
Abstract
Design-based inference from probability samples is valid by construction for target parameters that are descriptive summaries of finite populations. We develop a novel approach of design-based predictive inference for finite populations, where the individual-level predictor is learned from a probability sample using any models or algorithms for incorporating the relevant auxiliary information, and the uncertainty of estimation is evaluated with respect to the known probability design while the outcome and auxiliary values for modeling are treated as constants. Unlike the existing theory of design-based model-assisted estimation for finite populations, design-based predictive inference is as well suited for individual-level prediction in addition to producing population-level estimates.
Keywords
1. Introduction
Throughout the twentieth century, design-based inference from finite-population probability sampling has been established as the standard approach to official statistics; see Hansen (1987), Smith (1994), Kalton (2002), Rao (2005, 2011), Beaumont and Haziza (2022) for reviews and appraisals. In this context the target parameters for estimation are descriptive, observable summaries of a given finite population, such as the population total, mean or quantiles of some specific values associated with the given population units, and the inference is characterized as descriptive or predictive (Smith, 1983; Geisser, 1993), in contrast to analytic inference of theoretical, unobservable targets such as the life expectancy (of a hypothetical cohort of individuals) or a parametric model that can be used to understand the given population.
By design-based inference from probability samples, the uncertainty of estimation is evaluated with respect to hypothetically repeated sampling from the same finite population, while all the other values involved are treated as constants associated with the given population. Design-based inference is valid by construction because it is based on the known sampling design, “whatever the unknown properties of the population” (Neyman 1934). In contrast, by model-based inference, the uncertainty of estimation is evaluated with respect to an assumed statistical model of the observations, while the available sample is typically treated as fixed; see for example, Valliant et al. (2000). Although models are necessary for analytic targets or if the available observations are not obtained by probability sampling, model-based inference may be invalid to the extent the assumed model is misspecified in respects that matter to the task at hand.
Design-based inference can be made more efficient by using auxiliary information in addition to the sampling design. This can largely recover the ‘loss of efficiency’ compared to model-based inference that uses the same auxiliary information optimally under the assumed model. For instance, calibration estimation (Deville and Särndal 1992) is a general approach that makes adjustments to the design weights with respect to the known auxiliary population totals. Or, empirical likelihood methods can yield confidence intervals that have better properties than normal approximation based on the central limit theorem (Hartley and Rao, 1968; Rao and Wu, 2010; Berger and De La Riva Torres, 2016). More relevant to our development is the model-assisted approach where an assisting model is explicitly formulated but inference remains design-based, whether or not the adopted estimator has optimal properties with respect to the assisting model. One can use linear models (Särndal et al. 1992), generalized linear models (Wu and Sitter 2001), or many other models under a unified “construction recipe” as reviewed by Breidt and Opsomer (2017).
To justify any model-assisted estimator that is not design-unbiased, it is common to seek a proof that it can be design consistent asymptotically for a hypothetical sequence of populations of increasing sizes. As Smith (1994) points out, this “asymptotic notion of consistency” is not immediately applicable to the given population as “a real entity”. In contrast, for a given population and sampling method, if
We emphasize that asymptotic consistency of a point estimator or an interval estimator is unnecessary, if the estimator is Neyman-Fisher consistent in the sense Neyman and Fisher have used the term “consistent” for finite-population inference. This will be our perspective to design-based predictive inference in this paper, which may also be called fully design-based inference in contrast to asymptotically design-consistent inference (that has been traditionally more common for model-assisted finite population estimation).
Now, we notice that design-unbiased ratio or linear regression estimators for population totals have been proposed by Hartley and Ross (1954) and Mickey (1959), which are finite-population Neyman-Fisher consistent. More recently, Sanguiao-Sande and Zhang (2021) developed a design-unbiased approach, called subsampling Rao-Blackwellisation (SRB), which allows for any assisting Machine Learning (ML) models or algorithms that have become increasingly common. The SRB approach combines three classic ideas in statistical inference, (i) model-assisted estimation for survey sampling, (ii) cross-validation for error estimation by ML methods, and (iii) the Rao-Blackwell Theorem (Rao, 1945; Blackwell, 1947) for efficiency improvement.
In this paper, we extend the SRB approach to a larger class of population estimators, which are commonly referred to as the prediction estimators, as well as the associated individual-level predictors for the out-of-sample units. Notice that, traditionally, due to the lack of a design-based prediction theory, individual outcomes must be treated as random variables for model-based prediction and the term predictor is common in this context. Although from a design-based inference perspective the term prediction estimator would seem more appropriate also at the unit level, we shall keep the term predictor at the individual level for convenience and familiarity reasons. Notice also that the two terms “unit” and “individual” are used interchangeably in this paper, such as in “statistical unit” or “individual prediction.”
It may be helpful to make some remarks immediately regarding the nature of our inference approach and its advantages compared to the more familiar model-assisted inference.
First, we consider predictive inference by definition, where the sample-based prediction estimator (using any given ML model or algorithm) aims at some out-of-sample quantity that varies with the sample, the property of which is evaluated only with respect to repeated sampling from the given population. This design-based predictive inference outlook differs from model-assisted estimation that is aimed at fixed population parameters (such as totals or means).
Next, we develop Neyman-Fisher consistent uncertainty estimators, which accommodate any given assisting model (or algorithm) and apply generally to sampling from finite populations. In contrast, asymptotically design-consistent inference may not hold in a given setting of finite population sampling, but still requires tailored asymptotic arguments to be developed for different nonparametric assisting models, such as random forest or support vector machine, which will remain a challenge as new models or algorithms emerge.
Finally, while our approach is model-assisted in the sense that the sampling design remains the inference basis despite the model introduced, it provides as well a design-theoretical basis for individual level prediction (estimation). This is another important difference to standard model-assisted estimation that is only applicable to population parameter estimation.
1.1. Prediction Estimator
Denote by

We shall consider
Notice that individual level features are required to compute the prediction estimator, Equation (1), except for example, in the case of using linear models. However, this is a requirement common to all individual-level prediction models, regardless the inference framework. There may be situations where such information is unavailable, which would limit one’s choice of models. But the ability to utilize individual level covariates is certainly not a limitation of our approach not least because, as we shall explain, design-based individual-level predictive inference can provide a valid theoretical basis for producing census-like statistical data, which fills a gap in the current literature.
Note that many design-based estimators in survey sampling can as well be given as prediction estimators, Equation (1). For example, let
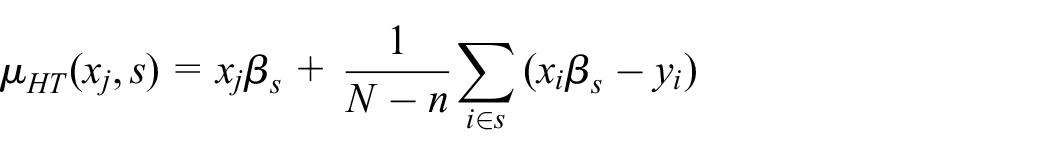
where
However, we are interested in design-unbiased inference of the prediction estimator, Equation (1) generally, including when
The theory of design-based predictive inference for population totals and individuals will be developed and illustrated in Sections 2 and 3, respectively, an illustrative application to Structural Business Survey is given in Section 4, and some final remarks are given in Section 5. However, before we get into the details of the development, let us first motivate below what design-based predictive inference can do for official statistics.
1.2. Introduction to Total Estimation
Design-based predictive inference is clearly relevant to the perennial design versus model controversy in survey sampling, as traditionally the two main strands of approaches to finite population estimation.
In the design-based approach, estimators depend on the sampling design through the sample inclusion probabilities or other known sampling probabilities. Although auxiliary information in addition to the sampling design can be incorporated by various techniques, the validity and the associated uncertainty of the resulting estimator are still based on the given sampling design. In contrast, the model-based prediction approach, frequentist or Bayesian, depends on an assumed working model, which typically ignores the sampling design and treats the available sample as fixed when it comes to the assessment of the associated uncertainty.
Meanwhile, it is possible to evaluate any design-based estimator, such as the HT estimator or a generalized regression estimator, with respect to an assumed model, in which case it is common to conclude that design-based estimation is inefficient or lacks desirable conditional properties (e.g., Valliant et al. 2000). Conversely, a prediction estimator derived optimally under a working model can be evaluated with respect to the sampling design, in which case the danger of model misspecification is frequently noted (e.g., Hansen et al. 1983).
Design-based predictive inference takes the last analysis further, whereby one explicitly evaluates the design-based bias and variance of any given model-based prediction estimator, Equation (1). One can then compare the given model-based estimator to any other estimator, whether the latter is dependent on the design or a working model, and choose according to their design-based properties regardless how they are constructed. The merit of such an approach rests now on the fact that design-based uncertainty assessment is valid, which does not require the model underlying any given estimator to be correct.
