
Abstract
In a digitized world where artificial intelligence (AI) is rapidly infiltrating every aspect of our lives, it is crucial to utilize generative AI tools effectively. While the demand for AI technologies is increasing rapidly, challenges arise in their practical use. Accordingly, this study aims to develop a novel scale to measure users’ level of competence in prompt engineering. The psychometric properties of the Prompt Engineering Competence Scale (PECS) were evaluated using data obtained from 437 users. An exploratory factor analysis was performed to investigate the factor structure of the PECS. The results revealed a one-factor structure with a Cronbach's alpha value of 0.92. Confirmatory factor analysis results indicated that the one-factor model provided a good fit to the data. In the final stage, the item discrimination index was calculated to improve further the reliability and validity of the newly developed scale. The results suggest that the scale items were able to reliably discriminate users. These findings collectively indicate that the PECS is a valid and reliable instrument for measuring users’ level of competence in prompt engineering.
Introduction
The emergence of “Artificial Intelligence” (AI) has transformed nearly all industries and sectors, reshaping the way we interact with information in the age of the AI revolution (Verma and Singh, 2022). Generative AI, a subset of AI and the poster child of OpenAI's ChatGPT, has grown rapidly and set a record as “the fastest-growing consumer application” in history (Reuters, 2023). Tools such as ChatGPT have paved the way for users to create and share new knowledge and interact in ways never before seen in human history (Lo, 2023b). However, as with every new technology emerging in the digital space, mastering how to use these technologies effectively has never been more important (Reddy et al., 2020; Thompson et al., 2014). Digital literacy has emerged as a fundamental skill for users of computer and Internet-mediated tools (Thompson et al., 2014). As we enter the new and rapidly developing era of AI, a new digital literacy skill, also known as AI literacy, is needed (Walter, 2024).
Prompt engineering is considered a critical aspect of AI literacy (Walter, 2024). Prompt engineering is also becoming one of the most needed skills for interacting with generative AI (Lo, 2023a; Meskó, 2023). Prompt engineering is “the process of designing, crafting, and refining contextually appropriate inputs or questions to elicit specific types of responses or behaviors from an AI language model” (Bozkurt and Sharma, 2023). Another definition for prompt engineering is the “process of constructing queries or inputs (i.e., prompts) for AI language models to elicit the most precise, coherent, and pertinent responses. In essence, it is the art of fine-tuning the questions or commands provided to AI models to optimize their performance and guarantee that they produce the desired results” (Lo, 2023b). This emerging skill is creating a new digital divide, separating those who can prompt generative AI effectively from those who cannot, thereby paving the way for a new form of digital literacy known as AI literacy (Haugsbaken and Hagelia, 2024; Lo, 2023a; Meskó, 2023; Walter, 2024). On the world stage, prompt engineering has been revered as the number one “job of the future” (Whiting, 2023).
The importance of this new form of AI literacy in prompt engineering has been addressed through several frameworks and methods from academia, strategies from thought leaders, and guiding principles from industry-leading companies, such as OpenAI. They are all means and ways for users of generative AI to follow in order to effectively engineer the prompt. Among them is the CLEAR framework (Lo, 2023b) from the information science and librarian discipline, which provides a standard approach for composing effective prompts for generative AI models, consisting of an explicit, concise, logical, reflective, and adaptive approach for prompt engineering. On the other hand, numerous methods of prompting, such as “Input-Output Prompting” and “Chain of Thought Prompting” from different scholarly disciplines such as computation and language, computer science, and machine learning (Liu et al., 2022, 2023; Wang et al., 2023a, 2023b; Wei et al., 2022; Xu et al., 2023; Yao et al., 2023; Zhou et al., 2023). From industry leaders in generative AI, OpenAI introduced “OpenAI Six Strategies” to get better results (OpenAI, 2024). However, thought leaders in prompt engineering introduced the “Five Principles of Prompting” (Phoenix and Taylor, 2024).
As with any new and emerging skill, it is essential to educate users and empower them to master it. On the other hand, measuring the competence of mastering the new skill is critical. Up to now, several measures have been developed related to generative AI, such as “AI self-efficacy for acceptance of Generative AI” (Wang and Chuang, 2024) and “teacher AI competence self-efficacy” (TAICS) to assess teachers’ AI knowledge and ethics (Chiu et al., 2025). Still, none of the existing studies have developed a scale to assess the competency of prompt engineering, which is the primary skill required to interact with generative AI models. This study proposes a new scale that measures users’ competency in prompt engineering, given the importance of this emerging AI literacy skill. The new scale is developed based on the above well-established frameworks and industry leaders’ best practices in prompt engineering, paving the way for measuring this new form of AI literacy.
Theoretical framework
The emergence of generative AI has profound implications for our societies, as it is rapidly expanding and entering many industries. Hence, the practical usage of this tool will be of the utmost importance for many users of this newly emerging technology. AI models, such as ChatGPT, are developed based on the transformer's architecture and trained on a large volume of text (Brown et al., 2020). These tools help demonstrate the application of translation, summarization, and question-answering in a conversational format that has never been seen before in the history of computing (Brown et al., 2020; Lo, 2023a).
