
Abstract
Estimating the 6D pose of textureless objects from RGB images is an important problem in robotics. Due to appearance ambiguities, rotational symmetries, and severe occlusions, single-view based 6D pose estimators are still unable to handle a wide range of objects, motivating research towards multi-view pose estimation and next-best-view prediction that addresses these limitations. In this work, we propose a comprehensive active perception framework for estimating the 6D poses of textureless objects using only RGB images. Our approach is built upon a key idea: decoupling the 6D pose estimation into a two-step sequential process can greatly improve both accuracy and efficiency. First, we estimate the 3D translation of each object, resolving scale and depth ambiguities inherent to RGB images. These estimates are then used to simplify the subsequent task of determining the 3D orientation, which we achieve through canonical scale template matching. Building on this formulation, we then introduce an active perception strategy that predicts the next best camera viewpoint to capture an RGB image, effectively reducing object pose uncertainty and enhancing pose accuracy. We evaluate our method on the public ROBI and TOD datasets, as well as on our reconstructed transparent object dataset, T-ROBI. Under the same camera viewpoints, our multi-view pose estimation significantly outperforms state-of-the-art approaches. Furthermore, by leveraging our next-best-view strategy, our approach achieves high pose accuracy with fewer viewpoints than heuristic-based policies across all evaluated datasets. The accompanying video and T-ROBI dataset will be released on our project page: https://trailab.github.io/ActiveODPE.
Introduction
Textureless rigid objects occur frequently in industrial environments and are of significant interest in many robotic applications. The task of 6D pose estimation aims to detect objects of known geometry and estimate their 6DoF (Degree of Freedom) poses, that is, 3D translations and 3D orientations, with respect to a global coordinate frame. In robotic manipulation tasks, accurate object poses are required for path planning and grasp execution (Deng et al., 2020; Song et al., 2017; Tremblay et al., 2018; Wang et al., 2019). For robotic navigation, 6D poses serve as valuable cues for localization and obstacle avoidance (Fu et al., 2021; Liao et al., 2024; Merrill et al., 2022; Salas-Moreno et al., 2013; Wang et al., 2021b).
Due to the absence of appearance features, 6D pose estimation for textureless objects has typically been addressed using depth data (Bui et al., 2018; Cai et al., 2022; Drost et al., 2010; Gao et al., 2020, 2021; Li and Stamos, 2023; Yang et al., 2021b) or RGB-D images (Doumanoglou et al., 2016; He et al., 2020; Li and Schoellig, 2023; Saadi et al., 2021; Tian et al., 2020; Wada et al., 2020; Wang et al., 2019; Wen et al., 2020, 2024bib_wen_et_al_2020bib_wen_et_al_2024). These methods demonstrate strong pose estimation performance when high-quality depth data is available. However, despite advances in depth sensing technology, commodity-grade depth cameras frequently produce inaccurate depth maps, with errors or missing data occurring on glossy or dark surfaces (Chai et al., 2020; Yang et al., 2024a; Yang and Waslander, 2022), as well as on translucent or transparent objects (Liu et al., 2020; Sajjan et al., 2020; Xu et al., 2021). These depth limitations can severely degrade object pose estimation performance. Therefore, RGB-based approaches have received a lot of attention over the past decade as a promising alternative (Brachmann et al., 2016; Hinterstoisser et al., 2011).
Due to the numerous advances in deep learning over the last decade, some learning-based approaches have recently been shown to significantly improve object pose estimation performance using only RGB images (He et al., 2023; Hodan et al., 2020; Kehl et al., 2017; Labbé et al., 2022; Li et al., 2018; Peng et al., 2019; Sun et al., 2025; Sundermeyer et al., 2018; Xiang et al., 2018; Xu et al., 2024). However, due to the inherent scale, depth, and perspective ambiguities from a single viewpoint, RGB-based solutions often suffer from low accuracy in the final 6D pose estimation. To this end, recent works leverage multiple RGB views to enhance their pose estimation results (Deng et al., 2021; Fu et al., 2021; Haugaard and Iversen, 2023; Labbé et al., 2020, 2022bib_labbé_et_al_2020bib_labbé_et_al_2022; Maninis et al., 2022; Merrill et al., 2022; Shugurov et al., 2021). Although fusing multi-view information can enhance overall performance, addressing challenges such as appearance ambiguities, rotational symmetries, and occlusions remains difficult. Additionally, even when multi-view fusion mitigates some of these issues, relying on a large number of viewpoints is often impractical for many real-world applications, such as robotic manipulation.
To address these challenges, we present a comprehensive framework for both object pose estimation and next-best-view prediction using multi-view RGB images. First, we introduce a multi-view object pose estimation method that decouples the 6D pose estimation into a two-step sequential process: we first estimate the 3D translation, followed by the 3D orientation of each object. This decoupled formulation first resolves scale and depth ambiguities from single RGB images, and then leverages the resulting translation estimates to simplify object orientation estimation in the second stage. To address the multimodal nature of orientation space, we develop an optimization scheme that accounts for object symmetries and counteracts measurement uncertainties. The second part of our framework focuses on next-best-view (NBV) prediction, which builds upon the proposed multi-view pose estimator. We introduce an information-theoretic approach to quantify object pose uncertainty. In each NBV iteration, we predict the expected object pose uncertainty for each potential viewpoint and select the next camera viewpoint that minimizes this uncertainty, ensuring more informative RGB measurements are collected. Figure 1 illustrates the effectiveness of our multi-view approach on transparent objects, demonstrating accurate 6D pose estimations even under challenging conditions. 6D object pose estimation using multi-view acquired RGB images. (a) The input multi-view RGB images with known camera poses. (b) The pose estimation results using CosyPose and PVNet. (c) The pose estimation results using our approach. The green and red colors represent correct and incorrect pose estimations, respectively.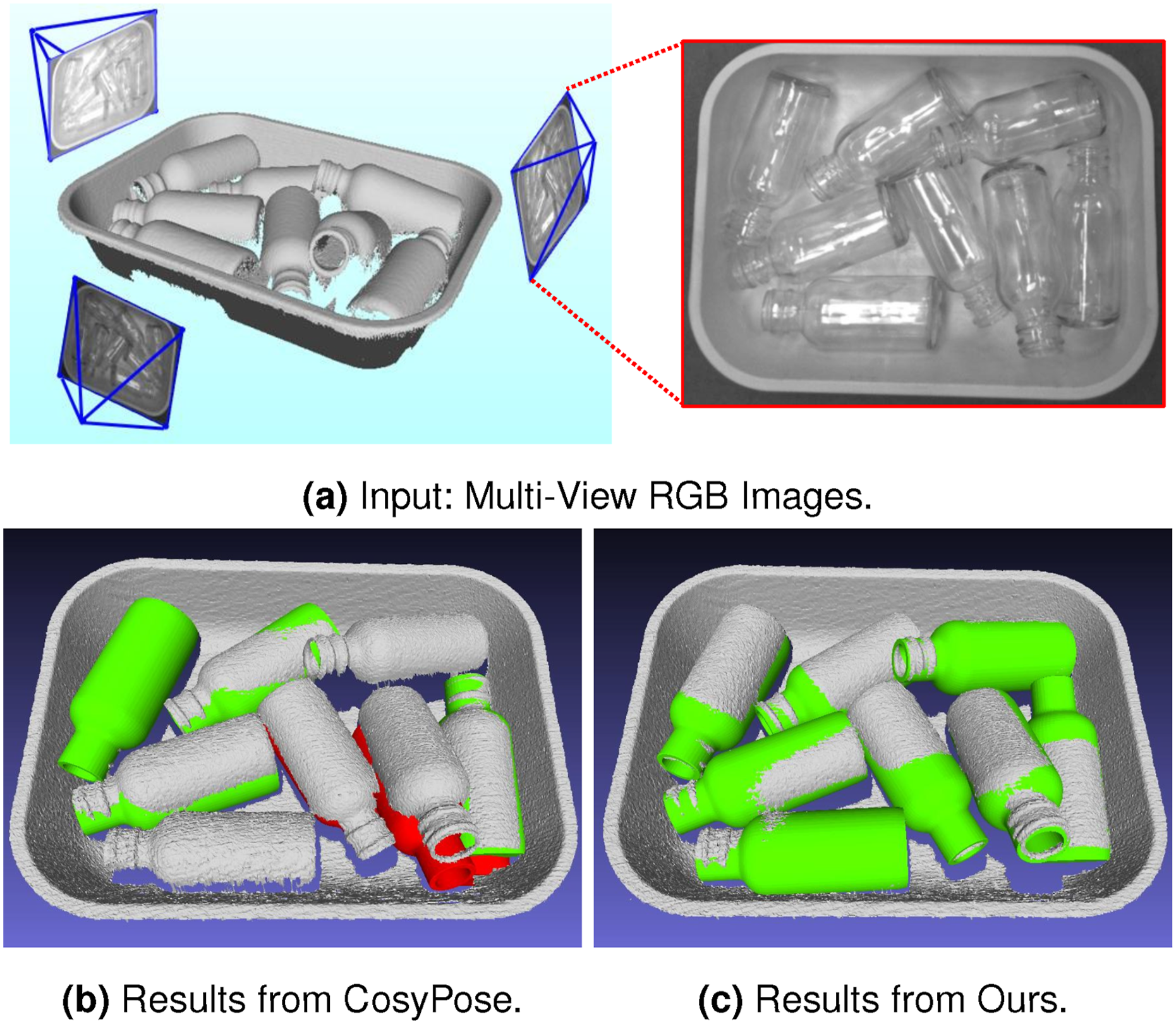
We conduct extensive experiments on the public ROBI (Yang et al., 2021a) and TOD (Liu et al., 2020) datasets, as well as on a challenging transparent object dataset, T-ROBI, that we present. To support network training, we also propose a large-scale synthetic dataset based on both ROBI and T-ROBI. Our approach significantly outperforms state-of-the-art RGB-based methods. Compared to depth-based methods, it achieves comparable performance on reflective objects and fully surpasses them on transparent objects, despite relying solely on RGB images. Furthermore, compared to baseline viewpoint selection strategies, our next-best-view strategy achieves high object pose accuracy while requiring fewer viewpoints.
Our work makes the following key contributions. We propose a novel 6D object pose estimation framework that decouples the problem into a two-step sequential process. This process resolves the depth ambiguities from RGB frames and greatly improves the estimate of orientation parameters. Building on our proposed pose estimator, we introduce an information-theoretic active vision strategy that optimizes object pose accuracy by selecting the next-best camera viewpoint. We introduce a multi-view dataset of transparent objects, specifically designed to evaluate 6D pose estimation for transparent parts in cluttered and occluded bin scenarios. To support network training, we create a large-scale synthetic dataset that includes all parts from both the public ROBI and our T-ROBI dataset.
It is important to note that this work substantially extends our previous conference paper (Yang et al., 2023b), as follows: Improved Orientation Estimation. To enhance object orientation estimation, we introduce a new head into the neural network architecture that extracts per-frame object edge maps, serving as more accurate and consistent shape inputs for the object orientation estimator. Active Vision. We extend our previous approach by integrating an active vision strategy that selects the next-best-view to improve the object pose accuracy. Transparent Object Dataset. The dataset allows evaluation of our method under real-world, challenging scenarios, while also serving as a valuable benchmark for researchers working on transparent object pose estimation. Synthetic Dataset. We generate a large-scale synthetic dataset to provide a comprehensive benchmark for training and fair comparison on ROBI and our transparent object dataset. Expanded Real-World Results. We include detailed ablation analysis, three additional baselines, and more extensive real-world results on the ROBI, TOD and our transparent object datasets.
Related works
Object pose estimation from a single RGB image
Traditional methods
Due to the lack of appearance features, traditional methods usually tackle the problem via holistic template matching techniques (Hinterstoisser et al., 2011; Imperoli and Pretto, 2015), but are susceptible to failure due to scale change and occlusion. Later advances (Brachmann et al., 2016) improved the efficiency of template matching by jointly regressing object coordinates and labels via a learning-based framework, but its accuracy is far below modern deep learning methods.
End-to-end methods
With advances in deep learning, many works leverage convolution neural networks (CNNs) (Kehl et al., 2017; Labbé et al., 2022; Li et al., 2018; Wang et al., 2021a; Xiang et al., 2018) or vision transformers (ViTs) (Amini et al., 2021; Jantos et al., 2023) to estimate object pose end-to-end. Among these, SSD-6D (Kehl et al., 2017) was the first to regress 6D object pose from a single RGB image with CNNs. To avoid complex rotation parametrization, it discretizes rotation as a classification problem. PoseCNN (Xiang et al., 2018) improved this by decoupling translation and rotation with separate branches, leading to more accurate estimates. Building on these, DeepIM (Li et al., 2018) iteratively refines object poses by matching rendered object image to the input image. To better facilitate end-to-end methods, a continuous 6D rotation representation (Zhou et al., 2019) was introduced, offering advantages over other parametrizations for network training. This representation is subsequently adopted in end-to-end works (Amini et al., 2021; Jantos et al., 2023; Labbé et al., 2022; Wang et al., 2021a), further improving 6D pose estimation.
