
Abstract
Technical drawing is a core skill for any Mechanical Engineering program, intended to equip students with the fundamentals of technical design communication while assimilating key concepts such as views, perspectives, dimensioning, tolerancing and materials selection. Technical drawings are manually-graded by the lead instructor by assessing the drawing's proficiency and quality based on a set of standards and marking criteria. For large student cohorts, this becomes a time-consuming activity, potentially leading to ‘marking fatigue’, usually producing highly variable grades and feedback. By using a dataset of 32 student drawings and a five-criterion rubric, we compare AI-generated grades with historic human-marker scores through error analysis, ANOVA and Kruskal–Wallis tests. Results suggest there is no significant statistical difference between the marks/grades awarded by AI and a human marker. This, however, will depend on the prompting engineering techniques applied, together with additional practices such as role-setting and context-setting. The study also identifies limitations—such as OCR-induced hallucinations, variability between LLM platforms, and lack of batch-processing capabilities—that currently constrain full automation.
Introduction
Technical drawing is one of the core skills that engineering students are expected to develop in a typical higher education engineering course, and one of the tools most usually required for industry positions in the engineering design jobs market. 1 Technical two-dimensional (2D) drawings remain the standard and predominant way in which engineers define not only shapes, views, and dimensions, but also tolerances, materials, inspection strategies, orientations, quality control and manufacturing intent, hence their importance as a core academic coursework element. Given their content-intensive nature, technical drawings can only be perused by engineering design experts who can identify potential mistakes and provide relevant, actionable feedback. This represents a challenge where instructors are tasked with assessing and marking hundreds of technical drawings within short deadlines, which is usually the case in higher education. The physical exhaustion due to the repetitive nature of individually grading large cohort assignments is commonly denominated ‘marking fatigue’, which has been directly linked to high variability in marking as well as inter-rater reliability drops.2,3
This work explores the potential of Generative-AI and in particular Large Language Models (LLM) as a tool for assessing 2D technical drawings in the context of engineering design courses. While some risks and disadvantages become rapidly apparent, some AI-grading strategies can be deployed for education professionals to leverage their expertise with currently available AI tools. Far from being ‘replaced’, academic experts play an important role in how these tools can be implemented in educational settings.
Literature review
Automatic analysis of 2D engineering drawings has been attempted at various levels. Ling et al. 4 proposed an engineering drawing recognition system based on vision libraries such as OpenCV, YOLO and PyTorch to scan and process a collection of existing drawings with 70% accuracy. Their work draws on previous trends in character recognition based on Convolutional Neural Networks with a focus on ASME Y14.5 as the reference Geometric Dimensioning and Tolerances standard (GD&T). The system relies on feature extraction by dividing the drawing layout into sections; however, it is sensitive to text and symbol orientation and requires an extraordinary degree of standardisation, corrections and post-processing to work successfully. Kreske et al. 5 applied the YOLO algorithm as an object detection method for gearbox design to support university students developing enhanced spatial visualisation skills (project AssistME). The system focuses on mechanical assembly cross sections for part identification, rather than for drawing analysis for assessment and feedback purposes.
Elyan et al. 6 applied the YOLO model for symbol recognition in electronic diagrams, applying Generative Adversarial Neural Networks (GANNs) to train a model based on a collection of standard symbols, all of them detected with dissimilar accuracy levels ranging from 25 to 100%. Similar attempts by Nguyen et. al., 7 Schlagenhauf et. al 8 and Haar et al. 9 were proposed for object and text recognition of technical drawings, mostly focusing on digitalisation of existing paper drawings. Most of the early proposed solutions in literature rely on computationally heavy features and text extraction, requiring strict drawing standardisation for successful processing, which is not the usual scenario in student-generated 2D drawings.
Jianwu et al. 10 proposed a web-based 2D drawing marking, the AMCAD AI algorithm which made use of OpenCV libraries to convert raster images into PDFs; it included image analysis for feature and alignment detection for comparing student drawings to a predefined optimal benchmark. Detection. It however lacks the ability to detect GD&T symbols, annotations and other content rich features. Bryan 11 developed an algorithm to assess AutoCAD-native formats based on parsing to extract precise coordinates of lines and basic geometric shapes, which are then compared to a predefined correct drawing. The system, however, cannot detect general patterns and other drawing elements such as templates, metadata, text or GD&T data. Younes and Bairaktarova 12 developed ‘ViTA’ (Virtual teaching Assistant), the only system reported in literature fully intended as a grading platform for academic 2D drawings. It relies on image processing for the comparison of basic features however is mostly limited to hatching, outlines and thickness analysis.
Despite the recent popularity gain by LLMs, their application to CAD and drawing analysis seems scarce. Zhang et. al., 13 compared the influence of LLMs on engineering design tasks across two different groups, concluding that while LLMs promote idea diversification, they tend to induce a strong bias towards common pre-existing design solutions. Kumar et al. 14 proposed an approach for generating basic three-dimensional shapes from LLM prompting as an input; however, this feature is currently offered as a standard option by most mainstream LLM engines, by generating C++ or Python scripts which can then be interpreted by CAD software as 3D volumetric shapes. Li and Shao 15 used LLMs to automate repetitive tasks in Civil Engineering drafting, proposing a framework where LLM performs automatic assessments while a human operator performs post-processing. On a general note, Bernabei et. al, 16 studied LLMs adoption by engineering students reporting a high acceptance and high perceived usefulness via the Technology Acceptance Model (TAM); yet they report concerns by the survey students about LLMs overreliance, weakness in deep analysis as well as risks in detectability.
While the wider implications of LLM usage can spark a debate on critical thinking, ethical aspects, intellectual property and overall learning integrity, the main focus on this study is the technical capabilities afforded by LLM agents for automatic marking, as this needs to be well established ahead of any potential alternative debate.
Methodology
Different LLMs were tested in their capacity to generate automatic grades and feedback for a collection of 2D engineering drawings, produced by third-year Mechanical Engineering students as part of the course: ES3C2 – Advanced Mechanical Engineering Design. 17 The proposed methodology (Figure 1) includes the steps taken from 2D drawing compilation to a marking and feedback repository, which is made available as a CSV file as part of this work. 18 The initial dataset includes the human-marker grades awarded to each design. These grades are based on a single human-grader (the course's lead instructor) with no input from additional markers or moderators.
