
Abstract
The aims of this study were to identify children’s reactions towards speech sound disorders (SSD) in other children and whether these reactions can be related to specific speech characteristics. Six audio samples, each containing minute-long resumes of short animated film by five children with SSDs and one child with typical speech (TS), aged 5–9 years, were played back to 17 10–11-year-olds, during four focus group interviews. The transcribed interviews underwent a qualitative content analysis. The analysis resulted in five identified main themes of listener reactions, concerning the experiences as a listener, the perspective of the speaker, as well as observations of speech characteristics. Reactions of empathy were expressed towards a perceived misalignment between speaker age and speech production proficiency. Awareness of peer reactions are clinically useful, for the understanding and acknowledgement of everyday contextual factors of children with SSDs, during planning and motivation of speech intervention. The children’s self-selected terminology may serve future quantitative investigations to further determine the boundaries of acceptability towards SSDs as well as towards non-standard sociolects or language varieties.
Keywords
I Introduction
Speech sound disorders (SSD) are represented in around 4% of children in the ages of 6 to 8 (Shriberg et al., 1999; Wren et al., 2016), and indicate speech production difficulties of specific speech sounds, or groups of speech sounds, as well as/or difficulties in motor planning and sequencing of speech sounds (Bowen, 2014). In terms of communicative consequences, an SSD may result in reduced intelligibility, i.e. that listeners will struggle to understand what the child is saying. Another potential consequence is reduced acceptability, i.e. the perceived ‘differentness’ of the child’s way of speaking. Both these aspects are influential on the child’s access to education and social communication (Krueger, 2019), and an association between SSDs and activity limitations and/or participation restrictions in informal relationships with friends have been observed (McCormack et al., 2009). Mild speech impairments may reduce communicative opportunities disproportionately (Yorkston et al., 2001), and qualitative methodologies have therefore been presupposed to capture factors that affect the communicative participation, beyond quantitative measurements of intelligibility (Dykstra, 2013).
Acceptability has been studied in the context of cleft lip and/or palate (CLP), dysarthria and laryngectomy (Dagenais et al., 2006; Eadie et al., 2013; Mendelsohn et al., 1993), but considerably less so in the context of SSDs. However, a few studies exist that have reported listener attitudes towards children’s misarticulated speech. For example, listeners have been observed to react negatively towards misarticulated /r/ and /s/ (Hall, 1991; Silverman, 1976; Silverman and Paulus, 1989). Further, adults in preschoolers’ environments have been found to associate misarticulated speech with lower levels of cognitive maturity (Burroughs and Tomblin, 1990). Hence, the research on listener attitudes towards SSDs suggests a link between misarticulated speech and negative listener reactions.
Most studies of listener reactions to children’s misarticulated speech are based on listener ratings, with reference to so called semantic differentials (e.g. Hall, 1991; Silverman, 1976; Silverman and Paulus, 1989). Some more recent studies, exploring similar issues in the context of speech from children with CLP, have taken a different approach. Nyberg and Havstam (2016) compared statements of 10-year-old children from focus group interviews to speech and language therapists’ (SLTs’) assessments of the speech samples from children with CLP. The findings included that the 10-year-old children indeed perceived and reacted to articulatory characteristics, that frequently may be observed in children with SSD. Similar results were found regarding 7-year-old children’s perception about cleft-palate speech in peers (Nyberg et al., 2020).
In the context of the International Classification of Functioning, Disability and Health: Children and Youth version (ICF-CY) (World Health Organization, 2007), listener attitudes fit well among contextual factors that may affect an individual’s health and well-being. In line with the ICF, national health bodies often advocate for consideration of such contextual factors in the process of clinical decision making (e.g. American Speech-Language-Hearing Association, 2016). In light of this, the current dearth of knowledge regarding listener attitudes in the field of children’s SSDs is clearly unsatisfying.
Other children make up an important part of children’s social context, and negative attitudes and peer victimization contributes to poor mental health in adolescence significantly (Rigby, 2000). Considering suggestions that SSDs evoke negative perceptions among people in the speaker’s environment, other children’s reactions to misarticulated speech may inform clinicians of how specific traits cause disruption in the child’s everyday life, and consequently acknowledge these in intervention. Consequently, the aim of this study is to identify and characterize listener reactions towards SSDs among children aged 10–11 years. The research questions are: 1) What listener reactions can be identified? and 2) Can these reactions be related to specific speech characteristics?
