
Abstract
Cost-effectiveness analysis (CEA) models are routinely used to inform health care policy. Key model inputs include relative effectiveness of competing treatments, typically informed by meta-analysis. Heterogeneity is ubiquitous in meta-analysis, and random effects models are usually used when there is variability in effects across studies. In the absence of observed treatment effect modifiers, various summaries from the random effects distribution (random effects mean, predictive distribution, random effects distribution, or study-specific estimate [shrunken or independent of other studies]) can be used depending on the relationship between the setting for the decision (population characteristics, treatment definitions, and other contextual factors) and the included studies. If covariates have been measured that could potentially explain the heterogeneity, then these can be included in a meta-regression model. We describe how covariates can be included in a network meta-analysis model and how the output from such an analysis can be used in a CEA model. We outline a model selection procedure to help choose between competing models and stress the importance of clinical input. We illustrate the approach with a health technology assessment of intravenous immunoglobulin for the management of adult patients with severe sepsis in an intensive care setting, which exemplifies how risk of bias information can be incorporated into CEA models. We show that the results of the CEA and value-of-information analyses are sensitive to the model and highlight the importance of sensitivity analyses when conducting CEA in the presence of heterogeneity. The methods presented extend naturally to heterogeneity in other model inputs, such as baseline risk.
Cost-effectiveness analysis (CEA) models are routinely used to inform health care policy decisions between health care options. 1 Relative treatment effects for effectiveness outcomes are among the key input parameters to CEA models. For policy decisions to reflect the evidence available, it is important that the relative effect inputs and their uncertainty are reflected appropriately in CEA models. CEA models are also used in value-of-information analyses that explore the need for, and optimal design of, new research studies. 2
Relative treatment effects are typically obtained from meta-analyses or network meta-analyses (also termed mixed treatment comparisons)3–5 of all the available relevant randomized controlled trials (RCTs) that report the outcomes of interest. Ideally, all the RCTs estimate a common true treatment effect, and the only reason for differences between study estimates is sampling error. In this case, a fixed effect (FE) model can be used to deliver a single pooled estimate for each treatment comparison of interest. However, more often than not, there is additional variability between studies due to differences in inclusion criteria and/or trial conduct, such that the RCTs estimate different true treatment effects. It is then usually assumed that the study-specific true relative effects are similar in the sense that they can be described as coming from a common random effects (RE) distribution (usually assumed Normal). 6 The relative effect that is reported is usually the mean of this distribution, although the predictive distribution or the entire RE distribution has been proposed,7,8 and some alternative approaches have been suggested recently in a short letter. 9
Heterogeneity in relative effects can arise as a result of an imbalance in treatment effect–modifying patient characteristics across studies and/or in study-level parameters. If study-level parameters have been reported, then they can be included as covariates in a meta-regression model.3,6,10,11 Ideally, to avoid ecological bias, 12 individual patient data are required to explore the impact of imbalance in patient-level characteristics, although for binary outcomes reported by subgroup, then aggregate-level data are sufficient, which is a simple example of meta-regression. Inclusions of treatment effect–modifying covariates are expected to lead to a reduction in heterogeneity and, in the extreme case, will eliminate heterogeneity entirely, reducing an RE model to an FE model. There may be many covariates that could potentially be included in a meta-regression, and a strategy is required to choose between models.
Where there is evidence of heterogeneity, careful thought needs to be given as to the most appropriate input to use in a CEA model. If subgroups have been identified, and it is acceptable to make different treatment recommendations in different subgroups, CEA models can be developed separately for each subgroup. 13 The results from a CEA may be sensitive to the choice of which covariate model is selected, and so a structured approach to model selection is desirable. For example, an RE model with no covariates will result in less precise relative treatment effect estimates than those from an RE model in which some of the heterogeneity is explained by covariates. RE models can be summarized and interpreted in a variety of ways,7–9 and this needs to be reflected in a CEA model. Again, results from a CEA may be sensitive to this choice. 9
In this article, we describe a general framework to model and account for heterogeneity in relative effect inputs to CEA models and set out a general strategy for model selection. Although we focus on relative treatment effects, the ideas extend naturally to other model inputs that exhibit heterogeneity. We illustrate the approaches with a recent health technology assessment of intravenous immunoglobulin (IVIG) for the management of adult patients with severe sepsis and septic shock. 14 This case study exemplifies how risk of bias information can be incorporated into CEA models that, to our knowledge, has not been addressed in the literature previously.
Methods
Net Benefit
We assume there is a cost-effectiveness model with a net benefit function
Meta-Analysis Models in the Absence of Covariates
In all that follows, we assume that relative effects are modeled on an appropriate scale (e.g., log-odds ratios for binary observations). When there are two treatments being compared, a pairwise FE meta-analysis model assumes that the true relative treatment effects,
When there are several competing treatments, relative effect estimates can be obtained from a network meta-analysis 4 :
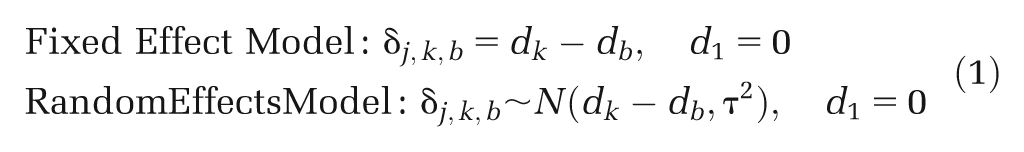
where
Meta-Analysis Inputs to CEA in the Absence of Covariates
Note that in all that follows, parameter inputs are estimated with uncertainty, and this uncertainty needs to be averaged over to obtain expected net benefit.
For an FE model, assuming that the treatment effect in the target setting for the decision is no different from those in the studies that make up the (network) meta-analysis, then the
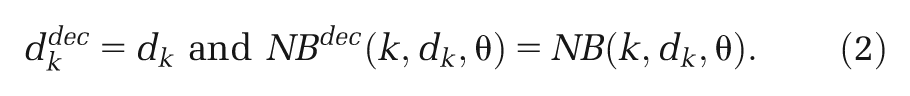
There are several possible approaches to summarize an RE model to provide inputs to a CEA model, which depend on our interpretation of the heterogeneity in the studies included in the (network) meta-analysis and how this relates to the target setting for the decision. 9
(a) Random effects mean. The most commonly used approach is to use the mean of the RE distribution as the input for the CEA model, so that
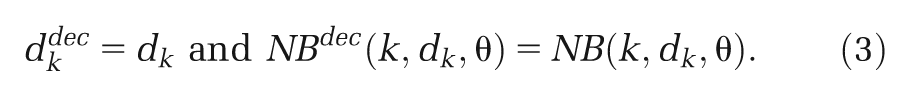
This assumes that the target setting for the decision is exactly equal to the average setting from the studies included in the (network) meta-analysis. This is unlikely to be the case in practice. One possible scenario when equation (3) might be appropriate is if the cause of the heterogeneity is due solely to bias resulting from flaws in study conduct but that the bias across studies is centered on 0. Then the RE mean represents the treatment effect in an unbiased study.
