
Abstract
Grammar competition has been proposed as a model for second language (L2) acquisition. Variational Learning provides a framework within which to investigate the idea of grammar competition as the model requires a marriage of quantitative properties of the input with Universal Grammar. A diachronic variational model of grammar competition is extended to second language acquisition (L2A) to explore verb-second word order optionality in L2 English. Patterns of L1-German–L2-English word order acquisition are reviewed in light of a study of classroom discourse as input to first language (L1) German speakers. A variational model of word order patterns in the input identifies differences in patterns of word order optionality, which may contribute to the trajectory of acquisition identified for L2 English.
I Introduction
Frequency effects in input are vital ingredients in second language acquisition (SLA). But they are not easy to reconcile with formal generative models. Variational Learning (VL; Yang, 2002) requires a marriage of quantitative properties of the input with Universal Grammar to investigate diachronic change and first language (L1) acquisition. Adapting this model provides a worthwhile avenue to explore potential effects of input properties on the development of second language (L2) syntax. Slabakova (2008: 116) has noted that VL is logically extendable to SLA. However, the missing empirical ingredient is quantification of the input properties available to second language learners. This proves a more difficult issue in L2 research compared to the L1 or diachronic change settings to which variational learning has thus far been applied. In this paper, an application to second language acquisition (L2A) is explored as a first step to fostering further consideration of potential input effects in a formal model of development. Along the way, empirical issues specific to L2 settings are highlighted to promote further research in this area.
Corpora of child-directed speech and large-scale general corpora can be interrogated for input frequencies to children. Such methods are not readily applicable in SLA given the more variable sociolinguistic experiences of L2 learners. Classroom talk in foreign language instruction provides one avenue to explore in a variational framework applied to L2A. Classroom discourse represents a significant proportion, sometimes likely the totality, of L2 contact for learners acquiring a foreign language in formal education. Furthermore, much research in generative SLA has been conducted with instructed learners. However, we do not yet have a detailed characterization of the linguistic features of this sociolinguistic setting. As such, making assumptions about the trajectory of acquisition in response to ‘target language input’ is potentially uninformative if the target language as represented in a classroom setting differs substantially from what might be expected in analyses of the target language as it occurs in native-speaking speech communities.
It is well-known that speakers will automatically adapt and simplify their speech to aid communication with interlocutors who are non-native speakers (see Ferguson, 1975, and much subsequent work on ‘foreigner talk’) and that this might impact on learning outcomes. It is to be expected therefore that input to learners is quantitatively and qualitatively distinct from the target language as represented in native speech communities. While this has been studied more extensively in interactionist and educationally oriented approaches to L2 development (e.g. Cullen and Kuo, 2007; Tarone, 1980), VL provides one way of incorporating such insights into a formal model of grammatical development. This is not to say that all properties of L2 development are reducible to input effects. There are of course crucial poverty of the stimulus issues (see Schwartz and Sprouse, 2013). Learners will also creatively project grammatical properties onto the input that they are exposed to. So this should not be mistaken for an assumption of any simplified correlations, either between input and linguistic knowledge, or between input and learner output. But the point remains nevertheless that for linguistic properties 1 which rely on any notion of triggering or input cues, a more precise characterization of the nature of the input is invaluable in order to potentially explain acquisition trajectories, or at the very least to be able to discount input effects as a possible explanation.
In what follows, we pursue this approach by exploring properties of L2 English classroom talk as input to L1 German-speaking learners in light of previous findings on the loss of verb second (V2) during L2 development. The logic is as follows. The trajectory of L2 development in the acquisition of verb placement by instructed L1-German–L2-English learners is reviewed. Properties of the input in classroom discourse are quantified to investigate whether the observed patterns of L1 transfer are amenable to analysis in a variational learning model. The aim is principally methodological as a proof of concept for the use of a variational grammar-competition approach to L2 development. Given the paucity of appropriate input datasets and resulting limitations with the current study, this can only be a heuristic approach with the aims of highlighting the potential of input quantification and sharpening discussion of the role of specific input effects in syntactic development.
II Verb second in L2 English as grammar competition?
For ease of exposition, only the basic distribution of V2/V3 is presented without technical assumptions. 2 V2 involves verb movement to the complementizer phrase (CP) in matrix clauses. This results in word order differences between V2 and non-V2 languages after topicalization or adverbial-fronting, illustrated with German data in (1). 3
(1) a. Ich schrieb gestern ein Gedicht. I wrote yesterday a poem. ‘I wrote a poem yesterday’ b. Gestern schrieb ich ein Gedicht. Yesterday wrote I a poem c. Ein Gedicht schrieb ich gestern. A poem wrote I yesterday
Although English does not permit verb movement, it does have residual V2. Interrogative CPs require the presence of finiteness in C, satisfied by movement of aspectual/modal auxiliaries, copula be, or do-support (see translation equivalents 2-3).
