
Abstract
The opacity of machine learning (ML) algorithms is a significant concern in academic and regulatory circles. An emergent sociology of algorithms, however, argues that far from opacity being an inherent quality of algorithms, it is socially constructed and contingent upon certain choices and decisions. In this article, we show that a valorization of opacity is a key component of the epistemic culture of ML experts. While earlier campaigns for mechanical objectivity contrasted the inconsistency of human experts with the reliability of procedures and machines, we found that ML experts valorize precisely those moments when complex algorithms ‘surprised’ them with unexpected outcomes. They thereby endowed machines with a mysterious capacity to make predictions based on calculations and factors that humans cannot grasp. In this way, they turned opacity from a problem into an epistemic virtue. We trace this valorization of opacity to the jurisdictional struggles through which ML expertise emerged and differentiated itself from its two competitors: the ‘expert systems’ type of the ‘artificial intelligence’ sub-field of computer science on the one hand and inferential statistics on the other. In the course of these struggles, ML experts absorbed a theory of human expertise as tacit and inarticulable, extended it to include algorithms, and then leveraged this newly acquired version of opacity to dramatize the differences that separated them from statisticians. The analysis is based on sixty in-depth, semi-structured, and open-ended interviews with ML experts and data scientists working today, as well as historical research on the origins of data science.
Keywords
As machine learning (ML)-based Artificial Intelligence (AI) algorithms enter diverse fields of expertise (Brayne & Christin, 2021; Christin, 2017; Faulconbridge et al., 2025; Lebovitz et al., 2022; Suchman, 2023), there are increasing warnings about algorithmic opacity in academic and regulatory circles (O’Neil, 2017; Pasquale, 2015; Zuboff, 2015). Scholars in the social sciences and legal fields raise red flags about opaque algorithms, concerned that the well-documented problems of bias and discrimination embedded, for example, in the training data or the weights employed by proprietary algorithms would become intractable (Eubanks, 2018; Noble, 2018; Pasquale 2015). Justifiably, they worry that minorities and lower-income individuals would likely bear the brunt of high-stakes legal, financial, or medical decisions made by algorithms without being able to challenge their opaque inner workings. Opacity, moreover, complicates the already fraught question of legal accountability for algorithmic decision-making (Christian, 2021, p. 88; Martin, 2019). Even within the ML-based AI community itself, opacity is occasionally formulated as a problem, as in the field of ‘AI safety’ where it constitutes a barrier to detecting whether an AI system has ‘gone rogue’ (Ahmed et al., 2024).
Accordingly, the ‘right to explanation’ formulated in the European Union’s General Data Protection Regulation (GDPR), and its proposed Artificial Intelligence (AI) Act of July 2021 requires that AI systems be explainable for high-risk decision making (European Commission, 2021). The confrontation clause of the US Constitution has been interpreted, at least by some judges, as requiring public scrutiny and explainability of the source code of probabilistic DNA profiling algorithms (Pullen-Blasnik et al., 2024; Roth, 2017).
This critical literature seems to accept at face value, however, the idea that all algorithms are opaque and that all of them are opaque in mostly the same way. This idea is problematized by an emerging sociology of algorithms. Sociologists and others have noted that opacity is not necessarily an inherent quality of algorithms. Some algorithms are opaque not because they are complex but because they are proprietary, and corporations are interested in protecting their trade secrets and competitive advantage (Burrell, 2016; Pasquale, 2015). Other algorithms are effectively opaque not because it is impossible to scrutinize them but because of a scarcity of technical skills required for understanding the algorithmic source code (Burrell, 2016; Christin, 2020; Diakopoulos, 2013). Other algorithms operate at high mathematical dimensionality, making it exceedingly difficult for humans to understand their workings (Burrell, 2016). However, even in these cases, there are techniques— saliency maps, feature visualization, multiple outcomes—to ‘peer inside’ and undo some of the opacity (Christian, 2021, pp. 103–112; Lipton, 2018). Finally, in many cases, opacity is due not to the complexity of the computational and mathematical calculations involved but the complexity, multiple layers, and sheer size of the socio-technical assemblage in which these calculations are embedded and the many ‘hidden’ human decision-making points of which the assemblage is composed (Ananny & Crawford, 2018; Christin, 2020; Widder & Nafus, 2023).
The upshot of this emerging sociology of algorithms is that opacity can come in different flavors and intensities, it can be caused by diverse processes, and it is not an inherent quality of algorithms. It is contingent on certain decisions and choices. Dare we say it? Opacity is socially constructed. Partly, no doubt, the social construction of opacity is a cynical, self-interested strategy of the ‘new artificial intelligentsia’ (Benjamin, 2024), but as we will argue here, this explanation fails to take account of the ways in which opacity is embedded as an epistemic virtue in the work practices of ML experts.
In this article, we build on the insights of this emerging sociology of algorithms but add another set of factors that shapes the social construction of opacity: the historically formed epistemic culture, work practices, professional interests, and jurisdictional claims of ML experts and data scientists, namely the developers, promoters, and users of ML-type algorithms. As we will show, the jurisdictional struggles (Abbott, 1988) through which this form of expertise emerged and differentiated itself from its competitors led many ML experts to construct opacity not as a bug, something to fix or overcome, but a feature, exactly what makes their form of expertise so powerful, exciting and valuable (Keane, 2025, p. 137).
This means, however, that ML experts constantly equivocate between two renditions of opacity: On the one hand, they frame opacity as a function of the complexity of the algorithm itself, which is, therefore, mirrored in the complexity of the expertise necessary to build, tame, tweak, and understand such complex entities. In this rendition, they highlight the esoteric nature of their training and the methods and heuristics they developed in order to render the inner workings of algorithms understandable. On other occasions, however, opacity is a function of the complexity of the phenomena that the algorithm is trying to model and, therefore, is mirrored in its internal complexity, which transcends human abilities. In this rendition, ML experts welcome and celebrate surprising and counter-intuitive results provided by the algorithm as evidence of its mysterious and superhuman computational abilities, of which they themselves are merely humble stewards and conduits.
This Janus-faced alternation between two different accounts and uses of opacity originates from needing to conduct jurisdictional struggles on two fronts. On one front, ML and specifically ‘deep learning’ expertise formed itself in opposition to the ‘expert systems’ approach and the attempt to build AI by making experts’ knowledge explicit (Forsythe, 1993). In this, they relied on philosophical and anthropological critiques that detected a recalcitrant opacity at the very core of human expertise, namely tacit knowledge possessed by experts in a form that resists explication (Dreyfus, 1992; H. L. Dreyfus & Dreyfus, 2005; S. E. Dreyfus & Dreyfus, 1980; Polanyi, 1966[1980]). Distinguishing themselves from AI researchers developing expert systems, i.e., distinguishing their skills from those in codifying knowledge into rules that machines can follow (e.g., decision trees), entailed laying claim to esoteric expertise in how complex algorithms learned from data and how this learning could be supervised and finetuned. Examples of such esoteric expertise are the claims to transcribe into computational languages brain functions, evolutionary processes, or Bayesian probabilities. The story of how their largely successful campaign to wrest the AI sub-field of computer science away from expert systems has been told multiple times (Guice, 1998; Olazaran, 1996; Rella, 2024; Ribes et al., 2019), and we will not repeat it beyond a brief sketch.
