Proportion of TiO2 to SiO2 in STF system.

Rheological testing
Using a rheometer (TA Instruments AR2000, United States), the rheological characteristics of the produced TiO2/SiO2-STFs with different TiO2-to-SiO2 ratios were assessed in both steady-state and dynamic conditions. The experiments were performed at 19°C, a controlled ambient temperature. In this research, the cone-plate gap was maintained at 52 μm, and all measurements were conducted using the cone-plate geometry (diameter = 25 mm, cone angle = 2°). To prepare for testing, STF samples were evenly distributed on the rheometer’s bottom plate. After that, the top cone plate was lowered until the desired 52 μm gap was reached. The rheometer’s built-in temperature regulator was used to maintain temperature control throughout the trials. To assess the outcome of temperature on the STF samples’ performance, their rheological behaviour was examined over a range of 15 to 50°C. The shear rate was varied from 0.1 to 1000 s−1 to perform the steady shear rheological testing. As a result, shear-thickening behaviour, including viscosity variation and the critical shear rate under different stress conditions, could be evaluated.
To perform dynamic rheological testing, oscillatory shear stress was applied to the STF samples over a range of 0.1-1000 Pa. These experiments provide insight into the STFs’ viscoelastic properties, including their ability to effectively store and dissipate energy under both low and high-stress conditions. The integration of steady-shear and dynamic rheological analysis provided a comprehensive understanding of the TiO2/SiO2-STFs’ viscoelasticity, shear-thickening behaviour, and temperature sensitivity. These results are essential for improving STF formulations for sophisticated uses.
Machine learning methods
Researchers have employed various ML techniques to predict the rheological and viscosity-related properties of complex fluids. In this study, the viscosity behavior of TiO2/SiO2-based STFs is modeled using both individual and ensemble learning approaches. SVR is applied as a particular method, while ensemble-based algorithms, RF, XGBoost, and CatBoost, are implemented to improve predictive performance through bagging and boosting frameworks. Hyperparameter tuning for all models was performed using BO_GP to ensure efficient and robust convergence. These models and the BO_GP optimization were selected for their proven effectiveness in capturing nonlinear, multivariate interactions and for their robustness in materials science prediction tasks. 36
Support vector regressor
The Support Vector Machine (SVM), introduced by Corinna Cortes and Vladimir Vapnik in 1995, 37 is a supervised learning algorithm that constructs an optimal separating hyperplane by maximizing the margin between classes. Its strong generalization capability, particularly in high-dimensional spaces, and its ability to handle nonlinear relationships through kernel functions make it well-suited for complex pattern recognition problems. 38
In the regression context, referred to as SVR, the objective is to determine a function that approximates the target values while controlling model complexity. This is achieved by minimizing a regularized risk function under an ε-insensitive loss, where deviations within a predefined threshold ε are not penalized. The SVR model predicts a continuous output variable using input data represented by K-dimensional feature vectors
The SVR prediction function is expressed as equation (1):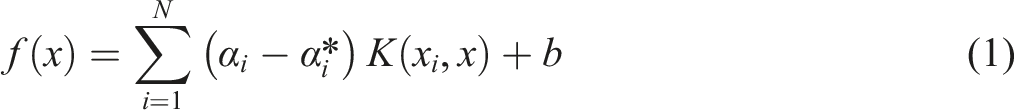
Random forest
The Random Forest (RF) algorithm, an ensemble learning method based on Classification and Regression Trees (CART), was formally introduced by Leo Breiman in 2001. 40 It has since been widely applied across diverse domains due to its strong predictive performance and robustness. As a statistical learning technique, RF employs bootstrap resampling (bagging) to generate multiple subsets from the original dataset. 41 Each subset is used to train an individual decision tree, with an additional layer of randomness introduced through feature subsampling at each split.
The final prediction is obtained by aggregating the outputs of all individual trees. For regression tasks, this aggregation is typically performed by averaging, expressed as equation (2):
This ensemble strategy enhances model stability and generalization by reducing variance without substantially increasing bias. Contrary to common misconceptions, bagging primarily reduces variance, rather than increasing it, thereby mitigating overfitting. The use of both bootstrap sampling and random feature selection ensures that individual trees are decorrelated, which improves the robustness of the aggregated model. Consequently, RF is particularly effective for handling high-dimensional data and complex nonlinear relationships while being relatively insensitive to noise and outliers. 41
Extreme gradient boosting regression
XGBoost is a highly optimized, scalable implementation of the gradient boosting framework, specifically designed to improve predictive performance and computational efficiency. Unlike traditional gradient boosting algorithms that rely solely on first-order derivatives, XGBoost leverages both first- and second-order derivatives (gradients and Hessians) of the loss function, enabling more precise and stable parameter estimation at each boosting iteration. 42
To control overfitting and enhance generalization, XGBoost introduces an explicit regularization term into its objective function. This includes both L1 (Lasso) and L2 (Ridge) penalties applied to the leaf weights of the decision trees. The regularization framework penalizes model complexity by constraining the number of leaves and the magnitude of leaf weights, thereby discouraging overly complex tree structures. Additionally, a gain-based splitting criterion is employed to evaluate candidate splits, ensuring an optimal balance between model fit and complexity.
From a computational perspective, XGBoost is engineered for efficiency and scalability. It supports parallel and distributed computation, utilizes cache-aware data structures to improve memory access patterns, and incorporates sparsity-aware algorithms to handle missing or sparse data efficiently. These optimizations enable significantly faster training and superior performance compared to traditional gradient boosting implementations, particularly for large-scale and high-dimensional datasets. 43
The objective function of XGBoost is defined as equation (3):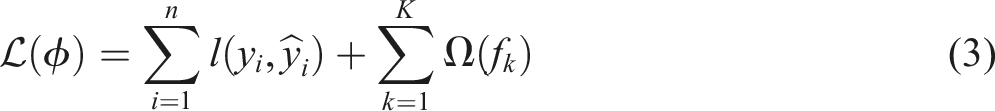
The regularization term is given by as presented in equation (4):
CatBoost
In 2017, Yandex introduced its ML algorithm, CatBoost, which is based on Gradient Boosting Decision Trees (GBDT). 45 CatBoost models operate by constructing a series of decision trees, each progressively reducing the loss. Configuration settings initially determine the tree generation rate, while an overfitting detector helps maintain model stability and prevent erratic behavior. 37
The model updates in CatBoost are driven by an iterative objective function, mathematically represented as equation (5):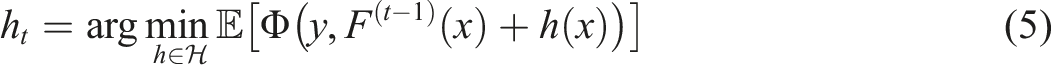

Building a tree in CatBoost involves several steps: computing candidate splits, converting categorical features to numerical representations, selecting the tree structure, and computing the leaf values. To improve prediction accuracy, CatBoost predominantly uses greedy algorithms. Features are organized by splits and assigned to each leaf in a consistent structure. Before constructing a new tree, feature permutations are applied rather than simple random shuffling. Pre-modelling parameters set the tree depth and constrain the selection of structure. When constructing subsequent trees, CatBoost evaluates performance based on a metric that reflects the improvement in the objective function. 46
Bayesian optimization
Hyperparameter optimization is a critical step in ML, traditionally approached through methods like grid search and random search. 47 Grid search systematically evaluates every possible combination of hyperparameters within the parameter space to find the optimal set, but it becomes computationally prohibitive as the parameter space expands due to its exponential complexity. 48 Random search addresses this limitation by sampling a subset of parameter combinations, offering improved efficiency and suitability for high-dimensional datasets. However, both methods lack adaptability and rely on exhaustive or randomized search strategies.
