
Abstract
Objective
To evaluate the accuracy of ChatGPT and DeepSeek in answering guideline-based clinical questions in cardiology.
Methods
In August 2025, responses generated from four large language models to eight clinical questions based on the 2025 Society for Cardiovascular Angiography & Interventions/Heart Rhythm Society guidelines were evaluated. Three cardiologists independently rated accuracy using a six-point Likert scale: (a) completely incorrect; (b) more incorrect than correct; (c) nearly equally correct and incorrect; (d) more correct than incorrect; (e) nearly all correct; and (f) completely correct. Reproducibility (Fleiss’ kappa coefficient, five repeated queries) and inter-rater reliability (intraclass correlation coefficient) were assessed.
Results
The median (interquartile range) accuracy scores were 5.5 (5, 6) for ChatGPT-5, 6 (5, 6) for ChatGPT-4o, and 5 (4, 6) for both DeepSeek-R1 and DeepSeek-V3, with a significant overall difference (p < 0.001). Pairwise comparisons showed significantly higher accuracy for ChatGPT models than for DeepSeek models (all p < 0.001), whereas no significant differences were observed between ChatGPT-5 and ChatGPT-4o (p = 0.518) or between DeepSeek-R1 and DeepSeek-V3 (p = 0.812). Reproducibility (Fleiss’ kappa coefficient) was excellent for ChatGPT-5 (0.803) and good for ChatGPT-4o (0.574), DeepSeek-R1 (0.577), and DeepSeek-V3 (0.618). Overall inter-rater reliability was moderate (intraclass correlation coefficient = 0.463).
Conclusions
ChatGPT and DeepSeek demonstrated high accuracy and reproducibility but moderate inter-rater reliability, necessitating further validation for educational use.
Introduction
Cardiology education faces the dual challenges of a rapidly expanding body of evidence and clinical guidelines, alongside increasingly complex decision-making in clinical practice. Conventional teaching methods are often inadequate to meet these evolving demands, highlighting the transformative potential of artificial intelligence (AI) to bridge this educational gap and enable more adaptive, personalized learning tools for ongoing medical training. 1
Generative AI, particularly large language models (LLMs) such as ChatGPT and DeepSeek, represents a distinct paradigm capable of producing novel, multimodal outputs (e.g. text, images, and audio) that emulate patterns learned during training. Unlike traditional AI systems focused on classification, prediction, or data retrieval, generative AI creates original educational materials, simulates patient interactions, and adapt dynamically to learners’ needs. 2 These capabilities highlight its promising role in cardiovascular medicine in facilitating information exchange, supporting clinical decision-making, and enhancing medical education. 3
Evidence indicates that generative AI can pass rigorous medical examinations (United States Medical Licensing Examination 4 and European Exam in Core Cardiology); 5 generate high-quality exam questions;6,7 and provide personalized, real-time feedback to learners.8,9 Given these capabilities, it has become an important component of healthcare education, with global implementation across medical institutions.10,11 Nevertheless, persistent concerns regarding medical accuracy and reliability of generated knowledge remain unresolved. 12 Performance variability is evident in ChatGPT’s failure to pass American College of Gastroenterology self-assessments, 13 suggesting domain-specific limitations.14,15
A notable knowledge gap exists regarding the efficacy of LLMs in cardiology education, particularly in interpreting clinical practice guidelines.3,16,17 Although preliminary studies have begun to explore this area, critical questions concerning the accuracy, reproducibility, and clinical safety of LLM-generated guidance remain unresolved.18,19
Nonvalvular atrial fibrillation affects more than 52 million individuals worldwide and confers a fivefold increased risk of stroke, primarily due to thromboembolism originating in the left atrial appendage. 20 Although transcatheter left atrial appendage occlusion (LAAO) has emerged as an effective alternative to oral anticoagulation for stroke prevention, 21 its appropriate implementation requires a precise understanding of evolving guidelines. The recently updated 2025 Society for Cardiovascular Angiography & Interventions (SCAI) and Heart Rhythm Society (HRS) clinical practice guidelines on transcatheter LAAO (2025 SCAI/HRS guidelines) serve as a critical reference for LAAO management, outlining eight key clinical questions (CQs). 22 This study evaluated the accuracy of ChatGPT and DeepSeek in responding to these guideline-based CQs, thereby assessing their potential to support evidence-based cardiology education.
