
Abstract
We describe an optimization-based framework to perform complex locomotion skills for robots with legs and wheels. The generation of complex motions over a long-time horizon often requires offline computation due to current computing constraints and is mostly accomplished through trajectory optimization (TO). In contrast, model predictive control (MPC) focuses on the online computation of trajectories, robust even in the presence of uncertainty, albeit mostly over shorter time horizons and is prone to generating nonoptimal solutions over the horizon of the task’s goals. Our article’s contributions overcome this trade-off by combining offline motion libraries and online MPC, uniting a complex, long-time horizon plan with reactive, short-time horizon solutions. We start from offline trajectories that can be, for example, generated by TO or sampling-based methods. Also, multiple offline trajectories can be composed out of a motion library into a single maneuver. We then use these offline trajectories as the cost for the online MPC, allowing us to smoothly blend between multiple composed motions even in the presence of discontinuous transitions. The MPC optimizes from the measured state, resulting in feedback control, which robustifies the task’s execution by reacting to disturbances and looking ahead at the offline trajectory. With our contribution, motion designers can choose their favorite method to iterate over behavior designs offline without tuning robot experiments, enabling them to author new behaviors rapidly. Our experiments demonstrate complex and dynamic motions on our traditional quadrupedal robot ANYmal and its roller-walking version. Moreover, the article’s findings contribute to evaluating five planning algorithms.
Keywords
1. Introduction
When humans and animals engage in complex locomotion behaviors, the motions involve a fast interaction between the feet and the environment’s contact. Additionally, whole-body coordination operating near physical limits or over challenging obstacles is demanding, requiring look-ahead planning to decide the upcoming steps carefully. The synchronization of fast interactions and look-ahead planning is a fascinating research direction. Planning such physically feasible motions for (wheeled-)legged robots, as shown in Figure 1, is challenging since the whole-body movement results from contact forces at the feet (or wheels). Therefore, we need to carefully choose the interaction at these contact points with the environment to achieve the desired behavior while respecting physical laws. Our quadrupedal robot ANYmal (Hutter et al., 2017) with wheels executes complex and agile skills through offline TO and online MPC. With our novel approach, the robot achieves dynamic and artistic motions in challenging terrain. First image: Terrain-aware locomotion over a 0.20 m high step (32 % of leg length). Second image: Ducking motion under a table. Third image: Dynamic 180°turn in approximately 1 s. The dotted lines show the TO’s offline trajectories of the whole-body, while the solid lines show the online solution of the MPC. A video available at https://youtu.be/39rRhTqcQc0 showing the results accompanies this article.
1.1 Offline and online optimal-control
Designing high-dimensional trajectories, for example, whole-body trajectories including ground reaction forces, is difficult. In most cases, it is not feasible to hand-craft due to the complexity of the constraints. When analyzing the literature in Section 2, it appears that optimal-control algorithms can be separated from a practical point of view into two groups: offline and online algorithms.
The usage of trajectory optimization (TO) (see reviews by Betts (1998); Rao (2009)) offers the chance to solve the locomotion problem over the task’s time horizon while optimizing a higher-dimensional variable space composed of the whole-body trajectory, gait sequences, and timings. With a task-specific goal, these variables are found automatically while considering constraints imposed by physical restrictions. In the last few years, legged locomotion research experienced a surge in TO approaches that solve the locomotion problem over long-time horizons from scratch (Geilinger et al. 2018, 2020; Herzog et al., 2015; Jelavic and Hutter 2019; Mastalli et al., 2017; Medeiros et al., 2020; Melon et al., 2020; Mordatch et al., 2012; Park et al., 2016; Posa et al., 2014; Todorov 2011; Winkler et al., 2018; Yeganegi et al., 2019). Most of these approaches share one aspect in common that their algorithms run offline and, due to the computational complexity, reliable online execution on the real robot becomes one of the main challenges.
Instead, a large amount of pioneering work in model predictive control (MPC) (see reviews by Morari and Lee (1999); Mayne et al. (2000); Bertsekas (2005); Diehl et al. (2009)) focuses on the online execution of whole-body optimization problems on the real robot in a task-generic fashion (Caron and Pham, 2017; Bjelonic et al., 2021; Bledt and Kim 2019; Bledt et al., 2018; Dantec et al., 2020; Dai et al., 2014; Erez et al., 2013; Farshidian et al., 2017; Grandia et al., 2019a, 2019b; Herdt et al., 2010; Henze et al., 2014; Koenemann et al., 2015; Laurenzi et al., 2018; Mason et al., 2018; Neunert et al., 2018; Paparusso et al., 2020; Zimmermann et al., 2015). Due to fast update rates, MPC finds solutions on the fly while correcting the motion under unforeseen conditions, such as modeling errors and external disturbances, thus offering feedback control. In contrast to TO, these motions are generated over relatively short-time horizons and neglect complex optimization variables and constraints, such as gait timings and higher-order model complexities, to speed up the solver time. Therefore, the optimization may not guarantee an optimal solution for tasks requiring a longer time horizon and a more accurate physical representation, for example, parkour over obstacles. The characteristics of both fields can be summarized as follows:
Offline trajectory optimization. Offline computations of long-time horizons and task-specific problems are solved from scratch while considering higher-order model complexities.
Online model predictive control. Online computations of short-time horizons and task-generic problems are solved by a shifted guess from the previously computed optimal solution and explore task simplifications for computational reasons.
1.2 Contribution
We formalize, evaluate, and analyze a complete planning and control solution for the relatively underexplored domain of hybrid wheeled-legged locomotion. Our article’s theoretical contribution is a whole-body
1
approach to locomotion planning that combines offline motion libraries and online MPC, generating complex and dynamic motions for (wheeled-)legged robots. The former finds complex motions enabling whole-body coordination near robot limits and over challenging obstacles (see Figure 2) with task-specific time horizons. We then use these offline trajectories as the online MPC’s cost, which explores reactive optima over a fixed look-ahead. Moreover, we can store offline trajectories in a motion library where each motion can be composed into a single maneuver. Our quadrupedal robot ANYmal with wheels overcomes two steps in a row (upper image) and steps up-and-down (lower image) through the terrain-aware TO and MPC. The maximum step height is 0.20 m (32 % of leg length) and the robot locomotes the obstacle course with a maximum speed of 1.5 m/s while only lifting its legs when needed.
We showcase three state-of-the-art TO algorithms for the offline computation of complex trajectories, namely an interactive TO, a terrain-aware TO, and a sampling-based method, allowing motion designers to choreograph complex motions. With this demonstration of different offline motion planners, we verify that our complex motion composition can be extended with other algorithms providing whole-body trajectories.
The main conceptual contribution of this work is the real-time execution of the offline trajectories on the real robot. To this end, our online optimization is based on a whole-body MPC that closes the offline-to-online gap. Similar to the TOs, it is based on a single task formulation that simultaneously optimizes feet (or wheels) and torso motions. Due to the real-time joint velocity and ground reaction force optimization based on a kinodynamic model, the MPC can follow a high variety of different offline motions, thus is general with respect to (w.r.t.) the task. Also, we discuss the importance of incorporating a look-ahead along the offline trajectories, which enables the anticipation of future events. Traditional MPC with a short-sighted plan can generate a sub-optimal solution for tasks over longer time horizons. In our work, the augmentation of the MPC’s cost with offline trajectories avoids these problems.
As shown in Figures 1 and 13, the experiments demonstrate complex and dynamic motions on our traditional four-legged robot ANYmal and its roller-walking version, further demonstrating the findings’ generalizability and approach’s applicability to any robot with legs and wheels.
Succinctly, the six main findings (C1) to (C6) of this article can be summarized as follows:
(C1) Whole-body coordination. The online MPC coordinates offline trajectories of complex, whole-body motions operating near robot limits while being responsive to the terrain.
(C2) Offline-to-online gap. The online MPC optimizes from the measured state, resulting in feedback control, which adds a certain degree of robustness and reliability to the offline trajectory’s execution by recomputing solutions on the fly and reacting to unforeseen conditions, such as modeling errors and external disturbances. Also, the MPC anticipates future events of the offline trajectory.
(C3) Rapid motion prototyping. Executing offline trajectories on the real robot is a tedious task requiring tuning robot experiments. Due to the properties (C1) and (C2) of our online motion planner, motion designers can choose their favorite motion generator to iterate over behavior designs offline without tuning robot experiments, enabling them to author new behaviors rapidly.
(C4) Motion composition. Motion designers can compose multiple offline trajectories into a single maneuver. Since these (composed) trajectories are fed into the MPC as a cost (and not as a constraint or initialization method) and due to the look-ahead of the MPC, our approach makes it possible to smoothly blend between trajectories even in the presence of discontinuities, avoiding hand-tuned heuristics at these transitions.
(C5) Performance and generalization. The robot can conduct artistic motions, dance, and find optimal solutions over non-flat terrain. Our framework is not restricted to our roller-walking robot ANYmal and is generalized to any robotic creature with legs and wheels.
(C6) Evaluation of offline motion planners. The article’s findings serve as an evaluation of three offline motion planners for ANYmal.
2. Related work
In the following, we categorize existing approaches to legged locomotion planning by offline TO and online MPC methods and, finally, review techniques that combine both optimal-control approaches.
2.1 Offline trajectory optimization
Most of the related work in the field of TO for legged locomotion precomputes complex trajectories over a task-specific time horizon. Due to offline generation and a focus on higher-order optimizations, reducing the computation time becomes a lower priority compared to MPC. As such, TO algorithms choose from a set of models that captures the real robot’s dynamics more accurately. For example, the rigid body dynamics (RBD) model only assumes non-deformable links and the equations of motion (EOM) can be rewritten as the Centroidal dynamics (CD) model without loss of generality (Orin et al., 2013; Kuindersma et al., 2016). Budhiraja et al. (2019) discuss the dynamic consensus between centroidal and the RBD models. The single rigid body dynamics (SRBD), on the other hand, assumes that the legs are massless and, as can be seen below, is another commonly used model in TOs (Herzog et al., 2015).
Winkler et al. (2018) propose a phase-based end-effector parameterization for simultaneously optimizing gait and whole-body motion over non-flat terrain. A nonlinear programming (NLP) algorithm solves the problem, and, as a model, the authors deploy the SRBD of a legged robot. The approach is augmented by Medeiros et al. (2020) to incorporate wheeled locomotion without stepping. The optimization problem, however, becomes prone to local minima and, as such, depends on a good initialization. Melon et al. (2020) propose a learning-based scheme to solve this problem by initializing the NLP based on offline experiences. In contrast, Mordatch et al. (2012) and Carius et al. (2019) present a contact invariant TO formulation to synthesize legged robots’ motions. As shown by Deits and Tedrake (2014) and Aceituno-Cabezas et al. (2017), mixed-integer optimization problems can solve the combinatorial complexity of simultaneous gait and motion planning.
Recently, research in hybrid locomotion showed a rise of new TO methods. Skaterbots show impressive results based on the CD model of robots with wheels and legs (Geilinger et al. 2018, 2020). In contrast to the work of Winkler et al. (2018) and Medeiros et al. (2020), the authors of Skaterbots have access to the leg’s kinematics, which becomes even more critical for wheeled-legged robots since the estimation of the rolling direction is required. Thus, the work of Medeiros et al. (2020) requires a heuristic that approximates the rolling constraint. A whole-body, kinematic TO (Jelavic and Hutter 2019) and a sampling-based method (Jelavic et al., 2021) showcase static motions for legged excavators in visualization only.