II Method
1 Participants
Seventeen 10–11-year-old children (fourteen girls and three boys) participated in four focus group interviews, with 3–6 participants in each group. The children were recruited from fourth grade at one primary school in Stockholm County, Sweden. The selected school’s demographic properties concerning gender distribution, proportion of foreign backgrounds, and parents’ educational background corresponded well to a cross section of the statistics of schools in Sweden as a whole, according to statistics obtained from the Swedish National Agency for Education (Skolverket, 2017). To be eligible for inclusion, the children needed to speak Swedish at a native level. This decision was based on concerns of alleviating subsequent interpretation of utterances, but also on ensuring participants’ level of exposure to Swedish, which could affect their perception of the speech samples. Among the 17 participants, Swedish was their primary native language, although a few also spoke other languages at home. Prior to the interview sessions, the parents of the participating children signed informed consent and filled out a demographic form; these were returned and collected by the children’s teacher. The children themselves had given verbal consent to participate in the interviews.
2 Materials
Audio samples were selected from a pool of recordings of 40 children in the age 4–10, collected within a larger project (see description in Öster Cattu Alves et al., 2019). Twenty-six of the children had been recruited through SLTs in the counties of Stockholm and Västra Götaland in Sweden, by the criterion of having an SSD impacting intelligibility (as judged by their treating SLT). The remaining 14 children were recruited via mainstream preschools and schools in the same regions and had no suspected SSD. Recordings constituted of the children narrating or retelling one of two three-minute long animated Pingu films, for an experimenter purporting not to be familiar with the film. The original recordings were processed by excluding retakes, repetitions and long pauses, as well as portions where the experimenter’s voice was heard, into one-minute samples of continuous speech from each child.
From the pool of 40 one-minute samples, six samples were selected for inclusion in the present study, restricted by an effort to obtain variation in speech characteristics. In this selection, two evaluators (both certified SLTs) prioritized samples with audible speech errors, and discarded samples that did not contribute to the variety of speech error types. For the purpose of the present study, the selection of speech samples was further based on the age of the child, aiming to match the speakers’ age to that of the children in the focus groups as closely as possible. The final set consisted of samples from six children, one girl and five boys, aged 5–9 years. The test leaders noted the speech characteristics of the samples, see Table 1 for a description of these.
