
Abstract
Strongly disliked music has the capacity to evoke strong negative emotions and physical sensations—at least in some listeners. Although previous (qualitative) studies on disliked music have provided valuable descriptions of listeners’ experiences, more generalizable approaches are needed for understanding individual differences in the intensity of music-evoked aversive experiences. This study set out to explore these individual differences by developing a standardized questionnaire to measure the intensity of aversive musical experiences, the Aversive Musical Experience Scale (AMES). Furthermore, we explored the hypothesized predictors and potential underlying mechanisms (such as emotional contagion and a general sensitivity to sounds) by measuring trait emotional contagion, misophonia, tendency to experience autonomous sensory meridian responses (ASMR) and frissons, and personality. Based on the results of exploratory and confirmatory factor analyses, a final 18-item version of AMES was constructed, comprising three subscales: Sensations, Social, and Features. Misophonia and emotional contagion emerged as the strongest predictors of global AMES and its subscales. Furthermore, the personality traits of neuroticism, agreeableness, and openness to experience, as well as age and musical expertise emerged as significant predictors of at least one of the scales. The implications and limitations of the findings are discussed with respect to sound-sensitivity, music-induced emotions, and personality theory.
Music plays an important role in many people’s emotional lives. In fact, music’s emotional effects are often cited as one of the most common reasons for people to engage with music in the first place (Juslin & Sloboda, 2010). An impressive number of empirical studies have demonstrated that music-evoked emotions can be highly pleasurable and musical engagement has been shown to entail many positive and even therapeutic dimensions (Baltazar & Saarikallio, 2019; Eerola & Vuoskoski, 2013; Koelsch, 2018; MacDonald et al., 2012; Sloboda & Juslin, 2010). Because of this positive emphasis on emotional wellbeing, music and ill-being has gained very little scientific attention until quite recently.
Although music can help an individual to dispel negative emotions and feelings of aggression, it also has the potential to promote or intensify adverse affective states (Wölfl, 2019). According to preliminary evidence, disliked music can evoke strong physical reactions and negative emotions, which can lead to aggression, anxiety, or paralyzing feelings, depending on the listener (Peltola & Vuoskoski, 2022). Furthermore, since musical preferences build heavily on aesthetic value judgments, they have an inherent social dimension that encompasses learned ideals and beliefs. Thus, disliked music can function as a tool for discriminating the “out-group” from the “in-group,” which is likely to promote the cohesion between people who share certain musical preferences; at the same time, the listeners of “the other music” can be discriminated against (Ackermann & Merrill, 2022). Music that violates a person’s aesthetic or moral ideals can be associated with people who listen to this music. Involuntary engagement with this kind of music can, in the worst case, lead to aggressive behavior toward the associated people or the (sub)culture they are thought to represent (Frank, 2007; Peltola & Vuoskoski, 2022). These kinds of aversive responses to disliked music can lead to listeners’ own conceptualizations of aversive music. Aversive music consists of complex layers of meaning, encompassing physical responses to musical sounds, music preference, and cultural and social connotations associated with disliked music, and the definitions of the specific attributes of any of these layers depend on the individual listener. We use the concepts aversive music and musical aversion when referring to strongly disliked music and music-evoked aversive experiences, respectively.
Although musical aversion seems to be a serious and even adverse experience to some individuals, not all listeners react to music as strongly. In our previous study (Peltola & Vuoskoski, 2022), we identified two listener types: one with a strong negative attitude toward aversive music and another with a more neutral attitude. Because of the qualitative research approach adopted in the study in question, we could not identify background variables that would potentially explain these differences between the respondents. Thus, a more generalizable scientific investigation exploring the various aspects of aversive music engagement is necessary, since we do not quite understand when, how, or why music can have such strong, negative effects on some listeners. Furthermore, existing scales aiming to measure individual differences in music preferences and affective responses to music, such as the Short Test Of Music Preferences (STOMP; Rentfrow & Gosling, 2003), the Healthy-Unhealthy Music Scale (HUMS; Saarikallio et al., 2015), or the Music Use and Background Questionnaire (MUSEBAQ; Chin et al., 2017) do not capture aversive reactions to music. To address this gap, the present study aims to investigate individual differences in the intensity of music-evoked aversion and proposes the Aversive Musical Experience Scale (AMES) for further measuring these experiences.
Emotional contagion and music
As briefly mentioned earlier, there is a substantial degree of variability in how individuals respond to music. Research aiming to explain interindividual variability in emotional responses to music has discovered a number of individual difference variables, such as trait empathy and trait emotional contagion, that seem to predict the intensity of emotional reactions evoked by certain kinds of music (e.g., Eerola et al., 2016; Vuoskoski & Eerola, 2017). Emotional contagion is a phenomenon where an individual “catches” the emotional state of another spontaneously (often without conscious awareness), resulting in emotional “convergence” between individuals (e.g., Hatfield et al., 1993). Emotional contagion can occur between individuals, within large groups, and even between music and the listener (e.g., Egermann & McAdams, 2012; Juslin & Västfjäll, 2008; Vuoskoski & Eerola, 2012).
Emotional contagion often involves unconscious mimicry of others’ facial expressions, body postures, and body and speech gestures, and internal feedback from the activated muscles is thought to lead to changes in subjective emotional experience (Hatfield et al., 1993). More relevantly for music listening, this motor mimicry can also take the form of embodied simulation of emotion concepts, where congruent facial expressions can be elicited by exposure to words with emotional connotations, for example (Niedenthal et al., 2009). Indeed, music listening has also been shown to elicit facial muscle activations that are congruent with the music’s emotional expression in the absence of any visual information about the performers’ facial expressions (e.g., Lundqvist et al., 2009). However, it should be noted that since music listening is also able to activate premotor areas related to vocal sound production (Koelsch et al., 2006) as well as larger-scale motor circuits (e.g., Alluri et al., 2012; Koelsch, 2011) in the absence of overt singing or movement, it is possible that music listening also involves some degree of internal simulation of actual motor actions/gestures perceived in the music.
While experiencing contagious positive emotions may be desirable, being susceptible to negative emotional contagion can sometimes have adverse effects on wellbeing: High emotional contagion has been associated with heightened stress, depression, and risk of burnout when exposed to stressful situations or environments (Petitta & Jiang, 2020; Prikhidko et al., 2020). In the context of music listening, those with a heightened tendency to experience emotional contagion across a variety of situations have been shown to experience more intense sadness in response to sad music (Eerola et al., 2016; Vuoskoski and Eerola, 2017). Thus, it is possible that those prone to experiencing emotional contagion may sometimes experience music expressing strong negative emotions (such as anger or aggression; see Thompson et al., 2019) as aversive due to the contagion of these negative emotions. It may also be that listeners with high emotional contagion may be more sensitive to music that involves unpleasant visual or semantic content (e.g., lyrics) or musical cues that are expressive of emotions that the listener finds unpleasant to experience.
Sensitivity to sounds
It has been proposed that aversion to musical sounds is at least partially context-dependent, since exposure and familiarization to certain frequencies and high volume within a specific musical genre, for instance, can modify listeners’ perception of them (e.g., Dermott, 2012). Nevertheless, musical sounds are sounds with specific physical and acoustic qualities, with concomitant effects on the listener. Some people are more sensitive to sounds in general, having a decreased sound tolerance, which can have multiple negative effects on their everyday lives (Baguley, 2003; Jastreboff & Jastreboff, 2015). Although no systematic evidence has yet been documented between sound-sensitivity and the enjoyment/dislike of music, individual differences at the neural level might partly explain why some listeners react more strongly to music compared with others.
According to Sachs et al. (2016), people who experience more intense emotions in response to music have stronger white matter connectivity between neural regions involved in sensory and emotional processing, for instance. The most visible reactions to music are musical chills, or frisson (Sloboda, 1991), which is a psychophysiological phenomenon that has gained plenty of scientific interest. According to Goldstein’s (1980) definition, the experience of frisson consists of a pleasurable tingling sensation in the area of the upper spine and back of the neck; it can spread upward over the scalp, outward over the shoulders, arms, and down the spine. Frisson can be accompanied by evident “goose bumps,” especially on the arms. Other physical reactions, such as tears, lump-in-the-throat, and muscle tension/relaxation can co-occur with or be included in frisson (see Harrison & Loui, 2014). Although music seems to be the most common frisson-producing stimulus (Goldstein, 1980; Grewe et al., 2007; Guhn et al., 2007; Panksepp, 1995), other sounds, social interaction, and visual stimuli can also cause aesthetic chills. For instance, experienced beauty within the contexts of nature, art, film, poetry, and religion can elicit frisson as a part of private or shared experiences associated with peak pleasure and being moved (Bannister, 2019; Goldstein, 1980). Chills can be also induced through other tactile and gustatory stimulation, and even by mental self-stimulation without any external stimulus (Grewe et al., 2011).