In contrast to MPC, some TO methods offer the chance to be immune to local minima when the domain has discontinuous dynamics (Erez et al., 2012). These algorithms, however, are often too slow to be applied online on the real robot, though impressive results are being showcased in visualization and inside simulation environments. On the real robot, the related work struggles with the execution of these motions. For example, Winkler et al. (2018) only manage to run a few simple trajectories on flat terrain. The authors use a tracking controller that only looks at one set point at a time to execute the offline trajectories.
2.2 Online model predictive control
The task of MPC is to find the robot’s continuous-time motion over a fixed time horizon, that is, the torso’s trajectories and feet (or wheels). Moreover, the algorithm must carefully plan the ground reaction forces to achieve the desired behavior.
To reduce the model complexity and enable real-time execution, the research community is experimenting with simplifying the real robot’s dynamics. For example, by modeling the robot as a linear inverted pendulum (LIP) model, the zero-moment point (ZMP) developed by Vukobratović and Borovac (2004), or the center of pressure (COP), is used to control only the motion of the center of mass (COM) position and acts as a substitute for the contact forces (Bellegarda et al., 2018; Bellicoso et al., 2018; Bjelonic et al. 2019, 2020; Caron et al., 2017; De Viragh et al., 2019; Jenelten et al., 2020; Kalakrishnan et al. 2010, 2011; Krause et al., 2012; Mason et al., 2018; Mastalli et al., 2020; Sardain and Bessonnet 2004; Winkler et al. 2015, 2017; Zucker et al., 2011). Additionally, the locomotion planning’s high-dimensional problem can be decomposed into a separate torso and feet (or wheels) planning problems. Thus, the resulting two lower-dimensional sub-tasks become more tractable (Bellicoso et al., 2018; Bjelonic et al., 2020; Buchanan et al., 2020; Di Carlo et al., 2018; Englsberger et al., 2014; Focchi et al. 2017, 2020; Griffin et al., 2019; Kajita et al., 2001; Jenelten et al., 2020; Kalakrishnan et al., 2010; Klamt and Behnke 2018; Laurenzi et al., 2018; Kudruss et al., 2015; Naveau et al., 2017; Park et al., 2015; Rebula et al., 2007; Tsounis et al., 2020; Wieber 2006; Wieber et al., 2016; Zucker et al., 2011).
In our previous work (Bjelonic et al., 2021), we verify that the full set of possible solutions cannot be discovered by such a decomposed method. The individual components do not consider the complete set of physical constraints. Instead, a single task approach should be deployed that treats the continuous-time decision problem as a whole without breaking down the problem into several sub-tasks. Such holistic solutions automatically discover complex and dynamic motions that are impossible to find through hand-tuned heuristics at the cost of higher computation times. Also, a single set of parameters for all behaviors makes the algorithm general w.r.t. the task, which is crucial when executing different offline trajectories. Another finding shows that the LIP model does not accurately capture the real model’s accuracy, and higher-dimensional models, for example, SRBD models, are required for more complex tasks.
In the last few years, traditional legged locomotion research experienced a large amount of pioneering work in MPC that now reliably runs single task optimizations based on an SRBD or CD model (Caron and Pham 2017; Dai et al., 2014; Erez et al., 2013; Farshidian et al., 2017). Bledt and Kim (2019) implement a regularized predictive controller for simultaneous footstep and ground reaction force optimization. The authors show their results on the quadrupedal robot, MIT Cheetah 3 (Bledt et al., 2018). Similarly, Grandia et al. (2019a, 2019b) and Neunert et al. (2018) deploy an MPC on the ANYmal robot (Hutter et al., 2017). In contrast, the former work introduces a kinodynamic model, which defines the SRBD model along with the kinematics for each leg.
MPC offers robust and reactive control for even high-dimensional (wheeled-)legged robots. Running MPC over a short-time horizon does not result in optimal motions over the task’s full receding horizon. The effects of using a short-sighted optimization become evident when considering tasks that involve crossing challenging obstacles like stepping stones (Dantec et al., 2020; Grandia et al., 2021; Magaña et al., 2019; Mastalli et al., 2020) and stairs (Fankhauser et al., 2018; Jenelten et al., 2020). Here, the robot makes unnecessary steps over the terrain patches, and depending on the difficulty of the obstacle, the robot can be guided into inescapable situations. Moreover, the MPC gets stuck in local minima when the domain has discontinuous dynamics (Erez et al., 2012).
2.3 Combination of trajectory optimization and model predictive control
Neunert et al. (2016) propose a method that uses a sequential linear quadratic (SLQ) algorithm in an MPC setting to unify the optimization of trajectories over multiple seconds and tracking within only a few milliseconds. The results, however, are only shown on a hexacopter and a ball balancing robot. Running these algorithms with a planning horizon of multiple seconds in real-time on a switched system like legged robots, as demonstrated by Neunert et al. (2018) and Farshidian et al. (2017), becomes unfeasible and requires a novel control approach. In contrast, Li et al. (2020) formulate a single optimization problem posed over a hierarchy of two models achieving trajectories over a longer time horizon than traditional MPC with a single model. To achieve this, the authors fall back to a simplified model at longer time horizons. The MPC posed over two models face the same challenges as the traditional MPC approach. It misses the ability to solve task-specific problems, is prone to local minima and the simplified model has a limited solution space at the system’s limitations and over challenging obstacles. Similarly, Zimmermann et al. (2015) generate motion plans for the immediate future using higher-fidelity models, while coarser models are used to create motion plans with longer time horizons. All motions are shown on a bipedal robot in simulation.
Erez et al. (2012) use offline TO to find the limit-cycle solution of an infinite-horizon, average-cost optimal-control task and apply its quadratic approximation as the online MPC’s terminal cost. Their work, however, is only verified in a simulation environment. In aeronautical research, Lapp and Singh (2004) use the two optimal-control paradigms by feeding the TO’s offline solution as a cost term to the MPC.
The combination of offline TO and online MPC has not been studied in depth in the field of (wheeled-)legged robotics. Boston Dynamics’ bipedal robot Atlas demonstrates dynamic and parkour-like motions over challenging obstacles (Boston Dynamics 2019). The video’s description and a presentation by Kuindersma (2020) reveal that the company is working on a similar approach, as introduced in our article. A TO transforms high-level descriptions of each motion into dynamically-feasible reference motions tracked using an MPC. Due to Atlas’s missing publications, there is no in-depth knowledge about Boston Dynamics’ locomotion framework.
3. Complex motion composition
In the following, we give an overview of our complex motion composition framework that combines the advantages of offline TO and online MPC. Figure 3 visualizes our complete locomotion controller that is discussed in more detail in the following sections. Overview of our complex motion composition. The TOs transform high-level tasks into dynamically feasible motions stored in a motion library. Based on the operator’s chosen motions, individual motions from this library are composed into a single offline trajectory with a total time horizon TTO. This trajectory is fed into the MPC, optimizing joint velocities and contact forces over a shorter time horizon TMPC. Finally, the inverse dynamics transforms the desired online trajectory into actuator commands.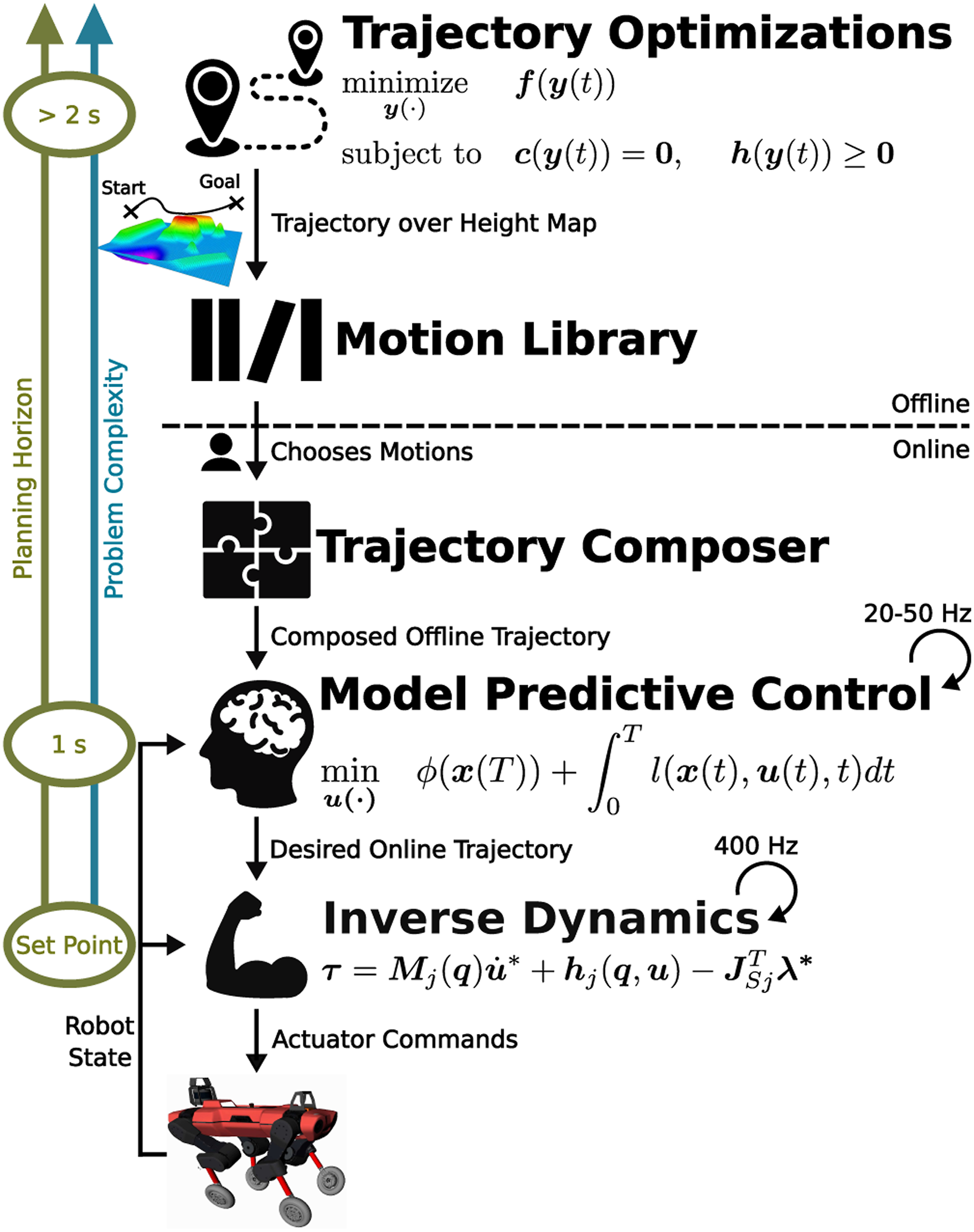
3.1 Problem formulation and solution
Optimizing and executing a complex motion on the real robot comes with different and opposing challenges, making our hierarchical structure’s design crucial. On the one hand, we aim for a general-purpose solution that can take any offline trajectory as input for real-time execution. These offline trajectories can contain different polynomial representations with a variable number of nodes. Concatenating multiple trajectories results in jumps that are difficult to track and, in some cases, might result in the online optimization failing. On the other hand, our online optimization needs to be self-contained. The system should act independently without relying on perfectly modeled offline trajectories even under unpredicted disturbances.
We, therefore, propose to integrate the offline trajectory as a cost to our online MPC that contains three essential characteristics: (1) prediction over a short horizon, (2) flexible offline trajectories as inputs, and (3) self-contained online execution. The prediction over a short-time horizon enables the robot to anticipate the offline trajectory. Even in more significant tracking discrepancies, the robot can plan its whole-body trajectory back towards the desired offline motion. In contrast, as shown in the results, tracking only one set point at a time does not result in a robust motion execution. The second characteristic, that is, flexible offline trajectories as inputs, comes through integrating the offline trajectory as a cost term. The motion designer does not need to make sure that the composed motions are continuous or dynamically feasible. Adding the offline trajectory as a hard constraint or initializing the optimization might make the problem unfeasible. The last characteristic ensures that even in large tracking offsets, the online planner can still find robust motions. In the next section, we present our approach in more detail.