(2) a. When b. Wann (3) a. Where b. Wo
Copula be has a stronger V2 distribution in English, similar to lexical verbs in V2 languages, illustrated in grammaticality patterns in (4-5).
(4) a. Under the bed is a monster. b. *Under the bed a monster is. (5) a. Unter dem Bett ist ein Monster. b. *Unter dem Bett ein Monster ist.
These comparisons generate a range of complementary patterns of grammaticality, but also identical surface word orders between V2 and non-V2 languages. Frequently occurring declarative SVO and copula clauses are ambiguous with respect to the underlying parameter as the surface string is compatible with a number of parameter settings. This input variability has been assumed to complicate acquisition and processes of historical change in models which assume dedicated cues or triggers for grammar restructuring (e.g. Westergaard, 2008).
An alternative, or at least complementary, approach to variability in input and development is to take mutually exclusive expressions of underlying grammatical properties at face value and assume that speakers internalize more than one grammatical representation to analyse input. In addition to VL, such grammar competition has been proposed in various guises to account for historical change (Kroch, 2001), dialect and register variability (Roeper, 1999) and creolization (Aboh, 2015). An explicit connection to L2 development is proposed by Zobl and Liceras (2005, 2006), who compare V2/V3 word order variation during diachronic change and during L2A, and conclude that grammar competition is a preferable model to account for L2 variability compared to suggestions that access to UG is impaired. Now, whether grammar competition really explains L2 variability is open to question. It certainly provides a framework within which to describe development of L2 grammatical variability by analogy with diachronic change. However, in the absence of consideration of input properties, any appeal to grammar competition amounts to a restatement of the fact that grammatical optionality is characteristic of L2 learning, as opposed to explaining that optionality.
In order to provide steps towards an explanation, one would want to establish whether the optionality evident in L2 performance correlates with the rate at which such optionality occurs in the input (see below). Ideally, the goal would be to predict L2 acquisition outcomes based on statistical properties interacting with UG. This will have to wait for future research. For the time being, the paucity of available L2 input data forces us to adopt a post-hoc view. Here, we re-review the data from Sorace and Robertson (1999) discussed by Zobl and Liceras and seek to explore the acquisition trajectory in instructed L2 English learning by L1 German-speakers in light of the sort of input to which this learner population may be exposed. The learner population studied by Robertson and Sorace mirrors that represented in the input corpus presented below.
Robertson and Sorace (1999) demonstrate the de facto existence of grammar competition, albeit without drawing on a competition model. Learners in English foreign language classes at school and university (represented by G and U, respectively, in Table 1) in Germany were tested using magnitude estimation of sentence preferences. Learners at the lowest level (G8) had approximately three years of instruction. The most advanced learners were in the fourth year of degree programmes in English. Table 1 summarizes results from magnitude estimation for the learners’ acceptance of non-target verb second (*V2) as compared to the target English V3 order, hence *V2>V3 refers to the numbers of learners at each level who maintain a preference for the non-target word order pattern.
Preferences for V2 compared to V3 by L1-German–L2-English Learners (percentages in parentheses).
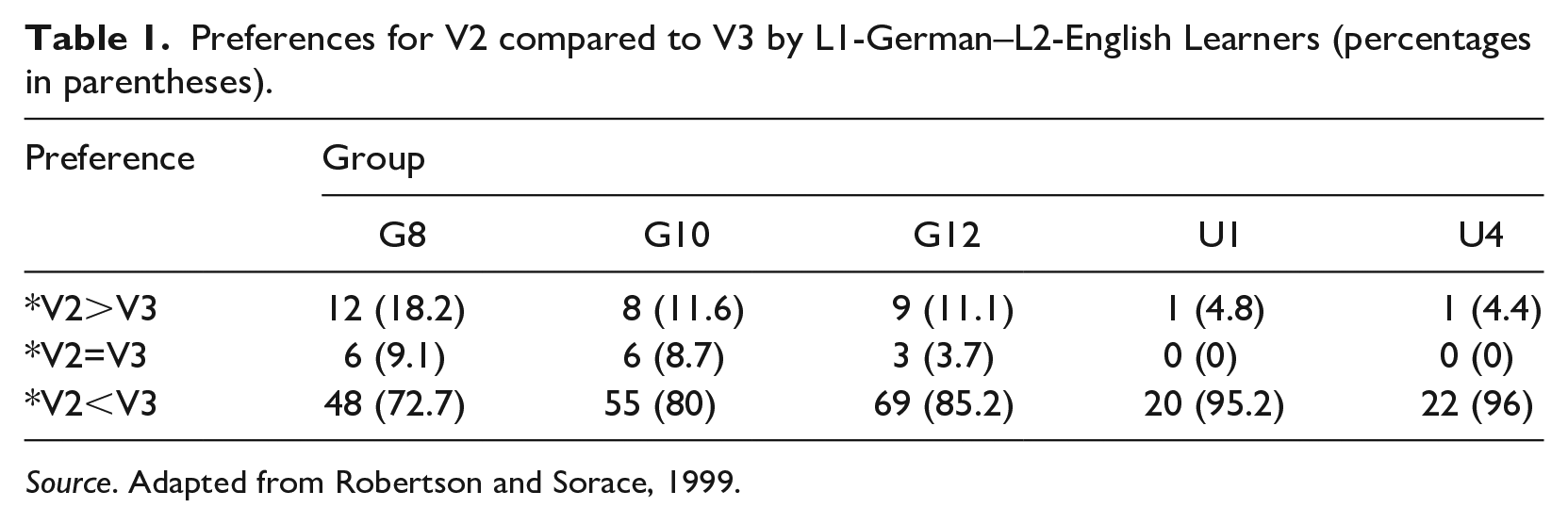
Source. Adapted from Robertson and Sorace, 1999.