Learning-based indirect methods
While classical feature and geometric-fitting methods fail on textureless objects, deep learning overcomes this by learning discriminative features. Recent indirect methods use deep networks to predict 2D object keypoints (He et al., 2023; Pavlakos et al., 2017; Peng et al., 2019; Rad and Lepetit, 2017) or dense 2D–3D correspondences (Haugaard and Buch, 2022; Hodan et al., 2020; Park et al., 2019; Su et al., 2022; Zakharov et al., 2019), then compute poses via RANSAC/PnP (Lepetit et al., 2009). More recently, the representation power of diffusion (Ho et al., 2020) and foundation models (Cherti et al., 2023; Oquab et al., 2023) has further improved indirect methods (Xu et al., 2024), enabling zero-shot 6D pose estimation (Ausserlechner et al., 2024; Deng et al., 2025; Fan et al., 2024; Sun et al., 2025).
Although these methods perform well on 2D metrics, their 6D pose accuracy is limited by depth ambiguities and occlusions from a single viewpoint. Consequently, depth data is often needed to refine object poses (Deng et al., 2021; Yang et al., 2024a; Zhang and Cao, 2019).
Object pose estimation from multi-view RGB images
Multi-view approaches address the scale and depth ambiguities that commonly occur in single-viewpoint scenarios, improving the accuracy of estimated poses. Traditional methods rely on local features (Collet and Srinivasa, 2010; Eidenberger and Scharinger, 2010) but struggle to handle textureless objects. More recently, multi-view object pose estimation has been revisited with neural networks. These approaches employ an offline, batch-based optimization framework, where all frames are processed simultaneously to produce a consistent interpretation of the scene (Chen and Jiang, 2024; Haugaard and Iversen, 2023; Kundu et al., 2018; Labbé et al., 2020; Liu et al., 2020; Shugurov et al., 2021). The most notable work is CosyPose (Labbé et al., 2020), which integrates single-view pose estimates into a globally consistent scene and is agnostic to the choice of pose estimator. Using a similar multi-view setup, a pose refiner further improves accuracy via differentiable rendering (Shugurov et al., 2021).
Other approaches address multi-view pose estimation in an online manner. 6D object pose tracking (Deng et al., 2020, 2021; Labbé et al., 2022; Moon et al., 2024) focuses on estimating object poses relative to the camera, whereas object-level SLAM simultaneously estimates both camera and object poses within a shared world coordinate frame (Chen and Jiang, 2024; Fu et al., 2021; Merrill et al., 2022; Wu et al., 2020; Yang and Scherer, 2019). PoseRBPF (Deng et al., 2021) represents an early effort in online 6D object pose tracking, combining particle filtering with deep neural networks to achieve robust estimation under challenging conditions. In contrast, MegaPose (Labbé et al., 2022) and GenFlow (Moon et al., 2024) uses an end-to-end framework, enabling 6D tracking of novel, previously unseen objects. While these methods handle single objects well, they cannot track multiple objects simultaneously. Object-level SLAM approaches (Fu et al., 2021; Merrill et al., 2022; Wu et al., 2020; Yang and Scherer, 2019), on the other hand, can recover the poses of multiple objects at once, offering a more comprehensive understanding of the scene.
While the above methods improve performance using only RGB images, they still face challenges in handling object scales, rotational symmetries, and measurement uncertainties. Our approach follows the principles of online object-level SLAM, but with the known camera poses. Using per-frame neural network predictions as measurements, our approach resolves depth and scale ambiguities through a two-step sequential formulation. It also handles rotational symmetries and measurement uncertainties within an incremental online framework.
Pose uncertainty and visual ambiguity
In practice, the estimated object pose may carry state uncertainty or be subject to visual ambiguity. Representing these factors is crucial for many robotic applications, such as manipulation (Deng et al., 2020; Wang et al., 2019) or navigation (Fu et al., 2021; Salas-Moreno et al., 2013). Object pose uncertainty reflects variability in translation and orientation, potentially with different variances along each axis (e.g., depth uncertainty along the optical axis from a single viewpoint). A straightforward strategy is to assume a unimodal distribution and represent the pose with a single covariance matrix. To estimate this covariance, several works (Merrill et al., 2022; Peng et al., 2019; Richter-Klug, 2019; Yang and Pavone, 2023) adopt a structured strategy that first computes the uncertainty of 2D keypoint detections and then propagates it to the 6D pose. Extending this idea to depth information, studies such as (He et al., 2020; Liao et al., 2024; Salas-Moreno et al., 2013; Yang et al., 2024a) predict depth or 3D keypoint uncertainty and propagate it to the pose as well. Under the unimodal assumption, the resulting covariance can be further reduced by incorporating additional measurements.
Although the unimodal assumption is effective, it may fail to capture complex uncertainties, particularly when objects appear similar under different poses due to shape symmetries, occlusion, or repetitive textures, which is also known as visual ambiguities (Bui et al., 2020; Deng et al., 2022; Höfer et al., 2023; Hsiao et al., 2024; Manhardt et al., 2019; Okorn et al., 2020). It is important to model such visual ambiguities using more expressive, multimodal distributions. Furthermore, when distinctive object features are visible, the distribution should naturally converge to a more confident, unimodal estimate. For this purpose, sampling-based methods (Haugaard et al., 2023; Kendall and Cipolla, 2016; Shi et al., 2021) generate multiple pose hypotheses to estimate this uncertainty, but achieving high accuracy requires many samples, making these approaches computationally costly. Alternatively, Manhardt et al. (Manhardt et al., 2019) learn orientation distributions using a Winner-Takes-All (WTA) strategy (Rupprecht et al., 2017) over multiple hypotheses. To capture full orientation distributions, AAE (Sundermeyer et al., 2018) and PoseRBPF (Deng et al., 2021) adopt a discrete representation, whereas Okorn et al. (Okorn et al., 2020) use a histogram-based approach. While effective, these methods are inherently limited by discretization. To address this limitation, some approaches employ mixture of Gaussian (Fu et al., 2021) or Bingham mixture models (Deng et al., 2022; Gilitschenski et al., 2019) to represent multimodal orientation distributions.
