
Abstract
The statistical production process of many National Institutes is increasingly exploiting the integration of administrative data and sample surveys. Administrative data are generally affected by errors; among others, under and over-coverage may introduce bias in the statistics produced. In this paper, we propose a method to make inference on the population sizes at different aggregation levels by leveraging administrative data in the presence of coverage errors. We introduce a Bayesian statistical model for integrating nonprobability (register-based) and probability samples. The use of a Bayesian model allows a natural quantification of the uncertainty of estimates through the posterior distribution of the unknown target parameters. Although the framework we discuss is quite general, we will mainly refer to the setting of the Italian Permanent Census. We first assess the model performance using simulated data closely related to the real one; then, we provide results for the real data.
Keywords
1. Introduction
The use of non-survey data, especially administrative data, is becoming crucial in the statistical production system of National Statistical Institutes (NSIs). The reasons for this widespread use are discussed in Citro (2014): a data production context that leverages multiple sources is the best way to meet the user’s needs and to avoid high rates of non-response in questionnaires. A relevant framework concerning the integration of administrative and survey data is that of building statistical registers. Statistical registers allow NSIs to compute different summaries of the target population, including its size. Computing summary statistics directly from registers is an essential task of the NSIs today; the availability of register-based statistics allows the NSIs to have a sort of backbone for some core variables. Under the principles of standardization and coherence, such sources may be used in the production of all the related statistics of the NSIs. This is the case of North European countries that have produced purely register-based statistics since the 1990s (Statistics Denmark 1995; Statistics Finland 2004; Wallgren and Wallgren 2007).
Today, this framework is being adopted in many other countries (Istat 2016), and the register is widely considered a formal and reliable statistical product, where every estimate should be accompanied by its degree of uncertainty. This is a crucial point to consider; in the past, registers were assumed to be affected by negligible errors, while today, they are filtered and processed using old and new statistical methods to account for errors.
Errors may occur in different ways, as discussed by Biemer and Lyberg (2003) and Groves et al. (2011) for sample surveys and by Zhang (2012) for register-based statistics and data integration of nonprobability samples—such as administrative data. For instance, non-probability samples obtained from administrative data sources are typically affected by coverage errors. On the one hand, statistical units belonging to the target population may not be included in the sample (under-coverage); on the other hand, some units that do not belong to the target population may erroneously be included in the sample (over-coverage). For a discussion and illustration of these issues, see Wolter (1986) and Zhang (2015).
In this paper, we propose a Bayesian statistical model to make inference on the population size at different aggregation levels by leveraging administrative data and survey data in the presence of coverage errors. This model naturally accounts for different sources of error and quantifies the uncertainty of the estimates. The flexibility of the Bayesian approach has been proven crucial in managing complex models in similar contexts (see, e.g., the recent Elleouet et al. 2022). Through the simulations and analysis based on the 2018 “Italian Permanent Census” data, we show that a Bayesian approach can manage the different sources of error and adequately summarize the uncertainty through a suitable synthesis provided by the posterior distribution.
The paper is structured as follows: Section 2 describes the general statistical model. Section 3 details the motivating example, namely the 2018 Permanent Census. We empirically assess the model’s performance using a simulated dataset closely reflecting the Permanent Census data in Section 4. In Section 5, the model is applied to real data. The conclusions follow.
2. Model Setting
2.1. Notation
Let

Representation of the data sources and the target population. The height of the rectangles represents the number of units included in the set; the width represents the amount of information (covariates), which is assumed to be common to all sources.
Let
Let
Similarly, we denote with
We leverage the information contained in
One can be interested in estimating the in-target population at a specific domain level (e.g., municipality, gender, age class). Hence, we add the subscript
Example of Observed Data Structure.

Note. The Domain
2.2. Bayesian Model for Coverage Errors’ Correction
To predict the population counts at the specified domain level, one needs to learn about the probabilities of under- and over-coverage. In a Bayesian framework, it amounts to say that one must compute the joint posterior distribution of such probabilities, which are considered random. To this aim, we first explicitly state the likelihood function arising from our model and then discuss suitable prior distributions for the unknown parameters of the model.
This section describes a hierarchical Bayesian model for combining information from a non-probabilistic sample (from an administrative source) and the two random samples. In the first stage, we introduce a statistical model for describing the data-generation mechanism and deduce the resulting likelihood function; then, we model the probabilities of under- and over-coverage and specify the prior setting.
