
Abstract
Despite a growing literature suggesting that the lyrics of music may have an emotional effect, there are as of yet no studies examining which elements of lyrics influence emotional experience. The present study explored the emotional effect of lyrics sung without a melodic accompaniment, examining whether the vocal expression or the semantic content of the lyrics had a greater influence on emotional state. A sample of 170 participants were presented four variants of sung lyrics, representing all possible combinations of vocal expression (happy; sad) and semantic content (happy; sad) condition, with emotional state being measured using the Brief Mood Introspection Scale (BMIS) following each presentation. A 2 × 2 repeated-measures analysis of covariance (ANCOVA) revealed that, after controlling for familiarity with the song, both the emotional valence of the vocal expression and the semantic content influenced emotional experience, though the vocal expression did so to a greater magnitude. Therefore, the vocal expression of lyrics may have the dominant effect on emotions, though the semantic content still has a minor influence.
Music can consistently be linked to emotional experience (Juslin & Sloboda, 2010). Research has illustrated that ‘basic’ emotions, including happiness, sadness and anger, can be recognised by people in music cross-culturally, with international samples recognising the same acoustic cues to these emotions (Eerola & Vuoskoski, 2012; Juslin & Laukka, 2004; Patel, 2010; Västfjäll, 2001). For example, a piece of music in a major key with a fast tempo and a high pitch will be defined as happy, while a piece with the opposite features will be defined as sad (Patel, 2010; Västfjäll, 2001). Further research suggests infants as young as 3 years old display the ability to recognise musical emotional cues (Cunningham & Sterling, 1988; Kastner & Crowder, 1990; Nawrot, 2003; Saarikallio et al., 2019). There is a wealth of evidence to suggest that humans have an intrinsic ability to recognise emotions conveyed by music. However, further research has suggested that music may not just convey emotions but also influence emotional state (Juslin & Laukka, 2004). In a review, Juslin and Laukka (2004) found that music displayed a consistent ability to influence mood and emotions, and is used to regulate or alter emotional state. Despite evidence suggesting that music can modulate emotions, there is no consensus regarding the mechanisms underlying this effect.
Many theories explaining the emotional effect of music have been summarised in the BRECVEMA model (cf. Juslin, 2019; though see Lennie & Eerola, 2022, for recent critiques). Though a full review is outside the scope of this article, one will notice that despite the wealth of theories proposed, there is a notable gap in the literature. Given that music is commonly paired with lyrics, there is a dearth of research exploring the emotional effect of lyrical music (Fiveash & Luck, 2016; Ransom, 2015). However, the literature available suggests an important role for lyrics in influencing emotions. Juslin et al. (2009, as cited in Juslin et al., 2010) asked 706 participants what they believed caused their most recent emotional experience with music. The data from the open response question were coded into categories. In 45% of cases, participants attributed their emotional experience to ‘musical factors’, which often included ‘the singing voice’ (vocal expression). In addition, in 10% of cases participants referred to ‘lyrics’, referencing ‘the words’ or ‘the message of the lyrics’ (semantic content). Overall, a large proportion of the sample referred to the lyrics as having an emotional effect, whether that effect be via the vocal expression or semantic content.
Further literature regarding the role of lyrics is largely comprised of studies comparing whether the lyrics or the melody of music have a stronger influence on emotions. Some evidence suggests that the lyrics may have a stronger magnitude of influence. Stratton and Zalanowski (1994) presented participants either the lyrics, the melody, or the paired lyrics and melody of a sad song. When presented with the isolated melody, a slight increase in participants’ positive affect and a decrease in depression was observed. However, when the isolated lyrics or lyrics with melody were presented, a significant increase in depression occurred, illustrating the power of the lyrics in facilitating an emotional reaction.
Subsequent studies yielded similar results, with a recent study finding that while the isolated melody of a sad song had a slight suppressive effect on emotional state, the emotion suppression effect of the isolated lyrics and the paired lyrics and melody was of a far greater magnitude (Pond & Leavens, 2024). Furthermore, Pieschl and Fegers (2016) found that a piece of music containing antisocial lyrics led to an increase in self-reported anger, whereas a piece with near identical prosocial lyrics did not. This was observed regardless of changes to the tempo of the underlying melody, suggesting this effect was due to the change in lyrical content. However, this remains a point of contention, with some studies suggesting the melody of music may have a stronger emotional effect than the lyrics (Ali & Peynircioğlu, 2006; Sousou, 1997). While it is not this author’s intention to assert that the melody of music holds no emotional influence, there is enough evidence suggesting that lyrics have an influence to warrant further investigation.