Nonetheless, as with any newly emerging digital tool, such as generative AI, a new skill emerges that empowers users to use it effectively. Several studies pointed out that practical, prompt engineering helps generate high-quality results (Liu et al., 2024; Wang et al., 2023a, 2023b). Furthermore, crafting suitable prompts helps ensure that the generated content is both relevant and accurate (Meskó, 2023). Prompt engineering skills can help expand the application range of generative AI in various areas by diversifying its use in fields such as network design, the arts, and design education, assisting students in refining their ideas and further exploring different areas and possibilities (Cotroneo and Hutson, 2023). Furthermore, it has been recognized as a means to enhance professional competence, as prompt engineering skills are becoming increasingly important in areas such as healthcare, where they are utilized to augment the use of AI tools in clinical tests (Meskó, 2023). With the increasing significance of AI literacy through prompt engineering, it can be argued that prompt engineering aims to formulate effective prompts in natural language. These prompts skillfully guide AI models to respond based on content, tone, and structure, producing accurate and valuable outcomes (Bozkurt and Sharma, 2023).
Several frameworks, methods, guidelines, and strategies have been introduced for crafting effective and rigorous prompts. From the scholarly practice area of information science, the CLEAR framework was introduced (Lo, 2023b), and from areas of computation languages and the area of machine learning, several prompting methods were introduced (Liu et al., 2022, 2023; Wang et al., 2023a, 2023b; Wei et al., 2022; Xu et al., 2023; Yao et al., 2023; Zhou et al., 2023). From the professional practice, OpenAI's “ChatGPT Best Practices for Prompt Engineering” (OpenAI, 2024) and “Five Principles of Prompting” were introduced (Phoenix and Taylor, 2024).
The CLEAR Framework's objective was to “provide a standard method for composing effective queries for generative AI models such as ChatGPT” (Lo, 2023b). The model consists of five components: 1. “Concise: Brevity and clarity in prompts,” 2. “Logical: Structured and coherent prompts,” 3. “Explicit: Clear output specifications,” 4. “Adaptive: Flexibility and customization in prompts,” and 5. “Reflective: Continuous evaluation and improvement of prompts” (Lo, 2023b). Similarly, several scholarly studies have been conducted on various methods to prompt generative AI in diverse areas, including computer languages, computer science, and machine learning. They paved the way for seven distinct methods of promoting generative AI: 1. Input-Output Prompting: “Simple and basic prompts that map inputs to specific outputs” (Liu et al., 2023), 2. “Chain of Thought” Prompting: “Uses a step-by-step approach to guide generative AI using a particular reasoning approach” (Wei et al., 2022), 3. Tree of Thought Prompting: “Discovering numerous reasoning scenarios and providing different results based on various scenarios” (Yao et al., 2023), 4. Role-Play or Expert Prompting: “Assigning a specific type of persona to guide the context of the prompt for generative AI” (Xu et al., 2023), 5. Generated Knowledge Prompting: “Developing context or background by creating intermediate knowledge” (Liu et al., 2022), 6. Self-Consistency Prompting: “Creating numerous outputs and selecting the most consistent and appropriate one” (Wang et al., 2023b), 7. Automatic Prompt Engineering: “Usage of AI to enhance prompts systematically” (Zhou et al., 2023).
On the other hand, from professional practice, OpenAI introduced “six strategies for getting better results,” namely, 1. “Write clear instructions,” 2. “Provide reference text,” 3. “Split complex tasks into simpler subtasks,” 4. “Give the model time to think,” 5. “Use external tools,” and 6. “Test changes systematically” (OpenAI, 2024). In the same vein, the “Five Principles of Prompting,” written by James Phoenix and Mike Taylor, are guiding principles that are stated to be “not short-lived tips or hacks but are generally accepted conventions that are useful for working with any level of intelligence, biological or artificial” (Phoenix and Taylor, 2024). These five principles are: “1. Give Direction: Describe the desired style in detail or reference a relevant persona.” 2. “Specify Format: Define the rules to follow and the required structure of the response.” 3. “Provide Examples: Insert a diverse set of test cases where the task was done correctly.” 4. “Evaluate Quality: Identify errors and rate responses, testing what drives performance.” and 5. “Divide Labor: Split tasks into multiple steps, chained together for complex goals” (Phoenix and Taylor, 2024).
Table 1 provides a comprehensive overview of digital competency scales developed in various educational contexts, covering key areas such as digital learning, AI literacy, and teacher- and student-specific competencies. These scales were designed using robust methodologies, including “Exploratory Factor Analysis” (EFA), “Confirmatory Factor Analysis” (CFA), and “Structural Equation Modeling” (SEM). Results consistently demonstrate the reliability and validity of these scales in measuring core competencies, with frameworks that address critical areas such as technology use, cognitive processing, collaboration, and AI competence—fundamental in modern educational settings.
Summary of digital competence scales.