Bayesian Optimization (BO) offers a more intelligent alternative by leveraging prior knowledge to guide the search. By combining the previous probability of the objective function with observed data, BO iteratively updates a posterior probability distribution to identify hyperparameters that minimize the objective function. This adaptive approach ensures that each iteration refines the search, focusing computational resources on promising regions of the parameter space. BO not only accelerates the finding of optimal hyperparameters but also reduces manual effort and improves model performance, making it a powerful tool for automating hyperparameter tuning in ML. 49
BO aims to identify the optimal hyperparameters that minimize validation errors. Given a defined hyperparameter space and an objective function targeting the reduction of validation error, the optimization process within the BO framework is mathematically represented as equation (7):
Shapley additive explanations
Tree-based ensemble learning methods like RF inherently offer feature relevance by counting how often a feature appears during model tree construction 44 While evaluating feature importance through various methods reveals valuable insights, it doesn’t fully capture the overall impact of features or the complex relationships (both positive and negative) between features and the output. Therefore, understanding the full significance of the model’s features and their connections to the target variable is essential. This can be achieved through SHAP analysis, as proposed by Lundberg and Lee. 51
SHAP analysis uses Shapley values, derived from game-theoretic principles, to quantify each feature’s contribution. Global feature importance is typically obtained by averaging the absolute Shapley values across all instances in the dataset. These values are then visualized in descending order, where each point represents the Shapley value for a specific feature and instance. The x-axis represents the Shapley values (impact on model output), while the y-axis lists the features. The color gradient reflects the feature value (e.g., low to high), not the level of importance. Additionally, SHAP dependence plots capture the effects of feature interactions on the target variable, providing more detailed insights than traditional partial dependence plots. 52
Lundberg and Lee developed several SHAP analysis methods, including DeepSHAP, LinearSHAP, KernelSHAP, and TreeSHAP. This study uses TreeSHAP. The explanation model for a prediction is formulated as equation (8):
Feature attribution for each feature is calculated as equations (9) and (10):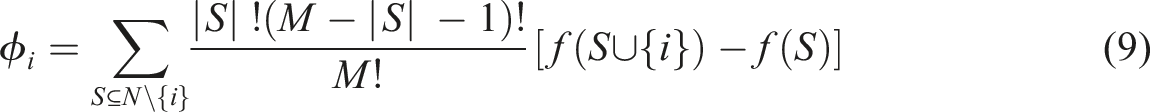

Statistical Metrics
Three statistical metrics were employed to evaluate the efficacy of the ML models used in this investigation: coefficient of determination (R2), Mean Absolute Error (MAE), and Root Mean Square Error (RMSE). The following equations define these metrics, equations (11)–(13):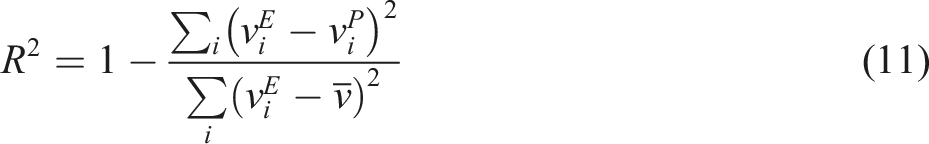

Result and discussion
Steady-shear rheological analysis of STFs
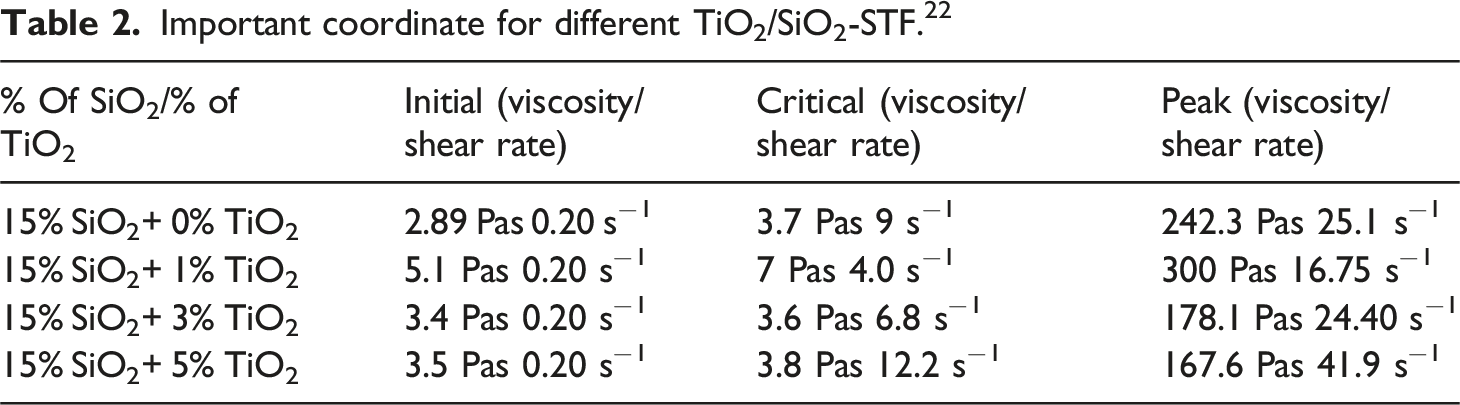
Important coordinate for different TiO2/SiO2-STF. 22
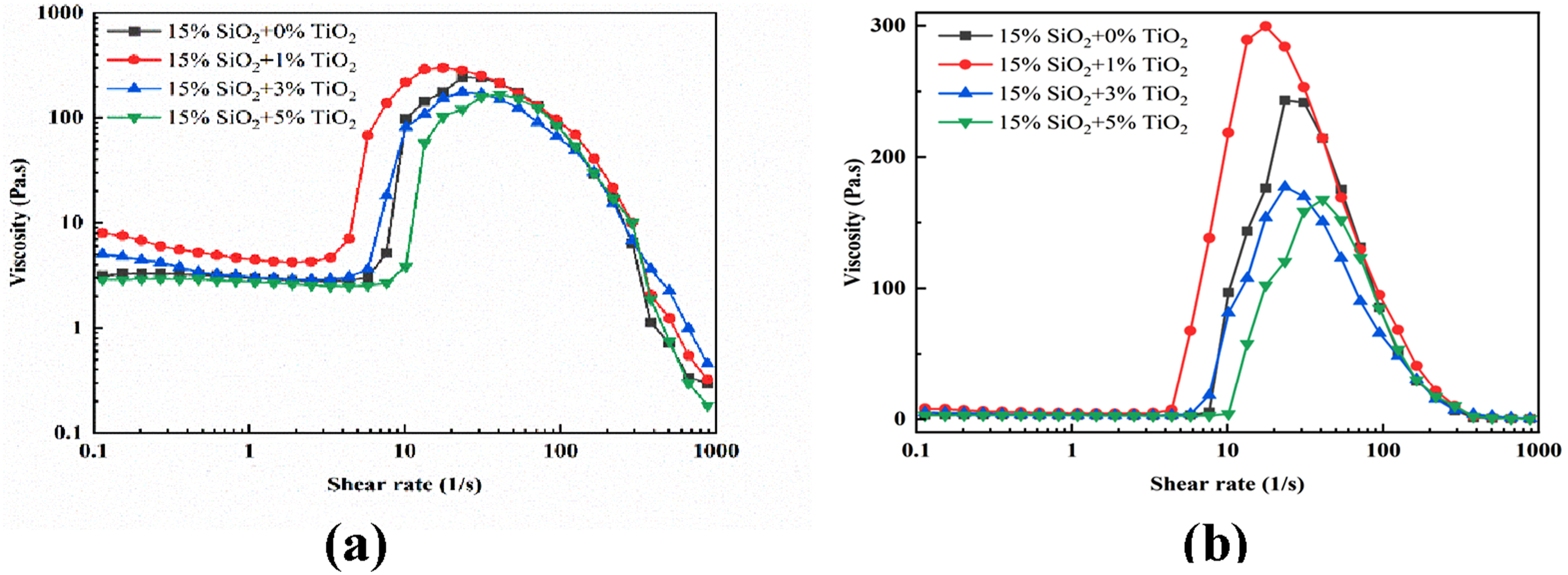
Viscosity versus shear rate for the SiO2/TiO2-STF sample at numerous SiO2/TiO2 proportions. (a) Logarithmic Graph (b) Semi-Logarithmic Graph. 22
When the proportion of dispersed TiO2 particles rose, the system’s viscosity also rose; the curve was not constant, as demonstrated in Figure 1(a) and (b). For the TiO2 mass fraction ratio, 1% is chosen as the optimal cut-off threshold. The SiO2/TiO2-STF system’s initial viscosity reduced, the apparent highest value rose, and the critical shear rate improved as the TiO2 mass ratio increased whenever the TiO2 percentage ratio passed this edge, which implies that a minor amount of TiO2 boosted the silica particles’ interface, resulting in a greater shear-thickening impact and increased viscosity. Increasing the TiO2 proportion to 3% and then to 5% decreased the top viscosity and increased the critical shear rate, as observed with 1% TiO2. This indicates that increasing the TiO2 concentration in the fluid, encouraging fluid flow, and generating a lubricating effect reduce internal friction. This is because TiO2 particles act as a dispersion agent, stabilizing the fluid’s silica particles and reducing their direct contact, thereby lowering viscosity and increasing the critical shear rate. These results suggest that the addition of TiO2 has a complex effect on the system’s shear-thickening behaviour. Even though 1%TiO2 provides the best viscosity and shear thickening characteristics, dispersion stabilization and lubrication effects may cause peak viscosity to decrease, and the shear thickening effect may not constantly be enhanced by increasing the TiO2 concentration beyond this point.