Despite evidence suggesting that lyrics have an emotional influence, there is little literature available that directly theorises about how lyrics might influence emotions. The first delineation is to establish whether the vocal expression or the semantic content of the lyrics influences emotions to a greater extent. The vocal expression refers to the acoustic delivery of the lyrics by the singer, whereas the semantic content refers to the meaning of the lyrics. Understanding which element has a stronger emotional effect may provide an insight into the underlying mechanisms; however the emotional effects of these features have not been compared. There is a case to be made for an emotional influence of both features.
There is evidence to suggest that vocal expression may have the dominant emotional effect. A key theory of musical emotion in the BRECVEMA model is emotional contagion theory, which posits that acoustic cues to emotion present in both the melodic expression of music and the vocal expression of the singer influences emotional state due to automatic neural modulation (Juslin, 2019; Juslin & Laukka, 2004). The theory has been well supported, with an experience sampling study finding that emotion contagion theory was the most endorsed explanation of the cause of musically induced emotional states (Juslin et al., 2008). Furthermore, biological research has found that automatic emotional neurological processing occurs in response to music, with Koelsch and Siebel (2005) reporting that when listening to music, the thalamus becomes stimulated and sends neuronal signals to the amygdala and medial orbitofrontal cortex, brain areas linked to emotional processing and regulation of emotional behaviour. While this research focuses on music generally, many researchers argue that the acoustic cues present in music mimic the acoustic cues to emotion present in speech (Coutinho & Schuller, 2017; Juslin & Laukka, 2004). Thus, research presented in favour of emotional contagion theory naturally supports the role of vocal expression in influencing emotions.
Studies assessing whether emotional information can be gleaned from vocal expression have been promising. Patel (2010) notes that listeners are good at decoding basic emotions from the sound of a voice, even when words spoken are emotionally neutral or semantically unintelligible. Banse and Scherer (1996) presented participants with 280 emotional portrayals of two semantically meaningless sentences, differing only by altered vocal expression. Participants were instructed to listen to each portrayal and indicate which emotion, out of the 14 listed, they felt the speaker was conveying. They identified the intended emotion in 48% of cases, well above chance level. This suggests one is generally able to identify the emotion of a speaker in the absence of semantic content. A review by Juslin and Laukka (2003) found that across 39 studies of emotional vocal expression, participants were consistently able to identify the target emotion at well above chance levels. While these studies assessed spoken words, it is reasonable to assume that lyrics sung with similarly emotive vocal expression should be equally capable of being recognised as a given emotion and eliciting an emotional reaction.
While there is compelling evidence for the emotional influence of vocal expression, this fails to explain literature regarding semantic content. Pieschl and Fegers (2016) found that while presenting participants a piece of music with violent lyrics led to an increase in self-reported anger, presenting a piece with near identical prosocial lyrics had no such effect. While the semantic content changed, the vocal expression was identical across both pieces. Therefore, this change in emotional influence may only be attributed to the change in semantic content. A meta-review exploring the influence of violent compared with nonviolent lyrics on the affective state of anger came to the same conclusion (Anderson et al., 2003). Furthermore, Ali and Peynircioğlu (2006) reported that while the melody of sad and happy songs had the strongest emotional influence, sad songs with emotionally congruent sad lyrics increased the endorsement of sadness. This was not the case when the lyrics were happy, suggesting emotionally incongruent lyrics did not influence emotions. This suggests the semantic content determined whether the lyrics impacted emotional experience. Meanwhile, Pond and Leavens (2024) found that isolated lyrics of a sad song had a stronger influence on emotional state than the isolated melody, with a thematic analysis of open response questions suggesting that emotional effects of the lyrics were more often associated with the semantic content.
