
Abstract
Social scientists aim to create explanations of the world. For each social phenomenon, scientists have proposed a myriad of theories to explain its working mechanisms. Traditionally, these theories are tested by generating hypotheses, translating them into a statistical model, and assessing the significance of the model’s coefficients. Such an approach, however, often leads to the specification of a large number of (at times contradictory) models, all asserting that they capture the same theory. As things currently stand, there is no framework that allows for a comparison of these models. In this article, we argue that benchmarks can serve as a standard frame of reference that can help to determine which models fit better with empirical observations in a specific context. A benchmark is a standardized validation framework that allows for a direct comparison of the prediction accuracy of various models that address the same research problem. We outline the potential of organizing benchmark challenges in the social sciences and provide recommendations for their utilization.
Introduction
Social scientists aim to create explanations of the world. For each social phenomena, scientists have proposed various theories to explain its working mechanisms. Traditionally, a specific theory is tested by generating hypotheses, translating them into a statistical model and assessing the significance of the model coefficients. However, this approach is not free of shortcomings. Most importantly, it can lead to the specification of a variety of models that are based on different statistical techniques, or include different predictors of the social phenomena studied. While these models are all equally plausible and well-justified, they often produce contradictory results and lead to inconsistent findings. As things currently stand, there is no framework that allows for a comparison of these models and the question of which model works better under which circumstances remains unanswered (Watts, 2017).
In the current article, we present a perspective on the use of benchmarks in the social sciences and argue that they can serve as such a standard frame of reference. We define a benchmark as a standardized validation framework that allows for a direct comparison of the prediction accuracy of various models that address the same research problem.
The use of benchmarks has touched many fields of science, including computer and data science (Bennett et al., 2007; Russakovsky et al., 2013), physics (Amrouche et al., 2020; Amrouche et al., 2023), biomedicine (Antonelli et al., 2022), and the humanities (Candela et al., 2021; Larson et al., 2017; Papadimos et al., 2023). Traditionally, participants are invited to submit their models to the benchmark, which is commonly referred to as ‘organizing a benchmark challenge’ or ‘organizing a data prediction challenge’. Other frequently used terms are shared or common tasks and competitions. Such challenges have enabled the detection of major breakthroughs. For instance the ImageNet challenge demonstrated the vast potential of deep learning, after which it was rapidly adopted in various fields (Iosifidis and Tefas, 2022; Russakovsky et al., 2015; Witten and Frank, 2002). In computational pathology, opening up large datasets with clinically relevant tasks to the general public through challenges was identified as a key driver of progress in the field (Hartman et al., 2020). This progress led to machine learning (ML) approaches outperforming humans on some of these tasks (Litjens et al., 2022).
In benchmark challenges, predefined evaluation criteria are used to compare how well different methods can predict the outcome variable given the predictors at hand. Although these challenges are mostly focused on assessing predictions rather than causality, we argue, following Hofman et al. (2017, 2021) and Verhagen (2022), that predictions and explanations should be treated as complements rather than substitutes. Using predictions to validate the explanatory power of models does not imply that complex prediction models should replace traditional approaches in the social sciences. Instead, researchers should start by defining a research question that is of substantive interest and then design a prediction exercise that addresses this question. Also, rather than adopting a ‘black box’ approach, the choices made during the modeling process should be clearly stated and justified (Hofman et al., 2017). The incorporation of predictions in typical social science research can bring about several benefits. For instance, the use of predictions allows for a more detailed assessment of model fit, and it provides a measure that allows researchers to compare the fit of highly different methodological approaches (Verhagen, 2022).
Despite growing excitement about computational methods in the social sciences, the field has seen very few large-scale applications of benchmarking. The most well-known social science benchmark challenge to date is the Fragile Families Challenge (Salganik et al., 2019), in which participants were asked to predict several life outcomes of adolescents in the United States. The outcomes of the challenge showed that overall, the predictability of these life outcomes was poor, and that ML (data-driven) approaches were not more effective than human-designed (theory-driven) approaches. One possible explanation of these findings is the use of a relatively small, well-studied survey data which is arguably not well suited for ML approaches. Nevertheless, the Fragile Families Challenge provides key insights into how follow-up benchmark challenges should be designed. In this article, we advocate for increased use of benchmark challenges in the social sciences. We contend that they have great potential to answer and advance long-standing questions in this field.