In this work, we focus on modeling pose uncertainty rather than explicitly resolving visual ambiguities, enabling more efficient representations for robotic tasks.
Active vision
Active vision (Aloimonos et al., 1988; Bajcsy et al., 2018; Chen et al., 2011), or more specifically Next-Best-View (NBV) prediction (Connolly, 1985), refers to actively manipulating the camera viewpoint to obtain the maximum information in the next frame for the required task. Active vision has received a lot of attention from the robotics community and has been employed in many applications, such as robot manipulation (Breyer et al., 2022; Fu et al., 2024; Morrison et al., 2019), calibration (Choi et al., 2023; Rebello et al., 2017; Xu et al., 2023; Yang et al., 2023a), object pose estimation (Doumanoglou et al., 2016; Eidenberger and Scharinger, 2010; Sock et al., 2020; Wu et al., 2015; Yang et al., 2024a), 3D reconstruction (Forster et al., 2014; Isler et al., 2016; Yang and Waslander, 2022), and localization (Davison and Murray, 2002; Falanga et al., 2018; Hanlon et al., 2024; Zhang and Scaramuzza, 2018, 2019). The next-best-view selection is often achieved by finding the viewpoint that maximizes the information gain or minimizes the expected entropy (Choi et al., 2023; Doumanoglou et al., 2016; Kiciroglu et al., 2020; Rebello et al., 2017; Xu et al., 2023; Yang et al., 2023a, 2024abib_yang_et_al_2023abib_yang_et_al_2024a; Zhang and Scaramuzza, 2018, 2019). To estimate 6D object poses, Doumanoglou et al. first present a single-shot object pose estimation approach based on Hough Forests (Doumanoglou et al., 2016). The next-best-view is predicted by exploiting the capability of Hough Forests to compute the entropy. To eliminate reliance on the Hough Forests, recent studies show that the next-best-view can be achieved by maximizing the Fisher information of the robot state parameters (Forster et al., 2014; Rebello et al., 2017; Yang et al., 2023a, 2024a; Zhang and Scaramuzza, 2018, 2019). For example, in robot localization, the authors in Zhang and Scaramuzza (2018, 2019) use the Fisher information maximization to find highly informative trajectories and achieve high localization accuracy. Our approach lies in extending this principle to 6D object pose estimation. We actively move the camera to maximize the Fisher information, selecting viewpoints that most effectively reduce object pose uncertainty.
6D pose estimation using multi-view optimization
Problem formulation
Given a 3D object model and multi-view images, the goal of 6D object pose estimation is to estimate the rigid transformation

Given measurements
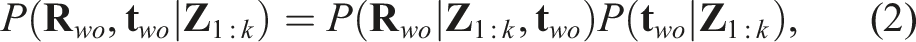
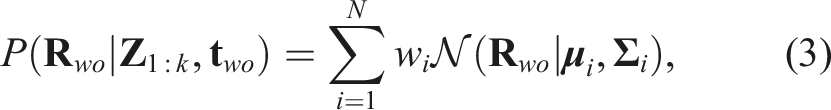
Our decoupling formulation implies a useful correlation between the object’s translation and orientation in the image domain. The 3D translation estimation An overview of the proposed multi-view object pose estimation pipeline with a two-step optimization formulation. We decouple the 6D pose estimation into a sequential process: first estimating the 3D translation, then the 3D orientation of each object. At each viewpoint, SEC-Net predicts the object’s 2D center, mask, and edge map. Using observations from K frames, we estimate translation via multi-view optimization, which provides object scale and center for re-cropping the edge map. Per-frame orientations are then obtained and fused via a max-mixture optimization.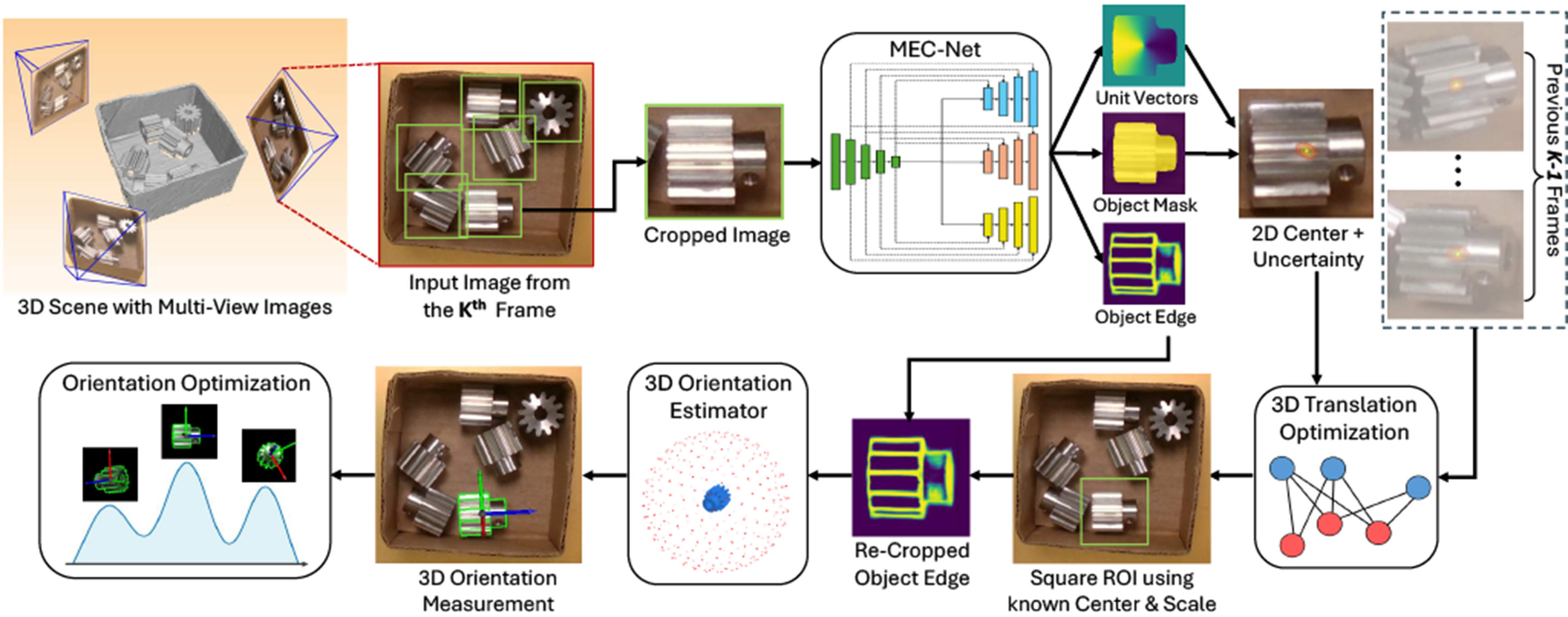
To implement this formulation, a key step in our framework is estimating per-frame measurements using a neural network, which are then integrated into our two-step sequential process. The network outputs the object’s 2D edge map, segmentation mask, and the 2D projection of its 3D center. We refer to our network as MEC-Net (Mask, Edge, Center Network) for the remainder of this paper. With these estimates, we proceed to the first step, where we estimate the 3D translation
3D translation estimation
As illustrated in Figure 3, the 3D translation Object, world, and camera coordinate frames. The 3D translation 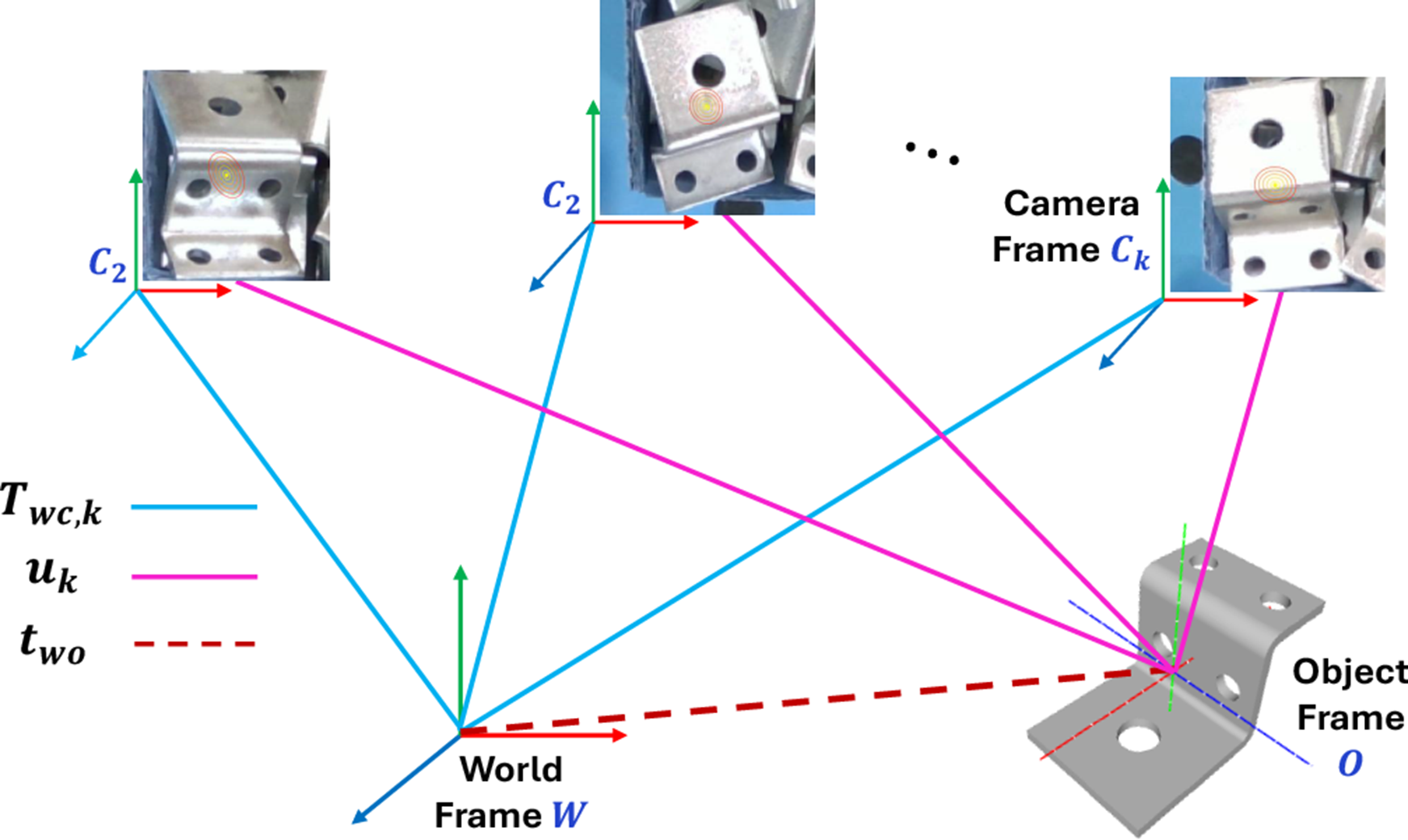
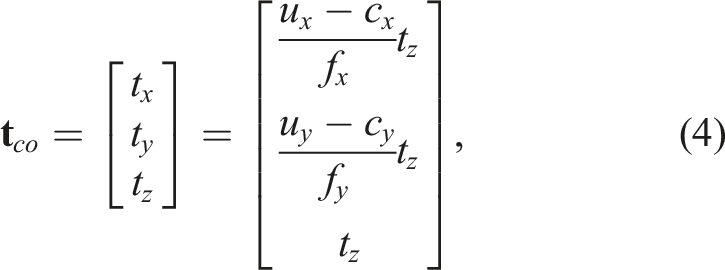
Our MEC-Net architecture is shown in the upper part of Figure 2 and is based on PoseCNN (Xiang et al., 2018) and PVNet (Peng et al., 2019). To handle multiple instances within the scene, we first employ YOLOv8 (Sohan et al., 2024) to detect 2D bounding boxes of the objects. These detections are then cropped and resized to 128 × 128 before being passed to the network. To estimate the object 2D center, the MEC-Net first predicts pixel-wise binary labels and a 2D vector field towards the object center. A RANSAC-based voting scheme is then applied to compute the mean
Given a sequence of measurements, we estimate the object’s 3D translation
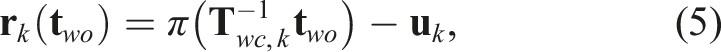
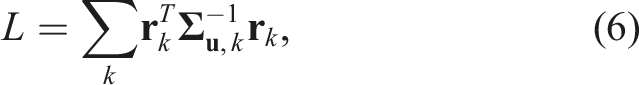
We solve the NLLS problem (Equation (5) and (6)) using an iterative Gauss-Newton procedure:
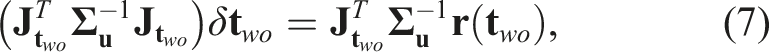
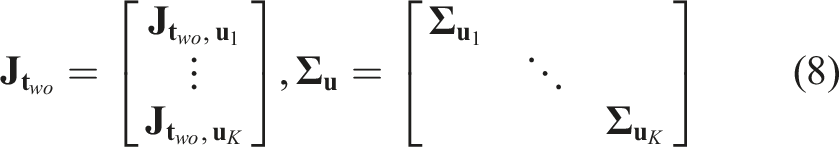
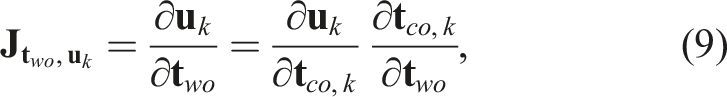
3D orientation estimation
The procedure for estimating the object orientation
Per-frame orientation measurement
The process of acquiring the per-frame object orientation measurement, The process of acquiring the per-frame object orientation measurement, 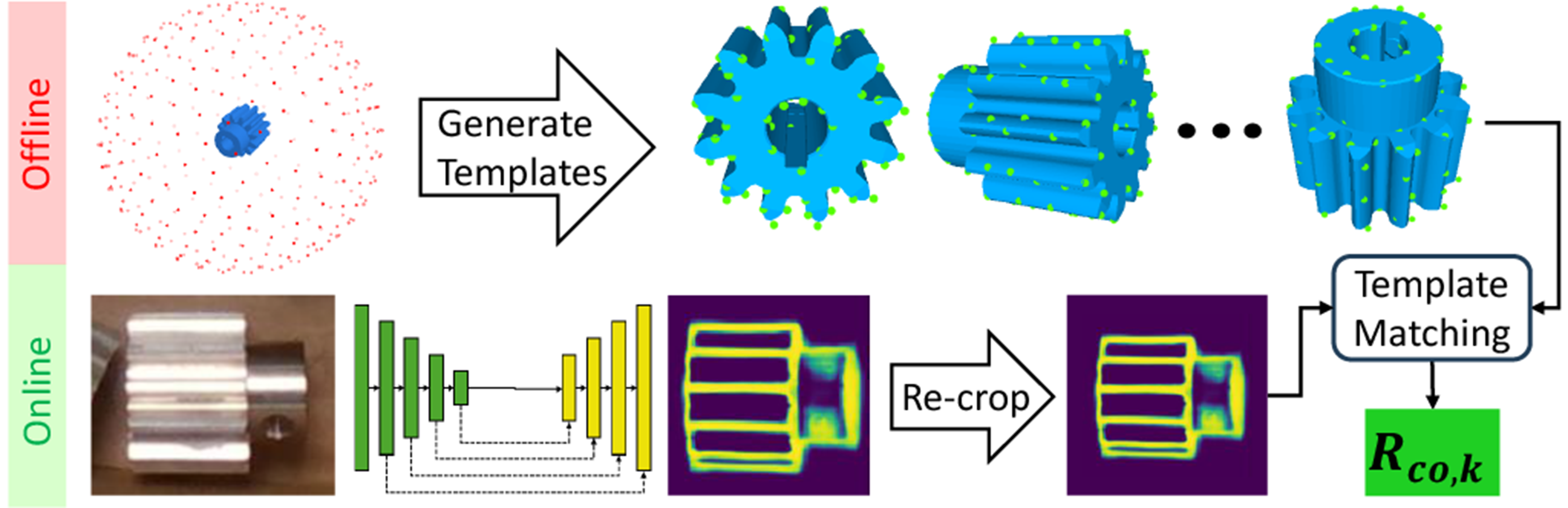
Predicting object edge map
To bridge the gap between rendered templates and RoI images, and to reduce the impact of spurious edges, we leverage our MEC-Net to directly generate the object’s edge map. As illustrated in Figure 2, we extend our previous approach (Yang et al., 2023b) by adding an extra network head specifically for estimating the object’s 2D edge map. To handle partial occlusion, which is common in real-world scene, we incorporate occlusion augmentation in our training data, similar to the approach used in AAE (Sundermeyer et al., 2018). During training, we treat the edge map as a binary classification task and minimize the cross-entropy loss. At inference, we apply the sigmoid function to map edge pixel values to the range of [0, 1], with higher values indicating greater confidence that a pixel belongs to the object edge.
