
Abstract
The COVID-19 pandemic significantly impacted the transportation sector, altering travel demand patterns and posing challenges for local systems. Evidence of spatial heterogeneity underscores the necessity for a comprehensive understanding of these disruptions. Origin–destination (OD) matrices are generally used to compare travel patterns. Direct observations like smartphone data to construct OD matrices may limit causality in trip distribution, emphasizing the need for a methodology enabling comparison of travel patterns and exploration of factors contributing to this heterogeneity. To this end, this study develops a novel two-phase methodology. The first phase involved capturing heterogeneity in the weekly progression of zonal trip-generation patterns (via structural similarity of OD matrices) and then clustering them together based on similarity. The second phase involved examining the factors influencing cluster membership of zones. We demonstrated the proof-of-concept using two case studies: home-based work trips on weekdays and home-based other trips on weekends. The case studies focused on the Northern California Megaregion. The data used in the first phase include passively collected mobile phone data. The second phase used data on explanatory variables (e.g., mean household income, employment density, the share of white- and blue-collar workers and half-mile transit accessibility) for the multinomial logit model. This additional data to augment the data set is sourced from American Community Survey five-year estimates and the US Environmental Protection Agency. This study uniquely applies a novel methodology to two case studies, showcasing how insights into factors driving travel pattern changes can assist local and regional policymakers in optimizing resource allocation, particularly for public transportation.
The COVID-19 pandemic has had a profound and varied impact on travel demand patterns. The disruptive influence on demand patterns has affected local transportation system funding and caused a significant decline in revenue streams. For example, California’s local optional sales tax revenues, which support local transportation systems, experienced a decline during the initial months of the pandemic ( 1 ). Public transit systems faced severe drops in ridership and farebox revenue, and their path to recovery remains uncertain ( 2 ). At the state and federal levels, reduced vehicle usage led to a decline in fuel tax revenue, significantly impacting surface transportation funding. While the situation may have since evolved, the travel patterns did not fully return to their prepandemic state in the years following the lifting of travel restrictions ( 3 ). These lingering differences underscore the importance of understanding the shifts in travel patterns associated with disruptions during the COVID-19 pandemic. The goal is to minimize uncertainty for policymakers and transit agencies, enabling them to better plan for potential future shocks to transportation systems.
Travel demand patterns are generally analyzed using origin–destination (OD) matrices. These matrices have been used to understand the change in travel demand before and during the pandemic ( 4 , 5 ). Traditionally, the OD matrices are estimated via iterative procedures as part of the four-step transport modeling process. However, advancements in data availability now allow for the direct construction of OD matrices without the need for this iterative approach. Nevertheless, OD matrices derived solely from direct observations, such as GPS location data from mobile devices, might lack the ability to establish causality in trip distribution. This limitation becomes especially crucial when attempting to explain changes in travel demand patterns before and after specific events or interventions using OD matrices. Consequently, there arises a need for a methodology that not only facilitates the comparison of observed travel patterns (OD matrices) but also enables the exploration of the factors contributing to these changing patterns.
In this context, we propose a novel two-phase study to examine travel demand dynamics. The first phase employs a data-driven approach that uses a structural similarity metric (SSIM) to compare weekly OD matrices extracted from passively collected mobile device location data via the StreetLight platform ( 6 ). This phase focuses on exploring the continuous spatial and temporal variations in travel demand. In the second phase, a regression-based analysis is performed to further enrich the insights derived from the data-driven exploration in the first phase. Together, this methodology can enable a comprehensive understanding of travel behavior and factors contributing to observed travel patterns. We provide proof-of-concept through two case studies: home-based work trips on weekdays and other home-based trips on weekends. The data set covers the timeframe from January 2019 to October 2021, and the travel demand in 2019 acts as a reference for understanding the impact of the pandemic on travel patterns. We restricted our analysis up to October 2021 because StreetLight Data gradually changed their data sources around this period, which may impact the pre- and postpandemic comparisons. (For more details on their data sources, please read StreetLight Data [ 7 ].)
The remainder of this paper is organized as follows. The next section covers the relevant literature on efforts to understand pandemic-related disruption/recovery of travel demand using passively collected data. We then describe the data and study area, and the subsequent section provides a detailed overview of the methodology used in the study. Following is a discussion of the results, and we close the paper with a summary and conclusions, accounting for the limitations of this study.
Literature Review
The literature on the impacts of the pandemic on mobility is vast and has been the subject of multiple review articles ( 8 – 11 ). Previous studies have used various data sources and mobility indices to investigate travel behavior during and after the pandemic. Many researchers have used surveys to collect travel-related information, such as daily trip counts and vehicle miles traveled (VMT), from a sample of the population since the emergence of the pandemic ( 12 – 17 ). A benefit of administering a survey is the ability to collect detailed sociodemographic information and attitudinal responses from participants that can be used to explain heterogeneous travel behaviors at a disaggregate level. On the other hand, the travel-related information is limited to what respondents can recall from memory, which can result in unreported trips or inaccurate spatiotemporal details. Survey data are also often cross-sectional and therefore limited in their application to study changes in travel behavior over time. A travel diary survey, which involves collecting travel-related information from participants over multiple days, can overcome this limitation somewhat, and be used to study intra-individual heterogeneity. Some travel diary surveys also involve a GPS tracking smartphone app, which can more accurately record the occurrence, locations, and lengths of trips ( 18 ). However, the prohibitive costs of survey data collection and the attrition of participants generally limits the duration of a travel diary survey to one or more weeks, which precludes the study of long-term changes in travel behavior. Surveys also often suffer from sparse geographical coverage because of small sample sizes.
In contrast with surveys, direct observations of traffic counts can provide accurate estimates of continuous travel demand volume at specific locations based on measurements of every vehicle that passes the counting devices. Previous studies have used traffic count data to study vehicular emissions and air quality during the pandemic ( 19 ), or changes in nonmotorized travel activities ( 20 ), among other topics. On the other hand, these data do not include trip characteristics such as origin, destination, and trip purpose, which are important for analyzing travel demand distribution. Analyses of traffic count data are limited to aggregate flows on the instrumented parts of the road network. Traffic counts also do not capture travelers’ sociodemographic information, and it is difficult to infer such information. It is also possible that these aggregate-level metrics recovered to their prepandemic levels. However, the disaggregate travel patterns (OD patterns) did not return to the prepandemic levels or returned later. For example, super-commuting, measured as commutes over 50 mi or 90 min in one direction, has increased in many counties in California during the pandemic ( 21 ), possibly as a result of migration. It is hard to capture such changes using trip volume or VMT.