While limited literature is available regarding how semantic content may influence emotional experience, research suggesting an overlap between brain areas associated with language processing and music processing may provide some insights. Koelsch et al. (2002) discovered that brain areas previously considered to be domain specific for language processing may also be involved in the processing of musical information, including Wernicke’s area, a cortical region associated with the processing of the semantic content of language. In addition, Brattico et al. (2011) found that lyrical music activated Brodmann area 47, a region associated with the processing of both music and language syntax. This suggests music may have an influence on the processing of the semantic content of words, with Koelsch et al. (2004) finding that music may prime certain semantic concepts and thus influence how words are processed.
Research suggests the emotional valence of music may influence the processing of the semantic content of lyrics, with Fiveash and Luck (2016) reporting that more errors were detected in lyrics containing error words when they were paired with sad music as opposed to happy music. The authors proposed that while positively valenced music may prime a positive emotional state, and thus lead to heuristic based processing of the lyrics (assimilation), negatively valenced music may prime a negative emotional state, leading to more detailed processing (accommodation). This aligns with Brattico et al.’s (2011) findings that sad music with lyrics activated Brodmann area 47 to a greater extent than happy music with lyrics. Therefore, it could be argued that negatively valenced music leads to more in-depth processing of the semantic content of lyrics and thus the semantic content may be more likely to influence emotional state.
There is evidence to suggest both the vocal expression and the semantic content of lyrics may have an emotional influence. However, the magnitude of emotional influence of these aspects has never been compared. Therefore, the aim of the present study was to investigate whether the vocal expression or the semantic content of lyrics has a stronger effect on emotions. Through an online survey, participants were presented audio samples of a pop-ballad being sung without melodic accompaniment, with variants of the song being presented in counterbalanced order: one with sad lyrics and sad vocal expression (Lyrics Sad, Vocal expression Sad; LSVS), one with sad lyrics and happy vocal expression (Lyrics Sad, Vocal expression Happy; LSVH), one with happy lyrics and sad vocal expression (Lyrics Happy, Vocal expression Sad; LHVS) and one with happy lyrics and happy vocal expression (Lyrics Happy, Vocal expression Happy; LHVH). Emotion measurements were taken before the presentation of any stimuli (a baseline measure), as well as after hearing each variant of the lyrics. In addition, participants were given the opportunity to answer open response questions, allowing them to provide a qualitative insight into why they felt the lyrics influenced their emotions. Given Fiveash and Luck’s (2016) finding that happy and sad melodic information (provided in the present study by the vocal expression) may lead to less and more in-depth processing of semantic content, respectively, it was predicted that vocal expression of the lyrics would lead to a significant change from baseline emotional state when expression was happy, while the semantic content would only lead to a significant change when vocal expression was sad.
Method
Participants
Initially, 250 participants were recruited via an advert posted in a number of high traffic websites, including a University forum, social media and ‘Psychological Research on the Net’ (URL: https://psych.hanover.edu/research/exponnet_submit.html), a study sharing site for psychological researchers. Following the removal of data from participants who did not complete the survey (n = 71), chose to withdraw (n = 3), or were over the age of 60 (n = 6), 1 the final sample comprised of 170 participants aged between 18 and 59 years (M = 24.43, SD = 10.03). Of the sample, 118 were female, 49 were male, and 3 identified as an ‘other’ gender. Ethical approval was obtained from the School of Psychology, University of Sussex (ER/NP286/3).
Materials
Brief Mood Introspection Scale (BMIS). 2
Designed by Mayer and Gaschke (1988), the BMIS is a 16-item scale that indicates how pleasant or unpleasant one’s emotional state is, with higher scores indicating a more pleasant emotion. Each item uses a 4-point Likert scale, ranging from 1 (definitely do not feel) to 4 (definitely feel), in response to emotion-related adjectives, such as ‘Lively’ or ‘Drowsy’. A Meddis response scale is presented to participants (where 1 = XX, 2 = X, 3 = V, 4 = VV) to reduce response bias, which is converted into a numerical 1 to 4 scale for scoring. The scale has very good reliability (α = .83) and its brevity allows for the capture of brief changes in affective state (Mayer and Gaschke, 1988). Furthermore, it has been used in previous empirical music research (Bowles et al., 2019; Mayer et al., 1995).