Handling object scale change
To address the scale change issue, the original LINE-2D generates object templates at multiple distances and scales, which increases run-time complexity. In contrast, our approach fixes the 3D translation to a canonical centroid distance: (a) The inference of object size l
s
from its projective ratio. (b) Incorrect object orientation estimates on the original edge map due to scale changes. (c) Re-cropped object RoI using the object translation estimate, resulting in correct orientation estimation.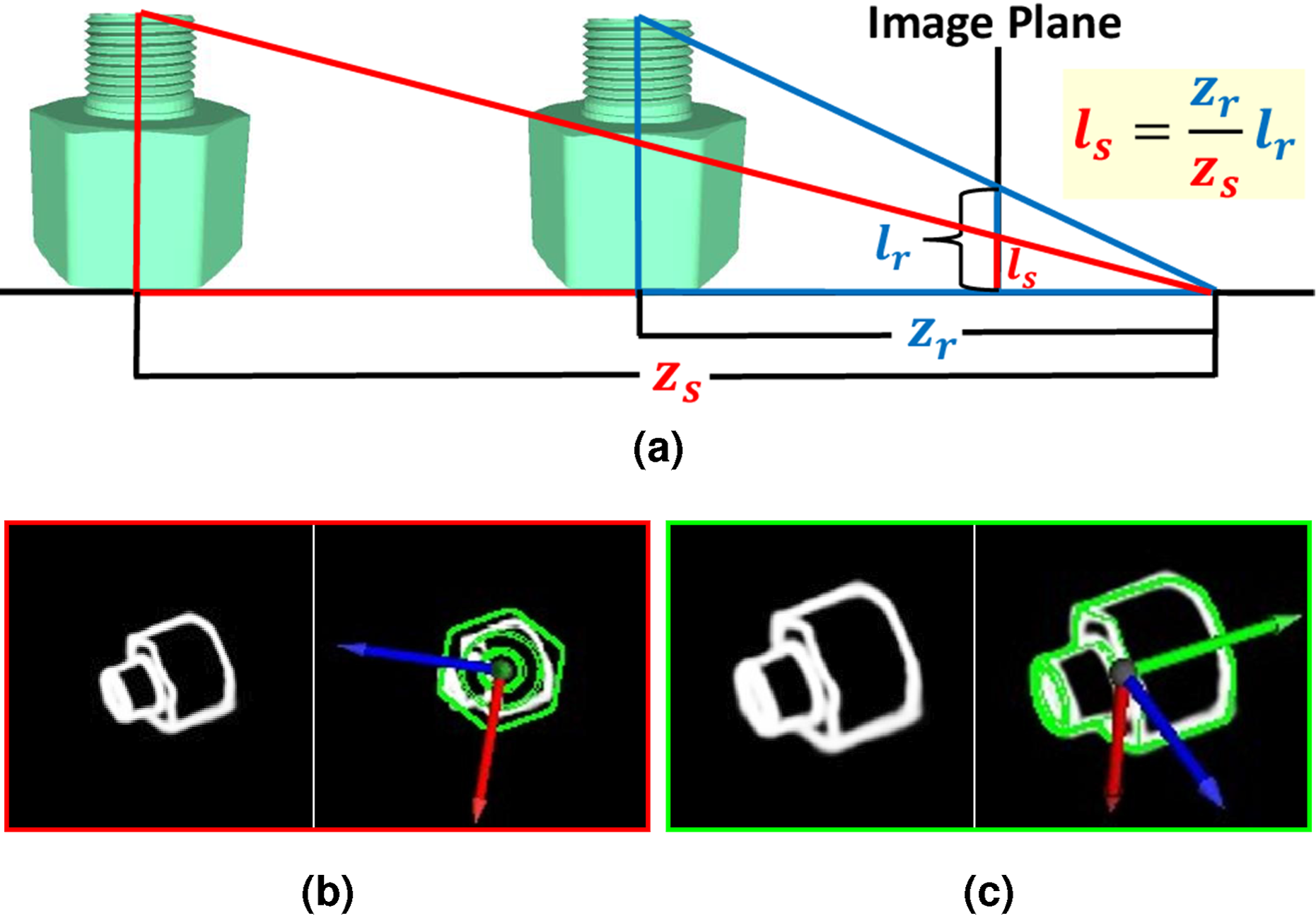


Optimization formulation
Given the multi-view orientation measurements,
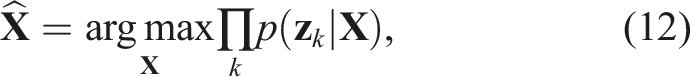
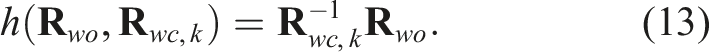
We formulate the optimization problem by creating the residual between the object orientation,
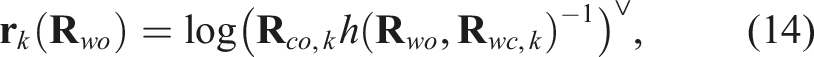
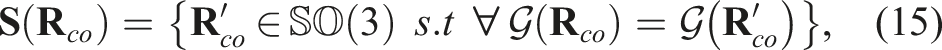
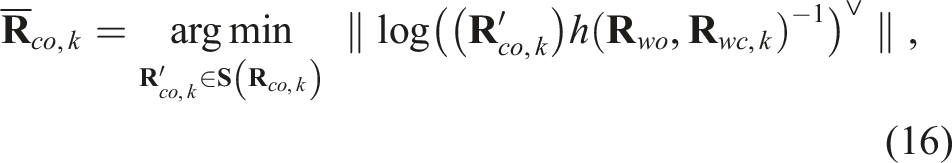
Measurement ambiguities
Due to the complex uncertainties, such unimodal estimates are insufficient to fully capture the uncertainty associated with the object orientation. To this end, we now consider the sum-mixture of Gaussians as the likelihood function:
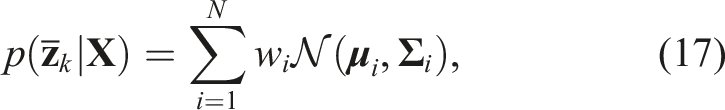
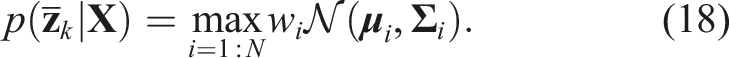
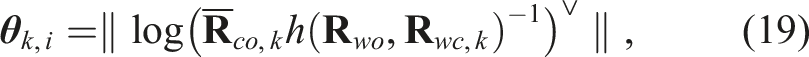
For each Gaussian component, we optimize the object orientation
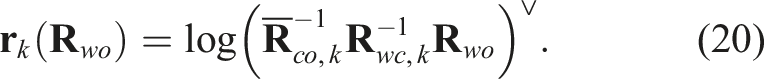
We perform the optimization in the tangent space
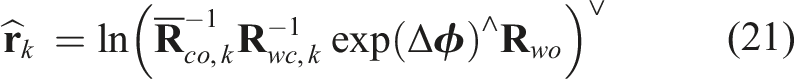
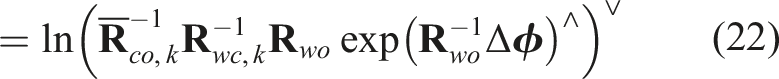
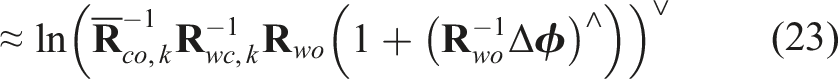
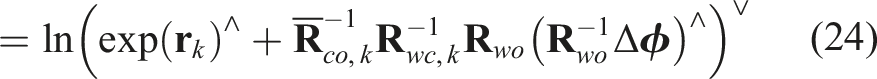
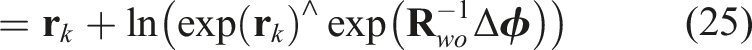
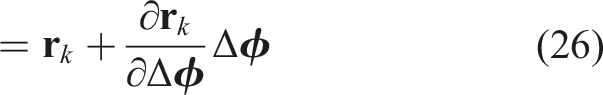

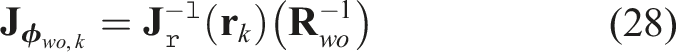

Similar to the 3D translation approach (Equation (7)), we optimize the object orientation,
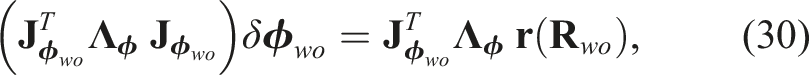
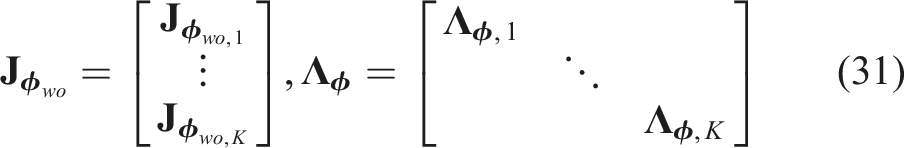
To compute the weight, w
i
, for each Gaussian component, we accumulate the LINE-2D confidence score, c
i
, from the orientation measurements within each component across the viewpoints. The weight can be approximated as Max-mixtures for processing the object orientation measurements. Note that we show the distribution only on one axis for demonstration purposes. (a) Acquired orientation measurements from different viewpoints. (b) Mixture distribution after two viewpoints. (c) Mixture distribution after five viewpoints. (d) Mixture distribution after eight viewpoints.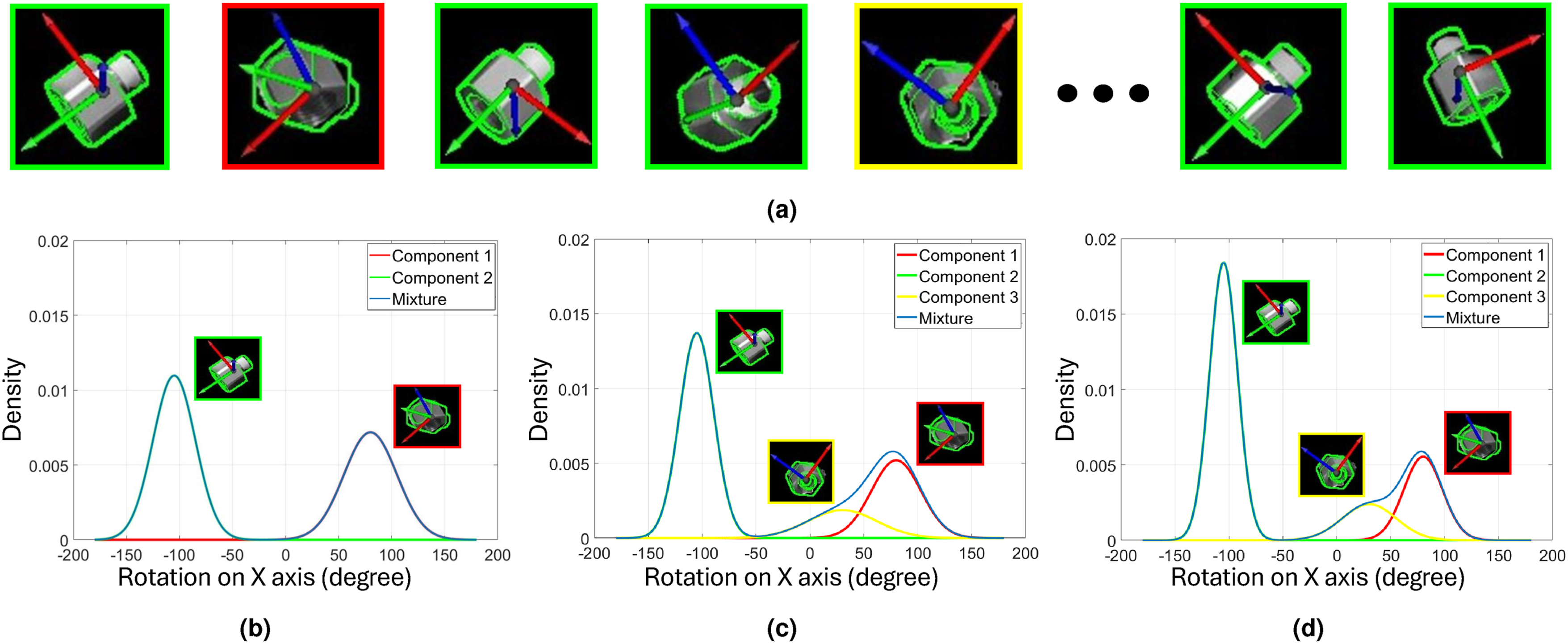

Active pose estimation using next-best-view
In the last section, we solve the multi-view object pose estimation problem using a two-step optimization formulation. However, the accuracy of the estimated object pose heavily depends on the collected RGB measurements from the selected camera viewpoints. Moreover, in many real-world applications, capturing a large number of viewpoints is impractical. To overcome this limitation, we introduce an active object pose estimation process. This approach not only estimates the uncertainty of the object pose but also predicts the next-best-view to minimize that uncertainty.
