
Abstract
Music has a cross-modal influence on the emotional appraisal of pictures, probably due to a misattribution of emotion from music to the visually perceived images. Moreover, dichotic listening studies have demonstrated a left-ear (right-hemisphere) advantage for processing emotional and/or musical stimuli. The present study investigated the role of laterality in cross-modal affect misattribution: that is, whether visual judgments of emotion would be affected differently depending on which ear was presented with music via the dichotic listening task. Participants rated the emotionality of happy, sad, and neutral faces while listening to happy or sad music in one ear and white noise in the other. Baseline ratings without music were used as a comparison to see whether and how emotionality judgments shifted in the music conditions. As predicted, the results showed that happy music played to the left ear had a stronger cross-modal influence on ratings of sad faces than the same music played to the right ear. Furthermore, sad music affected the ratings of all faces regardless of whether it was played to the left or right ear. These results do not fully align with any given lateralized model of emotion processing, suggesting that other factors such as negativity bias may play a role.
Music is often used as a means of self-regulating emotions and mood (Saarikallio, 2011) and reducing stress (Linnemann et al., 2015). Music also influences physiological responses in accordance with the particular mood of the music (Krumhansl, 1997). Interestingly, research has shown that listening to music can influence the perception of affective pictures (see Hanser & Mark, 2013, for a review). This cross-modal transfer of emotion from the auditory to the visual domain (and vice versa) has been demonstrated both when the music was directly attended to (Baumgartner, Esslen, & Jäncke, 2006; Baumgartner, Lutz, et al., 2006; Spreckelmeyer et al., 2006), and when it was unattended background music (Hanser et al., 2015). The results of these studies show that the emotional valence of the concurrent music, whether congruent or incongruent, shifts affective ratings of pictures to be more in line with the valence of the music. For example, Jeong et al. (2011) examined the effect of music on ratings of facial expressions in both emotionally congruent and incongruent conditions. In their study, happy and sad music clips (Samuel Barber’s Adagio for Strings and Johann Strauss’s Blue Danube Waltz, respectively) were paired with happy and sad faces, and participants rated the facial expressions on a scale from −7 (saddest) to +7 (happiest). When presented with happy music, they rated happy faces more happy and sad faces less sad. When presented with sad music, they rated happy faces less happy and sad faces sadder.
It is not clear why emotion has a cross-modal influence, but one theory is that emotional valence from one domain (e.g., music) is unintentionally misattributed, or transferred, to the other domain (e.g., images) (Weinreich & Gollwitzer, 2016). Affect misattribution has traditionally been examined within a unimodal (visual) domain only, using an emotive prime followed by a neutral stimulus (e.g., Gawronski & Ye, 2014), although there are studies using emotional sounds as a prime preceding a visual emotion judgment (Logeswaran & Bhattacharya, 2009; Weinreich & Gollwitzer, 2016). The results of these auditory prime studies demonstrate the implicit influence of music and other affective sounds on visual ratings of emotion, even with short (2 s) excerpts.
However Bar-Anan and Nosek (2012) suggest that the results of studies of affect misattribution could simply be an artifact akin to demand characteristics; the way the experiments were designed made it obvious to participants what outcomes were predicted, so they adjusted their performance in alignment with these expectations. In their study, Bar-Anan and Nosek found that even when told to ignore the emotional prime and base their judgment on the rating task, some participants retrospectively reported intentionally basing their judgments on the prime. Following on from this, Weinreich and Gollwitzer (2016) tested both the affect misattribution and the demand characteristics hypotheses. They found that subjective ratings of visual stimuli, and physiological responses accompanying these ratings (skin conductance and facial electromyogram), were influenced by the particular valence of music at any given timepoint in the song that was being played concurrently. This was the case even when the experimental procedure was designed to reduce the chances of participants anticipating the hypotheses. Thus, there is evidence that cross-modal transfer of emotion from music to images still occurs even after controlling for potential demand characteristics.
Music and emotion lateralization
Previous research has shown that both emotions (Gainotti, 2021) and music (Wang & Agius, 2018) are processed predominantly by the right hemisphere (RH), and that these functions are inextricably linked (Trimble & Hesdorffer, 2017). In a study by Blood et al. (1999), participants listened to pleasant and unpleasant (dissonant) music while changes in cerebral blood flow were measured using positron emission tomography (PET). The results showed preferential activation of multiple RH regions that have been associated with aspects of musicality and emotion processing. This suggests that unique, predominantly RH neural networks are associated with emotional responses to music.
