
Abstract
Dynamical system (DS) based motion planning offers collision-free motion, with closed-loop reactivity thanks to their analytical expression. It ensures that obstacles are not penetrated by reshaping a nominal DS through matrix modulation, which is constructed using continuously differentiable obstacle representations. However, state-of-the-art approaches may suffer from local minima induced by non-convex obstacles, thus failing to scale to complex, high-dimensional joint spaces. On the other hand, sampling-based Model Predictive Control (MPC) techniques provide feasible collision-free paths in joint-space, yet are limited to quasi-reactive scenarios due to computational complexity that grows cubically with space dimensionality and horizon length. To control the robot in the cluttered environment with moving obstacles, and to generate feasible and highly reactive collision-free motion in robots’ joint space, we present an approach for modulating joint-space DS using sampling-based MPC. Specifically, a nominal DS representing an unconstrained desired joint space motion to a target is locally deflected with obstacle-tangential velocity components navigating the robot around obstacles and avoiding local minima. Such tangential velocity components are constructed from receding horizon collision-free paths generated asynchronously by the sampling-based MPC. Notably, the MPC is not required to run constantly, but only activated when the local minima is detected. The approach is validated in simulation and real-world experiments on a 7-DoF robot demonstrating the capability of avoiding concave obstacles, while maintaining local attractor stability in both quasi-static and highly dynamic cluttered environments.
1. Introduction
Modern robotic systems are expected to operate in a variety of environments and interact with static and dynamic objects, as well as other agents, such as humans, animals, and other robots. While direct contact may be necessary to accomplish certain tasks, almost any motion requires a reaching phase where the robot must move its end-effector to a desired location while avoiding collisions between the robot body and obstacles or and other agents. For future reference, we assume that the obstacles in the environment are moving unpredictably, and reactive motion assumes feasible plan generation on frequencies above 100 Hz.
Techniques to generate collision-free motion can be categorized into two paradigms: offline and feedback/reactive planning (LaValle, 2006). In the former, the problem is divided into two phases—offline planning of collision-free paths (typically sampling-based algorithms or trajectory optimization) followed by trajectory execution (Spong et al., 2020). However, depending on the complexity of the environment and the dimensionality of the robot configuration space, offline planning may take a significant amount of time, which hinders operation in dynamic environments with moving obstacles and active agents.
Early works in reactive collision-free motion generation rely on local alternation of the system’s dynamics in the vicinity of obstacles via Artificial Potential Fields (Khatib, 1986) or navigation functions (Rimon and Koditschek, 1992). Such classical feedback motion planning techniques, although reactive, are vulnerable to local minima and limited to parametric obstacle representations such as convex (spheres, ellipsoids, etc) or star-shaped obstacles. To ensure reactive collision-free motions with convergence guarantees the modulated dynamical system (DS) based approach was introduced by Khansari-Zadeh and Billard (2012). In this approach, the nominal robot motion is generated by a DS that defines a vector field in the task space for end-effector motion (in this case, an additional Inverse Kinematics controller is required) or in joint space to describe the whole-body state-dependent motion law. The proposed modulation locally changes this law in order to navigate around obstacles.
Local modulation of DS for obstacle avoidance is performed with relatively low computation cost, however, convergence guarantees can only be ensured for conservative obstacle types such as convex (Khansari-Zadeh and Billard, 2012) or star-shaped (Billard et al., 2022; Huber et al., 2019). Further, a saddle point local minimum trajectory still remains for such parametric shapes. These shortcomings limit the applicability of reactive DS modulation approaches to complex spaces with arbitrarily shaped obstacles that are hard to convexify such as joint space of redundant manipulators.
Receding horizon path planning approaches such as Model Predictive Control (MPC), can be used to generate collision-free trajectories in real-time (Erez et al., 2013; White et al., 2022). However, these methods are often computationally expensive, and finding a balance between computation speed and trajectory quality can be challenging (Bhardwaj et al., 2022). The computational complexity of MPC methods grows cubically with state dimensionality and time horizon (Richter et al., 2012), which can be prohibitive for cases when the robot with a high number of degrees of freedom (DoF) is required to reactively navigate in cluttered environments while avoiding obstacles.
1.1. Contributions
In this paper, we aim to combine the advantages of DS motion planning and sampling-based MPC to allow for instantaneous obstacle avoidance and swift feasible trajectory generation for any type of environment. We adopt a modulated DS approach (Billard et al., 2022; Khansari-Zadeh and Billard, 2012) as a primary motion generator and empower it with a popular sampling-based MPC algorithm known as Model Predictive Path Integral (MPPI) control (Williams et al., 2017), to navigate the robot away from the local minima caused by concave obstacles. We prove theoretically that the impenetrability and local convergence properties of the modulated DS are preserved with the MPC-based additive terms. Additionally, we focus on the challenging problem of joint space control and validate the proposed method using a 7-DoF robot. Example of a reaching task executed by the robot is shown in Figure 1. Apart from presenting a simulated benchmark, we demonstrate the collision avoidance controller running at 500 Hz (on a modern laptop CPU) with a real robot, generating reaching motions while avoiding the human that tries to obstruct the robot reaching motion with a concave arm trap. The source code for running the presented algorithm in simulation and on real robot is available online.
1
The robot begins in the blue state (start joint configuration) and must reach the attractor configuration (green state) while avoiding a concave task-space obstacle represented by a set of red spheres. The nominal robot dynamics is a linear motion in joint space towards the attractor. The standard modulated DS approach (Khansari-Zadeh and Billard, 2012) exhibits a local minimum (represented by the red robot state) in this scenario. Our proposed method is able to reactively navigate around the obstacle and reach the attractor successfully.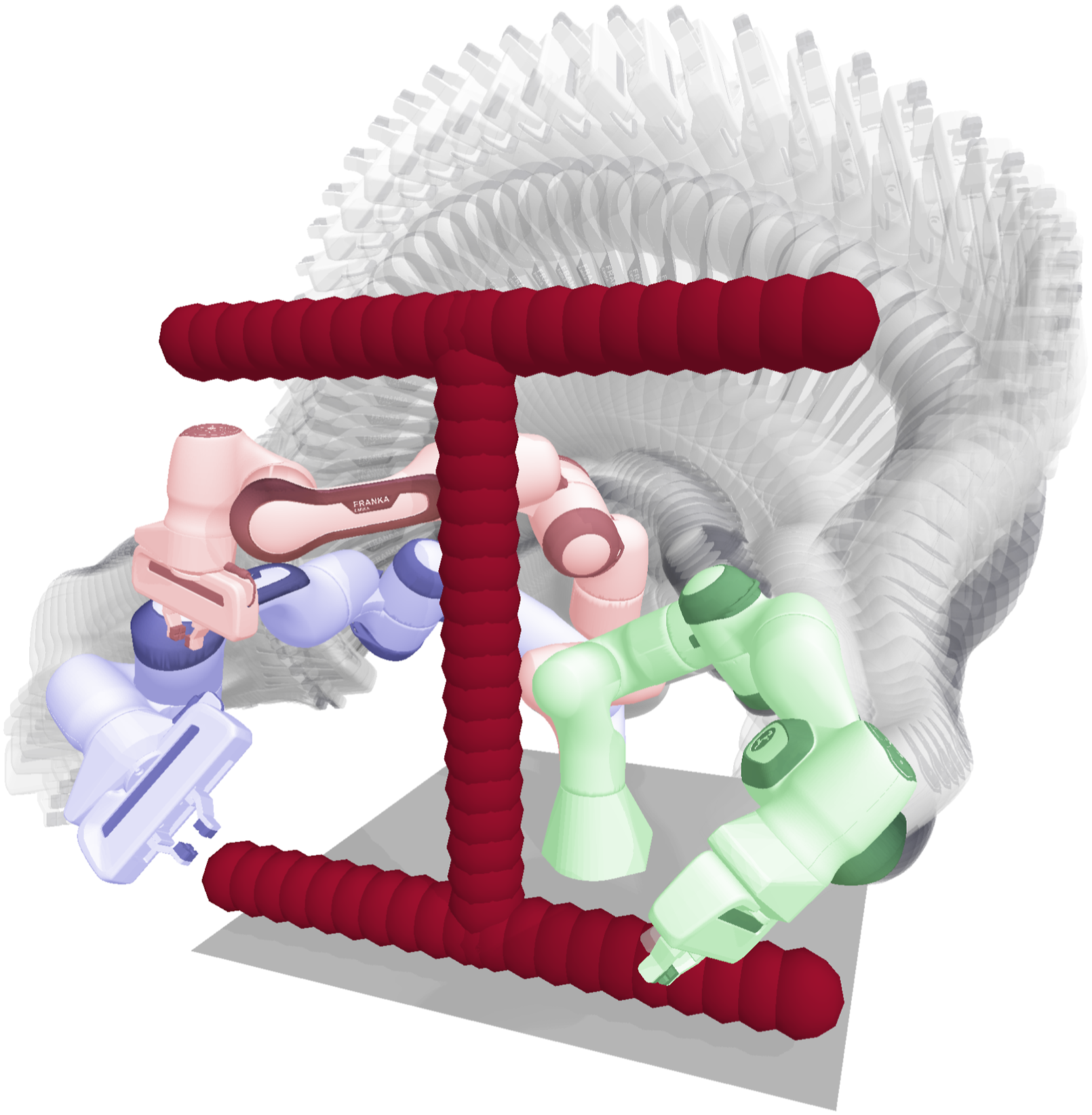
1.2. Paper organization
In Section 2, we summarize related works for task space and joint space robot motion planning in the presence of obstacles. Section 3 presents the mathematical problem formulation, including assumptions, definitions, and goals of this paper. In Section 4, we present the background of the DS modulation method, as it is the basis of our approach. Our method formulation is then presented in Section 5. Further, Section 6 introduces the basics of the state-of-the-art MPPI algorithm, and describes our approach to leveraging optimization to find optimal DS modulation strategies. Section 7 outlines various implementation details, and presents our approach to implementing the hybrid controller combining modulated DS and MPPI methods. Finally, Section 8 presents the validation of the method in simulation and on a real robot.
2. Related work
In this paper, we consider the generation of feasible paths in the configuration space of a robotic manipulator. For manipulators with revolute joints, the configuration space coincides with the robot’s joint space. In this section we cover the state-of-the-art in motion planning in high-dimensional spaces, as well as collision detection techniques.