Initialization and uncertainty estimation
We initialize our active object pose estimation process with a collection of measurement sets,
3D translation
As discussed previously, we assume that the object’s translation,
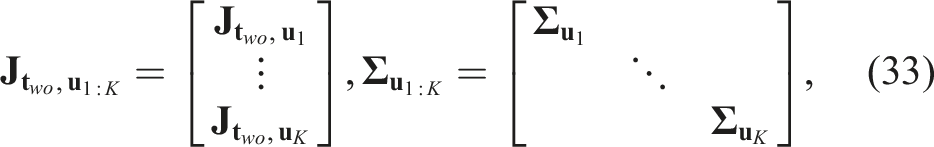
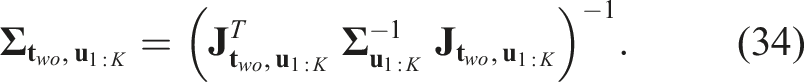
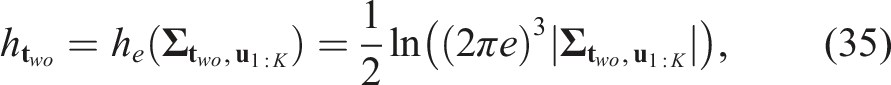
3D orientation
In contrast, the uncertainty calculation for the object orientation is more complex due to the Gaussian-mixture formulation, (a) Low orientation uncertainty when edge alignment is accurate (
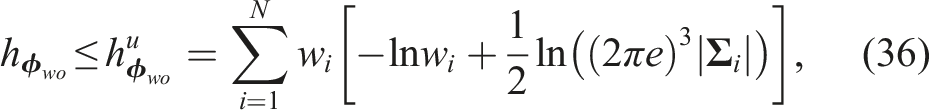
We begin by deriving the Jacobian of the projected edge points and their associated measurement uncertainties, which will later be used to compute the orientation covariance. For a set of N 3D model edge points, we denote their stacked coordinates as
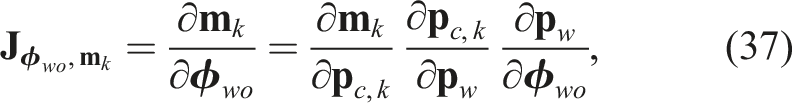
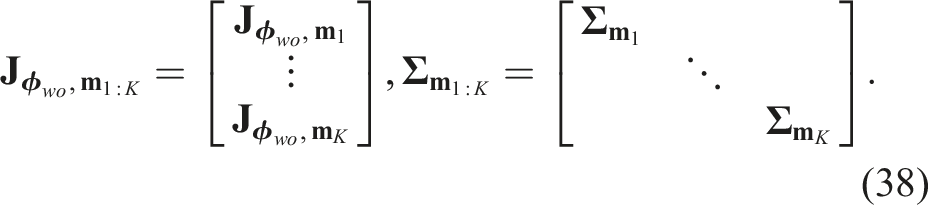
The covariance matrix,
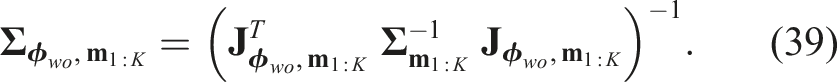
To compute the total entropy over the Gaussian mixture, we apply Equations (37)–(39) to each Gaussian component and substitute the results into equation (36):
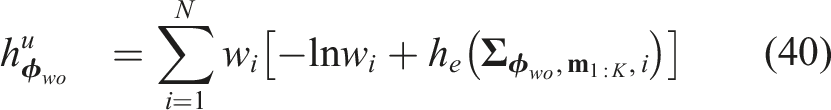
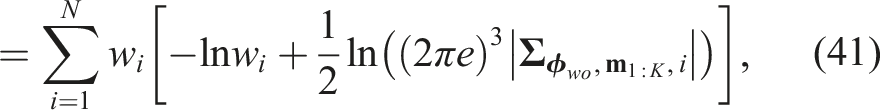
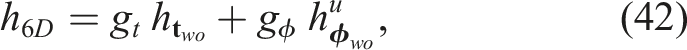
Next-best-view prediction
In our next-best-view setup, we operate with a predefined set of camera viewpoints,
Suppose we have already collected object center measurements,
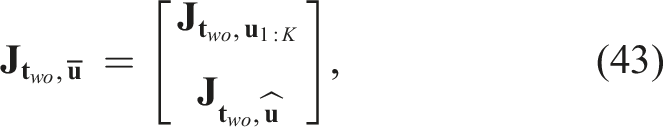
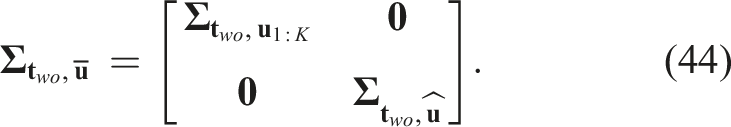
For the orientation component, similarly, for each Gaussian component, we define the stacked Jacobian, Visualization of the covariance matrix construction for object 3D translation. (a) The construction from collected measurements and (b) the construction when predicting NBV.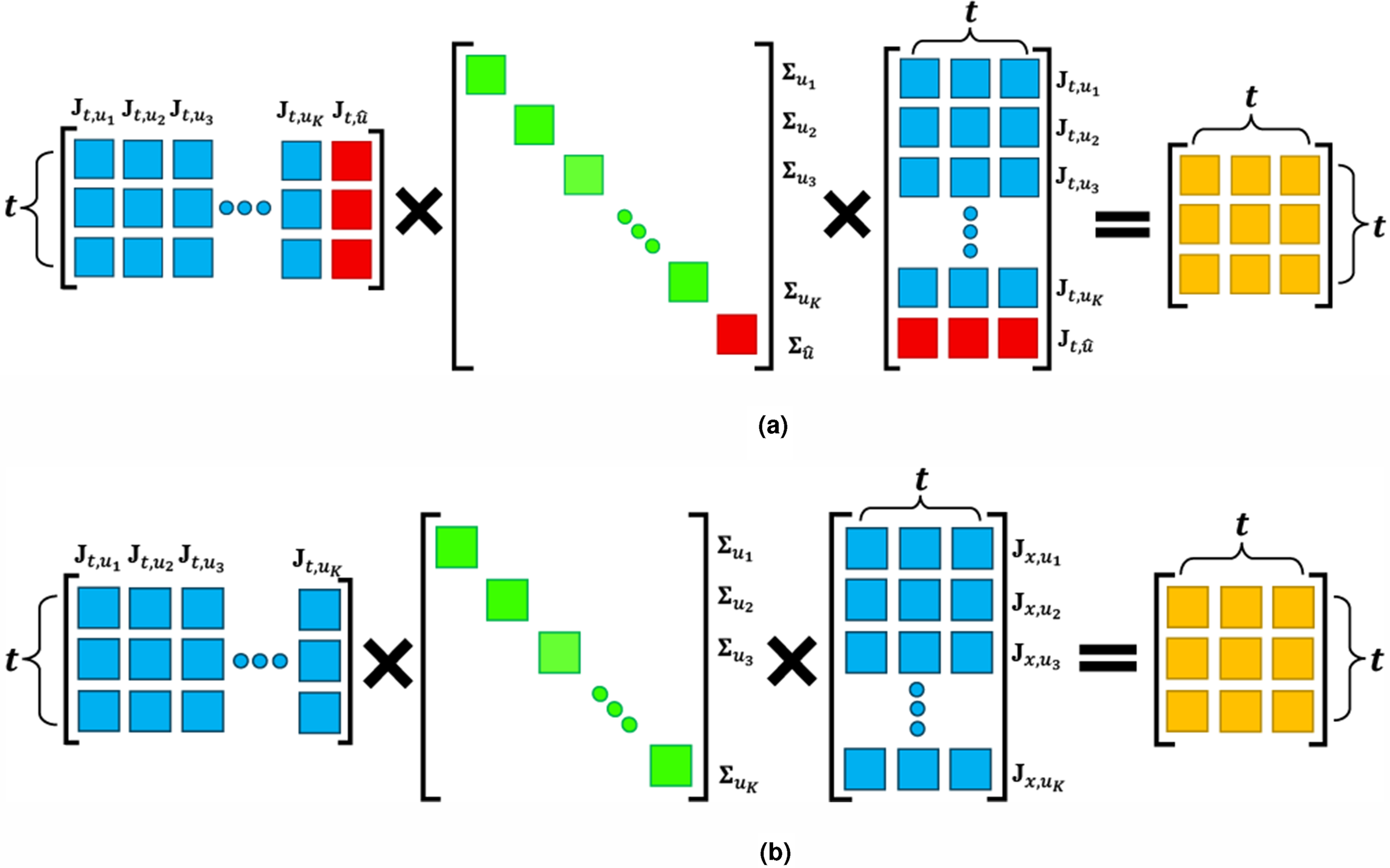
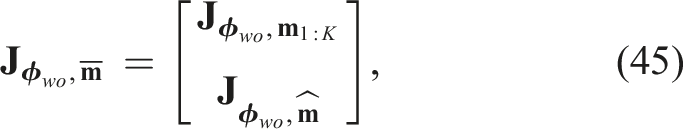
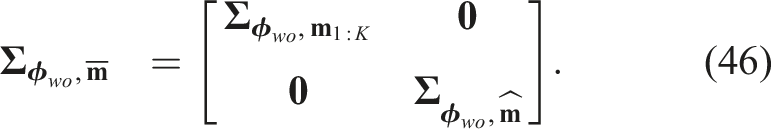
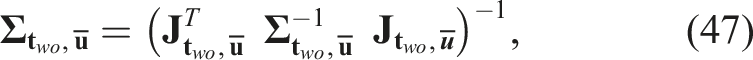
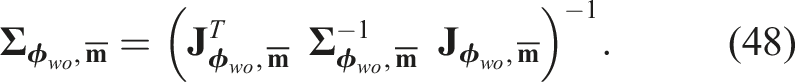
We determine our NBV from the candidate viewpoint set,
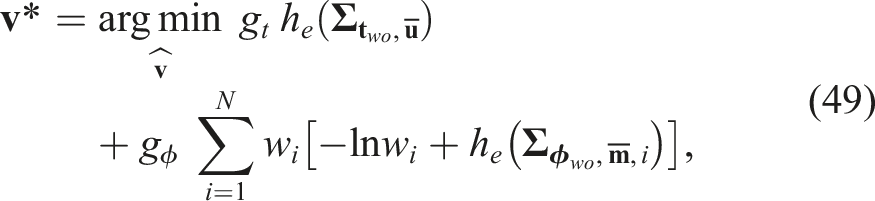
Once the next-best-view
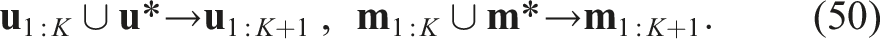
Experiments
Datasets
We evaluate our framework on three challenging real-world datasets: the public ROBI (Yang et al., 2021a) and TOD (Liu et al., 2020) datasets, and a new dataset of textureless transparent objects, T-ROBI, which we created for this work. The ROBI dataset contains seven textureless reflective industrial parts placed in complex bin scenarios, recorded from multiple viewpoints using two sensors: a high-end Ensenso camera and a commodity-level RealSense camera. The TOD dataset contains 15 transparent objects across six categories, each captured in isolated settings with diverse backgrounds and multiple RGB-D views per scene.
T-ROBI dataset
To further validate the effectiveness of our approach, we introduce the T-ROBI (Transparent Reflective Objects in BIns) dataset. This dataset includes two representative components: a “Bottle” and a “Pipe Fitting,” as illustrated in Figure 9. Unlike other publicly available transparent object datasets (Liu et al., 2020; Sajjan et al., 2020; Xu et al., 2021), which typically focus on isolated objects, our dataset presents a more challenging scenario. It consists of images containing multiple identical parts randomly stacked within a bin, thereby significantly increasing the difficulty of object pose estimation. For each object, we captured six distinct scenes from 55 camera viewpoints using the high-end Ensenso N35 camera (IDS, 2025). For each viewpoint, both monochrome images and depth maps are provided. However, as illustrated in Figure 9(b), the transparency of the objects results in significant depth inaccuracies or missing data, making it particularly challenging to label ground-truth 6D object poses. To address this, we adopted the ground-truth labeling method from the ROBI dataset (Yang et al., 2021a), utilizing a scanning spray (AESUB, 2025) to capture accurate ground-truth depth maps of all bins. The example ground-truth depth map, object CAD model, and annotated 6D object poses of the T-ROBI dataset are shown in Figure 9(c)–(e), respectively. Upon the publication of this work, we will release a public version of our T-ROBI dataset. This dataset is designed to support 6D pose estimation (Chen et al., 2023; Liu et al., 2020) as well as depth estimation tasks (Sajjan et al., 2020; Xu et al., 2021) for transparent objects in challenging cluttered and occluded bin-picking scenes. T-ROBI dataset: (upper) the object “Bottle” and (lower) the object “Pipe Fitting.” (a) Monochrome images, (b) raw depth maps, (c) ground-truth depth maps, (d) 3D CAD models of the objects, and (e) ground-truth 6D object poses.
Synthetic dataset
To facilitate network training, we introduce a large-scale synthetic dataset comprising objects from both the ROBI and T-ROBI datasets, as illustrated in Figure 10. For each scene, we provide the RGB images, depth maps, object masks, and 6D poses. Our simulation environment is built using the Bullet physics engine (Coumans and Bai, 2016) in conjunction with Blender software (Community, 2018). The process begins with importing each object’s CAD model into Blender, where we manually specify its color and material properties. After preparing the object, we load it into the simulation and drop it from various positions and orientations within the bin using the Bullet physics engine. This approach allows us to generate a wide variety of object poses, clutter levels, and occlusions. Next, we adjust both the light source and camera pose to different viewpoints above the bin and render the scene using Blender, resulting in high-quality visual representations for our dataset. Finally, we utilize the Ensenso SDK (IDS, 2025) to generate synthetic depth images, as shown in Figure 10(c). For each object, we produce approximately 6000 to 13,000 images. We will also release our synthetic dataset upon publication. Examples of our generated synthetic data using the Blender rendering software (Community, 2018) with the Bullet physics engine (Coumans and Bai, 2016). (a) The RGB images, (b) the object masks, (c) the depth maps, and (d) the ground-truth 6D object poses. From top to bottom: the object “D-Sub Connector,” “Zigzag” from ROBI dataset (Yang et al., 2021a) and “Bottle” from T-ROBI dataset.
YOLO detection performance
YOLOv8 object detection performance on the ROBI and T-ROBI datasets under different IoU thresholds. The table reports the detection rate and false detection rate for both thresholds.