To illustrate, under the linear model
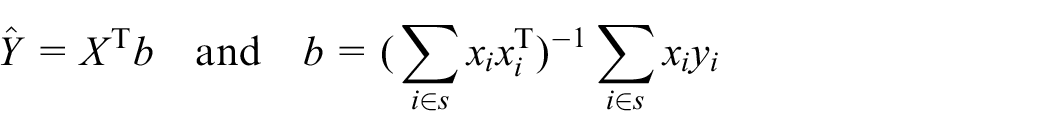
where
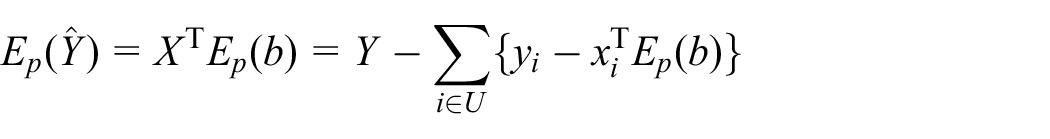
where
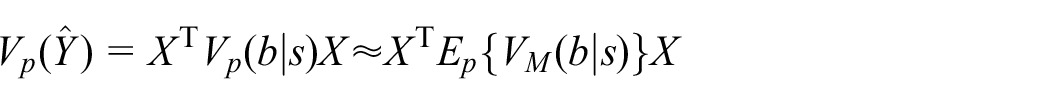
with respect to sampling, where
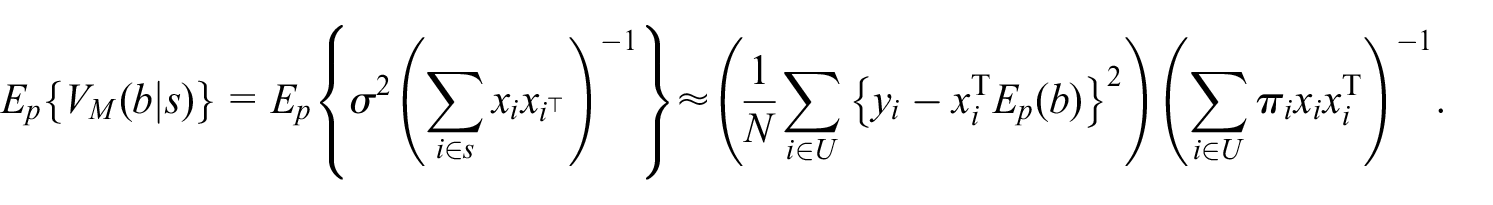
Both
Thus, a chief advantage of adopting design-based predictive inference to population total estimation based on probability sampling is to circumvent the design versus model controversy, by providing a valid common ground for uncertainty assessment. A theory applicable to the class of prediction estimators, Equation (1), which will be developed in this paper, would allow one to use any assisting ML models or algorithms that can often make more efficient use of auxiliary information than the standard design-based calibration estimation or model-assisted estimation methods.
1.3. Introduction to Individual Estimation
Individual estimation requires the most extremely disaggregated results. It can be useful for constructing statistical registers or census-like statistical data as the basis for descriptive official statistics. However, there has never been a design-based theory for estimation at the individual level.
For instance, having taken a simple random sample of all but two units in a given population, the traditional design-based estimation theory would only allow one to make inference about the total (or mean) of the two out-of-sample units, but not each on its own, no matter how large the sample is or how much auxiliary information one has in addition. This is clearly unsatisfactory, which requires extension of the design-based inference theory.
To illustrate the conceptual issue at hand, suppose on observing
One possibility is to assume a model. For instance, under the model that
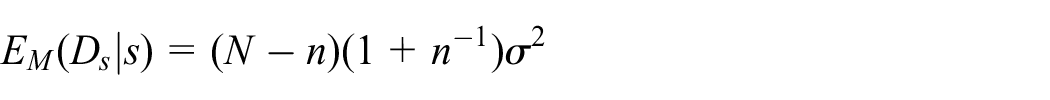
with respect to the IID model conditional on the given subset
However, we notice that a fundamentally different, design-based approach would in fact be possible if
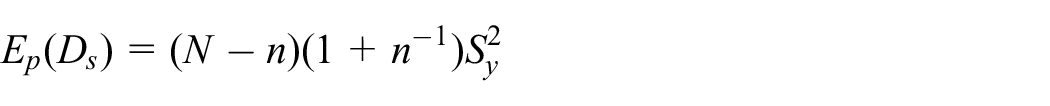