(b) Predictive distribution. Due to the difficulty in interpreting the RE mean, the predictive distribution has been proposed as a more realistic way to characterize the uncertainty in the treatment effect we may expect to see in the future. A prediction
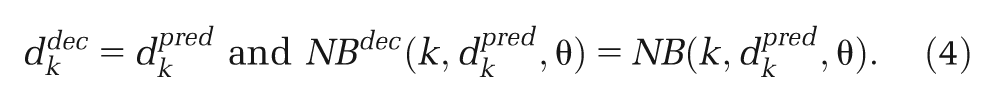
This assumes that the target setting for the decision is “similar” to those in the studies included in the (network) meta-analysis in the sense that
(c) Independent study-specific estimate. If we consider the target setting for the decision to be represented by a single study population,
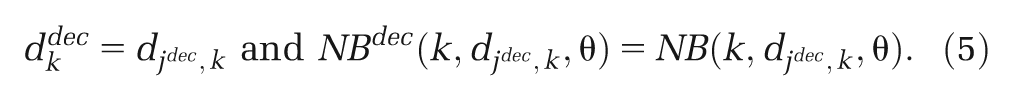
This might be the case if all studies except one are deemed to be at high risk of bias, and if this is the cause of the heterogeneity, then we may want to only use the results from the study not at high risk of bias. Note, however, that this approach is limited, as it can only be used for treatment comparisons that have been included in study
If a subset of the studies are considered representative, then either the pooled estimate from an FE model on that subset of studies or the predictive distribution from an RE model on that subset of studies may be used.
(d) Shrunken study-specific estimate. If we consider the target setting for the decision to be “similar to” those in the studies included in the (network) meta-analysis (as for the predictive distribution), but it is most closely represented by a single study population,
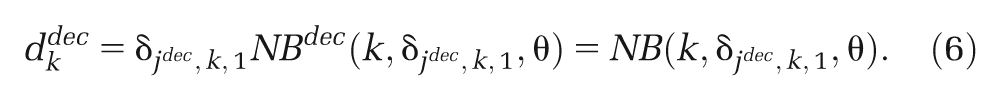
If study
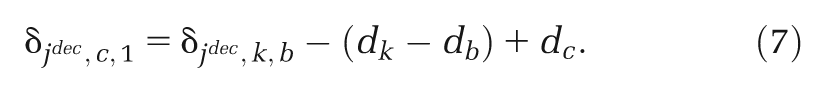
(e) Random effects distribution. If we consider the target setting for the decision to be made up of those included in the studies in the (network) meta-analysis, then we would expect heterogeneity estimated in the (network) meta-analysis to be also seen in the decision setting. This may be the case where there is inherent variation between clinicians delivering the treatments. It is then necessary to integrate over the entire RE distribution in the CEA model to obtain the net benefit for the decision population,
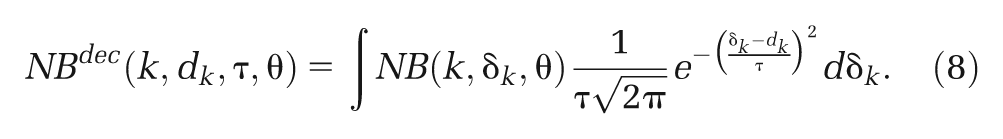
As in all cases above, the uncertainty in the parameters
Meta-Regression with Study-Reported Covariates
Allowing for covariates provides the potential to explain some of the heterogeneity. Covariates can include study characteristics, such as whether an in- or outpatient setting was taken, and patient characteristics, such as disease severity. Ideally, patient-level data would inform estimation of patient covariate effects, but in meta-analysis, it is often the case that only study-level summaries are available. Let
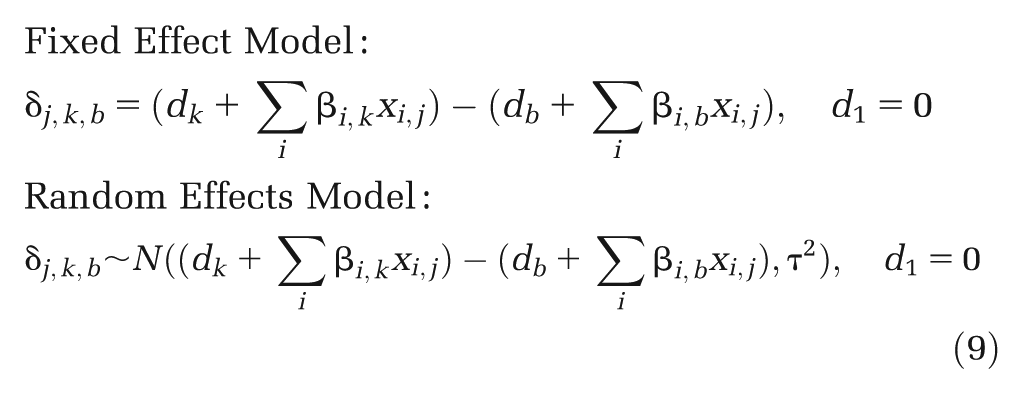
where
Meta-Analysis Inputs to CEA in the Presence of Covariates
The incorporation of covariates in an RE model may reduce the heterogeneity parameter or even reduce the RE model to an FE model in the extreme case. Equations (2) to (8) can all be applied to the resulting RE or FE model to obtain inputs to a CEA model. However, some adjustments are required to account for the covariates.
Binary covariates
Suppose covariate
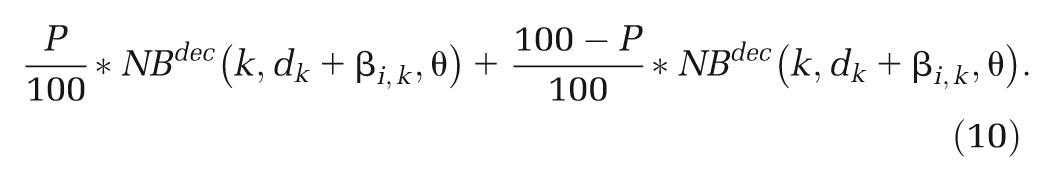
The uncertainty in the parameters
Continuous covariates
Suppose covariate
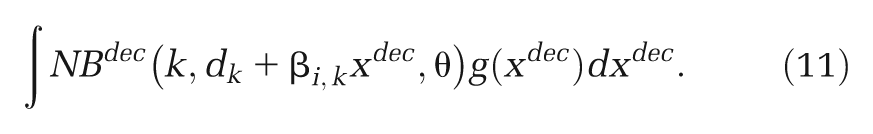
The same approach applies for study-level ordinal effect modifiers, but the integration is replaced by a sum over all possible levels of the covariate.