In another line of quantitative research on COVID-19’s impacts on mobility, passively collected travel data based on GPS traces from smartphones and connected vehicles is gaining popularity among researchers. The raw GPS data is collected and processed to create meaningful transportation measures. Several previous studies have used passively collected data to quantify the impacts of the pandemic on travel behavior ( 4 , 22 – 28 ). Unlike traffic count data, passively collected data can be used to generate OD matrices, allowing researchers to analyze the spatial distribution of travel demand. However, these passively collected OD matrices, derived from direct observations of human mobility, lack the ability to establish causality in changes in travel demand.
This study focuses on developing a two-phase methodology where the first phase is data-driven, and the second phase explains the factors contributing to the observed travel trends. The key idea behind the data-driven phase is the use of the structural similarity metric (SSIM) to analyze disaggregate-level OD travel patterns (trip generation) during and after the pandemic. A handful of studies in the past have explored SSIM to compare OD matrices, but they have their own limitations. For example, van Vuren and Day-Pollard ( 29 ) improved the existing method by suggesting a 4-dimensional mean SSIM that considers the Euclidean distance between OD pairs. Another approach, the geographical window-based SSIM (GSSI), introduced by Behara et al. ( 30 ), manually rearranges the OD matrices to represent local windows corresponding to geographical regions. However, the GSSI method may not fully capture the natural flow of travelers, especially when people commute long distances between counties for various reasons like affordable housing and efficient transportation. Therefore, in our study, we consider a local window based on the trip-generation pattern from a specific zone to all other zones in the study area and, by doing so, we do not miss the natural flow of travelers. Therefore, the window in the SSIM method is represented by an entire row of an OD matrix.
This paper, through two case studies, empirically analyzed weekly OD matrices for the period between January 2020 and October 2021 by comparing them with corresponding weekly OD matrices from 2019 to account for seasonality. Instead of comparing travel patterns from two time periods to understand disruption or recovery (as often done in the literature), we focused on studying the continuous weekly evolution of trip-generation patterns during the pandemic. We used a hierarchical agglomerative clustering algorithm to cluster zones with similar disruption and recovery patterns. Later, we used a multinomial logit model (MNL) to explain the cluster membership of zones, with clusters comprising the alternatives of the choice set.
Study Area and Data
We used two data sets in this study. The first data set is weekly OD matrices used to quantify spatial heterogeneity. The second data set consists of explanatory variables aggregated at the predefined zone level, which were used to learn the cause of heterogeneity. First, we provide an overview of the study area and then explain the data sets in detail in the following subsections.
Study Area
This study focused on the Northern California Megaregion, which consists of 21 counties in the San Francisco Bay area, Sacramento region, Northern San Joaquin Valley, and Monterey Bay area. The region encompasses diverse geographic characteristics and a wide range of economic activities. For example, the San Francisco Bay area has many hi-tech jobs and high average household incomes. The Northern San Joaquin Valley is more agriculture-focused and is also home to many commuters who travel to/from the San Francisco Bay area but who reside in the valley to reduce housing costs. We divided the study area into 150 Traffic Analysis Zones (referred to simply as zones in the remainder of the paper), as shown in Figure 1. The following three key considerations were considered while constructing the zone system.
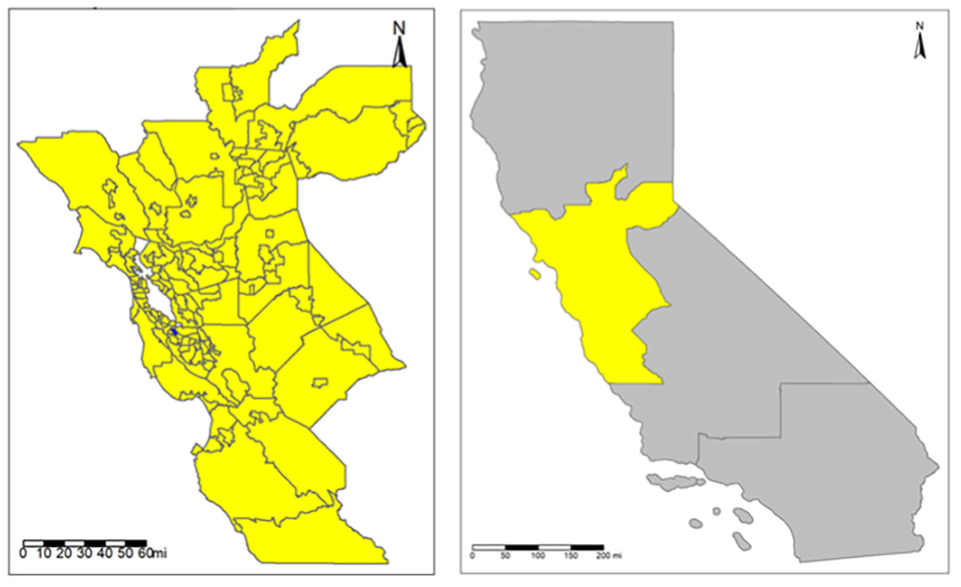
Left: zones in the study area; right: study area in the map of California.
Geographical and Administrative Boundaries
The zones in the study were created to align with county boundaries, enabling analysis of travel patterns within and between counties. At the lower level, the zones were aggregated from census tracts.
Land Use and Infrastructure
The design of the zones considered land use and infrastructure factors, influencing their shapes and sizes. Zones were clustered based on place types ( 31 ): urban, suburban, and rural, including specific areas like downtown San Francisco and downtown San Jose. Special zones were created for major transportation hubs, such as airports (Oakland, Sacramento, San Francisco, and San Jose). This approach aimed to study telecommuting patterns, remote teaching effects, and so on. We also created dedicated zones for large university campuses, enabling the potential evaluation of remote teaching and COVID-19 impacts on densely populated areas, for example, Stanford University, the University of California, Berkeley, and the University of California, Davis
Sociodemographic Information
We tried to preserve the homogeneity of sociodemographic information for census tracts within each zone. For example, income level and population were maximally kept consistent for each zone. In addition, we allocated certain zones to equity priority communities derived from Metropolitan Transport Commission (MTC) methodology ( 32 ) and SB535 criteria ( 33 ).
We also acknowledge several constraints of the defined zone system. First, we were limited to a budget of 150 zones when purchasing the data from Streetlight Data. However, it is important to cover the entire Northern California Megaregion, which enabled us to capture long-distance travel and its recovery from COVID. For example, trips between the Bay area and Sacramento region have been an important element of Northern California regional travel. As a result, each zone defined is much larger in size than traditional traffic analysis zones in the existing California Statewide Travel Demand Model. For this study, we removed three zones which represented three airports and used the remaining 147 zones for analysis.
