
Abstract
This study demonstrates how sequence analysis, which is a method for identifying common patterns in categorical time series data, illuminates the nonlinear dynamics of dyadic conversations by describing chains of behavior that shift categorically, rather than incrementally. When applied to interpersonal interactions, sequence analysis supports the identification of conversational motifs, which can be used to test hypotheses linking patterns of interaction to conversational antecedents or outcomes. As an illustrative example, this study evaluated 285 conversations involving stranger, friend, and dating dyads in which one partner, the discloser, communicated about a source of stress to a partner in the role of listener. Using sequence analysis, we identified three five-turn supportive conversational motifs that had also emerged in a previous study of stranger dyads: discloser problem description, discloser problem processing, and listener-focused dialogue. We also observed a new, fourth motif: listener-focused, discloser questioning. Tests of hypotheses linking the prevalence and timing of particular motifs to the problem discloser’s emotional improvement and perceptions of support quality, as moderated by the discloser’s pre-interaction stress, offered a partial replication of previous findings. The discussion highlights the value of using sequence analysis to illuminate dynamic patterns in dyadic interactions.
Keywords
A substantial body of work in social psychology and communication assumes that features of conversations both reflect and affect qualities of participants and interpersonal relationships. Accordingly, empirical evidence shows that conversations reveal important individual differences (e.g., attachment style, Kafetsios & Nezlek, 2002; mental health, MacGeorge et al., 2005), contribute to important outcomes (e.g., conflict resolution, Thomson et al., 2018; emotional improvement, Jones & Wirtz, 2006), and mediate the impact of pre-existing conditions on changes in relationship well-being (e.g., Pietromonaco et al., 2021). Despite widespread acknowledgement of both the diagnostic and consequential importance of dyadic interactions, scrutiny of the behaviors that unfold during conversations is uncommon within research on interpersonal relationships. One impediment to the study of the turn-by-turn exchanges between partners is unfamiliarity with the computational tools for modeling the nonlinear and dynamic ways in which dyadic interactions unfold. In this paper, we illustrate how sequence analysis can be used to interrogate the nonlinear dynamics of conversations between social and personal relationship partners.
Probing the inner workings of conversations involves identifying the behaviors enacted as interactions unfold—often using categorical coding schemes that operationalize communicative acts in each partner’s speaking turns—to produce longitudinal representations of the partners’ alternating actions. Unfortunately, the most common methods for analyzing longitudinal dyadic data were developed for use with variables measured on a continuous scale that are obtained simultaneously from dyad members (e.g., random intercept cross-lagged panel models, Mulder & Hamaker, 2021). Moreover, methods that were developed for analysis of categorical data (e.g., hidden Markov models, Visser, 2002; sequential analysis, Bakeman & Gottman, 1997), tend to assume stationarity (i.e., the transition probabilities between categories are stable across an interaction) and emphasize lag-1 dependencies (i.e., from one turn to the next). Thus, prevailing methods for longitudinal dyadic data analysis are unable to capture some of the important nonlinear dynamics that manifest in categorical time series data from dyadic conversations.
We forward sequence analysis, a procedure that detects meaningful common patterns within sequenced phenomena (MacIndoe & Abbott, 2004), as a method for studying conversations. Originally, this method supported work in biology where the goal was to identify the similarity of DNA strands based on the sequencing of specific molecules. Sociologists, noting the similarity between DNA strands and their categorical sequence data, adapted sequence analysis to study life course patterns revealed by sequences of participation in education, family, and (un)employment across time (Gauthier et al., 2013). In our application, sequence analysis enables the study of nonlinear dynamics embedded in dyadic conversations in two ways. First, sequence analysis is a data driven, inductive approach that captures how conversations shift categorically; therefore, it can describe the wide variety of different directions conversations may take without being constrained by assumptions about linear change. Second, the results of sequence analysis can be used to model nonlinear and time-variant associations between the prevalence of particular sequences and theoretically important antecedent or outcome variables.
To illustrate these possibilities, this paper uses sequence analysis to identify multi-turn patterns in supportive conversations where one person, the discloser, discusses a source of distress with a partner, the listener. We use the resulting sequences, which we call supportive conversational motifs, to (a) illuminate dynamic patterns within conversations and (b) evaluate how those conversational patterns may be related to the discloser’s emotion regulation outcomes. As a foundation for this illustrative example, we begin by reviewing research on sequences of interaction within supportive conversations.
Sequences within Supportive Conversations
Multiple programs of inquiry have documented the importance of patterns of behavior within conversations between relationship partners. Ground-breaking research on marital interaction, for example, demonstrated that distressed and non-distressed couples can be distinguished by their tendency to reciprocate negative responses during conversations, more so than by aggregate summaries of their conversational behavior (Gottman et al., 1977). Theory and research on influence interactions suggests that an individual’s compliance with a request is shaped by the presence or absence of pre-request messages, the sequencing of requests by magnitude, and the provision and timing of reasons to comply (see Dillard & Knobloch, 2011). Similarly, Levine’s (2020) recent truth default theory proposes that deception detection can be dramatically improved when truth-seekers ask questions in a particular order. To anchor our application of sequence analysis to supportive conversations, the following paragraphs review research on the ordering of messages within these conversations, theoretical perspectives on the overall structure of supportive episodes, and our previous research on supportive conversational motifs.
Although most research on supportive messages has focused on either features of discrete messages (e.g., verbal person centeredness, Bodie et al., 2012) or properties of supportive conversations as a whole (e.g., support strategy, Barbee et al., 1998), the notion that particular sequences of messages within interactions affect the outcomes of supportive conversations is widely held. For example, the active listening paradigm emphasizes the importance of following a discloser’s speaking turn with acknowledgement, paraphrasing, reflecting feelings, assumption checking, or open questions (Bodie et al., 2015). The assumption pervading this body of work is that well-timed verbal responses convey attentiveness, communicate empathy and a desire to understand, and encourage a speaker to keep talking (e.g., Nugent & Halvorson, 1995). Likewise, research demonstrates that advice messages are perceived as higher quality when they are at the end of a sequence that begins with emotional support, turns next to problem inquiry and analysis, and concludes with advice (Feng, 2009, 2014). Advice message sequences matter, in part, because leading with emotional support conveys positive regard for the advice recipient (Feng et al., 2017). In total, this research illustrates how sequences of messages within supportive interactions can shape outcomes.