Multiple covariates
Where there are multiple covariates
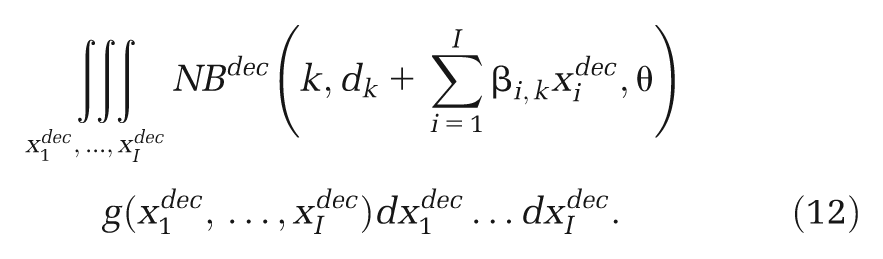
The integration is replaced by a summation for binary and ordinal covariates.
Heterogeneity in treatment definitions
Treatment definition is a common cause of heterogeneity (e.g., formulation, dose, timing, and duration of treatment). Where there is a clinical rationale for a differential effect across treatment definitions, each distinct definition should ideally be considered a separate treatment in a network meta-analysis (equation (1)). However, this approach may lead to an unconnected network of treatment comparisons, and even if it is connected, there may be only a limited amount of evidence on each comparison. An alternative is to include aspects of the treatment definition (e.g., dose) as covariates. This may be reasonable where there is good evidence on the functional dose-response relationship, with the potential to increase precision of effect estimates. However, the assumed relationship needs to be transparent and fit to the data assessed. Another alternative is to consider different groupings for the treatments, with fixed or random treatment effect within grouping,10,15,16 and compare model fit to help aid the choice of treatment definitions. For example, it could be that doses within a particular range are homogeneous but that very small or large doses lead to differential treatment effects.
Risk of bias and small study effects
There is some evidence that treatment effects are vulnerable to methodological flaws in study design that introduce a risk of bias.17,18 For example, if the randomization process in a trial is inadequately concealed, selection bias may be introduced. There is also evidence that treatment effects have a tendency to be stronger in smaller studies.17,18 Risk of bias indicators (e.g., whether randomization was adequately concealed or not) can be included in a meta-regression as binary or ordinal covariates, and the treatment estimate used to inform cost-effectiveness should be associated with studies at low risk of bias (i.e., having adjusted for risk of bias) in the CEA (i.e., set
Study size,
Model Selection Strategy
The choice of covariates to include may in part be driven by what is reported in the included studies but should also be supported by clinical experts. There may be several potential covariates for inclusion in the meta-regression, and a strategy is required to help choose between them. We propose the following approach to model selection (although note there may be other systematic approaches that can be taken):
Step 1 Fit FE and RE models with no covariates and use model fit statistics and the estimated heterogeneity parameter,
Step 2 Fit the FE model with each of the potential covariates alone (i.e., univariable models), including different network meta-analysis structures to capture heterogeneity in treatment definitions. Compare model fit statistics to identify the key covariates that explain some of the heterogeneity. For those key covariates, also fit an RE model. Note that models including covariates may fit equally well to an RE model without covariates, but
Step 3 Consider combinations of the key covariates identified in step 2 by adding additional covariates and comparing model fit statistics and
Step 4 Report results from all of the best-fitting models that achieve a similar model fit, and obtain clinical input on the interpretation/justification of covariates to help guide model choice. If necessary, repeat the process in light of the clinical input.
If a Bayesian approach is taken, then the posterior mean residual deviance and deviance information criterion (DIC) measures 21 for model fit and model comparison can be used. If a frequentist approach is used, then the deviance and Akaike information criterion (AIC) measures 22 can be used for model fit and comparison.
Illustrative Example: IVIG for Severe Sepsis and Septic Shock
Background and CEA Model
Sepsis is a syndrome characterized by a systemic inflammatory response to infection that leads to rapid acute organ failure and potentially rapid decline to death. Severe sepsis (sepsis with acute organ dysfunction) represents approximately 31,000 patient episodes and 15,000 in-hospital deaths per year in the United Kingdom. Intravenous immunoglobulin (IVIG), a human blood product, has been proposed as an adjuvant therapy for severe sepsis, but evidence regarding the use of IVIG in severe sepsis is conflicting. 23 We were commissioned to perform a systematic review, meta-analysis, CEA, and value-of-information analysis of IVIG for severe sepsis and septic shock, with an aim to assess the potential value and design of additional primary research. 14 A full description of the studies and the data that were extracted is available in Tables 7 to 13 of this report. 14 The primary effectiveness outcome from the RCT studies was all-cause mortality. The CEA model, comparing IVIG with standard care, consisted of a decision tree to model for short-term survival of a sepsis event and a Markov model for the mid- to long-term consequences of surviving sepsis. A meta-analysis of the RCT studies informed the relative effects of treatments on short-term mortality following a sepsis event. Other model inputs to the CEA model came from a variety of registry and cohort evidence sources (see report 14 for full details). All programs and data available from NJW on request.