3.2 Overview
Our approach to optimizing complex locomotion strategies for (wheeled-)legged robots consists of a hierarchical structure, as visualized in Figure 3. First, the Trajectory Optimizers transform high-level tasks, for example, user-guided or terrain-aware maneuvers, into dynamically-feasible trajectories. These trajectories are stored in a Motion Library that is accessible by an operator at run time. Moreover, the operator can choose multiple motions. Given the commanded motion reference(s), the Trajectory Composer concatenates each trajectory into a single Offline Trajectory fed into our Model Predictive Control algorithm, which tracks this trajectory and smoothly blends from one maneuver to the next. Finally, the Inverse Dynamics computes actuator commands that are sent to the robot, and a state estimator predicts the robot’s state.
3.3 Timings and problem complexity
It is essential to look more closely at planning horizons, problem complexities, and update rates of each module in Figure 3. When it comes to the former two categorizations, we can see that the planning horizon and problem complexity increase vertically. The inverse dynamics is only looking at one set point at a time, while the MPC looks-ahead with a fixed planning horizon of one second. In contrast, the TO generates complete maneuvers, often incorporating a more complex dynamic model with a task-specific time horizon up to multiple seconds. Due to this long-time horizon and the complexity of the task, for example, dynamic behaviors at the robot’s limits or terrain-aware maneuvers over obstacles, the motions are computed offline. The composition of these offline trajectories results in even longer time horizons. With the decrease of the problem’s complexity from top to bottom, the MPC and the inverse dynamics can achieve update rates on the robot of around 20–50 Hz and 400 Hz, respectively.
In the following sections, we introduce our main theoretical contributions, the definition of the offline trajectory including the three offline motion generators, the online MPC, and the trajectory composer in more detail.
4. Offline motion generation
In general, the offline TO’s problem is expressed as a nonlinear optimization problem with objective

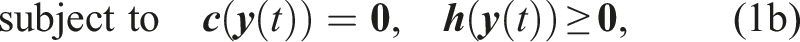
4.1 Offline trajectory
In this work, the combination of offline TO and online MPC comes through the offline trajectory. The offline motion generation might include additional optimization variables that are not considered by the online MPC. To this end, we split the optimization variable
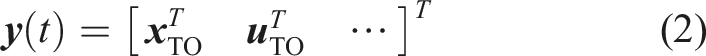
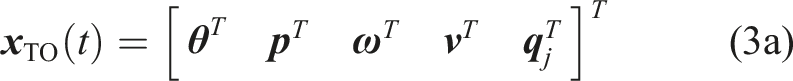

In the following, we present two TOs and a combination between sampling and optimization-based planning that solve various tasks while incorporating different model complexities. The solution of each TO provides the offline trajectory
4.2 Interactive trajectory optimization
One way to generate offline motions is to use the interactive TO, that is, a tool allowing a two-way flow of information between the motion optimizer and designer. Motion designers can add and modify high-level motion goals, such as target COM position and orientation at specific moments in time. Meanwhile, trajectory optimization finds motion plans that satisfy kinematic and dynamic constraints. Also, the immediate visual feedback allows the motion designer to choreograph complex motions interactively.
The interactive TO is based on the work of Geilinger et al. (2018) and Geilinger et al. (2020). In the following, we briefly summarize the optimization problem solved by the interactive TO.
4.2.1 Problem formulation
The motion generation’s model is based on the CD model and complemented with geometric constraints to ensure the generated motions’ consistency with the robot’s kinematics. Depending on the type of end-effector, for example, traditional point feet or actuated wheels, constraints on the ground reaction forces and the end-effector’s state trajectories are instantiated. We find that this approach strikes a favorable balance between predictive power, simplicity, and computational efficiency for rapid motion prototyping.
Based on a robot’s morphology and high-level motion goals, trajectory optimization finds a motion plan
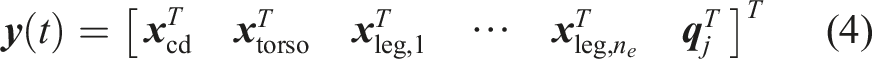
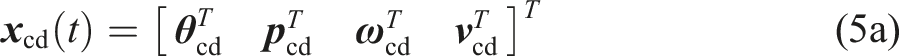
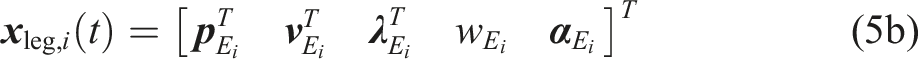
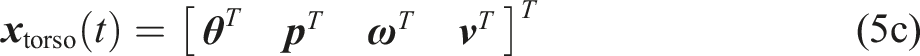
The centroidal coordinate frame is represented by the robot’s orientation and COM position in world frame W,
With the motion plan’s parameters in place, we define the cost terms and constraints that arise from the dynamics and kinematics that govern a robot’s motion in Appendix A. At the core of this interactive TO lies its interactive capabilities and underlying CD model. The former gives the motion designer interactive control over the robot’s motion by formulating a set of objectives at specific times.
4.3 Terrain-aware gait and trajectory optimization
Our second TO in this work relies on a terrain-aware approach to optimize gait and motion simultaneously. Motion designers merely add start and goal poses of the robot’s torso to the optimization problem, including a terrain representation as a 2.5D elevation map. Meanwhile, TO finds motion plans that satisfy kinematic and dynamic constraints over non-flat terrain.
The terrain-aware gait and TO formulation for (wheeled)legged robots is presented in the following section and is based on the work of Winkler et al. (2018). In contrast to Medeiros et al. (2020), the optimization problem can generate simultaneous driving and stepping motions, that is, hybrid locomotion. Here, we overview the optimization problem generating regular walking and hybrid locomotion trajectories.
4.3.1 Problem formulation
The motion designer provides an initial and desired final state of the robot, the total time horizon TTO, and a gait schedule including an approximate duration of each leg’s contact and swing timings. With this information and a given height map hterrain (x, y) of the terrain, the algorithm finds Overview of the terrain-aware gait and TO’s variables. Here, the robot overcomes a step with a height of 0.15 m, and the visualization shows the optimized trajectories xtorso(t) and xleg,i(t). Each of the variables is introduced in Section 4.3.1.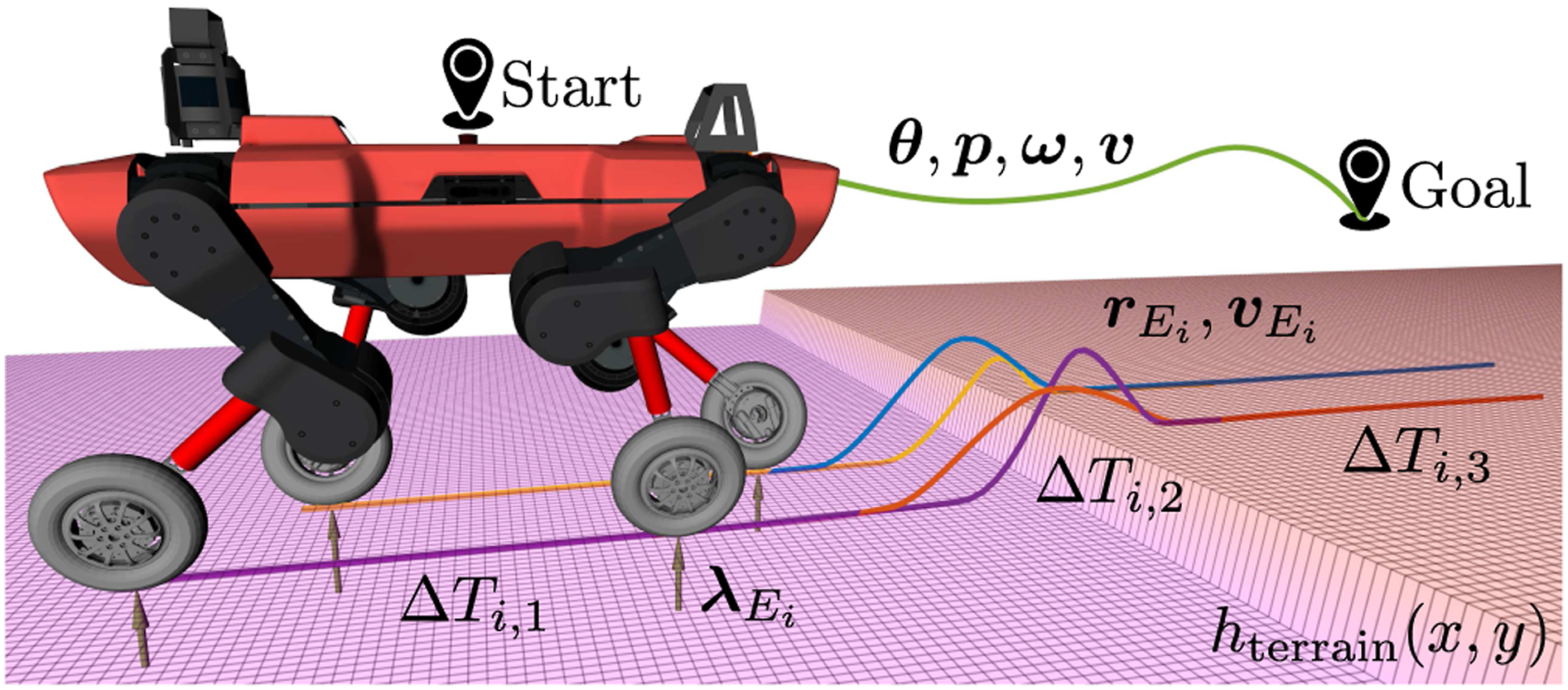

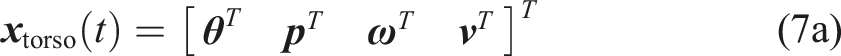
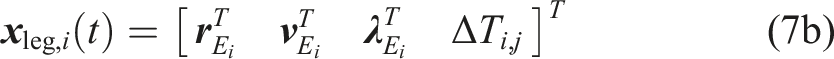
Appendix B describes each of the optimization problem’s constraints. At the core of this terrain-aware TO lies its rough terrain capability and underlying SRBD model. Here, the former integrates the information of the height map hterrain (x, y) and makes sure that the end-effector stays in contact with the ground while the leg is in stance phase.
4.3.2 Inverse kinematics
The optimized trajectories
4.4 Combined sampling and optimization-based planning
Optimizing gait timings over challenging terrain is a complex problem for (wheeled-)legged robots and can be solved through sampling-based methods. In our work, we adopt the approach of Jelavic et al. (2021) that is designed for legged excavators and apply it to our wheeled-legged robot ANYmal. This offline motion generator combines an initialization and refinement step. The former is a sampling-based planner that samples robot poses through a Rapidly-Exploring Random Tree (RRT) (Karaman and Frazzoli 2011) and the second step refines the motion with a nonlinear optimization, producing kinematically feasible and statically stable offline trajectories.
5 Online model predictive control
The offline generated trajectory in Section 4.1 is fed into our online MPC as a cost, allowing us to reactively optimize along the offline trajectory even in the presence of discontinuous transitions and unpredicted disturbances. This feedback control re-optimizes the offline trajectories from the measured state. The following sections describe the underlying optimization, as well as the integration of the offline trajectories into the online execution.
