
Abstract
Political scientists increasingly use crowdworkers to produce data, predominantly in the context of coding researcher-curated text or to retrieve simple data from the internet. In this article, we provide a theoretical and empirical basis for understanding when crowdworkers can provide data of sufficient quality to substitute for other types of coders. First, we introduce a typology of data-producing actors – experts, trained coders and crowds – and hypothesize factors that affect the substitutability of crowdworkers. We then examine how crowdworkers perform across coding tasks that vary along multiple dimensions of difficulty: information verifiability, availability and complexity. The results provide scope conditions bounding the substitutability of crowdworkers in political science applications. Although crowds can substitute for trained coders in the context of relatively simple information retrieval tasks, there is little evidence that crowdworkers can substitute for experts, whose tasks require both information retrieval and data synthesis.
Political scientists frequently rely on experts to assign categorical or numeric values to concepts that are difficult to observe (Carey et al., 2019; Lindberg et al., 2014; Hooghe et al., 2010); they often ask trained coders to code more directly observable phenomena (Cruz et al., 2021; Hyde and Marinov, 2019; Marshall and Jaggers, 2017). At the same time, crowdsourcing – large-scale recruitment of laypersons to accomplish coding tasks – has emerged as a competing tool for social science data collection. Theoretically, crowdsourcing can offer improvements over expert-coded data in terms of reliability, validity, cost efficiency and replicability. 1
However, existing crowdsourcing applications are largely limited to asking crowds to either: (a) code or compare expert-aggregated and curated text excerpts with varying levels of complexity (Benoit et al., 2016; Carlson and Montgomery, 2017; Horn, 2019; Lehmann and Zobel, 2018; Narimanzadeh et al., 2023; Skytte, 2022; Voong et al., 2020); or (b) perform web-based information retrieval (Porter et al., 2020; Sumner et al., 2020). The potential application of crowdsourcing to a more general class of coding tasks in political science remains largely unexplored. In particular, many political science tasks demand information retrieval (gathering relevant information about a concept as applied to a specific case), curation (organizing and prioritizing these data) and synthesis (summarizing and making sense of these data).
Although these information retrieval and synthesis (IRS) tasks range in complexity, they are often substantially more demanding than the tasks crowdworkers typically perform. As a result, crowdworkers may not be substitutable for the other actors who conduct these common coding tasks. Exploring the boundaries of crowdworker substitutability – and the contexts and conditions under which they are more or less substitutable – is thus an important endeavour.
In this article, we provide a conceptual framework, backed by empirical evidence, for understanding crowdworker substitutability. First, we consider a typology of three actors who code data in social scientific applications: experts, trained coders (henceforth ‘coders’) and crowdworkers. Using this typology, we hypothesize and test how task attributes and crowdworker incentives enhance or diminish the substitutability of crowds for coders and experts. We find evidence that crowdworkers can sometimes substitute for coders, but find only limited evidence that crowdworkers can substitute for experts. Although crowdworkers can often perform information retrieval, and can sometimes classify observations according to social scientific concepts, our results show that crowdworkers lack the background and training to interpret or synthesize complex information when any informed subjective judgement is required.
Theorizing experts, coders and crowds
Multiple types of actors – experts, coders and crowdworkers – code data for social science research. Though scholars often refer to these actors interchangeably, the actors exhibit important differences in skills and incentives. 2
According to Morris (1977), an expert is ‘anyone with special knowledge about an uncertain quantity or event’. Researchers typically recruit experts to perform IRS tasks, relying on them to retrieve – or already know – hard-to-find information. Researchers expect experts to be able to classify observations by synthesizing data that the experts themselves have collected. Typically, experts have spent years developing specialized case and domain knowledge, and therefore have substantial practice in retrieving and synthesizing task-relevant information. In exchange for lending their expertise to a coding enterprise, experts generally receive both monetary and non-monetary (e.g. reputation) benefits.
Unlike experts, trained coders often lack prior task-relevant knowledge. Coders are often graduate students and their tasks may be part of paid responsibilities or serve as a kind of research apprenticeship; coders are pre-screened for general suitability and given task-specific training. Like experts, coders also have a mixture of monetary and non-monetary incentives. Although coders typically receive financial compensation, in the process of their coding work they may also obtain research experience to facilitate future study or employment. Indeed, because coders often commit considerable time to a project, they may develop a level of knowledge in the topic that approximates expertise.
Coders can perform multiple types of tasks. Some simply retrieve observable information, such as the names of mayors of US cities. Others classify expert-aggregated materials, applying researcher-generated rubrics to curated data points. For example, coders may classify sentences from party manifestos as liberal or conservative. Previous research on crowdsourcing in political science has largely focused on supplanting these two sorts of coders (Benoit et al., 2016; D’Orazio et al., 2016; Honaker et al., 2013; Horn, 2019). A third category of coders performs both tasks: retrieving information which they also classify.
Crowdworkers are independent contractors hired through enterprises such as Amazon Mechanical Turk. Their compensation is almost purely financial. Unlike experts, crowdworkers do not have substantial domain-specific expertise. Unlike coders, researchers cannot recruit crowdworkers specifically for their aptitude at research-related tasks, nor can they give them substantial task-specific training. Instead, crowdworkers conduct many different tasks, without spending substantial time on any of them. As such, crowdworkers are unlikely to master any specific task.