Consistent judgements are the exception. Cross-linguistic influence is evidenced by optionality of V2 and V3 orders and a minority of learners maintain a preference for ungrammatical V2 (c. 18% at the lowest proficiency level, 5% at the highest). As a result, Robertson and Sorace (1999: 335) suggest that ‘any account of the data which is based on the assumption that individual grammars are either consistently V2 or not V2 cannot be sustained’. In other words, there is grammar competition at the level of the individual learners. Robertson and Sorace analyse V2 as the result of a functional feature in the lexicon, which is copied into the L2 English lexicon. Like other lexical items, it is subject to attrition such that it is less likely to be included in derivations as proficiency increases, resulting in weakening cross-linguistic influence. In this way, the variability is confined to acquisition of a particular feature, rather than invoking grammar competition in the sense discussed by Zobl and Liceras, and similar approaches. However, this presents conceptual difficulties: a feature-based analysis standardly has binary settings (strong vs. weak, interpretable vs. uninterpretable). What it means for a feature to weaken in the way suggested by Robertson and Sorace is unclear. The spirit of the suggestion is, of course, readily translatable into a variational competition model, in which strengthening/weakening of representations are core concepts. That is, the lack of consistency within one grammar is viewed as competition between two distinct grammars.
In order to facilitate exploration of competition effects, some discussion of the linguistic details of cross-linguistic influence is in order. Robertson and Sorace did not specifically test for effects of verb-type. Having identified in production evidence that learners exclusively produced ungrammatical V2 patterns with non-thematic verbs, only auxiliaries and copula inversion were tested in the magnitude estimation task. Based on this observation, and other work, it seems reasonable to assume that there is a general auxiliary-lexical distinction in the acquisition of verb placement. Learners whose L1 has a V2 constraint produce and/or accept non-target V2 patterns in L2 English more often and more persistently with non-lexical verbs (Rankin, 2012; Westergaard, 2003). Robertson and Sorace did test for effects of type of preposed constituent and found that non-target V2 was more likely to be accepted with preposed adverbials compared to topicalized arguments. 4
Based on a corpus of classroom input to a similar learner population as studied by Robertson and Sorace, the aim is to explore whether these patterns would be licensed on the basis of calculations of the relative strength of V2 in different contexts (adapting Yang’s 2000 application of such an approach to historical change in English). Before introducing the study, we outline next how a variational competition approach can be reconciled with existing assumptions about L1 influence and UG access.
III Full Transfer and grammar competition: Exploring transfer in L2A
VL sees optionality during language development as changes in the relative strengths of competing grammars, provided by the algorithm in (6) (Yang, 2002).
(6) Upon the presentation of an input datum s, the child a. selects a grammar Gi with probability Pi b. analyses s with Gi c. if successful, reward Gi by increasing Pi, otherwise punish Gi by decreasing Pi
Variability is modelled as probabilistic strengthening of the grammar that allows the most robust analysis of the input. Slabakova (2008: 115–117) states that this is logically extendable to L2 acquisition but observes that there is much more variation to explain in L2 learning compared to primary language acquisition by children. A crucial question posed by Slabakova is: What is the status of the native parameter setting, is it just one among many, or does it have some privileged status among values? Even though Slabakova does not explicitly provide an answer to the question at that point, a Full Transfer perspective seems to be what she has in mind. And it would be reasonable to assume that the native parameter value does indeed have a privileged status among all possible values. This is justified on conceptual grounds by invoking Full Transfer / Full Access (FT/FA, Schwartz and Sprouse, 1996), which models the initial state of L2 acquisition as involving a copy of the L1 grammar, which is then to be restructured on the basis of input parsing. Empirical support comes from Grüter (2006) and Grüter and Conradie (2006), who show that initial-state learners’ comprehension of wh-questions indicates that the learners have used the full L1 representation to license parses of the input clauses.
