
Abstract
In this paper, I provide a general response to the points made in the commentaries. One of the major questions probed is whether gradient, variable output is diagnostic of gradient mental representations. I argue that this is not necessarily the case, and look to aspects of the learning theory (such as input processing, restructuring, and cue reweighting), as well as the architecture of the phonology/phonetics interface to account for such variation. I argue for a conservative, incremental restructuring process as the basis of the transition theory of Ln developmental paths. I reiterate the nature of the projection problem at various levels of the prosodic hierarchy when it comes to the input underdetermining the cues to abstract, algebraic phonological constituent labels. The question of whether Ln grammars are consistent with the structural properties of natural languages (i.e. constrained by UG) is discussed. I conclude with a presentation of the idea that linguistic representations can be considered wavelike superstates. This has the potential of capturing what has been described as the fuzziness of representations, as well as the benefit of unifying our treatment of mental and physical objects.
Let me begin by thanking the commentators for their thorough, thoughtful, and constructive responses to my article. There is much food for thought, and many deep questions are raised. Given the brevity of my reply, I will not be able to do justice to (I’m sure) most of the points that arise. Nevertheless, let me try to pull some of the threads from the disparate commentaries together. At the risk of belabouring my Shakespearean imagery, the surprising unity and common themes (along with appropriate admonitions) which emerge remind me of Hippolyta’s lines in A Midsummer Night’s Dream, ‘Never did I hear Such gallant chiding . . . I never heard So musical a discord, such sweet thunder.’ So, let the play begin.
Dresher (‘On the poverty of the stimulus in phonology’) focuses on the fundamental incommensurability between the input data and the acquired mental representations, and I thank him for expanding the discussion to include the notion of the projection problem. He further bolsters the arguments I presented in the domain of segmental representations by showing that the same incommensurability exists with respect to metrical representations (in this case the Russian lexical accent system). His graphic presentation of how the projection problem extends to the learnability of Ln is very helpful in succinctly capturing the role of previously-acquired grammars and UG in setting up a new grammar. I will return to Dresher’s commentary later, as well.
Shea (‘What do we know and how do we know it? Epistemic questions and debates’) argues that the input to the phonological system of the learner is rich enough to minimize the need for innate structures (while recognizing the importance of abstract representations) by invoking innate biases to the learning system. For me this is reminiscent of the claim made by Cowper and Hall (2014) that learners do not choose from an innate feature inventory but rather possess an ‘innate principle of contrast’.
Building on exemplar-base models, she suggests that hierarchical behaviour can emerge from systems that are not hierarchical (e.g. statistical learning). She draws on research which shows gradient, variable performance to argue that this implies gradient, variable representations (exemplar clouds). Structural units like syllables ‘emerge through shared phonetic properties of words stored in the mental lexicon.’ Such models require explicit theories of analogy, and the devil here may well be in the statistical co-occurrence details. I will not tackle the exemplar model issue head-on here with the excuse that it really is too large a question to address satisfactorily in such a short response, but I will say that I find the kind of neurobiological evidence presented in, say, Hestvik and Durvasula (2016: 18) that ‘phonological representations are more sparsely represented than phonetic representations’ quite compelling.
Shea draws on Moore-Cantwell et al. (2024) to suggest that stress placement/representation too is probabilistic given that participants’ (a mixture of monolinguals and bilinguals) stress patterns are influenced by the patterns they have recently produced. I think what may be at play here is the influence of both top-down and bottom-up activation patterns. In a production task learners will be influenced by many aspects of their recent production (starting letter, tongue twister properties, etc.). In arguing for symbolic representational abstraction, I am not minimizing the sophistication of the human production machinery. Taking this example of stress, I have seen actors who can improvise convincingly and rapidly in Shakespearean iambic pentameter, yet I would not argue that iambic pentameter is built into the representational system.
I concede that the phonology = syntax equation is perhaps oversimplified in my piece. My intent was to focus the reader on the learnability issues shared across these domains. The phonetic input (whether spoken or signed) most likely gives the learner more cues to what type of phonological representation to set up than it does to what kind of morphosyntactic representation to set up. Archibald (2024a) provides a recent attempt to show how variation in the phonetic input can actually be a reliable cue to setting up phonological markedness representations.
I suggest there are commonalities in the approaches though: a minimal UG; discovering the role of third factors in learning, thus determining the boundaries of modularity (Samuels, 2009); determining the computational properties that lead to accurate versus inaccurate ‘prediction’ in the processing of the speech stream (Monahan et al., 2022). But I would also emphasize that the rich phonetic input does still present a ‘challenge’ (if not a ‘problem’) as we can see by the different behaviour of languages when it comes to representing laryngeal contrasts (implemented by VOT) in terms of features like [voice] or [spread glottis] or perhaps dimensions like Glottal Tension or Glottal Width (see Avery and Idsardi, 2001; Nelson et al., in press). I know that both Shea and I would agree that representations are not mere simplistic encodings of the acoustic environment. Of course, Reiss and Volenec (2022) would argue that phonetics is invisible to phonology; there is still a range of argument in the field.