2.1. Offline path planning
A hierarchical approach, in which a feasible path is first generated offline and then executed by a high-frequency controller, can be considered the dominant paradigm in robotic systems. Several sampling-based methods exist to generate paths in the high-dimensional joint space of the robot, such as Rapidly-exploring Random Trees, Probabilistic Roadmaps, and their variants (Kavraki et al., 1996; Kuffner and LaValle, 2000; Sandakalum and Ang Jr., 2022). These methods provide probabilistic completeness, but their computation and memory costs are often significant (Kingston et al., 2018). The path generation time can range from seconds to minutes, depending on the complexity of the environment and the system’s dimensionality (Chase et al., 2021). Although these methods are suitable for many applications, they may not be the best choice for rapidly changing environments that require online replanning at frequencies exceeding 100 Hz. Trajectory optimization methods, such as CHOMP (Ratliff et al., 2009) and TrajOpt (Schulman et al., 2014), can optimize for feasible trajectories within a tight, frequently sub-second time budget, providing control frequency of 1–5 Hz. However, quick optimization convergence requires a good initial guess for the trajectory (Zucker et al., 2013), which can be problematic in a changing environment. Due to the amount of time needed to calculate a trajectory, these methods are unsuitable to use in highly dynamic environments with moving obstacles, and are mainly applied in a static environments with pre-computed distance fields (Yang et al., 2019).
2.2. Receding horizon path planning
An approach that differs from hierarchical model involves repetitive solving of a nonlinear optimization problem with a receding horizon. It encapsulates tasks for the system and system dynamics as constraints in nonlinear optimization problem and generates dynamically feasible trajectories online. Such methods have wide range of applications, including humanoid robot control (Erez et al., 2013) and autonomous driving (Frasch et al., 2013). The main limitation of MPC methods lies in polynomial scaling with number of parameters in the optimization. Typically, the computational cost has complexity O (n3), where n is number of parameters determined by number of states, control inputs, and time horizon (Domahidi et al., 2012; Richter et al., 2012). Thus, the operating frequency of these methods typically does not exceed 20 Hz for high-DoF robots. As this approach is unable to provide replanning at 100 Hz rate, it cannot fulfill the objectives of this paper. However, such methods may be applied in a hybrid controller scheme to generate high-level motion policies (Hansel et al., 2023).
Recent developments in computational hardware, such as GPU chips allowing for massive parallelization, have enabled a new generation of optimization methods that rely on sampling-based exploration for approximating the optimal input distribution (Williams et al., 2017). Such methods are capable of handling complex dynamics and non-differentiable cost functions. For instance, Bhardwaj et al. (2022) use MPPI approach and demonstrate online trajectory optimization via sampling-based model predictive control operating at 125 Hz on a 7 DoF robotic manipulator. This method can be considered reactive, as it is capable of quickly moving the robot away from collisions if an obstacle moves towards the manipulator. At the same time, thanks to trajectory planning with a look-ahead horizon, this method can navigate relatively complex environments. However, the method may still require some specific sampling heuristics, or increased number of samples to find paths in cluttered environments (Sacks and Boots, 2022; Yoon et al., 2022). We use MPPI in our method in combination with sampling in locally obstacle-tangent space to achieve improved path-planning.
2.3. Reactive planning
Similar to the artificial potential fields approach (Khatib, 1986) mentioned in the introduction, control-barrier functions (CBF) method can be used to reactive motion generation (Singletary et al., 2021). However, CBF requires solving a QP problem on each iteration, thus reducing scalability to higher dimensions, such as robot joint space.
Dynamical systems, which represent a pre-defined state-dependent law acquired by learning from demonstrations or manually defined by the user, are another classical method for robot motion generation (Gribovskaya et al., 2011; Khansari-Zadeh and Billard, 2011; Kronander et al., 2015). They can encapsulate complex behaviors and guide the robot to follow the desired trajectory without extensive real-time computations (Figueroa and Billard, 2018; Figueroa et al., 2020; Shavit et al., 2018a). While DS approaches generally do not consider obstacles, an extension was proposed to enable navigation around convex (Khansari-Zadeh and Billard, 2012) and star-shaped (Huber et al., 2019) obstacles. This method relies on obstacle-related information, such as distance function and normal direction, to modulate the DS close to the obstacles. While many objects can be approximated with convex and star shapes, such approximations may be too restrictive in some cases. We build upon this method as it allows for reactive any-frequency collision avoidance.
In recent years, Riemannian Motion Policies (RMPs) (Ratliff et al., 2018) have emerged as an alternative to modular reactive motion generation, formulated as second-order DS with associated Riemannian metrics in various task spaces. For each objective or constraint, for example, target reaching, orientation control, obstacle avoidance, redundancy resolution, and joint limits, an individual RMP must be designed. To combine them into a global reactive motion policy while ensuring geometric consistency Cheng et al. (2018) introduced RMPflow, a computational graph representing tree-structured task-maps of RMPs. The global motion policy synthesized by RMPflow is Lyapunov-stable if the underlying policies (subtasks) are a class of stable RMPs known as Geometric Dynamical Systems (GDS), the closure property relating to task consistency is preserved and task priorities are properly tuned. Such restrictions may lead to suboptimal performance and unnecessary energy consumption by the system. To alleviate this, Li et al. (2019) offer a relaxation of the GDS assumption and reinterpretation of the stability guarantees of RMPflows through the lens of control lyapunov functions. Van Wyk et al. (2022) further improved RMPflow by introducing geometric fabrics, which utilize Finsler geometries and bending terms to enhance expressivity of subtasks while ensuring stability and convergence to a local solution and transform trees to combine them. In a similar vein, Composable Energy Policies (CEP) (Urain et al., 2021) offer modular reactive motion generation by optimizing over products of stochastic policies, effectively resolving conflicts between multiple motion objectives via a Bayesian network energy tree.
While the latter methods offer desirable performance and stability guarantees, they require the construction of graphs or trees or entail multi-objective optimization, which can be computationally intensive compared to our modulation approach—which is a closed form solution that only requires local reshaping of a nominal DS. Furthermore, when performing collision avoidance of non-convex boundaries all of these methods are prone to local minima and must resort to adhoc environment heuristics (as in Van Wyk et al. (2022)) or learning the adhoc obstacle avoidance subtask behavior (as in Urain et al. (2021)). In contrast, the modulated DS framework offers a general approach for obstacle avoidance, avoiding the need for complex constructions, intensive optimizations or adhoc heuristics. We achieve couple the modulated DS approach with MPPI control, to achieve a practical and intuitive, yet powerful solution for reactive motion planning.
Our proposed approach shares similarities with the hybrid planning architectures introduced by Löw et al. (2021) and Hansel et al. (2023) that combine local reactive motion policies with longer horizon planning schemes. The former approach, named PROMPT incorporates probabilistic movement primitives (ProMPs) (Paraschos et al., 2013) in both sampling and optimization based trajectory planners to generate high quality feasible paths. This is achieved by leveraging the constraint conditioning and blending capabilities of ProMPs. Nevertheless, this approach is not applicable to reactive scenarios with highly dynamic obstacles nor is it scalable to high-dimensional spaces as its computational complexity increases relative to state space dimensionality, planning horizon and number of samples. This is evidenced by experiments reporting 1 Hz of planner runtime for 2D state spaces. The hierarchical policy blending as inference (HiPBI) approach (Hansel et al., 2023), built upon the RMPflow framework, addresses local minima through an online sampling-based planner. It reformulates RMPs as Gaussian policies and blends them using the product of experts technique. To dynamically optimize weights, a high-level, sampling-based online planner operates on the parameter space, mitigating local minima seen in the standard RMPflow approach. While our approach shares similarities with HiPBI, latter is constrained by RMPs, requiring specific subtask policy construction and a prior distribution assumption. Although HiPBI simplifies task-tree construction and weight tuning, it remains computationally intensive, reporting a 10 Hz planning frequency for a 7DoF manipulator robot. In contrast, our approach uses modulated DS for reactive motion policies, ensuring stability guarantees and achieving a 500 Hz execution rate. This choice enhances collision avoidance and reactivity, resulting in natural trajectories. The coupling with the high-level MPPI controller further enhances local minima free navigation in complex scenarios.
2.4. Differentiable collision checking
Although all the methods mentioned above can consider various constraints for generating paths, collision avoidance is usually the most critical constraint in motion planning. Importantly, the collision checking routine (and corresponding gradient computation, where needed) often takes up the majority of computation time (Pan and Manocha, 2016). Based on the implementation, speedups can be achieved by simplifying collision shapes (by means of convex hulls, geometric primitives, or spheres) (Stasse et al., 2008) or by pre-computing the static environment (Zucker et al., 2013). Recently, there were developments in approximating the distance functions using Machine Learning (ML) based methods (Koptev et al., 2021; Liu et al., 2022; Salehian et al., 2018; Zhi et al., 2022) for efficient use in robot control. In this paper, we rely on our previous work (Koptev et al., 2023), which learns a signed distance as a function of robot joint states and 3D points in the robot’s environment. Properties such as batched evaluation or continuous differentiability enable efficient use of this function in the proposed method.
3. Problem definition
3.1. Assumptions and definitions
In this paper, we consider a robot with K physical links and d degrees of freedom (DoF). The joint state of the robot is defined as a vector of joint angles

We assume that the nominal DS
Obstacles (static or dynamic) can be defined as a set of points
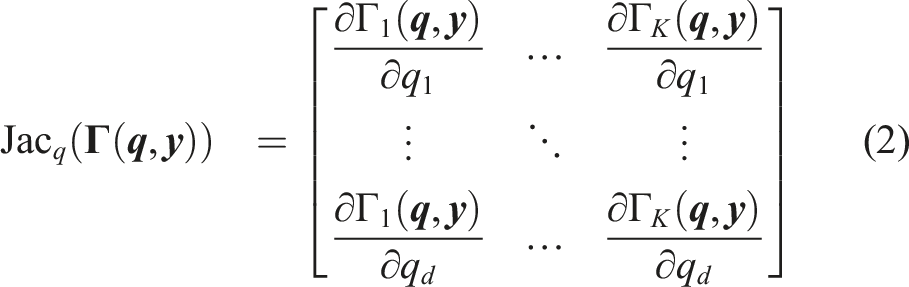
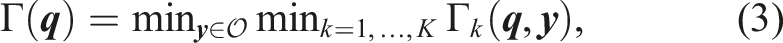
3.2. Goals
The main goal of this paper is to design a modulation algorithm that reshapes
To this end, we aim to leverage the parallelization and differentiability properties of the learned function Γ(
4. Background
In this section, we provide the mathematical preliminaries describing the DS modulation method for obstacle avoidance, as it is essential for understanding our approach. We begin in Section 4.1 by introducing the original DS modulation method by Khansari-Zadeh and Billard (2012) that ensures impenetrability of obstacle boundaries, yet suffers from spurious attractor generation. Next, in Section 4.2 we describe the improved approach by Huber et al. (2019) designed to ensure convergence for convex and star-shaped obstacles (a unique subset of non-convex obstacles) almost everywhere except at a single saddle point trajectory. We further interpret this improved method from a controlled system perspective, setting the groundwork for our novel locally deflected obstacle-tangent space dynamics approach, that allows circumnavigation of complex non-convex obstacles in high-dimensional state spaces, detailed in Section 5. For an in-depth description of DS as motion policies and their robotic applications, please refer to (Billard et al., 2022).