Materials and methods
Study design and questions
In August 2025, we assessed the performance of four LLMs, including ChatGPT-5 (OpenAI), ChatGPT-4o (OpenAI), DeepSeek-R1 (DeepSeek), and DeepSeek-V3 (DeepSeek), in responding to eight CQs derived from the 2025 SCAI/HRS Guidelines (Supplementary Table 1). These CQs were structured using the Population, Intervention, Comparison, and Outcome framework and prioritized according to the Grading of Recommendations Assessment, Development, and Evaluation (GRADE) approach. The guideline recommendations were developed through systematic evidence reviews, data synthesis, and GRADE-based certainty assessments and were further refined using the Evidence-to-Decision framework. During the evaluation, all models were granted access to the internet. However, their training datasets did not include the 2025 SCAI/HRS guidelines, as these were published after each model’s knowledge cutoff date. Particularly, the knowledge cutoff dates were 30 September 2024 for ChatGPT-5, October 2023 for GPT-4o, and July 2024 for both DeepSeek-R1 and DeepSeek-V3.
Ethical review was not required for this AI-based study, as no human or animal subjects were involved.
Assessment of responses from ChatGPT and DeepSeek
The original English CQs were entered as prompts into ChatGPT and DeepSeek to generate responses. Three certified cardiologists independently assessed the accuracy of these AI-generated responses. Based on a previously established framework, 23 accuracy was rated using a six-point Likert scale: (a) completely incorrect; (b) more incorrect than correct; (c) nearly equally correct and incorrect; (d) more correct than incorrect; (e) nearly all correct; and (f) completely correct. No prior training was provided to the evaluators to standardize their assessments. To assess reproducibility, each CQ was queried five times in separate chat sessions. Responses were evaluated using the six-point Likert scale, and the scores were statistically analyzed after data collection.
Statistical analysis
Data were systematically entered into Microsoft Excel (Microsoft; Redmond, Washington) and analyzed using R software (version 4.2.2, R Foundation for Statistical Computing; Vienna, Austria). To evaluate the accuracy of responses generated by ChatGPT and DeepSeek to the CQs, as rated by three independent cardiologists on a six-point Likert scale (ranging from 1 to 6), we calculated the median and interquartile range (IQR) of the scores assigned across five separate iterations. The data had a hierarchical structure, comprising eight CQs, each repeated over five independent iterations, with responses generated by four models and each response rated by three cardiologists. We explicitly accounted for the nested and clustered nature of the observations in all inferential analyses. For comparisons of scores across the four models, the Friedman test was applied as a nonparametric equivalent of repeated-measures analysis of variance (ANOVA), appropriate for clustered ordinal data. This was followed by pairwise post hoc comparisons using the Durbin–Conover test. In these analyses, the unit of analysis was the aggregated score for each model across all CQs, iterations, and cardiologists, thereby preserving the replicated, multirater structure without assuming independence of individual ratings. To assess reproducibility, the Fleiss’ kappa coefficient was calculated to evaluate inter-rater agreement for each model across five separate iterations. The level of agreement was categorized as follows: poor (Fleiss’ kappa coefficient < 0.40), good (0.40–0.75), or excellent (>0.75). 19 Here, the unit of analysis was the aggregated scores per model across all CQs and cardiologists over the five iterations, enabling a global assessment of reproducibility across repeated measurements. Inter-rater reliability among the three cardiologists was further evaluated using the intraclass correlation coefficient (ICC) and its 95% confidence intervals (CIs), estimated via a two-way random-effects model for single measures. ICC values were interpreted as follows: poor (<0.50), moderate (0.50–0.75), good (0.75–0.9), or excellent (>0.90). 24 The unit of analysis for this assessment was each individual rating across all CQs, iterations, and models, providing an overall evaluation of rater consistency across the full dataset. A two-tailed p-value <0.05 was considered statistically significant for all analyses.
Results
Table 1 presents the six-point Likert scale scores assigned by three cardiologists to responses generated from ChatGPT and DeepSeek for each CQ derived from the 2025 SCAI/HRS guidelines. All responses were evaluated across five independent chat sessions (a complete rater-by-iteration matrix is provided in Supplementary Table 2).