Recently Du and Durvasula (2024: 8) have argued against what they call the ‘common strawman view of discrete representations’ which views the phonology/phonetics interface as ‘a feed-forward system where the (categorical) form of the output of the phonology . . . wholly determines the phonetic outcome’. Rather they argue for the ‘classic generative phonology’ view that ‘competence (abstract/discrete lexical and phonological knowledge . . .) is only one of the factors affecting performance.’ Thus, in the absence of a comprehensive performance theory, gradient output is not diagnostic of gradient mental representations.
Zsiga (2020; citing Scobbie, 2007) provides three metaphors for the phonology/phonetic interface to characterize the position taken by different models. The interface can be seen as a transducer, a fence, or a beach. I’ve been leaning toward the transducer model when it comes to production and perception, but I think when it comes to acquisition and the learning theory necessary to acquire phonological representations, then the interface functions more as a beach or even a tidal pool. It’s not always easy to tell what is land and what is sea, and sometimes difficult to tell the marine animals from the creatures of the terra firma. Acquiring a phonological representation involves signal processing, assigning a phone to a phonological category after noting the patterning and distribution of said phone, as well as the meaning changes that are connected to the phonetic variation while recognizing that the input signal is often ambiguous (Gwilliams et al., 2018a, 2018b). Ultimately, I agree with Shea that (1) variation is not ‘just’ noise in the signal but rather crucial information, and (2) understanding how abstractions are represented cognitively and neurally is critical for progress to be made in the field. In the words of Monahan (personal communication) we want to level up to biologically-plausible models of speech. In this vein, Gwilliams et al. (2024) show that hierarchical structure is encoded neurally which reinforces the cognitive reality of such abstract representations.
However, whether we assume discrete or gradient representations, psycholinguistics must prepare to tackle the question of how symbols are represented at the neural level. Papers such as Poeppel et al. (2008) and Monahan (2018) outline the incommensurability of the fundamental vocabulary of linguistics and neurology, and psycholinguists are ideally positioned to bridge the gap. We know that representational hierarchies are reflected in neural responses for syntax (Ding et al., 2016) and for phonology (Khalighinejad et al., 2017). We know that underspecified features behave differently than specified features (Lahiri and Reetz, 2010), and that underspecification cannot be seen as a direct encoding of the acoustic signal. We know that contrastive and redundant features behave differently neurally (Scharinger et al., 2016) even though they are equivalent acoustically. We know that phonological representations and processes are structure dependent in that they rely on category labels that are not direct encodings of physical reality (Kabak and Idsardi, 2007). Such results connect phonological research to another important literature in acquisition research. Pienemann et al. (2024) make the point that linguistic systems have intentionality (Brentano, 1874); their representations are ‘about’ something. At stake here is the question of whether the natural world and the mental world are fundamentally different. Can one model explain both celestial mechanics and mental dynamical systems with the same machinery? In short, mental states are ‘about’ something but that something is a mental representation; they do not connect to objects/events in the so-called ‘real world’. In contrast, the consensus is that animal cued representations connect to objects/events in the physical world (Berwick and Chomsky, 2016).
Most of this type of literature addresses the properties of lexical/conceptual representations and their (lack of) connection to the physical world as mental objects. To my mind, the work of, say, Kabak and Idsardi (2007) which shows that phonological well-formedness is determined by abstract constituent labels such as coda as opposed to physical adjacency (a property easily read of the acoustic signal and, hence, connected to the physical world) demonstrates that phonology has intentionality which makes it different than the properties of physical systems. I will return to Kabak and Idsardi (2007) later.
Yazawa and Escudero (‘Combining phonetics and phonology in Ln acquisition using current theoretical models and probabilistic approaches’) begin by providing a valuable commentary on the position taken by the three leading cross-linguistic speech models – the Revised Speech Learning (SLM-r) Model, the Perceptual Assimilation Model (PAM-L2), and the Second Language Linguistic Perception (L2LP) model – on abstract phonological representations by essentially suggesting that I was perhaps (1) too harsh in saying that they rejected phonological representations, and (2) too simplistic in saying that they focused primarily on segmental-level phenomena. These contextualizations are valuable and for the most part my response would be ‘fair enough, point taken’. However, while the SLM-r refers to constructs such as ‘position’ and ‘feature’ I think it is also true that these notions are not really probed in depth. My take on position would be that it tended to be largely operationalized by linear order or segmental adjacency rather than hierarchical structure. Furthermore, such speech models are ill-equipped to tackle suprasegmental and cross-word phonology. As for the PAM-L2 my only comment would be that the tone examples presented focus more on the phonetics of tone (of undeniable interest) rather than on the phonological patterning of tones. As for the L2LP, I thank the authors for their clarification as to the breadth of abstract phonological structures sanctioned in the model. The second major point made by Yazawa and Escudero is outlining the benefits of acquisition models which embrace probabilistic accounts, e.g. Stochastic OT (optimality theory), or Harmonic Grammar (including Serial and Noisy varieties). I certainly agree that these models have a great deal of potential in revealing important aspects of Ln acquisition. There are also promising approaches which meld gradient symbolic representations (Smolensky and Goldrick, 2016) with Harmonic Grammar (Hsu, 2022; Tessier and Jesney, 2021).