Demographic descriptions of the speakers and their respective speech samples.
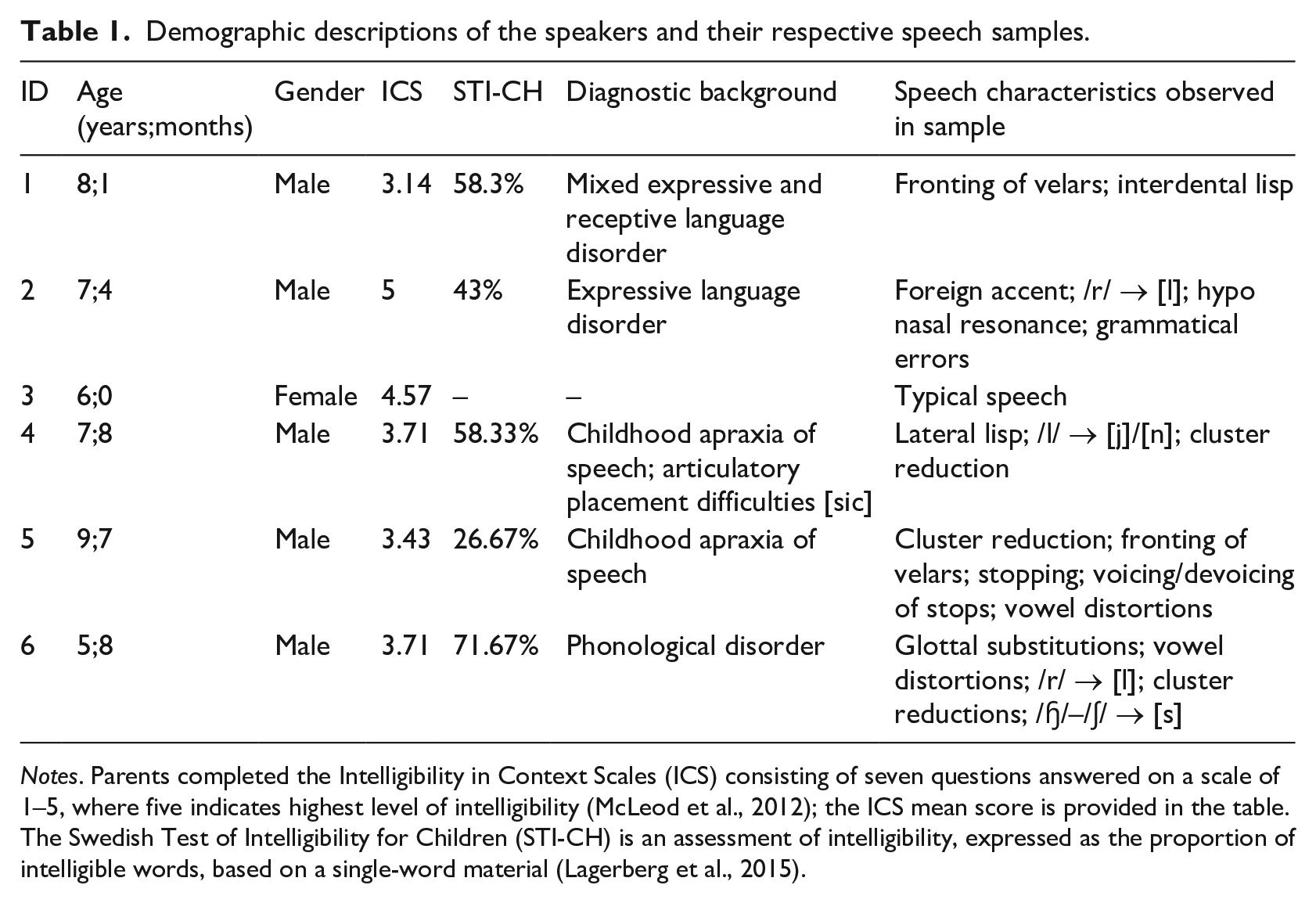
Notes. Parents completed the Intelligibility in Context Scales (ICS) consisting of seven questions answered on a scale of 1–5, where five indicates highest level of intelligibility (McLeod et al., 2012); the ICS mean score is provided in the table. The Swedish Test of Intelligibility for Children (STI-CH) is an assessment of intelligibility, expressed as the proportion of intelligible words, based on a single-word material (Lagerberg et al., 2015).
3 Procedure
As in previous works by Nyberg and colleagues (Nyberg and Havstam, 2016; Nyberg et al., 2020), focus group discussions were chosen to collect data due to their potential to correspond to authentic everyday situations for children in school-age. The four focus-group interviews were completed in a separate room in the school building with three to six participants in each group. A semi-structured interview guide was compiled to ensure consistency across sessions. Before the interviews, all participants watched the two animated Pingu films, to obtain an idea of the content of the speech samples. Through this procedure, the participants were assumed to be able to focus on the quality or characteristics of speech rather than on decoding its content. Participants were informed about the speakers’ ages prior to each sample playback, to compensate for the absence of visual cues that typically would have indicated speaker age in a naturalistic face-to-face encounter. Following every playback, a test leader asked the questions: 1) how does this sound to you? 2) what do you think about this way of speaking? and 3) what do you think it feels like to talk this way? After approximately five minutes, the subsequent discussions had faded out, and the test leader asked if the participants had additional thoughts to express, aiming to ensure saturation of discussion. No other questions were asked. Grade of saturation was considered across interview sessions: the test leaders’ general perception was that additional interviews would unlikely result in novel latent concepts, fundamentally differing from the ones already obtained.
All samples were played twice, allowing the participants to reconsider their opinions. Each interview session was concluded with a general discussion considering all samples and was finished after approximately 1–1.5 hours. Participants were instructed immediately after the interviews not to share the content of the interviews with fellow classmates, to minimize any influence on results in subsequent sessions. The procedure was tested in a pilot interview to identify possible weaknesses. After all interviews were completed however, both test leaders agreed to include the pilot interview in the result data, as no deviations from the interview guide were found during transcription of the interviews.