Weekly OD Matrices
The passively collected location-based data from the StreetLight Data platform ( 6 ) from January 2019 to October 2021 was used for analysis. The StreetLight Data has been used in several studies to understand the impact of the pandemic on travel ( 23 – 26 , 34 ). The OD matrices were available for different periods of the day, day of the week, and trip purpose. The two types of days are: a typical weekday (average of daily OD values from Monday to Thursday, excluding Fridays) and a typical weekend (average of OD values from Saturday and Sunday). The unit of analysis was the estimated average daily OD trip volume.
StreetLight Data also infers travelers’ home and work locations based on their device’s location during night times (7 p.m. to 8 a.m.) and during the daytime (11 a.m. to 4 p.m.) on weekdays. (For more details on the methodology to infer home and work location, please refer to StreetLight Data Support [ 35 ].) The NextGen National Household Travel Survey Passenger OD Data products also classify home and workplace locations in a similar way ( 36 ). The home and work location together are used to deduce the purpose of each trip. The two types of trip purposes used in the two case studies are:
Home-based work trip: trips between home and work location.
Home-based other trip: trips between home and non-work locations such as grocery stores.
Data for Explanatory Variables
The data used to create explanatory variables for the MNL came from the 2019 American Community Survey (ACS) 5-year estimates, the United States Environmental Protection Agency (EPA) Smart Location Database ( 37 ), and the California Department of Public Health (CDPH) COVID-19 Vaccine Progress Dashboard. We also used the share of the population in a zone belonging to equity priority tracts (as derived from MTC methodology [ 32 ] and SB535 criteria [ 33 ]). We downloaded version 3.0 of the Smart Location Database and used the tidycensus R package ( 38 , 39 ) to download variables from the ACS. From the CDPH, we downloaded the most recent data on COVID-19 vaccines administered by demographics and by county as of July 25, 2023 ( 40 ). While the Smart Location Database variables are only defined at the census block group level (CBG), we were able to extract ACS variables at the census tract level. Table 1 lists the variables we extracted from these data sources.
Explanatory Variables Extracted from the 2019 American Community Survey (ACS) 5-Year Estimates and the United States Environmental Protection Agency Smart Location Database
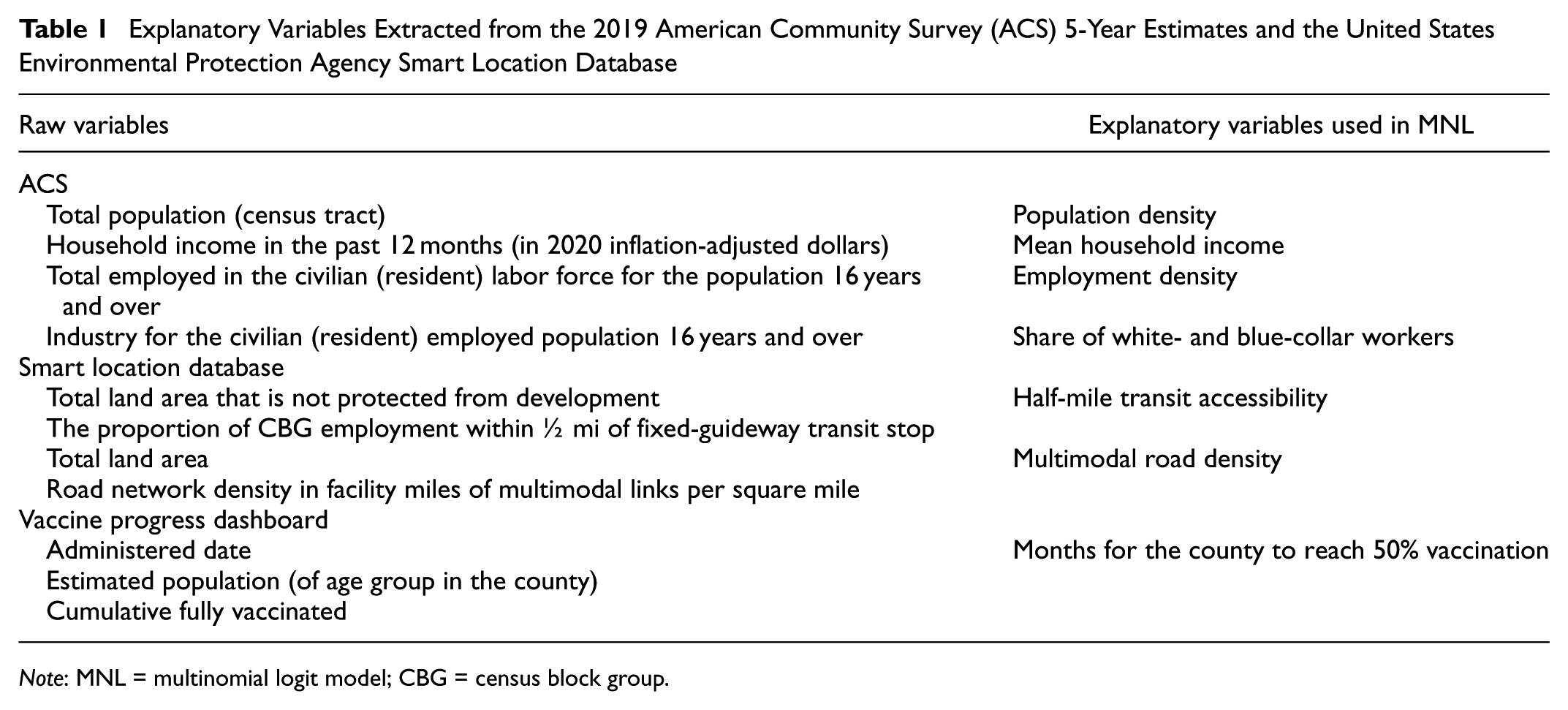
Note: MNL = multinomial logit model; CBG = census block group.