As it travels from the ear to the brain, auditory information takes multiple pathways, both ipsilateral and contralateral (Nieuwenhuys, 1984). However, when conflicting information is played to each ear, the ipsilateral pathways are suppressed and most of the auditory information arrives in the contralateral hemisphere (Brancucci et al., 2004; Kaneko et al., 2003). This provides an interesting opportunity to explore the lateralized processing of auditory stimuli such as language and music in a behavioral paradigm known as the dichotic listening task (Kimura, 1967). In this task, different sounds are played simultaneously to each ear and accuracy and/or reaction times to the sound stimuli are measured. Language sounds in particular are typically processed by the left hemisphere (LH; Knecht et al., 2000; Vigneau et al., 2006), and are identified more accurately and faster when played to the right ear compared with the left (Westerhausen & Kompus, 2018). This is because the linguistic information from the right ear can be processed by the LH immediately, whereas information from the left ear needs to be transferred from the RH to the left before it can be processed. The effectiveness of this paradigm in measuring the laterality of brain function has been shown using functional magnetic resonance imaging (fMRI) applied to participants while undergoing a dichotic listening test (Noort et al., 2008), revealing the activation of areas of the brain concerned with auditory and speech perception.
In contrast to a right ear advantage for language, numerous studies have shown a left ear (RH) advantage for musical and emotional stimuli (Bryden & MacRae, 1988; Godfrey & Grimshaw, 2015; Grimshaw et al., 2009). Music and poetry are rated more pleasant when heard from the left ear (Beaton, 1979); the left ear has an advantage in identifying the emotional tone of short musical passages (Bryden et al., 1982); and a left ear advantage is found for humming sounds in a tone identification task (Mei et al., 2020).
Although most of the results of research using dichotic listening tasks support the RH hypothesis of emotion processing, the results of some studies (Erhan et al., 1998; Prete et al., 2020) suggest that positive valence is processed by the LH. In a dichotic emotional prosody detection task, Erhan et al. (1998) found general support for the RH hypothesis, but also noted that participants with a strong left ear advantage for negative emotions showed a weaker bias for positive emotions. In a more recent study, participants imagined hearing a sentence with positive or negative valence spoken into one of their ears (Prete et al., 2020). The results showed that they tended to imagine positive sentences in their right ear, supporting the role of language processing in the LH. However, this right ear advantage disappeared when they were imagining negative sentences, supporting the idea that RH activation is due to negative, but not positive, valence attenuated by the right ear advantage. In the visual domain, some studies (Jansari et al., 2011; Natale et al., 1983; Reuter-Lorenz & Davidson, 1981 ; Reuter-Lorenz et al., 1983) have also shown a left visual field advantage for angry or sad facial expressions, and a right visual field advantage for happy facial expressions. This appears to suggest that the LH is dominant for positive emotions and the RH for negative emotions.
However, research by Killgore and Yurgelun-Todd (2007) suggests that the RH is dominant for processing all emotions, even if the left is capable of processing simple emotional information. Participants in Killgore and Yurgelun-Todd’s study underwent fMRI while they viewed chimeric faces expressing happiness or sadness on one side and a neutral expression on the other. These were presented briefly (20 ms) to each visual field. The study found a general RH advantage for all the faces regardless of valence. However, when happy faces were shown to the right visual field, the LH was activated significantly. This effect was not found with sad faces. Therefore, it appears that the non-emotionally dominant LH has limited capacity for processing positive emotions. This may be because positive emotions are easier to identify, as they all fall into the general category of happiness. However, there are many facets of negative emotions that fall into different categories; for example, sadness and anger are very different. Thus, it appears that the RH is generally dominant for processing emotions but is particularly adept at distinguishing the complexities of negative emotions (Benowitz et al., 1983; Perry et al., 2001).
The current study, aim, and hypotheses
Previous studies showed that music can influence the emotional appraisal of pictures (Baumgartner, Esslen, & Jäncke, 2006; Baumgartner, Lutz, et al., 2006; Hanser et al., 2015; Hanser & Mark, 2013; Jeong et al., 2011; Spreckelmeyer et al., 2006), probably due to a transfer or misattribution of emotion from music to the visually perceived images (Logeswaran & Bhattacharya, 2009; Weinreich & Gollwitzer, 2016). Furthermore, dichotic listening studies (Beaton, 1979; Bryden et al., 1982; Bryden & MacRae, 1988; Godfrey & Grimshaw, 2015; Grimshaw et al., 2009; Mei et al., 2020) have demonstrated a left ear (RH) advantage for detecting or distinguishing between emotional and/or musical stimuli. However, no study has examined whether dichotic presentation of music itself can influence the misattribution of emotional and neutral photos. If lateralized emotion and music processes contribute to this misattribution process, then it can be inferred that visual ratings would be affected in different ways depending on the ear to which music is presented. In the current study participants completed a facial expression judgment task alone (music-absent condition) or with music played in one ear and white noise in the other. It was hypothesized that ratings of facial expressions portraying different emotions would be influenced by the valence of the music played to the left ear (RH) to a greater extent than the same music played to the right ear (LH). This would be the case both when the music and faces expressed the same emotion (e.g., happy faces would be rated as even happier when paired with happy music in the left ear) and when the music and faces expressed different emotions (e.g., sad faces would be rated as less sad or happier when paired with happy music in the left ear).
