
Abstract
This is a visual representation of the abstract.
Introduction
Large volumes of medical device adverse event data accumulate daily. For example, in 2022 nearly 3 million medical device adverse events were recorded in the United States Food and Drug Administration’s Manufacture and User Facility Device Experience (MAUDE) database. 1 Multiple studies have evaluated events related to angiographic equipment, venous stents, and inferior vena cava filters, highlighting MAUDE’s value in interventional radiology (IR).2-4 However, MAUDE reports are heterogeneous with most data captured in a free-text data field. When attempting to generate meaningful insights from such databases, human analysis is limited by multiple factors like expertise, time required, lack of uniformity, and fatigue. 5 Consequently, databases that house critical safety information may be underutilized.
Recent advances in artificial intelligence (AI), including foundational models such as the large language model (LLM) GPT-4, continue to fuel excitement about the future of AI in radiology.6-8 Prior studies demonstrated that GPT-4 performs well on radiology-specific tasks, including board exam-style questions, study protocolling, and CT report mining.9-13 The ability of these models to perform well in natural language processing (NLP) tasks with relatively little technical expertise required by human users is a leap toward overcoming tasks that may otherwise be too costly from a human resource perspective. 14 However, one challenge with LLMs is that they are limited by the number of context tokens (a discrete unit of text, eg, 4000 tokens may equal 2500 words) and text data, like safety event reports, may be in the thousands or millions of tokens.1,15 Nevertheless, LLMs may present a possible solution to the problem of identifying, classifying, and analyzing the immense volume of safety data in radiology, enabling faster, easier, and more meaningful human analysis.
Microwave ablation (MWA) is a commonly performed IR procedure and awareness of reported device malfunctions is important for safe use. 16 Prior studies have mostly examined types of patient-related complications with MWA, such as infection, vascular injuries, tumour seeding. 17 However there is little research on modes of device malfunctions. 18 This study aims to assess the feasibility of applying artificial intelligence to analyze device malfunction data, specifically through an example using MWA devices. This is performed through generation of a human-labelled dataset of MWA device malfunctions that were captured in the MAUDE database. In particular, the performance of the LLM GPT-4 in 2 tasks is assessed: the classification and summarization of MWA data. We hypothesize that a state-of-the-art LLM, GPT-4, will be able to accurately label the type of malfunction through in-context learning (ie, by providing examples in the prompt). Additionally, we hypothesize that through a process of content distillation, the LLM context window limitations can be overcome to generate an overall summary with insights from the data similar in quality to the human-guided analysis. This proposed AI implementation is potentially high-value and low-risk, as it could reduce the cost to analyze, annotate, and gain insights from safety data.
Materials and Methods
Study Design
This was a feasibility study using retrospective data from the open MAUDE database. 1 Therefore, research ethics board approval was waived. The study follows the applicable Checklist for Artificial Intelligence in Medical Imaging criteria. 19
Data
Summarization and Classification Training/Validation Data
A dataset from MAUDE (accessed March 31, 2022) examining microwave ablation devices (n = 1189 events; “System, Ablation, Microwave, and Accessories”) from January 1, 2011 to December 31, 2021 was used for human-guided analysis of MWA device malfunctions and subsequent LLM-powered analysis prompt development training and validation (Figure 1). The data was cleaned and analyzed by 3 radiology residents and the final data was analyzed by an interventional radiology fellow. Cleaning involved removal of duplicate and irrelevant data (eg, non-ablation or literature related entries). The final dataset after cleaning contained 664 events. The data were then randomly split into prompt development/training data (n = 25) and validation data (n = 639).