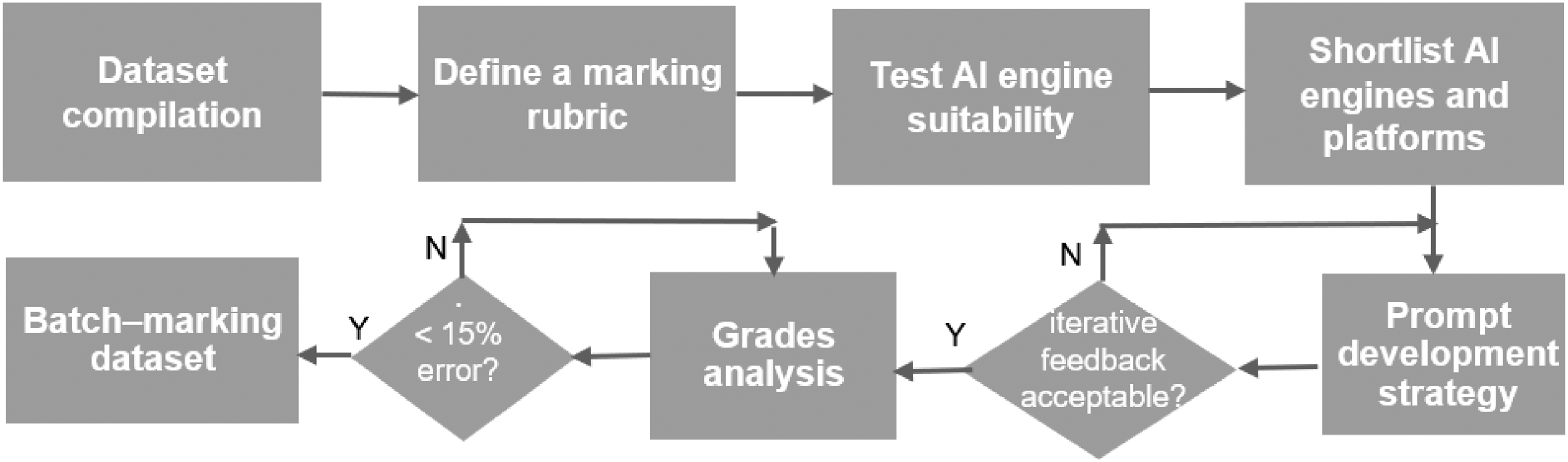
Methodology workflow for LLMs evaluation.
Dataset compilation
A collection of 32 drawings was converted from PDF format into individual image files (.png or .jpg), which can be interpreted by the AI models being used. All drawings feature an automotive hub as part of a Formula Student car suspension design exercise. Some of the expected elements on a typical 2D drawing include: an identifiable projection method (First-Angle, Third-Angle), inclusion of isometric views, clear scaling, correct use of geometric Dimensioning and Tolerancing (GD&T), text-box information, as well as manufacturability and material selection annotations. Automotive hubs have been selected as a prime example of a rotating component within a suspension (Figure 2), which is subjected to long-cycle combined stresses; therefore, they require a combination of general suspension knowledge, materials selection, mechanical design and lightweighting design. All drawings were made in Autodesk Fusion and exported as PDF files for submission as per the course-brief rules. 19
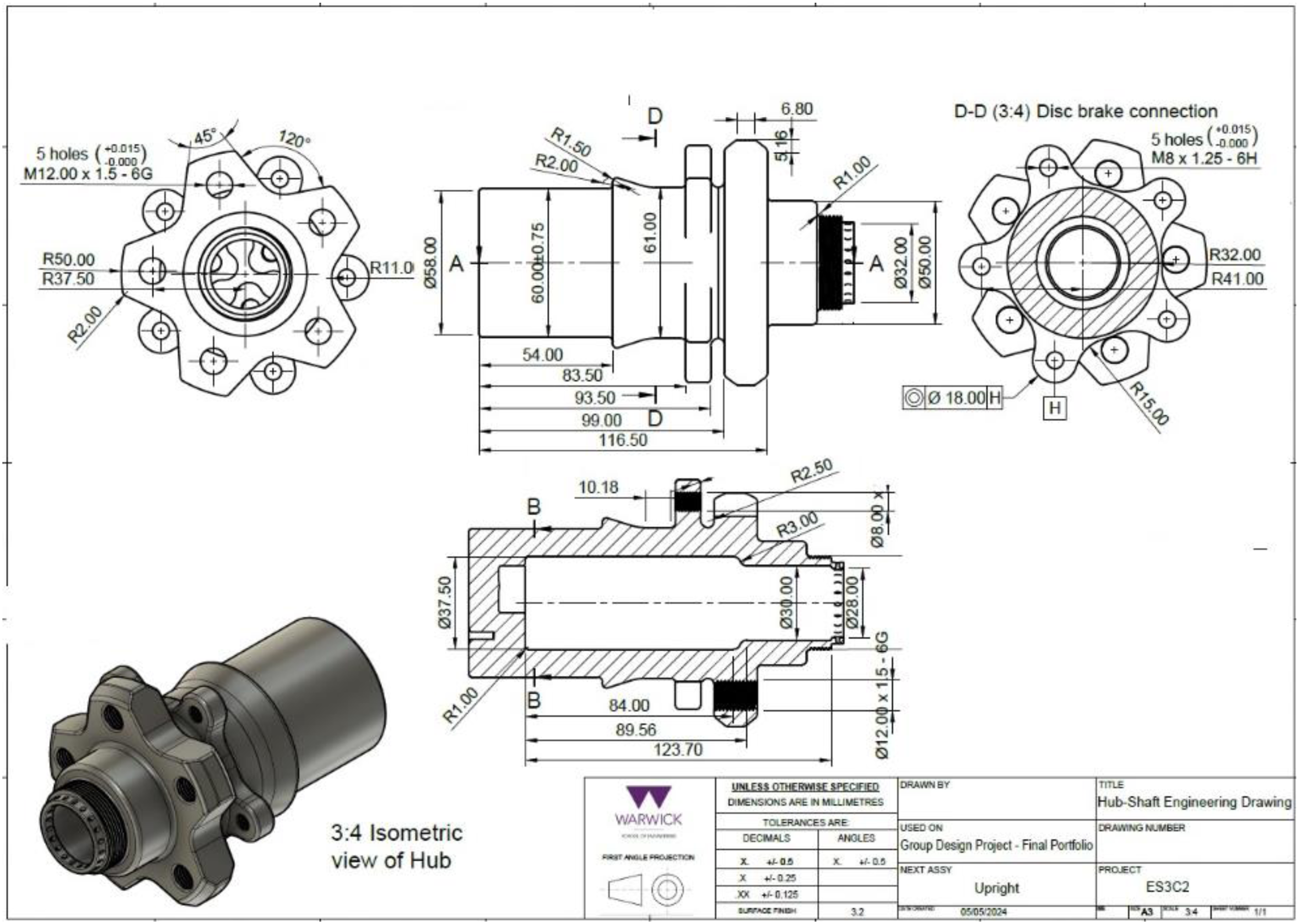
Typical 2D engineering drawing including projections, isometric views, textbox and in-drawing annotations. 19
Marking rubric design
The Course's marking rubric is designed with five equally weighted criteria to facilitate efficient marking and to provide students with useful, specific feedback. It also includes a text field for specific technical feedback (Table 1).
An equally weighted 5-point marking rubric for 2D technical drawings.

Shortlisting AI platforms
The core requirements for candidate LLM agents to be used in this work included:
Ability to analyse drawings in a compatible format (PDF, IMAGE or native DXF, DWG format) Capable of providing text-based reasoning, feedback generation and feature and text extraction via Optical Character Recognition (OCR). Not requiring a paid subscription, i.e., it's widely accessible to a large pool of students and general users. Run from a web interface, i.e., without downloading stand-alone apps.
Following the above, three mainstream AI platforms were selected, based on the number of users and accessibility (Table 2): 1) ChatGPT, reporting 3–5 billion monthly visits.20,21 2)GROK with over 3 billion monthly visits on the x.com domain 20 and 3) DeepSeek with 100 million monthly active users. 22
Ai platforms used for this study, accessed via their public web interfaces between August and September 2025, using the versions listed.

Prompt development strategy
AI models receive commands via ‘prompts’, which are instructions designed to obtain accurate and repeatable outputs.23,24 The selection and refinement of such text-based instructions is usually referred to as ‘Prompt Engineering’. Unlike conventional computer programming, where instructions are universal, prompts are commonly used in conjunction with written or spoken examples, contextual information and feedback for fine-tuning by a human operator. Prompts are commonly classified according to the number and frequency of examples or ‘shots’ being used to refine the LLM response. 23 As such, a zero-shot prompting strategy means a single instruction with no sample outputs being provided.