Covers of excerpt from ‘Mad World’ by Gary Jules
‘Mad World’ was chosen for adaption due to its emotive lyrics and mood. A 44-s excerpt comprised of the first verse of the song was adapted for the present study. A short section was used as opposed to the full song to increase engagement with the study. Previous findings have shown that a 30- to 60-s musical stimulus is enough to obtain a measurable emotional response (Eerola & Vuoskoski, 2012). The song was covered by a singer hired by the researcher, who was instructed to sing four variants of the first verse: LSVS, LSVH, LHVS and LHVH. The sad lyrics were the original lyrics, while the happy lyrics had been adapted by replacing key negative emotion words in the lyrics with positive emotion words, while keeping the original flow of the song (see Table 1). The singer was advised as to the features of vocal expression most associated with happy and sad emotions (for example, major key for happy, minor key for sad). To avoid a confounding variable, the tempo was kept the same between all variants (88 bpm). The audio clips of each version of the song were uploaded to YouTube, then embedded into the survey.
Lyrics Presented to Participants in Each Semantic Content Valence Condition.

Online survey
The survey was designed using the Qualtrics software, Version March 2022 of Qualtrics.
Design
A 2 × 2 within-groups design was implemented, with a within-subjects design being chosen to minimise the influence of individual differences on the results. The independent variables were the emotional valence of the vocal expression (happy, sad) and the semantic content (happy, sad) of the performance of ‘Mad World’. Participants heard every version of the song, and the order of presentation was counterbalanced across participants (for a breakdown of the number of participants assigned to each order, see Table 2). The dependent variables were the participants’ BMIS scores reported at baseline and following each song presentation.
Orders of Presentation of Lyrical Stimuli, With Number of Participants in the Given Order.

Note. 1 = LHVH; 2 = LHVS; 3 = LSVH; 4 = LSVS.
Procedure
Participants completed the survey remotely from their personal computers. First, participants were asked to read and complete an information and consent form, before providing their age and gender. The study then began with participants being instructed to fill out the BMIS to give an indication of their emotional state at baseline. Next, participants were presented either the LSVS, LSVH, LHVH, or LHVS version of ‘Mad World’. After listening to the song, participants were instructed to fill out another BMIS, based on their current mood, disregarding how they answered previously. In addition, an open response question was presented, asking ‘Why did this music make you feel the way it did?.’ These stages then repeated with each version of ‘Mad World’. Upon completion, participants were asked whether the song was familiar to them (yes/no), to allow testing for familiarity effects. Finally, participants were debriefed and given the option to withdraw their results from analysis. After submitting their results, participants were given the option to enter a prize draw to win a £25 Amazon voucher.
Results
Participants’ BMIS scores were calculated for each time point. Following this, the four BMIS scores for each participant following the presentation of each stimulus (LSVS, LSVH, LHVS, LHVH) were subtracted from their baseline BMIS scores to obtain BMIS difference scores. These values represent the change in BMIS score from baseline emotional state to emotional state following the presentation of the given musical stimulus. Furthermore, an aggregate mean BMIS difference score was calculated for each participant, by calculating the average of their four BMIS difference scores following each musical stimulus.
Preliminary analyses
Normality was assessed by viewing the distribution of aggregate BMIS mean difference scores. The Kolmogorov-Smirnov test suggested the assumption of normality was met, D(170) = 0.988, p = .200, while visual inspection of the histogram and Q-Q plot revealed a symmetrical, unimodal distribution.
In addition, the influence of confounding variables was assessed. First, the influence of participant gender on BMIS scores was assessed. A one-way independent-samples ANOVA found that gender identity had no significant influence on aggregate mean BMIS difference scores, F(2, 169) = 0.993, p = .373,
Quantitative analysis
A 2 × 2 repeated-measures analysis of covariance (ANCOVA) was conducted on the BMIS difference scores, with the semantic content valence (happy, sad) and the vocal expression valence (happy, sad) as the independent variables, and familiarity (Yes, No) as a covariate.