5.1 Problem formulation
The main advantage of MPC is that it allows the current input to be optimized while considering future desired states. Such an optimization is achieved by optimizing over a finite time-horizon of TMPC, repeatedly, enabling the anticipation of future events. At each iteration of the MPC, we solve the optimization problem based on The optimized trajectory of the MPC while tracking the offline trajectory of Figure 4. Here, the robot’s front legs are stepping up the obstacle, and the visualization shows the optimized trajectories 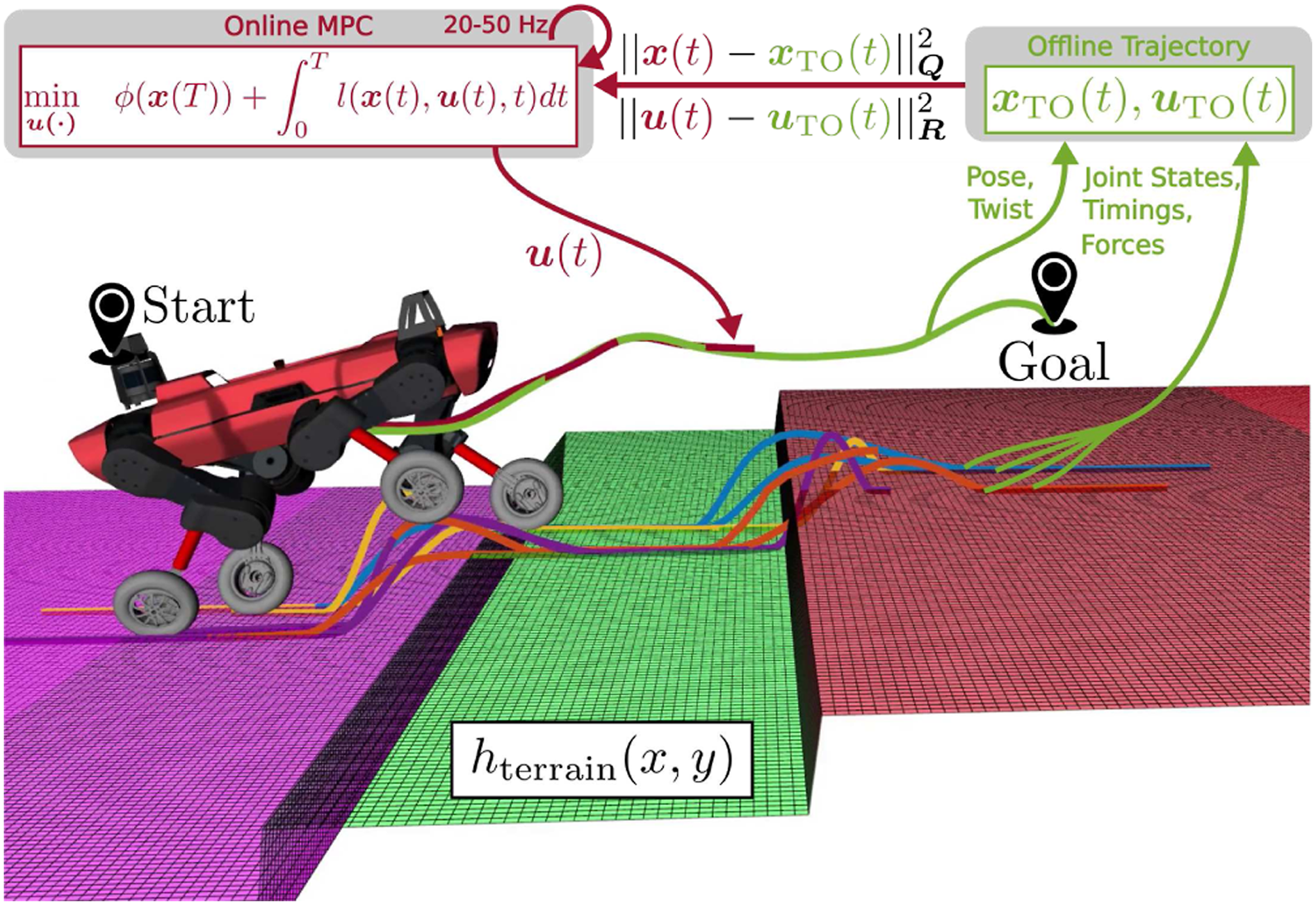
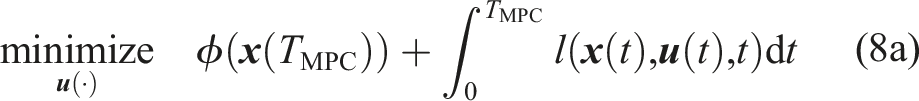
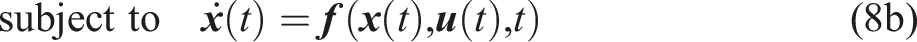




In contrast to Bjelonic et al. (2021), which does not incorporate any offline trajectories or perception, our article’s contribution comes through the MPC’s cost function that incorporates the TO’s offline trajectories. The set of constraints that we have chosen makes the MPC a general-purpose optimization problem that can deal with slight mistakes from the motion designer while considering the terrain and offline trajectory in front of the robot. Our article continues with more details about the implementation of the cost function and constraints.
5.1.1 Cost function
As discussed in Section 3.1, incorporating the offline trajectory given by
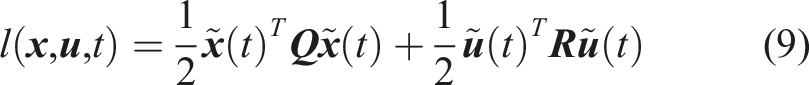
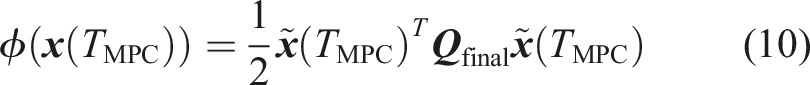
5.1.2 Equations of motion
The system’s dynamics in (8b) is based on a kinodynamic model of a (wheeled-)legged robot. In contrast to the EOM of the terrain-aware TO in (22), it defines the SRBD model along with the kinematics for each leg. It is given by


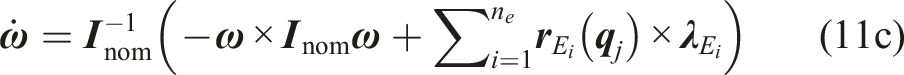


5.1.3 Legs in contact
The MPC models some of the contact constraints in a similar fashion as the terrain-aware TO in (23), (24), and (25). The optimization variables of the MPC, however, include the kinematic information of each leg, which gives us
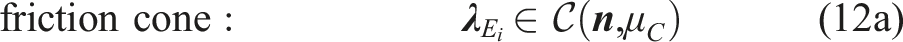
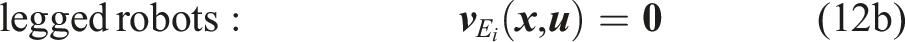
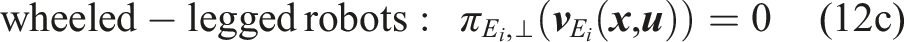
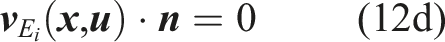
The traversal of challenging terrain requires additional inequality constraints that respect safe terrain regions. To this end, we segment the height map hterrain (x, y) into convex terrain regions given by a number n
h
of half-space constraints

5.1.4 Legs in air
Legs in swing phase are not capable of generating ground reaction forces and need to follow collision-free trajectories. This restriction can be incorporated into the MPC as


5.2 Torque generation
As visualized in Figure 3, we send torque commands to the embedded control loop of each motor. To this end, the optimized control input vector
6 Trajectory composer
Our final theoretical contribution proposes composing individual offline trajectories from the motion library into a single trajectory at run-time to produce longer and more complex maneuvers, as shown in Figure 12. For this reason, we leverage the MPC in Section 5. Before the motion is sent to the robot, we evaluate each transition to ensure the whole trajectory is feasible. The composed trajectory is then sent to the robot enacting the transitioning motions in real-time. It is important to note that no additional reference trajectories are added to the composition since the MPC can transition between (discontinuous) motions. If necessary, the motion composer adds additional time or a repositioning sequence to decrease the transitioning cost.
6.1 Trajectory composition
As shown in Figure 3, the operator can choose individual motions from the motion library, and the motion composer concatenates these motions into a single (composed) offline trajectory. To this end, an ordered list of motions, that is, individual offline trajectories
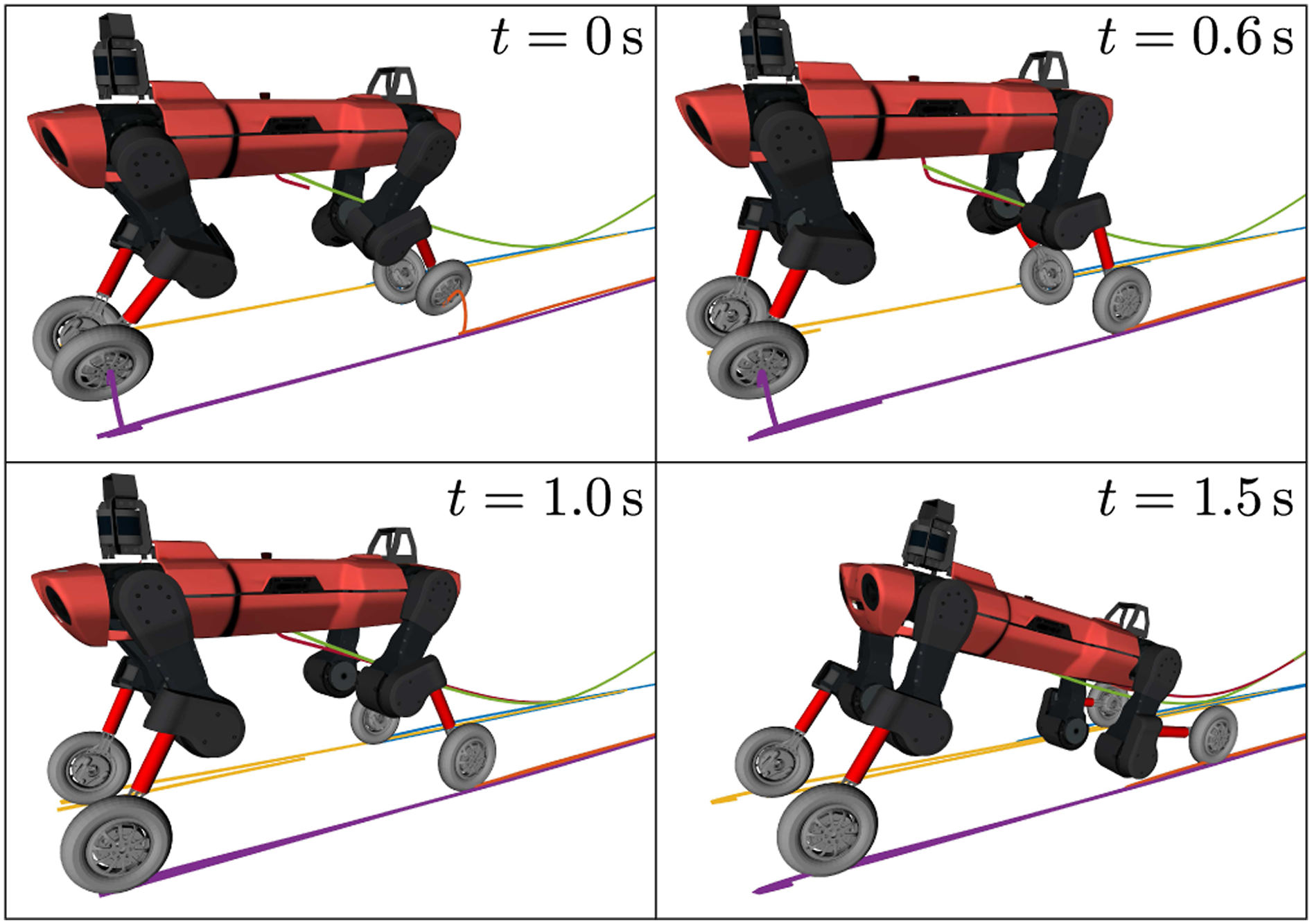
Transition strategies. In this article, we present three different strategies for the transitions 1. No transition: The transitioning duration TTD,k is set to zero, which invokes no transition between consecutive offline trajectories, that is, 2. Time transition: We add a transitioning time between consecutive offline trajectories 3. Repositioning transition: We add a transitioning maneuver before scheduling the next trajectory. To this end, we choose a trotting gait that repositions the whole-body of the robot to the desired state of the following trajectory. Similar to the previous strategy, the transition Ducking motion based on the interactive TO in Section 4.2. Here, the initial state of the end-effectors at t = 0 s is too far away from the offline trajectory. Thus, the robot performs a trotting gait to reposition its legs, that is, first the right-front and left-hind legs reposition at t = 0.6 s, and then the left-front and right-hind legs reposition at t = 1 s. The visualization shows the torso and end-effector trajectory of the offline trajectory and the MPC’s solution.