The remainder of the article is structured as follows. In the following section, we explain in more detail the benchmark challenge concept in a scientific context and elaborate on the breakthrough that benchmark challenges have led to. We then outline the potential of benchmark challenges in the social sciences given the insights gained from other fields. While existing evidence does not allow us to fully comprehend the benefits of benchmarking in our field, we demonstrate its potential through the Fragile Families Challenge, as well as our own pilot benchmark challenge on predicting precarious employment in the Netherlands. We then use these experiences to provide recommendations for the utilization of benchmark challenges in the social sciences, in terms of data, design, and infrastructure, that need to be met to fully realize the potential of benchmarking. We also provide practical recommendations on how to set up a benchmark challenge. Finally, we offer some concluding remarks.
Benchmark challenges in science
Benchmark challenges are highly popular in computer science and a number of related fields, such as data science (Kaggle; CodaLab) and medical image analysis (Grand Challenge). While there are many examples of challenges that have led to advancements in various fields, we focus here on a few illustrative cases with a particularly high level of scientific relevance.
An example of how benchmark challenges can help monitor progress and detect methodological breakthroughs in a field is the annual ImageNet Large Scale Visual Recognition Challenge, which was used to benchmark the performance of visual recognition methods. Initially, some of the earlier submitted algorithms showed improved performance, but after some time no further improvement was registered, despite the fact that new methods were submitted regularly. This situation lasted for an extended period of time, leading many to believe that a saturation point had been reached and that no further progress in terms of performance was possible. However, in September 2012 a submission using deep convolutional neural networks demonstrated a dramatic increase in performance confirming that these types of algorithms can further advance the field of visual recognition methods. This finding, in turn, boosted the uptake and application of deep learning in various fields thereafter (Salganik et al., 2019).
Benchmark challenges can also lead to the adoption of techniques from other fields. For instance, in the field of physics, the Tracking Machine Learning Challenge was organized to open up the task of particle trajectory tracking to a broader audience of participants with a particular interest in ML engineers. This was done in the hope of finding novel, high-performing, and fast methods that could boost the field. The challenge was divided into two parts: an accuracy part in which the performance accuracy of the submitted algorithms was assessed (Amrouche et al., 2020), and a throughput part in which the speed of the methods was evaluated (Amrouche et al., 2023). The accuracy phase resulted in the submission of many ML methods, which were considered highly innovative in the field (Amrouche et al., 2020). In the throughput phase, the three top-ranked submissions in terms of speed were shown to be considerably faster than the state-of-the-art algorithms in the field at the time (Amrouche et al., 2023).
Finally, challenges can also be used to assess the generalizability of methods beyond the specific context in which they were originally developed, and to encourage the development of new, more broadly applicable methods. In medical image analysis, for example, a decathlon benchmark challenge was organized in which participants had to apply their method to a wide variety of medical image analysis tasks (Antonelli et al., 2022). In this challenge, participants were asked to develop a prediction method that worked for different organs such as the brain, lungs, or heart (while traditionally in the field different methods are designed for different organs and data types). This challenge showed that a method performing well on multiple different tasks, generalized well to a previously unseen task and outperformed more traditional methods that were specifically designed for one task only.
As illustrated above, the organization of benchmark challenges can lead to novel insights in various fields. However, what is still largely lacking in most benchmark challenges organized to date is a clear understanding and definition of the benchmark challenge design and how it can be used to address a specific research problem and generate scientific knowledge. Understanding the context in which methods are compared is key to being able to assess the relevance and added value of a benchmark challenge. The framework proposed by Mendrik and Aylward (2019) fills this gap by providing a comprehensive approach to the design and setup of a benchmark challenge that places greater emphasis on the scientific context in which it is placed. An illustration of the proposed framework is shown in Figure 1. The application of the framework to a social science benchmark challenge can be found in Appendix 1.