Six-point Likert scale scores for responses generated from ChatGPT and DeepSeek to each clinical question from the 2025 SCAI/HRS guidelines across five independent chat sessions.
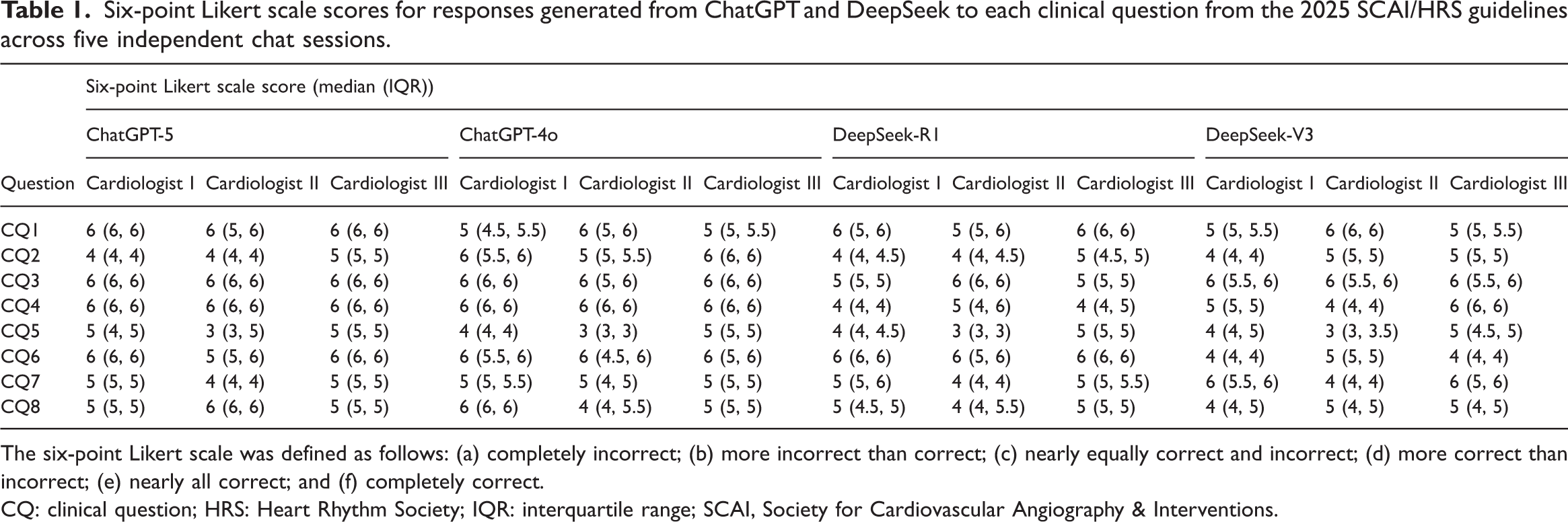
The six-point Likert scale was defined as follows: (a) completely incorrect; (b) more incorrect than correct; (c) nearly equally correct and incorrect; (d) more correct than incorrect; (e) nearly all correct; and (f) completely correct.
CQ: clinical question; HRS: Heart Rhythm Society; IQR: interquartile range; SCAI, Society for Cardiovascular Angiography & Interventions.
Overall, the median (IQR) accuracy scores, as assessed by the three evaluators, were 5.5 (5, 6) for ChatGPT-5, 6 (5, 6) for ChatGPT-4o, and 5 (4, 6) for both DeepSeek-R1 and DeepSeek-V3, with a significant overall difference (p < 0.001), as detailed in Table 2 and Figure 1. Pairwise comparisons performed using the Durbin–Conover post hoc test (Table 3) demonstrated that accuracy scores were significantly higher for both ChatGPT models than for both DeepSeek models (ChatGPT-5 vs. DeepSeek-R1, p < 0.001; ChatGPT-5 vs. DeepSeek-V3, p < 0.001; ChatGPT-4o vs. DeepSeek-R1, p < 0.001; ChatGPT-4o vs. DeepSeek-V3, p < 0.001). In contrast, no significant differences were observed between ChatGPT-5 and ChatGPT-4o (p = 0.518) or between DeepSeek-R1 and DeepSeek-V3 (p = 0.812).