A ‘few-shot prompting strategy’ is used to help the AI model structure its answer based on a small number of sample outputs being provided by the user, typically between 3–5 examples.25,26 Another prompting strategy is defined as Chain-of-Thought (CoT) prompting, which requires the AI model to reason and provide a step-by-step rationale for the answer. An additional prompting strategy is ‘Human-in-the-Loop’, where a human operator provides feedback to the LLM agent until an acceptable output is reached. 27 This can offer the possibility of fine-tuning the AI outputs progressively as they work through the submission items. In this work, a 3-level prompting strategy was used, with the different prompting types tested for accuracy by comparing their outputs to real historic, manually graded coursework submissions.
Designing a ‘virtual assessor’ or persona
A common first step before prompt design is to establish a persona, usually called role-based prompting, where AI is given a particular role that shapes its responses.
28
This role is assigned to provide AI with a contextual framework in relation to the field being studied. For this work, the AI ‘persona’ is deemed to reflect the main ‘institutional traits’ of the lead coursework marker, with a range of additional technical traits to set the expectations for the need to grade industry-level drawing submissions:
Role Definition: An Engineering Design expert instructor, with shopfloor experience as a machinist and familiar with Senior product development roles. Context definition: “based in a UK Higher Education institution”. Output form definition: Grading style in line with the UK Degree-Classification System
29
A pilot prompt statement was then introduced, which sets the expectations for the AI to perform the required analysis, along with the marking scheme and the specific items of feedback to be included (Table 3).
Standard prompt to be used across every drawing submission analysis

Iteration and testing
The grading outputs for three prompting strategies (Case 1–3) were compared using 5 drawing submissions to validate their efficiency before deploying them on the full 32 drawing dataset:
Case 1: ‘Zero-shot’ strategy. The prompt is entered without providing further examples or previous historic marking examples to the AI-agents. Case 2: ‘Few-shot’ strategy. Three sample drawings were presented to the AI-agents, indicating the real-life marking scores. Case 3: ‘Human in the Loop’ (HITL). Three sample submission results to be offered, including expert feedback on five consecutive results. Additional contextual feedback can be provided, describing specific aspects of the technical drawing being examined, such as views, annotations or DG&T data.
Marking and feedback analysis
The spread and distribution of all marks generated by all AIs using the three prompting strategies were graphically compared via box and whisker plots to illustrate the extent of the distributions and to identify any potential skewness. The mean absolute error was calculated for each of the three prompting cases. Based on the error levels, the prompting strategy yielding the lowest error rate, ideally below 15% of the real mark, was taken forward and deployed for the whole collection of 32 drawings.
Written feedback analysis
The written feedback offered by AI was assessed in terms of the qualitative aspects included in Table 4, which incorporates elements from the Warwick Assessment Strategy 30 set out for taught courses at the School of Engineering. The feedback analysis is intended to shape the LLM response so that the comments provided align with the expected academic standards.
Basic criteria to assess written feedback produced by LLM agents.

Results
LLM agent selection
Initial attempts were made to use PDF format drawings to prevent any potential quality-loss when converting files to an image. The results were varied, with some drawings being interpreted in high detail (ChatGPT), while other files were reported as faulty, corrupted or empty. DeepSeek failed at uploading all PDF files; therefore, it was decided to adopt an image-based analysis (.jpg or .png formats) for consistency across all platforms.
Prompt strategy testing
Case 1: Zero-Shot (ZS) approach
All models were interrogated using the developed rubric as a prompt without additional contextual information, and without presenting previous examples or providing feedback on the results generated. It was at this stage that DeepSeek was identified as having constant difficulties parsing and interpreting graphical information, resulting in ‘hallucinations’ where the resulting feedback was based on ill-detected text (Figure 3). This led to DeepSeek being discarded for this research, as the resulting grades and feedback were largely affected by its difficulties in successfully extracting text from images. ChatGPT and GROK tended to grade drawings above 80% which did not align with the human-marked average grades.
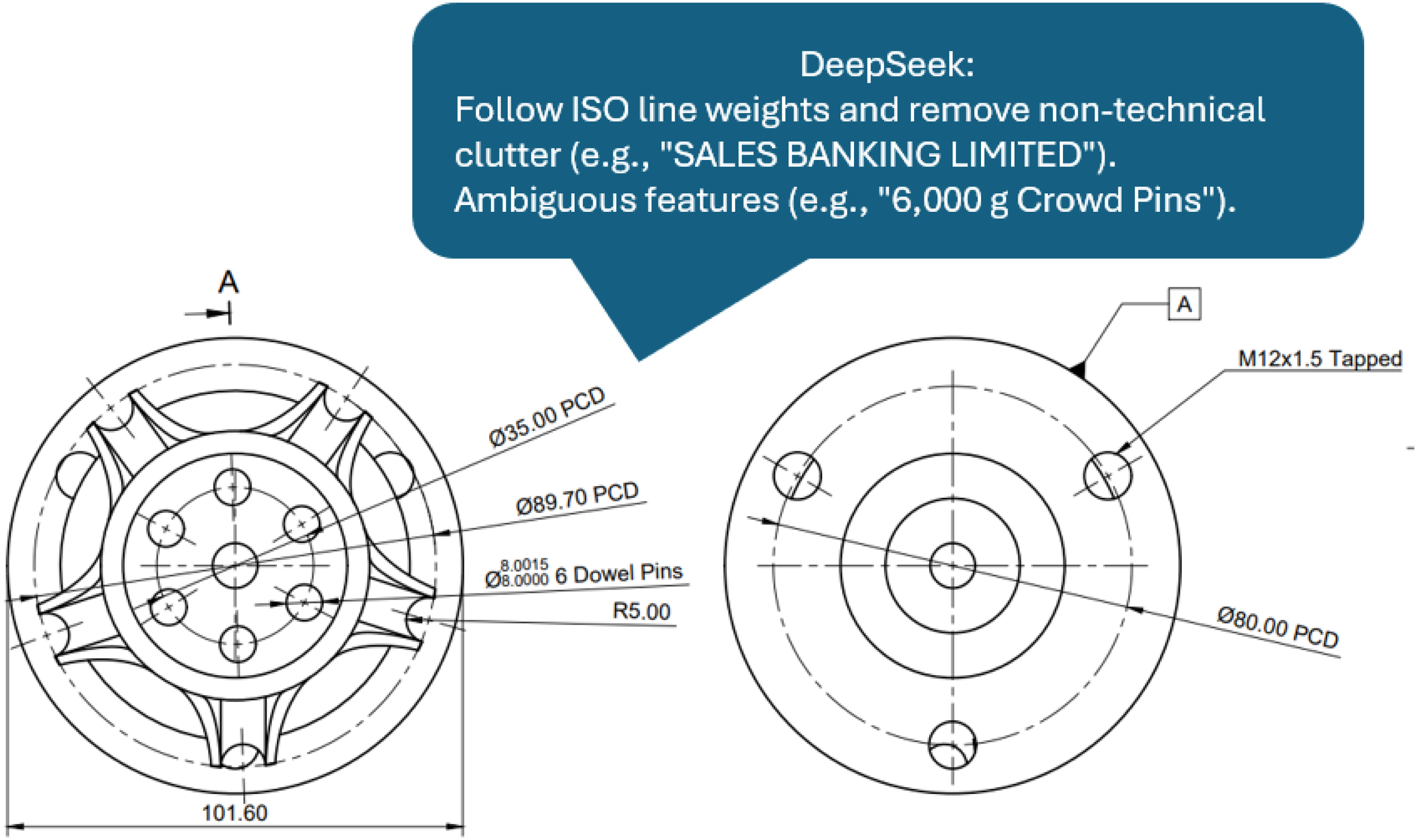
Sample feedback statements delivered by DeepSeek based on ‘hallucinations.