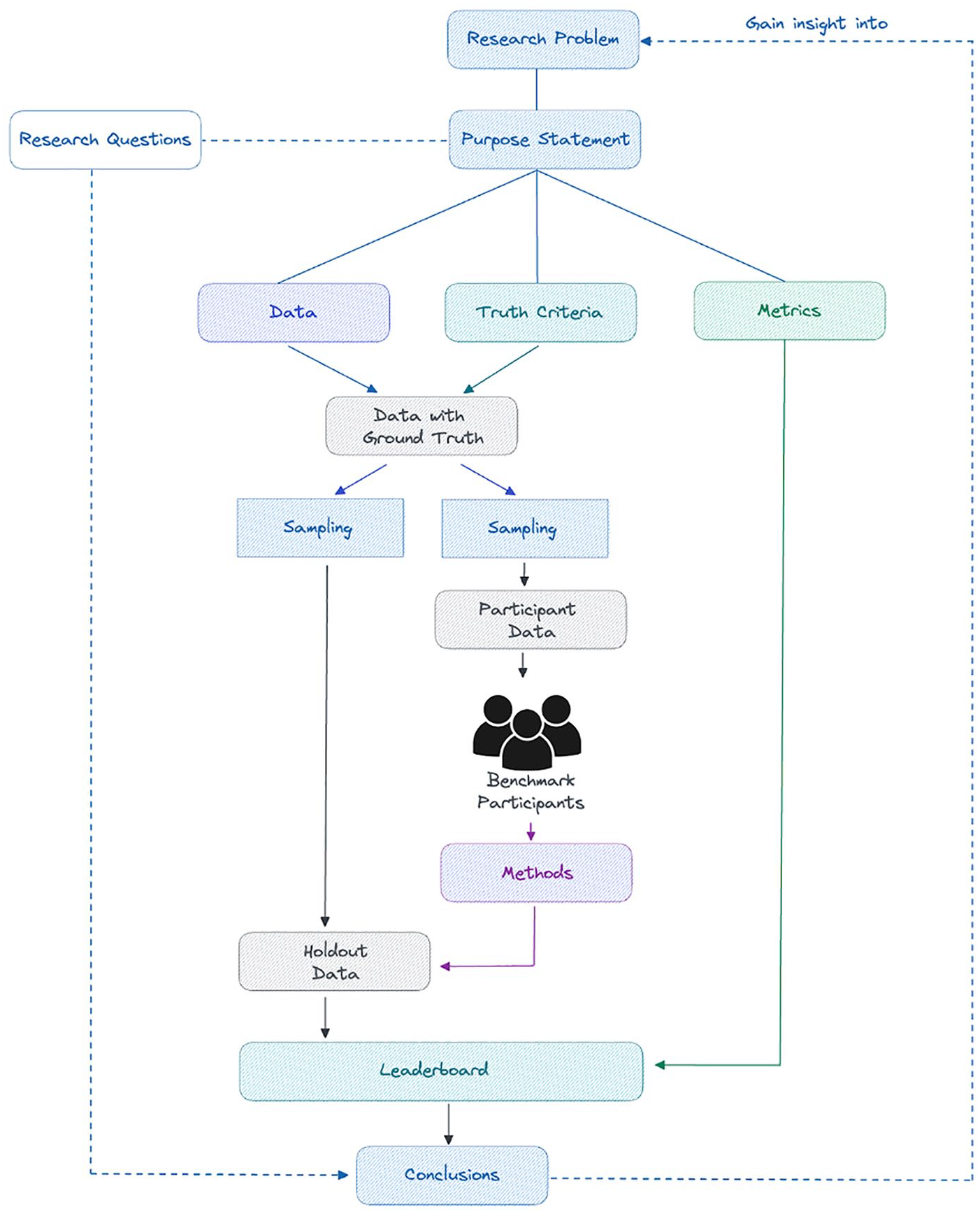
Benchmark challenge framework based on Mendrik and Aylward (2019).
The first step to organize a benchmark challenge is to clearly define the research problem that will be addressed. The research problem can be of theoretical or practical nature. In the former, the focus is on filling a knowledge gap, while in the latter, the focus is on solving an applied or real-life problem. Since research problems tend to be rather broad and often cannot be fully addressed with one challenge, the second step is to formulate a purpose statement that defines the prediction task of the challenge and specifies which aspect of the research problem will be covered by the benchmark challenge. The purpose statement also clarifies the extent to which the findings of the benchmark challenge can be used to make inferences about the research problem at hand and defines the limitations of the benchmark challenge in terms of generalizability. Next, one needs to specify the research questions that the benchmark challenge aims to answer. In a prediction 1 benchmark challenge, the purpose statement and the research questions help to determine which data (predictors), truth criteria (outcome of interest), and metrics (evaluation criteria). The selection of the metrics should be such that they evaluate the extent to which the research questions posed in the challenge can be answered with the proposed method. Put differently, the metrics evaluate whether and to what extent the assessed method can contribute to further understanding the research problem at hand.