The main purported advantage of crowdworkers over experts and coders is that they are numerous and relatively inexpensive to hire. In addition to facilitating large-scale data-gathering projects, this advantage could also lend itself to the creation of reproducible crowd-coded datasets (Benoit et al., 2016).
This advantage hinges on two key assumptions. First, crowdworkers can produce data of similar quality to those which experts and coders produce. Second, crowdworkers are sufficiently cheap and numerous to actually substitute for these other coders.
While the remainder of this paper investigates the first assumption in detail, we briefly note here that there is considerable reason to doubt the second assumption. First, analyses in Appendix A demonstrate that recruiting a sufficiently large number of coders to reproduce a large-scale expert-coding enterprise, such as the Varieties of Democracy (V-Dem) dataset as of 2017, would be much more expensive than using experts and would likely require recruiting more crowdworkers than existed in 2017. Second, less than a quarter of the crowdworkers we recruited for this project (54 out of 229) correctly responded to all screener questions and more than 50% of our ‘gold standard’ questions (more cognitively demanding screener questions). 3 This latter result aligns with the findings of others who have noted challenges both in screening and compensating high-performing crowdworkers (Boas et al., 2020; Carlson and Montgomery, 2017; Chandler et al., 2019; Horton et al., 2011; Loepp and Kelly, 2020; Pyo and Maxfield, 2021; Strange et al., 2019), and in comprehensively accounting for crowdworker incentive structure in designing tasks (Brown and Pope, 2021; Chandler et al., 2019). Cumulatively, such findings indicate that it is necessary to over-recruit crowdworkers and have them complete a high volume of tasks in order to obtain accurate estimates. In applications such as the cross-national data-gathering enterprise we discuss here, the costs associated with doing so may outweigh the benefits of recruiting crowdworkers over experts or trained coders.
When can crowds replace experts and coders?
Previous research demonstrates that crowds can substitute for experts and coders when coding expert-curated data. There is also more tentative evidence that crowdworkers can perform the more complicated IRS tasks on which we focus here. In the context of political science, Sumner et al. (2020) deploy crowds to code recent experiences with financial distress for US cities. In a set of analyses that spans three other social-scientific contexts, Porter et al. (2020) find that crowdworkers perform well when asked to find and code easily accessible online data for data augmentation purposes. Finally, La Barbera et al. (2024) positively assess the ability of crowdworkers to conduct fact-checking of political statements. Since performing all of these tasks requires retrieval, curation and synthesis; these lines of research provide a proof-of-concept for crowdsourcing IRS tasks.
