
Abstract
Deformable linear objects (DLOs) are widely encountered in everyday life, taking forms such as plastic tubes, wires, ropes, and cables. They are prevalent across diverse settings, including industrial, domestic, and medical environments, as well as in outdoor applications like electric power lines, subaquatic cables, and aerial transport systems. These objects are termed deformable due to their ability to undergo significant shape changes under external forces, and linear because their length vastly exceeds their cross-sectional dimensions. Despite their importance and widespread presence, developing robotic systems capable of interacting with DLOs poses numerous challenges. This survey presents a comprehensive review of the state-of-the-art methods developed over the past decade to address these challenges. It covers key areas including physical and data-driven modeling techniques, simulation environments, perception approaches based on vision and tactile sensing, as well as strategies for estimation, planning, and control. It also reviews common manipulation tasks such as grasping, shaping, routing, knotting, suturing, and transport. The survey concludes with a critical discussion of current limitations and outlines promising directions for future research.
Keywords
1. Introduction
Deformable Linear Objects (DLOs) are a class of elongated Deformable Objects (DOs) that include items such as cables, ropes, and tubes. The term deformable emphasizes their ability to undergo significant shape changes in response to external forces, while linear reflects their geometry, that is, their length greatly exceeds their cross-sectional dimensions. Importantly, DLOs exhibit complex, highly nonlinear behavior, making their modeling and manipulation particularly challenging. In the literature, DLOs are often classified as uniparametric DOs (Sanchez et al., 2018).
DLOs play an essential role in a wide range of practical applications across multiple domains. They are commonly encountered in domestic environments, where they appear as cables, ropes, and wires. In industrial sectors such as automotive (Jiang et al., 2011; Trommnau et al., 2019) and aerospace (Shah et al., 2018), DLOs are present not only as individual electrical cables and wires but also as complex branched structures composed of multiple interconnected elements, such as wiring harnesses and hose bundles. These are often referred to in the literature as Deformable Multi-Linear Objects (DMLOs) or Branched Deformable Linear Objects (BDLOs) (Caporali et al., 2025; Zürn et al., 2023b). In the healthcare domain, DLOs also appear in the form of surgical materials such as suture threads (Lu et al., 2022). Despite their widespread presence, automating processes involving DLOs remains a significant challenge (Trommnau et al., 2019), largely due to the limited availability of effective robotic solutions for accurately perceiving and manipulating these highly flexible and deformable objects.
Throughout this survey, the term DLOs is used broadly to encompass common objects such as ropes, alongside more specialized types like DMLOs and suture threads. Specific distinctions are made only when necessary to highlight key differences relevant to the discussion.
Although interest in DLOs has been growing, the literature still lacks a dedicated and comprehensive survey addressing their unique challenges. Existing reviews primarily focus on the broader category of DOs, often emphasizing planar or volumetric DOs (Arriola-Rios et al., 2020; Hou et al., 2019; Jiménez, 2012; Sanchez et al., 2018; Yin et al., 2021; Zhu et al., 2022). Among these, only Jiménez (2012) and Sanchez et al. (2018) explicitly address DLOs in detail. The former offers a limited discussion, focusing solely on model-based planning strategies. The latter presents a classification of DOs based on physical and geometric aspects, and includes DLO-specific challenges in modeling, perception, and manipulation. However, the coverage remains limited and outdated, lacking recent advancements in the rapidly evolving field of DLO research.
This review provides the reader with a well-structured overview of the current literature and state-of-the-art approaches to the modeling, perception, and manipulation of DLOs, offering valuable insights to both newcomers and experienced researchers in the field.
The literature search for this work followed the guidelines of the preferred reporting items for systematic reviews and meta-analyses (PRISMA) approach (Page et al., 2021), encompassing identification, screening, eligibility, and inclusion stages. In the identification stage, a comprehensive search was conducted across electronically indexed databases, followed by manual searches of indexed conference and journal papers, as well as the bibliographies of identified articles, to ensure thorough coverage and mitigate biases from automatic-only searches. This survey included, reviewed, and classified more than 260 articles.
The remainder of this survey is structured as follows. Section 2 discusses modeling aspects of DLOs, followed by perception methods in Section 3. Challenges related to estimation, planning, and control are discussed in Section 4. Key manipulation tasks, including shaping, routing, and unknotting, are examined in Section 5. A discussion of current limitations and promising directions for future research is outlined in Section 6. Finally, Section 7 concludes the survey. An overview of the survey’s structure is illustrated in Figure 1, providing a visual map of the main topics and their connections to help guide the reader through the subsequent sections. General overview of the survey’s contents. Section 2 reviews the current literature on DLO modeling, beginning with an introduction to the Cosserat physical model as a baseline, followed by an analysis of existing modeling approaches and a summary of recent trends in DLO simulators. Section 3 covers various perception methods for DLOs, including vision-based tasks such as segmentation and tracking, tactile sensing, and additional modalities like proximity and force/torque sensing. Section 4 examines DLO-specific techniques for parameter and model estimation, as well as control and planning strategies, providing a comprehensive classification. These three sections serve as background for a task-oriented analysis presented in Section 5, which offers an overview of DLO manipulation methods for tasks including shape control, routing, and transport.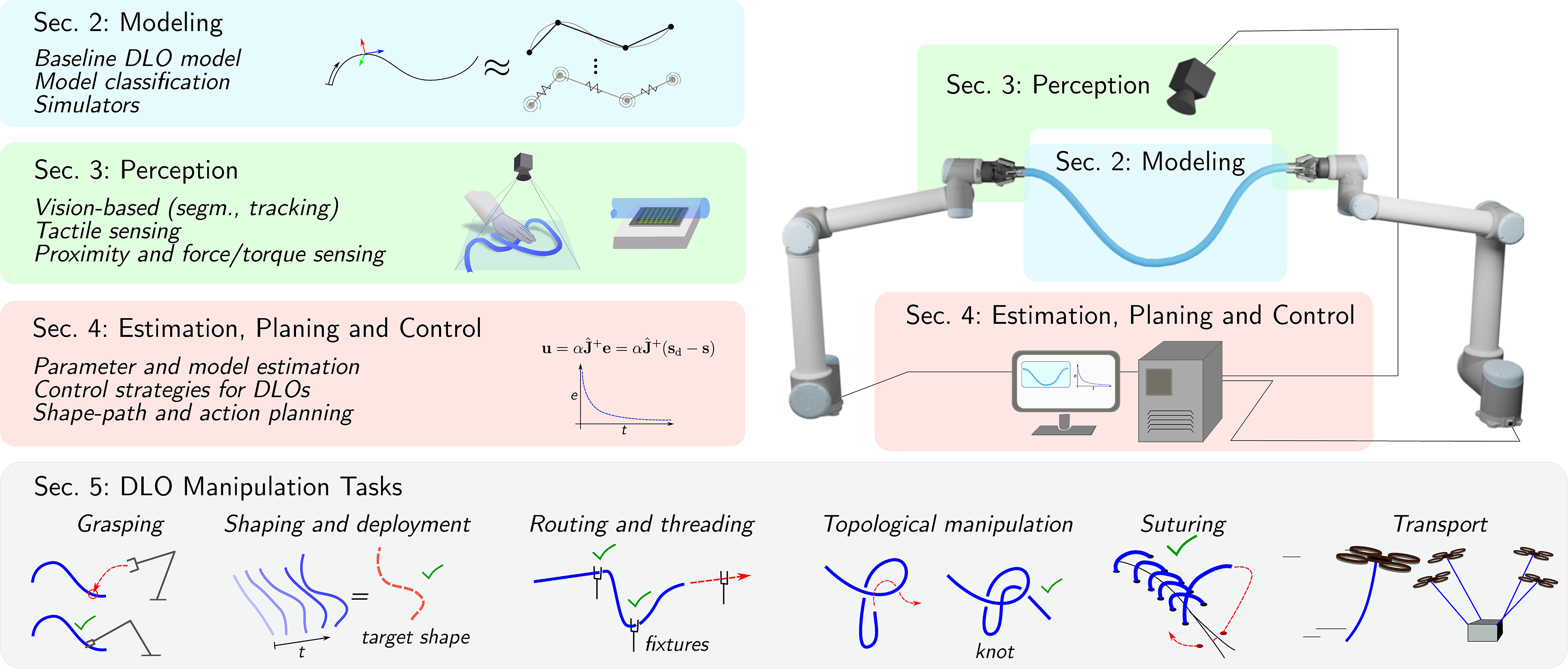
2. Modeling
In this survey, the term model refers to both classical physical formulations and other representations of DLO behavior, including geometric and data-driven approaches. This section begins by introducing the physical formulation for DLO modeling based on Cosserat rod theory, which will serve as reference and baseline for characterizing and comparing other widely used models in the literature in this survey’s proposed DLO model classification. For a broader overview of slender-object modeling techniques, readers are referred to the review by Lv et al. (2020) whose scope is primarily oriented toward non-robotic contexts, in contrast to the robotics-centered perspective of this survey.
2.1. DLO baseline model: Cosserat rod theory
DLOs are continuous mechanical systems, for which the Cosserat rod theory (Antman, 1972) offers a particularly complete physical formulation. It models both the 3D position and orientation of the DLO’s centerline through a director field, and accounts for bending, torsion, shear, and axial deformations via constitutive relations.
2.1.1. Cosserat rod formulation
In Cosserat rod theory, DLOs are modeled as continuous bodies through a curve
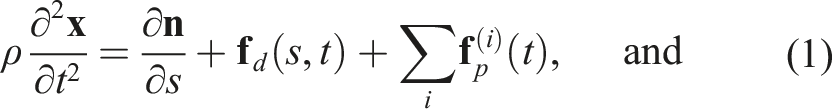
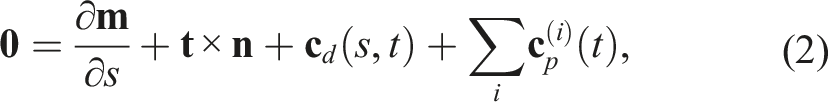
The differential equations (1) and (2) incorporate constitutive laws that describe how internal forces and moments arise from deformations. That is, these relations connect strains to stresses based on the object’s physical properties, describing how bending, twisting, stretching, and shearing generate internal forces and moments depending on the rod’s material properties and geometric characteristics. For slender, isotropic, and linearly elastic rods (common assumptions for DLOs), the constitutive laws are typically expressed as:
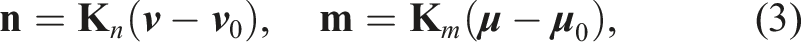
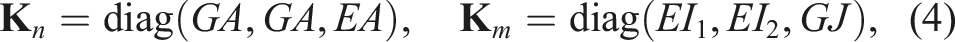
2.1.2. Boundary conditions
Solving differential equations (1) and (2) requires boundary conditions (BCs) that establish the model within a specific manipulation scenario, thereby defining the physical context for the model. In the context of DLOs, boundary conditions typically fall into two main categories: actuation, which describes how the object is controlled or manipulated, and environmental constraints, representing interactions with external elements such as surfaces, fixtures, or obstacles.
2.1.2.1. Actuation
Refers to boundary conditions that can be actively modified during manipulation. Typical setups include single-end grasping (one grasped end, the other free), dual-end grasping (both ends are grasped, i.e., clamped DLO), and variable contact points (e.g., a DLO pushed on a table at different points). These impose specific pose and force constraints and determine the numerical strategy for solving (1, 2). In single-end cases, the problem is usually solved via shooting methods, while dual-end cases are formulated as two-point boundary value problems (BVPs) and can be solved, for example, through spectral collocation. Specialized DLO models with BCs arising from continuous actuation along the domain, such as tendon-driven actuation, are also common in related fields like soft robotics (e.g., Tummers et al., 2023).
2.1.2.2. Environmental constraints
Refer to external factors that affect the DLO but cannot be actively modified during DLO manipulation. These typically include factors such as distributed forces like gravity, friction and contacts with surfaces (Jilani et al., 2025), fixtures, and obstacles in the environment.
2.2. Classification of DLO models
The continuous formulation of the Cosserat rod model, as outlined in Section 2.1, provides a strong physical foundation. However, in the practical context of DLO manipulation, it presents several challenges. Solving equations (1) and (2) can be computationally intensive, particularly when simulating complex interactions or real-time scenarios. Additionally, the accuracy of Cosserat’s model is highly dependent on precise material properties and detailed geometric data of the DLO (3), such as length or cross-sectional areas and shapes. These limitations have led to the use of alternative models for DLO manipulation, which are classified in this survey based on criteria designed to enhance both clarity and practicality for the reader. As illustrated in Figure 2, different modeling approaches for DLOs vary significantly in terms of physical realism and computational complexity. Comparison of different modeling approaches for DLOs, evaluated according to their physical fidelity and spatial resolution. This overview highlights key trade-offs between model accuracy and descriptive power versus computational efficiency, guiding the selection of appropriate models for different robotic applications.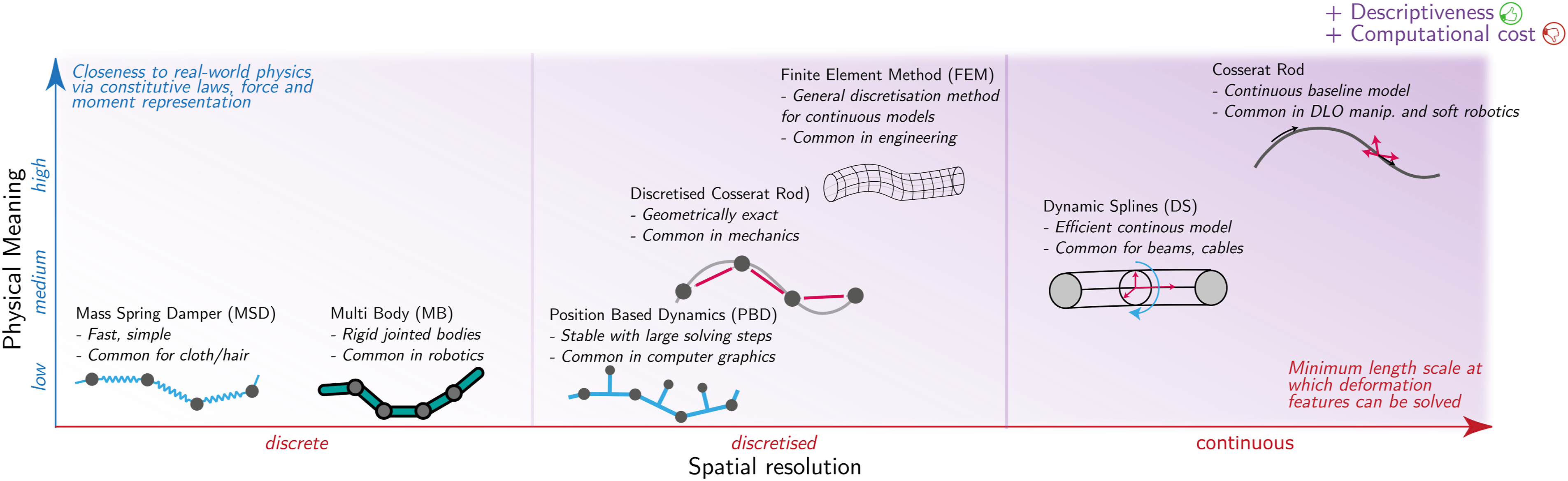
2.2.1. Spatial resolution
It refers to the level of granularity with which a model represents the geometry and deformation of a DLO along its length. Therefore, spatial resolution affects both model accuracy and computational cost. Models can be categorized into: • • •
2.2.2. Static/quasi-static vs dynamic models
In DLO manipulation, many setups and tasks are quasi-static, assuming negligible inertial effects (e.g., a foam rod grasped by two grippers), while others require full dynamic modeling (e.g., a rope rapidly shaken by a robot). According to this criterion, models are classified into: • •
2.2.3. Physics-based vs physics-inspired vs empirical/heuristic
This classification differentiates DLO models according to the degree to which they rely on fundamental physical principles. According to this criterion, models are classified into: • • •
2.2.4. Numerical versus data-driven
This classification considers the computational approach typically used by models to simulate or predict DLO behavior. Analytical (closed-form) solutions are disregarded here due to their rarity in practical DLO models. • • •
2.3. Simulation of DLOs
Several physics-based simulators support DLO modeling, each providing unique numerical methods, levels of physical realism, and degrees of integration with robotic platforms. Below is an overview of some of the most prominent simulators commonly employed in DLO research, highlighting their core modeling approaches and key references (see Table 1 for a summary): • Bullet (Coumans, 2025) and MuJoCo (Todorov et al., 2012): These are widely adopted open-source physics engines that employ PBD-like solvers for real-time simulations. In Bullet, DLOs can be represented either as FEM-like soft bodies or as chains of cylindrical segments connected by 6D springs, mimicking MB models. MuJoCo offers two main representations: cables, which model inextensible rods with bending and twisting stiffness using a geometrically exact formulation discretized into capsules or boxes; and 1D flex, recommended for simulating extensible strings under tension, such as rubber bands. • AGX Dynamics
1
: Proprietary physics simulation platform that employs a hybrid constraint-based solver for real-time simulations. It offers specialized modules such as Wires, for simulating long, bendable structures under extreme tension and in large-scale scenarios, and Cables, which capture elastic deformations as well as plasticity, using sequences of rigid bodies connected by constraints. • Obi
2
: Real-time particle-based physics engine that uses extended PBD to simulate deformable objects, available as a plugin for Unity. It supports rod simulations with stretch/shear and bend/twist constraints, and rope simulations with distance and bend constraints. • FleX (Macklin et al., 2014): Open-source GPU-accelerated particle-based simulator that represents all objects, including DLOs, as particle systems governed by PBD. • IsaacLab (Mittal et al., 2025): A GPU-accelerated simulation and robot-learning framework built on Isaac Sim and PhysX, and the successor to Isaac Gym. It provides parallel physics, photorealistic rendering, and rich multi-modal sensor simulation, together with tools for domain randomization and large-scale data collection. While not DLO-specific, IsaacLab exposes PhysX’s GPU-accelerated FEM soft-body capabilities, enabling simulation of cables and other deformable linear structures within robotic environments. • Elastica (Naughton et al., 2021): Open-source software package designed to numerically solve systems made up of collections of Cosserat rods. While not a general-purpose simulator and not real time, it offers physically accurate modeling of slender structures. Overview of widely used physics-based frameworks for DLO simulation in robotics, highlighting their core DLO modeling approaches and representative references.