Once the research problem, purpose statement, research questions, as well as data, truth criteria, and metrics are all decided upon and clearly described, the benchmark challenge can be set up. This involves creating two datasets: a participant dataset and a holdout dataset, both of which include the predictors and the outcome variable. During the challenge, participants are provided with the participant dataset. They use these data to specify, train, and fine-tune their methods to obtain the best possible predictions of the outcome variable. The performance of the methods submitted by the participants is evaluated on the holdout dataset using the metrics. That is, the submitted method is used to obtain predictions of the outcome of interest based on the predictors in the holdout data, and these predictions are compared with the actual values of the outcome. This setup of a participant and a holdout dataset allows the models to be evaluated fairly, removing p-hacking, and ensuring replicability. The prediction scores of the submitted models are presented in the form of a leaderboard. When determining the leaderboard rankings, it is important to make sure that the metric used is aligned with the purpose statement and thus allows one to gain insights into the research problem.
To summarize, benchmark challenges have proven to lead to advancements in many scientific fields. However, we still lack a clear standardized framework. This prevents us from fully understanding the value of benchmark challenges and the context in which they are useful. We believe that wide adoption of the aforementioned framework will help to address this gap and unlock the full potential of benchmark challenges. We provide a practical example of the research problem, statement, and methodological choices in Appendix 1.
Benchmark challenge in the social sciences
Given the breakthroughs that the use of benchmark challenges has led to in different fields, we argue that they also have the potential to advance the field of social sciences. Most notably, benchmark challenges provide a standardized approach to compare competing models applied to the same research problem. This enables us to justify model specification and variable selection, and evaluate the suitability of different statistical techniques in answering a given research question. Having a standardized and objective way to assess different approaches in the social sciences can help us to answer long-standing, open research questions in our field. This is particularly important, as the available empirical studies utilize a variety of different methods and as a result provide inconclusive and at times contradictory findings.
Benchmark challenges also provide an opportunity to measure, understand, and manage the rapid diversification of methodologies and leverage them for the needs of social research. This is particularly important in the current era of computational social science, where ML approaches are increasingly being adopted. The use of benchmark challenges allows for a comparison of more traditional social science methods that are more theory-driven, that is, the human-designed approach to social science, with these new ML approaches that are more data-driven. What is more, it is possible to assess how beneficial a combination of both approaches is (Agrawal, 2020; Peterson et al., 2021; Savcisens et al., 2023).
Relatedly, benchmark challenges offer the opportunity to identify the specific limitations and blind spots of various approaches, as well as to see how they can be further developed to overcome the challenges encountered. For instance, understanding which sub-populations are less predictable given the state-of-the-art methods will allow us to understand where further research is needed, and where policy interventions may create unexpected results.
From the perspective of theory development, the use of prediction on large datasets also has the potential to identify meaningful insights outside of conventional theoretical frameworks (Agrawal, 2020; Peterson et al., 2021). However, the ability to do this must consider how the construction of a benchmark challenge and the data on which it is drawn are grounded in existing theories and ontologies of the social world. This grounding constrains the degree to which data-driven approaches are expected to be valuable, and the degree to which resulting algorithms and models might be generalizable outside of the context of the specified benchmark challenge.
In addition to evaluating different models and approaches, the framework of a benchmark challenge also offers the means to evaluate the role of researchers themselves and the role of their methodological choices in shaping outcomes. Systematic reviews of the role of researchers in research outcomes have revealed that research results in the social sciences depend crucially on the subjective choices of the researchers (Breznau et al., 2022). This is compounded by a diversification in the range of analytical tools open to social scientists. The rapid adoption of ML techniques and methods deployed in a range of other scientific fields is potentially highly beneficial to the field of social research, but researchers also risk drowning in the possibilities open to their field and the methodological choices they have to make.
Finally, introducing a culture of benchmarking in the social sciences can increase collaboration and multidisciplinarity. Benchmark challenges encourage researchers from different fields with diverse backgrounds and expertise to work together on the same research problem. The organization of a benchmark challenge is also often a multidisciplinary and collaborative effort, as it is a complex task that requires advanced substantive, technical, and statistical knowledge.