Moving from conversational segments to interaction episodes, two theoretical perspectives elucidate how supportive conversations might unfold through a sequence of phases that help a person in distress gain a less upsetting understanding of a problem. In one line of work, Jefferson (1988) used a qualitative, inductive method (i.e., conversation analysis) to detect six ordered phases of “troubles talk”: (a) approach signals the presence of a problem; (b) arrival establishes the intention to communicate about it; (c) delivery is marked by disclosers elaborating on specifics of the stressor, while listeners acknowledge, ask questions, and further elaborate on the events; (d) work-up involves sharing related experiences and jointly examining consequences and options to promote a deeper understanding; (e) close implicature, which integrates the stressor into everyday life while also looking ahead, sees a decrease in listener questions and discloser elaborations, an increase in listener reflections, and the appearance of advice; and (f) exit includes ending the conversation or starting a new topic. In another line of work, conversationally induced reappraisal theory (CIRT) proposes that conversations can yield supportive benefits when (a) disclosers are willing to talk about the event, (b) disclosers are able to articulate their feelings, and (c) emotions are discussed in a way that facilitates reappraisals (Burleson & Goldsmith, 1998). Both Jefferson (1988) and Burleson and Goldsmith (1998) suggest a structured organization of supportive conversations that moves from describing experiences, to elaborating on the situation, and ultimately to developing new insights that facilitate reappraisal of stressful events. Moreover, both perspectives predict that supportive conversations, when executed accordingly, lead to greater emotional improvement.
Supportive Conversation Turn Types from Solomon et al. (2021).

Note. The speech acts are based on the Stiles’ Verbal Response Mode coding scheme: see Bodie et al. (2021) for more details.
The Three Most Frequent Turn Types Comprising Each Turn in the Five-turn Supportive Conversational Motifs from Solomon et al. (2021).

a None of the frequencies for other turn types exceeded 1%.
Solomon et al. (2021) also examined how the prevalence and timing of the three motifs were related to differences in discloser’s emotional improvement after the conversation; based on the dual-process model of supportive communication (Bodie, 2013), we also considered how those associations were moderated by the discloser’s pre-interaction stress. One trend suggested that the discloser’s post-conversation emotional improvement was negatively associated with the prevalence of the listener-focused dialogue motif in the first phase of the conversation. In addition, when disclosers reported relatively low levels of stress, emotional improvement tended to increase with more prevalent discloser problem processing motifs in the first phase of the conversation and decrease with more prevalent discloser problem description motifs in the middle phase of the interaction. Among disclosers who reported relatively high pre-interaction stress, increases in the prevalence of the discloser problem description motif in the middle phase of the conversations tended to correspond with more emotional improvement.
In total, we draw three conclusions from the body of work on sequences in supportive conversations. First, theory and research on supportive communication highlights the importance of types of speech acts (e.g., questions, acknowledgements, disclosures), more so than the emotional valence or semantic content of a speaking turn (e.g., what, specifically, a disclosure is about). Although some research has focused on those qualities in supportive conversations (e.g., expression of negative emotions, Bodie et al., 2012; problem- vs. emotion-focused coping, Barbee et al., 1998), the theoretical perspectives we reviewed emphasize how it is the opportunity for disclosure and elaboration that is encouraged by questions or acknowledgements, regardless of valence or semantic content, that leads to problem (re)appraisal and fosters emotional improvement. Second, we observed that multi-turn segments of conversations are theoretically and empirically meaningful. Third, Jefferson’s (1988) model, CIRT, and evidence from Solomon et al. (2021) suggest that the effects of different multi-turn segments on conversational outcomes depends on when in the conversation those segments occur, as well as the discloser’s initial levels of stress. Next, we describe how to conduct sequence analysis to advance research that builds on these insights about supportive conversations and applies to the study of dyadic interaction, in general.
Applying Sequence Analysis to Conversations
There are five conceptual and empirical considerations involved when using sequence analysis to advance research on the dynamics of dyadic conversations. First, sequence analysis requires univariate categorical time series data, such that each unit in the sequence is represented by one, and only one, categorical code. 1 In applications to conversational data, the speaking turn provides a natural unit of analysis that focuses attention on the back-and-forth exchange of messages between partners. As summarized in Table 1, our analysis of supportive conversations focuses on the specific kinds of speech acts individuals use during speaking turns because theory and research in this domain emphasizes how different types of speech acts enable cognitive processes that foster emotional improvement (e.g., Burleson & Goldsmith, 1998). Analyses of other types of conversations might instead be attentive to the conversational moves that vary in valence (e.g., constructive or destructive conflict tactics, Canary & Spitzberg, 1987) or the semantic focus of speaking turns (e.g., Levine, 2020).
Second, applying sequence analysis to conversations requires specifying subsets of speaking turns that constitute potentially meaningful chains of behavior. At the extremes, the number of units (e.g., speaking turns) within a segment can range from two to the total number of units in the entire sequence. To capture nonlinear patterns, segments must consist of at least three units to allow for nonlinear change. When the time series reflect speaking turns between two partners, at least five turns are required to assess nonlinear patterns because a five-turn segment ensures that one partner has the minimum of three turns. When theory does not clearly point to the number of units that define a segment—and at this point, we are unaware of any theories that do—determining the number of units within segments follows an inductive process of generating solutions using segments of different lengths. For example, Solomon et al. (2021) explored the interpretability of conversational motifs that manifested across multi-turn segments of different lengths (i.e., 5, 7, 10, and 20 turns). Thus, evaluating the clarity of distinctions between the results of alternative analyses and their alignment with theory informs the conclusions the researcher draws about the number of units used to define conversational motifs.
Third, decisions about segment length are complemented by the determination of segment overlap, ranging from a 1-unit offset to start each new segment to zero overlap between segments. Where possible, this decision is also informed by theory. In our previous work on conversations, we used a 2-turn overlap (a moving window with 2-turn offset), so that each sequence begins with a discloser’s speaking turn. When dyad members are not distinguishable by role, a 1-unit offset may be preferable to allow either member of the dyad to initiate a conversational motif. When the structure of dialogue is experimentally controlled, such that a manipulation restarts a sequence of interest after a specified number of turns, it may be useful to specify zero overlap between contiguous segments. As was the case with specifying the length of sequences, these decisions are embedded within the particular theories relevant to the conversational episode, tied to research protocols, and informed by exploratory analyses.