3. Perception
DLOs perception is primarily achieved using vision-based (Section 3.1) or tactile sensors (Section 3.2). Additionally, less common proximity sensors and force/torque sensors are reviewed in Section 3.3. An overview of the section’s structure is provided in Figure 3. Perception-related challenges and future research directions are discussed in Section 6.1. The three main DLO perception method groups analyzed in Section 3: vision-based, tactile, and other sensor-based (e.g., proximity, force/torque).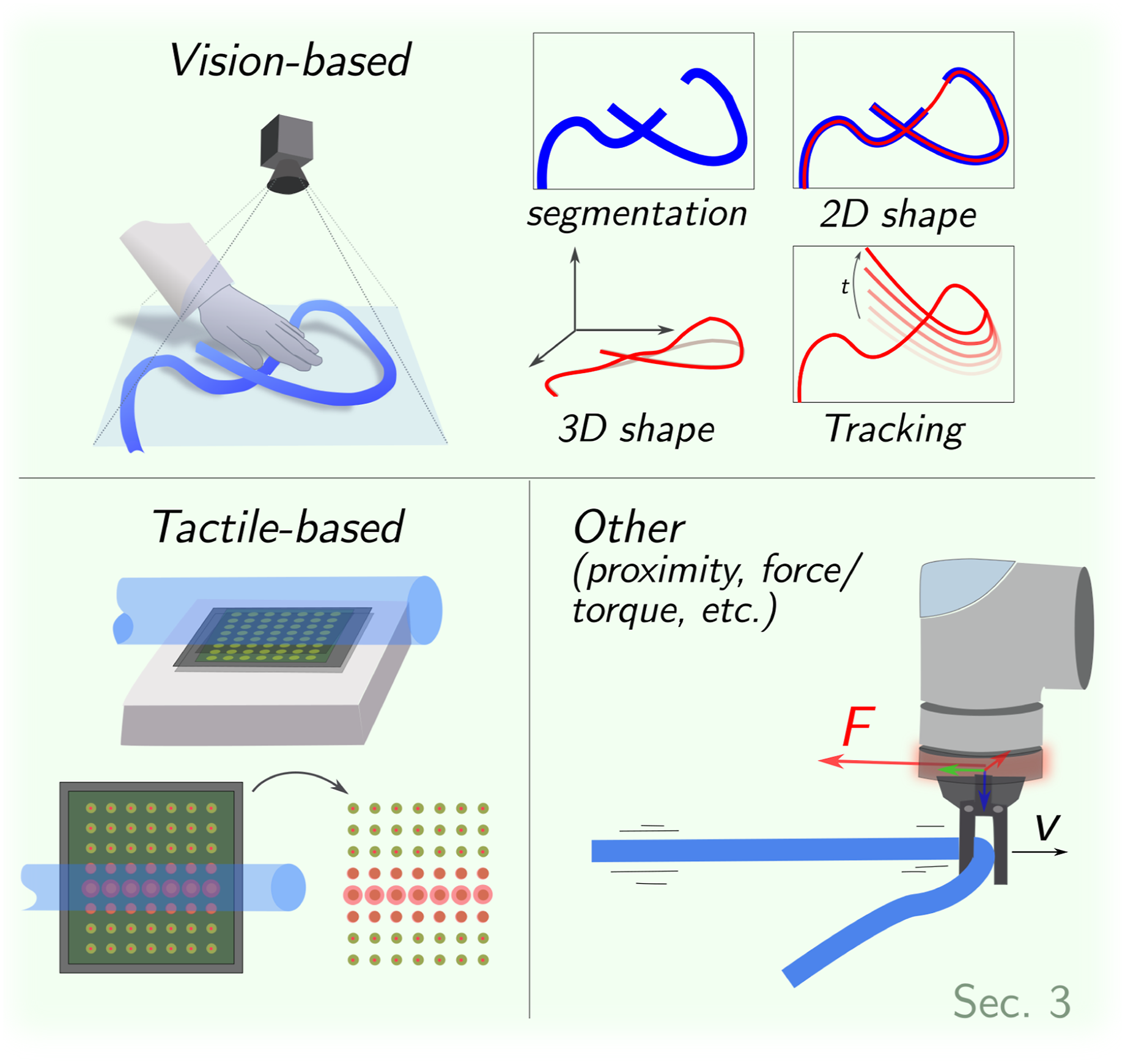
3.1. Vision-based perception
Vision-based perception is the most common sensing modality for DLOs, thanks to the availability of diverse sensors and cameras that integrate seamlessly with robotic platforms. The main perception tasks for DLOs include Data-driven Segmentation (Section 3.1.1), 2D Shape Estimation (Section 3.1.2), 3D Shape Estimation (Section 3.1.3), and Tracking (Section 3.1.4). Sections 3.1.5 and 3.1.6 offer a brief overview of vision-based perception methods specifically developed for DMLOs and suture threads. Finally, Section 3.1.7 presents vision-related Emerging Tasks.
3.1.1. Data-driven segmentation
Among various vision tasks, some provide limited utility for DLO manipulation. For instance, while object detection can generate bounding boxes around DLOs, these often fail to capture precise information about the DLO shape and configuration, details crucial for manipulation. In contrast, semantic segmentation, and particularly instance segmentation, delivers richer pixel-level information by accurately identifying DLO regions within an image, as illustrated in Figure 4. Example of semantic and instance segmentation tasks involving four DLOs in an industrial scenario.
Semantic segmentation involves classifying each pixel of an image with a unique class, for example, the DLO class or the background class. Instance segmentation further distinguishes individual DLO objects by assigning unique identifiers to each instance, allowing differentiation among multiple DLOs in the scene.
Traditional segmentation techniques, like color-based thresholding or background difference, rely on substantial assumptions about the scene, making them usually unsuitable as general solutions. Recently, deep learning approaches have demonstrated their viability in effectively solving some of the segmentation challenges related to DLOs, driving research toward data-driven segmentation of DLOs (Caporali et al., 2023c; Dai et al., 2022; Dirr et al., 2023; Huang et al., 2024; Jin et al., 2022; Song et al., 2019; Sun et al., 2024; Wu et al., 2022b; Zanella et al., 2021).
3.1.1.1. Dataset generation
The key issue in deep learning approaches increasingly revolves around the challenge of gathering and labeling large amounts of data for training purposes. Several works rely on manual annotation procedures to generate a training dataset, as seen in Wu et al. (2022b); Dai et al. (2022), Song et al. (2019), and Huang et al. (2024). However, the manual process is notoriously tedious, inaccurate, time-consuming, and not scalable. Furthermore, as visual perception tasks grow more complex (such as in DLO segmentation), the annotation effort becomes increasingly slow and challenging.
Some works have focused on investigating dataset-generation approaches that require minimal or, ideally, zero human intervention. In Jin et al. (2022), a self-supervised method is presented that collects training images by moving a camera mounted on a robot arm. Initial labels are generated using color thresholding on a high-contrast DLO, and a deep-learning segmentation network trained on augmented data is employed to enhance the estimator’s ability to generalize across varying cable colors and backgrounds.
A similar approach is investigated in Zanella et al. (2021), which proposes a two-phase data labeling method for semantic segmentation: first, foreground masks are created using color difference between the DLO and background; second, these masks are combined with synthetic backgrounds to form the training dataset. Initial images are collected with minimal human effort by moving the DLO against a uniform background, and the dataset is then augmented to improve generalization to new scenes.
Compared to Jin et al. (2022), the method in Zanella et al. (2021) enables generalization across the general DLO class and is not limited to specific scenes, due to the use of synthetic backgrounds. The main limitations of both Jin et al. (2022) and Zanella et al. (2021) are (1) susceptibility to incorrect labels due to color separation from video, which is sensitive to lighting and shadows, necessitating validation; and (2) the need for human intervention in data gathering, particularly for the movement and deformation of DLOs.
To reduce human involvement in dataset generation, alternative approaches advocate fully synthetic processes using rendering engines (e.g., Blender) to create photorealistic datasets (Caporali et al., 2023c; Dirr et al., 2023; Fresnillo et al., 2024). Synthetic images offer the added benefit of automatically generating accurate and error-free labels for both semantic and instance segmentation. Although labeling is eliminated, significant time is still required to set up and implement the synthetic scene generation pipeline. Additionally, the use of synthetic data raises concerns about the domain gap between simulated and real-world environments.
To mitigate the domain gap, Caporali et al. (2023c) propose a weakly supervised method that leverages keypoint annotations on real DLO images captured from multiple viewpoints. Then, a neural network refines the sparse keypoint-based annotations into dense segmentation labels. Although these methods effectively capture real-world details, they require multiple annotations to account for scene variability, limiting their scalability. Nevertheless, small-scale real datasets remain valuable when combined with synthetic data to reduce the domain gap (Caporali et al., 2023c).
3.1.1.2. Semantic segmentation
The semantic segmentation of DLOs is performed using off-the-shelf deep learning models based on convolutional neural networks (CNNs): UNet (Ronneberger et al., 2015) in Dai et al. (2022) and Jin et al. (2022); FCN (Long et al., 2015) in Wu et al. (2022b); and DeepLabV3+ (Chen et al., 2018) in Zanella et al. (2021), Dai et al. (2022), and Caporali et al. (2023c). A CNN-based encoder-decoder architecture is proposed in Huang et al. (2024) and Song et al. (2019).
Concerning real-world and synthetic datasets, both Dai et al. (2022) and Caporali et al. (2023c) evaluate their respective synthetic datasets against the electrical wires dataset (featuring real DLOs images but with synthetic backgrounds) released by Zanella et al. (2021). From the comparisons, synthetic images emerge as a viable alternative to real-world image labeling. Moreover, mixing synthetic images with real-world images is shown to improve segmentation performance compared to the synthetic-only case (Caporali et al., 2023c).
3.1.1.3. Instance segmentation
The pipelines introduced in Caporali et al. (2023c) and Dirr et al. (2023) enable instance-wise mask generation using fully synthetic approaches. When applied to instance segmentation models (e.g., YOLACT (Bolya et al., 2019) in Caporali et al. (2023c) and SOLOv2 (Wang et al., 2020) in Dirr et al. (2023)), performance is generally weaker than in semantic segmentation tasks, particularly in scenarios where different DLOs intersect. This underscores the need for further research into fully deep-learning-based instance segmentation methods tailored to DLOs, or the exploration of alternative strategies, as discussed in Section 3.1.2.
3.1.2. 2D shape estimation
Accurately estimating the shape of a DLO is crucial for effective manipulation. As a result, many vision-based algorithms have been developed to robustly extract the DLO’s state, typically represented as a sequence of keypoints that describe its shape and configuration. This section focuses on methods for 2D shape estimation, while 3D shape estimation techniques are covered separately in Section 3.1.3.
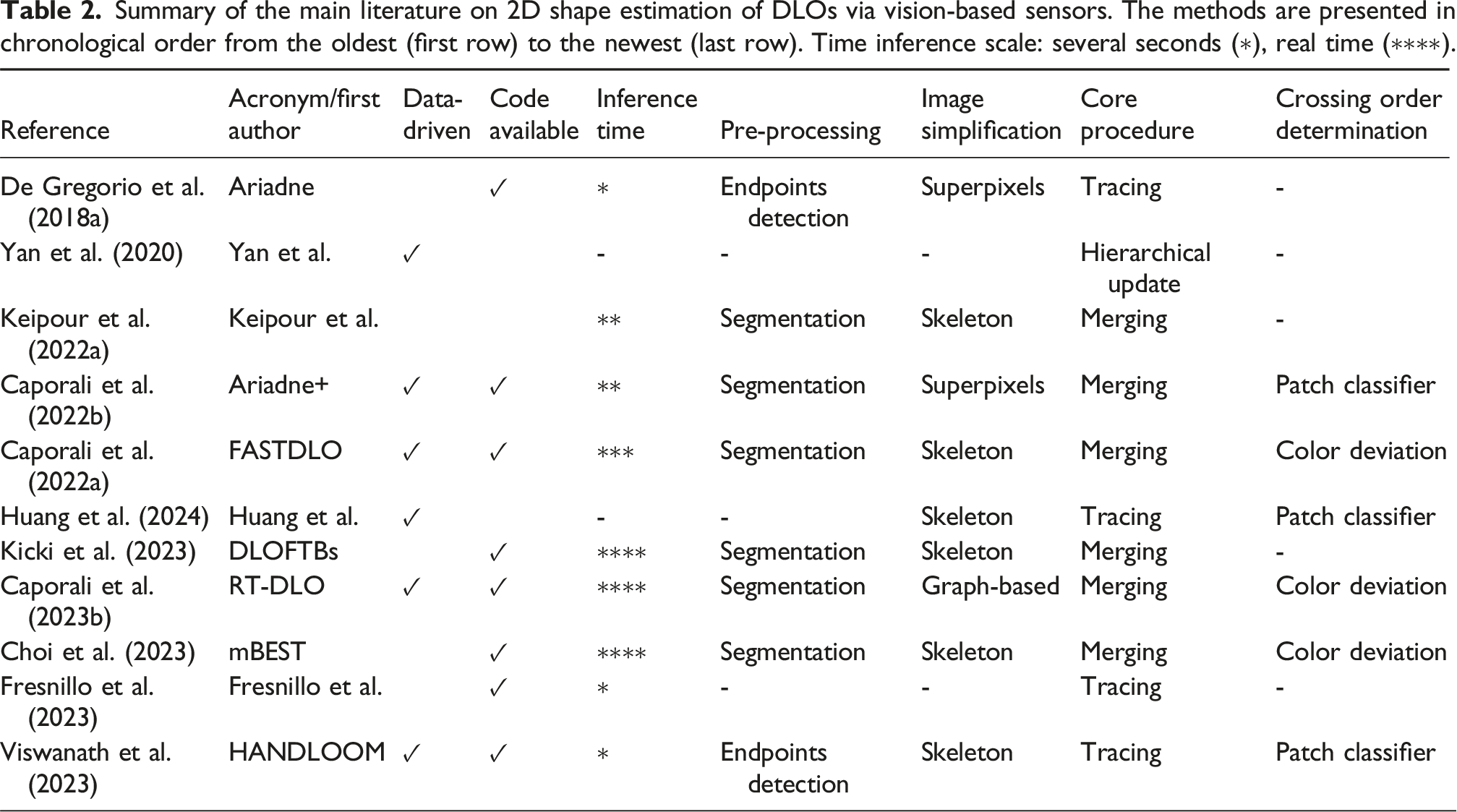
Summary of the main literature on 2D shape estimation of DLOs via vision-based sensors. The methods are presented in chronological order from the oldest (first row) to the newest (last row). Time inference scale: several seconds (∗), real time (∗∗∗∗).
3.1.2.1. Pre-processing
The majority of the approaches assume the utilization of a pre-processing step to generate a semantic segmentation mask of the scene. This mask is typically a binary image, where pixels corresponding to the DLO are labeled as 1, and background pixels as 0. This step is common across methods such as Caporali et al. (2022a,b, 2023b), where a semantic segmentation network is employed (see Section 3.1.1), color-based thresholding methods as in Choi et al. (2023) and Keipour et al. (2022a), or depth-thresholding approaches as in the case of the RGB-D camera in Kicki et al. (2023).
In contrast, some approaches necessitate initialization with endpoint locations. Specifically, endpoints are supplied by specific CNN-based object detection networks in De Gregorio et al. (2018a) and Viswanath et al. (2023). Similarly, external knowledge of the scene structure is harnessed in Fresnillo et al. (2023) to initialize the algorithm.
Alternatively, Huang et al. (2024) uses a dedicated segmentation network to extract a gradient map of the DLOs directly from RGB images, eliminating separate segmentation and endpoint detection steps. However, its generalizability beyond training-like scenarios needs careful assessment (see Section 3.1.1). Yan et al. (2020) avoid both segmentation and endpoint detection but relies heavily on strong contrast between the DLO and background in its self-supervised process.
3.1.2.2. Image simplification
The methods summarized in Table 2 propose various innovative solutions for DLO shape estimation, yet many approaches share common image processing strategies. A prevalent approach is to reduce image complexity using either superpixels or skeleton-based techniques. To highlight the differences between these two strategies, Figure 5 presents a side-by-side comparison of their application to the same input image. Superpixel and skeleton-based image simplification techniques. The first is applied directly to RGB images. The latter requires a binary mask.
Superpixel segmentation, as used in De Gregorio et al. (2018a) and Caporali et al. (2022b), groups pixels with similar properties into coherent regions. De Gregorio et al. (2018a) employ the SLIC algorithm (Achanta et al., 2012), while Caporali et al. (2022b) use MaskSLIC (Irving, 2016), which incorporates a binary mask to restrict focus to targeted areas within the image.
Skeletonization is an alternative approach consisting of a thinning procedure performed on a binary mask. It is a widely chosen method for mask-based simplification (Caporali et al., 2022a; Choi et al., 2023; Huang et al., 2024; Keipour et al., 2022a; Kicki et al., 2023; Viswanath et al., 2023). Its popularity is attributed to several key properties: (1) after the skeleton operation, both the connectivity and general topology of the DLOs are preserved; (2) since the segments are only 1 pixel wide, traversals along segments are not prone to path ambiguity; and (3) fast implementations are feasible. Among various algorithms, one of the most frequently used methods is Zhang and Suen (1984). Applied to a binary mask, the skeleton approach is quite sensitive to the mask quality.
Unlike superpixel- and skeleton-based methods, Caporali et al. (2023b) use a graph-based representation where nodes are generated by dilating the distance transform (Borgefors, 1986) and applying farthest point sampling (Qi et al., 2017), improving robustness to poor masks. Methods like Yan et al. (2020) and Fresnillo et al. (2023) bypass any form of image simplification and instead process raw images directly.