We assume that, independently for each domain
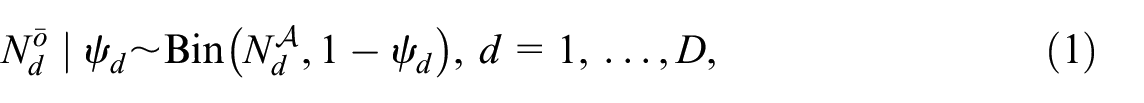
where
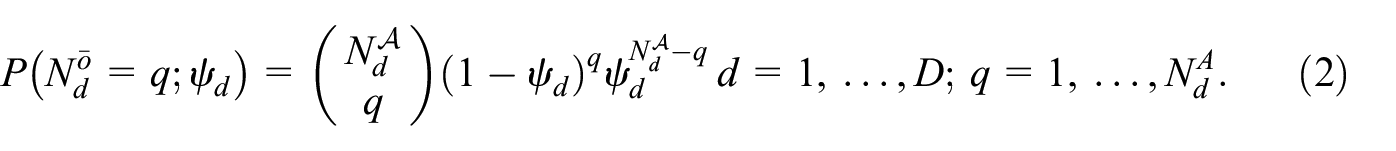
Regarding the under-covered counts, we still assume independence among domains. However, assuming a Binomial model is not suitable in this case since we do not have a well-defined number of Bernoulli trials. Yet, one can interpret the number of units missed by
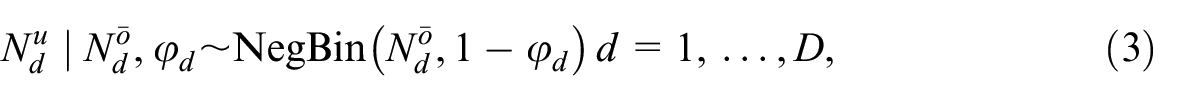
That is,
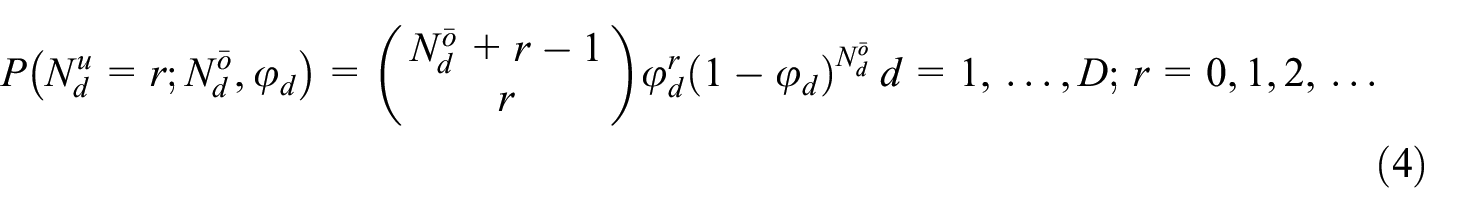
We assume simple random sampling for both
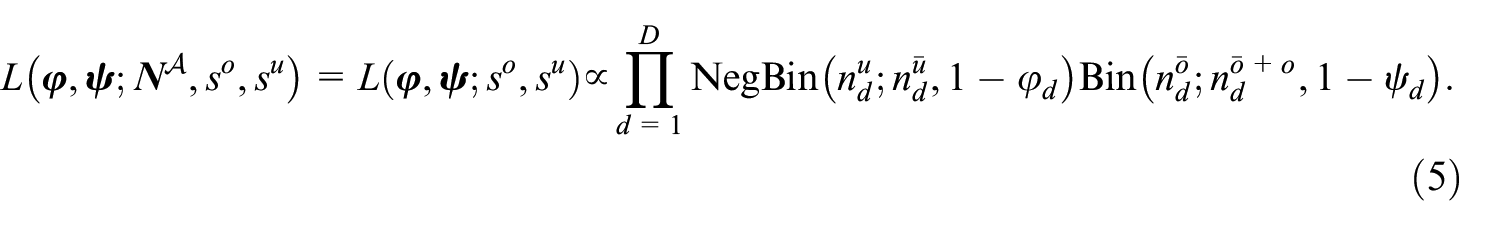
It is important to stress that the hypothesis of simple random sampling for both
In the second stage, we model the probabilities of over and under-coverage as

and

where

independently for each
The probabilities of under and over-coverage,

We assume the elements of

with
The posterior distribution, which is proportional to the product of the likelihood and the parameters’ joint prior, will be
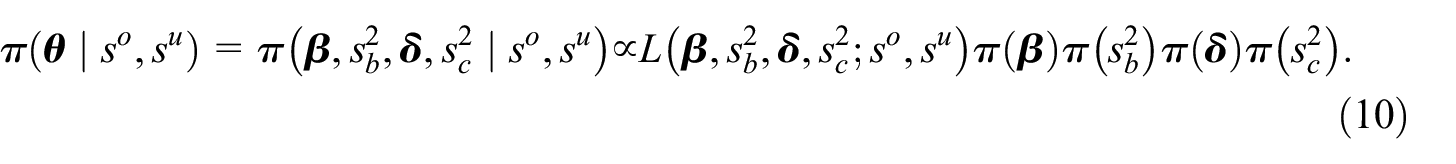
Our goal is the predictive distribution
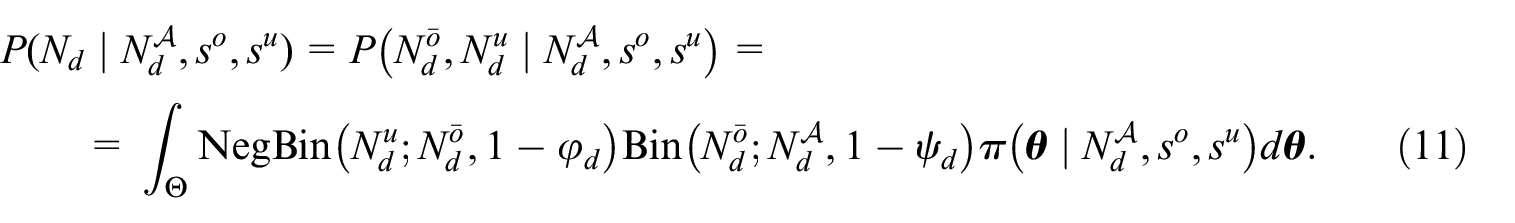
We obtain a posterior sample via Hamiltonian Monte Carlo algorithm implementing the model in Stan (Stan Development Team 2023).
3. 2018 Italian Permanent Census Data
3.1. The Motivating Example
In 2018, Italy shifted from a survey-based paradigm to a register-based one, establishing the Italian Permanent Population Census (Falorsi 2017). Population counts were produced using an integrated administrative source, the Base Register of Individuals (BRI), corrected for over- and under-coverage by two sample surveys. Righi et al. (2021) proposed, similarly to Pfeffermann et al. (2015), to estimate population counts by correcting the BRI counts with a function of the probabilities of under- and over-coverage estimated on two distinct sample surveys designed to account for coverage errors. The two samples consisted of (i) a list survey, a probabilistic sample of the BRI, and (ii) an area survey, a probabilistic sample of the target population. The list survey was designed to estimate the over-coverage, whereas the area survey was designed to assess the under-coverage. Both surveys used a two-stage sampling design, with the Italian municipalities as the primary sampling units. The secondary sampling units differed in the two samples: the households for the list sample and either addresses or enumeration areas for the area sample. A strategy proposed by Mancini and Toti (2014) consisted of applying a GLMM approach to obtain probabilities of over and under-coverage at an individual level, conditional on individual characteristics such as gender, age, and citizenship. The major limitation of that approach was that the analytical form of the correction term, based on the plugged-in estimated weights, made it very complex to obtain an explicit expression for the accuracy evaluation of the count estimates. The analysis of the Italian municipalities proceeded separately for each Italian Region (NUTS2) and differently for municipalities with a population above or below 18,000 individuals. The aim was to estimate the population counts for each municipality at the profile level, with profiles determined by the combinations of some individual characteristics: individuals’ sex, age class, and citizenship.