We thus arrive at a variational take on FT/FA. However, with respect to the ‘access’ part of the framework, Slabakova points out that questions about ‘access to Universal Grammar’ are in some sense moot under a VL perspective. Rather than assuming that UG needs to be accessed, it can be assumed that all UG-sanctioned properties remain available in principle. Rather than a fundamental question of being able to access new properties, it is proposed that all non-L1 properties begin with a probability of 0 at the initial state of L2 acquisition, while L1 parameters begin with a probability of 1. In the case of speakers of a V2-language acquiring English, the learner grammar will initially have p = 1 for V2. But other V-movement constellations remain available. ‘[T]he new, and testable, idea is that the rise of the target value from probability 0 to 1, and even conceivably fossilizing at 0.8, is going to be correlated with the percentage of sentences in the input than unambiguously reward the target parameter value and punish all others’ (Slabakova, 2008: 117) in line with the algorithm in (6).
One additional factor needs to be accounted for in applying this thinking to L2A. By definition, we are dealing with a two-grammar system rather than just the rise of a single grammar. A diachronic variational model allows exploration of the dynamics of a two-grammar system. Yang (2000) proposes that, after some linguistic innovation due to historical or socio-cultural developments, a speech community is modelled as a mixture of expressions generated by two distinct grammars G1 and G2, yielding the linguistic environment EG1,G2. A proportion of utterances generated by these grammars will be uniquely compatible with one of them and incompatible with the other, these proportions represented by α and β. The frequencies of these unique signatures in the input are used to calculate the relative strength of each grammar. 5
Let’s translate this into L2: The commencement of L2 learning represents the socio-cultural innovation leading to the introduction of new grammatical properties to the L2 learner. At the initial state, the learner accesses the L1 properties to parse L2 input. The L2 environment is of course made up of target language input (EG2). However, the fact that a number of these input strings can be parsed by the L1 grammar means that the L2 environment is de facto a mix of L1 and L2 properties, from the point of view of the L2 parser.
Returning to Slabakova’s suggestion of testing the correlation between the rise of the target value and the input distributions, the relative frequencies of input strings which are uniquely compatible with G2 and consistently punish G1 predict how quickly the target value will rise, or conversely, how persistent L1 transfer will be. By calculating these values in L2 English input to L1 German-speakers, the aim is to explore in how far patterns of V2 transfer identified by Robertson and Sorace (1999) can be modelled by the approach outlined above. We thus aim to explore whether the L2 English input (i) would lead to a thematic/auxiliary distinction, and (ii) an adverbial/topicalization distinction with respect to non-target V2.
Having outlined these aims, a couple of caveats are necessary. First, exploring Slabakova’s proposal by adapting a two-grammar diachronic model is a simplification in order to facilitate analysis. The assumption is that after the initial state, L1 and L2 values are in competition. However, L2 learners can of course creatively project a range of grammatical representations, depending on how parameters/features might interact and be licensed by input patterns. With respect to V2, Hulk (1991) finds that L1-Dutch–L2-French learners show judgement patterns that might betray underlying grammatical properties which are neither Dutch-like nor French-like. Similarly, Westergaard et al. (2019) propose that L2 data supports an asymmetric analysis of V2 such that learners will more quickly lose verb movement to C, but may continue to allow movement to a lower projection. It is, however, noteworthy that this is justified as follows: ‘For a number of reasons related to the frequency and salience of the relevant input cue, the unlearning of V-to-I will be harder and take longer’ (Westergaard et al., 2019: 721). This could be amenable to exploration on the basis of a variational analysis of input frequencies. But it also hinges crucially on the status of a cue such as do-support (see more discussion below).
A second caveat relates to the wider empirical picture of input. As already noted, we do not currently have a clear empirical characterization of the nature of learner-directed input. While it can be expected that target language input in a foreign language learning context will differ qualitatively and quantitatively from input in a native-speaking speech community, exploring such classroom talk clearly only fills in part of the picture. Though surely an extremely important part. More work would be necessary to add further data from additional input sources. The current approach therefore follows in the vein of studies of classroom discourse seeking to correlate L2 grammatical difficulty with the distribution and form of grammatical properties in classroom talk (e.g. Collins et al., 2009). Additionally, we might also investigate patterns in media production from the target language speech community to ascertain whether certain properties are likely to be available to learners from general input (Shimanskaya, 2016). Accounting for the full range of variation would require combining all of these approaches, something which must wait for future more extensive research projects. We might also mention that such complications can be avoided in lab-based studies of acquisition of artificial grammar, although these suffer issues of ecological validity (see, for example, Erickson and Thiessen, 2015). The method adopted below must therefore be seen as a proof-of-concept on the basis of the available data, with the caveat that this is just part of the L2 input puzzle, and should be complemented in the future by more of the sort of work just mentioned.
