
Abstract
Market participants, such as producers and audiences, often use a list of categories to label, evaluate, or promote products. Extant category research focuses overwhelmingly on a category's social properties and connectivity to explain why a category is used to describe a product. However, categories often cluster together, and little is known about how this clustering affects the appearance of a category in the description of a product. In this article, we define the easily reproducible clustering of categories as a category bundle and develop a novel measurement, bundle congruence, to measure the fitness of the category bundle. We argue that audiences employ bundle congruence to choose or exclude categories. In markets in which audiences dominate product categorization, a category's bundle congruence in a product's descriptions increases the probability that it is used for the product. Moreover, the overall bundle congruence of a product elevates the economic returns of the focal product. Our arguments are supported by an empirical analysis of feature films produced in North America. This study not only enriches the understanding of the bundle structure of the category system but also provides a novel explanation of why category spanning remains ubiquitous, despite the findings of previous studies, which assert that category-straddling products are prone to be punished financially.
Keywords
Understanding product categories is a critical task in management and organization studies. From the perspective of product audiences (e.g., customers), categories “provide an anchor for making judgments about value and worth” (Vergne & Wry, 2014: 58), whereas from the perspective of producers, categories highlight their specialties and appeal to audiences who are interested in the offerings. Given the mediating function of categories in the market, researchers have sought to decipher what determines whether a category will be used for a product (e.g., Carnabuci, Operti, & Kovács, 2015; Negro, Hannan, & Rao, 2011; Pontikes & Barnett, 2015) and how a product's category membership shapes its market outcomes (Hsu, 2006; Hsu, Hannan, & Koçak, 2009; Lo & Kennedy, 2015; Wry, Lounsbury, & Jennings, 2014; Zuckerman, 1999). Extant research maintains that investigations into product categorization should be conducted in a holistic manner, accounting for the connections between categories (Glynn & Navis, 2013; Ruef & Patterson, 2009) and the multiplicity of market participants (i.e., producers and audiences; Shipilov, Gulati, Kilduff, Li, & Tsai, 2014; Shipilov & Li, 2012). According to this literature, a category's connections with other categories in the category system contain information on its position and value in the marketplace, which in turn suggests how different market participants will interpret the focal category. For example, a category that occupies the “central” position in the category system has broad connections with different categories. Producers are hence inclined to use such a category because it can fit into a wide range of market niches and target a wide audience (Pontikes, 2012; Pontikes & Barnett, 2015). On the other hand, a “central” category becomes less unique and cannot be set apart from other categories. Consequently, audiences hesitate to use it because of the high cognitive burden of differentiating and comprehending this category (Kovács, Carnabuci, & Wezel, 2021). In brief, market participants employ private knowledge of category connections to label products they encounter.
Whereas recent studies have advocated a holistic view of categorization that encompasses a wide range of market participants and thorough considerations of category connections (Boghossian & David, 2021; Granqvist & Ritvala, 2016), they are limited in two aspects. First, market participants are often not involved in product categorization to the same degree (Durand & Paolella, 2013). In many contexts, it is market participants who have professional knowledge (patent examiners, scientist-entrepreneurs, etc.) or who have strong motivations to participate (e.g., IMDb users) that dominate the categorization process (Granqvist & Ritvala, 2016). The categories associated with a product, correspondingly, only reflect the insights, dispositions, and cognitions of some participants. Second, regarding the cognitive side of categorization, the emphasis on identifying systemwide connections of categories might reflect the knowledge and cognitive bases of producers and market intermediaries, but it does not fit well with the cognitive mechanisms that general audiences employ to make sense of a product (Glynn & Navis, 2013). In-depth considerations of a category's systemwide connections require an individual's clear-cut understanding of the category system, which is cognitively taxing for general audiences (Rosch, 1975; Simon, 1979). Because of time and cognitive constraints, audiences seldom perform a systematic (“holistic”) check of a category's connections when they consider a category; instead, they likely conduct a quick (“myopic”) search to recall only the memorable “patterns” in which the focal category connects with other categories and discern whether these patterns are “reproduced” in the focal product (Kovács & Hannan, 2015). If similar patterns do reappear in the focal product, the use of the category in question can be legitimized. In other words, while extant literature emphasizes that market participants focus on the connection breadth of a category, audiences actually take their cue from the connection depth of a category to include or exclude the focal category. We identify this distinction as a gap in the extant literature and provide an additional approach to categorization decisions that considers the cognitive proclivity of audiences.
To illustrate our ideas, consider an example from the academic job market. Imagine that a faculty search committee is browsing the applicant pool for a junior tenure-track position in the management department, and search committee members (SCMs) come across a PhD job candidate with the following “Research Interest” section in her resume: Research Interest: Entrepreneurship, Organizational Theory, Institutional Theory, Regression Analysis, Social Network Theory, Big Data.
SCMs are essentially audiences who are looking for a particular product—research talent—from a group of producers (i.e., PhD job candidates). The keywords are six research categories. Assume that the SCMs are interested in the “big data” field shown on the resume and would like to evaluate the focal candidate using this keyword. In addition, let us further assume that although the SCMs have a general understanding of “big data” (e.g., “an emerging field that uses advanced machine learning techniques”), none of the SCMs specializes in big data. The SCMs in effect have two approaches to gauge the qualification of the candidate. According to the first approach, SCMs can systematically check the position of big data in the domain of management by examining relevant questions: Is big data merely a peripheral category in which few researchers are interested? Are big-data experts well connected in academia? Is the big-data technique a lenient category that can be applied in many research categories? After a comprehensive examination of the scope of “big data” and its connections, the SCMs may reach the conclusion that big data is a promising category progressing toward the mainstream of the domain and, consequently, favor the candidate because of her specialization in this category.
The first approach, termed by us the connection approach, is easier said than done. The connection approach requires significant cognitive efforts because the evaluator must launch a wide-ranging search to determine whether a category holds wide connections in the category system (Kovács & Johnson, 2014; Wry & Lounsbury, 2013). The second approach, which we articulate as the bundle approach, is more likely used for market participants who either have limited cognitive resources or are reluctant to devote substantive cognitive resources to the task. According to the bundle approach, upon seeing “big data” on the resume, the SCMs attempt to retrieve the memorable patterns they have seen involving big data. For example, the SCMs may recall that a few scholars conduct research in regression analysis, social network theory, and big data; this association is the common pattern that the SCMs recognize regarding “big data.” Then, the SCMs can straightforwardly form a revealing, coherent image of the individuals who show this pattern (i.e., this person knows social network, graph, and complexity theories; has strong statistical and programming capabilities and is skilled in extracting patterns from a large amount of data). Because such a vivid, coherent image is “triggered” by the focal candidate's profile, the SCMs can swiftly understand her strength and ability in big data and, ceteris paribus, are more likely to shortlist the focal candidate.
In this article, we define the easily reproducible pattern of categories as a category bundle. A category bundle is a set of categories that are cognitively coherent and meaningful when they are viewed and conceptualized concurrently. In management research, for example, regression analysis, social network theory, and big data form a coherent category bundle. In feature films, adult, comedy, and romance constitute a congruent bundle that signals a film market niche—sex comedy. We contend that in copious contexts, market participants who have limited cognitive resources and/or would like to spend their cognitive resources sparingly employ the bundle approach to expedite the evaluation process. The bundle approach is thus particularly appealing to audiences. When audiences appraise a category for a product, they search their mental reservoir for category bundles that include the focal category. Such a “myopic” search for bundles (vis-à-vis a holistic search for all connections of the category) can alleviate audiences’ cognitive load in that (a) if audiences find pertinent category bundles in their reservoir, they can reuse the cues of bundles in their apprehension of new products; and (b) when a bundle approach is used, audiences process multiple categories concurrently and thus decrease their workload. Therefore, if one member of a highly fitted two-category bundle is listed for a product, the chance that audiences recall the other member and associate it with the product will also increase.
In this study, we formally define the concept of “bundle congruence” to capture the degree of fitness of a category bundle. Extending the bundle logic to category choices and product-level outcomes, we develop two relevant concepts to measure (a) a category's bundle congruence in a product's descriptions and (b) a product's overall bundle congruence. We posit two arguments. First, at the category level, audiences favor categories that can form highly congruent bundles in a product, even if all other known mechanisms that may affect the choice of categories are factored in. Second, at the product level, because products containing congruent bundles are more discernable, they are more likely to attain high economic returns. We test our hypotheses in the North American feature film market, in which audiences to a large extent dominate the categorization of films. A sample of 6,159 feature films produced in the United States and Canada and released from 2000 to 2015 was gathered. We find significant incremental validity of our bundle approach vis-à-vis other approaches (Carnabuci et al., 2015; Hsu, Negro, & Perretti, 2012; Pontikes, 2012; Pontikes & Barnett, 2015; Wry & Castor, 2017) to explain why the category appears in a film's genre list. We also find that a film with highly congruent category bundles attains larger box office revenues.
This article advances our knowledge of category membership in two ways. First, we propose a novel bundle approach to complement extant research on how market participants choose categories. We posit that general audiences use category bundles as mental shortcuts. When they assess a category, they do not delve into the category's breadth of connections to the extent suggested by the connection approach but, rather, rely on their knowledge of category bundles to exclude/include categories (Paolella & Durand, 2016). The bundle approach is particularly suitable when audiences must categorize products in a short space of time and with limited cognitive resources. In contrast, the connection approach is suitable when producers and market intermediaries categorize products with sufficient time and cognitive resources. Both approaches have their own scopes of application and should become two pillars that uphold the theoretical underpinning of category research. Second, we provide a novel explanation for why category spanning remains ubiquitous, although existing studies find that category-straddling products are prone to receiving penalties (Hsu et al., 2009; Zuckerman, 1999). In certain conditions, the so-called category spanning may be simply the embodiment of category bundles. As long as audiences’ cognition of a category bundle is evoked to appraise a product, category spanning will occur. Correspondingly, the performance penalty proposed in the categorical-imperative argument needs to factor in the performance impacts of category bundles. In a post hoc analysis, we find that after the bundle congruence of a category has been incorporated into the model, the penalty associated with category spanning dissipates.