We processed the raw variables in Table 1 to derive new variables. The household income variables provide the estimated number of households within a census tract that fall into each of the 16 income groups, ranging from less than $10,000 to $200,000 or more. For each census tract, we computed the average household income as the weighted mean of the middle values of each income range, using the household estimates as weights. We also grouped industries in which the census tract residents are employed into white-collar and blue-collar categories. White-collar industries include information; finance and insurance; real estate; rental and leasing; management of companies and enterprises; professional, scientific, and technical services; administrative, waste management, and other services; and public administration. Blue-collar sectors include agriculture, forestry, fishing, and hunting; mining, quarrying, and oil and gas extraction; utilities; construction; manufacturing; wholesale trade; transportation and warehousing; and retail trade. The Smart Location Database estimates the proportion of CBG employment accessible to a fixed-guideway transit as the ratio of the area of unprotected land within one-half mile (crow-fly distance) of a fixed-guideway transit stop to the total unprotected land area. Therefore, before aggregating the transit accessibility variable to the zones in our study area, we first multiplied the transit accessibility variable by the area of unprotected land to get the area of land accessible to transit in each CBG. Similarly, the road network density in facility miles of multimodal links per square mile is estimated as the ratio of the total facility miles to the total land area. The definition of multimodal road facilities is based on the attributes of road links including speed category, number of lanes, direction of travel, and auto and pedestrian restrictions. Multimodal road facilities accept travel by both auto and pedestrians. (For more information about the Smart Location Database variables, please see their technical documentation [ 41 ].)
Next, we aggregated the data to the 147 zones in our study area. To calculate the population and employment densities of each zone, we summed the constituent census tract populations and employment numbers. We divided the results by the total area of the zone in square miles. For household income in each zone, we computed the weighted mean from the average household incomes of the constituent census tracts using the total number of households as weights. We calculated the shares of white- and blue-collar workers in each zone by summing the counts of each type of worker across the constituent census tracts and dividing the results by the total of employed residents. The Smart Location Database variables had to be aggregated from the CBG level to the zone level. After combining the transit-accessible land areas to obtain the total area for each zone, we divided the total area of land accessible to transit by the total area of unprotected land for each zone to retrieve the estimated proportion of employment within one-half mile of a fixed-guideway transit stop.
From the earliest date in the CDPH data when vaccines were administered in any of the counties of interest, for each county, we calculated the number of months until the percentage of people under 65 who had completed the primary vaccination series passed 50%. We excluded people 65 and older because this segment of the population was prioritized for vaccine administration and would introduce a systemic bias to the data. For each zone in the same county, we assigned to each of them the number of months for that county to reach 50% vaccination coverage in the population under 65, as the data were available at the county level.
Methodology
The methodology utilized in this paper consists of two primary components, as shown in Figure 2. First, we examined the spatial-temporal variation in trip generation at a disaggregate level for different zones. The SSIM concept, especially the consideration of the entire OD row as a local window, is based on trip generation, which adds value to our methodology (more details about SSIM are discussed in the subsequent section). Next, we employed agglomerative hierarchical cluster analysis to group zones with similar continuous temporal variations. In the second component, we delved into understanding the reasons behind these clusters using multinomial logit model (MNL).
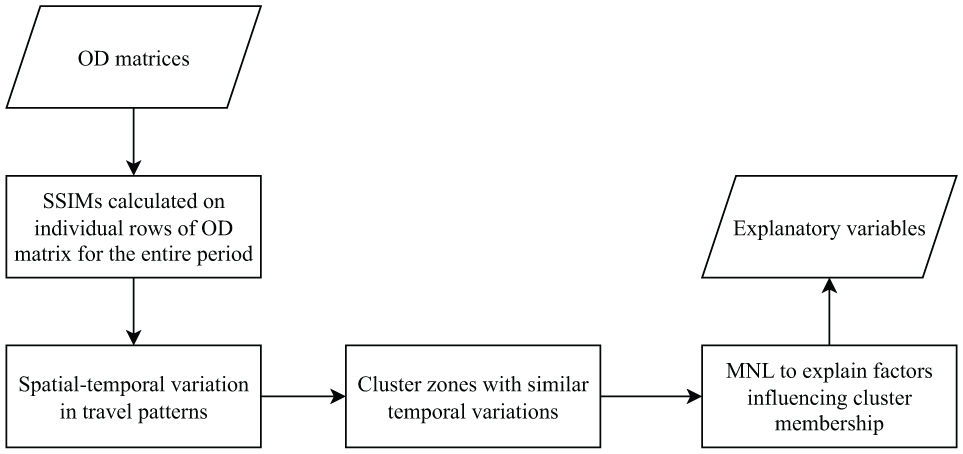
Conceptual diagram of the study methodology.
Trip Generation-Based Window for SSIM
Although OD flow primarily provides two-dimensional information concerning the trip origin and destination, the structure of an OD matrix (or a segment of it) can offer valuable insights into the distribution of travel patterns. Recent studies have been dedicated to developing methods that capture this additional information through SSIMs (
30
,
42
–
44
). The SSIM represents the structural similarity between submatrices of two OD matrices, a measure of similarity that accounts for correlations between different OD pairs. The SSIM is a product of three components that correspond to the mean
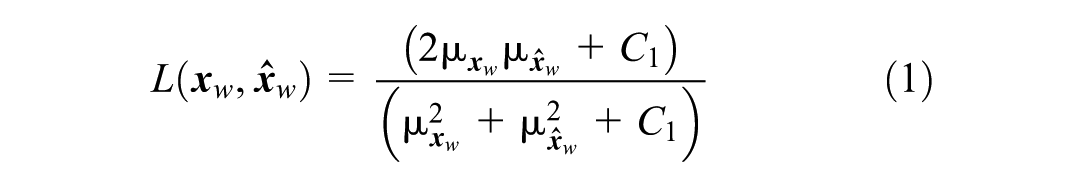
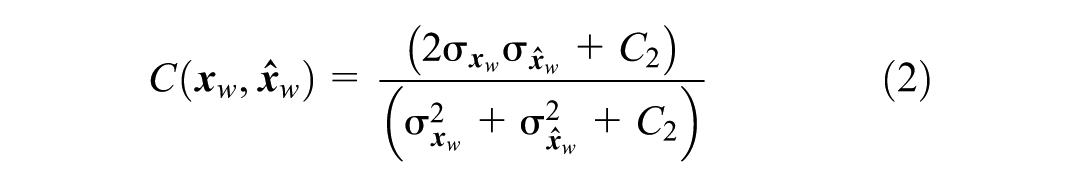
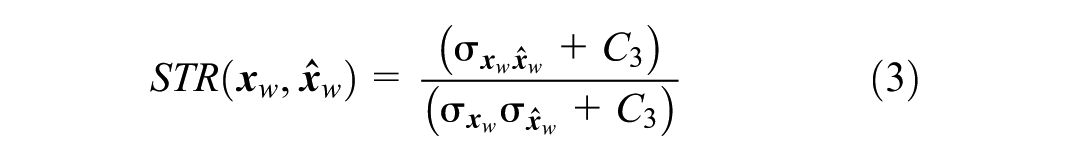
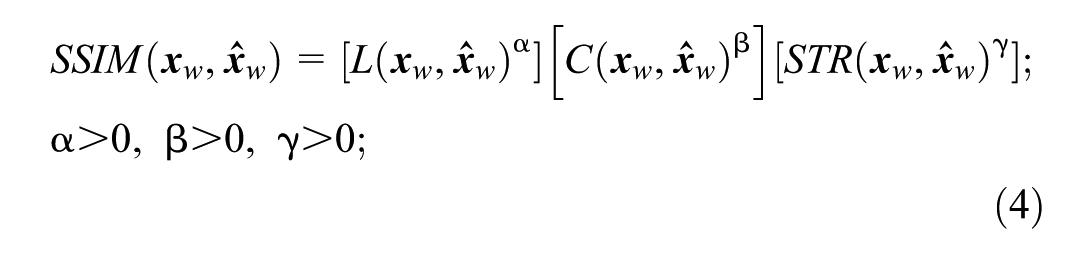
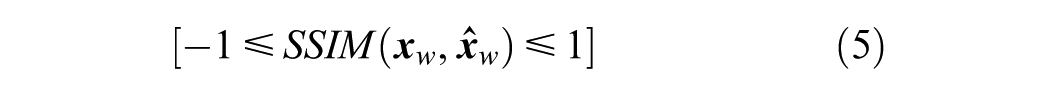
where
In this study, we propose to consider the entire row of an OD matrix as a local window for SSIM calculation. By considering trips generated from a specific zone (entire row of an OD matrix) to all other zones in the network, we capture the natural movement of travelers.