Here we explore the bounds of substituting crowds for experts and coders, investigating the extent to which crowds can holistically retrieve, curate and synthesize information. Most broadly, we hypothesize that crowds can substitute for experts and coders in IRS tasks (
Determinants of substitutability.
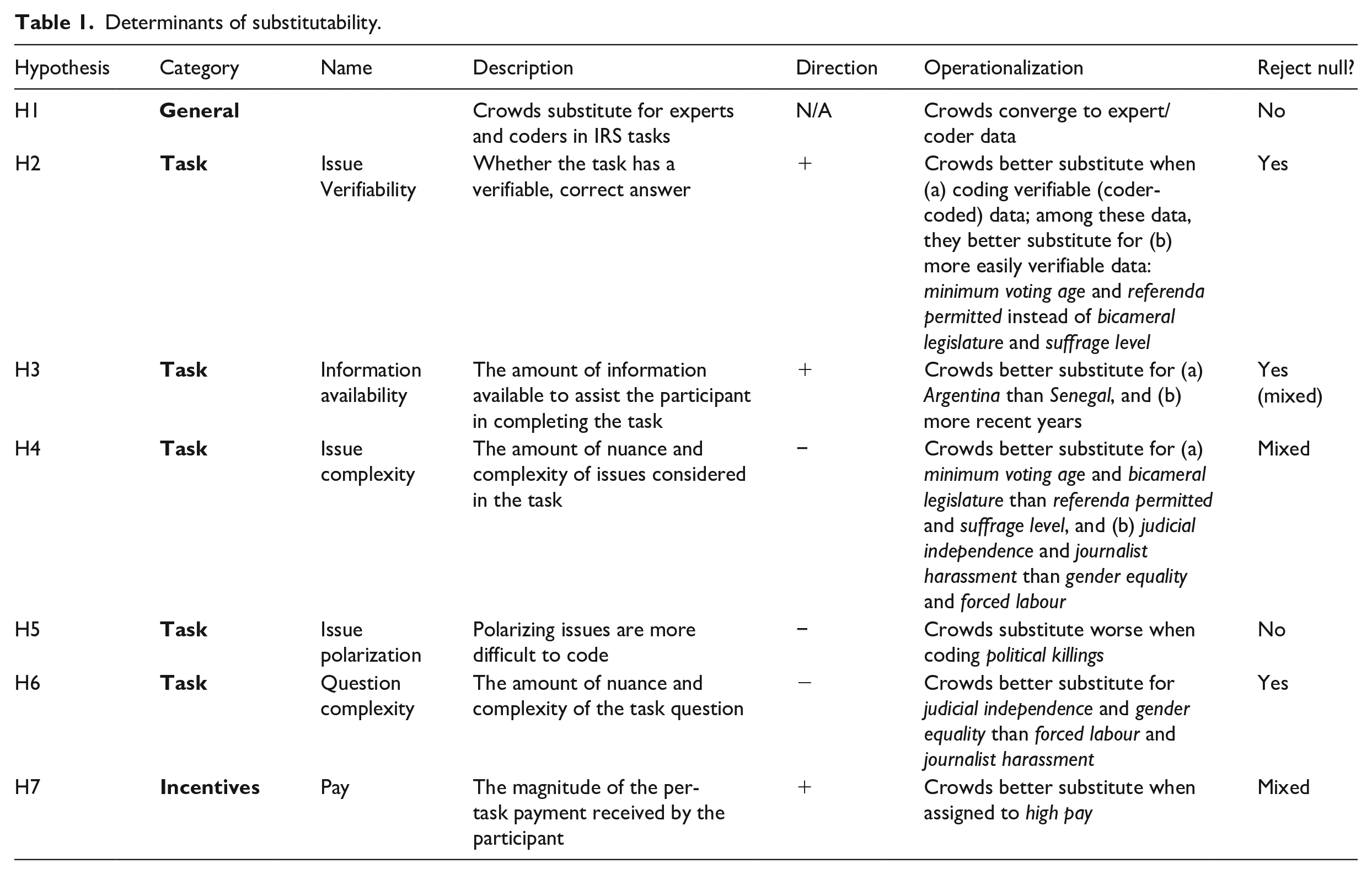
In the interest of space, in the text we focus on the first two dimensions and relegate crowdworker attributes to a brief discussion. 4 With regard to the dimension of task attributes, we hypothesize that five attributes should have a substantial effect on crowd substitutability for other coders. Two of these attributes relate to information retrieval, whereas the remaining three relate to information curation and synthesis.
With regard to information retrieval, we hypothesize that information availability should increase substitutability (
We also hypothesize that information verifiability should increase the substitutability of crowds (
Along these lines, different aspects of curating and synthesizing material may present particular hurdles to effective coding by crowds. First, certain political phenomena are more complicated than others. Although experts possess the background to weigh different issues when making judgements about these phenomena, and coders have the time and resources to investigate them in detail, crowds have none of these attributes. As a result, increasing issue complexity should reduce the substitutability of crowds (
Finally, we hypothesize that incentives should influence the substitutability of crowds. Whereas experts often decide to provide codings for non-monetary reasons, and coders provide codings for a mix of monetary and non-monetary reasons, crowds are primarily pay-motivated. As a result, high pay should increase the motivation of crowdworkers to provide quality coding and thus increase their substitutability for experts and coders (
Research design
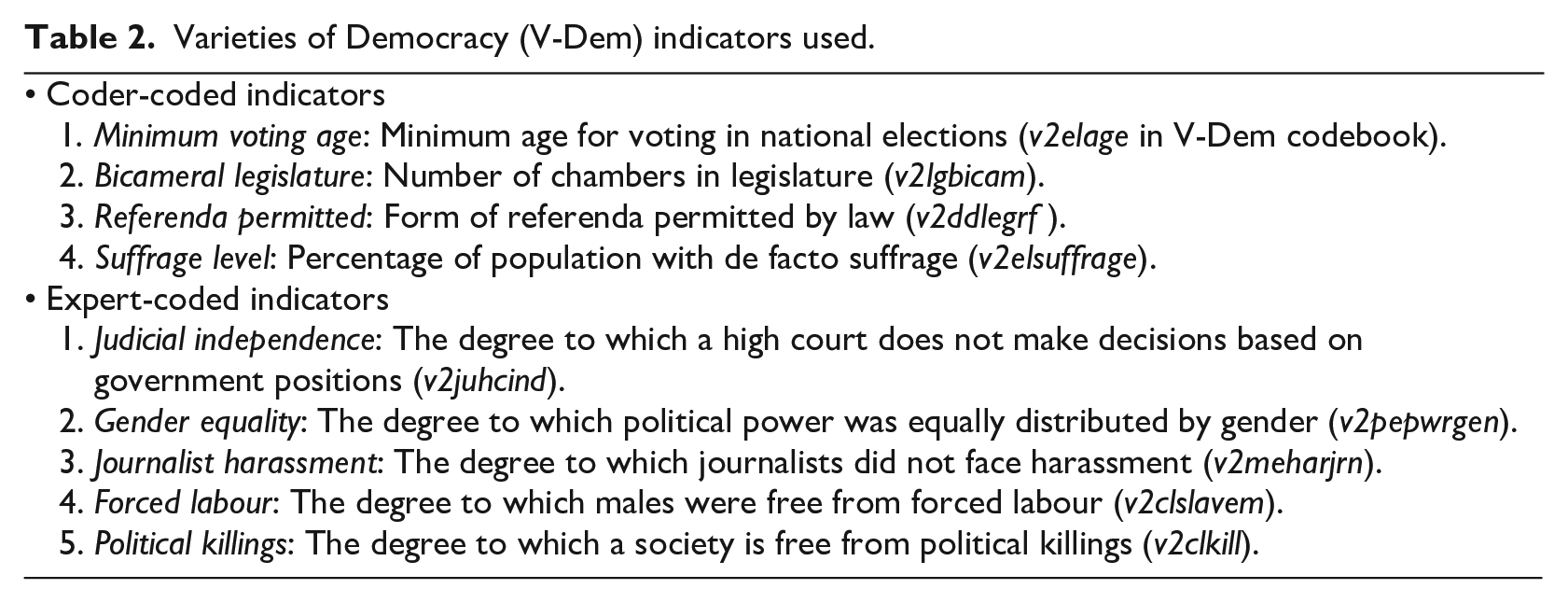
We rely on questions from the V-Dem project to test our hypotheses (Coppedge et al., 2017). V-Dem is a large-scale data-gathering enterprise that provides country-year measures of political institutions. To do so, V-Dem recruits both experts and coders to code political phenomena. To code directly observable (‘verifiable’) questions, V-Dem uses coders whom the project trains and provides with scholarly oversight to ensure the accuracy of their data. To code concepts that are difficult or impossible to directly measure – and thus require substantial, informed judgement to code – V-Dem uses experts. These experts are generally scholars who hold a PhD and have a research focus on specific countries and concepts (Marquardt et al., 2019). V-Dem provides these experts with a standardized survey with Likert-scale response categories, which experts use to code concepts across cases.