Antecedents of Category Membership
Category Membership as a Collective Effort of Market Participants
Categories are social agreements about the meanings of labels (Negro et al., 2011; Rosa, Porac, Runser-Spanjol, & Saxon, 1999). Embedded in a wider category system, categories serve as the interface for market transactions. In mature industries, once a product is categorized, market participants (e.g., audiences and producers) arguably have reached a consensus on the features (e.g., technologies, potential uses, and cultural meanings) of the focal product (Vergne & Wry, 2014). Extending this argument, early scholarship views the categorization of a product as a cooperative venture between market participants (Glynn & Navis, 2013; Navis & Glynn, 2010). Studying the emergence and stabilization of the minivan category in the automobile industry, Rosa et al. (1999) identify the iterative sociocognitive dynamics between manufacturers and consumers in which both bring their own conceptualization of minivans into the field and calibrate their understanding based on market reactions. The stabilized meaning of the minivan category naturally crystallizes the knowledge and cognition of both producers and audiences.
A more recent line of argument, however, posits that previous research has overemphasized the cooperative feature of categorization. According to this view, product categories remain the collective efforts of multiple market participants, but the consensus is built on a competitive basis in which market participants imbue products with categories that reflect their inclinations (Kodeih, Bouchikhi, & Gauthier, 2019). Competition in categorization stems from the divergent stances that actors represent in the market. For example, producers would like to manipulate the category list of a product so that optimized economic and social outcomes are attained (Barlow, Verhaal, & Hoskins, 2018; Durand & Khaire, 2017; Pontikes & Kim, 2017). They may position products in niches that can ease competitive pressure and gain favorable evaluations, even if the actual features of their products do not completely support their category membership claims (e.g., Vergne, 2012). On the other hand, general audiences often possess less industry knowledge (Bowers, 2015). Hence, they may “drag” product categorization into the fields with which they are familiar (Durand, Granqvist, & Tyllström, 2017). When market participants independently add categories for a product, the finalized category membership of the product will be a mosaic of categories, with each piece supported by different market participants for its advantageous social properties, such as high reputation and popularity (good for producers; see Negro, Hannan, & Fassiotto, 2015; Vergne, 2012; Verhaal & Dobrev, 2022) or popularity and simplicity (appreciated by general audiences; see Leung & Sharkey, 2014).
The Connection Approach
While the appreciation of the social values of categories is self-evident and well documented (Vergne, 2012; Verhaal & Dobrev, 2022; Wry & Castor, 2017), categorization entails more than cherry-picking appealing categories. Researchers argue that the theorization of categorization processes should account for “the broader classification system in which categories are embedded” (Boghossian & David, 2021; Durand & Boulongne, 2017; Glynn & Navis, 2013: 1132) and the market participants who reside in the social context of categorization (Granqvist & Ritvala, 2016). Narrowly defined as a set of socially constructed labels (categories) to partition the market space, the category system can be broadened to include multiple market participants whose interests, perceptions, and insights incubate, stabilize, and transform the system (Durand et al., 2017; Montauti, 2019; Montauti & Wezel, 2016).
Within the system, categories are not “orthogonal” to each other. Rather, they are interconnected (McDonald & Allen, 2021; Wry & Lounsbury, 2013). As Montauti (2019: 823) colorfully puts it, categories are “like the regions of a map that outline a maritime area and ease navigation. . . . Similar to seafarers looking at a . . . nautical chart, producers and consumers . . . rely on a mercurial map of the market.” The nautical-chart metaphor implies that just as regions are linked by shipping routes in the chart, categories are mutually correlated in a category system. Market participants (seafarers) carefully check the connections (shipping routes) to determine the categories (destinations). One distinctive feature of a category system is that categories are not equally connected (Wry & Lounsbury, 2013). As with major ports, “central” categories enjoy wide connections with all other categories in the system, whereas “peripheral” categories, like the ports of remote islands, have only weak connections with the continent. Figure 1 is a map of categories (genres) used in the North American audiovisual industry from 1945 through 2015. Not surprisingly, drama is the most connected genre throughout history; the most peripheral genre, game show, has only tenuous connections with other genres. The surrounding market participants, including studios (producers), moviegoers (general audiences), and movie platforms (market intermediaries, such as IMDb and Rotten Tomatoes), also form an integral part of the system. Their participation and interactions maintain and “evolve” the genre system.
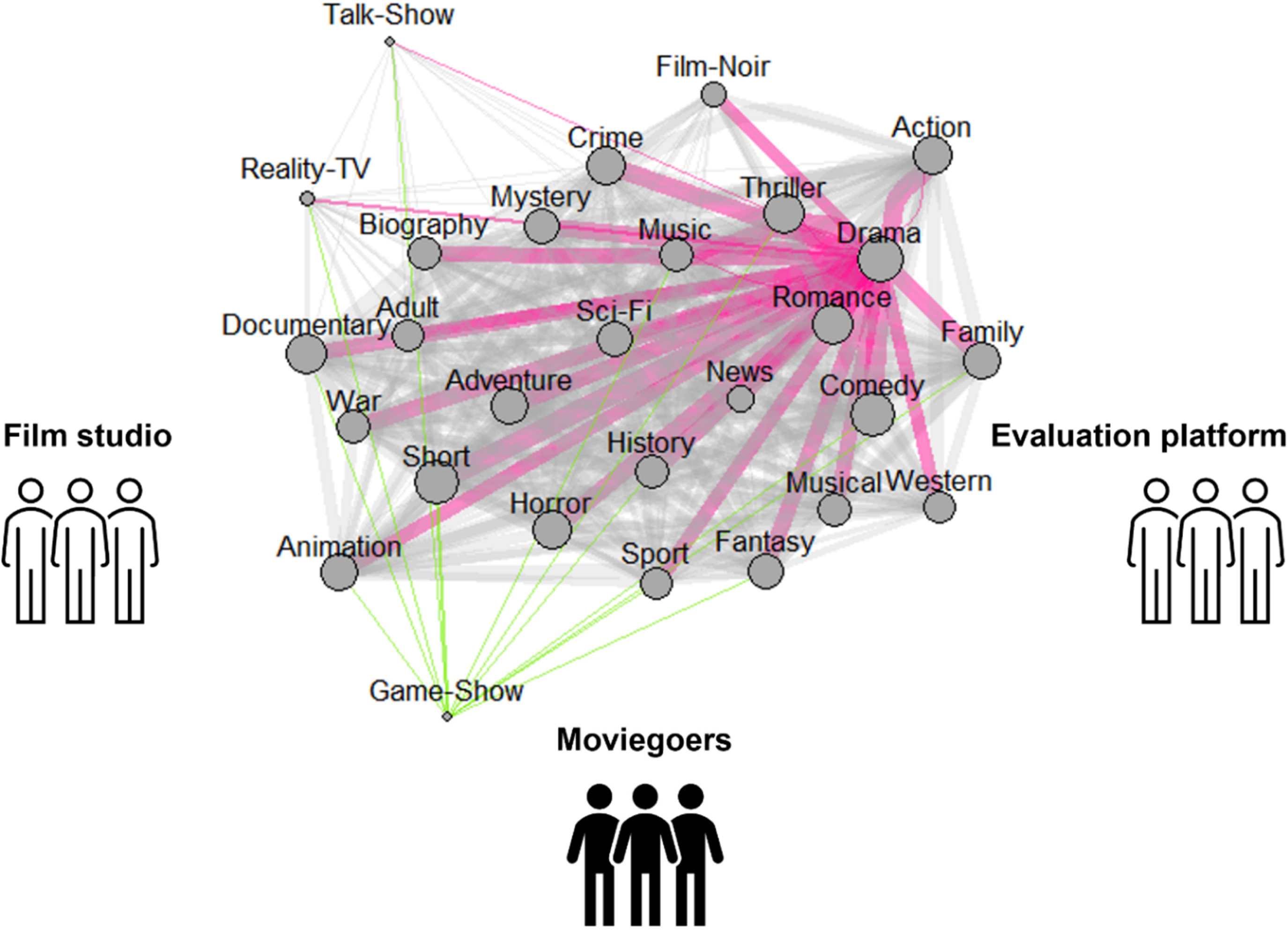
The Genre (Category) System of North American Audiovisual Industry
The way categories are connected suggests how they are viewed and used by market participants. Because of the variety of stances, knowledge bases, and cognitive models, market participants emphasize different facets of category centrality (Montauti & Wezel, 2016; Wry & Lounsbury, 2013). Producers welcome well-connected (central) categories because of their high leniency. A central category encompasses a broad range of product attributes, offers a flexible choice of market niches, and enables producers to achieve multiple goals (to underline the versatility of their products, to project a malleable company image, etc.; Hsu et al., 2012; Pontikes & Barnett, 2015). All else being equal, producers are more likely to choose a lenient category to describe their products.
On the other hand, audiences have valid reasons to dislike central categories due to their high fuzziness (Montauti & Wezel, 2016; Pontikes, 2012). A central category does not have a clear contrast to another category with which it coappears (Carnabuci et al., 2015; Hsu et al., 2012). With less in-depth knowledge, audiences struggle to develop a shared understanding of fuzzy central categories; burdened by their limited cognitive resources, audiences are also reluctant to exert much cognitive effort to appraise a product with fuzzy categories. Therefore, audiences tend to shun fuzzy categories in categorization (Pontikes, 2012).
Last, producers and audiences also evaluate connections from the angle of category similarity. Category similarity measures the extent to which a category coappears with other categories (Wry & Castor, 2017). A central category, therefore, is more “similar” to other categories than peripheral categories are. A similar category conveys that it can be safely added to a product without overloading the cognitive burdens of market participants. In the PhD candidate example, institutional theory is more similar to other research areas than big data, an area demanding specialized knowledge (e.g., computer science) atypical in management research. This difference explains why producers (PhD candidates) and audiences (SCMs) tend to feel more comfortable with “institutional theory” on a resume.
In summary, the connection approach contends that the connectivity of a category (central vs. peripheral) with other categories affects its chances of appearing in a product description. In a setting in which multiple market participants contribute to product categorization, the participants utilize different connection attributes to add or exclude categories. Audiences frown upon fuzzy categories (Carnabuci et al., 2015; Pontikes, 2012); producers, as “market makers,” are motivated to choose lenient categories (Pontikes, 2012; Pontikes & Barnett, 2015). Moreover, both audiences and producers favor categories that are similar to other categories. Taken together, connection patterns entail essential clues for category inclusion: Baseline hypothesis (the connection approach): In settings where market participants jointly determine the category membership of products, producers are more likely to pick a category of high leniency and high similarity, and audiences are more likely to pick a category of low fuzziness and high similarity.