Spatial-Temporal Variation in Trip Patterns
In this study, we compared the weekly trip-generation patterns of each zone in the study area for the period between January 2020 and October 2021 with corresponding weeks in 2019 to account for seasonality. The resulting time series of a SSIM curve captured the temporal variations in the trip-generation patterns of a zone. The variation among these curves represents the spatial heterogeneity in disruption and recovery among zones. These 147 SSIM time-series curves were clustered using an agglomerative hierarchical clustering algorithm. Each cluster represented zones with similar temporal patterns in the disruption and recovery from the pandemic. We conducted the entire exercise for two kinds of OD matrices: 1) home-based work trips on a typical weekday; and 2) home-based other trips on a typical weekend.
Agglomerative Hierarchical Clustering
The SSIM curve of each zone consists of weekly SSIM values between January 2020 and October 2021. The 147 SSIM curves (each curve/observation is very high dimensional) were grouped using the agglomerative hierarchical clustering technique. We used the stats package in R ( 46 ) for clustering. We used “Euclidean” distance to compute the distance matrix and later tried different agglomeration (linkage) methods. Ward’s minimum variance method suggested the strongest clustering structure and was used in further analysis. Based on judgment and several trials, we decided to use three clusters in the study.
Multinomial Logit Model
The objective of this study is to explore the factors influencing the heterogeneity in disruption and recovery during and after the pandemic. The membership of a zone to one of the clusters, each of which represents different levels and rates of disruption and recovery, depends on multiple factors. Therefore, we specify a MNL of cluster membership. Equation 6 shows the probability,
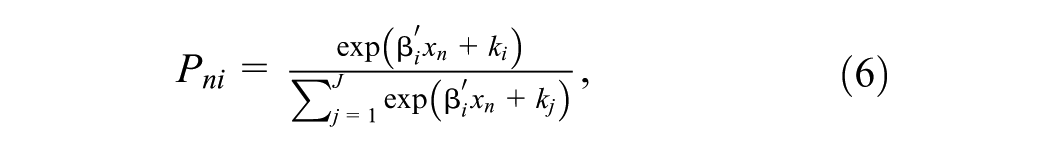
where
Results
This section discusses the results for disruption and recovery of two types of trip purposes: home-based work trips on a typical weekday and home-based other trips on a typical weekend. The zones with similar responses to the pandemic were clustered, and later, MNL was employed to explain the factors influencing cluster membership. The detailed results are presented in the following two subsections.
Spatial-Temporal Variation of Travel Demand
The SSIM curves are created for each zone for both analyses separately. The curves were then clustered into three groups. Figures 3 and 4 show the three clusters of SSIM curves in both analyses. The first cluster (in yellow) is named “minimum impact,” and it represents the zones that experienced the least disruption and fastest recovery. The second cluster (in blue) is named “intermediate impact,” and it represents the zones that experienced more disruption and slower recovery. The third cluster (in red), named “maximum impact,” represents zones that experienced the most disruption and late recovery. The left plot of Figures 3 and 4 shows the width of clusters, represented using different colors. The width of a cluster at any given week represents the minimum and maximum value of the middle 80% of the SSIMs of that week. The middle 80% of SSIMs are used to avoid overlapping clusters and for better visualization. The right plots show the zones in the study area colored by their cluster membership, allowing us to visualize them better. Detailed discussions of both trip purposes are presented in the next subsection.
