
Abstract

La présentation de données est un enjeu fondamental en science. En effet, une synthèse optimale de l’information numérique est la clé pour que les lecteurs saisissent bien les données exposées (Hibbard et Peters, 2003). L’objectif de cette lettre est de se questionner sur la présentation de certaines données, publiées en septembre 2019 par le Dr Ferro, qui portent sur la détresse psychologique des adolescents canadiens, plus spécifiquement sur certains éléments inscrits au tableau 2 (p. 651).
Les données analysées provenaient de l’Enquête sur la santé dans les collectivités canadiennes (ESCC) de 2012 -Santé mentale. Le concept de détresse psychologique a été mesuré à l’aide de l’échelle abrégée de Kessler en 6 questions (K6). L’auteur présente les moyennes de chacune des six questions (ainsi que la moyenne du score total) pour l’ensemble des adolescents et des adolescentes. Des tests de t ont été utilisés afin de déterminer si des différences significatives existent entre les deux groupes.
Dans son article, l’auteur mentionne que les six questions sont codées de 1 (tout le temps) à 5 (jamais) (p. 649). Il indique ensuite que les questions ont été recodées de 0 (jamais) à 4 (tout le temps) et que le score total présenté varie alors entre 0 et 24, ce dernier score étant le score de détresse le plus élevé. Les moyennes des scores obtenus aux questions et la moyenne du score total ont été présentées selon ces deux logiques de codage différentes, ce qui complexifie l’interprétation des données. Pour les six questions, une augmentation du score signifie que la composante mesurée a été moins présente au cours du dernier mois. Pour le score total, c’est plutôt l’inverse, c’est-à-dire que plus le score augmente, plus le niveau de détresse est élevé. Les données sont reproduites ci-dessous à la deuxième colonne du tableau (Tableau 1).
Moyennes (écarts-types) des données présentées dans l’article de Ferro (2019) et données inversées et recodées dans le même sens que le score total.
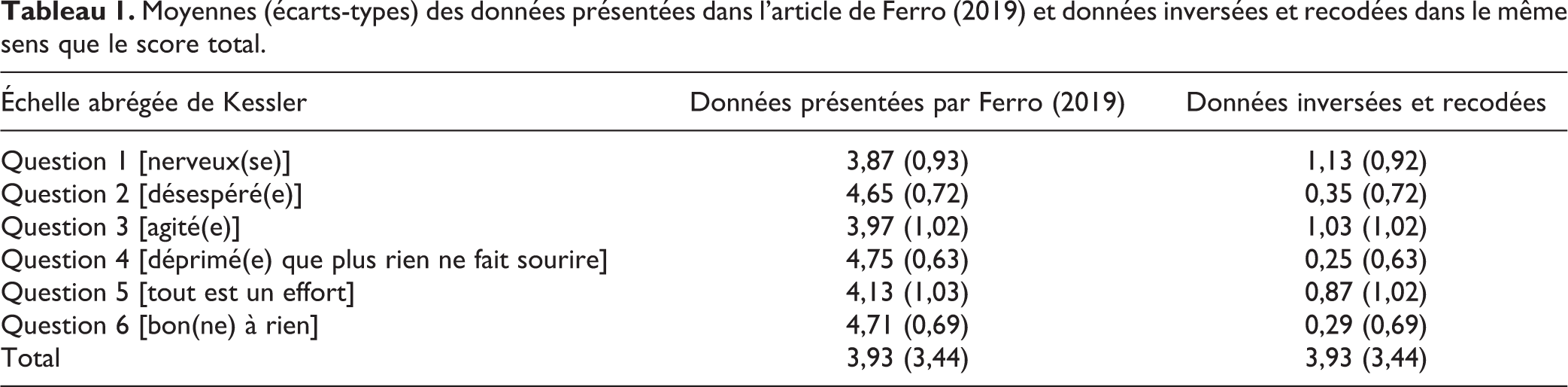
Les moyennes présentées à la troisième colonne ont été recodées de 0 (jamais) à 4 (tout le temps) afin de respecter la logique du score total (de 0 à 24). Cette méthode est à privilégier car les questions et le score total vont alors dans le même sens et la compréhension des données est beaucoup plus facile pour les lecteurs. Cette façon de procéder permet de mieux apprécier la contribution de chacune des questions au score total. En effet, il apparaît clairement que les moyennes les plus élevées se retrouvent aux questions 1 (1,13) et 3 (1,03). De plus, si on additionne les moyennes des six questions, on obtient la moyenne du score total, contrairement aux moyennes exposées à la deuxième colonne.
L’auteur a utilisé des tests de t afin de statuer sur la présence ou non d’une différence significative entre les moyennes des adolescents et des adolescentes. Il a constaté des différences significatives pour toutes les questions dont la probabilité est inférieure à 0,001, sauf pour la question 5 où la probabilité est inférieure à 0,05. Cette question est celle qui porte sur la sensation que tout est un effort.
Les tests de t semblent avoir été effectués à partir de l’échantillon qui tient compte uniquement de la pondération normalisée (soit la division de la pondération individuelle par la moyenne de toutes les pondérations de l’échantillon). Les tests auraient dû se faire en utilisant la pondération normalisée qui tient compte de l’effet de plan (Hahs-Vaughn, 2005). L’effet de plan permet de tenir compte de la distorsion du plan d’échantillonnage complexe de l’enquête par rapport à un échantillonnage aléatoire simple. Cette méthode aurait dû être privilégiée afin de réduire la probabilité de faire une erreur de type I.
Les analyses ont été refaites à partir des données disponibles à l’intérieur du fichier de micro-données à grande diffusion de Statistique Canada, en utilisant la pondération normalisée ajustée selon l’effet de plan. Pour ce faire, nous avons utilisé le logiciel SPSS (version 21). Les résultats indiquent des différences significatives à toutes les questions, sauf pour la question 5. La probabilité à cette question est égale à 0,261; il faut donc accepter l’hypothèse nulle de l’égalité des moyennes entre les adolescents et les adolescentes. Nous avons également refait le test de t en utilisant uniquement la pondération normalisée et la probabilité est alors égale à 0,049 à la question 5, soit le résultat présenté dans l’article de Ferro (p < 0,05).
Dans cette recherche, le recours aux tests de t ne constitue pas la meilleure stratégie d’analyse compte tenu de l’asymétrie marquée de la distribution des données de chacune des questions et du score total. Des tests non paramétriques de Mann-Whitney auraient pu être utilisés afin de tenir compte de cette particularité des données. Aussi, la transformation des données aurait pu être envisagée.
Lorsque l’on présente des données numériques, il est facile de tomber dans le piège de présenter les données selon la codification présentée dans le fichier de travail et ainsi nuire à la compréhension des résultats. Il est préférable de recoder les questions et le score total dans le même sens. Aussi, il est important de rappeler qu’un test statistique doit se faire en utilisant la pondération normalisée ajustée selon l’effet de plan lorsque l’on travaille avec les données d’une enquête à plan d’échantillonnage complexe comme l’ESCC. Un test statistique effectué en utilisant la pondération normalisée (sans l’effet de plan) augmente la probabilité d’une erreur de type I. Il est important de rappeler cette distinction aux lecteurs.