The Bundle Approach
Although the connection approach taps into the collective work of market participants and the effects of systemwide connections, it has yet to realize its full potential because it does not fully consider the idiosyncrasies of market participants, particularly, discrepancies in their cognitive resources in categorization (Granqvist & Ritvala, 2016). First, while previous research models a collective categorization process (Khaire & Wadhwani, 2010; Vergne & Wry, 2014), which is accurate in a general sense, categories are commonly decided by some rather than all market participants. For example, entrepreneurs unilaterally attach category labels to their start-ups (since they know more about their forthcoming products and core technologies than anyone else). Market intermediaries, such as patent examiners, may act as institutional gatekeepers. In audience-centric markets (consumer electronics, restaurants, movies, etc.), producers intentionally let general audiences label and evaluate offerings (Hsu, 2006). It is hence theoretically intriguing to examine the approaches of different market participants to categorize offerings. Second, while producers and market intermediaries (patent examiners, wine experts, film critics, etc.) have sufficient knowledge and cognitive resources to gauge the systemwide connections of categories, general audiences do not. Instead of a systematic check of connection attributes, general audiences rely heavily on cognitive shortcuts and heuristics to navigate offerings (Bowers, 2015; Glynn & Navis, 2013). When general audiences are considering a category (“adult” genre) for a product (film), they may simply search memorable patterns of “adult” (category bundles) from their mental reservoir and compare those patterns with the focal product. If they do get a match (“This is a sex comedy, which should include ‘adult,’ ‘comedy,’ and ‘romance’!”), the chance that they add “comedy” and “romance,” along with “adult,” to describe the product will increase.
We define the discernable and aggregated patterns of categories in a category system as category bundles. A category bundle can include any number of categories from the category system, as long as audiences can fathom them simultaneously and reduce their cognitive load in product evaluation. In formal terms, a category bundle B can be a set of k categories, B = {g1, g2, . . . gk}. Category bundles do not appear arbitrarily. To be processed as a bundle, the k categories must be either taxonomically close enough (Rosch, 1975; Rosch & Mervis, 1975) or perceived as coherent by audiences (Heylighen & Chielens, 2009). For bundles formed by taxonomically close categories, research on psychology and sociology has made substantial progress by unveiling the “cohort” structure of categories (Rosch, 1975; Rosch & Mervis, 1975; Wry & Castor, 2017). Hannan et al. (2019) defined a cohort as a set of related categories with a tree-diagram-like structure. A tree diagram includes (a) a root category and (b) the categories nested in the root category. All categories nested under a given root category share common features inherited from that root category, and it is intuitive for audiences to concatenate and think about same-cohort categories together. For example, “management” is a root category housing the categories of organizational behavior, human resource management, strategy, organizational theory (OT), entrepreneurship, and so on. It is common for business scholars to bundle strategy with OT to ascertain the interests of the scholar who includes both keywords in her resume. For categories from different cohorts, the chances that they are recognized as a category bundle are not high. For example, criminology is not in the cohort of management. Even if a scholar declares both strategy and criminology on their resume, other scholars are unlikely to bundle these two categories together in appraising the focal scholar.
Category bundles can also be formed by perceptually coherent categories, even if the member categories are taxonomically distant from each other. A perceptually fit category bundle often results from a novel combination of preexisting dissimilar elements. Despite the slim chance (Hsu et al., 2012), once a product with taxonomically distant categories receives critical acclaim in the market, the unique bundles of categories will be remembered and spread swiftly from one individual to another (Dawkins, 1976). At one stage, the novel combination will become a cultural trait that is transmitted to and permeates the whole society and is reused by varied audiences (Heylighen & Chielens, 2009). When audiences detect a trace of a cultural trait in a product, they activate their memory of the cultural trait to understand the product. For example, “cyberpunk” is a notable topic (category bundle) in cultural fields (films, novels, video games, etc.) that centers on the strong contrast in a futuristic dystopia between widespread advanced technologies and the struggles of people at the bottom of the hierarchy. Deemed a novel combination of sci-fi, crime, and film noir elements, cyberpunk became a cultural trait in the 1980s and has continuously produced excellent works since then (Blade Runner, The Matrix, Akira, etc.).
Our empirical data also shed light on category bundles in feature films. To explore possible category bundles, we select a subset of single- and two-genre films from the network in Figure 1 and draw a heat map. Figure 2 presents the results. The depth of color represents the number of films in a genre(s), the diagonal boxes denote the frequency of single-genre films, and the nondiagonal boxes denote the frequencies of two-genre films. We find that certain two-genre films are even more common than cognate single-genre films. For example, “thriller” tends to be bound with “horror,” and “history” is often linked with “documentary.” The frequencies of thriller-horror and history-documentary films are higher than those of thriller films and history films. The popularity of multiple-genre films attests to the face validity of category bundles.
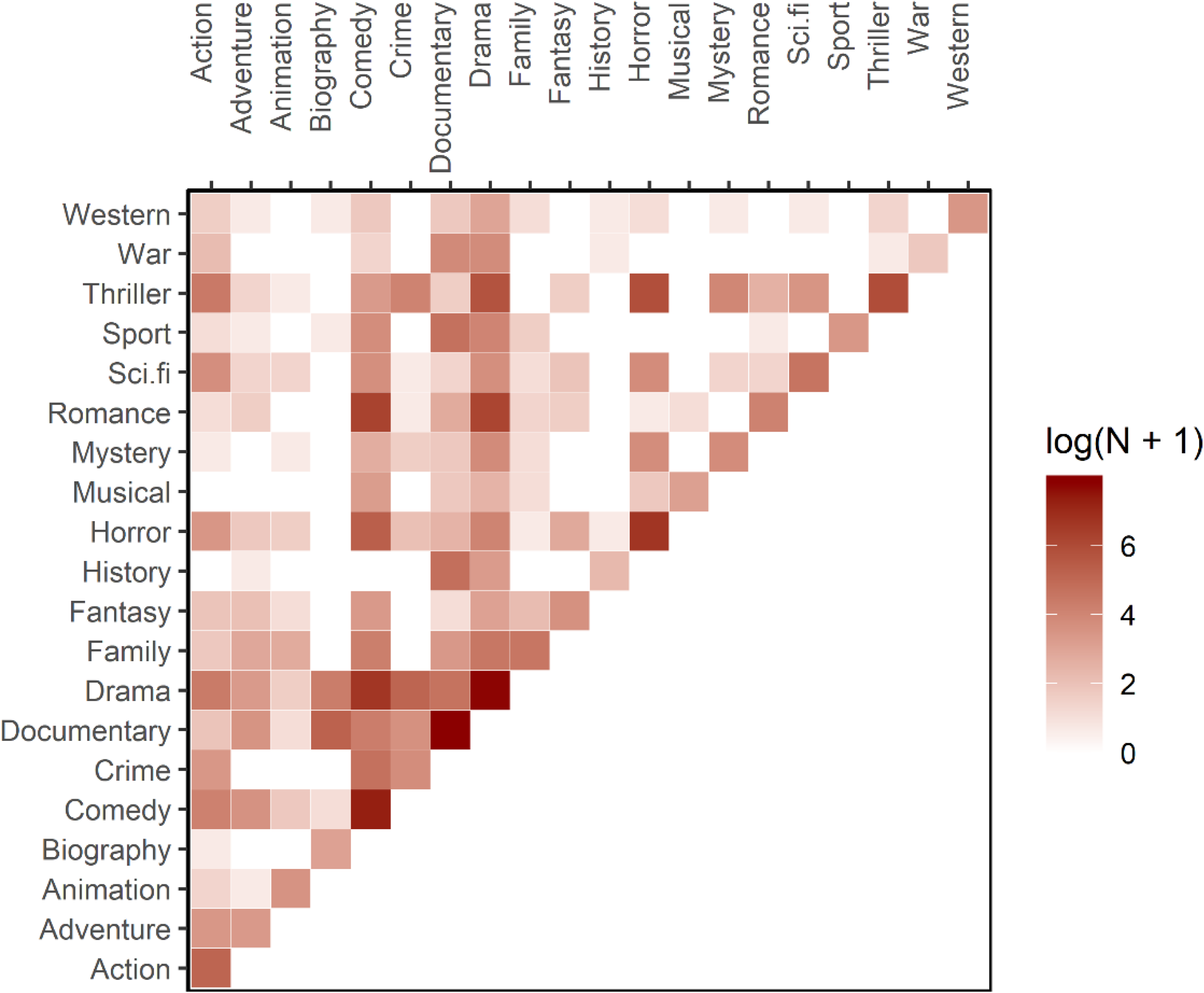
The Heat Map of Feature Films With One or Two Genres Released Between 2000 and 2015
Although we define category bundles as congruent aggregations of categories, such a definition does not exclude the possibility that category bundles can vary in terms of the congruence perceived by audiences. Certain category bundles, such as comedy-romance in feature films, have appeared so congruent to audiences that some audiences even recognize them as an independent category (e.g., rom-com). In contrast, other bundles (e.g., pseudo-documentary) are visible to and deemed compatible only by niche audiences. The level of congruence of a category bundle, denoted Congruence B , can be mapped to how often audiences observed it in the past (Kovács & Hannan, 2015; Paolella & Durand, 2016). Repetition is the root cause for the momentum that audiences record a category bundle in their mental reservoir and later recall it to categorize products. In summary, the more frequently a presumable bundle appears, regardless of the reason (same-cohort categories or a cultural trait) it is assembled, the more likely audiences will perceive it as a congruent category bundle and use it to categorize products.
Extending the bundle logic to individual category choice(s) for a specific product, audiences naturally employ their idiosyncratic knowledge of cohorts and/or cultural traits to add or exclude a category. For example, when audiences consider using “sci-fi” for a film, some individuals may recall bundles formed by categories from the same cohort (e.g., fantasy–sci-fi); others may recollect a cultural trait (e.g., cyberpunk). Audiences as a whole take into consideration all relevant category bundles irrespective of their sources. Denoted Bundle_Congruence
ig
, category g's bundle congruence for product i hinges on the congruence (Congruence
B
) of all bundles (B) it can form if it appears in product i's category list. The higher the category's bundle congruence (Bundle_Congruence
ig
) is, the more likely audiences will use it for the product. Hypothesis 1 (the bundle approach): In settings where audiences unilaterally determine the category membership of products, they are more likely to pick a category that can form highly congruent bundles in a product's category list.
Table 1 summarizes the core arguments of the bundle approach and its differences from previous research.