Their suggestion is that phonetic approaches to second language (L2) speech have been preferred over traditional phonological accounts because the phonetic approaches tackle variability more successfully. I believe there are several points to be made here. The first is that I would take issue with the claim that adopting non-gradient representations would predict exceptionless, non-variable performance on any task. Any phonological learning theory needs to account for two broad properties (Rice and Avery, 1995): global uniformity and local variation. Understanding the performance mechanisms will deepen our understanding of the whole machine (on a model of articulatory complexity, see, for example, Patience, 2022). Variability in production and perception is a well-documented phenomenon, and one which can also be handled by the phonological learning theory (i.e. not only in the phonetics module) without necessarily forming part of the representational theory. I have explored this in a preliminary fashion (Archibald, 2024a) in work which draws on the Natvig and Salmons (2021) idea that there is greater variation found in the phonetic implementation of unmarked features compared to marked features. Such principled variation is also a property of the input to the learner, and a cue which can be informative to the learner. A developing grammar may be less stable and exhibit more variability than a stable end-state system, but the system does settle down (we’ll save the discussion of complex dynamic systems for another day). The second point I would make is that our theory also needs to be able to account for the fact that listeners sometimes ignore variation (e.g. in categorical perception, or phonological constancy across voices) but sometimes attend to it. I think this point is connected to their third major point, which is to catalogue the importance of the work in cue re-weighting paradigm (Harmon et al., 2019). Progress in this area is what will inform our understanding of input processing, and potentially help us to understand why methods such as High-Variability Phonetic Training (Ylinen et al., 2010) work as a training tool (Hayter and Archibald, 2022).
In conclusion, I would agree with the authors that a theory of phonological acquisition needs to recognize gradient phenomena but the grafting of two cultivars is complicated as witnessed by some of the responses to Pater’s (2019) attempt to meld generative theory with connectionism (e.g. Berent and Marcus, 2019). Our goal is to produce an internally-consistent, comprehensive theory.
Broselow’s commentary also highlights the importance of accounting for variability in Ln grammars. She sets the historical context nicely, and I greatly appreciated the Chomsky quotations. One of the points that Broselow makes is that some observed behaviour does not seem to be consistent with other natural languages. One example given is the first language (L1) Mandarin tendency (noted in Broselow et al., 1988) to insert an epenthetic vowel after voiced obstruents in English monosyllabic forms. This is indeed an interesting pattern and I think that it is consistent with a range of phonetic facts. Patience and Steele (2023) note that voiced obstruents tend to have longer periods of vocal fold vibration during the stop closure. In their empirical data they reported that L1 Mandarin learners of French inserted more epenthetic vowels after voiced obstruents than after voiceless ones. In combination with the Broselow, Chen and Wang data this suggests that there is something natural going on but that it is phonetically motivated. In production tasks such as these the learners are effortfully maintaining the obstruent closure. If the voiced obstruent closure is released then a vowel will result; if the voiceless obstruent closure is released then aspiration may result. Relatedly, Flege (1989) showed that the stop burst is the most salient cue for final stop identification in L1 Mandarin learners of English. If this burst cue is the most salient in the L1 perception than it is not unexpected that the burst cue be preserved in production.
A second data set refers to the well-studied phenomenon of the repair of L2 complex syllable onsets, particularly the behaviour of the s-clusters. Broselow (2015) notes that ‘the repair of complex onsets exhibits considerable variability both across and within L1s’. For example, the position of the epenthetic vowel in [st], [sl], [sm], and [sn] might vary across languages, or within a language we may see different epenthetic placement in different lexical items (compare Wolof [somokiŋ] ‘smoking jacket’ versus [esmok] ‘smoke’. Now, hands down, I’m sure Broselow knows these data better than I do, but I will make a few comments. Regarding the former scenario, one phonological possibility is the structural analysis adopted by Goad (2016) where the /s/ is a coda of an empty-headed syllable. This then opens up the possibility (explored by Enochson, 2014; Archibald et al., 2022) that the syllable preference laws of Murray and Venneman (1983) apply to motivate syllable repair. For example [s.t] is a good contact and very unlikely to be repaired while [s.l] is the least-preferred contact so the most likely to be repaired (and [s.n] is in the middle). Under this approach, different languages could have different thresholds of the point on the preference scale that will be repaired. Regarding the latter scenario of lexical variation within a language, this is, of course, a vast issue but in the domain of loanword phonology we know that many factors can influence the behaviour of individual items including time of borrowing (diachronically) and frequency of usage. My speculation clearly reflects my agreement with Broselow that this is something to be explained but perhaps not by phonological representation alone.