Fourth, once the categorical time series data are segmented according to the specified length and overlap, an optimal matching algorithm is used to calculate the dissimilarity among all the sequences. Specifically, the dissimilarity between each pair of sequences is calculated as the minimum number of insertions, deletions, and substitutions needed to transform one sequence into the other. To illustrate, consider the two pairs of five-turn sequences depicted in Figure 1. The first pair of sequences has a lot in common, and only one substitution is needed to make them identical. In contrast, the second pair of sequences has different types of turns on all five steps of the sequence; so it would take five substitutions to make them match. Typically, the insertion and deletion costs are set to = 1, and substitution costs are set = 2 (because a substitution requires one deletion and one insertion); however, substitution costs can also be weighted based on theoretical considerations or derived statistically from category prevalence in the data (see Gauthier et al., 2009). The chosen insertion, deletion, and substitution costs are then used in an optimal matching algorithm (Needleman & Wunsch, 1970) to iteratively determine the minimum cost of transforming each observed sequence into every other observed sequence. Repeated across all sequences in the sample (n = number of sequences), one obtains an n x n dissimilarity matrix that describes the dissimilarities among all the observed sequences. Two exemplar sequence transformations.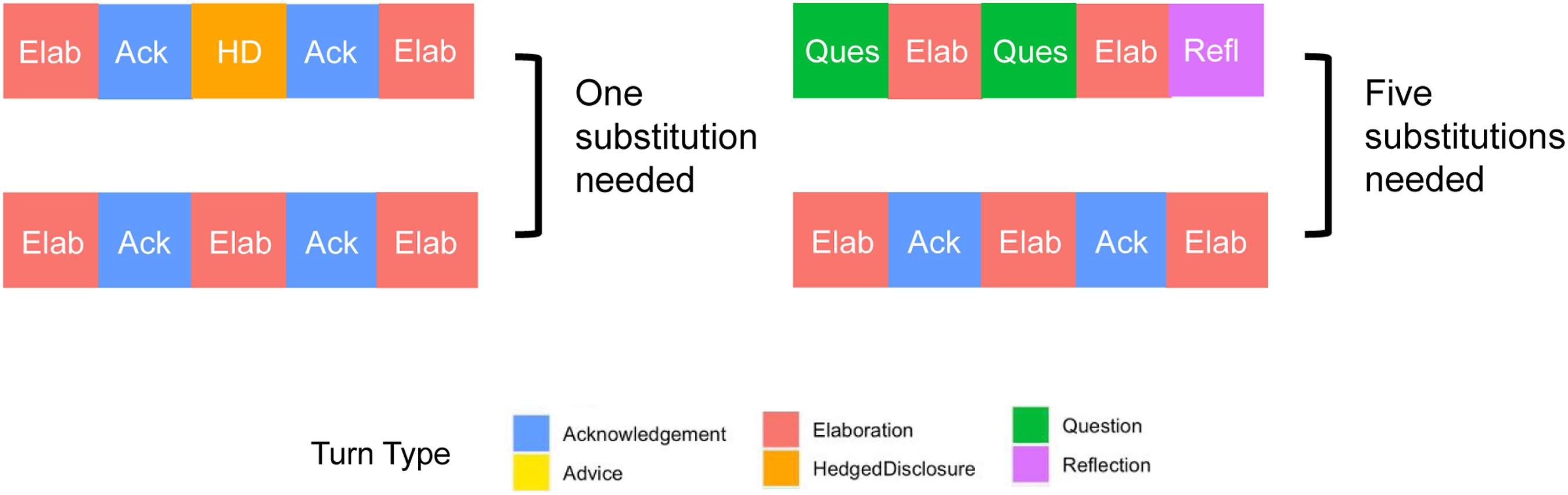
Fifth, the dissimilarity matrix is used as input into a cluster analysis to obtain a parsimonious typology of sequences. For example, hierarchical cluster analysis, using Ward’s (1963) single linkage method, first groups together sequences that are the least dissimilar (i.e., have a dissimilarity of 0 from each other), and then iteratively aggregates groups of sequences that are least dissimilar from each other until all the groups are combined. The clustering solution, often represented as a dendrogram with each observed sequence represented by a vertical line at the bottom of the dendrogram and groups represented by horizontal lines connecting the vertical lines directly below it, facilitates identification of the number of clusters that are represented in the data. Although the choice of number of clusters is somewhat subjective (but informed by cluster fit statistics), the goal is to select a cut point that clearly cuts across (relatively) long vertical lines in the dendrogram. Sometimes, multiple cut points (i.e., different numbers of clusters) may seem viable, in which case it is useful to explore alternative solutions and consider the theoretical interpretation and contributions of each. Once the number of clusters is chosen and the typology developed, researchers can assign the observed sequences to a cluster, describe differences among the groups of sequences, and examine sequences in relation to other theoretically meaningful constructs that vary within or between dyads.
The Present Study
With an understanding of sequence analysis in place, we return to our illustrative application to supportive conversations. As summarized previously, Solomon et al. (2021) identified three supportive conversational motifs using sequence analysis. Because the approach is inherently inductive, those conclusions are bound by the parameters of the specific stranger dyad data analyzed in that study. Thus, further research is needed to test whether the three supportive conversational motifs identified in our previous study replicate in other data sets. Formally, we ask:
RQ1: Are the supportive conversational motifs identified by Solomon et al. (2021) replicated in a set of supportive conversations that are more diverse with regard to research protocol and relationship type? In addition, we test specific hypotheses about how the prevalence and timing of supportive conversational motifs are linked to conversation outcomes. Guided specifically by the trends observed in our previous study and assuming those motifs replicate, we propose three hypotheses. The first hypothesis reflects evidence that listener-focused dialogue may be less helpful when it occurs early in a supportive conversation. The second and third hypotheses specify how the outcomes associated with discloser problem processing and discloser problem description are contingent on their timing and the discloser’s pre-interaction stress. Specifically:
Method
Data for our analyses are drawn from three laboratory observation studies in which 285 dyads comprised of strangers (High & Solomon, 2016), friends (Cannava & Bodie, 2017), or dating partners (Priem & Solomon, 2011) had a conversation focused on one partner’s (the discloser’s) source of distress. In a previous report on these data (Bodie et al., 2021), we described how these conversations were transcribed and unitized into uninterrupted utterances within speaking turns, which were then coded with Stiles’ (1992) Verbal Response Modes (VRM) taxonomy. Specifically, the VRM identifies eight categories that are used to code both the form and intent of each utterance: disclosures (revealing thoughts and feelings), edifications (stating objective information), advisements (attempting to guide behavior), confirmations (comparing speaker’s experience with partner’s), questions (requesting information), acknowledgements (conveying receipt of or receptiveness to other’s communication), interpretations (explaining or labeling the partner), and reflections (putting partner’s experience into words). 2 Patterns of co-occurrence among utterances within speaking turns suggested parsimonious representation with the six distinct types of speaking turns summarized in Table 1: acknowledgement, advice, elaboration, hedged disclosure, question, and reflection. The data analyzed here are the turn-by-turn categorical time series for each dyadic conversation, disclosers’ pre-conversation ratings of stress, and disclosers’ post-conversation self-reports of emotional improvement and perceived support quality.
Participants and Procedures
All three studies obtained data from college students and employed similar research protocols. The overlap in the procedures allows us to combine the data and evaluate sample differences. At the same time, the samples are quite homogeneous. Although the data are suitable for demonstrating sequence analysis and illuminating nonlinear patterns in supportive conversations, conclusions about the particular supportive conversational motifs that characterize these interactions are necessarily bounded by the demographic qualities of the participants in these three studies.