with respect to
Since
We shall develop a general design-based theory for the out-of-sample loss, provided the observations are obtained by probability sampling. This would yield valid inference of the associated risk with respect to the given sampling design, where all the outcomes
2. Total Prediction Estimator
Consider the prediction estimator, Equation (1), where
Denote by
As in Sanguiao-Sande and Zhang (2021), we shall refer to the sampling design that yields
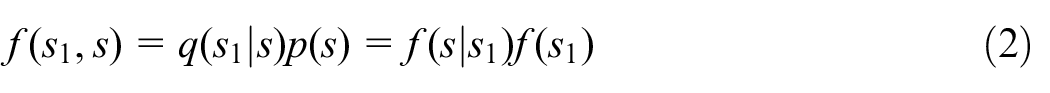
where the last product indicates that, conditional on the training set
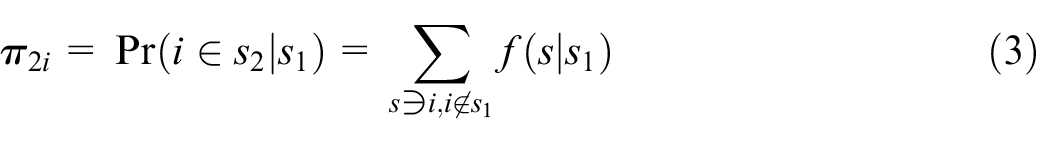
be its conditional
The theory of design-based predictive inference we develop below, including both Theorems 1 and 2, apply generally provided any well-defined
Now, conditional on any given
2.1. SRB Prediction Estimator
Given
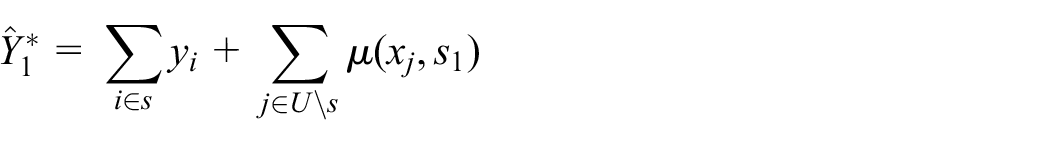
whose total error for

where
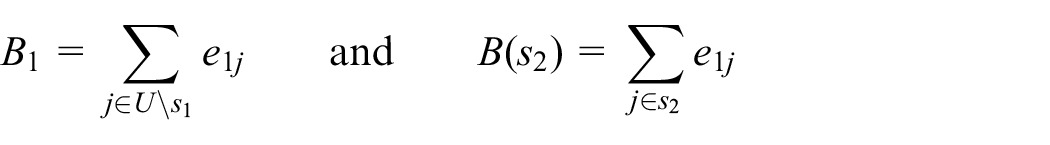
Note that
Applying Rao-Blackwellisation to
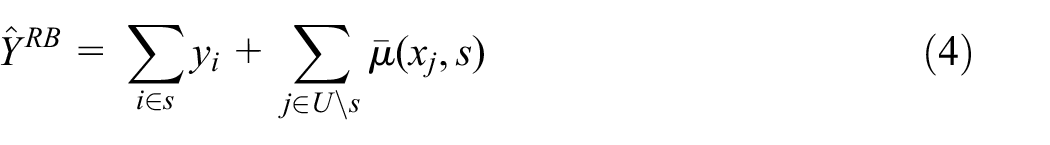
where

Notice that
It follows from the definition that the bias of
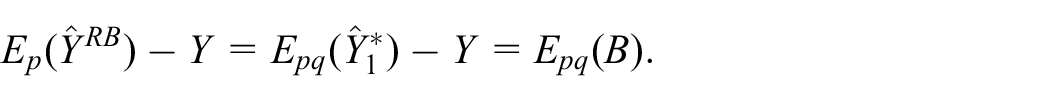
Given

in the sense that, as
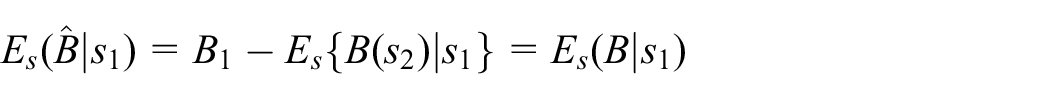
since

as an unbiased estimator of the bias of
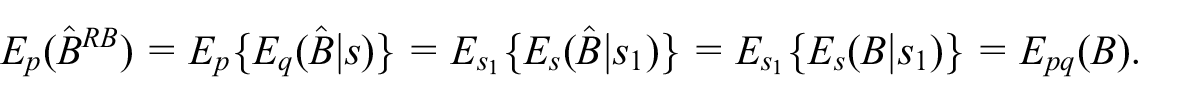
Notice that one needs at least
Moreover, one can estimate unbiasedly the MSE of
Theorem 1. For any given
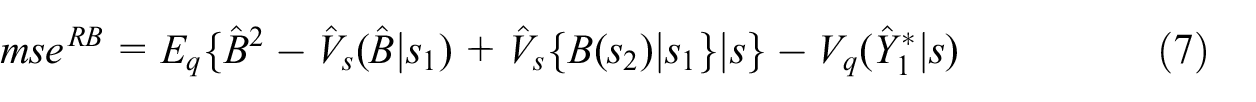
where
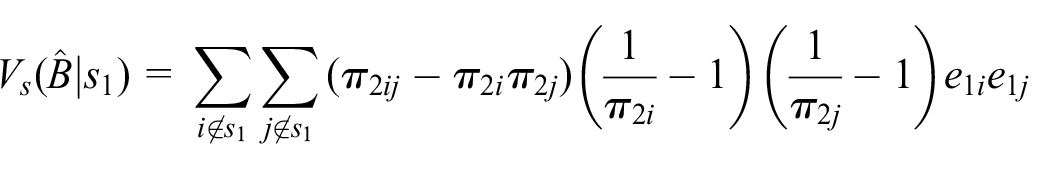
where
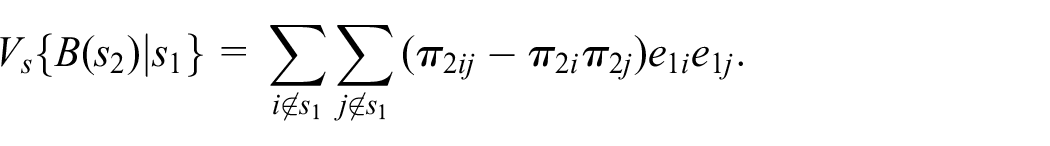
Notice that one needs at least
2.2. Discussion
In a recent discussion of cross-validation for prediction error estimation under the IID model of
We have obtained design-unbiased MSE estimator, Equation (7), for the SRB prediction estimator
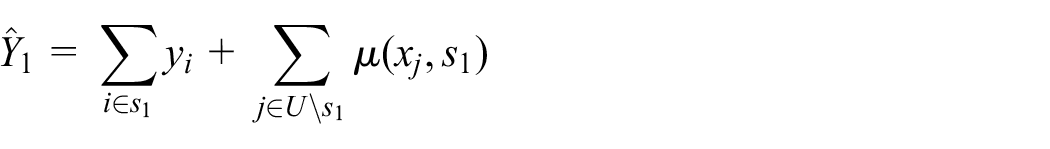
as if
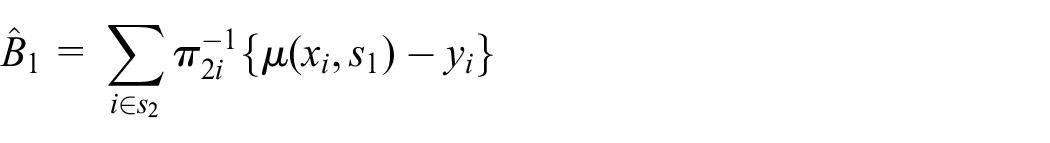
and
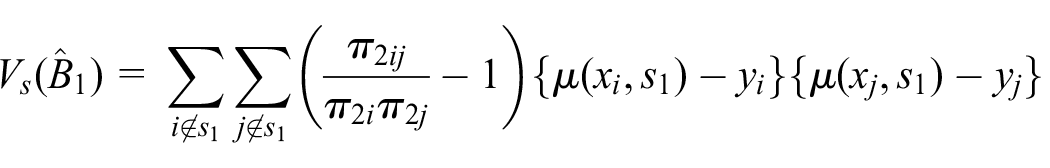
Next, as will be illustrated later, we note that
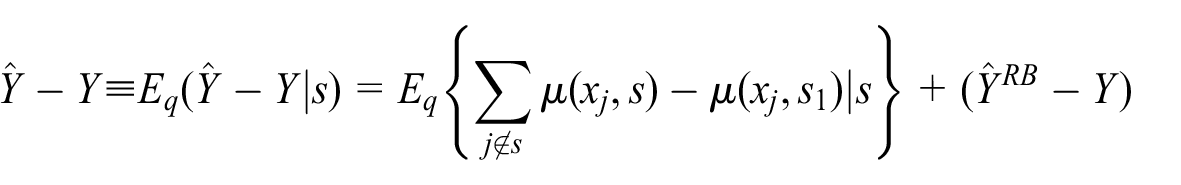
