
Abstract
Progressively, information systems (IS) researchers draw on digital trace data to capture the emergent dynamics of today’s digitalized world. Digital trace data enable researchers to generate highly context-specific insights into the features and dynamics of socio-technical phenomena. We suggest how IS researchers can use digital trace data to develop situated explanations, that is, explanations that capture the idiosyncratic features of real-world problems in order to generate impactful solutions to these problems. We outline five key principles to build situated explanations based on digital trace data. We make several suggestions on how the information system field can adjust its research and publication practices to embrace the development and dissemination of situated explanations.
Keywords
Introduction
Computational research leveraging digital trace data is an emerging new research genre in information systems (IS) (Lindberg, 2020; Miranda et al., 2022; Tremblay et al., 2021). Broadly speaking, digital traces are online records of activities and events, left behind whenever digital technologies are used (Freelon, 2014). Since much of what people do in their modern daily lives is mediated or enabled by digital technologies (Yoo, 2010), digital trace data accrue in all kinds of private and work-related contexts. They can be collected from all kinds of sources, from system log files to internet cookies or wearable devices (Lazer et al., 2020; Osterlund et al., 2020). They are of interest to many fields studying human behavior but in particular to information systems, a field that has always been concerned with the phenomena that occur at the intersection of social and technical systems (Lee, 1999; Sarker et al., 2019). It is exactly phenomena at this intersection that digital trace data provides records of.
Information systems researchers become increasingly aware of the advantages of digital trace data (Osterlund et al., 2020; Pentland et al., 2020). Several IS scholars have developed approaches for using digital trace data to develop new theory (Berente et al., 2019; Lindberg, 2020; Miranda et al., 2022). One argument in that context is that digital trace data can enable the development of highly context-specific explanations that take into consideration the specific features of a given local context over time (Leavitt et al., 2021; Ram and Goes, 2021; Tremblay et al., 2021). Such explanations, it is hoped, can be used to design impactful solutions to these problems (Hirschheim, 2019; Ram and Goes, 2021). With impactful solutions, we mean instantiated and concrete responses to demands in real-life practice that palpably and effectively solve the demand.
This quest to generate practical impact has become an increasingly relevant demand in academic work. The U.K.’s Research Excellence Framework (https://www.ref.ac.uk/), for example, requires all researchers, from IS and other fields, to demonstrate practical impact of their research. Similar regulatory movements are underway across the Commonwealth (e.g., the Excellence in Research in Australia, see Australian Research Council, 2022), Europe (European Commission, 2022), and the United States, among other regions (Kamenetzky and Hinrichs-Krapels, 2020). Moreover, it has also been demanded that academic answers to pressing real-life problems can be generated in a speedy and timely manner (Agerfalk et al., 2020; Karanasios, 2022; Oliver et al., 2020). This means that research outcomes should be evaluated against their ability to generate real-world solutions to given problems as they occur; hence, they do not necessarily need to become part of explanations that withstand the tests of time and space. They are thus “in flux” and may even unlikely turn into generalizations (Leavitt et al., 2021; Tremblay et al., 2021).
Given these demands, our aim is to complement and extend the current conversations around the use of digital trace data by focusing on the development of what we call situated explanations. Situated explanations are highly context-specific explanations that leverage the idiosyncratic features and dynamics of a problem context with the explicit aim to develop impactful solutions (Leavitt et al., 2021; Ram and Goes, 2021; Tremblay et al., 2021). They are based on processual patterns that describe the evolution of a specific real-life problem in a specific context over a specific period of time. We focus on how IS researchers can develop situated explanations in an impactful and speedy manner.
Our proposal is timely in two ways. First, digital trace data have only recently become available at such volume and granularity that idiosyncratic features and dynamics of real-world problems can be captured at large (Oliver et al., 2020). Moreover, it has only now become possible to develop situated explanations in quick and reliable ways (Oliver et al., 2020; Ram and Goes, 2021) thanks to the astonishing progress in computational techniques to analyze digital trace data. Second, we are echoing calls that researchers––in information systems and beyond—are now expected to be more concerned with generating solutions to real-world problems (Agerfalk et al., 2020; Gaieck et al., 2020; Rosen, 2018). Since the COVID-19 pandemic, in particular, there has been a rising expectation for scientists to provide relevant and timely advice in order to inform political decision-making and policy-making (Maani and Galea, 2021; Pataro et al., 2021; Van Bavel et al., 2020). We sketch how the development of situated explanations can enable information systems researchers to realize such expectations by leveraging their unique socio-technical competences (Agerfalk, 2010; Díaz Andrade et al., 2019; Levy et al., 2020; Sarker et al., 2019).
We proceed as follows. We review literature on digital trace data, impactful research, and the role of theory in developing explanations. Next, we develop five new principles to follow for IS researchers interested in developing situated explanations. Then we review the implications that would follow when IS researchers increasingly develop situated explanations. We finish by reviewing limitations and conclusions.
Background
Using digital trace data to address real-world problems
Digital trace data present an exciting prospect for IS researchers to learn more accurately and precisely about socio-technical phenomena in an increasingly digitalized world. Not only can work be hardly meaningfully decoupled from digital technology anymore (Bailey et al., 2022; Orlikowski and Scott, 2008), but also most if not all aspects of our life are increasingly mediated by digital technologies (Alaimo and Kallinikos, 2017; Yoo, 2010). As the name suggests, digital trace data capture digitally mediated actions and events as they unfold over time, at an astonishing level of precision and granularity (Pentland et al., 2020). Every keystroke, every transaction, even every heartbeat and eye movement can potentially be logged (Power, 2022). This allows more precise and more voluminous data on actions and events than traditional modes of data collection, such as observations, interviews or archival data (Schensul et al., 1999).