Case 2: Few-Shot (Fs) approach
LLM agents were presented with three sample drawings along with the real-life marks associated with them. Although this dramatically reduced the total average grades, it resulted in two opposite behaviours: while ChatGPT produced grades above 60%, GROK generated lower grades consistently below 60%, suggesting both models have significantly different interpretations of the same drawing sets.
Case 3: Human-In-The-Loop (HITL) approach
AI was provided with comments and feedback on their performance for 5 consecutive results, which was taken as an opportunity to moderate and shape their responses, behaviour and grading levels continuously. Figure 4 shows a sample iteration of HITL feedback for a given drawing, which is intended to inform the AI agent not only of the real grades that were expected but also of the rationale and the potential reasons why the AI marks and the real marks differ.

GROK 3 chatbot reacting to the provided HITL feedback for a sample drawing. The LLM is triggered to re-evaluate its previous output with a new one that aligns more closely with human markers’ expectations.
The comparative boxplot (Figure 5-left) exhibits differences across prompting strategies, with zero-shot prompting producing higher grades than the other prompting strategies, as shown in the interquartile range for both AI models. The Few-shot strategy reflects a downward trend for the marking average, with GROK-FS exhibiting a narrower data spread. The HITL strategy depicts a more naturally spread plot for both AI engines, with GROK leaning towards a normal distribution. The error-bar plot provides a more accurate representation of the error levels resulting from the different prompting inputs (Figure 5, right). Although the overall difference between the Few-shot and the HITL approaches is small, the HITL method has the potential of being refined further in response to the feedback conditioning provided by the human operator at various steps.
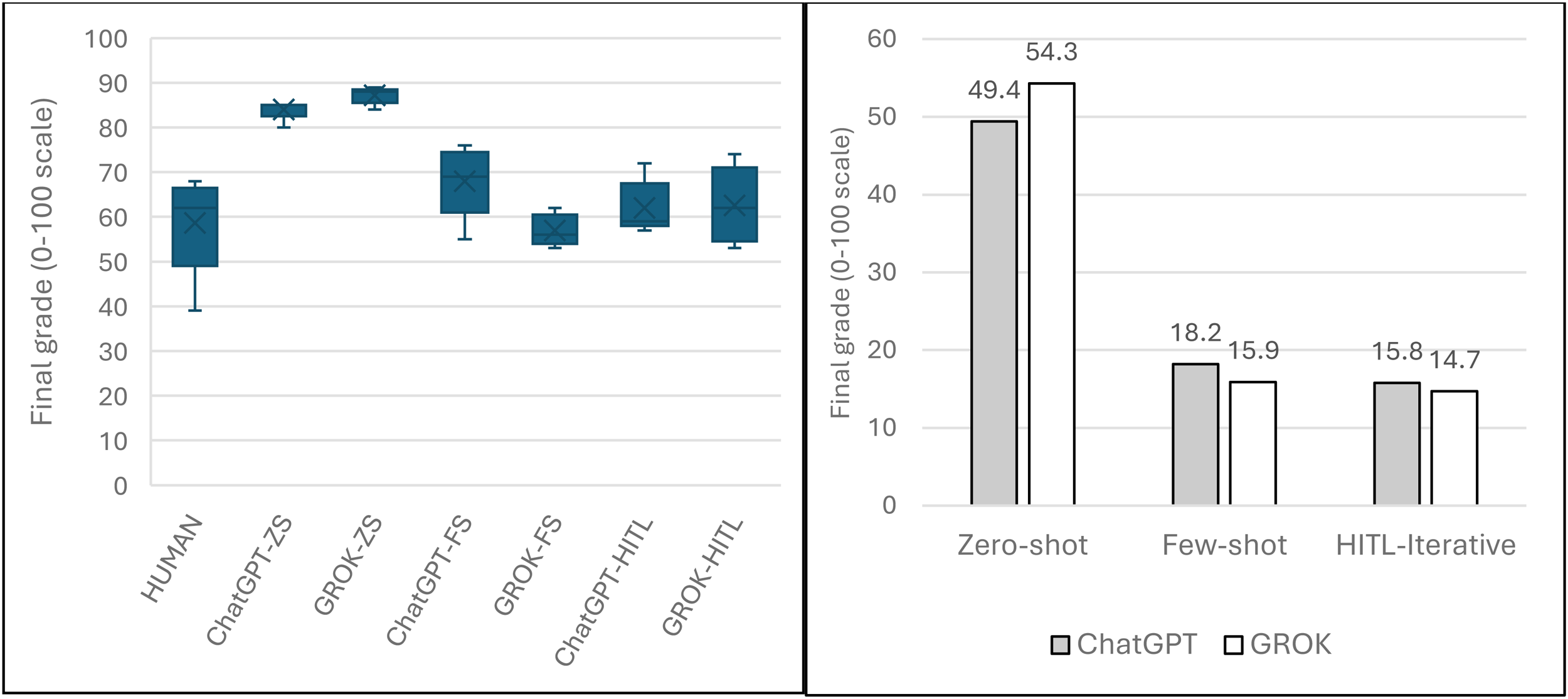
Left: grading distribution based on manual marking vs prompting strategy: Zero-Shot (ZS), Few-Shot (FS) and human in the loop (HITL). Right: Average % error for the various prompting methods vs real assignment marks.
Following the preliminary analysis, HITL was chosen as the main prompting strategy for the complete drawing dataset as it demonstrated the ability to harness LLM's potential to inform and shape the overall AI-model reasoning process by providing feedback and comparing against real human-marker grades.
Full dataset marking and statistical analysis
A total of 32 Engineering drawings were graded by ChatGPT and GROK using HITL prompting and compared against the real grades awarded by a human marker (Figure 6). None of the AI agents awarded any ‘fail-marks’; instead, they tended to award high-marks in some cases above 80%, which should correspond to outstanding submissions.