Potential Covariates in the Meta-Analysis of RCT Studies
Treatment definitions
In the 17 identified RCT studies, IVIG was either standard IVIG or IgM-enriched IVIG (IVIGAM) and differed in the duration of treatment (days), daily dose (g/kg−1/d−1), volume of fluid (mL/kg−1/d−1), and total dose (g/kg−1). Furthermore, there were several different formulations. All studies had two arms and used either albumin or no treatment (in addition to standard treatment) as control. For the different IVIG and control preparations, we considered 5 different possible treatment comparison models (numbered according to number of treatments), also displayed in Figure 1:
Model T2: (IVIG or IVIGAM) v. (albumin or no treatment) Model T3a: IVIG v. IVIGAM v. (albumin or no treatment) Model T3b: (IVIG or IVIGAM) v. albumin v. no treatment Model T4: IVIG v. IVIGAM v. albumin v. no treatment Model T10: sandoglobin v. intraglobulin v. gamma-venin v. polyglobin v. endobulin v. gamumin N v. IVIG unspecified v. IVIGAM v. albumin v. no treatment
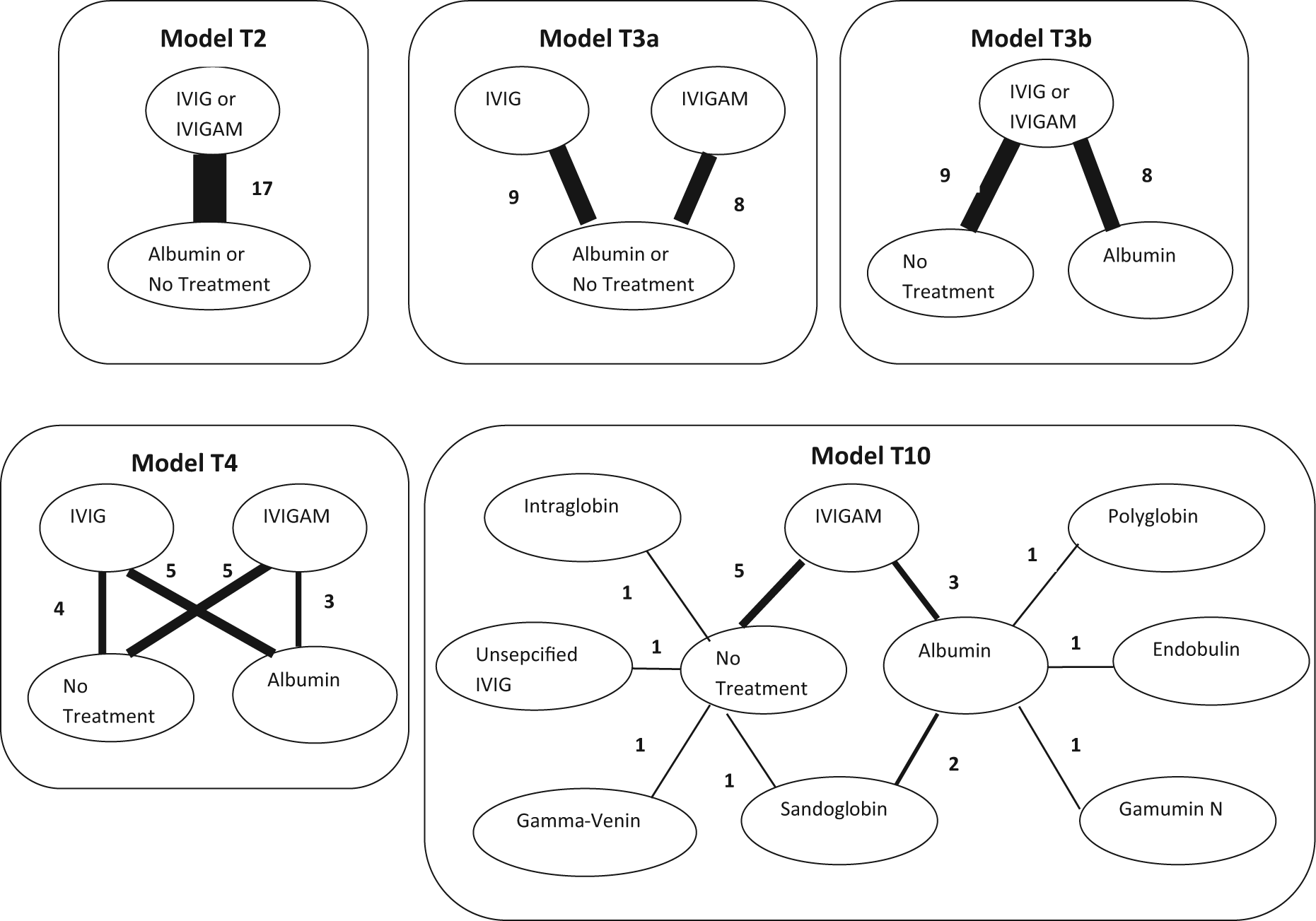
Network plots for each of the 5 treatment models considered. Treatments connected by a line indicate where randomized controlled trial (RCT) evidence is available, and the width of the line is proportional to the number of RCTs making that comparison. IVIG, intravenous immunoglobulin; IVIGAM, IgM-enriched IVIG.
We initially explored extending the range of treatment comparison models according to dosing regimen, but this did not always result in a connected network. Instead, we considered the attributes of the dosing regimen (average daily dose, volume, duration, and total dose) as arm-level covariates.
We consider the simplest treatment model T2 as the reference “no covariate” case (step 1) and explore each of the other more complex treatment effect models in turn alongside the univariable models for the other covariates (step 2). We have a preference for the simplest treatment model that achieves adequate fit (i.e., the most parsimonious).
Risk of bias
We also extracted the following risk of bias information: intention-to-treat analysis performed (yes/no), concealment of allocation to treatment (adequate/unclear/inadequate), blinding to treatment (adequate/unclear/inadequate), randomization procedure (adequate/unclear/inadequate), Jadad score 24 (which is based on a composite score for adequacy of randomization [0–2 points], blinding [0–2 points], and presence or absence of attrition information [0–1 points], yielding a score from 0 to 5, where 5 represents the best quality score), publication date, and sample size (intervention arm), which were considered potential covariates.
Other study characteristics
We also considered as covariates whether the study reported that the trial was carried out in a critical care setting or not and follow-up period (weeks).
Patient characteristics
We included baseline risk (control arm log-odds of mortality) as a covariate. Although other covariates (such as scores for severity of illness and number and sites of organ failure) were considered possible effect modifiers, they were not reported in sufficient detail in enough studies to be explored.