Stranger dyads: Students (N = 238, 119 dyads, M age = 20.30 years, SDage = 2.12) enrolled in a general education communication course at a large public university in the northeastern United States (i.e., State College, Pennsylvania) received a small amount of course credit for completing procedures (High & Solomon, 2016). Participants (n = 114 male, n = 124 female) identified as Caucasian (n = 183), African American (n = 14), Asian/Asian American (n = 31), or Hispanic/Latinx (n = 10). Participants who were randomly assigned to the discloser role identified and rated an upsetting event (e.g., school stress, relationship issues) they were willing to discuss with a stranger who served in the role of the listener. To increase variance in the quality of enacted support, listeners were randomly assigned to one of three supportive communication conditions, and provided definitions, examples, and strategies for enacting low, moderate, or high person-centered support (see High & Solomon, 2016, for information on manipulation checks). 3 Conversations lasted up to 10 minutes and were recorded. Then, participants separately completed post-conversation surveys.
Friend dyads: Undergraduate students (N = 164, 82 dyads, M age =19.99 years, SDage = 3.28) in general education and communication studies courses at a large public university in the southern United States (i.e., Baton Rouge, Louisiana) signed up for a lab time and brought a friend (Cannava & Bodie, 2017). Participants (n = 108 female, n = 56 male) identified with one of the following categories: Caucasian (n = 123), African American (n = 32), Asian/Asian American (n = 7), Hispanic/Latinx (n = 4), Pacific Islander (n = 1), or Other (n = 3). Friends were randomly assigned to listener or discloser roles. Disclosers then identified, rated, and discussed a stressful event. Conversations lasted 5 minutes, were recorded, and were followed by a post-conversation survey.
Dating dyads: Undergraduate students (N = 206, 103 dyads, M age = 20.4 years, SDage = 1.97) from the same university where the stranger dyad study was conducted (State College, Pennsylvania, United States) brought their dating partner to the lab (Priem & Solomon, 2011). Data from 84 heterosexual dyads (168 people) with complete data were included in the current analyses. 4 Participants identified as Caucasian (n = 139), African American (n = 8), Asian/Asian American (n = 6), Hispanic/Latinx (n = 5), or Other (n = 2; missing, n = 4 dyads). Most (93.5%) were in a “serious dating relationship.” Upon arrival at the lab, participants and partners were separated, and participants completed activities to simulate negative performance experiences, negative feedback, and social evaluation with the goal of resembling minor, everyday stressors. After the tasks, the researcher gave the participant feedback, which indicated that the participant’s performance reflected negative personal qualities. Partners (i.e., listeners) were randomly assigned to engage in neutral listening (i.e., refrain from offering personal opinions, feelings, or thoughts) or supportive listening (e.g., maintain eye contact, ask questions that probe the participant’s feelings, and validate the participant’s feelings). 5 Following instructions to the listeners, partners were reunited to have an eight-minute conversation about the participant’s experience and performance feedback, after which they separately completed a post-conversation survey.
Measures
Our illustration of sequence analysis makes use of the turn-by-turn categorical (6-category) time series for each dyadic conversation, as well as the discloser’s self-reported pre-interaction stress and two measures of two conversational outcomes: the discloser’s report of emotional improvement and the discloser’s evaluations of support quality. 6
Pre-interaction stress: All three studies included a measure of stress that was completed prior to the conversation. Participants in the stranger dyads study reported the severity of their stressor on a 100-point scale (1 = not at all severe, 100 = extremely severe; M = 80.84, SD = 16.35). To facilitate analyses, scores were divided by 100 and multiplied by 7 so that problem severity was indexed on a 7-point scale (M = 5.66, SD = 1.14). Friends assigned to the role of discloser evaluated the severity of the situation they had identified by responding to one item on a scale ranging from 1 = not at all emotionally stressful to 7 = very emotionally stressful (M = 4.57, SD = 1.29). Within the study of dating dyads, disclosers reported on their stress levels after the stress-inducing tasks by indicating their agreement (1= strongly disagree to 7 = strongly agree) with the statement “After the task, I feel stressed” (M = 4.90, SD = 1.85).
Emotional improvement: In the study focused on the stranger dyads, emotional improvement was operationalized by four items: (a) “The conversation made me feel better,” (b) “I don’t feel any better after that interaction” (reverse-coded), (c) “That interaction made me feel worse” (reverse-coded), and (d) “The conversation made me feel better about my problem.” Participants reported their agreement with each item on a 5-point scale (1= strongly disagree to 5 = strongly agree; M = 3.54, SD = 0.79; α = 0.85), which we transformed to a 7-point scale by dividing by 5 and multiplying by 7 (M = 4.98, SD = 1.05). Both the friend and dating dyad samples included three items from Clark et al.’s (1998) Comforting Response Scale: (a) “I feel better after having talked with my friend,” (b) “My friend made me feel better about myself,” and (c) “I feel more optimistic after having talked with my friend.” Responses to these items were assessed on 7-point scales (1= strongly disagree to 7 = strongly agree; friend sample M = 5.38, SD = 1.24, α = 0.91; dating sample M = 4.95, SD = 1.19; α = 0.91).
Evaluations of support quality: In the stranger dyads study, support quality was indexed by four items from Canary and Spitzberg’s (1987) Interpersonal Communication Competence measure (“He/she seemed sensitive,” “Everything, he/she said was appropriate,” “He/she is a good listener,” and “He/she is easy to talk to”). Responses were recorded on a 5-point Likert scale (M = 3.94, SD = 0.71, α = 0.70), which we transformed to a 7-point scale (M = 5.53, SD = 0.92). Both the friend and dating dyads data sets included four items from Goldsmith et al. (2000) with responses reported on 7-point semantic-differential scales and scored such that higher values indicated evaluations of higher quality support. For friends, adjective pairs were preceded with “To what extent do you think the behavior of your friend was…,” and followed by “sensitive-insensitive,” “helpful-hurtful,” “useful-useless” and “considerate-inconsiderate” (M = 5.30, SD = 0.71, α = 0.81). For the dating dyads data set, items began with the stem “During the conversation, my partner’s behavior was…,” and followed by “sensitive-insensitive,” “helpful-unhelpful,” “effective-ineffective,” and “appropriate-inappropriate” (M = 5.77, SD = 1.27, α = 0.91).
Data Analysis
To identify the conversational motifs that manifest in these conversations (RQ1), we combined the three data sets and worked through the sequence analysis steps outlined previously. Following Solomon et al. (2021), we segmented all conversations into a collection of 12,310 complete (i.e., no missing data) five-turn sequences (discloser–listener–discloser–listener–discloser) using a two-step moving window (so sequences always started with a discloser turn). The dissimilarities among sequences were calculated using the optimal matching algorithm with a constant substitution cost matrix (i.e., the cost of substituting one category for any other category was always = 2; MacIndoe & Abbott, 2004), and clustered hierarchically to identify a collection of conversational motifs (i.e., groups of similar sequences). Next, for descriptive purposes, we summarized how the identified motifs manifested temporally by summarizing their frequencies in the beginning, middle, and final thirds of the conversations. 7 Then, to examine how the prevalence and timing of motifs were associated with emotional improvement and support quality, as moderated by pre-interaction distress (H1-H3), we used a multiple-group structural equation model (implemented using the lavaan package in R, R Core Team, 2020; Rosseel, 2012) that accommodated multiple post-conversation outcomes and attended to differences between the methods employed in the subsamples.