In addition to frisson, other types of bodily reactions to sounds can feel pleasurable. Autonomous sensory meridian response (ASMR) is a term that has gone viral on social media among people who report experiencing pleasurable bodily feelings and “tingling” feelings in response to “triggering” sounds and/or visual stimuli. Typical ASMR triggers include whispering, lip smacking, speaking softly, “crisp sounds,” tapping on different kinds of surfaces, and slow hand movements (del Campo & Kehle, 2016; McGeoch & Rouw, 2020; Poerio et al., 2018; Tuuri & Peltola, 2019). Despite the fact that ASMR and frisson seem to be somewhat distinct experiences (Fredborg et al., 2018; Roberts et al., 2020), they share similarities when it comes to physiological and psychological mechanisms. According to neuroscientific evidence, both ASMR and frisson show some similar neural activation patterns, specifically increased activation of the insula and anterior cingulate cortex, which are involved in detecting and selecting emotionally relevant information (Blood & Zatorre, 2001; Lochte et al., 2018). Both frisson and ASMR have been associated with specific personality traits, especially openness to experience, although, simultaneously, ASMR is also associated with neuroticism (Colver & El-Alayli, 2016; Fredborg et al., 2017). Poerio et al. (2022) proposed that similarly to intense emotional responses to music, ASMR may also be associated with individual differences in how sensory inputs and emotional experiences are integrated at the neural level. In their recent study, Poerio et al. (2022) found connections between ASMR and the heightened sensitivity to sensory and environmental stimuli (including external and internal cues; the social environment, e.g., other people’s moods; and responses to aesthetic stimuli), further suggesting that ASMR and strong emotional responses to music might indeed be connected.
A third phenomenon that shares similarities with frisson and ASMR is misophonia, which can be defined as “aversive reactions to particular sounds and the events that generate those sounds” that are not commonly considered to be negative or aversive to the general population (Mednicoff et al., 2022). Although misophonia seems quite in contrast to the pleasurable sensations of ASMR, they are often experienced by the same individuals, which suggests that they both might be underpinned by a heightened sensitivity to external sensory stimuli, particularly sounds (Poerio et al., 2022). Furthermore, they can both be triggered by similar stimuli, typically repetitive, human-made sounds (McGeoch & Rouw, 2020; Mednicoff et al., 2022) that can evoke pleasure in some listeners and aversion in others (del Campo & Kehle, 2016). Unlike hyperacusis, which is often defined as a disorder of loudness perception or heightened noise sensitivity, misophonic reactions can be triggered by both loud and very soft everyday sounds (Baguley, 2003; Baliatsas et al., 2016; Jastreboff & Jastreboff, 2015). Misophonia has been linked to autistic traits and poorer emotion regulation abilities; Rinaldi et al. (2023) propose that some of the same neurological underpinnings causing unusual negative emotions in response to unpleasant sounds might be playing a part in the emotion dysregulation in general. Misophonia seems to be associated with heightened neural activity similar to that associated with frisson and ASMR (Kumar et al., 2017; Schröder et al., 2019), and all three phenomena have been associated with increased skin conductance and heart rate (see Mednicoff et al., 2022). Since both ASMR and misophonia triggers bear a resemblance to certain qualities associated with aversive singing voices (Ackermann & Merrill, 2022; Peltola & Vuoskoski, 2022), it can be postulated that these two phenomena might also be linked with increased sensitivity to aversive musical experiences.
The present study
Previous studies on aversive and disliked music have relied on qualitative research approaches and limited samples of participants. Although these studies have provided valuable descriptions of listeners’ experiences, more generalizable approaches are needed for investigating individual differences potentially predicting strong aversion to disliked music. The main aim of this study was to explore these individual differences using a wider and more diverse sample of participants. With this goal in mind, we set out to develop a standardized questionnaire to measure the intensity of aversive musical experiences. Furthermore, in order to explore the hypothesized predictors and potential underlying mechanisms of music-induced aversion—such as emotional contagion and a general sensitivity to sounds—we also measured trait emotional contagion, misophonia, proneness to ASMR and frisson, and personality. We hypothesized that emotional contagion, sensitivity to sounds (misophonia and proneness to ASMR and frisson), and personality traits associated with negative emotionality (i.e., neuroticism) would be positively associated with the intensity of music-evoked aversion.
Method
Participants
A total of 354 participants completed an online survey hosted on the Qualtrics platform. Native English speakers living in the United Kingdom were recruited via the Prolific participant recruitment service. In addition, native Finnish speakers were recruited via both Prolific and social media channels (Twitter and Facebook). The Prolific participants were paid £2.50 for completing the survey, and the participants that were recruited via social media channels were entered into a lottery for a gift card worth 100 €. To filter out poor quality data, mean interrater correlations were calculated for each participant (separately for the English and Finnish language responses). Participants with mean interrater correlations more than 2 SD below average were removed from the data, resulting in the removal of 16 participants. The final sample consisted of 338 participants (232 British and 106 Finnish) aged 16–87 (M = 40.32, SD = 13.55), out of whom 218 were female, 117 male, and 3 non-binary.
The AMES
The development of a preliminary selection of items for measuring aversive musical experiences was informed by the qualitative data of our previous study (Peltola & Vuoskoski, 2022). Using qualitative inquiry for scale development is useful, since it provides the means for grounding concepts into real-life situations and human experience, and thus brings more validity to their quantitative exploration (e.g., Padgett, 1998). The free descriptions of 102 Finnish participants were used as the starting point for formulating statements about the experience of listening to aversive music. We aimed to maintain a balance between statements describing strong, negative experiences and those with a more neutral tone. The original list of statements in Finnish was reviewed by both authors and a research assistant, who were all native Finnish speakers. After removing items with too much overlap, the preliminary version of the AMES comprised 46 statements, 5 of which were reversely scored. These statements were independently translated into English by the first author and a research assistant, both proficient in English, and discrepancies between the translations were discussed and adjusted. Finally, the translated items were reviewed by a native English speaker and the suggested minor edits were reviewed and approved by the first author. Rather than merely translating the final scale to English, our aim was to develop both Finnish and English versions of the AMES concurrently, ensuring that the most consistent and reliable items across translations and samples would get included in the final scale. Full versions of all 46 items, as well as the final AMES scale in both Finnish and English, can be found in the supplementary materials (https://doi.org/10.17605/OSF.IO/VRNFA). In the scale instructions, aversive music was defined as “strongly disliked music.” Each of the statements were rated on a 5-point Likert scale, where 1 = strongly disagree, 2 = somewhat disagree, 3 = neither agree nor disagree, 4 = somewhat agree, and 5 = strongly agree.
Survey
Participants completed the survey online using the Qualtrics platform. In addition to the preliminary version of AMES, participants completed a set of standardized questionnaires measuring personality traits and other individual differences:
Misophonia
The Misophonia Questionnaire (MQ; Wu et al., 2014) is a 17-item questionnaire measuring the symptoms, emotions, and behaviors related to misophonia. The MQ comprises two subscales: the Misophonia Symptom Scale, and the Misophonia Emotions and Behaviors Scale. In the present study, the combined score was used.
Emotional contagion
The Emotional Contagion Scale (ECS; Doherty, 1997) has 15 items that tap into the susceptibility to “catch” others’ emotions, and measures the tendency to experience happiness, sadness, fear, anger, and love through contagion. In the present study, the combined score was used.
Personality
The Ten-Item Personality Inventory (TIPI; Gosling et al., 2003) is a very short measure of the Big Five personality traits: extraversion, neuroticism, agreeableness, conscientiousness, and openness to experience (2 items each).
ASMR
The experience of ASMR was measured using a question developed by Rouw and Erfanian (2018), which was slightly modified for the present study to include the word “relaxing”: Do you ever experience a relaxing, pleasurable tingling sensation in the head, scalp, back, or peripheral regions of the body (e.g., hands and/or feet) in response to visual, auditory, tactile, olfactory, or cognitive stimuli? (for example, experiencing a strong, desirable tingling sensation when someone is whispering in your ear or rubbing fingers on a rough surface).
Participants chose either Yes/No, and were asked to explain their experiences if they responded “Yes.” These open responses were checked for potential confusion with music-induced chills, and only the responses pertaining to ASMR experiences were retained.