Digital trace data provide plenty of opportunities for IS scholars, but serious methodological adjustments are required to consider the particularities of this new type of data. In consequence, recent works in IS have started to shed light on the implications of using digital trace data for research, especially for the development of theory (e.g., Berente et al., 2019; Lindberg, 2020; Miranda et al., 2022). For example, it has been suggested that digital trace data need to be framed within a theoretical lexicon in order to contribute to a specific discourse (Berente et al., 2019). Also, there have been works that focus on the interplay of human and computationally-enabled sense-making to detect patterns in digital traces (Kallio et al., 2022; Lindberg, 2020). Others have examined the quality and features of digital trace data sets, along with their opportunities and threats for theorizing (Howison et al., 2011; Pentland et al., 2020). Furthermore, there have been discussions about the general implications of digital trace data for theory building (Grover et al., 2020; Osterlund et al., 2020). What has received relatively little attention in this scholarly discourse is that digital trace data also provide ground for developing impactful solutions to real-world problems (Ram and Goes, 2021; Tremblay et al., 2021; vom Brocke et al., 2021). To this end, representing and analyzing digital trace data enables researchers and policymakers to gain an in-depth understanding about what is happening at a specific point in time, and what could be done to stir a given problem context into more desirable directions (Agerfalk, 2010; GovLab, 2021; Oliver et al., 2020).
We do not mean to suggest that impactful solutions to real-world problems based on digital trace data do not yet exist. Researchers and policymakers are already using all kinds of digital trace data to understand problem contexts as they evolve over time (Kogan et al., 2021; Mbunge et al., 2021; Oliver et al., 2020), sometimes in complement with other data sources, such as interviews or databases (Knippenberg and Meyer, 2020; Kogan et al., 2021). Researchers in China, for example, used digital trace data collected from Baidu, a national search engine, to understand how the COVID-19 pandemic was spreading as well as to evaluate the effectiveness of non-pharmaceutical interventions, such as travel restrictions and social distancing (Hu et al., 2021; Lai et al., 2020).
Situated explanations and impactful research
In recent years, there has been an increasing number of calls for researchers to address real-world problems and gain a deeper understanding of the contexts in which they occur (e.g., Pataro et al., 2021; Rosen, 2018). Such an understanding requires the creation of insights and solutions that consider the specific factors and circumstances relevant to a given problem and sharing them with relevant stakeholders, such as policymakers, at the appropriate time (Gaieck et al., 2020; GovLab, 2021; Lai et al., 2020). During the COVID-19 pandemic, for example, researchers, policymakers, and other stakeholders collaborated to address various emerging problems as they occurred. Some interventions were informed by available theory, while some new theory development occurred ex-post as a result of certain interventions (Ruggeri et al., 2022; Van Bavel et al., 2020). But irrespective of whether theory was the starting or end point, the primary focus has been to “bring about informed change” (Agerfalk, 2010: 251) in a specific context. The pandemic also showed that the quest for practical, impactful solutions can at times increase demand for timeliness to such an extent that traditional quality assurance processes in science were paused or altered (consider, e.g., the enormous uptake of pre-print and pre-review publication of scientific output (Hoy, 2020)). It appeared at times that the appetite for timely and impactful solutions trumped the demonstration of rigor (Oliver et al., 2020).
Impactful solutions thus create a need for situated explanations to be both specific and timely, two requirements that go beyond the traditional demands for theoretical explanations to be generalizable across time and space (Gregor, 2006; Hirschheim, 2019; Weber, 2012). The process of generalizing typically means that an explanation is abstracted from a given context so that it can be compared and integrated with a larger body of knowledge (Farhoomand, 1987; Hirschheim, 2019; Lee and Baskerville, 2003; Williams and Tsang, 2015). But this process may ignore important contextual details that, in turn, impede the application of an explanation to a specific problem context (Davison and Martinsons, 2016: 2), a limitation that the development of situated explanations can avoid.
The view that explanations should be specific and timely is not entirely new to the IS field. Several scholars have suggested in the past that generalizable explanations may not always be needed, or even useful, for solving real-world problems (e.g., Agerfalk et al., 2020; Hirschheim, 2019; Ram and Goes, 2021). In order to address real-world problems, these claimants suggest, information systems research should be primarily concerned with the development of an in-depth understanding of a given problem context by leveraging the increasing availability of digital trace data—regardless of whether they have theoretical value or significance (Hirschheim, 2019; Ram and Goes, 2021; Tremblay et al., 2021).
However, realizing that we can leverage the idiosyncratic features of a given problem-contexts to produce impactful solutions with situated explanations is only a first step. If our ambition is to leverage the potential of digital trace data for practical impact, we need to understand how situated explanations can be built. Previous works that called for using digital traces to develop “theories in flux” (Tremblay et al., 2021) or “local theories” (Leavitt et al., 2021) have been silent about the actual ways through which one can develop practical impact. This is what we set out to achieve with this article. Thus, in what follows, we present five principles to develop situated explanations based on digital trace data to generate timely and practical impact.
Five principles for developing situated explanations on the basis of digital trace data
Embracing idiosyncratic and dynamic representations to develop situated explanations
Our starting point is the observation that we live in a world in flux (Mousavi Baygi et al., 2021; Tremblay et al., 2021), which means that we need to pay attention to the idiosyncrasies of problem contexts and how they evolve over time. The challenge is to represent both the idiosyncratic features and the temporal dynamics of real-world problems. A representation of a problem––be it in the form of a text, a figure or a picture, an animation or a video, a sound or an audio file, or any combination of these meaningful symbolic elements––can be useful for developing situated explanations as long as it depicts the problem in such a way that it is informative to a wide variety of different actors and stakeholders, and supports them in effectively reflecting on that problem in practice (Munger et al., 2021; Oliver et al., 2020; Tremblay et al., 2021) and as long as it describes the evolution of the relevant idiosyncratic features over time.
For example, during the COVID-19 pandemic, policymakers needed to define and evaluate effective measures to promote social distancing. To that end, researchers created representations of mobility patterns of populations and their changes in real-time and at scale (Whitelaw et al., 2020). To build these representations, they collected mobile phone data from sources, such as cell towers, dedicated smartphone applications, Bluetooth functionalities, and others 1 (GovLab, 2021; Grantz et al., 2020; Oliver et al., 2020). Leveraging these data allowed policymakers and researchers to depict a highly complex, dynamic, and distributed phenomenon in a comprehensible way. It enabled fruitful discussions among a diverse group of stakeholders, including both scholars and policymakers (Knippenberg and Meyer, 2020; Oliver et al., 2020). All of this played a crucial role for designing effective policies in a collaborative and iterative process (Budd et al., 2020; GovLab, 2021; Oliver et al., 2020; Van der Drift, Wismans and Olde Kalter, 2022). Box 1 summarizes the approach taken by the European Commission’s Joint Research Centre in their efforts to restrict the transmission of COVID-19.