IV Input corpus: Materials and method
The Flensburg English Classroom Corpus (FLECC, Jäkel, 2010) contains transcriptions of 39 English foreign language lessons in German schools, sampled from 3rd (c. 8-year-olds) to 10th (c. 16-year-olds) year of instruction, corresponding roughly to the school-age learner population tested by Robertson and Sorace. The corpus was part-of-speech tagged and concordance searches extracted finite verb forms. Only positive declarative matrix clauses involving at minimum a subject and a verb were included in the database of input clauses, yielding a total of 1,654 clauses.
Questions and negation were excluded, for two reasons. First, Robertson and Sorace only studied (non-)inversion in declaratives as V2 properties and we follow that lead to maximize comparability by investigating how this V2 signature is manifested in input. Similarly, Yang (2000) only considers inversion patterns in declaratives in his study of V2 in diachrony. Second, how to analyse do-support and other possible variations of questions and negative declaratives poses problems, as highlighted above by the mention of cues for asymmetric V2. Do-support can be viewed as a cue for a lack of any verb movement, and from that perspective presumably consistently punishes any verb-raising value. However, Subj-do-neg-V is compatible with a V-to-C parse if the parser treats do as just another auxiliary (as discussed in White, 2003: 163 with respect to do-support as an input cue for L1-French–L2-English learners). Indeed, there is production evidence showing that L1 German speakers innovate ungrammatical V2 structures using do-support in L2 English, exemplified in (7-8).
(7) Everywhere do human beings perform plays . . . (Robertson and Sorace, 1999: 317) (8) Nowadays do not only students cry out loud . . . (Rankin, 2012: 151)
Excluding questions with residual V2 and negation with do-support avoids these theoretical complications. 6 Future research should of course seek to consider the import of the frequent occurrence of do-support in combination with a clarification of the its theoretical status with respect to verb-movement parameters, as well as in L2 parsing/processing. For present purposes, this would require conceptual and theoretical discussion beyond the limited aims of the paper.
The 1,654 input sentences were sorted and coded for the range of properties in (i)–(iii) below to facilitate analysis. These are generally self-explanatory. Compatibility with V2 refers simply to linear order of the clauses: where a finite verb immediately follows an initial non-subject XP, this was coded as +V2 (in cases of stylistic inversion or ungrammatical learner production, see (9–10)), initial non-subject XPs followed by a subject were coded as −V2 (as in 11).
(9) Here comes the Easter Bunny. [teacher production] (10) And then must you turn right into Blake street. [learner production] (11) In ten minutes we will have the presentation. [teacher production]