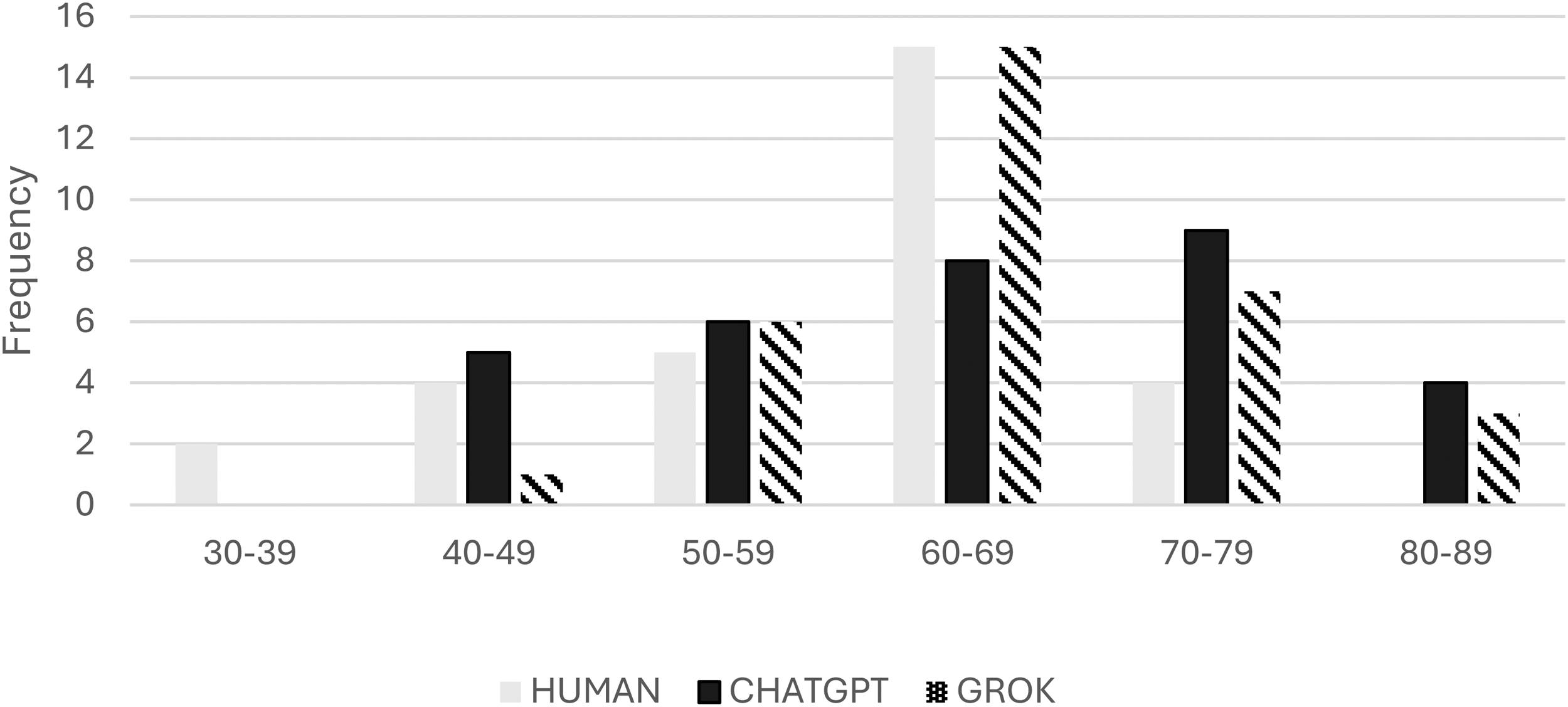
Distribution of human, ChatGPT and GROK grades. Noticeably, LLMs have awarded no fail marks, and instead have a tendency to generate high-level marks above the expected thresholds.
Although the visual distribution pattern across the three datasets seems similar, GROK displays a higher average, with ChatGPT having the widest range (45) and the highest standard deviation, indicating higher variability. In terms of frequency, the human or manual marker peaks in the 60–69 range, suggesting a possible skewness in the distribution; GROK also peaks in the same range as the manual marker (60–69), although it also awards marks in the >80 range. The overall statistical parameters for the three groups being compared are presented in Table 5.
Grading comparison statistical parameters

The box and whisker plot (Figure 7 and Table 6) illustrates the overall graphic behaviour of the three marking methods using an inclusive median, with the manual marker's whiskers extending from 35 to 70, with no outliers, as all data points fall between 1.5 times the interquartile range. ChatGPT shows a higher Q3 level (≈74) with no outliers, whereas GROK has at least one outlier on the lower whisker.
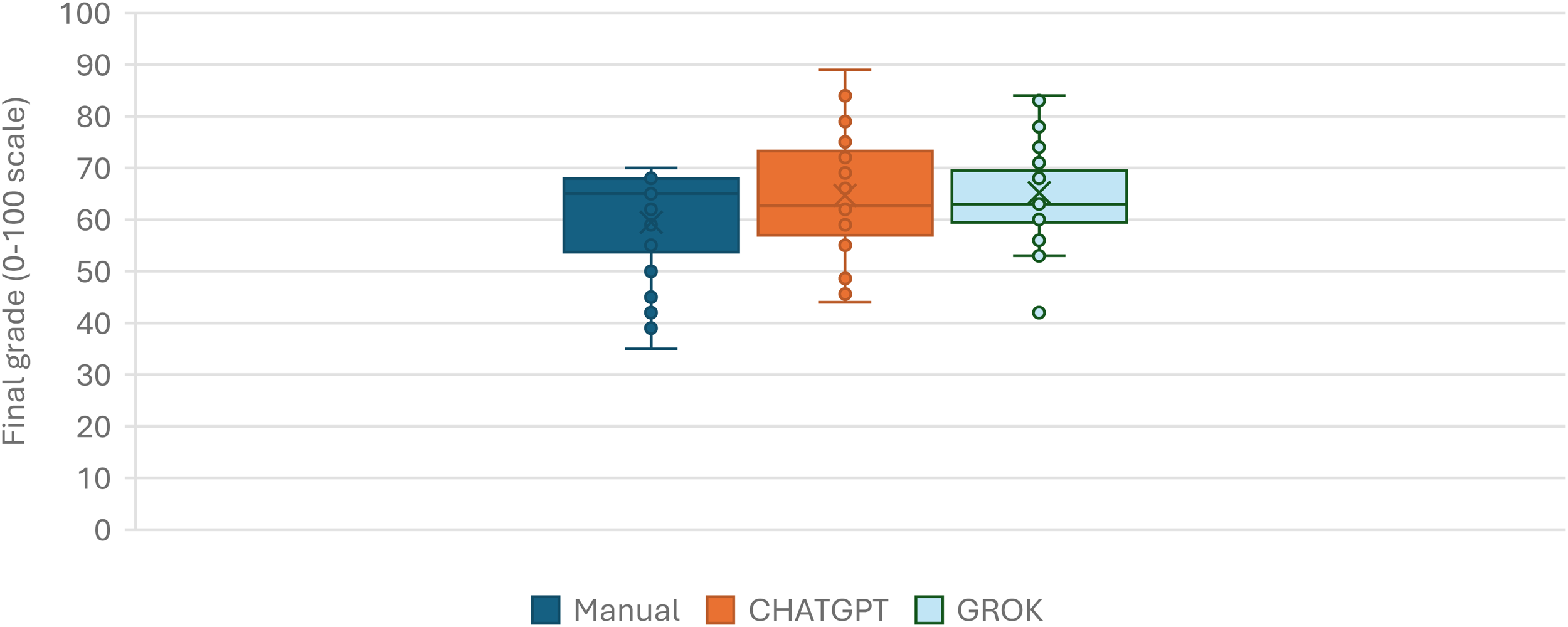
Marking distribution based on 32 samples. While averages appear within a similar range (>60%), the maximum and minimum marks levels are noticeable different.
Statistical parameters specifying interquartile ranges and fence limits for the marking distribution.

Statistical analysis of the three different marking datasets suggests a normal distribution for both AI models, confirmed visually by the QQ plots for each group (Figure 8). The manual marking distribution suggests skewness with a noticeable cluster between 65–70, so further proof is needed to test for normality.