Here, we consider the 2018 Permanent Census our motivating example; however, in this work, we make a simplifying assumption and consider the list and area surveys as simple random samples; see Subsection 2.2. We further discuss our simplifying assumption in the Conclusions.
3.2. An Application of the Theoretical Model
We exploit the idea of the Permanent Census to empirically assess the performance of the model introduced in Section 2. The notation introduced in Subsection 2.1 is suitable to the aim; however, instead of considering a generic domain
As covariates in the logistic regressions modeling the over- and under-coverage probabilities (Equations (6) and (7)), we use the whole set of variables that define the profiles
The random effects vary according to groups defined by the interactions between the area (as defined above) and the province (NUTS3) to which the municipality belongs. We estimate separate models for the twenty Italian Regions: Abruzzo (ABR), Basilicata (BAS), Calabria (CAL), Campania (CAM), Emilia-Romagna (EMI), Friuli-Venezia Giulia (FRI), Lazio (LAZ), Liguria (LIG), Lombardy (LOM), Marche (MAR), Molise (MOL), Piedmont (PIE), Puglia (PUG), Sardinia (SAR), Sicily (SIC), Trentino-Alto Adige (TRE), Tuscany (TOS), Umbria (UMB), Aosta Valley (VAL), Veneto (VEN).
In the next section, we assess the model’s performance regarding coverage, bias, and variability using simulated data that closely mimic the 2018 Permanent Census. In Section 5, we analyze accurate 2018 Permanent Census data.
4. Simulation Study