Model Selection
We used a Bayesian framework to fit the models and assess model fit using the posterior mean residual deviance,
Step 1: No covariates (model T2). The FE shows substantial lack of fit (
Model Selection Steps 1 and 2
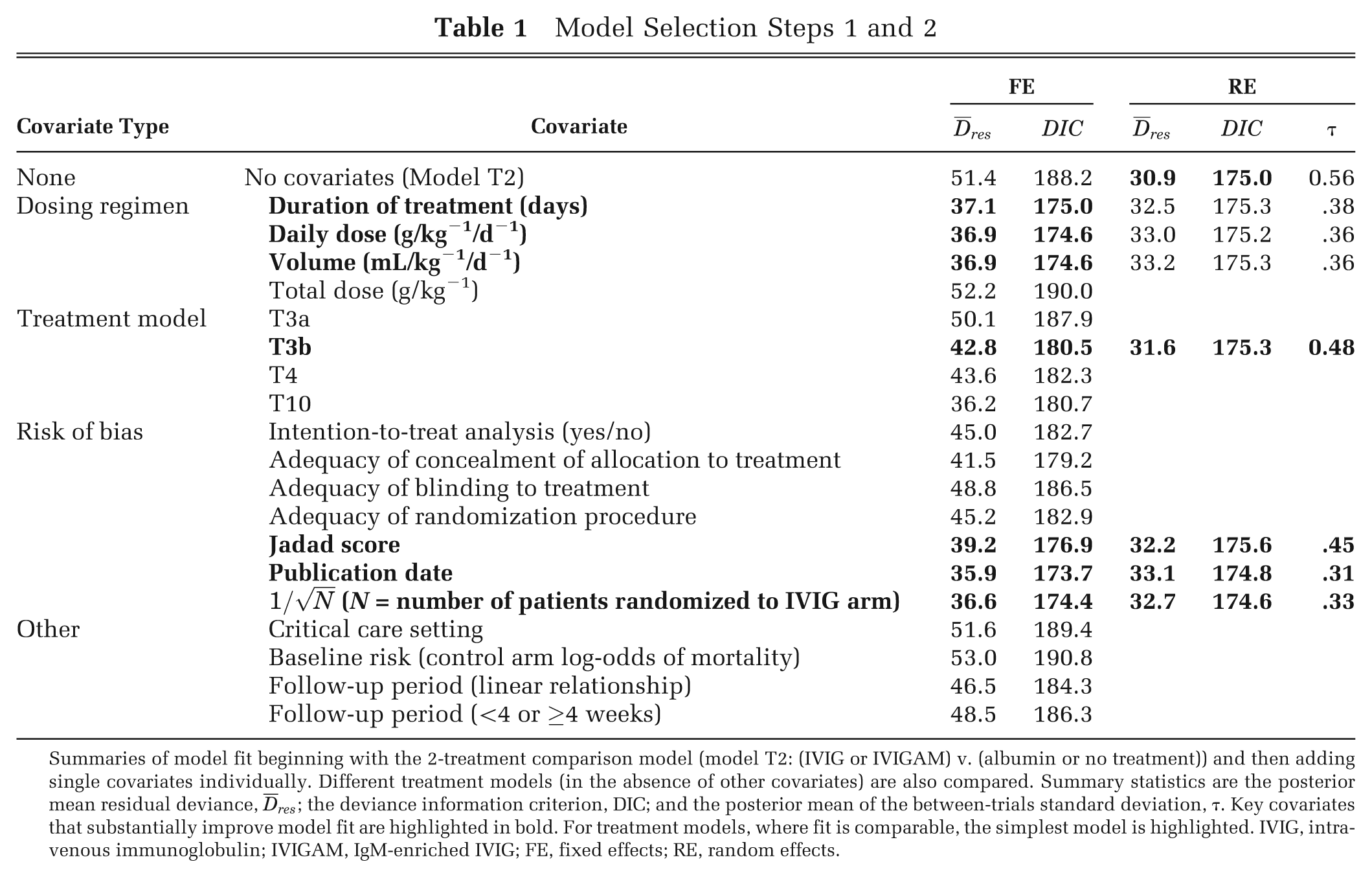
Summaries of model fit beginning with the 2-treatment comparison model (model T2: (IVIG or IVIGAM) v. (albumin or no treatment)) and then adding single covariates individually. Different treatment models (in the absence of other covariates) are also compared. Summary statistics are the posterior mean residual deviance,
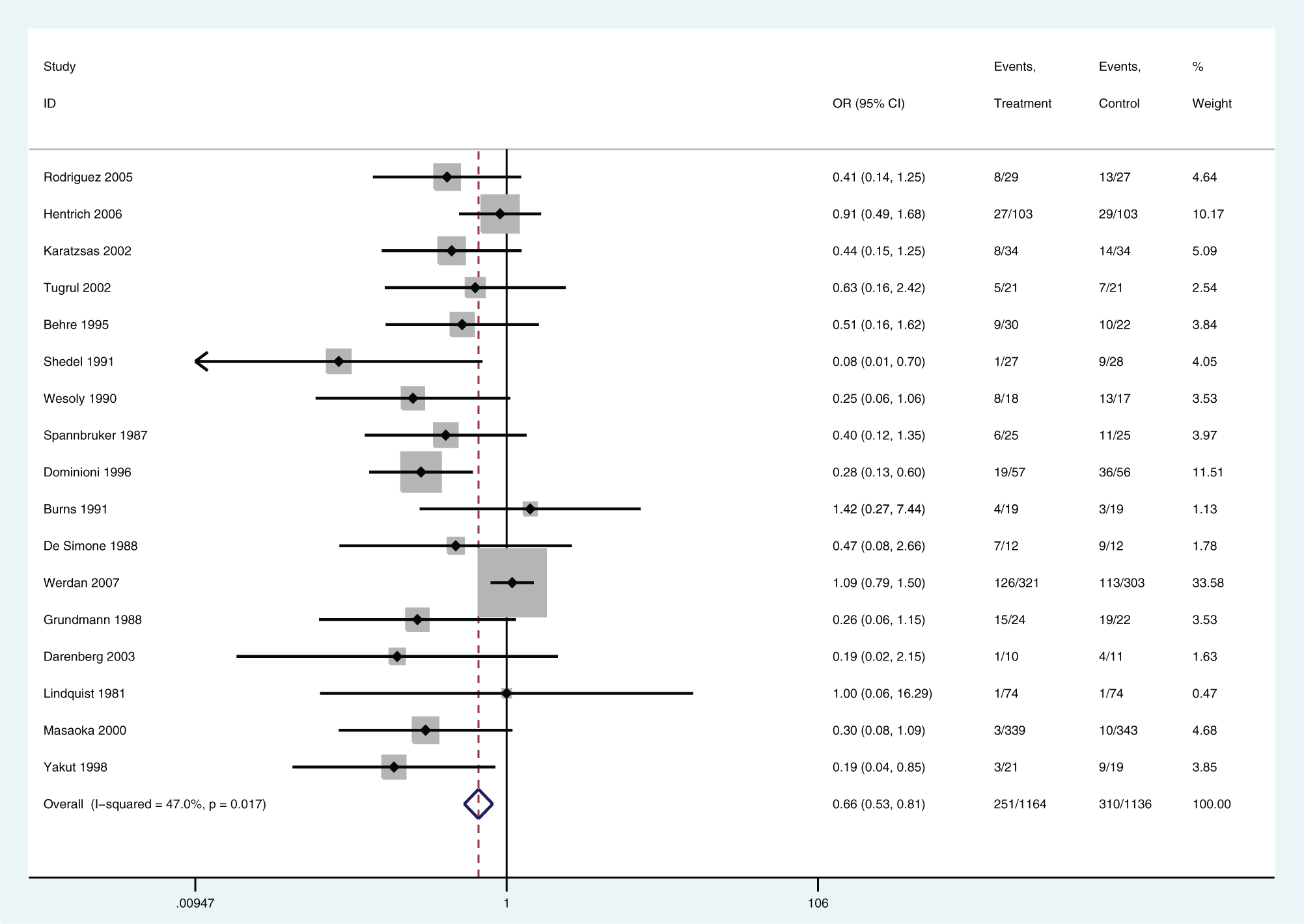
Forest plot for (IVIG or IVIGAM) v. (albumin or no treatment). Random effects model. IVIG, intravenous immunoglobulin; IVIGAM, IgM-enriched IVIG.