where the term
Finally, notice that, apart from familiarity and custom, there is no reason why one cannot adopt the SRB prediction estimator, Equation (4), for which MSE estimation is unbiased, instead of using the once-trained predictor
2.3. Notes on Implementation
2.3.1. Sampling Probability
By definition, Equation (3),
One can use instead another sampling probability of the
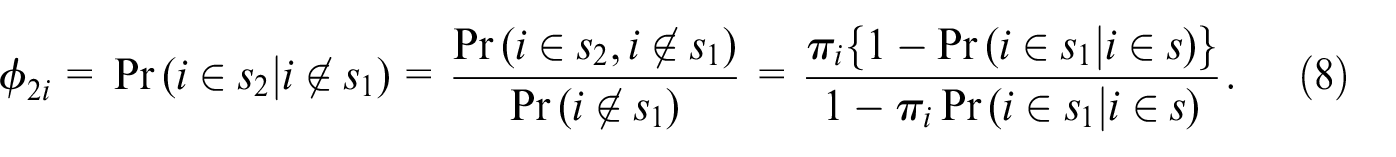
Given
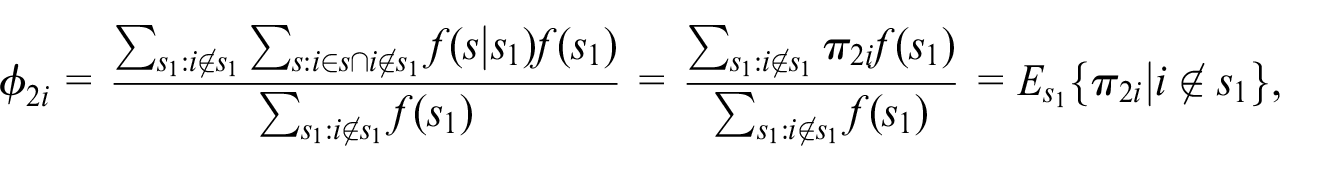
it is the conditional expectation of non-zero
To illustrate, take the special case of SRSWOR of
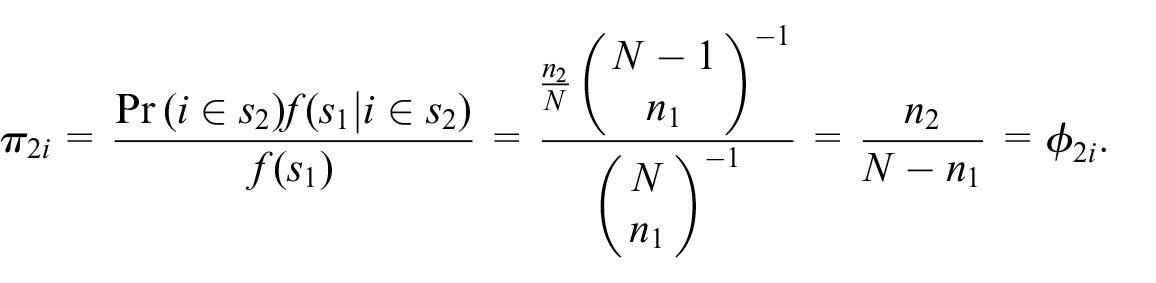
Similarly, instead of
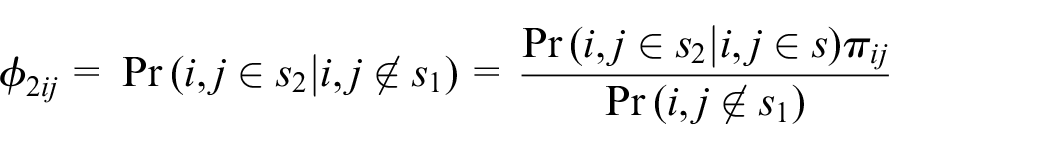
where
2.3.2. Monte Carlo SRB
By Equation (7), the exact
The exact SRB operation may be infeasible if

based on sample splits
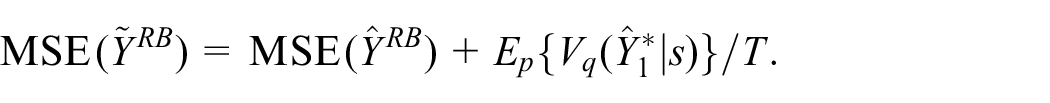
The unbiased exact-RB estimator of
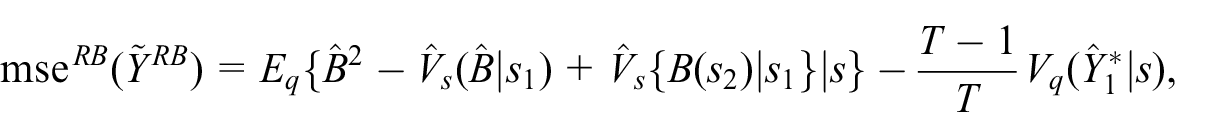
such that the unbiased MC-RB estimator of
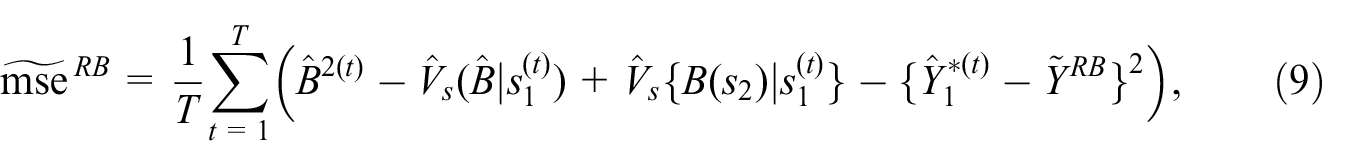
where the index
For the LTO
Therefore, in practice, one can first explore the MC variance of
2.4. Illustration
Let us illustrate with a simple example. Generate and fix a population of size
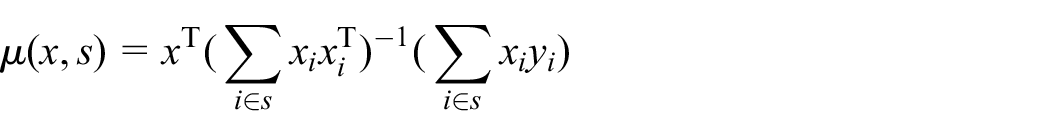
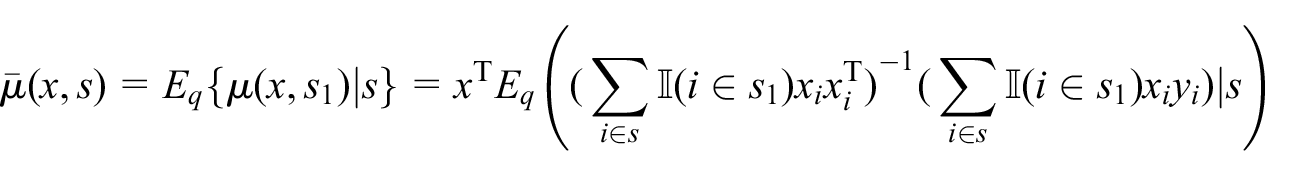
Given a single realized sample
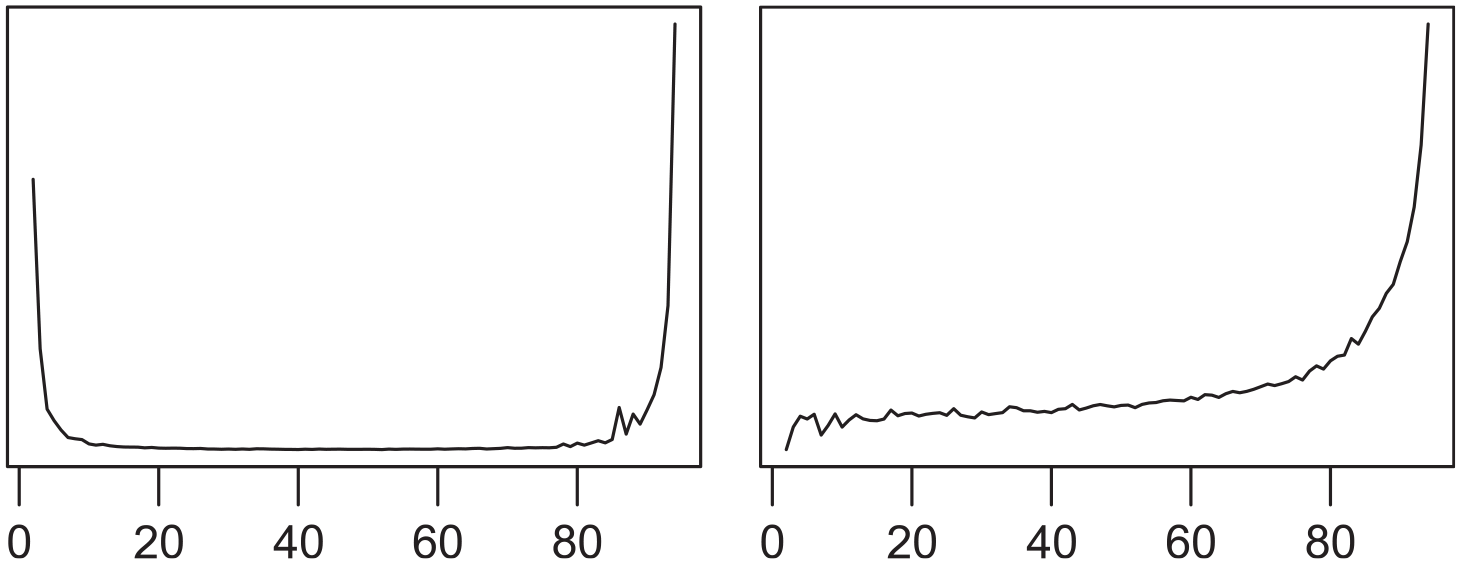
MC variance (left) and expectation (right) of
Table 1 shows the results of simulating MSE estimation based on 250 independent samples, given
MSE Estimation from 250 Samples,
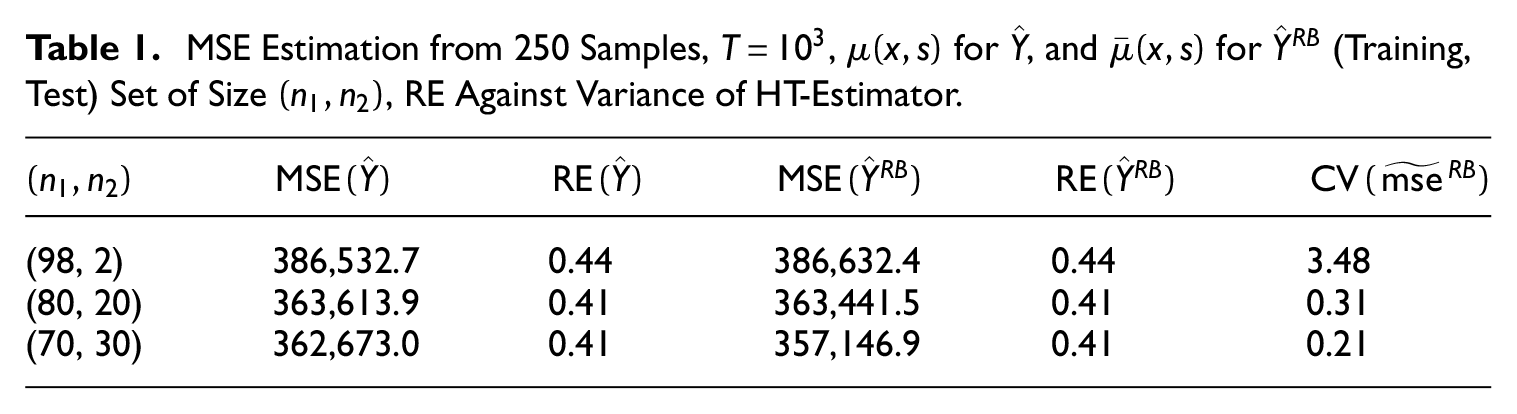
For
In terms of the choice of estimator, we notice that the mis-specified predictor
3. Individual Prediction Estimator
Consider the individual-level predictor
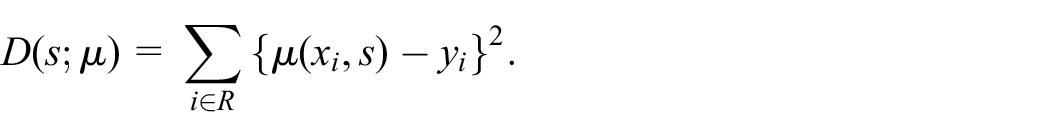
For design-based individual-level predictive inference, we define the risk of

We stress that only
3.1. Risk of SRB Predictor
Under the same

which can be observed for any unit in the test set

be the TSE of
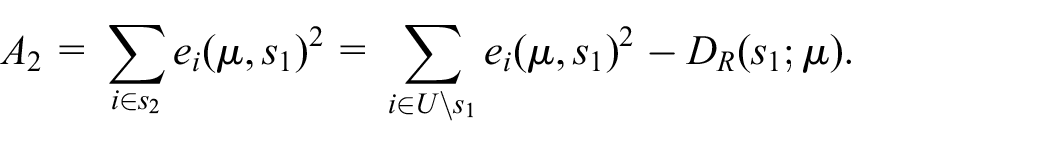
Given