To empirically test the model’s performance, we simulate a complete synthetic dataset on which it is possible to distinguish all (otherwise unknown) components of the population: the units correctly listed in
In the next subsection, we describe the data simulation; results are shown in Subsection 4.2.
4.1. Data Simulation
First, we generate a synthetic data set composed of three components: (1) units that belong to the target population,
The parameters used to generate this synthetic data set are based on the 2018 Census data. The details of the simulation follow.
1. Generation of a data set
We start with a data set composed of real counts of the Base Register of the Individuals involved in the 2018 Italian Permanent Census,
1.1 We randomly generate the count of subjects that are correctly enumerated in
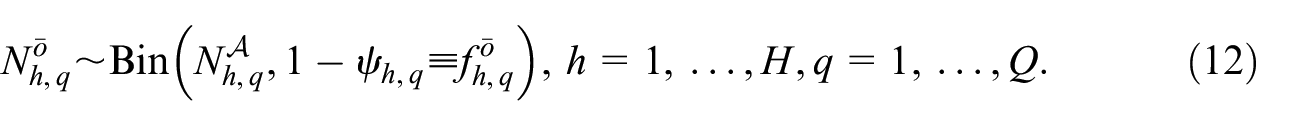
1.2 We randomly generate the count of under-covered subjects,
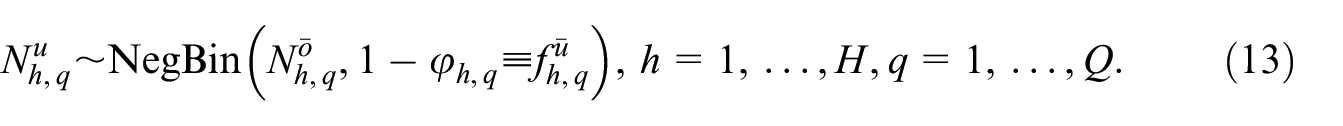
The values
2. Drawing of the two samples for coverage correction
For each municipality,
4.2. Analysis of the Synthetic Data and Results
The simulation of a synthetic data set, as detailed in the previous subsection, allows us to evaluate the performance of the proposed model knowing the (simulated) target population size,
Before presenting the simulations’ results, let us naively compare the target population size to that estimated using the administrative source. Let us set

Figure 2 shows distribution of the
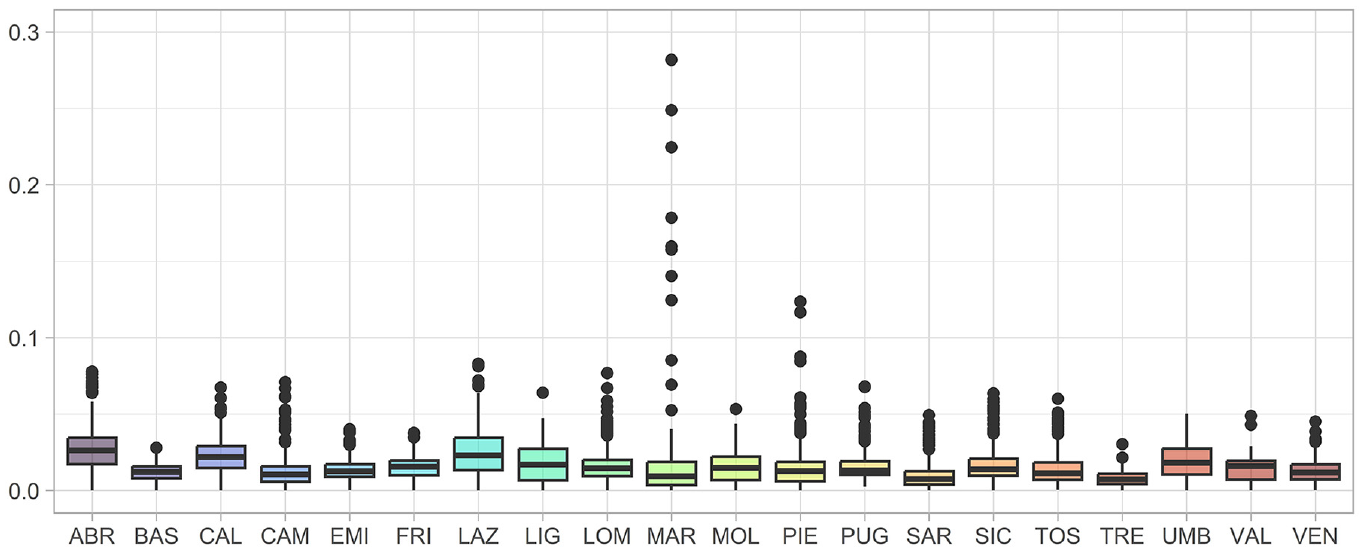
Distribution of the municipal