3.1.2.3. Main procedure
Among the examined algorithms of Table 2, two core processes consistently appear: tracing and merging. For clarity, these processes are illustrated in Figure 6. Illustration of DLO shape estimation procedures based on tracing and merging approaches. In tracing, the DLO curve is expanded incrementally by adding small, locally guided segments one at a time. In contrast, merging combines larger, pre-estimated segment hypotheses into longer, coherent curves based on similarity scores or geometric compatibility.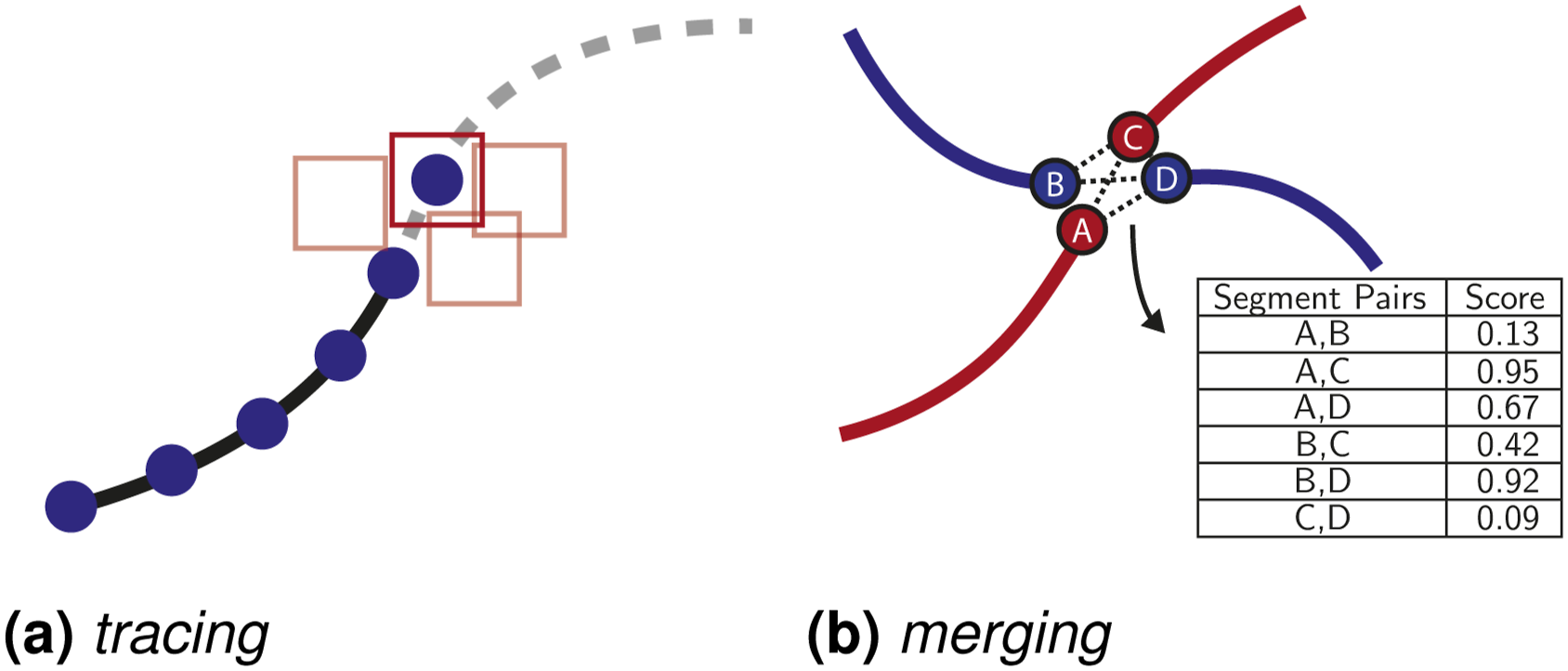
The tracing process iteratively extends the existing path of a DLO by adding new segments, building upon previously traced portions. In contrast, merging algorithms combine smaller, independent segment estimates into a unified detection. Although similar in goal, the key difference lies in scale and dependency: tracing operates locally and sequentially, while merging handles fewer, independent operations that can be performed in any order, often in parallel. This flexibility offers notable advantages in reducing inference time.
Several algorithms leverage forms of tracing to extract paths (De Gregorio et al., 2018a; Fresnillo et al., 2023; Huang et al., 2024; Viswanath et al., 2023). For example, De Gregorio et al. (2018a) generate candidate paths by tracing through superpixels from endpoints, selecting paths based on color, curvature, and distance. Fresnillo et al. (2023) trace in both forward and backward directions for increased robustness. Huang et al. (2024) use a skeleton map to trace between endpoints, while Viswanath et al. (2023) introduce a data-driven approach, using a UNet-based trace predictor to produce probability heatmaps that guide the tracing process.
Merging-based algorithms use cost functions to evaluate and merge candidate segment pairs (Choi et al., 2023; Kicki et al., 2023; Keipour et al., 2022a; Caporali et al., 2022a, 2022b, 2023b). Across these approaches, the choice of metric varies substantially. A data-driven metric in Caporali et al. (2022b) employs a CNN to assess superpixel similarity, whereas Caporali et al. (2022a) use a similarity network to compare sampled feature vectors. In contrast, analytical metrics such as curvature, distance, and shape smoothness are adopted in Choi et al. (2023), Keipour et al. (2022a), and Caporali et al. (2023b), with Choi et al. (2023) introducing a merging criterion based on bending energy.
In practice, merging is often performed over an intermediate structural representation of the object. A common implementation relies on a skeleton map, as initial segments can be formed by linking skeleton pixels with two neighbors, then resolving intersections via merging. This approach is employed by Keipour et al. (2022a), Choi et al. (2023), and Caporali et al. (2022a). In Caporali et al. (2022b), superpixels replace the skeleton map but apply a similar merging strategy exploiting the segmentation masks. In Caporali et al. (2023b), the sparsity of nodes prevents standard merging, so each node is merged individually with its neighbors. Unlike tracing, this merging is performed concurrently across all nodes, based on both their similarity and spatial proximity.
Unlike merging and tracing methods, Yan et al. (2020) use a neural network to hierarchically update DLO segment endpoints and predict new center points, progressively increasing the granularity of the shape representation.
3.1.2.4. Crossing order determination
In cases of crossings or intersections, for example, whether between different DLOs or loops of the same DLO, determining which segment lies on top is essential for manipulation tasks, such as deciding which DLO to move (see Section 5.4). The two common strategies for this, illustrated in Figure 7, are data-driven patch classifier methods and analytical color deviation techniques. Illustration of two strategies for determining the crossing order of DLOs: (a) data-driven patch classifier, which predicts the top segment from a cropped image region; (b) color deviation method, which infers the top segment by comparing color variability along the intersecting paths.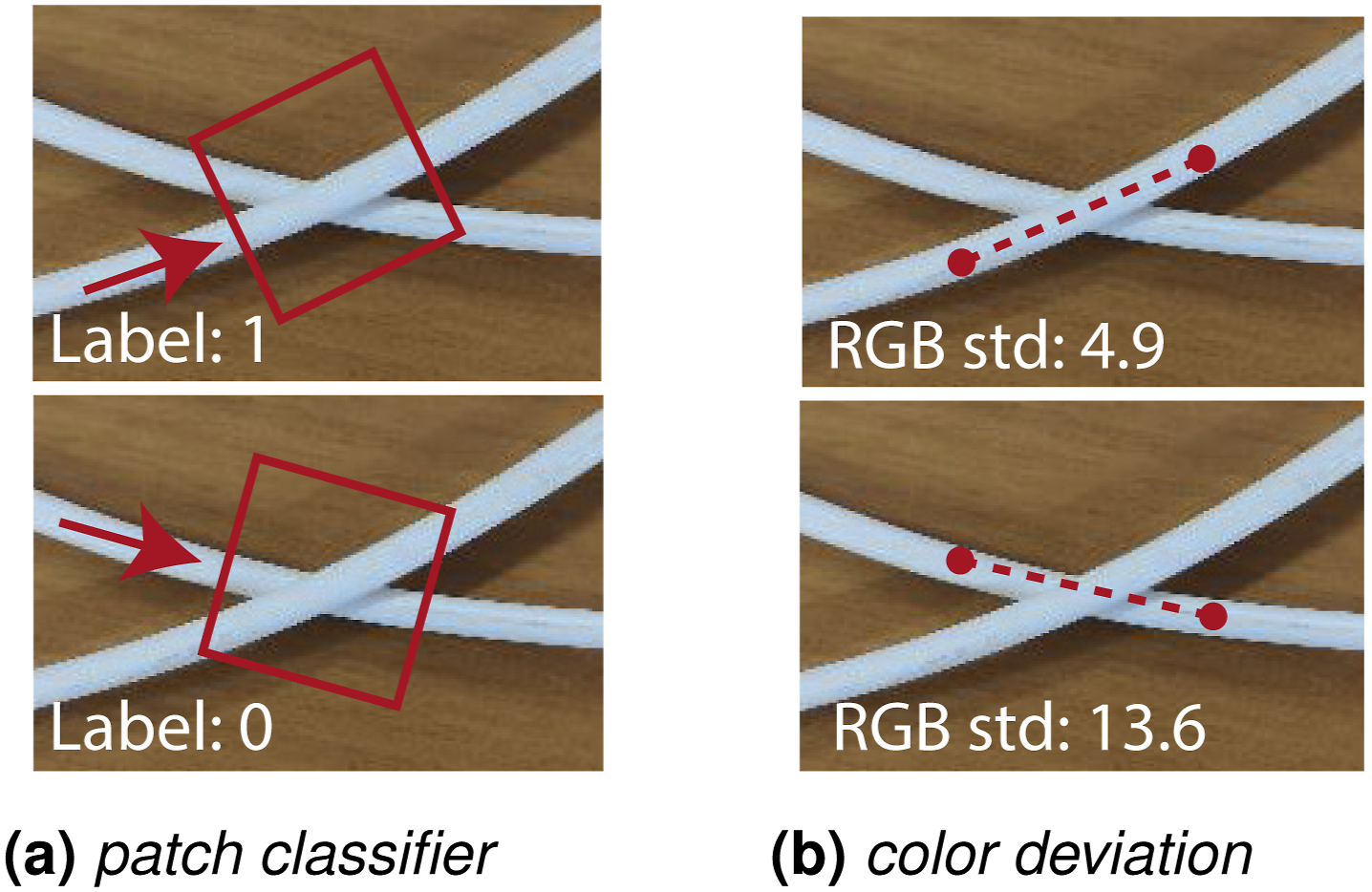
CNN classifiers based on ResNet architectures analyze masked image crops centered on the crossing region to predict which segment lies on top (Caporali et al., 2022b; Viswanath et al., 2023). To enhance robustness and ensure rotation invariance, the crops are often rotated or oriented so that the DLO segments are aligned consistently before classification (Huang et al., 2024).
Alternatively, analytical methods determine order by comparing the color variability along each path near the crossing, selecting the segment with lower RGB channel variance as the top (Caporali et al., 2022a; 2023b). This approach is further refined by using blurred images to reduce glare effects (Choi et al., 2023).
3.1.3. 3D shape estimation
While estimating the 2D shape of a DLO (see Section 3.1.2) provides valuable information, it is often insufficient for effective grasping and manipulation. The ultimate objective is to recover the DLO’s configuration in 3D space. However, direct 3D shape estimation remains less explored than its 2D counterpart. Indeed, a common strategy involves first estimating the 2D shape and subsequently projecting it into Cartesian space using depth information (Kicki et al., 2023; Sun et al., 2024).
One reason for the limited number of 3D shape estimation methods is the challenge posed by current sensing technologies. As highlighted in a benchmark of 3D camera systems for DLO perception (Cop et al., 2021), only high-end depth sensors can reliably capture the shape of thin, cylindrical objects like DLOs. These high-performance cameras tend to be bulky—making them difficult to mount on robot end-effectors—and their cost restricts widespread use in research settings. In contrast, popular robotic cameras such as the Kinect Azure and Intel RealSense often struggle to detect DLOs with diameters under 1 cm.
To mitigate the impact of depth sensor noise, Sun et al. (2024) incorporate a smoothness prior using a discrete elastic rod model (see Section 2). Reliable 3D detection of DLOs is also explored in Caporali et al. (2023a), which leverages a multi-view stereo approach using a single 2D camera in combination with 2D shape detection algorithms (see Section 3.1.2). This method proves effective for reconstructing the 3D shape of DLOs for grasping and manipulation tasks. However, achieving accurate results requires detecting multiple, closely spaced DLO segments, making the process time-consuming. Additionally, the approach is limited to static scenes, restricting its use in dynamic environments.
3.1.4. Tracking
DLOs are theoretically characterized by an infinite number of degrees of freedom, which makes tracking challenging, particularly under real-time constraints. In practice, they are discretized into a finite set of key nodes (as described in Section 2), and tracking (in its basic form) reduces to estimating the positions of these nodes over time while handling potential occlusions (as in Figure 8). These occlusions may result from self-occlusion within the DLO or from external factors, such as interactions with a robotic manipulator. Example of DLO tracking during manipulation. The DLO key nodes are tracked despite partial visibility and environment interactions.
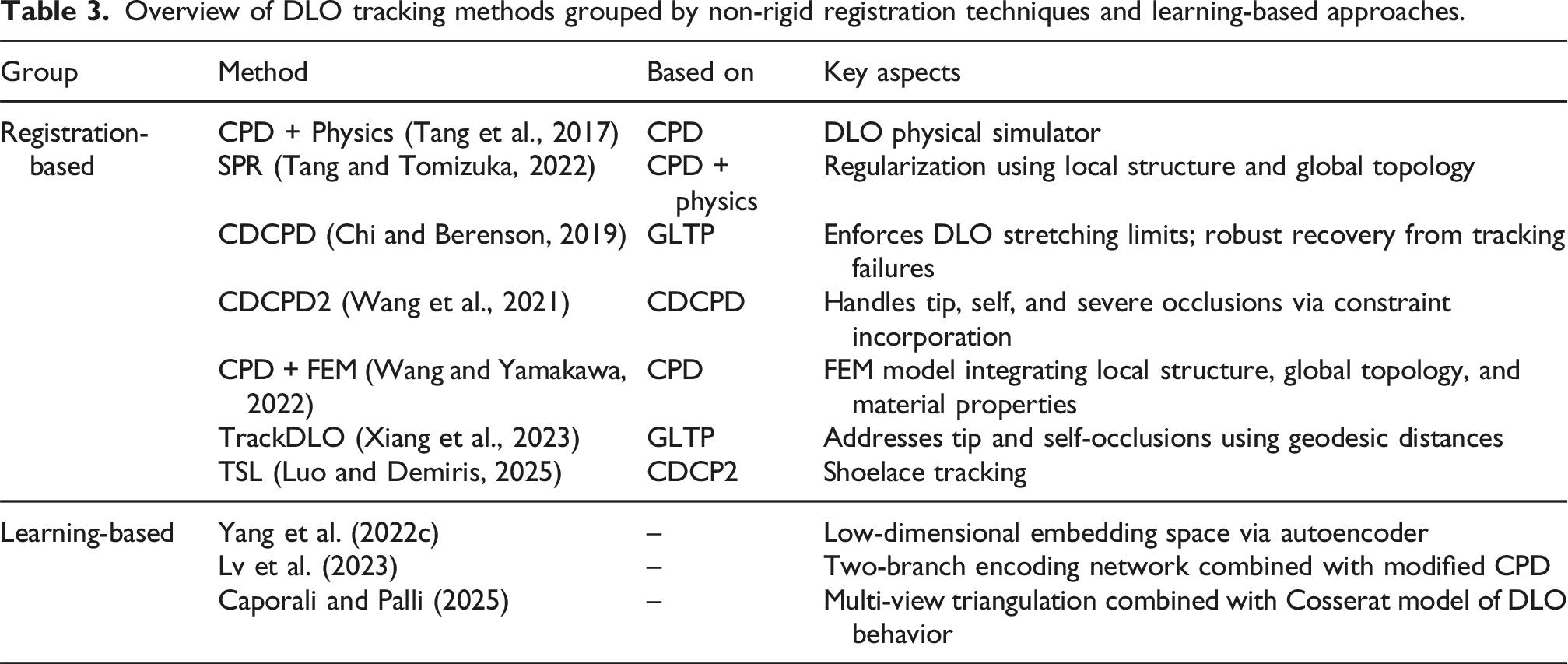
Overview of DLO tracking methods grouped by non-rigid registration techniques and learning-based approaches.
3.1.4.1. Registration-based methods
A widely adopted approach to DLO tracking formulates the task as a point-set registration problem, leveraging algorithms such as CPD and GLTP. In CPD, registration is framed as a probability density estimation problem, where one point set—the Gaussian mixture model (GMM) centroids, typically represents the estimated positions of key nodes along the DLO, and the other set consists of observed data points from the current camera frame. A key feature of CPD is the enforcement of coherent motion among the GMM centroids, ensuring smooth and physically plausible deformations (Yuille and Grzywacz, 1989). GLTP extends CPD by introducing a local regularization term based on locally linear embedding (Roweis and Saul, 2000), complementing CPD’s global regularization.
While CPD and GLTP are effective for non-rigid registration, they do not inherently incorporate physical constraints or domain knowledge specific to deformable objects. To address this limitation, several DLO tracking approaches have extended these algorithms by integrating physics-based simulators or introducing regularization techniques tailored to DLO behavior. As summarized in Table 3, each registration-based approach enhances the core registration pipeline with DLO-specific constraints or priors to improve tracking accuracy and robustness. A common direction involves embedding physical knowledge, either through a physics simulator (Luo and Demiris, 2025; Tang et al., 2017; Tang and Tomizuka, 2022) or an analytical model from Section 2 (Wang and Yamakawa, 2022). Alternatively, constraints based on stretching limits (Chi and Berenson, 2019) or geometric/topological properties (Wang et al., 2021; Xiang et al., 2023) are employed to improve robustness and accuracy.
3.1.4.2. Learning-based methods
Recent work in DLO tracking has explored data-driven approaches (Caporali and Palli, 2025; Lv et al., 2023; Yang et al., 2022c), as shown at the bottom of Table 3. These methods aim to overcome challenges such as high dimensionality, occlusions, or the need for explicit physical modeling.
In Yang et al. (2022c), an autoencoder is used to learn a low-dimensional embedding of DLO states, enabling efficient tracking via particle filtering in the latent space. This approach captures physically plausible behaviors directly from data, without requiring a physical simulator or regularization during deployment. Lv et al. (2023) employ a PointNet++ encoder to extract features from input point clouds, followed by a two-branch fusion strategy: a regression branch that models global DLO topology, and a voting branch that estimates local geometric offsets. Thus, a modified CPD algorithm fuses both branches.
A key advantage of these learning-based methods is their independence from initial DLO state estimates, simulators, or hand-crafted constraints at inference time. Instead, they encode physical priors during training. For instance, Yang et al. (2022c) use synthetic data matching specific DLO properties, though performance may degrade when real-world behavior deviates from the training distribution. In contrast, Lv et al. (2023) apply domain randomization to improve generalization to real-world scenarios.
Tracking methods often require high-quality depth or point cloud data, difficult to obtain given the small size of DLOs (Cop et al., 2021), and depend on pre-segmented inputs, which are challenging to acquire outside controlled settings. To address these issues, Caporali and Palli (2025) propose using multiple 2D images for segmentation in cluttered scenes (see Sections 3.1.2 and 3.1.3) combined with a learned physics-based DLO model to handle occlusions, enabling estimation and tracking of the 3D DLO shape during manipulation. However, this approach depends on knowledge of the robot’s actions and has limited use of tracking history.
3.1.5. Vision-based perception of suture threads
A notable subclass of DLOs is represented by suture threads, which are extensively studied in the field of surgical robotics. These threads are typically inextensible, have very small diameters, and are often connected to a curved metal needle. Suture threads pose unique challenges for vision-based perception due to their extremely thin structure. Indeed, in typical surgical imaging setups, the thread amounts to roughly 0.25% of the total image width (Joglekar et al., 2023). This makes them significantly more difficult to detect and track than larger deformable objects such as ropes or cables. An overview of perception methods for suture threads is provided here, while a broader discussion on robotic suturing for manipulation tasks is presented in Section 5.5.
Various methods have been proposed for reconstructing thread geometry from visual input, including stereo-based curve fitting using non-uniform rational B-splines (Jackson et al., 2018; Schorp et al., 2023), shortest path computations between thread endpoints (Lu et al., 2020, 2022), and minimum variation splines (Joglekar et al., 2023). These methods typically incorporate prior knowledge of thread continuity and curvature to compensate for weak visual cues. Many treat the problem as a curve-fitting task (Jackson et al., 2018; Schorp et al., 2023). Some connections with the methods discusses in Section 3.1.2 are also present, for example, the cost-based path growth in Jackson et al. (2018) closely resembles the tracing approach.