While the use of benchmark challenges in the social sciences remains rather limited, there are some examples of challenges that have been organized in recent years. The most notable social science benchmark challenge organized to date is the Fragile Families Challenge (Salganik et al., 2019).
We discuss this challenge in more detail below, while focusing on the lessons learned and reflecting on possible improvements going forward. We also describe the pilot benchmark challenge that we organized during the 2022 ODISSEI-SICSS Summer School to gain further insights.
The Fragile Families Challenge
The Fragile Families Challenge (Salganik et al., 2019) is defined by the organizers as ‘A mass collaboration that combines predictive modeling, causal inference, and in-depth interviews to yield insights that can improve the lives of disadvantaged children in the United States’. The challenge used data from the Fragile Families and Child Well-being Study (FFCWS) (Reichman et al., 2001) and consisted of two stages. First, participants were asked to predict six different life outcomes and the predictive performance of the submitted models was evaluated on a holdout data. Second, the best performing models were used to conduct further substantive and methodological research.
One of the main strengths of the challenge is its diverse and multidisciplinary nature: organizers attracted participants from various disciplines, and they managed to combine social science and data science approaches. The challenge was also exceptionally powerful in identifying infrastructural constraints to the implementation of social science benchmark challenges, such as machine-actionable metadata (Kindel et al., 2019) and the collection and storage of reproducible code using existing social science workflows (Liu and Salganik, 2019).
A key finding of the Fragile Families Challenge was that life outcomes were not highly predictable, and that ML approaches were not more effective than established human-designed approaches. One possible reason for the limited advantage of ML approaches in this context is the use of survey data as the sole data source. Survey data is designed and constructed by researchers based on sociological theory. These theories are then integrated into the survey, limiting the potential added value of ML approaches, which are better suited to examining data from a wide, complex, and diverse range of data sources. Using survey data therefore means that ML approaches can only draw on concepts that have already been identified by social scientists as being relevant to the topic (Goode et al., 2019). This does not mean that the concepts and frameworks used by social scientists are wrong or inappropriate, but it does limit ML approaches to utilizing only these established frameworks and their operationalizations. In essence, it means that ML approaches, which are designed to be more data-driven, are still largely theory-driven.
In addition, surveys tend to have relatively small sample sizes, compared, for example, with digital trace data or administrative data, and are therefore arguably less suitable for complex ML approaches. ML algorithms tend to perform better and have higher prediction accuracy when trained on larger datasets. Another issue worth mentioning is the specific context in which the benchmark challenge was organized. The Fragile Families Challenge used a sample and data generated for a very explicit purpose, which limits the replicability and generalizability of the challenge (Reichman et al., 2001). This is a superlative design for the sociological purpose of understanding the role of fathers in ‘fragile families’, but means that the methods submitted to the challenge should not be expected to generalize for predicting life outcomes more broadly.
Finally, the fact that both the data-driven and theory-driven approaches performed rather poorly might be a result of a low overall predictive limit. Some phenomena, particularly complex social ones, are inherently unpredictable or only partially predictable. Therefore, even with an abundance of data and with the use of sophisticated modeling techniques, one cannot predict the occurrence of certain outcomes with high accuracy (Hofman et al., 2017).
Despite these limitations, the Fragile Families Challenge was groundbreaking in its application of benchmark challenges in social research. It was the first project to invite mass collaboration on a prediction challenge within the social sciences and attempt to integrate principles of open science to ensure active progress on answering a specific social research question (Liu and Salganik, 2019). The Fragile Families Challenge, has in this respect, laid the foundations for realizing the potential of benchmark challenges within the social sciences.
The ODISSEI benchmark challenge pilot
During the 2022 ODISSEI-SICSS Summer School, we organized a pilot social science benchmark challenge. This was the first iteration of an ODISSEI benchmark challenge that we plan to repeat annually on different topics to gradually improve the process. The aim of the 2022 challenge was to predict precarious employment in 2020 using predictors from 2010 or earlier. The benchmark challenge description, which followed the framework described in the previous section, can be found in Appendix 1. The instructions that were provided to the participants are available in Appendix 2.