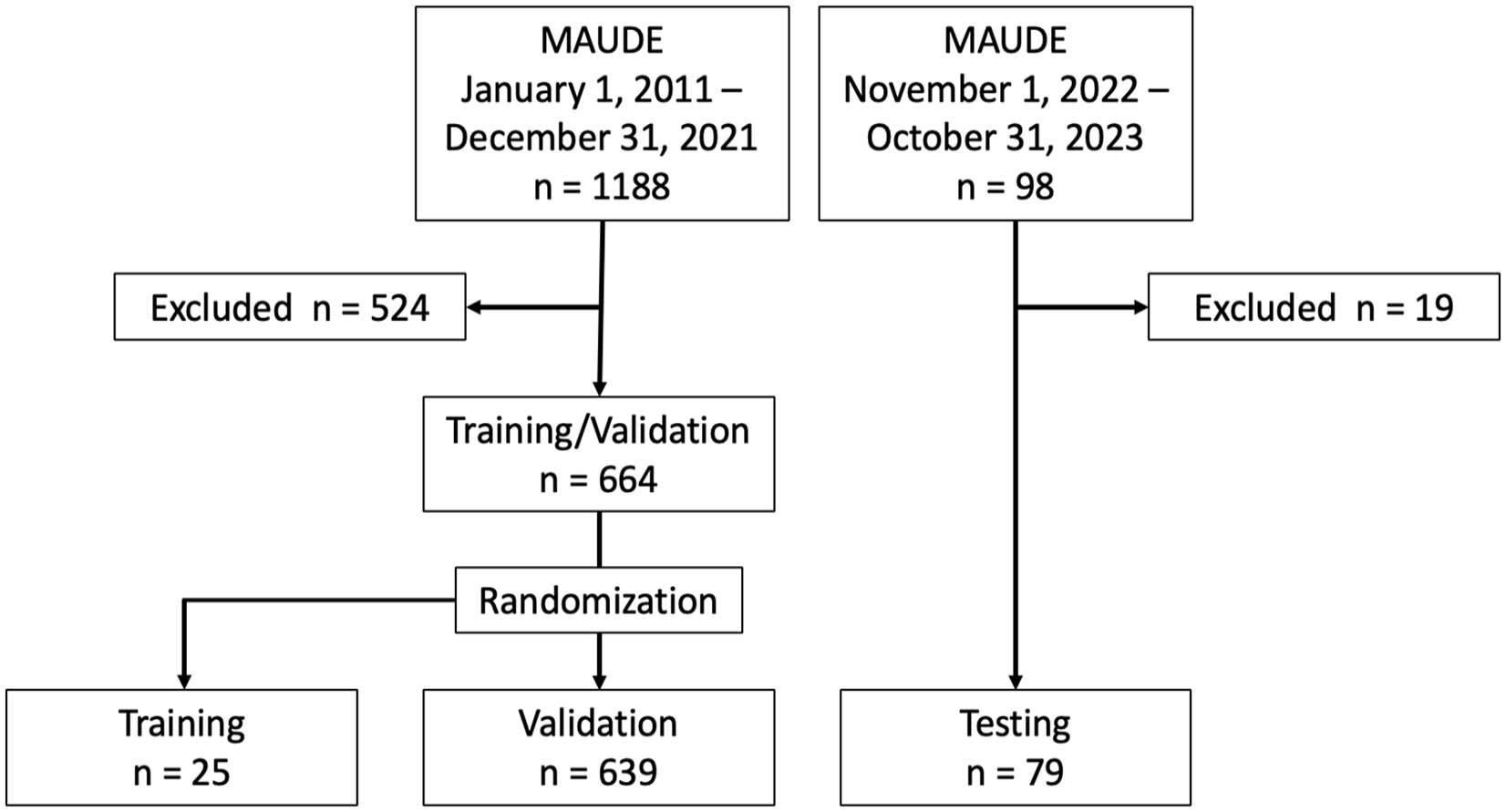
MAUDE data used in the study.
Classification Testing Data
A second smaller test dataset (n = 98 November 1, 2022-October 31, 2023) was retrieved from MAUDE (accessed Nov 6, 2023) after the training and validation data had been analyzed, to mitigate data leakage in prompt development and evaluate the classification performance of the LLM. This was preprocessed and analyzed by the IR fellow using the same classification system and cleaning process (n = 79 post cleaning).
Human Analysis
Initial human data analysis of the training/validation dataset involved review of the first 50 cases by all 3 diagnostic radiology residents, to achieve consensus on a classification system. The classification system for device malfunctions was generated in conjunction with the staff interventional radiologists and co-authors. The remaining data were then divided and analyzed individually by the residents. One resident then merged and reviewed all data, ensuring consistency in classification. A final review was then performed by an interventional radiology fellow. The test data were reviewed and classified by the IR fellow, but not included in the summary generation as this would/could have resulted in data leakage in the prompt development.