On the second front, the emerging form of expertise comprising data science and ML had to sharply distinguish itself from inferential statistics, which was used by most other scientific disciplines, such as the medical and life sciences, the social sciences, engineering, etc. We will tell this story in some detail below. For the moment, it suffices to say that in this struggle led in the opposite direction. Champions of ML declared a ‘scientific revolution’ (Anderson, 2008), accentuating the contrast between ‘two cultures’ of statistical modeling (Breiman, 2001). As against the purported reliance of inferential statistics on the ‘genius’ of human experts to simplify the data and come up with testable hypotheses, they presented data science and ML as focused solely on prediction, letting ever more powerful algorithms match the complexity of phenomena, without needing to understand how (namely without causal inference). Opacity moved from the esoteric nature of the expertise involved in building and supervising such algorithms into the phenomena itself. It became an epistemic virtue, a form of mechanical objectivity where ‘good science’ is equated with the elimination of all ‘subjective’ human judgment and perspective (e.g. Andrews, 2023; Daston, 1992; Daston & Galison, 1992; Porter, 1995).
When such opacity is criticized, ML experts can repurpose what they have learned from the philosophical and anthropological critique of expert systems. They argue that the opacity of computing machines is no different from the opacity of human experts’ tacit knowledge, just superior in terms of speed, computing power, never getting tired, and ‘mechanical’ freedom from bias. Therefore, in their campaign for legitimacy, opaque black-boxed algorithms are homologous yet superior to what they frame as ‘the black box of human experts’ minds’. This homology between the opacity of human experts’ minds and the opacity of complex computational machines encouraged ML experts to treat opacity as an epistemic virtue, a stance very much in tune with engineering’s long-time favoring of machines and experimentations over theorizing in dealing with nature’s uncertainties (Layton, 1976).
Expertise and opacity in the debate about expert systems: Absorbing Dreyfus’s critique
In the sociological and philosophical literature about expertise, there are two versions of its relationship with opacity. A limited version simply points out that to be an expert is to know what is opaque to others. The social distinction between ‘lay’ and ‘expert’ implies that what the experts know, the lay do not (Hughes, 1958). If expert knowledge was known, transparent or fully explainable to the lay, there would be no basis for a claim to expertise. In this version, opacity is, to some extent, manipulable, as the experts clearly have an interest in limiting lay access to their body of knowledge and training.
There is, however, a second version in which the link between expertise and opacity is not contingent, but inherent and inevitable. Based on the notion of tacit knowledge (Polanyi, 1966[1980]), ‘what we know and cannot tell’ (like his celebrated example of learning to ride a bicycle), knowledge comes from immersion in practical activity and is often inarticulable, even by the experts themselves. Dreyfus (1980) characterized ‘expertise’ as ‘an understanding of rules that cannot be expressed’ (see also Collins & Evans, 2007, p. 17). In the Dreyfus brothers’ five-stage theory of the development of expertise (H. L. Dreyfus & Dreyfus, 2005; S. E. Dreyfus & Dreyfus, 1980), the highest level, expertise, is automatic, below conscious awareness, and hard to explain verbally. In this version, therefore, the decision-making processes of experts are often depicted as opaque even to the experts themselves. Even when experts make fully articulate judgments of causality, when they determine, for example, that a patient’s condition is caused by a certain disease or bodily variable, thus necessitating a definite type of intervention, what remains inarticulable is the full field of probabilities informing their reasoning, namely the full set of possible factors that their experience has taught them to consider improbable.
The strong version of this theory is clearly inadequate as a theory of the social functioning of expertise. No court or public will rely on an expert who told them that they ‘know but cannot tell’. To make experts accountable for their decisions and assessments, conventions have been set in place to allow similarly trained, like-minded peers to evaluate each other’s decisions and provide explicit defenses of their evaluations (Shapin, 1995). This has been termed ‘disciplinary objectivity’ (Megill, 1994; Porter, 1995). Society’s acceptance of the institution of expertise is based on the institutions of disciplinary objectivity, and the ability of experts to explicate their evaluations even to non-experts. This has been codified in US courts as the principle of ‘general acceptability’ of a theory or method within a community of experts in evaluating the admissibility of expert testimony.
Given the sociological implausibility of the strong version, its broad influence would seem curious. It is fully explainable, however, when we realize that it was originally formulated by Dreyfus (1972, 1992) as a critique of expert systems, namely of the first wave of AI. Dreyfus was not trying to formulate a sociological theory of how expertise functions in society, but to show that the attempt to ‘extract’ the rules guiding expert decision-making and encode it in software represented a misunderstanding of the nature of expertise and was bound to fail. Historically, the effort to build artificial intelligence, and especially ML-based AI, has been inspired by studies of the human brain and specifically experts’ thoughts processes (Forsythe, 1993; McCulloch & Pitts, 1943; Minsky, 1970; Rumelhart et al., 1985). Accordingly, some of the current reactions within the AI community to the growing demand for algorithmic interpretability, transparency, explainability and—ultimately, accountability—are rooted in the history of the field’s grappling with the nature of expertise, and reflect Dreyfus’ prescient objections. AI scholars, of both the expert system stream and the ML stream, occasionally refer to him (Boden, 2013; Feltovich et al., 1997; Ramsey et al., 2013), mainly to argue that he proved ‘Good Old-Fashioned AI’ (GOFAI), i.e. expert systems, wrong. Accordingly, as the first ‘AI winter’ settled in, the new generation of ML experts drew on Dreyfus’ theory to present expert systems, the effort to extract expert knowledge in the form of rules, as leading nowhere (Feigenbaum, 1984). They presented the field as having learned the hard way that expert knowledge is opaque, tacit, contextual, and never fully articulable (Ramsey et al., 2013). How they drew the contrast between expert systems and their own approach to AI is now part of the origin story of this group, alongside a popularized version of Dreyfus’s critique.
We do not want to suggest that the ML-based AI community is a monolithic block, with all members adhering to one version of opacity inspired by the equation of human expertise with tacit knowledge. In fact, there are various reactions within it to the current demand for algorithmic interpretability, explainability and transparency. For example, the FAccT (Fairness, Accountability, and Transparency) community of computer scientists cooperates with scholars from other disciplines in trying to make algorithms less opaque, fairer, more accountable, and transparent. This includes attempts to create algorithms that will decipher the activity of more opaque algorithms (Pierce et al., 2022). Moreover, as grounded studies have shown (Christian, 2021, pp. 98–103; Lorenz, 2023), in the daily work of ML experts they might opt to use a simple algorithm in anticipation of a demand for explicit explanations.
We are arguing that the origin story of the debacle of expert systems offers this community a set of oppositions— between epistemic virtues and vices—that can be activated in the present, in situations that demand justification of some sort. As we will see in the empirical section of this article, contemporary data scientists may hold more nuanced views (and their practices may be even more complex), but they also frequently resort to the language of opacity as an epistemic virtue.
Indeed, a dominant response in ML literature is to problematize the very concepts of explainability, interpretability, or transparency as ill-defined (Lipton 2018; Phillips et al., 2020; Vilone & Longo, 2021), and epistemologically suspect. As the authors of a report on explainable AI argue, ‘human-produced explanations for their own judgments, decisions, and conclusions are largely unreliable’ (Phillips et al. 2020, p. 18). Echoing Dreyfus, they claim that when it comes to experts, ‘producing verbal explanations can interfere with decision and reasoning processes .… It is thought that as one gains expertise, the underlying processes become more automatic, outside of conscious awareness, and therefore, more difficult to explain verbally’ (p. 19). Explainability is recast as an epistemic vice because it is unreliable and can interfere with decision-making processes. If so, why demand of machines what we should not demand of experts?
The irony is that the thinking of Dreyfus, who warned about the dangers of AI, is mobilized here in defense of black box, connectionist algorithms that he had never endorsed (Dreyfus, 1992). If the attempt to articulate the underlying rules of the expert decision-making process has proven ineffective and is detrimental to this very process, if verbal explanations are harmful to expertise, then algorithmic opacity should be understood as an epistemic virtue, a feature essential for ML algorithms’ transhuman ability to cope with complexity. It is certainly not a bug to fix. Instead of explainability (a vice), the dominant tendency in the ML community is for expertise to be judged by the accuracy of prediction. The origins of this convention are in the struggle to differentiate itself from inferential statistics.