4 Equipment
Two sets of recorders (H4nex handy Recorder) as well as microphones (Rode NT4) were used during interviews to ensure sufficient audio quality and backup in case of technical failure. Loudspeakers were connected to a PC laptop for demonstration of the short animated films as well as for presentation of audio files. The audio-recorded interview files were then uploaded and copied to an external hard drive as a backup.
5 Analysis
Qualitative content analysis was used to organize, condense and decipher data from the interviews. The method is recognized as valuable when exploring human ideas or conceptions, where the aim is to obtain a broader spectrum of opinions and perceptions rather than confirmation of a pre-defined hypothesis (Malterud, 2001).
One of the test leaders transcribed the interviews verbatim using ELAN 5.2 (Wittenburg et al., 2006). Both test leaders read the transcripts twice individually to familiarize themselves with the content, after which they joined for discussions to determine and calibrate relevancy of each quotation to the study. Agreement was met, that all quotations regarding topics other than the speech samples or related issues, were to be excluded. With the chosen quotations, i.e. codes, initial categories were developed through dialogues between the two test leaders, and consensus was eventually achieved when disagreement occurred. After these initial cooperative discussions, one test leader completed the categorization, as well as the grouping of categories into themes. The suggested categorizations were overseen by the other test leader, after which discussions were scheduled for further considerations, resulting in the final categorizations (see Table 2).
Themes and their subordinate categories representing recurrent types of perceptions of 10–11-year old children listening to speech samples with or without speech sound disorders (SSDs).

6 Ethical approval
The application to the Regional Ethical Review in Stockholm was approved for the current study, as an addition to the existing approved application for the research project ‘Functional consequences of misarticulation in children’s continuous speech’ (record numbers 2016/1628-31/1 and 2017/2261-32).
III Results
The content analysis resulted in five main themes of listener reactions, each further divided into two to three categories. Several codes were placed in more than one category, depending on their multifaceted latent meanings. The main themes and their respective subordinate categories are defined in the section below, where digits indicate main themes and the subsequent letters indicate categories; for overview, see Table 2. The categories are, when informative, illustrated by codes, translated into English from Swedish. This translation was conducted by the first author, and has been checked by an English–Swedish bilingual associate. If a comment was made about a specific speech sample, it is specified in square brackets following the quote, i.e. ‘[s1]’ = speech sample 1. Categories unrelated to the research questions are described but not further analysed.
Theme 1: Experiences as a listener
Participants sometimes hypothesized the experience as a conversation partner to the speaker (category 1A):
[it must be] hard because I think it can get quite difficult for others to understand, that makes it hard and people can tease you if you kind of like don’t talk in a way people understand. [s1]
Comments on how watching the film prior to presentation of audio files helped the participants understand the context of the speakers’ utterances, were often present when speech intelligibility was particularly low (1B). Participants’ reactions of guilt often occurred subsequent to one’s own or peers’ laughing at speech or imitations of speech (1C): ‘I don’t want to be mean, but it was kind of funny when he talked’ [s2]. Participants would sometimes laugh at certain speech samples. Immediate urges to imitate speech occurred in similar situations as when laughing and would consequently not be an expression of an attempt to understand or analyse the sample.
Theme 2: Taking the perspective of the speaker
Some of the most frequent comments were expressions of pity or sympathy for the speakers. They sometimes lead to ideas of how to cope with SSDs. Among the most common expressions was ‘jobbigt’ (Eng. ‘hard’ or ‘difficult’) – commonly used to communicate understanding and consideration. (2A): ‘I think it must be pretty hard to make oneself understood with this language’ [s6]; ‘I think it must be quite hard to have like a speech error, or speech error, well you know’; ‘terrible’ [s5]; ‘very difficult’ [s5] and ‘[it must be] hard I think you must be falling quite much behind’ [s5]. Comments conveying compassion were recurrent when participants were presented with the most severe and unintelligible kinds of speech samples (2A): ‘If I’d have been this person I would probably have become angry with a lot of people because they didn’t understand what I said’ [s6]; ‘I would’ve become sad’ [s2] and ‘he might have felt stressed, maybe he knew we were going to listen to them’ [s6]. Statements in this category could express awareness of social norms and deviances:
I think it’s very sad that actually our ideal is like if you can’t talk pretty normal then you’re not normal, you’re supposed to be in a certain way in order to count as normal and hang out with the others and maybe have like a pretty good life, I think it’s very sad it’s like that.