Artificial Intelligence Large Language Model (AI LLM) Analysis
OpenAI’s GPT-4 (model = “gpt-4,” accessed Oct.-Nov., 2023) was used as the LLM in this study via API access using Python (OpenAI, Delaware; Python Version 3.11, Python Software Foundation, Delaware). GPT-4’s stochasticity “temperature” parameter was set to 0.1 (ie, more deterministic) but was not tuned to select this number. 7 Hyperparameter tuning was not performed as the prompt was considered the main varied hyperparameter in this study, to emulate a real-world deployment by a non-AI expert. As the event descriptions are free-form text reports, the corpus of reports would exceed the maximum tokens of the LLM (8192 tokens). Therefore, content distillation through iterative summarization was required (Figure 2). First, a small portion of data (n = 25) was used to iteratively develop a prompt to both (1) classify the event into one of the 8 classes and (2) summarize the event into a free-form text summary to reduce token count (prompt shown in Figure 3). The small sample size (n = 25) for prompt development was chosen to emulate real-world deployment, where it would not be possible to have a large training dataset and limited examples of each class may be seen. Indeed, it was chosen to be half of the size of the initial human analysis where 50 events were reviewed. The entire event summary text field was submitted with no other pre-processing other than extracting it from the correct column and formatting it into a single list of events for GPT-4 to analyze. Upon satisfactory performance of classification and summarization, the summary prompt was applied to the whole cohort of data on an individual basis, that is, each event was submitted with the prompt via the API, one-by-one (Figures 2 and 3). The summarized events were then batched based on the context limitation (batches of 7000 tokens to allow over 1000 tokens for a response; GPT-4’s context limit = 8192) and a summarization instruction prompt was provided, leading to a mid-level (2nd) summarization. Finally, the last summarization/conclusion was created using the mid-level summarizations. Classification labels were extracted from the summaries. Second and third summarizations were performed (1) with the classification + summary and (2) with only the summary text using a modified mid-level prompt without classification (ie, classification stripped from the text and no classification framework provided), to examine the impact of a provided classification on the summary.
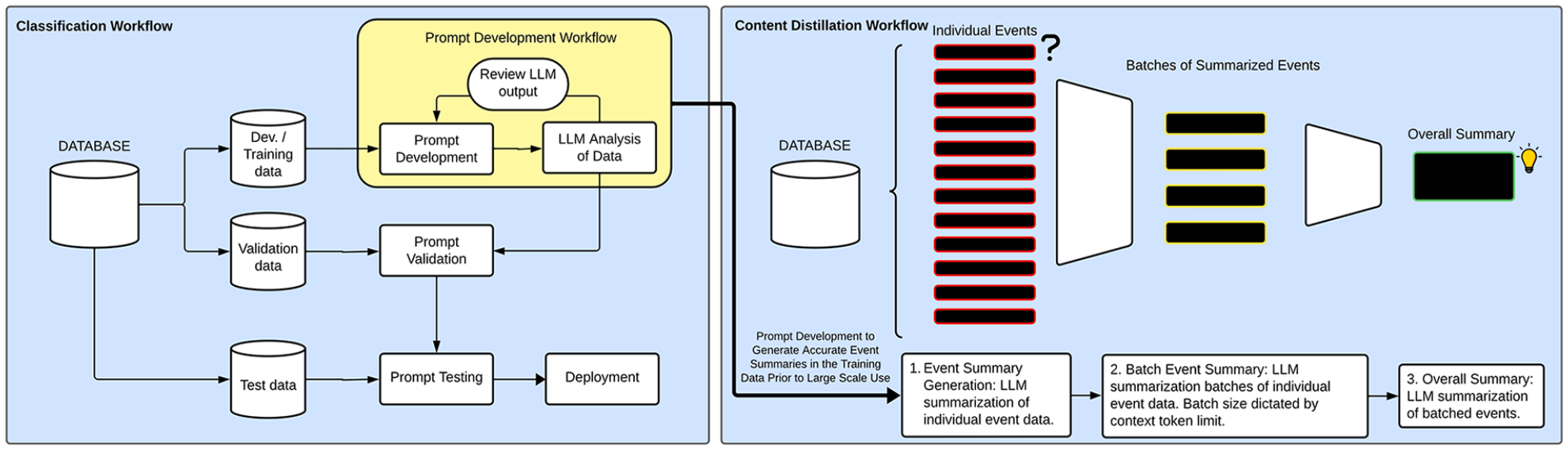
Classification and content distillation workflow and study protocol. Development/Training data is emphasized as this is not a traditional machine learning/deep learning workflow but rather based on prompt development. The prompt development workflow can be applied at any phase of prompt development, that is, in a summarization workflow, at each summarization step modification may be required to create outputs that meet the desired outcomes. In this study, the test data were reserved for only the classification task, as the content distillation was based on previously explored data known to the researchers.