Expertise and opacity in the debate with inferential statistics: Breiman’s ‘two cultures’
The ML-based AI community formed itself not only in opposition to expert systems. Discussions on how to perform data analysis date back to debates between Bayesian and frequentist statistics (Efron, 2005). However, ML and data science emerged from the combined industry, military, and academic efforts to use computers to learn from digitally recorded data. One of the main hubs for this effort was Bell Labs, which at one point employed leading statisticians and computer scientists, such as John Tukey, John Chambers, and William Clevland, alongside physicists and engineers in different data-intensive projects (Abbott, 1988, pp. 235–236; Donoho, 2017). The statisticians cited the practical success of these collaborative projects as a reason for their disenchantment with their own discipline. If statistics was the science of learning from quantitative data, they said, then in its present incarnation, it was too focused on theory and failed to address the practical problems of analyzing big amounts of digitally recorded data (see Donoho, 2017 for a review of this history). Tukey (1962) wrote about how working in these computerized, data-intensive environments such as Bell Labs changed his identity as a statistician. He criticized the focus on confirmatory data analysis prevalent in statistics and called for an inductive, exploratory science of learning from data. These critiques from inside the discipline preceded the external critiques by computer scientists (Fayyad et al., 1996; Naur, 1974).
The full case against statistics’ inability to guide quantitative data analysis, however, was built by the ML community. Importantly, opacity played an important part in their case. The most exemplary statement of the ‘case against statistics’ was formulated by Breiman (2001) in his ‘Statistical modeling: The two cultures.’ (Breiman, 2001). This paper was called ‘one of the few anthropological papers in the field of statistics’ (Baiocchi & Rodu, 2021), because he depicted ML and statistics as two distinct epistemic cultures, originating in different disciplines, appealing to different clients, employing different criteria of success, and based on different epistemic virtues and forms of objectivity. Most importantly, each implies a different stance with respect to opacity, its locus, and the value placed on countering it with explainability. Some of the main points we derived from his account are summarized in Table 1.
Leo Breiman’s account of the two cultures.
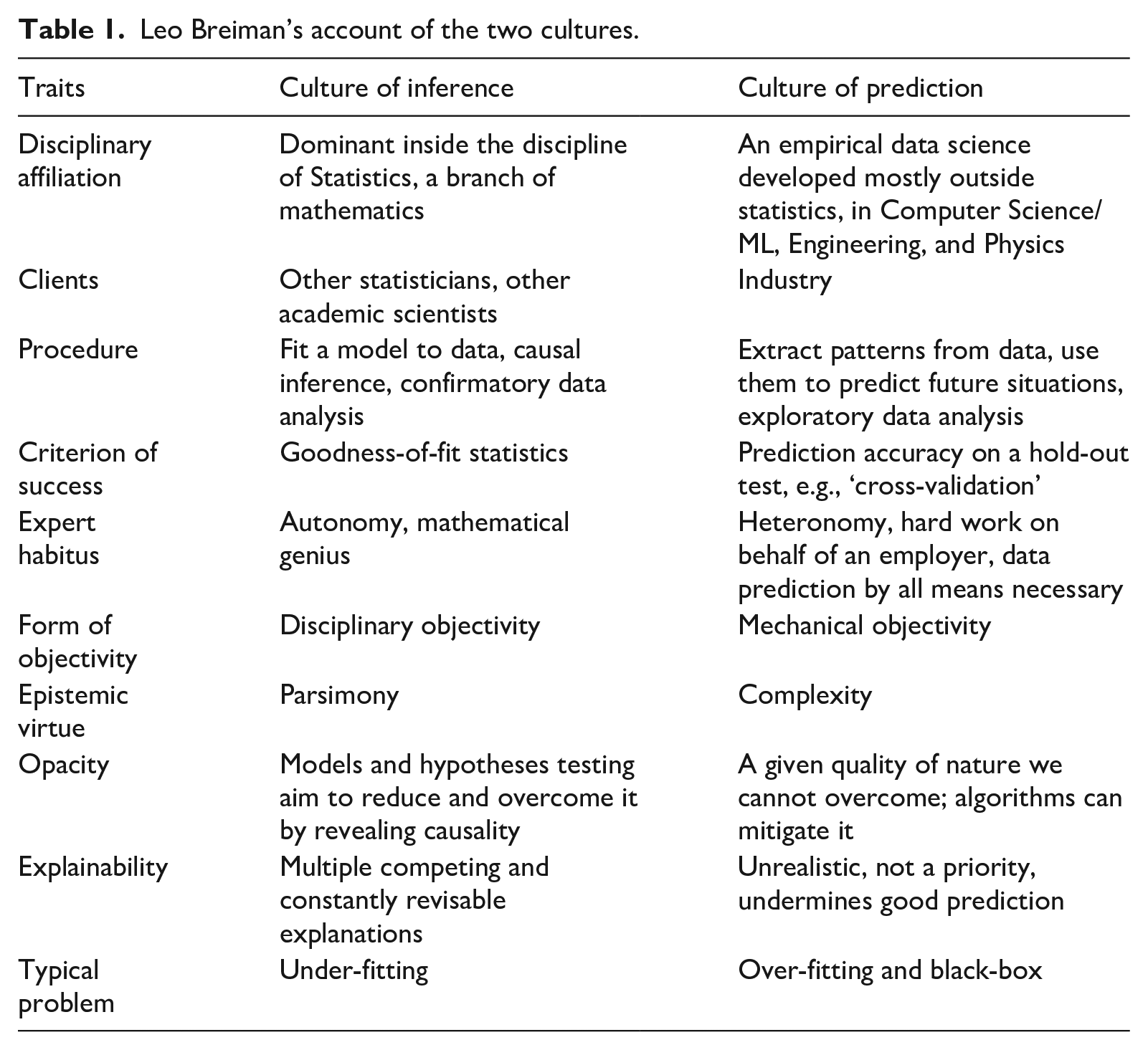
We choose this article as exemplary because Breiman is a figure who can claim to be a native of both these cultures, and so reports on both ‘from within’. On the one hand, he was trained as a statistician and attained stature in this field. On the other hand, he worked as an industry consultant, outside of academia, as had Tukey before him, and he made a profound contribution to the field of ML by developing the random forest algorithm.
Before we delve further into Breiman’s account, we need to clarify how we use it. We do not treat its claims as an accurate historical account. For example, a former President of the American Statistical Association disagreed with Breiman and argued that prior to the data science ‘hype,’ and its ‘secret sauce’—open competitions on large, public datasets—similar approaches were already prevalent in non-linear statistics (Donoho, 2017). We take no position on the accuracy of either historical account. We are interested in Breiman’s article as another origin story of ML expertise, similar to the one we analyzed in the previous section, and especially in the role that opacity plays in this story. As we shall see, opacity is used by Breiman as the most dramatic contrast, setting the two cultures apart. If you worry about the opacity of algorithms, you are a statistician; if you do not, you are a data scientist (or an AI researcher, or ML engineer). The same caveat applies as before. We do not claim that Breiman’s origin story captures how all ML experts think and practice but that it furnishes them with a set of oppositions between virtues and vices that they often activate in situations requiring justification. To our minds, the crucial role that opacity plays in this origin story indicates why, despite a great deal of pressure for explainability and interpretability, and in fact, a lot of work within ML on this issue, the data scientists and ML experts we interviewed, as well as many of those working on explainable AI, often fell back on the defense according to which opacity does not constitute a problem at all.