Antecedents of Category Inclusion

The Criticality of the Bundle Approach
Weighing the Connection and Bundle Approaches
We have juxtaposed the bundle approach with the connection approach to explain how market participants conduct product categorization. In this section, we parse their distinctions and scopes of application and discuss how they can be integrated to strengthen the theoretical foundation of category membership research. First, both approaches emphasize that the linkage between categories matters for individuals’ understanding and use of categories (Rosch, 1975; Rosch & Mervis, 1975), yet they employ varied cognitive assumptions and lean on different connection attributes. The connection approach assumes that market participants have abundant knowledge and unrestricted cognitive resources to review categories. Therefore, the connection approach focuses on the connection breadth of a category. To wit, market participants comprehensively review a category's overall position (i.e., central or peripheral) in the category system to include or exclude the category (see Appendix A for illustrations at the operationalization level). The bundle approach, on the contrary, assumes that certain market participants either do not have or are reluctant to deploy ample cognitive resources to categorize products; they simply resort to heuristics and cognitive shortcuts (Wry & Durand, 2020) to pin down the categories that “stick out” as bundles. Therefore, market participants focus on a category's close relationship with a limited number of other categories (i.e., connection depth). The divergent requirements on cognitive resources suggest that “market makers,” such as producers and market intermediaries, are more likely to use the connection approach (Pontikes, 2012), while general audiences tend to adopt the bundle approach in categorization. Our baseline hypothesis and Hypothesis 1 summarize these arguments.
Second, our analysis reveals the scenarios that best fit the connection vis-à-vis bundle approaches and vice versa. Fundamentally, the two approaches are not mutually exclusive choices. It is uncommon (due to the hefty cognitive requirements) but still feasible that market participants adopt both approaches to cross-validate their decisions. In the job market candidate example, SCMs can take the cognitive shortcut of a category bundle (big data, regression analysis, and social network theory) to form a first impression of the candidate; then, the SCMs may undertake thorough research of “big data” to further evaluate the candidate. The utilization of the second approach complements, rather than substitutes, decision makers’ understanding of the category in question. Furthermore, by clarifying their cognitive assumptions, major actors, and scope of application, we argue that the bundle approach serves as a new pillar of the category membership literature and reinforces its theoretical underpinnings.
Taken together, the two approaches have varied cognitive assumptions and focus on different connection attributes of a category. Compared with producers and intermediaries, audiences have less information, time, and cognitive resources. Therefore, cognitive shortcuts and heuristics are more convenient than comprehensive sensemaking for audiences to make categorization decisions. The bundle approach is hence more likely to be deployed by audiences to include and exclude categories. Reflected in statistical models, we hypothesize the following: Hypothesis 2: In settings where audiences unilaterally determine the category membership of products, compared with variables proposed by the connection approach (e.g., fuzziness, leniency, and similarity), the variable proposed by the bundle approach (i.e., bundle congruence) contributes more to the incremental validity of models accounting for audiences’ choice of categories.
Economic Impacts
We have made the claim that when audiences dominate the product categorization, a category's bundle congruence for a product not only increases the chance that it is selected for the product but also predicts audiences’ choice of categories better than the connection variables. A logical question follows: at the product level, what are the implications for a product with highly congruent category bundles? We argue that products with highly congruent bundles are particularly noticeable to general audiences, and the extra attention to these products will ultimately translate into superior product performance. To expound this argument, we have explained that audiences, as typical cognitive misers, tend to use heuristics and cognitive shortcuts to make sense of a product (Wry & Durand, 2020). When they assess multiple offerings from producers, those containing meaningful category bundles are more likely to be noticed. Once audiences devote more attention (i.e., cognitive resources) to parsing the category bundles of those products, they will obtain a keen grasp of the nature of the products over other alternatives.
Regarding the relationship between audiences’ understanding of a product and its economic performance, we contend that greater understanding generally enhances product performance for two reasons. First, a fundamental idea advanced by sociological theories of markets is that how entities (e.g., firms, products) are cognitively perceived and grouped by market participants impacts their competitive positions and economic outcomes (Porac, Thomas, & Baden-Fuller, 1989); entities that do not conform to prevailing social expectations raise concerns regarding their legitimacy and tend to be penalized by market participants (DiMaggio & Powell, 1983). Category literature refers to audience perception as one pillar upholding the categorical-imperative argument (Hsu et al., 2009; Zuckerman, 1999); namely, when audiences deem products that span multiple categories confusing and difficult to evaluate (Zuckerman, 2004), they ignore or devalue those products (Leung & Sharkey, 2014; Negro & Leung, 2013). Overall, audiences’ confusion over a product's identity prevents the product from gaining market success (Zuckerman, 1999), and the dearth of clear, decipherable information is one critical cause for the confusion. Holding constant the tastes of audiences, the more information they extract from observing a product's category bundles, the greater the meaning and legitimacy they can inject into the product (Negro et al., 2015; Wry & Lounsbury, 2013) and thus choose it (Negro & Leung, 2013).
Second, audiences’ in-depth understanding of products from analyzing category bundles enables them to make taste-based decisions.1 For individual audiences, their heterogeneous tastes (or preferences) are the driving force of consumption decisions. When audiences receive the same amount of information from two alternatives, they naturally choose the product that better matches their tastes. For example, when moviegoers have the same level of confidence that the two films from which they can choose are comedy-romance and crime-thriller, they will go for the film that they personally enjoy. The essential premise of taste-based decisions, however, is that audiences must collect sufficient information regarding the choice set before they make comparisons. When audiences cannot reasonably anticipate the contents of the offerings or obtain fair access to all offerings, implementing taste-based decisions will be difficult. For example, a moviegoer is uncertain that film A is a comedy-romance but very confident that film B is a crime-thriller. Although they like comedy-romance more than crime-thriller, it is still risky to choose A because the seemingly better choice might be neither comedic nor romantic.
Because the congruent category bundles “fill in” extra and comprehensible product information for the audience, audiences can utilize the information derived from highly congruent bundles to make taste-based decisions. In summary, more taste-based decisions will occur among products with highly congruent bundles than among products with incongruent bundles. Combining the preceding, we argue the following: Hypothesis 3 (economic outcomes at the product level): In settings where audiences unilaterally determine the category membership of products, a product that includes highly congruent category bundles generates higher economic revenues.
Although congruent category bundles generally increase a product's economic revenues by reducing confusion and enabling comparisons, we do not negate the rare cases in which certain audiences perceive a product with more information as less appealing. For such audiences, their preferences are opposite of those of mainstream audiences. Namely, the more information they obtain from sensemaking the category profile of a product, the less likely they will choose the product because the “surprise” of consuming an unknown product reduces.
We argue that in our research context (feature films), audiences’ motivation to pursue surprise is unlikely to overturn the relationship between bundle congruence and economic outcomes (Hypothesis 3) for two reasons. First, a larger proportion of moviegoers are “market takers,” who use category information to navigate the offerings and find the offering that satisfies their requirements (Pontikes, 2012; Zuckerman, 1999). Unlike “market makers” (e.g., producers and market intermediaries), audiences are not interested in redefining the market structure or creating innovative combinations (Pontikes, 2012). Second, pursuing surprise hampers audiences’ taste-based decisions. When audiences cannot reasonably anticipate what they are exposed to, taste-based consumption will essentially become a “lottery draw”: They either watch excellent work or have an awful experience in the screening room (Hsu et al., 2012). We expect that in most cases, moviegoers prefer a taste-based decision to a lottery draw.
Data and Method
Setting
Our empirical context is the feature film industry in North America (the United States and Canada). The category (genre) data were retrieved from the Internet Movie Database (IMDb), the largest database of this kind on the Internet. The setting of feature films affords several advantages. First, the feature film industry has had an institutionalized category system, that is, genres, for more than a century. In this context, we can exclude category decisions driven by the emergence of nascent categories (Montauti, 2019) or the evolution of category systems (Ruef & Patterson, 2009) and focus on how a category's bundle structure affects its usage in products. Second, our preliminary analysis suggested that genres do cluster together (see Figure 2). Last, product categories (genres) are mostly classified and evaluated by audiences (moviegoers) in the feature film market. A platform of more than 580,890 feature films and 13 million genre descriptions (as of July 2021), IMDb emerged as a fan-operated website and has remained so since it was acquired by Amazon. Information extracted from IMDb (presented later) points to the idea that feature film categorization is highly audience-centric: (a) With a few exceptions, the editing of film information is open to all registered users. IMDb put up “Edit” icons on all film pages (Figure 3a), and users can add or update information by filling out a well-designed drop-down menu that is resistant to human errors. (b) IMDb carefully maintains a courteous and engaging atmosphere in the community forum. Every year, IMDb sends a message to its contributors, in which the founder and CEO (a cinephile himself) releases the list of the top 300 contributors and shares the future plan with the community. In the 2020 list, the top three contributors made 2.6 million, 495,984, and 477,084 edits, respectively (see Figure 3b). (c) Editing work is unpaid. The only reward contributors can obtain are virtual badges. Badges display beside a user's forum posts and on their personal page (see Figure 3c). From this information, we deem that the feature film industry is an appropriate setting to examine how audiences employ their bundle-level knowledge to make category decisions. We limited our sample to feature films produced and released from 2000 to 2015 because recent works have complete information on genre classification. Moreover, earlier films tend to have more missing information for the construction of our control variables, although the causes of missing information are irrelevant to our research question.