The third data set concerns the phenomenon of illusory vowels in perception. She notes that the Kabak and Idsari (2007) study has been reanalysed by Daland et al. (2019) as showing that it is the sub-phonemic, non-contrastive properties of the consonants rather than their coda status that predicts the occurrence of illusory vowels. Durvasula and Kahng (2015: 385), in an approach inspired by Bayesian models of speech perception, argue, acknowledging the import of both sub-phonemic and phonemic properties, that ‘the phenomenon of perceptual illusions will be modulated not only by surface phonotactics and the acoustics of the speech tokens, but also by the phonological alternations of a language.’ Guzzo and Garcia (2024) introduce a theoretical construct which they call ‘marginal representations’ to account for a situation where a target string is ‘neither adapted to the L1 phonology nor remains faithful to the foreign input’. Such modifications, they note, are mostly driven by perception. Such an approach is consistent with an integrated I-grammar model (López, 2020) of phonology as well. Both of these approaches invoke the processing of the input signal to map onto and construct a new phonological representation. Such a mapping process could well lead to variable learning paths. Gwilliams et al. (2022) show that this mapping is neurologically grounded when they note: the brain continuously encodes the three most recently heard speech sounds in parallel, and maintains this information long past its dissipation from the sensory input . . . these representations are active earlier when phonemes are more predictable, and are sustained longer when lexical identity is uncertain.
Three of these commentaries (Broselow, Yazawa and Escudero, and Shea) address the common theme of defining and delimiting the scope of the phonological grammar, not an easy task. Dresher and van der Hulst (2022) provide a valuable overview of the history of phonology which highlights the complexity of the endeavour. Dresher’s commentary too outlines many of the critical questions for the phonological enterprise to address concerning the nature of representation (e.g. what are the primes?) and computation (e.g. parallel or serial?). Dresher’s illustration of the learnability challenges in the empirical domain of the acquisition of lexical accent in Russian is also a telling example of how the input is impoverished to guide the learner to a complex representational end state that accounts for knowledge of Russian. He furthermore questions the feasibility of an emergentist approach (e.g. Archangeli and Pulleyblank, 2015) to explain the projection of a specific phonological grammar. Such an approach is perhaps the closest phonological analogue we would have to the type of sparse UG advocated by Roberts (2019), but it does not solve the projection problem as currently formulated. One can imagine, in fact, how Roberts’ principles (e.g. postulate as few formal features as possible; maximize available features) augmented by principles of statistical learning and computational efficiency (see Lidz and Gagliardi, 2015; Yang et al., 2017) could be applied to phonological learning as well. This reminds us of the point that such things as principles of input processing and cue reweighting can be conceived of as part of a learning theory in which the learner perceives gradient, analogue environmental input and uses it to create discrete mental representations. Variability in accessing these representations, be it in perception or production, is to be expected.
Recurring points involve the role of perception and production in representation, as well as explaining variability in both production and perception. This is reminiscent of the kind of work exemplified by Colantoni and Steele (2007), which showed that articulation factors need to be taken into account when describing the production of French obstruent+liquid clusters, where the rhotic is often preceded by an epenthetic vowel while the lateral is not. Crucially, this will be the input that learners of French will be exposed to. Thus, if we see these learners treating the clusters differently, it could well be because of an input effect. These are the sorts of phenomena that Broselow labels so aptly as the ‘richness of the stimulus’, a notion I wholeheartedly agree with, though Dresher’s cautionary phrase resonates: ‘a basic incommensurability between an acoustic signal and whatever representation learners assign to it’. It is also worth noting that even such an apparently fundamental notion as contrast is potentially gradient (on the notion of ‘marginal’ contrast, see Hall and Hall, 2016) to which we will return later.