As insiders to this debate have already argued (Efron, 2001; Hoadley, 2001; Mitra, 2021; Parzen, 2001), the distinction of ‘two cultures’ is an ideal type that simplifies the actual practices of data analysis. It is less of an accurate description of necessary differences, and more of an ‘objectivity campaign’ that claims jurisdiction by problematizing the honed judgment of experts as subjective (Andrews, 2023; Eyal, 2019), while championing a form of mechanical objectivity as universally, omnivorously applicable to all fields of science and expertise (Avnoon, 2024a, 2024b; boyd & Crawford, 2012; Pasquale, 2023; Ribes et al., 2019). In this objectivity campaign, data science and machine learning are presented as a meta-expertise that ‘through the application of agnostic data analytics the data can speak for themselves free of human bias or framing … meaning transcends context or domain-specific knowledge, thus can be interpreted by anyone who can decode a statistic or data visualization. These work together to suggest that a new mode of science is being created, one in which the modus operandi is purely inductive in nature’ (Kitchin, 2014, p. 4).
Breiman’s arguments are often used by ML experts, as we will show below, to signal their epistemic cultural affiliation (Knorr-Cetina, 1999) and justify their comfort with opaque algorithms. His decisive demarcation of two cultures can be used to derive multiple insights also about the anthropological, sociological, and even political dimensions of this methodenstreit. It is highly instructive not because the demarcation of the two cultures is an accurate reflection of reality but because the clear contrast it draws between the attitudes, practices, instruments, relations, concepts, labor markets, and work environments of the two cultures captures how ML experts construct their identity by distinguishing themselves from inferential statistics. In fact, Breiman’s article was suggested to us as a source by one participant in the study and was mentioned by others as well.
A native of statistical inference culture, Breiman became a convert and a spokesman of prediction culture because of his experience working in industry, arguing,
There are two cultures in the use of statistical modeling to reach conclusions from data. One assumes that the data are generated by a given stochastic data model. The other uses algorithmic models and treats the data mechanism as unknown. The statistical community has been committed to the almost exclusive use of data models. This commitment has led to irrelevant theory, questionable conclusions, and has kept statisticians from working on a large range of interesting current problems. Algorithmic modeling, both in theory and practice, has developed rapidly in fields outside statistics. (Breiman, 2001, p. 199)
Breiman named the first culture the ‘data modeling’ culture. He argued it originated with and is practiced by the statistical community. It is a culture of inference, offering its services, as well as its modes of reasoning and data manipulation, to allied academic disciplines (the social sciences, medicine, population genetics, etc.). He contrasted it with ‘algorithmic modeling’, which he referred to as a ‘culture of prediction’. According to Breiman, it developed outside the statistical community, in the mid 1980’s, following the development of new tools and methodologies: ‘A new research community using these tools [neural nets and decision trees] sprang up. Their goal was predictive accuracy. The community consisted of young computer scientists, physicists and engineers plus a few aging statisticians’ (Breiman, 2001, p. 205). Importantly, opacity figured prominently in Breiman’s story as the key epistemic virtue differentiating the ML research community from inferential statistics.
Nature is opaque; this opacity is impenetrable to the human mind
The statistical culture of inference, per Breiman, assumes that each set of data is generated by an underlying stochastic model, which the statistician seeks to specify. The theoretical model postulated by the statistician can only approximate the underlying generative process, but importantly, it should facilitate an in-depth understanding of this process. This understanding takes the form of hypothesis testing. Hypotheses are typically formulated as a system of causal relationships between independent and dependent variables. Hence, this is known as ‘causal inference’. The success of the entire procedure is judged according to goodness-of-fit-tests (of the model to the data).
In contrast, per Breiman, the culture of prediction uses algorithmic modeling that assumes nothing about the data prior to analysis, focuses on prediction rather than understanding the relationships between variables and casual effects, and tests success as prediction accuracy on a holdout test set (the cross-validation practice). In this new culture of data analysis, as Breiman defined it, presuppositions or hypotheses derived from theory or human judgment, explicit or tacit, are unrealistic due to the complexity of natural or behavioral phenomena. Accordingly, they are unnecessary because the data, provided it is ‘big’, and its analysis, provided it is done with enough computational resources, will furnish the necessary insights without the biases inherent in human experts’ subjectivity.
Somewhat caricaturing his colleagues, Breiman depicted their approach as relying on so-called ‘mathematical genius’, a honed ability to see in one glance what model generated this data and then test their hypothesis only through a number of goodness-of-fit tests. Breiman thought that attributing such an ability to any expert is wrong because nature is too complicated and opaque for the human mind to grasp, and thus this process introduces subjective human bias into data analysis.
Complexity and opacity as epistemic virtues; a complex and opaque model outperforms simple models
To draw a radical contrast from inferential statistics, Breiman attacked its core epistemic virtue: parsimony. Statisticians test models one against the other, in order to whittle them down to the model that most parsimoniously accounts for the most variation. Breiman contrasts this ethos with the epistemic virtue of complexity common to a new community of ML researchers. This community makes use of algorithmic methods, rich with data and calculations, and often inscrutable to humans. Three theoretical insights combine to accentuate the contrast between parsimony and complexity as epistemic virtues: (1) The ‘Rashomon effect’ means that there is no value in trying to settle on the one best model. For every problem, every data set, there are always going to be multiple available effective models, and the more, the better. (2) ‘Occam’s dilemma’ (in contrast with parsimony’s totem—Occam’s razor) means that contrary to the accepted norm in science, scientific simplicity and parsimony are not necessarily a sign of accuracy; a complicated neural network gives more accurate results than simple linear regression, and random forests that randomly select variables hundreds of times are more accurate than decision trees, which select the significant variables only once. (3) Finally, inverting the accepted norm that an excess of variables is a curse, Breiman called it ‘Bellman’s blessing’ and encouraged the practice of increasing the number of variables, which he calls ‘features’, to increase the amount of information that can be extracted from the data.
Ultimately, these three insights combine to support an argument that the opacity of algorithms is, in fact, an epistemic virtue. If natural reality is so complex as to defy the computational abilities of the human mind, then the explainability of the model is a mirage, while its opacity is a good index of its realism, especially if its predictions prove accurate. Nature is complicated and murky. The real black box is not the algorithm, but the natural mechanism that the algorithm attempts to replicate. Hence, a complex and opaque model mediates nature’s opacity for limited humans. In contrast, the parsimony of statistical models that might be easy for domain experts to understand and interpret is unrealistic, does not reflect nature, and consequently does a poorer job in data analysis and prediction. Thus opacity is not a bug, but a feature. In the epistemic culture of prediction, explainability is not an epistemic virtue. It is seen as potentially harmful to ML-based AI’s full capacity to discover patterns and predict outcomes.
Whereas Breiman’s ideas were initially resisted within the statistical community and did not have a fundamental impact there (Cox, 2001; Efron, 2001; Hoadley, 2001; Parzen, 2001), his paper has become a founding text for ML experts. The rejections it employed, the distinction between old-fashioned statistics and innovative data science, between ‘trust in experts’ (statistics) and ‘trust in numbers’ (data science) have shaped how this community talks about epistemic virtues. It provided the community with a good conscience about algorithmic opacity and a set of arguments for why attempts to open ‘the black box of algorithms’ may be ill-conceived:
Most of the models that have been built with ML and deep learning has been labeled ‘black-box’ by scholars because their underlying structures are complex, non-linear and extremely difficult to be interpreted and explained to laypeople … it is part of human nature to assign causal attribution of events. A system that provides a causal explanation on its inferential process is perceived as more human-like by end users as a consequence of the innate tendency of human psychology to anthropomorphism. (Vilone & Longo, 2021, p. 91)
This quote exemplifies a characteristic reaction within the AI community to the demand for explainability. The authors dismiss the ‘black box’ accusation as stemming from a weakness of human psychology. The opacity of the model indexes its realism, objectivity, and usefulness, hence it is an essential component of the ML expert community; they are comfortable with it, while statisticians and laypeople are (irrationally) not.