3
After controlling for familiarity, this analysis revealed no statistically significant interaction between the semantic content valence and the vocal expression valence on influencing BMIS difference scores, F(1, 676) = 2.07, p = .150,
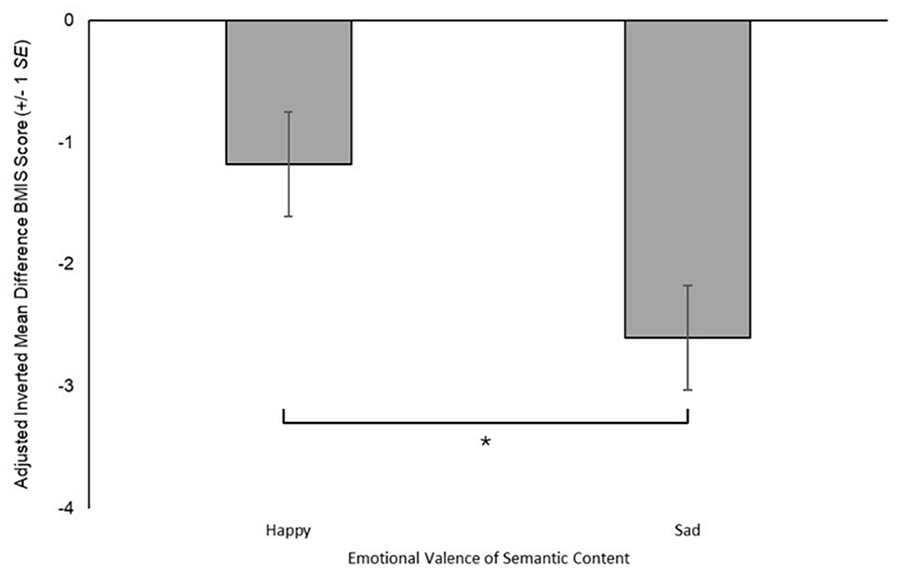
Adjusted Inverted Mean Average BMIS Difference Score (±1 SE), in Relation to Semantic Content Valence (Happy, Sad), Controlling for the Effect Familiarity (*p = .019).
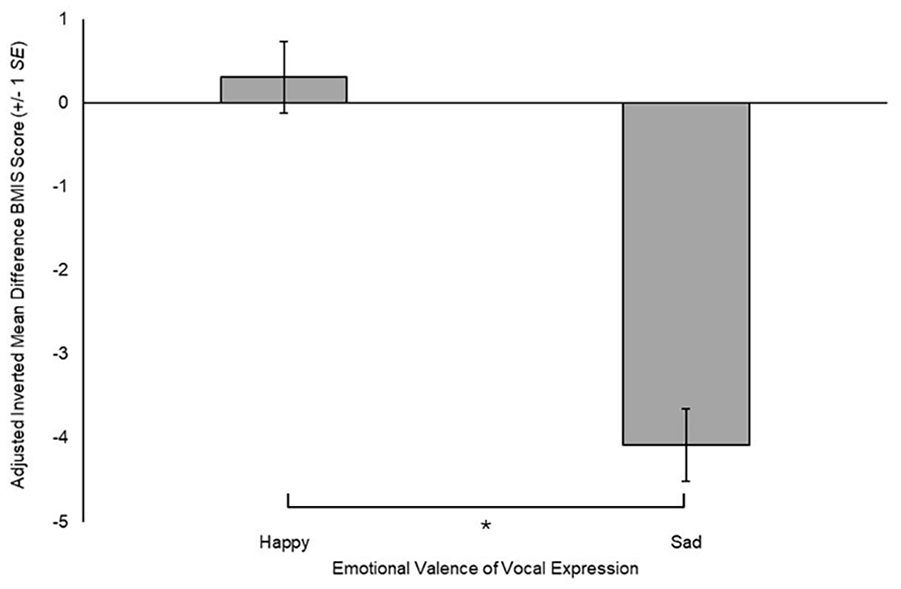
Adjusted Inverted Mean Average BMIS Difference Score (±1 SE), in Relation to Vocal Expression Valence (Happy, Sad), Controlling for the Effect of Familiarity (*p < .001).
