
Abstract
The institutionalization of occupations tends to assume homogenization of occupational values. This study addresses the question of how members of an occupation with dissenting preferences reach consensus on a code of ethics. We build on prior theorization of occupational institutionalization and institutional discourse to theorize ethical codification as a dynamic discursive process of internal dissent and consensus culminating in a professional code of ethics. We use email data from the IEEE-ACM Software Engineering Ethics and Professional Practice Committee tasked with producing the 1997 Software Engineering Code of Ethics to show how ethical codification follows a process of initial competition followed by semantic convergence. This study demonstrates how natural language processing and semantic network analysis can contribute to discourse analyses of institutional processes.
Keywords
Introduction
The publication of a Code of Ethics is often viewed as a milestone in occupational institutionalization, signaling shared standards and even claims toward professional legitimacy. However, occupations are not monolithic; they represent communities of individuals with diverse, and often conflicting, values and motivations. How does an occupational community with divergent ethical values come to agree on a shared code of ethics? This question is fundamental to understanding how values are negotiated, formalized, and codified into artifacts that shape occupational identities.
While prior research highlights the importance of discourse in institutionalization, it often leaves underexplored the mechanisms of discourse variance trajectory—how competing values converge or persist in the process of codification. Theories of discourse have proposed two key outcomes during institutionalization: focus, where discourse narrows to emphasize dominant values, and ambiguation, where multivocality allows for competing values to coexist under ambiguous framing. Yet the antecedents, mechanisms, and contextual factors driving these outcomes remain unclear. This study addresses the gap by investigating how discourse variance evolves during ethical codification and how leadership and artifact publication shape this trajectory.
Using a unique dataset of email correspondences from the committee tasked with creating the 1997 software engineering Code of Ethics, this study integrates computational semantic network analysis and topic modeling with qualitative interpretation to examine the codification process. Through the lens of critical discourse analysis, we show how discourse shifts from competing sociolects to a more unified narrative. We find that (1) modularity decreases (i.e., the language homogenizes) approaching codification; (2) the discourse shifts from the more regulative standardization rhetoric of one faction to the more normative education rhetoric of the competing faction; and (3) committee leadership plays a significant role in this rhetorical shift that shapes the code, and the associated occupation, toward a particular ethical identity. This study contributes to institutional theory by advancing our understanding of the discursive mechanisms underlying ethical codification, offering a methodological framework for analyzing contested values. Whether applied to emergent occupations or other institutional contexts, this framework demonstrates the power of integrating computational and qualitative approaches to uncover the dynamics of discourse in institutionalization.
Ethical Codes in Occupational Institutionalization
The institutionalization of an occupation often involves the publication of an occupational code of ethics. Occupational codes of ethics, such as the American Medical Association’s Code of Medical Ethics, establish agreed-upon standards of appropriate practice in an occupation. In addition to society and clientele, codes of ethics serve a peer audience. For peers, ethical codes enable status differentiation (Abbott, 1983), distinguishing, for example, “professionals” from amateurs (David, Sine, & Haveman, 2013). As codifications of an occupation’s mandate (Fayard, Stigliani, & Bechky, 2017), ethical codes reflect occupational values, or “the sayings and doings in organizations that articulate and accomplish what is normatively right or wrong, good or bad, for its own sake” (Gehman, Trevino, & Graud, 2013, p. 84). Ethical codes are not generally legal mechanisms with enforcement or even effectiveness across an occupation, but rather normative guides for the legitimate practice of the occupation that differentiate right from wrong (Abbott, 1983; Johnson, 2020). Whether or not they are effective, the codification of ethics into a public document is an important signal of collective coordination and institutionalization of an occupation.
While they may signal coordination, ethical codes are not mere reflections of a homogeneous occupational community. Rather, occupations are an amalgam of people with sometimes divergent or even competing values that are not necessarily represented in the final code of ethics. Occupational group members often have conflicting values, especially if the occupation is emerging from other pre-existing occupations with distinct values. As conditions change, some values within the occupation gain strength while others weaken (Bucher & Strauss, 1961). Convergence toward a set of shared ethical values is not guaranteed.
The mechanisms through which diverse occupational members codify values into ethical standards remain underexplored. While studies on occupational identity work (e.g., Chan & Hedden, 2023; Murphy & Kreiner, 2020) highlight internal conflicts, they do not link these to codification. Research on legitimation (e.g., Croidieu & Kim, 2018; David et al., 2013) focuses on external validation, while studies of emergent practices (e.g., Anteby, 2010; Fayard et al., 2017) overlook how contested practices formalize into codes. This study addresses this gap by theorizing how internal contests shape codified standards, contributing to our understanding of how occupational values are negotiated and institutionalized.
Recent work has revisited the codification of occupational values, yet critical gaps persist. Evans (2021) examined National Academy of Science guidelines for ethical stem cell practices, and Stice-Lusvardi, Hinds, and Valentine (2023) analyzed text artifacts between data analysts and managers, but these studies neglect how discourse structures shape codified artifacts. Relational approaches to discourse reveal how vocabularies—“systems of words and their meanings commonly used by social collectives” (Loewenstein, Ocasia, & Jones, 2012, p. 42)—mediate the translation of diverse values into shared artifacts. Relational approaches illuminate how power dynamics, alliances, and negotiation processes influence which values are prioritized, reframed, or suppressed during codification. Augustine (2021) traced sustainability managers’ development of the Sustainability Tracking, Assessment, and Rating System, offering insights into codification dynamics, though her methodology limits generalizability. This study explores how ethical codes emerge from internal contests within occupational communities, advancing the understanding of ethical codification as a dynamic process shaped by discourse and values.
Ethical Codification Discourse
As an institutionalization process, ethical codification is inherently a product of discourse (Green Jr., Li, & Nohria, 2009; Phillips, Lawrence, & Hardy, 2004). Before an occupational group codifies its ethics into a published code, its members debate which values to include and which practices to categorize as ethical or unethical. As Fayard et al. (2017) note, “values are not observable per se but tend to be articulated through discourse during activity” (pp. 273–274). Because ethical codification is a discursive process, discourse provides a site for the direct measure of the ethical codification process.
The trajectory of discourse variance during institutionalization
If occupational values are observable in ethical codification discourse, as assumed by Evans (2021), Augustine (2021), and Stice-Lusvardi et al. (2023), then heterogeneity of values in an occupational community should be observable as heterogeneity in ethical codification discourse. Discourse can be homogeneous, with a narrow or shared vocabulary of common interpretation, or heterogeneous, with a fragmented vocabulary or even contradictory interpretations. For example, Bechky (2003) describes how heterogeneity of language in a factory setting hindered coordination until the cross-functional teams established a common linguistic understanding.
Discursive variance changes over time, and existing literature disagrees on its trajectory during institutionalization. Some studies, such as Dunn and Jones (2010), highlight the coexistence over time of pluralistic logics, like care and science, in medicine. Others emphasize semantic homogenization as practices become legitimized. For instance, Gondo and Amis (2013) argue that discourse becomes more focused as practices become legitimized and broad acceptance leads to less detailed reflection, while Zbaracki (1998) suggests that ambiguity in discourse can facilitate legitimacy by encompassing diverse interpretations. Multivocality, or the strategic use of ambiguous framing, allows organizations to sustain multiple coherent interpretations and adapt identities over time (Hidayah, Lowe, & De Loo, 2021; Vedres, 2022). Hidayah et al. describe this as “drift,” where organizations embrace divergent voices to build a multi-rational ethical identity. Beyond ethical codes, Ferraro, Etzion, and Gehman (2015) discuss “multivocal inscription,” which promotes coordination among diverse audiences by enabling flexible interpretations without requiring explicit consensus. These perspectives suggest three possibilities for an occupational code of ethics: semantic homogenization leading to a singular code; pluralistic semantics resulting in multiple codes; or a singular but ambiguous code that serves as a compromise, reflecting fragmented vocabularies and divergent interests while fostering broad acceptance.
Mechanisms of discourse variance in ethical codification
To answer the question of how an occupational community with diverse ethical values comes to agree on a shared code of ethics, we need to identify the mechanisms that covary with discourse and might explain why discourse variance changes over time. One approach to identifying such discursive mechanisms is critical discourse analysis (cf. Romani & Szkudlarek, 2014). Fairclough (1992, 2005) organizes critical discourse analysis into three co-constructive levels: text, discourse, and social context. By analyzing each of these levels in relation to the other, we gain a more holistic understanding of the potential mechanisms informing structural changes in discourse during the ethical codification process.
Ethical codification artifacts
The foundation of ethical codification discourse is the publication of a code of ethics text. This text is a referential cultural artifact that symbolizes the ethical identity of the occupation. The publication of the code of ethics is also an event that separates time into pre- and post-codification. However, codes are not static. New codes are produced over time to replace old codes. Moreover, codes do not always appear singularly, but may be published in a series of drafts or volume sets.
Ethical codification discourse
The code of ethics text is embedded in discourse about the text. Discourse occurs across many communities and audiences, and is documented in public archives, such as news media, scientific publications, and social media, as well as private archives, such as diaries, emails, and meeting transcripts. As stated above, discourse about the codification of ethics in an occupation is a key site for internal contests over which ethical values to prioritize in the institutionalizing occupation.
Ethical codification actors
Discourse about a code of ethics is further situated within a social context. This social context includes the people and organizations involved in creating, and those affected by, the code of ethics. Because ethical codes enable status differentiation (Abbott 1983), power dynamics among these actors can play an important role in the co-construction of discourse, texts, and social relations (Phillips, Sewell, & Jaynes, 2008; Vedres, 2022). Selected people and groups, such as committees on ethics, are allocated power to define the values represented in the occupation and the boundaries of ethical practice, materialized in the code of ethics.
Under this critical discourse analysis frame, we can use semantic network analysis to measure changes in discourse variance, identify qualitative shifts in the dominant ethical values of an occupation, and analyze the influence of power dynamics in the ethical codification process to better understand how members of an occupation, with divergent values, come to publish a uniting code of ethics.
Structuring ethical codification discourse as semantic social networks
While traditional discourse analysis allows for capturing and linking contestation to codification holistically, direct measurement of the link between corpora, topic, and claims requires a more structural approach. Mohr (1998) suggested that meaning can be captured in the analysis of “meaning structures,” or “the system of relations that link cultural objects” (p. 351). Semantic networks are one such “system of relations” that link codes of ethics to the underlying dynamics of codemakers with heterogeneous ethical values.
In a semantic network, clusters of words that co-occur in a document reveal linguistic subcultures. When a semantic network is built from ethical codification discourse, or the discussion of the contents of a code of ethics, these clusters describe subcultures of occupational values, where some words are clustered into semantic communities reflecting sets of occupational values that are graphically distant and disassociated from other occupational values. Once ethical codification is structured into a semantic network, we can measure the number and diversity of semantic communities as the number and diversity of ethical values in the represented occupation, and the relational dynamics, based on interconnectivity (e.g., modularity) and distance in the graph, across these values.