Box 1: Developing situated representations to understand real-world problems: The case of the European Commission’s Joint Research Centre during the Covid-pandemic.
At the beginning of the pandemic in March 2020, the European Commission faced the challenge of implementing social-distancing measures to prevent the spread of the virus, while at the same time, keeping the economic damage to a minimum (GovLab, 2021). Urgently and with little lead time, the European Commission negotiated with various European mobile network operators to obtain mobility data. Subsequently, the European Commission’s Joint Research Centre (JRC) carried out several initiatives to analyze real-time mobility in order to inform policymakers and other decision-makers (Santamaria et al., 2020). The JRC received mobile positioning data which were recorded by cell towers servicing mobile phones as users make calls, write texts or retrieve data (GovLab, 2021). These data were delivered in the form of anonymized Origin-Destination Matrices, which depict the number of movements of mobile phone users from one area to another. To represent these data in meaningful ways, the JRC took two steps. First, they developed measures, such as Mobility Functional Areas (Iacus et al., 2020), to represent how populations move, regardless of fixed administrative boundaries (such as districts or cities) (Iacus et al., 2020). These areas were used to compute real-world mobility trends by means of various indicators, including those that occurred within this area, those that started in this area and led to another area, and those that started in different areas and ended in a given area. Second, members of the JRC produced a variety of informative representations in order to depict mobility trends—and thereby, the potential spread of the pandemic—from various angles. These representations showed, for instance, movements across regions and countries, and they could be used to evaluate the effects of specific interventions. Exemplary representations can be found in Iacus et al. (2020) and Santamaria et al. (2020).
But it is not enough that representations are informative about a given problem context. In a world that is in constant flux, most problems are going to be “moving targets” that change their shape over time. Since a problem context dynamically evolves, representations must capture idiosyncratic features at least at two points in time. Therefore, it will be more important to produce temporal sequences of representations quickly, rather than having a method that might produce a near-perfect representation but takes excessive computation time. Hence, the value of any representation should be evaluated by how timely and useful it is to depict a given problem context effectively (Agerfalk, 2010; Levy et al., 2020).
It is also important that we arrive at such representations in a reliable, that is, consistent and reproducible, way. Reliability is often high if algorithms and scientific workflows are used to produce representations in a deterministic and systematic way. This is because computational methods, at least deterministic ones, guarantee that different actors can independently arrive at the same representation of a problem, fostering the shared understanding necessary for effective collaborative problem solving processes (Okhuysen and Bechky, 2009). FAIR principles of data (Wilkinson et al., 2016) and research software (Lamprecht et al., 2020) support this ambition, in particular regarding reproducibility. For example, some process mining algorithms are known to produce representations (such as network graphs) with high reliability (Van Der Aalst, 2016). But not all computational methods guarantee reliable construction of outputs. For example, several pattern discovery algorithms are known not to be reproducible because they generate new visualizations of patterns in every execution (Indulska et al., 2012). Likewise, most traditional qualitative research methods produce representations (such as coding tables or concept maps) that can be subjective and unreliable (Silverman, 2013).
Taken together, what we envision is a complementary form of knowledge accumulation that centers around our ability to develop informative representations of idiosyncratic problem dynamics quicker (i.e., requiring less time to produce the representation) and more reliably (i.e., with higher chance of different scholars arriving at the same representation independently of each other). Together, this leads us to our first principle:
In a world in flux, digital trace data should be used to develop informative representations of idiosyncratic and dynamic real-world problems in quick and reliable ways.
Processual patterns are the most useful type of representation for a world in flux
In order to systematically unpack the meaning of our first proposition, we need to specify the type of representations we are talking about. We thus address the following question: What type of representation will be most effective in helping actors understand the challenges that arise for them in a world where change is all there is (Mousavi Baygi et al., 2021)? We suggest that a processual pattern should be the primary form of representation around which situated explanations are built.
Generally speaking, a pattern describes recurrent aspects of a phenomenon or problem in a recognizable yet abstract form (see also Alexander, 1977; Miranda et al., 2022). That is, a pattern is a form of representation that focuses our attention on those aspects that are (at least somewhat) repetitive and, therefore, recognizable. Patterns have always played a key role in the social sciences (e.g., Gioia and Poole, 1984; Goffman, 1974), but patterns are not theories, and processual patterns are not process theories; instead they are empirical generalizations (Handfield and Melnyk, 1998). Still, patterns have become an important building block for theoretical contributions IS scholars seek to make when using digital trace data (Berente et al., 2019; Miranda et al., 2022). Patterns make latent structures in empirical data visible and thereby allow for more parsimonious and, therefore, potentially insightful descriptions of the world around us. Detecting a pattern thus provides an opportunity to intervene into a problem because one will be better able to see why and how a problem persists (Oliver et al., 2020; Tremblay et al., 2021).
While patterns are useful because they point to recognizable aspects of a problem, it would be misleading to focus only on those aspects of a problem which remain stable over time. Static patterns are not the best way of representing real-world problems because problem contexts can and will change their structure. This process typically has characteristic rhythms (Ancona and Chong, 1996) which, amongst other things, imply “windows of opportunity” during which interventions are more likely to be effective (Tyre and Orlikowski, 1994). Hence, to account for variation and change over time, we need to develop processual patterns. We define a processual pattern as a representation of one or multiple sequences of actions and events that captures their recurrent aspects in a recognizable form as the phenomenon of interest changes over time.
Processual patterns describe recurrent properties of a problem, but also reveal how a problem forms, changes, and dissolves over time. In analogy, while static patterns are pictures, processual patterns are movies. As a specific type of representation, processual patterns sensitize actors for the volatile, sometimes even unpredictable dynamics that the digital age confronts us with now and in the future (Mousavi Baygi et al., 2021). An understanding of these dynamics, we argue, will be key to design and evaluate solutions to these problems over time (Oliver et al., 2020; Tremblay et al., 2021).