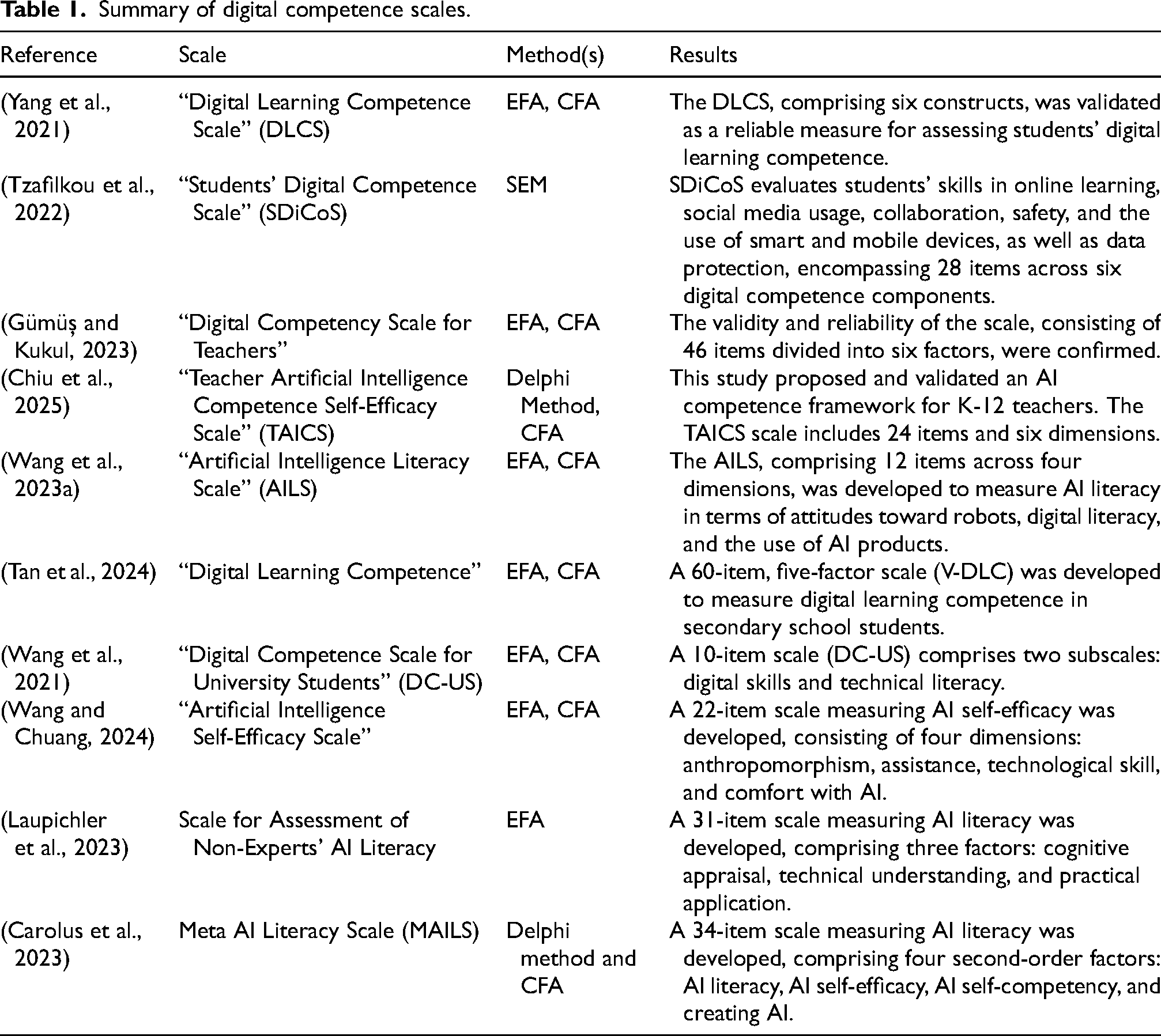
However, despite the availability of these tools, a notable gap remains in competency scales that focus on prompt engineering. This skill is becoming increasingly important in the context of AI-driven technologies. With the rapid proliferation of generative AI, the ability to create effective prompts has become crucial for users to interact efficiently with these systems. This paper addresses this gap by developing a new tool, the Prompt Engineering Competence Scale (PECS), to assess users’ proficiency in prompt engineering. The PECS serves a critical need and contributes to the growing field of AI literacy by providing a reliable and valid tool to assess users’ proficiency in effectively using generative AI technologies.
Method
The methodology employed in this study involves a multi-stage research design for scale development (Arpaci and Sevinc, 2022; Tabachnick and Fidell, 2021). The sequential approach to the development and evaluation of the measurement tool consists of nine basic steps: 1) Development of the initial item pool, 2) Evaluation of the content and face validity through panel reviews, 3) Revision of the item pool in line with the feedback, 4) Further revision of the items performing a pilot study, 5) Data collection for the EFA, 6) Conducting the EFA, 7) Collecting data for the CFA, 8) Conducting the CFA, 9) Item analysis to determine item discrimination power. Figure 1 illustrates the development process for the scale.