Semantic networks have been used in other contexts to study institutionalization. Green Jr. et al. (2009), for example, use changes in the syllogistic structure of rhetoric surrounding total quality management practices to theorize the effects of institutionalization on social action by showing how setting aside a major premise of the argument implies that the major premise has become taken for granted. Meyer and Höllerer (2010) use multiple correspondence analysis of news and magazine articles to show how divergent rhetorical framing of the concept of “shareholder value” in 1990s Austria was related to the actor’s occupational field. Bucher, Chreim, Langley, and Reay (2016) analyze distinctive framing in policy reports and responses to delineate discursive strategies used by professions in order to claim professional jurisdiction. In the context of ethical codes, Canary and Jennings (2008) apply centering resonance analysis to compare the semantic networks of 46 corporate codes of ethics before and after the passage of the 2002 Sarbanes-Oxley (SOX) legislation, finding that post-SOX codes concentrated on SOX compliance.
Semantic networks without social context are limited in interpretability—diverse clusters of ethical or occupational values may be expressed by enemies, by collaborators, or even by the same individual. To assess the trajectory of discourse variance in an institutionalization process, we need to analyze the semantic network within its social context. Semantic network analysis simultaneously allows for semantic and social group identification defined by the relationships and lack thereof across meaning-laden clusters. The ties among people, organizations, and these terms and topics illuminates the structure of intra-occupational values, defining occupational subcultures and the boundaries of intra-occupational contestation. By connecting clusters of words to people and their organizational environment, we can evaluate not only change in the discourse but also covariance in the social composition of the discourse, revealing who comes to be represented in the final code and how. When semantic communities of co-occurring words in discourse about an occupation’s ethics are linked to social units (such as authors or institutional affiliations), they reflect ethical sociolects, or subcommunities of occupational members with similar or distinctive ethical values. Sociolects are groups of social units (e.g., individuals, organizations, or conversations) with similarities in language use (Louwerse, 2004; Reynolds et al., 2013). Because they are groupings of similar ethical values and separate distinctive ones, sociolects that are present in ethical codification discourse may reflect ethical subcultures and internal contests over ethical values within discourse.
Measuring the semantic social network of ethical codification over time, we can observe the trajectory of discourse variance as the change in number and interactions of sociolects. Fewer sociolects indicate semantic homogenization, while more sociolects imply semantic plurality. Furthermore, such semantic network structures give us leverage to investigate mechanisms for homogenization or heterogenization of discourse variance. For example, if discourse exhibits high engagement across social groups but shifts from multiple distinct sociolects to a dominant sociolect referencing a small cluster of specific words, we can argue that we have observed a focus or concentration of discourse. Alternatively, if multiple sociolects remain present or significant in size or quantity but connected to a dominant sociolect with a large cluster of more ambiguous vocabulary, we can argue that we have observed a process of ambiguity or multivocality. Incorporating changes in leadership of the organizations responsible for creating a code of ethics further contextualizes changes in discourse variance and can contribute to identification of potential political mechanisms. By measuring the trajectory of variance in ethical codification discourse, and the covariance of the respective artifacts and actors, we can address the question of how an occupational community with diverse values comes to agree on a shared code of ethics.
Methods
To analyze the process of ethical codification, we take the following steps: First, we collect the email exchanges from the committee tasked with constructing the 1997 software engineering Code of Ethics. We then apply semantic network analysis to graph this discourse into networks. To identify distinct ethical subgroups within these semantic networks, we employ network community 1 detection algorithms. These clusters are then socially contextualized through qualitative historical analysis (Bearman, Moody, & Faris, 2002). Finally, we compare these semantic communities to the established IEEE-CS/ACM “Software Engineering Code of Ethics” to explore the relationship between the discourse and the codification outcomes. This mixed computational, quantitative, and qualitative analysis of pre-codification discourse is made possible through access to both (1) a rich history of the development of the software engineering code of ethics by Michael Davis (2009), and (2) archived email communications from within the committee tasked with building the 1997 IEEE-CS/ACM “Software Engineering Code of Ethics and Professional Practice” (Gotterbarn, Miller, & Rogerson, 1997).
Social context: Software engineering pre-1997
By many accounts, the label “software engineering” was developed in order to differentiate the professional standards of software engineers from the scientific research of computer scientists and the “hacker ethic” of programmers at the time. Ensmenger (2012) documents a “rhetoric of crisis” that drove the institutionalization of software engineering, stating that by the mid-1960s all of the elements of the subsequent debates had been articulated: a widespread critique of the artisanal practices of programmers; the growing tension between the personnel demands of industry employers and the academic agenda of university computer science departments; emerging turf battles between technical experts and traditional corporate managers; and a shared perception that software was becoming increasingly expensive, expansive, influential, and out of control. (p. 24)
In 1968, the North Atlantic Treaty Organization (NATO) hosted a Conference on Software Engineering that established the expectations of “software engineering” as a “real engineering discipline” (Campbell-Kelly & Aspray, 1996, p. 201). In 1989, the Pentagon funded the establishment of the Software Engineering Institute (SEI), which would play an influential role in the institutionalization of software engineering, including the development of the 1997 software engineering Code of Ethics.
The development of the code of ethics began as a debate about licensing. In 1991, under the cultural climate of “software in crisis” (Ensmenger, 2012), Fletcher Buckley submitted a bill to the New Jersey House of Representatives to license the software engineering field (Davis, 2009). The bill was rejected due to concerns that software designers and others within this field were not “engineers.” 2 Buckley then submitted a draft motion “to establish software engineering as a profession” in the Forum for Academic Software Engineering email listserv and to the board of governors of the Computer Society division of the Institute of Electrical and Electronics Engineers (IEEE-CS), of which he was a member. To make the motion more inclusive of IEEE-CS’s “industry, research, and academic” constituencies, Elliott Chikovsky, another member of the IEEE-CS board of governors, filed a substitute motion to establish a steering committee to design, rather than assert, a code of ethics, curriculum, and licensure recommendations. This steering committee came to be known as SEEPP: the Software Engineering Ethics and Professional Practice task force (Davis, 2009).
SEEPP was a joint task force uniting the two dominant software engineering communities at the time: the Computer Society division of the Institute of Electrical and Electronics Engineers (IEEE) and the Association for Computing Machinery (ACM). In 1990, the IEEE Computer Society represented 107,049 members (ETHW, 2023) and the ACM represented 64,400 members (Patterson, 2006). As of 2024, these two communities remained significant, with the membership of the IEEE Computer Society exceeding 375,000 members (IEEE Computer Society, 2024) and the ACM exceeding 100,000 (ACM, 2024). Despite their overlapping interests and membership, these two organizations prioritized different occupational values that would position them as competing subcommunities in the institutionalization of software engineering. The IEEE Computer Society was formed in 1946 by electrical and radio engineers who worked in computing (Strawn, 2021). IEEE members prioritized standardization for engineering interoperability and innovation of technology, such as the IEEE 802.11 Wi-Fi networking standard introduced in the 1990s (Lansford, Stephens, & Nevo, 2001). In contrast, ACM was founded by academics at Columbia University in 1947 with a core value of education (Akera, 2007). By 1990, ACM had established a largely academic reputation “dominated by—and catered pretty much to—PhD mathematicians” (Ensmenger, 2001). ACM members prioritized education and the advance of computing as a science. Ensmenger (2012) summarizes the divergent interests of these two factions, stating: “as early as 1959, the outlines of a battle between academically oriented computer scientists [i.e. ACM] and business programmers [i.e. IEEE] had taken shape around the issue of professionalism” (p. 189). “Professionalism,” namely the status hierarchy of the computing occupations and their practices, entailed the prioritization of standardization for IEEE and education for ACM. While they shared many values in common, such as technical innovativeness and service to humanity, their divergent prioritization of the issues of “standardization” and “education” presented an internal conflict in the design of the code of ethics.
Ethical codification artifact: IEEE-CS/ACM Software Engineering Code of Ethics
The work of SEEPP culminated in publication of the joint IEEE-CS/ACM Software Engineering Code of Ethics in 1997 (Gotterbarn et al., 1997). Before the 1997 Code of Ethics, SEEPP produced four drafts. The first draft was an outline shared internally in September 1996. A second draft was shared publicly in January 1997. A third public draft was shared in August 1997, and the final version was published in December 1997.
Discourse data: SEEPP committee email communications
This study takes advantage of a novel dataset of committee discourse text preceding publication of the 1997 Software Engineering Code of Ethics. With the support of the National Science Foundation, the Illinois Institute of Technology’s Center for the Study of Ethics in the Professions (CSEP) archived the email discussions of SEEPP. As described by CSEP: This online archive of correspondence documents the drafting and final adoption of the ‘Software Engineering Code of Ethics and Professional Practice.’ The archive is composed of the original emails, faxes, regular mail, and other related documents compiled by the IIT research team, and documents generously donated by members of SEEPP. The SEEPP correspondence documents the emergence of a new profession, and the development of a professional code of ethics from the bottom up. One of the most interesting aspects of the archive is that much of the drafting was done via email. The electronic correspondence in the archive reflects both the advantages and drawbacks of online communication for complex projects. Efforts have been made to make the archive as complete as possible, though some gaps exist. (CSEP, 2020)
This dataset includes 613 emails sent between April 1991 and April 1998, capturing the critical stage of the codification process preceding publication of the 1997 Software Engineering Code of Ethics (see Figure 1).