Temperature sensitivity of STF
Figure 2(a) and (b) illustrates the correlation between the apparent viscosity and strain magnitude of the 1% SiO2/STF at different test conditions temperatures. The following temperatures were used for the environmental testing: 15°C, 20°C, 30°C, 40°C, and 50°C. The shear rate’s scanning range is 0.1-1000 s−1. TiO2/SiO2/STF sample viscosity versus shear rate over temperature. (a) Logarithmic Graph (b) Semi-Logarithmic Graph.
22
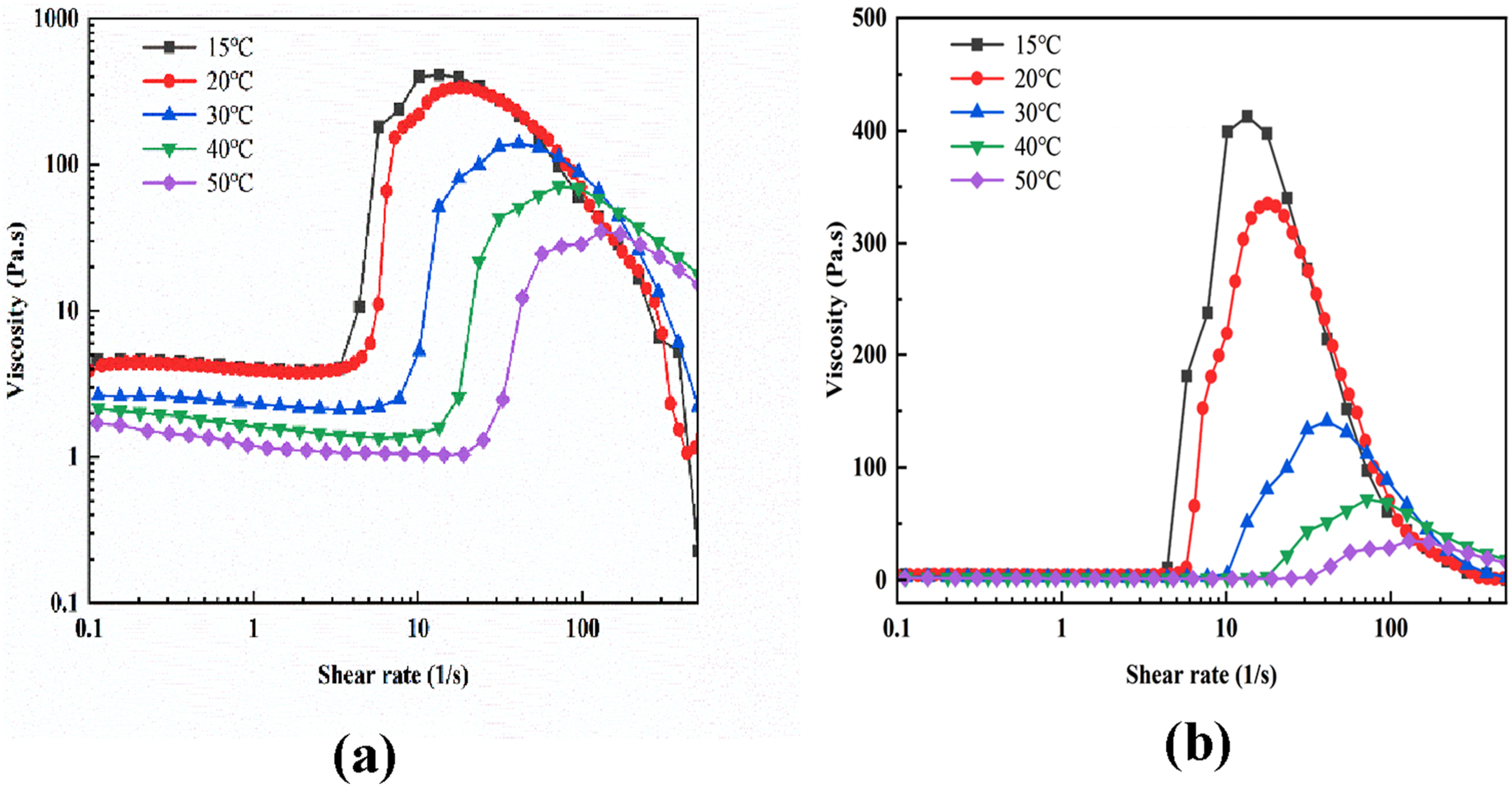
The viscosity is similarly affected by the temperature shift, as seen in Figure 2(a) and (b) for the 1% STF system. Beginning and peak viscosities, fall, and the critical shear rate all increase with temperature, causing the viscosity curve to move downward accordingly. Because temperature rises have a considerable impact on the ST effect, it is noteworthy that, at every measured temperature, the system demonstrated exceptional stability with a 1% STF. At 15°C, the 1% STF system showed a roughly 36.20% reduction in the critical shear rate and a 27% increase in maximum viscosity compared with the controlled sample. At 50°C, the critical shear rate declined by up to 25.42%, while the viscosity of the 1% STF system significantly increased, reaching up to 51% higher than the 0% STF sample, as illustrated in Figure 2(a) and (b). However, this doesn’t lead to improved thermal stability. This is because temperature rises have a significant impact on the ST effect. In summary, the 1% STF consistently outperforms the 0% STF in terms of peak viscosity, critical shear rate, and resistance to temperature fluctuations. Adding only 1% TiO2 to the shear-thickening fluid markedly improves its thermal stability, making it well-suited for applications that demand consistent performance in dynamic and elevated-temperature environments. These outcomes highlight that the TiO2-based shear-thickening fluid has the potential to enhance STF performance and is a promising shear-thickening material.