Özçelik’s thorough commentary (‘Second language phonology: the phonetics–phonology divide, its underrepresentation in L2 research, and the richness of phonological representations from segments to prosodic structure’) echoes many key points, and I was delighted to read his take on the complexity issue when he suggests that phonology ‘may even surpass syntax in complexity’. In this vein, though, he notes that the claim that phonology is recursive is not ‘widely accepted’, although I must point out that quite a range of researchers do argue for it (Alderete, 2009; Booij, 1988; Dresher and Lahiri, 1991; Hunyadi, 2010; Kabak and Revithiadou, 2009; van der Hulst, 2010). Özçelik maintains that phonology could be better characterized as iterative, much in line with Idsardi’s (2018) argument that phonology is concatenative rather than recursive. The point here is that recursion may not be a prerequisite for representational complexity. Ultimately, this may be an empirical question that can only be resolved by a more careful examination of Ln grammars. As highlighted in the Pirahã ‘exceptionality’ debate (Everett, 2007; Nevins et al., 2009), within a given grammar recursion may be found for some phrase types (e.g. VP) but not others (e.g. DP) and this could well be true for phonological grammars as well. In addition, the question of what the triggering data are for setting up recursive structures remains somewhat elusive: what input would decide between triggering a concatenated versus a recursive structure? We should also learn from Sauerland’s (2018) methodological innovation of using comprehension tests as a diagnostic for recursive structures in Pirahã as we design future experiments to resolve the question with regards to possible recursion in Ln grammars. Ultimately (as fascinating as it is), whether or not phonology is recursive does not affect the basic argument for the relevance of phonological representation to the understanding and explanation of Ln phonological grammars.
Özçelik also addresses the question of Ln grammars as natural languages that Broselow raised but comes down on the other side of the argument. His work has demonstrated that learners do not sanction what may be plausible hypotheses (e.g. weight-insensitive iambs in L1-English learners of L2-Turkish) motivated by frequent patterns in the surface input and even overt pedagogic instruction if those hypotheses violate the principles of UG. Özçelik’s advocacy of such domain-specific modularity reminds us that impossible grammars are not just impossible physical states but rather illicit representations. These claims are based on such rich theoretical and typological work as Hayes (1995) and McCarthy and Prince (1986), who note this gap of quantity-insensitive iambs in the metrical inventory of the world’s languages. Finally, he takes issue with my suggestion that the focus on Optimality Theory’s computational properties has led to the neglect of modelling multilingual phonology by noting that the field of first-language phonology has not been similarly affected. Without resorting to brute-force counting, my sense is that more of the phonologically-informed learnability studies in OT have more recently relied on artificial grammars than actual child data (pace Tessier, 2015).
Goad’s commentary (‘A role for features in speech perception’) provides two valuable case studies that demonstrate the explanatory value of positing abstract features to account for L2 learner behaviour in speech perception. The first (Martinez et al., 2022) shows how the L2 processing of nasality in the speech stream is affected by the phonological status of a feature (either contrastive or allophonic). The L1 French speakers were able to redeploy their phonemic [nasal] feature in a way that L1 English speakers could not redeploy their allophonic [nasal] feature in discriminating Brazilian Portuguese input. Furthermore, the data from Martinez et al. (2022) show that with longer exposure learners are able to redeploy an L1 feature from one domain in the L1 (in this case consonants) to another domain in the L2 (in this case vowels). Such a pattern is also evidenced in Nelson (2023) who demonstrates that L1 English speakers are able to redeploy their L1 vocalic [RTR] feature to build an L3 consonantal [RTR] representation for uvular consonants.
The second case study (Mah, 2011; Mah et al., 2016) documents the persistent difficulty that L1 French speakers have been documented to have when it comes to acquiring the English phoneme /h/ (see Janda and Auger, 1992; John and Rigoulot, 2023; LaCharité and Prévost, 1999). Goad describes the English/French difference as being captured by English having a [spread glottis] feature contrastively (see also Davis and Cho, 2003) while French has a [voice] feature (Honeybone, 2005). Note that this is precisely the feature that French is lacking. So why is it so difficult to acquire? There is clear evidence that other new contrasts can be acquired in an L2, so why not /h/? Before turning to Goad’s answer, let me digress briefly to present evidence (and a slightly different take) on the ability to acquire new laryngeal contrasts in an additional language. Two studies (Nelson, 2023; Nelson et al., in press) have looked at the L3 acquisition of Mayan ejectives with the Dimensions/Gestures model of Avery and Idsardi (2001). Under this model, English would have a Glottal Width dimension which can be completed with either a [spread] or [constricted] gesture. A language like French (or Spanish) would have a Glottal Tension dimension that can be completed with either a [stiff] or a [slack] gesture. Languages such as Yucatec Mayan or Kaqchikel have laryngeal contrasts which are based on a Laryngeal Height Dimension that can be completed with either a [raised] or a [lowered] gesture. The empirical data show that L1 English and L1 Spanish participants can successfully acquire (based on discrimination data) the L3 ejectives. Nelson et al. (in press) argue that the L1 English speakers transfer their L1 Glottal Width dimension and learn the new completion gesture of [constricted glottis] while the L1 Spanish speakers transfer their L1 Glottal Tension dimension and learn the new completion gesture of [stiff]. Thus, L1 dimensions can be redeployed and Ln gestures can be learned. With this background, let us ask what might explain the difficulty of the L1 French speakers learning the English /h/.
