
Abstract
Background and methods
In this narrative review, we introduce key artificial intelligence (AI) and machine learning (ML) concepts, aimed at headache clinicians and researchers. Thereafter, we thoroughly review the use of AI in headache, based on a comprehensive literature search across PubMed, Embase and IEEExplore. Finally, we discuss limitations, as well as ethical and political perspectives.
Results
We identified six main research topics. First, natural language processing can be used to effectively extract and systematize unstructured headache research data, such as from electronic health records. Second, the most common application of ML is for classification of headache disorders, typically based on clinical record data, or neuroimaging data, with accuracies ranging from around 60% to well over 90%. Third, ML is used for prediction of headache disease trajectories. Fourth, ML shows promise in forecasting of headaches using self-reported data such as triggers and premonitory symptoms, data from wearable sensors and external data. Fifth and sixth, ML can be used for prediction of treatment responses and inference of treatment effects, respectively, aiming to optimize and individualize headache management.
Conclusions
The potential uses of AI and ML in headache are broad, but, at present, many studies suffer from poor reporting and lack out-of-sample evaluation, and most models are not validated in a clinical setting.
Keywords
Introduction
This review is intended as a primer for headache clinicians and researchers, aiming to provide an overview of artificial intelligence (AI) and its applications in headache. Initially, we provide a general introduction to AI, presenting key concepts and definitions aimed at a clinical readership. Subsequently, we present a thorough literature review of the use of AI in headache, identifying six main research topics. Finally, we explore the ethical, regulatory and political perspectives, as well as challenges and prospects for future research.
AI and machine learning
AI is a comprehensive field of computer science focused on creating systems that can perform tasks requiring human-like intelligence. At its core, machine learning (ML) uses computational models with the ability to automatically learn and improve from experience (1). ML algorithms analyse data to recognize patterns and subsequently make predictions and draw inferences. AI has today become a ubiquitous term for all complex modelling relying on ML. Table 1 presents a glossary of central AI and ML concepts.
Glossary of key artificial intelligence and machine learning concepts and definition.

Two main types of ML are typically used in medical research (Figure 1) (1). (i) Supervised learning, where algorithms learn from labelled data to make predictions or decisions. Supervised learning can be used for classification, where the outcome one wishes to predict is binary or categorical; and regression, where one predicts continuous outcomes. (ii) Unsupervised learning, which uses unlabelled data to discover unknown structures within datasets.

Schematic overview of the main categories of machine learning. In both supervised and unsupervised learning, each dot represents a sample that is described by n features. For simplicity, the schematic is two-dimensional (i.e. visualizing only two features). In supervised learning, the observations are labelled (orange = case, blue = control) during training. The model learns which combinations of features correspond to a given label to create a decision boundary that attempts to separate the classes (dotted line). When the model is tested, it uses the features of new observations to predict the label, and these predictions are compared with the ‘ground truth’. In unsupervised learning, the observations are unlabelled. During training, the model seeks to identify similar samples, which then can be grouped.
In addition, it is essential to address self-supervised learning. In self-supervised learning, data is typically not labelled, but the models use inherent information in the data to generate labels, guiding downstream learning. ML models can also be categorized as discriminative or generative. Discriminative models aim to separate classes or categories, whereas generative models aim to generate new samples that resemble the training data.
The potential applications of AI and ML in medicine are vast and of particular importance when dealing with complex patterns not intuitively visible to the human eye (2). Few AI tools have been adopted into routine medical practice at the time of writing, but AI has repeatedly been shown to be successful in a wide variety of domains and applications in retrospective studies (2). This includes automated interpretation of medical imaging (3) and pathology slides (4); predictive analytics of disease progression, patient outcomes and treatment effects (5); natural language processing to extract information from clinical notes and patient records (6); drug discovery (7); and therapeutic and mechanistic inferences (8). Still, the adoption of these proven concepts into routine medical practice remains a challenge.
Reading ML studies in headache research
Although a detailed description of strategies for reading and reviewing medical AI and ML papers is beyond the scope of this article, key concepts essential for understanding the papers presented in the following sections will be highlighted. The proposed assessment is based on dedicated guides for reading AI publications (9,10), guidelines for reporting of ML (11), research by Jaeschke et al. (12,13) on evaluating and applying the results of diagnostic tests, and the TRIPOD Checklist (14).
We have structured the assessment into four principal categories: research question, data, modelling methodology and assessing model performance.