4.1. Dynamical system modulation
A nominal Dynamical System, as in equation (1), defines a state-dependent vector field that can be altered, or modulated, by rotating the field with a modulation matrix

When starting from a G.A.S. DS
DS modulation using matrix
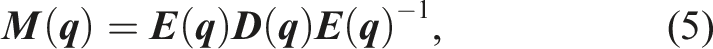
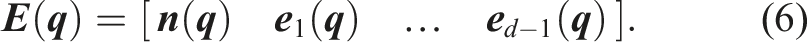
The diagonal matrix
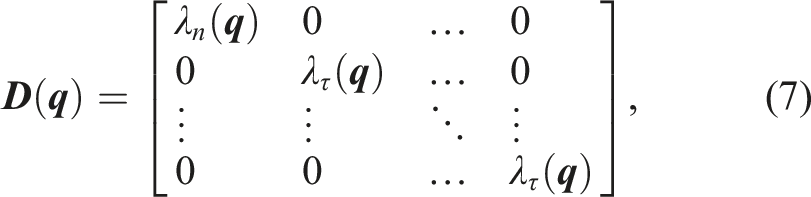
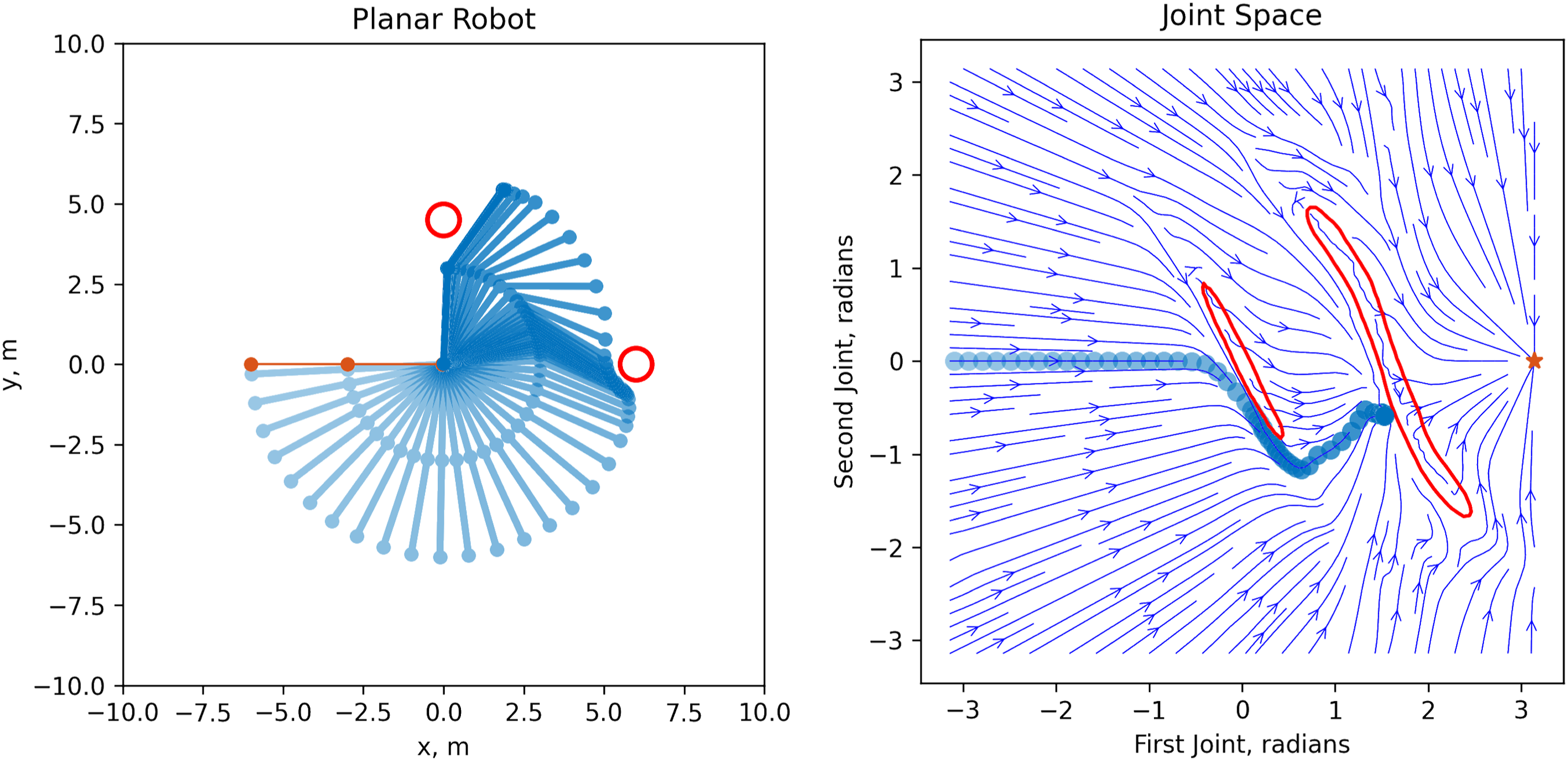
While the definition of Γ( Nominal linear DS motion (equation (1)) of a planar 2-DoF robot. The robot sweeps through the workspace in the absence of obstacles. The task space is visualized on the left, while the joint space is on the right. Modulated DS motion (equation (4)) of a planar 2-DoF robot in presence of two circular obstacles (in red). The robot avoids the first obstacle but gets stuck near the second due to the vanishing tangential component after modulation.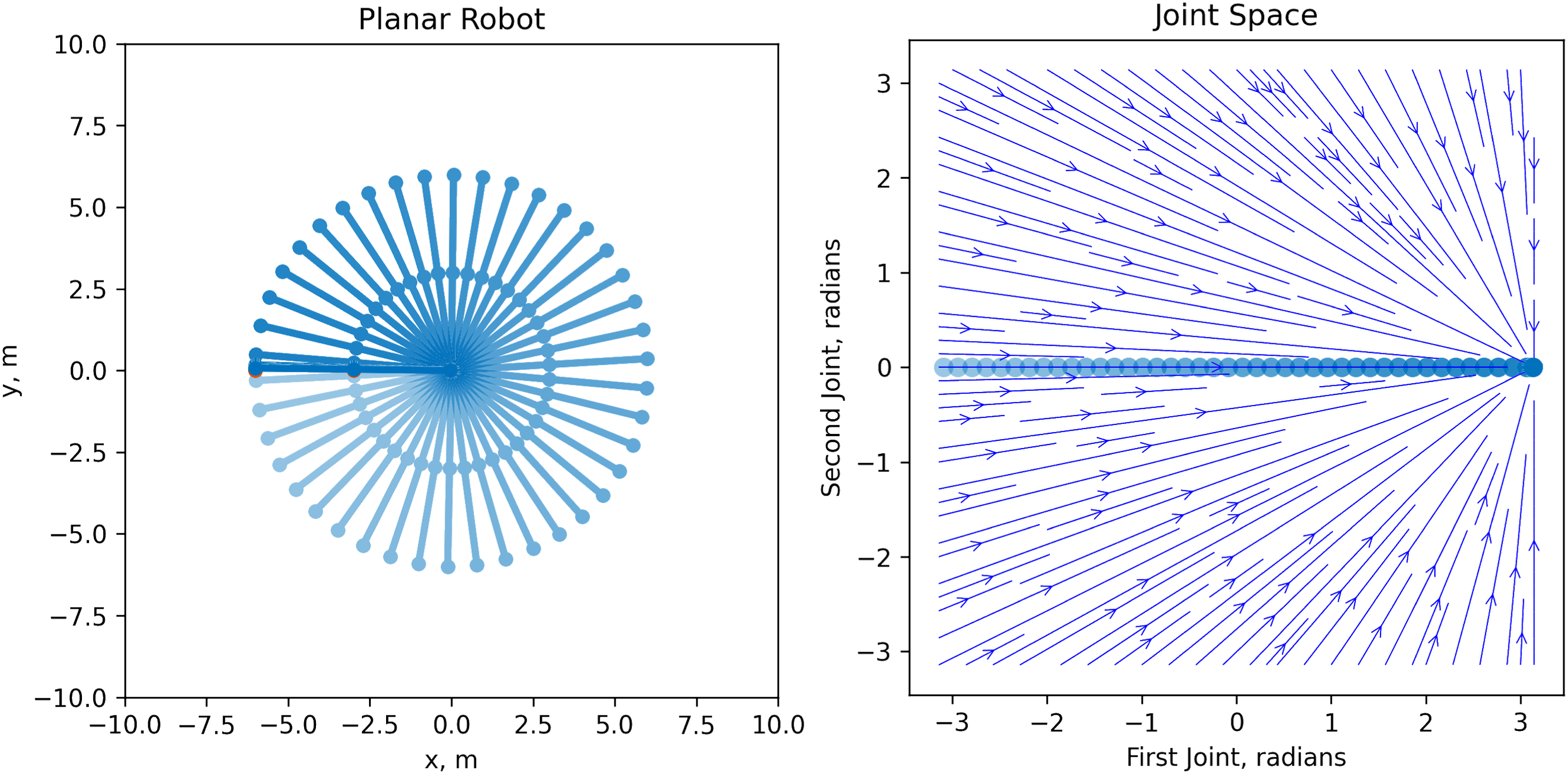
However, the collision avoidance properties of such modulation are restricted to a subset of convex obstacles. There is also an edge case within the subset of states located on the obstacle boundary
(Neumann boundary condition). Consider an obstacle whose boundary is described by a smooth function Γ(
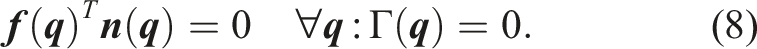
Definition 1 is derived from (Khansari-Zadeh and Billard, 2012). Nonetheless, this definition is only valid for the continuous case, whereas any robotics application necessitates discretizing the dynamics. Specifically, even for the case of convex obstacles, if the integration timestep δt is sufficiently large, a single iteration could bring the system state inside the obstacle. For concave obstacles, an additional mode of failure arises, in which any motion in the tangential plane will violate the obstacle boundary if the system starts on the obstacle surface. We propose a more general definition of impenetrability for the discretized case. Notably, it is still applicable for continuous dynamics.