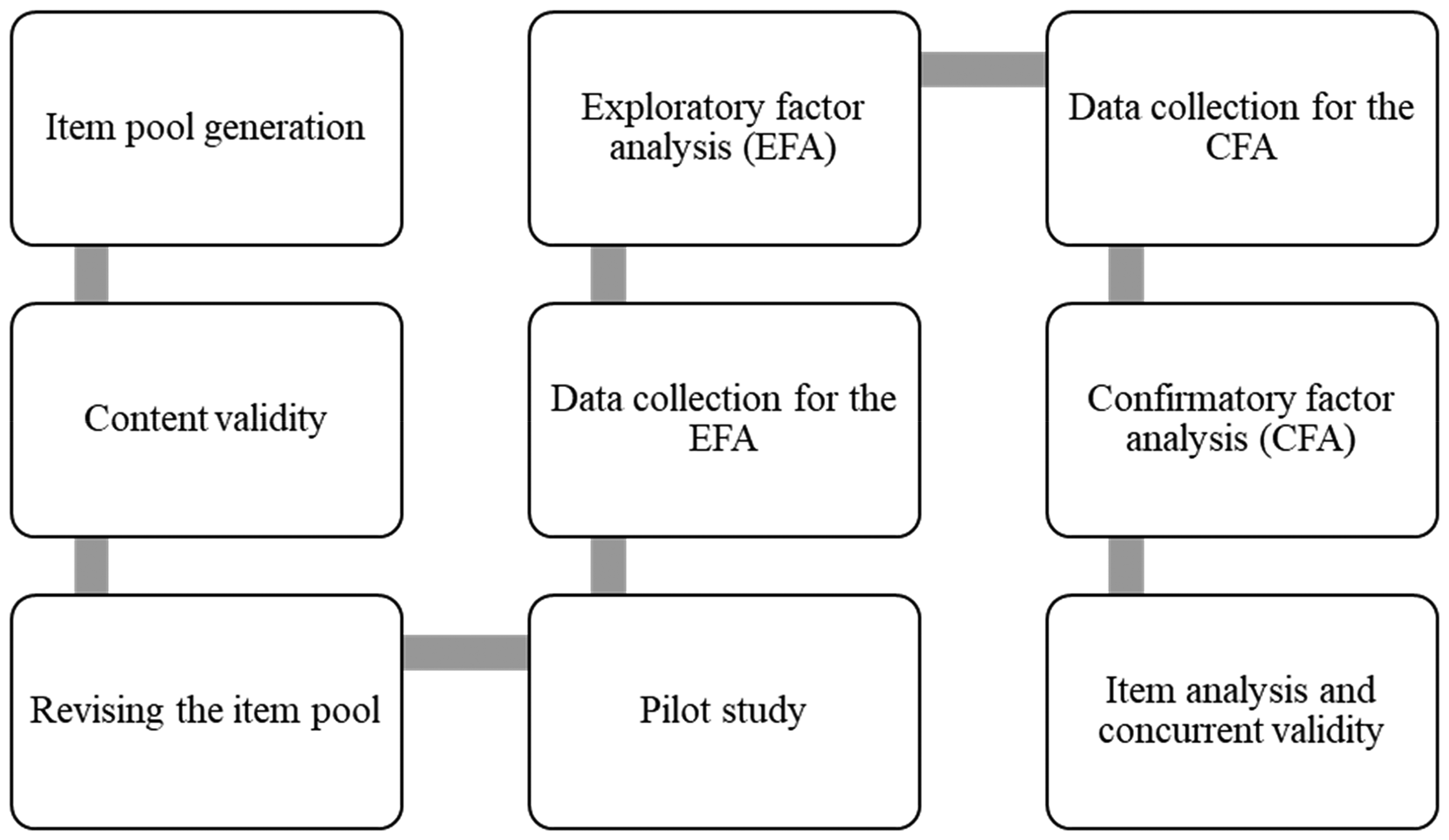
Scale development stages.
Item development
The development of the PECS items followed five key stages (DeVellis and Thorpe, 2021). The first stage involved identifying the construct to be measured, which led to the decision to create a scale assessing users’ proficiency in prompt engineering. In the second stage, the item pool was developed by analyzing existing frameworks, methods, and strategies related to prompt engineering, including the “CLEAR Framework Component,” “Prompting Methods,” “OpenAI Six Strategies,” and “Five Principles of Prompting.” From these, key competencies were identified and converted into scale items, resulting in an initial pool of 20 items. The third stage focused on determining the measurement method, and the commonly used “5-point Likert-type scale” was selected (Winke and Brunfaut, 2020). The scale ranged from “(1) Strongly disagree” to “(5) Strongly agree.” In the fourth stage, an expert review was conducted, soliciting feedback from two language specialists to ensure the accuracy, grammatical correctness, and clarity of the items. Additionally, three field experts in Information Systems reviewed the scale, and the Delphi technique was used to compile expert opinions systematically. Following revisions from the expert panel, 11 items were removed, and a nine-item initial form was developed. Finally, a pilot study with 20 users was conducted to identify ambiguities and inconsistencies in the scale. Participants provided feedback on the clarity and wording of the items. Several items were reworded for clarity, and confusing items were modified based on their input. The revised items were then reviewed to ensure clarity and alignment with the research's objectives, resulting in the final version of the scale, which comprises nine items and is presented in Appendix A.