Is the research question suited for ML? Assess the quality of the data used to train the models. What type of data was used and how was it collected? How were the labels, or ‘ground truth’, defined? Was the studied population representative of the target clinical population? Assess the ML methodology. What type of ML models were used, and were they appropriate for the research question? Was the modelling strategy reported in sufficient detail to be replicated? Figure 2 is a schematic illustrating the central steps in developing and evaluating a ML model. Assess the strategies used to evaluate the models. Were the models compared to a reference standard (e.g. diagnosing headaches by clinicians), and are they clinically relevant? Were appropriate metrics reported, and, crucially, was the performance assessed in an independent test set not involved in model training (Figure 2)? If only cross-validated model performance is reported, one must be aware of the lack of generalizability and the risk of overfitting. This is especially true when models increase in complexity, when the number of evaluated experiments increases; and when the models are intended to be clinically applicable (15). Therefore, the gold standard is to evaluate the developed model on a holdout test set, that has not been any part of model training (5,16). Table 2 outlines important methods and metrics for evaluating ML performance.
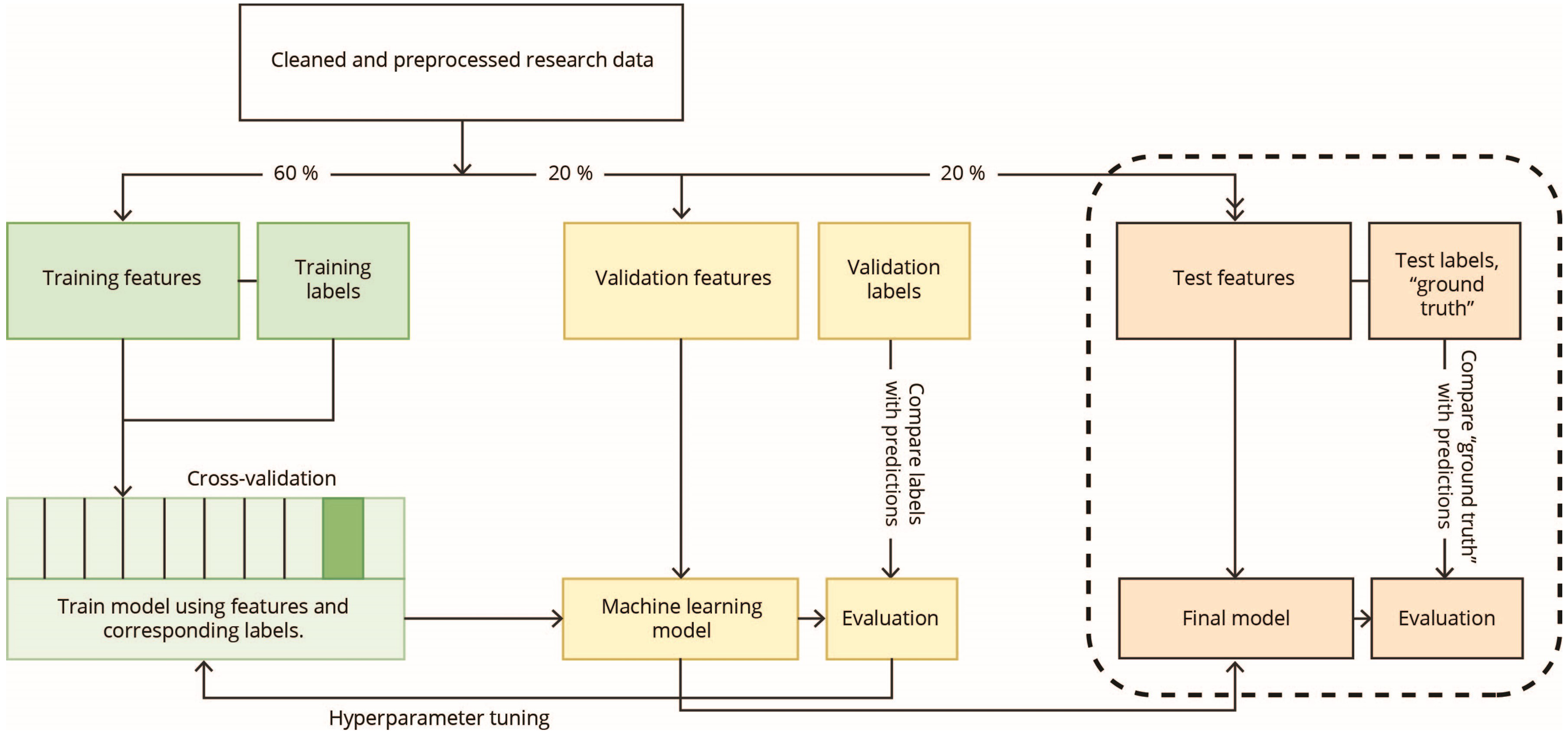
Schematic illustration of the development, tuning and evaluation of a supervised machine learning model. Typically, medical data is often incomplete and of variable quality which necessitates cleaning and preprocessing of the data before any machine learning can take place. The research data is then typically split into a training subset, a validation subset and a test subset. The training subset is used for training the model to learn which features correspond to which labels. The validation set is used for temporary evaluation of the model and tuning of the hyperparameters. The test set is held out from all training and tuning and will be used to evaluate the model only once a final model has been decided on. Training performance can also be assessed using cross-validation, where the training data is split into k folds. The model is trained on all but one fold, which is used for testing. This is repeated for all folds and the average accuracy is calculated.