Now, we implement the model described in Section 2 and detailed in Subsection 3.2 with the aim of obtaining population size estimates closer to the target population size than the administrative counts. A Bayesian approach allows us to estimate the posterior distributions of population sizes at the profile level; consequently, any aggregation at the municipal or provincial level is easy to obtain. For instance, Figure 3 shows an example of a single municipality’s posterior distribution of counts. The solid line represents the (simulated) target population size
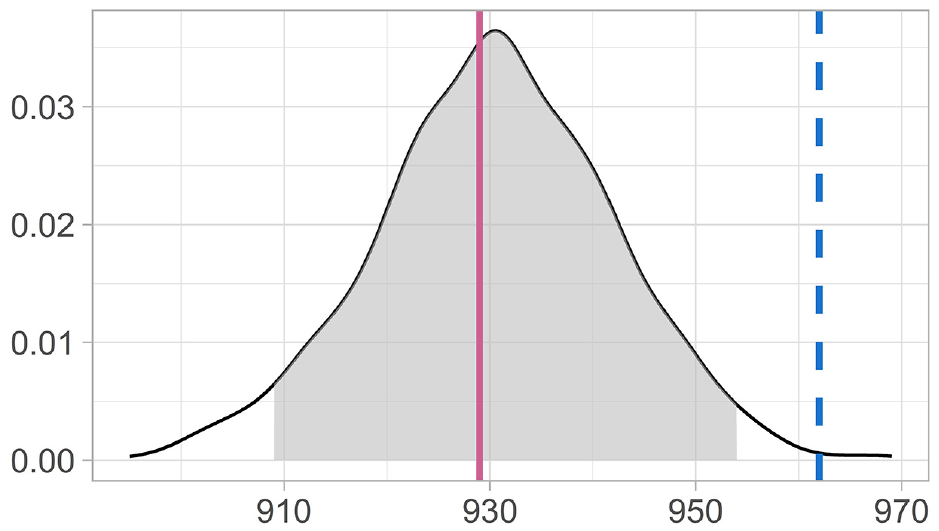
Example of a posterior distribution of counts for a single municipality
For this simulation study, we have specified the hyperparameters of our model as follows:
4.2.1. Coverage
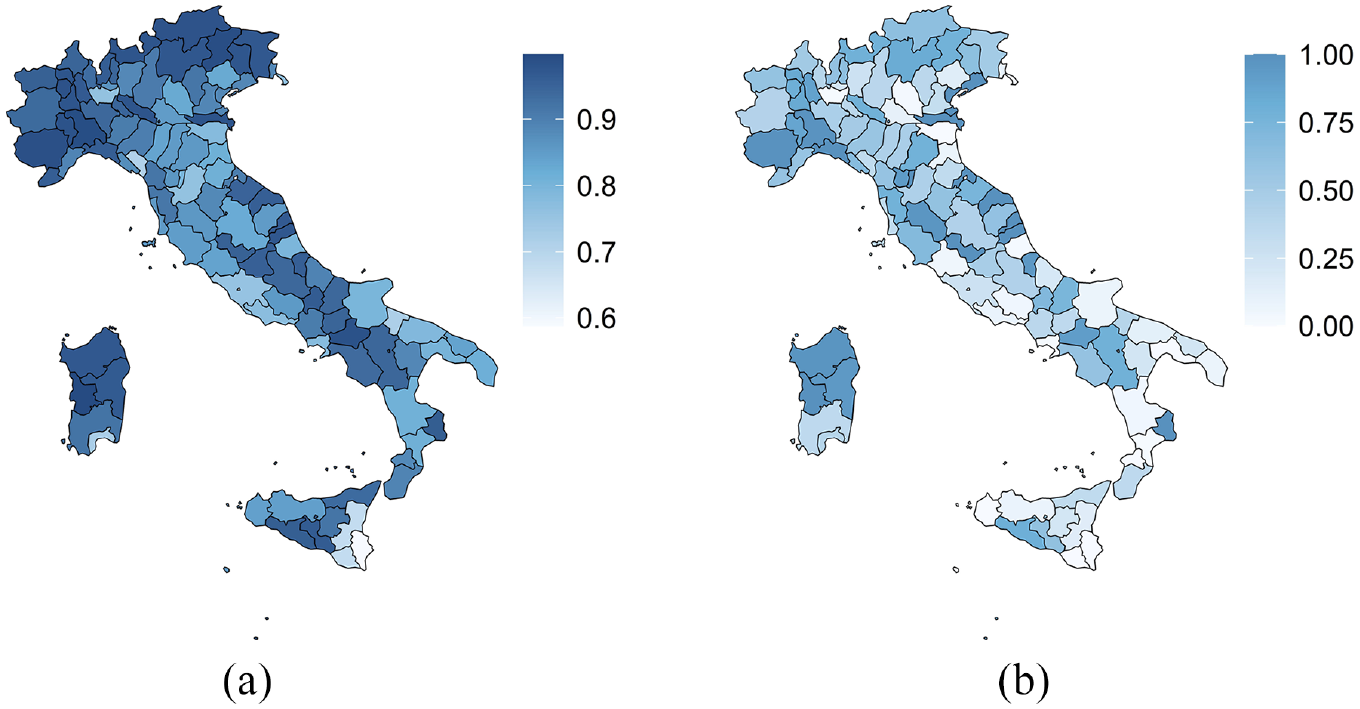
The coverage of the proposed method is explored in Figure 4, which is a map showing the coverage by province. Figure 4a shows the coverage at the profile level for each province,
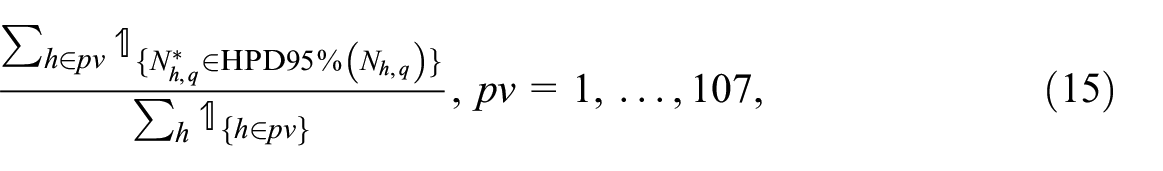
whereas Figure 4b shows the coverage at the municipal level for each province
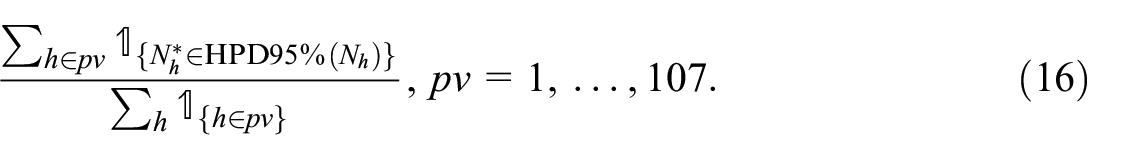
The profile level coverage (Figure 4a) is extensively high, that is, around 95%. There are exceptions. For instance, coverage is below 75% for the provinces of Trieste (TRE), Bologna (EMI), Latina (LAZ), Ragusa, and Siracusa (SIC). Yet, looking at the municipal level coverage (Figure 4b), we can observe a critical improvement. The coverage is still under 75% for the province of Latina (LAZ) only.
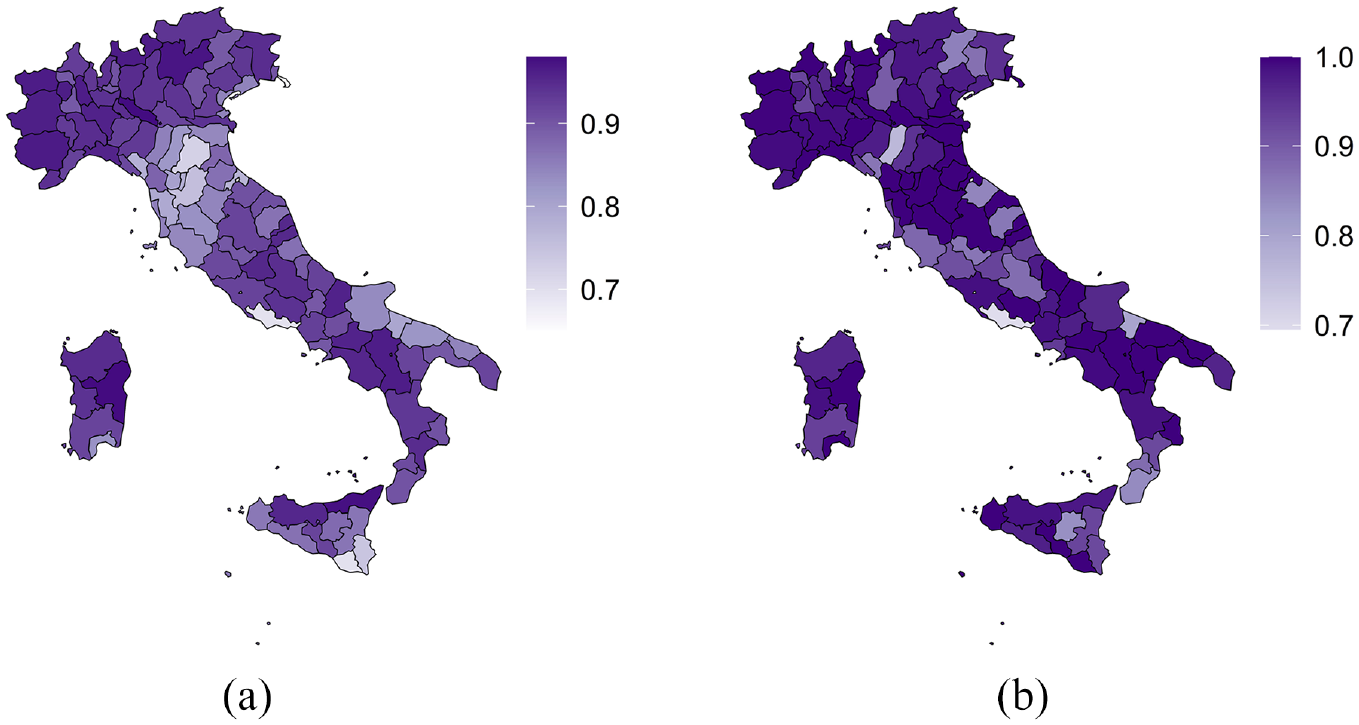
Coverage at the profile and municipal level, HPD95%. Provincial average. Simulated data. (a) Profile level and (b) municipal level.