The challenge made use of the administrative microdata available from Statistics Netherlands (CBS), which was motivated by the limitations of survey data as discussed in the context of the Fragile Families Challenge. The relational data structures of the administrative data at CBS greatly increase the degrees of freedom for researchers tackling a particular challenge and are better suited for ML approaches. These data are also largely a by-product of administrative processes and therefore its collection is not influenced by existing theories or concepts. The challenge took place during the second week of the Summer School and resulted in six submissions from teams consisting of three to four participants. Each team was required to submit their predictions for the holdout data, their workflow (including pre-processing, feature selection, and modeling), and a short narrative explaining the method. The submissions of the teams were evaluated (1) quantitatively, by looking at the prediction accuracy of precarious employment in the holdout dataset, and (2) qualitatively, by external experts who ranked the submitted narratives based on their embeddedness in existing research and literature as well as innovativeness.
During the challenge we encountered several limitations. The overarching limitation encountered was the time allocated to the benchmark challenge. A week proved to be insufficient for participants to generate their predictions, as they spent the vast majority of the week on data wrangling and feature selection and were left with very little time to validate their models. One of the main reasons for this might be that the administrative data environment provided to participants contains a rather difficult to navigate data catalog, which made it hard to search and identify key concepts and to link those to the existing dataset. Ultimately, this meant that many teams omitted features because they were unable to link them properly to the analysis, limiting the effectiveness of their models. To exacerbate this situation, the analytical environment used had limited processing power. When teams eventually moved past the data wrangling stage, they found that even rudimentary ML approaches took a very long time to run given the size and the scope of the data. Finally, one thing that was not actively encouraged enough was collaboration between teams. After a short time, the teams started collaborating with each other, sharing solutions and working together to solve practical problems. This was very effective as the collaboration helped the teams to find practical solutions faster and to concentrate more on the key decisions in their model development that were of ultimate interest.
In subsequent iterations of the ODISSEI Summer School Benchmark Challenges, we overcame the limitations encountered by taking the following measures: (1) encouraging participants to use the provided code for the evaluation metrics, to validate their predictions on the participant data at earlier stages; (2) clearly instructing participants to start with a simple baseline approach and use a smaller sub-sample at first, so that they could start to actively develop their model at an earlier stage and further fine-tune it later on; (3) using an enhanced and more flexible version of the computing environment with more memory, so the participants could take advantage of the full potential of the administrative data (in terms of the number of observations and variables); and (4) encouraging collaboration among the teams from the outset, using the so-called ‘Peloton’ approach 2 . This can also be done by, for instance, providing the opportunity for participants to submit their methods for validation on the holdout dataset halfway through the challenge. This allows the participants to see the other submissions (including the code) and their corresponding rankings, and this way learn from each other.
Overall, the ODISSEI Challenge has brought us a step closer to understanding how to ensure that the potential of benchmark challenges can be realized in the social sciences. The lessons learned and insights gained from this challenge have guided the design and organization of the Predicting Fertility Data Challenge (PreFer), the first large-scale benchmark challenge in the social sciences in the Netherlands, which focuses on fertility predictions (for more information see Sivak et al., 2024).
Explanation versus prediction
Despite the focus on predictions in most benchmark challenges, including the two discussed above, the benefits associated with their wide adaptation in the social sciences extend beyond simply evaluating the predictive performance of different models and increasing the predictive accuracy of certain phenomena. As argued in Hofman et al. (2021), benchmark challenges can also potentially be useful for the explanatory modeling community, which has traditionally dominated the social sciences.
The Fragile Families Challenge, for instance, raised new questions and generated new insights about the predictability and, consequently, explainability of different life outcomes. What is more, it is also possible to organize challenges that focus specifically on explanations, such as the Universal Causal Evaluation Engine (Lin et al., 2019). The objective of this challenge is to assess the causal inference of models using synthetic data for which the true causal effects are known. Thus, the use of benchmark challenges can bring the predictive and explanatory modeling communities closer together and better integrate the two approaches, which in turn can improve and further advance the social sciences field. However, such an integration is not without its challenges and needs to be carefully executed. Hofman et al. (2021) and Breznau et al. (2022) provide recommendations and suggestions on how to effectively combine explanatory and predictive modeling in social scientific research.
Setting up and organizing a benchmark challenge in the social sciences
We use the insights gained from major benchmark challenges in different fields, including the Fragile Families Challenge and our pilot benchmark challenge, to provide recommendations for the design and organization of benchmark challenges in the social sciences.