We note, however, that like all objectivity campaigns, this ‘culture of prediction’ does not really get rid of subjective human judgment but merely backgrounds it—both the expert judgments of the algorithm’s designers, and the judgments of domain experts who still help with algorithmic design, label or annotate training data, and inform the evaluation of what constitutes predictive success (Andrews, 2023; Avnoon, 2024a). Predictive success, after all, can be misleading without such input, as famously demonstrated by Obermeyer et al. (2019).
By interviewing ML experts and data scientists we show that they routinely draw on the oppositions offered in Breiman’s origin story as they reason about what makes for good ML practice.
Methods
The data for this study were collected between 2016 and 2018, as part of a larger research project examining the emergence and institutionalization of data science/ML/AI as a nascent form of expertise. As sociologists of expertise, we had no background in technical AI and were never employed in the field. Sixty open-ended, semi-structured interviews were conducted with experts employed in the Israeli high-tech industry, including start-ups, medium-sized companies, and multinational corporations located in Israel. Of these, 50 were employed as data scientists in these companies, while five interviews were conducted with data science managers (two startup founders, one CEO of an AdTech startup, and two managers in the security industry), and five more with professors of data science in leading Israeli universities and institutes. The fact that the study was conducted in Israel represents an obvious limitation in generalizing from its findings. Nonetheless, despite its small size and complicated politics, Israel has a developed high-tech sector with over 9,000 high-tech companies, and 515 research and development (R&D) branches of multinational corporations in fields such as FinTech, AdTech, data storage and infrastructure, healthcare, and cybersecurity (Israel Innovation Authority, 2024; Kotliar, 2020; Maggor, 2021). Most of these companies are located in the greater Tel Aviv area—the center of the country—forming what is known as the ‘Silicon Wadi’, the dense Israeli tech ecosystem. Accordingly, Israel has one of the highest densities of data scientists (Stich, 2016).
The sample of workers focused on self-titled data scientists (then the leading title for ML/AI experts) in the professional social network, LinkedIn. In most cases, the interviewees for this study held more than one degree: MA (46%), doctoral (27%), and postdoctoral education (10%); the remaining 17% had bachelor’s degrees. Most had studied only in Israel, but several acquired their advanced degrees in the US or Britain. In terms of disciplinary affiliation, most of the interviewees alternated throughout their academic journey between disciplines, such as computer science, statistics, physics, math, software engineering, industrial engineering, management of information systems, brain science, bioinformatics, biotechnology, and more. Those who stayed in one discipline for more than one degree usually did so in computer science, statistics, or physics. The disciplinary affiliations of all degrees studied by the interviewees are listed in Figure 1. As shown in previous studies, the diversity of academic disciplines in the sample is representative of the larger field; it is part of the ethos of data science and the AI community (Pasquale, 2015; Ribes et al., 2019). Accordingly, the data scientists and AI experts worked in diverse industries (Figure 2). Most interviewees had worked for more than one company and in more than one industry. The gender ratio of the sample favored men; only four women data scientists were interviewed, and the other 46 were men. This ratio is representative of the field. Studies show only 16% of practitioners in data science and AI are women, globally and in Israel (Goldstein, 2018; Kaggle Survey, 2019).
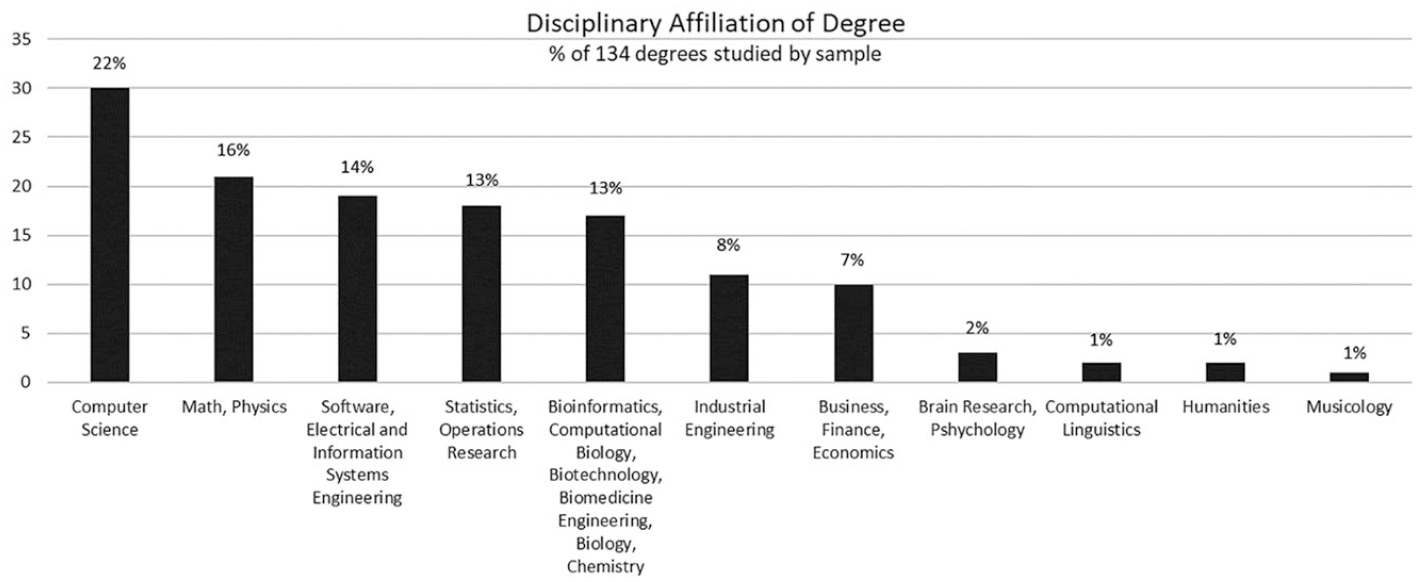
Disciplinary affiliation of degree (excluding the professors).
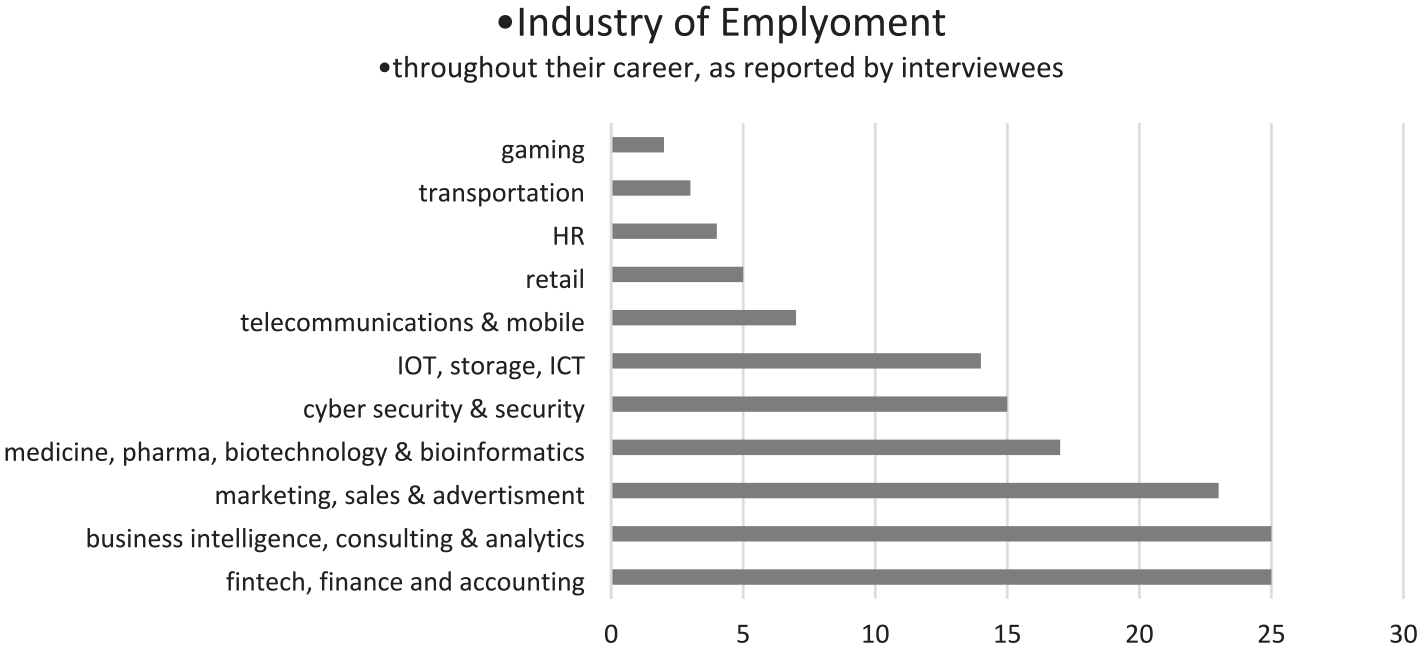
Industry of employment (excluding the professors).