All the data preparation and analyses were conducted in R (R Core Team, 2020). Specifically, we used the dplyr package for data preparation (Wickham et al., 2020), the TraMineR package for sequence analysis (Gabadinho et al., 2011; Studer & Ritschard, 2016), and the cluster package for cluster analysis (Maechler et al., 2021). The online supplemental materials include annotated step-by-step R code that walks the user from description of the categorical time series data through sequence and cluster analysis to the examination of how conversational motifs are related to outcome variables. The step-by-step code we provide assumes users are familiar with R (e.g., can read in and prepare the categorical time series data), but it is accessible for users who have not previously conducted sequence or cluster analysis. A related tutorial can be found online on the Longitudinal Human Analytics Made Accessible website (https://lhama.la.psu.edu).
Results
The Three Most Frequent Turn Types Comprising Each Turn in the Five-turn Supportive Conversational Motifs.
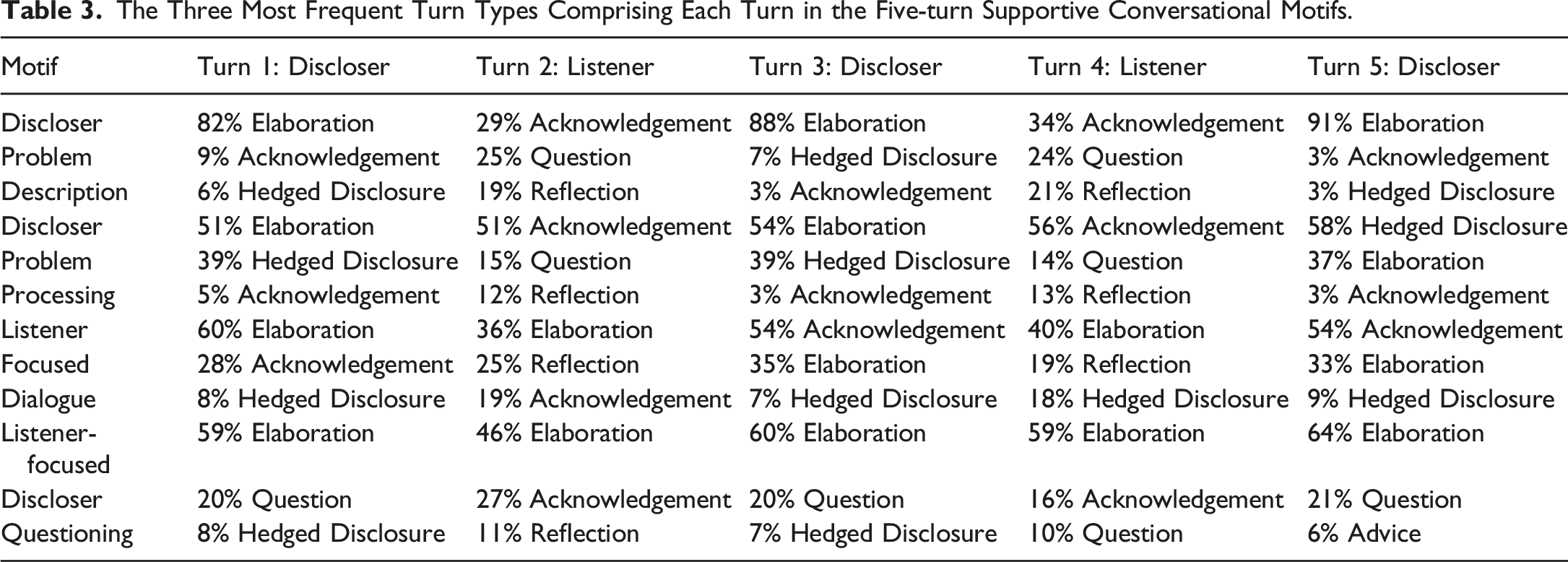
Descriptive analyses showed that the frequency of motif use changed across time as the conversations unfolded. Following Solomon et al. (2021), conversations were divided into three phases, with equal proportions of turns placed in each phase. As shown in Figure 2, changes in how frequently each motif was used across the conversation indicated that: (a) the discloser problem description motif was consistently prevalent across time; (b) the discloser problem processing motif manifested less frequently across time; and (c) the listener-focused dialogue and listener-focused, discloser questioning motifs manifested more frequently across time. Differences in average prevalence of each supportive conversational motif in each phase.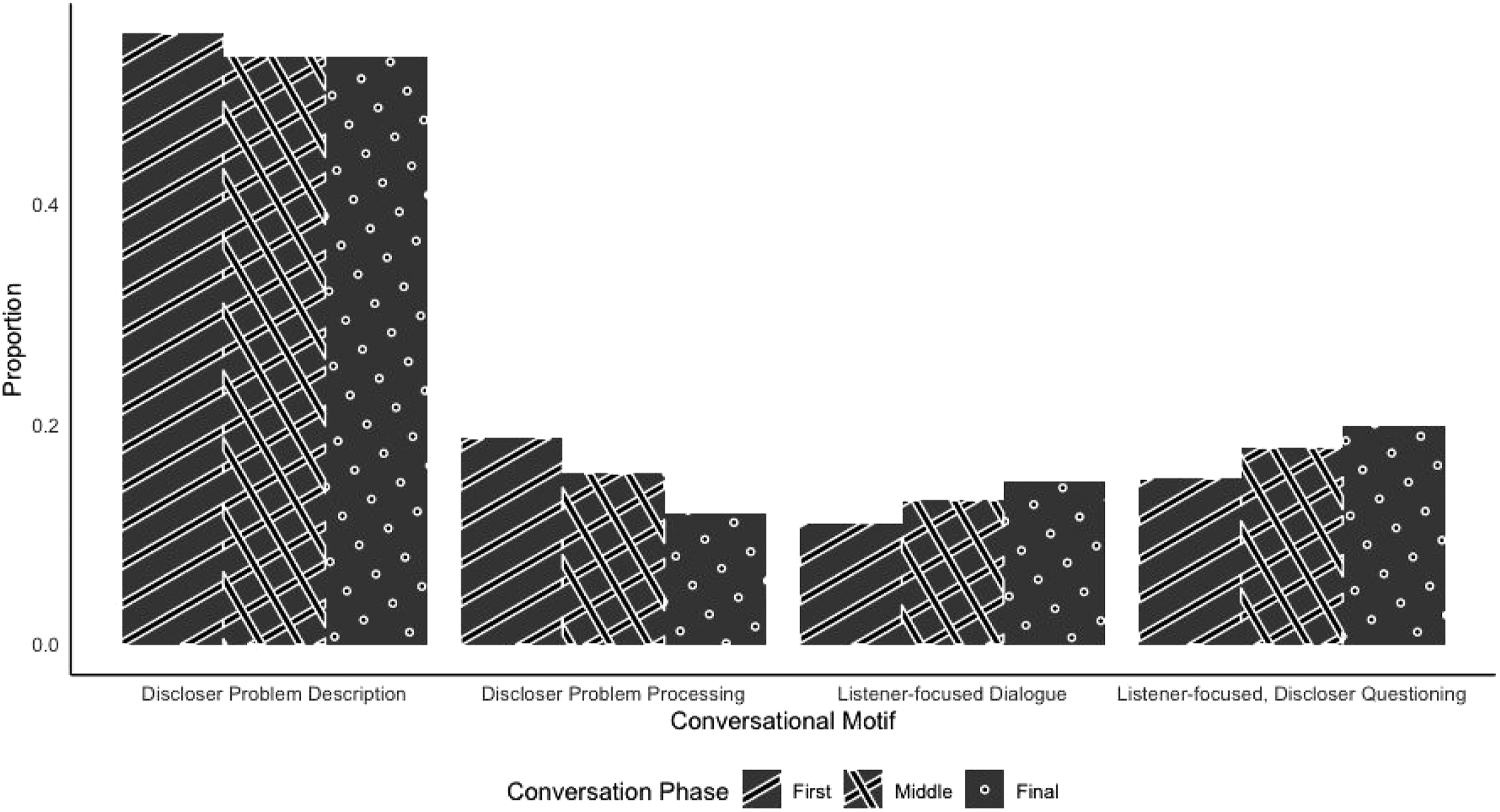
Using the supportive conversational motifs identified through sequence analysis, we then tested our hypotheses linking the prevalence of each motif in the first, middle, and final thirds of conversations to emotional improvement and evaluations of support quality. 