The V-Dem project strictly limits coders to providing data for directly observable indicators, assuming that they do not have the relevant conceptual or case expertise to code indicators that require informed judgement. In the terminology of the project (Coppedge et al., 2017), coders provide ‘A’ data and experts provide ‘C’ data. This variation and clear delineation of data sources between experts and coders makes V-Dem an ideal context for examining the practical potential of crowd-sourcing for IRS coding tasks with different levels of verifiability and complexity.
To assess crowd substitutability, we compare both coder-coded (‘A’) and expert-coded (‘C’) V-Dem data to crowdworker responses from a March 2017 survey. 5 Following Benoit et al. (2016), we ran the study on CrowdFlower. 6 Crowdworkers self-selected into the research pool, although we randomized task attributes and pay. Per pre-analysis power calculations, our sampling strategy aimed to obtain 20 observations per indicator-country-year-treatment group, with a 20% buffer for attrition. Though this strategy would yield 216 individuals, our sample included 229 crowdworkers because of practical constraints to precisely stopping recruitment. Crowdworkers used an interface similar to that used by V-Dem. 7 We used ‘gold standard questions’ and screeners to weed out low-quality crowdworkers and bots. The analyses we present in the main text include only the 54 crowdworkers who correctly answered at least 2 of 4 ‘gold standard’ questions and all screeners (roughly 12 crowdworkers per V-Dem indicator). 8
We reiterate that V-Dem data collection is a difficult task for crowdworkers. In addition to the difficulty of retrieving information on some concepts and cases, V-Dem questions use technical language to convey complex social-scientific concepts in a way that is difficult to explain to a neophyte without extensive training. 9 As such, we intend for this project to test the boundaries of what tasks crowds can and cannot perform, thereby establishing scope conditions lacking in other work on this topic.
Operationalization and variable description
To assess the effect of task attributes on crowdworker substitutability, we randomly assigned crowdworkers to two of nine V-Dem indicators that varied along important metrics (Table 2). 10 We assigned crowdworkers to only two of these indicators to avoid overextending them. For similar reasons, instead of asking crowdworkers to code the full time period, we asked them to code each of these indicators sequentially for six five-year periods for one country, Argentina. Following completion of coding the second indicator, we asked crowdworkers to code that indicator for an additional set of six time periods for another country, Senegal. 11
Varieties of Democracy (V-Dem) indicators used.
Our logic in choosing Argentina and Senegal as the two countries for crowdworkers to code was twofold. First, both of these countries are internationally prominent. Accordingly, any cross-national dataset with pretensions of complete global coverage must include data for these countries. Second, Argentina and Senegal are not the most prominent countries in terms of relevant information being easily accessible using English-language materials. As a result, they represent good test cases for assessing whether crowdworkers can provide substitutable data for cross-national datasets. Had we chosen the most easily accessible cases (e.g. the United States), our results would only have generalized to the easiest cases in a cross-national dataset. 12
The choice of these two countries also allows us to test the information availability hypothesis (
That said, since all crowdworkers coded Argentina first, then had the option to continue coding for Senegal, differences in substitutability between countries could also be due to fatigue.
14
We therefore use an additional metric to assess the effect of information availability: time period. Since information should be more accessible for more recent years (
In addition to information availability, we also expect information verifiability to influence crowd substitutability (
However, within coder-coded data there is also variation in how much effort information retrieval and verification requires; some data are more findable than others. For example, although the legal provisions for suffrage are located in the legal documents of a country, the suffrage level in practice is not always officially published. As a result, we expect crowds to better substitute for more easily verifiable coder-coded indicators, such as minimum voting age and referenda permitted, than indicators such as bicameral legislature and suffrage level (
We expect issue complexity (
Selected Varieties of Democracy (V-Dem) coder-coded indicators.

We base our metric for the issue complexity of expert-coded V-Dem indicators on the assumption that experts become less confident when rating more complex issues. This assumption allows us to use the average self-reported expert confidence across indicators in the V-Dem dataset to assess the issue complexity of specific V-Dem indicators. Specifically, V-Dem experts report their confidence in their codings for each indicator-country-year combination; we take the average of these scores across experts, years and countries for each indicator as our metric for its overall complexity. Based on this metric, our analyses include two low-complexity questions (i.e. questions for which experts are relatively confident, journalist harassment and judicial independence) and two high-complexity questions (i.e. questions for which experts are relatively not confident, gender equality and forced labour).