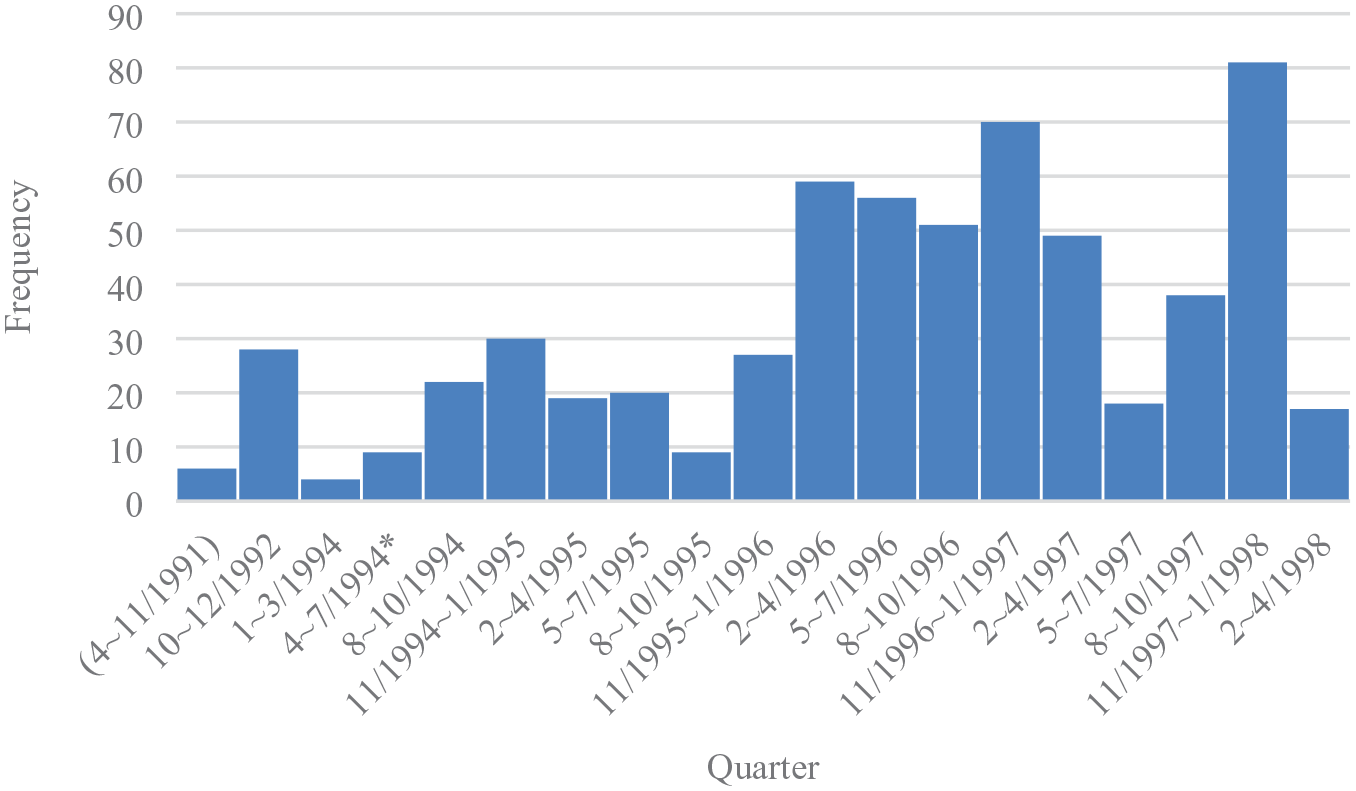
Frequency distribution of emails in the Software Engineering Archive, by quarter.
In addition to the email archive dataset, we also rely on the ethnographic account of SEEPP’s creation of the 1997 code of ethics written by Michael Davis (2009) for historical and organizational context to the discourse.
Analysis
Our computational analysis involves two key steps: (1) semantic network analysis to track changes in discourse variance; and (2) theoretically grounded topic modeling to identify rhetorical shifts that reflect the dominant ethical values of the committee tasked with developing the 1997 Software Engineering Code of Ethics. Semantic network analysis captures structural changes in discourse, while topic modeling delves deeper into its content, uncovering specific themes and their association with key actors within the committee. By linking topics to individuals or groups, we reveal how different stakeholders influence rhetorical shifts and ethical priorities. Together, these methods provide a comprehensive view of both the structural dynamics of discourse and the social roles shaping the ethical narrative. Finally, we contextualize these findings qualitatively using Davis’s (2009) historical account of the committee discourse.
Measuring discourse variance using network community detection and modularity
To measure ethical codification discourse, we graph the SEEPP email content into “semantic networks” (Berners-Lee, Hendler, & Lassila, 2001; Carley & Palmquist, 1992; Collins & Loftus, 1975; Doerfel, 1998; Griffiths, Steyvers, & Tenenbaum, 2007; Howard, 1989; Mohr, 1998; Sowa, 1992; Woods, 1975). Semantic network analysis is the process of mapping words onto a graph based on their common co-occurrence in a text unit (cf. Diesner & Carley, 2005; Hellsten, Opthof, & Leydesdorff, 2020; Roth & Cointet, 2010; Rule, Cointet, & Bearman, 2015). Rule et al. (2015), for example, use co-occurrence networks to display changing associations among words in State of the Union addresses. Here, our text unit is an email. Thus, terms (words) co-occur within the context of the email. The nodes in our semantic network are terms, and an edge, or tie, between these nodes is defined by co-occurrence within an email. To observe changes over time, we use the emails-by-quarter unit of analysis.
Once we structure ethical discourse as a semantic network of co-occurring words, we then have access to a wide range of graph-based tools for dissecting the interdependencies and dynamics of ethical discourse. To measure variance in ethical values, we use network community detection. Community detection algorithms (Blondel, Guillaume, Lambiotte, & Lefebvre, 2008; Sawhney, Prasetio, & Paul, 2017; Yang & Leskovec, 2013) measure the convergence and divergence of network communities and subcommunities, or nodes that are more interconnected in a network. Community detection algorithms were applied to semantic and other sociolinguistic networks as early as 1975 (cf. Hendrix, 1975; more recently Siew, 2013; Siew, Wulff, Beckage, & Kenett, 2019; Surian et al., 2016). Bail (2016) demonstrated the application of semantic community detection to the study of subcultures, showing how different network clusters of Facebook users employed different rhetoric about autism spectrum disorder. Using a similar approach, we can also partition the SEEPP discourse into subcommunities of co-occurring words (where nodes are words and edges are defined by co-occurrence) describing distinctive subcommunities of ethical values.
Community detection algorithms define communities by network structure, typically using some measure of tie strength (e.g., in agglomerative methods) or centrality (e.g., in divisive methods such as the Girvan-Newman algorithm) (Fortunato, 2010; Newman, 2006). The field of community detection continues to advance, yet the Louvain method (Blondel et al., 2008), based on network modularity, remains a reliable method for community detection (see Appendix A for technical details).
Applying a similar approach to ethical vocabularies, we measure ethical consensus based on the modularity of a semantic network, or the degree to which the network is composed of disconnected communities. High modularity, or a graph composed of many disconnected subgraphs, implies semantic heterogeneity and, in the case of ethical codification discourse, low consensus on ethical values, at a given time.
We use historical longitudinal analysis to identify the change in discourse structure over the ethical codification process (Rule et al., 2015). By observing changes in the structure of semantic communities within ethical codification discourse longitudinally, we observe the dynamics of convergence toward and divergence away from ethical agreement in the occupation. The longitudinal analysis measures changes in the co-occurrence networks and their composition by a given period (here, quarterly). Change is measured at the level of network modularity, as well as topic composition as described in the next section. Network modularity quantifies the degree to which a network can be divided into distinct communities. Composition encompasses the specific terms, or vocabulary, that characterize a particular community.
The culmination of ethical codification is measured by the publication of a “code of ethics” in the occupational community. The 1997 Software Engineering Code of Ethics serves as the outcome variable text of our analysis, comprising the culminating semantic community against which we contrast the preceding semantic community. Following Santana, Hoover, and Vengadasubbu (2017), we measure alignment of each semantic community with the 1997 Code of Ethics using cosine and Jaccard similarity coefficients (see Appendix A for technical details). A higher cosine or Jaccard coefficient indicates higher semantic similarity between two documents. When the comparator document is the Code of Ethics, the similarity coefficient describes the dominant semantic community represented in the Code of Ethics.
Measuring rhetorical shifts via theoretically grounded topic modeling
Finally, to qualitatively understand the rhetorical content of these semantic communities and how that content shifts, we use topic modeling (Blei, 2012; Hannigan et al., 2019). Topic modeling is a computational text analysis method for inductively identifying topics within a set of documents. Latent dirichlet allocation (LDA) is a common topic modeling approach that estimates the probability of a given topic as the document-topic distributions based on the topics represented in a given document and the topic-word distributions based on the words represented in each topic of the document set (Blei, 2012; Blei, Ng, & Jordan, 2003). Topic modeling is useful for identifying latent topics in a set of documents. Here, we use topic modeling to identify divergent topics within the SEEPP emails, which should reflect divergent ethical values of the subcommunities involved in the ethical codification process. We use LDA topic modeling with Gibbs sampling, a class of Markov chain Monte Carlo algorithms, to estimate the document-topic and topic-word distributions. Our determination of the optimal number of topics follows Murzintcev (2014), using Cao, Xia, Li, Zhang, and Tang (2009) and Deveaud, SanJuan, and Bellot (2014) to find the optimal number of topics k.
The LDA analysis produces a probabilistic distribution of topics-per-document (θ), measured by the per-topic word distribution probability (β). Using θ, we identify divergent topics within each quarter of our dataset as a distinctive ethical topic. Using β, we rank terms within a topic to identify the importance of a given value, such as “standards” or “education,” in that topic. By measuring changes in β over time, we can observe the rise and fall of a given value’s importance in the discourse over time.
We use Davis’s (2009) historical ethnography of the development of the 1997 Software Engineering Code of Ethics to identify potential topics and terms that are meaningful to the different organizational factions (IEEE and ACM) building the code.
Results
Descriptive statistics of semantic network over time
The resulting semantic co-occurrence networks are summarized by quarter in Table 1 below. In this table, the third column describes the number of emails written in the given quarter, and the fourth column indicates the number of authors writing those emails. Column 6 describes the number of community clusters in the given quarter’s semantic network, and column 5 describes the modularity, or interconnectedness, of those communities. Columns 7 and 8 describe the number of nodes (words in emails) and number of edges between nodes (co-occurrence of words in an email) in that quarter’s semantic network. Finally, columns 9 through 12 provide the summary statistics of that quarter’s network. The smallest network occurs in quarter 3 of the dataset (January–March 1994) with 439 nodes and 436 edges. The largest network is in quarter 18 (November 1997–January 1998) with 2,917 nodes and 4,227 edges. Because it is a semantic network, the size of the network tends to follow the number of emails in that quarter.
Summary Statistics of Ethical Codification Discourse Term Co-Occurrence Network by Quarter.