Learning-based techniques have also been introduced to enhance suture perception. Lu et al. (2020) apply transfer learning to improve generalization, while Lu et al. (2022) propose a semi-supervised segmentation approach to improve thread detection with limited labeled data.
Some systems require manual initialization, such as seeding a starting point (Jackson et al., 2018; Lu et al., 2022). In contrast, more recent methods achieve fully automatic suture reconstruction without user input (Joglekar et al., 2023). Both Joglekar et al. (2023) and Lu et al. (2022) also address a critical challenge in stereo-based perception of false correspondences across stereo image pairs, especially due to the thread being tangent to the epipolar line (Joglekar et al., 2023).
A key challenge in suture thread perception is the lack of standardized benchmarks and public datasets (see Section 6.2), which are especially essential in data-scarce clinical settings where real-world samples are limited (Joglekar et al., 2023).
3.1.6. Vision-based perception of DMLOs
As a subclass of DLOs, DMLOs share many of the same properties but are uniquely characterized by the presence of branch points, where two or more linear components converge (Caporali et al., 2025). Extending DLOs vision-based perception methods to DMLOs introduces additional challenges, primarily due to the complexity of bifurcations. Moreover, the integration of rigid elements such as plugs, clips, and connectors further complicates the visual processing and interpretation of these structures.
Most research on DMLOs centers on automotive wiring harnesses, highlighting the need for advanced automation. Nguyen and Franke (2021) use data-driven segmentation methods (see Section 3.1.1) for optical inspection, though with limited manually annotated data. In follow-up work (Nguyen et al., 2022), synthetic data from CAD models is introduced, demonstrating its effectiveness and benefits over limited real data. In Kicki et al. (2021), DMLO branch classification is explored using a manually annotated, small-scale dataset, with data augmentation applied to counter limited data availability.
Several works represent DMLOs as graphs generated around branch points (Zürn et al., 2022, 2023b, 2023a). For instance, Zürn et al. (2023b) estimate correspondences between a known (CAD-based) directed topology and an image-derived undirected graph. Zürn et al. (2022) introduce a DMLO tracking method using rigid and non-rigid registration but assumes non-overlapping configurations. Zürn et al. (2023a) address branch point detection with a data-driven method and semi-manual annotation, though its evaluation is limited to a single user and DMLO type.
Caporali et al. (2025) present a learning-based graph method for representing DMLO topology using graph neural networks trained on synthetic data. The method’s effectiveness is demonstrated in a dual-arm disentangling task (see Section 5.4). However, since it relies solely on the segmented mask of the scene, it remains vulnerable to significant errors caused by mask inaccuracies.
Despite significant progress in DMLO perception, future research should focus on developing systems that are not only accurate but also adaptable, scalable, and robust to the inherent variability of real-world environments, as discussed in Section 6.2.
3.1.7. Emerging vision-related tasks
Recent advances in computer vision have enabled the exploration of novel tasks in the context of DLO perception.
3.1.7.1. Multi-modal segmentation
Few works have explored multi-modal approaches for DLO segmentation. The segment anything model (SAM) (Kirillov et al., 2023) has been applied in zero-shot settings. For example, Sun et al. (2024) prompt SAM using generic keywords such as “ropes” or “cables,” but require several post-processing steps to achieve satisfactory segmentation masks. Caporali et al. (2024a) leverage both visual and textual modalities to segment only the target DLO. It introduces two main improvements over prior works: (1) task-specific prompts for accurate target-object segmentation, and (2) a lightweight, real-time capable architecture, unlike the larger foundation models.
3.1.7.2. Interactive segmentation
It is the process of leveraging forceful physical interactions with objects to enhance and inform the perception process (Bohg et al., 2017; Weng et al., 2024). Holešovskỳ et al. (2024) propose an optical flow-based approach for segmenting moving DLOs, inspired by how humans use motion—specifically poking—to distinguish and separate tangled cables. They also introduce an automatically annotated dataset with instance and motion ground truth. Due to reliance on flow magnitude thresholding, the method may merge multiple moving cables. To address this, Holešovskỳ et al. (2025) incorporate motion correlation and interactive grasping strategies to improve accuracy. The approach is evaluated on small motions and thick DLOs, given vision limitations in more complex scenarios (see Section 3.1.3).
3.2. Tactile-based perception
Vision-based perception can be challenging in tight spaces and with occlusions. Moreover, when the robot is actively manipulating the object, having additional information on the grasp itself becomes crucial. Tactile sensors represent a valuable alternative to overcome the limitations of vision-based perception of DLOs. Concerning DLOs’ touch perception, three types of tactile sensor technologies are usually employed: photoreflector-based (Cirillo et al., 2021b; Palli and Pirozzi, 2019; Pirozzi and Natale, 2018; Zanella et al., 2019), camera-based (She et al., 2021; Wilson et al., 2023), and capacitive (Monguzzi et al., 2023; 2024a).
Photoreflector tactile sensors are employed in Pirozzi and Natale (2018) and Palli and Pirozzi (2019) for automatic wiring tasks. Assuming a known DLO diameter, the tip of a grasped DLO is estimated by modeling the grasped section with a quadratic function and the external section with a linear segment. In contrast, Cirillo et al. (2021b) propose a data-driven method to estimate the DLO diameter, leveraging both tactile measurements and gripper closure levels to classify diameters and generalize across varying grasp levels. Additionally, tactile sensing is also applied to estimate external forces acting on the grasped DLO through a data-driven approach based on RNNs (Zanella et al., 2019).
Camera-based tactile sensors allow for the estimation of pose and friction force (She et al., 2021; Wilson et al., 2023). Pose estimation is achieved through processing the depth image and applying principal component analysis (PCA). The friction force is determined by computing the marker flow on the tactile surface, with the estimated displacement assumed to be proportional to the friction force. Additionally, She et al. (2021) introduce grasp quality, assessed by evaluating the area of the tactile imprint in relation to a predefined threshold boundary.
Capacitive tactile sensors are employed in Monguzzi et al. (2023, 2024a), where capacitance measurements are exploited to estimate DLO diameter and alignment.
Both photoreflector and capacitive-based tactile sensors provide low-resolution output (usually a 4 × 4 or 5 × 5 map), unlike high-resolution camera-based sensors that generate depth-image-like outputs (see Figure 9). However, photoreflector and capacitive sensors are generally more compact and slim, making them better suited for use in confined or tight spaces where larger camera-based sensors may not fit. Photoreflector-based and camera-based tactile sensors. Images courtesy of (a) Palli and Pirozzi (2019) and (b) Wilson et al. (2023).
Several works combine vision and tactile sensing to overcome their individual limitations in DLO manipulation. De Gregorio et al. (2018b) employ vision for tip detection and tactile sensors to assess grasp quality. In Pecyna et al. (2022), vision and tactile data are integrated within a manipulation framework, highlighting the importance of fusing both sensing modalities.
3.3. Proximity and force/torque sensing
This section discusses two relatively underexplored sensory modalities for robotic perception of DLOs: proximity sensing and force/torque sensing.
3.3.1. Proximity sensing
Leveraging recent advancements in time-of-flight sensors, Cirillo et al. (2021a) present a proximity sensor enabling pre-touch sensing to improve depth accuracy in thin DLO perception and proposes a 3D scanning method to reconstruct DLO shapes as point clouds for grasping. However, this approach faces three main limitations: it is restricted to uncluttered environments where DLOs are well separated; it requires the sensor to be positioned very close to the object (necessitating an initial rough estimate of the DLO’s location); and it suffers from low reconstruction speed.
3.3.2. Force/torque sensing
For purely elastic DLOs, each equilibrium configuration of a Kirchhoff elastic rod corresponds to a unique point in a subset of
Initially introduced in Mishani and Sintov (2021), the framework assumes a quasi-static DLO in a straight, undeformed configuration with high stiffness and inextensibility. Leveraging the mapping between F/T measurements and DLO configurations derived from Bretl and McCarthy (2014), a neural network is trained to predict the shape from sensor data. However, this method requires prior estimation of the DLO’s mechanical properties and exhibits reduced accuracy when the underlying assumptions are violated. To address these challenges, Mishani and Sintov (2023) propose an enhanced approach using an autoencoder neural network that directly maps F/T sensor readings to DLO shapes, significantly improving both estimation accuracy and computational efficiency. A key limitation remains the necessity to retrain the model for each new DLO.
4. Estimation, control, and planning for DLO manipulation
This section covers three core components of DLO manipulation: Estimation (Section 4.1), Control (Section 4.2), and Planning (Section 4.3). An overview of their roles and interconnections is illustrated in Figure 10. Overview of a representative DLO manipulation pipeline, highlighting the core components studied in this section: estimation, which infers physical properties or local models from data; control, which regulates the DLO’s state during interaction using feedback; and planning, which generates action sequences or desired DLO configurations to achieve task-level goals.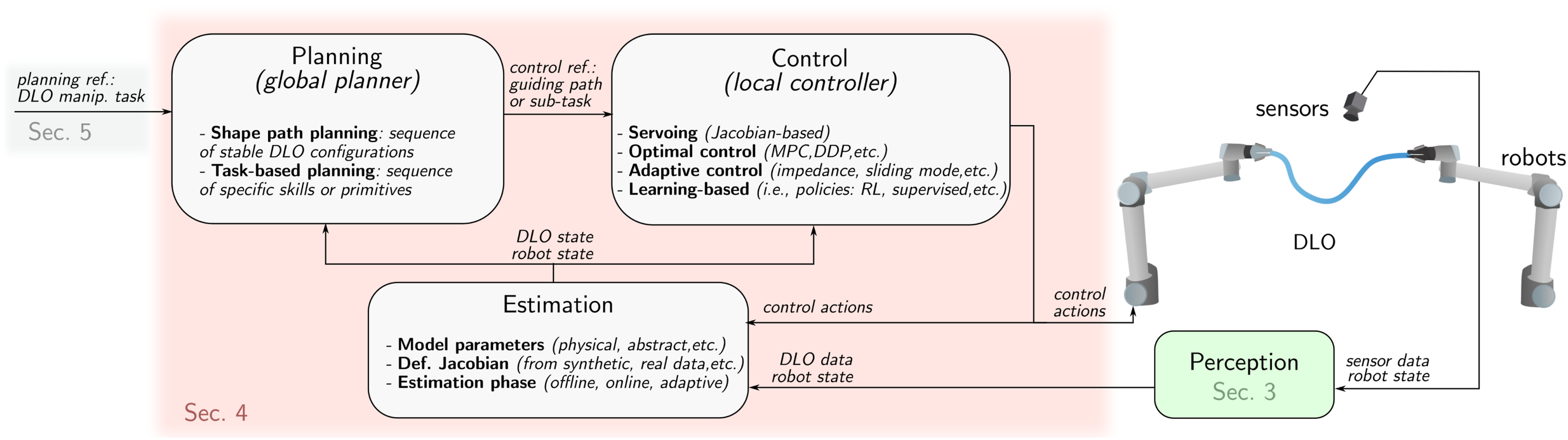
4.1. DLO state and model estimation techniques
In DLO manipulation, estimation refers to the process of identifying physical or kinematic models, such as deformation Jacobians or material parameters, that capture the behavior of deformable objects. Reliable estimation improves the fidelity of DLO models for planning and control, and is critical for narrowing the gap between simulation and reality.
Discrepancies between simulated and real-world DLO behavior often result from idealized assumptions in physical modeling, such as neglecting dynamic effects, contact interactions, or non-homogeneous material properties. These omissions lead to inaccurate predictions even when using high-resolution or computationally expensive models.
To improve alignment with real-world behavior, two estimation approaches are commonly used. The first involves identifying unknown physical parameters—such as stiffness, damping, or friction—to calibrate analytical models (Section 2). The second constructs local approximations of DLO behavior directly from data, for instance by estimating deformation Jacobians that map manipulator motions to object deformations.
Estimation strategies can be implemented offline, based on data obtained before the manipulation process; online, by continuously updating model estimates during task execution; or through adaptive schemes that selectively refine offline estimates based on observed discrepancies.
4.1.1. Model parameters
The models, described in Section 2, utilize several parameters to characterize the behavior of DLOs. These parameters may have a direct physical interpretation, such as length, mass, or bending stiffness, or they may serve primarily to adjust the model’s response under varying conditions, even if they are not directly measurable or lack an intuitive physical interpretation.
Certain parameters, such as length or mass, can be measured non-invasively and with relative ease. In contrast, material properties like Young’s modulus or damping coefficients require specialized and more invasive tests that are often impractical in robotic setups. Even with accurate identification, model approximations and measurement noise limit the prediction and simulation-to-reality fidelity of DLO behavior (Hermansson et al., 2016).
To improve model accuracy, a common strategy is to optimize model parameters to minimize the discrepancy between simulated deformations and reference shapes observed in the real world. Various optimization techniques have been explored for this purpose. Heuristic and gradient-free methods are commonly used, such as heuristic search (Lv et al., 2022; Tong et al., 2024), the cross-entropy method (Yan et al., 2020), evolution strategies (Lim et al., 2022; Yang et al., 2022a; Zhang et al., 2024a), particle swarm optimization (Yu et al., 2025), and Bayesian optimization (Zhang et al., 2024a). In contrast, gradient-based approaches are used in works that exploit differentiable models or simulation environments (Caporali et al., 2024b; Liu et al., 2023).
Beyond parameter tuning, recent studies also emphasize the importance of action and trajectory design in the estimation process. For instance, Yu et al. (2025) proposed a specific trajectory in which the DLO shape is affected by twisting and gravity effects, enabling more accurate identification. Similarly, Zhang et al. (2024a) introduce action sequences aimed at maximizing the object’s displacement.
4.1.2. Deformation Jacobian estimation
As an alternative to the pre-computed models of Section 2, a widely adopted strategy is to estimate a local deformation model, often referred to as the deformation Jacobian. This model captures the relationship between local changes in actuation and changes in the DLOs state.
The deformation Jacobian can be derived either from simulation data, or through real-world interactions (Artinian et al., 2024; Navarro-Alarcon et al., 2013). In some cases, analytical expressions of the deformation Jacobian are available for specific formulations, such as the ARAP model (Shetab-Bushehri et al., 2023). While some methods estimate the deformation Jacobian purely from data, others assume a predefined structure on the matrix and estimate parameters within that structure. For example, Berenson (2013) and Wang et al. (2015) assume that the robot’s influence on the object decays exponentially with the distance between the end-effector and the manipulated point, and focus on estimating the decay rate.
In contrast to pre-computed models, deformation Jacobians are typically valid only within a narrow range of configurations. As such, they are most effective for local, small-scale deformation tasks and are not suited for long-horizon predictions or transfer to different tasks (Yu et al., 2022). Despite this limitation, deformation Jacobian models are attractive due to their ability to capture object-specific behavior without requiring accurate physical modeling.
4.1.3. Modes of estimation: Offline, online, and adaptive
In many works, model parameter estimation is computationally intensive and typically performed offline, either before task execution (Lv et al., 2022; Zhang et al., 2024a) or during the generation of training datasets for learning-based methods (Yan et al., 2020; Yang et al., 2022a). An alternative is the method proposed in Caporali et al. (2024b), which performs online parameter estimation in parallel with task execution.
Similarly, deformation Jacobians can be estimated either offline or online. Online estimation strategies include incremental updates using the Broyden update rule (Navarro-Alarcon et al., 2013) or adaptive updates schemes such as those in Qi et al. (2021).
Beyond traditional estimation, several learning-based approaches address the sim-to-real gap through online adaptation. For instance, in Yu et al. (2022, 2025), a globally learned deformation Jacobian serves as a coarse approximation, which is then refined online via gradient-based updates using a sliding window of recent observations. Similarly, Wang et al. (2022) introduce a hybrid approach where an offline model is augmented with a local linear residual correction, computed online to enhance prediction accuracy. When source (e.g., simulation) and target (e.g., real-world) environments differ in specific regions, Mitrano et al. (2023) introduce a method that dynamically reweights dataset samples based on a learned similarity metric, enabling “targeted” model adaptation.
Assessing the reliability of a model and determining whether adaptation is required is another critical aspect of minimizing the sim-to-real gap. To this end, Mitrano et al. (2021) propose a learned classifier that predicts the reliability of a trained dynamics model. However, reliability assessment, fault detection, and recovery remain underexplored, as discussed in Section 6.2.
4.2. Control methods for DLO manipulation
In the context of DLO manipulation, control refers to the use of feedback information to regulate the object’s state during interaction. Control is critical for DLOs due to the difficulty of accurately modeling their highly nonlinear and typically underactuated behavior. It also becomes highly relevant to compensate for uncertainty and external disturbances during manipulation.
The aspects typically subject to control include the DLO’s shape, the position of relevant feature points, or the regulation of contact forces. This section provides an overview of the most commonly employed control strategies in DLO manipulation. These control strategies will be framed within the task-oriented classification of methods in Section 5.
4.2.1. Servoing
This control paradigm uses the deformation Jacobian matrix (or interaction matrix, using servoing terminology) to relate control inputs directly to changes in the DLO state:
In the Jacobian-based control context, the DLO state
A conventional feedback control law is given by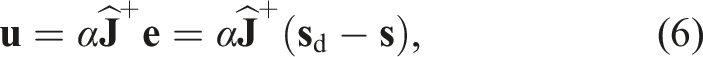
Since DLOs are typically underactuated (N ≫ M),
4.2.2. Optimal control
It formulates the DLO manipulation task as a trajectory optimization problem, aiming to regulate the shape or the position of key features over a finite horizon while minimizing a predefined cost. This cost typically balances control effort with task-related objectives and may also penalize internal stress (Aghajanzadeh et al., 2022c). Besides methods with quasi-static models (Aghajanzadeh et al., 2022c; Azad et al., 2023), second-order (dynamic) models have been employed in trajectory optimization methods, including Newton solvers and differential dynamic programming (DDP), both of which have been compared for optimal trajectory generation in Zimmermann et al. (2021).
Model predictive control (MPC) has gained popularity in the context of DLO manipulation, particularly when paired with learned dynamics models. For example, Wang et al. (2022) incorporate an offline-trained model into the MPC formulation as a constraint within a trust region. Similarly, Yang et al. (2022b) integrate online model learning with MPC, enabling continuous adaptation and model refinement during execution. Other MPC-based variants include Ma et al. (2022), where a graph-based MPC framework applied to a sparse set of learned keypoints is proposed, and Yu et al. (2023a), which introduces a single-step MPC controller used as a local feedback module within a broader planning framework. Serving as a tracker for the planning strategy in Yu et al. (2025), MPC control is employed along with an adaptive Jacobian model, allowing for collision avoidance and over-stretch constraints. As per approaches employing nonlinear MPC, Shen et al. (2025) apply proper orthogonal decomposition (POD) to reduce the dimension of a PDE–ODE model for a quadrotor with a hanging cable, enabling position and shape tracking.