Common methods and metrics for evaluating machine learning models.

Methods
To identify relevant literature for this review we searched PubMed, EMBASE and IEEEXplore from their inception to 23 April 2024. The following search term was used on all databases: ((headache) OR (migraine) OR (tension-type headache) OR (trigeminal autonomic cephalalgia)) AND ((machine learning) OR (artificial intelligence)).
Publications were considered eligible for inclusion in this review if they were original publications in the English language, that used AI or ML methodology applied to any type of primary or secondary headache disorders as defined by the International Headache Society (17,18).
In total, 1493 records were identified. Of these, 225 were removed by automated duplicate identification using EndNote 21, and an additional 34 duplicates were identified manually. The title and abstract of the remaining 1234 records were screened using the above eligibility criteria. Some 110 records were found to be potentially eligible based on their title and abstract, and were reviewed in detail. Among the 110 records, 66 were excluded because they did not use AI methodology or did not adhere to International Headache Society criteria for headache disorders. In total, 44 publications met the eligibility criteria and were included in this review. The identified publications were categorized thematically into the following topics:
Natural language processing methods building on ML applied to headache research. Diagnostics, classification, and phenotyping of headache disorders. Prediction of future disease status. Forecasting of headaches using ML. Prediction of treatment effects. Machine prescription.
Results
Natural language processing methods building on ML applied to headache research
ML has the potential to significantly ease the handling and processing of research data. Advances in natural language processing (NLP), based on ML, enable effective extraction and systematization of research data, such as turning unstructured electronic health record data into structured data suitable for downstream analyses (19,20). Chiang et al. (20) developed and evaluated a series of large language models to effectively extract headache frequency, defined as the number of days with headache in a month, from unstructured neurology consultation notes. This demonstrates how researchers may effectively capture real-world data from the vast amounts of patient information that is recorded every day in routine clinical practice. Extending the use of NLP and ML, two studies have also demonstrated the possibility of classifying headache disorders based on unstructured text data (21,22). Among these, a remarkable 2022 study from the Netherlands, researchers showed that migraine and cluster headache can be effectively distinguished using NLP and ML on patients’ self-reported narrative of their headache disorder (21).
Diagnostics, classification and phenotyping of headache disorders
Diagnostics and classification of headache disorders are by far the most common application of ML. We identified 27 publications using ML to diagnose, classify or group headache disorders. From this body of literature, two main sources of input data seem to crystallize: (i) Headache classification based on medical records and self-reported data and (ii) classification of migraine versus healthy controls or other headache disorders based on magnetic resonance imaging (MRI) or other paraclinical data.
Classification based on medical records and self-reported data
There already exists a sizeable body of literature on computerized migraine diagnostic tools, not necessarily coined as AI. A systematic review from 2022 identified 41 studies evaluating various computerized and automated migraine diagnostic tools with a median diagnostic concordance accuracy of 89% (23). A comprehensive overview of these studies was also provided (23).
Recently, several ML studies investigating classification of headaches using data from medical records and self-reported data have been conducted (24–31). In all these studies, diagnoses (labels) were set by neurologists or headache practitioners according to the International Headache Society criteria, and sample sizes ranged from a few hundred to several thousand. Input data for the models were typically demographics such as age and sex, and headache characteristics such as duration, location, intensity, quality and associated symptoms. The performance of the different models ranged from around 80% to well over 90%. Several studies assessed performance only in cross-validation and not in an independent test set. One should also keep in mind that the use of data from questionnaires, as well as self-report and medical records, along with diagnostic models building on headache characteristics, has some limitations when it comes to performance and clinical applicability (a detailed discussion is provided below).
The best model achieved an overall micro-average accuracy of 93.7% for classifying migraine and/or medication overuse headache, tension-type headache (TTH), trigeminal autonomic cephalalgias, other primary headaches and other headaches (including secondary headaches) in a test set (25). Of note, there was a low sensitivity for classifying other headaches at 36.8%, indicating that potentially serious secondary headaches could be missed. A similar model by the same group was also evaluated for its feasibility in improving non-specialists’ diagnostic accuracy (24). Fifty headache patients, unseen by the model during training, were diagnosed by non-specialists based on their prior knowledge, and thereafter again with the support of the ML model. The baseline diagnostic accuracy was 46%, which increased to 83% when using the ML model. The latter study demonstrates the potential of using ML as a decision support system to enhance diagnostics, especially for healthcare providers with less experience with headache diagnostics.