Sample and procedure
The data was collected in Kuwait, which is an important factor in understanding the cultural context of the findings. To ensure participant privacy, all responses were kept confidential and anonymous. Informed consent was obtained explicitly from all participants, ensuring they were completely aware of their rights and the research's purpose, including the unconditional right to withdraw at any time. Furthermore, the study adhered to the ethical standards established by the university (IRB-41/2024-25), which reviewed and approved the research protocol.
The population consisted of individuals who used generative AI tools. To mitigate concerns regarding “Common Method Variance” (CMV) (Campbell, 1976), separate data sets were collected for the EFA and CFA. The initial stage of the study involved 200 individual users with a mean age of 20.42 years (SD = 3.976). 53.5% of the respondents were women (107 women and 93 men). 70.5% of the participants are undergraduate students. 91% of the respondents are between 18 and 24 years old. All participants reported using at least one of the AI tools. 81% of the respondents stated that they use ChatGPT. Copilot, Gemini, and Bing AI are the other tools used. Twenty percent of the respondents reported using it daily, 47.5% use it weekly, 19% use it monthly, and 13% use it several times a year. 68.5% of the respondents declared that they use AI tools for research and education.
The sample for the second stage of the study consisted of 237 different users, ranging in age from 18 to 26, with an average age of 22.47 years (SD = 4.831). 81% of the respondents were female (192 women and 45 men). 99.6% of the participants were undergraduate students. The participant demographics were as follows: 33.1% were juniors, 31.1% were sophomores, 30.8% were seniors, and 5.0% were first-year students. 77.2% of the participants reported using ChatGPT. Other preferred tools include Bing AI, Gemini, and Copilot. 24.5% of the participants reported using ChatGPT daily, 32.9% reported using it weekly, 18.6% reported using it monthly, and 24% reported using it several times a year.
Results
Exploratory factor analysis
Bartlett's “test of sphericity” (χ²(36) = 1102.976, p < .001) and the KMO measure (0.909) confirmed the suitability of the scale items for factor analysis. The factor loadings shown in Table 2 ranged from 0.742 to 0.856, exceeding the threshold of 0.40 (Hair et al., 2019). Moreover, the commonalities, ranging from 0.551 to 0.733, are more significant than the threshold of 0.30 (Child, 2006). EFA with “maximum likelihood inference” and Varimax with “Kaiser Normalization rotation” were conducted to identify the factor structure of the newly developed scale. The findings indicated that the proposed scale comprises a single factor with nine items. The single factor explains 61.294% of the variance. The scree plot of the eigenvalues obtained from the analysis, shown in Figure 2, indicates that the instrument should consist of a single factor, as there is a significant decrease in eigenvalues after the first factor.
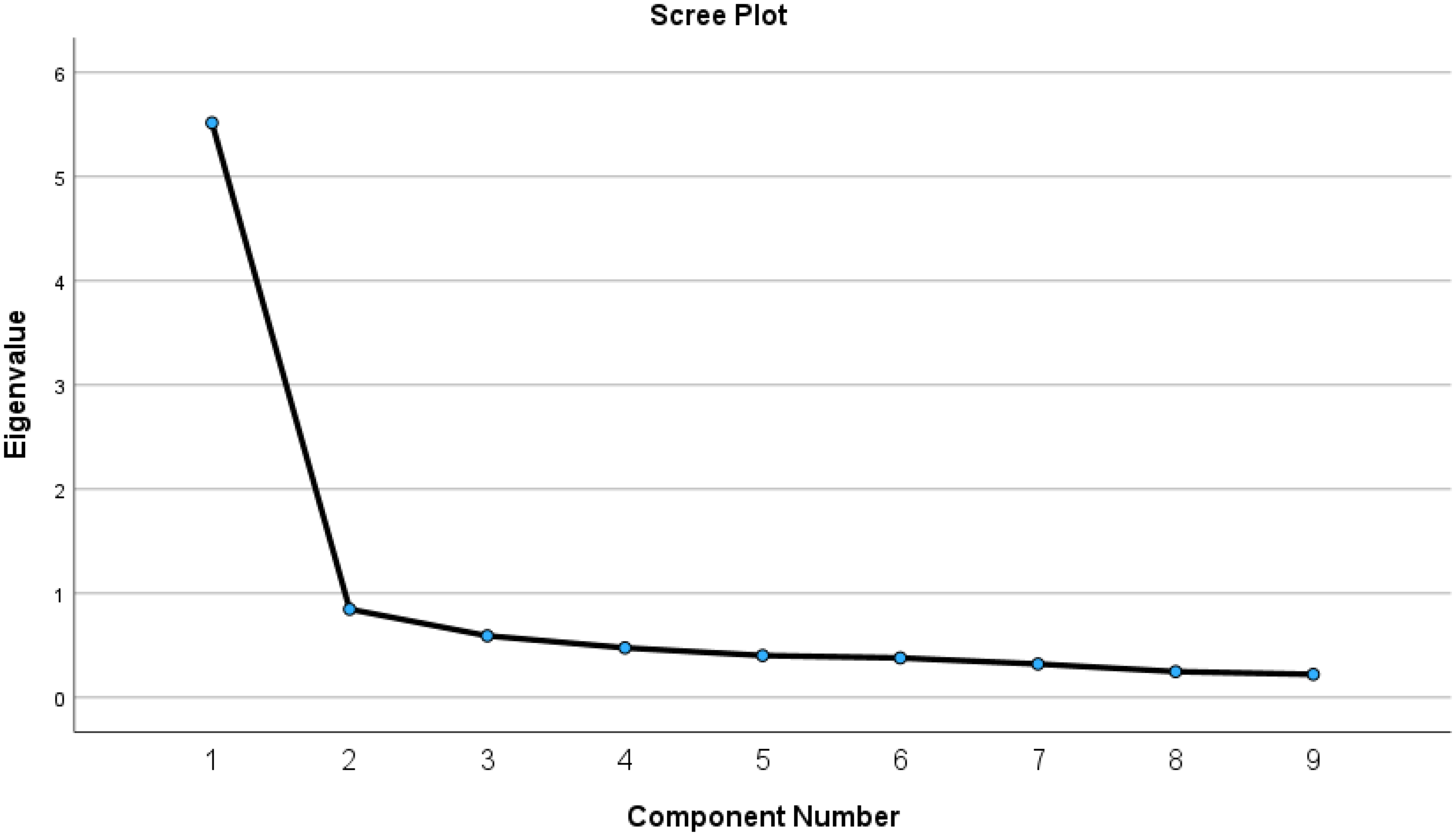
The scree plot.