Final summary prompt used to instruct the LLM to summarize each safety event. Initial background information on the role and task are provided first. Next, the classification system is outlined with minimal required description, this is where modifications may be required with iterative prompt development to ensure accuracy in the early phases. Next, a formal example is provided, furthering the “in-context” learning, the process of providing examples in the prompt to guide the task. Lastly, the commencement of the task is clearly provided.
Statistical Analysis
The assessment of content distillation and summarization is subjective, and the final reports were subjectively reviewed for accuracy regarding the summarization content. Classification performance was assessed using Cohen’s kappa, to reflect the interobserver agreement for classification, as GPT-4 would be considered a “second reviewer” in this workflow. Additionally, accuracy (95% CI) and micro-averaged F1 Score, selected for class imbalance are reported. Statistical analysis performed using R (version 4.3.0, R Foundation for Statistical Computing). A P value of .05 was used for significance.
Results
Data
Prompt development training/validation and test data were collected from the MAUDE website with 1189 events in the training/validation data and 98 in the test data. Following data cleaning, 663 unique events included in the final human analysis/summarization (the training and validation dataset; Figure 1). Test data included 79 events in the final analysis. The data were class imbalanced, as shown in Table 1 and Figure 4.
Classification of Microwave Ablation Device Malfunctions and Count From the Ensemble of Training, Validation, and Test Data.
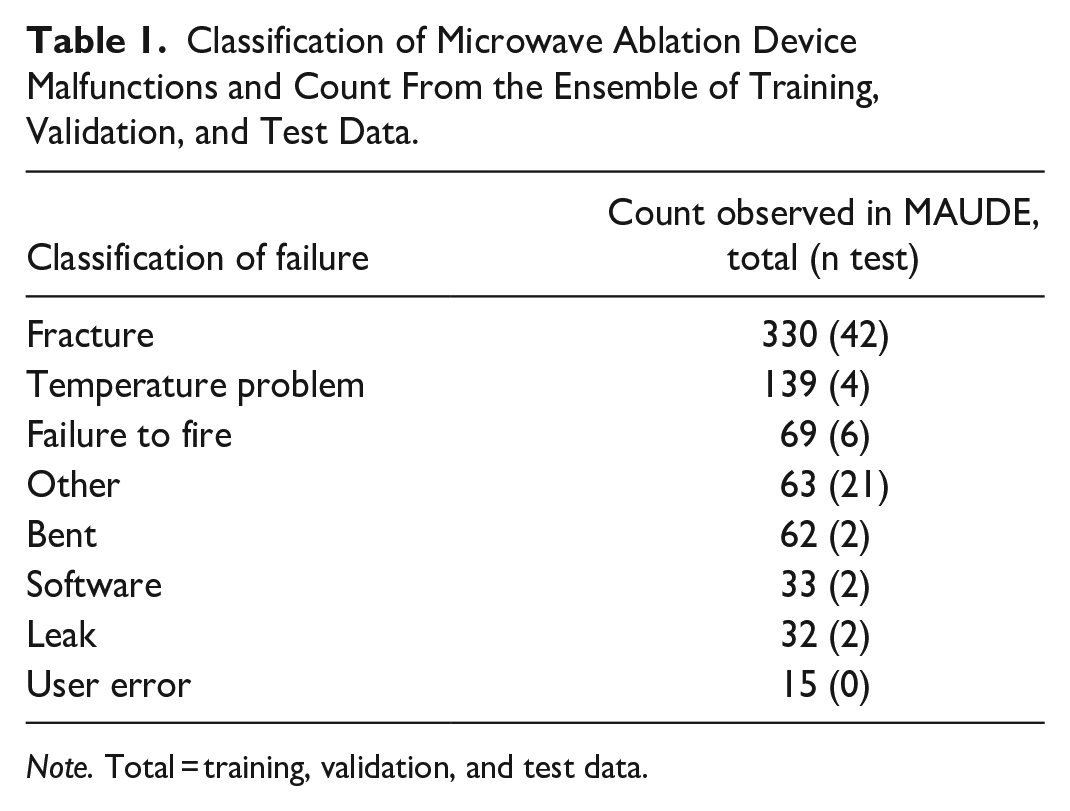
Note. Total = training, validation, and test data.