Another study attempted to identify secondary headaches using real-world data from more than 120,000 patients presenting to UK primary care practices with complaints of headaches (32). The input data for the models included age, sex and laboratory results of 10 complete blood count parameters. Approximately 10% of the population was finally diagnosed with secondary headaches. The best-performing random forest model achieved a cross-validated accuracy of 74%.
ML has also been used to discriminate headache disorders from associated and adjacent disorders. A 2023 odontology study developed a linear discriminant model using retrospective medical record data to identify migraine or TTH among patients presenting to a gnathology clinic with an area under the curve (AUC) of 0.627 (33). A study from the German Centre for Vertigo and Balance disorder used a deep learning model to identify vestibular migraine and Ménière's disease based on an otoneurologist's anamnestic, sociodemographic and diagnostic assessments building on established diagnostic criteria. Vestibular migraine and Ménière's disease were classified versus all other diagnoses in two separate models, achieving F1-socres of 90.5 and 90.0 in cross-validation, respectively (34).
In the setting of ML-based diagnostics is important to distinguish between symptomatically/criterially defined disorders and aetiologically defined disorders. Because primary headaches are defined by symptom criteria, it is problematic to use that same information (i.e. headache characteristics) as input data for the models. First, this approach means that the model merely learns the diagnostic patterns of those that defined the labels. More importantly, it results in data leakage, meaning that the model has access to the information it is trying to predict. The same data (headache characteristics) define both the features and the label. In theory, a model that is trained to classify migraine versus TTH using typical headache phenotype characteristics (e.g. laterality, pulsating/non-pulsating quality, pain severity, aggravation by physical activity, nausea/vomiting and photo-/phonophobia) will achieve an accuracy of 100%, as long as the labels are correctly classified (because migraine and TTH are almost mutually exclusive). However, the reality is rarely so clear, and clinical practice diagnoses are not always so obvious. For example, probable tension-type headache and probable migraine often exhibit overlapping symptoms, complicating clear-cut classifications in accordance with International Classification of Headache Disorders, 3rd edition (ICHD-3) (17). Indeed, inter-rater agreement for the primary headache category (e.g. migraine versus TTH) has been estimated at a Cohen's kappa of 0.566 among physicians working in a neurology clinic, and at 0.798 among board-certified neurologists (35). It is theoretically impossible to obtain a classification accuracy better than the inter-rater agreement on the label (i.e. diagnosis) in a given scenario, meaning that in practice, classification accuracies approaching 100% are virtually impossible. These drawbacks will always make diagnostic models relying on the symptoms that constitute the diagnostic criteria limited.
By contrast to classification, an important utility of ML is in data-driven phenotyping of complex disorders. In a 2021 study, it was shown that demographic and diagnostic information of cluster headache patients could be subjected to unsupervised learning to reveal novel phenotypic clusters (36). The same is true for a 2023 study seeking to identify naturally occurring subgroups of new daily persistent headache (37). This type of approach bypasses the inherently problematic task of classification of criterially defined disorders based on diagnostic information, as previously described. Nevertheless, the identification of clusters does not necessarily mean the clusters have value or clinical relevance.
Classification based on MRI or other paraclinical data
Several studies have investigated classification of headaches using MRI data (38–44). The reported accuracies are impressive, ranging from 68% to 97%. In two studies, structural and MRI-derived functional connections were used to distinguish individuals with migraine from healthy controls (42,43). Principal component analysis was used to identify important brain areas or functional connections, and downstream ML methods were used for classification. The accuracies were 68% and 81% for structural and fMRI data, respectively. Different ML models have also been used to classify migraine and post-traumatic headache (PTH) based on MRI data and questionnaire data (assessing headache characteristics, sensory hypersensitivities, cognitive functioning and mood) (45,46). Questionnaire data alone achieved an accuracy of 71.9%, but this was improved to 78% when including imaging data. Of note, the performance of many of these models was evaluated with cross-validation on relatively small samples, which is prone to overfitting and limits their generalizability.