Reliability and normality.
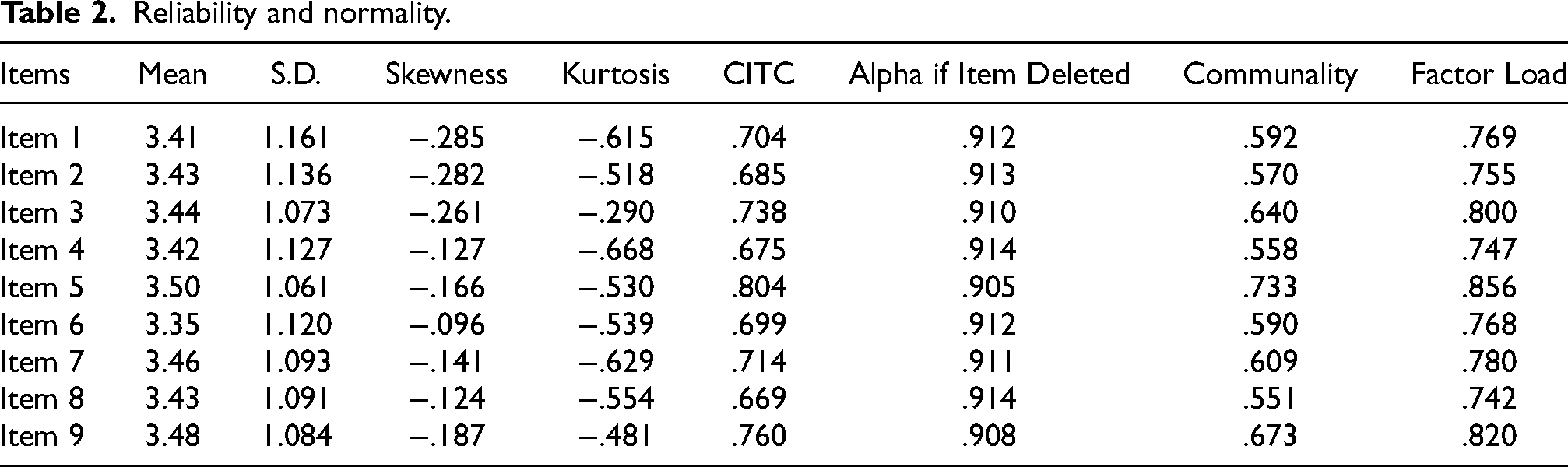
The one-factor scale, comprising nine items, demonstrated reliability with Cronbach's alpha, McDonald's omega, and Guttman's lambda values of 0.920. The same reliability values indicate that the scale is highly unidimensional, with all items consistently measuring a single underlying construct and exhibiting minimal multidimensionality. “Corrected Item-Total Correlation” (CITC) values were all above 0.30, indicating that each item was reasonably consistent with the overall scale. Furthermore, since the skewness (SE = 0.342) and kurtosis (SE = 0.172) values fall within the range of −3 to +3, it can be concluded that the data follow a normal distribution (Hair et al., 2019). Table 2 shows descriptive statistics as well as results regarding reliability and normality.
Confirmatory factor analysis
The findings of “Bartlett's test of sphericity” (χ2(DF = 36) = 1561.844, p < .001) and the “K-M-O measure of sampling adequacy” (.922) showed the data collected for the second stage of the study were factorable. Communality values ranged from 0.673 to 0.853 and were higher than the cut-off value of 0.30 (Child, 2006). Furthermore, factor loadings ranged between 0.710 and 0.859 and were higher than the cut-off value of 0.40 (Hair et al., 2019). Cronbach's α coefficient of the single-factor scale was .931. The reliability coefficient is much higher than the cut-off value of 0.70 (Cronbach, 1951).