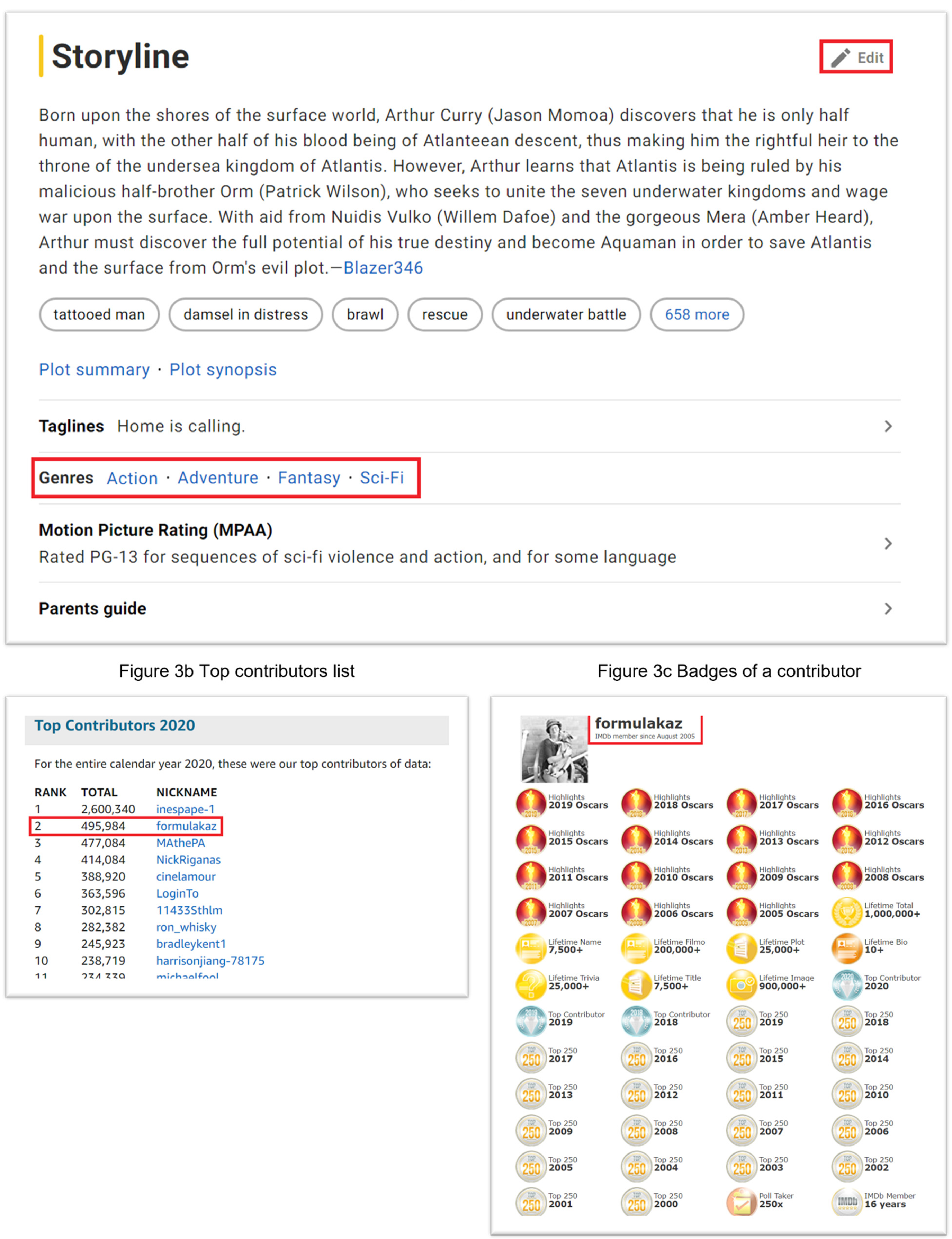
IMDb and Its Contributors: (a) Film Page of Aquaman (2018), (b) Top Contributors List, (c) Badges of a Contributor
Sample Construction and Variables
In this section, we first introduce the sample, data, and variables for Hypotheses 1 and 2. The methodologies for Hypothesis 3 are presented at the end of the Data and Method section.
Full-sample design
The unit of analysis for Hypothesis 1 and Hypothesis 2 is genre-film. For each film, we considered the choice of 20 genres: action, adventure, animation, biography, crime, comedy, documentary, drama, family, fantasy, history, horror, musical, mystery, romance, sci-fi, sport, thriller, war, and western. These genres are universally recognized categories that are employed by most film databases (IMDb, Rotten Tomatoes, Movie Database, etc.). “Game show,” “reality TV,” “short,” “TV movie,” and “news” were removed since they are not used to describe feature films on IMDb. “Film noir” was also not considered since IMDb considers film noir as a genre from 1927 to 1958, a period outside of our observation window. “Music” and “adult” were also removed to maintain data consistency with previous research (e.g., Hsu, 2006; Hsu et al., 2009). Finally, films with missing values were excluded. The final sample included 6,159 feature films released from January 1, 2000, to December 31, 2015. We first used a full-sample design, in which all 20 genres were considered for each film. Using this approach, we obtained 123,180 (6,159 × 20) observations. A genre is set to 1 if it appears in the film description and 0 otherwise. For example, for Aquaman (2018), action, adventure, fantasy, and sci-fi are set to 1, while the other 16 genres are set to 0.
Coarsened exact matching (CEM) sample
One issue with the full-sample design is that it may boost the sample size by including unrealistic genre choices. For example, the full-sample design assumes that “musical” is considered and not chosen by audiences in the genre decision of Aquaman, which does not make sense for moviegoers who have heard about the film. We thus used CEM to obtain a more balanced sample (see examples in Carnabuci et al., 2015; Rogan & Sorenson, 2014; Shipilov, Li, & Li, 2020). Because Hypothesis 1 and Hypothesis 2 juxtapose the connection and bundle approaches and argue that the latter has stronger explanatory power than the former in genre-choice models, we use CEM to prune a sample of observations that enables a fair comparison of the two approaches. Thus, the observations should have enough variances in bundle- and connection-based attributes and reduce imbalance over other variables (Iacus, King, & Porro, 2012). In addition to bundle- and connection-based attributes, prior research has focused mostly on how category-level social properties and product-level attributes affect a category's use in production descriptions (Hsu, 2006; Negro et al., 2011, 2015). Our task is hence to filter out their effects by gathering a sample that has similar social properties and film-level attributes between the selected and unselected genres. For social properties, we chose three representative variables: category reputation, category prosperity, and category popularity (Hsu, 2006; Negro et al., 2011, 2015). A category's reputation is the average IMDb rating of all films with this genre (Vergne, 2012). A category's prosperity is the total box office revenues of all films with this genre. Popularity is the sum of the number of films having genre g in the past 5 years (Hsu, 2006). We have detailed explanations of their measurements in the Control Variables section.
To reduce the confounding effects of film-level attributes, we conduct CEM independently for each film instead of pooling all films together. By conducting independent matching for each film, all genre choices are provided with the same film-level attributes (IMDb rating, budget, producer, etc.), and the effects of film-level attributes can be eliminated.2 We first trisected category social properties (reputation, prosperity, and popularity) by their numerical value so that each social property is divided into three strata (e.g., reputation is “coarsened” to low reputation, median reputation, and high reputation). Combining three variables, we obtain 27 unique blocks (low/median/high reputation × low/median/high prosperity × low/median/high popularity). Next, we place all 20 genres in one of the 27 blocks based on the corresponding numerical values of the three variables. For example, action may be denoted as low reputation, median prosperity, and high popularity, while sci-fi may be in the block of high reputation, high prosperity, and low popularity. Last, we drop the blocks that have only chosen or unchosen genres so that all remaining blocks have at least one chosen genre and one unchosen genre. The CEM procedures ensure that all remaining observations are similar in terms of their social properties. We repeated the procedures for each film until all films in our sample were matched. Using this approach, we obtained a total of 16,673 genre choices for 4,677 films. Figure 4 illustrates our approach.
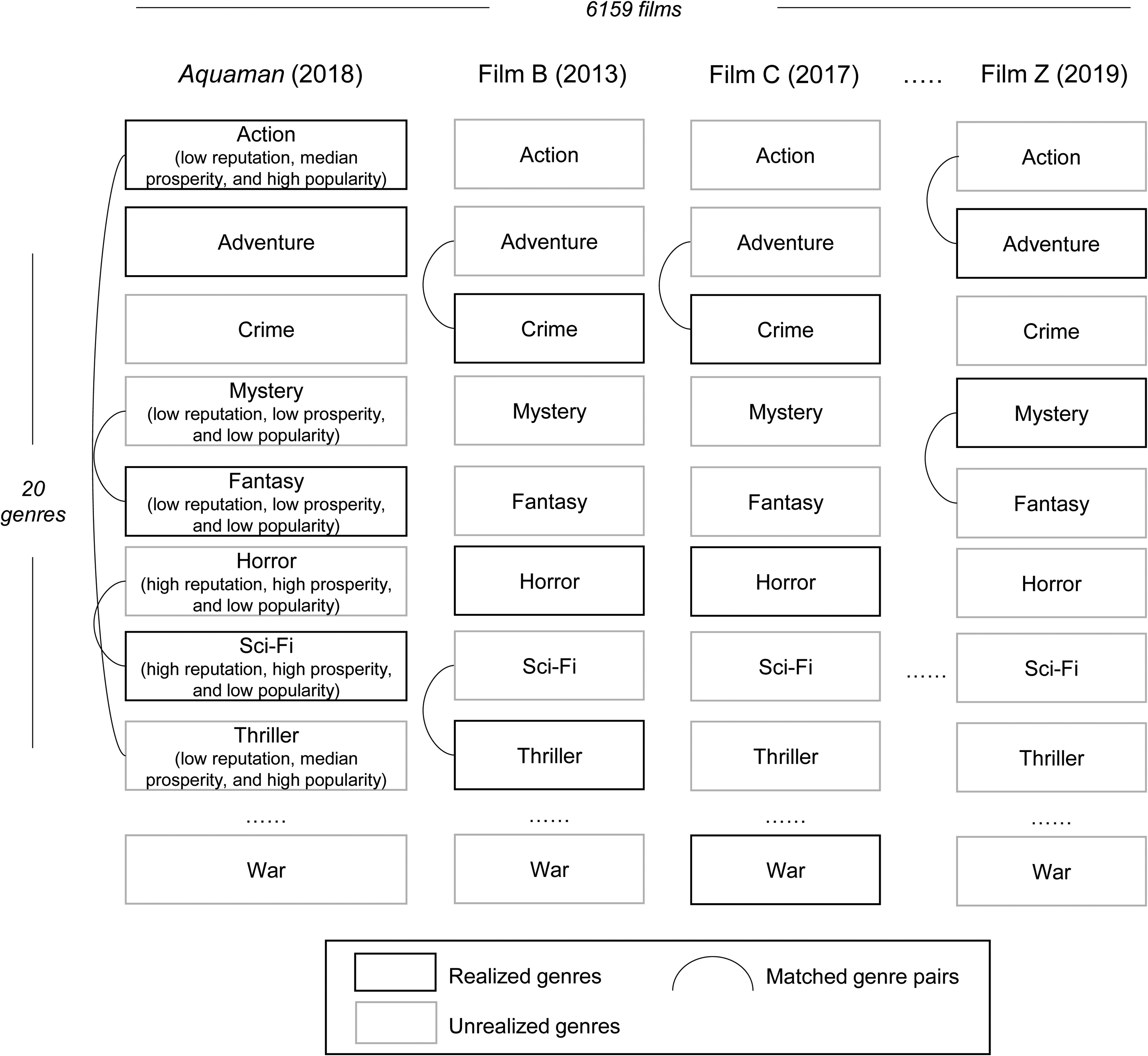
Sample Construction Using Coarsened Exact Matching (CEM)
Dependent variable
For Hypothesis 1 and Hypothesis 2, the dependent variable is a dummy variable coded as 1 (genre g is chosen for film i) or 0 (not chosen).