ML model development and assessment
To ensure the robustness and generalization of the developed ML models, the complete dataset generated from the rheological experiments was first partitioned, with 15% of the observations reserved as an independent validation set. The remaining 85% of the data was then randomly split into a 70% training subset and a 15% testing subset. Each subset contained the same set of input variables and a single output variable (viscosity, η). The input features consisted of nanoparticle concentration (wt.%), shear rate (s−1), temperature (°C), and the TiO2 mass ratio, all of which govern the shear-thickening behaviour of the SiO2/TiO2-based system STFs. The input features were normalized to the (0, 1) range using min-max scaling for visual comparison, as shown in Figure 3, which displays the distributions of the training, validation, and test datasets. The consistency in distribution shapes across all three subsets demonstrates that the data partitioning was performed effectively, minimizing sampling bias and ensuring that the models are trained and tested on statistically similar populations. Distribution of independent features and target viscosity.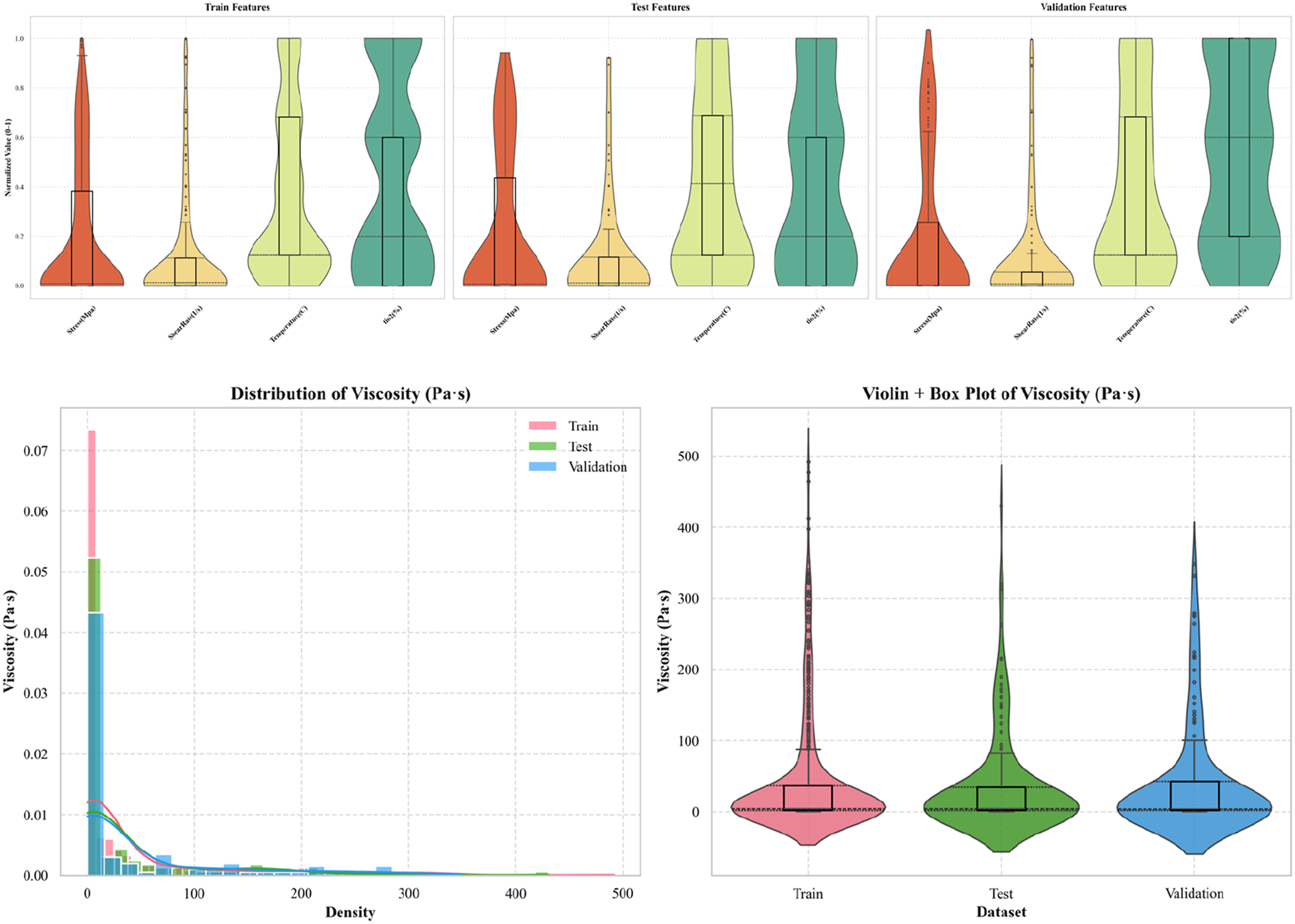
Figure 3 also presents the distribution of the target variable, viscosity. The histogram with kernel density estimation reveals a positively skewed distribution. This is expected for STFs, as most data points represent lower-viscosity states, with fewer observations capturing the high-viscosity shear-thickening regime. The violin-box plot confirms that the median viscosity is consistent across the training, validation, and test datasets. The elongated upper tails and outliers in this plot represent the critical, high-viscosity responses that are essential for accurately modelling the extreme shear-thickening behaviour. These distributions confirm that the dataset spans both low- and high-shear viscosity regimes, enabling the ML models to learn from the full rheological spectrum of the TiO2/SiO2-STFs.
Hyperparameter optimization using Bayesian optimization Gaussian process
In this study, BO_GP was implemented to optimize the hyperparameters of the SVR, RF, XGBoost, and CatBoost models. The optimization aimed to minimize the five-fold cross-validated RMSE across the training set, ensuring robustness and mitigating overfitting.
Optimized parameters found by BO_GP for SVR, RF, XGBoost, and CatBoost.

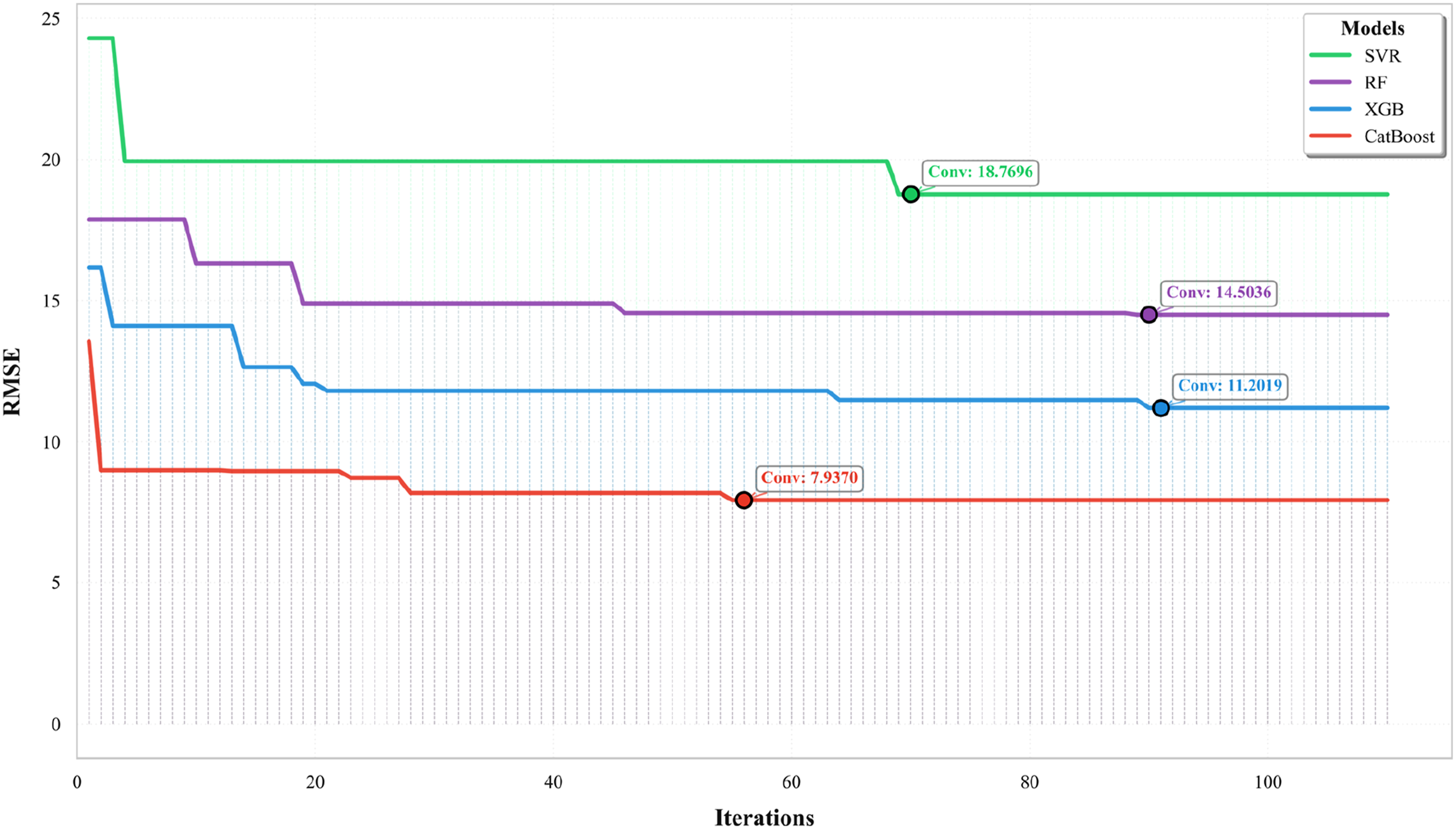
Bayesian optimization, Gaussian process five-fold CV convergence during training.