Music-induced chills
The tendency to experience music-induced chills was measured using two questions modified from Bannister (2020): “Do you ever experience pleasurable chills (shivers down the spine, gooseflesh and/or tingling sensations) when listening to music? (Yes/No).” If participants responded “Yes,” the question was followed by: “How often do you experience these music-induced chills? (every few months/monthly/weekly/daily/every time I listen to music).” The responses were coded 0 for “No,” and 1–5 for the different frequency options.
Demographics
We also included questions about the participants’ age, gender (male/female/other), and musical expertise. Musical expertise was measured using one question from the Ollen Musical Sophistication Index (Ollen, 2006): “Which title best describes you? (nonmusician/music-loving nonmusician/amateur musician/serious amateur musician/semi-professional musician/professional musician),” which has been validated as a single-item measure of musical expertise (Zhang & Schubert, 2019). The response options were scored on a scale from 1 to 6.
Analysis
For all analyses, the British data was combined with the Finnish data. The aim of this decision was to facilitate the selection of the most consistent and reliable items across translations and samples. The ratings on reverse-scored items were converted before analysis. As a first step in item selection, an exploratory factor analysis was carried out to explore item covariances and the underlying dimensionality of the data. Items were selected for further analysis based on factor loadings and interpretability. To enable the cross-validation of the factor structure using confirmatory factor analysis (CFA), the data were split into two random samples of n = 169 (from here on Subsamples 1 and 2). Subsample 1 was used for exploratory factor analysis, and Subsample 2 for CFA. Finally, predictors of individual differences in the final AMES scores were explored in the entire sample using regression analyses. The data were preprocessed in MATLAB, and statistical analyses were carried out in JASP (version 0.16.3; JASP Team 2022), MATLAB, and SPSS Statistics (version 29). Data and supplementary materials are provided in the OSF repository; https://doi.org/10.17605/OSF.IO/VRNFA.
Results
Exploratory factor analysis
An exploratory factor analysis was carried out on the responses of Subsample 1 to the 46 AMES items, using principal component analysis with Promax rotation as the extraction method. An oblique rotation method was selected because the components were expected to be correlated. The Kaiser–Meyer–Olkin measure of sampling adequacy was .87, well above the threshold of .60 required for a good factor analysis (see Tabachnick & Fidell, 2007). The number of components to be retained in the model was determined using parallel analysis. The analysis yielded six components explaining 53% of the variance (see Figure 1 for the scree plot). Since the number of items is positively related to the (future) reliability of a factor, components with fewer than six items satisfying the initial retention criteria (factor loading >.4 and cross-loadings <.4) were discarded from further consideration (see e.g., Worthington & Whittaker, 2006). The remaining three components (Components 1, 2, and 4) were interpreted based on the item loadings. Factor 1 had the highest loadings from items related to physical sensations, bodily reactions, and feelings and was labeled “Sensations.” For Factor 2, six out of the nine highest loading items referred to social relationships and attitudes, and the factor was thus labeled “Social.” Finally, Factor 3 contained items that referred to specific musical and acoustic features that participants found aversive, and was labeled “Features.” For each of the three components, the six highest loading items corresponding to the main theme of the factor (and without cross-loadings above .4 with any of the retained components) were selected for a CFA. The only exception was item 28 in Factor 1, which was the only reverse-scored item that fulfilled the selection criteria (and was excluded to maintain consistency). The item loadings for all 46 items are displayed in Table S1 in the supplementary material.
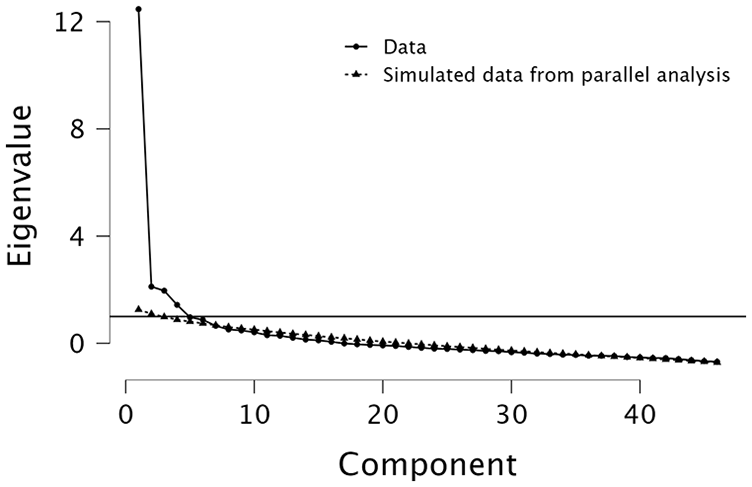
The Scree Plot of the Principal Component Analysis and Parallel Analysis.
CFA
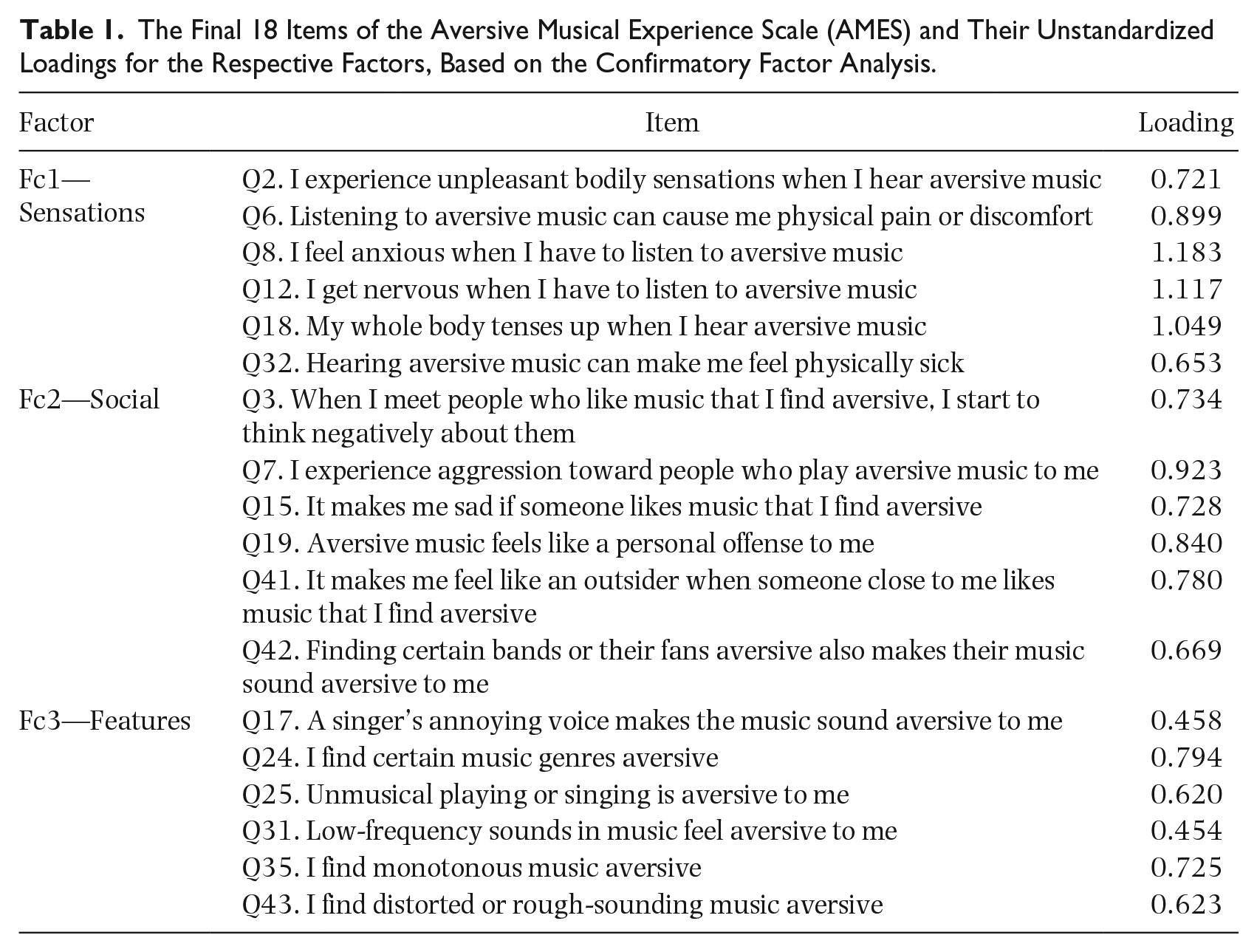
The preliminary three-factor structure of the 18 selected items (6 items per factor) was tested using the AMES responses of Subsample 2. CFA was carried out using structural equation modeling (SEM). The factor solution had an acceptable fit, with a Comparative Fit Index (CFI) above .90 (CFI = .91) and root mean square error of approximation (RMSEA) below .08 (RMSEA = .067; see, for example, Browne & Cudeck, 1993). The factor solution is displayed in Figure 2, and the individual items loading to each factor are shown in Table 1.