There are, of course, many cases where we see learning of a new element taking time in acquisition; advanced learners with more exposure may be more accurate than beginners with limited exposure. However, what seems to set the francophone learning of /h/ apart is its apparent recalcitrance to acquisition (perhaps an extreme case of Orwell’s Problem (Archibald, 2024b; Chomsky, 1986)). Goad suggests that the learners may lack incentive to restructure; why acquire [spread glottis] in your L2 when your current L1 feature [voice] will be functionally adequate to discriminating the voiced from the voiceless stops? However, there are learners who modify their L2 VOT in English (e.g. Olson, 2019) and the question would remain why they do not extend this [spread glottis] feature to /h/. Other solutions have been proposed. Jackson and Cardoso (2023) argue that it is the variability of the English grapheme to phoneme correspondence that is causing the problem. John and Rigoulot (2023) argue that some dialects of Quebec French have an allophonic [h]/[ʃ] alternation which they take as evidence that there is an active [spread glottis] feature in the language, so the question remains as to why the production is so variable, and why the learning of /h/ is so difficult. They propose that the learners have a diacritic non-linguistic marker which takes the place of /h/. While I am uncomfortable to this sort of admission of non-UG-based content into the developing grammar, I acknowledge the thorny nature of the problem they are trying to solve.
Archibald (2023), in a paper on differential substitution, also discusses the French difficulty with English /h/. Adopting a Contrastive Hierarchy (Dresher, 2009) approach, he argues that the English /h/ invokes a high-ranked [±supralaryngeal] contrast (with /h/ being [–supralaryngeal]); French lacks any item at the [–supralaryngeal] level. If we connect this representational hierarchy with the learning theory of Archibald (2024a), which invokes a conservative and incremental process beginning at the bottom of the phonological tree, then it would follow that acquiring a new high-ranked contrast would take time. When coupled with the subtle acoustics, the variability of the phonetic implementation of /h/ due to coarticulation with the following vowel, and the lack of reliability in the grapheme/phoneme correspondence, this may well be a recipe for lack of learning.
Goad’s commentary demonstrates the utility of featural presence and featural status in accounting for Ln behaviour. She concludes by noting that ‘a feature-based approach does not deny a role for phonetic cues in perception . . . instead, features can skew how L2ers interpret these cues, thereby facilitating or hindering the establishment of new contrasts.’ Indeed these claims could well be tested via techniques of Bayesian data analysis which adopt different phonological representations as priors. Rocca et al. (2025) present a fine overview of non-phonological factors that can influence the ease or difficulty of phonological acquisition.
Broselow’s closing line provides us with a nice opportunity to segue into a discussion of broader architectural concerns: ‘phonology has been increasingly successful in modeling the interaction between mental representations and the way these representations are implemented and processed by language users.’ Indeed, phonologists are not alone in seeking to reconcile the role of grammar, production and perception. Momma and Phillips (2018), in a thorough overview of syntactic processing state: we have advanced the view that a single mechanism for building sentence structure may be sufficient for structure building in comprehension and production, synthesizing previous proposals and challenges on this issue. There are many superficial differences, but these may reflect input differences rather than distinct mechanisms.
They elaborate by saying: Evidence that the distinction between the real-time structure-building system and the grammar is unnecessary comes from two broad domains. First, rapid structure building processes during comprehension are highly grammatically sensitive (Lewis and Phillips 2015; Phillips et al., 2011). Second, standard grammatical analysis may benefit from assuming a structure-building system that proceeds in the same order as comprehension and production processes (Bianchi and Chesi, 2014; Kempson et al., 2001; Phillips, 2003; Shan and Barker, 2006; Steedman, 2000).
Their arguments are both empirical and philosophical. Parsimony suggests that we explore single-mechanism models of grammar/parsing/production before resorting to more complex solutions.
These issues springboard us to even broader philosophical questions relating to the nature of human knowledge and how we come to know what we know (returning to some of Shea’s questions). There is a long-standing discussion in philosophy on the role of the environment in accounting for the content of mental representations often characterized as the debate between empiricism and rationalism (e.g. Piattelli-Palmarini, 1980). Empiricist models would emphasize the role of sensory input in shaping the mental representation, and would also presume a direct link between the mental representation and a real-world entity. This stimulus-bound property is true of animal communication systems as noted by Goodall (1986: 125 cited in Berwick and Chomsky, 2016): ‘the production of a sound in the absence of the appropriate emotional state seems to be an almost impossible task.’