Professors and employers were snow-balled sampled from interviewees’ recommendations. The five professors were from four different universities in Israel, and five different departments: computer science, statistics, software engineering, management, and a new data science program that has since developed into a School of Data Science. The professors were all veterans in their fields, with knowledge of databases, preprocessing, processing, and modeling. One had industry experience prior to joining academia, and one consulted for industry companies.
The managers were all men. The two startup founders were approached via LinkedIn or their companies’ emails. Two of them were data scientists, one managing a large bioinformatics startup and the other a large natural language processing startup for customer service. The third had no experience in data science but had a background in advertising and was managing an AdTech company. An interviewee refered us to him. The other two security industry managers were not data scientists but trained as engineers. They were older and managed data science teams. One was approached at a data science community event organized by the Israeli professional engineering association, and the other was recommended by the first.
Most interviews with data scientists were held during lunch breaks or after work hours, in nearby coffee shops. Some interviewees insisted on meeting inside the employing company and arranged for the proper authorizations. The professors and managers were interviewed in their offices. All interviewees signed consent forms. Interviews focused on participants’ identity work (Snow & Anderson, 1987), the way they view ‘good scientific practice’ in data analysis, and how they thought about opacity and explainability. All interviews, except for the two security industry managers, were recorded and transcribed.
Following grounded theory principles (Lamont & Swidler, 2014; Strauss & Corbin, 1997), the analysis focused on the emic perspectives of interviewees, how they understand and explain their social world. Accordingly, the Breiman debate and the demarcation of ‘two cultures’ were not envisioned in advance as a focal part of the interviews.
Findings
Fifteen years after Breiman’s article was published, interviewees (a) often mentioned the split between two cultures of data analysis, (b) at times described themselves as identified with one or the other (depending on their academic and career trajectory), but (c) more often invoked the opposition when seeking to explain and justify their view of opacity. They would affiliate themselves with the algorithmic modeling culture by presenting the opacity of algorithms as a non-issue, a miraculous solution to complicated problems. Trusting algorithms to perform opaque and transhuman calculations was presented as a virtue, a signal of belonging to a superior, innovative, and advanced data analysis culture. In contrast, the few data scientists in our sample, who received training in statistics departments, affiliated themselves with the statistical modeling culture by presenting their expertise as consisting of having a solid theoretical understanding of the inner workings of modeling. What the others presented as comfort with opacity, they saw as the novice’s blind application of algorithms to data.
Mentions of a cultural divide
Tal, an AI expert working for a multinational corporation in the field of data infrastructure, with doctoral training in both statistics and computer science (he studied both simultaneously for his BSc, MSc thesis, and PhD project), described the methodenstreit:
There was, in my opinion, not exactly a war, but kind of, each defined its own concepts, for example, in data mining they spoke of variables, and in machine learning of features, the names were different. The methodology was different. In data mining they tried to apply statistical expressions, tests, validity, such things, and in machine learning they said, it works, ok, we don’t have to check why it works. The methodologies were different.
ML work, prevalent in computer science departments, in Tal’s experience, is characterized by letting computers perform, without deeply understanding why. In statistics (which he refers to as ‘data mining’), the methods were different.
Roi was an assistant professor at the time of the interview but went back to industry shortly after. He was trained only in computer science in Israel and the US (BSc, MSc, and PhD) and worked for several companies throughout his career, including multinational corporations and data science associations. He was more radical in his view of the cultural divide, the role of human expertise, and disciplinary objectivity:
There are really two methods here. In one method, the domain expert brings the best features, and it works the best. But in the other method, we do feature generation, build as much as possible of everything you can think of. You don’t have to be an expert. You will take everything that exists, and then you will test combinations … every possible combination. And then … you can’t do it manually. I’m really talking about … you start with … hundreds of thousands, and you reach hundreds of millions, like that. This is the magnitude. Then you give it to the algorithm, and from that, it learns the good features. It does feature selection already by itself. I mean, you’re not involved in that, either.
Roi differentiates two methods of data analysis: In the first method, a domain expert, or a statistician who consulted with a domain expert, is required to come up with variables to test. In the other method, the interesting part of the work is scaling up in terms of data and variables, exactly as Breiman described in his Bellman’s blessing principle. This scale of processing is only possible with the help of computers. High-dimensionality is a virtue ML experts aspire to and that sets them apart, in Roi’s account, from statisticians.
In contrast, Vadim, a data scientist with a BSc and MSc in statistics, working for a multinational software and hardware corporation, articulates the divide from the point of view of statisticians. From this vantage point, the divide is seen as a ‘problem’, because mere terminological differences prevent the two sides from understanding one another, even as they are in fact doing the same thing. Vadim’s rendition is thus analogous to that of statisticians whose reaction to Breiman was to assimilate data science practices to some version (‘non-linear’) of statistics:
Another recent problem in the field is that basically it is a mixing of someone coming from here and someone coming from there. For that matter, those who come from statistics know that it’s called regression. And the parameters of the regression are called Betas, and the cutter is called intercept. Those who came from computer science, they know that estimator is weights, and the intercept was given another name, bias, or something like that. It’s just the same thing, exactly the same thing, really, two identical things.
Vadim frames the culture divide during the interview as a problem for the emerging field of data science and mainly a terminology issue—he presents himself in other parts of his interview as being able to translate the language of computer scientists to newly arrived statisticians coming into the company. As a trained statistician, he doesn’t recognize ML experts claims to novelty.
Identifying with one modeling culture against the other
Breiman (2001) argued for an extreme version of mechanical objectivity, wherein human judgment regarding the data mechanism is presumed to be inevitably wrong and biased. Roi identified with this extreme version:
I don’t really believe in theories. I believe in data. Let the data speak. The data will lead to theories …. In a certain field, I can take all the data there is. Research in general is becoming a different type of research. How does the researcher do research? He has a hypothesis, and he tests it with data. We say, no, we take all the data, everything there is, look from above, and you can always identify anomalies in any data if we take everything, and it is guaranteed that it is all there is. There is always something that is farthest from the average. It is an anomaly. Obviously, it’s top-down; it’s not bottom-up.