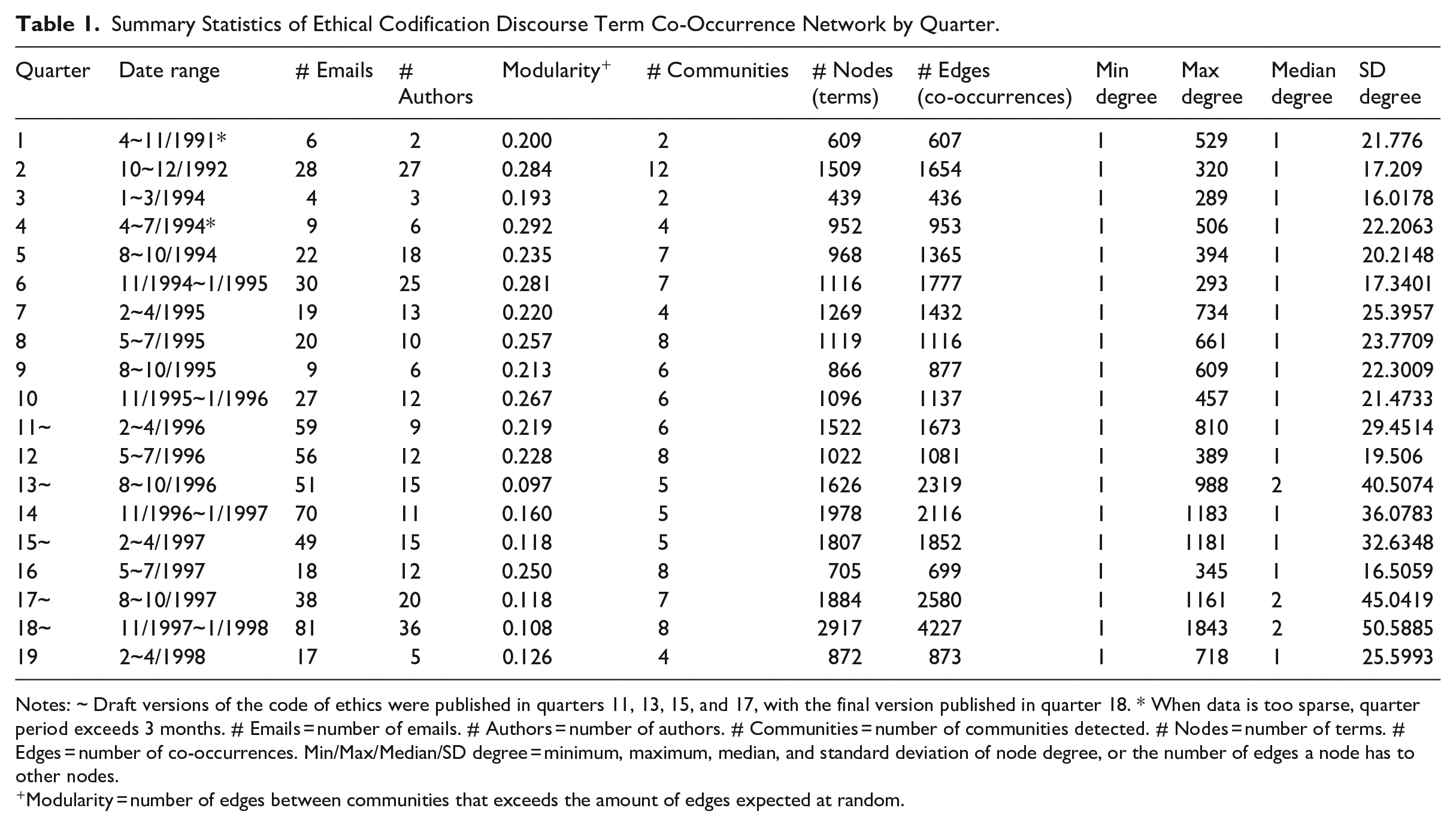
Notes: ~ Draft versions of the code of ethics were published in quarters 11, 13, 15, and 17, with the final version published in quarter 18. * When data is too sparse, quarter period exceeds 3 months. # Emails = number of emails. # Authors = number of authors. # Communities = number of communities detected. # Nodes = number of terms. # Edges = number of co-occurrences. Min/Max/Median/SD degree = minimum, maximum, median, and standard deviation of node degree, or the number of edges a node has to other nodes.
Modularity = number of edges between communities that exceeds the amount of edges expected at random.
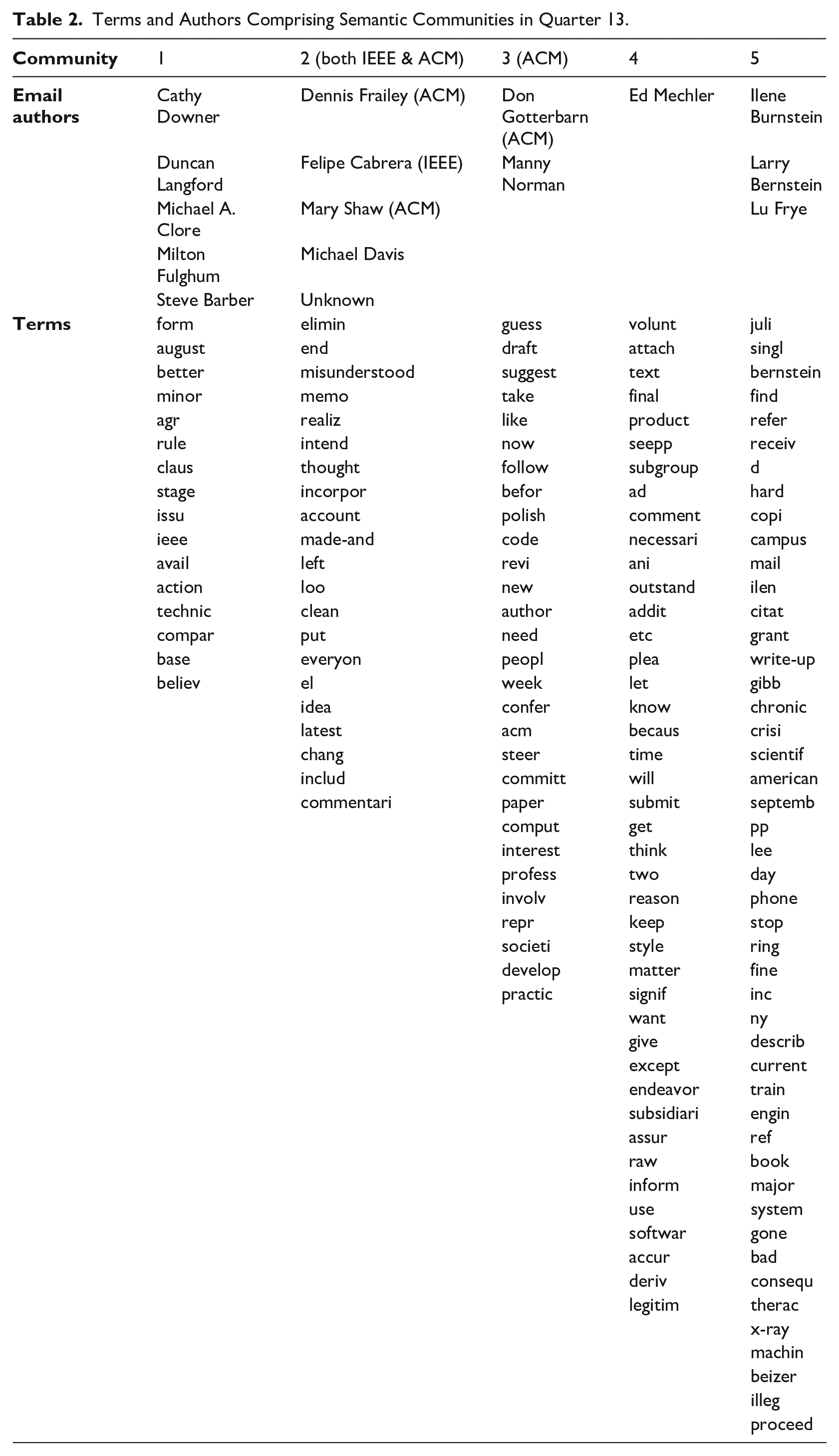
The resulting modularity and community data for each quarter’s semantic network is summarized in Table 1 and Figure 2. Modularity decreases on average from 0.284 in quarter 2 to 0.108 in quarter 18 in which the code of ethics is published. Modularity is not linear, but does trend downward (y = −0.009x + 0.2894; R² = 0.5289). This means that the polarization of communities within the ethical codification discourse decreases over this period. The number of semantic communities remains stable at around six communities on average (y = −0.0165x + 6.3791; R² = 0.0016), implying that the ethical discourse remains heterogeneous. An example community from quarter 13, after the first internal draft code V0 was shared, is provided in Figure 3 and Table 2, showing emails from or mentioning Ed Mechler, an IEEE representative who led the construction of the V0 draft, associated more with terms such as “product,” “subgroup,” “assur-,” “softwar-,” and “deriv-,” while emails from or mentioning Don Gotterbarn, an ACM representative who chaired the SEEPP committee, are associated with terms such as “comput-,” “profess-,” and “practic-.”
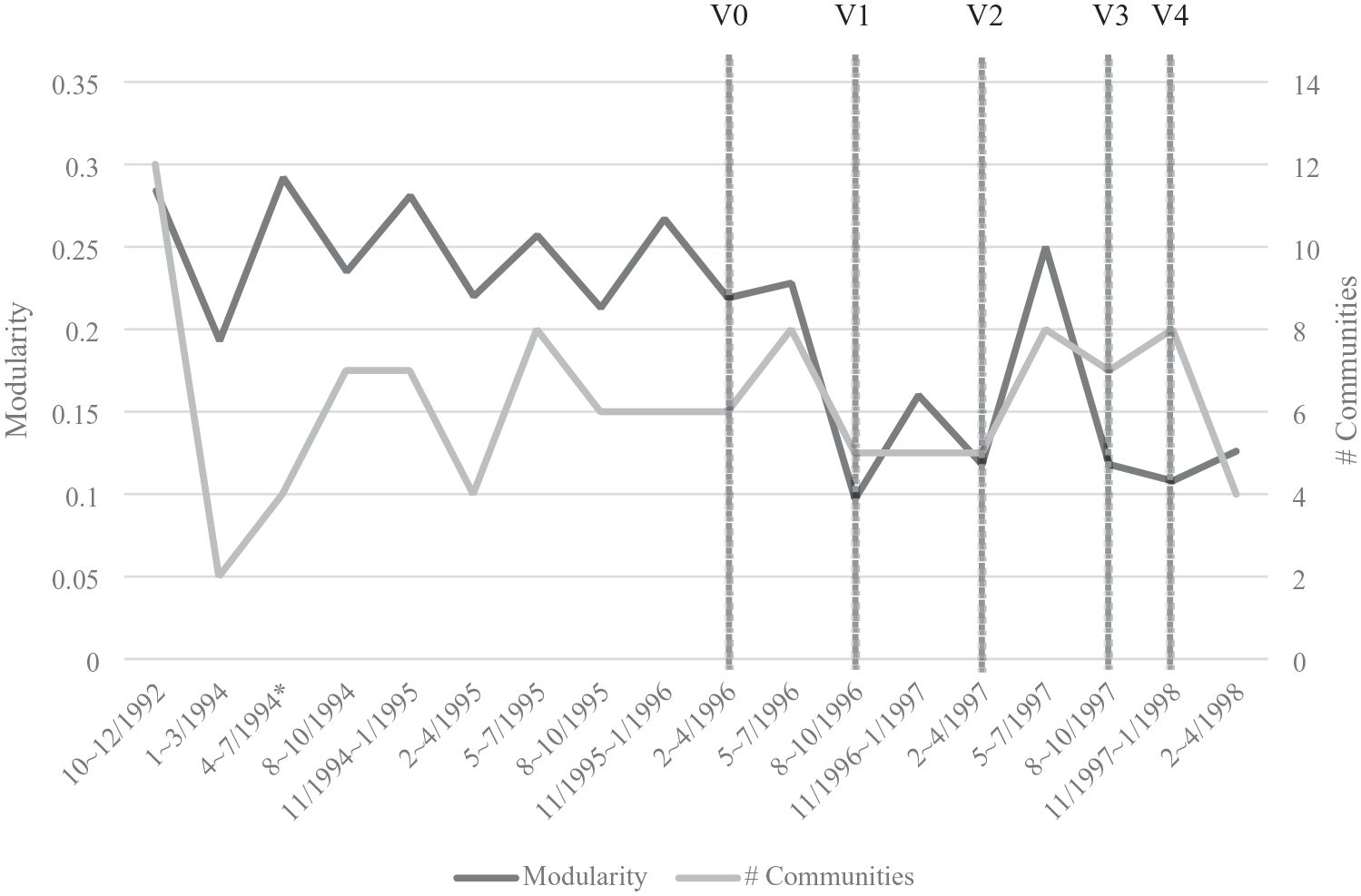
Modularity of SEEPP email semantic network by period.