Method
Participants
A total of 45 participants were recruited from a Scottish university (29 female) with a mean age of 22.6 years (SD = 2.85, range = 19–30 years). All students were right-handed, with a mean score of 84.7 (SD = 24.7, range = 0–100) on the Edinburgh Handedness Inventory—Short Form (Veale, 2014). All participants had normal or corrected vision, and one participant reported an auditory impairment. However, the ratings of this participant were within the normal range of scores so were not excluded from the analyses. The participants, some of whom took part in the study for course credit, were tested between October 2019 and February 2020. This study was approved by the University of the West of Scotland’s Education and Social Sciences Ethics Committee.
Materials
The experiment was run on an Alienware 17 laptop using E-Prime 2.0 Professional. The happy music used in this experiment was a 130 s excerpt from Beethoven’s Symphony no. 6 (3rd movement) and the sad music was a 130 s excerpt from Samuel Barber’s Adagio for Strings. These particular excerpts were chosen because they were shown to be effective in inducing emotions in previous studies (Baumgartner, Esslen, & Jäncke, 2006; Jeong et al., 2011; Krumhansl, 1997). Each musical excerpt was modified in Audacity 2.3.0 to play exclusively to one audio channel (left or right) with white noise added to the other channel. This resulted in four conditions consisting of happy music played to the left ear, happy music played to the right ear, sad music played to the left ear and sad music played to the right ear. All music was played through the same pair of headphones at the same volume level, and the headphones were sterilized with alcohol swabs between uses.
The facial stimuli were chosen from the JACFEE and JACNeuF face databases (Matsumoto & Ekman, 1988). There were 24 faces in total: 8 happy, 8 sad, and 8 neutral. A 5-page response booklet accompanied the facial expression judgment task, one page (24 ratings) for each condition. The rating scale ran from −7 (very sad) to +7 (very happy), with 0 indicating a completely neutral facial expression.
Within each block, the order in which faces appeared was semi-randomized using an online list randomizer (random.org). Thus, the order of faces was different for each block, but all participants saw the same faces in the same order within each block. This was done for ease of scoring the manual booklet. All participants completed the music-absent block first, but the order of the musical experimental blocks was randomized. The page order was checked against the block order post-participation and labeled appropriately, prior to scoring. All faces were shown centrally on the screen for a total of 5 s.
Procedure
Participants gave their informed consent before beginning the study. They were seated at the laptop in a private testing room and started by completing a demographic questionnaire. Participants were given verbal and written instructions for the experimental task and, following this, the experimenter gave them headphones and started the facial expression judgment task. This task consisted of five blocks: one music-absent block of faces (baseline) and four experimental blocks of faces paired with happy or sad music. For the baseline music-absent block, the faces were presented sequentially for a duration of 5 s each, totaling 120 s in all. Next, the dichotic listening blocks began. A total of 10 s of music was played at the start of the block with a blank screen to allow the participant to become acquainted with the music. After this, the music continued and the face ratings began, with the participant again rating 24 faces, each presented for 5 s. Thus, each experimental block lasted for 130 s (see Figure 1). After completing the entire task (120 facial ratings in total), participants were thanked for their time and debriefed.