4.2.3. Adaptive control
In this paradigm, the aim is to adjust controller parameters online to account for model uncertainty or variability in the object’s properties. In Qi et al. (2023), an adaptive controller is proposed for shape regulation based on B-spline and NURBS representations, allowing the system to account for dynamic changes in the DLO geometry. Chen et al. (2023) develop an adaptive impedance controller for clip fixing tasks, enabling stable interaction under varying contact conditions. In Aghajanzadeh et al. (2022a), the authors present an adaptive feature-space controller with formal Lyapunov stability guarantees, allowing feedback regulation of keypoints even under uncertain or time-varying dynamics. Another adaptive strategy is presented in Qi et al. (2021), which exploits sliding mode control with two variants, a linear and a finite-time method, with an online-updated adaptive term.
4.2.4. Learning-based control
These strategies are typically formulated in terms of a policy, a learned function or model that generates control signals to achieve a desired goal or to maximize a reward function within a given environment. These approaches are most commonly applied to action selection problems (Nair et al., 2017; Wang et al., 2019). The objective is to learn an action policy that, given current and goal observations of the system, produces actions that guide the system from its initial state toward the target state.
The observations (i.e., inputs) often come from raw sensory inputs like images (Nair et al., 2017; Wang et al., 2019), though more compact representations, such as DLO states, are also used (Zanella and Palli, 2021).
The output of the policy can take various forms depending on the control task. For instance, the predicted action may be a target position in Cartesian or image space (Nair et al., 2017; Wang et al., 2019; Zanella and Palli, 2021), or it may represent a velocity command (Daniel et al., 2024; Laezza and Karayiannidis, 2021).
Policy learning is often framed within standard reinforcement learning (RL) paradigms, where the agent interacts with the environment and improves based on reward signals (Daniel et al., 2024; Laezza and Karayiannidis, 2021; Zanella and Palli, 2021). Alternatively, policies can be learned through supervised learning approaches that leverage expert demonstrations or offline datasets (Nair et al., 2017; Seita et al., 2021; Wang et al., 2019).
4.3. Planning approaches in DLO manipulation
Planning approaches for DLO manipulation are broadly categorized into two main types, based on how manipulation is represented and structured: Shape Path and Action-Based planning. Though not mutually exclusive, methods involving both are classified by their main central component.
Shape Path Planning focuses on generating sequences of stable DLO configurations that connect an initial and a goal state, typically grounded in quasi-static models and supported by local controllers for trajectory tracking.
Action-Based Planning, on the other hand, formulates manipulation as a sequence of discrete task-oriented actions, also referred to as “skills” or “primitives,” such as grasping, sliding, or clipping. These are low-level, reusable, and parameterized actions that perform a specific movement or interaction. They can be sequenced or combined to achieve higher-level manipulation tasks.
4.3.1. Shape path planning
These approaches generate energy-minimized deformation trajectories for DLOs by exploring geometric or physical configuration spaces using sampling-based planners such rapidly-exploring random tree (RRT) or bidirectional variants (BiRRT).
As one of the pioneering works, Moll and Kavraki (2006) introduced a planner that operates entirely within the space of minimal energy curves, that is, stable configurations under manipulation constraints. An adaptive representation and a local planner connect energy-minimizing states, producing smooth, physically plausible paths for applications such as routing or surgical suturing (Sections 5.3 and 5.5).
The Kirchhoff elastic rod model, detailed in Section 2.2, is the fundamental building block of several works (Roussel et al., 2015, 2019; Sintov et al., 2020; Wu et al., 2022a). It is used to sample valid configurations for DLOs. The static equilibrium of a DLO is defined as an optimal control solution, considering the configuration space of a one-end-fixed Kirchhoff elastic rod as a six-dimensional manifold, which is suitable for using sampling-based planning algorithms (Bretl and McCarthy, 2014). However, the direct application of this formulation for sampling-based planning becomes computationally intensive, as highlighted by Sintov et al. (2020), and is limited to collision-free configurations. Roussel et al. (2015, 2019) extend the model with dynamic simulation, allowing contact interactions, including sliding, to traverse narrow passages. To avoid costly on-the-fly integration, Sintov et al. (2020) pre-compute a roadmap of elastic rod equilibrium shapes tightly coupled with robot joint configurations. A constrained BiRRT in this combined space enables rapid dual-arm manipulation planning without repeatedly solving differential equations. Wu et al. (2022a) combine a differentiable Kirchhoff rod model with a configuration distance descent strategy to iteratively guide the manipulated end along a predefined six-dimensional equilibrium manifold track, significantly improving convergence and success rates compared to sampling only or straight line approaches.
The Cosserat rod model is applied in Golestaneh et al. (2024) to represent multi-agent formations, formulating the planning task as a partial differential equation constrained optimal control problem, solved via nonlinear programming. Similarly, Azad et al. (2023) define minimal elastic energy trajectories by optimizing the Cosserat rod model to generate the commands required for desired deformations.
To improve computational efficiency, several works adopt simplified DLO models (Guo et al., 2020; Monguzzi et al., 2025; Yu et al., 2025). Guo et al. (2020) use a geometric spline representation combined with classical minimal-energy theory under quasi-static assumptions, enabling fast path planning in constrained environments. Yu et al. (2025) instead use a simplified discrete elastic rod model within a dual-arm framework, combined with a constrained BiRRT planner. Both Yu et al. (2023a) and Monguzzi et al. (2025) utilize a MSD model. The latter further incorporates clip constraints, particularly important for routing tasks involving fixed anchoring points. Learning-based models have also been applied to DLO planning to improve efficiency by approximating complex dynamics. For example, McConachie et al. (2020) propose planning in a reduced state space using a learned dynamics model from data obtained by simulation.
Simplified models inherently introduce approximations that may diverge from real DLO behavior, potentially resulting in shape inaccuracies or unforeseen collisions. Thus, in Yu et al. (2025), the resulting coarse paths guide a local model predictive controller (Section 4.2.2) to track deformation trajectories. Instead, Guo et al. (2022) propose a deviation-aware replanning strategy that monitors execution discrepancies, classifies their severity, and applies local corrections using potential fields. These corrections are then smoothly merged back into the original plan using a time-decaying fusion policy, enhancing execution robustness. McConachie et al. (2020) use a learned classifier to determine the reliability of the approximated learned model in comparison to the real system. The role of the classifier is to guide the planner by discouraging actions whose approximation lacks reliability. While connected to the strategies discussed in Section 4.1.3, these approaches are specifically tailored for planning.
4.3.2. Action-based planning
The main idea is to decompose DLO manipulation into a sequence of discrete primitive actions, such as alignment, clipping, or Reidemeister moves (Section 5.4), and rely on simplified object models for planning.
In these settings, a hierarchical planning scheme is often adopted, where a high-level planner selects among available primitive actions, and a low-level controller executes motion to achieve the resulting sub-goals (Huo et al., 2022; Shah et al., 2018). Central to this hierarchy is the design of the high-level planner, which determines the sequence of actions based on the current task state.
Heuristic or rule-based strategies are frequently exploited. For example, a heuristic planner is deployed in Waltersson et al. (2022) trying to solve the DLO routing across several fixtures. When a plan fails, a genetic algorithm is employed to find a recovery sequence. The high-level plan is then translated into joint-level motions, while vision modules track the DLO and environmental features. Similarly, Shah et al. (2018) propose a planner that sequences clamp and grip actions to respect link constraints and place cables under gravity. Viswanath et al. (2021) approach unknotting with a graph-based planner that uses image-predicted keypoints to select actions that remove crossings and control slack.
The decision-making process is typically guided by visual observations, including visual input of the DLO state (Chen et al., 2023; Viswanath et al., 2021), fixture positions (Waltersson et al., 2022), fixture contact state (Huo et al., 2022), or fixture contact level indicators (Zhu et al., 2019).
Other recent advances explore learning-based approaches for high-level action selection. For instance, Luo et al. (2024) propose a deep neural policy that selects manipulation primitives based on multi-camera visual embeddings and the history of previously executed actions.
Some works have investigated alternative representations of the task space to significantly simplify and accelerate the planning process. For example, Keipour et al. (2022b) encode DLO configurations as sequences of convex subspaces via spatial decomposition, enabling planning using modified dynamic programming. In contrast, Jin et al. (2022) use a compact spatial vector encoding cable-fixture relations, enabling action selection via incremental state changes. Both methods leverage simplified, discrete representations to model DLO configurations, facilitating efficient and generalizable planning without relying on exact geometric correspondence.
5. Manipulation tasks
This section builds upon the previous discussions on DLO modeling (Section 2), perception (Section 3), and estimation, control, and planning (Section 4), and categorizes the existing DLO manipulation literature based on the specific manipulation tasks addressed (see Figure 11). The primary tasks identified are: Grasping (Section 5.1), Shaping and Deployment (Section 5.2), Routing and Threading (Section 5.3), Topological Manipulation (Section 5.4), Suturing (Section 5.5), and Transport (Section 5.6). Each task-specific subsection not only reviews representative approaches but also highlights open challenges and gaps in the literature. A broader discussion of manipulation-related issues and future research directions is provided in Section 6.2. Overview of main DLO manipulation tasks identified in the literature: Grasping (Section 5.1), Shaping and Deployment (Section 5.2), Routing and Threading (Section 5.3), Topological Manipulation (Section 5.4), Suturing (Section 5.5), and Transport (Section 5.6). These categories build upon prior discussions of DLO modeling (Section 2), perception (Section 3), and estimation, control, and planning (Section 4).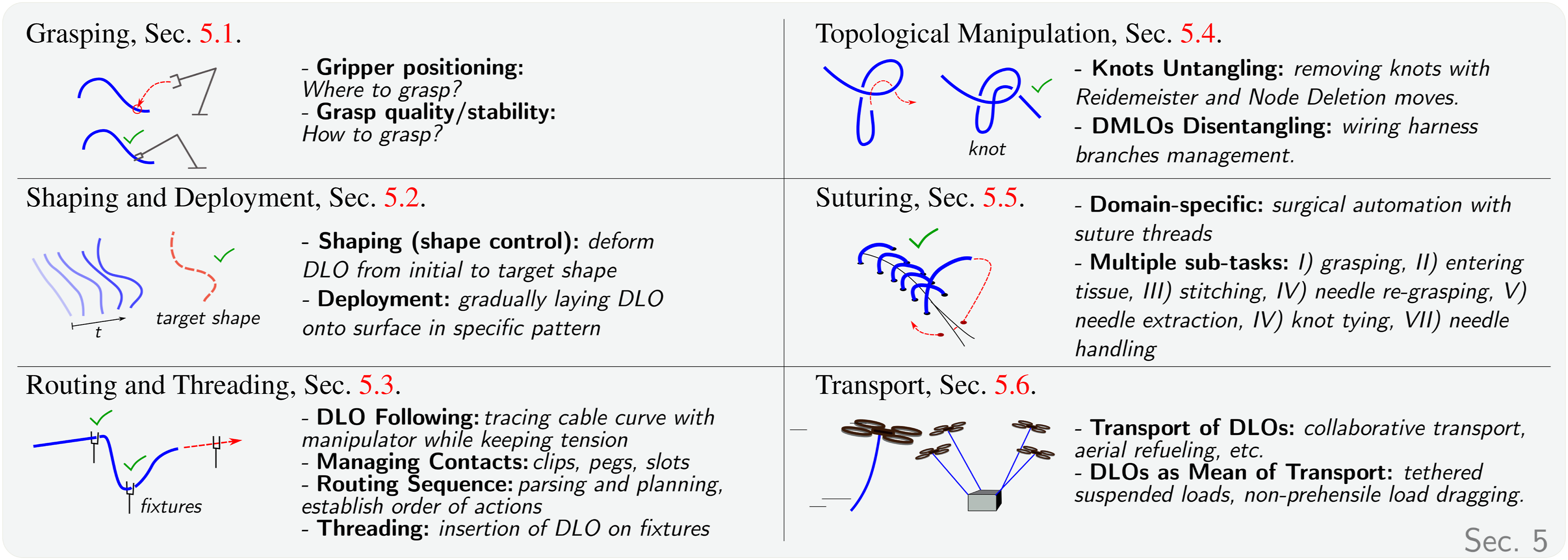
5.1. Grasping
In the context of DLO manipulation, grasping refers to the process of establishing a controlled contact between a manipulator and the deformable object to constrain its motion and enable purposeful interaction. Unlike rigid object grasping, DLO grasping must account for compliance, shape variability, and the potential for deformation during contact, often requiring strategies that ensure stability without inducing unwanted strain or slippage. Although grasping is a fundamental component across diverse DLO manipulation tasks, it remains considerably underexplored, as most works assume predefined grasp points and stable contact conditions.
The problem of grasping can be decomposed into two related but distinct challenges: where to grasp, usually addressed as gripper positioning (Cuiral-Zueco et al., 2022); and how to grasp, thus concerning grasp quality and stability (Roa and Suárez, 2015).
Gripper positioning for deformable objects focuses on identifying optimal grasp placements that facilitate related tasks such as shape control (Section 5.2) or topological manipulation (Section 5.4). For these tasks, parallel yaw grippers are widely used for both shaping (Yu et al., 2022), disentangling (Caporali et al., 2025; Lui and Saxena, 2013), or bin picking in cluttered environments (Zhang et al., 2022, 2024b, 2024c; Dirr et al., 2024).
Conversely, the grasp strategy, that is, how to grasp, is particularly critical in tasks such as routing (specifically DLO following, see Section 5.3), where grasp stability is more easily compromised during task execution. Despite parallel-jaw grippers still being widely deployed (She et al., 2021), dexterous hands are gaining traction due to the increased versatility (Yu et al., 2024).
Moreover, several transport-related tasks (Section 5.6) have explored alternatives to direct grasping. In particular, non-prehensile transport methods (see Section 5.6.2) leverage the compliant properties of DLOs to manipulate external objects through indirect interactions—such as dragging, wrapping, or tethering—without the need for rigid attachment (Zhi et al., 2024). These approaches are especially advantageous in environments where grasping is difficult, costly, or infeasible. A discussion on the role and potential of non-prehensile DLO manipulation is presented in Section 6.2.
5.2. Shaping and deployment
Shaping involves manipulating a DLO from an initial configuration to a desired target shape using one or more robotic manipulators (Cuiral-Zueco and López-Nicolás, 2024), as illustrated in Figure 12. A closely related task is DLO deployment, which concerns the objective of gradually laying the DLO onto a surface following a specified shape or pattern (Lv et al., 2022; Tong et al., 2024). Shape control process where an ABB YuMi-IRB 14000 manipulates a blue Ethernet cable from an S-shape to a U-shape (experiment from Cuiral-Zueco et al. (2023)).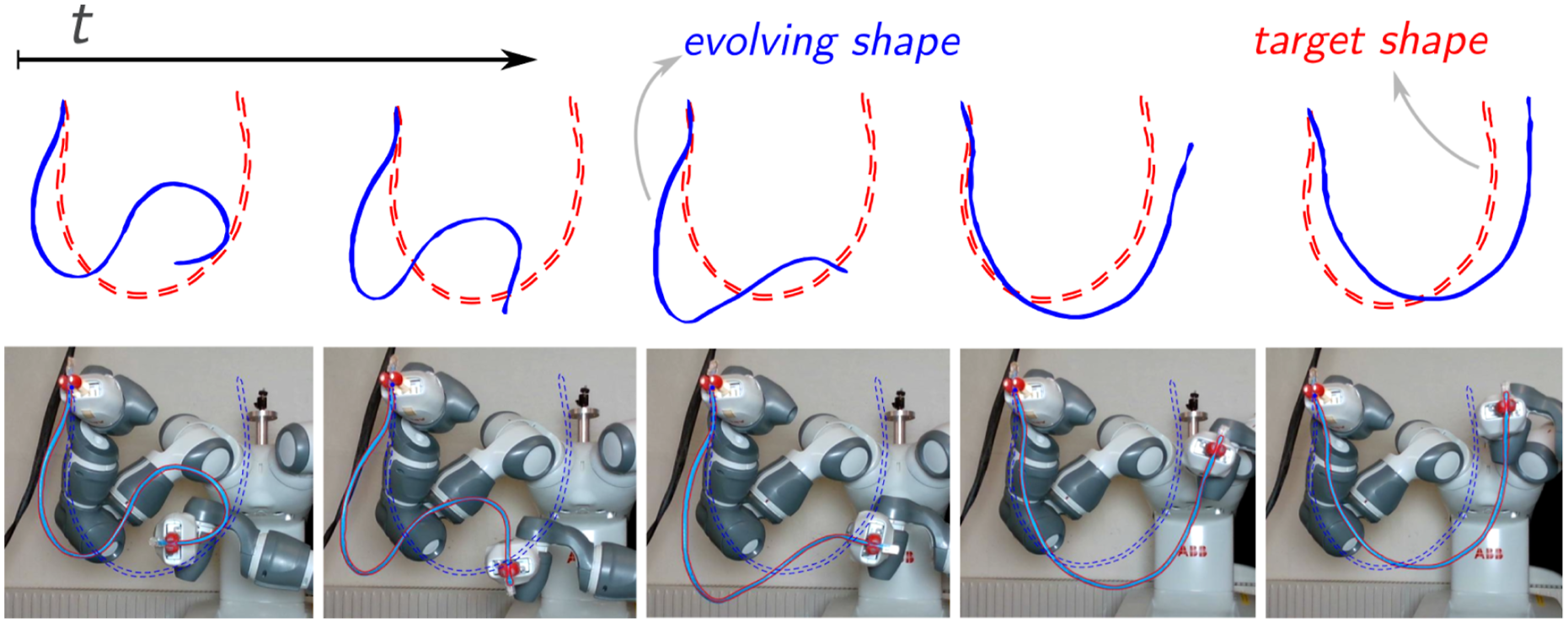
Shaping and deployment tasks, following Cuiral-Zueco and López-Nicolás (2024), can be expressed in the standard form: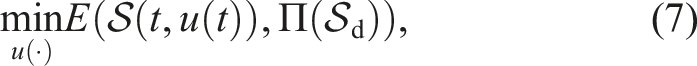
5.2.1. Quasi-static shaping and deployment
Table 4 provides a comprehensive overview of the main literature addressing DLO shaping tasks. Among the various aspects considered, a key distinction is made based on the behavior of the DLO, that is, how its shape changes in response to manipulation by the robotic arm. The DLO behavior can be broadly classified as follows
3
: • • • Summary of the surveyed literature on DLOs shaping. State estimation combined with online Jacobian modeling via least squares (LS) emerges as the predominant approach. Learning-based methods are most commonly integrated within short-horizon MPC frameworks. Elastoplastic behavior and contact-rich manipulation remain largely underexplored.