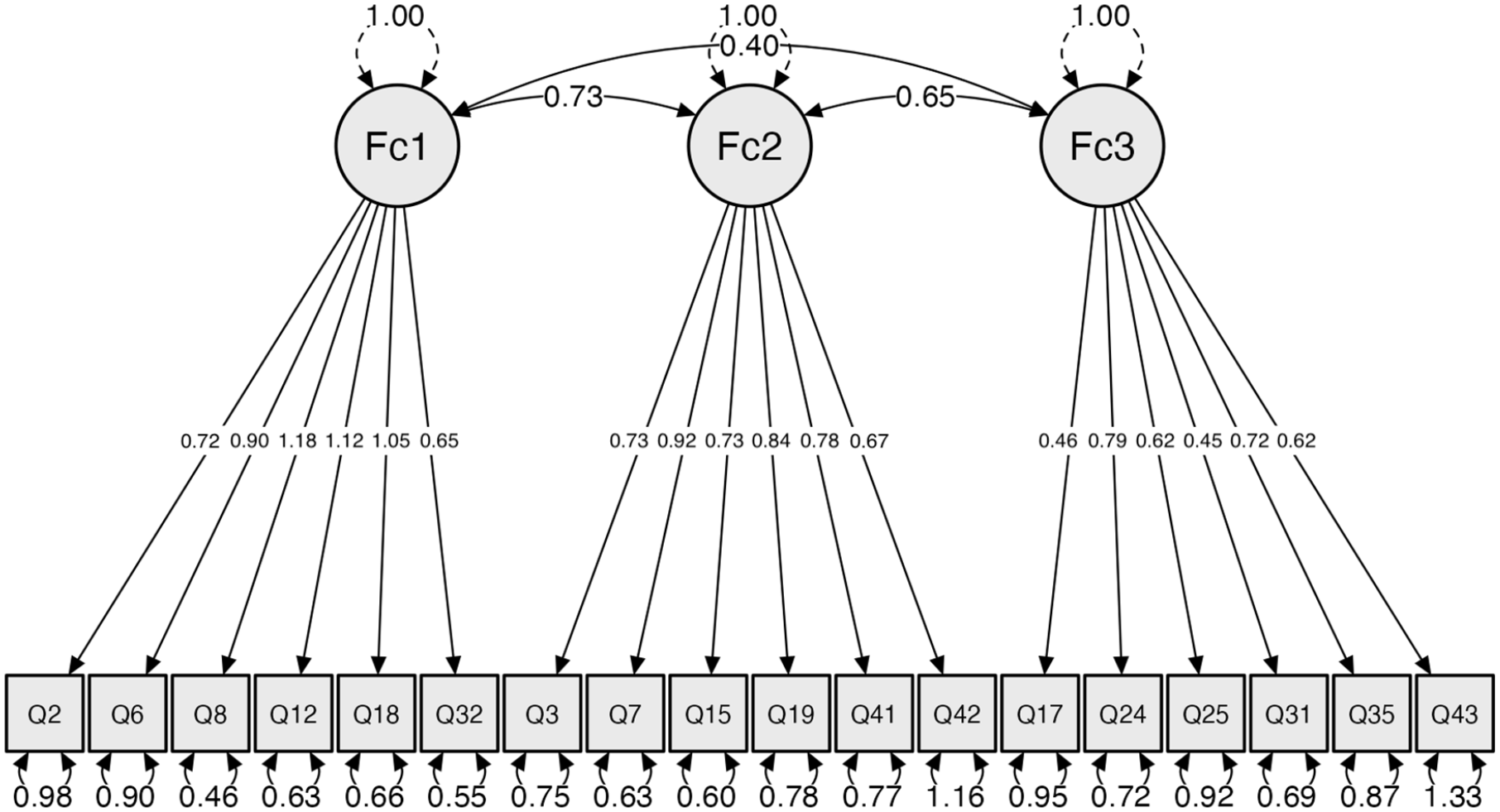
The Final Factor Solution of the Confirmatory Factor Analysis, Displaying the Loadings of the Individual Items, Their Residual Variances, and Correlations Between Factors (Fc1 = Sensations; Fc2 = Social; Fc3 = Features).
The Final 18 Items of the Aversive Musical Experience Scale (AMES) and Their Unstandardized Loadings for the Respective Factors, Based on the Confirmatory Factor Analysis.
Internal consistency
Using the entire sample of N = 338, the internal consistency of the AMES scale and its subscales was assessed using Cronbach’s alpha. All scales demonstrated acceptable consistency (α > .70), with α = .87 (AMES total), α = .87 (Sensations), α = .81 (Social), and α = .72 (Features).
Individual differences in aversive musical experiences
Finally, we explored potential predictors of individual differences in aversive musical experiences. Scores for the final 18-item AMES and its three subscales (Sensations, Social, and Features) were calculated for each participant by summing the ratings on the respective items. The means and standard deviations (or distributions, where applicable) for all variables of interest for both samples (British and Finnish) are provided in Table 2.
The Means and Standard Deviations (in Parentheses), or Distributions (Where Applicable), for All Variables of Interest for Both the British (n = 232) and Finnish (n = 106) Samples.
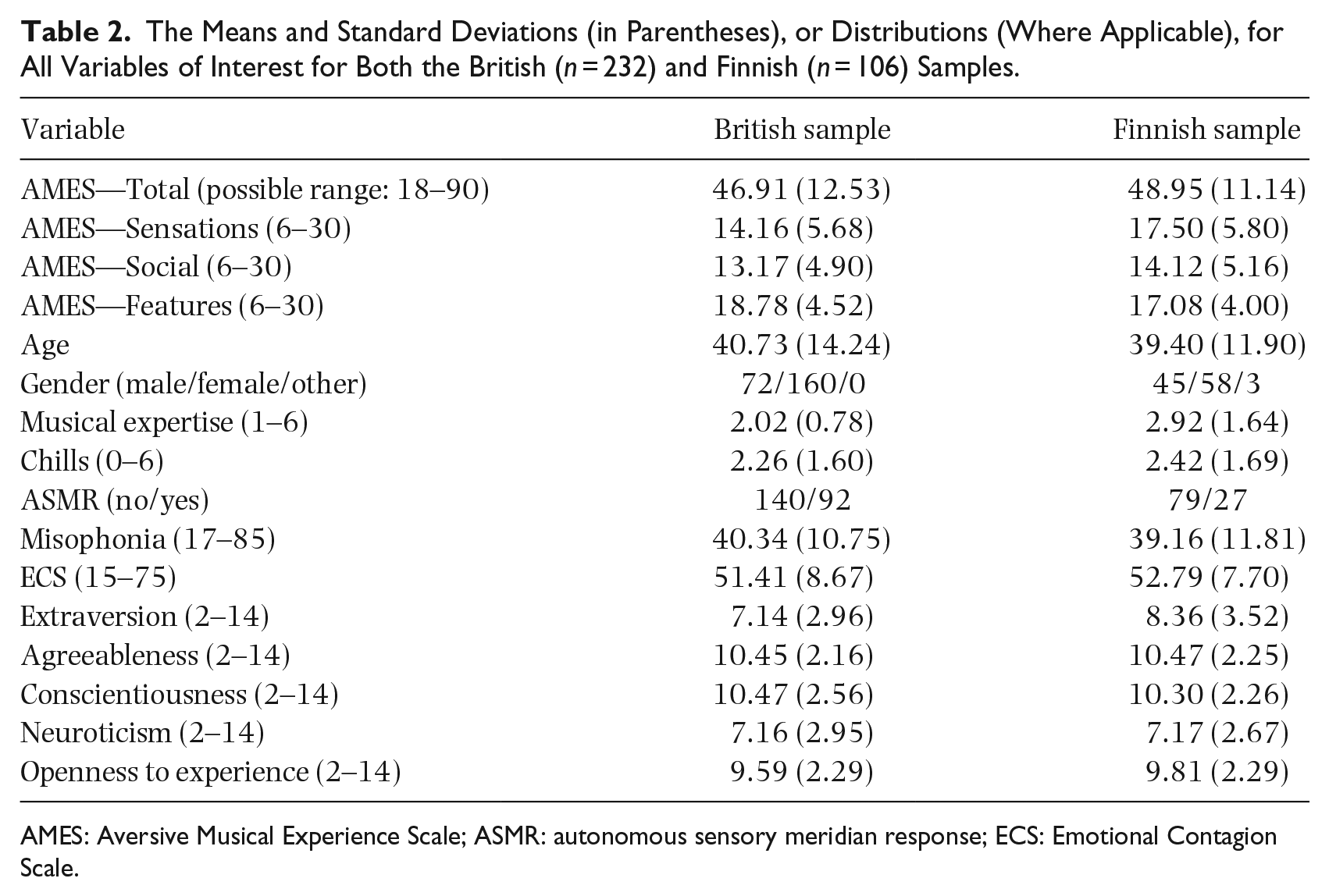
AMES: Aversive Musical Experience Scale; ASMR: autonomous sensory meridian response; ECS: Emotional Contagion Scale.