8 We assessed four multi-group structural equation models (one for each motif type), in which the predictors were (a) the proportion of the conversational motif in the first, middle, and final thirds of the conversation, (b) pre-interaction stress, (c) three interaction term variables, computed as the product of the proportion scores and pre-interaction stress scores, and (d) the length of conversation as a control variable. 9 All variables were grand-mean centered based on the full data set (i.e., combining samples of stranger, friend, and dating dyads). The two outcome variables, emotional improvement and support quality, were specified as latent variables with a single indicator to accommodate unreliability of measurement (specifying the variance of the manifest indicators = [(1 – α)*(σ)] using the specific reliabilities observed in each of the three samples; see Bollen, 1989, p. 169).
Differences across relational contexts in the associations between prevalence and timing of conversational motifs and conversational outcomes were examined using three nested models. In the first model, the intercepts and regression paths were constrained to be equal across the three groups; these fully constrained models did not fit the data well. 10 In the second model, the intercept parameters for emotional improvement and support quality could differ across groups; these models fit the data reasonably well. In the third model, the intercepts and regression parameters could differ across groups (a fully unconstrained and saturated model). Likelihood ratio tests of relative fit of the second and third models indicated that the fully unconstrained model did not fit the data significantly better than the more constrained model (ps > .24), indicating that the prevalence and timing of conversational motifs (and pre-interaction stress) were related to post-conversation emotional improvement and support quality in a similar way in all three relational contexts.
Results from Multi-group Structural Equation Models Examining How Prevalence and Timing of Conversational Motifs Are Related to Post-Conversation Outcomes.
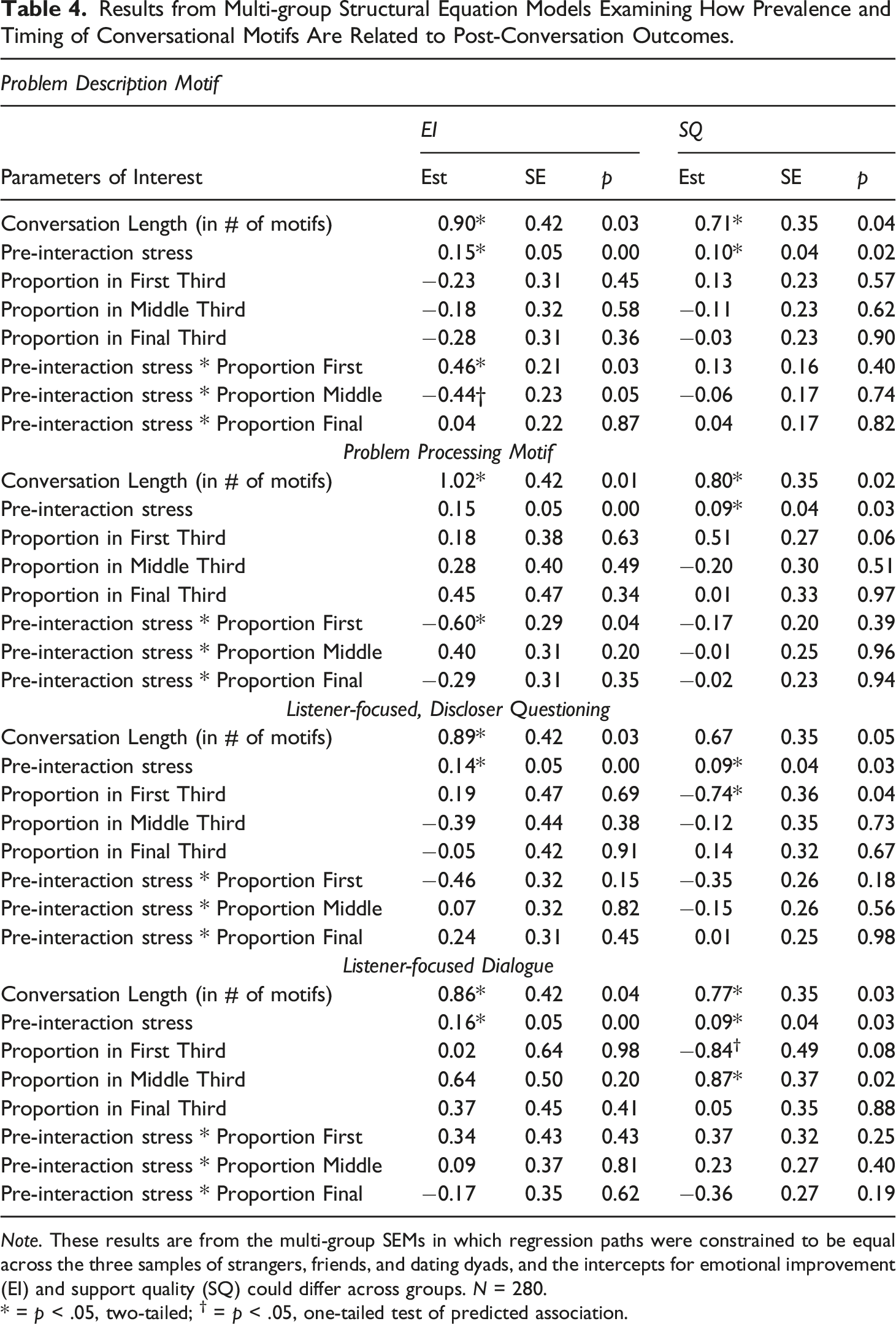
Note. These results are from the multi-group SEMs in which regression paths were constrained to be equal across the three samples of strangers, friends, and dating dyads, and the intercepts for emotional improvement (EI) and support quality (SQ) could differ across groups. N = 280.