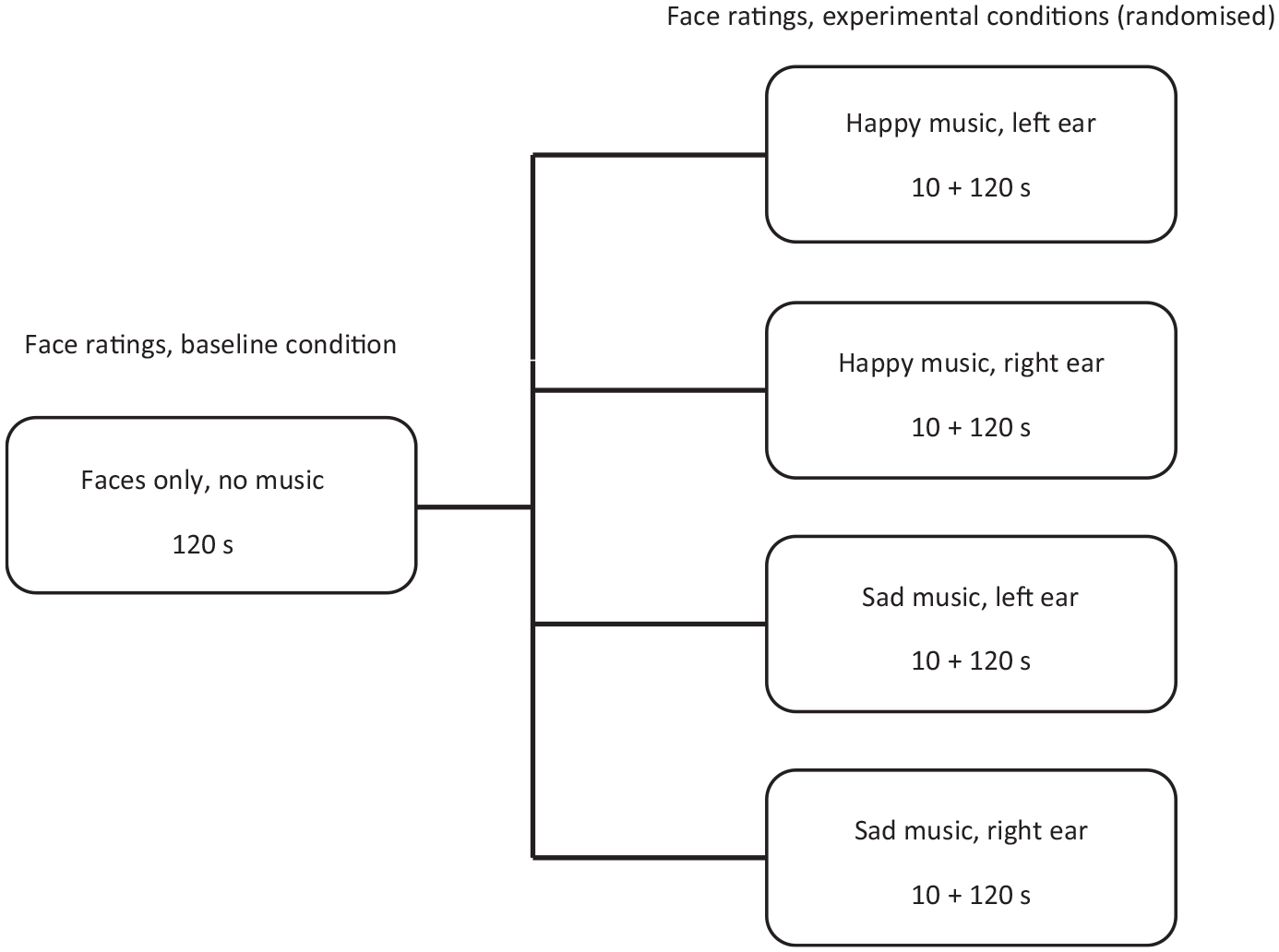
The sequence of blocks for the experiment.
Results
Analyses
A 3 (music presentation: left ear, right ear, no music) by 3 (face: happy, sad, neutral) repeated-measures analysis of variance was run separately for the happy music and the sad music to examine how these factors influenced the ratings given to faces. It was not possible to run a single full-factorial model with all variables because the same set of scores for the music-absent (baseline) condition is needed for both of the present analyses. Follow-up Bonferroni-corrected paired comparisons were run as needed to further explore significant interactions. Descriptive statistics were graphed to display the full set of results for each condition, shown in Figure 2. The vertical bars represent the mean scores (± SE) for the music-absent conditions, against which the line graphs for the music-present conditions can be compared. It is evident from this figure that the happy, neutral, and sad faces were given appropriately distinct ratings of emotion, with a reminder to the reader that positive values indicate happiness, negative values indicate sadness, and scores closer to 0 indicate weak/no emotion. It also appears that happy music increased the ratings of faces in multiple (although not all) music conditions compared with the baseline, and that sad music decreased emotionality ratings in many of the music conditions compared with baseline. Most bars also have a negative slope, indicating a left ear advantage compared with right ear. We next explored whether any of these differences were statistically significant.