For the SVR model, the BO_GP optimization identified a high penalty parameter (C = 9433.76), indicating that the model required strong regularization to minimize training error. The kernel-specific parameters gamma (0.0981) and epsilon (0.3442) were tuned to control smoothness and margin tolerance, thereby ensuring accurate fitting of nonlinear rheological relationships.
In the RF model, the optimizer selected a maximum depth of 10 and 134 estimators, suggesting a moderately deep ensemble with sufficient trees for stability. The optimized values of max_features = 0.7811, min_samples_split = 2, and max_samples = 0.9905 indicate a balance between variance control and computational efficiency, enabling effective averaging across diverse decision trees.
The XGBoost model was optimized with reg_alpha = 0.6785 and reg_lambda = 0.6147, demonstrating the need for both L1 and L2 regularization to prevent overfitting. The learning rate (0.1788) and maximum depth (4) provided a good trade-off between model complexity and convergence stability, while subsample (0.8256) and colsample_bytree (0.7647) enhanced generalization through random feature and sample selection.
The CatBoost model achieved the lowest cross-validated RMSE via BO_GP optimization, as shown in Figure 4. The model converged after approximately 60 iterations, reaching a minimum RMSE of 7.937 and outperforming other algorithms. The optimal parameters included depth = 4, iterations = 497, learning_rate = 0.0716, and subsample = 0.6805, confirming the model’s ability to capture nonlinear dependencies effectively while preventing overfitting. Additionally, l2_leaf_reg = 1.0446 and colsample_bylevel = 0.5905 provided appropriate regularization and a balanced feature sampling, reinforcing CatBoost’s robustness in handling complex rheological patterns.
Prediction results
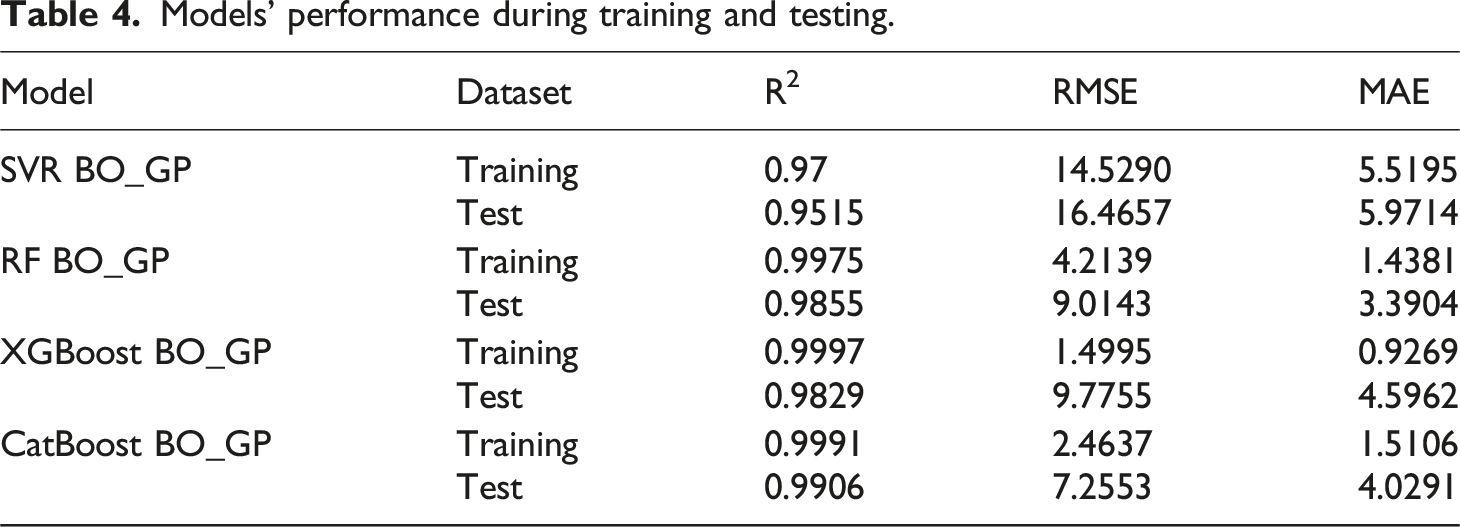
Models’ performance during training and testing.
Models’ performance on validation data.
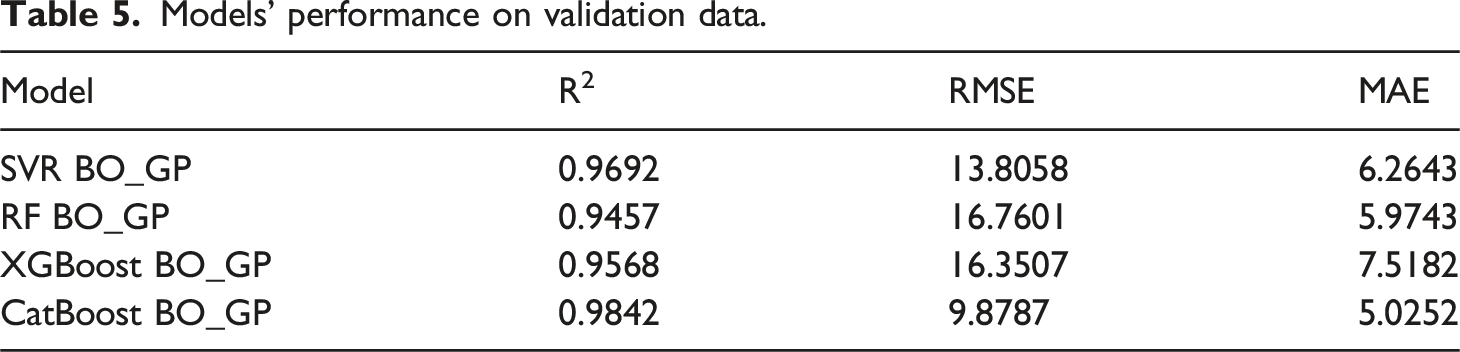
The XGBoost and RF models also exhibited high predictive accuracy, reflecting their effectiveness in modeling nonlinear systems. However, both showed slightly higher error values and marginally lower R2 scores compared to CatBoost, suggesting reduced sensitivity to extreme viscosity variations. The SVR model, while performing reasonably well, showed comparatively higher errors, indicating its limited ability to capture abrupt rheological transitions characteristic of shear-thickening behavior.