(Impenetrability). Consider an obstacle whose boundary is described by isosurface Γ(
Definition 1 is useful for analyzing the stability properties of modulation. Spurious attractors, which can be can be local minima or saddle points, are induced when the nominal DS and obstacle normal are collinear at the obstacle boundary, that is, |⟨ Two-dimensional toy example demonstrating the behavior of the modulated DS in presence of obstacle (blue). The system is linear with stable attractor (red) at (8,0). Orange lines indicate trajectories integrated forward in time. 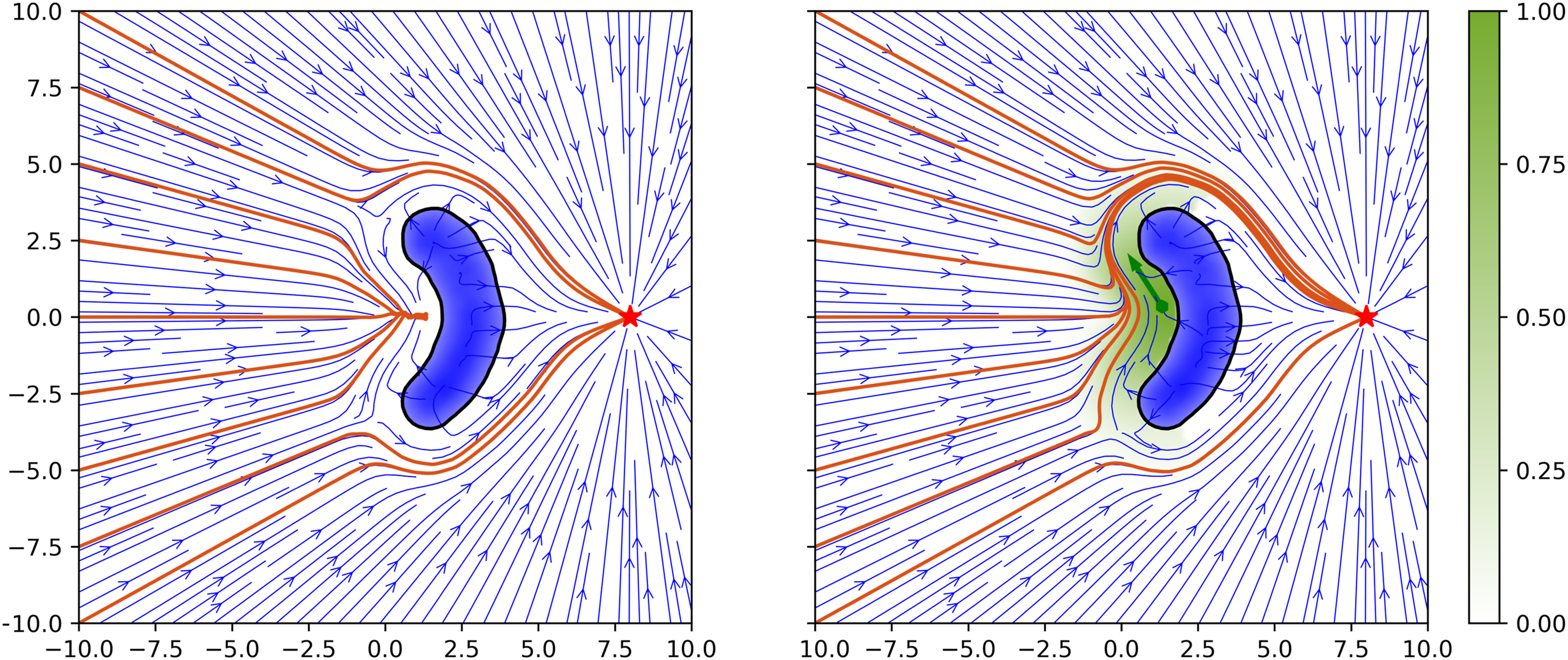
4.2. Convergence for star-shaped obstacles
An improvement upon the modulation framework for obstacle avoidance to avoid spurious attractors and preserve stability is proposed by Huber et al. (2019, 2022). Instead of using the obstacle normal
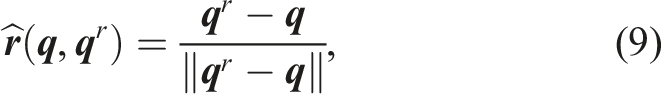
While discarding the orthonormality of the basis
Interestingly, the improved modulated DS approach using reference direction (9) to construct
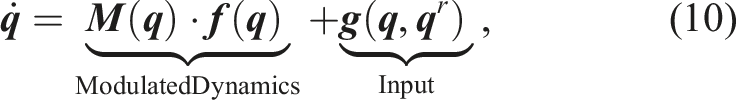
While (10) alleviates the creation of spurious attractors by inducing additional tangent space velocities through the additive nonlinear function
5. Locally deflected obstacle-tangent space dynamics
Inspired by the state-input system interpretation introduced in (10), we present our approach for creating meaningful obstacle-tangent deflections that are locally active in the regions of potential local minima of the modulated nominal DS. To alleviate the shortcomings of (Huber et al., 2019; Khansari-Zadeh and Billard, 2012), we propose the following formulation for modulating the DS:
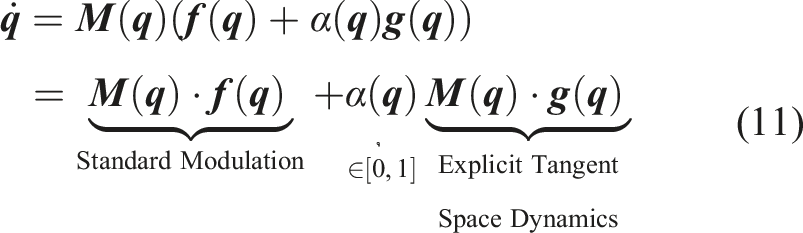
Continuous scalar-valued activation function
The advantage of (11) over (Huber et al., 2019; Khansari-Zadeh and Billard, 2012;) is that
5.1. Distance function adaptation
Our goal is to use a learned model of the true distance-to-collision, as defined in (3), to define the collision boundary. To preserve the collision avoidance properties of the modulation
We employ a parametrized sigmoid function:
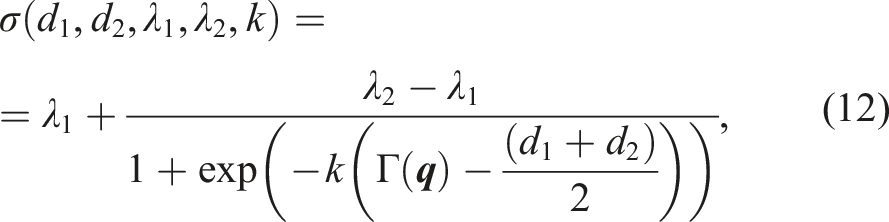
To define λ
n
(
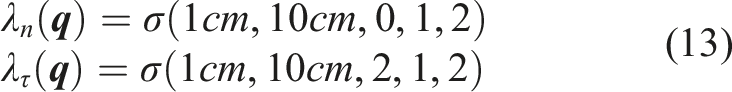
Impenetrability. Consider an obstacle in the task space of the robot, represented by a set of points Proof: See Appendix B.
5.2. Explicit tangent space dynamics as navigation kernels
We propose to construct the vector field
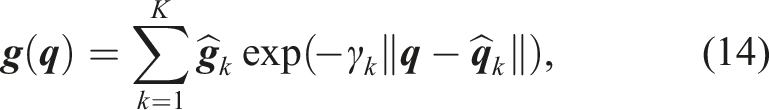
Essentially, formulation (14) allows
5.3. Navigation kernel activation
The navigation kernels defined in (14) are activated in the deflected dynamics (11) by a state-dependent scalar-valued function α(
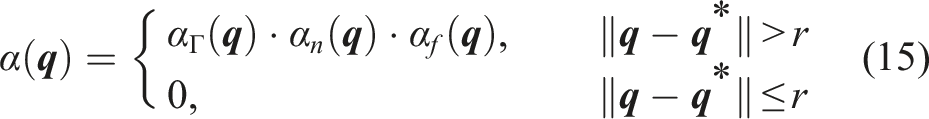
Additionally, we enforce α(
(L.A.S). Consider a modulated DS in the form Proof: See Appendix C.
5.4. Navigation kernel parameter optimization
The combination of K kernels allows to define a policy that is locally active, and is able to provide meaningful tangential components to the nominal DS enabling navigation around obstacles. The described policy is defined by direction
The MPPI algorithm provides a framework for finding the optimal parameters of a navigation policy by sampling a distribution of system parameters and then evaluating the corresponding cost of each trajectory generated by these samples. In our proposed formulation, we apply MPPI to learn the parameters of the navigation kernels. Specifically, the MPPI algorithm will be used to search over the space of
6. Navigation kernel parameters optimization via sampling-based MPC (MPPI)
Section 6.1 provides an introduction to the classical MPPI method. Subsequent Sections 6.2-6.4 detail how we utilize MPPI to determine the optimal parameters for navigation kernels introduced previously.
6.1. MPPI algorithm description
The idea behind the MPPI method is to sample the system parameters from a distribution, and then to use the sampled parameters to generate a set of trajectories. The cost of each trajectory is computed, and used to change the distribution and bias the sampling procedure towards the parameters that lead to the lower cost. Eventually, the procedure converges to parameters that minimize the defined cost function (Yoon et al., 2022).
Let’s consider an autonomous discrete-time Dynamical System of the form
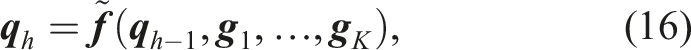
At each iteration, N candidate parameter sets

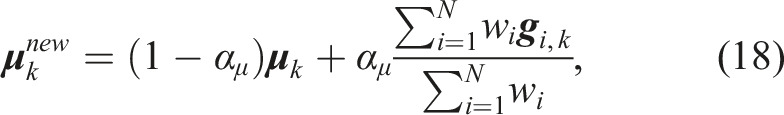
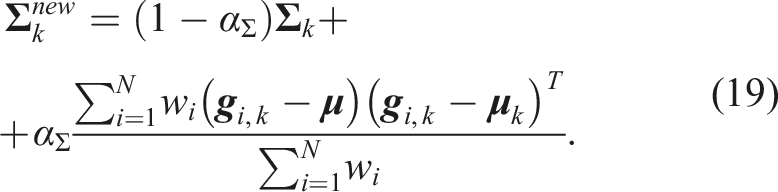
After updating distributions parameters with
In (18)-(19), α μ and αΣ are the learning rates for the mean and covariance matrix, respectively. The parameter β > 0 is a temperature parameter that controls the amount of exploration. The higher the temperature, the more the distribution is spread out, and the more the exploration is performed. Williams et al. (2017) prove that such process iteratively converges to the optimal parameters that minimize the cost function.
6.2. MPPI application
Navigation vector field
We propose to utilize the MPPI framework to determine the local navigation direction
While kernel widths γ
k
can also be optimized via MPPI, for simplicity we fix
At each iteration of the MPPI algorithm, parameter set
Next, the cost of each trajectory is computed, which is then used to bias the sampling procedure to achieve a lower cost. The weights for each sample are calculated using equation (17), and the mean of the parameter distributions is updated using equation (18). Once the new sampling distribution has been determined, we update the system state, sample new sets of parameters, and the process repeats.
An example of a placed navigation kernel with parameters optimized using MPPI is demonstrated in Figure 4. Notably, in this two-dimensional toy example, the navigation strategy is relatively straightforward—track the obstacle boundary in either the left or right direction. However, in three dimensions, the tangential plane consists of an infinite number of directions to track the obstacle boundary. As dimensionality increases, it becomes exponentially more challenging to find valid navigation strategies. We apply the MPPI algorithm to a 7-DoF robot arm, where an infinite number of navigation strategies can be explored. Examples of successful navigation strategies for such cases are illustrated in Figures 1 and 11.