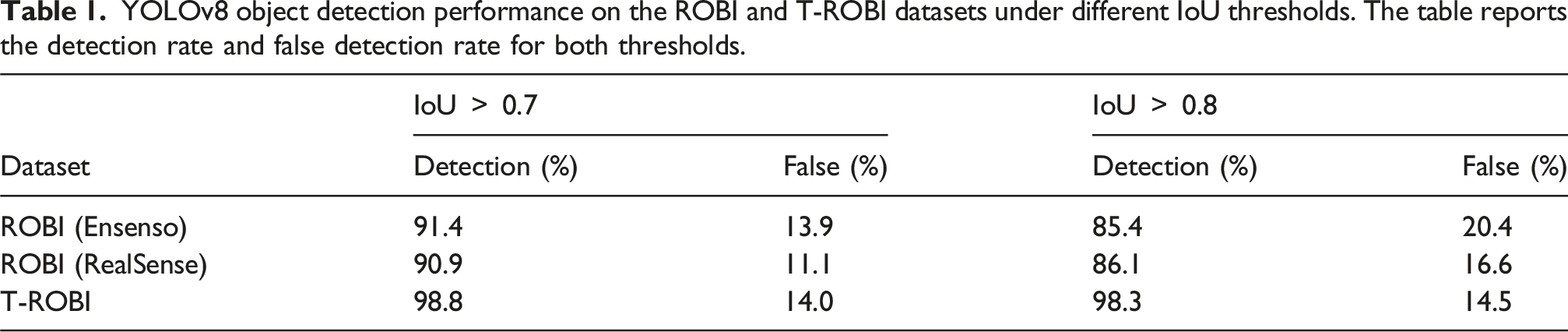
As shown in Table 1, YOLOv8 achieves a high detection rate (above 90%) and a low false rate (below 15%) across all datasets when evaluated with the 0.7 IoU threshold. Even under the stricter 0.8 IoU criterion, the detection performance remains consistently strong. Representative results in Figure 11 further confirm that YOLOv8 provides sufficiently accurate detections for the subsequent object pose estimation stages. Qualitative results of YOLOv8 object detection on the ROBI and T-ROBI datasets. Detections with IoU 
Baselines and implementations for pose estimation
We quantitatively evaluate our approach against three prominent baselines: Multi-View 3D Keypoints (MV-3D-KP) (Li and Schoellig, 2023) and two variants of CosyPose (Labbé et al., 2020). To ensure a fair comparison, all methods are trained only on the synthetic dataset. During run-time, we utilize identical object bounding box detections and provide ground-truth multi-view camera poses. MV-3D-KP: Multi-View 3D Keypoints (MV-3D-KP) (Li and Schoellig, 2023) builds upon the single-view approach of PVN3D (He et al., 2020) and specializes in estimating 6D object poses by leveraging both RGB and depth data. MV-3D-KP provides excellent scalability, allowing for the incorporation of additional views that enhance accuracy and reduce uncertainty in pose estimation. As shown in Li and Schoellig (2023), this method demonstrates exceptional performance on the ROBI dataset, setting a high standard in the field. CosyPose+PVNet: CosyPose (Labbé et al., 2020) is a multi-view pose fusion solution which takes the 6D object pose estimates from individual viewpoints as the input and optimizes the overall scene consistency. Note that, CosyPose is an offline batch-based solution that is agnostic to any particular pose estimator. In our implementation, we utilize a learning-based approach, Pixel-Wise Voting Network (PVNet) (Peng et al., 2019), to acquire the single-view pose estimates. The PVNet approach first detects 2D keypoints and then solves a Perspective-n-Point (PnP) problem for pose estimation. This approach naturally deals with object occlusion and achieves remarkable performance. CosyPose+LINE2D: To provide single-view pose estimates for CosyPose, we additionally utilize the LINE-2D pose estimator. In our implementation, we utilize the LINE-2D pose estimator with the same object center, object edge, and segmentation mask (from our MEC-Net). To feed the reliable single-view estimates to CosyPose, we use two strategies to obtain scale information. For the first strategy, we generate the templates at multiple distances during training (9 distances in our experiments) and perform standard template matching at inference time. This strategy can significantly improve the single-view pose estimation performance by sacrificing run-time speed and is treated as the RGB version. For the second strategy, we directly use the depth images at inference time to acquire the object scale and refer to it as the RGB-D version.
We implement our MEC-Net using the PyTorch library, employing ResNet-18 (He et al., 2016) as the backbone network. The MEC-Net is trained from scratch using the Adam optimizer (Kingma and Ba, 2015), with a batch size of 640 and a learning rate of 0.001 over 100 epochs on an RTX A6000 GPU. To ensure a fair comparison between MV-3D-KP and PVNet, we use the same ResNet-18 backbone and maintain consistent hyperparameters during training.
Evaluation metrics for pose estimation
In our evaluation, we consider a ground-truth pose only if its visibility score is larger than 75%. We adopt two metrics to evaluate pose estimation performance: the symmetry-aware average model distance (
For objects with known geometric symmetries, the standard ADD metric (Hinterstoisser et al., 2012) may incorrectly penalize poses that are visually indistinguishable under the object’s symmetry group. A commonly used alternative, ADD-S, handles symmetry via nearest-neighbor matching but can tolerate large pose errors. To address this, we adopt a symmetry-aware variant of ADD, denoted as ADD*, that leverages the object’s known symmetry group. Let 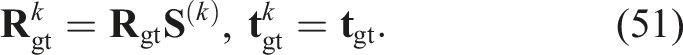
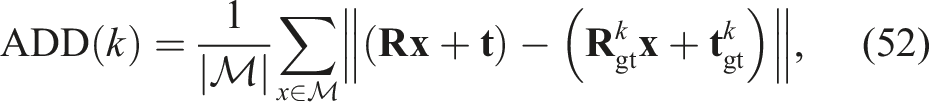
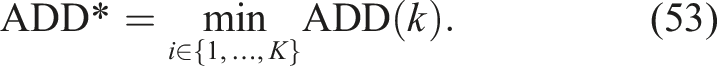
To further evaluate pose accuracy, we also use the stricter 5-mm/10-degree (5 mm, 10°) metric. We reuse the symmetry-equivalent ground-truth poses defined for ADD*. The rotation and translation errors are evaluated against each symmetry-adjusted pose
Pose estimation results on ROBI
We conduct experiments on the ROBI dataset with a variable number of viewpoints (4 and 8), with the viewpoints carefully chosen to provide broad coverage of the scene. Figure 12(a) illustrates the qualitative superiority of our approach. Quantitative results on the Ensenso and RealSense test sets are presented in Tables 2 and 3, respectively. The results show our method outperforms the RGB baseline by a wide margin, and is competitive with the RGB-D approaches, without the need for depth measurements. Qualitative results of our approach for the ROBI, T-ROBI datasets. Pose estimation performance is depicted using color coding: green indicates detections that satisfy the ADD* metric, while red indicates those that do not. The results are generated using eight camera viewpoints. To enhance visualization, the estimated object poses are overlaid on the ground-truth depth map. Detection rates of 6D object pose estimation on Ensenso test set from ROBI dataset, evaluated with the metrics of ADD* and (5 mm, 10°). There are a total of nine scenes for each object. aIn our evaluation, we treat the object “Gear” as symmetric about the Z-axis with an order of 12. bIn our evaluation, we treat the object “D-Sub Connector” as symmetric about the Z-axis with an order of 2. Detection rates of 6D object pose estimation on RealSense test set from ROBI dataset, evaluated with the metrics of ADD* and (5 mm, 10°). There are a total of four scenes for each object.
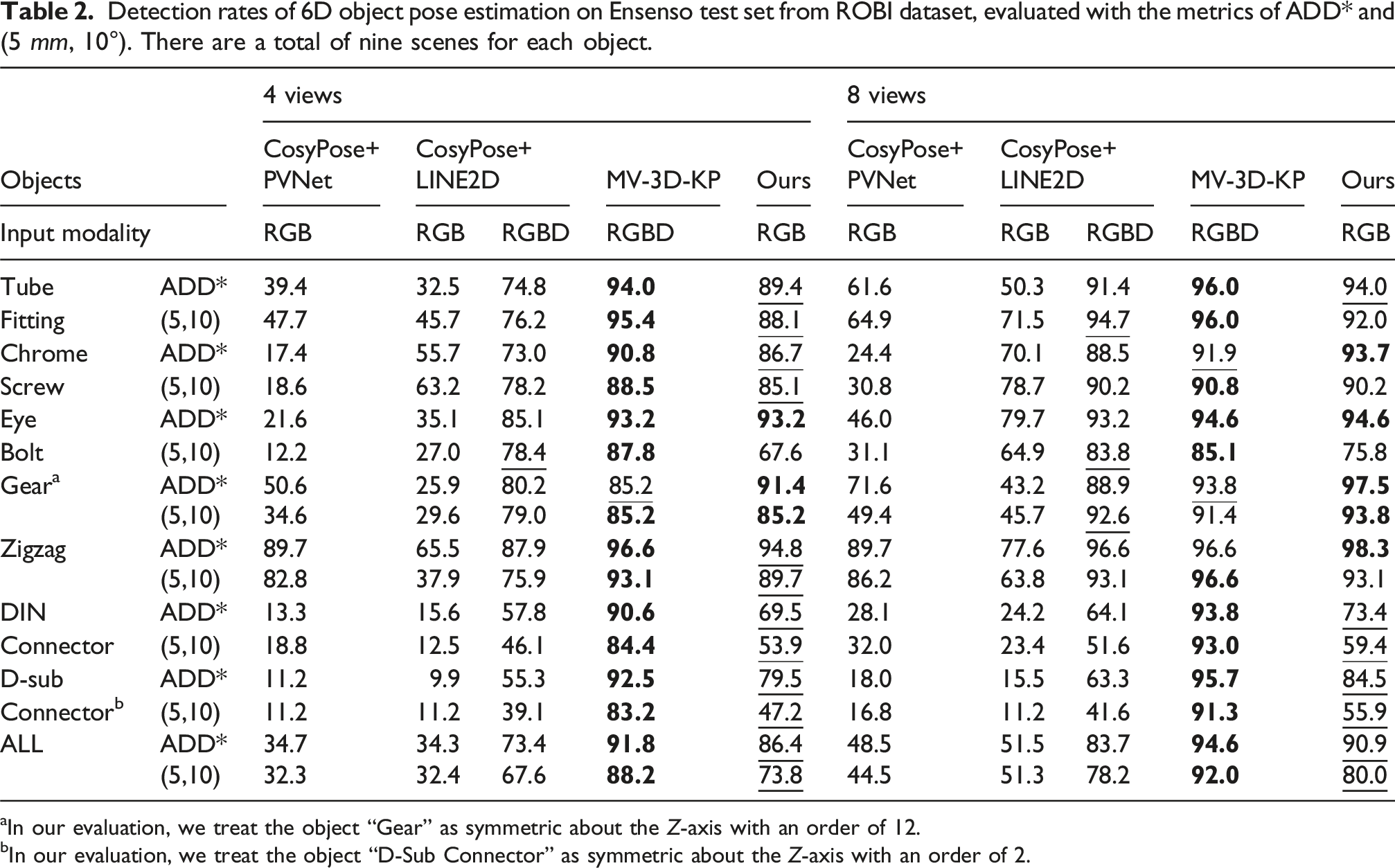
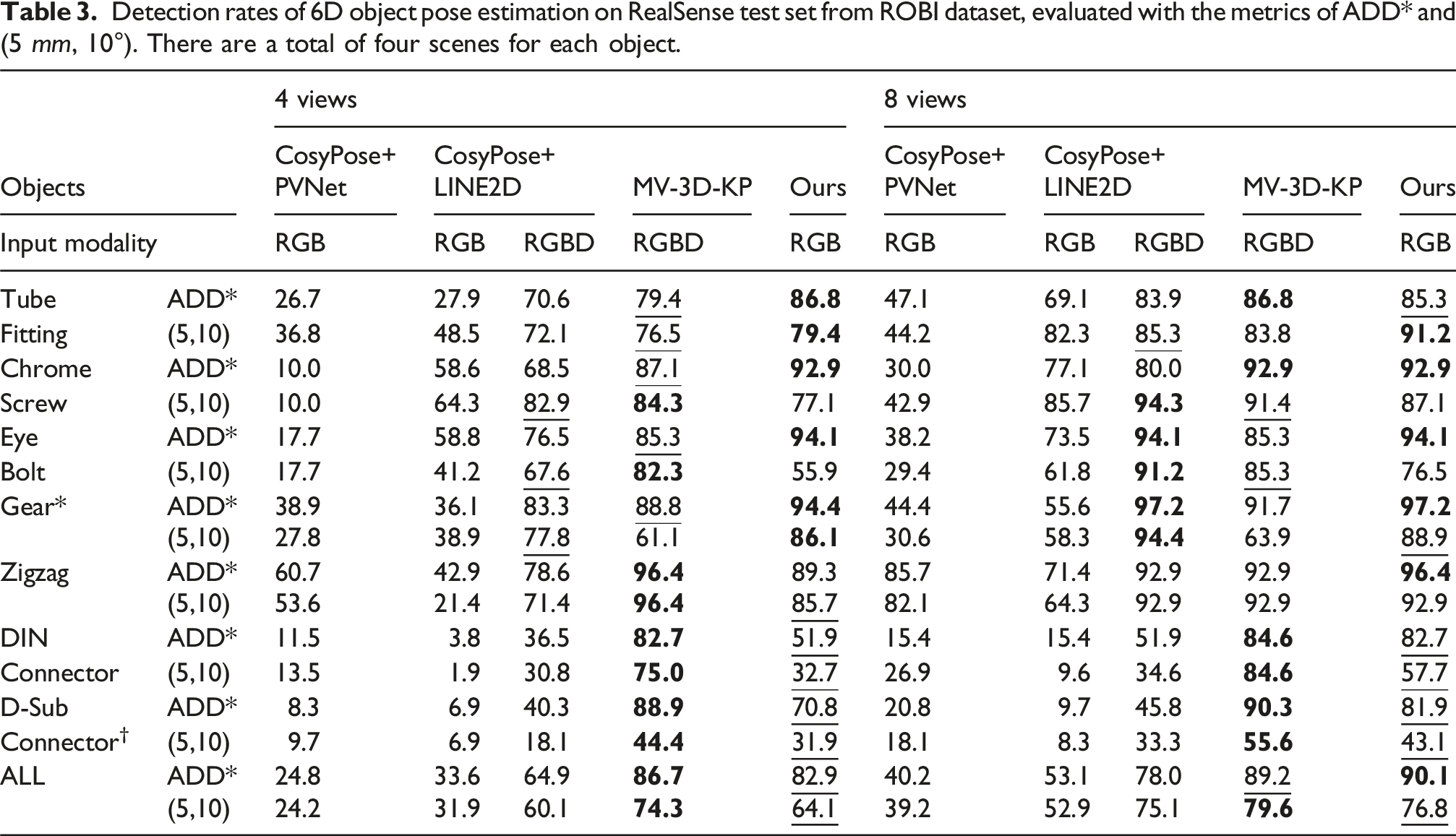
In the Ensenso test set, it is noteworthy that “MV-3D-KP” demonstrates exceptional performance, achieving state-of-the-art results on the ROBI dataset. This success is largely attributed to the high-quality depth maps produced by the Ensenso 3D camera. Specifically, when utilizing RGB-D data, the “MV-3D-KP” method achieves an overall detection rate of 91.8% using four views and 94.6% using eight views, as measured by the ADD* metric. Additionally, it achieves an overall detection rate of 88.2% with four views and 92.0% with eight views using the (5 mm, 10°) metric. In comparison, despite relying solely on RGB data, our approach demonstrates competitive performance, with detection rates only 5.4% and 3.7% lower than MV-3D-KP for four-view and eight-view data, respectively, as measured by the ADD* metric. When utilizing only RGB images, our approach significantly outperforms both “CosyPose+PVNet” and “CosyPose+LINE2D,” achieving margins of at least 51.7% and 39.4% for the 4-view and 8-view configurations, respectively, as measured by the ADD* metric. With the availability of depth data, the performance of “CosyPose+LINE2D” shows substantial improvement, representing its upper bound. In contrast, our method exceeds this upper bound by a clear margin, achieving detection rates that are 13.0% and 7.2% higher on the 4-view and 8-view test sets, respectively, with the ADD* metric. A similar margin is observed when using the (5 mm, 10°) metric.