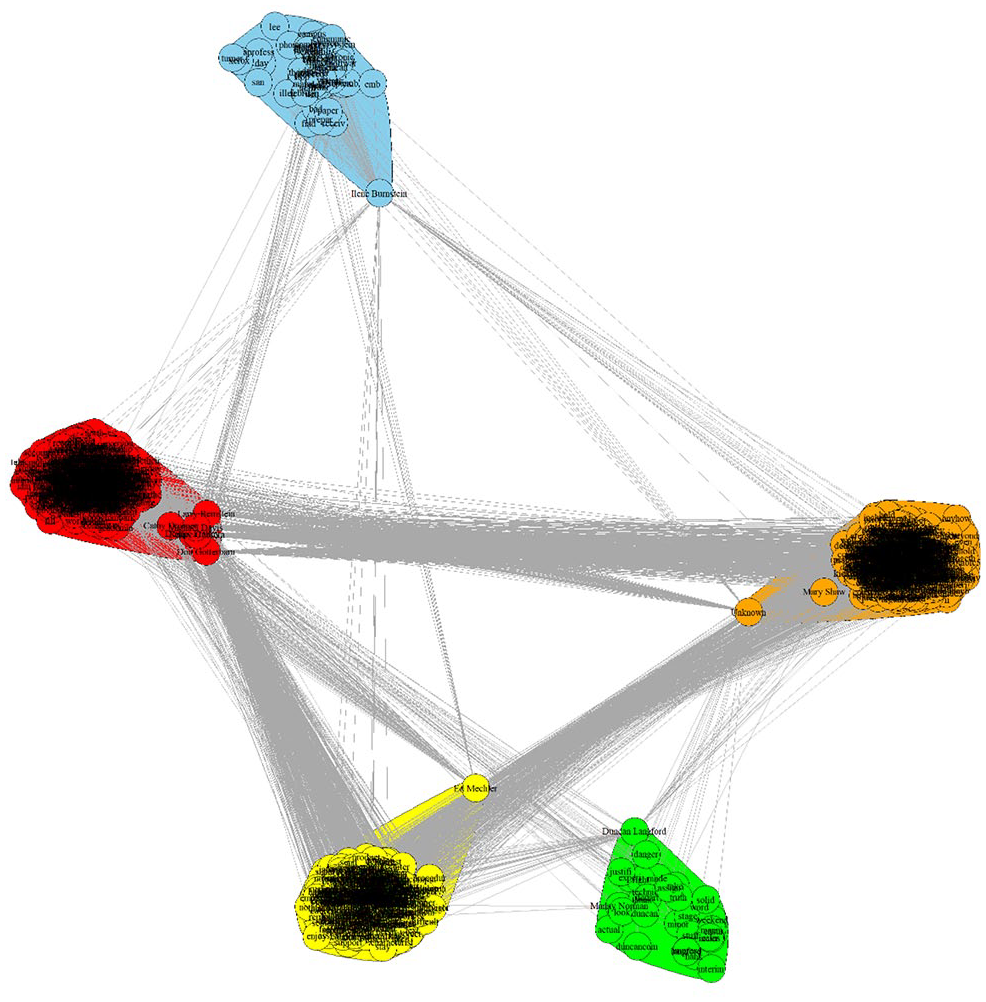
Semantic Community Structure of Quarter 13. Nodes are terms in emails, including the name of the email author. Terms and authors are listed in Table 2 (Communities in red, orange, green, blue, and yellow indicate Community 3, Community 2, Community 1, Community 5, and Community 4, respectively, in Table 2). Edges indicate co-occurrence in an email within the given quarter. Color of nodes indicates distinct network communities.
Terms and Authors Comprising Semantic Communities in Quarter 13.
Descriptive statistics of topics over time
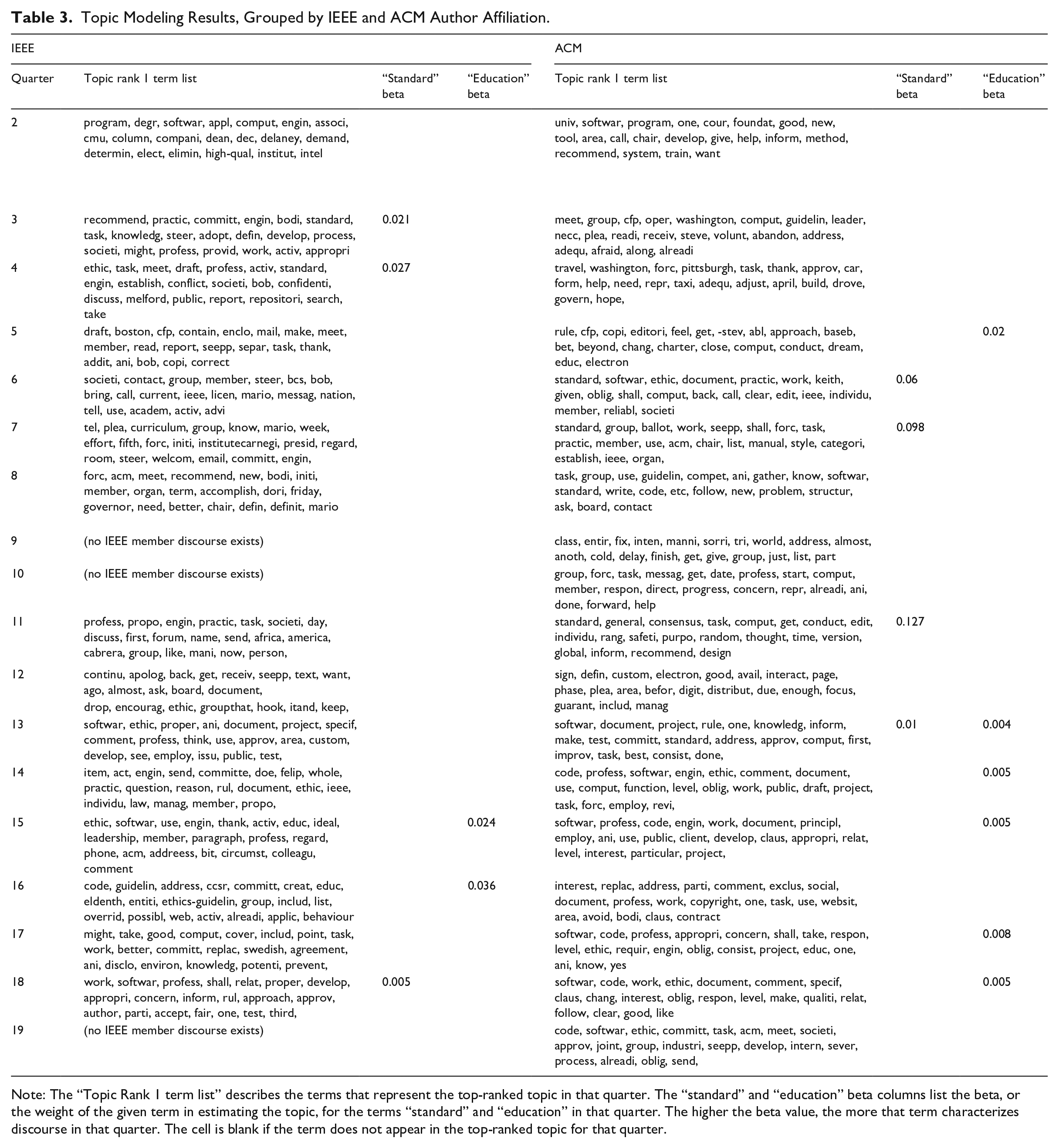
The two dominant factions in this semantic network over time are members of the IEEE and ACM. Other people who appear in the network were not registered members of IEEE or ACM, but were active practitioners of software engineering. Given the distinctive interests of the IEEE and ACM groups mentioned above, we expected to observe variation in these groups’ ethical discourse, measured by group-labeled semantic co-occurrence networks and topics. The results of our LDA topic model analysis are summarized in Table 3 in Appendix B, categorized by IEEE and ACM affiliation of the email author. The “topic rank 1 term list” describes the terms that represent the top-ranked topic in that quarter. From Davis (2009) and Ensmenger (2012), we identify the dominant ethical interests of IEEE as “standardization” and of ACM as “education.” Given this, we focus on the beta value for “standard,” a term representing the “standardization” interests of IEEE, and “education,” representing the interests of the ACM. The “standard” and “education” beta columns list the beta, or the weight of the given term in estimating the topic, for the terms “standard” and “education” in that quarter. The higher the beta value, the more that term characterizes discourse in that quarter. The cell is blank if the term does not appear in the top-ranked topic for that quarter. We see that these terms are not heavily mentioned in quarters 2, 8 to 10, 12, and 19. We see that IEEE mostly references “standard,” while ACM mostly references “education.” We also see references of “education” exceeding those of “standard” after quarter 14. A portion of an example email showing early predominant references to “standard” is shown in Figure 4.

Example email from dataset.
We next compare the content of these semantic communities with the published Code of Ethics to determine whether one group (ACM or IEEE) is dominantly represented in the final code. We use cosine similarity to measure both the variance across semantic community content and their proximity to the final Code of Ethics. Table 4 describes the representation of the ACM and IEEE factions in the semantic communities that most closely resembled the final Code of Ethics in quarter 18. We see that the semantic community with the greatest similarity to the Code of Ethics is Community 2, which does not include the emails by ACM or IEEE members. ACM-authored emails are clustered into Community 4, which also includes a large contingent of IEEE-authored emails. Interpreting both tables, we observe that, while the ACM value of “education” overtakes the value of “standardization,” the discourse within the cluster is authored by both ACM and IEEE emails. The value ultimately adopted in the final Code of Ethics was shown most clearly in emails with other non-ACM or non-IEEE member communities.