Subject-initial S-V-XP or S-Aux-V-XP clauses were coded as ambiguous, as they are formally compatible with either grammar.
i. compatibility with V2 [+V2, −V2, Ambiguous] ii. finite verb-type [lexical, copula, aspectual auxiliary, modal auxiliary] iii. clause-initial element [adverbial, argument]
The proportions of these different patterns in the input was calculated for the input corpus as a whole. The corpus sampled input at fairly wide intervals (with instances of individual lessons at different grade-levels). As already mentioned, details of variation over time will require new datasets.
V Results
Table 2 presents overall results for proportions of input clauses compatible with syntactic representations.
Compatibility of input clauses with syntactic patterns.

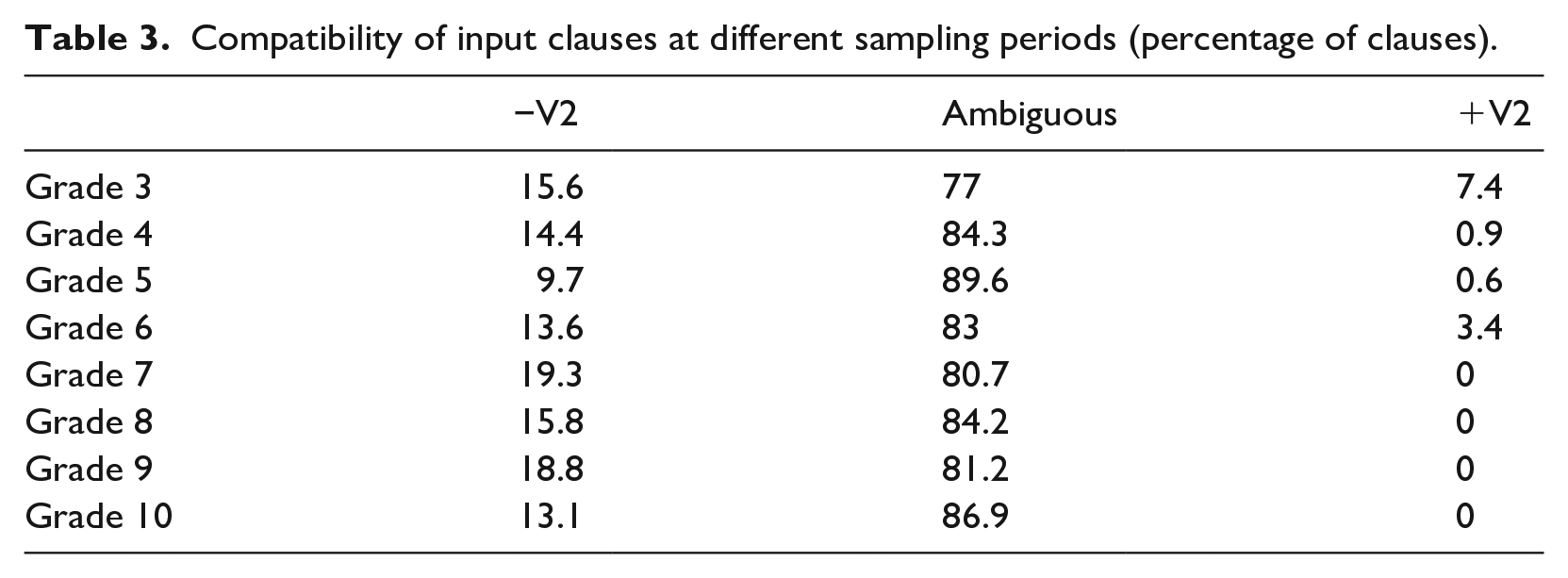
13% of declarative clauses in the input are uniquely compatible with a non-V2 grammar; that is, parsing these requires learners to access a different grammatical property from the verb-raising value. Only 2% are uniquely compatible with a +V2 grammar. Applying Yang’s (2000) proposal that G2 overtakes G1 if β > α, we see that −V2 enjoys a marked advantage and so the loss of V2 and the rise of the target value in L2 English is predicted, because 13.4 > 2. However, we noted previously that the learner at the initial state will preferentially access the L1 grammar to parse any compatible input string. The overwhelming majority of input clauses is ambiguous with respect to the underlying grammar. Coupled with an initial preference for L1 parses, this can be expected to slow the strengthening of the target L2 representation. An additional issue with respect to consistency of input emerges from the data. Yang (2000: 239) suggests that values for grammar strengths in speech communities are presumably constants which characterize the distributions produced by the respective grammars. Unsurprisingly perhaps, the input properties may differ markedly at different points of time in the instructed input (see Table 3). Of course, this reflects input sampled from classes at random intervals. It would be necessary to conduct more work on instructed input in combination with target language exposure outside of education in order to determine whether such variation is flattened out in more fine-grained data. The empirical point for a consideration of VL in SLA is that input to learners, especially in instructed settings is quantitatively and qualitatively more variable than general TL input.
Compatibility of input clauses at different sampling periods (percentage of clauses).
Recall that we want to establish whether competition between V2 and V3 is conditioned by verb-type and by type of fronted constituent in line with the L2 findings (and diachronic work by Yang, 2000). Table 4 breaks down the overall corpus results by verb type. The relative advantage of the target grammar for input parsing is calculated simply by subtracting the proportion of unique +V2 signatures from unique −V2 signatures.