Step 2: Univariable models (single covariates). The key covariates that appeared to explain some of the heterogeneity in the meta-analysis were dosing regimen covariates (duration of treatment, daily dose, and volume), treatment definition (T3b was the most parsimonious), and risk of bias covariates (Jadad score, publication date, and a measure of sample size:
Step 3: Multivariable models (combinations of key covariates). There was no improvement in model fit from including all key dosing regimen covariates compared with including just one (Table 2). Similarly, for the “risk of bias” covariates, it was only considered necessary to include one of these covariates in further models (Table 2). Combining a dosing regimen covariate with a risk of bias covariate improved model fit and led to reductions in DIC (Table 2). This suggests that these two types of covariates measure different aspects of heterogeneity. Furthermore, for treatment model T3b, adding risk of bias covariates did not lead to much change in model fit, suggesting that the choice of control explains the same aspect of heterogeneity as the risk of bias covariates (Table 2). The FE models that give the lowest DIC are highlighted in bold in Table 2. The best-fitting FE model (and lowest DIC) was obtained for treatment model T3b with duration of treatment as a covariate (Table 2). This model fitted as well as the RE model with no covariates (Tables 1 and 2), suggesting that for this example, there are two dimensions of heterogeneity, one relating to the dosing regimen and the other to risk of bias.
Model Selection Step 3
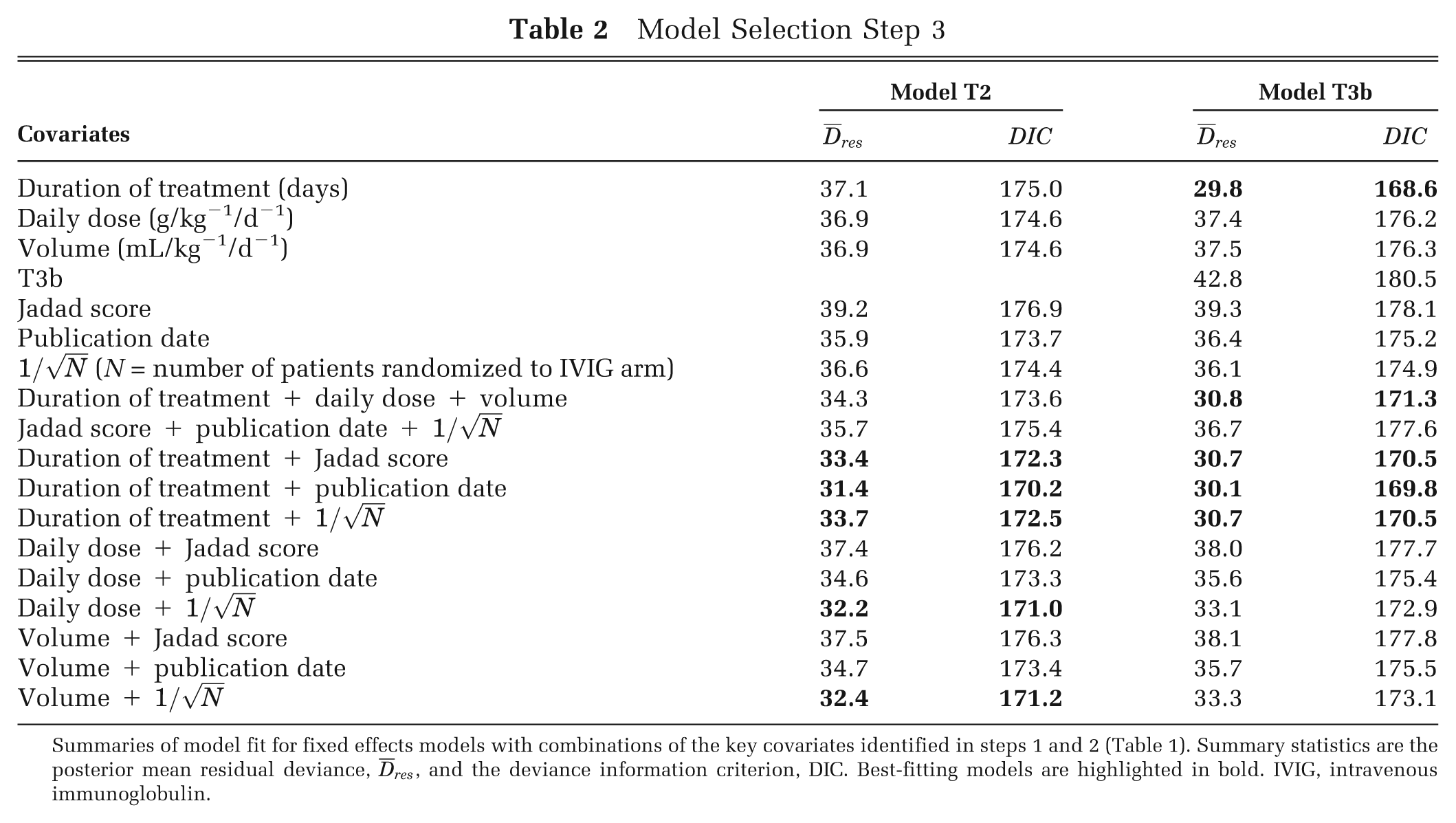
Summaries of model fit for fixed effects models with combinations of the key covariates identified in steps 1 and 2 (Table 1). Summary statistics are the posterior mean residual deviance,
Step 4: Incorporation of expert opinion and sensitivity analyses. We found that aspects of treatment regimen (duration of treatment, daily dose, volume) were associated with treatment effect. However, discussions with the expert advisory group for the project highlighted that there was no clinical mechanistic rationale why these aspects of treatment regimen would affect treatment effects across the ranges examined within the included studies. Because these aspects of treatment regimen were not compared within studies, there was the worry that the effects we had observed were subject to ecological bias, highlighting the lack of early phase studies for IVIG for severe sepsis and septic shock. In particular, studies with longer duration of treatment may reflect a healthier population that could be treated for longer. The expert advisory group agreed that risk of bias indicators were important covariates to include and that the choice of control could be a proxy for risk of bias because albumin resembles IVIG, indicating adequate blinding. We therefore report results from RE models with one key risk of bias covariate as a sensitivity analysis, in addition to results of the best-fitting model (FE model T3b with duration of treatment as a covariate). In these RE models, the heterogeneity that can be explained with the dosing regimen covariates was left unexplained, reflecting a belief that these covariates were a proxy for other, unmeasured, differences between the studies.