We also hypothesize that crowdworkers are less substitutable for experts when they are asked to code more difficult tasks. To measure question complexity (
We expect crowds to best substitute for the indicators that have low issue and question complexity; and least for those which have high complexity on both dimensions. Table 4 presents a two-by-two table of our four expert-coded indicators along these metrics, illustrating that judicial independence (low complexity on both metrics) should be the indicator for which crowdworkers are most substitutable, and forced labour (high complexity on both metrics) should be the indicator for which they are the least substitutable.
Selected Varieties of Democracy (V-Dem) expert-coded indicators.

Finally, we also hypothesize that crowdworkers are less substitutable for experts when they code indicators with high issue polarization (
Incentives
To test our high pay hypothesis (
Results
In contrast to
Crowdworker substitutability for coders
In order for crowdworkers to substitute for trained coders, a majority (ideally large) of crowdworkers would need to provide correct values for the indicators they code. If that is the case, a data-gathering enterprise could recruit multiple coders and relatively safely assume that the modal response is the correct value. We therefore assess the substitutability of crowdworkers for coders over different indicators by estimating the probability that a crowdworker would provide the correct answer for a given indicator-country-year.
Figure 1 illustrates this relationship, showing results from a dichotomous probit regression analysis of the probability that a crowdworker exposed to different task characteristics would provide a correct response. 16 Dots represent point estimates of this probability and horizontal lines represent 95% confidence intervals.
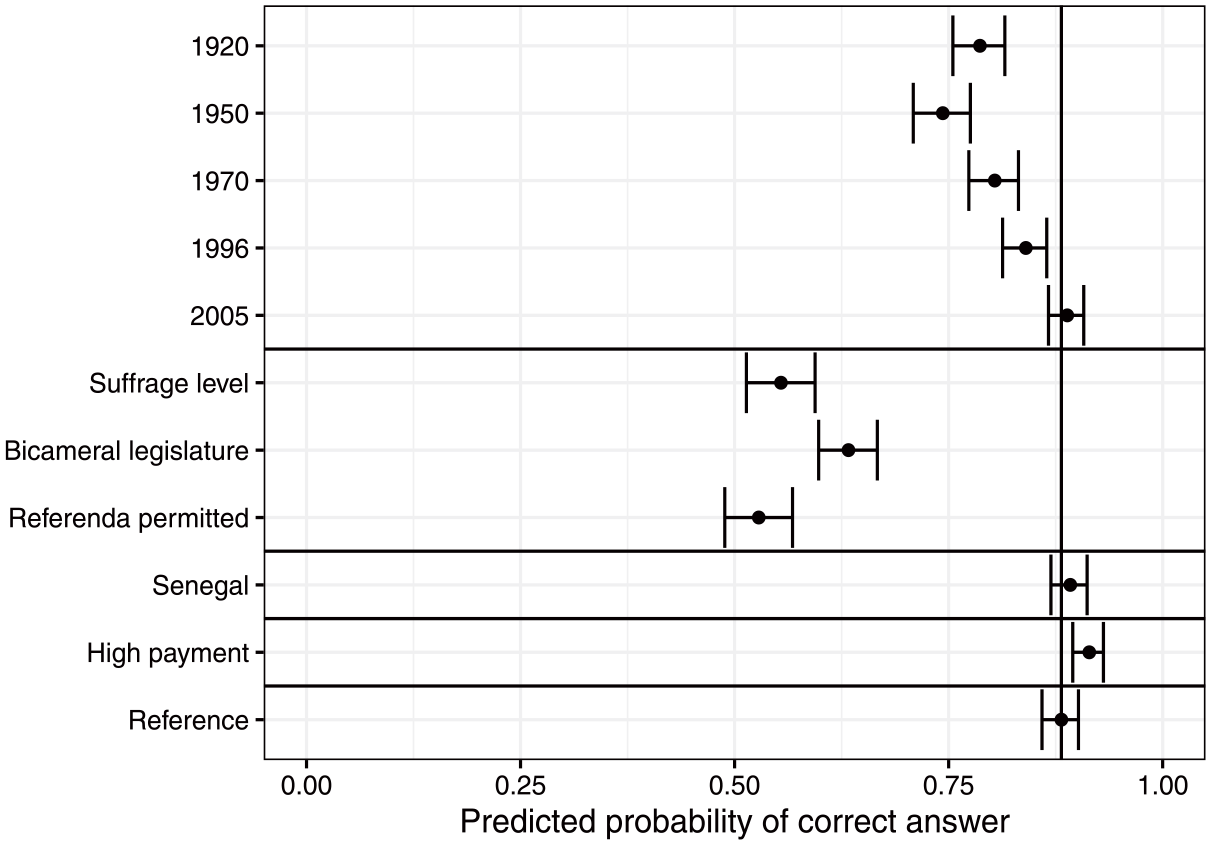
Substantive effect of task characteristics on the probability of correct answer to coder-coded questions.