The availability of digital trace data makes it feasible to generate such processual patterns. We gain more and more digitally logged evidence of activities and events that occur around us (Freelon, 2014; Lazer et al., 2020; Power, 2022), which allows us to infer patterns in peoples’ behavior (Leonardi and Treem, 2020) and how these patterns change over time (Pentland et al., 2020; Zhang et al., 2021). Together, they allow us to generate rich contextualized descriptions of actions situated in particular contexts such as time (now, later, …), place (here, there, …), subject (me, you, …), or technology (smartphone, app, computer, …) (Barnes and Law, 1976; Suchman, 1987). Moreover, processual patterns are insightful not because they are highly generalizable, but because they embrace the situated dynamics of real-world problems (Oliver et al., 2020; Pentland et al., 2020).
To illustrate: During the COVID-19 pandemic, policymakers across the globe recognized that digital traces stemming from mobile phone use were not only useful to monitor the dynamics of virus transmission, but also to evaluate the effectiveness of interventions. Various forms of mobile phone data offered them “specific, reliable, and timely data not only about infections but also about human behavior, especially mobility and physical co-presence” (Oliver et al. 2020: 1). Since different forms of mobile phone data had particular strengths and weaknesses (Grantz et al., 2020; Ojokoh et al., 2022), they were used for different areas of inquiry throughout the epidemiological cycle (Schlosser et al., 2020). For example, in the early stages of the pandemic, digital traces from mobile phone use, primarily collected through connections between mobile phones and cell towers, enabled situational analysis to understand if and to what extent the population adhered to lockdown orders (Perra, 2021) (see Box 2). At subsequent stages, other mobile phone data, such as data from smartphone apps and Bluetooth functionalities came increasingly into effect (GovLab, 2021; Van der Drift et al., 2022). In any case, these data allowed researchers and policymakers to examine human mobility and interaction patterns at various stages of the pandemic as they indicated, for example, the extent to which populations adhered to lockdown interventions over time (GovLab, 2021).
Regardless of the specific initiative and the type of mobile phone data that were used, key is that they allowed to track the temporal process through which the pandemic unfolded over time. Throughout the pandemic, the use of mobile phone data provided policymakers and other relevant stakeholders with the opportunity to produce quick and reliable representations of the problem context as they identified patterns about human behavior that changed at different points in time (Chang et al., 2021). This, in turn, allowed them to analyze and react to problem contexts as they unfolded over time. We illustrate this point in Box 2 by elaborating on the example by the European Commission’s Joint Research Center.
Box 2: Developing processual patterns to understand real-world problems: The case of the European Commission’s Joint Research Centre during the Covid-pandemic.
Members of the JRC developed a number of processual patterns that enabled policymakers to recognize changes in mobility patterns indicating how populations moved and potentially contributed to the spread of the virus (GovLab, 2021; Iacus et al., 2020). Santamaria et al. (2020) show mobility indicators for different regions in Spain over time, and how they changed after the lockdown had been imposed. Such representations, in turn, made it possible to see in which regions certain interventions were more or less effective. By comparing areas in Spain, for example, time-based representations showed that the first lockdown in March 2020 was leading to a significant decrease in mobility patterns, as represented through movements within, from and to specific areas (Santamaria et al., 2020). Over time, however, this effect remained to different extents and mobility patterns changed at different paces (Santamaria et al., 2020). From a broader perspective, the JRC was also able to compare how mobility patterns changed across European countries (Santamaria et al., 2020), showing how different lockdown policies led to different effects over time. Also, it was possible to compute mobility indicators for areas and countries to evaluate the effectiveness of mobility restrictions (Santamaria et al., 2020). Insights obtained through such patterns, in turn, proved valuable for evaluating lockdown interventions, informing early warning applications and modeling-based analyses of the pandemic (GovLab, 2021; Iacus et al., 2020).
In short, we envision that the generation of processual patterns will aid the development of situated and impactful explanations. The second principle we propose is:
Situated explanations should be based on representations of idiosyncratic and dynamic problem contexts by means of processual patterns generated from digital trace data.
Developing situated explanations at the intersection of problem, processual patterns, and data
In order to implement the two principles developed above, the development of situated explanations should focus on the relations between (1) real-world problems, (2) digital trace data, and (3) processual patterns (see Figure 1). Developing situated explanations on the basis of situated representations (Principle 1) in the form of processual patterns (Principle 2).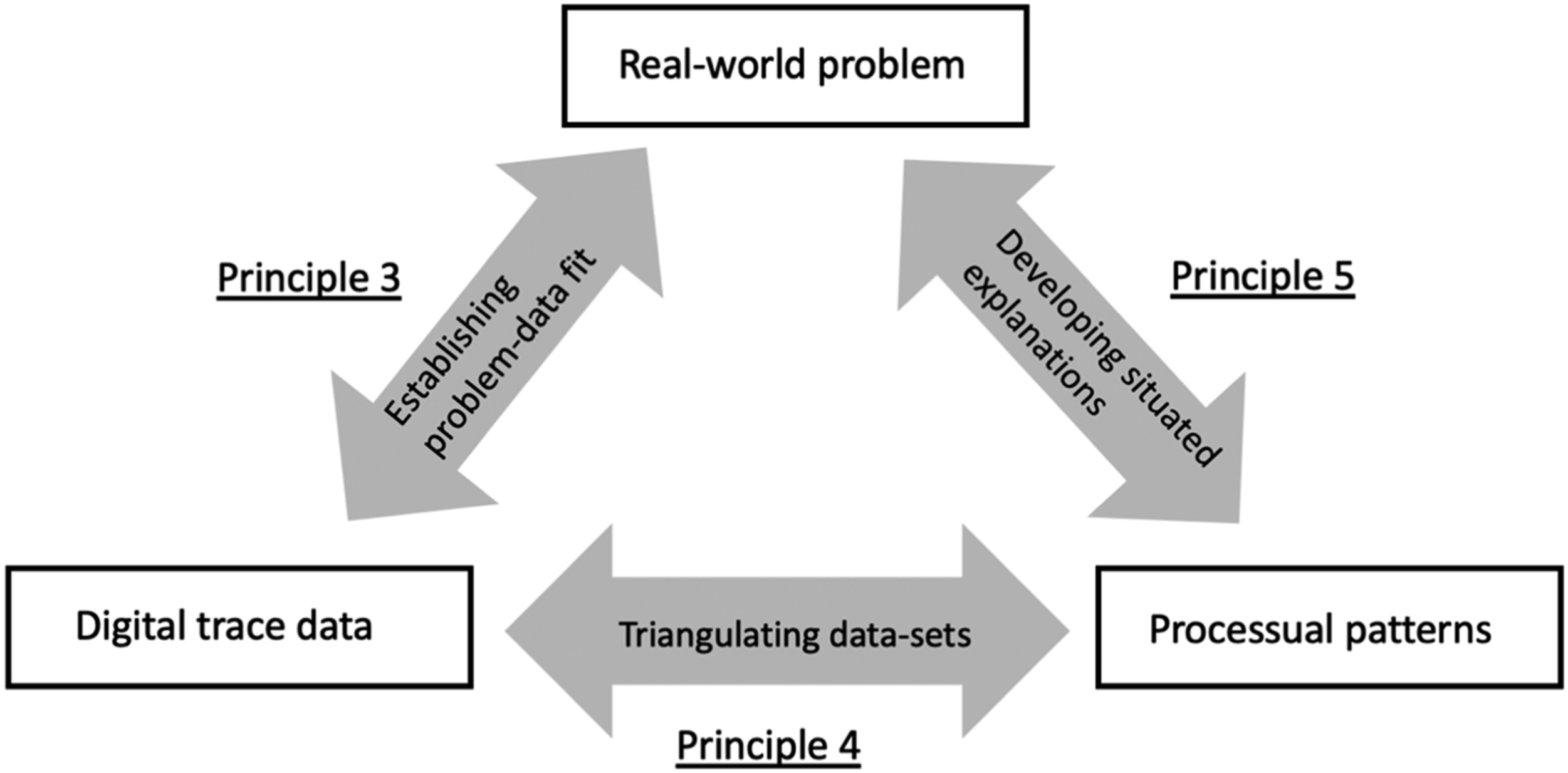