Transitioning cost evaluation. The three transitioning strategies are evaluated based on a transitioning cost, which is assessed online before the operator’s motion command is sent to the real robot. To this end, we evaluate the MPC’s solution of (8) over one iteration for each transition in (15) considering the previous and following trajectory, that is, the trajectory between consecutive trajectories
6.2 Alignment with initial state
The composed trajectory
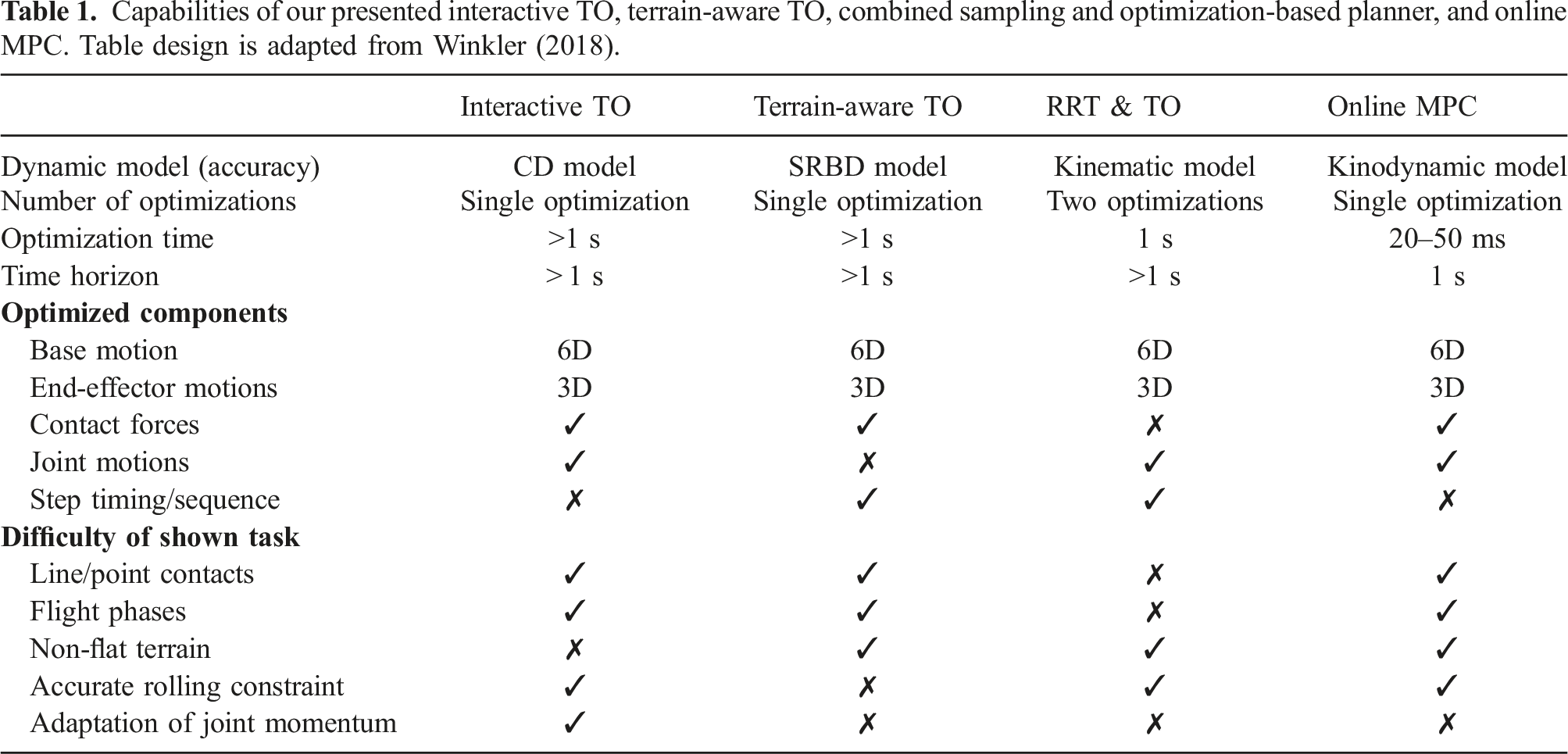
7. Experiments
Capabilities of our presented interactive TO, terrain-aware TO, combined sampling and optimization-based planner, and online MPC. Table design is adapted from Winkler (2018).
7.1 Experimental setup
Our trajectory composer, online MPC, inverse dynamics, and state estimator run in concurrent threads on a single PC (Intel i7-8850H, 2.6 GHz, Hexa-core, 64-bit). All offline trajectories are computed on a laptop (Intel E3-1505MV6, 3.0 GHz, Quad-core, 64-bit) and stored in a motion library on the robot. The robot is entirely self-contained in computation and sensing.
The estimation of the robot’s state and the torque commands are computed together in a 400 Hz loop. The former requires the fusion of the inertial measurement unit (IMU) readings and the kinematic measurements from each actuator to acquire the robot’s state, that is, the pose of the torso B w.r.t. the world frame W, as described by Bloesch et al. (2013). To this end, each leg’s contact state is determined by estimating the contact force, which considers the measurements of the motor drives and the full-rigid body dynamics.
7.2 Results and discussion
In the following, we verify our six contributions (C1) to (C6) introduced in Section 1.2 by categorizing each result and discussion as part of its underlying contribution.
(R1) Whole-body coordination. The algorithms in Table 1 are mostly based on single optimization problems (except RRT & TO) optimizing over the whole-body trajectory, including the base pose, end-effector motion, contact force, and two of the algorithms also optimize the joint motion, while the terrain-aware TO computes gait timings. Thanks to this single optimization of the whole-body, the robot can coordinate complex and artistic motions, as shown in Figures 1 and 2, operating near robot limits and cumbersome to hand-craft through heuristics. The motion over the steps includes front-legs and hind-legs jumps at a speed of up to 1.5 m/s (see Figure 7). When ducking under a table, the optimization algorithm can discover specialized motions for our wheeled-legged robot. Here, the robot reaches its maximum torque limits of the hip motors. The turning motion includes a complex coordination of all joints, as shown in Figure 9. We further discuss the motion over the step and the turning motion in the following paragraphs. Results of the terrain-aware TO in combination with the MPC while executing the motion over the step in Figure 1. The plot shows the euclidean norm of the COM’s linear velocity over the COM’s forward position in world frame W. The MPC’s solution equals the robot’s measured state, that is, the measured velocity is equal to 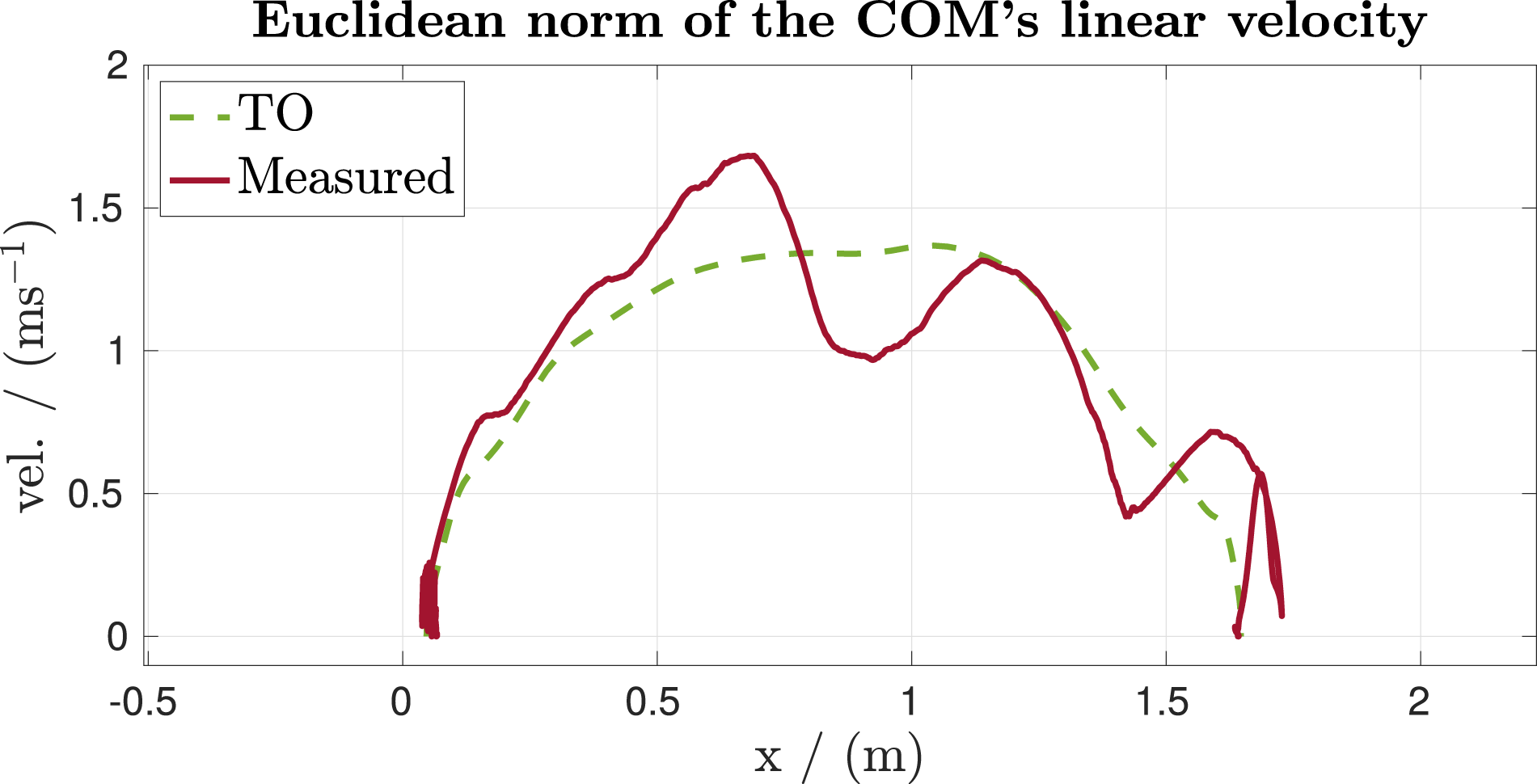
The first maneuver in Figure 8 presents the motion of the base and end-effectors over a 0.2 m step. Here, it can be seen how the MPC’s solution corrects the offline swing trajectory over the step preferring collision-free trajectories. The result shows that the MPC uses continuous optimization to correct mistakes from the offline trajectory. Results of the terrain-aware TO in combination with the MPC while executing the motion over the step in Figure 1. The plots show the two optimization problems’ motion, that is, the torso and the four end-effector trajectories. The dotted lines are the offline generated trajectories, while the solid lines represent the MPC’s solution over a one-second horizon at a time when the left-front end-effector lifts its leg. The equivalent COM’s speed profile can be obtained in Figure 7.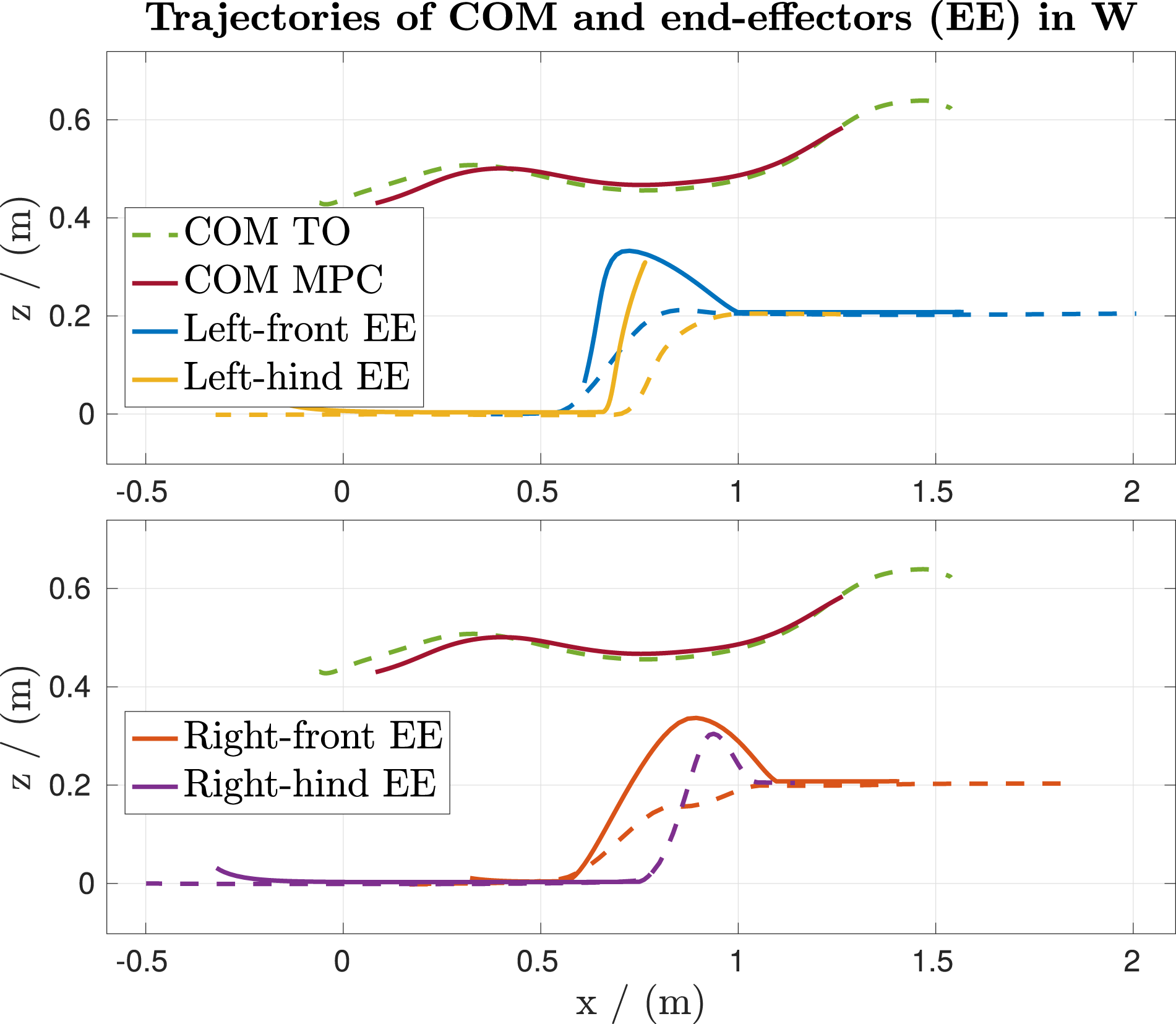