6.3. Cost function
At each iteration of the MPPI algorithm, a cost for each roll-out
6.3.1. Goal reaching
The first cost term is a goal reaching cost, which is defined as follows:
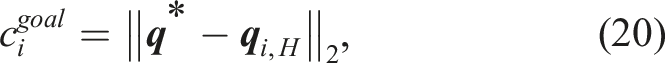
We only consider the final position of the roll-out, as sampled trajectory may temporarily move away from the goal while navigating around the obstacle. This cost penalizes trajectories that do not approach to the goal in the integration horizon H.
6.3.2. (Self-)Collision avoidance
Distance estimator Γ(

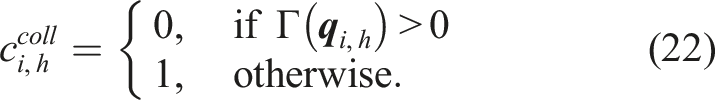
For self-collision avoidance cost
6.3.3. Joint limits avoidance
We treat joint limits violation in the same way as collisions. Each state is penalized for violation of the joint limits, and the cost is defined as follows:

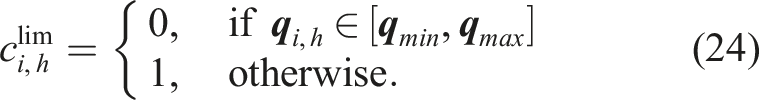
Since we assume the DS control in the joint space, we are not concerned by low-manipulability issues, thus do not dampen the joints close to joint-limits.
6.3.4. Stagnation avoidance
The cost function also includes a term that penalizes trajectories that do not move with time. This cost is defined as follows:
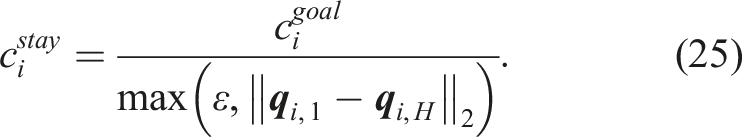
This cost encourages the exploration, while penalizing the stagnant trajectories away from the attractor, thus helping to avoid getting stuck in local minima. To some extent, this cost also acts against appearance of limit cycles, that are theoretically possible for the DS modulation approach. However, the length of a cycle should correspond to the horizon of the MPC path prediction. As the trajectories converge to
6.3.5. Nominal DS similarity
Another cost component we propose to use measures the difference between the nominal DS and the actual trajectory. This cost is defined as follows:
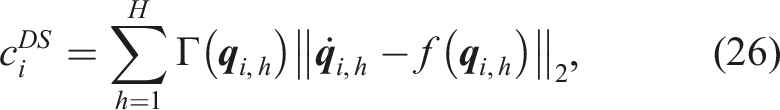
6.3.5.1. Total cost
The total cost for each trajectory is defined as a weighted sum of the cost terms defined above:

6.4. New kernel placement
MPPI algorithm is essentially a sampling-based motion planner generating new explorative trajectories at each iteration. For each point
If stable region of the nominal DS attractor is not reached yet, the distance-to-collision is less than a threshold parameter, and system is within the region of possible local minima a new navigation kernel can be placed. Local minima detection can be characterized as scalar product value
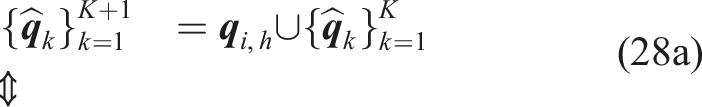

After the new candidate for a navigation kernel is found, it is added to the existing set of kernels, centered at
The sampling policy is also changed to include the new mean Progression of three states of a planar 2-DoF robot with our algorithm applied. The task space motion is in the top row, while the joint space is visualized at the bottom. By means of sampling of the tangential deflection, a local policy (in green) is generated, allowing the robot to avoid both obstacles and reach the goal. Light blue trajectories show the horizon of MPPI sampling. Figures 2 and 3 demonstrate the corresponding nominal and modulated motions, respectively.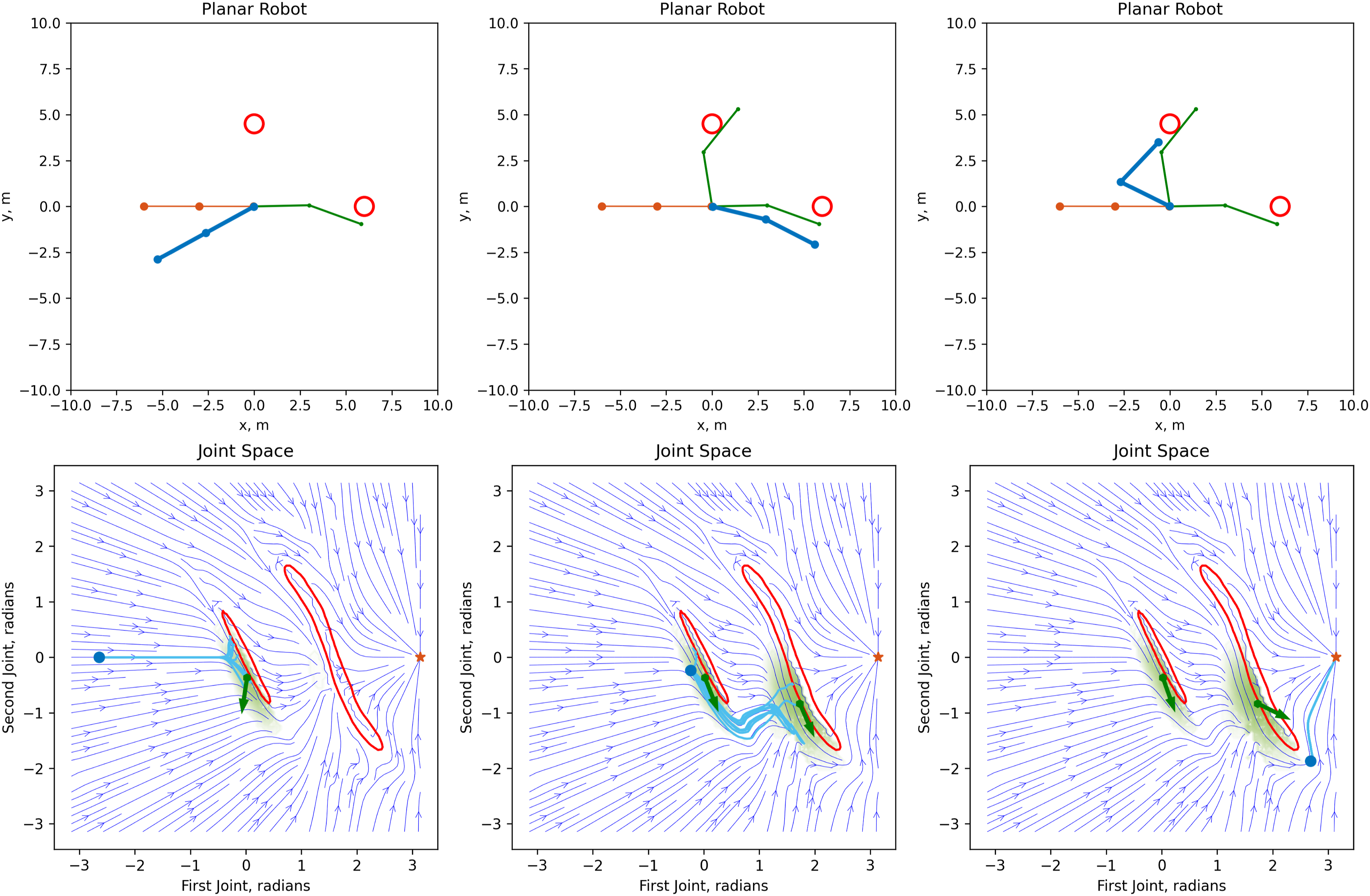
7. Implementation details
7.1. Tail effect compensation
Modulation 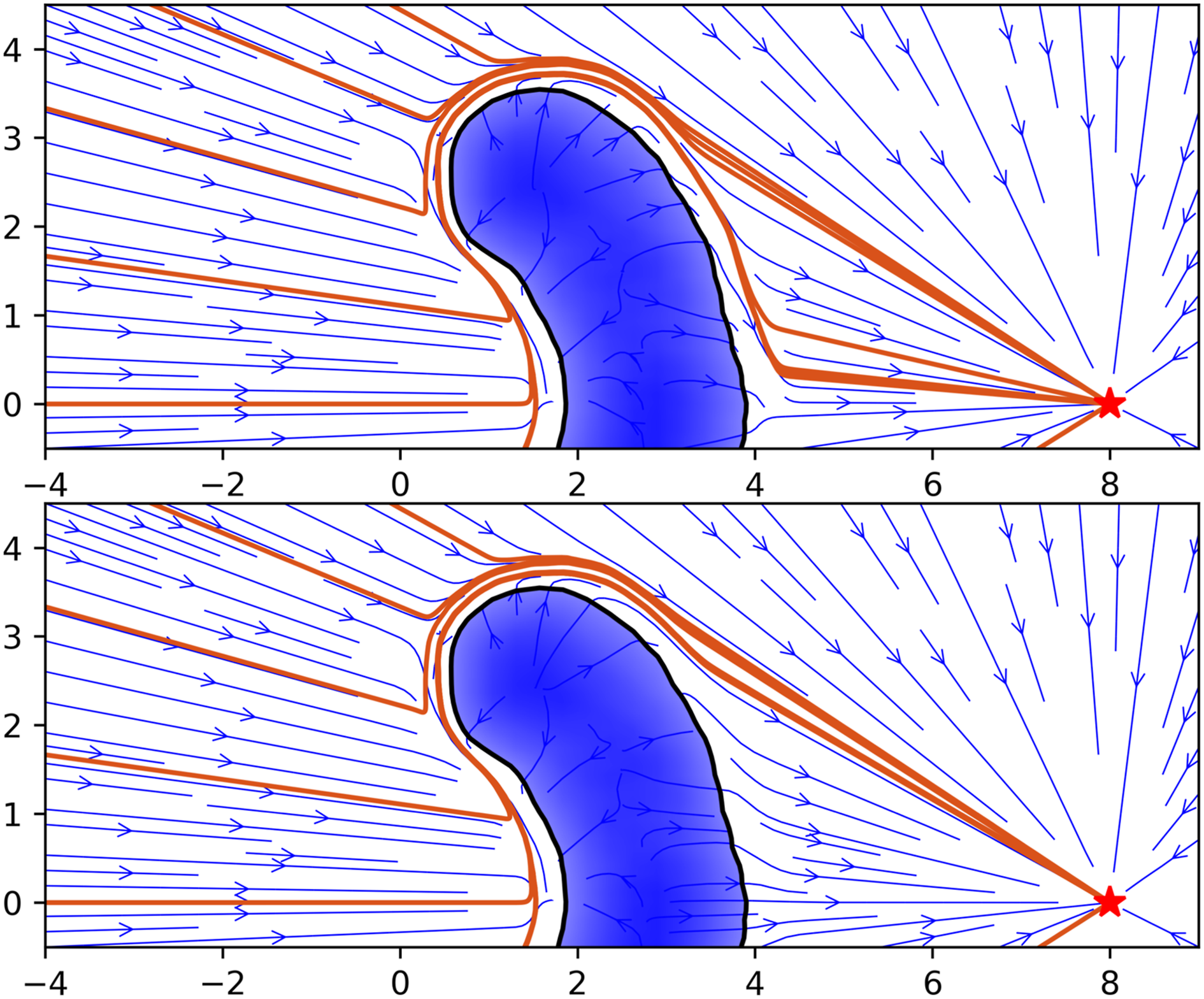
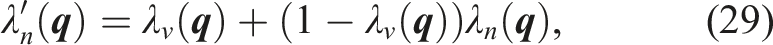
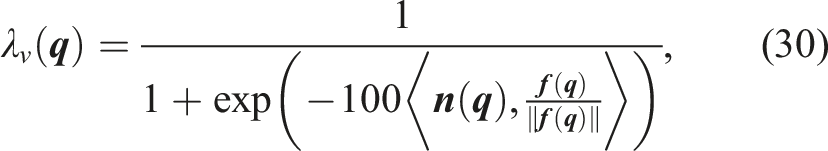
7.2. Navigation kernel activation implementation
For the local activation of navigation kernels, we define parameters αΓ(
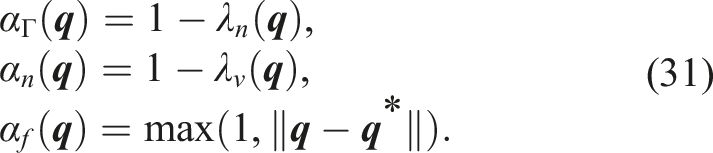
7.3. Navigation kernel tangentiality
As stated in Section 5, we define navigation kernel dynamics to be locally tangential to the obstacle boundary. While parameters
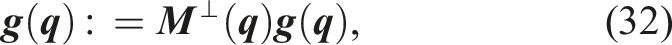
7.4. Discrete system obstacle impenetrability
Proposition 1 ensures that continuous dynamics defined by (11) do not penetrate the obstacle boundary Γ(
In practical applications, ensuring the non-penetrability of obstacles requires additional considerations. Apart from issues arising from numerical integration, the obstacle’s normal is provided by a learned network, which only approximates the normal, thus not guaranteeing impenetrability. To mitigate that, a combination of safety threshold ɛ, local obstacle repulsion field
By design, for system (11),
Taking these factors into account, impenetrability for obstacles in discrete system integration can only be violated if a single integration step results in Γ(
Assuming that the system integration is performed using the Euler method, the magnitude krep can be estimated by calculating the current undesired penetration through the threshold: ɛ − Γ(
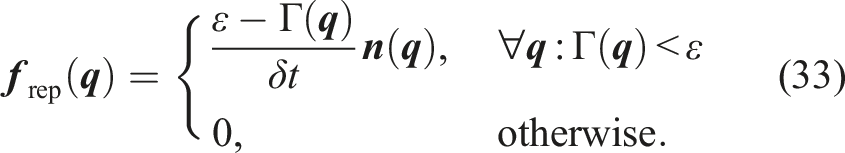
Overall, the continuous dynamics (11) take the following discrete form:
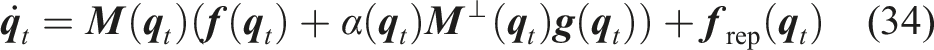

7.5. Algorithm implementation