Similarity between Communities and Code of Ethics V.4 (Published 1997) in Quarter of Publication (Quarter 18).
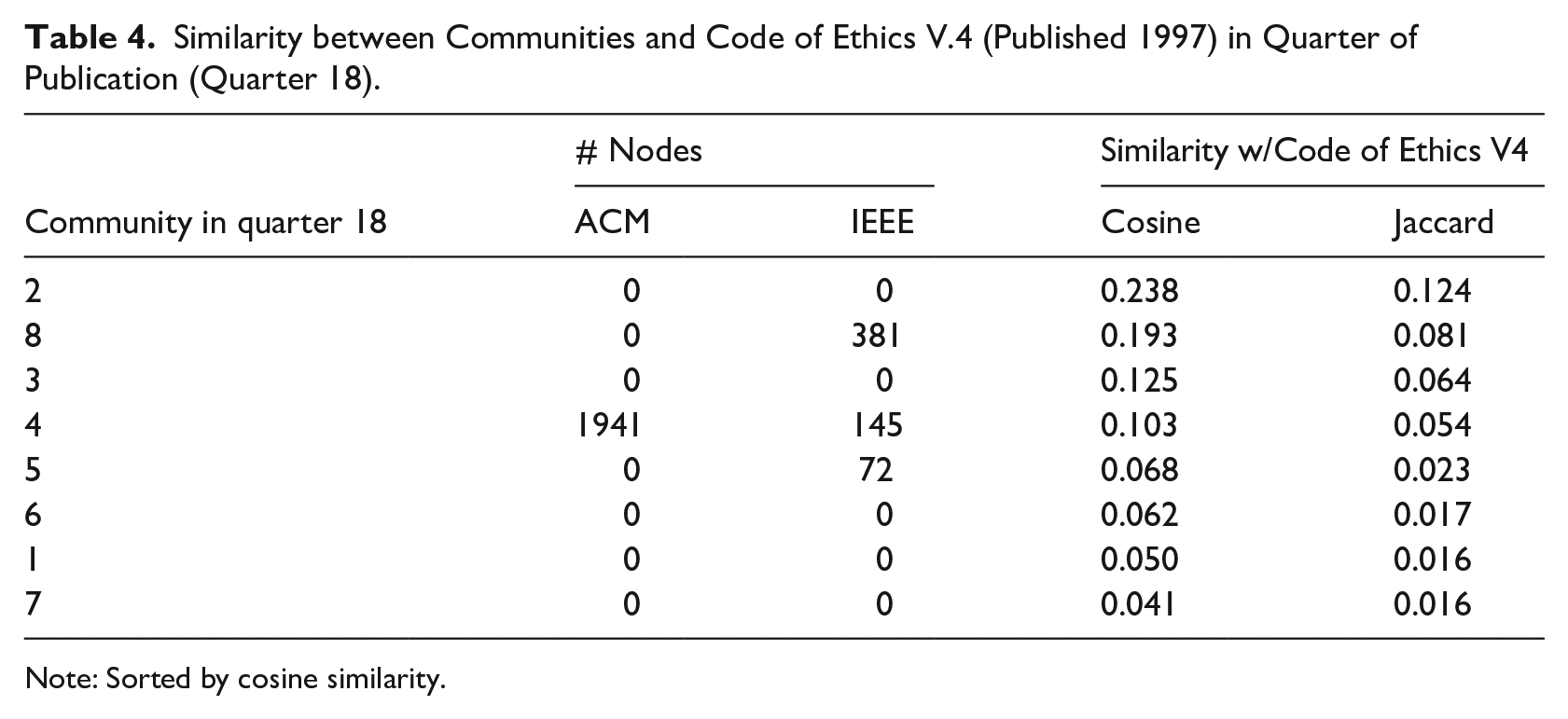
Note: Sorted by cosine similarity.
A discursive process of ethical encodification
We organize our findings into stages of ethical codification driven by three text artifact events identified from Davis (2009): (1) the internal publication of the first code draft V0 (April 1996); (2) the external publication of the code draft V2 (August 1997); and (3) the publication of the final code of ethics (December 1997). For each stage, we describe below our findings on discourse variance (modularity and rhetorical content) and power dynamics within each stage.
Codification stage 0: Pre-artifact distributed discourse
The first stage of encodification of ethics is one in which discourse is distributed among diverse groups of actors with diverse values. A set of factions among the social actors—here, IEEE and ACM—equivalently dominate the discourse. Because the actors engage less across factions, the discourse is highly modular with large numbers of sociolect communities. The process transitions to stage 1 when a draft code, representing the discourse of predominantly one faction, is published internally.
In the software engineering case, stage 0 of the codification process occurred from Q1 (April 1991) to Q11 (April 1996) of our dataset. During this time, SEEPP was established and remained in a planning mode for the majority of this period. Committee leadership was shared between an IEEE representative (Robert Melford) and an ACM representative (Don Gotterbarn). The actors leading the codification task force interacted infrequently and made relatively little progress. Under this context of indecision, two subgroups began work separately towards an initial outline of the code. Most of this work involved collecting codes of ethics from other occupational communities, such as the pre-existing ACM Code of Ethics and the British Computer Society Code of Conduct. From these models, the two groups began selecting items to include in the software engineering Code of Ethics.
These two parallel groups are observable as separate semantic communities in our co-occurrence network, and represent the two IEEE and ACM factions. This can be clearly visualized in the co-occurrence network when arranging only the terms from the two groups, while controlling for the lengths of edges between co-occurring terms. For example, Figure 5 shows the co-occurrence network in quarter 7 (February–April 1995), with terms from emails written by IEEE representatives in red and by ACM representatives in green. The two divergent communities (out of eight total semantic communities in this quarter) are clearly visible with few brokering terms residing between the two larger clusters.
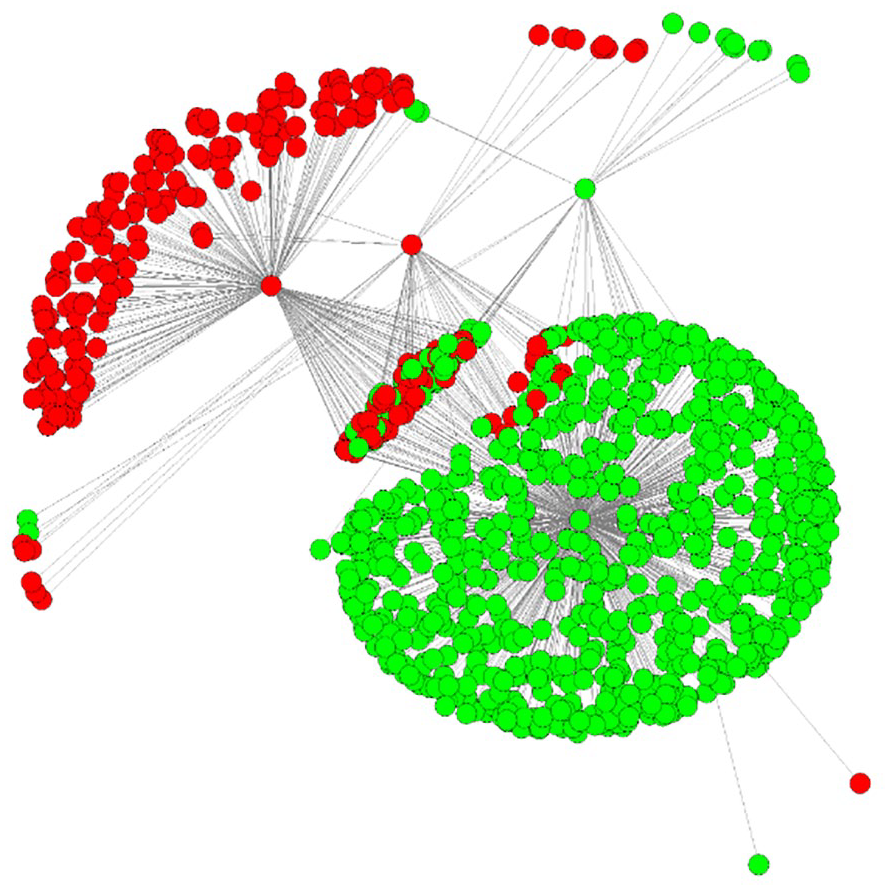
Term co-occurrence network in Quarter 7.
In Figure 2, we see modularity begin high in quarter 2 and decrease on average over this early codification stage, from 0.284 in October 1992 to 0.219 in April 1996, as these groups worked in parallel and in general isolation from each other. Modularity is high as more members with more diverse values join the two groups.
This early codification stage ends with the internal posting of version 0 of the code by one of the subgroups, provoking the polemical discourse of codification stage 1.
Codification stage 1: Artifact-driven internal debate
The internal publication of a draft code representing one faction results in debate with other factions. Discourse in this period is characterized by low modularity and a low number of communities, as the factions engage with each other in polemical debate. Codification advances to stage 2 when an effective leader selects a value set and publishes the draft code for an external audience.
In the software engineering case, stage 1 occurred from Q12 (May 1996) to Q13 (October 1996). The key event triggering this period was the internal sharing in August 1996 of version 0 of the code—a “straw man” (Davis, 2009, p. 93) to provoke feedback from group members. Because the two groups were working in relative isolation, the “straw man” V0 appeared unexpectedly for one group. As a product of subgroup A, V0 did not reflect the values of the second subgroup B. One member of the subgroup B responded: In general, I think this expresses some good ideals, but is entirely impractical in a number of cases. The problem is that many of the things being proposed are vaguely defined, impossible to accomplish, or not under the control of the software engineer. A few others might not be generally accepted as the “right” thing to do. (Frailey, 1996, SEA archives, October 4, 1996)
A second member of the subgroup B further responded: I share [member X’s] general concern that this is fine in theory but hard to apply. I realize that codes of ethics should be idealistic, but they also must be credible; that is, practitioners should be able to see how the code shapes their work. Another way of saying this is that this draft seems a little naive. (Shaw, 1996, SEA archives, October 8, 1996)
While this stage is characterized by polemical discourse, the “straw man” was an important reference point around which the discourse began to congeal, reflected by the decreasing modularity of this period. This decrease in modularity occurred as the conversation content focused on the most important items to include in the code. While stage 0 of the codification process included discussion of model codes with diverse content and high modularity, the discussion in stage 1 focused more specifically on the proposed values to include in the code. In reaction to the straw man code V0, the committee began arriving at consensus on what to include in the code as the dominant value set, and modularity decreased.
This stage of the codification process culminated with the code version 2 shared externally as a representation of the subgroups within the committee now working together.