The dynamic turning motion in Figure 1 represents a challenging motion and requires the coordination of all DOF. In particular, the robot needs to step and turn the torso at the same time while respecting all physical constraints. To this end, the TO discovers a hybrid locomotion strategy since the roller-walking robot ANYmal does not incorporate any steering mechanism for its wheels. To achieve the fast turning motion over almost 180°, the robot coordinates the legs in contact onto a common wheel axis line, enabling it to turn through actuating its wheels. Figure 9 shows the comparison of the offline trajectory and the MPC’s solution over the task’s time horizon represented by the robot’s estimated state. The plot represents only a fraction of all whole-body states tracked through the MPC’s cost function in Section 5.1.1. With a single parameter set Results of the interactive TO in combination with the MPC while executing a repositioning motion (0–1 s) and the turning motion in Figure 1 (1–2.7 s). The plots compare the optimized whole-body trajectory of both algorithms. Here, the MPC solution is represented by the robot’s measured state, which is the equivalent of the initial state vector 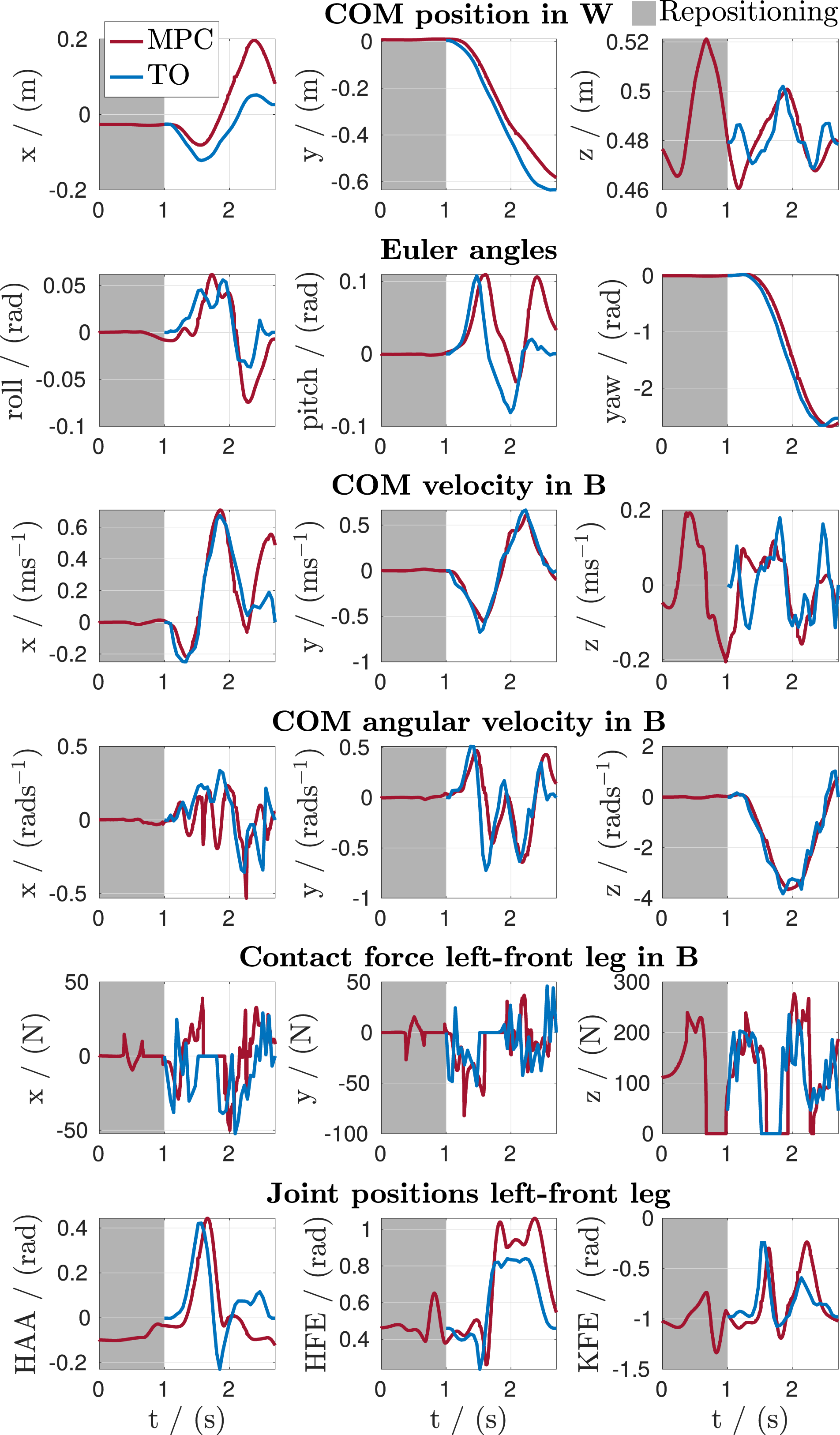
(R2) Offline-to-online gap. One of the main challenges of running offline trajectories is the online reaction to unforeseen conditions. The key to this challenge is our online MPC that robustifies the maneuver to a certain degree by recomputing solutions on the fly and adding feedback control. As shown in Table 1, the MPC recomputes optimal solutions on a 20–50 Hz loop while looking-ahead the offline trajectory over a one-second horizon. In the following, we present the results that show how the recomputation of optimal solutions can benefit the online execution of offline trajectories.
First, Figure 10 shows six scenarios where the robot recovers from unforeseen events. In all cases, the online MPC reacts to these events and successfully executes the offline trajectory. Such unexpected scenarios can either occur from mistakes that occur during offline motion prototyping or an unpredictable disturbance throughout the online execution. For example, the former is shown in the top-left and middle-right image, which shows two scenarios of incorrect modeling of the obstacle and the robot’s collision body, respectively. The latter is exemplified in the top-right, middle-left, lower-left, and lower-right images that exemplify the terrain’s misalignment, slippage, and purposely misplaced obstacles. Our approach can react to such unforeseen disturbances while anticipating future events of the offline trajectory. With these anticipating skills and the feedback control, the MPC can rescue the robot from these unforeseen situations. Recovery of the online MPC to unforeseen events. In all situations, the MPC could successfully recover and finish the executed offline trajectories. Top-left image: The motion designer did not correctly model the platform’s width, and as such, the robot’s front-left leg fell from the platform. Top-right image: While stepping up two steps, the end-effector moved the top platform since it was not properly secured. Due to this misalignment of the terrain, the front legs fell from the platform. Middle-left image: The front part of the torso hit the table while executing a dynamic 90°turn. Middle-right image: The hind legs’ knee protectors collided with the ground during a ducking motion since the offline trajectory did not consider the protector’s collision model. Lower-left image: The robot faced an unmodeled disturbance (wooden incline) on the ground while executing an offline trajectory assuming flat terrain. Lower-right image: The snapshot shows a time instance when the hind legs overcome the step. Here, the front legs slipped on the platform, and the front part of the torso collided with the platform.
Second, the MPC’s look-ahead also improves the tracking of offline trajectories in the presence of discontinuities, which might occur at the transitions to the offline trajectories. The MPC can blend between two motions and converge to the offline trajectory. For example, in Figure 9, the vertical movement along the z-axis of the COM’s position and velocity experiences a discontinuity at t = 1 s, where the robot switches from a repositioning motion, as described in Section 6, to the offline trajectory. It can be seen how the red trajectory anticipates along its receding horizon the upcoming offline trajectory and finds a solution respecting the whole-body state.