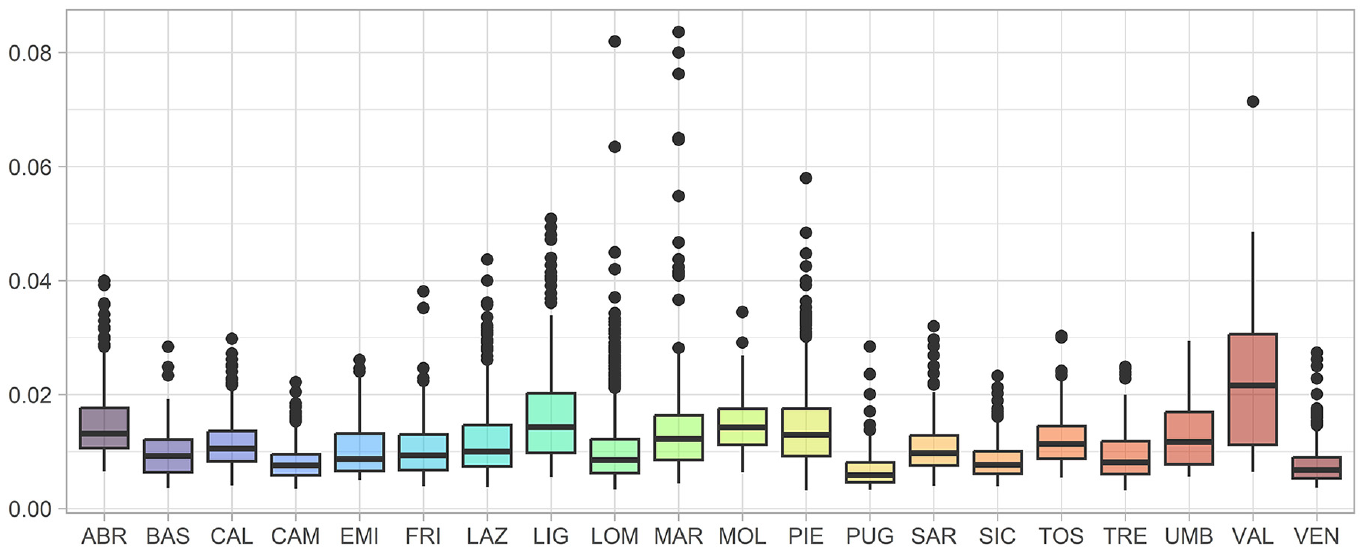
4.2.2. Relative Bias
Beyond coverage, we may also look at a relative measure of the bias of our estimates, evaluated as:
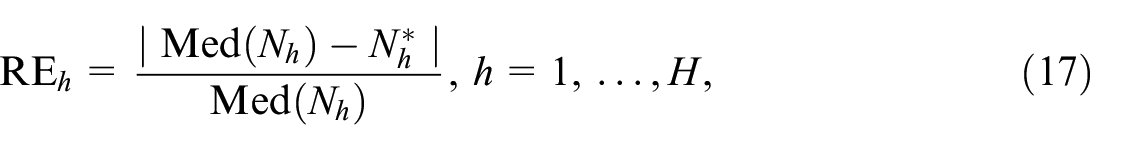
where Med
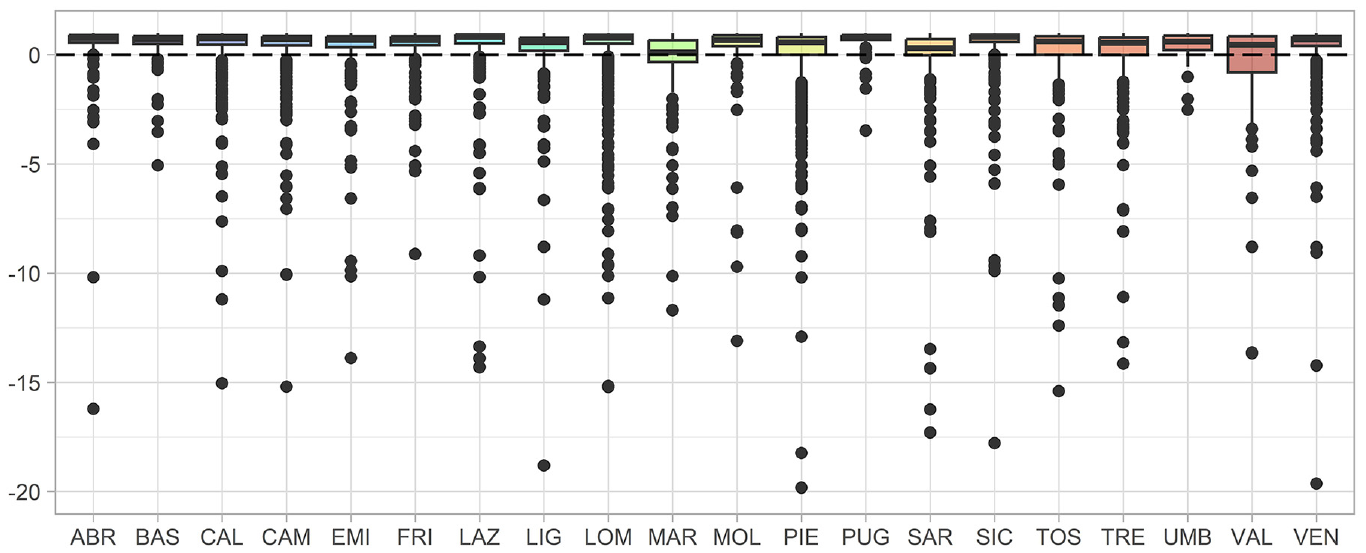
Distribution of the relative gains
4.2.3. Variability
We provide a measure of the variability of our estimates by computing a robust version of the coefficient of variation, that is, the ratio between the interquartile range and the median at the municipal level, that is,
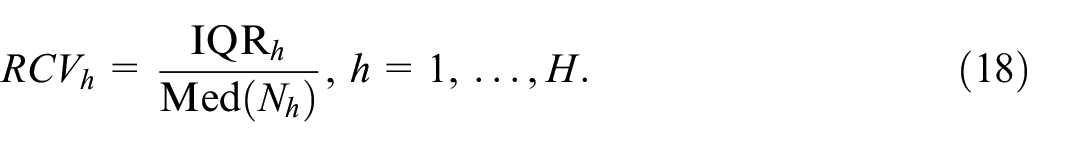
Results are shown in Figure 6. All values are below 8.4%; more than 90% of the municipalities have a
Distribution of
5. The Bayesian Model Applied to the 2018 Permanent Census Data
In the previous Section, we assessed our model performance using simulated data. In this Section, we analyze the real 2018 Permanent Census data. We implement the model described in Section 2 and detailed in Subsection 3.2 for every Italian region, using the 2018 Permanent Census data. Figure 7 shows the posterior mean of the probability of over (Figure 7a) and under-coverage (Figure 7b) at profile level averaged at a province level. Overall, over-coverage is the most relevant error source that the Base Register of Individuals (the administrative source) might be affected by; the province average ranges between 3% (Cuneo, PIE) and 15% (Siracusa, SIC), whereas the average under-coverage probability is always below 3.9% (Crotone, CAL).