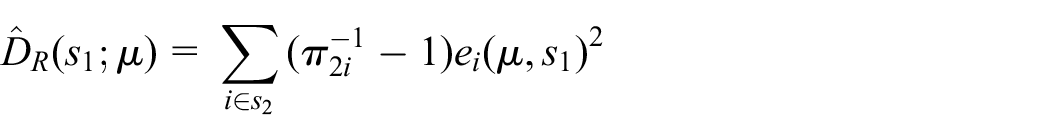
is unbiased for
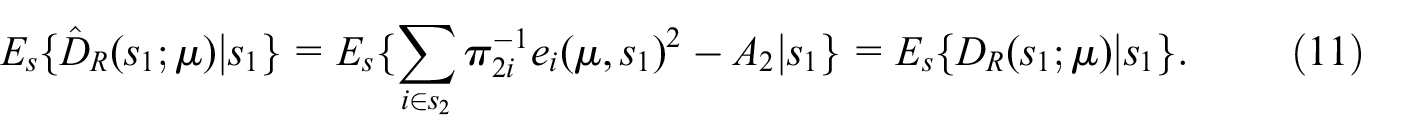
Meanwhile, the TSE of the SRB-predictor
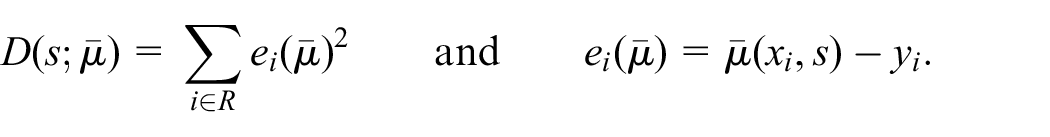
For any
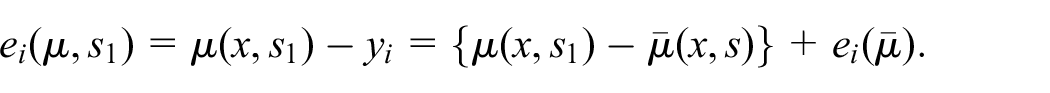
Since
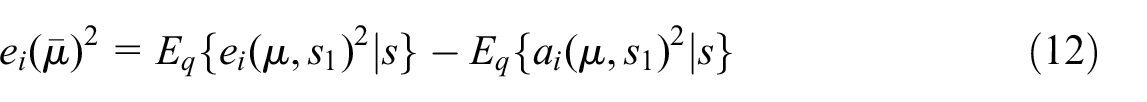
where
Theorem 2. For any given
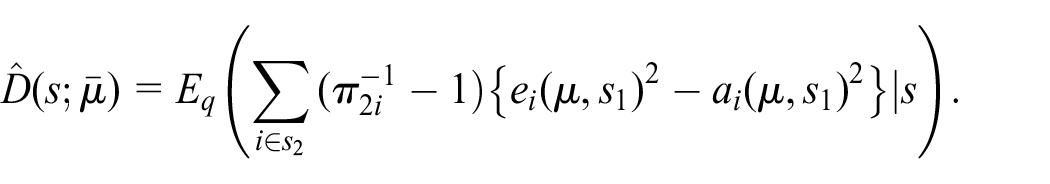
In practice, where exact SRB is infeasible numerically, one can use the MC-SRB predictor based on
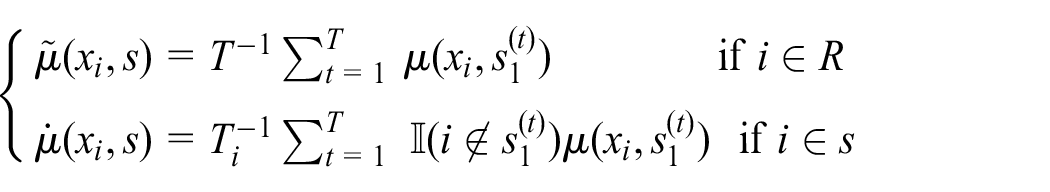
where
To estimate the risk, for any
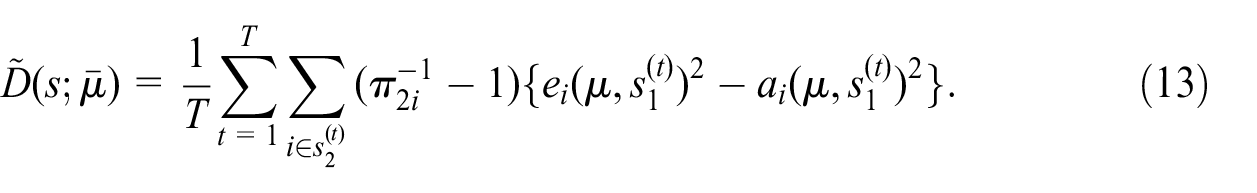
3.2. Using an Ensemble of Predictors
By design-based predictive inference, there is no need to assume that a true model exists for
3.2.1. SRB-Selector
Consider selecting a single model by voting given an order-

where we discount the possibility of
In practice it is a common approach to apply cross-validation and majority-vote, where cross-validation is based on
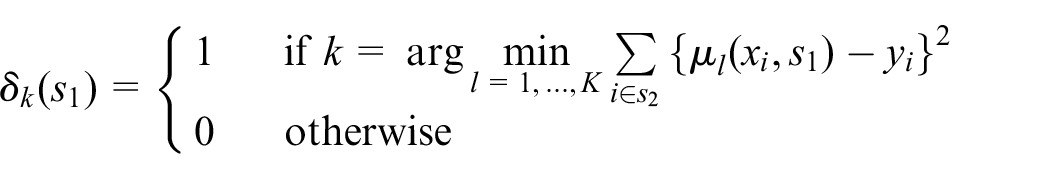
indicate which predictor has the least TSE in
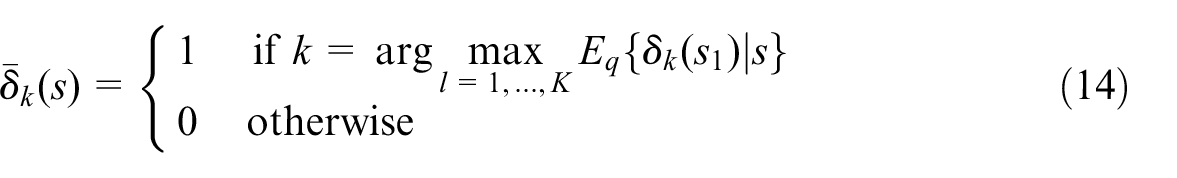
is a classifier of
3.2.2. Mixed SRB-Predictor
Consider averaging given an order-

where
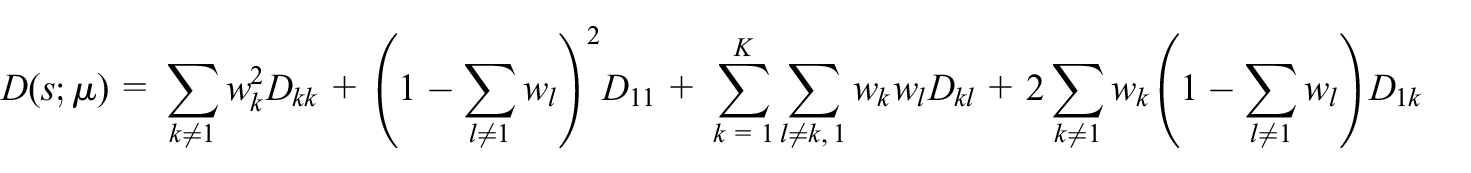
now that
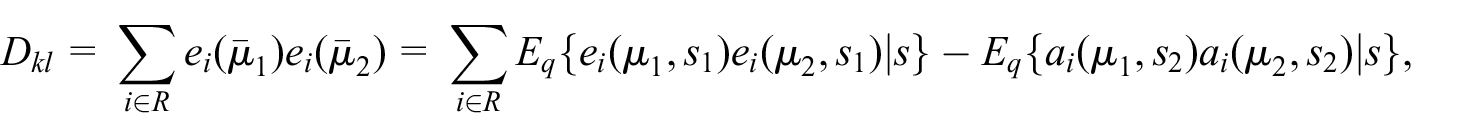
that is, similarly to Equation (12). An estimator of
The optimal mixing weights
Whilst the above approach aims at minimising the risk, it may experience instability if the ensemble is not sufficiently heterogeneous. A robust approach to mixed ensemble prediction should automatically aim at the same mixing weight of two component predictors that are equal to other.
For any
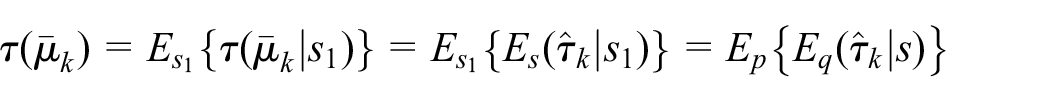
where
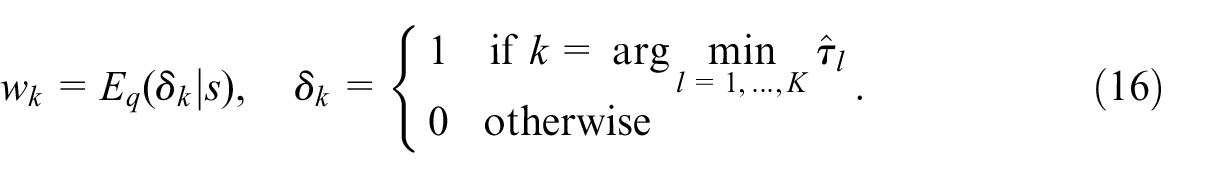
The corresponding mixed SRB-predictor, Equation (15), is robust against
3.3. Illustration
Simulations below provide a simple illustration of design-based individual-level predictive inference. For better appreciation of the design-based approach, we include also the risk estimator under an assumed IID error model.