Bhardwaj et al. (2022) report frequencies of up to 125 Hz for sampling-based MPC scheme similar to ours; however, it is only possible due to simple integration of the roll-outs, where the state is linear function of the control input. That enables the evaluation of the state sequence by means of lower-triangular integration tensor, achieving parallelization both across multiple timesteps and multiple samples. However, we rely on Γ(
While the method leverages the parallel execution for multiple exploration samples, and is fully suitable for GPU implementation, we found that QR decomposition of obstacle bases can only be efficient on CPU, thus all setup runs exclusively on CPU. Newer generations of processors with relatively large cache allow quick computation of the MLP, and overall performance is satisfactory. Notably, more traditional methods to evaluate distance-to-collision and repulsive gradient would lead to even more significant slowdowns.
As such frequencies may still not be sufficient for environments where obstacles are not static, we leverage the modular structure and concurrent execution to improve the performance. A simple one-sample one-timestep integration of modulated DS is not as computationally expensive and can be performed with frequencies up to 500 Hz. We asynchronously compute the modulated DS with latest known Modulation Policy, and stream the data to the low-level impedance controller that is executed at 1 kHz. This controller also mitigates potential abrupt changes in the DS-generated commands that may occur due to discontinuities in the distance function between the robot’s links and the obstacles represented by spherical primitives. This allows us to achieve real-time performance in dynamic environments.
Importantly, the MPC does not need to operate continuously in the background, using up computational resources. The MPC sampling is activated only if the predicted robot state comes close to navigation kernels, and it is not engaged in situations where there is no risk of local minima induced by obstacles. In practice, the MPC can run asynchronously at all times, but the number of samples can be varied dynamically. Generally, a single roll-out is required to predict the future trajectory and identify local minima. Once the minima is detected and a navigation kernel is placed, the number of samples increases to determine the optimal deflection direction. When the nominal propagated motion encounters no local minima (or navigation kernels), the sample complexity can be reduced back to a single sample for trajectory prediction. This pattern is further explored in Section 8.
Nominal DS is a parameter to both Modulated DS module and MPC module, and obstacles positions are streamed using Optitrack at 120 Hz. Notably, we do not use ROS for streaming, instead we opt for a lightweight setup based on ZeroMQ publisher-subscriber sockets (Hintjens, 2013).
Overall flowchart of the implemented algorithm is shown in Figure 7. All frequencies are reported for Apple Silicon M2 3.7 GHz CPU. The source code for running the presented algorithm in simulation and on a real robot is available online.
3
The algorithm contains a large set of hyperparameters, all of which are introduced and explained in the text. For clarity, we have compiled all meaningful parameters of our method in Table 4 located in Appendix D. Flowchart of the implemented algorithm. Message passing between modules is performed asynchronously. Approximate operating frequencies for each module (shown in red boxes) are estimated for execution on Apple Silicon M2 3.7 GHz CPU.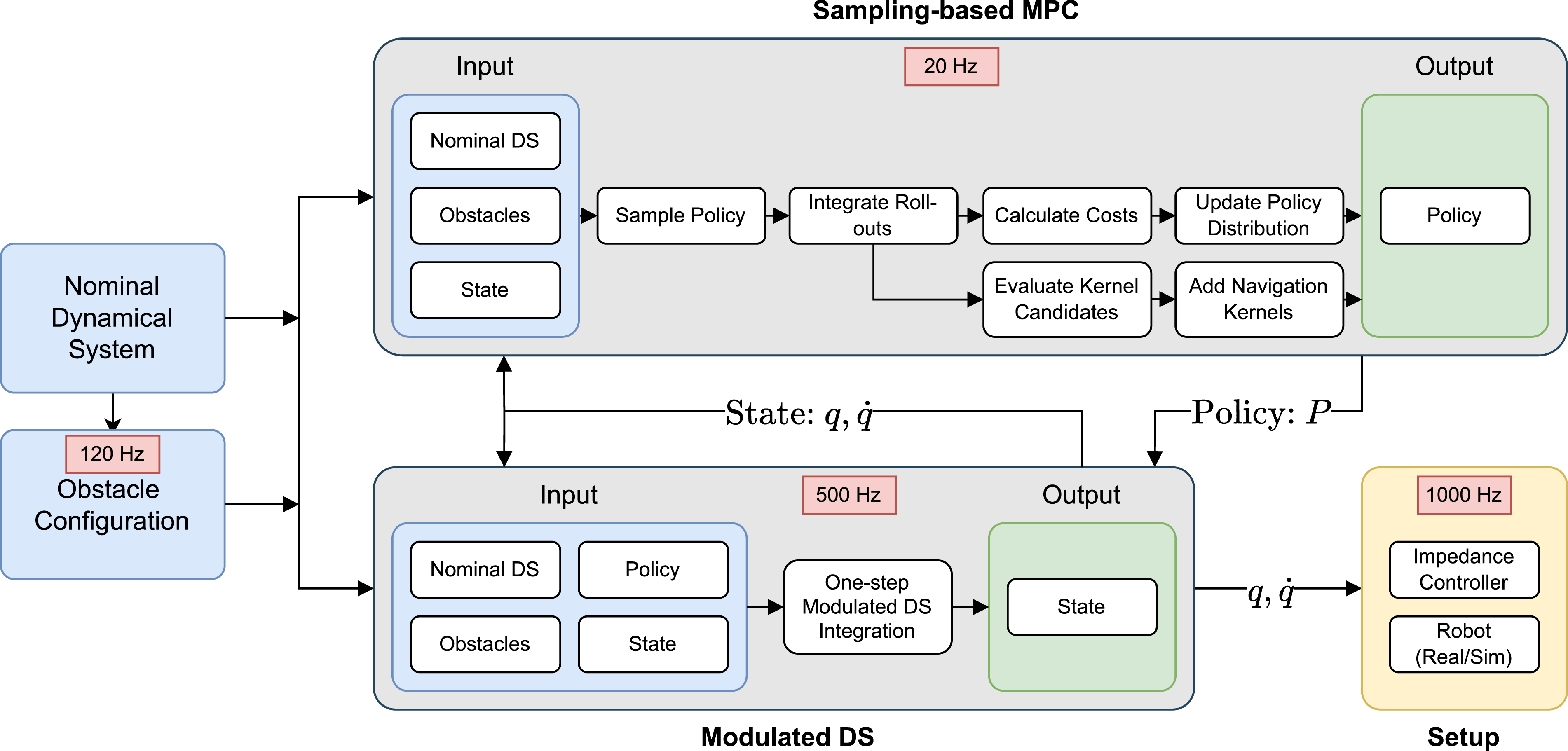
7.6. Computational complexity
The proposed hybrid controller combines two underlying algorithms—DS and MPC. For both algorithms, the major part of computations is related to state propagation, particularly the computation of the Modulation matrix, which depends on the implicit distance function. This function is represented by a Multi-Layer Perceptron (MLP) with analytical computational complexity O (s⋅d⋅n + m⋅n2), where s is the number of input queries; d is the input dimension (robot DoFs); m is the network depth; and n is the number of neurons per layer. Additionally, the number of inputs s = N⋅p can be expressed as the product of the number of robot states N and the number p of collision spheres (or points) in the robot’s environment. The MPC algorithm performs these computations sequentially for H steps along the horizon, resulting in a total computational complexity for the sampling-based MPC of O(H(s⋅d⋅n + m⋅n2)). Although the integration steps in MPC can be parallelized for multiple states and obstacles, the nonlinear integration procedure requires sequential evaluation of the time dimension. Consequently, the MPC evaluation frequency does not exceed 30 Hz in our experiments.