Establishing data-problem fit
Digital trace data can only ever provide a partial representation of the real-world processes that left these traces (Power, 2022). In analogy, even a movie is just a series of snapshots; and every dataset however large and comprehensive is essentially only a case study at particular points in time and context (Indulska et al., 2012). Thus, every digital trace dataset allows us to see some aspects of a problem while hiding others (Freelon, 2014; Stier et al., 2020). In turn, to move from the recognition of a real-world problem to an understanding of the requirements for a digital trace dataset that will allow us to generate situated explanations requires the establishment of data-problem fit. Data-problem fit means selecting and analyzing digital trace from one or more digital trace datasets such that they allow scholars to (a) understand the problem’s core properties, (b) identify opportunities to mitigate it, and (c) monitor the effects of interventions over time (Latif et al., 2020; Oliver et al., 2020). It defines the task for the researcher to obtain data that fits the problem.
For example, the usefulness of mobile phone data to examine the transmission of the COVID-19 pandemic was quickly recognized by countries all over the world (GovLab, 2021; Klein et al., 2020; Lyons, 2020). This was because infection-relevant parameters could be directly obtained from various forms of these data, including mobility, interactions, and social proximity (Oliver et al., 2020). This approach established data-problem fit, which in turn, informed further actions by researchers and policymakers. Box 3 illustrates this point as it further elaborates on the example by the European Commission.
Box 3: Establishing data-problem fit: The case of the European Commission’s Joint Research Centre during the Covid-pandemic.
The European Commission requested data from mobile network operators for different reasons (GovLab, 2021; Iacus et al., 2020; Santamaria et al., 2020; Vespe et al., 2021). First, mobile phones are daily companions in peoples’ everyday life, and they are used for private as well as job-related purposes. Hence, the data obtained through mobile phone use was expected to depict mobility patterns within populations across various member states of the European Union, including Austria, Belgium, Denmark, Germany, Finland, France, and Greece, among others. Second, these data could be used for various purposes, such as the evaluation of social distancing measures and the potential spread of the pandemic over time. An official document by the European Commission states that mobile phone data, “if pooled and used in anonymized, aggregated format in compliance with EU data protection and privacy rules, could contribute to improve the quality of modeling and forecasting for the pandemic at EU level” (European Commission, 2020: 5).
When relevant behaviors are not enacted with digital technologies, it can be challenging to determine which data sets can lead to meaningful representations about a specific real-world problem (Mureddu et al., 2020; Power, 2022). We still know next to nothing about how we can go about in evaluating the appropriateness of a digital trace dataset for such purposes (Alamo et al., 2020). One suggestion is to initiate the inquiry on the grounds of available data (e.g., from a work system in an organization), to subsequently frame the resulting patterns under a specific theoretical lexicon (Berente et al., 2019; Miranda et al., 2022; Pentland et al., 2021). This implies that the (theoretical) relevance of these data is evaluated after data have been accessed and evaluated.
Even if we have useful digital trace data sets at hand, it might not be immediately clear how data-problem fit could be achieved, and what kind of representations work well. Research on big data-based policy-making (Desouza and Jacob, 2017) and decision-making (Merendino et al., 2018) suggests that users need to explore and experiment with such digital trace data-based representations as they gradually understand problems and develop appropriate solutions. This happens, for example, when they explore a given set of digital traces with different analysis techniques (Desouza and Jacob, 2017; Elgendy and Elragal, 2016; Merendino et al., 2018). During the COVID-19 pandemic, for example, predictions were made through a variety of computational models and under different assumptions (Boland and Zolfagharifard, 2020). In this way, data-problem fit emerges over time from a co-evolution of problem understanding that informs data requirements and available data that contributes to problem understanding, similar to the coevolution of problem and solution observed in design studies (Dorst and Cross, 2001).
The question we need to address is: How can we predict with sufficient accuracy if we will be able to find processual patterns that are potentially insightful regarding a given real-world problem in a trace dataset with given characteristics? Accordingly, the establishment of data-problem fit in quick and reliable ways would need to be a central effort along which we should and could collectively accumulate knowledge. The principle we put forward is:
Developing situated explanations is contingent on the establishment of data-problem fit.