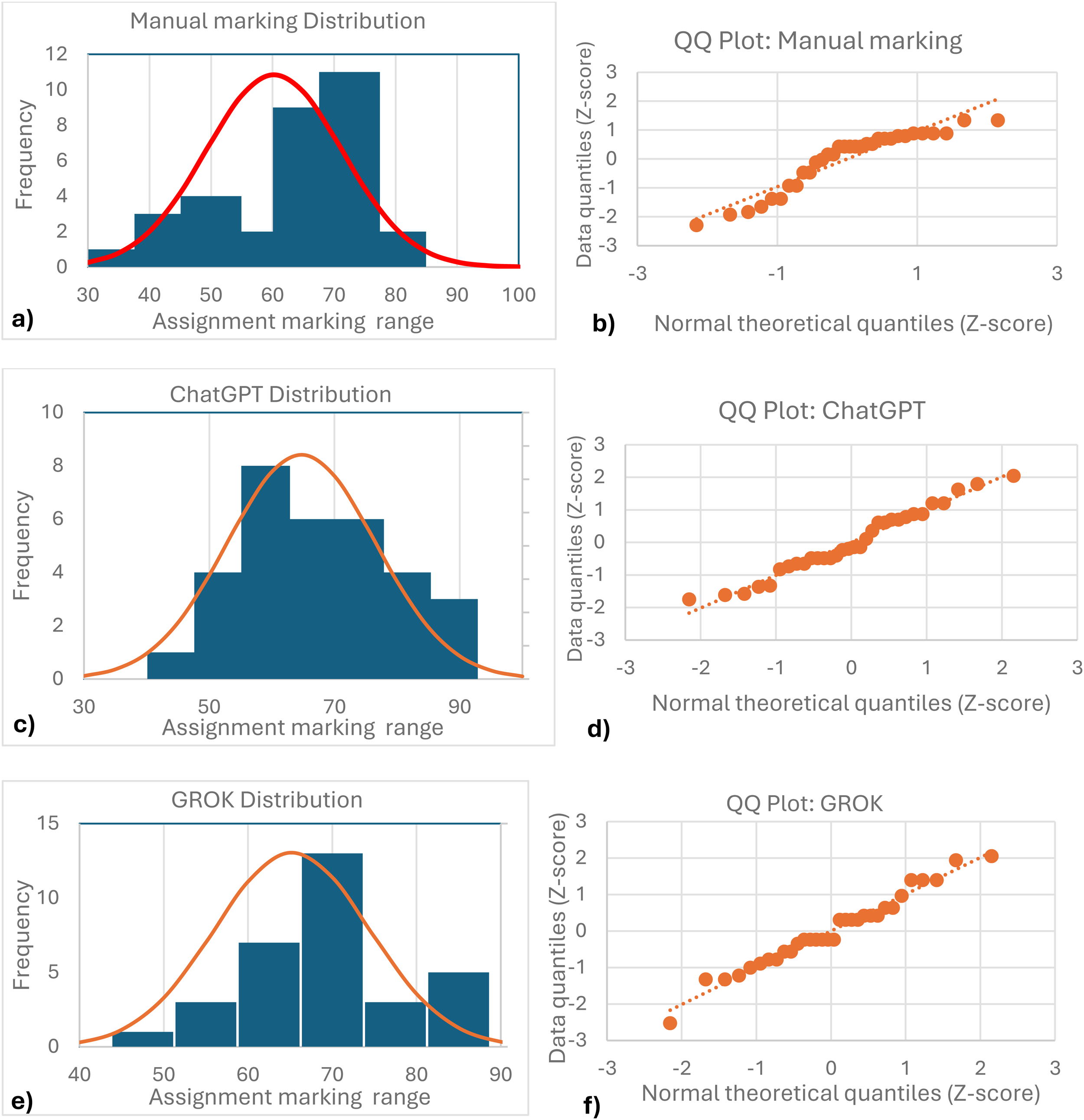
Histogram and QQ plots for each group: manual marker (a-b), ChatGPT (c-d) and GROK (e-f).
The Shapiro-Wilk test was then performed to determine normality for each dataset, assuming the null-hypothesis (H0) that each sample comes from a normally distributed sample. The main test statistic (W) measures how closely the datasets resemble a normal distribution, depending on how close the value W is to 1, with a p-value considered at a significance level α = 0.05. Results in Table 7 show that the manual marker sample distribution does not clearly exhibit a normal trend.
Normality testing results for the three grading methods

Although results for the three marking methods exhibit W values close to 1, the p-value for the Manual marker is significantly below 0.05; therefore, H0 is rejected in this case. Both AIs display a normal distribution, although the p-values are close to the threshold. A one-way ANOVA analysis was conducted to assess the marking method's effect on grades, following the following (Table 8):
independent variable: Marking methods (manual, ChatGPT, GROK) and Dependent variable: Student scores
One-way ANOVA analysis results for the comparison across marking means

The following hypotheses were then established:
H0- There are no significant differences across the three groups (based on mean scores) H1- At least one group has a mean which suggests that differences are present.
With a significance level (α = 0,05) hypothesis H0 is not rejected. The difference in means is primarily driven by the lower Manual-marker mean (59.5); however, the within-group variability is considerable, reducing the effect of the F-statistic value. Although the ANOVA test is robust in the presence of non-normalities, it is desirable to confirm this behaviour by an alternative non-parametric statistical analysis that does not assume normality; the Kruskal-Wallis H test was conducted based on key elements like the H-statistic, degrees of freedom, and p-value.
The Kruskal-Wallis H-statistic is calculated as: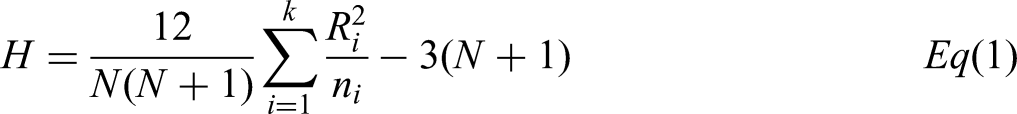
Where:
N = 96 (3 groups of 32) k = 3 (number of groups) ni = 32 (number of data points)
The resulting H value is approximately ≈5.80. A p-value derived from chi-square distribution tables for a value X2 = 5.8 is approximately 0.055. Working with the same hypothesis as in the previous case, where:
H0- There are no significant differences across the three groups (median scores) H1- At least one group has a median which suggests that differences are present.
At a significance level α = 0,05, it is now possible to establish the following relationship: α = 0.05, P-value p≈0.055, therefore 0.055 > 0.05, indicating that there is no significant difference across the medians of the three groups. To complement the significance testing, we computed effect sizes for both tests. The ANOVA yielded η2 = 0.0566, and the Kruskal–Wallis's test produced ε2 = 0.0409, both indicating small practical differences between marking methods. These effect sizes support the conclusion that, for this dataset, no statistically significant differences were detected (ANOVA p≈0.067; Kruskal–Wallis p≈0.055).
Feedback analysis
Whereas Section 4.2 focuses on OCR-related extraction errors which may arise from ill-defined text/geometry recognition, this section examines a different class of errors that occur independently of the input fidelity and translate into, at times, inconsistent text outputs. AI-generated written feedback is a critical aspect of grading which must receive utmost attention from human graders to ensure consistency, neutrality and at times, language and tone moderation.
Tone
Most comments use a neutral tone with plain technical descriptions of the issues identified in the drawing. DeepSeek results from short-shot prompting focused on errors and shortcomings of the designs, whereas ChatGPT and GROK tend to highlight correct work made by students, prior to offering feedback.