A noteworthy, and methodologically solid study from 2023 achieved what we consider to be the hereto best performance in classifying both migraine and post-traumatic headache compared to healthy controls using MRI data (47). Structural MRI data from 95 individuals with migraine, 48 individuals with acute PTH, 49 individuals with persistent PTH and 532 healthy controls were used. Data were split into training, validation and test subsets, and a deep learning model was trained on the MRI data. Deep learning in this situation allows for the inclusion of all available imaging data, omitting the need for human selection of presumed important brain areas. Classification accuracies in test sets, with even distributions of cases and controls, were 75% for migraine versus healthy controls, 75% for acute PTH versus healthy controls and 92% for persistent PTH versus healthy controls.
Many studies use other types of paraclinical data to classify headaches (48–54). Among these, Hsiao et al. (52–54) have conducted a series of studies reporting that migraine can be distinguished from healthy controls and other pain conditions. In two of the studies, data from resting state magnetoencephalography were used to develop ML classifiers to distinguish healthy controls, episodic migraine, and chronic migraine (52,54). The magnetoencephalographic features most discriminative of the groups were used to develop different ML classifiers. The models were tested in an independent test set and achieved accuracies between 85.3% and 97%. At present, the use of magnetoencephalography to classify headache disorders is likely impractical because the cost outweighs the benefit. Still, such high-performing models are valuable as the provide insights into possible pathophysiological differences between headache disorders and healthy controls, and may guide future research efforts. In a separate study with 80 participants, a similar approach using electroencephalography (EEG) to capture evoked oscillatory responses was used to classify patients with chronic migraine versus healthy controls (53). Here, the performance was also assessed in an independent test set with an accuracy of 94.1%.
Some of the reported accuracies are most impressive; however, it is important to note that sample sizes often are limited when using data such as MRI scans and EEG. Many ML models are prone to unstable performance under small data regimes, which can lead to overfitting and limit both interpretability and generalizability (55). Moreover, pre-processing strategies such as manual selection of highly discriminative features could lead to reduced generalizability because the selected features might be especially discriminative for the dataset at hand, but not necessarily for other datasets of s similar population. Ideally, all diagnostic models should be evaluated in a temporally and geographically independent sample before absolute performances can be confirmed. This strategy will address the issues with data leakage, overfitting and low inter-rater agreement, and establish the true generalizability of a model (15).
Prediction of future disease status
Already in 1999, a study utilized a neural network to make predictions of future disease status (56). In a cohort of 64 patients with chronic TTH, the study used a series of self-reported psychological factors such as anger, depression and coping appraisal and strategies to predict pain interference measured by the multidimensional pain inventory. The neural network predicted interference scores to within 10% error for 80% of test cases. More recently, a model was developed to predict future medication overuse among 777 patients with migraine, utilizing demographic and clinical data collected through semi-structured questionnaires and clinical assessment as well as biochemical data on blood cell counts, coagulation profile, glucose and lipids (57). The optimized model was able to predict which patients became medication overusers with an AUC of 0.83 in the held-out test set. Finally, a 2023 study, reported that patients with migraine had a structurally ‘older’ brain, as defined by the MRI-based Brain Age metric when compared to healthy controls (58). Yet it is difficult to ascertain which clinical outcomes this translates to.
Forecasting of headaches using ML
Although headache precipitants have been a research topic of interest for a long time, recently, ML models have been used in attempts to forecast headaches. There are three main categories of predictors that are used in forecasting models: (i) self-reported data such as triggers, headache status and premonitory symptoms; (ii) physiological measures captured by wearable sensors; and (iii) external data. A 2023 study by our research group demonstrated that a combination of headache diary data and wearable data could be used to forecast headaches in patients with migraine (59). The predictive model was developed based on self-reported headache diary data, including premonitory symptoms, and measures of peripheral skin temperature, heart rate variability and neck muscle tension captured from a wearable biofeedback device. The top-performing model achieved a modest AUC of 0.62. Despite the low performance, we consider that this confirms the concept and feasibility of forecasting by AI, particularly because the evaluation was carried out in in a test set of individuals independent of the model training. Additionally, two studies have demonstrated the concept of predicting migraine attack onset based on measurements from wearable sensors on a per-patient basis (60,61). However, both these studies were limited by small sample sizes and limited external validation. The first study included seven individuals and showed an average per-person accuracy of 84.1%, but a user-independent accuracy of 47.4%. The second included two individuals, demonstrating per-person F1-scores between 0.57 and 0.95 within a 47 minute time window. Finally, a Japanese study used headache diary data linked to weather data to develop deep learning models aimed at predicting headache occurrence (62). The model was evaluated on a separate dataset of 2844 users with an R2 value of 0.537.