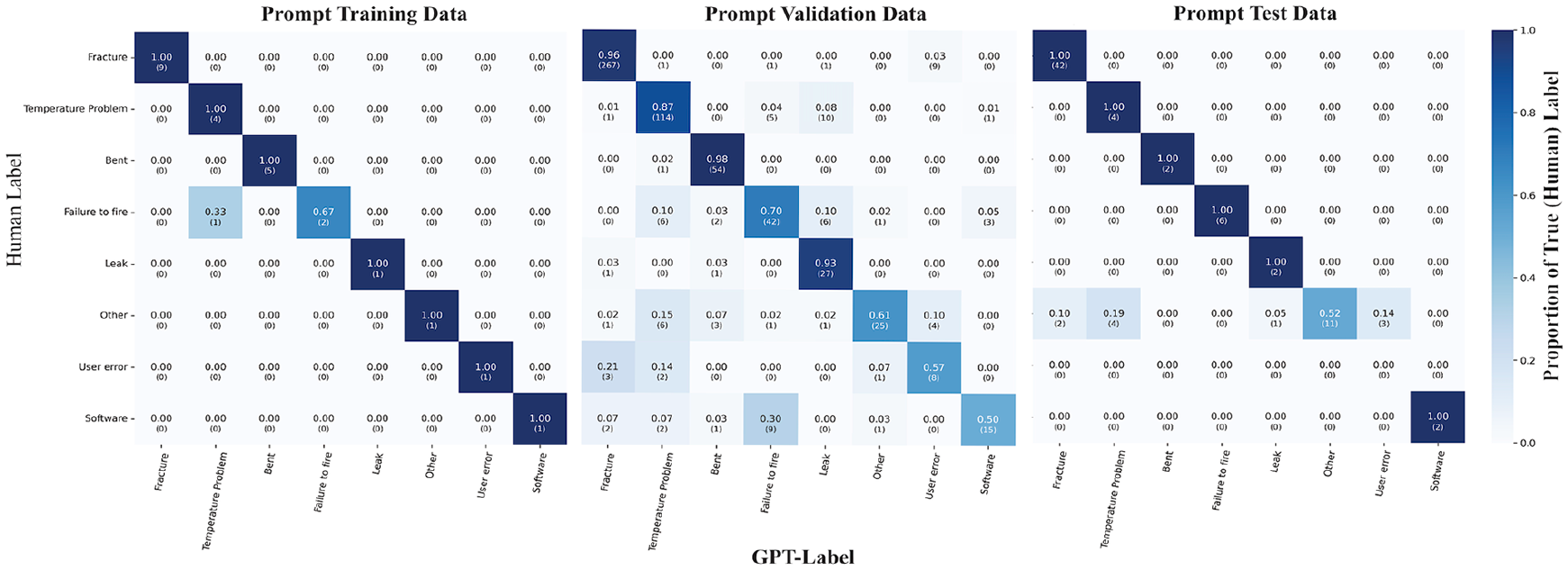
Heatmaps demonstrating the classification performance of the LLM in the training (n = 25), For Peer Review validation (n = 639), and test (n = 79) data. Human labels on the Y axis and LLM (GPT-4) predicted labels on the X axis. Proportion of the true (human-standard) labels for each data in a row-wise fashion.