Specificity
Although most of the comments are precise, there are contradictions in certain fields related to the same object. Figure 9 shows LLM agents detecting different projection types, despite the projection name and symbol being explicitly included in the original drawing. ChatGPT recognises the opposite type of projection (first angle), whereas DeepSeek avoids mentioning the type of projection in question.
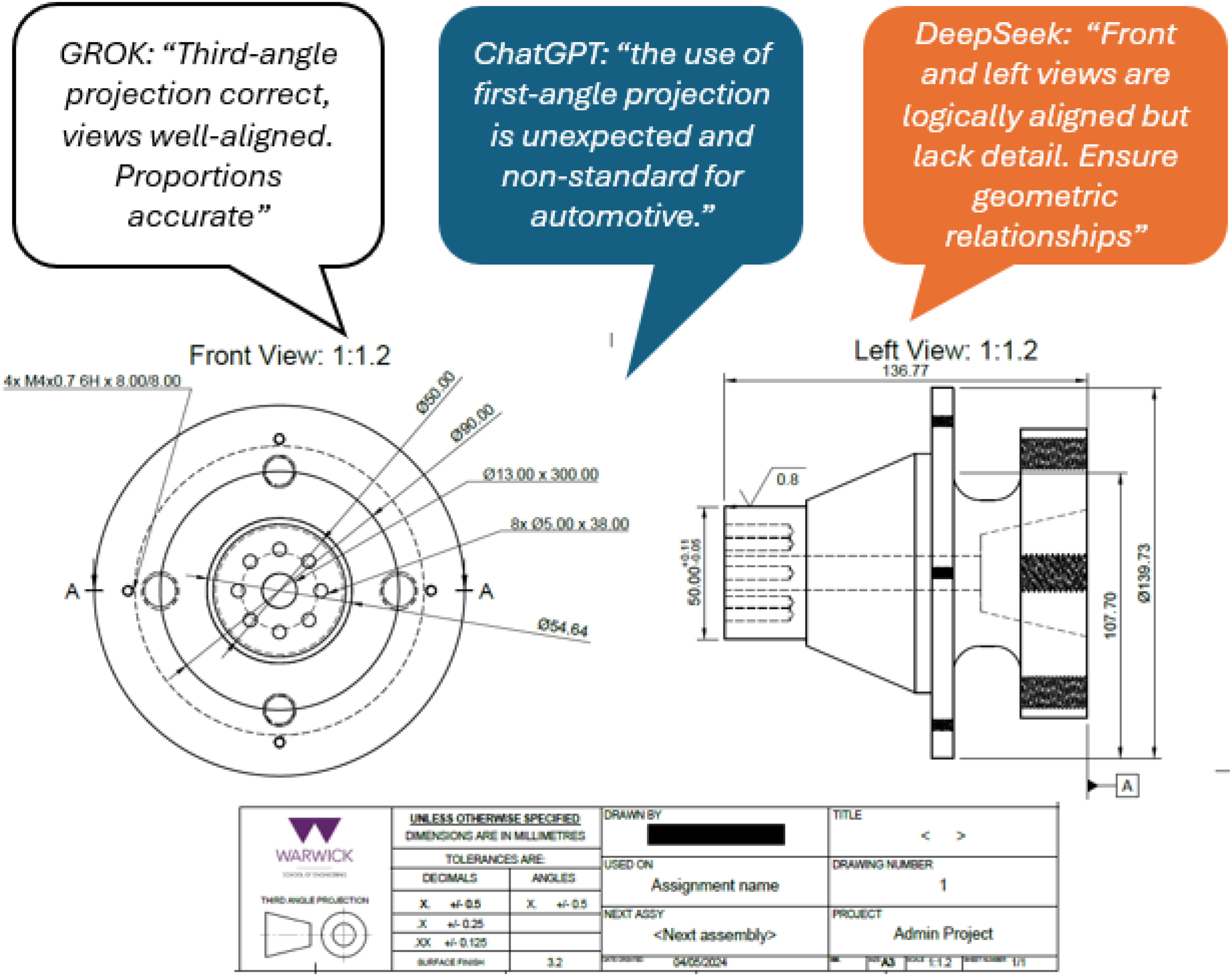
Contradictory information was provided by three AI agents exhibiting difficulties in extracting graphical information from the drawing template.
Actionability
Actionable feedback refers to the reflective comments which involve a quality judgement on the submitted work, while providing a clear outline of the action to improve. Actionable feedback is one of the qualities most engineering students value in mid-term satisfaction surveys, as well as in National Student Surveys. 31 All AI-models seem capable of providing actionable feedback, with some samples shown in Table 9.
Actionable and non-actionable feedback examples across different AI agents

Balance
LLMs can be efficiently conditioned at the prompting stage to offer a balance of positive comments, including acknowledgement of meritorious achievements, while highlighting shortcomings and errors made. This structure is usually defined in literature as “praise–critique sequencing” or “sandwiched feedback”,
32
and it's reported to reduce students’ anxiety when having their work examined,
33
making it highly suitable in the context of engineering technical drawing, particularly in cases where students are submitting their first designs. Two sample pieces of ‘sandwiched feedback’ produced by AI agents are shown below:
“Good use of layout and conventions, but overlapping dimensions in the front view can cause visual clutter”. “The isometric view provides helpful context, but a clearer visual representation would aid in understanding assembly flow.”
Assumptions
Standard technical drawing vocabulary is proficiently used by all AI agents for sketching, tolerancing, dimensioning, formatting and including materials and manufacturing information. In a higher education design course, students are expected to be familiar with standard abbreviations and terminology such as GD&T (DATUM, MMC, TP, etc.), threads and fasteners (UNC/UNF, LH, RH, etc) and also to identify and understand the standards that must be followed (BS 8888, BS 3643, ISO 128-series, ISO 129-series, etc.). Therefore, when AI models offer actionable feedback by referencing specific standards to be observed, students are assumed to know which references to go to for amendments, rather than being offered a comprehensive list of specific corrections.
Discussion
Natural language feedback analysis
LLMs proved efficient in extracting precise information from relevant drawing standards such as BS 8888, ISO 128/129, etc. This has the potential to aid design instructors in detecting specific conventions and rules which a human marker may inadvertently omit. There is, however, an aspect of holistic understanding of the student's own work which is inherent to the human marker. Figure 10 illustrates a typical example of a technically correct drawing which will tend to attract high grades from AI engines, despite exhibiting several deficiencies which a human/manual marker should be able to identify, namely:
The material selected by the student (Carbon steel) involves a rather high complexity for machining, which would be undesirable or impractical for a Formula Student context. The material is defined as an AISI, US/American standard, when it should provide either the UK/European equivalent, or a locally/nationally sourced material. It does not indicate the material's condition. The component design, although correct, does not exhibit any light-weighting strategies for weight reduction. Threads have been left as a 3D projection rather than following a double line.