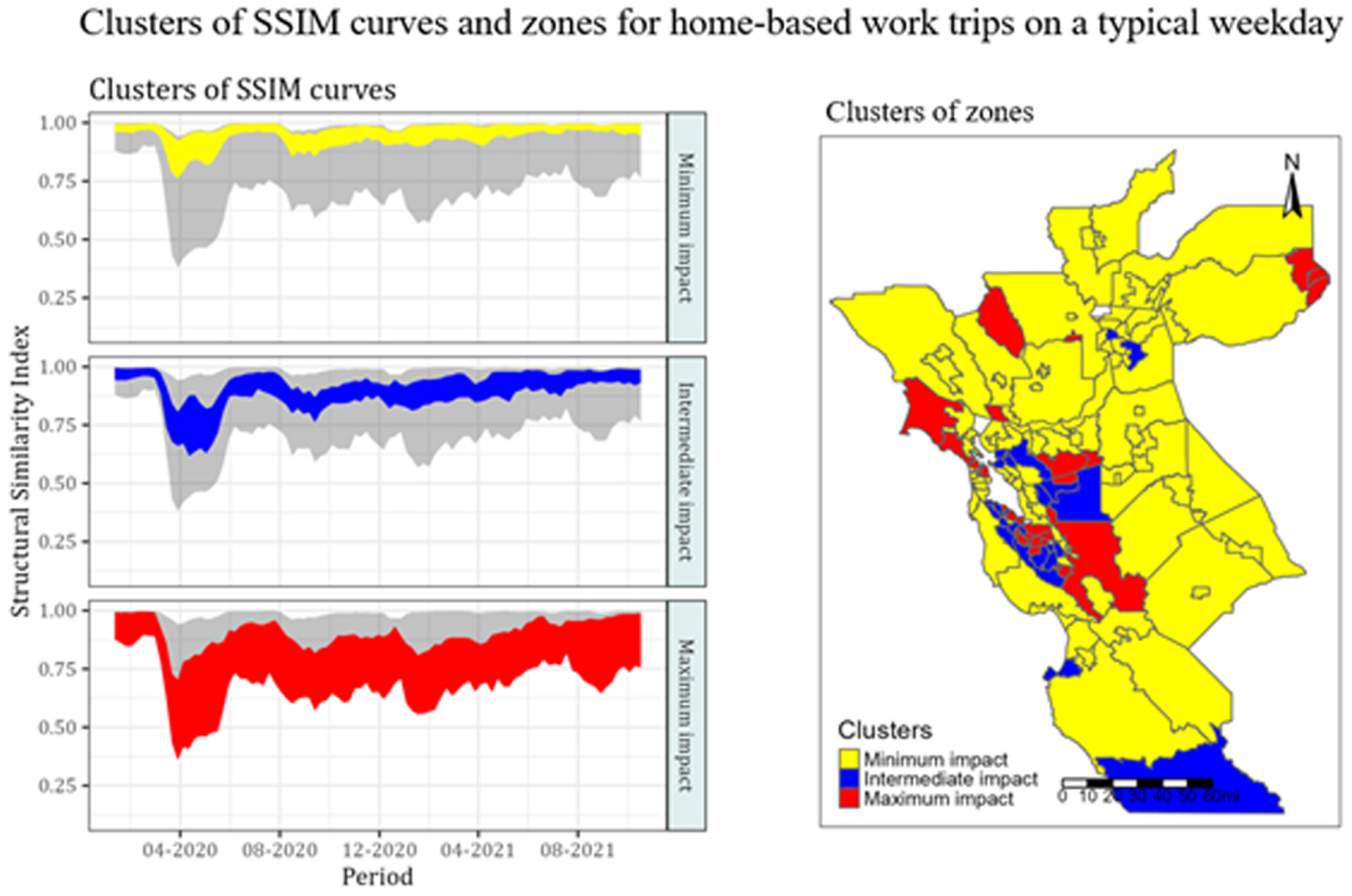
Clusters of SSIM curves based on home-based work trips on a typical weekday.
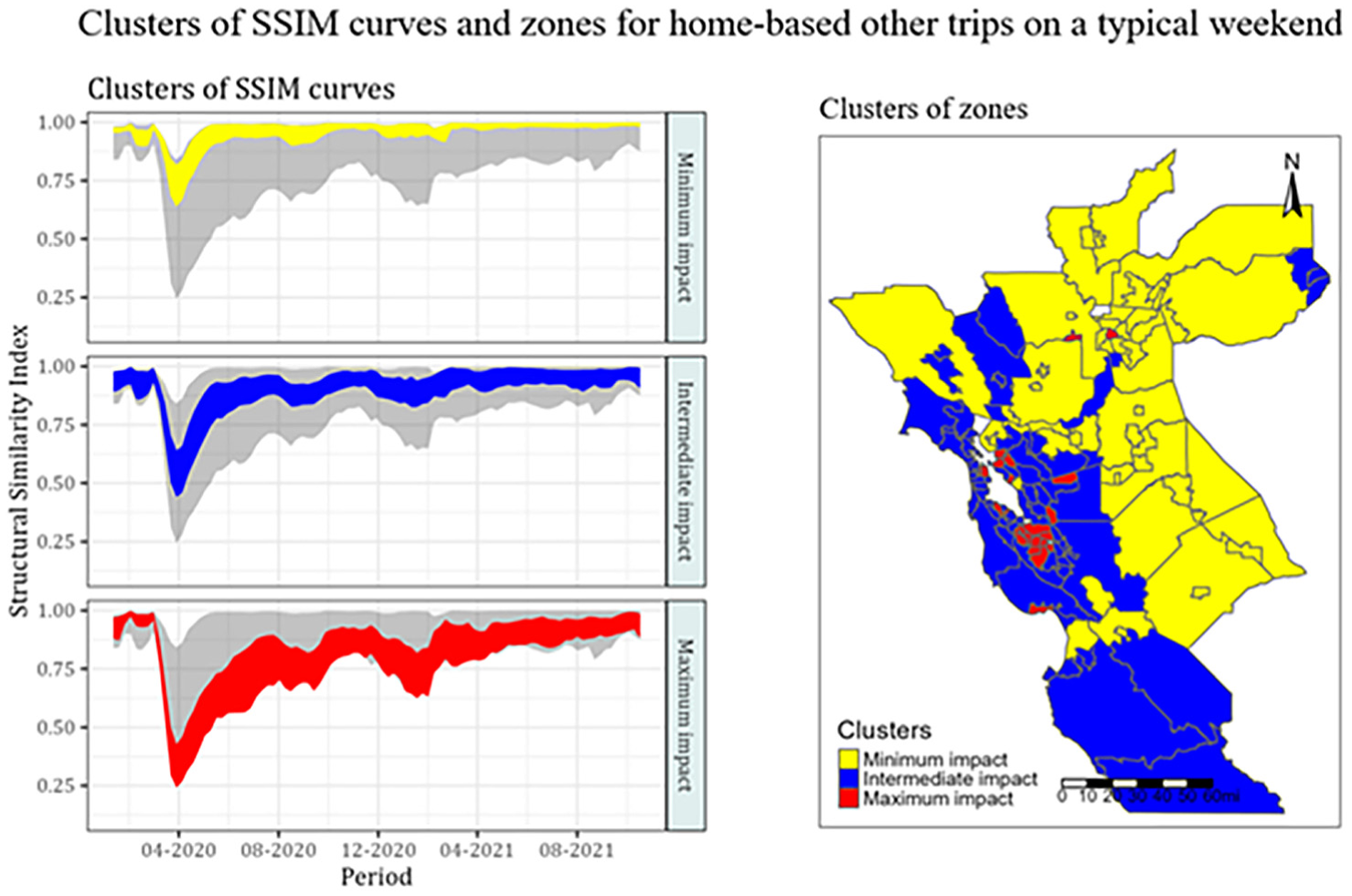
Clusters of SSIM curves based on home-based other trips on a typical weekend.
Please note that the SSIM values lie between −1 and 1, where 1 represents the OD matrices that are perfectly similar, and −1 presents the maximum dissimilarity between them. The SSIM values do not have an intuitive meaning, and the study only observed the variation among SSIM curves to demonstrate the heterogeneity in the disruption and recovery of travel demand.