Triangulating data sets
Because establishing data-problem fit means a digital trace data set must allow for (a) understanding the problem’s core properties, (b) identifying mitigation opportunities, and (c) monitoring intervention outcomes time (Latif et al., 2020; Oliver et al., 2020), single sources of data are not likely to be sufficient to develop a comprehensive representation of a real-world problem (Knippenberg and Meyer, 2020; Osterlund et al., 2020). We will need multiple datasets to identify the patterns that are most relevant to a problem at hand, such as patterns in how, when and where people move (e.g., through devices producing GPS data), with whom they communicate (e.g., through mobile phone use), how they work (e.g., through work systems), and what their motifs are (e.g., through social media posts), etc. (Whitelaw et al., 2020). Hence, if we want to obtain a more comprehensive, more informative representation of a real-world problem, we will need to engage in triangulation, that is, we need to relate multiple sources of evidence about a problem context (Jick, 1979). For situated explanations, triangulation is important because it helps establish a nuanced picture of the idiosyncrasies of any situated action. It also helps increase trust that any potential processual pattern is in fact recurrent and recognizable. Moreover, by triangulating digital trace data from different sources, we can better represent the dynamics of the situation in which a problem is embedded (Freelon, 2014; Pentland et al., 2020).
The use of mobile phone data alone, for example, points to changing mobility patterns within populations (Oliver et al., 2020) but it provides limited insights into the extent to which a virus is being passed on (Heiler et al., 2020; Ienca and Vayena, 2020; Ojokoh et al., 2022), which is why that data was triangulated with other data about the same content and timeframe. Box 4 discusses how the European Commission’s Joint Research Centre triangulated data.
Box 4: Establishing data-problem fit: The case of the European Commission’s Joint Research Centre during the Covid-pandemic.
Despite the various advantages of mobile phone data, they miss information surrounding the context in which they were collected; they show when and where mobility took place, but they do not explain why this is the case. Hence, the European Commission planned to include other digital trace data sources, such as data collected from social media, in order to obtain information about social interactions and early indications of disease spread (e.g., by means of search requests or postings) (European Commission, 2020). From a broader perspective, it proved crucial that initiatives had access to various data pools in order to complement and standardize different data sets for comprehensible analyses (GovLab, 2021; Vespe et al., 2021).
Triangulation is not easy to achieve. Given a problem and a first dataset to begin examining it, there are several issues to consider as we identify and integrate additional data sources. Since most of what we do is enabled through multiple digital technologies, it is challenging to define boundaries in regard to what should be considered relevant data (Hsiang et al., 2020; Latif et al., 2020). In our example, for instance, depending on the specific problem at hand, mobile phone data can be complemented through information from search engines (Ginsberg et al., 2009), social media platforms (Tsao et al., 2021), travel websites (Kogan et al., 2019), wearable devices (Radin et al., 2020), among others (Kogan et al., 2021), with the timeframe and focal objects (e.g., users) being the pillars around which to integrate the data. Kogan et al. (2021) exemplify how the integration of several disparate health and behavior-related digital trace data sources––such as data from Twitter, Google, Apple, clinical databases, and others––provides a multiproxy estimate of COVID-19 outbreak with much higher accuracy than mobile phone data alone.
Obtaining and combining multiple data sets for purposes of triangulation can be challenging. Relevant digital trace data sources may stretch across multiple digital platforms (Ienca and Vayena, 2020). Some data may be publicly accessible (e.g., open science initiatives or linked open data, see GovLab, 2021); others may be owned by companies and thus require a strong and trustful partnership between these companies and researchers (Power, 2022). Furthermore, data sets might be flawed (Alsudais, 2021) and data from different datasets are rarely standardized in terms of their semantics. They thus may need to undergo quality checks and considerable pre-processing before analyses can be performed (Jain et al., 2010). For example, events in digital trace data might be logged at different levels of granularity with unclear semantic linkages between datasets (Baier et al., 2018). Given all of this, it is key for the development of situated explanations to collect and combine multiple datasets in quick and reliable ways. Our fourth principle is:
Situated explanations should include triangulated digital trace datasets that comprehensively capture real-world problems.
Moving from processual patterns to situated explanations together with relevant stakeholders
Until now, we have focused on highlighting several critical challenges in generating processual patterns as dynamic and informative representations more quickly and more reliably. However, situated explanations require us not only to represent but also to understand the idiosyncratic features of a given problem. This involves “investigating […] how we can make sense of what happened, and how such an understanding might help develop policy/strategy” (Hirschheim, 2019: 1340). To quickly and efficiently make sense of what happened and what is represented in data and patterns, we thus suggest including into the sensemaking process the actors who are involved in the problem that we are trying to understand. That is, we propose that only a substantial involvement of relevant stakeholders will allow us to leverage the processual patterns generated from digital trace data as a basis for arriving at situated explanations of what is going on.
Sensemaking allows establishing meaningful correlations in data (Desouza and Jacob, 2017). Various approaches to sensemaking exist (e.g., Desouza and Jacob, 2017; Elgendy and Elragal, 2016; Tay et al., 2018). Research on big data analytics points to different factors that facilitate sensemaking and the development of explanations on the grounds of various forms of representations. For example, representations are effective when those who are exposed to them are familiar with the problem context and pursue a certain goal. The interpretation of representations and the evaluation of patterns can be facilitated by means of graphical aids (e.g., using different colors for different data properties in visual representations) (Sinar, 2015). Furthermore, interdisciplinary teams––involving policy makers but also data scientists, among others––have been found to facilitate a joint understanding about a problem context based on representations of various kinds (Desouza and Jacob, 2017; Oliver et al., 2020).
Turning to the example of COVID-19 containment, several studies emphasize that digital trace data alone was not a sufficient means to design appropriate interventions (Benjamins et al., 2022). What proved to be important was that different stakeholders, such as data analysts and policymakers, formed partnerships where they jointly learnt about the problem context, defined relevant parameters, as well as mutual expectations (Coudin et al., 2021; Oliver et al., 2020; Vespe et al., 2021). Different forms of representations turned out to be useful for different purposes and at different points in time (GovLab, 2021). Box 5 illustrates this point in relation to the example by the European Commission’s Joint Research Centre.
Box 5: Moving from representations to explanations: The case of the European Commission’s Joint Research Centre during the Covid-pandemic.