The measurement model was evaluated using “Confirmatory Factor Analysis” (CFA) in SPSS AMOS (ver. 29). The results show that the study data and the measurement model fit well: [x2 = 42.400, DF = 22, x2/DF = 1.927, GFI = .963, CFI = .987, TLI = .978, RMSEA = .063, LO90 = .033, HI90 = .091, PCLOSE = .213, SRMR = .0233]. These results indicate that the structural model accurately reflects the underlying factor structure and demonstrates the reliability of the scale. Additionally, the acceptable model fit supports the suitability of the CFA model for the data, providing evidence for the validity of the measurement structure.
Item distinctiveness
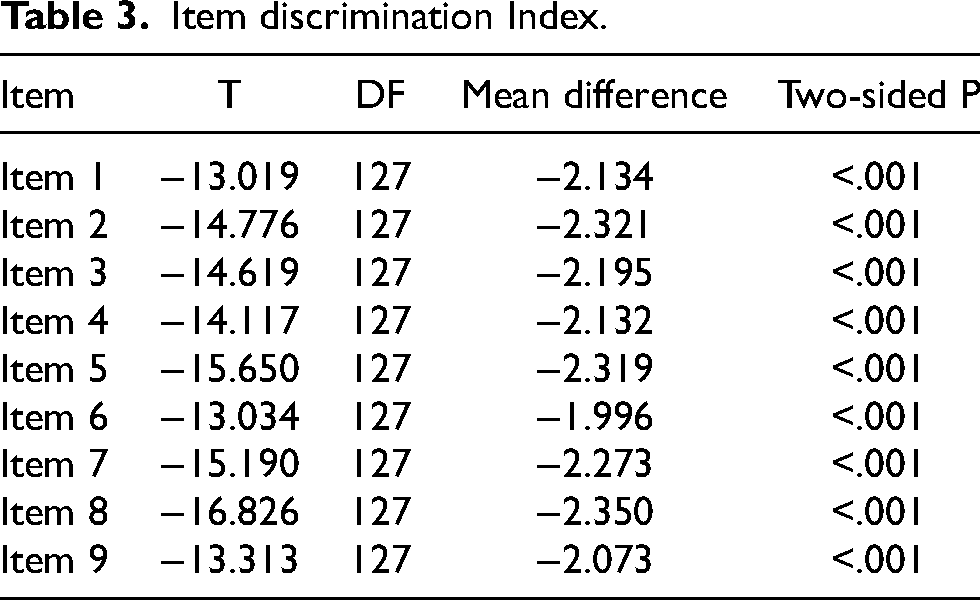
The item discrimination index is a statistical method used to determine the extent to which a scale item can distinguish between individuals with the trait it intends to measure and those without it (Arpaci, 2016). The item discrimination index was calculated to determine whether an item should be included in the assessment tool. The results of this analysis confirm the reliability and validity of the scale once again. In this method, the participants (n = 237) were ranked according to their total test scores, and the lower and upper groups were formed by selecting the 27% with the lowest scores and the 27% with the highest scores, respectively. Responses to each item were compared between the lower and upper groups using an independent sample t-test. The results show that these groups differ statistically in terms of the trait measured by their responses to each item. The findings presented in Table 3 indicate that the scale items can reliably distinguish between novice and expert users.
Item discrimination Index.
Concurrent validity
The Pearson correlation analysis was conducted to assess the concurrent validity of the scale. The results indicate a positive correlation between PECS and the Sustainable Use scale, reinforcing the robustness of our findings (Arpaci, 2024). The fact that the correlation is significant and relatively high (r = 0.605, p < 0.01) supports the idea that there is a link between high-quality prompts and the sustainable use of AI.
Discussion
In the digital world, numerous AI tools have been developed to enhance human life (Arpaci, 2024). Utilizing these AI tools effectively within ethical boundaries is crucial for enhancing productivity in both business and academic settings (Garg et al., 2025). Therefore, how effectively these tools are used is an important research question. However, the effectiveness of AI systems in use depends on how effectively you can write prompts (Knoth et al., 2024). Measuring how effectively users can write prompts is necessary to answer this critical question. Accordingly, this study developed a novel scale to assess users’ competence in basic prompt engineering.
The Prompt Engineering Competence Scale (PECS) is compatible with existing frameworks, methods, and strategies related to prompt engineering, including the CLEAR Framework Component, Prompting Method, OpenAI's Six Strategies, and the Five Principles of Prompting. Table 4 maps the items from the PECS to the existing frameworks, methods, and strategies. Each PECS item is aligned with the corresponding components, methods, strategies, and principles to provide a comprehensive understanding of prompt engineering competence.
Mapping of the items with the four approaches.