The results demonstrate clear variation in the substitutability of crowdworkers for coders. In line with hypothesis
Point estimates and 95% confidence intervals from a probit regression analysis. Vertical line represents the point estimate at the reference level (2015, Argentina, minimum voting age, standard payment).
Cumulatively, these results suggest that crowdworkers can substitute for coders when they are presented with very simple tasks with easily accessible data: for recent years and simpler indicators, the estimated probability that a (screened) crowdworker provided a correct response is well over 0.50. However, the probability that a crowdworker provides a correct response is much lower for more complicated indicators and for coding periods further back in time, substantially lowering their substitutability in these contexts.
Crowdworker substitutability for experts
The fundamental promise of crowd-sourced data is that average responses will converge toward true values as the sample size increases. Our primary metric for the substitutability of crowdworkers for experts is therefore the convergence of crowdworkers to a benchmark with an increasing sample size. In the case of expert-coded data, a reasonable benchmark is the average score across experts. We therefore assess the bootstrapped standard errors – the squared difference between the average bootstrapped crowdworker score and the average expert score – using a varying count of bootstrapped crowdworkers across our expert-coded indicators. Specifically, for increasing values of n, we randomly draw n crowdworkers with replacement for different country-year-indicator combinations, calculate the mean scores within these groups and compute the difference in means between these n-coder groups and the full set of available expert scores. We repeat this process 100 times for each value of n = 1,2,…,10. 17
For purposes of comparison, we also examine the convergence of the V-Dem experts who coded these cases to the expert mean using the same algorithm, but with bootstrapped draws of these experts. By design, expert scores converge toward zero since their average score was the benchmark. We therefore intend for these analyses to serve purely as a heuristic to enable comparison.
Figure 2 presents the bootstrapped standard errors between bootstrapped groups and overall expert averages. Points represent the errors for a country-year for a given number of crowdworkers (grey) or experts (black). Standard errors should tend toward zero as the number of crowdworkers increases, indicating that the crowdworker average approaches the expert average as the number of crowdworkers increases. Although the the figure provides evidence that a greater number of crowdworkers decreases error for all indicators, this convergence is sharply bounded. Even with the maximum number of bootstrapped crowdworkers for even the best-performing indicators (judicial independence, gender equality and political killings), a substantial number of country-year errors are above one, indicating that crowdworker averages tend to diverge by more than one point on a 5-point scale from the expert average.
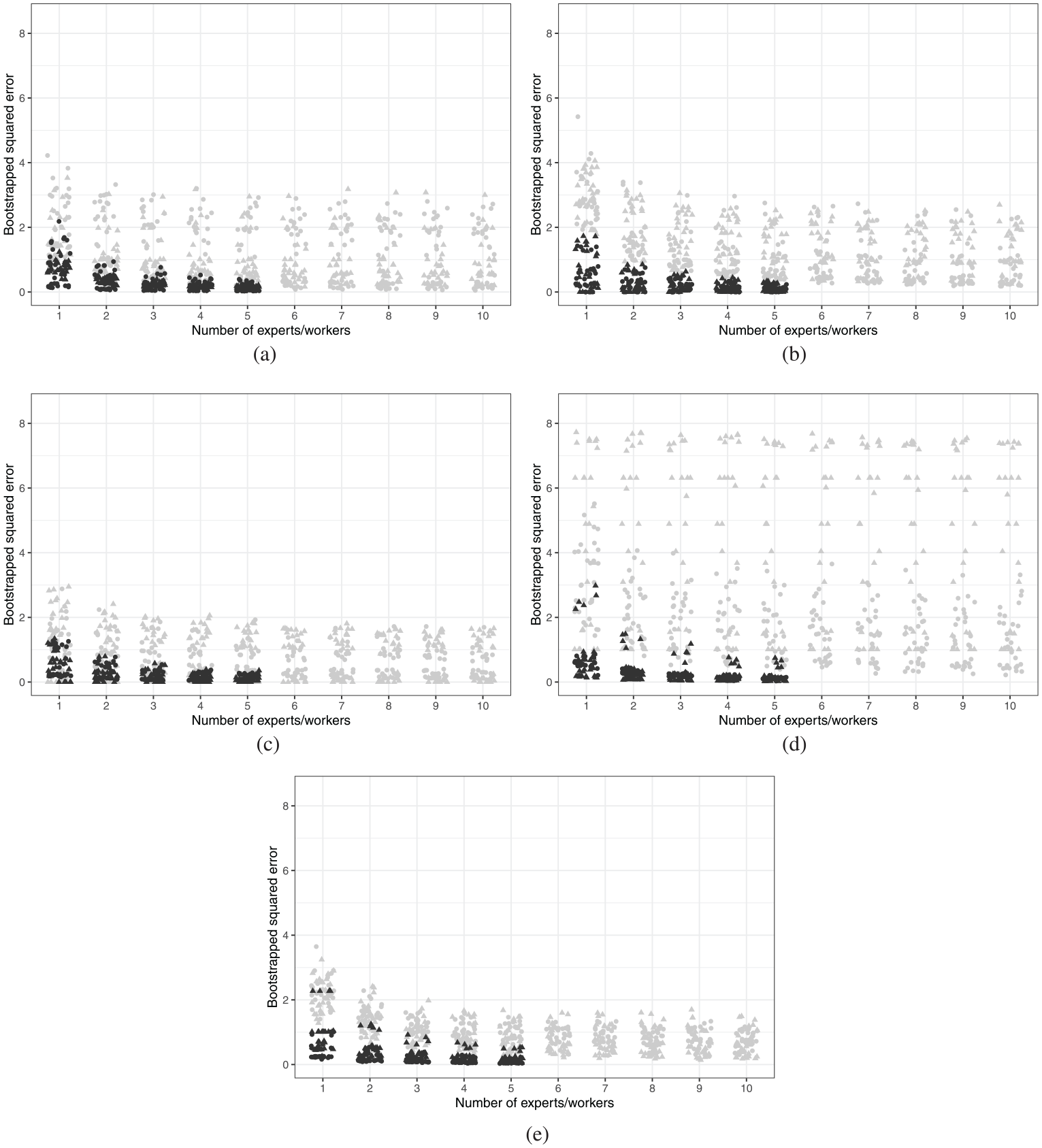
Bootstrapped standard errors across expert-coded indicators by number of experts (black) and crowdworkers (grey). (a) Judicial independence. (b) Journalist harassment. (c) Gender equality. (d) Forced labour. (e) Political killings.