* = p < .05, two-tailed; † = p < .05, one-tailed test of predicted association.
Our remaining hypotheses specified that conversational outcomes would be predicted by interactions between pre-interaction stress and (H2) the proportion of the discloser problem processing motif in the first third of the conversation and (H3) the proportion of the discloser problem description motif in the second phase of the conversation. These interactions were statistically significant (p < .05 one-tailed) for emotional improvement, but not support quality. Although not hypothesized, we also observed that emotional improvement was significantly predicted by the interaction between pre-interaction stress and the proportion of the problem description motif in the first third of the interaction (p < .05 two-tailed).
Finally, we plotted the significant interactions to clarify their form. As shown in the left panel of Figure 3, a greater proportion of the discloser problem processing motif in the first third of conversation was associated with (a) more emotional improvement when pre-interaction stress was low and (b) less emotional improvement when pre-interaction stress was high. This pattern is consistent with H2. With regard to H3, we determined that the form of the interaction involving the discloser problem description motif in the middle third of the conversation ran counter to the prediction; because this association was not significant using a two-tailed test, we do not discuss it further. In the right panel of Figure 3, we see that a greater proportion of the discloser problem description motif during the first third of conversation was associated with (a) more emotional improvement when pre-interaction stress was high but (b) less emotional improvement when pre-interaction stress was low. This pattern, which was not anticipated by our hypotheses, suggests that opening the conversation with problem description had a negative effect on emotional improvement for disclosers who were not especially distressed before the interaction. In sum, H2 was supported when emotional improvement, but not support quality, was the outcome variable, and H3 was not supported. Associations between prevalence of two supportive conversational motifs during the first third of interaction and emotional improvement, as moderated by pre-interaction stress (with standard error bars).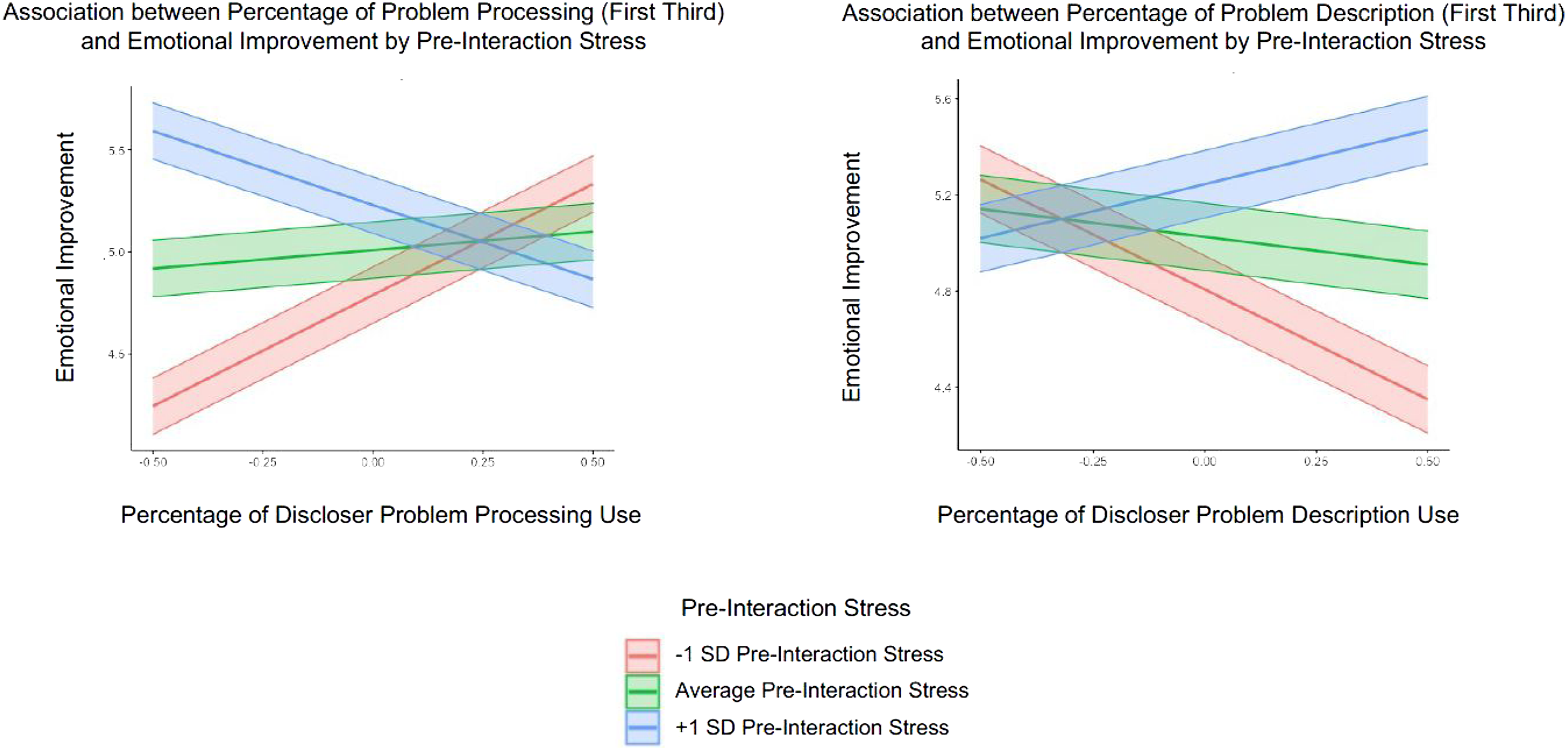
Discussion
This study illustrated how sequence analysis can be used to identify patterns of categorial turn-taking behavior—conversational motifs—within dyadic interaction. Because this method allows researchers to identify meaningful and multi-turn shifts in behavior, it departs from the more common focus on incremental, linear change or two-turn contingencies. Instead, sequence analysis allows researchers to detect and describe nonlinear variations in behavior in dyadic interactions. In turn, researchers can conduct analyses that evaluate how motifs are related to conversational antecedents and outcomes, and those analyses can also assess nonlinear and time-variant patterns. Thus, sequence analysis merits a place in the toolkit of researchers seeking to articulate nonlinear and dynamic frameworks in their study of interpersonal relationships. In the paragraphs that follow, we highlight some of the different ways relationship researchers can use sequence analysis.