Measuring a category's congruence in a product
For the testing of Hypothesis 1 and Hypothesis 2, we refer to a category's congruence in a product as the overall congruence of all category bundles that this category can possibly form in the product. We calculate this variable using a three-step procedure: (1) For a given category, list all the possible category bundles it can form in the product; (2) measure the congruence of each category bundle; and (3) calculate the overall congruence of the category in the product using information we obtain in the first two steps. Table 2 summarizes the procedures. Detailed explanations come next.
The Three Steps to Calculate the Congruence of a Genre for a Film

The values of Density B and Density g are based on a hypothetical setting introduced in Appendix B.
The first step is to list the possible category bundles. This is essentially a combination question. For example, when we consider why “action” appears in the profile of Aquaman, which has four genres—action, adventure, fantasy, and sci-fi—on IMDb, we list seven possible bundles (Step 1 of Table 2); if we consider an unselected genre (e.g., thriller), the number of possible bundles will be 15. The formula to calculate the number of possible bundles is shown in Step 1 of Table 2.
In Step 2, we calculate the congruence of each category bundle listed in Step 1. The congruence of a category bundle can be loosely related to how often audiences saw member categories together (Kovács & Hannan, 2015; Paolella & Durand, 2016). Our calculation is inspired by ecological research. Ecologists use a general overlap index to measure to what extent different species cohabit in the same type of geographic location (Arita, 2017). Similarly, we use it to measure how congruent a bundle is. Assuming that B is a category bundle of k genres (B = {g1, g2, . . . gk}), we calculated the congruence of bundle B using the following equation:
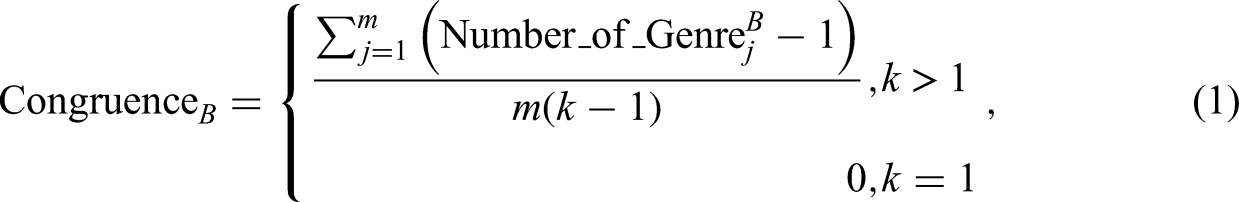
where k is the number of genres of bundle B, m is the number of films in the past 5 years that included at least one of the k genres, and
In Step 3, we calculate a category's bundle congruence in a specific film i. Note that we are not considering the congruence of a single category bundle here (as we have done in Step 2). When we determine whether a category is suitable for a specific product from the bundle perspective, we have to consider the congruence of all bundles that this category can possibly build. Hence, we proposed a weighted measurement to proximate the overall impacts of presumable category bundles. We argue that audience decisions will be affected by category bundles that appeared more often in the past than by bundles that were less common. We used the ratio of the density of the category bundle to the density of the genre as a weight in calculating the congruence of a particular genre (denoted as genre g) in film i:
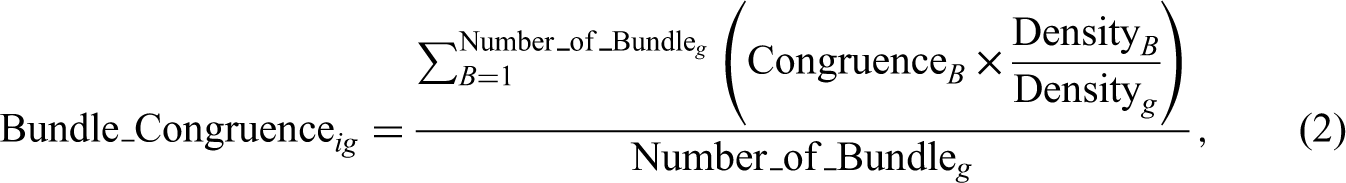
where subscript B is the category bundles listed in Step 1, Congruence B is the congruence of a bundle calculated in Step 2, Number_of_Bundle g denotes the number of bundles obtained in Step 1, and Density B and Density g measure the frequencies of bundle B and genre g, respectively, in the past 5 years. In general, the congruence of genre g in film i, which is a genre-level measure, is the weighted average of “closeness” on all possible category bundles g can form in film i.
With the assumption that audiences are more likely to notice and process common bundles, the weighted sum of all possible category bundles is consistent with the measurements in the early category literature (see Zuckerman, 1999; 2004). Number_of_Bundle g serves as a penalty term here to offset the advantages of multigenre films in calculating bundle congruence. The value of bundle congruence ranges from 0 to 1, where 1 suggests that genre g is a perfect fit for film i and 0 suggests that genre g should never be included in the focal film.
Control variables.
We included a number of control variables to account for other factors that may confound the role of a genre's bundle congruence, including the genre's social properties, connection attributes, and film-level control variables. For social properties, we included category reputation to account for the attractiveness of reputable genres to audiences. Category reputation was measured as the average IMDb rating of all films with genre g in the past 5 years (Vergne, 2012). We also considered a category's prosperity and popularity. Prosperity is the resource space a genre occupies in the market. We defined the resource space of genre g as the logarithm of the total box office revenues of all films with genre g released in the past 5 years. Popularity is the appearance frequency of a genre. We measure popularity by the fuzzy density of a genre (Hsu, 2006), which is the sum of the number of films having genre g in the past 5 years weighted by the grade of membership of genre g in each film. A genre's grade of membership in a film is the reciprocal of the number of categories included in this film. For example, if a film is assigned to three genres, e.g., horror, romance, and sci-fi, then we would assign 1/3 grade of membership to each genre to which this film is attached (also see Hsu et al., 2009; Kovács & Hannan, 2010).
We also controlled for three variables that capture the effects of the overall connection patterns of a category with other categories. The first variable is category fuzziness (Carnabuci et al., 2015; Kovács & Hannan, 2010):
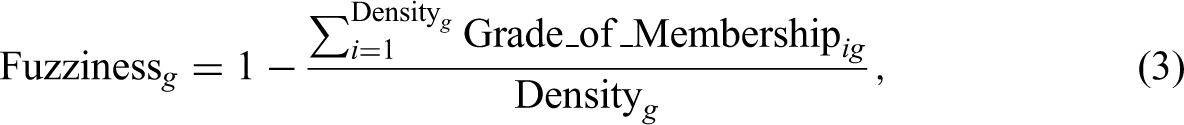
where Density g is the number of products that contain category g. The numerator, Grade_of_Membership ig , denotes the grade of membership of category g for product i. When a category is frequently connected with different categories, its identity becomes too blurry for audiences to reach a consensus on the quality of the product to which this fuzzy category is allocated (Carnabuci et al., 2015; Kovács & Hannan, 2010). The second connection property is category leniency. Researchers have found that although lenient categories may confuse audiences, they are attractive to producers and market intermediaries (Pontikes, 2012; Pontikes & Barnett, 2015) because of their high flexibility and wide range of fit. We controlled this variable but made minor changes to the original formula to ensure the validity of this variable in our research context:
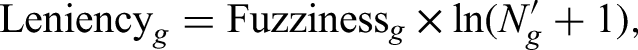
where
The last connection property is category similarity. Previous research found that the more similar a category is to other categories, the less cognitive burden it places on audiences when used concurrently with other categories (Wry & Castor, 2017). Following Wry and Castor (2017), we measured the relative similarity of a category to all other categories using Pearson's correlation coefficient. For a given year, we calculated the pairwise Pearson correlation of all genres using all film data in the past 5 years; we then calculated a genre's overall similarity with other genres by taking the average of the Pearson correlations it has with all other categories (Wry & Lounsbury, 2013).
Film-level variables that may affect the category membership of a film were also included. We included the IMDb rating of the focal film (1–10) to loosely control the effects of audience perception of product quality on audiences’ category decisions. Normally, IMDb contributors (moviegoers) can categorize a film whenever they feel comfortable doing so. They may assign genres when they read an article on the progress of a film project in a trade magazine (e.g., Hollywood Reporter); they may check the IMDb ratings, visit the cinema, and return to IMDb to correct inaccurate genre information that others have provided. Because rating behaviors do not systematically happen after film categorization, the concern over endogeneity caused by reverse causality is alleviated. However, one point is clear: Moviegoers tend to have an approximate idea of the quality of a film before they categorize the film. Since the IMDb rating is the most comprehensive indicator of the quality of a film, we include it in regressions to control the effects of perceived quality on audiences’ choice of genres. Studios enjoy considerable power over the filmmaking process in in-house production, and audiences may interpret in-house production as a signal of high-quality products. We used a dummy variable, in-house production, in which a studio acts as both distributor and producer, to account for the impacts of this feature. Film budget is another driving factor of film quality, so we controlled for the information of film budget (logarithm) on the choice of the film's genre(s). Major studios have different filmmaking and distributing strategies vis-à-vis smaller independent studios. Major studios also have the financial resources and influence to hire a versatile film crew and produce the most-high-profile works. Knowing these differences, audiences may set different expectations when categorizing works from major studios. We used a dummy representing whether the studio making the focal film is a “Major 6” studio (Warner Brothers, Disney, Universal Pictures, 20th Century Fox, Columbia Pictures, and Paramount Pictures) to approximate the effects. Table 3 reports the descriptive statistics and bivariate correlations.