However, Berwick and Chomsky (2016: 85) note that syntax and the lexicon have really cut the connection with sensory input when they say that human language and thought are ‘not automatically keyed to emotional states, and they do not pick out mind-independent objects or events in the external world’. I would argue that this maintains for phonology as well as morphosyntax; phonological categories do not need to directly reflect the external world, but the signal is a source of information for the learning of the phonological representation. A syllable, or foot, or mora are not linked to external objects or events but may be cued by such external, physical events or properties. That being said, our understanding of the role of the environment in the development of biological systems has grown substantially since Piattelli-Palmarini (1980). Just because Lamarck was wrong about the environmental influence on inheritance does not mean that the theory of epigenetics is wrong (Loison, 2021); our understanding of the role of the linguistic environment has also advanced over the years.
Let us move from here to another broader architectural question related to the nature of the mental lexicon (which includes phonological information). As we have seen a standard assumption of cognitive science has been that the mental representation (knowledge) in the mind is well defined and discrete while the implementation/access (process) is gradient. Several of the commentaries here have focused on the idea that both representation and process are better modelled as gradient. I would like to stretch some of these boundaries even further here. Shea (and many others) assume that the lexical item is discrete and well defined while the phonology is gradient, but Libben’s (2022) work pushes the boundaries even further to suggest that the lexical item itself is not well defined. He introduces the notion of ‘superstate’ into linguistic nomenclature. The term comes from quantum physics, in which a quantum system or particle behaves as if it is in multiple states or positions at the same time until it is measured. This has also been referred to as wave/particle duality; the wave states have potential, and then their potential is realized resulting in particle-like behaviour. Libben connects this to linguistics by presenting examples from novel compounds like clampeel, feedraft and wardrug. Empirical tests reveal that all of the possible roots are activated in the processing of such forms which in the first example would be: clam, clamp, peel, and eel. Libben conceives of these potential representations as superstates which are only made concrete when they are activated, or measured, or processed. Graphically, he shows this as in Figure 1.
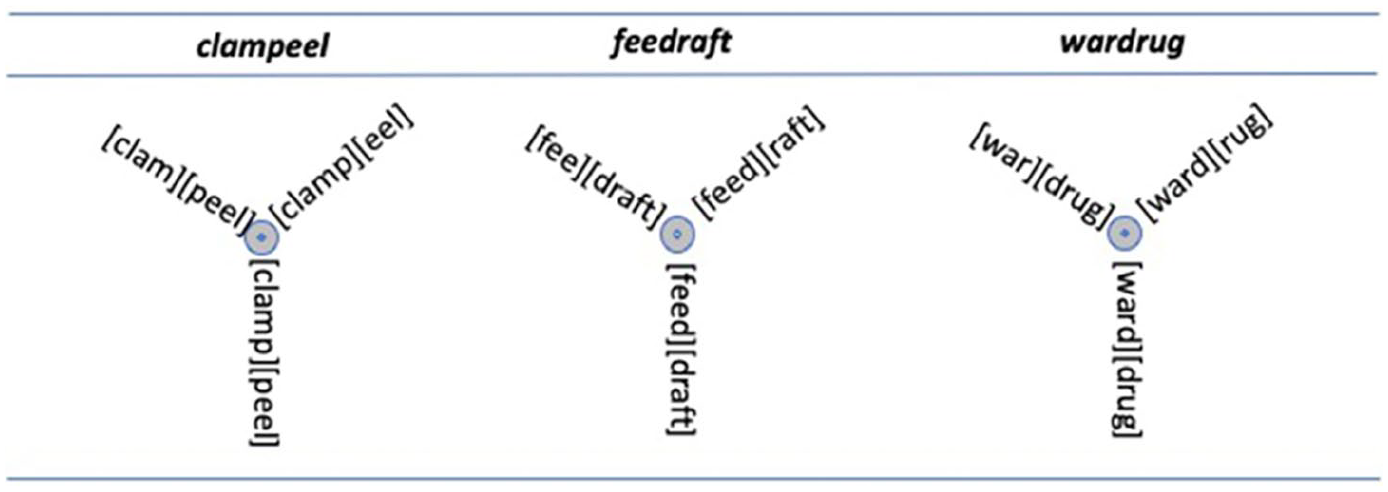
The superstates of novel compounds.