The comparative scatter plots of predicted versus experimental viscosity values for all models across the training, testing, and validation datasets are presented in Figure 5. These plots provide a direct visualization of each model’s predictive fidelity and generalization capability. Ideally, a perfect prediction aligns along the 45° parity line, representing complete agreement between measured and predicted values. Among the models, the CatBoost BO_GP model exhibits the most coherent and compact distribution of data points along the parity line across all datasets, demonstrating exceptional consistency between predicted and experimental viscosities. The minimal deviation and tight clustering confirm the model’s strong generalization and its ability to accurately capture both low- and high-viscosity regimes. Scatter comparison of train, test, and validation for CatBoost, XGBoost, RF, and SVR.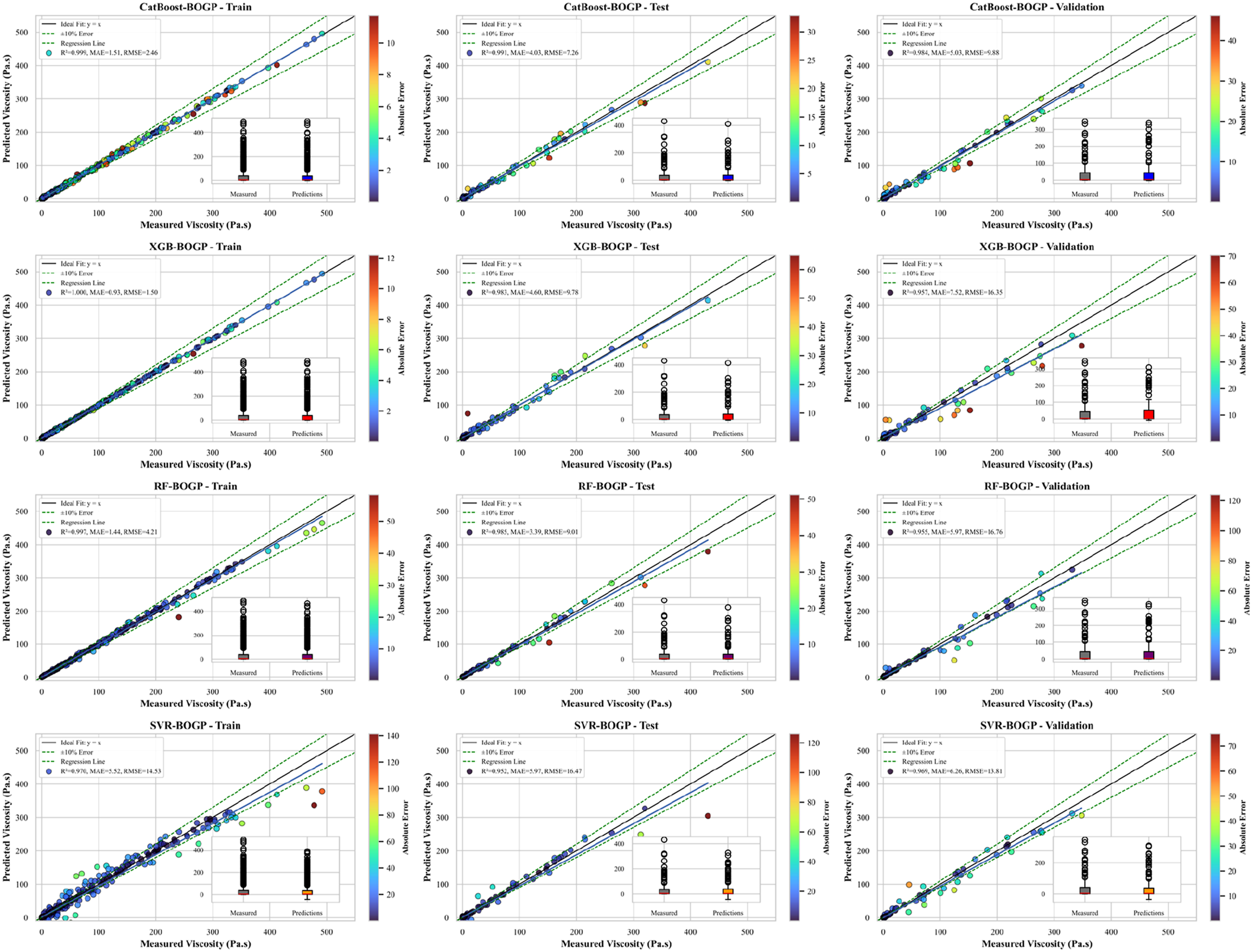
The residual distributions illustrated in Figure 6 further validate these observations. The CatBoost BO_GP model displays a narrow, symmetric residual distribution centered around zero, indicating unbiased predictions and minimal systematic error. Most residuals fall within a range of −30 to 45, confirming the model’s stability and reliable performance across all datasets. The XGBoost BO_GP and RF BO_GP models exhibit wider residual spreads, with a slight tendency toward random deviations at higher viscosities. In contrast, the SVR BO_GP model exhibits the broadest and most uneven distribution, reflecting less stable predictive behaviour. Comparison of actual viscosity value and model predictions of train, test and validation, and residual histograms.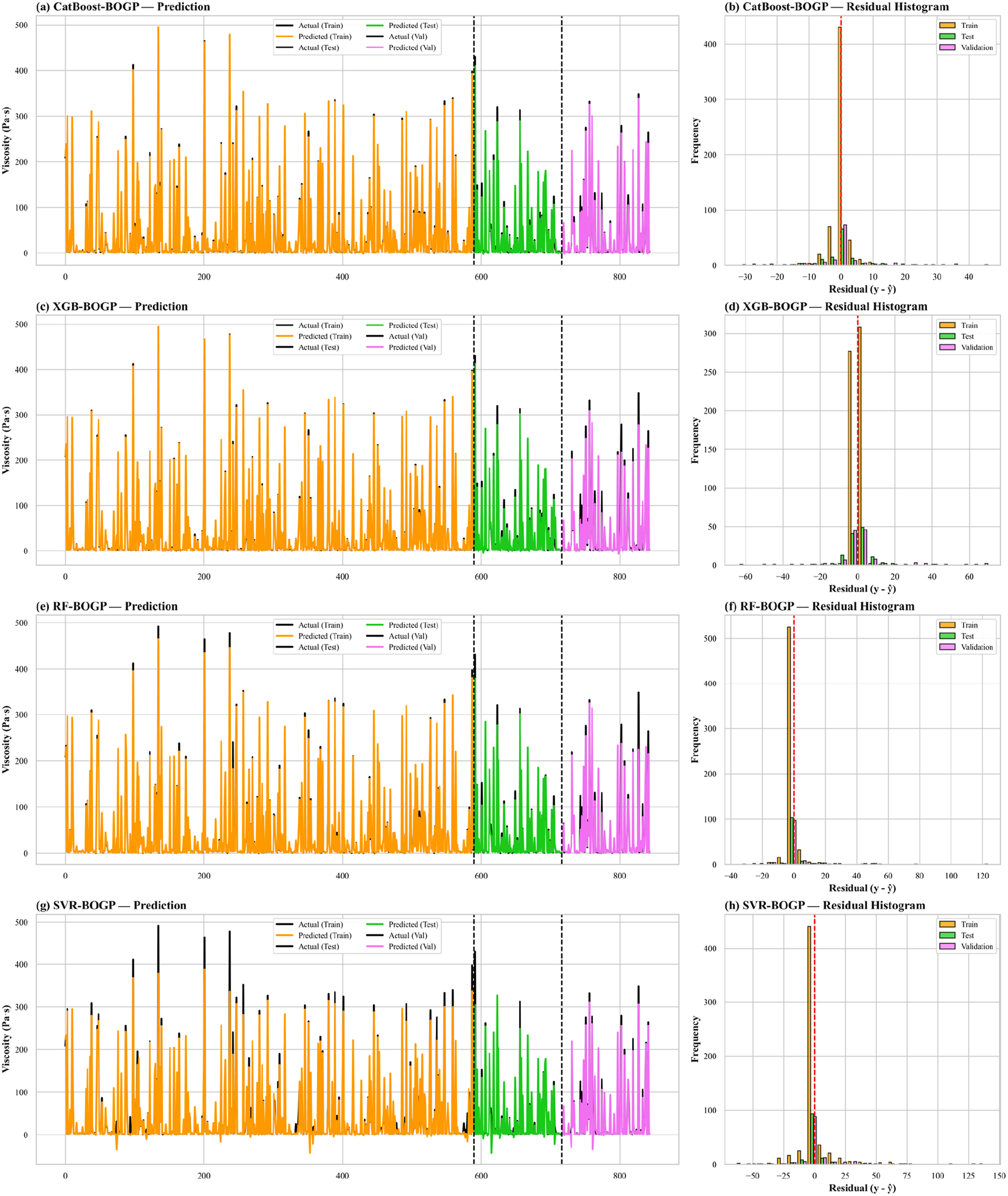
The Taylor diagram in Figure 7 provides a unified assessment of model performance by comparing correlation, standard deviation, and centered RMSD across the entire dataset. The CatBoost BO_GP model is positioned nearest to the reference point (R = 1, σ/σ_ref = 1), indicating the highest correlation and the most accurate replication of experimental viscosity variations. This close alignment confirms CatBoost’s superior capability to capture both the trend and amplitude of the rheological data with minimal deviation. Taylor diagrams of models on the entire dataset, CatBoost interpretations.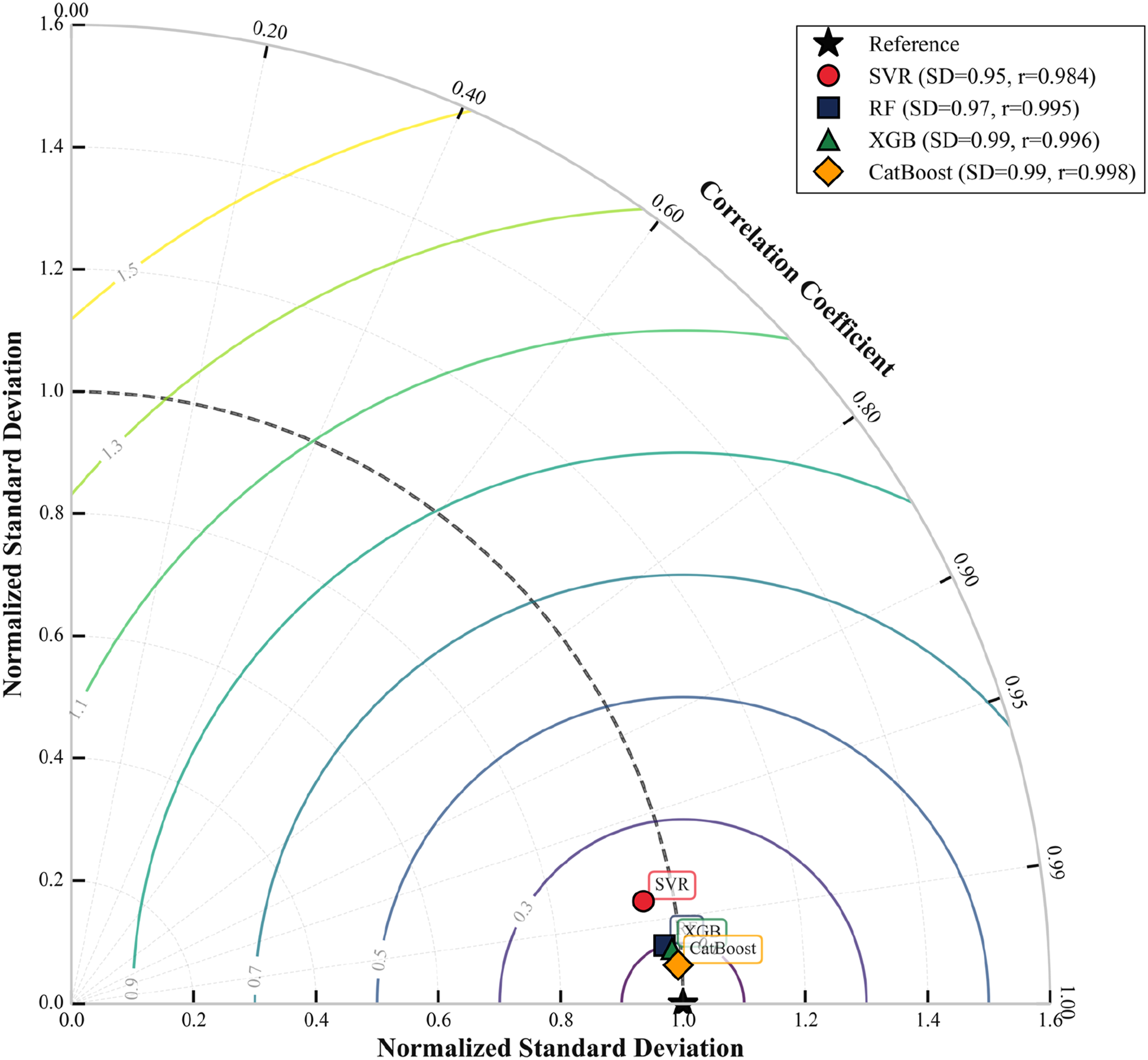
Prediction model interpretation
The SHAP analysis was performed to quantitatively interpret feature importance and directional effects in the BO_GP CatBoost model. The analysis was computed using the trained model on the testing set to evaluate the contribution of each input variable to the predicted viscosity of STFs.
As shown in Figure 8, the mean absolute SHAP values indicate that Stress (58.51) is the most influential feature, consistent with the literature on h-BN, which found that stress has a substantial influence on predicting STF viscosity
21