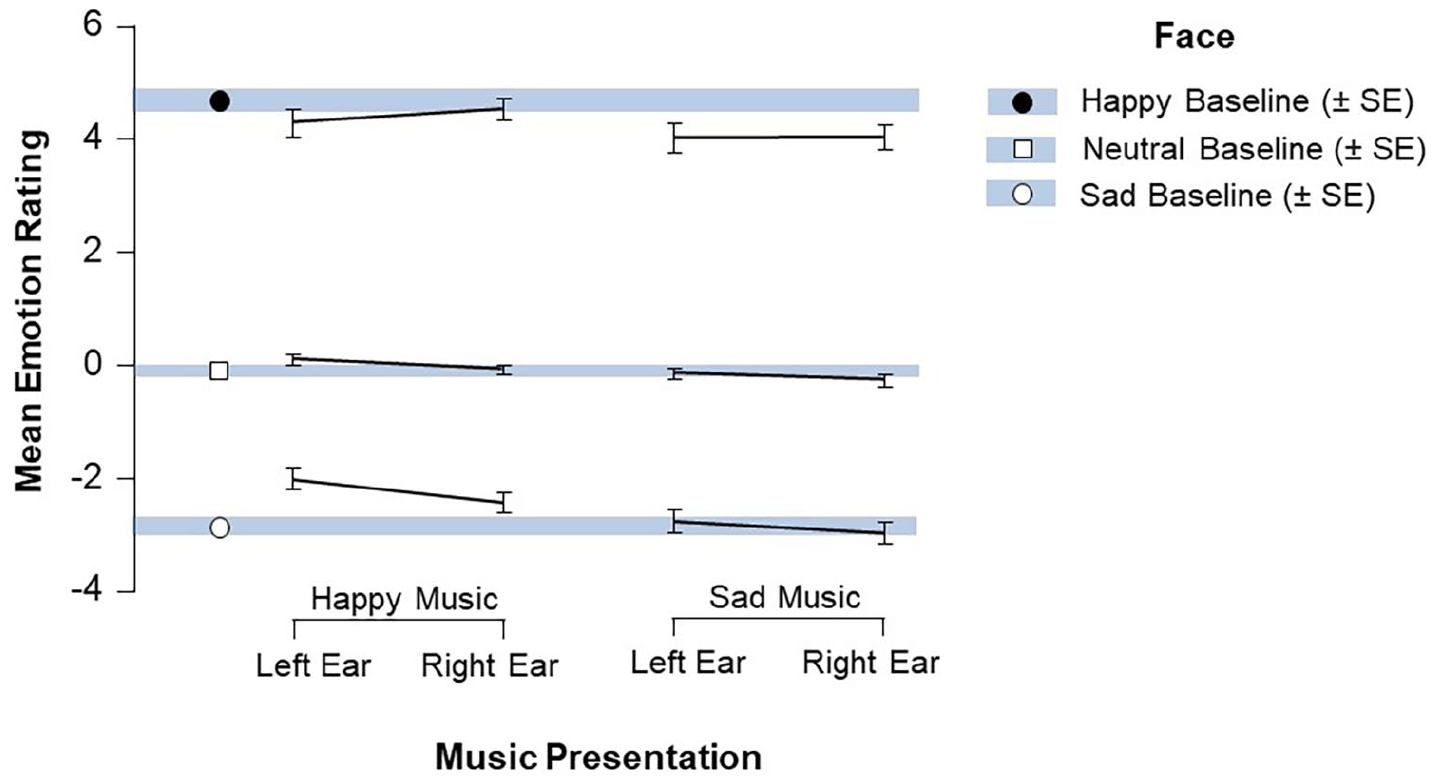
Mean values (with SEM error bars) for the ratings of happy, sad, and neutral faces for the sad and happy music conditions, as compared with the baseline music-absent conditions.
Happy music condition
First, analyses were run to test whether happy music played to the left ear, right ear, or neither (music-absent condition) affected the ratings of happy, sad, and neutral faces. Mauchly’s test of sphericity indicated that the assumption of sphericity had been violated for the two-way interaction, χ2 (2) = 86.31, p = < .001, so a Greenhouse–Geisser correction was applied (ε = .55). There was a significant main effect of music presentation, F(1.9, 84.8) = 4.67, p = .01,
There was also a significant interaction between happy music presentation and faces, F(1.2, 52) = 8.76, p = .003, ηp2 = .166 (see left half of Figure 2). Several planned paired comparisons were run to examine this interaction. Sad faces were rated as significantly happier when music was presented to both the left ear, t(44) = 4.29, p < .001, and the right ear, t(44) = 2.83, p = .007, compared with baseline. Importantly, sad faces were also rated as significantly happier in the left ear condition than the right ear condition, t(44) = 2.32, p = .025. However, no such effects were found for ratings of happy faces or neutral faces (all ps > .07). Thus, happy music played to either ear significantly affected ratings of sad faces, although happy music played to the left ear had a significantly stronger effect on ratings of sad faces than the same music played to the right ear.