Human Analysis
Review of the MWA data demonstrated patterns of device malfunctions which resulted in the following classification system for MWA device malfunction: (1) Fracture: fracture of the microwave ablation device, (2) Temperature Problem: temperature-related issues, (3) Bent: bending of the device, (4) Leak: fluid leaks from the device, (5) User Error: user error leading to malfunction but not including fractures, (6) Software: software failures, (7) Failure to Fire: when the device would not start despite no other failure, (8) Other: all other malfunctions. The results are presented in Table 1. Mechanical malfunctions (fracture or bending) were the most common reported malfunction accounting for over half of the malfunctions (392/744; 52.7%). Specifically, fracture of the MWA probe was the most frequently reported malfunction accounting for 44.4% of the events (330/743). In 42.7% (141/330) of the fractures, a portion of the fractured device was retained in situ. Temperature problems were also common, mostly related to overheating of the ablation probe preventing further use (139/743; 18.7%). User error was uncommon (15/743; 2.0%).
AI LLM Classification
Iterative prompt engineering was performed using the training data for the event classification and summarization step (Figure 3 demonstrates the third and final prompt). 20 It manually reviewed and the prompt revised until accurate summarization of the events was observed (Table 2 and Figures 3 and 4, 1/25 incorrect, 96% accuracy [95% CI 79.7, 99.9]). The prompt was then applied to the entire validation dataset and subsequently the test data (Table 2 and Figure 4). The results demonstrated high agreement to the human labels with a Cohen’s kappa score of 0.95 in the prompt training data with the final prompt, 0.82 with the validation data, and 0.81 with the out of sample test data. All instances of misclassification were reviewed, with examples of misclassification shown in Table 2. High accuracy was seen for physical problems throughout all data, such as Fracture (96%-100%), Temperature problems (87%-100%), and Bending (98%-100%) as demonstrated in the Figure 4 heatmap. Software, User Errors, Failure to Fire, and Other showed lower accuracy; with the lowest at 50% in the software category for the validation data. Compared to the no information rate, GPT-4 classification was statistically more accurate (Table 2, accuracy range 86.4% [validation] to 96.0% [training], P < .001 for all data). Additionally, micro-averaged F1 scores and Cohen’s Kappa scores were all above 0.8, suggestive of strong model performance despite minimal prompting.
Results From GPT-4 Classification.
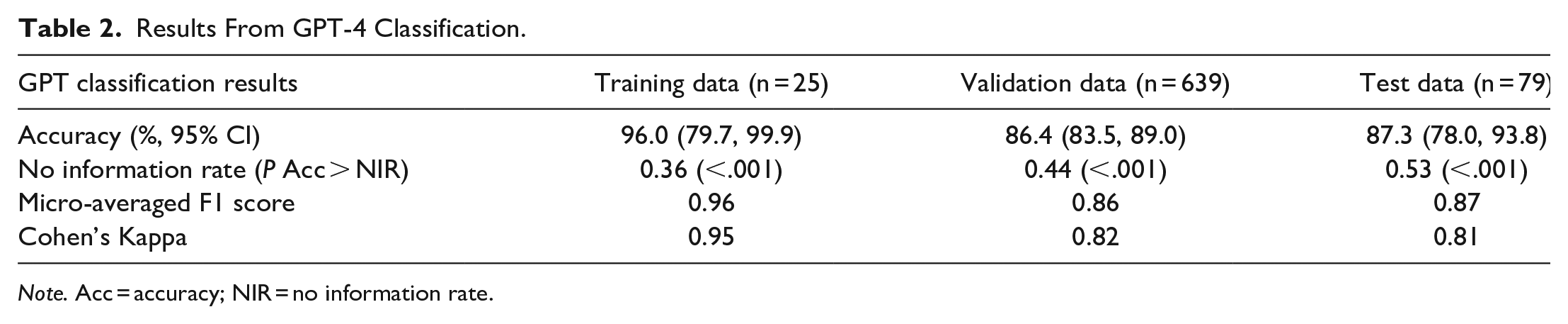
Note. Acc = accuracy; NIR = no information rate.