Results from Meta-Analysis
Table 3 shows the results from the models identified in the model selection process. Results are reported for albumin as the comparator for treatment model T3b and for the following covariate values: duration = 3 days (in the absence of any other rationale, 3 days was the most commonly reported treatment duration in the included studies), Jadad score = 5 (least risk of bias), publication date = 2007 (most recent in included studies), sample size
Predicted Odds Ratio (95% Credible Intervals) for the Best-Fitting FE Model T3b with Duration of Treatment as a Covariate and for RE Models with a Key Risk of Bias Covariate (Reporting the Predictive Distribution, Option b)

For illustration, results reporting the RE mean (option a) are presented for the RE model T3b. IVIG, intravenous immunoglobulin; FE, fixed effects; RE, random effects; OR, odds ratio.
For the RE models, there are a variety of options as to the relevant predicted treatment effect to report and use in CEA (options (a)–(e) above). No single study or subsets of studies were considered more relevant than the others to the decision setting, and so options (c) to (d) were not appropriate. There was no reason to expect that the heterogeneity between studies was inherent variability (e.g., between hospitals/centers) that would be experienced in a roll-out of the intervention, and so option (e) was not considered appropriate. As described above, the random effects mean, option (a), is unlikely to be a good summary in general, and so we report results from the predictive distribution, option (b), which reflects the additional uncertainty resulting from the unexplained heterogeneity. For comparison, we report both options (a) and (b) for the RE T3b model.
The results show that the uncertainty in the treatment effect estimate is smallest for the FE T3b model with duration as a covariate (Table 3). For the RE model T3b, the uncertainty in the treatment effect estimate is much wider for the predictive distribution compared with the RE mean summary (Table 3).
The results are highly sensitive to the choice of model, with predicted odds ratios ranging from 0.6 (IVIG beneficial), for an RE T3b model reporting the RE mean, to 1.27 (IVIG harmful), for the RE T2 model with
Results from the CEA and Value-of-Information Analysis
The results from the CEA were highly sensitive to the choice of model (Table 4), with the incremental cost-effectiveness ratio (ICER) ranging from £15,000 to IVIG being dominated. The optimal decision depends on the model used, especially for the £20,000 threshold. There is considerable uncertainty in the optimal treatment under all models, with the probability that IVIG is cost-effective at the £20,000 threshold ranging from 0.3 to 0.7, with the RE mean giving more certainty than the predictive distribution for model RE T3b (Table 4). The expected value of information for all parameters (EVPI) and for the relative effect parameters (EVPPI) indicate that, regardless of the model used, there is substantial potential value in new research, including a well-conducted RCT comparing IVIG with standard care (Table 4). However, the optimal design of such a study is highly sensitive to the model selected (Table 4), ranging from 800 to 1900 per arm.
Results from the Cost-Effectiveness Model 14 for the Best-Fitting FE Model T3b with Duration of Treatment as a Covariate and for RE Models with a Key Risk of Bias Covariate (Reporting the Predictive Distribution, Option b)
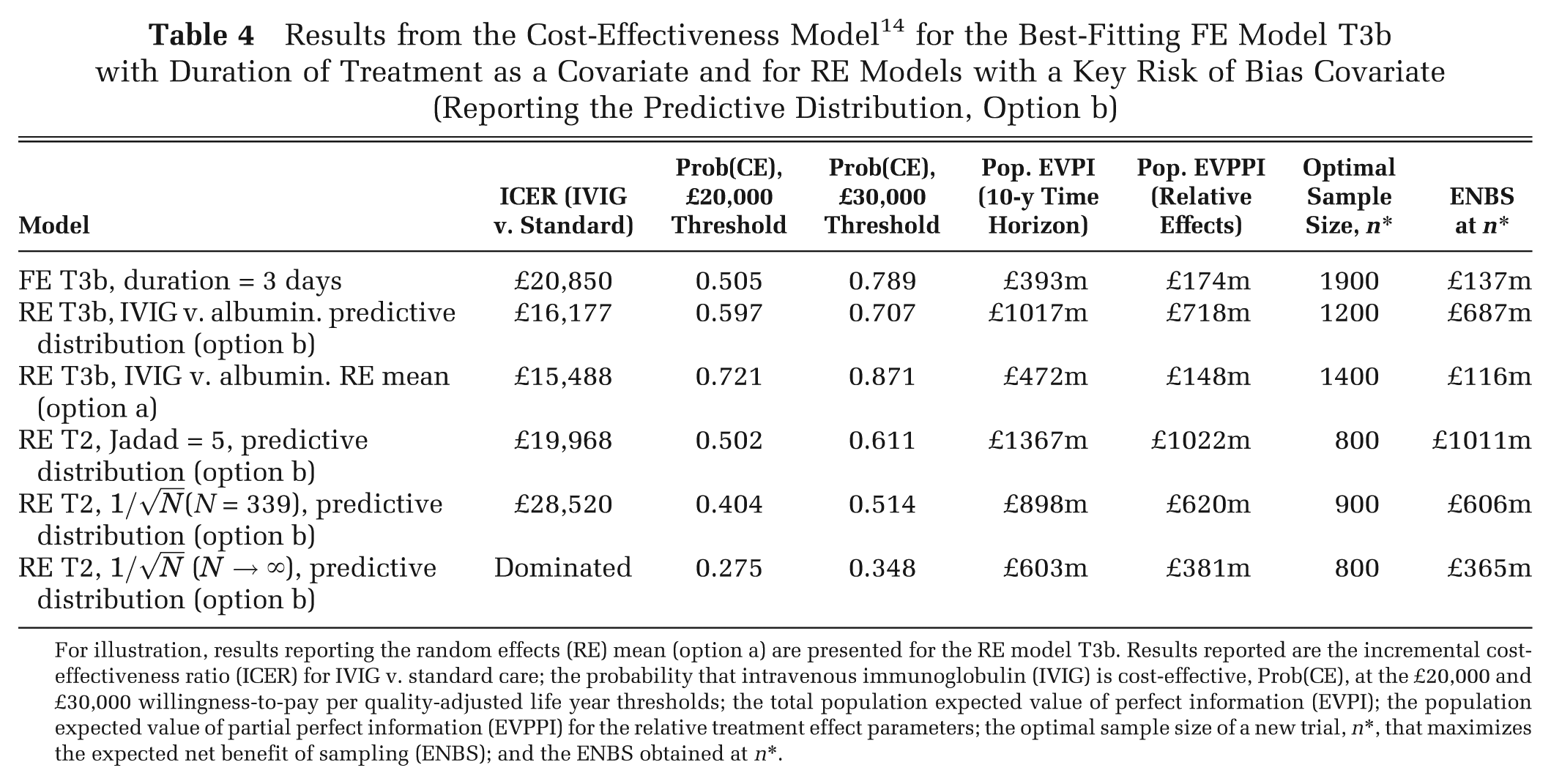
For illustration, results reporting the random effects (RE) mean (option a) are presented for the RE model T3b. Results reported are the incremental cost-effectiveness ratio (ICER) for IVIG v. standard care; the probability that intravenous immunoglobulin (IVIG) is cost-effective, Prob(CE), at the £20,000 and £30,000 willingness-to-pay per quality-adjusted life year thresholds; the total population expected value of perfect information (EVPI); the population expected value of partial perfect information (EVPPI) for the relative treatment effect parameters; the optimal sample size of a new trial, n*, that maximizes the expected net benefit of sampling (ENBS); and the ENBS obtained at n*.