Using independent samples t-tests, we investigated whether there were significant differences between men and women in terms of the intensity of self-reported aversive musical experiences. The analyses revealed significant differences in total AMES, t(333) = −3.28, p = .001, d = −0.38; Sensations, t(333) = −3.81, p < .001, d = −0.44; and Features, t(333) = −4.34, p < .001, d = −0.50 scores, with women scoring higher than men. There was no significant difference in Social scores. Next, we explored whether those who reported experiencing ASMR also reported experiencing more intense musical aversion compared with those who do not experience ASMR. Independent samples t-tests did not reveal any significant differences in total AMES scores or its subscales. We further explored whether ASMR experiences are related to sensitivity/reactions to sounds more generally (i.e., misophonia and music-induced chills). Independent samples t-tests revealed significant differences in both misophonia, t(336) = −3.36, p < .001, d = −0.38 and the frequency of music-induced chills, t(336) = −2.21, p = .028, d = −0.25, with those who experience ASMR scoring higher. The distributions of the scores are shown in Figure 3.
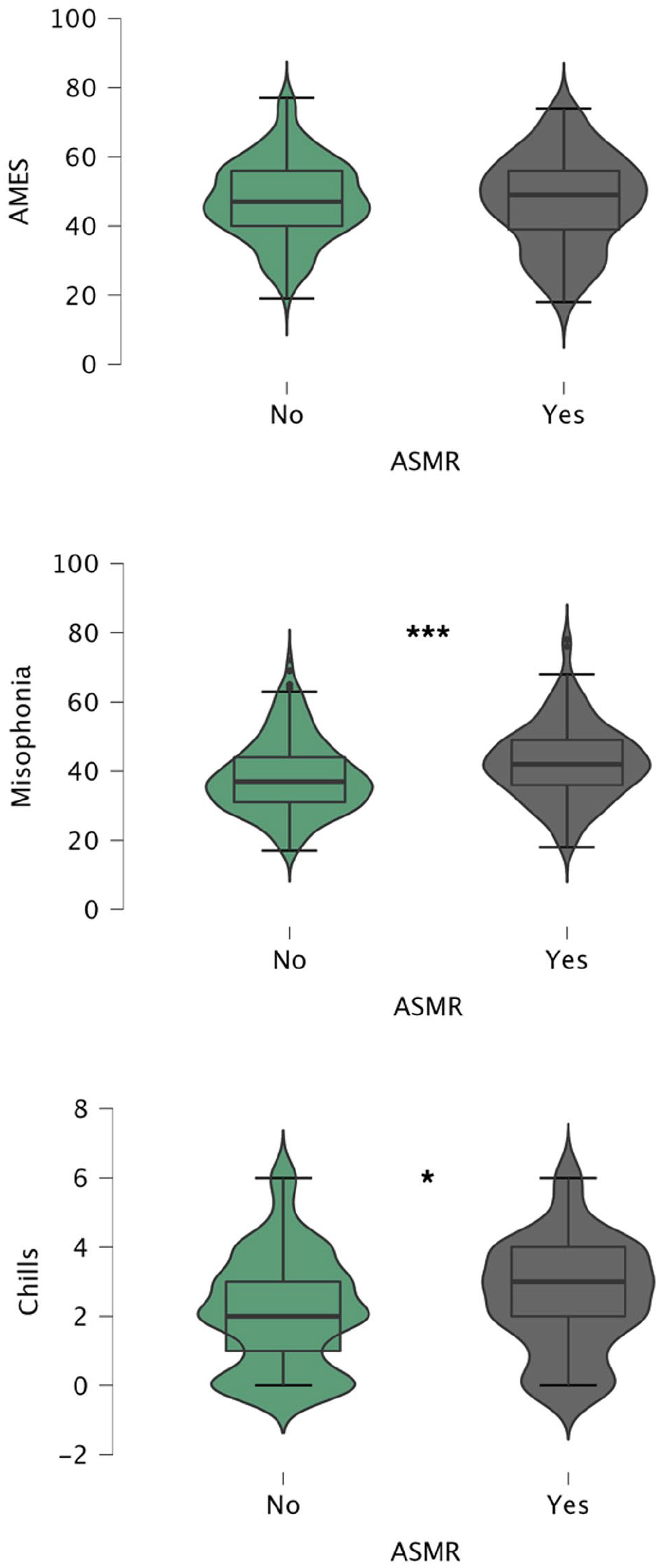
Boxplots Illustrating the Distributions of AMES, Misophonia, and the Frequency of Music-Induced Chills Among Those Who Report Experiencing ASMR (n = 119) Compared With Those Who Do Not (n = 219).
Using multiple regression analysis, we explored predictors of interindividual differences in the intensity of aversive musical experiences. Furthermore, this enabled us to investigate the convergent validity of the AMES in comparison to the Misophonia Questionnaire. As a first step, we explored Pearson correlations between the AMES scales (AMES total, Sensations, Social, and Features) and misophonia (MQ), emotional contagion (ECS), personality traits (TIPI), age, musical expertise, and the frequency of music-induced chills (see Table 3 for the correlations with AMES scales, and Table S2 in the supplementary material for the intercorrelations between all variables). Since the correlation coefficients serve a descriptive purpose here (i.e., significant predictors of AMES will be tested in subsequent regression analyses), we have not adjusted the p-values for multiple tests. Misophonia had the highest correlations with the total AMES (r = .54) and all its subscales (rs = .39 to .47), followed by emotional contagion (rs = .13 to .34) and neuroticism (rs = .16 to .27). Since the Features subscale had the lowest internal consistency, we also investigated Spearman correlations between individual difference variables and the individual items (see Table S3 in the supplementary material for the coefficients). Misophonia correlated significantly with all six individual items, ECS with four, and neuroticism with three out of six items.
Pearson Correlations Between the AMES Scales and Misophonia (MQ), Emotional Contagion (ECS), Personality Traits (TIPI), Age, Musical Expertise, and the Frequency of Music-Induced Chills.