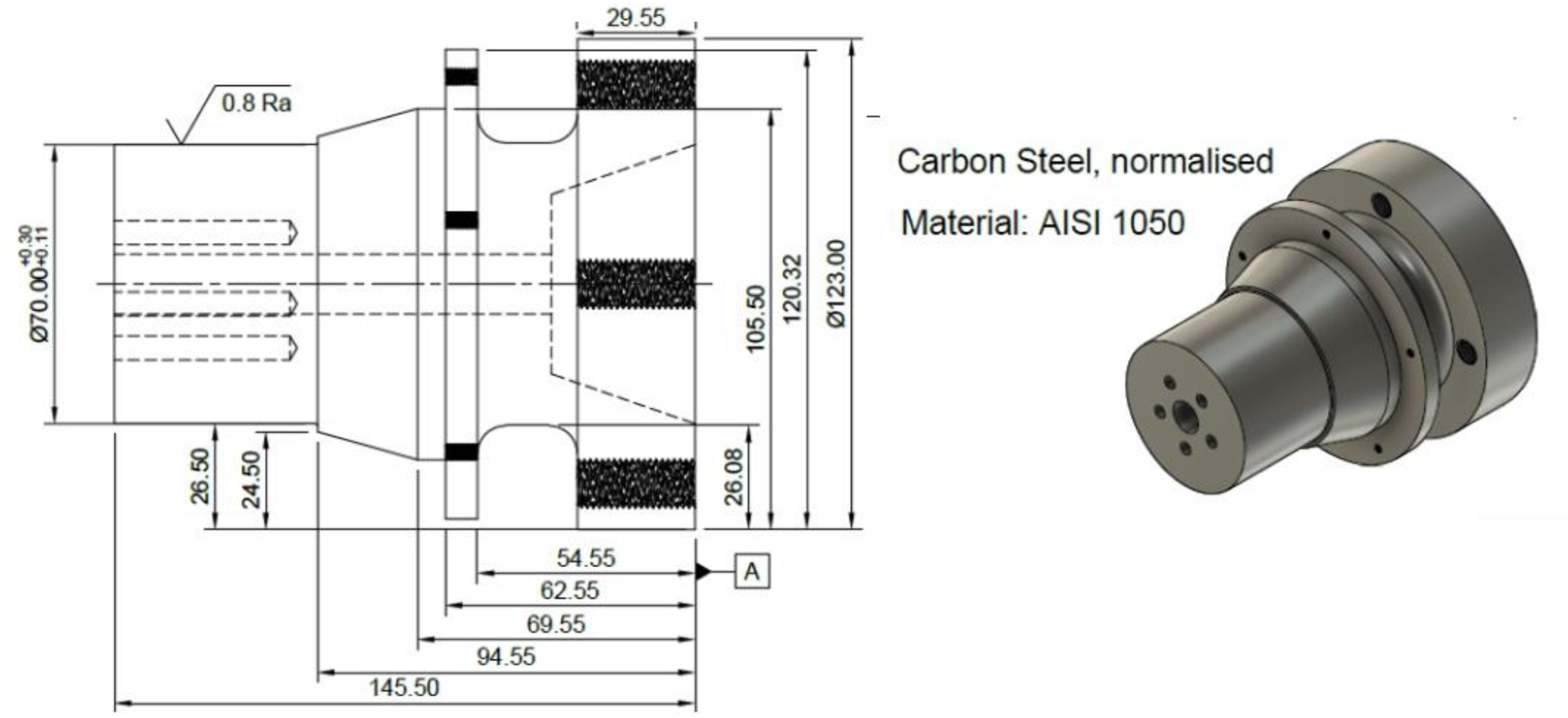
A sample drawing including design characteristics not picked up by AIs such as lightweighting features, material suitability and materials standards.
As such, there are elements of the design which will not be recognised or ‘picked up’ by the AI agent being used, which require human intervention to be identified and actioned as part of the provided feedback to students.
Adaptive system behaviour
LLM agents are mostly non-deterministic, meaning that the same AI agent, under similar prompts, is likely to produce different results, even when the same prompting and feedback conditions are repeated. 34 When students use AI to obtain feedback and grading estimates, they will usually obtain significantly different feedback, observations and overall grades compared to the model used by the main human marker. This is due to the prompt design, feedback loops and contextual information being provided in different ways for each individual user.
Risks of AI-automatic marking
Alignment bias
Modern generative AI models have been developed to align with the human operator's perceived preferences and expectations, even in cases where the user's prompting strategy and communication is unclear, ambiguous or even incorrect. This is usually referred to as ‘alignment bias. 34 LLM agents generally prioritise ‘user satisfaction’ by avoiding disagreement with the operator, often at the expense of correctness or objectivity. While this is an expected LLM trait, it is not aligned with the rigour expected in academic assessment, making it necessary to ensure a level of moderation is in place.
Image to text detection errors
LLMs are reported to have limited success at error-free Optical Character Recognition (OCR) when extracting text strings from images, PDFs and scanned documents. 35 Typical behaviours in OCR-related errors include altering numbers, mislabelling data and adding or missing words. This type of behaviour in the AI domain is called ‘AI-visual-hallucinations’ 36 and is inherent to the way LLMs are usually built. In this work, hallucinations were mostly exhibited by the DeepSeek algorithm, causing it to be ruled out from further analysis. However, while ChatGPT and GROK did not exhibit frequent hallucinations, the possibility of misrecognitions may be present across any multi-modal LLM, 36 thus becoming a considerable setback for automatic image analysis and a widely recognised limitation of current AI models.
Parsing errors are another type of shortcoming where AI agents do not recognise text characters correctly, artificially generating grammatical errors which cannot be attributed to the human designer. They are mostly caused by the code used to convert data or images to text. This was more prevalent for DeepSeek, which struggled to recognise text correctly in most drawings. This can have potentially negative downstream consequences if automatic feedback is released to students, which contains ‘detection errors’ which have impacted on the overall student marks.
Grade inflation
Marking schemes and marking criteria in higher education are carefully designed to assess levels of performance and ensure the produced grades reflect the student's attainment in relation to the whole cohort. 37 Delegating marking to AI has the potential to lead to artificial grade inflation, meaning that a considerable number of grades fall on a higher-than-expected or lower-than-expected band as a result of the AI agent's own interpretation. This was observed in the Short-shot Case 1 prompting analysis, where all AI agents defaulted to assigning high grades due to the lack of contextual information and benchmarking feedback to tune their scores.
Conclusions
This work assessed the viability of using LLM AI agents for 2D engineering drawing assessment, grading and feedback generation. The results are applicable to a sample size n = 32, and although the relevant statistical methods have been deployed to ensure significance, a larger sample would be ideal to be able to generalise this trend across other 2D design challenges. Different prompting strategies were used, which differ in the amount of user feedback and interactions used as input to shape the AI responses. Although no statistical difference was found between the grades awarded by the AI agents and the human marker, this result does not suggest one can replace the other, as current LLMs’ limitations remain, particularly regarding OCR robustness and prompt sensitivity.
Using LLM agents for automatic marking will likely result in highly variable outcomes, dictated by the prompting strategy, the language structure being used and the frequency and detail of the feedback provided at each interaction. It must be noted that this study's findings relate to the overall mark behaviour rather than the individual rubric criteria. It will therefore be relevant for course leaders to adopt a systematic approach to grading, incorporating actionable and well-organised historic repositories of their own marking for the creation of key datasets that can help train and refine marking models, effectively a ‘Knowledge base’.
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
This study demonstrates the LLM potential as an assisted assessment tool when used within a moderated, “human-in-the-loop framework.” The combined use of LLMs, in conjunction with traditional expert systems, relational databases, historical datasets and heuristic rules, will probably be the most likely method to yield consistent results; therefore, there is room for engineering educators to explore the development of personalised tools, beyond the sole use of commercially existing LLM agents.
Data availability statement
The 2D drawing datasets used for this research are permanently available using the following access link DOI: https://doi.org/10.5281/zenodo.16876577