When presented with the sample of TS, participants expressed reflections of successful speech treatment (2B): ‘It feels like this person has . . . practices much more than the others did’ [s3]. Concern about intervention in general was also expressed: ‘but you can get help from like speech therapists to do exercises at home?’ Participants commonly visualized possible outcomes of having an SSD, ranging from duration of speech issues to social consequences for the speaker (2B): ‘it might last for life’ or ‘you might get bullied for feeling speeded’ [s2] when referring to a speaker who was claimed to speak fast. When presented with [s2] (see Table 1), participants frequently expressed assumptions of either how the speaker wanted to speak, or was unable to control speech (2C): ‘it feels like he just wants to talk fast’; ‘it feels a little like he/she was talking carelessly’; ‘well like he/she tried to be cool’ and ‘I think he doesn’t know what he is saying but he talks superfast.’
Theme 3: Reflection on or judgment of speech
The theme of reflections or judgments of speech included concepts of rate, intelligibility, normality or acceptability of speech. Many remarks about speech rate were made (3A): ‘I think he talked a little fast so you couldn’t follow . . . skipped a few sounds’ [s1]. The most recurrent type of comment regarded intelligibility and followed nearly all presented speech samples (3B): ‘a little hard to understand’ [s1]; ‘you sort of didn’t understand anything’ [s5]. The TS sample lead to statements on how well the speech was understood (3B): ‘I understood everything’; ‘I think it might be easier to make oneself understood with this language than talking like the 9-year-old did.’ Observations of the speech sounding konstigt (English ‘awkward’ or ‘strange’) were often made succeeding speech samples with other deviances than apparent /s/- or /r/-errors and when intelligibility was low (3C): ‘it felt like he talked baby-talk or kind of like his own language’ [s5]; ‘it’s a little weird’ [s5] and ‘it sounded like the child spoke a completely different language and how could it [sic] be 9 years old?’ [s5]. The TS sample generated many positive opinions, as did the samples of the younger speakers (3C): ‘it sounded super cute’ [s6]; ‘it sounded very good’ [s3] and ‘I thought it sounded very cute because it sounds like a 5-year-old’ [s6].
Resemblance with foreign accents or dialectal differences were pointed out a few times by participants (3D): ‘it sounded like he/she had a Swedish, Finnish and Norwegian accent’ [s5]; ‘eh I started to think of eh I don’t know why but I started thinking about Gothenburg and Scanian dialects’ [s4] and ‘I started thinking about someone who comes from Arabia or whatever it’s called’ [s2]. Comparisons between speech samples were naturally made following the test leaders’ final question of ideas or thoughts, taking all speech samples into consideration (3E): ‘it was almost the youngest that you could hear quite well or very well’ and ‘I think that they were similar in the sense that they all had trouble pronouncing certain letters and sounds like /ʃ/ and sounds like that.’ Participants would often react to the (mis)alignment of speaker age and perceived speech proficiency (3E): ‘yes I almost think this one was harder [to understand] than the 5-year-old’ [s2]; ‘I thought you would understand if it was a 9-year-old’ [s5]. Comparisons with speech of relatives, peers or one owns earlier stages in speech development were made (3F): ‘this person talks like my little sister she’s like five I think’ [s3] and ‘I lisped when I was little but it was just . . . I had lost my front teeth . . . a girl in my class actually teased me because of that.’
Theme 4: Observation of articulatory traits
Participants frequently attempted to analyse or give suggestions of what specific speech traits a speaker exhibited. Many observations were made on inadequate /r/-production (4A): ‘I don’t think the person could pronounce “R” that well because all the R’s that were supposed to be there were like not used, they like skipped “R” ’ [s1]. Along with observations of erroneous /r/-production, observations of lisp or otherwise deviant /s/-production were among the most commonly pointed out (4B): ‘he lisped a little’ [s1] and ‘it was really hard for him to say “S” and /ʃ/’ [s6]. Observation of other omitted or replaced speech sounds were also made (4C): ‘hard to say like “P” so he said like “D” instead, “dingu” or “pingu”, same thing as when he said “papa” [dad] he said like “dabba” or “data” ’ [s5]; ‘it seemed like the child had difficulty saying “K” ’ [s3]; and ‘maybe he couldn’t maybe say like this “U” because he said “ognen” so it was like an “O” so it wasn’t “ugnen” ’ [s6]. (The letter ‘U’ refers to the Swedish phoneme /ʉː/, of which the short realization would be [ɵ], as in the word ‘ugnen’; /ˈɵŋnɛn/ = the oven. The letter ‘O’ is the Swedish orthographic form of the phoneme /u:/).