If we pursue this approach, then phonology (i.e. algebraic variables) is about potential (for more details, see Archibald and Libben, 2025). The actual implementation of the phonological wave, however, is not deterministic. In this way, a quantum world is not a strictly reductionist world (in which we can predict the final state by looking at the behaviour of the parts) insofar as the quantum world produces a probability distribution. This is similar to Bayesian approaches in which effects are viewed as probability distributions instead of fixed point estimates. Phonology in this light could view variables as probability distributions over inputs; superstates can be modelled by a wave equation. Such a world view would seem to be consistent with the nomenclature of fuzzy representations as well (see Darcy et al., 2024); Libben’s superstates capture the ‘fuzziness’ of what Darcy et al. would call a phonolexical representation. One might imagine that the notion of fuzziness is intended to capture the best of both a categorical and gradient representations. To me, the visual metaphor of fuzziness has never seemed quite right as it suggests faulty eyesight in which there is a real, well-defined object to be perceived, and that those who need glasses cannot perceive it accurately and thus the object appears fuzzy because the optical image is itself fuzzy. For the language learner, though, the mental representation may well be categorical yet non-target-like. Perhaps it would be more appropriate to talk of the functionality of the representation with respect to (in the case of phonemes) contrast. The representation in the developing grammar might not generate the same set of contrastive representations as the representation in a monolingual grammar. This is reminiscent of what Hall and Hall (2016) discuss when they invoke the information-theoretic notion of entropy. Entropy is used to quantify the unpredictability of a distribution. A traditional assumption would be that phonemes are unpredictable while allophones are predictable. They suggest that predictability is, in fact, on a continuum from perfect allophony to perfect contrast as shown in Figure 2 (where each triangle represents an individual phone). Given this type of model, the ‘fuzziness’ of non-native representations is captured by the entropy of a given phone.
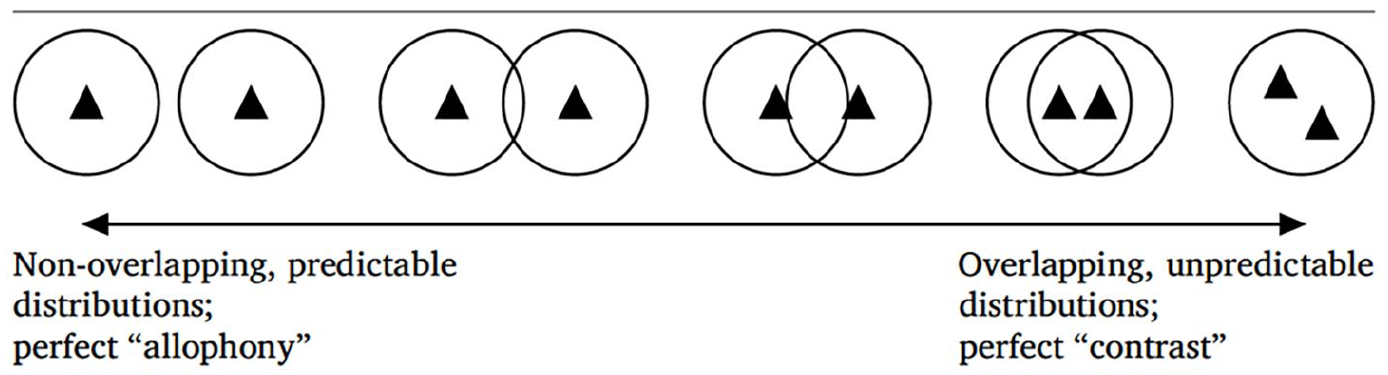
A continuous set of phonological relationships.
Thus, to return to my earlier quantum metaphor, a non-target-like representation may have different entropy than a target-like representation. So, the activation of a phonological superstate may not lead to a single, pre-determined mechanistic single-point outcome. Such a model also captures the phenomenon of what Broersma and Cutler (2007) refer to as phantom competitors (see also Archibald, 2019). Imagine the case of an L1-Japanese speaker (who lacks a phonemic liquid contrast). When listening to a word like rake in the process of word recognition potential candidates would include both [r]-initial words and [l]-initial words; the non-target-like representation generates a different competitor set for activation than the nativelike competitor set.
The predictions may be uncertain and the future may be ‘jittery’ in the words of Mitchell (2023). We may not know which phonetic particles emerge from a given phonological wave until we produce or comprehend it. All of this suggests that an underlying mental representation encodes potential which is collapsed into a single state in action, turning traditional linguistic models upside down, while simultaneously unifying the treatment of physical and mental objects (see Chomsky, 2015). Only time will tell if our musings will bear any valuable fruit.
Conclusions
In their own small corner of the globe, those who pursue the nature of phonological knowledge as well as its implementation in the multilingual mind and brain are tackling fundamental questions of humanity. As in any discipline, there is disagreement (sweet thunder) which accompanies and guides us down the path of progress. So, as we strive to probe such notions as gradience, discreteness, predictability, variability, contrast, etc., and as I reflect upon the knowledge and experience reflected in these insightful Commentaries, I cannot think of a better troupe of players to have been part of as we all, in the words of Macbeth, strut and fret our hour upon the stage.
Footnotes
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Research on the project was supported by SSHRC grant 435-2022-1097.