Conveniently ignoring that digital data cannot represent all data (boyd & Crawford, 2012), and in tension with the fact that he does cooperate with domain experts in different fields, Roi advocates a ‘data first, theory later’ approach. There is no need to draw on theories to generate hypotheses or research questions. Purely inductive anomaly detection will furnish these. Perhaps nothing is more telling than how the usual top-down/bottom-up trope is inverted in Roi’s way of thinking. A statistician or a sociologist would use the term ‘top-down’ for a theoretical approach that starts with a causal hypothesis; they’ll reserve the term ‘bottom-up’ for an inductive approach that starts with the data. Roi inverts these terms because what is dominant in his account is the perspectival and discursive position in which he places the data scientist, who ‘looks from above’ at all the data. In line with Tukey’s exploratory approach (1962) and Breiman’s (2001) ‘no need for theory’ approach, Roi views inductive learning as superior to hypothesis testing, making it dispensable. In contrast, if one ‘comes from statistics’, said Vadim, ‘a strong theoretical basis’ is valued because it makes it ‘very, very easy to understand’ the model.
As we argued earlier, the opposition between the ‘two cultures’ is a symbolic resource drawn upon by our interviewees in specific situations when they were required to justify what constitutes good data analysis practice. In other situations, however, and primarily when dealing with clients, they indicated that they would choose transparent models over opaque ones. As Noah, a data scientist and a founder of a startup company, said:
[O]ne of the problems is that people need to understand …. Presumably, I would have expected that people would accept it when someone with a PhD comes and tells them, ‘Here, I have this black box that does this sort of voodoo magic. … Many times, we actually accept things like that. We drive a car. We don’t understand all the systems inside … but in this type of business … if people do not understand why, they do not implement it … My take-home from this is that … you always need to keep it simple … so I can explain it, even to a layman, without using almost any black box terms’
Noah says that to get clients to adopt his product, he has to offer transparency. Clients do not share his comfort with the opacity and magic-like quality of complex predictive algorithms. They want him to be able to explain how the algorithm works, and so he ‘keeps it simple’ and transparent. But note that by referring to this as a ‘problem,’ Noah registers his distance from the naïve need for explanation, and thereby indicates in passing a sort of cultural division between experts and ‘laymen.’
The opposition between the two cultures was also evident in how the data scientists interviewed spoke about their work practices. Roi drew on the opposition between ‘heavy’ and ‘light’ to justify his preference for certain tools and his disdain for the way statisticians build models:
What is statistics? You build a model characterization; a compact, short, abbreviated, contracted model of what is in the data. [But when] you have a million data instances, you cannot describe your data instances by saying, data instance number one is like this, data instance number two is like that. By the time you reach a million, you are probably getting old. That’s statistics. … what we see, as data scientists, [is that] once there is big data, the heavy models, you can’t run them. They don’t run. They don’t work because the statisticians don’t care, that their model, they implement it in Mat-Lab. They don’t care if it runs. They take ten data instances; voila, it works for them. With a hundred data instances, it’s a bit difficult. A thousand, they don’t think about it. For me, I don’t care if it’s less than a hundred thousand. I work on very, very simple models, which are easy to run on huge data because heavy models cannot be run. (emphasis ours)
When Roi says that statisticians’ models are ‘heavy’, he does not mean having too many parameters. Rather, he points out that the programming languages favored by statisticians, R or Mat-Lab, require a lot of computing power. Being ‘heavy’ means that statistical models coded in R or Mat-Lab cannot be run on large data sets. He contrasts these with the practices of ML experts, which use ‘light’ programming languages that can run on big data. He papers over the fact that to overcome the problem of calculating multiple parameters for multiple variables (high dimensionality and lack of parsimony), ML experts rely on cluster computing, which takes time and a lot of computing resources. Only after the cluster is done, the features selected and the parameters have been tuned, can their practices be seen as ‘lighter’. Clearly, Roi’s main concern is to formulate a sharp contrast between the two epistemic cultures and justify his identification with one. While statistics cares for mathematical robustness (clear definitions of data instance number one, data instance number two, and so on) and does not care about implementation on big data, the algorithmic modeling culture cares for the practical application of the models on big datasets with suitable technology and the ability to generate predictions generalized on very large numbers.
Indeed, the identification with one culture was most evident in the use of tools, where open-source software was preferred over statistical software, as Tal put it:
Traditional statistical tools such as SAS and SPSS are off the list. The demand, as I see it, is for much more versatile tools, much more flexible tools that allow you to really write code and actually resolve anything you would want, and not packages that will enable you to do regression and variance analysis or such things. As opposed to statistical software, where the mathematical procedures are closed off to the user and are protected by intellectual property laws and proprietary licenses, open-source software allows more flexibility to the user, who can intervene in the mathematical process and adjust it to their needs (see Widder et al., 2023 for a critique of this position).
Once again, we let Vadim articulate how statisticians see the same issue, and why they defend statistical software languages as more reliable:
In terms of R versus Python, in R if you look at almost every R package it is written at an academic level. And it’s really neat … in Python it’s more pirate, that means anyone can write more or less what they want, Python is all kinds of students, who are not necessarily less good, but … you understand the difference in terms of approach.
Opacity as an epistemic virtue
Per Breiman’s formulation, the interpretability of the model is less important in the ML epistemic culture. For example, Eran, a data scientist who worked for multiple multinational corporations and startups, and held a PhD in computer science, described how he works with clients in his current organization, trying to convince them to use ML methods:
The human approach is, I will understand how the machine works, how this screw effects this screw, how the ‘mechanics’ work, and then he [the client] can perform the thought process himself. But data science doesn’t need this because we look at the statistical behavior … I don’t study the whole machine, the machine has two hundred screws, three disks, and a software version, and I choose to observe one disk, two screws, and the software version, and I detect a statistical correlation between shared values and behavior of malfunction … but the client wants to know how the machine works. He thinks, the better … [I] understand it … the better I can predict … but this is such a complicated machine, and those who make the screws don’t understand the disks, and those who make the disks don’t understand the software, and the software doesn’t understand them both. So, we say, forget about understanding. I will look into patterns in the data, and machine learning will understand by itself and predict the malfunction. You have to make the client take a leap of faith.
In Eran’s view, the human attempt to understand how complicated socio-technical systems work is futile. It is better for the clients he works with to let the algorithm (that he designed) learn patterns in data. Then, he tries to convince them to take a leap of faith and believe that the opaque probabilistic predictions made by the algorithm are preferable to a mechanical-casual understanding of the machine. Eran uses the term ‘mechanical’ differently than how we use it; for us, following the literature on mechanical objectivity (e.g. Daston, 1992; Daston & Galison, 1992; Eyal, 2019) ‘mechanical’ means no involvement of human judgment. For him, ‘mechanical’ means knowing how connections are made. While both meanings relate to trust in machines, in Eran’s opinion, understanding how the mechanical machine works is unnecessary; the client should trust the probabilistic machine (the algorithm) to predict malfunctions accurately and initiate maintenance in advance.
In a different part of the interview, Eran extends his willingness to leave the machine opaque, to how he thinks about the opacity of algorithms:
Deep learning, which is neural networks, they have an architecture, and how is the architecture determined? A type of magic. In retrospect, it is possible maybe to analyze parts of the mathematics of it, it’s like genetic programming, all these things, I call them black magic.
While Eran characterized himself for most of the interview as a man of rigorous science, when it came to ML algorithms, he suddenly used terms such as ‘leap of faith’ and ‘black magic’, endowing computational machines with the mystery and magic previously reserved in our society for human experts’ exceptional minds, the tacit dimension allowing them to make high-risk decisions.