We generate 200 sets of
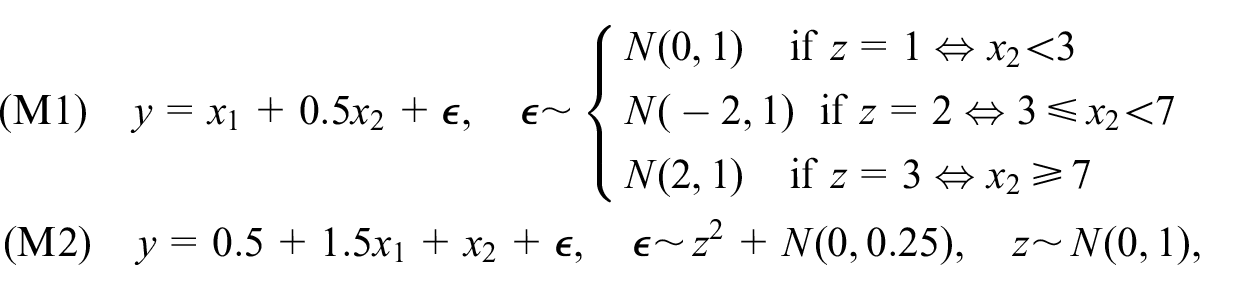
From each population we draw a sample of size
Let an order-3 model ensemble contain linear regression, random forest, and support vector machine. Let the feature vector be
For each SRB predictor, we estimate its standardized risk, Equation (10),
The average of the 200 true
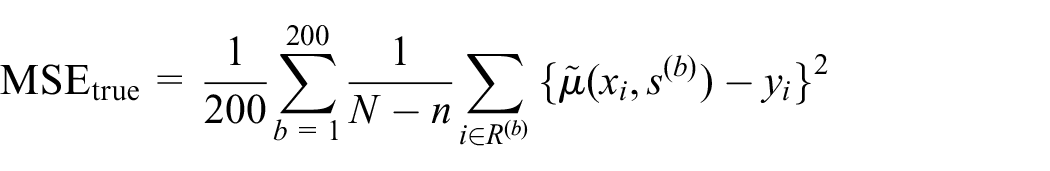
where
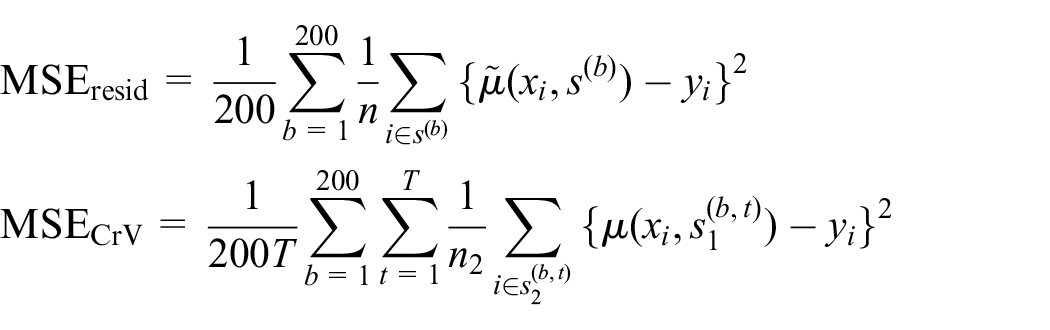
where
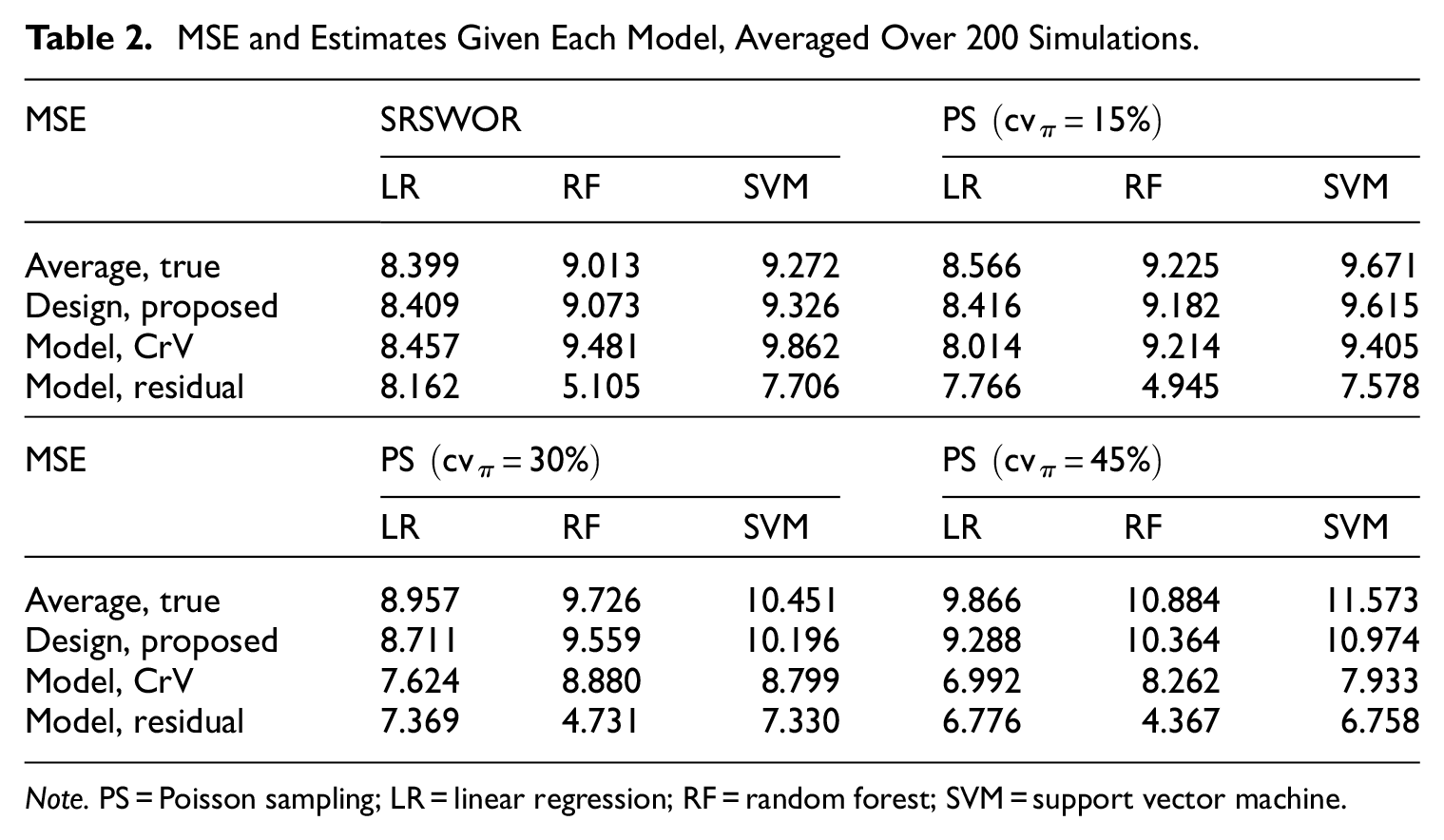
Table 2 displays average true MSE and its estimates across the simulation settings. Regardless the model, the proposed design-based risk estimator Equation (13) is unbiased under SRSWOR
MSE and Estimates Given Each Model, Averaged Over 200 Simulations.
Note. PS = Poisson sampling; LR = linear regression; RF = random forest; SVM = support vector machine.