The reliability and validity of the PECS were evaluated through “Exploratory Factor Analysis” (EFA) and “Confirmatory Factor Analysis” (CFA) using two separate datasets. The results demonstrated a high reliability level, with identical reliability values (Cronbach's alpha, McDonald's omega, and Guttman's lambda all equal to 0.92), exceeding the commonly accepted benchmark of 0.70. The identical reliability coefficients indicate that the scale is highly unidimensional and the items consistently measure the same basic construct. In a subsequent study with a different dataset, the alpha value was recorded at 0.93, further supporting the scale's strong internal consistency. Additionally, CFA results confirmed a good model fit, validating the one-factor structure and the nine-item measurement instrument.
Several scales have been developed to assess the use and acceptance of generative AI technologies. For instance, Wang and Chuang (2024) designed the AI Self-Efficacy (AISE) scale to measure individuals’ perceived confidence in using generative AI. Based on data from 314 participants, EFA and CFA analyses resulted in a 22-item instrument with four dimensions (Wang and Chuang, 2024). Similarly, Yilmaz et al. (2024) proposed a measurement tool grounded in the “Unified Theory of Acceptance and Use of Technology” (UTAUT) to evaluate four key sub-dimensions of generative AI adoption. The EFA and CFA findings confirmed the 20-item scale with a four-factor structure (Yilmaz et al., 2024). Similarly, Park et al. (2024) introduced a scale to examine individuals’ perceptions of AI in the workplace. Their study validated a six-factor structure with 25 items, encompassing perceived humaneness, perceived adaptability, AI use anxiety, personal utility, job insecurity, and perceived AI quality (Park et al., 2024).
A recent study developed the “Teacher AI Competence Self-Efficacy (TAICS)” scale using a Delphi method (Chiu et al., 2025). They conducted a CFA based on data collected from 434K-12 teachers. The 24-item scale comprises six dimensions: “AI assessments, AI knowledge, AI ethics, AI pedagogy, professional engagement, and human-centered education.” A similar study aimed to measure competence in the use of generative AI by developing the “AI Literacy Scale” (AILS) (Wang et al., 2023a). The proposed 12-item scale comprises four dimensions: “awareness, evaluation, utilization, and ethics.”. While all these scales aim to measure attitudes or competencies related to AI tools, there is an important gap: no measurement tool has been developed for prompt engineering, which is the primary method for effectively utilizing these tools. This study significantly contributes to AI literacy by filling this gap by introducing the PECS.
Concluding remarks
In this study, a new scale was developed, and its psychometric properties were evaluated using a multi-stage research design. The results showed that PECS is a valid and reliable instrument for measuring users’ level of competence in prompt engineering. Furthermore, the results indicated that the PECS can reliably distinguish individuals with the measured trait from those without it. Overall, this research significantly improves our understanding of users’ basic level of competence in prompt engineering.
PECS could be employed at different dimensions across organizational levels. The World Economic Forum has identified prompt engineering as the number one “job of the future.” (Whiting, 2023). At the organizational level, PECS can be employed as a means of assessing employees’ prompt engagement competency during the hiring or training stage. This would help ensure that newly hired or current employees are equipped with the skills necessary to leverage AI tools effectively. At the Educator level, this scale can be utilized as a diagnostic tool to identify gaps in students’ understanding of prompt engineering, empowering educators to tailor educational content that fills these knowledge gaps. At the individual level, user of generative AI can use PECS to self-assess their competence and therefore explore and pinpoint areas in their knowledge gap that can then be improved with prompting, engaging competency development.
In conclusion, this study makes a significant contribution to the literature with a systematically developed and carefully validated original measurement tool. It offers practical implications and enhances the understanding of prompt engineering. The newly developed Prompt Engineering Competence Scale (PECS) is a valuable addition to the field of AI literacy research. This study is significant for its potential to enhance users’ competence and promote the effective utilization of generative AI.
The manuscript presents a novel contribution to AI literacy with a rigorously developed scale. Nevertheless, some limitations should also be noted. Firstly, the data is drawn from a single national context, which limits the generalizability of the findings across cultures. Future research should consider diversifying the participant population by including data from multiple countries, allowing for cross-cultural comparisons and thereby enhancing the generalizability of the findings. Such diversification would also provide a more robust assessment of the scale's validity across different cultural contexts. Second, this study assessed users’ basic level of prompt engineering competence. Future work could extend this study by developing measures to evaluate users’ competence at more advanced levels of prompt engineering, thereby further broadening the scope of the scale. Third, future studies should consider diversifying the participants by including users from different sectors or groups, such as corporate employees or medical personnel who regularly interact with Generative AI using prompts, thereby enhancing the generalizability of the scale. Lastly, there was a significant gender imbalance between the EFA and CFA phases, with 53.5% of the EFA sample being female and 81% of the CFA sample being female. This gender disparity may affect the representativeness and generalizability of the study findings, limiting their applicability to a broader, more diverse sample. Future studies could aim to ensure a more balanced gender representation to improve the external validity and overall robustness of the results.
Footnotes
Acknowledgements
This project has been partially supported by Gulf University for Science and Technology and the Center for Sustainable Development under project code: ISG – Case #151.
Data availability statement
Data will be available upon request.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Institutional review board
The study was conducted in accordance with the Declaration of Helsinki and approved by the Institutional Review Board (IRB-41/2024-25).
Informed consent statement
Informed consent was obtained from all subjects involved in the study.