Descriptive Statistics and Correlations
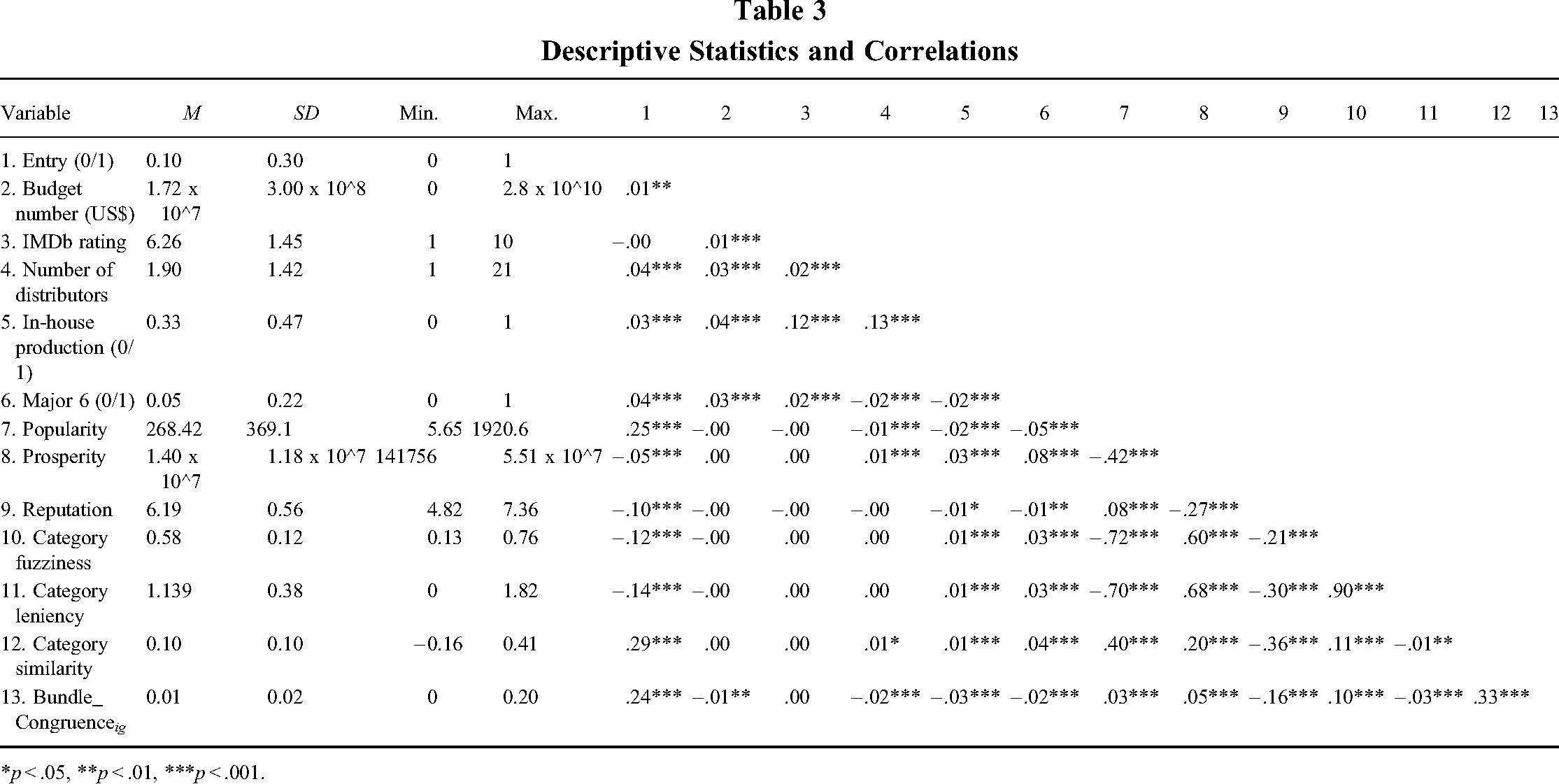
*p < .05, **p < .01, ***p < .001.
Analytical Methods
The empirical model for Hypothesis 1 and Hypothesis 2 is at the genre-film level. We fitted the alternative-specific conditional logit (McFadden's choice) model:

where Pig is the chance that genre g appears in film i,
Hypothesis 2 argues that a model into which the bundle-based explanation is incorporated will have stronger explanatory power than models that include only connection-based explanations. We examined this hypothesis using receiver operating characteristic (ROC) curve analysis. ROC curves have been used extensively in biostatistics, clinical medicine, and machine learning to evaluate the diagnostic accuracy of tests or the assessment of classification models (Bradley, 1997; Erdreich & Lee, 1981). The ROC curve analysis plots the true positive rate (TPR; i.e., the proportion of actual positives that are correctly identified, or statistical power in hypothesis testing) against the false positive rate (FPR; i.e., the proportion of actual negatives that are correctly rejected, or Type I errors in statistics) of a model at various cutoffs. The goal of the ROC curve analysis is to find the model that achieves the higher TPR at the given level of FPR. The better the performance of a model is in terms of FPR and TPR, the larger the area the model will occupy under the ROC curve in the plot. We used a statistical test suggested by DeLong, DeLong, and Clarke-Pearson (1988) to examine the equality of the areas under the curves. We argued that a model considering the bundle-based explanation will have a larger area under the ROC curve.
Sample, Method, and Data for Estimating Economic Outcomes
To test Hypothesis 3, we examine at the product level whether bundle congruence affects the economic returns of a product. The sample is still the feature films we used to test Hypothesis 1 and Hypothesis 2, but the unit of analysis is film rather than genre. The dependent variable for Hypothesis 3 is a film's domestic box office revenue.3 The box office data are from 16 consecutive years (from 2000 to 2015). To offset the variation in box office revenue generated from currency inflation, we adjust the box office revenue using the average ticket price from the Motion Picture Association of America (MPAA). We detail how we adjusted box office numbers in Appendix C. Because the dependent variable is a continuous variable, we used the ordinary least squares method.
The independent variable is the bundle congruence of a film. This value can be calculated by taking the average of the bundle congruence scores of all genres that appear in film i: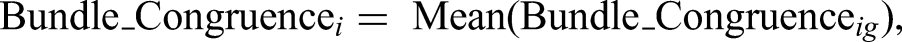
where Bundle_Congruence ig comes from Equation 2. Similarly, we also calculated a film's overall fuzziness and leniency by taking the average value over all categories that appear in the focal film (Pontikes, 2012).
To test Hypothesis 3, we included a number of control variables in the box office equation. Their operationalization can be found in Appendix C. A large body of literature has used these variables to account for a film's box office revenues. We also included year dummies to capture other unobserved year-fixed heterogeneous effects. All data are from IMDb.
Results
Table 4 reports the results of McFadden's choice model. This model estimates the likelihood that a genre is chosen to describe a film. We standardized key variables (bundle congruence, fuzziness, leniency, similarity, reputation, prosperity, and popularity) to ensure that their coefficients were comparable in all regressions. Model 1 includes only the category social properties and film-level controls. In Model 2, we added connection-based variables to test the baseline hypothesis that category fuzziness, leniency, and similarity affect the use of categories. Consistent with the baseline hypothesis, fuzziness decreases the likelihood that a genre is selected (p < .001; see also Carnabuci et al., 2015; Negro et al., 2011), and similarity is positively related to the chance of a genre being chosen (p < .001; see also Wry & Castor, 2017). However, leniency is not significant. In Model 5, we used the CEM sample to replicate Model 2. Again, fuzziness is highly significant (p < .001), while similarity and leniency are only marginally significant (p = .072; p = .056) in Model 5. This result is not surprising for two reasons: (a) General audiences, as “market takers,” are not as interested in category leniency as producers are (Pontikes & Barnett, 2015); and (b) scholars have found a high correlation between fuzziness and leniency in other industries (Pontikes, 2012). Given that they are highly correlated (r > .9), multicollinearity can eliminate the significance of leniency. Our results largely support the baseline hypothesis that a category's connection attributes affect its usage in products (Pontikes & Barnett, 2015; Wry & Castor, 2017). Among the connection attributes, fuzziness attains the highest level of significance, as we are testing the hypothesis in a setting where audiences make the categorization decisions.
McFadden's Choice Models of Genre Entry: 2000–2015
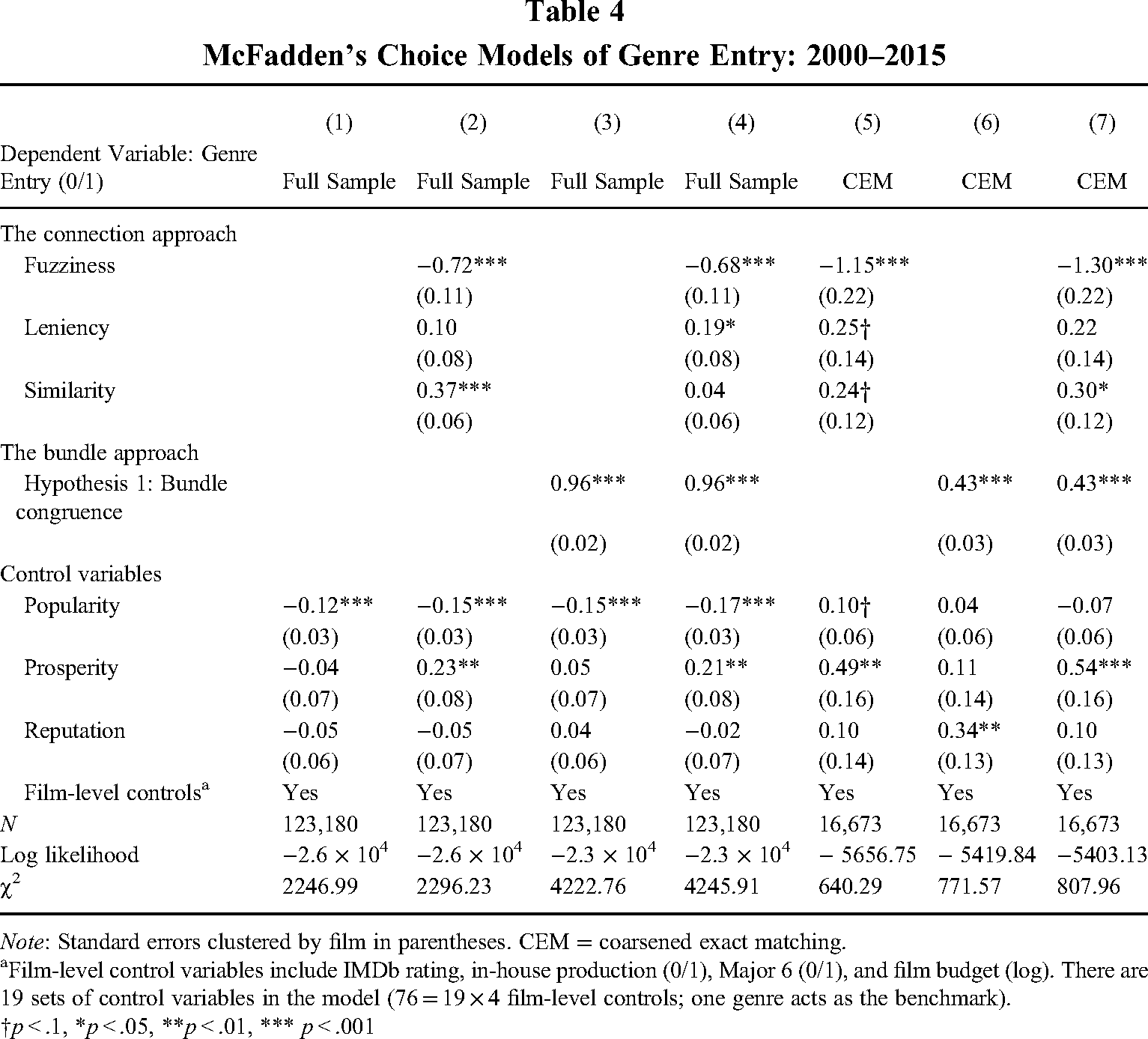
Note: Standard errors clustered by film in parentheses. CEM = coarsened exact matching.