The CrV-based IID-model MSE estimator is also essentially unbiased under SRSWOR, because the out-of-bag squared errors in the test sample
The CrV-based MSE estimator can become severely biased though, if the IID model does not hold for the actual sample selection mechanism, as illustrated here for Poisson Sampling with increasing
Next, to illustrate inference for ensemble individual prediction, we obtain the SRB-predictor Equation (5) selected by Equation (14), and the two mixed SRB-predictors using the weights that are either optimal for Equation (15) or robust Equation (16). Given any ensemble MC-SRB predictor
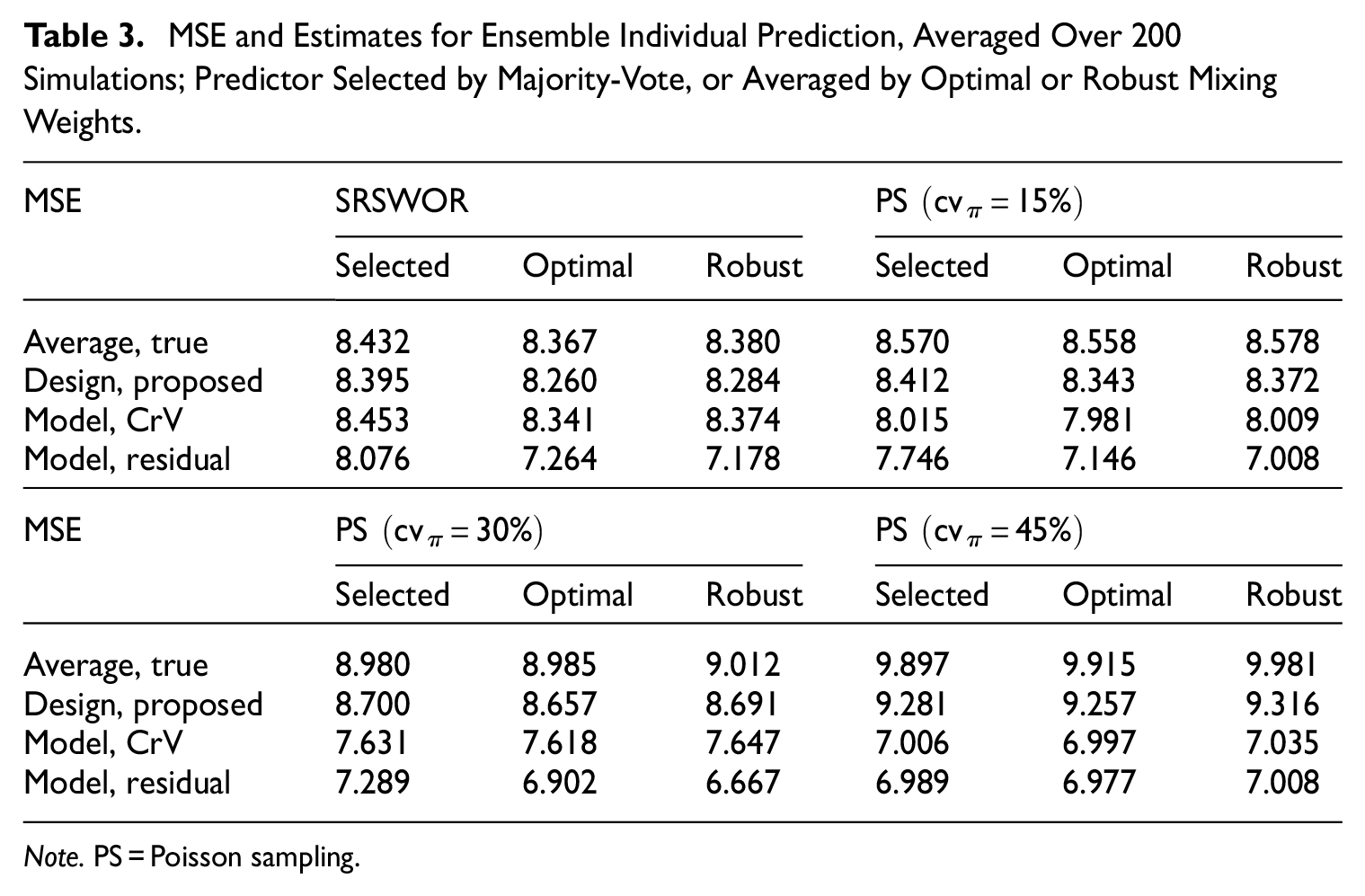
Table 3 presents average true MSE and estimates for the SRB selector and mixed SRB predictors across the simulations. The average true MSE by the SRB-selector is similar to that of the linear model in Table 2, where the MSE is the smallest by this model than random forest or support vector machine. The two mixed SRB predictors achieve largely the same true MSE for individual prediction, in each simulation setting, illustrating the robustness of ensemble prediction approach even when it cannot improve on the best single model in the given ensemble. In terms of MSE estimation, the results in Table 3 are seen to be consistent with what we have observed for Table 2.
MSE and Estimates for Ensemble Individual Prediction, Averaged Over 200 Simulations; Predictor Selected by Majority-Vote, or Averaged by Optimal or Robust Mixing Weights.
Note. PS = Poisson sampling.
4. Illustrative Application
Here we describe an illustrative application of design-based prediction estimation for the Spanish Structural Business Survey (SSBS). The SSBS provides information about the main structural and economic characteristics of businesses, such as employed personnel, turnover, purchases, personnel expenses, taxes, and investments. The target population consists of businesses classified in one of the following economic sectors: industrial sector, commercial sector, and services sector.
We take the year 2020 for reference, where the SSBS population contained 2,615,811 business units and the estimated total turnover was 1,785 billion euros, which is related to the total value of market sales of goods and services to third parties during the reference year. The SSBS estimation is traditionally based on the HT-estimator. One of motivations of this study, which is directly related to the SSBS, is the need to investigate whether it is possible to reduce the SSBS sample size, by developing and introducing more efficient estimation approaches.
4.1.
-Design for SSBS
The SSBS sample contains both fully surveyed business units and other units that are mainly imputed. For our purpose here, we shall only consider the sample of fully surveyed units, which are selected using a stratified random sampling design. There is as usual an exhaustive (i.e., take-all) stratum for the largest businesses, which will be excluded from the application below, since sampling error does not exist there. In addition, any stratum with only one or two sample units will be removed, because some variance smoothing techniques would be needed for these strata in practice, which have no direct relevance to the theory of design-based predictive inference.
A total of 9,681 strata are retained in this way, which contain altogether 2,018,561 population units. As shown in the top plot of Figure 2, the stratum population size is relatively small for most strata but has a skewed distribution. The biggest stratum does have 54,770 units and there are 319 strata with more than one thousand units. The histogram of stratum sample size is given in the bottom plot of Figure 2. Around a half of all the strata have five or fewer sample units, whereas the number of strata with sample size greater than 25 is 339. The total sample size is 80,280.
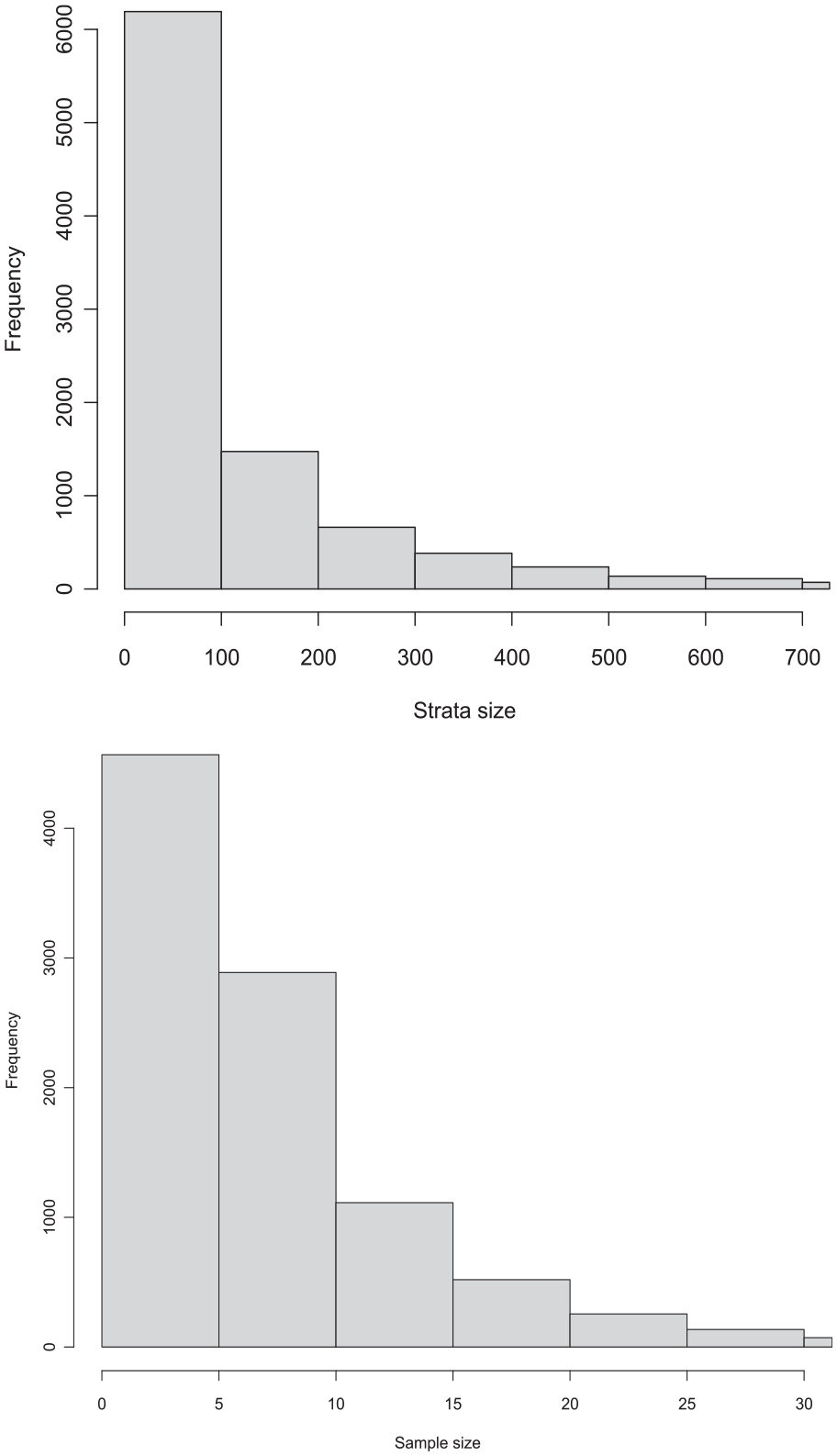
Histogram of stratum size in population (top) and sample (bottom).
To investigate the potentials of sample size reduction, we selected randomly and without replacement 45% of the original sample units in each stratum, subjected to a minimum of three sample units in each stratum. The resulting total sample size is 40,514, which is about half of the original sample size. Alternative model-assisted estimators (to be described below) will be compared based on this reduced sample, which would demonstrate both the proposed inference approach and the potentials of sample reduction.