Home-Based Work Trips on Weekdays
Home-based work trips represent trips whose one trip end is home and another trip end is the workplace. The home-based work trips on weekdays are mainly responsible for congestion during peak a.m. and peak p.m. A better understanding of spatial-temporal variations of home-based work trips is essential for traffic management centers and transportation planners to allocate limited resources optimally to manage congestion, and so on. Out of 147 zones, 94 zones were in the “minimum impact” cluster and experienced the least impact, 23 zones were in the “intermediate impact” cluster, and the remaining 30 zones were in the “maximum impact” cluster. The ribbon plot of the “maximum impact” cluster is wider than other clusters and shows higher volatility. It also highlights that the trip-generation patterns have not returned to the prepandemic patterns in the “maximum impact” cluster by the end of the study period. In comparison, the other two clusters seem to have nearly returned to the prepandemic levels by October 2021. The left plot also shows that the first two clusters had some recovery during June 2020 and later experienced minor disruptions during the subsequent waves of the pandemic. On further investigation, we observed an unexpected decline in trip volume in June 2019. Therefore, trip-generation patterns of June 2020, when compared with those of June 2019, give an impression of some recovery. We suspect the recovery in June 2020 is caused by an issue in the data.
The right image in Figure 3 shows the cluster membership of the zones. The rural zones in the east, north, and south sides of the study (mainly characterized by the large size of the zone) belong to the “minimum impact” cluster and have experienced the least disruption and quicker recovery. While many zones in the San Francisco Bay area (in the west) belong to the “intermediate impact” or “maximum impact” cluster, indicating these zones experienced a larger impact of the pandemic. These zones also have higher proportions of white-collar employees who could opt for remote work. For example, the city of Davis, which is a college town and home to the University of California Davis also belongs to “maximum impact” cluster, possibly because universities continued to operate in remote/hybrid mode during the study period. Some zones in Sacramento, the capital of California, also belong to the “intermediate impact” cluster, possibly the result of the higher share of white-collar employees.
Home-Based Other Trips on Weekends
Home-based other trips represent trips whose one trip end is home, but the other trip end is not a workplace. For example, a trip from/to home to/from the grocery store or gym. The home-based other trips on weekends constitute a significant proportion of the weekend trip volume. The SSIM curves were clustered into three groups based on the zonal level response to the pandemic. Out of 147 zones, 57 zones are in the “minimum impact” cluster and experienced the least impact, 66 zones are in the “intermediate impact” cluster, and the remaining 24 zones are in the “maximum impact” cluster. As is visible from Figure 4, the SSIM curves of home-based other trips on weekends experienced relatively higher disruption than home-based work trips on weekdays during the early phase of the pandemic. This is possibly because of the closure of businesses, stay-at-home orders, and so on. The trip-generation patterns of the zones in the “minimum impact” cluster recovered quickly after the first wave of the pandemic, followed by zones in the “intermediate impact” cluster. The zones in the “maximum impact” cluster recovered quite late but were less volatile than the corresponding cluster in the home-based work trip. The right plot in Figure 4 shows the cluster membership of the zones. A larger proportion of zones belonged to the “intermediate impact” or “maximum impact” cluster, mainly covering the Bay Area, parts of Sacramento, the city of Davis, Napa, Marin, Monterey, and San Benita Counties.
Multinomial Logit Model Results
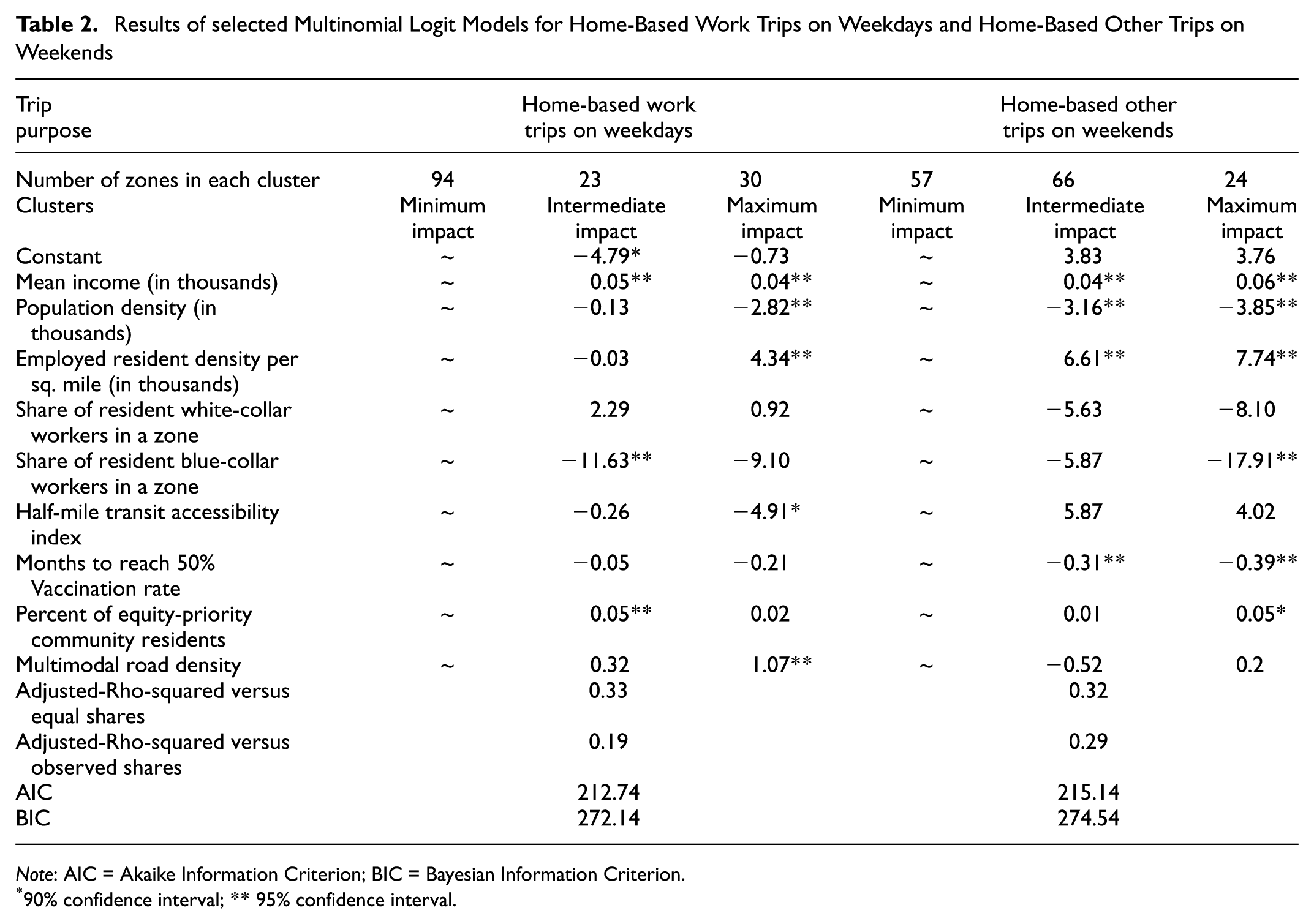
The second phase of the proposed methodology includes the MNL to explain the factors influencing cluster membership of each zone for both analyses. The explanatory variables used in the model were described in the methodology section and were presented in Table 1. The estimates of MNL models are shown in Table 2. The first model explains home-based work trips on weekdays, and the second model explains home-based other trips on weekends.