Compatibility of input clauses with syntactic patterns by type of finite verb.
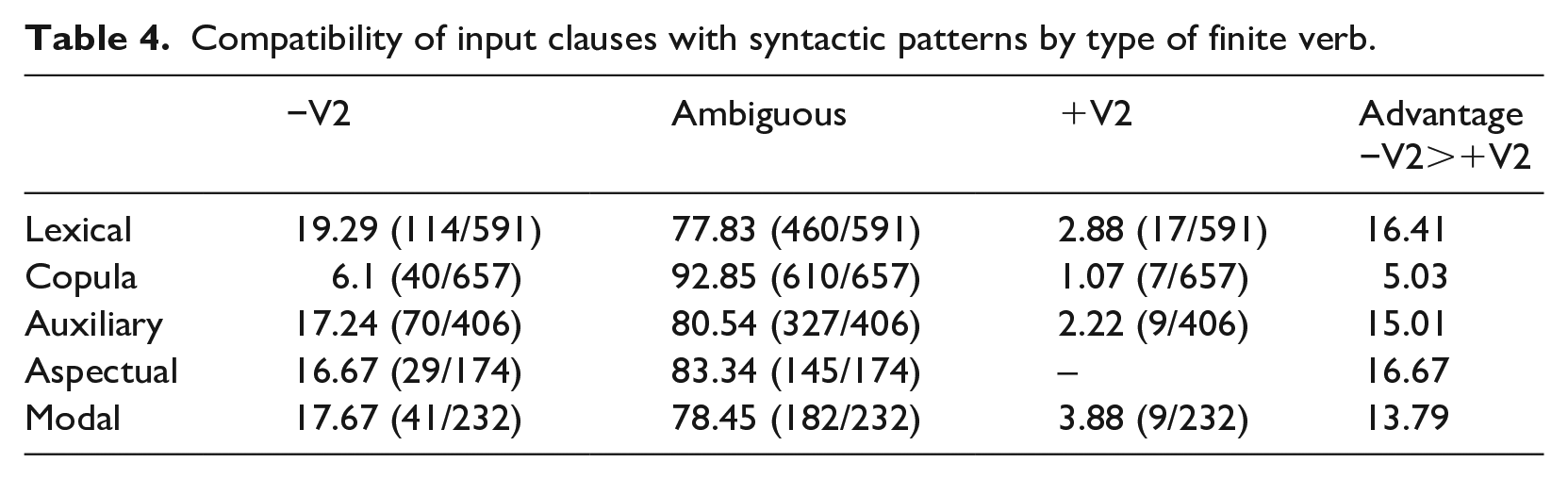
Lexical verb placement most consistently punishes V2 grammar. Auxiliary verbs are marginally more frequently amenable to a V2 representation. We would therefore conclude on the basis of the proposed correlation between the frequency for parameter signatures in input and the speed of parameter setting that learners would be less quick to establish target patterns with auxiliary verbs compared to lexical verbs. This is what has been identified in the studies of L2 English by Robertson and Sorace (1999) and Westergaard (2003). However, previous studies differentiated only between lexical and auxiliary verbs. In the classroom input, there is an additional difference between modal and aspectual auxiliaries. This is due to the fact that ungrammatical V2 patterns produced by the learners in this particular corpus exclusively involve placement of modal verbs (see example 10 above and parallel example in 12). Because previous L2 studies have not differentiated between aspectual and modal auxiliaries in investigations of the loss of V2, it is not possible to say whether this reflects a more general trend so that learners treat modals differently from aspectual auxiliaries. We leave this simply as an observation derived from the production in this corpus and propose that future research could investigate whether an additional modal/aspectual distinction in verb placement is a consistent effect.
(12) And then must you go along London Road. [learner production]
Table 5 presents the relative distributions of syntactic patterns after fronted constituents. Obviously, in this context there are no ambiguous clauses: after a fronted XP there is either inversion or not, i.e. every clause is uniquely +/−V2. Note in these cases that +V2 clauses may be either ungrammatical production, or patterns of stylistic and locative inversion licensed in English, which are not differentiated for the purposes of quantification.
Rates of inversion and non-inversion of verbs after fronted XPs.
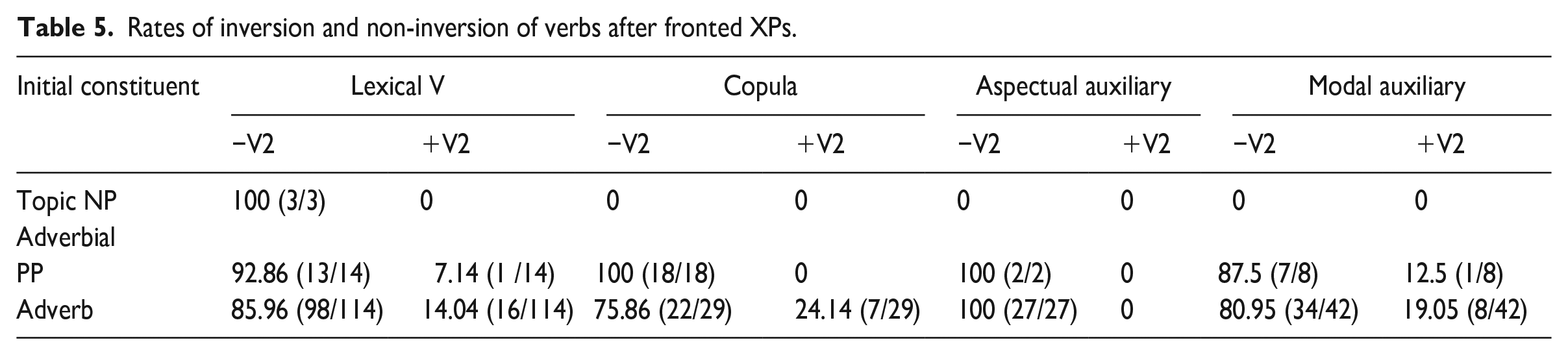
Topicalization is vanishingly rare. Westergaard (2003) suggested that infrequent occurrences of topicalization may lead to persistent cross-linguistic influence in the form of non-target V2 after topics. However, as noted above, Robertson and Sorace report the opposite finding: optionality of non-target V2 after fronted adverbials. We see that fronted adverbials do not consistently result in V3 in the input corpus, either because inversion is possible in English (as in 13), or because of the occurrence of non-target V2 (as in 14).
(13) Oh, here is my schoolbag! (14) And then must he turn left to the sports centre.