Codification stage 2: Leader-driven prioritization
In the software engineering case, stage 2 of the codification process occurred from Q14 (November 1996) to Q16 (July 1997). During this time, leadership of the taskforce consolidated, which accelerated the codification process. Before 1997, the taskforce reported to two co-chairs—one (Melford) representing the IEEE contingent and the other (Gotterbarn) representing the ACM contingent. In January 1997, the ACM-affiliated chair of the taskforce announced the departure of the IEEE-affiliated co-chair. The remaining chair was a politically experienced representative of the ACM faction that had weathered the debate of the prior quarter without taking sides. Newly empowered with sole authority over the taskforce and guided by his experience with this polarized group, the chair now accelerated the codification process.
We can observe the centralization of discourse that followed the concentration of the chair’s power using topic modeling and semantic network analysis, with rhetoric shifting for both groups from the “standardization” focus of IEEE to the “education” focus of ACM in Q14. In Table 3, we see from our topic model analysis that the topic of education slowly comes to replace the topic of standardization. While “standardization” enjoys a higher ranking beta value of 0.021 in quarter 3, the topic of “education” overtakes “standardization” in quarter 14, the quarter in which the leadership of the task force became centralized under an ACM representative.
This shift in rhetoric is also visible when comparing the co-occurrence networks of Q13 to Q15. We show the changes in Figure 6. In Figure 6, we see that the co-occurrence network of Q13 comprises at least three communities, one of which is dominated by IEEE communications. The network centralizes in Q14, as the co-chair exits. Over this timeframe, modularity of the discourse decreases from 0.160 to 0.118. The new dominance of ACM rhetoric is clear in Q15. Over these three quarters, as shown in Figure 6 with the clear dominance of green color (representing ACM), terms written by IEEE members disappear from the discourse while terms written by ACM members become representative of the discourse.

Term co-occurrence networks in quarters 13 (left), 14 (middle), and 15 (right).
Codification stage 3: Artifact-driven external debate
In Q16, the taskforce received external feedback on V2 of the code. Once the draft code is published externally to the broader professional community, discourse increases in diversity as more members of the broader professional community respond to the draft code. This feedback was diverse, coming from Europe, Australia, and the United States. This international injection of topics increased the number of communities and modularity of the discourse in Q16. This stage sees discourse increase in modularity and community count again. An effective leader serves as a mechanism for advancing the codification process through this period of dissensus to consensus.
Codification stage 4: Leader-driven codification
In the software engineering case, consensus emerged in Q17 just prior to the code being published in Q18. This stage included the internal posting of the code draft V3 for internal feedback. The chair of the taskforce, who had weathered the polemics of stage 2, successfully defended against further debates that could have terminated the codification attempt. Most notably, the chair of the ACM special interest group on software engineering (ACM SIGSOFT) responded to V3 with a list of issues to include, such as “the issue of modifying or changing existing software,” stating that “until some of these problems are clarified and/or fixed, ACM SIGSOFT does *not* endorse this draft code” (Notkin, 1997, SEA archives, November 1, 1997) The committee chair, with the help of other key authors of the code, responded diplomatically with a few appeasements, such as the addition of “a specific statement that will make clear that the term ‘development’ for the software engineer includes new development, enhancement of existing systems and correction of existing system,” but also with resistance against some requested revisions, such as the removal of a clause promoting software disclaimers (Gotterbarn, 1997, SEA archives, December 3, 1997).
This stage experienced a decrease in modularity at Q17, as the discourse concentrated on the final prioritized issues, and then stabilization at Q18, when the final version V4 of the software engineering code of ethics was officially published.
In Figure 7, we abstract these stages of the discursive process of ethical encodification from the 1997 software engineering Code of Ethics into a generalized model. Stage 0 is defined by the discourse preceding any code artifact. Leadership has not emerged, and discourse is distributed across multiple communities with little interaction across them. Stage 1 begins when a strawman draft code artifact appears. This strawman draft incites debate across communities, with dominant semantic communities emerging that reflect the dominant occupational values. The codification process moves into stage 2 when power increases to a faction, such as through the concentration of leadership or authority. This shift in power enables sufficient concentration of the discourse to facilitate the publication of another, in this case external, draft code. Presenting this draft to a new audience results in the addition of new semantic communities and new debate across these communities. However, if power is sufficiently restricted to a given faction (e.g., from stage 2), the leadership of that faction is able to control the debate, prevent it from escalating further, and conclude the discourse with the publication of a uniting Code of Ethics.
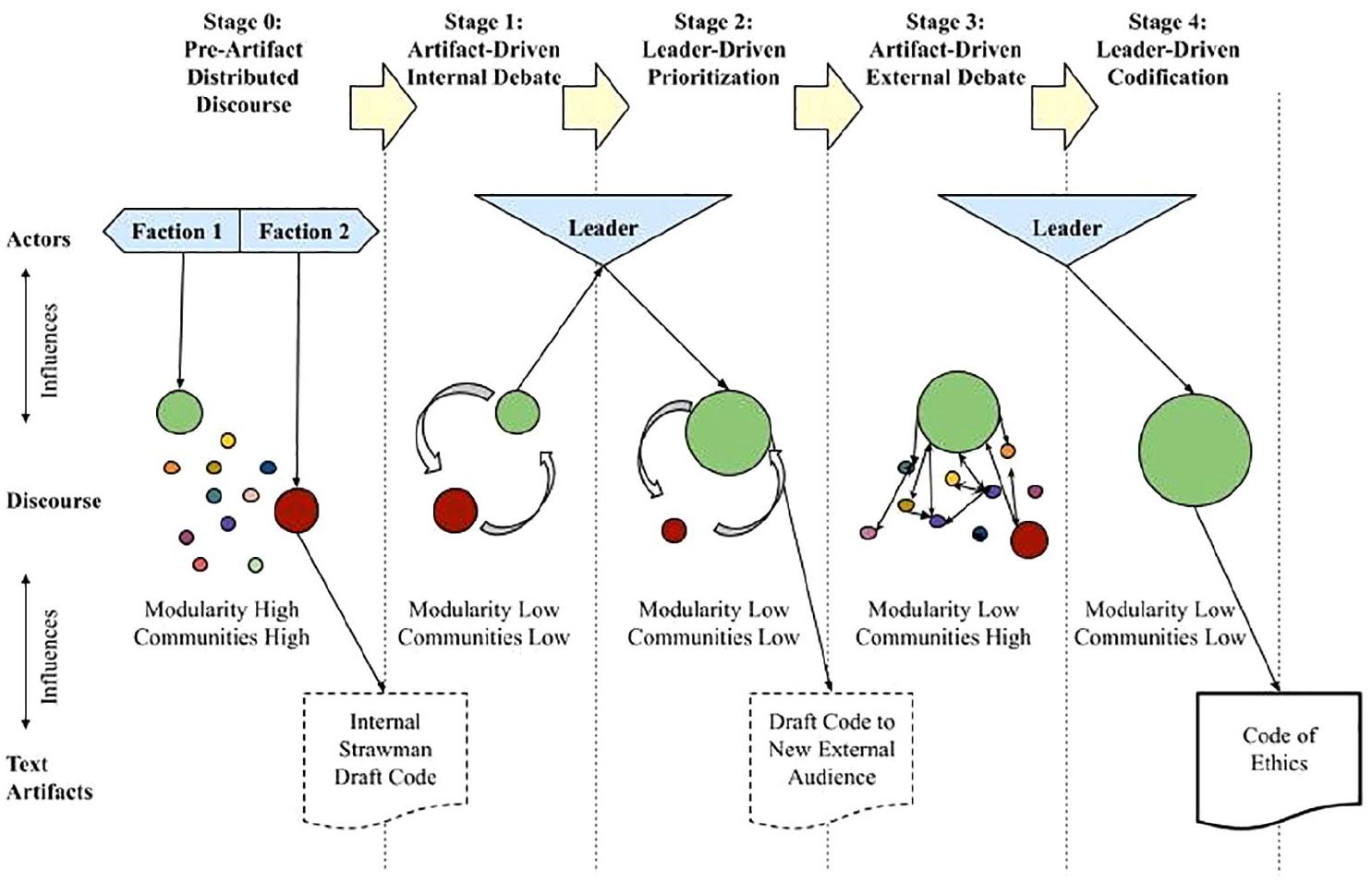
Discursive process of ethical encodification.
This model is intended to be both theoretical and generalizable. While the stages are presented linearly, we acknowledge that real-world cases may exhibit recursive loops, particularly between stages 1 and 2, as discourse evolves and power dynamics shift. The systematicity of each stage depends on the contextual factors, such as the degree of leadership centralization, the openness of discourse to external audiences, and the diversity of ethical values within the occupational community. For example, while some cases may proceed seamlessly to stage 3 due to concentrated leadership, others may revert to earlier stages if draft codes fail to achieve consensus. This process-based approach offers a framework for understanding how ethical codes are shaped through discourse and can be applied to other cases with similar dynamics of occupational contestation and codification.
Discussion
This study examines how an occupational community with diverse ethical values reaches consensus on a shared code of ethics. Institutional theorists have long emphasized the centrality of discourse in processes such as ethical codification (Green Jr. et al., 2009; Phillips et al., 2004), yet debates persist over the trajectory of discourse variance and the mechanisms shaping it. Our findings demonstrate how semantic network analysis, informed by qualitative interpretation and a critical discourse lens, contributes to this theoretical debate by uncovering how contested values converge during codification.
Using semantic co-occurrence network structuration of ethical codification discourse and community detection methods, we reveal that discourse transitions from reflecting divergent values across multiple sociolects to converging on a dominant—though not singular 3 —set of values before codification. By measuring discourse trajectory as change in modularity and number of communities, and investigating the content of these changes using a blend of network, topic model, and qualitative historical analysis, we find that in the software engineering case, the codification process moved from emphasizing “licensure” to “standardization” and ultimately to a dominant focus on “education.” These findings align with prior theorization that discourse tends to homogenize as practices gain legitimacy (Gondo & Amis, 2013; Green Jr., 2004), while also highlighting the potential for focal shifts between competing occupational values (Dunn & Jones, 2010).
We identify two key mechanisms driving these shifts. First, the sequential publication of draft codes acted as discursive forks, catalyzing debate while simultaneously consolidating semantic communities into fewer, larger sociolects. Second, centralized leadership prioritized certain values, framing education as central to the occupation’s ethical identity. Together, these mechanisms reduced modularity and sociolect diversity, fostering discourse homogenization. Importantly, our findings suggest that centralized leadership plays a crucial role in steering discourse trajectory, confirming prior assertions about the power of leadership to prioritize and frame values during institutionalization (Phillips et al., 2004; Vedres, 2022).