Sad music conditions
The next analysis tested whether sad music played to the left ear, right ear, or neither (music-absent condition) affected the ratings of happy, sad, and neutral faces. Mauchly’s test of sphericity indicated that the assumption of sphericity had been violated for the two-way interaction, χ2 (2) = 86.31, p < .001, so a Greenhouse–Geisser correction was applied (ε = .56). There was a significant main effect of music presentation, F(1.6, 69.7) = 8.67, p = .001,
Discussion
The current study explored whether dichotically presented music influenced the perception of facial expressions (happy, neutral, sad). The results showed that sad faces were rated as less sad when happy music was played, and importantly these ratings of sad faces were most strongly influenced when the happy music was played to the left ear compared with the right ear. This is in line with the RH hypothesis of emotion: when emotional music was sent to the RH predominantly from the left ear, the perception of facial expression was influenced selectively. When the same emotional music was sent to the LH predominantly from the right ear, the perception of facial expression was not affected. However, it is interesting that happy music only significantly influenced the perception of sad faces, but not happy or neutral faces. In contrast, sad music had the general effect of decreasing the ratings of facial expressions regardless of whether it was heard in the left or right ear. This result is similar to that of past research (Jeong et al., 2011), whereby participants listening to sad music rated happy faces less happy and sad faces sadder. The fact that there was no difference between ratings of sad music presented to the left and right ear respectively, however, does not align with the hypothesis that the left ear presentation would selectively influence ratings to a greater extent than the right ear.
Taken together, these results add to the growing body of evidence (Baumgartner, Esslen, & Jäncke, 2006; Baumgartner, Lutz, et al., 2006; Hanser et al., 2015; Hanser & Mark, 2013; Jeong et al., 2011; Spreckelmeyer et al., 2006) that emotional information from music can have a cross-modal influence on the perception of visual stimuli. Sad music facilitated cross-modal transfer (or misattribution) of emotion in general, regardless of facial expression or ear presentation, whereas happy music only demonstrated an influence on sad faces. Moreover, these results are unlikely to be produced entirely by demand characteristics (see Bar-Anan & Nosek, 2012); if this phenomenon underlay all participant responses then there should be no difference based on ear presentation. The fact that we found a stronger cross-modal influence for happy music played to the left ear compared with the right ear suggests that RH emotion processes facilitate cross-modal transfer of happiness in music to sad imagery. It is highly unlikely that participants would guess in advance the predicted outcomes of the laterality component of this research.
The role of emotion laterality
The results of the present study only partially support the RH hypothesis, as happy music had a significantly stronger influence on the ratings of sad faces when played to the left ear (RH) as compared with the right ear (LH). However, happy music did not have any effect on the ratings of happy and neutral facial expressions, and sad music influenced all the ratings of faces regardless of ear presentation. There are a number of alternatives to the RH hypothesis of emotion, including the valence hypothesis (pleasant vs unpleasantness) and the motivation hypothesis (approach vs withdraw). According to the valence hypothesis, the RH is specialized particularly for negative emotions, whereas positive emotions may be processed by the LH (Killgore & Yurgelun-Todd, 2007; Reuter-Lorenz & Davidson, 1981). In contrast, the motivation hypothesis (Davidson, 1992) conceptualized emotion laterality as differentiated by approach (left anterior hemispheric dominance) versus withdraw motivations (right anterior hemispheric dominance). In the present study, valence and arousal were confounded, as happiness is classified as representing both positive valence and approach motivation, whereas sadness is classified as representing both negative valence and withdraw motivation. The inclusion of anger would allow for differentiation between valence and motivation (Harmon-Jones, 2004) because it represents negative valence but also approach, rather than withdraw, motivation. Future research should take this into consideration.
Although the present study cannot distinguish between these two aspects of emotion, it is still worth considering whether some components of audio-spatial processing are sensitive to valence and/or direction of motivation. Support for this idea can be seen in a study in which music recognition abilities were tested in a group of patients who had undergone left or right temporal lobe resections (Khalfa et al., 2008). The patients were asked to rate the level of valence (unpleasant-pleasant) and arousal (relaxing-stimulating) that they perceived in happy and sad musical tracks. Patients with both LH and RH damage showed reduced recognition of sad music, suggesting that both hemispheres play a role in sad music perception. In contrast, only patients with left-medial temporal damage (including the amygdala) showed impairments in the perception of happy music. The left and right amygdala appear to have different roles in emotion processing (Gainotti, 2012; Morris et al., 1998), suggesting that the left amygdala processes conscious emotional stimuli (as in Khalfa et al., 2008) whereas the right amygdala has a role in unconscious emotion processing. This may be relevant to the present study, as the task did not require explicit attention to the emotional music. Thus, the pattern of results of the present study may be explained in this way, with sad music showing no lateralized results, but presumably unattended happy music showing RH dominance.