In contrast to
We also examine the degree to which substitutability varies with task characteristics and crowdworker incentives, using a similar strategy as for the substitutability of crowdworkers for trained coders. Specifically, we regress the absolute difference between the expert mean and crowdworker scores for a given country-year-indicator on task attributes and incentives. 18 Figure 3 plots the results of this analysis, illustrating predicted crowd substitutability for experts as a function of task attributes and crowdworker incentives. Points represent average difference, surrounded by 95% confidence intervals; lower values represent greater substitutability.
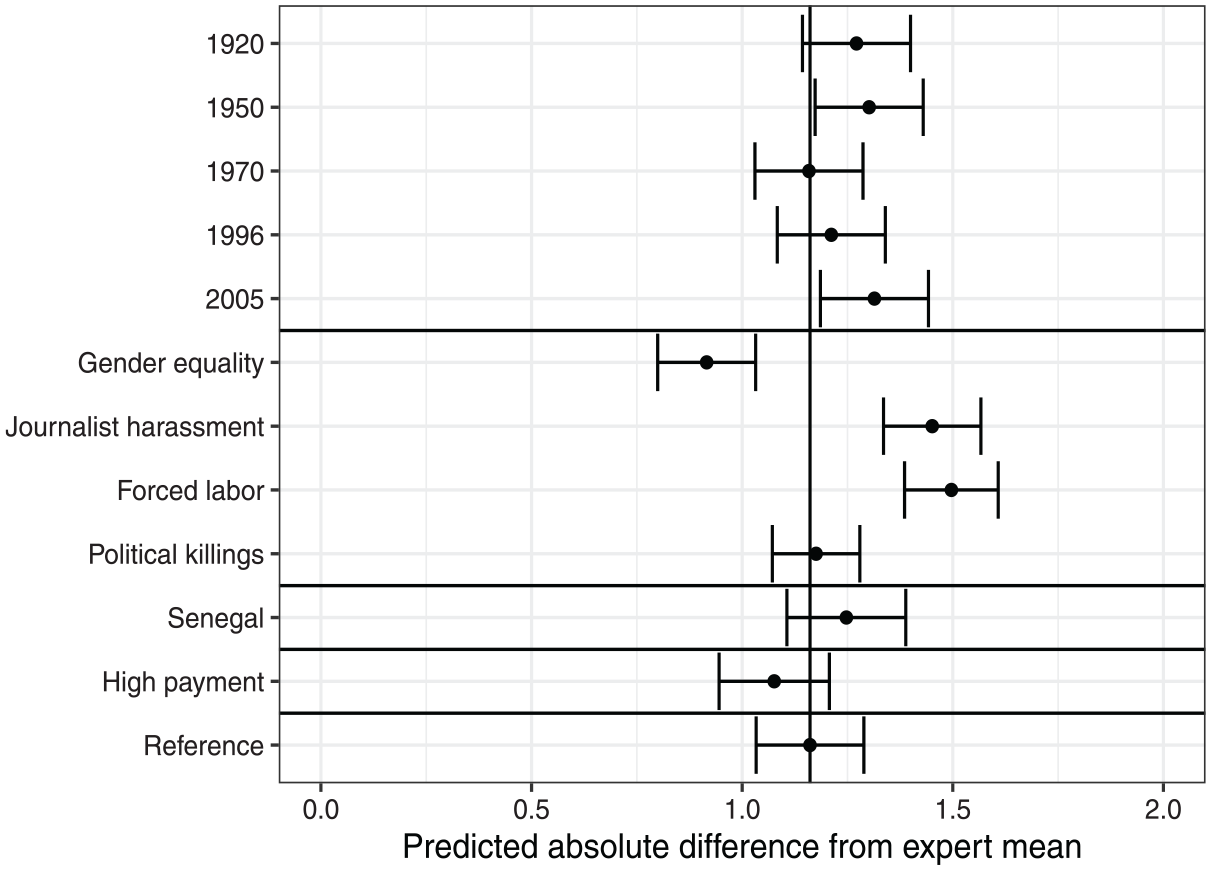
Substantive effect of task characteristics on distance from expert mean.