Qualitative analysis
An inductive thematic analysis, as described by Braun and Clarke (2006), was performed on the open response questions. A total of 168 participants engaged with these questions. The open response questions were read and relevant themes were noted down. Then, the data were systematically coded, with interesting features being organised into analytic categories (data could be included in multiple categories). To ensure each category gave an accurate representation of the data, the data were reviewed again and underpowered categories (those that occurred very few times) were discarded. The remaining categories were then sorted into overarching themes, which were reviewed against the data set to ensure they were an accurate reflection of the data. This resulted in a final set of 10 categories organised into three themes (see Table 3). To aid readability, the number of times each category occurred will be listed in brackets during the discussion of results.
Complete Set of Identified Themes From Thematic Analysis, With Relevant Categories.

Vocal expression had a stronger general influence on emotional responses than the semantic content. Across all four open response questions in the data set (672 responses in total), vocal expression was referenced most frequently as having influenced emotional state (n = 353), with participants discussing the ‘tone’, ‘tune’ or ‘pitch’ of the singing. Conversely, the semantic content of the lyrics was mentioned relatively infrequently (n = 111), with the emotional impact of the ‘lyrics’ or ‘words’ being discussed in these instances. This suggests the influence of the lyrics on participants’ emotions may have mainly been a function of vocal expression in the present data set.
When vocal expression was sad, the song was described using negative emotion adjectives. When vocal expression was happy, the valence of emotion adjectives was more varied. Of the responses given following music samples with sad vocal expression (total of 336 responses), the songs were described largely using negative emotion adjectives (n = 192), with participants referring to the pieces as ‘sad’, ‘gloomy’ or ‘depressing’. However, some participants referred to the pieces with positive adjectives (n = 78), describing the pieces as ‘calming’, ‘soothing’ and ‘upbeat’, but these responses were far less frequent. In contrast, of the responses following music samples with happy vocal expression (total of 336 responses), songs were described with a more even split of emotion adjectives (n = 129 negative, n = 145 positive). While pieces with sad vocal expression were largely described in negative terms, pieces with happy vocal expression were described with a mix of positive and negative terms. In the instance of pieces with happy vocal expression, when semantic content was happy (168 total responses), the piece was described more often with positive emotion adjectives (n = 81) than with negative emotion adjectives (n = 47). When the semantic content was sad (168 total responses), the piece was described more often with negative emotion adjectives (n = 82) than positive emotion adjectives (n = 64). Therefore, the semantic content of the song may account for the mixed emotional influence of the pieces featuring happy vocal expression.
When discussed, vocal expression was described with a mix of both positive and negative emotion adjectives. However, the semantic content was largely described using emotion adjectives of the intended valence. Of the responses that directly discussed emotional valence resulting from the vocal expression of the song (total of 299 responses), some respondents described the expression as having influenced their emotional state in the intended direction (n = 202), while others described the expression as having influenced their emotions in the opposite direction to what was intended (n = 97). In contrast, of the responses that directly discussed the semantic content of the song (total of 93 responses), the majority of participants described the semantic content as having influenced their emotional state in the intended direction (n = 85), whereas a minority reported the semantic content as having influenced their emotional state in the opposite direction to what was intended (n = 11). Therefore, while there was a general consensus regarding the direction of emotional influence of the semantic content, there was less consensus regarding the emotional influence of vocal expression.
Discussion
The present results revealed that both the vocal expression and the semantic content influenced emotional state, though the vocal expression did so to a greater magnitude. When vocal expression was sad, there was a substantial reduction from baseline emotional state. However, when vocal expression was happy there was a slight increase from baseline emotional state, though the confidence interval for this value did cross zero, suggesting that a slight decrease from baseline could plausibly be observed were this test readministered. Though sad semantic content similarly resulted in a reduction from baseline, happy semantic content also resulted in a reduction, albeit to a slightly lesser degree. This suggests that the semantic content alone was not sufficient to induce a positively valenced shift in emotional state. Furthermore, the negligible effect size suggests the magnitude of influence on emotional state was far weaker than the influence of vocal expression. In addition, a thematic analysis of the open response questions revealed that participants largely attributed the emotional influence of the lyrics to the vocal expression. However, while it was generally agreed that the piece was of a negative emotional valence when vocal expression was sad, there was no consensus regarding the emotional valence when vocal expression was happy. In these instances, the semantic content of lyrics may have influenced the valence of the reported emotional influence of the piece. Finally, while the vocal expression was described with a mix of emotion terms both congruent and incongruent with the intended emotion, the semantic content was largely described in terms of the intended emotion.