The last experiment regarding the offline-to-online gap further discusses the importance of incorporating a planning horizon into the online optimization problem. In contrast to a naive trajectory tracking that only looks at one set point at a time, for example, Kim et al. (2019), our approach can react to unforeseen conditions while looking ahead at the offline trajectory. With these anticipating skills, the MPC adds feedback to the execution of offline trajectories, as shown in Figure 10. Before presenting quantitative results, we first discuss our qualitative findings comparing the set-point-only tracking approach of offline trajectories. When running on the real robot, a tracking controller optimizing over set points has two different strategies in terms of the offline trajectory’s sampling frequency: (1) The offline trajectory’s sampling frequency equals the tracking controller’s update rate. (2) Sampling frequencies lower than the update rate require interpolations between the set points. The former strategy comes with longer optimization times of the offline TOs since the tracking controller’s update rates are synchronized with the actuator’s command loop (in our case, 400 Hz). Thus, this approach constrains the motion designer in terms of optimization speed and flexibility. The latter strategy comes with the caveat that the interpolated motion can not guarantee to be kinematically or dynamically feasible. In addition to the sampling frequency, Medeiros et al. (2020) experience that a naive trajectory tracking can not handle large tracking offsets. Therefore, the offline TO needs to be initialized with the robot’s measured state, which ties the motion designer down to real experiments next to the robot. In contrast, the MPC is flexible w.r.t. the offline trajectories’ sampling frequency and starting state. Figure 11 displays the tracking performance and disturbance rejection of a naive trajectory tracking developed by Bjelonic et al. (2019) compared to our proposed MPC. The MPC can handle the disturbance without falling, and as can be seen in the figure’s caption, the MPC offers flexibility for the motion designer. Comparison between a naive trajectory tracking (Bjelonic et al., 2019) over one set point at a time (lower plot) and the MPC over a receding horizon of 1 s (upper plot) while commanding a hybrid trotting gait through the terrain-aware TO. In this scenario, the robot needs to deal with an unmodeled inclination at x = 1 m, as shown in the lower-left image of Figure 10. The plots show the offline and measured trajectories, that is, the torso and two end-effector trajectories. The dotted lines are the offline generated trajectories, while the solid lines represent the online solutions. The MPC handles the disturbance and successfully finishes the motion, while the naive tracking controller makes the robot fall. Besides, the offline trajectories’ sampling frequency of the naive tracking controller requires 400 Hz, and its starting state has to coincide with the robot’s starting state. In contrast, the MPC is flexible w.r.t. the offline trajectories’ sampling frequency and starting state.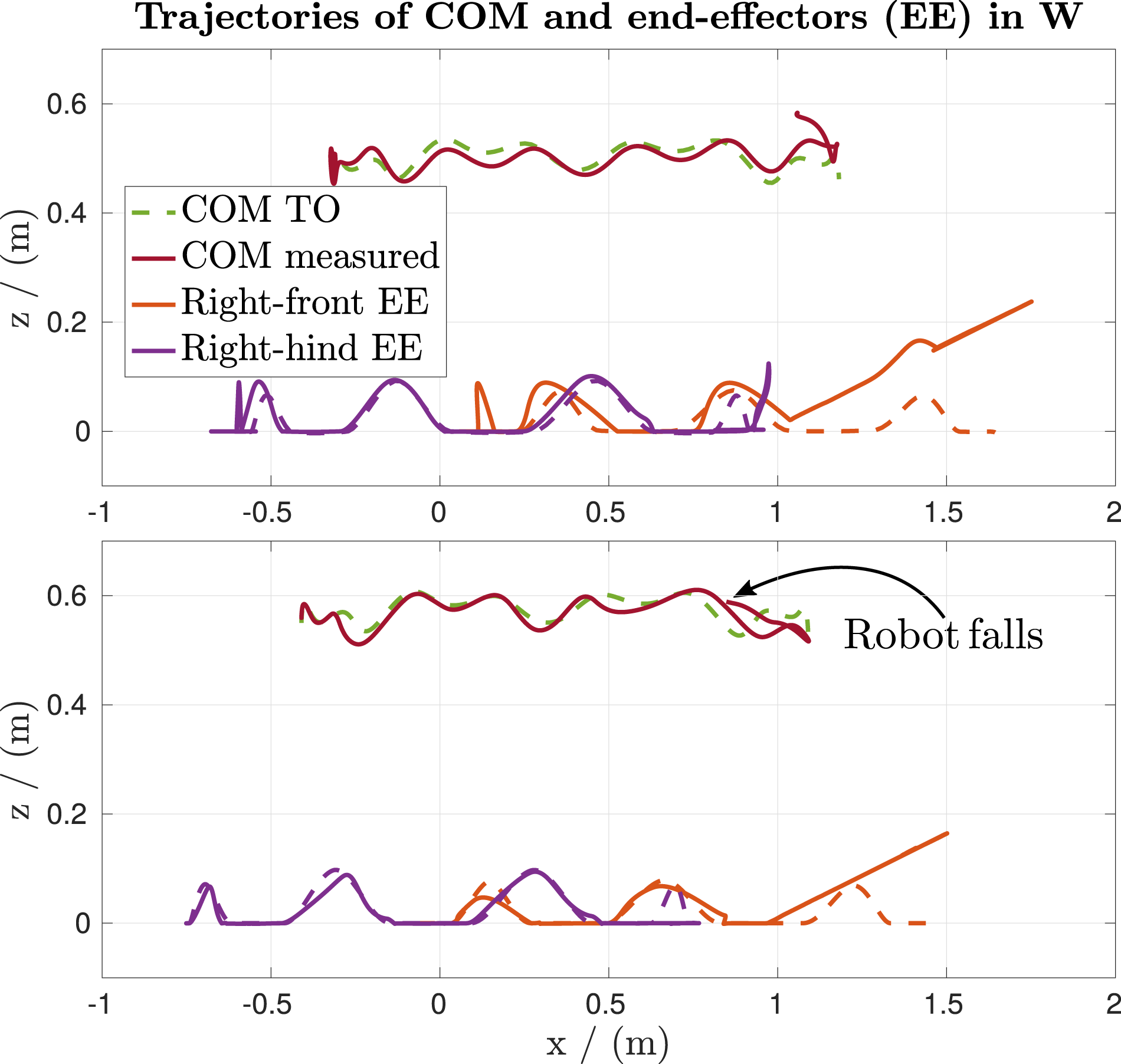
(R3) Rapid motion prototyping. As discussed in the paragraph before, the MPC decouples the locomotion problem into an offline and online computation. With this decoupling, six motion designers throughout this work could iterate over behavior designs offline without tuning robot experiments, which sped up the creation of new motions rapidly. We developed 30 motions throughout this work using the terrain-aware TO, 53 maneuvers based on the interactive TO, and six based on the sampling and optimization-based planner that run successfully on the real robot. Motion designers can craft new trajectories in a matter of minutes. We also experienced 16 maneuvers that had no success on our ANYmal robot, which is mostly due to motions at the torque limits, for example, motions over high steps with a speed over 2 m/s using the terrain-aware TO and too fast turning motions developed by the interactive TO. Twelve of the unsuccessful maneuvers, however, can be identified in our two steps verification process before running it on the hardware. The first step checks the offline trajectory’s feasibility in combination with the MPC using a visualization without any modeling errors and contact models. If feasible, the motion designers verify the maneuver in a simulation environment based on the Open Dynamics Engine (ODE) by Smith et al. (2005). This verification process helps the motion designer to iterate over behavior designs offline. None of the successful motions require retuning any of the MPC’s parameters, which frees the motion designer from adjusting the real robot’s performance.
(R4) Motion composition. Multiple offline trajectories can be composed into a single maneuver resulting in trajectories with longer time horizons. For example, Figure 12 shows the compositions of a ducking motion, a dynamic 90°turn, and another ducking motion. With a total duration of around 8 s, the motion composition’s benefit is displayed in this obstacle curse consisting of two tables. By combining multiple offline trajectories, the robot can find optimal maneuvers in terms of the robot’s physical constraints over a longer time horizon. Motion composition of three offline trajectories based on the interactive TO in Section 4.2. The upper visualization shows the torso and end-effector trajectory of the composed trajectory 
Transitioning between multiple trajectories requires appropriate transitions and the ability to blend between transitions and discontinuities smoothly. As already introduced before, Figure 9 shows a transition at t = 1 s between a repositioning gait and a dynamic turning motion. The whole-body trajectory shows that the MPC can anticipate future events and smoothly blend between both motions.
The video that accompanies this article shows a composed dancing trajectory with a total time horizon of 11 s. The motion is composed of eleven individual offline trajectories with a time horizon of 1 s per trajectory. Here, the motion composer did not add any transitions between the individual motions.
One of the main challenges that occur during the online execution of composed offline trajectories is the state estimation’s drift that accumulates along the offline trajectory. On flat terrain, we can execute dancing motions of up to 25 s without any noticeable drop in performance. The drift, however, becomes more crucial when executing motions over obstacles since the lift-off timings need to be synchronized with the terrain. In our case, the robot can successfully complete dynamic motions over obstacles with a time horizon of TTO = 5 s, as shown in Figure 2, and the maximum distance or time of the offline trajectories depends on the state estimator’s drift. For even longer offline trajectories, future work can study possible morphing strategies of the offline trajectories based on updated sensor data, as described by Kuindersma (2020).
(R5) Performance and generalization. With our novel framework, the robot can execute motions over challenging obstacles, unique motions through confined spaces, dynamic motions at the robot’s limits, and artistic dance moves. Each of the offline trajectories out of the motion library can be composed into a single maneuver. To the best of our knowledge, this work shows unprecedented motions on a roller-walking robot, as shown in Figures 1 and 2.