The results of the regression analysis reinforce the findings from Figure 2. Figure 3 shows that, at the reference level, crowdworkers tend to deviate by 1.16 Likert-scale points from the mean expert coding. This value is slightly less than a quarter of the scale range, indicating low substitutability, again contradicting
The final expert-coded indicator, political killings, shows similar levels of crowdworker substitutability to judicial independence, the reference level. This result indicates that issue polarization (
Examining information availability, we find no variation in crowdworker substitutability when they code the case with more information available (Argentina, the reference level, compared to Senegal). Similarly, there is little evidence that substitutability increases with the recency of the year of coding. These two results together indicate that we cannot reject the null for
Finally, increased coder pay slightly increased substitutability, per
These results cumulatively indicate that crowdworkers are not substitutable for experts: even in the best-performing indicator, crowdworker scores are, on average, roughly 18% of a 5-point Likert scale away from the expert average. Moreover, there is evidence that asking crowdworkers to code complex issues further reduces substitutability, and only weak evidence that paying them more can increase substitutability.
Demographic correlates of substitutability
Appendix G analyses the demographic correlates of crowdworker substitutability, focusing on the full sample of crowdworkers (i.e. both those crowdworkers who successfully completed screening tasks and those who did not). In short, there is little evidence that any demographic factor – political interest, education, familiarity with a case, performing well on screeners, coding diligence – affects the substitutability of crowdworkers for experts. However, demographics do have a strong effect on crowdworker substitutability for trained coders. More diligent coders – those who correctly complete screeners and take more time to code – are much more likely to provide correct responses than other crowdworkers, as are crowdworkers who report having spent time in the country they coded. Crowdworkers who report using the V-Dem dataset in their coding task are also more likely to provide the correct response, whereas political science majors are less likely.
In conjunction with the previous analyses of task characteristics, these results indicate that scholars can take concrete steps to increase the substitutability of crowdworkers for coders. Although the most important step is ensuring that the coding task is straightforward, scholars can also screen crowdworkers carefully before and during the coding period, and attend to their coding behaviour. However, there is little scholars can do to make crowdworkers substitutable for experts or coders of complicated tasks.
Conclusion
The literature on crowdsourced data in political science largely focuses on classification tasks, such as categorizing party manifestos, news articles or country descriptions. The success of such endeavours relies on expertise: experts obtain, curate and sometimes synthesize information before delegating classification to crowdworkers. However, social science data collection enterprises often more directly require their coders to perform information retrieval and curation, in addition to classification. Here we investigate whether crowds can economically and efficiently provide such labour. We do so by analysing the degree to which crowdworkers perform such tasks similarly to experts and coders.
We find little evidence that crowds can substitute for experts on IRS tasks. Our typology provides a possible explanation: most crowdworkers do not have the background, support or incentives to gather and analyse the types of data that experts do. IRS tasks are difficult to break into small chunks, and therefore it may not be surprising that crowdworkers perform poorly in our study. Nevertheless, since essentially every published study on crowdsourcing in political science reports on a success, it is valuable to highlight the method’s limitations.
However, we do find evidence for the substitutability of crowdworkers for coders in some tasks, though the boundaries of this substitutability are somewhat blurry. Although our results demonstrate that crowdworkers can substitute for coders in some simple information retrieval tasks, the difficulty of the task has a strong negative relationship with their substitutability.
Supplemental Material
sj-pdf-1-ips-10.1177_01925121241293459 – Supplemental material for Experts, coders and crowds: An analysis of substitutability
Supplemental material, sj-pdf-1-ips-10.1177_01925121241293459 for Experts, coders and crowds: An analysis of substitutability by Kyle L Marquardt, Daniel Pemstein, Constanza Sanhueza Petrarca, Brigitte Seim, Steven Lloyd Wilson, Michael Bernhard, Michael Coppedge and Staffan I Lindberg in International Political Science Review
Footnotes
Acknowledgements
We thank Ryan Bakker, Ken Benoit, Adam Glynn, Noah Nathan, Amy Semet and participants at the American Political Science Association Annual Meeting, the European Political Science Association General Conference, the Midwest Political Science Association Annual Conference and the V-Dem Annual Conference (all 2017) for comments on earlier drafts of this paper. We also thank three anonymous reviewers and the editor, Daniel Stockemer, for their valuable contributions during the review process. Josefine Pernes and Natalia Stepanova provided invaluable administrative support, and Paige Ottmar provided outstanding research assistance. Susan Williams copy-edited the final draft of the manuscript.
Author contributions
First authors are listed alphabetically and are followed by second authors, also listed alphabetically.
Data availability statement
All materials necessary to replicate the analyses in the text and appendices are available in the associated online supplementary materials.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship and/or publication of this article: Riksbankens Jubileumsfond, Grant M13-0559:1; the Knut and Alice Wallenberg Foundation Grant 2013.0166 and the National Science Foundation Grant No. SES-1423944; as well as internal grants from the vice-chancellor’s office, the dean of the College of Social Sciences, and the Department of Political Science at the University of Gothenburg. Michael Bernhard’s work on the article was supported by the University of Florida Foundation.
Ethical considerations
Human subjects research was approved by Regionala Etikprövningsnämnden i Göteborg, DNR 1079-16.
Supplemental material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.