The analysis of Table 4 reveals several recurring patterns in the literature. While earlier works often relied on image-based inputs, recent approaches increasingly provide the DLO state directly, either by adopting simplifying assumptions about perception or by leveraging learning-based methods, as discussed in Section 3. Most studies focus on elastic DLOs, whereas DLOs exhibiting plastic responses were more prevalent in earlier methods. Notably, DLOs with elastoplastic behavior have been investigated only in Laezza and Karayiannidis (2021). An interesting object type is manipulated in Qi et al. (2021), where shape servoing of composite rigid-deformable objects—including uniform and joint-like connected DLOs—is performed through contour moments analysis. The majority of shaping tasks are carried out in 2D environments, although a growing number of recent works address the complexities of 3D manipulation. The exploitation of contact-rich interactions or environmental constraints remains relatively rare, with only a few works explicitly incorporating them into the shaping process (Huang et al., 2023; Huo et al., 2022; Tang et al., 2024). Human-in-the-loop shaping has been analyzed only in Zhou et al. (2024).
Action types generally fall into two main categories: velocity-based actions, typically used in servoing controllers, and pick-and-place strategies, which are often paired with learning-based models or policy-driven controllers. The Exploited DLO Model column in Table 4 refers to the specific representation of the DLO that informs the control policy, that is, capturing how the DLO is expected to respond to a given action. These models may include analytical physics-based formulations, learned approximations aimed at accelerating prediction and control such as multi-layer perceptrons (MLPs), graph neural networks (GNNs), and recurrent neural networks (RNNs), estimated deformation Jacobians (see Section 4.1.2), or hybrid combinations. The choice of the exploited DLO model is closely tied to the applied control strategy, which predominantly includes servoing, sampling- or gradient-based MPC, or learned policies. Importantly, in the case of learned policies, for example, those trained via reinforcement learning (RL) or behavior cloning (BC), actions are predicted directly from input observations without relying on an explicit model of DLO behavior. As such, these entries are left empty in the Exploited DLO Model column, as no internal representation is used during control. The same applies to approaches using heuristic or rule-based motion primitives that do not explicitly incorporate any predictive model of the DLO response. This terminology aligns with the standard convention in the field, where a manipulation method is considered model-based only if it explicitly learns or utilizes a model (defined as in Section 2) to determine the manipulation actions.
Earlier works often favored RL and BC techniques, while the use of learned approximations of analytical models (such as neural networks trained to mimic physical dynamics) is becoming increasingly popular in recent approaches. While early studies primarily focused on simulation-only evaluations, a growing number of recent works demonstrate and validate their approaches in both simulation and real-world scenarios.
A strong correlation emerges between plastic material response, 2D environments, single-arm robot setups, pick-and-place actions, and learned models, characteristic of shaping tasks where the DLO is manipulated over a supporting surface. Conversely, the combination of elastic DLOs, dual-arm setups, and velocity-based actions is commonly associated with servoing tasks, which are prevalent in both 2D and 3D environments.
5.2.2. Casting and high-speed shaping
Dynamic manipulation of DLOs involves applying fast 4 , time-dependent motions to produce complex behaviors. This contrasts with quasi-static manipulation. These motions are typically executed open loop once generated.
Typical tasks in this domain include whipping (Chi et al., 2024a; Lim et al., 2022; Zimmermann et al., 2021), which generally involve free-end DLOs, and vaulting, knocking, and weaving (Zhang et al., 2021a), which are performed with fixed-end cables. Whipping (often addressed also as casting) is a dynamic manipulation task where a robot quickly moves one end of a DLO to generate high-speed motion that travels along it, using the object’s elasticity and inertia to control the free end and reach targets beyond the robot’s immediate reach. The latter tasks involve dynamically manipulating a DLO to (1) vault over an obstacle, (2) knock an object off an obstacle, and (3) weave the DLO between multiple obstacles.
In terms of modeling, an algebraic deformation model that assumes negligible gravity effects due to fast motion and models the DLO as a series of joints following the robot with a constant delay is proposed in Yamakawa et al. (2013). On the other hand, Zimmermann et al. (2021) study the dynamic manipulation of free-end beams using FEM models combined with optimal control techniques for trajectory optimization.
Given the complexity of dynamic DLO manipulation, learning-based approaches are commonly applied, often relying on low-dimensional, parameterized action spaces to simplify control and training: two sweeping arcs (Lim et al., 2022), apex point (Zhang et al., 2021a), and two joint angles (Chi et al., 2024a). Maximum velocity is also treated as a learnable parameter, and the task space is often constrained to 2D (Chi et al., 2024a; Lim et al., 2022). Resetting the object’s initial state before each action ensures consistency and repeatability (Lim et al., 2022; Zhang et al., 2021a).
Across all approaches, simulation plays a critical role, either for bridging the sim-to-real gap (Lim et al., 2022) or for bootstrapping the learning process (Zhang et al., 2021a). Iterative refinement strategies enable easy online adaptation to system changes (Chi et al., 2024a).
5.2.3. Existing literature gaps
Research on DLO shaping is predominantly confined to well-established setups, such as pick-and-place manipulation of plastic DLOs on planar surfaces or dual-arm manipulation of elastic DLOs. These scenarios often assume simplified environments without obstacles or complex interactions. However, in real-world applications (and in human manipulation), contact-rich interactions and environmental constraints play a crucial role, especially given the underactuated nature of DLO shape control (Huang et al., 2023; Huo et al., 2022).
A second gap lies in the predominant elastoplastic behavior of real-world DLOs, such as electrical cables, which received limited attention in existing research (Laezza and Karayiannidis, 2021).
Many existing approaches assume the desired target shape is reachable and valid without explicitly verifying these conditions, often relying on heuristic checks instead. This highlights a significant gap in the current research, where formal reachability analysis is lacking.
5.3. Routing and threading
Routing involves systematically arranging DLOs to conform to a target configuration while establishing contact with environment objects. A key aspect of routing strategies is the use of fixtures (e.g., clips or jigs), which anchor the manipulated DLO in place, and contact or pivoting points, which facilitate tension control and enable smooth directional changes of the DLO along the routing path. The key elements involved in the routing process are illustrated in Figure 13. Threading is a related sub-task frequently encountered in practical applications, such as threading a needle or inserting wires into industrial assemblies. It involves guiding the DLO through a designated hole or eyelet in the environment, typically demanding higher precision despite the intrinsic DLO flexibility. Examples of routing elements. Images courtesy of Chen et al. (2023).
Unlike the more general shaping task of Section 5.2, routing also requires managing the sliding motion of the DLO along the gripper fingers (as discussed in Section 5.1), as well as executing precise insertions into fixing points/holes and interacting with pivoting elements along the path.
Summary of the main literature on DLO routing and threading. The table highlights a strong reliance on tactile/force sensors for local execution tasks (Following, Contacts) and vision for global Planning. Notably, the field is heavily skewed toward 2D planar setups, leaving full 3D routing and dynamic harnessing relatively underexplored.
Regarding benchmarks (see connected discussion in Section 6.2), the NIST Assembly Task Board (NIST, 2025) has emerged as a standardized setup for evaluating robotic capabilities in routing tasks. Although it represents a simplified scenario, it is increasingly adopted in research to support reproducibility and comparative evaluation, as in Keipour et al. (2022b) and Zhang et al. (2024d). Beyond conventional routing tasks, the NIST board has also been employed to study more complex manipulation settings (Luo et al., 2025).
5.3.1. DLO following
It involves grasping one end of the cable and manipulating the gripper to trace its contour while maintaining tension by securing the opposite end, either with a fixture or a second grasp.
In this sub-task, tactile sensing (see Section 3.2) is commonly used (e.g., She et al. (2021); Hellman et al. (2017); Pecyna et al. (2022)) as it provides localized feedback that enables dynamic grip adjustments and precise alignment during sliding. Among tactile sensors, high-resolution, image-based sensors like GelSight (Yuan et al., 2017) are used by both She et al. (2021) and Wilson et al. (2023), offering detailed measurements of normal force, shear, and torque. Alternative approaches include capacitive-based sensors (Monguzzi et al., 2023; 2024a) and optoelectronic sensors (Galassi and Palli, 2021), which trade spatial resolution for higher update rates, supporting faster control loops. Galassi and Palli (2021) combine tactile sensors with force/torque sensing, Zhang et al. (2024d) use only force sensing, while Monguzzi et al. (2024b) explore the use of internal joint torque signals as a form of proprioceptive feedback. Instead, vision-based sensing is generally avoided.
Motion primitives to trace along the DLO are often either scripted (using predefined actions such as slide, grasp, or reorient, e.g., Süberkrüb et al. (2022)) or learned (RL policies, e.g., Pecyna et al. (2022); Hellman et al. (2017)). Monguzzi et al. (2023) propose tactile-driven skills such as local diameter estimation, 3D alignment, and adaptive sliding based on local predictions of the DLO shape. This approach is expanded in Monguzzi et al. (2024a) by considering collisions and a global instead of local DLO shape. In contrast, Monguzzi et al. (2024b) eliminate the need for explicit contact sensing by leveraging a compliant last robot joint while following an estimated local DLO shape. RL methods (e.g., Pecyna et al. (2022); Hellman et al. (2017)) show promising results for developing adaptive policies, particularly when leveraging multi-modal sensory feedback. Unlike the general approaches, a learned dynamic model of the wire behavior under force feedback is combined with an MPC strategy in Zhang et al. (2024d).
Specifically in terms of low-level tactile-driven control strategies, the task is frequently divided into DLO pose and grip controllers, as in She et al. (2021). These controllers jointly regulate the gripper’s position and applied force relative to the DLO, ensuring smooth path following while preventing slippage or buckling. A key simplification of She et al. (2021) is the horizontal gripper orientation, which removes gravity effects. In contrast, Galassi and Palli (2021) employ a tactile-based correction within a vertical grasp, while Yu et al. (2024) introduce a “V-shaped” grasping strategy using a robotic hand. A simple threshold-based method is used to maintain the DLO centered during sliding in Wilson et al. (2023).
5.3.2. Managing contacts
Clips, pegs, and slots play a crucial role in routing tasks. To handle these, specific motion primitives are typically designed to account for contact interactions. Most of these primitives are scripted or heuristic in nature. Luo et al. (2024) propose a learned slot-insertion policy. Importantly, these primitives need to be orchestrated by a planner, see Section 4.3.2. The choice of motion strategy and sensing modality often depends on the type of contact object. Manipulating clips generally requires the DLO to be tensioned during insertion (Galassi and Palli, 2021; Zhang et al., 2024d), whereas pegs impose a less stringent requirement, and slots typically do not require tensioning at all. Below is a summarized overview of motion strategies and sensing for each contact type (see also Figure 13): • Pegs are addressed in Zhu et al. (2019) through a vision-based angular contact mobility index that quantifies DLO–obstacle interactions, or via scripted primitives that incorporate tactile sensing (Galassi and Palli, 2021; Wilson et al., 2023). • Routing through slots is explored in Luo et al. (2024), where an imitation learning framework is used to train a slot-insertion policy from visual feedback collected via multiple cameras. Additionally, Wilson et al. (2023) propose a heuristic “weaving slot” primitive featuring a wiggling motion guided by tactile feedback. • For clips, force sensing is commonly used to monitor the DLO state in conjunction with scripted motion primitives (Galassi and Palli, 2021; Süberkrüb et al., 2022; Zhang et al., 2024d). In Chen et al. (2023), a dedicated clipping primitive is developed using threshold-based control on force signals to regulate motion during execution. Building on this, Chen et al. (2024) propose an enhanced set of contact indicators to improve detection accuracy.
Notably, Süberkrüb et al. (2022) also introduce a feature point estimation algorithm based on Kalman filtering, which identifies fixture locations, such as clips or jigs, by fusing multiple observations of force readings from a tensioned DLO.
5.3.3. Routing sequence parsing and planning
The placement of fixtures (i.e., determining where they need to be positioned) and their routing sequence are important aspects of the task. High-level task parsing is addressed in Wilson et al. (2023), exploiting a simple processing of visual observations. Chen et al. (2023) tackle fixture placement by optimizing their positions based on a target DLO shape. The approach minimizes deviation from the desired shape while maintaining adequate spacing between consecutive fixtures to ensure smooth execution by the dual-arm robot setup.
Regarding the representation of the routing problem, both Keipour et al. (2022b) and Jin et al. (2022) focus on modeling the environment to support planning. Keipour et al. (2022b) employ a convex decomposition of space to encode the DLO configuration, simplifying the planning process. In contrast, Jin et al. (2022) model the relative spatial relationships between DLOs and fixtures to facilitate efficient data collection and learning of three motion primitives for routing.
5.3.4. Threading
It requires precise manipulation of the DLO and accurate localization of both its tip and the target hole or eyelet.
To localize the DLO tip (or “tail-end”), some authors have proposed vision-based strategies (De Gregorio et al., 2018b; Wang et al., 2015), while others have leveraged tactile sensing by following the DLO shape (Yu et al., 2023b), similar to the approach described in Section 5.3.1. The location of the target hole or eyelet is typically assumed to be known in advance or determined using fiducial markers (Li and Choi, 2024). Yu et al. (2023b) leverage the same (camera-based) tactile sensor to localize the needle eyelet by employing a pre-trained (image-based) foundation model (see Section 6.1).
Grasping plays a crucial role in this task, as sufficient “slack” between the grasp point and the tip is necessary for successful insertion. Li and Choi (2024) parametrize the grasp point based on the DLO flexibility. When threading requires pulling the DLO further through the hole, re-grasping is typically employed (Li et al., 2025; Wang et al., 2015).
The actual insertion is performed via quite diverse strategies. In Wang et al. (2015), a diminishing rigidity Jacobian (Section 4.1.2) is used in combination with a virtual vector field for tip guidance. Zanella et al. (2019) explicitly address the deformability of DLOs by using a data-driven controller that adjusts insertion orientation in real time based on estimated force components from tactile feedback. Similarly, De Gregorio et al. (2018b) use tactile sensors with a data-driven regressor to evaluate grasp quality and predict insertion collisions.
RL has also been applied in recent work, although in simplified scenarios. In Yu et al. (2023b), a goal-conditioned tactile-driven policy that learns to output low-dimensional end-effector displacements from segmented tactile observations is proposed. However, this method relies on the eyelet being in continuous contact with the tactile surface, limiting its real practicality. In Li and Choi (2024), a policy conditioned on the DLO flexibility is used to produce two spatial waypoints for insertion. In a follow-up work, Li et al. (2025) leverage RL agents producing expert demonstrations to train a diffusion policy capable of both insertion and pulling. Both approaches are restricted to simplified 2D environments.
Unlike the previously discussed approaches, high-speed manipulation is used to generate centrifugal force during thread rotation, effectively transforming the task into a simplified peg-in-hole insertion (Huang et al., 2015). However, the method is limited to 2D and requires a custom robotic setup.
5.3.5. Existing literature gaps
Many existing approaches rely on hand-crafted motion primitives or models trained on specific types of DLOs (Wilson et al., 2023; Zhang et al., 2024d). This specialization may limit generalization, particularly when handling DLOs with varying diameter or stiffness properties.
Manipulation scenarios are frequently simplified through assumptions of quasi-static dynamics or restriction to planar environments (Jin et al., 2022; Keipour et al., 2022b; Yu et al., 2023b). These abstractions omit critical aspects of real-world 3D routing tasks, including complex spatial configurations, occlusions, and obstacle interactions. In contrast, Luo et al. (2025) move toward more realistic routing scenarios by addressing a challenging belt-threading and tensioning task involving a closed DLO, in which a reinforcement-learning–derived policy enables coordinated dual-arm task execution.
In perception, visual and tactile sensing are often deployed in isolated stages rather than being fused and utilized concurrently in real time (Wilson et al., 2023), which limits responsiveness and robustness in scenarios that may benefit from multi-modal sensing (Pecyna et al., 2022).
For contact-rich tasks involving clips, current strategies typically employ simplified geometries such as circular holes or loosely constrained channels (Galassi and Palli, 2021; Süberkrüb et al., 2022; Wilson et al., 2023; Zhang et al., 2024d), which generate minimal contact forces. However, more realistic clip designs, such as those capable of elastic deformation during insertion, introduce complex contact dynamics that remain underexplored (Chen et al., 2023).
Finally, repeated mechanical interactions such as tensioning or insertion of the DLO can induce material fatigue and degradation over time (Zanella et al., 2019; Zhang et al., 2024d). This raises concerns about long-term reliability and operational safety in real-world deployments, which are not addressed in current literature.
5.4. Topological manipulation
Topological manipulation focuses on the challenging task of untangling knots formed by one or more DLOs as well as disentangling branches of DMLOs. This task presents a complex challenge at the intersection of perception, planning, and manipulation. The key difficulty lies in perceiving and representing the knot or tangle structure, then determining a sequence of actions to simplify and ultimately untangle it.
Summary of the key literature on robotic topological manipulation, with knot untangling in DLOs (top) and DMLOs disentangling (bottom). The table highlights each work’s key perception and manipulation contributions. Generally, single-DLO untangling relies on graph-based topological abstractions and geometric moves (e.g., Reidemeister moves), whereas multi-object disentangling (DMLOs) additionally requires interactive perception and dynamic agitation strategies to overcome severe occlusion.
5.4.1. Knots untangling
Most solutions proposed in the literature to automatically unknot DLOs draw inspiration from knot theory, a branch of topology concerned with the mathematical properties of knots. Two key concepts commonly employed are the Dowker–Thistlethwaite (DT) notation and Reidemeister moves (Lui and Saxena, 2013). DT notation encodes knots as a linear sequence of integers, providing a compact, symbolic representation of crossings. In contrast, Reidemeister moves define three elementary primitives to remove intersections in the structure. Together, these tools form the basis of many state estimation and manipulation strategies in robotic knot untangling.
Early approaches typically assumed semi-planar, loosely tangled knots with visible ends, as in Lui and Saxena (2013), where the Node Deletion move is introduced. This move involves pulling a DLO out of an under-crossing intersection and is used in conjunction with classical Reidemeister moves to simplify tangled configurations (see Figure 14). The authors also propose a sufficient condition for entanglement, based on crossing transitions along the rope. Process of untangling a DLO using a node deletion followed by a Reidemeister move.
Building on Lui and Saxena (2013), later works refine several key aspects. Grannen et al. (2021) propose a sequential manipulation strategy that combines Node Deletion and Reidemeister moves, achieving a monotonic reduction in the number of crossings until the rope is untangled. Avoiding an explicit topological representation (e.g., linear graphs with DT notation as in Lui and Saxena (2013)), a learned perception system composed of a knot detector and a keypoint regressor is also proposed.
Further advancements are proposed by Sundaresan et al. (2021), which extends the linear graph representation of Lui and Saxena (2013) to handle non-planar configurations, enabling a generalization to more complex 3D entanglements. Additionally, they improve upon Grannen et al. (2021) by introducing a coarse-to-fine refinement strategy for keypoint predictions, significantly reducing grasping errors due to near misses, and a set of Recovery moves. Viswanath et al. (2021) further extend this work by considering multiple DLOs in the scene (“intra-cable” and “inter-cable” crossings) and introducing a new manipulation primitive: the Cable Extraction move. These works focus on dense knots as opposed to the loose ones of Lui and Saxena (2013), thanks to the capabilities of the employed robotic setup (see Table 6).