Theme 5: Observation of dysfluencies
Dysfluencies were at times plainly labeled as stuttering, albeit not regularly. Abrupt transitions between utterances were occasionally brought to light. To further distinguish types of dysfluencies, suggested categories encompass incoherency and abruptness in utterances. The category serves as a description of codes with the latent meaning of disjoint parts of speech, when it could not unambiguously be attributed to aspects of narration (5A). Participants often used the term ‘stuttering’/’to stutter’ when phrase, word or syllable repetition occurred (5B).
Identified themes unrelated to speech production
Comments about linguistic traits unrelated to speech sound production were recurring, however usually less specific: participants rarely labeled them to the same extent as for traits of speech production. Participants occasionally exemplified lexical or grammatical errors but did not describe them further. For instance, omitted genitive suffix -s was perceived: ‘in the beginning he put the words together like he said like “pingu little sister” or something like that’ [s6]. Lack of connectors did also cause reactions: ‘I thought a little like you earlier that they just say like “I swung I ran” like they didn’t say “and then . . .” ’ [s3].
IV Discussion
This study aimed to broaden the knowledge of contextual factors for children with SSDs, by identifying listener reactions as well as their possible associations to specific speech characteristics. To that end, children were targeted sources of valuable information on what reactions various SSDs evoke in everyday life for children affected by them. The most common subjective reactions to and comments on the speech samples were statements on low level of intelligibility and revealing empathy and pity for the children with SSDs. By the end of each interview session, when the participants had the chance to express thoughts of similarities or differences between the audio samples, many reactions related to the speakers’ ages and the perceived dissonance with the level of speech intelligibility or acceptability. Factual statements frequently consisted of observations of specific misarticulation types, in particular concerning misarticulated /s/ and /r/, which may be traced to the incidence of said misarticulations in the speech samples.
The findings partly align with previous related research confirming that children react explicitly to deviating /s/ and /r/-production, which also was found by Nyberg and Havstam (2016) and Hall (1991). It could be discussed whether the relatively late age of acquisition of these speech sounds (Blumenthal and Lundeborg Hammarström, 2014; McLeod and Crowe, 2018), as well as their frequency in the samples, could contribute to the high level of identification of these errors. Other types of misarticulation did not necessarily cause less reactions in the current study than the ones regarding /s/ and /r/, and might analogously have been less frequently represented among the speech samples. It is possible that the absence of a colloquial terminology of less frequently observed speech characteristics like incorrect voicing/devoicing, vowel distortions or unusual speech sound substitutions, resulted in less explicit verbalizations of the perceived deviations. Indeed, ‘lisp’ and ‘stutter’ are frequently used verbs in everyday language and popular culture, hence more likely accessible for non-professionals and children as well.
The set of speech characteristics that appeared to cause the most sympathy was co-occurrence of multiple speech errors, low intelligibility and/or the abovementioned less frequently observed speech characteristics, in a sample recorded from one of the oldest speakers. The age appeared to have an impact on the gravity with which the reactions were conveyed, as many reactions were explicitly associated with the age of the speaker. Participants seemed to become alarmed and concerned when facing the fact that the speaker was older than the others in the samples.
Participants reflected on perceived traits of foreign accent. Not only factual statements regarding speech and accent were uttered, but evaluative or judgmental ones, assuming the speaker wanted to sound ‘cool’ or did not know what to say. Moreover, speech associated with foreign accent caused many direct imitations and laughter. It cannot be precluded that sociolects associated with areas with lower socio-economic status (SES), as with native languages other than Swedish and possible remains of foreign accents, evoke certain reactions in peers. It would be further supported by the frequent comments regarding speech rate in the sample, a speech trait that along with syllable-timed utterances (in opposition to stress-timed in Standard Swedish), is commonly associated with sociolects spoken in said areas (Bijvoet and Fraurud, 2013). Participants were enrolled in the study according to the rationale of attending a school that was statistically representative for schools in Sweden in general. However, it cannot be ruled out that cultural factors such as the school’s urban localization, in an area associated with generally highly educated residents typically ascribed economic middle-class, had an impact on the reactions of this way of speaking.