Comparison of the accuracy scores of AI models in answering CQs from the 2025 SCAI/HRS guidelines.

AI: artificial intelligence; CQs: clinical questions; HRS: Heart Rhythm Society; IQR: interquartile range; SCAI, Society for Cardiovascular Angiography & Interventions.

Comparison of the accuracy scores assigned by three cardiologists across AI models. The inter-rater consensus median scores, derived from pooled evaluations of all three cardiologists, are summarized in Table 2. AI: artificial intelligence; IQR: interquartile range.
Pairwise comparisons of the accuracy scores across AI models using the Durbin–Conover post hoc test.

AI: artificial intelligence.
Inter-rater agreement across the five independent scoring iterations, assessed using the Fleiss’ kappa coefficient, was excellent for ChatGPT-5 (Fleiss’ kappa coefficient = 0.803) and good for ChatGPT-4o (Fleiss’ kappa coefficient = 0.574), DeepSeek-R1 (Fleiss’ kappa coefficient =0.577), and DeepSeek-V3 (Fleiss’ kappa coefficient = 0.618).
The ICC for inter-rater reliability among the three cardiologists indicated moderate overall reliability (ICC = 0.463, 95% CI: 0.353–0.564). Model-specific ICC values were 0.627 (95% CI: 0.449–0.769) for ChatGPT-5, 0.515 (95% CI: 0.310–0.689) for ChatGPT-4o, 0.355 (95% CI: 0.165–0.549) for DeepSeek-R1, and 0.257 (95% CI: 0.073–0.462) for DeepSeek-V3.
Discussion
This study represents the first assessment of ChatGPT and DeepSeek in answering CQs based on the 2025 SCAI/HRS guidelines. The findings indicate that all four evaluated models, including ChatGPT-5, ChatGPT-4o, DeepSeek-R1, and DeepSeek-V3, generated responses with high accuracy and reproducibility. Notably, both ChatGPT models demonstrated significantly higher accuracy than the DeepSeek models. Among them, ChatGPT-5 showed excellent inter-rater agreement across all five iterations, whereas ChatGPT-4o, DeepSeek-R1, and DeepSeek-V3 demonstrated good agreement.
Comparison with prior studies
To date, few studies have evaluated the accuracy of LLMs in responding to guideline-based CQs. For instance, one study assessed ChatGPT-3.5’s responses to CQs and other inquiries from the Japanese Society of Hypertension Guidelines for the Management of Hypertension, reporting accuracy rates of 80% for CQs and 36% for other questions. 18 Similarly, another study evaluated ChatGPT-3.5’s performance in addressing CQs from the Japan Atherosclerosis Society Guidelines for Prevention of Atherosclerotic Cardiovascular Disease 2022, reporting median accuracy scores between 5 and 6 for CQs. 19 Consistent with these prior findings, our study observed median accuracy scores of 5–6 for CQs. The high accuracy and reproducibility observed for both ChatGPT and DeepSeek in our analysis may be attributed to the nature of CQs, which were generally structured around clinical decision-making and often supported by evidence from randomized controlled trials (RCTs). 22 By processing extensive medical literature, these models can rapidly identify and synthesize publicly available RCT data,16,18,19,25 enabling evidence-informed responses to CQs. Although the four models were not trained on the 2025 SCAI/HRS guidelines, internet access was enabled during the evaluation, allowing retrieval of relevant information in real-time. Consequently, the findings reflect not only intrinsic model knowledge but also real-time retrieval and synthesis capabilities, a distinction that merits explicit acknowledgment. Overall, our findings suggest that LLMs such as ChatGPT and DeepSeek can provide reliable answers to guideline-based CQs, thereby reinforcing the conclusions of earlier studies.