Prediction of treatment effects
Over the last few years, a number of studies have explored the use of ML to predict the responses to various headache therapies (63–66). The reported performances of these models range from near chance to close to perfect. Martinelli et al. (65) attempted to predict the response rate of oonabotulinumtoxinA for chronic and high-frequency episodic migraine using demographic and clinical data collected at baseline and after the first injection among 145 patients. The response rate was classified into four quartiles based on percentage reduction in monthly migraine days (<25%, 25–50%, 50–75% and >75%). The evaluated models were unable to discriminate good and excellent responders from non-responders among individuals with chronic migraine. However, in a subgroup analysis of those with high-frequency episodic migraine, a random forest model discriminated responders from non-responders with a high classification accuracy of 85.71%. A 2022 study reported excellent performance in predicting the response rate of anti-calcitonin gene-related peptide monoclonal antibodies based on a prospective follow-up of 712 patients with migraine (67). Response rates were classified as 30–50%, 50–75% or >75% based on the reduction in monthly headache days. Different ML classifiers were trained using baseline headache days, reduction in headache days after treatment start and Headache Impact Test 6 scores to predict treatment effect at subsequent follow-ups. The AUCs ranged from 0.87 to 0.98 when evaluated in a separate test set. It is important to note that all models incorporated data on already observed changes in headache days after initiating the treatment, and did not consider demographic factors, migraine characteristics, historical data or acute medications, altogether limiting its applicability.
Two methodologically robust studies have demonstrated more modest accuracies. In one study, a model was developed to predict the acute treatment effect, defined as ≥50% reduction in pain intensity, of non-steroidal anti-inflammatory drugs on migraine in 610 individuals (68). Input features for the model included migraine-related clinical characteristics, as well as scores for anxiety, depression and sleep. The best model achieved a test set AUC of 0.744. A 2021 study used routinely collected phenotypic and MRI data to predict the effect of verapamil in cluster headache (36). A gradient boosting machine predicted the response to verapamil, defined as ≥50% reduction in mean attack frequency, using phenotypic and neuroimaging information with an AUC of 0.689 on cross-validation and 0.621 in the test set.
Machine prescription models
Machine prescription refers to the process of generating treatment recommendations using AI. The aim is to evaluate potential outcomes across therapies that exhibit heterogeneous responses at the population level. A cornerstone of this approach is estimation of individualized treatment effects. Inference of individualized treatment effect builds on the broader causal model framework by Rubin (69), and has in recent years advanced significantly by the works of, amongst others, Mihaela van der Schaar and colleagues (70–72). The task of estimating individualized treatment effects is an attempt to capture varying and highly heterogeneous treatment responses, and understand the effect of a specific treatment on a specific patient at a specific time, considering their unique characteristics, medical history and other relevant factors (Figure 3). Why does one patient respond excellently to a given anti-migraine medication, while another does not, under seemingly similar conditions? Although