Stress substantially outweighs Shear rate (30.60), while Temperature (10.25) and TiO2 concentration (4.01) demonstrate comparatively minor impacts. The beeswarm summary plot further elucidates the functional relationships: elevated Stress values correspond to strongly positive SHAP values, indicating a pronounced increase in predicted viscosity. In contrast, lower Stress values consistently reduce the model output. The relationship between Shear rate and viscosity is nonlinear, with both intermediate and high values exerting a negative influence on viscosity predictions. In contrast, Temperature and TiO2 concentration exhibit limited effect magnitudes and broader distributions of values, indicating secondary roles, though their optimal ranges contribute positively to the output. Shap interpretation: Mean SHAP value and features distributions.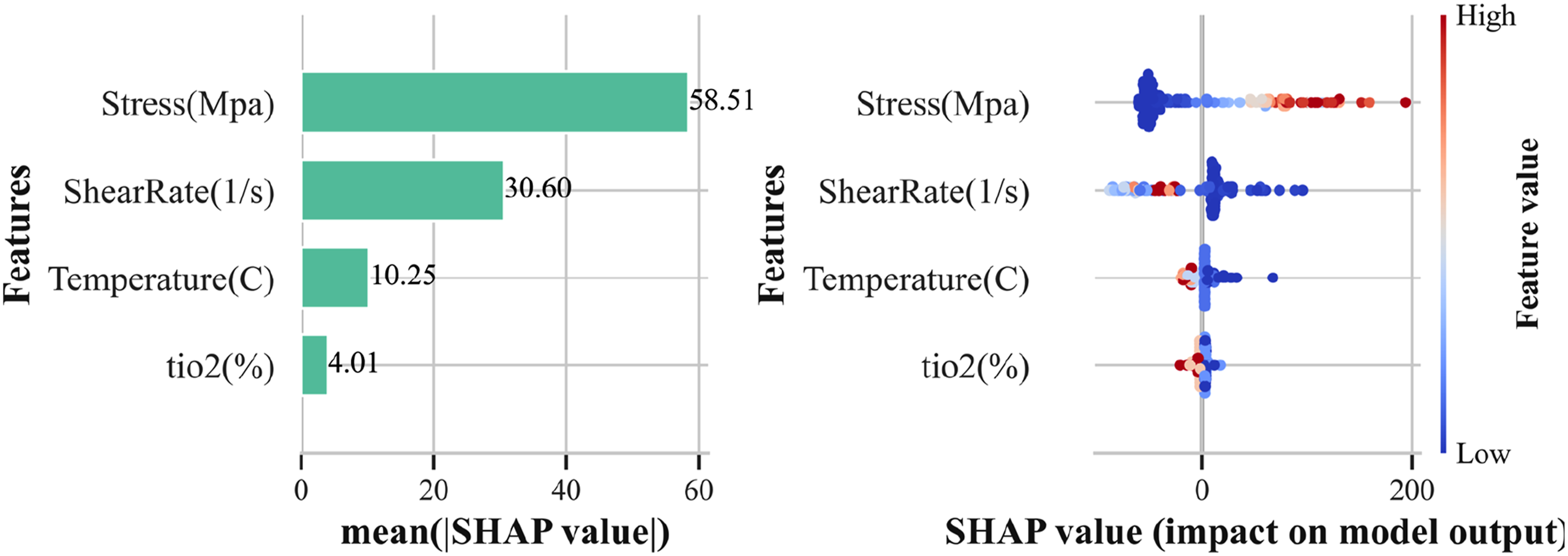
The SHAP dependence plots in Figure 9 elucidate the individual and interactive effects of features on the model’s viscosity predictions. Figure 9(a) reveals a strong positive relationship between Stress and the SHAP value. This relationship is moderated by Temperature, with the positive effect of Stress being most pronounced at lower temperature levels. Figure 9(b) shows a nonlinear relationship between shear rate and stress. SHAP values are positive at low to moderate shear rates but become negative beyond a critical threshold. This behavioural shift demonstrates a significant interaction with Stress, with combined high-stress and high-shear-rate conditions producing the most important adverse effect on viscosity predictions. Figure 9(c) indicates that increasing Temperature generally reduces the predicted viscosity. This negative correlation is particularly evident under low-stress conditions, indicating that Temperature acts as a moderating variable, attenuating stress-induced thickening. Figure 9(d) confirms that TiO2 concentration has a non-monotonic relationship with viscosity. The maximum positive contribution occurs at approximately 1% concentration, consistent with experimental observations of optimal nanoparticle loading. Beyond this concentration, the reinforcing effect diminishes, especially under combined conditions of high stress and elevated temperature. Collectively, these dependence analyses verify that the model has captured the fundamental shear-thickening physics, including the stress-activated transition, shear-rate-dependent response, thermal suppression, and the optimal nanoparticle loading effect characteristic of STF systems. SHAP features dependence plots of the test set of CatBoost.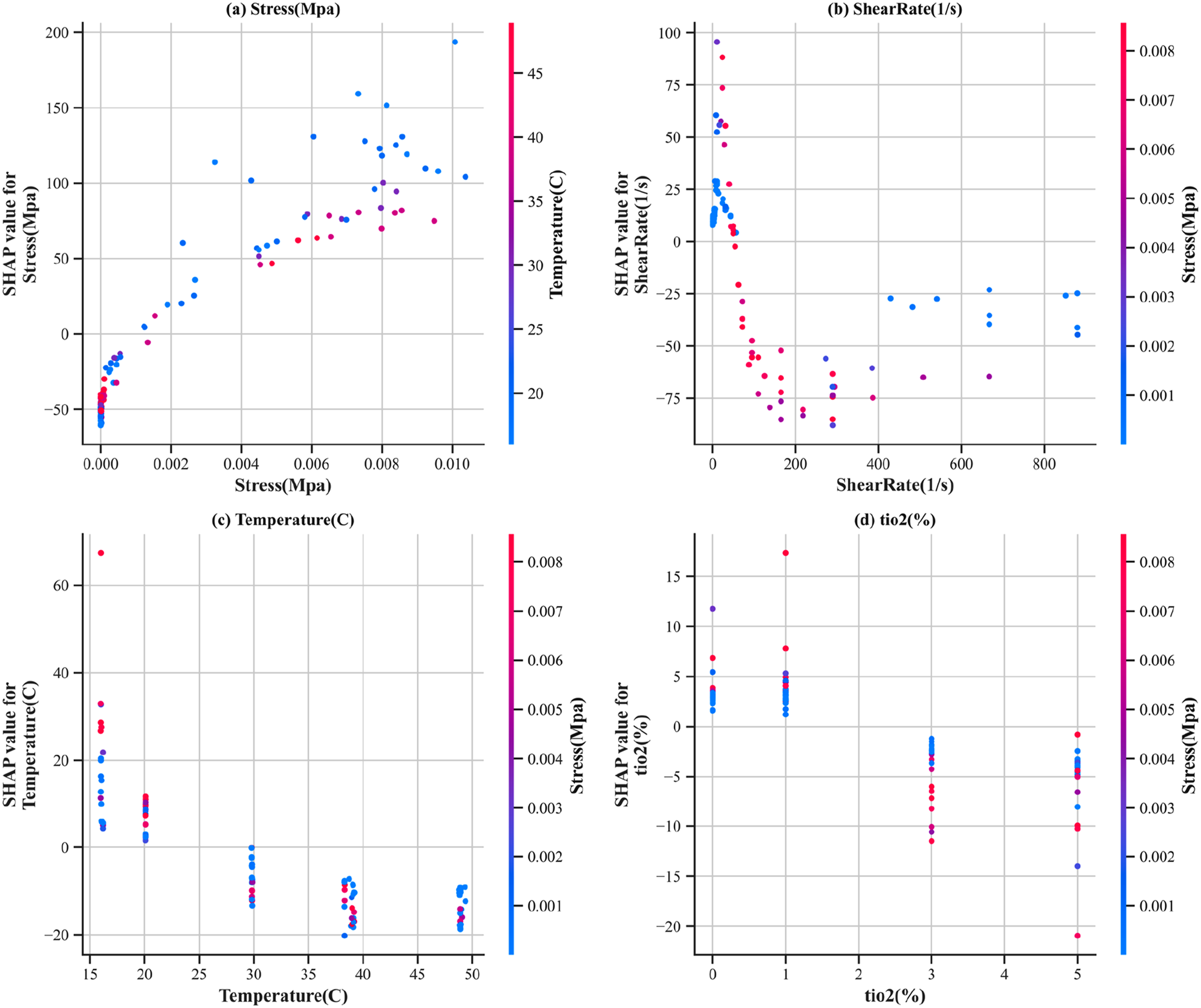
Conclusions and recommendations