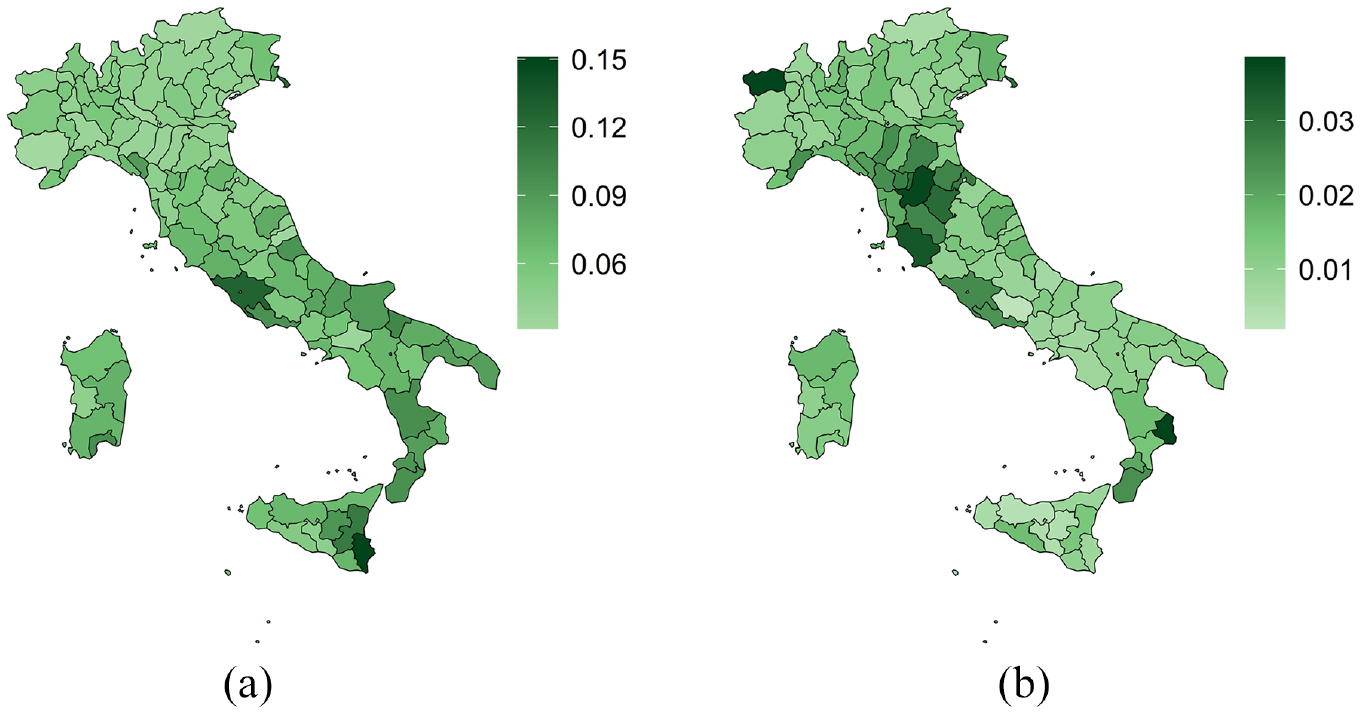
Over- and under-coverage probabilities at profile level, province averages. (a) Over-coverage and (b) under-coverage. 2018 Population census data.
The Appendix provides tables reporting the HPD95% of the
Figure 8 shows the relative frequency of the inclusion of the count registered in the Base Register of the Individuals (BRI) in the HPD95% interval at the profile and municipal level. The relative frequency is quite high at the profile level, especially in Northern Italy, some provinces of the center and the South, and Sardegna (SAR). When we aggregate the results to a municipal level, the BRI count falls short of the more shrunk HPD95% interval. This may also be due to an error’s accumulation. At the municipality level, the error due to the model prediction is much lower than the coverage errors; at the profile level, the error in the models and the coverage errors have the same intensity and do not discriminate against each other. Figure 9 shows the same relative frequency of inclusion of the BRI count in the HPD95% interval, yet obtained using the simulated data.