Contributions to institutional discourse and occupational theory
This study also contributes to debates on focus versus ambiguation in institutional discourse. While some literature highlights multivocality as a strategy for sustaining diverse values (Hidayah et al., 2021; Zbaracki, 1998), our findings show that mechanisms such as centralized power and iterative codification processes can also result in focused discourse. In contrast to cases where ambiguation enables coexistence of multiple occupational values, such as Ferraro et al.’s (2015) work on multivocal inscription, the software engineering case demonstrates how focused discourse can still enable identity drift, as the occupation shifted from a licensure-oriented identity to one rooted in education. This insight bridges debates on whether convergence in institutional discourse necessarily narrows identity or allows for adaptive evolution over time.
Furthermore, our findings advance understanding of ethical codification as a dynamic process shaped by internal contestation and external legitimacy. By linking mechanisms of artifact publication to changes in discourse structure, we expand on Fayard et al.’s (2017) argument that codification reflects the articulation of values through discourse. Additionally, we show how these discursive shifts are not merely byproducts of occupational values but are actively shaped by social context, including power dynamics and leadership centralization, resonating with theories of occupational boundary work (Abbott, 1983; Bechky, 2003).
Contributions to computational methods for analyzing meaning and culture
Our methodological approach demonstrates the potential of computational techniques to enhance organizational research on meaning, materiality, and culture. By employing semantic network analysis, this study extends prior work on discourse and institutionalization (Mohr, Wagner-Pacifici, Breiger, & Bogdanov, 2013; Phillips et al., 2004) with a scalable and replicable framework for analyzing how values evolve and converge during codification. Semantic network analysis provides structural insights into the relationships among terms, revealing clusters of meaning (sociolects) and their dynamics over time. These computational insights, integrated with qualitative interpretation, allow us to connect discourse trajectories to the social and organizational contexts of their production.
In addition, our use of theoretically grounded topic modeling complements the structural perspective of semantic networks by uncovering thematic content in ethical codification discourse. By linking themes to specific actors and tracing their evolution, we illuminate how particular individuals or groups shape the prioritization and framing of occupational values. This dual approach advances recent calls (Aceves & Evans, 2024; Goldenstein & Poschmann, 2019) to combine quantitative and qualitative methods for analyzing meaning and culture in large, complex datasets.
The methodological contributions of this study align with the special issue’s call to responsibly, transparently, and critically consider the epistemological and methodological challenges of computational analysis. For instance, we address the interpretive challenges of semantic networks by integrating them with qualitative historical analysis, ensuring that the patterns we observe are situated within the broader social context of the committee’s work. Furthermore, by using semantic modularity and community detection to quantify shifts in discourse variance, we contribute a replicable framework for studying the dynamics of meaning-making across other organizational contexts.
Our findings also highlight the importance of iterative methodological choices, such as selecting appropriate semantic units for analysis and calibrating the balance between computational precision and interpretive nuance. These decisions are crucial for ensuring that computational models capture the complexity of organizational discourse without oversimplifying its cultural and social dimensions, a challenge often highlighted in the interpretive tradition (Lena et al., 2019; Lindebaum & Ashraf, 2024). Future research could build on this foundation by incorporating advanced natural language processing (NLP) techniques, such as word embeddings and transformer-based models, to further refine the analysis of meaning structures in organizational discourse.
Finally, we acknowledge the limitations of our study. The relatively small email dataset restricts the generalizability of our findings and may underrepresent certain values or contestations within the occupational community. Future research could leverage larger datasets or examine different contexts to explore whether the mechanisms identified here—such as leadership centralization and artifact publication—apply across varied occupational settings. Extending this analysis to occupations with less centralized leadership or more pluralistic values could clarify when ambiguation, rather than focus, emerges as the dominant discursive trajectory.
Conclusion
This study shows how semantic network analysis and computational text analysis can be used to study the process through which an occupation, comprised of people with heterogeneous ethical values, arrives at a unifying code of ethics. The internal contests of the software engineering occupation are unlikely to be the last in which codes of ethics are cobbled together from subgroups with divergent values in the process of occupational institutionalization. Using computational methods to understand the process through which these codes of ethics are cobbled together is important for anticipating the future challenges of work, occupations, and organizations.
Footnotes
Appendix A
Appendix B
Topic Modeling Results, Grouped by IEEE and ACM Author Affiliation.
| IEEE | ACM | |||||
|---|---|---|---|---|---|---|
| Quarter | Topic rank 1 term list | “Standard” beta | “Education” beta | Topic rank 1 term list | “Standard” beta | “Education” beta |
| 2 | program, degr, softwar, appl, comput, engin, associ, cmu, column, compani, dean, dec, delaney, demand, determin, elect, elimin, high-qual, institut, intel | univ, softwar, program, one, cour, foundat, good, new, tool, area, call, chair, develop, give, help, inform, method, recommend, system, train, want | ||||
| 3 | recommend, practic, committ, engin, bodi, standard, task, knowledg, steer, adopt, defin, develop, process, societi, might, profess, provid, work, activ, appropri | 0.021 | meet, group, cfp, oper, washington, comput, guidelin, leader, necc, plea, readi, receiv, steve, volunt, abandon, address, adequ, afraid, along, alreadi | |||
| 4 | ethic, task, meet, draft, profess, activ, standard, engin, establish, conflict, societi, bob, confidenti, discuss, melford, public, report, repositori, search, take | 0.027 | travel, washington, forc, pittsburgh, task, thank, approv, car, form, help, need, repr, taxi, adequ, adjust, april, build, drove, govern, hope, | |||
| 5 | draft, boston, cfp, contain, enclo, mail, make, meet, member, read, report, seepp, separ, task, thank, addit, ani, bob, copi, correct | rule, cfp, copi, editori, feel, get, -stev, abl, approach, baseb, bet, beyond, chang, charter, close, comput, conduct, dream, educ, electron | 0.02 | |||
| 6 | societi, contact, group, member, steer, bcs, bob, bring, call, current, ieee, licen, mario, messag, nation, tell, use, academ, activ, advi | standard, softwar, ethic, document, practic, work, keith, given, oblig, shall, comput, back, call, clear, edit, ieee, individu, member, reliabl, societi | 0.06 | |||
| 7 | tel, plea, curriculum, group, know, mario, week, effort, fifth, forc, initi, institutecarnegi, presid, regard, room, steer, welcom, email, committ, engin, | standard, group, ballot, work, seepp, shall, forc, task, practic, member, use, acm, chair, list, manual, style, categori, establish, ieee, organ, | 0.098 | |||
| 8 | forc, acm, meet, recommend, new, bodi, initi, member, organ, term, accomplish, dori, friday, governor, need, better, chair, defin, definit, mario | task, group, use, guidelin, compet, ani, gather, know, softwar, standard, write, code, etc, follow, new, problem, structur, ask, board, contact | ||||
| 9 | (no IEEE member discourse exists) | class, entir, fix, inten, manni, sorri, tri, world, address, almost, anoth, cold, delay, finish, get, give, group, just, list, part | ||||
| 10 | (no IEEE member discourse exists) | group, forc, task, messag, get, date, profess, start, comput, member, respon, direct, progress, concern, repr, alreadi, ani, done, forward, help | ||||
| 11 | profess, propo, engin, practic, task, societi, day, discuss, first, forum, name, send, africa, america, cabrera, group, like, mani, now, person, | standard, general, consensus, task, comput, get, conduct, edit, individu, rang, safeti, purpo, random, thought, time, version, global, inform, recommend, design | 0.127 | |||
| 12 | continu, apolog, back, get, receiv, seepp, text, want, ago, almost, ask, board, document, | sign, defin, custom, electron, good, avail, interact, page, phase, plea, area, befor, digit, distribut, due, enough, focus, guarant, includ, manag | ||||
| drop, encourag, ethic, groupthat, hook, itand, keep, | ||||||
| 13 | softwar, ethic, proper, ani, document, project, specif, comment, profess, think, use, approv, area, custom, develop, see, employ, issu, public, test, | softwar, document, project, rule, one, knowledg, inform, make, test, committ, standard, address, approv, comput, first, improv, task, best, consist, done, | 0.01 | 0.004 | ||
| 14 | item, act, engin, send, committe, doe, felip, whole, practic, question, reason, rul, document, ethic, ieee, individu, law, manag, member, propo, | code, profess, softwar, engin, ethic, comment, document, use, comput, function, level, oblig, work, public, draft, project, | 0.005 | |||
| task, forc, employ, revi, | ||||||
| 15 | ethic, softwar, use, engin, thank, activ, educ, ideal, leadership, member, paragraph, profess, regard, phone, acm, addreess, bit, circumst, colleagu, comment | 0.024 | softwar, profess, code, engin, work, document, principl, employ, ani, use, public, client, develop, claus, appropri, relat, level, interest, particular, project, | 0.005 | ||
| 16 | code, guidelin, address, ccsr, committ, creat, educ, eldenth, entiti, ethics-guidelin, group, includ, list, overrid, possibl, web, activ, alreadi, applic, behaviour | 0.036 | interest, replac, address, parti, comment, exclus, social, document, profess, work, copyright, one, task, use, websit, area, avoid, bodi, claus, contract | |||
| 17 | might, take, good, comput, cover, includ, point, task, work, better, committ, replac, swedish, agreement, ani, disclo, environ, knowledg, potenti, prevent, | softwar, code, profess, appropri, concern, shall, take, respon, level, ethic, requir, engin, oblig, consist, project, educ, one, ani, know, yes | 0.008 | |||
| 18 | work, softwar, profess, shall, relat, proper, develop, appropri, concern, inform, rul, approach, approv, author, parti, accept, fair, one, test, third, | 0.005 | softwar, code, work, ethic, document, comment, specif, claus, chang, interest, oblig, respon, level, make, qualiti, relat, follow, clear, good, like | 0.005 | ||
| 19 | (no IEEE member discourse exists) | code, softwar, ethic, committ, task, acm, meet, societi, approv, joint, group, industri, seepp, develop, intern, sever, process, alreadi, oblig, send, | ||||
Note: The “Topic Rank 1 term list” describes the terms that represent the top-ranked topic in that quarter. The “standard” and “education” beta columns list the beta, or the weight of the given term in estimating the topic, for the terms “standard” and “education” in that quarter. The higher the beta value, the more that term characterizes discourse in that quarter. The cell is blank if the term does not appear in the top-ranked topic for that quarter.
Acknowledgements
We thank the anonymous reviewers and editors for their really valuable suggestions. This paper benefited from feedback received from Nelson Phillips, Steve Barley, Dev Jennings, the Technology and Organizations Research Seminar at the University of California, Santa Barbara, the 2023 Interpretive Approaches to Data Science in Management Researching working group at the University of Alberta, the 2021 Data Science Summit at the University of California, Santa Barbara, the 2021 joint International Network for Social Network Analysis Sunbelt and the Network Science Society annual meeting, and the 2021 American Sociological Association annual meeting. This study was made possible due to the work of Kelly Laas and the Center for the Study of Ethics in the Professions at the Illinois Institute of Technology.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article. This research was partially funded by a UC Santa Barbara Faculty Research Grant.