Although our example focused on supportive conversations in which one person was discussing a source of stress with a partner, this method can be applied to a variety of communication episodes. Consider, for example, the well-established demand-withdraw pattern that sometimes characterizes conflict interactions between romantic partners (e.g., Caughlin, 2002). Sequence analysis of multi-turn exchanges could clarify how various responses in subsequent turns cement or shift this problematic dynamic. Likewise, sequence analysis of conversations ranging from initial interactions between strangers (Kellermann & Lim, 1990) to patients consulting with a doctor (Robinson, 2003) and including technologically mediated exchanges (Brinberg & Ram, 2021) can all shed light on consequential nonlinear dynamics of conversation.
We also see value in research that can refine the application of sequence analysis to interpersonal processes and relationships. Using sequence analysis requires several decisions, including the length of the sequence to be examined, the cost of sequence transformations (i.e., insertion, deletion, and substitution costs), the algorithm for computing dissimilarity between sequences (e.g., Needleman–Wunsch optimal matching algorithm), the method for grouping sequences (e.g., cluster analysis), and the treatment of missing data. Given the relative novelty of applying sequence analysis to conversation data, it is not yet clear how these decisions impact results. Future research is needed to better understand how the characteristics of the data and analytical choices impact the discovery of the nonlinear dynamics embedded in conversation.
Although exemplifying the affordances of sequence analysis was our primary aim, this study also offered theoretically meaningful insight into qualities of supportive conversations. For example, we observed that the number of speaking turns was a significant predictor of differences in emotional improvement and support quality. Given that a greater number of turns imply shorter turns and more frequent turn-taking, this finding suggests that demonstrating conversational involvement through more rapid conversational back-and-forth can have supportive benefits (Clark, 1993). Aligning with Jefferson’s (1988) phase model of “troubles talk” and CIRT (Burleson & Goldsmith, 1998), our results also suggested the value of (a) keeping the focus on the discloser in the opening phases of supportive conversations, (b) encouraging people who are stressed to describe their situation initially, and (c) encouraging people to open conversation about minor stressors with hedged disclosures and elaborations. These findings resonate with the dual-process framework of supportive communication, which stipulates that the benefits of supportive messages depend on both their timing within conversation and the initial levels of stress that disclosers are experiencing (Bodie et al., 2012).
Directions for Future Research
Evidence that the relation between the prevalence and timing of conversational motifs and post-conversation outcomes did not differ across the three combined data sets is notable, especially because the research procedures and measures of the self-report variables were not identical across studies. Of course, one important similarity among samples was the recruitment of college students and the lack of diversity among participants. Another limitation is that we do not have information on sexual orientation, socio-economic class, or disability within these samples. Identifying and examining conversational motifs with more demographically diverse samples is an important direction for future research. In addition, all three data sets focused on conversations that occurred within the context of lab-based tasks and included experimental manipulations. Although this is a common paradigm in research on interpersonal interaction, we look forward to work that extends outside the walls of the interaction laboratory. As noted, we also look forward to research that identifies conversational motifs in other types of interactions (e.g., conflict, interpersonal influence, deception detection) and evaluates how the prevalence and timing of motifs contributes to conversational outcomes in those settings.
Other limitations point to additional directions for future research. For example, our final analysis split conversations into thirds, based on the number of speaking turns, to replicate our previous work and because we reasoned that our data likely reflected three phases of supportive conversation per Jefferson (1988; see footnote 7). The mismatch between each dyad’s execution of Jefferson’s conversational phases and the three equal phases we specified introduces uncertainty into our estimates of how the prevalence of specific communication behaviors within each phase leads to particular outcomes. Parsing conversations based on when shifts between phases actually occurred would improve the precision of the dynamic analyses we illustrated in this study. In addition, we recognize that our tests of dynamic dyadic effects relied upon static self-report measures of emotional improvement and support quality. Future research might use physiological stress measures and multi-point stimulated recall approaches to more directly track how emotion regulation changes as the conversation unfolds.
As a final direction for future research, we encourage the application of existing coding schemes and the development of machine coding to categorize behaviors that unfold during interactions. We recognize that the turn-by-turn coding that produced the data we analyzed is painstaking. At the same time, we know of many scholars who have recorded similar dyadic interactions in their research labs. Coding conversation is not infeasible, and by far the most time intensive and expensive part of such research is recruiting research participants and recording dyadic interactions in the first place. Transcribing conversations and coding them are costs that offer considerable added value to data already paid for and investments already made. This activity is feasible, and published coding schemes are available to guide future research (see VanLear & Canary, 2017).
Conclusion
This paper demonstrated the application of sequence analysis to the study of dyadic conversations. In an exemplar illustration focused on supportive conversations, we replicated three five-turn supportive conversational motifs (Solomon et al., 2021) and identified a fourth motif manifest in conversations between strangers, friends, and dating partners. We also found that the prevalence and timing of some of these conversational motifs were related to conversation outcomes. More generally, we illustrated how sequence analysis can contribute to the study of interpersonal communication dynamics that emerge across interaction episodes in social and personal relationships.
Supplemental Material
sj-pdf-1-spr-10.1177_02654075211066618 – Supplemental Material for Using Sequence Analysis to Identify Conversational Motifs in Supportive Interactions
Supplemental Material, sj-pdf-1-spr-10.1177_02654075211066618 for Using Sequence Analysis to Identify Conversational Motifs in Supportive Interactions by Denise H. Solomon, Susanne Jones, Miriam Brinberg, Graham Bodie and Nilam Ram in Journal of Social and Personal Relationships
Supplemental Material
sj-pdf-2-spr-10.1177_02654075211066618 – Supplemental Material for Using Sequence Analysis to Identify Conversational Motifs in Supportive Interactions
Supplemental Material, sj-pdf-2-spr-10.1177_02654075211066618 for Using Sequence Analysis to Identify Conversational Motifs in Supportive Interactions by Denise H. Solomon, Susanne Jones, Miriam Brinberg, Graham Bodie and Nilam Ram in Journal of Social and Personal Relationships
Footnotes
Acknowledgements
The authors are grateful to Andrew High and Jennifer Priem, who contributed two of the data sets used in this study. The authors would also like to thank James Dillard for his guidance on fitting the multi-group structural equation models.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by grants from the National Science Foundation (#1749474; #1749454; #1749255).
Open research statement
As part of IARR’s encouragement of open research practices, the authors have provided the following information: This research was not pre-registered.
The data used in the research are available upon request. The data can be obtained by emailing Miriam Brinberg:
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.