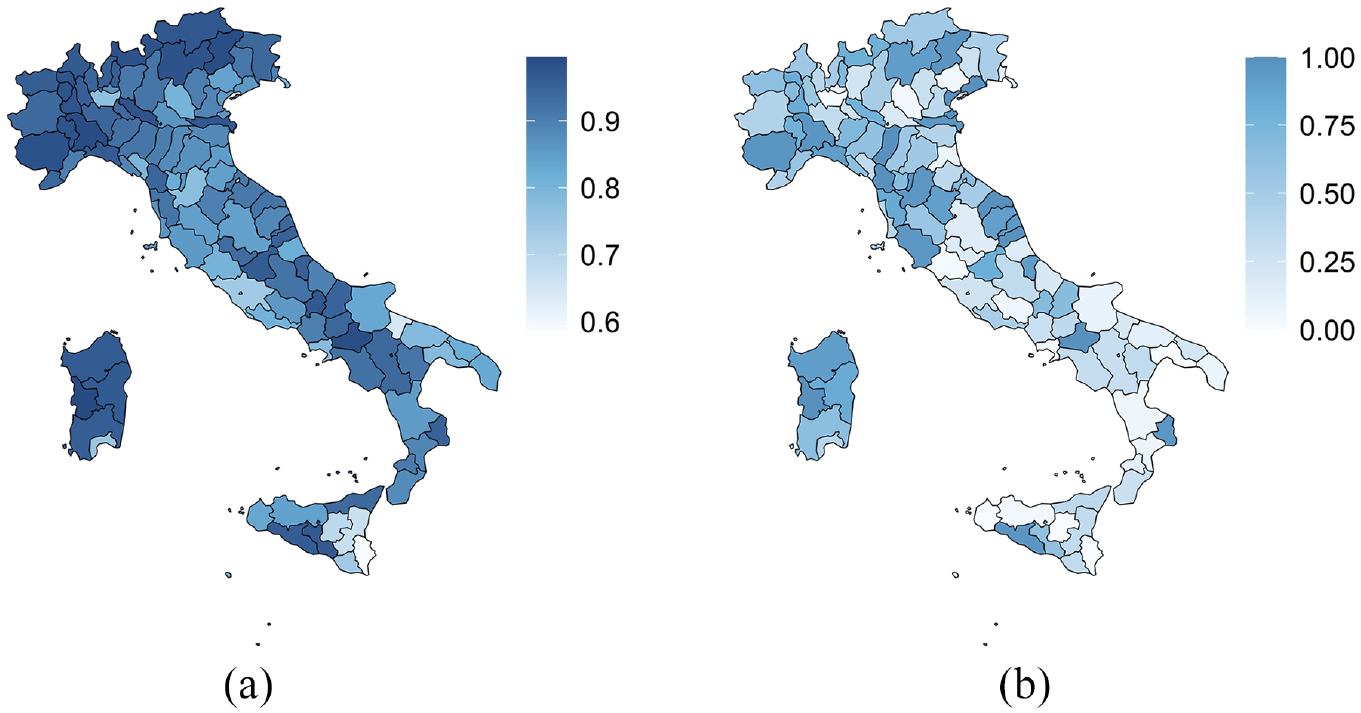
Relative frequency of the inclusion of the BRI estimate by the HPD95% at the profile and municipal level. Provincial average. 2018 Population census data. (a) Profile level and (b) municipal level.
Relative frequency of the inclusion of the BRI estimate by the HPD95% at the profile and municipal level. Provincial average. Simulated data. (a) Profile level and (b) municipal level.
Finally, let us define the relative distance of the posterior median to the BRI estimate at the municipal level as
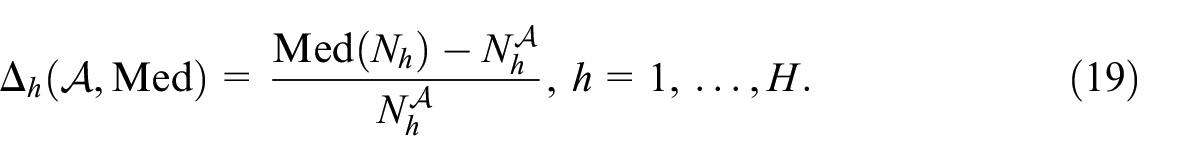
Figure 10 compares the regional distribution of

Relative distance between the municipal level posterior median, Med
6. Conclusions
This paper proposes a Bayesian approach to estimating count data by integrating a nonprobability sample from an administrative source, which is susceptible to coverage errors, and two sample surveys. The proposed model provides count estimates at a detailed level, and it makes the uncertainty estimation straightforward. The application of this approach in a simulated experiment and to the 2018 Italian census data demonstrates its effectiveness in improving the quality of estimates by reducing bias in the administrative data source counts. Furthermore, it proves its feasibility in complex scenarios such as the Population Census.
However, it is important to note that the i.i.d. assumption used in the model approximation may not fully capture the random structure of the data due to survey design features such as stratification, weighting, and clustering. To address this limitation, future research should incorporate information on the sampling design into the modeling process to mitigate the effects of model misspecification. The inclusion of variables determining the sampling design as covariates and the use of hierarchical Bayesian models with random effects for clusters can enhance the accuracy of the estimates. Little (2006, 2022) offer valuable suggestions within a Bayesian framework to tackle this challenging problem. Di Zio et al. (2024) provides insights and proposals for considering sampling design features within the context of the application studied in this paper.
Finally, it is worth noting that errors other than under- and over-coverage ones, such as misclassification of the covariates defining the profiles, can also impact these data. Although misclassification is not accounted for in this study, it is essential to develop a general theoretical framework that simultaneously addresses misclassification and coverage errors. In the specific case of the Italian application, the influence of misclassification is deemed negligible for the variables used as covariates in the model. However, for a comprehensive approach, future work will aim to incorporate misclassification and coverage errors simultaneously, illustrating the flexibility of the model described in Section 2.
Footnotes
Appendix A
Acknowledgements
We thank the anonymous referees for the suggestions that greatly improved the quality of this paper.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Brunero Liseo’s research has been funded by Sapienza University of Rome, grant no. RM122181612D9F93.
Received: July 2023
Accepted: December 2024