Recent works have extended topological manipulation to partially observable scenes, relaxing the assumption that DLO ends must be visible. In Huang et al. (2024), Reidemeister moves are combined with a novel Multi-Cable move to handle loosely entangled knots, similar to the setup in Lui and Saxena (2013). The focus is on learning a robust topological state representation of multiple DLOs using deep learning. In contrast, Shivakumar et al. (2023) address the single-DLO case and introduce interactive perception through modified manipulation primitives that actively explore the tangled DLO’s configuration.
With a quite diverse approach, Yamakawa et al. (2013) explore high-speed dynamic knot tying, where knots are formed by rapidly whipping cables upward and leveraging self-collisions of the DLO to achieve the final tie.
5.4.2. DMLOs disentangling
A practical application of DLOs disentangling is exemplified by the challenge of manipulating DMLO, for example, spreading the wiring harness branches free of intersections (Caporali et al., 2025), or extracting a wiring harness from a bin (Zhang et al., 2022).
The complex structure of a wire harness introduces additional complexities in both robotic bin picking and untangling, given its multi-branched configuration and the coexistence of deformable and rigid components (e.g., connectors and clips).
For DMLOs bin picking, Zhang et al. (2022) propose two distinct motion primitives for disentangling (i.e., a Helix and Spinning moves) combined with a learned perception system that leverages active learning to predict grasp points and estimate grasp success probabilities. Building on this, Zhang et al. (2024c) introduce a dual-arm closed-loop framework that enhances system robustness and accuracy.
To remove intersections among DMLO branches, Caporali et al. (2025) propose a topological representation constructed using a GNN from a single image of the scene. Based on the extracted topology, a dual-arm manipulation primitive is executed using a circular motion strategy that satisfies the topological constraints of the manipulated DMLO.
5.4.3. Existing literature gaps
Current methods predominantly rely on passive visual perception. This approach often struggles with tightly tangled knots or complex DMLOs entanglements. In contrast, active perception strategies remain underexplored and have so far been applied to single DLOs with loosely tied, simple knots (Shivakumar et al., 2023). Learning-based perception strategies are also usually trained on synthetic or specific real-world data over simplified scenarios (Grannen et al., 2021; Huang et al., 2024), making generalization to real-world scenarios hard.
Grasping and manipulation in dense, high-friction DLO configurations remain challenging. Common failure modes include missed or unintended multi-object grasps, as well as slippage during manipulation (Shivakumar et al., 2023; Zhang et al., 2022). Tactile sensors, which could potentially verify grasp quality and monitor the manipulation process in real time, are currently not exploited.
5.5. Suturing
Suturing is a highly complex and domain-specific task within surgical automation that integrates several DLO-related sub-tasks, such as routing, threading, and knot tying (Sections 5.3 and 5.4). However, its uniquely constrained clinical environment, specialized robotic setups and DLO characteristics (i.e., suture thread), and strict procedural demands distinguish it from more general DLO manipulation scenarios, as shown in Figure 15. These distinct characteristics motivate treating suturing as a dedicated manipulation task. Suturing task with dVRK and reconstructed 3D suture thread. Images courtesy of Joglekar et al. (2023).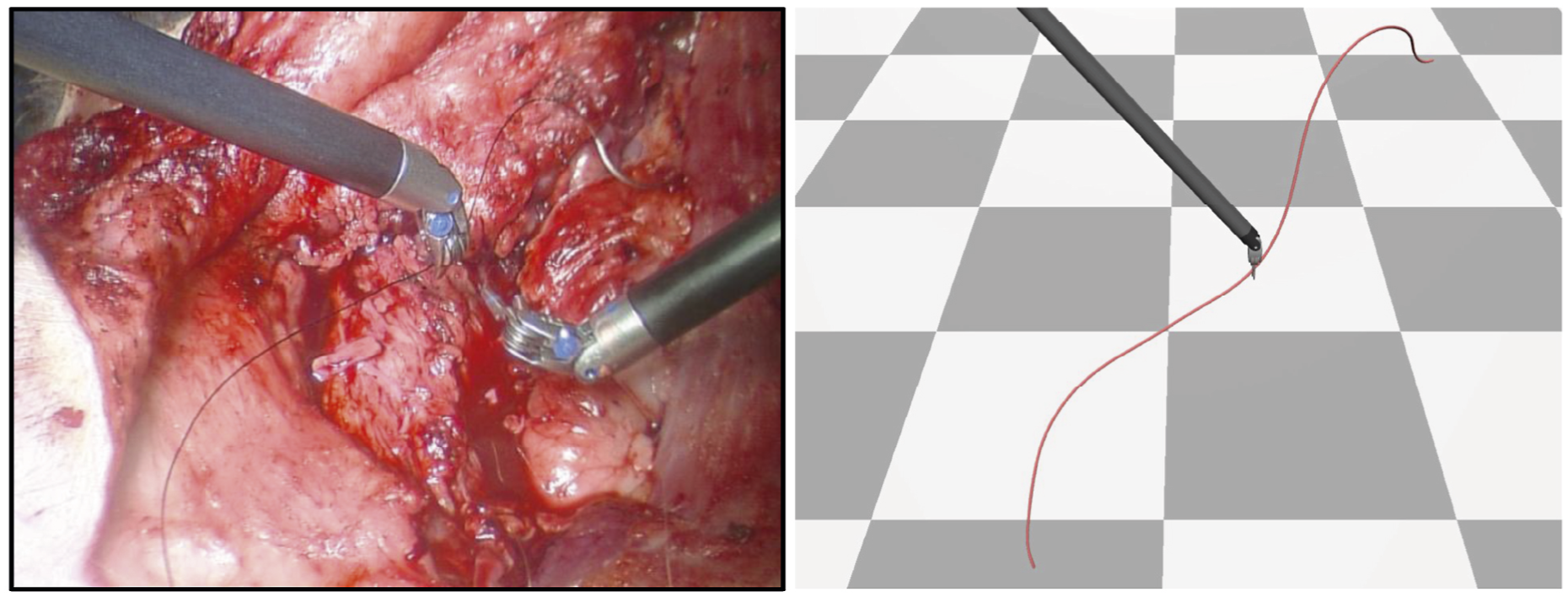
The suturing process can be broken down into seven steps, paraphrased from Pedram et al. (2021): (I) grasping the needle with the inserting arm, (II) moving toward the wound and entering the tissue perpendicularly, (III) stitching, (IV) grasping the needle with the extracting arm, (V) extracting the needle, (VI) knot tying and grasping the needle with the extracting arm, and (VII) handing off the needle to the inserting arm.
Existing approaches typically focus on specific subsets of these steps. For example, Pedram et al. (2021) cover steps II to V and VII, whereas Lu et al. (2019) focus exclusively on knot tying (step VI).
Regardless of the suturing process focus, most approaches address thread perception as a central component of their frameworks, as discussed in Section 3.1.5. Some works further link thread perception with grasp point estimation: Joglekar et al. (2023) introduce a perception-based confidence map for grasping, while Lu et al. (2022) compute optimal grasping poses directly. Another important perceptual focus is needle detection and pose estimation, as explored by Sen et al. (2016) and Pedram et al. (2021). The former also addresses automatic needle size selection as part of the task-oriented setup. Given the specialized requirements of needle and thread handling, several works have designed custom grippers to facilitate precise grasping and alignment (Jackson et al., 2018; Sen et al., 2016).
Regarding action planning and control, the typical approach is often optimization-based, including sequential convex programming (Sen et al., 2016), linear-quadratic control (Lu et al., 2019), nonlinear constrained optimization (Pedram et al., 2021), and MPC (Marra et al., 2024).
Summary of representative literature on robotic suturing. Subtask indices (I–VII) refer to the breakdown in Section 5.5. The table highlights a standard reliance on stereo vision for high-precision depth estimation and optimization-based control (e.g., MPC) to enforce safety constraints during tissue interaction. Furthermore, most works decouple the problem, focusing either on robust perception (Subtask I) or the execution of stitching mechanics (Subtasks II–V), with knot tying (VI) remaining an outlier.
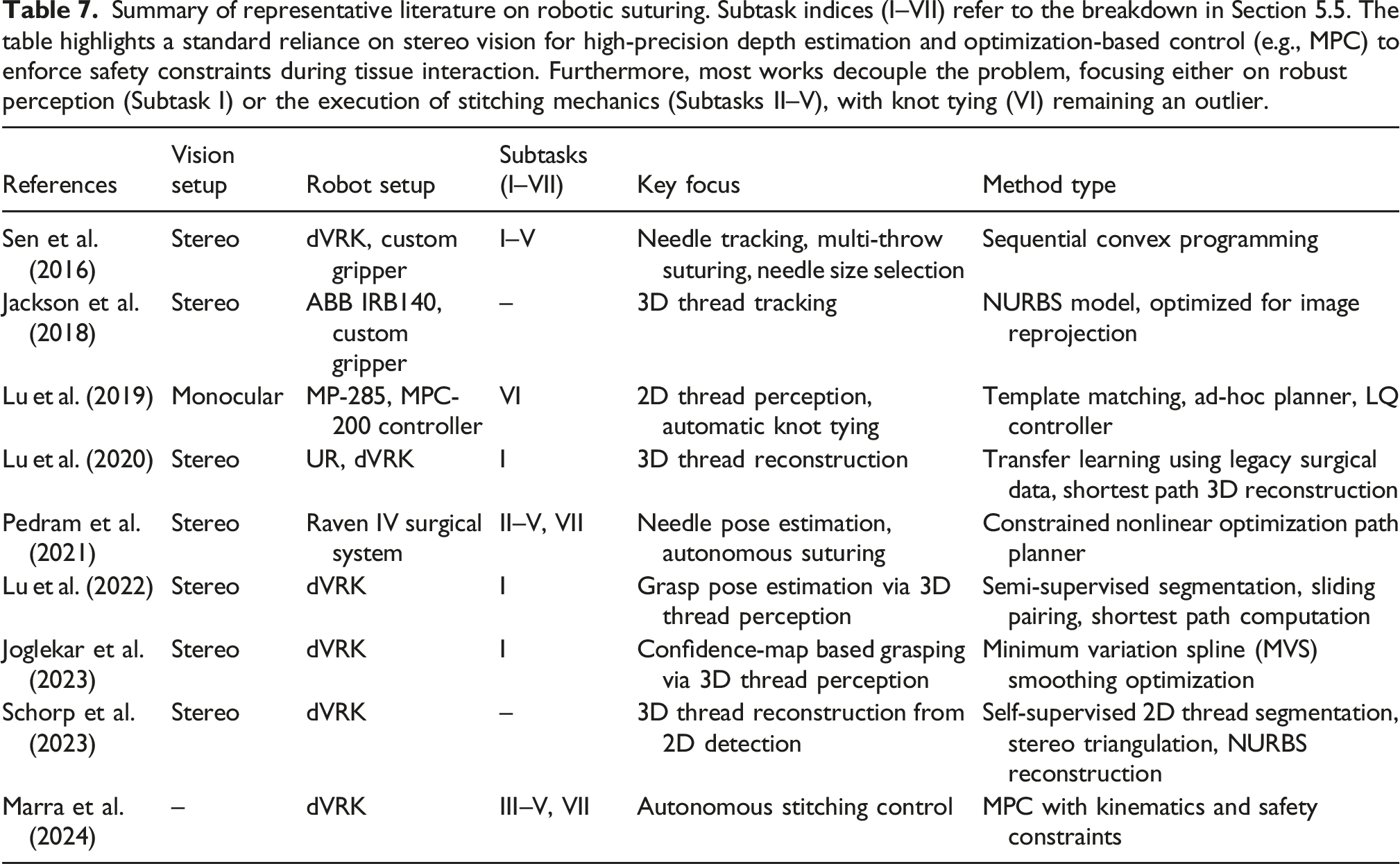
5.5.1. Existing literature gaps
While recent advances in autonomous suturing are promising, real surgical environments still pose significant challenges. Perception is often affected by poor lighting and tissue reflections, suspended particles (e.g., from laparoscopic insufflation), tissue deformation, surface motion (as considered in Jackson et al., 2018), and prolonged occlusions from surgical instruments. On the manipulation side, most approaches address specific sub-tasks, with fewer providing full end-to-end solutions. Effectively handling dynamic tissue behavior across the entire suturing process remains an open challenge.
5.6. Transport
Transport tasks involving DLOs can be broadly classified into two categories: transporting the DLO itself (Figure 16(a) and Section 5.6.1), and using DLOs as a means to transport external loads—either through direct physical coupling, as in cable-suspended systems, or via non-prehensile interactions without rigid attachment (Figure 16(b) and Section 5.6.2). Representative examples of transport tasks involving DLOs. Images courtesy of (a) Shen et al. (2025) and (b) Zhi et al. (2024).
Overview of selected literature on DLO transport. The table reveals a domain-dependent split: aerial works (e.g., Kotaru and Sreenath (2020); Xu et al. (2025)) predominantly prioritize dynamic stability via LQR or adaptive control and high-frequency state estimation (IMU/motion-capture), whereas ground-based approaches (e.g., Su et al. (2022); Zhi et al. (2024)) typically rely on optimization-based methods to manage interaction constraints and obstacle avoidance via exteroceptive sensing.
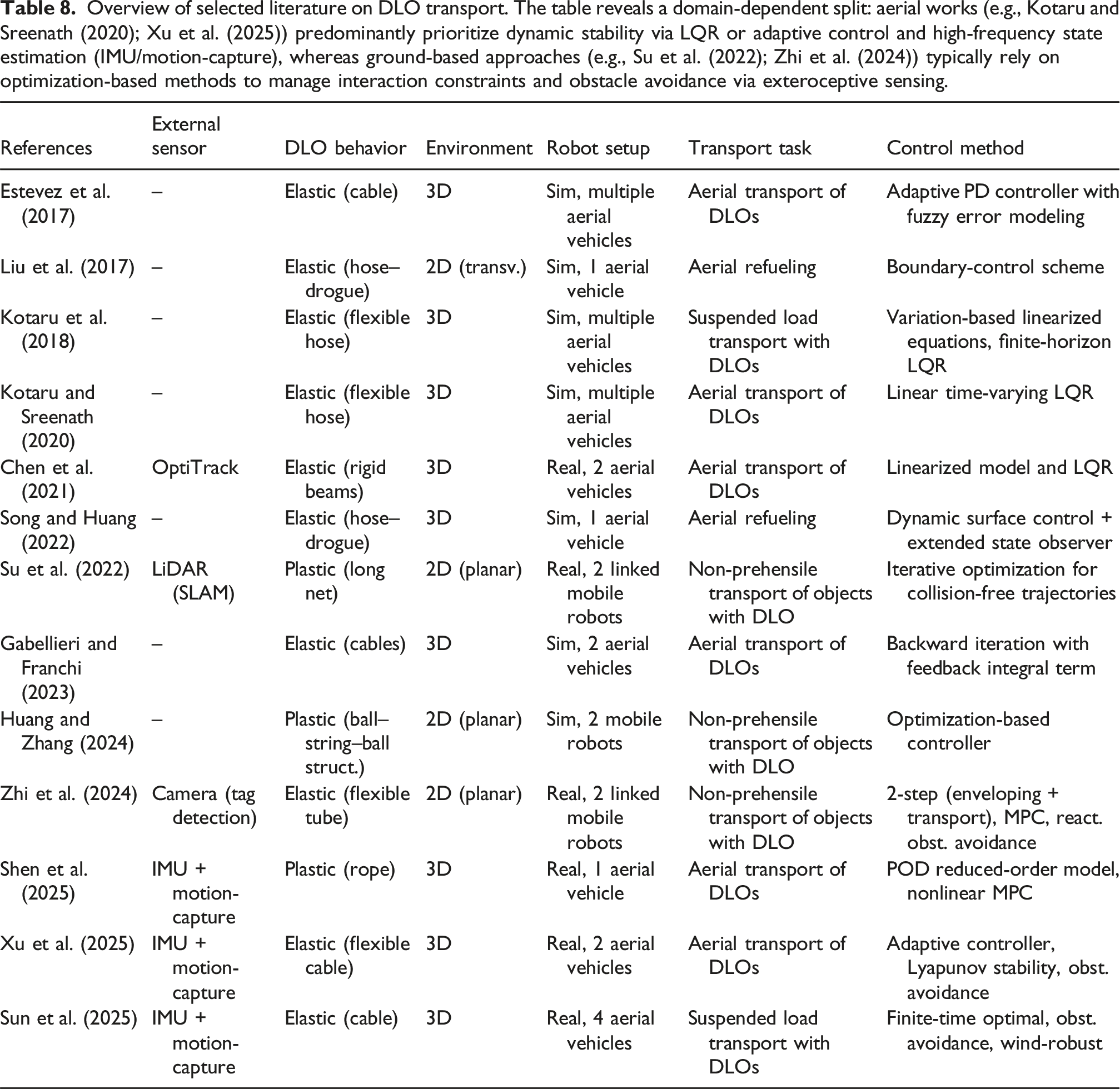
5.6.1. Transporting DLOs
Mobile robots (e.g., wheeled robots) and aerial systems (e.g., drones) have demonstrated the capability to transport DLOs using cooperative and autonomous strategies. Some methods involve pairs of drones collaboratively carrying flexible cables or beams (Chen et al., 2021; Xu et al., 2025), while others rely on single-drone solutions guided by second-order modeling and nonlinear MPC (Shen et al., 2025). In simulated scenarios, teams of aerial robots manipulate hoses using techniques such as time-varying linear quadratic regulation (LQR) (Kotaru and Sreenath, 2020), feedback-integrated planning (Gabellieri and Franchi, 2023), or adaptive proportional-derivative (PD) control with fuzzy error modeling (Estevez et al., 2017). As a related challenge, aerial refueling involves transporting and aligning hose–drogue systems, which can be achieved through approaches such as dynamic surface control (Song and Huang, 2022) or oscillation suppression with boundary-control strategies (Liu et al., 2017).
5.6.2. DLOs as mean of transport
DLOs have been increasingly explored as flexible media for tethered and non-prehensile transport in both aerial and ground-based robotic systems. In aerial contexts, cable-suspended load transport has been demonstrated in simulation with flexible hoses manipulated by multiple drones, modeled through variation-based linearization and finite-horizon LQR (Kotaru et al., 2018). In Sun et al. (2025), several drones collaboratively transport suspended loads in agile tasks exploiting a trajectory-based framework that solves the whole-body kinodynamic motion planning problem online, successful achieving obstacle avoidance and robustness against over 5 [m/s] winds. Aside from aerial transport, ground transport systems have achieved non-prehensile transport by enveloping objects with elastic tubes, coordinated via a two-stage MPC framework with reactive obstacle avoidance (Zhi et al., 2024), or by dragging a long net between mobile robots using iterative optimization for collision-free motion planning (Su et al., 2022). In simulation, soft structures such as a ball–string–ball mechanism have been employed for gathering and transporting objects, exploiting optimization-based control strategies (Huang and Zhang, 2024). These non-prehensile approaches (Huang and Zhang, 2024; Su et al., 2022; Zhi et al., 2024) demonstrate the versatility of DLOs as compliant transport tools, enabling object manipulation without the need for direct grasping, unlike traditional grasp-based methods (see Section 5.1).