Study strengths
A key strength of our study is the evaluation of four LLMs, including the recently released ChatGPT-5, which became available in August 2025. The findings indicate that although all four models demonstrated high accuracy and reproducibility, ChatGPT may be preferable to DeepSeek because of its superior accuracy. Specifically, the newest version, ChatGPT-5, achieved accuracy comparable to that of ChatGPT-4o and offered improved reproducibility. Nevertheless, DeepSeek remains a viable alternative, offering distinct advantages in affordability and open-access availability. Its adherence to the Massachusetts Institute of Technology license substantially lowers economic barriers, safeguards intellectual property, and encourages transparent and collaborative advancement, thereby broadening the adoption and adaptability of LLMs across diverse settings. 26
Educational implications
Cardiology education is a continuous process, and staying updated with the latest guidelines, techniques, and research remains challenging. In this context, LLMs such as ChatGPT and DeepSeek can serve as adaptive, personalized learning tools. By providing instant access to relevant and up-to-date medical information and resources in cardiology, these technologies support the enhancement of clinical knowledge and skills, thereby fostering continuous learning and expertise development in the field.27,28
Our study focused on assessing the accuracy and reproducibility of responses generated by ChatGPT and DeepSeek to CQs derived from established guidelines. These AI models can function as preclinical interactive tutors and ward assistants in clinical settings, helping students understand complex clinical scenarios. 29 However, it is important to emphasize that AI tools such as ChatGPT and DeepSeek should serve a complementary role rather than replace human instructors. 30 Therefore, we recommend formal integration of these tools as supplementary educational resources within cardiology training rather than as substitutes for traditional teaching.
Concerns regarding LLMs
Although both ChatGPT and DeepSeek demonstrated relatively high accuracy and reproducibility in responding to CQs, it is essential to acknowledge the inherent limitations of LLMs. The accuracy of these models is fundamentally constrained by the quality and scope of their training data, which are not publicly disclosed and likely provide limited coverage in specialized domains such as cardiology. 27 This lack of transparency regarding data sources raises concerns about potential inaccuracies, which may result in the incorporation of misinformation, unbalanced perspectives, or embedded biases during model training. 31 Furthermore, the lack of transparency increases the risk of generating factually incorrect information, commonly referred to as “hallucinations.” 32 Additionally, LLMs are trained on static corpora of internet text up to a certain date, depending on the version, and therefore lack the ability to access real-time information updates. 33 Consequently, it is crucial to recognize and operate within the current constraints of LLM technology.
To illustrate, consider CQ5 regarding antithrombotic therapy after LAAO. Current guidelines recommend either postprocedural oral anticoagulation (OAC) or dual antiplatelet therapy (DAPT). Early LAAO trials predominantly used OAC, resulting in a traditional preference for OAC over DAPT, which was sometimes perceived to carry a higher risk of device-related thrombus in the absence of randomized comparisons. However, updated evidence indicates that DAPT does not significantly increase the risk of thrombotic or major bleeding events compared with OAC, making either regimen reasonable. Moreover, less intensive antithrombotic regimens, including DAPT, may be particularly suitable for patients with newer-generation LAAO devices, which are designed to improve positioning and minimize exposed metal, thereby reducing thrombotic risk. In contrast, both ChatGPT and DeepSeek responded to CQ5 by stating that OAC is generally preferred after LAAO unless bleeding risk is prohibitive, a recommendation consistent with earlier evidence but not reflective of recent data. This discrepancy underscores the limitations of these models in accessing up-to-date information. Future LLMs capable of performing real-time searches and integrating the latest evidence could help mitigate such issues.
In summary, although LLMs such as ChatGPT and DeepSeek can serve as valuable supplementary tools in clinical inquiry, they must be applied with a clear understanding of their limitations, including their dependence on static training datasets, potential for generating inaccurate or outdated information, and lack of real-time knowledge updates. Until these limitations are addressed, users should critically evaluate LLM outputs and supplement them with current, authoritative sources.
Study limitations
The present study has several limitations that should be acknowledged. First, the analysis included only eight CQs, an insufficient sample size to generalize model performance. Future studies should include a broader set of questions to enable statistically robust comparisons. Second, the evaluation was restricted to a single guideline (2025 SCAI/HRS), limiting the generalizability of the findings. Further research is needed to assess LLM performance across diverse medical specialties and guidelines. Third, the study evaluated response accuracy but did not systematically assess other critical dimensions relevant to clinical deployment, such as answer completeness, potentially harmful omissions, or the occurrence of hallucinations. Furthermore, although the accuracy of ChatGPT and DeepSeek in answering CQs was demonstrated, the study did not investigate their actual effects on clinical decision-making or patient outcomes, a key limitation regarding real-world clinical relevance. Fourth, the evaluators did not receive formal training to standardize response assessment, which may have introduced variability in scoring. This limitation is reflected in the observed moderate ICC, indicating persistent differences in interpretation among raters. Therefore, further validation is warranted before integrating these models into educational contexts. Future studies incorporating rater training may improve scoring consistency. Finally, the specific model versions used are subject to ongoing updates and retraining, meaning their performance may change over time.