Content Distillation and Final Summary
The training and validation database was reviewed with overall insights known to the authors and therefore conclusions generated by GPT-4 were able to be subjectively assessed (Figure 5). Content distillation was trialed with and without the classification system to observe the effect on the final report. Indeed, the classification system appeared to guide the structure of the LLM’s final summary (Figure 5). When provided with the classification, the summary followed that structure. However, in the absence of the classification system, it was able to create its own classification that closely mirrored the human classifications. However, other important conclusions were also created including the flag of failure to return devices to the manufacturer and procedural delays. The count data was inaccurate relative to the classification in both instances: without the provided classification it reported only 214 fractures, and with the classification it reported 314, but the real number was 288 (Figures 4 and 5). As a result of the final summary, post-hoc analysis of the frequency of return of the devices and unnecessary sedation was performed. Unnecessary sedation with delayed or aborted procedures was seen in 7% (52/743). A total of 27.9% (207/743) devices were documented as returned to manufacturer. Supplementary text files are available for review containing both summaries, with and without the human classification.

Context distillation workflow with outputs. In the no classes final summary, the classes from the classification system were stripped from the input to the LLM, to limit influence on output. Note the outputs of all but the “FINAL SUMMARY NO CLASSES” are truncated to fit in the figure (denoted by “. . .”).
Discussion
This study demonstrates the feasibility and ease of use of AI implementation in safety data analysis for IR devices. The initial human analysis identified types of device related malfunctions that can occur with MWA and derived a classification system. Subsequently, with minimal prompting, the AI LLM GPT-4 was able to accurately classify and summarize the data to generate meaningful conclusions.
Microwave Ablation Malfunctions
Mechanical failures (bending or fracture) were among the most observed malfunctions, with tip fracture being the most common. This is a known complication in the MWA literature.17,18 Fracture of the tip of the probe can be related to improper or excessive force applied through the probe. In nearly half of the fracture events (42.7%, 141/330), the probe tip was left in situ, however, due to the limited nature of the MAUDE database, it is not possible to know what the long-term outcomes are.
Classification
This study demonstrates how in-context learning with an LLM, the process by which an LLM may “learn” based off a prompt and examples encapsulated within it, may be used to accurately classify adverse event data related to MWA devices with accuracy remaining greater than 85% in training, validation, and test data. 20 This is similar to other NLP tasks in radiology that have demonstrated high accuracy, including a recent GPT-4 study showing 96% accuracy in labelling free text CT reports.12,21 In our study, there was strong agreement between the human rater and the LLM generated classification (Cohen’s kappa >0.80 in all data), reflecting the strength of the LLM despite minimal prompting and only in-context learning. GPT-4 struggled in labelling non-mechanical malfunctions (eg, Temperature, Failure to Fire, Software). One explanation for this could be that these often have overlapping terminology, whereas mechanical issues such as device fracture are more clear cut. Another instance where the LLM struggled was in classifying an event as “failure to fire” when a temperature error code was also reported was likely due to the code descriptions being unknown to the LLM (eg, event 339 in Table 3). It is suspected that with further prompt development this could be mitigated. Despite these limitations, the overall classification showed high agreement with human generated labels. With a very small set of training data of only 25 cases, we were able to develop a prompt instructing the LLM to label microwave ablation safety data with good performance. This is a promising starting point for using LLMs to analyze safety data.
Example GPT-4 Classification Errors. The Event Text Excerpts Are Taken From the Event Descriptions From the Data, Chosen to Select the Most Relevant Portion. Note That the Event Number is a Random Internal Number Attributed by the Research Team to Index the Events and Not a MAUDE Event ID.