This suggests that, contrary to initial predictions, the vocal expression of the lyrics had the dominant influence on emotions in the present sample, with the semantic content of the lyrics having a negligible, albeit still significant, influence on emotional state. There was no interaction between the vocal expression and the semantic content, as was predicted following Fiveash and Luck’s (2016) findings. These results both support and contradict previous literature.
The finding that vocal expression had the stronger emotional influence supports previous studies advocating the emotional influence of vocal expression, as well as emotional contagion theory (Juslin & Laukka, 2003, 2004). In line with Juslin and Laukka’s (2003) review, participants detected emotions in the vocal expression of the singer, with participants regularly referring to the ‘tone’ or ‘pitch’ of the singer as ‘sad’ or ‘gloomy’. While there was some discrepancy in the emotion detected by participants from the vocal expression of the lyrics, with a significant minority reporting the expression to be ‘calming’ rather than ‘sad’, this does not entirely refute an emotional contagion effect, with there being some overlap between the acoustic cues associated with serenity and sadness (Västfjäll, 2001). Furthermore, some individuals may enjoy sad music and thus experience both positive and negative emotions in response to sad music (Taruffi & Koelsch, 2014; Vuoskoski et al., 2011). Therefore, the present study provides some support for the emotional effect of the vocal expression of lyrics and emotional contagion theory.
Despite this, the present results also highlight the limitations of the explanatory power of vocal expression and emotional contagion theory. The finding that the semantic content of the lyrics had a minor emotional influence cannot be explained by emotional contagion theory. While it was expected that the semantic content of lyrics would have an emotional effect, the nature of this effect contradicts previous literature. Fiveash and Luck’s (2016) findings suggest that when a piece of music expresses acoustic cues to a positive emotion, the lyrics may be processed in less depth and therefore be less likely to have an emotional effect. However, when the music expresses cues to a negative emotion, the lyrics may be processed in more depth and thus be more likely to influence one’s emotions. In contrast, after controlling for familiarity with the song the present study found no significant interaction between vocal expression and semantic content that would suggest the emotional expression of the lyrics influenced the depth of semantic content processing.
One potential explanation for the failure to reproduce this effect may be that in Fiveash and Luck’s (2016) paradigm, melodic music was used as an emotional prime. However, in the present paradigm there was no melodic accompaniment, with the vocal expression of the lyrics providing this acoustic emotional prime. One could argue that emotional cues gleaned from the vocal expression of lyrics may not modulate semantic processing in the same way. However, this explanation seems unlikely, given that the reason it is argued music influences semantic processing is due to previous research showing that music processing and language processing occurs in the same brain areas (Koelsch et al., 2002). One of the brain areas highlighted by Koelsch et al. (2002) is the superior temporal gyrus, known to be involved with both language processing and the processing of tonal and melodic information in music. Ethofer et al. (2009) found that the superior temporal gyrus was also essential for the processing of the emotional prosody of speech. As such, there is an overlap between the brain areas processing musical information, emotional vocal expressions, and language. Therefore, it is equally likely that emotional cues gleaned from vocal expression may influence the processing of the semantic content of lyrics in the same way as emotional cues gleaned from music.
There are two more plausible explanations that may explain the failure to reproduce Fiveash and Luck’s (2016) effect. First, given that the influence of the semantic content had a negligible effect size, it may be that the emotional effect of vocal expression is more dominant and dictates the overall direction of emotional influence rather than modulating the depth of semantic content processing. This would align with literature demonstrating that prosodic cues to emotions can reliably be decoded from the vocal expression of spoken words, even when the words are semantically unintelligible (Juslin & Laukka, 2003; Thompson & Balkwill, 2010). One study found that emotion recognition may be superior for words spoken in an unfamiliar language, suggesting that semantic content may sometimes inhibit the accuracy of emotion identification (McCluskey & Albas, 1981). Therefore, semantic content may be less important to emotion induction than Fiveash and Luck’s (2016) findings suggested, meaning an interaction effect where vocal expression modulates semantic processing may not occur.