Similarly to stuttering, SSDs do not necessarily fully resolve in every affected child when reaching adolescence or adulthood, despite therapy (Flipsen, 2015; Yairi and Ambrose, 2013). Treatment methods incorporating the perspective of contextual and individual attitudes towards these unresolved speech traits are indeed represented in the scope of stuttering therapy, i.e. acceptance and commitment therapy (Beilby et al., 2012). Such holistic arrays including attitudinal factors are nonetheless harder to find for SSDs, and are not listed among suggested treatment approaches for SSDs of influential national professional bodies, i.e. American Speech-Language-Hearing Association (2020) or The Royal College of Speech and Language Therapists (2019). The growing body of research on attitudes towards SSDs call for a clinical acknowledgment of residual and persistent speech errors, along with acceptance advocacy directed towards peers as well as the individuals with SSDs. On a non-medical side-note, this also applies when facing speech associated with non-standard dialects or sociolects of any given language.
V Limitations of the study
The interview questions did possibly prompt participant reactions that otherwise would not have been expressed. Despite the use of open-ended questions, the questions might have suggested to the participants that a reaction or response was expected to the speech samples. The reactions to the typical speech sample were two-fold and consisted predominantly of comments on how ‘well’ the child spoke, or how disconnected the speech was, the latter presumably relating to the nature of the sample recording and editing. However, single de facto false factual statements regarding the speaker’s inability to produce speech sounds were made. Throughout the interviews the participants normally concluded that the typical speech sample was ‘good’ nevertheless. This implies that reactions indeed were expressed following the interview questions, but that they systematically differed depending on the presence or absence of deviating speech.
There were more girls than boys among the focus group participants. In recruitment, efforts were not made to ensure gender balance; the composition of real-life classmates was prioritized. We refrain from speculating whether the factual gender composition may have influenced the results, but encourage readers to keep this in mind.
The speech material was selected to represent noticeable SSDs included in children at higher ages. To solely focus on the reactions towards speech characteristics of speakers in the same age as the participants would have been preferred, but according to both test leaders, SSDs were almost indiscernible in most samples of speakers aged 9–10 years in the larger dataset, hence insufficient to demonstrate the potential variety and severity of SSDs. The age of the participants allowed for the use of a more mature language with relatively distinctly expressed thoughts and opinions, hence more identifiable categories of reactions. It ought to be noted however, that younger and more evenly age-matched participants to speakers in speech samples, might use a language that, if not as developed as the 10–11-year-olds’, could be more instinctive and unconstrained, and contribute to the knowledge of listener attitudes among younger children.
In retrospect, including a sample with perceived foreign accent could have been discussed in advance, considering its notable impact on the results. The qualitative approach, on the other hand, was not to systematically assess the reactions to specific speech traits, rather to SSDs as they can appear among Swedish speakers regardless of their accent.
The comorbidity of SSDs and diagnoses associated with language difficulties and their respective associated traits, may have had an impact on the overall results. This despite the aim of the study to broaden the knowledge of listener attitudes towards SSDs, and the method designed to facilitate focus on speech rather than other linguistic features. During content analysis however, any reaction that did not straightforwardly match the description of a certain category was declared at the end of Section III (Identified themes unrelated to speech production).
VI Conclusions
Awareness of children’s reactions to and reflections about speech is beneficial in clinical practice when facing and confirming colloquial descriptions of SSDs, as well as when advocating for intervention. The findings suggest further research on the topics of what reactions specific misarticulation patterns cause, as well as whether SES of participants has an impact on how sociolects and SSDs are perceived, in both speakers themselves, peers, health care providers and teachers. The self-selected terms used by the participants could serve as labels in assessment instruments in future research, to complement the present qualitative findings with quantitative evidence.
Footnotes
Acknowledgements
Our sincere gratitude to SLP and research assistant Katarina Holm for crucial contribution during the materialization process of the research data. Thanks to all the participants, class teacher Anna Waziry for assisting the logistics of the focus group interviews, and native English-Swedish speaker SLP Carla Wikse Barrow for controlling translation of quotes.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research has been partially funded by the Swedish Research Council (VR2015-01525), with Sofia Strömbergsson as the PI.