As mentioned above, when setting up a benchmark challenge, the first step is to clearly define the research problem and the purpose statement (Figure 1). This choice should be motivated by how important the problem is in the field from both a theoretical and practical perspective. Organizing a benchmark challenge is highly resource- and cost-intensive and therefore should be well thought through. To illustrate, when many researchers work on the same problem and report contradictory results, benchmark challenges can help to compare the different approaches and reach a consensus in the field. Furthermore, when a complex social phenomenon remains unexplained despite numerous attempts to do so (i.e. the field appears to be ‘stuck’), a benchmark challenge can help to shed light and look at the problem from a different angle, as challenges tend to attract researchers from various fields. Finally, at times problems with high societal relevance remain understudied despite their importance. Benchmark challenges can draw attention to these problems and encourage researchers to work on them.
For benchmark challenges to be truly impactful, they need to attract a sufficient number of participants. An important aspect of this is the data used in the challenge. Benchmark challenges are expected to be particularly attractive for a diverse group of researchers if they make use of rich data that include different types, such as administrative records, social networks, medical images, and so on, as opposed to only traditional sources, such as surveys. Using more diverse data also allows for a broader perspective on the research problem. In our experience, benchmark challenges are more attractive when the data used are not publicly available in any other setting. Opening up data that were previously restricted can serve as an additional incentive to participate in the challenge. Using restricted data also facilitates a fair evaluation of the submissions, as the holdout data cannot be accessed by the participants.
While opening up data is arguably highly advantageous, it also involves considerable data privacy risks. This is critical in the social sciences, as often analyses are conducted at the level of the individual. The process of sharing data with a larger audience of researchers needs to be carefully implemented so that information cannot be traced back to specific individuals and their identities remain anonymous. If anonymizing data is not possible, rather than using the micro-data, one can use aggregate data or use the original data to generate synthetic datasets (Sun et al., 2023; van Kesteren, 2023). These simulated datasets can be made available to participants for them to train their methods on. Alternatively, one could also use an advanced and secure online environment with pre-authorized access. This would enable participants to work directly with the micro-data in a controlled setting. Finally, if the data are highly confidential and sensitive, it is possible to set up a benchmark challenge in which participants do not have direct access to the data at any time. For instance, participants can develop methods based on example data only and then submit these methods to be run and evaluated on the training data. Once they receive the evaluation outcomes, they can further fine-tune their methods based on these results in an iterative process.
Data quality also needs to be taken into account, as it affects the extent to which the benchmark challenge provides insights into the research problem. For instance, as was arguably the case in the Fragile Families Challenge, limitations related to the representativeness of the sample will have strong implications for the generalizability of the results. Any such limitations should be considered when assessing the predictive accuracy of the submitted methods. Otherwise, methods might be incorrectly deemed more or less suitable to the prediction problem at hand. While in the Fragile Families Challenge ML approaches were shown to be largely ineffective, they were trained on survey data which is considered suboptimal for these methods. Similarly, issues related to data validity and reliability, particularly of the ground truth or outcome variable, can also lead to incorrect evaluations of different methods. Therefore, data limitations should be thoroughly discussed, including the potential biases that can arise from these limitations. In the same vein, one also needs to describe the metrics used. The choice of metrics defines the aspects considered when comparing and evaluating different methods. For instance, the aim of our pilot benchmark challenge was to compare methods with regard to the ability of predicting precarious employment. Therefore, we focused on the prediction accuracy of this employment category in particular. Using a metric that evaluates the overall accuracy of predicting all employment status categories would have provided an inaccurate assessment of the methods given the purpose statement.
A prerequisite for a successful benchmark challenge implementation is appropriate infrastructure. As was highlighted when discussing the Fragile Families Challenge, benchmark challenges stimulate the need for an infrastructural alignment (Lundberg et al., 2019). The requirements of comparability and replicability that are inherent to benchmark challenges greatly increase the demands for interoperability and automation within researchers’ workflows. Submissions within benchmark challenges should all be replicable with a simple execution of a workflow. This standard was not met by the teams participating in the Fragile Families Challenge or our own challenge, and it is a difficult standard to enforce in the social sciences overall as workflows are often varied and non-standardized (Liu and Salganik, 2019). However, this replication requirement is necessary for deconstructing these workflows, assessing the impact of various elements on the overall quality of predictions, and identifying improvements for the future. As benchmark challenges are an effective tool for identifying and improving the elements of the workflow which need to be automated and machine readable, they can also facilitate the use of broader computational techniques in the field. For example, for the PreFer challenge (Sivak et al., 2024), to submit their methods, the participants used the benchmark challenge software service available on the Next platform that was developed by Eyra. This infrastructure requires participants to submit their method as an open-source automatic workflow based on a predefined template (see https://github.com/eyra/fertility-prediction-challenge for the full template and further details). As a result, all methods are open source, reproducible, and can be run on other datasets, such as the challenge’s holdout data.