Alternatively, happy vocal expression may not have induced an emotional state of a sufficiently positive magnitude to allow for an interaction effect to emerge. While vocal expression had a stronger magnitude of emotional influence, the emotion improvement effect observed in the happy valence conditions was less pronounced than the emotion reduction effect in the sad valence conditions. Although multiple studies suggest that emotions can be detected from the vocal expression of speech (Thompson & Balkwill, 2010), many studies suggest that listeners are more reliably able to recognise emotional cues to sadness than to joy (Banse & Scherer, 1996; Johnstone & Scherer, 2000; Scherer et al., 2001). For example, Scherer et al. (2001) found that of the emotional expression types assessed, the lowest recognition rate was for joy. Therefore, the happy vocal expression conditions may have failed to induce a sufficiently positive emotional state to modulate the depth of semantic processing, and thus an interaction effect was not detected.
There are several avenues for further research. First, replications of the study should be undertaken, to establish whether the lack of a significant interaction between the vocal expression and semantic content can consistently be observed. Future replications would also benefit from including a wider variety of musical stimuli to observe the generalisability of these results. In addition, given that the present findings contradicted Fiveash and Luck’s (2016) previously identified interaction between emotional valence of melodic information and the depth of semantic content processing, studies exploring the influence of melodic information on the processing of lyrics should be conducted. Finally, while the present study took a global perspective on patterns of responding to emotional lyrics, future research could explore how individual differences may mediate this global pattern of responding. For example, some individuals enjoy sad music and thus may experience both positive and negative emotions in response (Taruffi & Koelsch, 2014; Vuoskoski et al., 2011). Therefore, individual differences in enjoyment of sad music may impact the pattern of emotional responding to sad lyrics.
The present study had some key limitations. First, since all stimuli were kept to a tempo of 88 bpm to control for the confounding influence of differential stimulus speeds, it is possible that this relatively slow tempo may have biased toward a more negative interpretation of the stimuli in the happy vocal expression conditions. This may partially account for the smaller positive emotional shift in the happy vocal expression conditions relative to the emotion reduction effect in the sad vocal expression conditions. Second, due to the study being conducted in a naturalistic setting, participant listening environment could not be controlled. Some may have completed the study in a group while others may have done so alone, meanwhile some may have worn headphones while others may not, influencing the audio quality of the musical stimuli. Such factors of the listening environment are known to influence emotional responses to music (Västfjäll, 2001). Third, the stimuli in the present study were presented without a melodic accompaniment, so the emotional influence of the lyrical elements could be isolated. However, the lyrics may have had a different emotional influence if paired with a melody. Previous studies have suggested that isolated lyrics and paired lyrics and melody may have a similar magnitude of affective influence (Pond & Leavens, 2024; Stratton & Zalanowski, 1994). Nonetheless, further studies exploring the emotional effect of each element of the lyrics both with and without a melodic accompaniment may be needed before dismissing this as a potential limitation. Fourth, although the study was set up to observe a 2 × 2 interaction between vocal expression (happy, sad) and semantic content (happy, sad), this design means that each factor lacks a control condition. The effect of vocal expression could be partially controlled for by having a spoken word variant, while a ‘benign’ semantic content variant could be used as a control. Future research could implement such controls. Finally, this study adapted a single song, which may limit the generalisability of this pattern of results.
In conclusion, the study found that both vocal expression and semantic content had an influence on emotional state, though the effect of vocal expression was of a greater magnitude. However, there was no interaction between vocal expression valence and semantic content valence, which may have suggested that the vocal expression was influencing the processing of semantic content. These findings provide some clarification as to how lyrics influence our emotions, giving us some insight into the underlying mechanisms.
Footnotes
Acknowledgements
First and foremost, the author would like to thank their supervisor, Dr David Leavens, for his support throughout the conception of the project and his assistance during the analysis of the data. The author would also like to thank Catherine Vaughan for recording the vocal samples that formed the musical stimuli presented in the study. Finally, the author would like to thank Dr Ryan Scott for his helpful advice on a later revision of this manuscript.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the School of Psychology, University of Sussex.