In the analysis stage, it was crucial that the digital trace data obtained through mobile phone data were triangulated with other information to make sense of and explain the resulting representations. For example, considering information about various interventions, such as school closings or public information campaigns, was essential to interpret representations based on digital trace data and decide on further actions (GovLab, 2021; Santamaria et al., 2020). Furthermore, it was recognized that various stakeholders were important in this process. The European Commission, for example, explicitly expected that actions and decisions are based on insights by policymakers as well as scientists (European Commission, 2020). At the same time, post-evaluations of the bespoken initiative by the EU as well as several others (Benjamins et al., 2022; GovLab, 2021) showed that various stakeholders were important for making sense of problem contexts as well as defining appropriate actions; these included public health bodies, government agencies and data scientists. These post-evaluations also found that various capabilities were needed to inform actions on the grounds of mobile phone data, such as the capability to translate insights gained from representations into accessible language, or the capability to form and lead collaborative networks that bring in various data sources and analyze them from different angles (GovLab, 2021).
We suggest that developing situated explanations should involve collaborations with relevant stakeholders as co-equal partners in the research process (Hovorka et al., 2014; Tremblay et al., 2021). Practitioners, such as policymakers, are less concerned about developing theoretical explanations for a given problem (Hirschheim, 2019) but they possess knowledge that lies “in the action” (Bartunek and Rynes, 2014). They are able to point to aspects of a problem that seem important while dealing with it, which, in turn, can help researchers gain a deeper understanding of that problem (McKelvey, 2006) and identify additional data sources. They can also help devising interventions from emerging explanations and they simultaneously allow evaluating the effectiveness of the explanations and treatments (Oliver et al., 2020; Schwartz, 2014). This translational process is common in the professions such as law or medicine but it has so far been neglected in information systems (Schwartz, 2014). But when researchers and other stakeholders work on a problem together, they can address, clarify and advance solution strategies on an on-going basis, as they are accounting for their mutual perspectives (Bartunek and Rynes, 2014). Immersing into practical contexts helps researchers to adequately understand ongoing dynamics and see what is not immediately obvious (Rosen, 1991). Taken together, this leads us to our final principle:
Situated explanations should be developed through co-equal partnerships with relevant stakeholders.
Implications
At the core of our article is a proposal for developing situated explanations that provide an in-depth understanding about a problem context and help identifying appropriate responses to the problem. This main idea has several implications for IS research.
One key implication of our proposal for developing situated explanations is that these may provide a new pathway to solve real-world problems. Recent calls in IS––in the context of the COVID-19 pandemic (Agerfalk et al., 2020; Recker, 2021) and beyond (Hirschheim, 2019; Ram and Goes, 2021)––have emphasized that we as a field are in a prime position to engage in practical problem solving because we have deep knowledge about digital technologies, social interactions, as well as computational data analysis (Burton-Jones et al., 2021b; Díaz Andrade et al., 2019). Our field has indeed launched several attempts to provide impactful solutions, for example, through design-oriented research (Hevner et al., 2004), research on sustainability and resilience (Boh et al., 2023; Watson et al., 2010), or in debates about solving grand challenges (Becker et al., 2015; Ketter et al., 2020). Our proposal now provides further impetus to these initiatives by focusing on methodological questions that will allow us to develop situated explanations that in turn allow for the development of impactful solutions.
The quest for situated explanations does not obfuscate the need to continue developing generalizable explanations. In fact, building situated explanations and developing generalizable explanations can positively reinforce each other. Just as much as theory could be used for the development of practical solutions during the Covid pandemic (Van Bavel et al., 2020), theoretical contributions may inform the generation of situated explanations. Similarly, situated explanations––or elements of them, such as representations based on digital trace data––may inform the development of theory (Grisold et al., 2023; Munger et al., 2021). The key point we make is that situated explanations in their own right also represent legitimate means and ends of knowledge accumulation that help our discipline progress.
A second key implication flows from the observation that our proposal is strongly tied to the possibility that situated explanations can be developed, applied, and disseminated at speed. A given solution might be impactful at one point in time, but it may easily lose its relevance at a later point in time (Oliver et al., 2020). Hence, the quest for situated explanations must be tied to speed and our ability to share findings promptly. If we assess the contribution of a situated explanation according to its theoretical contribution to the larger body of knowledge (Farhoomand, 1987), for example, the time in which it can be published may be prolonged until authors and reviewers agree on positioning and framing of the findings.
To enable the development of situated explanations, the field can also recognize as knowledge contributions worth publishing elements other than theories, such as digital trace datasets, computational methods, or patterns. In relation to this, IS scholarship has started to implement some elements from the open science culture and increasingly recognizes transparency, openness, and reproducibility as vital values of scientific endeavor (e.g., Burton-Jones et al., 2021a).
Such moves, however, go hand in hand with institutional changes that pertain to the publication process and incentivization of innovative forms of knowledge contributions. A wider range of possible knowledge productions will necessitate a shift in how we might review and publish contributions, by decoupling at least partially the publication and review processes of scientific work (Mertens and Recker, 2020). For example, new problems, methods, and data might be disseminated openly without full double-blind peer review (GovLab, 2021; Grisold et al., 2023; Oliver et al., 2020). Since problem contexts may change dynamically, and solutions might emerge gradually over time and in relation to specific contextual factors (Suchman, 1987), it seems also important to discuss and share what has not worked in terms of addressing a given problem. Hence, specific publication outlets seem useful to share lessons learned and promote collective learning about problem contexts.
The good news is that we are already seeing several developments that point into this direction. For example, the policy section in the Journal of the Association of Information Systems (King and Kraemer, 2019), or the Covid-related section in the European Journal of Information Systems (Agerfalk et al., 2020) represent attempts to promote the development and dissemination of useful solutions to practical problems in speedy yet careful ways. Information & Organization provides a RICK section to “provide a forum that brings together innovative, reflective, and rigorous scholarship while being relevant for practice” (Information and Organization, 2023). Developments in other fields suggest even more possibilities. For example, the mission of the recently introduced Journal of Quantitative Description: Digital Media is to publish studies which focus on producing facts about digital phenomena. This mission is grounded in the idea that the complex dynamics of digital phenomena cannot be forced into generalizable explanations; rather, it seems more important to be able to represent them in adequate ways (Munger et al., 2021).