Content Distillation
LLMs are memory constrained which results in context token limits. 7 This limitation could be a hinderance to their utility in analysis of large volumes of text data. However, in our study, we demonstrate that content distillation can be used to generate informative summaries highlighting patterns of adverse events related to microwave ablation devices. While it is challenging to assess summarization given its subjective nature, the LLM-generated final report closely reflected the human analysis. The LLM also highlighted potentially valuable information and insights not initially recognized in the human analysis. Two key insights from the LLM were: (1) 7% (52/743) of ablation procedures were aborted after induction of anaesthesia/sedation without proceeding with the procedure or with significant delays, that is, unnecessary sedation (2) Only a quarter (27.9%, 207/743) of the devices were documented as returned to the manufacturer for evaluation. On the other hand, the LLM in our study was prone to inaccurate count data, which has also been shown in prior studies. 20 Separate research has demonstrated that GPT-4 has faltering math performance on certain tasks. Thus, any count data or mathematical insights from a task such as this should be interpreted with caution and may in part be a consequence of content distillation whereby count data are carried forward between summaries. 22 Fortunately, in this setting where classification and summarization are performed on an case-by-case basis, it is easy to generate count data programmatically rather than relying on the LLM to generate the counts. It is important that any user of an AI system critically analyze the output of the system to understand where it may have failed and where additional human analysis may be required. We are proposing herein that an AI may be used to augment rather than replace the human in this workflow. 23
Limitations
The MAUDE database is limited in that it is not a research database and ultimately provides only a snapshot into a clinical scenario with no long-term follow-up or additional clinical details. 24 Additionally, MAUDE does not reflect the volume of use of a device, and therefore no conclusions can be drawn regarding the incidence of device malfunctions. With respect to the AI in this study, use of in-context learning rather than fine-tuning to the task by training the LLM on additional data may limit maximal performance. 20 Additionally, more extensive prompt development, trial of different LLMs, and varying hyperparameters such as the temperature could be performed. However, the goal of the study was to assess performance in a constrained fashion to emulate real-world deployment, and satisfactory performance was seen with limited data and prompting. As LLM performance continues to improve and fine-tuned models become available, future studies will be able to examine the impact of larger context on outputs, which will likely improve performance; however data also continues to grow which will likely continue to challenge the models.
Conclusions
Patient safety data continue to grow and event reports are a valuable source of information to improve clinical practice and understanding of medical devices.1,3,4 This study demonstrates the feasibility of using AI to generate reports on data that might otherwise be under evaluated. Importantly, automated analysis of these data could be created by non-AI experts and the resulting LLMs could act as early detectors to identify important insights that may otherwise have not been explored. This proposed AI-human collaborative implementation would be low-risk, given the data most often already exist and the AI would be used to augment human analysis, with continued expert human oversight as the final safeguard.
Supplemental Material
sj-txt-1-caj-10.1177_08465371241269436 – Supplemental material for Feasibility of Artificial Intelligence Powered Adverse Event Analysis: Using a Large Language Model to Analyze Microwave Ablation Malfunction Data
Supplemental material, sj-txt-1-caj-10.1177_08465371241269436 for Feasibility of Artificial Intelligence Powered Adverse Event Analysis: Using a Large Language Model to Analyze Microwave Ablation Malfunction Data by Blair E. Warren, Fahd Alkhalifah, Aida Ahrari, Adam Min, Aly Fawzy, Ganesan Annamalai, Arash Jaberi, Robert Beecroft, John R. Kachura and Sebastian C. Mafeld in Canadian Association of Radiologists Journal
Supplemental Material
sj-txt-2-caj-10.1177_08465371241269436 – Supplemental material for Feasibility of Artificial Intelligence Powered Adverse Event Analysis: Using a Large Language Model to Analyze Microwave Ablation Malfunction Data
Supplemental material, sj-txt-2-caj-10.1177_08465371241269436 for Feasibility of Artificial Intelligence Powered Adverse Event Analysis: Using a Large Language Model to Analyze Microwave Ablation Malfunction Data by Blair E. Warren, Fahd Alkhalifah, Aida Ahrari, Adam Min, Aly Fawzy, Ganesan Annamalai, Arash Jaberi, Robert Beecroft, John R. Kachura and Sebastian C. Mafeld in Canadian Association of Radiologists Journal
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.