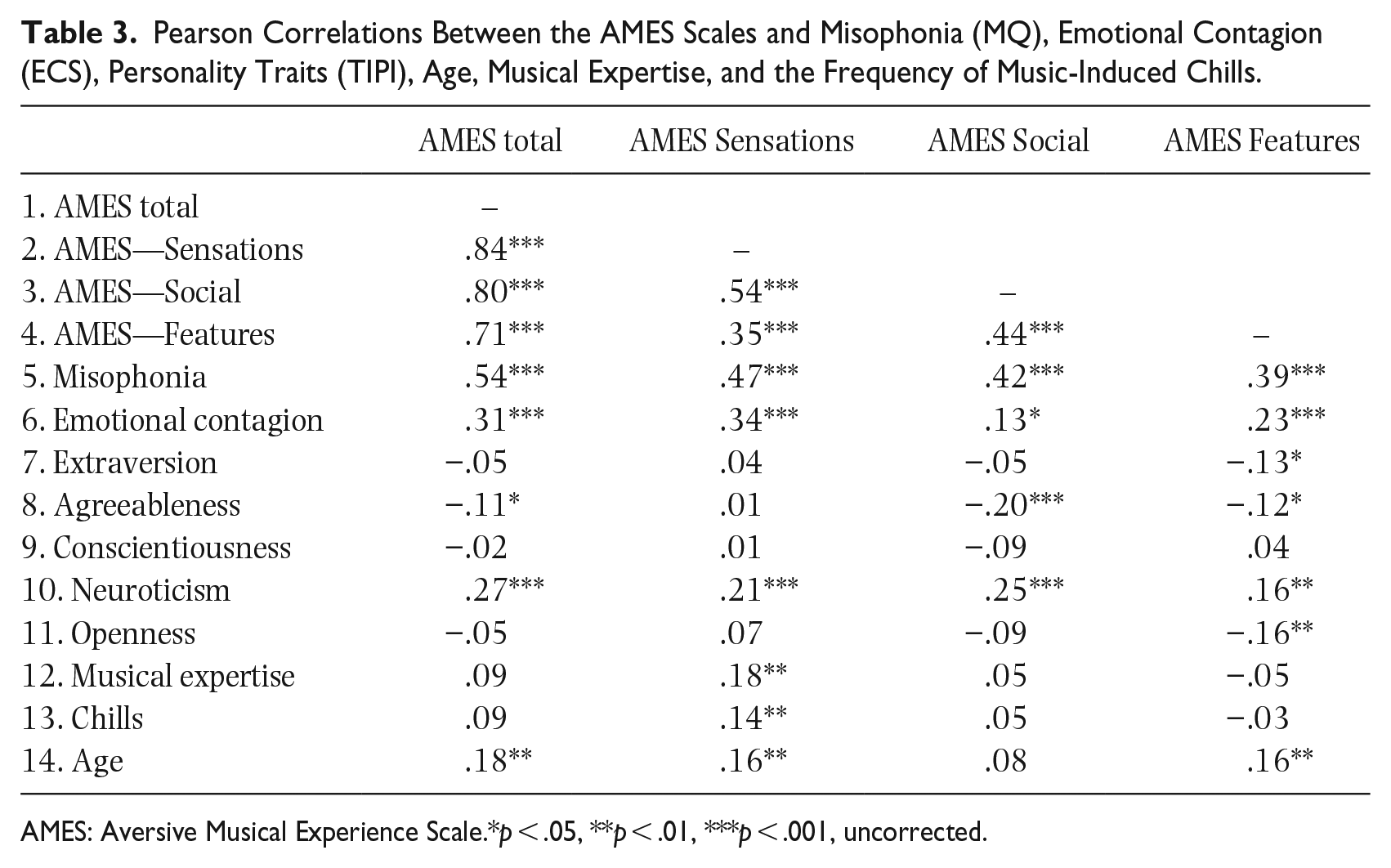
AMES: Aversive Musical Experience Scale.*p < .05, **p < .01, ***p < .001, uncorrected.
We proceeded by carrying out four stepwise regression analyses to explore the best unique predictors of AMES and its three subscales based on purely mathematical criteria. As predictors, we entered personality traits (extraversion, neuroticism, agreeableness, conscientiousness, and openness to experience), emotional contagion, misophonia, musical expertise, frequency of music-induced chills, and age. The explanation rates (adjusted R2) in the four models ranged from 20% to 35% and the number of significant predictors from 3 to 5. Misophonia, emotional contagion, age, neuroticism, and openness to experience explained 35% of the variance in total AMES scores. Misophonia emerged as the best predictor for all subscales, followed by emotional contagion (with the exception of the Social subscale). The model summaries are presented in Table 4.
Model Summaries of the Four Stepwise Regression Models Predicting Interindividual Variance in Total AMES Scores and the Three Subscales (Sensations, Social, and Features).
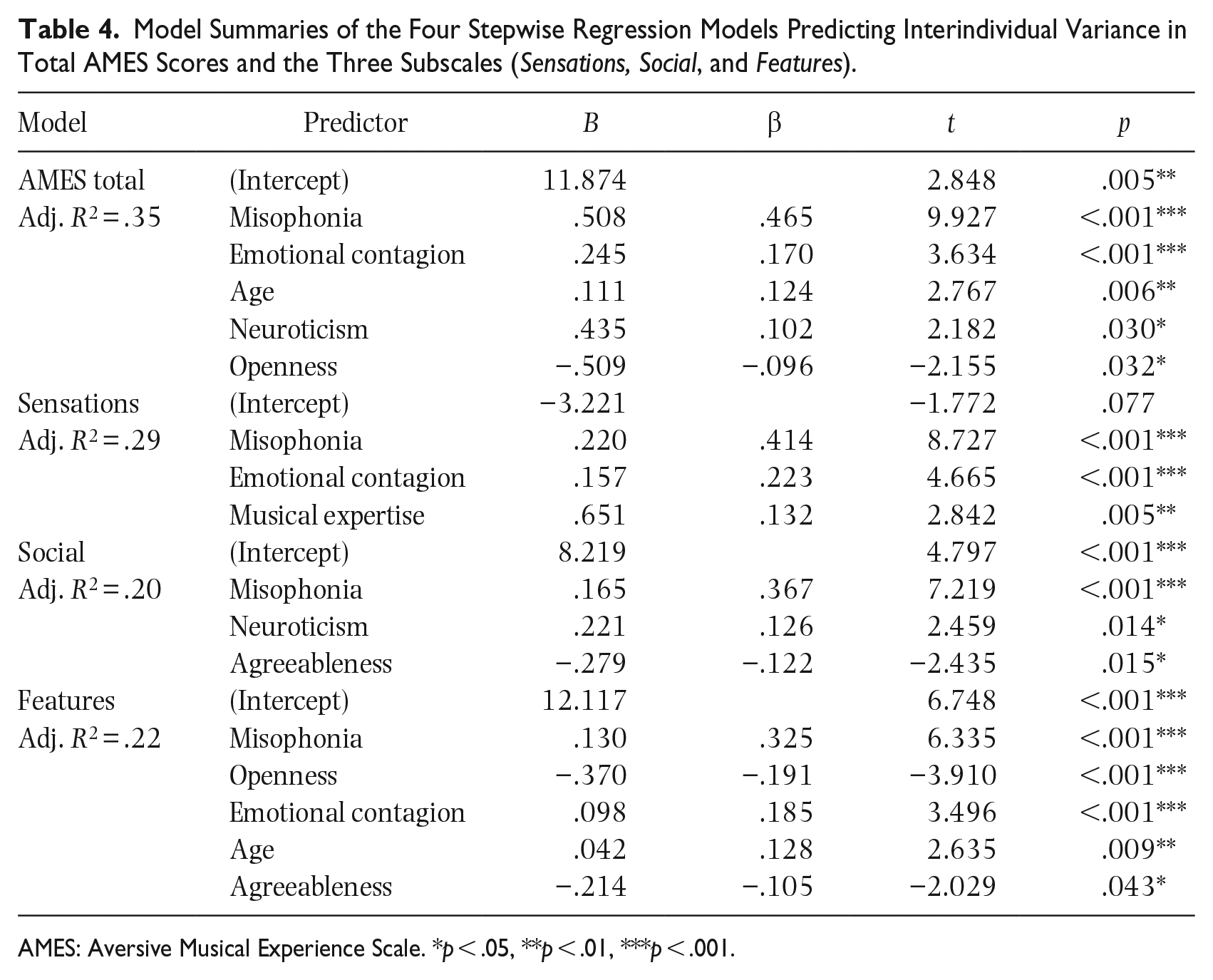
AMES: Aversive Musical Experience Scale. *p < .05, **p < .01, ***p < .001.
Since stepwise regression analysis is prone to Type I errors, we also carried out confirmatory regression analyses using the Enter-method, including dummy-coded variables for gender and ASMR experiences (dummy-coded variables could not be included in the stepwise models). The model summaries are presented in Table 5. Misophonia and emotional contagion remained the most significant predictors also in the confirmatory regression analyses that included all predictors. Age remained a significant predictor of total AMES and Features scores, and musical expertise remained a significant predictor of Sensations scores. Personality traits remained significant predictors of Social (neuroticism and agreeableness) and Features (agreeableness, openness to experience, and extraversion) scores, but not of global AMES scores. Neuroticism and openness to experience were significant predictors of global AMES in the stepwise regression model (but not in the Enter model), while extraversion was not a significant predictor of Features scores in the stepwise regression model. Additionally, ASMR experiences emerged as a significant (negative) predictor of total AMES, Social, and Features scores, and female gender emerged as a significant (negative) predictor of Social scores.
Model Summaries of the Four Linear Regression Models (Enter-Method) Predicting Inter-Individual Variance in Total AMES Scores and the Three Subscales (Sensations, Social, and Features).