Furthermore, producing impactful situated explanations starts with the detection of the problems we study (Watts, 2017). To a good share, this is a methodological concern. To address it, we need to seek inspiration from engineering-oriented fields to propel our ability to develop new methodological tools to study and address real-world problems. IS scholars will need to contribute to the development of new computational analysis techniques for digital trace data (Tseng et al., 2020). Moving into this direction will bring the IS field closer to computer science, but not to computer science in terms of system design from where it originated, but to the data mining and pattern-recognition community that has developed a proven record in being able to represent emerging problems and patterns quickly, reliably, and at scale as they occur. This involves that we concern ourselves with the development as well as curation of computational techniques (Grisold et al., 2023), for example, by making sure that their underlying code is up-to-date and reliable (Vigliarolo, 2022).
Finally, our argument implies re-thinking how we educate future scholars of our field. One obstacle in the social sciences to become more impactful has long been that the established training and education programs are not designed for impact (Watts, 2017). Complementary to problem-observing capacities, we need to equip PhD students with solution competencies that guide and help them to address identified problems. We also need to train students to extract, validate, and analyze digital trace data through pattern-recognition approaches (Simsek et al., 2019). Students need to become familiar with approaches from the social sciences as well as computer science (Lazer et al., 2020). This does not only imply that students learn to work with existing algorithms and computational techniques; they should also be able to conceptualize and design their own algorithms and techniques to be able to account for the idiosyncratic features of problem contexts to produce situated explanations and design effective solutions. Finally, since the value of a situated explanation lies in its usefulness to address a given problem (Agerfalk, 2010; Levy et al., 2020), there is no objective criterion to immediately determine when a right or wrong situated explanation has been found. Hence, it is important that aspiring information systems researchers learn to deal with various degrees of uncertainty as they assess and evaluate situated explanations.
Limitations
Our proposal comes with several limitations. First, it is conceptual. We make suggestions for how our field can develop situated explanations to develop practical impact. We have taken a broad view on the bigger steps that are involved in this endeavor, but we did not zoom into the specific aspects that are implied. For example, to suggest how situated representations can foster sensemaking in researchers and relevant stakeholders, we draw from research on big data analytics (Chen et al., 2012) to indicate which features make representations more comprehensible (Merendino et al., 2018; Tay et al., 2018). At the same time, this stream of research points to a number of challenges that need to be considered, such as the cognitive complexity or various cognitive biases that are evoked when interpreting such representations (Merendino et al., 2018; Tay et al., 2018). Future research should evaluate the practical implications of our proposal and recommend, for example, how specific stages in the generation of situated explanations can be facilitated.
Furthermore, our proposal capitalizes on the growing availability of digital trace data (Berente et al., 2019; Miranda et al., 2022). Since these data can be collected from all kinds of sources in private and work-related contexts (e.g., Oliver et al., 2020; Power, 2022; Weinmann et al., 2023) to generate representations of real-world problems in quick and reliable ways, we believe that they will become increasingly important in the digital age (Grisold et al., 2023). But the use of such data has key boundaries that need consideration. First, digital trace data should undergo systematic data quality checks to make sure that extracted data mirrors behavior as logged in the respective system (Alsudais, 2021). Furthermore, digital traces often represent certain, yet imperfect proxies of a given behavior in a specific context. For example, mobile phone data has been found to be flawed in cultures where people assign less value to possessing a mobile phone but share it, for instance, with other family members (Erikson, 2018). In a similar vein, there might be biases in digital trace data that privilege or deprivilege certain (age) groups with different user behaviors with digital technologies (Desouza and Jacob, 2017; Buolamwini and Gebru, 2018). Wrong expectations about mobile phone use can lead to misinterpretations; while the data itself may be of high quality, the implications that one can draw from them may be flawed when based on flawed assumptions. Hence, it is essential to have realistic expectations about what a given digital trace data set can tell or not tell, for that matter. Triangulation and the co-equal inclusion of relevant stakeholder-groups (Principles 4 and 5) are thus an important means to cross-check and validate assumptions about the validity of digital trace data.
Since digital trace data captures activities or events that were performed in the past or are performed in the present, situated explanations are not applicable to problems that are anticipated to occur at distant times in the future. As an example, our proposal is not useful for an organization that is planning to engage with a digital transformation process at some distant point in time, unless it encounters specific problems in the present (Wessel et al., 2020). Our proposal also implies that real-world problems can be represented by means of re-current activities or events that form, maintain or dissolve these problems over time (Feldman and Pentland, 2022). Hence, digital trace data sets need to entail temporal repetitions to reveal processual patterns. Even if a large-scale one-off event takes place (such as an earthquake), our proposal is only applicable to the extent that the problem to be solved involves on-going recurrent activities that can be represented through digital trace data (see, e.g., Nan and Lu, 2014).
Finally, the collection and use of digital trace data is often associated with privacy concerns. The collection and analysis of digital trace data from governmental as well as private company-owned sources might be challenging. The issue here is not only that organizations are generally averse towards sharing digital trace data, but there are legal constraints that pertain, for example, to the protection of privacy (Kaisler et al., 2013; Mergel et al., 2016). While an in-depth discussion of such legal matters goes beyond the scope of the article, researchers should be acquainted with the specific regulations in each context.
Conclusion
Following the growing interest in digital trace data for information systems research, we discuss how such data can be used to generate practical impact. We suggest a way for IS researchers to develop situated explanations––attempts to form an in-depth understanding about a given problem context––by leveraging digital trace data. Situated explanations can provide the basis to develop impactful and timely solutions to these problems in quick and reliable ways. Since, by definition, situated explanations are concerned with the idiosyncratic features and dynamics of a given problem context, we suggest that we as a community should develop methodological means to generate informative situated explanations quickly and reliably. At this, the notion of situated explanations can be seen as a complementary means for knowledge accumulation to generate impact, in addition to the traditionally established quest for theory in the form of generalizable explanations.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research by Jan Mendling was supported by the Einstein Foundation Berlin under grant EPP-2019-524 and by the German Federal Ministry of Education and Research under grant 16DII133. The research was also supported by the European Union through the Erasmus+ program [2019-1-LI01-KA203-000169]: “BPM and Organizational Theory: An Integrated Reference Curriculum Design.” Furthermore, this research was carried out, among others, within the “Process Science” Cluster at the European Research Center for Information Systems as well as the Schöller Senior Fellowship on “Process Science - The Interdisciplinary Study of Continuous Change”; it has also been funded by the Hilti Family Foundation Liechtenstein.