This study presents a systematic investigation of the complex viscosity behavior of a TiO2- SiO2 hybrid STF. The rheological performance is examined as a function of nanoparticle composition and temperature, with particular emphasis on the influence of TiO2 incorporation. The addition of a nominal fraction of TiO2 is found to significantly enhance the shear-thickening response. Among the formulations evaluated, the hybrid system containing 1 wt% TiO2 demonstrates an optimal balance of peak viscosity, critical shear rate, and thermal stability. Although temperature variations induce measurable changes in rheological behavior, this formulation retains a consistent shear-thickening characteristic, indicative of reliable thermal durability. The inclusion of 1 wt% TiO2 in the STF matrix underscores its potential for applications requiring energy absorption, vibration damping, and protective performance under dynamic loading conditions.
Complementing the STF’s experimental characterization work, a rigorous ML framework was employed to model the complex viscosity behavior. The CatBoost model, optimized via BO, proved to be the most robust predictor, achieving superior accuracy and generalization across all datasets. Subsequent SHAP analysis provided critical model interpretability, confirming that the model’s predictions are physically consistent with rheological principles. Stress was identified as the dominant positive feature, while Shear rate exhibited a significant, nonlinear influence. The minor roles of Temperature and TiO2 concentration align with the experimental observation of strong thermal adaptability and a defined optimal nanoparticle ratio.
The findings of this investigation confirm that the synergy between experimental characterization and ML modelling enables both the identification of optimal STF formulations and the development of accurate predictive tools. This integrated approach establishes a validated framework for advancing the design of functional fluids.
The analysis is based on a single dispersing medium, polyethylene glycol, and therefore does not account for the potential influence of alternative carrier fluids, such as silicon oil or ethylene glycol, on shear-thickening behavior. In addition, the predictive framework developed in this work is limited to rheological parameters derived from existing datasets, and application-oriented performance indicators such as impact absorption or energy dissipation efficiency were not included in the current modeling scope. Although the CatBoost model demonstrated superior performance among the tested algorithms, its predictions exhibited residual errors ranging from −30 to 45 Pa·s, indicating potential for further refinement. Future research should address these limitations by expanding the available dataset to encompass a broader range of nanoparticle concentrations, wider temperature intervals, and alternative dispersing media, thereby enabling the development of more comprehensive and transferable predictive models. Exploring advanced neural network architectures and physics-informed learning approaches could significantly improve predictive accuracy and extend model applicability to untested concentrations and conditions, ultimately enabling more efficient design of advanced STF systems.
Footnotes
Author contributions
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Data Availability Statement
Data will be made available on request.