randomized controlled trials are adept at identifying the unbiased effect of a treatment for the ‘average’ patient, it is the individual patient and not the average one that clinicians encounter in practice. Modern ML models now facilitate the estimation of individualized treatment effects using real-world and observational data, more reflective of everyday clinical settings (8). Although this methodology is still nascent, there are some noteworthy examples outside the headache domain including estimation of treatment effects in ischemic stroke, optimization of treatment of acute myelogenic leukaemia, and estimation of individualized treatment effects for chronic obstructive pulmonary disease exacerbations (73–75).
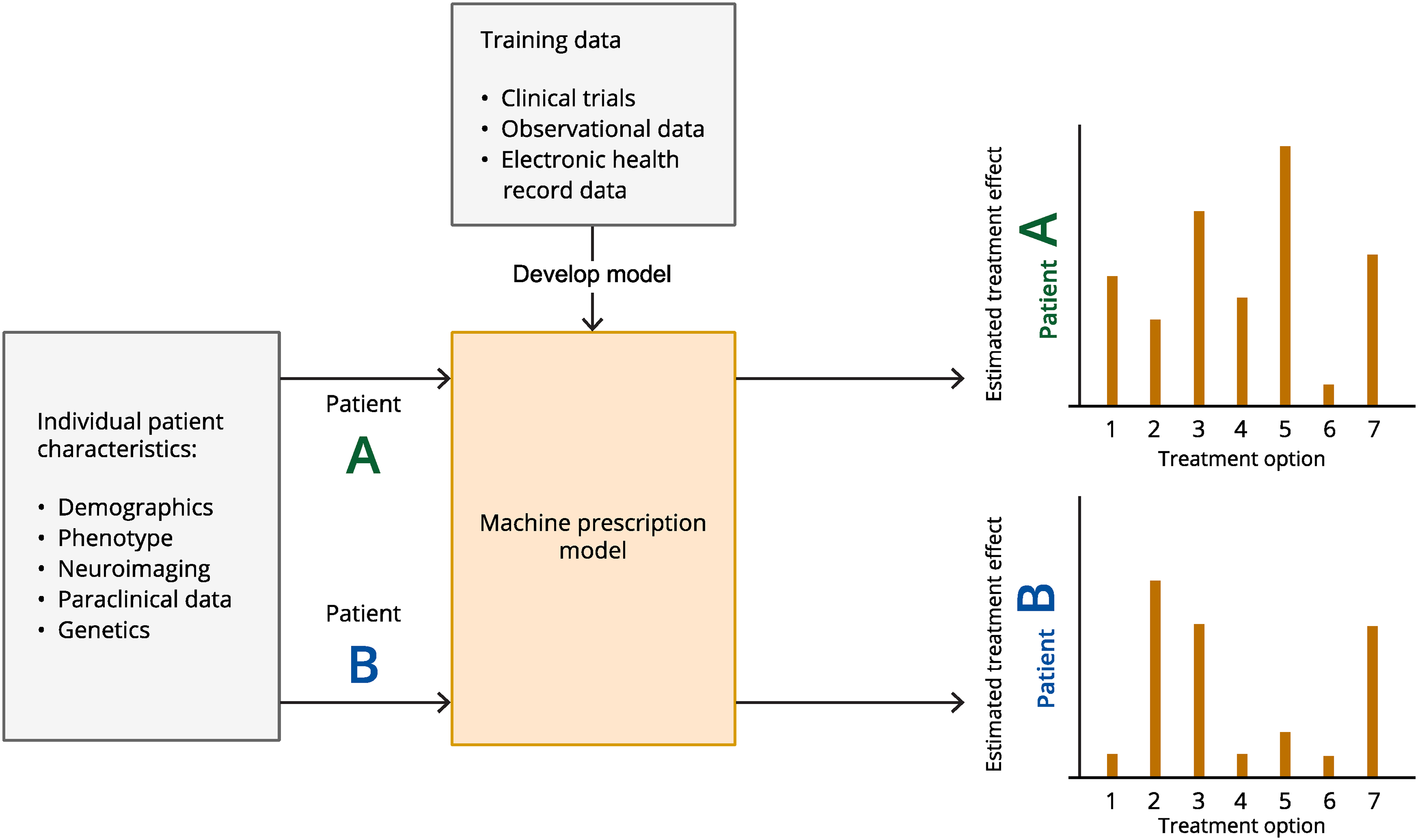
Schematic illustration of the concept of estimating individualized treatment effects and machine prescription. Data from, for example, clinical trials, observational studies or health records are used to train a machine learning model to make inferences of treatment effects. These inferences are based on individual patients’ unique characteristics, medical history and other relevant factors. Characteristics from new, unseen, patients can thereafter be put into the trained model to estimate and range the effect of different treatment options.
From these studies, it is evident that inference of individualized treatment effects is suited for heterogeneous, complex and multi-aetiological diseases, making primary headaches an ideal focus. There are rarely univariate and direct causal associations in headache disorders rendering the identification and development of simple causally effective treatments futile. We have previously published a study in which we implemented a causal multitask Gaussian process and demonstrated that individualized treatment effects may indeed be inferred from patient characteristics (76). Importantly, we contend that such a model could significantly streamline the optimal selection of treatment for chronic migraine, potentially resulting in significant societal and economic benefits. However, these models must be further refined and thoroughly evaluated in other populations before any firm conclusions can be drawn.
Discussion
AI and ML hold significant potential to enhance headache research and healthcare. Nevertheless, several challenges must be addressed to realise this potential fully. Large, harmonized high-quality datasets are crucial to make optimal and generalizable ML models, which necessitates international collaboration and coordination. The usefulness of harmonizing data has already proven useful in traumatic brain injury research (77). Collaborating internationally allows access to diverse patient populations and more comprehensive data sets, particularly important in more rare headache disorders. Models trained on diverse data are more likely to perform well across different populations and settings, improving the generalizability of research findings. Additionally, data from multiple countries can be used for cross-validation, increasing the robustness and reliability of AI models. Pooling resources and expertise can also accelerate the development and validation of new AI algorithms and treatments. Large-scale linking of health data from multiple sources is essential. Relevant data sources include medical records, imaging data, laboratory data, health registers, socioeconomic registers, clinical research databases, genetic databases, e-diary data, wearable data and public health surveys. Particularly valuable is the capability to link these data sources on an individual level (e.g. through a personal identification number).