Looking at the fronting data in total, −V2 enjoys a marked advantage over +V2 (87>13%). However, the input does license greater optionality after fronted adverbials compared to topics (the caveat about infrequency of topicalization notwithstanding).
VI Discussion
Let’s return to the question of whether an implementation of a variational analysis of L2 input can account for some of the acquisition patterns identified in previous SLA work. This is a post-hoc view on Slabakova’s (2008: 117) suggestion that quantifying parameter signatures can predict how quickly the target setting may rise from 0 to 1. In this respect, we can answer only tentatively in the affirmative. Analysis of input distributions would lead one to expect a thematic-auxiliary distinction in the rise of non-V2 in the acquisition of English by L1 German speakers given that the proportion of input clauses uniquely compatible with the target value is higher with lexical verbs compared to auxiliaries. The lack of data from topicalization makes it difficult to draw even tentative conclusions about the status of fronted constituents, but it does seem that fronted adverbials license a certain degree of word order optionality in this input sample. Of course, more robust implementations will have to await improved input datasets. Nevertheless, the exploratory study presented above is offered as a proof of concept for this approach. Existing models of L2 development can be accommodated within a variational, grammar-competition approach. Applying this approach to consideration of input may hold out promise for understanding some properties of L2 development, such as word order. Of course many questions remain open and ripe for future research.
On the empirical side, one major issue is the simple lack of robust input datasets. While we can use survey data to gauge L2 exposure, the actual linguistic properties instantiated in the input to instructed learners remain potentially mysterious. L2 research may often assume that target language input reflects the linguistic features we are familiar with from analysis of native speech communities of the target language. But whether and how the actual L2 input as it occurs in learners’ experience differs from the ‘target’ is an empirical question that deserves greater scrutiny. This applies whether we are dealing with instructed or naturalistic L2 settings. It is therefore crucial for acquisition theory to know more exactly what the properties of the L2 input are in order to be able to take account of these empirical facts. Alternatively, one may want to discount input properties; we know that learners creatively project grammar for any number of poverty-of-the-stimulus phenomena which are not well represented in the input. Either way, the point remains that knowing more about what is or is not in the input is advantageous for formal acquisition theory.
The findings presented above reinforce the importance of this as we see the occurrence of certain features that we would not necessarily expect from ‘general’ English input. Unsurprisingly given the context, there is the occurrence of non-target patterns. And while this is to be expected, it is nonetheless important to know how likely specific non-target patterns are in order to consider how these effects might play out in L2A. For instance, the ungrammatical patterns in the data are lexically specific and occur exclusively with the modal verb must. To what extent is this a quirk of this particular dataset? And if it is, what other quirks might one find in other datasets? Auxiliaries in English are of course more likely in general to occur in residual V2 constructions with interrogatives and negative inversion. It is therefore possible that learner grammars innovate V2 patterns for (certain classes of) auxiliaries. Such production in turn skews the L2 target language environment for the wider community of learners. From a variational perspective, this input is less likely to consistently punish non-target V2. Of course, in many respects this amounts to the banal assertion that the L2 linguistic environment is different from the linguistic environment of a target-language speech community. The empirical point remains, however, that we cannot know exactly whether and how the instructed input might differ in the absence of empirical investigation of that input.
We see why this is important when looking beyond just the occurrence of non-target production in the L2 input. There is also variability with respect to English grammatical options that would not necessarily be expected on any a priori grounds. For instance, locative/stylistic inversion occurs frequently in the sub-corpus of the lowest grade-level, in 7.5% (10 of 134) of finite declarative clauses. This may seem surprising in input directed at lower-proficiency learners, and given the restricted input available to L2 learners, it likely means that this structure is overrepresented in this particular segment of input. In context, it is clear that it is being used by the teacher to introduce particular characters or vocabulary items for an activity, as in (15) and (16).
(15) Here comes Mrs. Duck. (16) Here comes Mr. Fox.
Thus, we see that due to particular idiolectal quirks, or for specific communicative purposes, there may be surprising distributions of syntactic patterns in instructed input, which may in turn affect the trajectory of acquisition in a variational framework.
In this regard, Slabakova et al. (2014: 604) note that ‘linguistic input has emerged as perhaps the key factor in addressing the fundamental question of differences between native and L2 acquisition’. By adopting a variational approach, one can consider potential input effects in a framework which incorporates frequency effects as well as innate linguistic competence. If issues of input and exposure are indeed a key factor in understanding L2 acquisition, then it is crucial to understand exactly what is in that input. This is likely to be especially important for foreign language learners with a restricted exposure to the target language and where the linguistic properties of that exposure might not mirror exactly what one would expect of a general analysis of the target language as spoken in its native speech communities. At the very least, it gives us pause for thought with respect to constructing theoretical claims based on results from instructed learners without clearer understanding of potential input effects.
Footnotes
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.