In the RealSense test set, the degraded quality of depth data presents challenges for both the “MV-3D-KP” and “CosyPose+LINE2D” (RGB-D version) methods. In contrast and as expected, our approach maintains a comparable detection rate. Specifically, for the 4-view configuration, our approach exhibits only a slight decrease in performance compared to the “MV-3D-KP” by 3.8% and 10.2% using the ADD* and the (5 mm, 10°) metric. With the 8-view configuration, our approach achieves the best performance of 90.1% using the ADD* metric and is only 2.8% lower than “MV-3D-KP” under the (5 mm, 10°) metric.
Pose estimation results on T-ROBI
Detection rates of 6D object pose estimation on T-ROBI dataset, evaluated with the metrics of ADD* and (5 mm, 10°). There are a total of six scenes for each object.
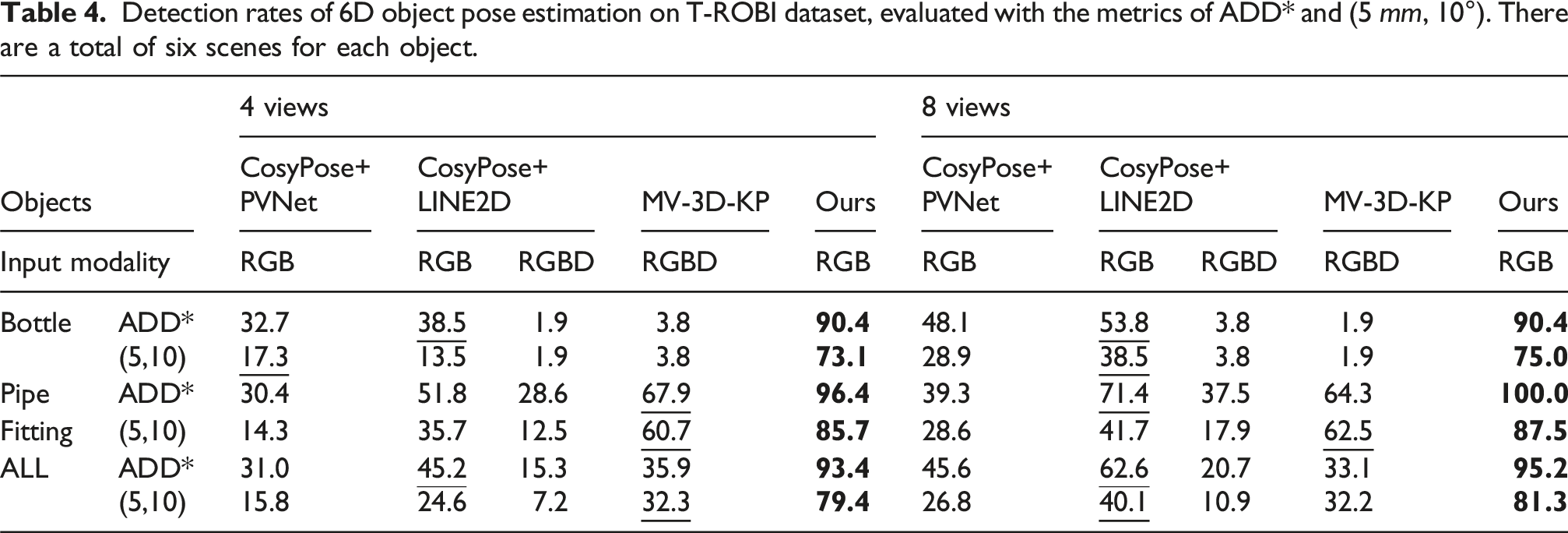
In contrast, the “MV-3D-KP” and “CosyPose+LINE2D” (RGB-D version) approaches show low detection rates, largely due to significant depth missing and inaccuracies. These results highlight the advantage of our RGB-only approach for transparent objects that typically challenge depth-based methods.
Pose estimation results on TOD
For evaluation on the TOD dataset (Liu et al., 2020), we compare against KeyPose (Liu et al., 2020), the state-of-the-art method for 6D pose estimation of transparent objects. KeyPose is also the leading approach reported on the TOD dataset. We follow the KeyPose experimental protocol, using the same training and testing data to ensure a fair comparison. In our experiments, we evaluate a total of six objects, selecting one representative object from each category. For each object, one texture is held out for testing, resulting in approximately 3000 training samples and 320 test samples per object.
Comparison of our method with KeyPose+CosyPose on the TOD dataset (Liu et al., 2020).
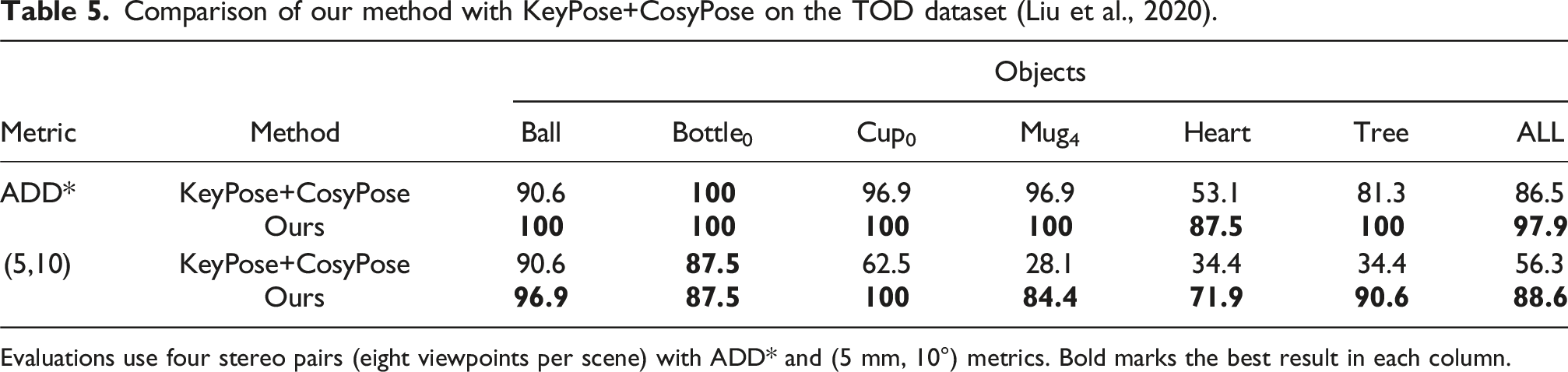
Evaluations use four stereo pairs (eight viewpoints per scene) with ADD* and (5 mm, 10°) metrics. Bold marks the best result in each column.

Qualitative results of our approach on the testing and validation sets of the TOD. The results are generated using four stereo pairs (8 viewpoints). From left to right: Mug4, Cup0, Tree, and Heart.
Comparison with RGB-D baselines
To evaluate the practical advantage of our RGB-only approach, we compare it against the MV-3D-KP baseline on ROBI and T-ROBI dataset under different depth configurations: Ground-Truth (GT) Depth: Captured with scanning spray and a high-end Ensenso sensor for optimal quality. This depth serves as an oracle reference and is not available in practice. Raw Depth: Directly captured from either a high-end Ensenso sensor or a commodity-level RealSense camera. DA+GT Scale: Depth is predicted from the RGB image using Depth-Anything V2 (Yang et al., 2024b). For each frame, the predicted relative depth is converted to metric depth by aligning it to the corresponding ground-truth depth using scale and shift (Ganj et al., 2025). This represents the upper-bound performance of Depth-Anything V2.
Comparison of our RGB-only approach against MV-3D-KP with different depth sources on the ROBI and T-ROBI datasets.
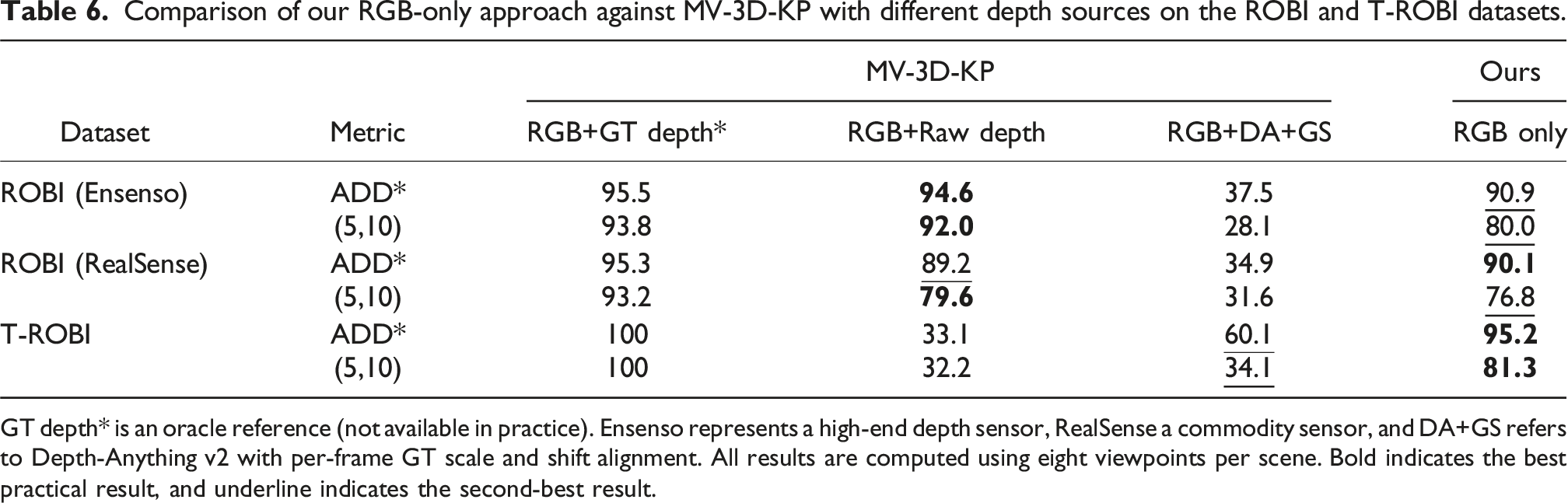
GT depth* is an oracle reference (not available in practice). Ensenso represents a high-end depth sensor, RealSense a commodity sensor, and DA+GS refers to Depth-Anything v2 with per-frame GT scale and shift alignment. All results are computed using eight viewpoints per scene. Bold indicates the best practical result, and underline indicates the second-best result.
When using Depth-Anything V2, MV-3D-KP performance improves slightly only for objects that are completely invisible to the sensor, such as the transparent objects in T-ROBI. Even in these cases, it still performs worse than our RGB-only method by at least 35.1%. In contrast, on the ROBI dataset, where objects are reflective but depth can be directly sensed, DA+GT provides minimal improvement and performs worse than on T-ROBI, mainly due to the high clutter in ROBI bins. For these ROBI objects, MV-3D-KP with DA+GT remains far below both its performance with real depth and our RGB-only approach. Overall, these results demonstrate that while predicted depth can help in extreme cases, it cannot replace real depth measurements or multi-view RGB cues for robust pose estimation.
Ablation studies on pose estimation
Ablation studies on different configurations for 6D object pose estimation on the ROBI and T-ROBI datasets.