An alternative explanation based on the present pattern of results may also rely on the valence/motivation hypotheses, with different hemispheres contributing in different ways to affect misattribution. Perhaps this misattribution or transfer of emotion from music to visual judgments is facilitated in conditions when there is any involvement of the RH. This could be why sad music, which is processed by the RH, effectively influenced ratings of faces regardless of facial expression or ear presentation. In contrast, happy music, a LH process, only influenced sadness, a RH process—and it did so especially when the RH (left ear) received the music. No such influence was found in the condition involving exclusive LH involvement (happy music, happy faces).
That said, one can again assume RH processing of neutral faces because participants carried out an emotional judgment task and the RH has expertise in facial processing (Kanwisher et al., 1997). Thus, if any RH involvement is sufficient for emotion transfer to take place, then both happy and sad music should have influenced the ratings of neutral faces. However this was found only for sad music, not happy music. Thus this explanation, too, fails to account fully for the results of the present study.
The one finding that is consistent across the study is that any involvement of sadness in either domain seems to influence the transfer of emotions. That is, processing of sadness was cross-modally influencing/influenced. This may align in some respects with the finding that visual processing of sad emotion and subsequent sad mood induction enhanced processing of right-ear stimuli in a dichotic oddball task, while no such effect was found for happy or neutral faces/mood in the same condition (Schock et al., 2012).
Recently researchers have posited the Hemispheric Functional Equivalence (HFE) model of emotional face perception, which suggests that although the RH is the default, environmental demands combine with neurophysiological, biological, and psychological modulators to redistribute hemispheric contributions (Stanković, 2020; Stanković & Nešić, 2020). In the present study participants were asked to judge the emotionality of facial expressions, but the addition of emotional music may have served as an increased environmental demand or made the judgment task more complex to process and complete. Research suggests that the LH is needed for higher level processing of emotional information (Shobe, 2014), emotional appraisal and categorization (Spence et al., 1996), and integrative processing of contrasting valences (Jung et al., 2006), which is in alignment with aspects of the HFE model in that both hemispheres are required for higher-level emotion processing. However, this would only fully explain the pattern of results for the sad music conditions, but not for the happy music conditions which did evidence asymmetrical hemispheric influence.
It is also prudent to consider that happy and sad auditory emotion stimuli may rely on, or evoke, different neural mechanisms. The present study found that, overall, sad music had a greater effect than happy music on influencing ratings of facial expressions. This could be because sad music generates a greater emotional response and draws more attention than happy music. For example, in a study examining how music influenced driver safety, Pêcher et al. (2009) reported that participants’ attention was automatically drawn to the rhythm and lyrics of sad music. An fMRI study by Mitterschiffthaler et al. (2007) found that happy music activated reward regions of the brain such as the ventral striatum, dorsal striatum, and anterior cingulate cortex. However, sad music activated emotional limbic regions including the amygdala and hippocampus. The amygdala in particular was only activated when listening to sad music (Mitterschiffthaler et al., 2007), which may imply that sad music has a greater emotional impact than happy music. This idea was supported by a PET study (Suzuki et al., 2008) that compared brain regions when participants were listening to major and minor chords. Major chords are typically associated with happy music and minor chords with sad music. The minor chords activated the right striatum, which is important for emotion and reward processing. In contrast, major chords produced substantial activity in the left middle temporal gyrus, which is a cortical structure related to audio-visual information processing (Suzuki et al., 2008). Therefore, it appears that sad music activates subcortical areas of the brain related to emotions, but happy music does not.