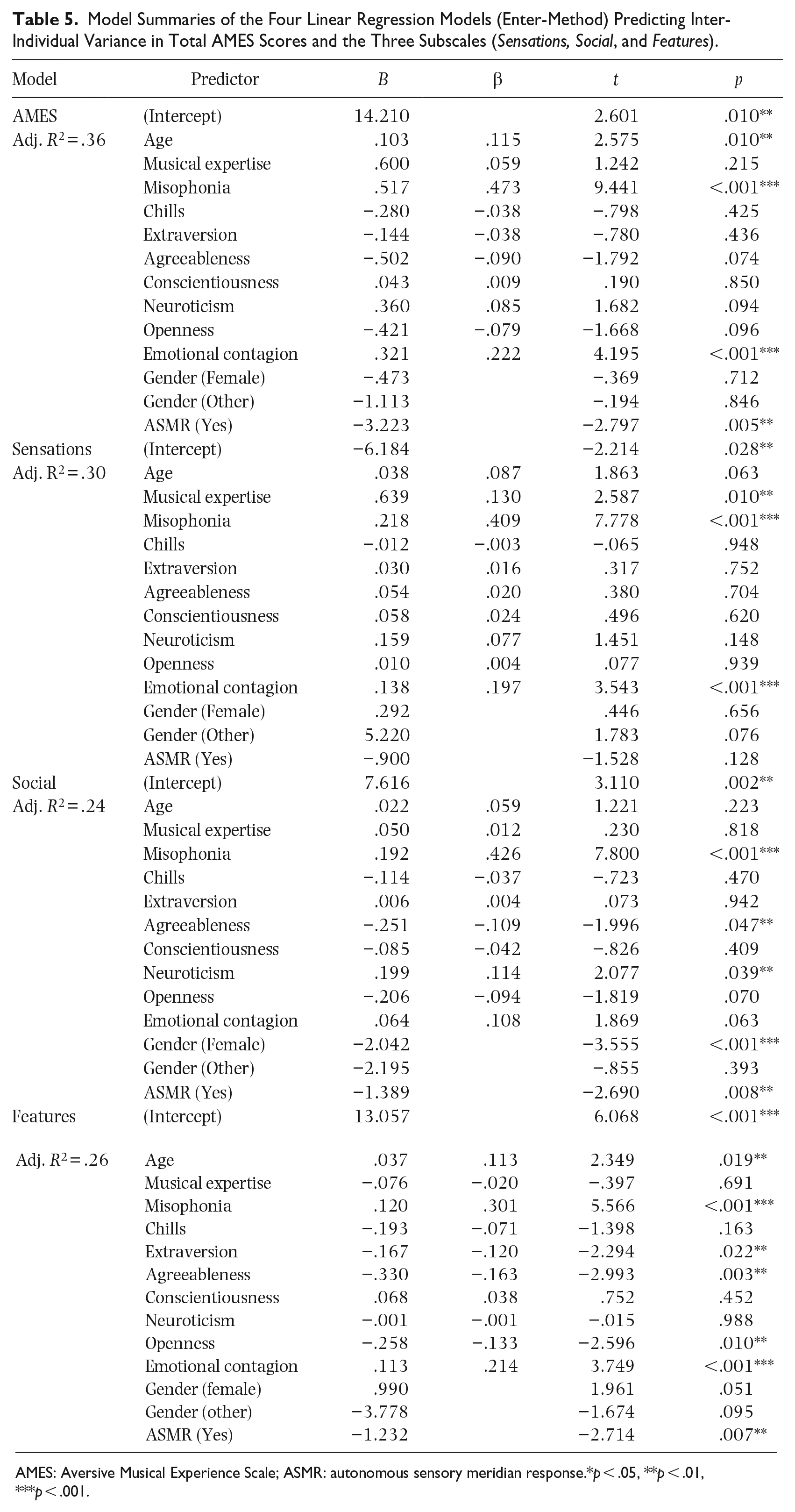
AMES: Aversive Musical Experience Scale; ASMR: autonomous sensory meridian response.*p < .05, **p < .01, ***p < .001.
Discussion
This study set out to develop a new measure of individual differences in the intensity of music-induced aversion, the AMES, and to explore the predictors of these individual differences. Based on the results of exploratory and confirmatory factor analyses a final 18-item version of AMES was constructed. The global AMES comprises three subscales: Sensations, Social, and Features. The Sensations subscale taps into feelings and bodily sensations evoked by aversive music, while the Social subscale measures reactions and attitudes related to people that are somehow associated with aversive music. Finally, the Features subscale taps into specific musical and acoustic features that are experienced as aversive.
Misophonia emerged as the strongest predictor of global AMES and its three subscales, explaining 9%–19% (adj. R2 change) of the interindividual variance in the scales in the stepwise regression models. This can be considered a large effect in the context of individual differences research, where effects above r = .30 (i.e., R2 = .09) are considered large (e.g., Gignac & Szodorai, 2016). The finding is in line with our hypothesis on general sound sensitivity at least partially explaining the susceptibility to music-evoked aversion. However, proneness to ASMR or chills experiences were not significantly associated with AMES or its subscales in the t-test or stepwise regression analysis (respectively). In the confirmatory regression analysis (where all predictor variables were included in the model), ASMR actually emerged as a negative predictor of global AMES and the Social and Features subscales. The frequency of chills experiences did correlate positively with the Sensations subscale (r = .14, p < .01), but did not emerge as a significant predictor in the regression models, potentially due to overlapping variance explained by better predictors such as emotional contagion, misophonia, and openness to experience. Since misophonia by definition relates to aversive reactions to sounds, and ASMR and chills are typically defined as pleasurable experiences, it appears that aversive responses to music are specifically associated with a sensitivity to sound-evoked aversion rather than a general responsivity to sounds.
In line with our hypothesis, emotional contagion also emerged as a significant predictor of AMES and two of its subscales, accounting for 2%–4% of unique variance (in the stepwise regression models) in global AMES, Sensations, and Features scores. It is possible that those scoring high in emotional contagion have difficulties in regulating or inhibiting the contagion of negative emotions from music, and thus can experience music expressing strong negative emotions as aversive. This interpretation is in line with the findings of Thompson et al. (2019), who found that empathic concern—a facet of trait empathy that is strongly correlated with trait emotional contagion (e.g., Lo Coco et al., 2014)—was a negative predictor of positive emotions (power and joy) evoked by violent death metal music. In contrast, power and joy were the strongest emotions experienced by fans of death metal (Thompson et al., 2019).
The personality traits of agreeableness, neuroticism, and openness to experience emerged as significant predictors of aversive musical experiences in both the stepwise and enter regression models. Agreeableness and openness to experience were significant (negative) predictors of Features scores (accounting for 1% and 3% of the variance in the stepwise regression model, respectively), while neuroticism was a positive and agreeableness a negative predictor of Social scores (each accounting for 1% of variance). Neuroticism is typically defined as the tendency to experience negative emotions such as anxiety, worry, and tension (e.g., Reisenzein & Weber, 2009) and thus in the present study we hypothesized that neuroticism would also be associated with the intensity of aversive musical experiences. However, although neuroticism correlated positively with total AMES and all its subscales, it only emerged as a significant predictor of Social scores, potentially due to overlapping variance explained by misophonia and emotional contagion. Agreeableness, on the contrary, is a prosocial trait characterized by kindness, tender-mindedness, and a tendency to be less anger-prone (e.g., Kuppens, 2005), while openness to experience is understood as the tendency to be imaginative and curious, to have wide interests, and to appreciate aesthetic experiences (e.g., John & Srivastava, 1999).
In line with the findings of the present study, Thompson and colleagues (2019) found that, in addition to empathic concern, also neuroticism was inversely (and openness to experience positively) associated with the feelings of power and joy elicited by violent death metal, suggesting that listeners scoring high in neuroticism may also experience music that expresses strong negative emotions as aversive. Agreeableness was a negative predictor of Features and Social scores, suggesting that listeners scoring high in agreeableness experience less intense music-induced aversion and less aggression toward people associated with aversive music. These findings are in line with studies linking agreeableness to the tendency to be less anger-prone and to control negative emotions in communication situations (Kuppens, 2005; Tobin et al., 2000). Finally, openness to experience has previously been associated with a preference for diverse and complex music styles (Rentfrow & Gosling, 2003), as well as for music expressing negative emotions (such as sadness and fear; Vuoskoski & Eerola, 2011). Our findings support the view of openness to experience as a trait associated with wide interests and curiosity that also extend to the musical domain.