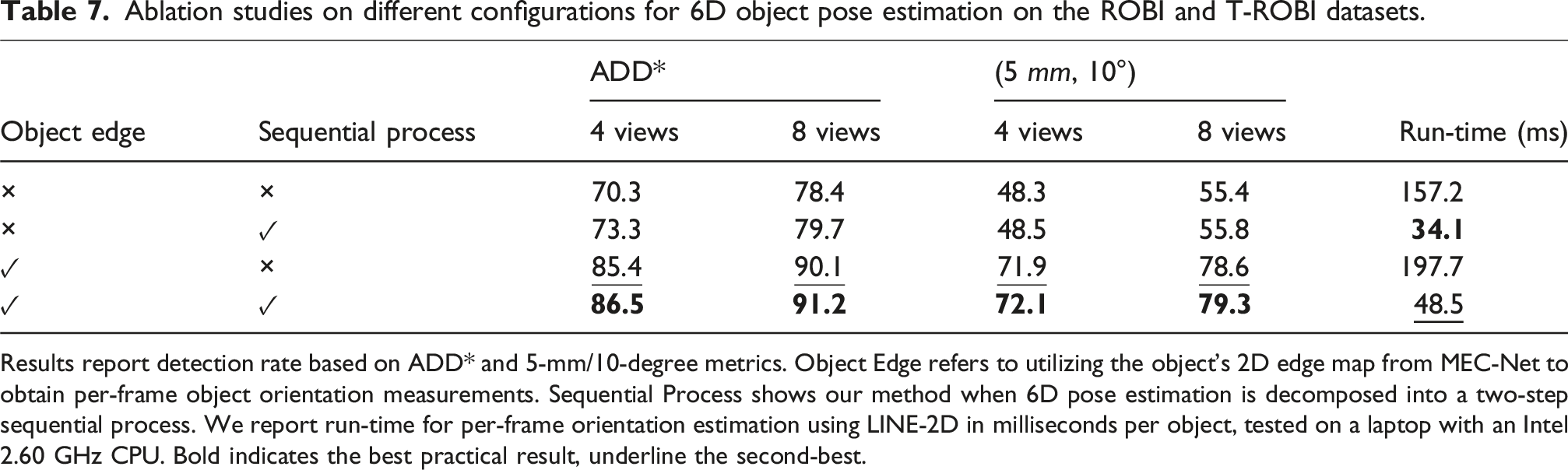
Results report detection rate based on ADD* and 5-mm/10-degree metrics. Object Edge refers to utilizing the object’s 2D edge map from MEC-Net to obtain per-frame object orientation measurements. Sequential Process shows our method when 6D pose estimation is decomposed into a two-step sequential process. We report run-time for per-frame orientation estimation using LINE-2D in milliseconds per object, tested on a laptop with an Intel 2.60 GHz CPU. Bold indicates the best practical result, underline the second-best.
Edge map
For optimizing the object 3D orientation, we use a template matching-based orientation estimator, LINE-2D, to obtain the per-frame object orientation measurement. However, LINE-2D is susceptible to issues related to occlusion and fake edges. Compared to our previous approach (Yang et al., 2023b), we address these problems by leveraging our MEC-Net to directly produce the object’s 2D edge map. To demonstrate the advantage of this approach, we conduct a comparison of the final results with and without using the edge map. In cases where edge maps are unavailable, we take the object mask from the MEC-Net and then feed the re-cropped object RoI into the LINE-2D estimator. Table 7 clearly shows a significant increase in the correct detection rate when utilizing the estimated edge map. This phenomenon is more obvious when using the metric, (5 mm, 10°), which imposes a stricter criterion for orientation error.
Sequential process
As discussed in the problem formulation, the core idea of our method is the decoupling of 6D pose estimation into a two-step sequential process. This process first resolves the scale and depth ambiguities in the RGB images and greatly improves the orientation estimation performance. To justify its effectiveness, we consider an alternative version of our approach, one which simultaneously estimates the 3D translation and orientation. This version uses the same strategy to estimate the object translation. However, instead of using the provided scale from the translation estimates, it uses the multi-scale trained templates (similar to the RGB version of CosyPose) to acquire orientation measurements. Table 7 shows that, due to the large number of templates, the run-time for orientation estimation is generally slow for the simultaneous process version. In comparison, our sequential process not only operates with a much faster run-time speed but also has slightly better overall performance.
Next-best-view evaluation
In our setup, we operate with a predefined set of camera viewpoints, and the evaluation consists of selecting the next-best viewpoint from this set. We compare our approach against two heuristic-based baselines, “Random” and “Max-Distance.” “Random” selects viewpoints randomly from the candidate set, while “Max-Distance” moves the camera to the viewpoint farthest from previous observations.
The evaluation is performed on the ROBI, T-ROBI, and TOD datasets. For all view selection strategies, we use our object pose estimation method to ensure a fair comparison. To obtain the results, we initialize the object pose with two viewpoints and progressively refine it by incorporating RGB measurements selected according to each view selection strategy.
Next-Best-View evaluation.
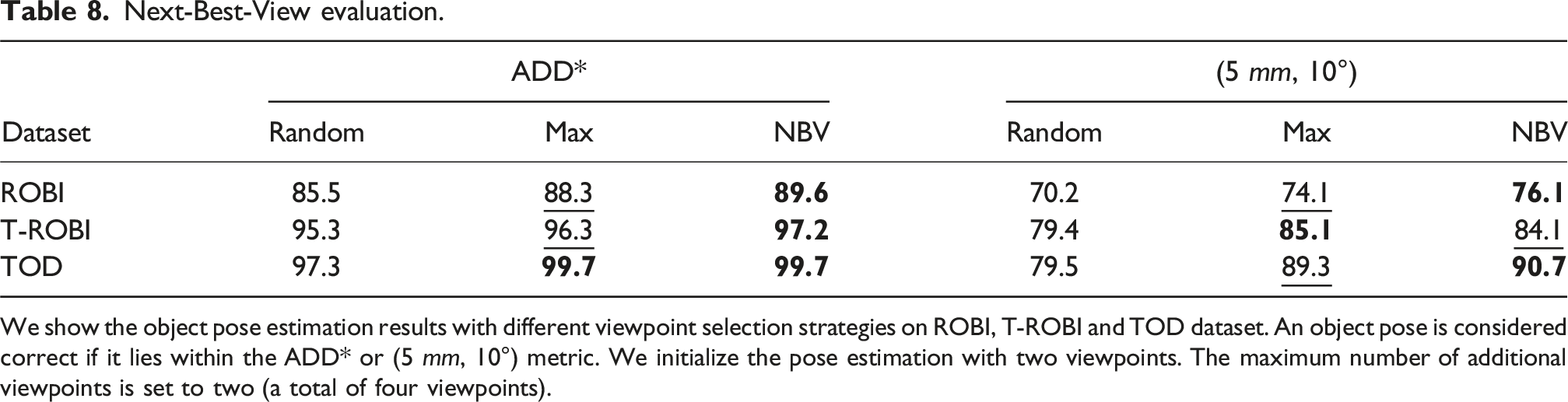
We show the object pose estimation results with different viewpoint selection strategies on ROBI, T-ROBI and TOD dataset. An object pose is considered correct if it lies within the ADD* or (5 mm, 10°) metric. We initialize the pose estimation with two viewpoints. The maximum number of additional viewpoints is set to two (a total of four viewpoints).
Figure 14 illustrates the trend more clearly when extending to four additional viewpoints (6 viewpoints in total). Compared to the “Random” (red curve) and “Max-Distance” baseline (green curve), our NBV policy (blue curve) consistently achieves higher or comparable ADD* performance on ROBI, T-ROBI, and TOD datasets, showing its reliability across different scene complexities. Evaluation of our next-best-view policy when comparing against heuristic-based baselines. We use our multi-view pose estimation approach for all the viewpoint selection strategies. The results are evaluated using the correct detection rate with the ADD* metric on the ROBI, T-ROBI, and TOD datasets. Our approach can achieve a high correct detection rate with fewer viewpoints.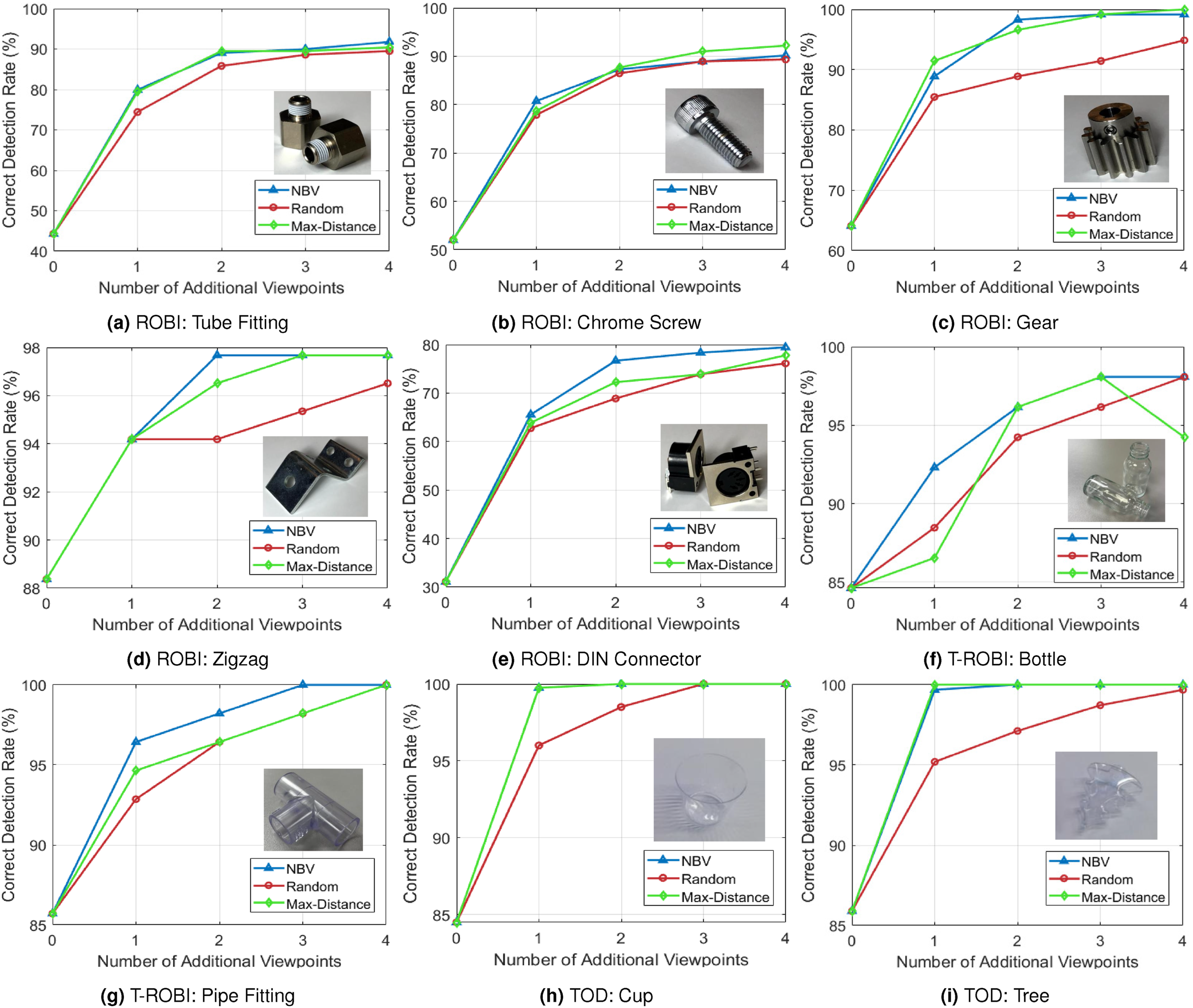
Limitations and future work
Although we have demonstrated the effectiveness of our approach in real-world scenes, there are several limitations that future work can address. First, in our problem formulation, we model the object translation distribution as a unimodal Gaussian. While this assumption generally holds, it can fail in heavily occluded cases, such as a cylindrical object with both ends occluded, and adopting a multimodal distribution (Bui et al., 2020) could allow the model to capture multiple plausible translations.
Second, in our next-best-view prediction, although the object’s orientation is modeled as a multimodal distribution, the predicted viewpoints are intended to refine the final pose accuracy under the assumption that the initial pose is unambiguous. Consequently, if the object exhibits inherent visual ambiguity (e.g., from occlusion), this approach cannot resolve it, since it does not explicitly account for disambiguating between multiple plausible modes (Manhardt et al., 2019). Addressing these ambiguities is an important direction for future work.
Third, in our NBV setup, we assume a predefined set of camera viewpoints, which can be directly mapped to the robot’s poses for execution on a real robot platform but restricts the robot to discrete positions. Generating continuous motions via trajectory optimization (Falanga et al., 2018; Wang et al., 2020) could enable more informative observations, particularly on platforms equipped with an end-effector-mounted camera.
Finally, our current approach requires a 3D object CAD model and known camera poses, which limits its applicability. Future work will investigate joint estimation of object and camera poses and explore extending the active perception framework to CAD-less objects (Wang et al., 2021b); Liao et al., 2024).
Conclusion
In this work, we present a complete framework of multi-view pose estimation and next-best-view prediction for textureless objects. For our multi-view object pose estimation approach, the core idea of our method is to decouple the posterior distribution into a 3D translation and a 3D orientation of an object and integrate the per-frame measurements with a two-step sequential formulation. This process first resolves the scale and depth ambiguities in the RGB images and greatly simplifies the per-frame orientation estimation problem. Moreover, our orientation optimization module explicitly handles the object symmetries and counteracts the measurement uncertainties with a max-mixture-based formulation. To find the next-best-view, we predict the object pose entropy via the Fisher information approximation. The new RGB measurements are collected from the corresponding viewpoint to improve the object pose accuracy. Experiments on public datasets ROBI and TOD, along with our T-ROBI dataset, demonstrate the effectiveness and accuracy compared to the state-of-the-art baselines.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Epson Canada Ltd.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.