5.6.3. Existing literature gaps
Existing DLO-related transport strategies are primarily tested in controlled indoor environments, limiting their validation to structured settings such as warehouses. In contrast, real-world transport often occurs outdoors, where wind, uneven terrain, and dynamic obstacles present significant challenges. In these conditions, DLO perception becomes highly unreliable due to sensor limitations, making perception-light methods such as Chen et al. (2021) particularly appealing.
Energy consumption is another often-overlooked factor, yet it critically affects the autonomy of mobile robots. This highlights the value of energy-aware control approaches, such as MPC-based (Shen et al., 2025; Zhi et al., 2024) and LQR-based methods (Chen et al., 2021; Kotaru et al., 2018; Kotaru and Sreenath, 2020), which can improve efficiency during transport.
Another key limitation is the common assumption that DLOs are already attached to drones or that loads are pre-attached to DLOs. However, the grasping/attachment process is nontrivial to automate in practice. Thus, non-prehensile methods (Huang and Zhang, 2024; Su et al., 2022; Zhi et al., 2024) offer a promising alternative by avoiding these attachment challenges, enabling more direct applicability in real-world scenarios. However, they are constrained by terrain conditions, typically requiring flat surfaces suitable for object dragging.
6. Discussion and future directions
Current DLO manipulation methods still struggle with generalization and robustness in the real world. For example, shaping techniques often assume contact-free environments, ignoring the elastoplastic behavior of real DLOs like electrical cables, and skip formal reachability analysis. Routing approaches frequently depend on task-specific motion primitives and are restricted to quasi-static, mostly planar environments, overlooking the complexities of clip-based interactions and long-term mechanical stress on the DLO. Topological manipulation is still dominated by passive visual perception, which performs poorly in the presence of dense entanglements and tight knots, resulting in frequent grasping failures and limited robustness. Most suturing approaches target isolated sub-tasks without offering robust end-to-end pipelines capable of managing tissue deformation, occlusions, and surface motion throughout the full procedure. Lastly, in transport, methods are typically validated in structured indoor settings and often assume pre-attached payloads, which limits their adaptability to outdoor or dynamic contexts.
Together, these limitations highlight the need for future research to address challenges across multiple fronts: advanced perception (Section 6.1), high-level and low-level manipulation strategies (Section 6.2), robust failure detection and recovery (Section 6.3), and scalable data collection and curation (Section 6.4). This broader perspective on next-generation DLO manipulation is reflected in the framework illustrated in Figure 17, which is intended as a guiding example rather than an exhaustive architectural specification. An illustrative full-system framework that addresses some of the most critical challenges in next-generation DLO manipulation. This flowchart outlines a system capable of handling unstructured, real-world complex DLO manipulation tasks (such as the process, shown in the illustration, of securing a branch to a pole in an agricultural setting). It links scalable DLO data-generation pipelines (bottom block, Section 6.4) directly to real-time online manipulation strategies. The runtime loop fuses advanced perception (right block, Section 6.1) with hierarchical manipulation strategies (middle block, Section 6.2), integrating high-level semantic and long-horizon planning (Section 6.2.2) with contact-rich, affordance-aware control (Section 6.2.1). Identifying a major future challenge, the framework explicitly includes fault prevention, detection, and recovery (top block, Section 6.3) as a critical requirement for transferring DLO manipulation research to real-world applications.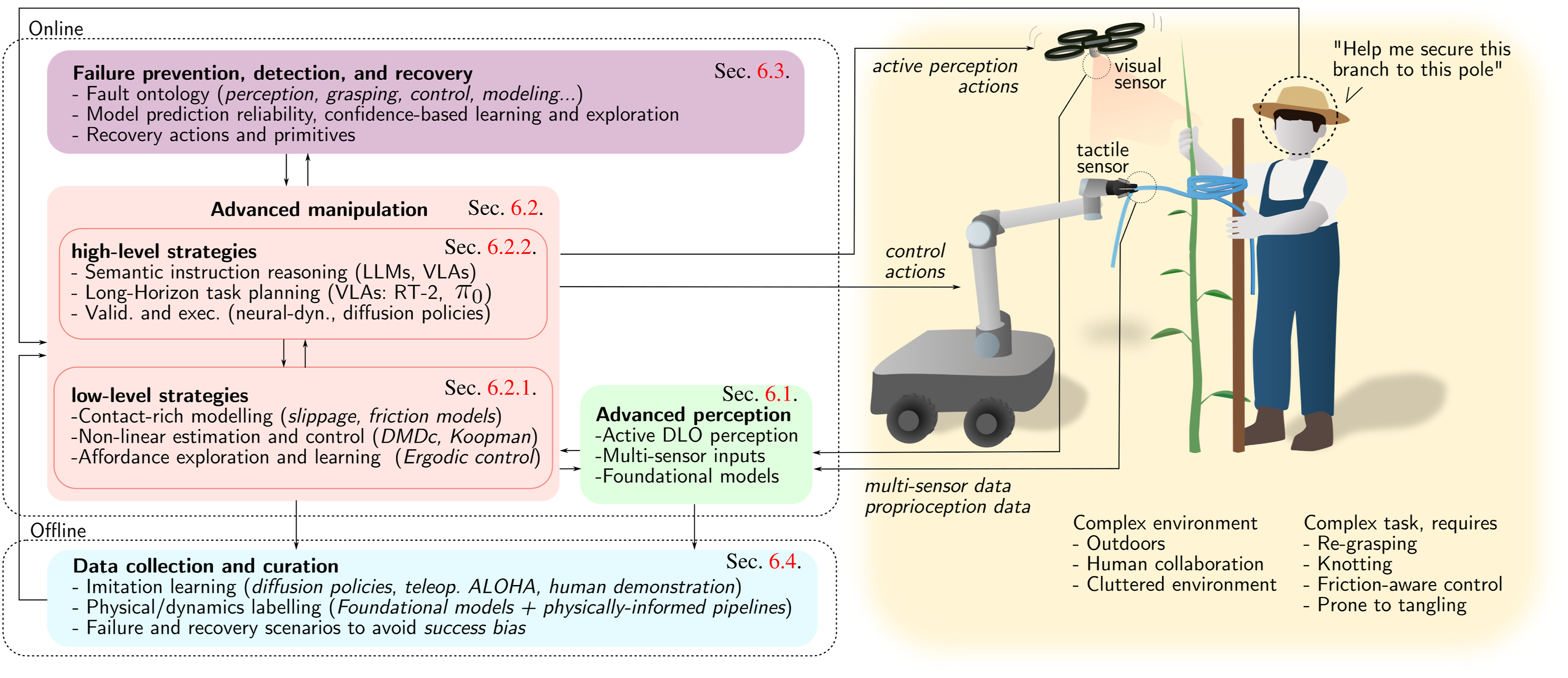
6.1. Advanced DLO perception
Reliable DLO manipulation increasingly requires force, tactile, and proprioceptive feedback. Vision alone struggles with real-world lighting, reflections, occlusions, and the visually uniform, thin nature of many DLOs. Even in human manipulation, vision mainly guides initial grasp selection, while successful handling depends on touch, force feedback, and purposeful physical interaction. Interactive perception (Bohg et al., 2017; Weng et al., 2024), where the robot actively probes and manipulates the object to gain information, naturally complements passive sensing and enhances robustness. Additionally, advances in sensorless and tactile strategies, such as those proposed in Monguzzi et al. (2023, 2024b), offer a promising path toward reliable, application-ready systems. While vision remains essential for grasp planning and state estimation, physical interaction sensing is a requisite for true application-ready systems.
Another issue is temporal resolution. Most methods reviewed here operate at low frequencies, restricting them to quasi-static tasks. Interestingly, this is also reflected in the manipulation tasks, usually exploiting quasi-static settings (see Section 6.2). Higher processing rates could simplify perception by minimizing inter-frame visual changes and enable dynamic manipulation. This requires optimizing current architectures or adopting new data sources, such as event cameras or reduced-order observers from force data.
Finally, DLO perception is usually task-specific, diverging from conventional setups that rely on large, general-purpose public datasets, like ImageNet (Deng et al., 2009). Foundation Models, pre-trained on extensive and diverse datasets, are increasingly being applied to robotic tasks (Firoozi et al., 2025). Their influence is now beginning to extend to DLO perception as well, for example, through text-driven segmentation (Sun et al., 2024) or the digital-twin reconstruction pipeline proposed in Jiang et al. (2025). The latter provides a compelling demonstration of foundation models-based DLO perception, reconstructing a physically accurate, simulation-ready digital twin of a real rope from sparse RGB-D video using pre-trained foundation models in zero-shot settings. However, the object is intentionally thick, which simplifies 3D perception of DLOs and also mitigates the difficulty of current foundation models when dealing with DLO-like thin objects, for example, under-representation in internet-scale data and difficulty with small-scale and thin details. Despite these limitations, research in this direction can substantially advance DLO perception by reducing reliance on task-specific data collection and manual annotation. Indeed, the strong generalization capabilities of foundation models can help bridge the real-world DLO variability gap and improve the robustness and adaptability of future DLO perception systems.
6.2. Manipulation of DLOs: What’s next
6.2.1. Adaptive and contact-rich control in unstructured environments
To move beyond quasi-static, fixed-grasp setups, the field must tackle contact-rich interactions like slippage, re-grasping, and environmental friction. A critical barrier is the accurate modeling of hybrid stick-slip transitions. While recent soft robotics research has progressed by incorporating contact constraints into analytical models like Cosserat rods (Jilani et al., 2025; Wiese et al., 2023), these high-fidelity formulations remain inherently nonlinear and computationally intensive, often limiting their utility for robust, real-time control.
Data-driven nonlinear control offers a faster alternative. Techniques like the Koopman operator and dynamic mode decomposition with control (DMDc) (Brunton et al., 2016; Kaiser et al., 2018, 2021) can map complex DLO dynamics into linear observable spaces. Paired with nonlinear model predictive control (NMPC) (Folkestad and Burdick, 2021; Korda and Mezić, 2020), these methods can manage high-dimensional DLO systems at industrial speeds.
In unstructured environments, however, physical properties are often unknown. Active learning and ergodic exploration (Abraham et al., 2021; Saviolo et al., 2023) allow the system to autonomously probe the object, gauging stiffness or friction. This active data gathering enables online adjustments, such as controlled sliding or re-grasping.
Validating these complex behaviors requires standardized hardware benchmarks like the NIST (2025) task boards (Luo et al., 2025; Qi et al., 2026) and shift from binary success criteria to continuous performance metrics (Laezza et al., 2021).
Lastly, human-robot collaboration with DLOs (Zhou et al., 2024) demands dexterity that quasi-static methods cannot provide. Adapting to human movements requires the robot to safely slip, regrasp (Zhaole et al., 2024), and manage varying grasp orientations (Yu et al., 2024).
6.2.2. Long-horizon planning and foundational intelligence
Complex DLO tasks require reasoning that inter-relates high-level semantic understanding with low-level physical interactions. While vision-language-action (VLA) models like π0 (Black et al., 2024) and RT-2 (Zitkovich et al., 2023) are promising, their precision in DLO manipulation is unproven. A safer approach decouples reasoning from execution (Qi et al., 2026): Large language models (LLMs) generate symbolic sub-goals (e.g., “grasp the cable end”), which physics-aware planners then execute.
Validating these symbolic plans requires accurate deformation modeling to cross the sim-to-real gap. Physics-informed methods like PhysTwin (Jiang et al., 2025) and Particle-Grid Neural Dynamics (Zhang et al., 2025) learn deformable physics directly from RGB-D video. By building simulation-ready digital twins, these methods let planners verify long-horizon sequences using real-world physics priors instead of manually tuned simulators (Xiang et al., 2025).
Finally, executing these plans requires policies that handle complex, multi-modal actions. Diffusion policies (Chi et al., 2025) are highly effective here, but their success depends on in-domain data. The scarcity of datasets capturing the full physical state-space of DLOs remains a severe bottleneck (see Section 6.4).
6.3. Fault prevention, detection and recovery
For real-world deployment, fault detection and recovery must be a core system capability, not an afterthought. Research should start by establishing a fault ontology for DLOs, categorizing failures across perception (occlusion, tracking loss), grasping (slippage), control (instability), and modeling (parameter mismatch). Some work has begun here: Mitrano et al. (2021) predict the reliability of learned DLO models, and Sundaresan et al. (2021) provide recovery strategies for tangled DLOs.
Because learning-based methods struggle with out-of-distribution events, integrating uncertainty estimation (Amini et al., 2020; Kendall and Gal, 2017) is vital for detecting impending failures. Similarly, during online adaptation, incorporating ergodic exploration from equilibrium with stability guarantees (Abraham et al., 2021) can actively enhance failure avoidance during system exploration.
Developing dynamic primitives for fault recovery is another critical area. Humans resolve tangles using dynamic motions like impulsive pulls or whipping. While some primitive-based untangling exists (Zhang et al., 2022), formalizing these into a taxonomy would give supervisors (like VLMs in the RACER framework (Dai et al., 2025)) the vocabulary to command complex, high-frequency maneuvers to fix entanglements. Multi-robot strategies (Aranda et al., 2025; Herguedas et al., 2019) can also mitigate local failures, using physical cues (like tension along a cable) to coordinate recovery when communication is poor.
6.4. Data collection and curation challenges
Recent advances in imitation learning, particularly using Diffusion policies (Chi et al., 2025), have shown that model-free approaches can master complex skills with relatively few demonstrations. Teleoperation frameworks like ALOHA (Zhao et al., 2023, 2025) can enable the learning of precise DLO-related tasks—such as cable routing or shoe lacing—given sufficient demonstrations. Complementing these hardware-intensive approaches, the Universal Manipulation Interface (UMI) provides a scalable alternative by leveraging in-the-wild human demonstrations through hand-held grippers (Chi et al., 2024b). Further reducing hardware requirements, human video-based learning methods directly translate RGB-D videos into robot supervision (Lepert et al., 2025). However, a critical bias limits the utility of these general-purpose data-collection pipelines. Since large-scale datasets naturally lean toward conventional, easy-to-record scenarios, it systematically underrepresents challenging environments (such as underwater cable inspection or highly congested DMLO routing) precisely where automation offers great value. As a result, these models often fail to generalize to DLOs with different physical properties, necessitating ad-hoc data collection for new materials or environmental variations.
One of the main causes of this poor generalization is that DLO dynamics are governed by latent physical properties (such as stiffness and friction) that are often visually imperceptible. To enable robust generalization, data collection must pivot toward multi-modal pipelines, synchronizing visual kinematics with high-frequency force and tactile feedback to resolve these invisible parameters. Novel hardware approaches, such as sensorized hydrogels (Hardman et al., 2021), offer a promising avenue for dataset generation by directly capturing mechanical deformation both internally and at the contact surface of the DLO. Alternatively, emerging foundation models address the physical annotation bottleneck computationally. By combining dense point tracking from models like CoTracker3 (Karaev et al., 2024) with physically-informed pipelines like PhysTwin (Jiang et al., 2025), it becomes possible to semi-automate labeling in the wild, effectively creating valid generators for dense, physics-informed datasets.
Finally, current datasets suffer from a “success bias,” as they consist almost exclusively of smooth expert demonstrations. Robust DLO manipulation, however, requires recovering from inherent instability and failure modes like snagging or entanglement. Because experts naturally avoid these errors, models trained on such data lack the support to handle out-of-distribution failures. Future datasets must therefore explicitly include failure and recovery trajectories, teaching the policy not only the nominal path but also how to untangle or re-route when the primary strategy fails.
7. Conclusions
This survey has reviewed the growing body of work on the robotic perception and manipulation of Deformable Linear Objects (DLOs). Designed as both an introduction for newcomers and a roadmap for experienced researchers, the literature reveals a clear takeaway: while DLO manipulation is a highly active and advancing area of research, it has not yet reached the maturity required for widespread industrial use.
To understand this maturity gap compared to established domains like rigid manipulation or navigation, we must reevaluate what constitutes a “baseline.” In mature fields, capabilities like tactile sensing and robustness to unstructured environments are often treated as advanced upgrades to an already functional system. For DLO manipulation, however, these capabilities are not optional enhancements; they are fundamental prerequisites for achieving even basic reliability.
Consider, for example, the coupling between tactile sensing and deformation. Simply touching a DLO to measure its state can inadvertently actuate it. This physical contact perturbs the object, significantly increasing measurement uncertainty. This problem peaks in near-singular configurations (such as buckling, pigtailing, or transitioning from slack to taut regimes). In these states, visual feedback cannot detect accumulated mechanical stress, making tactile data crucial; yet, it is exactly in these regimes that the DLO is most sensitive to touch.
Moreover, DLOs are inherently unstructured. Even in controlled environments, a DLO can generate complex and cluttered conditions on its own, including self-occlusions, knots, tangles, and high-friction self-contacts. While other robotics domains usually attribute unstructured conditions to external factors (like poor lighting or environmental obstacles in navigation), DLOs generate extreme complexity purely through their own geometry and deformation. Thus, robustness against these intrinsic dynamics is mandatory.
The main challenge to establishing standard, replicable baselines is this intrinsic physical complexity. DLOs are highly nonlinear underactuated systems plagued by singularities and abrupt behavioral shifts. Their configuration space explodes when accounting for varying shapes, materials, and grasp points. Because of this, purely data-driven approaches are rarely sufficient. Typically, black-box learning models (like foundation models) lack the interpretability and provable guarantees needed for industrial safety. Moving forward, the most promising path is to fuse the adaptability and context-awareness of modern machine learning with the rigorous stability and safety guarantees of classical mechanics and systems analysis.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Horizon Europe project IntelliMan - AI-Powered Manipulation System for Advanced Robotic Service, Manufacturing and Prosthetics [grant number 101070136]. Alessio Caporali is funded by FSE+ 2021–2027 under a research contract per Law 240/2010, Art. 24(3)(a), and D.G.R. 693/2023 (REF. PA: 2023-20090/RER - CUP: J19J23000730002). This work was also supported via project REMAIN S1/1.1/E0111 (Interreg Sudoe Programme, ERDF) and projects PID2021-124137OB-I00 and PID2024-159279OB-I00 funded by MICIU/AEI/10.13039/501100011033 and by ERDF/EU, and ANR-25-PERO-0003 PEPR Robotique - PC DRMI (Dexterous Robotic Manipulation for Industry).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.