Results of selected Multinomial Logit Models for Home-Based Work Trips on Weekdays and Home-Based Other Trips on Weekends
Note: AIC = Akaike Information Criterion; BIC = Bayesian Information Criterion.
90% confidence interval; ** 95% confidence interval.
The results suggest that the mean household income of a zone is positively associated with belonging to the cluster of zones that experienced intermediate or maximum disruption and slow recovery. As can be seen from Figure 3, most high-income zones in the Santa Clara Valley and East Bay areas, and to the northwest of downtown San Francisco, experienced an intermediate or maximum impact of COVID-19 on the generation of these trips. Population density was found to be negatively associated with both models’ maximum impact cluster of trips. Taken together, these results are consistent with the idea that higher-income households tend to be in less densely populated areas where travel patterns were not as greatly impacted by the COVID-19 pandemic.
On the other hand, the density of employed residents per square mile is positively associated with the maximum impact cluster of trips in both models. This may be explained by businesses closing or transitioning to telework after the onset of the COVID-19 pandemic and employees reducing expenditure on travel because of income security concerns. The share of blue-collar jobs in a zone is negatively associated with the intermediate impact cluster of home-based work trips on weekdays, and the maximum impact cluster of home-based other trips on weekends; which may be explained by blue-collar workers being less likely to transition to telework or e-shopping. The vaccination rate was negatively associated with intermediate or maximum impact clusters as expected. The percentage of equity-priority community residents in a zone is positively associated with the intermediate impact cluster of home-based work trips on weekdays and the maximum impact cluster of home-based other trips on weekends.
Several explanatory variables, such as the half-mile transit accessibility index and the share of white-collar workers, were insignificant, suggesting they did not influence the cluster membership. It is likely that 1) a small sample size of 147, 2) the dilution of explanatory information during aggregation from census blocks/tracts to the predefined zones, and 3) the correlation between explanatory variables limited the ability of the models to explain the factors effectively. However, the two case studies provide validation of our proposed novel approach, firmly establishing its proof-of-concept.
Summary and Conclusion
While OD matrices derived from passively collected data present exciting opportunities for transportation demand analysis, they lack causality in trip distribution. This study addresses this limitation by introducing a novel two-stage methodology, incorporating factors from secondary data sources like land use and sociodemographic information, contributing to a more comprehensive understanding of changing travel patterns and demand dynamics.
In this study, we developed a novel two-phase methodology to understand travel trends during and after the pandemic. The first phase used a data-driven approach based on SSIM to analyze detailed OD travel patterns. SSIM has been widely adopted for its ability to capture structural patterns in OD flow patterns that traditional metrics overlook. In contrast, conventional approaches, such as comparing trip-generation volumes through row sums, provide only a single-point, additive measure and fail to reflect complex, nonlinear distribution patterns. SSIM offers a more robust alternative by effectively capturing these nuanced structural variations.
While the formulation of the SSIM itself remains unchanged, the novelty of our approach lies in how we applied SSIM specifically to OD matrices, with a focus on analyzing trip-generation patterns. Unlike typical applications, we treated each row of the OD matrix, representing the distribution of trips generated from a given zone, as a window for comparison across years. This allowed us to quantify how the spatial distribution of trip generation from each zone diverged from the baseline year of 2019. To our knowledge, this row-wise application of SSIM to highlight shifts in trip-generation patterns has not been explored previously, offering a new perspective in travel behavior analysis. The second phase involves a MNL after clustering zones to understand factors influencing the disruption and recovery patterns.
Although this study presented a methodological approach, we demonstrated the proof-of-concept using two case studies: home-based work on weekdays and home-based other on weekends. The data include weekly OD matrices from January 2020 to October 2021 for the Northern California Megaregion and compare them with corresponding matrices from 2019 to account for seasonality. Data for the MNL comes from the 2020 ACS 5-year estimates and the EPA Smart Location Database. The explanatory variables used in MNL are residents’ (25 years or older) percentage with an associate degree or higher, mean household income, employment density, the share of white- and blue-collar workers, the share of white- and blue-collar jobs, and half-mile transit accessibility.
Some limitations affect this study and should be mentioned. In particular, the mobile phone data may not have the same coverage in the entire study, which may lead to some errors/biases. We only considered internal trips in the study but will extend the work later to account for trips terminating outside the study area. A small sample size of 147 zones and the dilution of explanatory information during aggregation from census blocks/tracts to the predefined zones have limited the ability of the MNL model to identify the influencing factors effectively. The future research should also consider weekend home-based work (HBW) and weekday home-based other (HBO) analysis which would enlighten the impacts on blue-collar versus white-collar workers for weekend HBW and investigate weekday HBO trips that are likely to be more utilitarian and less recreational in nature.
The key findings from the proposed methodology should help policymakers at the local and regional levels to better allocate limited resources, particularly for public transportation. For example, the findings from the case study revealed that HBW trips had a maximum impact on the city of Davis as a result of remote/hybrid university operations. This information can be used by policymakers to focus more on accessibility in areas with high concentrations of remote or hybrid workers or target marketing to encourage this segment of riders to use public transit for nonwork-related trips. The methodology in this study is limited to only two trip purposes, but a future study will focus on other trip purposes based on data availability.
Footnotes
Acknowledgements
The authors thank Ran Sun and Keita Makino for creating the zonal system and querying the Streetlight platform using APIs.
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: Siddhartha Gulhare, David Bunch, Giovanni Circella; data collection: Giovanni Circella; analysis and interpretation of results: Siddhartha Gulhare, James Giller, David Bunch, Krishna Behara, Giovanni Circella; draft manuscript preparation: Siddhartha Gulhare, James Giller, Krishna Behara, Giovanni Circella. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Giovanni Circella is a member of Transportation Research Record’s Editorial Board. All other authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was made possible with funding received from the University of California Institute of Transportation Studies from the State of California through the Road Repair and Accountability Act of 2017 (Senate Bill 1) and the Resilient and Innovative Mobility Initiative. Additional funding was provided by the 3 Revolutions Future Mobility Program of UC Davis.