We notice that although the ad hoc reductions of stratum sample sizes above should not be taken as a proposal for the new SSBS sampling design, the estimation results based on this realized sample are more “tangible” than the alternative, whereby one first estimates the MSE of a given estimator based on the original sample and then speculates how this MSE might have changed had the total sample size been reduced by 50%. Moreover, insofar as our aim here is not the specifics of the new SSBS sampling design, the single realized sample is large enough to warrant the comparison of different estimation approaches, and there is no need to simulate the sample reduction above many times which would only have generated largely similar results.
We adopt within-stratum SRSWOR as the subsampling
4.2. Models and Estimators
We use turnover as the target variable for illustration. The HT-estimators based on the original SSBS sample (with 80,280 units) and the reduced sample (with 40,514 units) provide the baselines for comparison. Four additional estimators will be applied to the reduced sample, which arise from the
The model is either linear or tree regression, defined globally regardless the design strata. The linear model uses four features:
• the “administrative” turnover from the corporate incoming tax if available, or imputed stratum-mean (of available administrative turnover) if missing;
• a binary indicator for whether the administrative turnover is missing;
• the operating income according to the tax administration if available, or imputed stratum-mean (of available operating income) if missing;
• a binary indicator for whether the operating income is missing.
The linear regression coefficients are estimated by weighted ridge regression, given the sampling design weights and a small tuning parameter
The tree regression model uses the following four features, where the missing values are not imputed but left as-is to the software package:
• the administrative turnover,
• the operating income,
• the first digit of the National Classification of Economic Activities,
• the number of employees according to the Business Register.
The tree model is built using the ready-made R package h2o for random forest, where one feature is chosen for each split (mtries = 1), the maximum tree depth is 20 (max_depth = 20) and the minimum number of observations per leaf is 5 (min_rows = 5). The observations are again weighted by the sampling weights.
Given either model, we consider the SRB prediction estimator Equation (4) and the design-unbiased model-assisted SRB-estimator (Sanguiao-Sande and Zhang 2021), where the latter can be given as
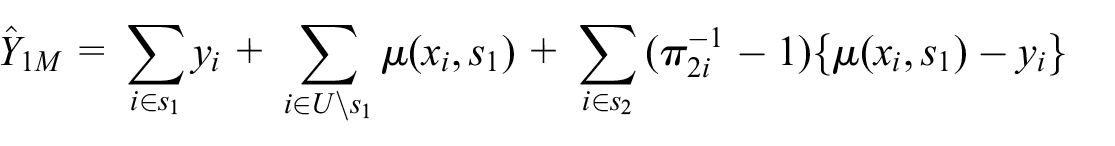
The SRB operation uses a constant 80-20 sample-split for the linear model and a constant 50-50 sample-split for the tree model. Notice that in the case of tree model, the SRB-predictor Equation (5) is a random forest by construction since it is then the average of
It is worth pointing out that, unlike the prediction estimator Equation (4) that applies
4.3. Results
Table 4 summarizes the results for the estimators described above. Apart from each estimate
Estimation Results (in Billion Euros),
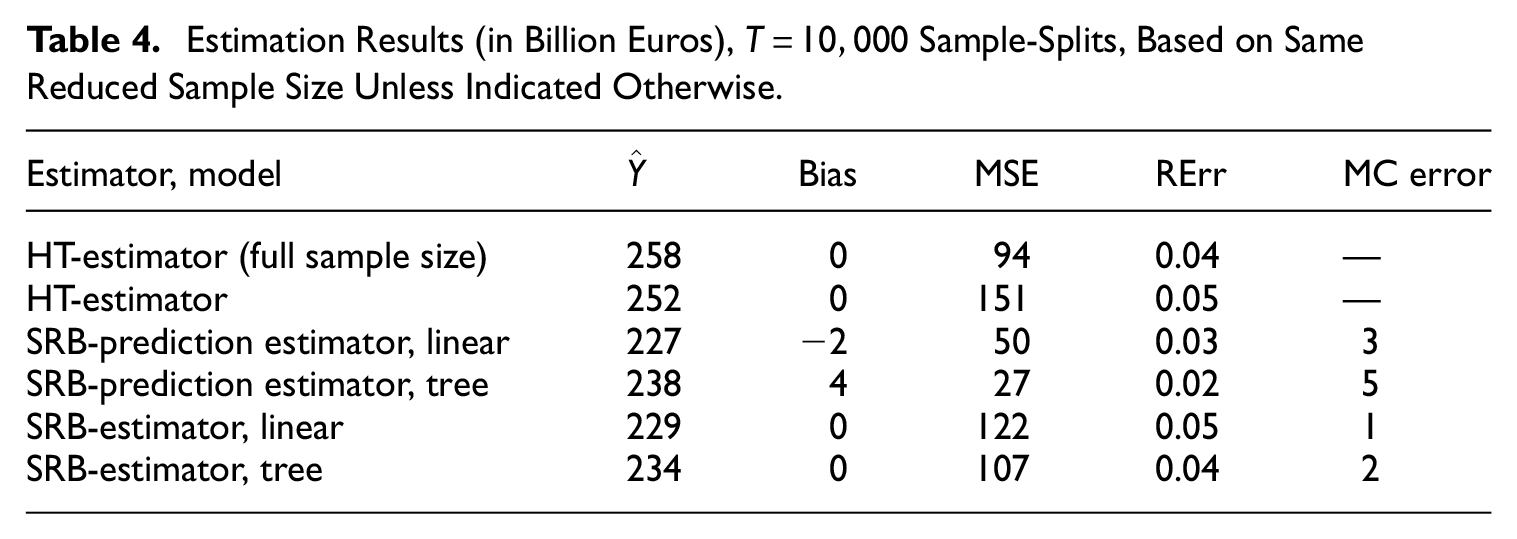
Exact Rao-Blackwellisation for MSE estimation is simply beyond reach in this case, where we have more than six thousand strata with sample size three in the reduced sample. If we leave out two units in each stratum under subsampling, then there are more than
The MC error is the bootstrap estimated standard deviation of the MC-MSE estimator, which is due to the loss of MSE estimation efficiency by Monte Carlo compared to exact Rao-Blackwellisation (with zero MC error). It can be seen that the relative MC error still does not vanish despite the large number of sample-splits
First, we notice that the two design-unbiased SRB-estimators have only led to moderate efficiency gains over the HT-estimator. The main reason is likely to be the large number of strata with very few sample units. Basically, in case the SRB-estimator uses
In comparison, the SRB-prediction estimators using the same models can be much more efficient precisely because they do not apply bias correction, that is, they are no longer stratified estimators as the SRB-estimators are, such that they can take full advantage of the reduced variance if the prediction biases are small. The MSE of the linear-model SRB-prediction estimator is only about one third of the sampling variance of the HT-estimator, given the same sample size, whereas the tree model further reduces the MSE by about 50% compared to the linear model. Meanwhile, while the bias of the linear-model prediction estimator is relatively small compared to its root MSE, this is no longer the case for the tree-model prediction estimator, that is, 4 against
This serves to remind one that it is often possible to reduce the MSE at some cost of increasing bias, such as when adopting either model-assisted or model-based estimators traditionally. The theory of design-based predictive inference allows one to estimate both the bias and MSE of a large class of prediction estimators Equation (1). This increases the scope of choice in practice, in order to achieve a sensible trade-off between bias and variance.
Finally, the illustrative results above suffice to demonstrate the potentials of sample size reduction for the SSBS. An appropriate scheme of stratum sample size reduction requires a more systematic investigation though. In particular, the accompanying estimator can be chosen from the broad class of prediction estimators Equation (1), assisted by any model or algorithm and the various features available from the administrative source. But a detailed analysis is needed to take into account the level of dissemination (instead of just an overall total here) and the tolerable trade-off between bias and root MSE.
5. Final Remarks
We have developed a theory of design-based predictive inference from finite-population probability sampling. For population total estimation, one would be interested in the total of the out-of-sample prediction errors, whereas the risk of individual-level prediction depends on the out-of-sample squared prediction errors. The SRB approach provides a unified treatment of both.
Adopting design-based predictive inference for official statistics allows one to circumvent the design versus model controversy. In addition to producing population-level estimates, it provides a theoretical basis for producing statistical registers or census-like data for descriptive official statistics. The theory we propose allows for any assisting ML models or algorithms, which can be more efficient than calibration estimation using only auxiliary totals or the parametric assisting models commonly used in survey sampling.
There are a number of issues worth further investigation, of which we only mention a few here. First, survey nonresponse is unavoidable in practice. Lee et al. (2023) apply a related SRB ensemble learning approach to missing data imputation. It would be helpful to develop a unified SRB approach, which can incorporate survey response under an extended quasi-randomisation framework. Next, other choices of risk than the total squared prediction errors may be considered for individual prediction, or interval estimation may be developed for population total inference wherever the design-based bias of the prediction estimator is deemed non-negligible. Finally, it is worth studying how better to balance between the risk of individual prediction and the MSE of population total estimation associated with the prediction estimator Equation (1).
Footnotes
Appendix
Acknowledgements
We thank three anonymous referees and the Associate Editor for comments that have helped to sharpen our message.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Received: November 2023
Accepted: August 2024