Our approach is not restricted to wheeled-legged robots, and, thus, in this experiment, we verify the generalizability of the approach to a traditional legged robot. Figure 13 shows the trajectory of ANYmal without wheels overcoming a step. The comparison to the wheeled-legged version in Figure 8 shows how the kinematic constraint influences the end-effector’s optimal trajectories. The legged robot requires five steps per leg to overcome the obstacle, while the wheeled-legged robot can use its wheels and only step once per leg. We want to highlight that also, in the legged robot’s case, the MPC can recover by optimizing the motion of the whole-body even in the presence of slippage, as presented in the figure’s caption. Results of the terrain-aware TO in combination with the MPC while executing the motion over the step with our traditional legged robot. The plots show the two optimization problems’ motion, that is, the torso and the four end-effector trajectories. The dotted lines are the offline generated trajectories. In contrast, the solid lines represent the MPC solution over a one-second horizon at a time when the left-front end-effector touches down on the step, as shown in the top-left image. Here, the right-front end-effector slipped and landed too close to the step. The MPC can deal with these situations by optimizing the whole-body’s motion, while considering the future trajectory of the offline TO.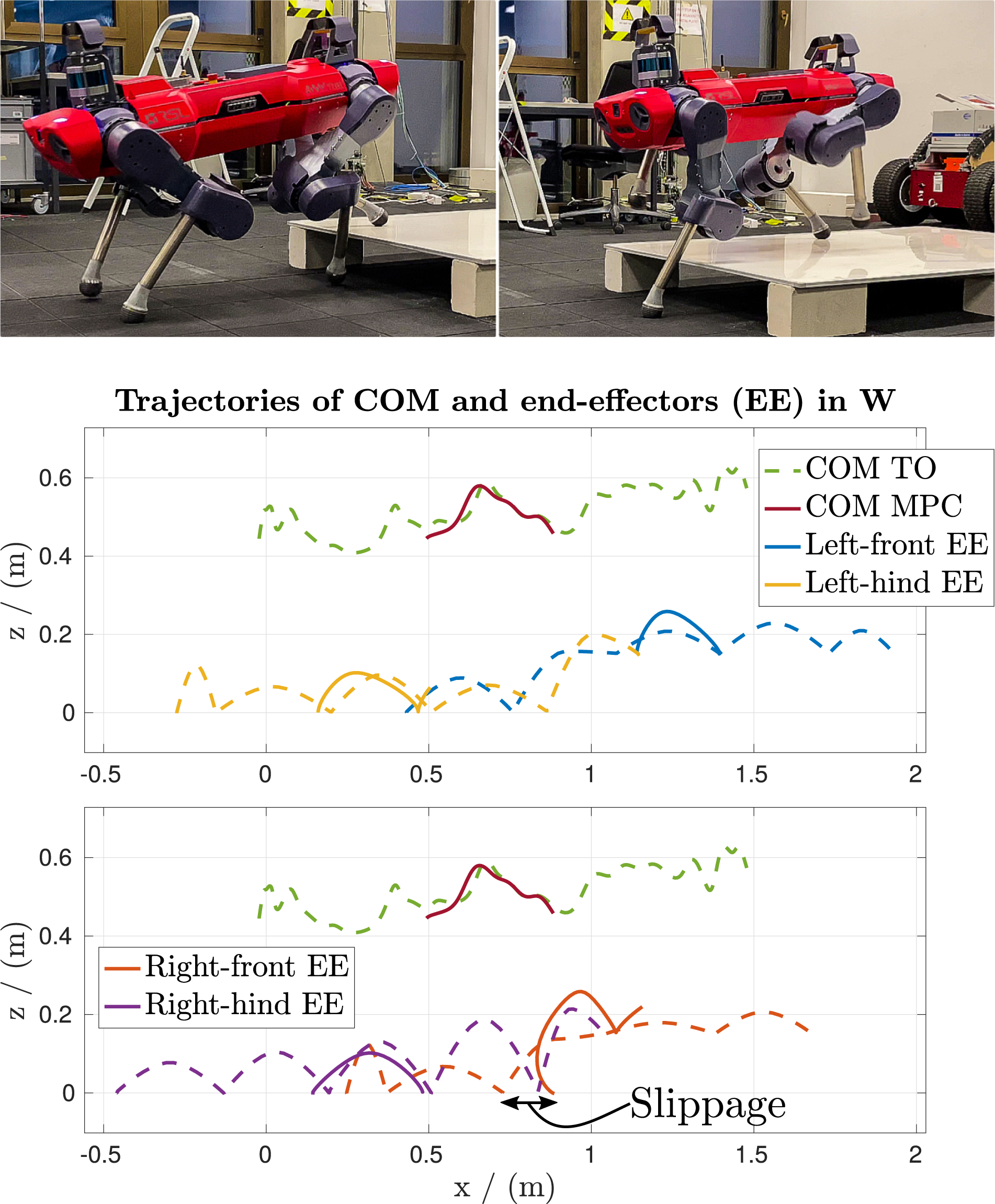
(R6) Evaluation of offline motion planners. The experiments show the execution of offline trajectories over longer time horizons generated through the interactive, terrain-aware TO, and sampling and optimization-based planner. The online MPC over shorter time horizons closes the offline-to-online gap. The following section discusses the performance on our robot ANYmal of each algorithm, while a summary of the algorithm’s performance is presented in Table 1 with a quantitative study in (R1) to (R5).
The interactive TO considers the robot’s CD model in (17) and finds motion plans that satisfy kinematic and dynamic constraints over flat terrain. With this higher-dimensional model compared to the SRBD, the offline trajectories incorporate more dynamic motions by respecting the inertia’s change through the joint movement. For example, the dynamic turning motions in Figures 1 and 9 achieve a turning rate of 4 rad/s, which sets a new record on our roller-walking robot. The accompanying video’s evaluation of the motion reveals that the robot coordinates a complex, whole-body trajectory. As described by Geilinger et al. (2018), the interactive TO comes with a suite of user-guided computational tools that support manual, semi-automatic, and fully automatic optimization of the robot’s trajectories. We demonstrate the method’s effectiveness by creating various unique motions for our robot ANYmal, for example, complex turning motions, unique motions through confined spaces (see Figure 12), and dance moves. Especially the generation of the dance motions reveals the fast and interactive capabilities of the approach. In minutes, the motion designer can generate dynamic motions, including a ”moonwalk” that is synchronized with the song’s pace. The optimization problem, however, does not consider non-flat terrain, and the motion designer needs to provide the gait sequences and timings.
In contrast, the terrain-aware TO does not provide user-guided computational tools that support manual or semi-automatic optimization. The algorithm operates fully automatic by giving a starting and a goal pose, optimizing motions over non-flat terrain (see Figures 2, 8, and 13). As shown in Figure 2, our roller-walking robot ANYmal achieves impressive results over a set of steps with a maximum speed of 1.5 m/s. Compared to the CD model of the interactive TO, this is achieved with a low-dimensional SRBD model. Still, the algorithm optimizes over the gait timings through a phase-based parametrization, as described in Appendix B and in more detail by Winkler et al. (2018). The optimization, however, is still sensitive to the initial gait schedule.
This sensitivity can be solved with our final offline motion generator. As shown in Figure 14, we verify for the first time the combination of sampling and optimization-based planning of Jelavic et al. (2021) on a real machine. With this combination, gait timings and sequences can be easily obtained through the RRT without any human supervision. The sampling-based TO can only generate statically stable motions, while the MPC refines these offline trajectories with a kinodynamic model. Furthermore, the results verify that our online motion planner is capable of handling offline trajectories that only contain kinematic information. Our quadrupedal robot ANYmal with wheels overcomes stepping stones (upper images) and steps up-and-down (lower images) through the sampling and optimization-based approach. All motions are statically stable, that is, the robot only lifts one leg at a time.
Our short-term motion planner is the online MPC that acts as a general-purpose algorithm integrating offline trajectories from any TO algorithm. Previous publications (Winkler et al., 2018; Medeiros et al., 2020) introducing the terrain-aware TO incorporate a naive tracking approach. With the incorporation of online MPC in our article, we finally manage to run these offline trajectories reliably on the robot even in the presence of disturbances and show agile motions on our robot ANYmal. In our previous work (Bjelonic et al., 2021), the MPC only considers future states up to a 1 s time horizon, which leads to unnecessary steps over obstacles. The video in https://youtu.be/_rPvKlvyw2w highlights this issue over stairs and steps. Combining offline and online optimization over the full-time horizon results in more optimal behavior in terms of speed and efficiency, as shown in Figure 2. Due to the task-generic properties of the MPC, any further development on the MPC benefits the execution of all offline trajectories.
8. Conclusions and future work
We present a method for the whole-body coordination of robotic platforms with legs and wheels, using TO to generate offline trajectories for complex motions and online MPC for continuous optimization along the offline trajectory. Our set of experiments involves complex locomotion maneuvers over challenging obstacles and at the robot’s limits. These experiments verify that our method can execute dynamic offline trajectories on the real robot even in the absence of perfect knowledge of the environment and under unforeseen conditions, such as modeling errors and external disturbances. Unlike most offline-to-online optimization methods, our approach incorporates an MPC capable of reacting to these disturbances while anticipating future events of the offline trajectory. Our experimental results demonstrate that our method can effectively execute a wide range of maneuvers, including fast motions over challenging obstacles, unique motions through confined spaces, dynamic motions at the robot’s limits, and artistic dance moves. The results also show that our method uses continuous optimization through MPC to correct mistakes from the offline trajectory and unpredictable disturbances. The reliable execution of offline trajectories enables motion designers to iterate over behavior designs offline without tuning robot experiments, allowing them to author new behaviors rapidly. Also, individual offline maneuvers can be composed into a single long-time horizon maneuver.
At a more general level, our work explores the synchronization of long-time horizon maneuvers with short-time horizon plans. We have chosen optimization-based approaches that generate trajectories over both look-ahead horizons. A promising direction for future experiments is to analyze how humans and animals incorporate look-ahead planning stages to decide on the upcoming steps. Maneuvers over challenging obstacles and at the physical limits are especially demanding, requiring look-ahead planning to decide on the upcoming steps carefully. In this regard, a hierarchical learning-based approach can be compared with our proposed method.
As indicated throughout the article, a human operator chooses maneuvers out of a motion library, suggesting that the automation of this stage could quickly increase the robot’s autonomy. A fascinating avenue for future work, therefore, could be the continuous computation of long-time horizon plans. Since our method can deal with unpredictable disturbances over the horizon of several offline trajectories, the update rate of the TO is not subjected to real-time constraints. With our framework, we can explore alternative algorithms, including mixed-integer optimizations, that simultaneously solve the whole-body trajectory, gait sequences, and timings, even if this complexity increases the solver time.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the Swiss National Science Foundation (SNF) through the National Centres of Competence in Research Robotics (NCCR Robotics) and Digital Fabrication (NCCR dfab). Besides, it has been conducted as part of ANYmal Research, a community to advance legged robotics.
Notes
Interactive trajectory optimization
In the following, we describe each of the interactive TO’s cost functions and constraints and drop the time dependency of the variables introduced in Section 4.2 to improve the equation’s readability.
Cost function. At the core of this TO lies its interactive capabilities. The motion designer can formulate a set of objectives that give the user interactive control over the robot’s motion. Moreover, the motion designer can add goals
Equations of motion. The global motion is described by the robot’s state
End-effector constraints. The ground reaction forces
Furthermore, no-slip and rolling constraints ensure that the end-effector position, orientation, and wheel speed are consistent with each other
Given the wheel’s orientation
Centroidal coordinate frame and hardware limits. In addition to the constraints described above, we instantiate a set of constraints to ensure the centroidal coordinate frame is consistent with the robot’s kinematics and a set of auxiliary end-effector variables. We also allow the motion designer to specify constraints that enforce physical hardware limits, such as joint angle limits and boundaries to avoid end-effector collisions.
Parameterization of optimization variables. With this set of constraints in place, we discretize the motion plan
Terrain-aware gait and trajectory optimization
In the following, we describe each of the terrain-aware TO’s constraints and drop the time dependency of the variables introduced in Section 4.3 to improve the equation’s readability.
Initial and final state. The initial and final state are fixed through the equality constraints given by
Equations of motion. The system’s dynamics is based on a SRBD model of a (wheeled-)legged robot. As described in Section 1.2, SRBD assumes that the limb joints’ momentum is negligible compared with the lumped COM inertia, and the inertia of the full-body system stays the same as to some nominal joint configuration. The EOM of the SRBD is given by
Kinematic limits. A feasible workspace constrains the end-effector’s position, that is,
Legs in contact. During contact phases, the unilateral constraint and the friction cone are enforced given by
The motion constraint of traditional legged robots is modeled through the end-effectors’ velocities, and when in contact, the velocity
In contrast, wheeled-legged robots can execute motions along the rolling direction when in contact. Thus, the motion constraint in (24) changes to
Besides, the end-effector is enforced to stay in contact with the terrain, and this equality constraint is formulated by
Legs in air. While leg i is in air, the ground reaction forces
Parameterization of optimization variables. A direct collocation method (Hargraves and Paris 1987) transcribes the continuous problem in Section 4.3.1 into an NLP problem optimizing the decision variables in discrete times sampled along the trajectory. Sequences of third- and fourth-order polynomials then obtain the continuous motion, which ensures continuous derivatives at the polynomial junctions. The duration of each predefined phase j, and with that, the duration of each end-effector’s polynomial, is changed based on the optimized phase duration ΔT i,j . Since these durations are continuous, the gait timings can be optimized without the need for mixed-integer programming. The optimization problem, however, becomes prone to local minima and, thus, sensitive to the motion designer’s initial gait schedule.