What is more, benchmark challenges should act as engines of standardization and replication in the social sciences and establish new norms and best practices that can then be adopted by the wider community. To put this in the context of contemporary science policy, benchmark challenges should promote the use of FAIR data and software 3 (Wilkinson et al., 2016). Carefully documenting the data preparation and preprocessing steps of benchmark challenge design can help to establish community standards for data handling. By providing guidelines for the annotation and classification of methods, benchmark challenges can help to set standards in the field regarding the terms used to describe the methods. This is particularly important in interdisciplinary research as terminologies in different fields within the social sciences often do not align. Therefore, establishing mappings and common vocabularies creates strong foundations for increased future interdisciplinarity.
To sum up, while the implementation of a benchmarking culture in the social sciences has the potential to be highly beneficial for this field, a careful consideration should be given to the design, setup, and execution of benchmark challenges for them to be truly impactful. We provide a list of recommendations for the organization of benchmark challenges in the social sciences in Appendix 3.
Summary and conclusions
Benchmark challenges are a promising tool that can drive the field of social science forward, as has been the case in other scientific disciplines. They do so by providing a standardized way to verify the quality of models and statistical methods, thus providing insights into which model specifications and measurements are more appropriate to study a research problem. Benchmark challenges are particularly useful when the problem definition closely aligns with a generally identified problem. This, in combination with the use of rich, interesting data, is expected to encourage a large pool of diverse researchers to participate in the challenge, which can further assure that the benchmark challenge achieves its intended goals. In addition to the research question and data used, other aspects of benchmark challenge design, such as privacy considerations as well as metrics used and their limitations, must be carefully considered for benchmark challenges to be impactful. Our experience to date suggests that realizing the full potential of benchmark challenges in our field also requires a recalibration of data infrastructure and workflows.
It is worthwhile noting that in addition to a macro-level approach that relies on organizing large-scale benchmark challenges that touch on key research problems in the field (and which was the focus of this article), it is also possible to adopt a more micro-level approach. Such micro-level approaches, if properly described and carried out, can act as a first step and help to gain valuable experience with benchmark challenges. This can greatly contribute to the adoption of benchmarking in the field overall. In biomedical image analysis, for instance, at the onset benchmark challenges were organized on a small scale and involved researchers opening up their own traditionally restricted datasets and inviting others to work on them in a short workshop format. With time, the approach to benchmark challenges was more embedded in the field and the challenges became larger and more standardized (Maska et al., 2023). Smaller benchmark challenges can also provide valuable information for the organization of large-scale benchmark challenges at a later stage. For instance, they can help to determine the research focus and setup of upcoming benchmark challenges, and they can shed light on the quality and limitations of the data used.
Footnotes
Appendix 1: Benchmark challenge description
Appendix 2: Instructions for participants
Acknowledgements
The authors thank the participants of the SICSS-ODISSEI 2022 Summer School whose work on the precarious employment prediction challenge provided valuable insights into the use of benchmarking in the social sciences. The knowledge gained was pivotal in furthering our understanding of the potential of benchmarks in our field and consequently in writing this article. The participants included Hekmat Alrouh, Lianne Bakkum, Dominika Czerniawska, Kasimir Dederichs, Melisa Lucia Diaz Lema, Reshmi Gopalakrishna Pillai, Gita Huijgen, Kyri Janssen, Ranran Li, Cecil Meeusen, Marilù Miotto, Anne Maaike Mulders, Daniela Negoita, Cecilia Potente, Mikhail Sirenko, Jarik Stam, Willem Vermeulen, Kevin Wittenberg, and Samareen Zubair.
Funding
The work in this paper was financed by NWO grant number 184.035.014 via the ODISSEI Roadmap project.