Negativity bias
An alternative explanation for the non-lateralized results for the sad music conditions, as compared with the happy music condition, could be the presence of a negativity bias. As negative stimuli have been found to draw more attention than positive stimuli (Smith et al., 2003), the sad music may have influenced ratings of faces regardless of which hemisphere preferentially processed the music. Moreover, negative stimuli can affect individuals even without conscious awareness (Delplanque et al., 2004). For example, Chen et al. (2008) used ERP to investigate the effect of music-primed moods on subsequent affective processing of positive and negative pictures. Longer reaction times were found for pictures following a sad music prime than following a happy prime, irrespective of the valence of the picture. Electroencephalogram amplitude differences between negative and positive pictures were larger with sad music primes than happy music primes. Also, negative pictures elicited greater negative evaluation regardless of whether the prime was happy or sad music. There was a negativity bias for happy and sad music prime conditions. Thus, the bias for negative images was strengthened by the negative mood induced by sad music. In the present study, this may be why sad music was effective in decreasing ratings for sad faces when this music was played to either the LH or the RH. It can also be also inferred that sad music demonstrated a general reduction in emotion ratings of faces, regardless of ear presentation or facial expression, due to negativity bias.
Limitations and future directions
One limitation of the current study is that lateral emotion processing was only tested with respect to auditory stimuli with the dichotic listening task; there was less focus on the laterality of visual stimuli. Future researchers may wish to pair the dichotic listening task with a visual field task, which would more effectively allow for consideration of the LH and RH contributions to visual facial expression processing. Moreover, prior familiarity with the music was not assessed. Research has found that familiar songs have greater emotional influence on listeners than unknown songs (Pereira et al., 2011; van den Bosch et al., 2013). The results of the study showed that the sad music was much more effective in influencing the perception of facial expressions than the happy music, so it could be that participants were more familiar with the sad music (Barber’s Adagio for Strings) than with the happy music (the third movement of Beethoven’s Symphony no. 6). Indeed, Adagio for Strings has been popularized through movies, television shows, video games, and even a number of electronic dance tracks (see IMDb, Samuel Barber [IMDb, n.d.] for a list of media). Thus, it is important to consider the role of familiarity in future research that uses these musical excerpts.
This study only investigated the effects of classical music on emotions. Future studies could explore other genres of music and their influence on visual emotion perception. Different genres of music can produce different effects on the listener, with studies (McCraty et al., 1998; Zentner et al., 2008) showing jazz and classical music produced reflective and peaceful feelings; techno and Latin American music produced excited, energetic feelings; and rock music feelings of anger and rebelliousness. Grunge rock, in particular, generated feelings of hostility, tension, and sadness. The moods induced by different genres may thus have differing influences on perceived emotionality of visual stimuli. Another avenue for future research could be to compare the effects of songs with and without lyrics on emotional appraisal. Lyrics in happy songs detract from the positive emotions conveyed in the songs; however, lyrics in sad songs enhance negative feelings (Ali & Peynircioğlu, 2006).
Finally, the results of this study build on previous findings that the emotional appraisal of visual stimuli is affected by music (Jeong et al., 2011). Our study shows that lateralized presentation of music may selectively influence the degree to which cross-modal transfer of emotion occurs; in particular, happy music played to the left ear may reduce perceptions of how sad a face looks. It would be interesting to examine whether this may be of therapeutic value. Indeed, music therapy is effective in the treatment of depression and other emotional disorders (Castillo-Pérez et al., 2010; Chong & Kim, 2010; Erkkilä et al., 2011). Researchers (Trimble & Hesdorffer, 2017) have noted that there is a need to explore music therapy in patients with neuropsychiatric disorders further, especially considering the cost-effectiveness and positive effects reported in the literature.
Conclusion
The present study examined whether dichotically presented music selectively influenced the perception of facial expressions (happy, neutral, sad) when presented to the left ear (RH) as opposed to the right ear (LH). While the results of the study suggest that this is the case, to a certain extent, emotion processing might be more complicated than posited by the RH hypothesis; it may also involve aspects of LH processing, or different structures based on valence or motivation. However, lateralized emotion processing alone could not fully account for the pattern of results, suggesting that other factors such as negativity bias may play a role. In the future, researchers could compare the effectiveness of other genres of music on influencing ratings of visual stimuli and may wish to consider the potential therapeutic implications of the selective reduction in the apparent sadness of sad facial stimuli when happy music is played to the left ear.
Footnotes
Acknowledgements
The authors thank attendees of the Virtual 7th North Sea Meeting on Laterality 2020 for their comments on this project, along with the very useful feedback from two anonymous reviewers and the Editor-in-Chief of Musicae Scientiae.
Authors’ note
The data in this manuscript have been reported in an undergraduate dissertation and at the Virtual 7th North Sea Meeting on Laterality 2020.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Institutional Review Board statement
The study was conducted according to the guidelines of the Declaration of Helsinki and the British Psychological Society, and approved by the School of Education and Social Sciences Ethics Committee of the University of the West of Scotland (protocol code 2019-8615-6937, 19 August 2019).