The DS can be considered as a single-step, single-sample MPC, and its computational complexity can then be expressed as O (d⋅n + m⋅n2). Given the relatively small size of the MLP used (n = 256, m = 4), the DS can be evaluated at frequencies up to 500–1000 Hz.
8. Evaluation
We systematically evaluate the proposed method in a simulated environment on a 7-DoF Franka Panda robot. We aim to compare the performance of our approach with two state-of-the-art methods that are capable of reactive robot motion towards the given goal configuration while avoiding collisions with obstacles in the robot’s workspace. Specifically, we compare the methods based on their ability to avoid collisions, achieve the goal and run at a high frequency. Additionally, we demonstrate the application of our method for a nonlinear joint space DS both in simulation and on a real robot.
8.1. Experimental setup
We consider a reaching task, in which the robot has to perform a reaching motion towards a goal configuration while avoiding obstacles in the workspace. We compare our method with a standard DS modulation framework introduced by Khansari-Zadeh and Billard (2012), and with a sampling-based MPC method (STORM) introduced by Bhardwaj et al. (2022). We define a single desired joint state
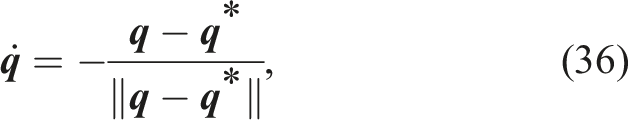

Standard modulation and our method are designed to act in the joint space given some nominal DS, however the STORM implementation considers costs defined in task space (i.e., end-effector position and orientation). To enable a fair comparison, we redefine the goal reaching and orientation costs as a quadratic cost similar to (20). This emulates the linear DS motion in the joint space, and allows us to compare the performance of methods on the same task. We use the same cost weights and hyperparameters as provided in the publicly available implementation 4 of STORM. Additionally, we leverage our previous work (Koptev et al., 2023) that introduced a Neural Network based Γ-function for collision checking, which improves the performance (in terms of frequency) of the method.
To make meaningful comparison in the reaching scenario, we design the experiment such that final goal state Reaching trajectory used in the benchmark. Robot is driven from the initial position (in blue) to the goal position (green) by linear DS defined in joint space. Concave obstacles are placed in the swept area in front of the robot to perform collision avoidance benchmark.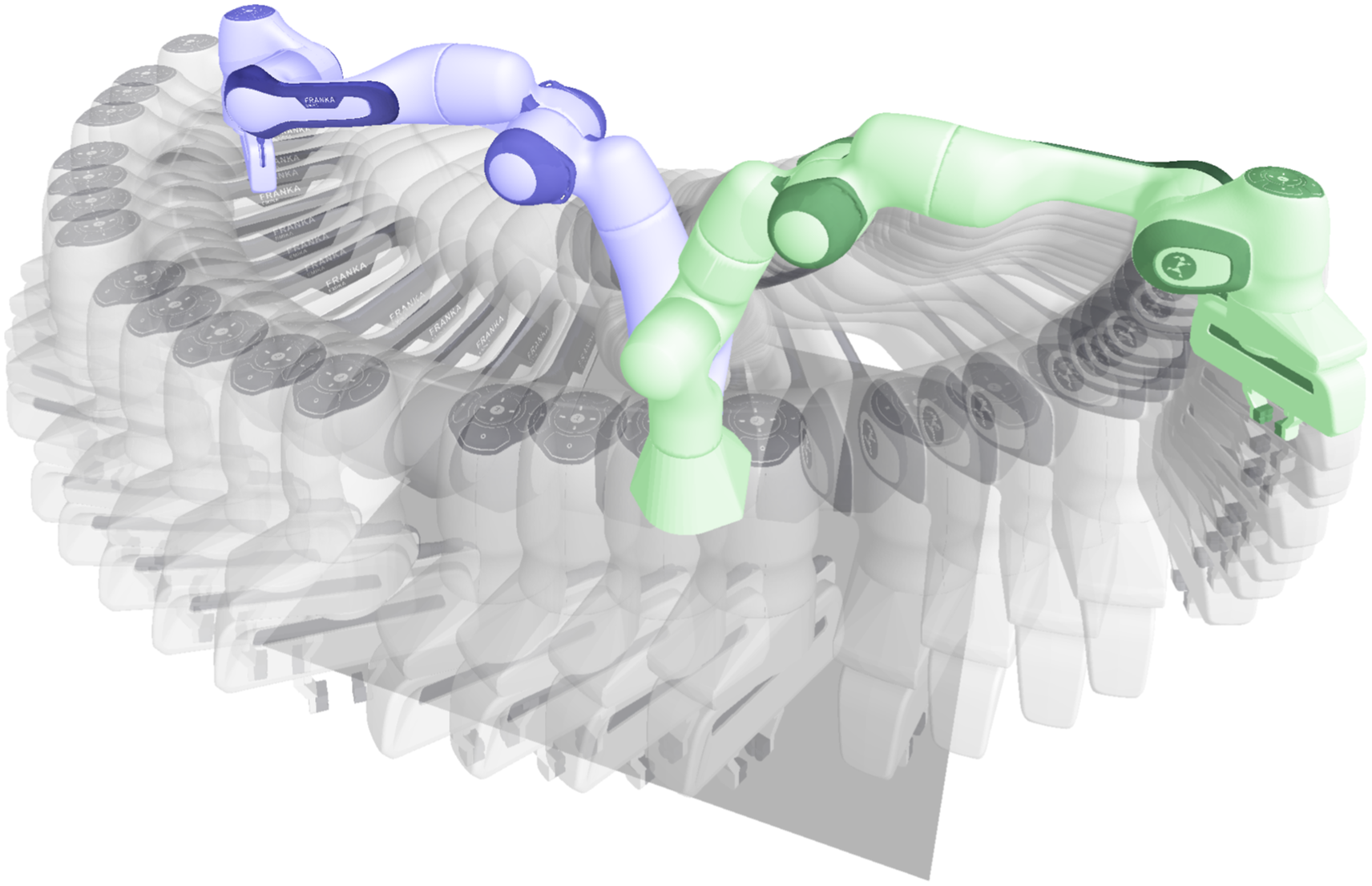
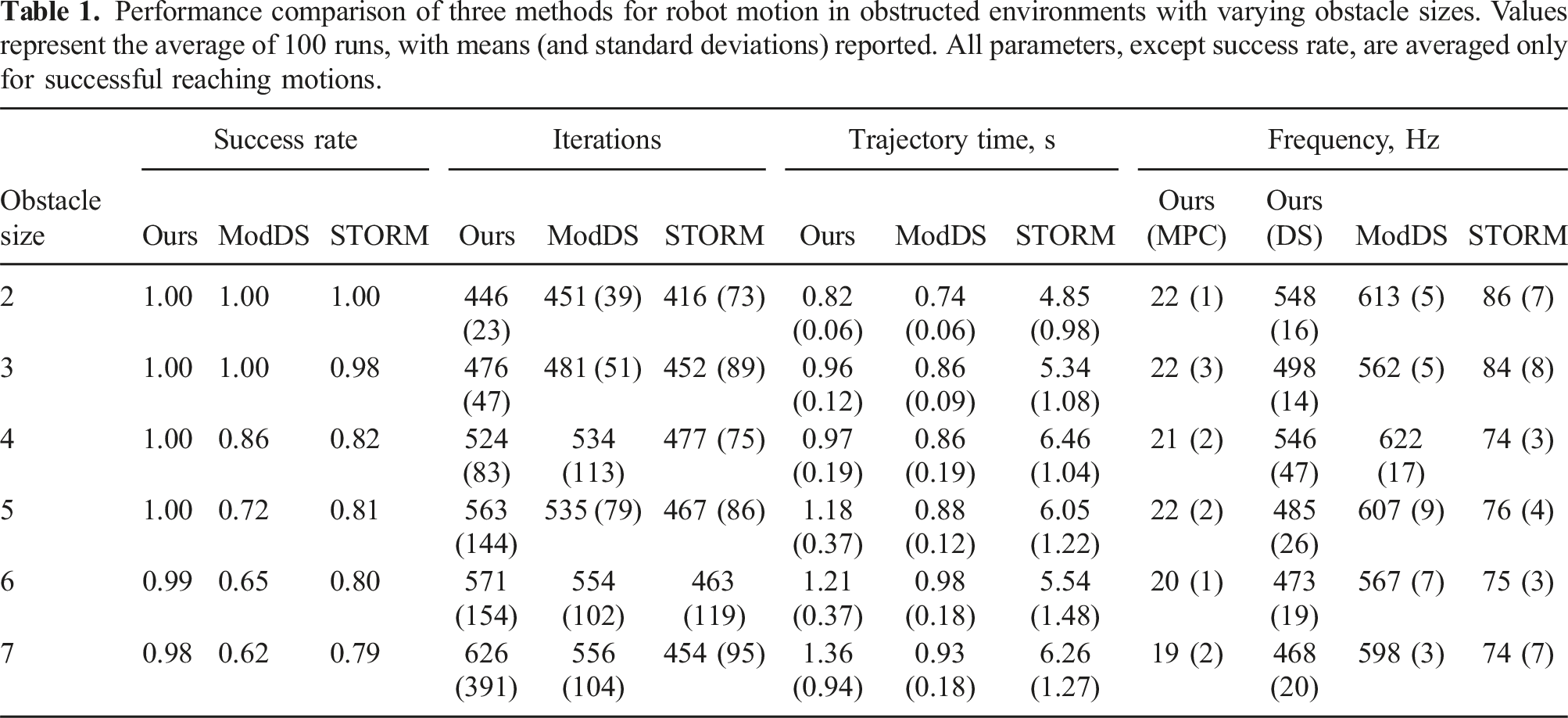
For the benchmark, we consider a static cross-shaped sphere structure placed in front of the robot. This arrangement of obstacle primitives effectively segments the robot’s workspace into four distinct quarters, a configuration that is representative of typical static environments or shelving scenarios encountered in robotic navigation. We investigate methods’ performance for various sizes of the obstacle. Some of the sizes are shown in Figure 9. In general, as the size of the obstacle increases, the robot’s workspace becomes more constrained. For each obstacle size we vary the height of the cross center and its distance from the robot across 100 reaching motions. Benchmark results are presented in Table 1. We consider reaching successful if it is performed within 10 s. Otherwise, we do not consider it in calculations of average number of iterations and trajectory time. Two-, three-, and four-spheres long obstacle cross configurations used in the benchmark. Performance comparison of three methods for robot motion in obstructed environments with varying obstacle sizes. Values represent the average of 100 runs, with means (and standard deviations) reported. All parameters, except success rate, are averaged only for successful reaching motions.