Conclusions
Our findings indicate that both ChatGPT and DeepSeek demonstrated relatively high accuracy and reproducibility, although only moderate inter-rater reliability, when responding to CQs derived from the 2025 SCAI/HRS guidelines. These results underscore the potential of these models to efficiently organize and present relevant guideline information, supporting their role as adaptive and personalized educational aids. Rather than generating new clinical information, ChatGPT and DeepSeek function as tools that enhance the rapid retrieval and interpretation of existing guidelines, thereby facilitating continuous learning and expertise development in cardiology. However, the observed moderate inter-rater reliability necessitates further validation before integration into educational settings. Notably, because internet access was enabled during the evaluation, the findings reflect both intrinsic model knowledge and real-time retrieval and synthesis capabilities, a distinction that warrants explicit acknowledgment.
Several challenges persist, including the models’ reliance on nontransparent training data and the risk of generating factually inaccurate content. These limitations suggest that although ChatGPT and DeepSeek can serve as valuable resources, they should complement rather than replace expert human instruction. We further underscore the need for more advanced models trained on curated, high-quality medical datasets, alongside the development of standardized frameworks to evaluate AI-generated medical content. With continued research and refinement, AI technologies such as ChatGPT and DeepSeek have significant potential to contribute meaningfully to cardiology education.
Supplemental Material
sj-pdf-1-imr-10.1177_03000605261438348 - Supplemental material for Accuracy of ChatGPT and DeepSeek in answering clinical questions from the 2025 Society for Cardiovascular Angiography & Interventions/Heart Rhythm Society left atrial appendage occlusion guidelines
Supplemental material, sj-pdf-1-imr-10.1177_03000605261438348 for Accuracy of ChatGPT and DeepSeek in answering clinical questions from the 2025 Society for Cardiovascular Angiography & Interventions/Heart Rhythm Society left atrial appendage occlusion guidelines by Yunpeng Jin, Chao Feng, Jianqiang Zhao, Wenting Lin and Bin Li in Journal of International Medical Research
Supplemental Material
sj-pdf-2-imr-10.1177_03000605261438348 - Supplemental material for Accuracy of ChatGPT and DeepSeek in answering clinical questions from the 2025 Society for Cardiovascular Angiography & Interventions/Heart Rhythm Society left atrial appendage occlusion guidelines
Supplemental material, sj-pdf-2-imr-10.1177_03000605261438348 for Accuracy of ChatGPT and DeepSeek in answering clinical questions from the 2025 Society for Cardiovascular Angiography & Interventions/Heart Rhythm Society left atrial appendage occlusion guidelines by Yunpeng Jin, Chao Feng, Jianqiang Zhao, Wenting Lin and Bin Li in Journal of International Medical Research
Footnotes
Acknowledgments
Not applicable.
Author contributions
Yunpeng Jin contributed to the conception and design of the work; Chao Feng, Jianqiang Zhao, Wenting Lin, and Bin Li contributed to the acquisition and interpretation of data; Yunpeng Jin drafted the manuscript, contributed to the analysis and interpretation of the data, and critically revised the manuscript. All authors have read and approved the final manuscript and agree to be accountable for all aspects of the work, ensuring its integrity and accuracy. Yunpeng Jin is responsible for the overall content.
Availability of data and materials
The raw data supporting the conclusions of this article will be made available by the authors without undue reservation.
Consent for publication
Not applicable.
Declaration of conflicting interests
The authors declare that they have no competing interests.
Ethics approval and consent to participate
Ethical review was not required for this AI-based study, as no human or animal subjects were involved. Consent to participate was not applicable.
Funding
This study was supported by the Foundation of Zhejiang Provincial Education Department (Grant Nos. Y202249328 and Y202558666) and the Foundation of the Fourth Affiliated Hospital, Zhejiang University School of Medicine (Grant No. JG20230203). The funders had no role in the study design, data collection and analysis, the decision to publish, or the preparation of the manuscript.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.