In addition, there are currently many legal, practical, societal and trust barriers to effectively integrating different data sources, both within and across borders. First, standards for harmonization of headache data should be developed. As an example, a set of harmonized core data for registration in electronic headache diaries should be developed. This would make merging datasets easier and allow for more efficient collaboration between headache research groups. Second, data-sharing facilities for raw variables between countries should be developed or utilized. Here, differences in national data protection laws and regulations are challenging, and one option may be to use existing or upcoming solutions for federated ML analyses. This allows for ML processing of data from different countries without the need for data to leave the original database. Third, ML competence is needed both when developing such models and also when interpreting them or translating them to a clinical environment. It is therefore important that clinicians do not enthusiastically cut the bonds to the ML engineer once the model produces a promising predictive value. Lastly, trustworthiness is extremely important. Patients, health personnel and the community need to be able to trust results derived from, or prediction tools built on, ML algorithms. In the European Union, ML prediction tools intended to be used on humans for diagnostic or treatment purposes need to be compliant with the Medical Device Regulation before being used on patients (78).
Some general limitations hamper many ML studies in headache. Methodological reporting is often limited, which hinders interpretation and replication. This also includes limited reporting of data acquisition, patient streams, diagnostic criteria, and methods to assess ground truth status (labels). Evaluation of the models is often not done in hold-out samples which limits the generalizability of the results and often leads to over-optimistic accuracies. Finally, there are very few studies assessing the clinical application and utility of developed models. We encourage researchers employing AI and ML in headache to use ML when appropriate to answer the intended research question, use high-quality data of sufficient size, thoroughly and transparently report their methodology, and evaluate all models out-of-sample. Diagnostic models can be extended to include combinations of demographic, clinical and paraclinical data to increase generalizability. Such data should be used for unsupervised data-driven identification of subgroups and to determine whether these correspond to the presently defined diagnostic groups. This is especially relevant for currently less clearly defined entities such as new daily persistent headache (37), and has already been fruitful in cluster headache (36). Forecasting models should explore different input features and their importance and the utility of between-person and within-person models and could then be integrated into patient care tools such as electronic headache diaries. Inferential models, such as those building on individualized treatment effects (70–72) should be used for modelling treatment effects to enable optimized management at the individual level. Finally, generative models represent an important future step in complex modelling in medicine (79). They enable the incorporation of multiple sources of variability, including biological, pathological and instrumental, enabling generalizable performance. We already see diverse use in medicine, including systems focusing on clinical documentation, transcription, automated question-answering systems (also with text-to-voice to communicate directly with patients), generation of synthetic data used by automated tutoring systems and decision support systems designed to support the medical professional (79). Of course, generative models will be dependent on a suitable representation of an underpinned causal model for optimal performance, which currently poses an issue in headache.
Conclusions
The use of AI in headache medicine is rapidly expanding, with applications in diagnostics, prediction of disease trajectories and treatment effects. However, the clinical applicability of current models is limited. Many studies suffer from poor methodology and incomplete reporting and do not externally validate their models. If such challenges can be overcome, we consider that AI can be used to create models and clinical decision-support tools and improve the management of headache disorders.
Clinical implications
Artificial intelligence (AI) and machine learning (ML) are increasingly being used in the headache field. Many challenges restrict the use of AI and ML. If the challenges can be overcome, AI and ML has a significant potential in headache research and clinic.
Footnotes
Declaration of conflicting interests
Anker Stubberud has received lecture honoraria from TEVA. AS holds a patent related to Cerebri developed by Nordic Brain Tech AS, an app intervention that includes headache forecasting. In addition, AS may benefit financially from a license agreement between Nordic Brain Tech AS and NTNU. Helge Langseth reports no conflicts of interest. Parashkev Nachev is funded by Wellcome and the NIHR BRC Biomedical Research Centre. He has shareholdings in two university spin-outs, Sonalis and Hologen. Manjit S. Matharu is chair of the medical advisory board of the CSF Leak Association; has served on advisory boards for AbbVie, Eli Lilly, Kriya, Lundbeck, Pfizer, Salvia and TEVA; has received payment for educational presentations from AbbVie, Eli Lilly, Lundbeck, Pfizer and TEVA; has received grants from Abbott, Medtronic and Ehlers Danlos Society; and has a patent on system and method for diagnosing and treating headaches (WO2018051103A1, issued). Erling Tronvik has received personal fees for lectures/advisory boards: Novartis, Eli Lilly, Abbvie, TEVA, Roche, Lundbeck, Pfizer, Biogen. Consultant for and owner of stocks and IP in Man & Science. Stocks and IP in Nordic Brain Tech (includes headache forecasting) and Keimon Medical. Non-personal research grants from several sources, including EU, Norwegian Research Council, Dam foundation, KlinBeForsk. Commissioned research (non-personal): Lundbeck, Eli-Lilly.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.