8.2. Discussion
The effectiveness of our proposed method in navigating in the presence of obstacles is demonstrated in Table 1, where it outperforms two other methods with consistently higher success rates. While the planning part of our algorithm is slower than STORM, the running frequency is comparable to that of a standard DS approach. It is worth noting that our algorithm runs on a CPU, while STORM efficiently leverages GPUs. However, the slow planning loop is not crucial for our method, as the primary modulated DS achieves motion reactivity at a high frequency. We should also note that this benchmark only evaluates the algorithms in quasi-static environments and does not consider their performance in dynamic scenarios. Future work could address this limitation by incorporating obstacle velocities into collision avoidance algorithms. Nonetheless, our method is capable of reacting to dynamic changes in the environment due to its high frequency of operation, as demonstrated in experiments with a real robot.
MPC activation metrics for the benchmark experiments. The columns indicate obstacle size, the number of trajectories where more than one navigation kernel was placed (i.e., MPC was required), and the corresponding proportion of iterations where the path passed by the navigation kernels along with number of kernels placed. Values are averaged over 100 runs, with means (and standard deviations) reported. MPC activation rate and number of kernels is averaged only for trajectories where MPC was active.
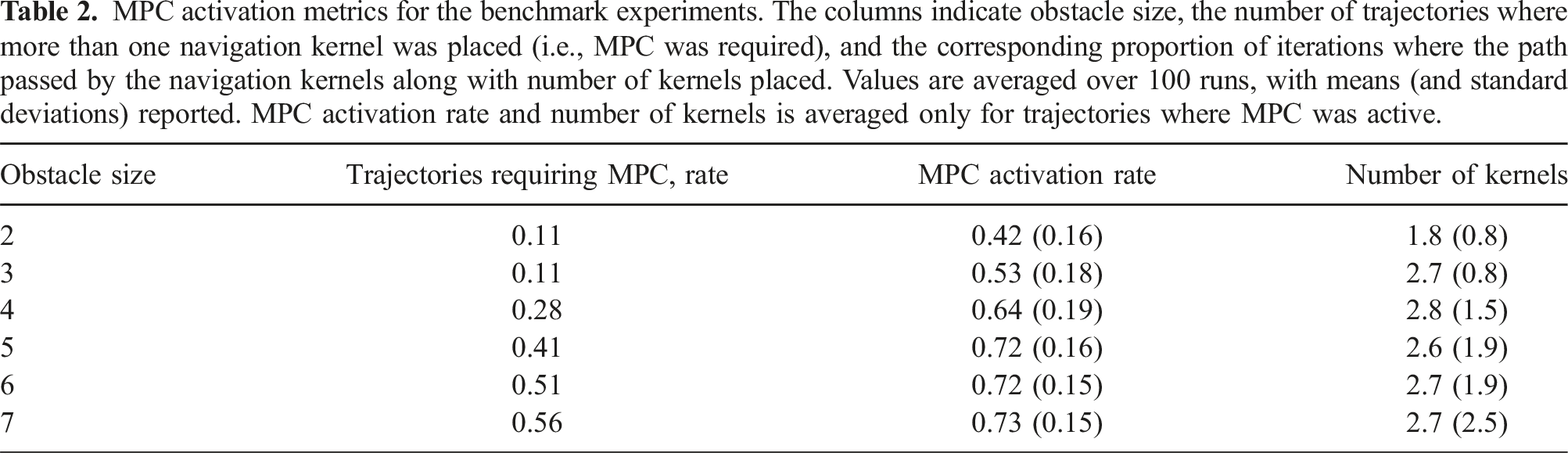
In the case of a dynamic unstructured environment, it is possible that previously placed navigation kernels may become irrelevant after obstacles have moved. This issue is addressed in our method through the coefficient αΓ (as defined in equation (31)) that deactivates the deflection as obstacle moves away. If an obstacle once again comes close to such a kernel, MPPI will automatically begin adjusting the kernel’s parameters.
8.3. Real robot experiments
We demonstrate the reactive collision avoidance properties of our method on a setup involving Franka Emika. We use a simple reaching trajectory similar to the one used in simulated benchmark. We then command the robot to alternate between these nominal dynamics to perform cyclic motion between two attractors following the reaching pattern. We fit a human shape with 70 spheres (see Figure 10) with variable radii, and randomly obstruct the robot workspace during the task execution. The keypoints on the human are tracked with OptiTrack at a 120 Hz rate. Modulated DS with latest available policy is evaluated at frequency of at least 500 Hz, and MPPI asynchronously updates the navigation policy at approximately 20 Hz. The robot is then controlled at 1 kHz by a custom low-level torque controller. Figure 11 demonstrates the snapshots of the experiment in which human dynamically appears in the robot workspace and obstructs the motion. Multimedia attachment shows the full video of the experiment. Spherical approximation of human upper body. 70 spheres of variable radii represent head, torso, and arms. Optitrack markers are used to determine six keypoints located on the human body. Two experiments in which human swiftly obstructs the robot motion with (a) raised arm, and (b) concave arm trap. Robot reactively avoids the collision and navigates the concavity, continuing the reaching task execution. Time difference between subsequent images is approximately 700 milliseconds. For more experiments please refer to the supplemental video.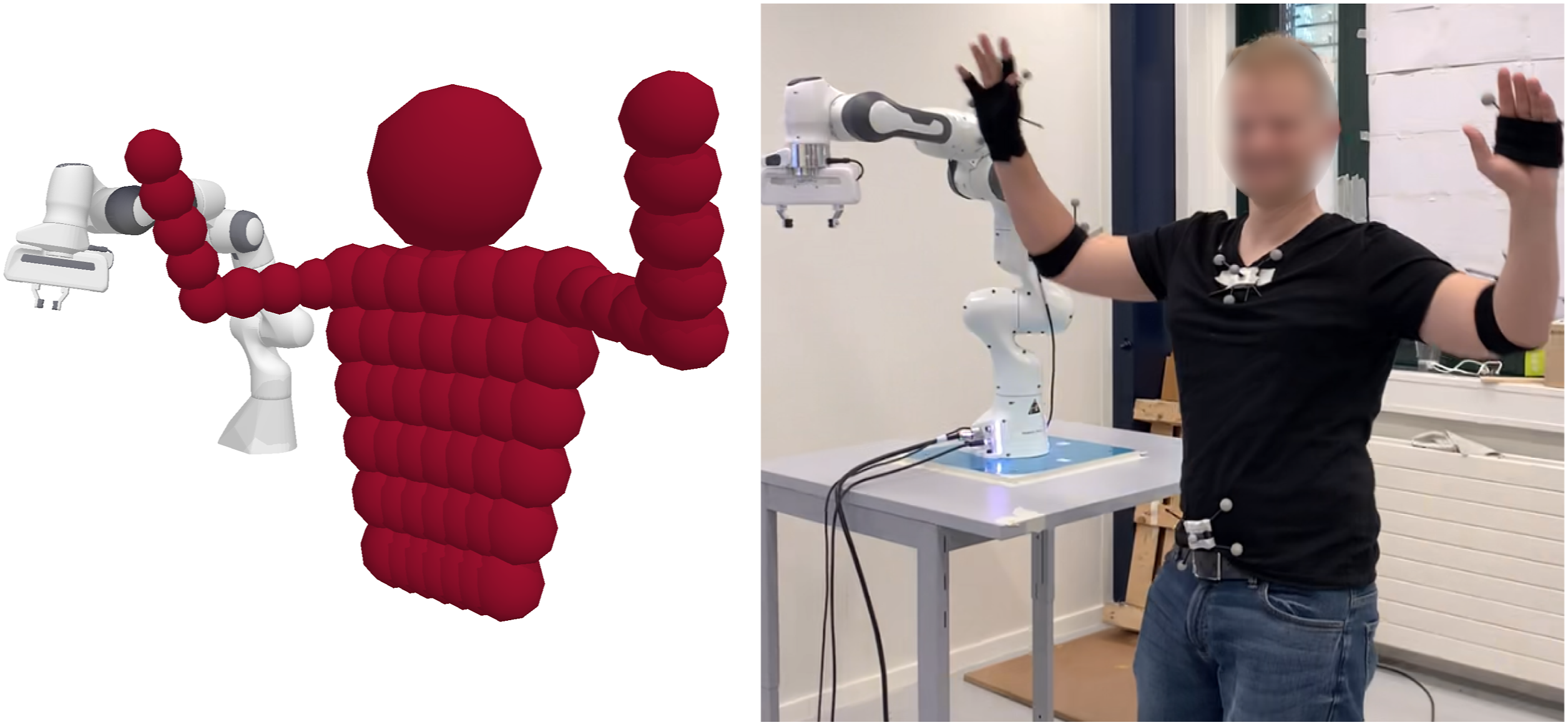

9. Conclusion and future work
We have presented a method to introduce deflections into a Modulated Dynamical System to enhance the navigation capabilities of the original approach proposed by Khansari-Zadeh and Billard (2012). Our method retains the properties of the Modulated DS, such as local stability and non-penetrability of obstacle boundaries.
We utilize Sampling-based Model Predictive Control to optimize the deflection parameters and leverage the Neural Signed Distance Function for real-time performance in the 7-dimensional joint space of a robotic manipulator.
Our proposed hybrid controller enables real-time, collision-free motion generation for any nominal DS motion. The underlying modulated DS can effectively control collision-free robot movement at frequencies up to 500 Hz, while the navigation policy updates at 20 Hz, allowing for path-planning in non-static and rapidly changing environments.
Future work could address some limitations of our approach, such as the generation of motion exclusively in joint-space. While this is natural for robots, it may not be ideal for real-world tasks. The hybrid controller could be enhanced by adding an Inverse Kinematics layer that calculates the desired final joint positions for each robotic task. Additionally, considering multiple DS attractors could fully exploit the redundancy of robot kinematics.
Another potential improvement involves developing a fully dynamic controller that considers not only obstacle positions but also their velocities, adding a new level of reactivity to the generated motions. This approach could be further refined by incorporating filtering and prediction of obstacle movements, enhancing the MPC policy generation.
Future work will explore advanced sampling strategies for MPPI optimization beyond standard Gaussian distributions Lambert et al. (2021); Barcelos et al. (2021). Tailoring these distributions to dynamic environments could yield quicker convergence and more nuanced motion planning, particularly in human-interactive settings. This refinement aims to bolster our method’s adaptability and performance in real-world applications.
Supplemental Material
Supplemental Material - Reactive collision-free motion generation in joint space via dynamical systems and sampling-based MPC
Supplemental Material for Reactive collision-free motion generation in joint space via dynamical systems and sampling-based MPC by Mikhail Koptev, Nadia Figueroa and Aude Billard in The International Journal of Robotics Research.
Supplemental Material
Supplemental Material
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the European Research Council (ERC) (Advanced Grant agreement No. 741945, Skill Acquisition in Humans and Robots)
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.