Discussion
We have presented a structured model selection strategy to incorporate covariates in evidence synthesis of relative treatment effects and described different model summaries that can be used as inputs to CEA models, depending on how the heterogeneity in the evidence relates to the setting for the decision. Applying the methods to our illustrative example allowed us to identify models that eliminated the heterogeneity to an FE model through the inclusion of covariates, although we also presented results from RE models after incorporating expert opinion. There have been several previous meta-analyses conducted on IVIG for severe sepsis/septic shock,25–30 and conflicting conclusions have been drawn. 23 Although all previous meta-analyses tested for heterogeneity, all (with the exception Turgeon et al. 27 ) performed a fixed effects meta-analysis. Our findings from univariate analyses are in concordance with findings from previous meta-analyses, but our meta-analysis is the first to simultaneously allow for type of IVIG/IVIGAM, control treatment, study quality/publication bias, dosing regimen, and other potential covariates. Without exploring the model space fully and integrating expert input, the sensitivity of results to choice of model and interpretation of that model may be missed.
We found that clinical input is essential to obtain results that are interpretable and to help choose between competing models that fit equally well. In our illustrative example, the expert opinion was valuable to make us wary of overinterpretation of the best-fitting FE models, which included aspects of treatment regimen; present results from other models that do not include treatment regimen covariates; and help us understand the difference between treatment definitions, particularly the difference between the no treatment and albumin controls, and the link with risk of bias. Of course, expert opinion may also be subject to cognitive biases,31,32 such as confirmation bias, and in panels of experts the “bandwagon effect.”
We have proposed a particular model selection strategy, but other structured approaches could have been taken. To explore the relative performance of different selection strategies would require a detailed simulation study, which is an area for further research. When there is no other rationale to choose between models, sensitivity analysis is essential. Model averaging could be used to obtain a weighted analysis over the plausible model space.33,34 A fully Bayesian approach could also use expert opinion to obtain prior model weights for different covariate models. However, model averaging does not help with the interpretation and understanding of causes of heterogeneity and, as such, does not deliver any advantage over a simple RE model with no covariates.
Heterogeneity in treatment definition is common, and treatments are often grouped together (e.g., over dose or treatment class). Our approach can help determine whether grouping together is reasonable, again with clinical input. For IVIG, it was found to be reasonable to group treatments across different IVIG preparations. However, dosing regimen led to treatment effect modification and must be included as a covariate or as unexplained heterogeneity in an RE model. It was concluded that basic science was needed to better understand the mechanism of action of IVIG and to determine appropriate dosing regimens through dose-ranging studies.14,35
Risk of bias information is routinely collected, but we are unaware of other examples where bias adjustment has been used in CEA. We found that sample size was an important covariate. The natural way to adjust for bias due to small study effects is to predict the treatment effect as
We have used meta-regression methods to identify effect modifiers, but these methods suffer from low power to detect effects and are vulnerable to ecological bias. 6 This is especially the case in the (common) situation where the spread of covariate values across studies is sparse (e.g., only a few studies where the covariate is absent). It was not possible to explore potential covariates where the data were sparse, although these may have been important treatment effect modifiers. Individual participant data (IPD) avoid many of these problems, although it may not be possible to obtain IPD from all (or any) of the included studies. There has been some recent work on methods for the combination of studies where there is IPD available for some but not all studies on a binary outcome. 36 However, there is no real substitute for IPD when continuous patient-level characteristics are important effect modifiers. One important potential treatment effect modifier is baseline risk. We found that including baseline risk as a covariate in our example did not improve model fit (results omitted). Note that by modeling relative effects on the log-odds scale already imposes an interaction between baseline risk and relative effects on the absolute probability scale (with smaller absolute probability differences when baseline probability is close to 0 or 1), which perhaps explains why there was no added benefit of explicitly using baseline risk as a covariate. Careful attention needs to be given to the scale on which the model acts and an awareness of what this implies in terms of interactions on an absolute scale.
We have assumed that there is a single effectiveness parameter that inputs to the CEA model. In practice, there may be multiple outcomes measured in the studies included in the meta-analysis (e.g., all-cause mortality, risk of stroke and bleeds), and these may be correlated. Multivariate meta-regression models 37 across outcomes will therefore be required. Methods for model selection with multiple outcomes and how the results from these models can be used in CEA is an area for further study.
We have focused on heterogeneity in relative treatment effects, but there may be heterogeneity in other inputs to a CEA model. In particular, heterogeneity in natural history parameters, such as baseline risk, is likely. Ideally, large cohort studies or registry data representative of the decision setting would be used to estimate baseline risk 38 and relative effects from the evidence synthesis applied to the baseline risk to obtain absolute risk for use in the CEA model. Where subgroups according to baseline risk can be identified, then CEA results can be broken down by subgroup to give tailored treatment recommendations, or the subgroups can be averaged over to give a population average treatment recommendation, as described in equations (10) to (12). In the absence of relevant cohorts or registries, the “standard care” arms from the RCTs included in a meta-analysis or network meta-analysis that are considered representative of the decision setting may be used to estimate baseline risk. To avoid introducing bias in the relative treatment effects, a synthesis of the “standard care” arms should be done in a separate analysis from the synthesis of the relative treatment effects. 38 All of the ideas presented in this article extend naturally to a synthesis of standard care arms to estimate baseline risk and also to any other model inputs that may exhibit heterogeneity.
Footnotes
This project was funded by the National Institute for Health Research (NIHR) Health Technology Assessment (HTA) Programme (project number 08/70/01). The views and opinions expressed therein are those of the authors and do not necessarily reflect those of the HTA Programme, NIHR, NHS, or the Department of Health.
NJW was supported by a UK MRC Methodology Research Fellowship and the MRC ConDuCT Hub for Trial Methodology Research (MRC G0800800).
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.