In addition to specific trait measures and variables related to sound-sensitivity, we also explored the relations between demographic variables and music-induced aversive experiences. Age was a significant positive predictor of global AMES and Features scores, suggesting that music-induced aversive experiences become more intense with increasing age. Age has previously been associated with decreasing engagement with music (e.g., Bonneville-Roussy et al., 2013) and decreasing levels of music preferences both in terms of one’s favorite music (Schäfer & Sedlmeier, 2010) and Intense (rock, punk, alternative, and heavy metal) and Contemporary (rap, soul/R&B, funk, and reggae) styles of music in particular (Bonneville-Roussy et al., 2013). Based on these findings, our results could potentially be explained by an overall decrease in music-evoked enjoyment associated with age and/or an increasing discrepancy between one’s musical preferences and mainstream popular music typically played in public places. While we found significant differences between males and females with respect to global AMES, Sensations, and Features scores (with females scoring higher than males), female gender only emerged as a significant (negative) predictor of Social scores when other individual difference variables were accounted for. This suggests that, with the exception of Social scores, surface-level gender differences in aversive musical experiences are accounted for by better predictors such as misophonia and/or emotional contagion. Finally, musical expertise was a significant predictor of Sensations scores, suggesting that those with more musical training experience more intense bodily sensations and negative feelings in response to aversive music.
Limitations, implications, and future directions
The current study has some limitations that are worth acknowledging and discussing. First, the scale development was based on a qualitative dataset collected from a somewhat homogeneous sample of WEIRD (see Henrich et al., 2010) Finnish participants. Due to voluntary participation, the sample may have been biased and thus not representative of the phenomenon in the general population, which may have further skewed the results of our previous qualitative analysis and the selection of statements for the present study. However, the sample size was rather large for a qualitative study (>100 participants), which provides broader insights into the phenomenon compared with the more limited samples of informants that are typical in studies that use qualitative inquiry for scale development. Furthermore, we aimed to limit the sample selection bias in our present study by offering remuneration for participation and by combining two samples collected in two languages from two different countries. Nevertheless, we ended up with a somewhat imbalanced gender distribution in our sample (64.5% female), which has some implications for the generalizability of findings. Participant remuneration may also have implications for data quality, since some participants may complete the survey quickly and superficially only to receive the monetary reward. In the present study, data quality was screened using mean interrater correlations. Furthermore, data collected via the Prolific platform (which were used in the present study to recruit most of the participants) have been shown to have better quality compared with other online platforms (e.g., Douglas et al., 2023; Eyal et al., 2022).
Second, the factor structure of the final AMES bears resemblance to some of the final themes of our previous qualitative analysis (“Material,” “Embodied experience,” and “Autobiographical aspects,” see Peltola & Vuoskoski, 2022). Although this might raise critical questions concerning circular argumentation and logical fallacy, we interpret the findings in the context of a circular reasoning process (Park et al., 2020), which entails building up a strategic sequence of complementary research methodologies for more robust findings. Moreover, the results of the factor analysis are also in line with the findings of Ackermann and Merrill (2022), further suggesting that there may be conceptual similarities between the expressions that people use to describe aversive musical experiences, even when they speak different languages.
Finally, since our participants were retrospectively reporting their experiences, it might have affected their evaluations concerning the intensity of their experiences. Collecting data in real-time during music listening could provide more accurate information about the duration and emotional and/or bodily aspects of the experiences evoked by aversive music. In the future, such research designs could be used to evaluate the predictive utility of the AMES with respect to physiological indices of music-induced stress responses.
We aimed to explain individual differences in the intensity of music-induced aversion, but it is possible that in addition to personality traits, misophonia, ASMR, and frisson, other traits or tendencies might have explained further interindividual variance in the phenomenon. For instance, general irritability, which is a trait associated with lowered thresholds for temper loss and a tendency to experience anger and negative moods (e.g., Deveney et al., 2019), may also be associated with the intensity of music-evoked aversive experiences. Irritability is often considered as one of the subcomponents of neuroticism (e.g., DeYoung et al., 2007), and in the present study neuroticism emerged as a significant predictor of AMES Social scores. However, since personality was here measured using the brief TIPI (Gosling et al., 2003), we were unable to explore how the various sub-facets of neuroticism relate to aversive musical experiences. Future studies should ideally utilize longer and more reliable measures of the Big Five personality traits to further investigate these aspects. Furthermore, Poerio et al. (2022) recently found that interoceptive sensitivity and bodily awareness predicted ASMR intensity, and that people with these kinds of sensory sensitivities were also more likely to be classified as highly sensitive persons (HSP). Although in our study ASMR emerged as a negative predictor, interoceptive sensitivity, bodily awareness, and HSP could be interesting traits to look into when exploring strong aversive music experiences further, since sensitive individuals are more reactive to both positive and negative aspects of their environment (Poerio et al., 2022).
Future studies on music-evoked aversive experiences should also investigate individual differences in musical reward sensitivity (see, for example, Belfi & Loui, 2020; Mas-Herrero et al., 2012). The lack of a negative correlation between AMES scores and the tendency to experience pleasurable music-induced chills suggest that the intensity of music-evoked aversive experience is not related to musical anhedonia (i.e., a lack of pleasure from music; Belfi & Loui, 2020), but this should be directly investigated in future studies. For instance, it could be that specific kinds of musical reward—as measured by the Barcelona Musical Reward Questionnaire (BMRQ; Mas-Herrero et al., 2012), for example—could be associated with the intensity of music-evoked aversion. Similarly, the positive association between musical expertise and AMES Sensations scores suggests that amusia (i.e., selective difficulties in music processing; Peretz, 2016) is unlikely to offer a viable explanation for aversive musical experiences, but this possibility cannot be ruled out without direct investigation.
Findings of this study provide a novel perspective on music-evoked emotional responses, which is relevant for various fields and future research. Studying aversive responses to music is crucial for gaining a holistic understanding of the range of affective effects that music has on people. In the future, the AMES could be used to investigate whether the people who report experiencing strong musical aversion also experience more arousal and stress at the physiological level when hearing aversive music. Moreover, the potential implications of music-evoked aversion for eliciting antisocial attitudes and/or behaviors (such as withdrawal or aggression) should be addressed in future studies using experimental and survey methods. This line of work would be important for gaining a better understanding of the potentially stress-inducing and socially destructive qualities of background music in public places, for instance. Although we did not investigate participants’ mental health in the present study, it is possible that those who are sensitive to music-evoked aversion have a higher risk for anxiety or depression, for example, since previous studies have found a positive association between misophonia and these mental health disorders (e.g., Beutel et al., 2016; Erfanian et al., 2019; Rouw & Erfanian, 2018; Schröder et al., 2019). In the future, the potential links between sensitivity to music-evoked aversion and mental health should be investigated more thoroughly, especially since intense and frequent experiences of musical aversion may contribute to social isolation. These future studies could also shed light on the applicability of the AMES as a screening tool for identifying individuals who are at risk for mental health disorders. Nevertheless, it is important to recognize that, in addition to the numerous benefits for individuals’ wellbeing, music can also have adverse effects on some listeners.
Furthermore, since misophonia has some links to autistic traits (Rinaldi et al., 2023), it is possible that the same also applies to musical aversion. Although not all autistic people have misophonia, and not all people with misophonia are autistic, the links between these two neurally-based phenomena should be further studied. Investigating whether aversive responses to music are more common among neurodivergent listeners compared with more neurotypical ones could provide important insights into both the musical experiences and the wellbeing of neurodivergent people.
Conclusion
This study developed a new tool for measuring individual differences in the intensity of music-evoked aversion: the AMES, measuring the feelings, bodily sensations, social experiences, and musical features associated with aversive musical experiences. Misophonia and sensitivity to emotional contagion emerged as the strongest predictors of interindividual differences in the intensity of music-evoked aversion, followed by personality, age, and musical expertise. Aversive responses to music appear to be specifically associated with a susceptibility to sound-evoked aversion rather than a general responsivity to sounds.
Supplemental Material
sj-docx-1-pom-10.1177_03057356241239336 – Supplemental material for The Aversive Musical Experience Scale (AMES): Measuring individual differences in the intensity of music-evoked aversion
Supplemental material, sj-docx-1-pom-10.1177_03057356241239336 for The Aversive Musical Experience Scale (AMES): Measuring individual differences in the intensity of music-evoked aversion by Jonna K. Vuoskoski and Henna-Riikka Peltola in Psychology of Music
Footnotes
CORRECTION (April 2024):
The name of the research centre has been added in the fourth affiliation.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by the Research Council of Norway through its Centres of Excellence scheme, project number 262762.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.