Similarly, Amit, an ML expert with a BSc and an MSc in computer science, and who worked in several startups and multinational software corporations, explained and gave an example of how the opacity of algorithms is admired in the ML culture:
We understood the algorithm we had there, of course. It was quite Bayesian … but it had twists, very significant twists … which changed the picture completely in many respects. So, we understood the algorithm, but when we implemented it, many times, we were surprised. I mean … you’re surprised. There are things that the machines are able to do, and you …. <laughing> For example, once, we received some text that was taken out of a speech-to-text engine … and we tried to classify it. Now, the speech-to-text engine could not do a good job … It tried letters and words by chance and put them together into something that sounds like a logical sentence, but when you try to read it—I’m not exaggerating at all—after one row, you are already desperate; after two rows, you get a headache. We then put it into our classification engine, and it managed to do some classification, not a great one. In all this mess, it caught all kinds of clues that we would never have thought about and managed to make a little classification out of them … So yes, there are things there that are a little mysterious like that. Even though you know the engine, you wouldn’t guess its outcomes in a certain case. Apparently, this happens more with deep learning. Few people understand what is really going on there.
Stories such as this one, where the mysterious algorithm achieves outcomes beyond human capacity, were frequent in the interviews. ML experts often show enchantment and fascination with the clever surprises the algorithms provide, frequently viewing them as superhuman. Yet, what is striking about Amit’s account is that even when the speech-to-text engine ‘could not do a good job’, and even when the result of the classification engine is ‘not a great one’, ML experts remain entranced by what is ‘mysterious’ about the engines. They tell stories that underline that even though you think ‘you know the engine, you wouldn’t guess its outcomes’.
We should also notice how Amit equivocates between two renditions of opacity and expertise: On the one hand, he attributes expertise to the ‘machine mind’ or ‘engine’ that picked up clues unnoticed by humans and managed to classify some of the text. This expertise of the engine is opaque. It has caught him by surprise many times. On the other hand, he attributes expertise to himself and his team by opening the story with the ‘very significant twists’ they made to the algorithm. At the end of his story, he attributes the same expertise to those ML experts who work with deep learning algorithms. They understand how the algorithm works, though their expertise is shared by ‘only a few people.’ Similarly, Oren, a freelance ML expert with a BSc in information systems and an MSc in Brain Research, prides himself on understanding how neural networks work because he ‘took a university course’. ‘Most algorithmiticians today,’ he says, ‘due to the developed ecosystem, do not know what happens under the hood. They know how to use it as a black box.’ He hastens to add that ‘these are relatively complex things that not everyone has to know.’
But for Vadim, who articulates the point of view of statistics, such surprises stemming from machines are unacceptable:
This is the big difference between voice and image processing and statistics because what interests them [ML in voice and image processing] is the final outcome, in principle, how well I recognize speech, see a photo, and they don’t care, I mean, you perform a mathematical function, that you won’t ever understand and won’t know what it is, as soon as it gives you a good outcome, you’re fine. But for me, in my work, that’s not good enough… I need to know the reason why something happened.
Vadim highlights the difference between himself and those from ML dominated fields, such as image processing and voice recognition. While ‘they’ profess a lack of interest in understanding how the model reached its outcome, and even value the ‘surprises’ furnished by an opaque model, he focuses on understanding reasons, namely causality, and views anything less than that as ‘not enough.’ In contrast, for Amit, Oren, and Tal, the ML experts, knowing the inner workings of the algorithms is not a requirement, just something ‘it won’t hurt to know’. One can still work with the algorithm without this understanding, and even when one does possess it, it comes bundled with openness to the surprises that algorithms produce.
Conclusions
In this study we examined the legitimacy campaign of ML experts and documented a new twist in how mechanical objectivity is claimed. While earlier campaigns for mechanical objectivity contrasted the inconsistency of human experts with the reliability of procedures and machines, we found that ML experts valorized precisely those moments when complex algorithms ‘surprised’ them with unexpected outcomes, thereby endowing machines with a mysterious capacity to make predictions based on calculations and factors that humans cannot grasp. In this way, they turned opacity from a problem into an epistemic virtue. It is not a ‘black box’ but ‘black magic’. Opacity is a feature, not a bug.
The origins of this valorization of opacity, we tried to show, are in the jurisdictional struggles that ML experts needed to conduct on two fronts. In the course of claiming jurisdiction from ‘expert systems’, they learned a particular mode of valorizing opacity as inherent to human expertise. Knowledge elicitation for expert systems, they learned, foundered on the obstacle represented by the opacity of expert tacit knowledge (Collins & Evans 2007; H. L. Dreyfus, 1972; H. L. Dreyfus & Dreyfus, 2005; S. E. Dreyfus & Dreyfus, 1980; Forsythe, 1993, 2001). From this, it was just a short way to valorizing the opacity of computational machines as an epistemic virtue rather than a bug to be fixed. In the course of defending their newly claimed jurisdiction against inferential statistics, they leveraged this conception of opacity as an epistemic virtue to distinguish themselves from statisticians and their approach to data. The two struggles combined to etch this more cavalier attitude to interpretability, explainability, and transparency in the work practices and epistemic commitments of ML experts.
In demonstrating the plausibility of this argument, we relied predominantly on showing similarities between how our interviewees speak about opacity today and past canonical statements by field leaders. A couple of decades (and an ocean away) after Breiman’s ‘two cultures’ article was published, the data scientists we interviewed still drew on the distinctions he articulated. They described a split between two epistemic work cultures, and often affiliated themselves with one of these: while statisticians test hypotheses, ML experts learn from data; while statisticians say ‘variables,’ AI experts say ‘features;’ while statisticians look for reasons, AI experts look for predictions; most notably, while statisticians rely on domain knowledge and mathematical acumen to formulate hypotheses, ML experts present themselves as cheerleaders of powerful yet mysterious machines, who detect probabilistic patterns in the data all by themselves. Paradoxically, in their accounts, the rigor of the process is evidenced by the almost magical surprises it affords.
It is telling that this identification with algorithmic modeling culture persists although it doesn’t always accord with the realities of data science and ML work. Even when ML experts admit that they are sometimes forced to work with a sample rather than all the data, and even when they acknowledge that dimensionality is a problem and not always a blessing, they remain committed to particular epistemic virtues—the humility of humans in the face of machines, rejection of theorizing, strict mechanical objectivity, opacity and the ‘surprises’ it provides. These virtues are integral to their professional identity and interests, and they entail very little commitment to explainability or transparency.
Indeed, in some of the answers our interviewees provided, the very idea of looking for explainability, understanding, or causality was presented as absurd, a human weakness, and counterproductive to the progress of ML-based AI. The mathematical complexity of the inner workings of algorithms serves them in a double role: The selected few who understand this complexity (and interviewees attributed such ability to themselves and to ‘a very few’ others) are guaranteed the prestige of being ‘an expert’ who can deliver with confidence the outcomes of the algorithm to lay clients. However, they turn around and profess that such understanding is not at all a requirement, and it is fine for the experts not to know how the complex mathematical function proceeds, as long as the outcome works according to their evaluation criteria. In this version, they present the algorithm itself as the true expert, to which opacity belongs as legitimately as it does to human experts.
By blurring how opaque algorithms are to them, these speakers communicate the minor importance of explainability in their epistemic culture: It is crucial to know how to use algorithms, tweak them if necessary, and know how to evaluate them. It is not crucial to really know how they work, although it adds an aura of expertise to a person. All things considered, to belong to this epistemic culture, one must put their trust in mechanical objectivity, and let the algorithm (and the data) speak for themselves. Against the efforts to make AI explainable by reducing opacity, the lack of commitment in the community of its developers to this goal should not go unnoticed as AI is integrated into high-stakes decision-making.
Footnotes
Acknowledgements
We thank the editors and two anonymous reviewers for their clever insights and brilliant suggestions. We also thank the interviewees of this study who let us into their epistemic culture.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was conducted with the support of the doctoral excellence scholarship, Graduate Study Authority, University of Haifa, and a travel grant for outstanding postdoctoral students, Tel Aviv University.