Film-level control variables include IMDb rating, in-house production (0/1), Major 6 (0/1), and film budget (log). There are 19 sets of control variables in the model (76 = 19 × 4 film-level controls; one genre acts as the benchmark).
†p < .1, *p < .05, **p < .01, *** p < .001
In Model 3, bundle congruence, the independent variable based on the bundle approach, was added. A genre's bundle congruence is positively associated with the probability that it is selected to describe a film (p < .001). A one-standard-deviation increase in the level of bundle congruence will increase the genre's odds of appearing in film descriptions by 161% ( = e0.96−1). Hence, Model 2 provides strong support for Hypothesis 1. In Model 6, we used the CEM sample to replicate Model 2. Although the matching algorithm significantly reduces the sample size (from 123,180 to 16,673), bundle congruence retains its positive association with the likelihood that the genre is chosen (p < .001). This result provides further support for Hypothesis 1.
In Models 4 and 7, we simultaneously included explanations from the connection and bundle approaches to examine the incremental explanatory power of models caused by the bundle congruence variable. One concern is that connection- and bundle-based variables are closely related at the theoretical level. Including them in the same model may lead to multicollinearity. We checked their correlation coefficients. The correlations of bundle congruence with fuzziness, leniency, and similarity are .10, −.03, and .33, respectively (p < .001 for all; see Table 3). The variance inflation factor (VIF) of bundle congruence is 1.33 in the full sample and 1.62 in the CEM sample, which is much lower than the rule-of-thumb value of 10. We hence believe that multicollinearity is not an issue here. With bundle congruence included, the χ2 statistics increase significantly (from 2,296 in Model 2 to 4,246 in Model 4; from 640 in Model 5 to 808 in Model 7). The coefficients of bundle congruence are also positive and significant (p < .001) in Models 4 and 7. Meanwhile, the coefficients of the connection variables are less stable. From Models 2 to 4, the coefficients of leniency change from insignificant to significant; the coefficients of similarity change from significant to insignificant. When we reexamine their coefficients in the CEM sample (Models 5 and 7), we observe opposite trends. The only stable connection variable is fuzziness, whose coefficient estimates are significant in Models 2, 4, 5, and 7. The χ2 statistics and patterns of coefficient estimates across models provide preliminary support for Hypothesis 2.
To further identify the incremental explanatory power of bundle congruence, we drew their ROC curves in Figure 5. The two plots at the top are based on the full sample, while the plots at the bottom are based on the CEM sample. For the ROC curves based on the full sample, the dashed dotted line represents Model 3 (bundle congruence only), the long-dashed line denotes Model 2 (connection variables only), and the solid line represents Model 4 (both connection and genre variables are included). There are two noteworthy points. First, in the top-left plot, except at the extreme cutoffs (near 0 or near 1), the ROC curve of the model including only the variable derived from the bundle approach (Model 3) occupies a higher position than the model including only variables driven by the connection approach (Model 2). The higher position of the ROC curve suggests that at any given level of FPR (Type I error), a model that considers bundle congruence has greater statistical power (i.e., TPR, the proportion of actual positives that are correctly identified) than a model that considers connection variables only. Second, in the top-right plot, although the model that includes both bundle congruence and connection variables (Model 4) occupies a higher position than the model that includes only the connection variables (Model 2), Model 4 shows only marginal improvement over the model that includes only bundle congruence (top left, Model 3). Across the two plots at the top, the ROCs of Model 4 and Model 3 are alike. To formally compare their predictive power, we conduct the equality-of-area test suggested by DeLong et al. (1988). We found that the ROC areas of Models 3 and 4 were significantly larger than those of Model 2: for the former, 0.8719 versus 0.8182, χ2(1) = 1729, p < .0001; for the latter, 0.8721 versus 0.8182, χ2(1) = 1749, p < .0001. However, the ROC area of Model 4 was only slightly larger than that of Model 3: 0.8721 versus 0.8719, χ2(1) = 5.19, p = .023. Taken together, a model that considers the connection variables and the variable based on the bundle approach (i.e., bundle congruence) has a stronger power than the model without them in predicting genre entry decisions, and bundle congruence contributes the most to the improvement of the explanatory power. Hypothesis 2 is thus supported. For ROC curves based on the CEM sample (at the bottom of Figure 5), the results are highly consistent with those of the full sample. In particular, the model with bundle congruence (Model 6) performs better than the model that considers only a genre's connection patterns (Model 5). The full model with connection patterns and bundle congruence (Model 7) shows only limited improvement over Model 6, which considers only the bundle-based explanation. The tests on the CEM sample provide further support for Hypothesis 2. Given the strongly enhanced explanatory power brought in by bundle congruence, we maintain that it is rewarding and critical to ponder the category membership of a product from the bundle perspective.
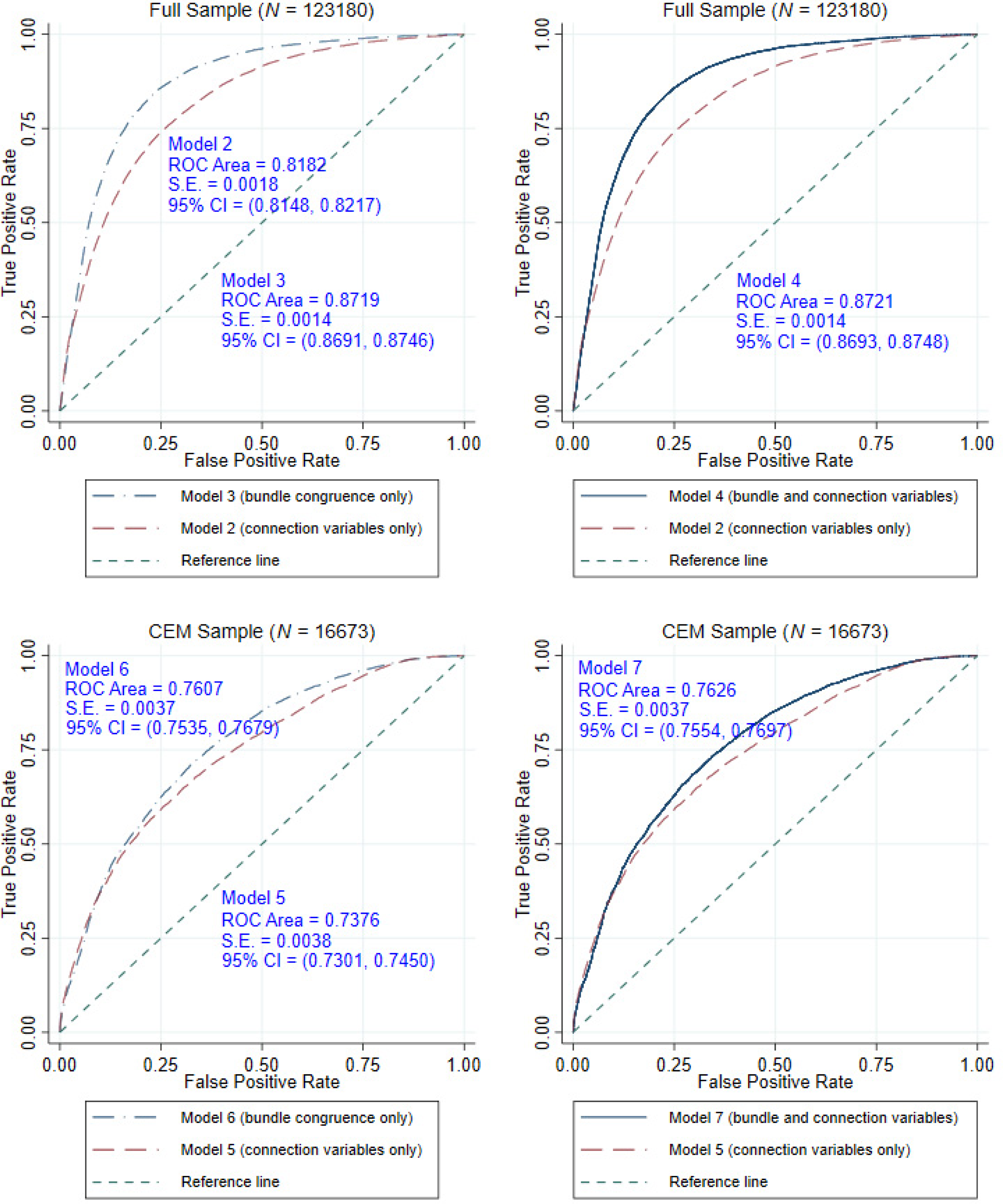
Receiver Operating Characteristic (ROC) Curves
Robustness Checks
We performed a number of robustness checks. We first checked the construct validity of the core independent variable, bundle congruence, and examined whether measurement error affected the results. In our algorithm, we manually gave the value of zero to the genres appearing in single-genre films in the calculation of the congruence of a bundle (see Equation 1). The rationale was that a genre that frequently appears in single-genre films transmits the information that it cannot form a congruent bundle. However, there may be a concern that the results are driven by a manually created mathematical truism. To mitigate such a concern, we dropped all single-genre films and ran the regressions again. The results are shown in Table 5. The coefficients of bundle congruence in Models 9 and 11 are positive, lending support for Hypothesis 1. In the unpresented ROC curve analyses, we found that the ROC areas of Models 9 and 11 are larger than those of Models 8 and 10, respectively. These results lend further support for Hypothesis 2.
McFadden's Choice Models of Genre Entry with Single-Genre Film Excluded
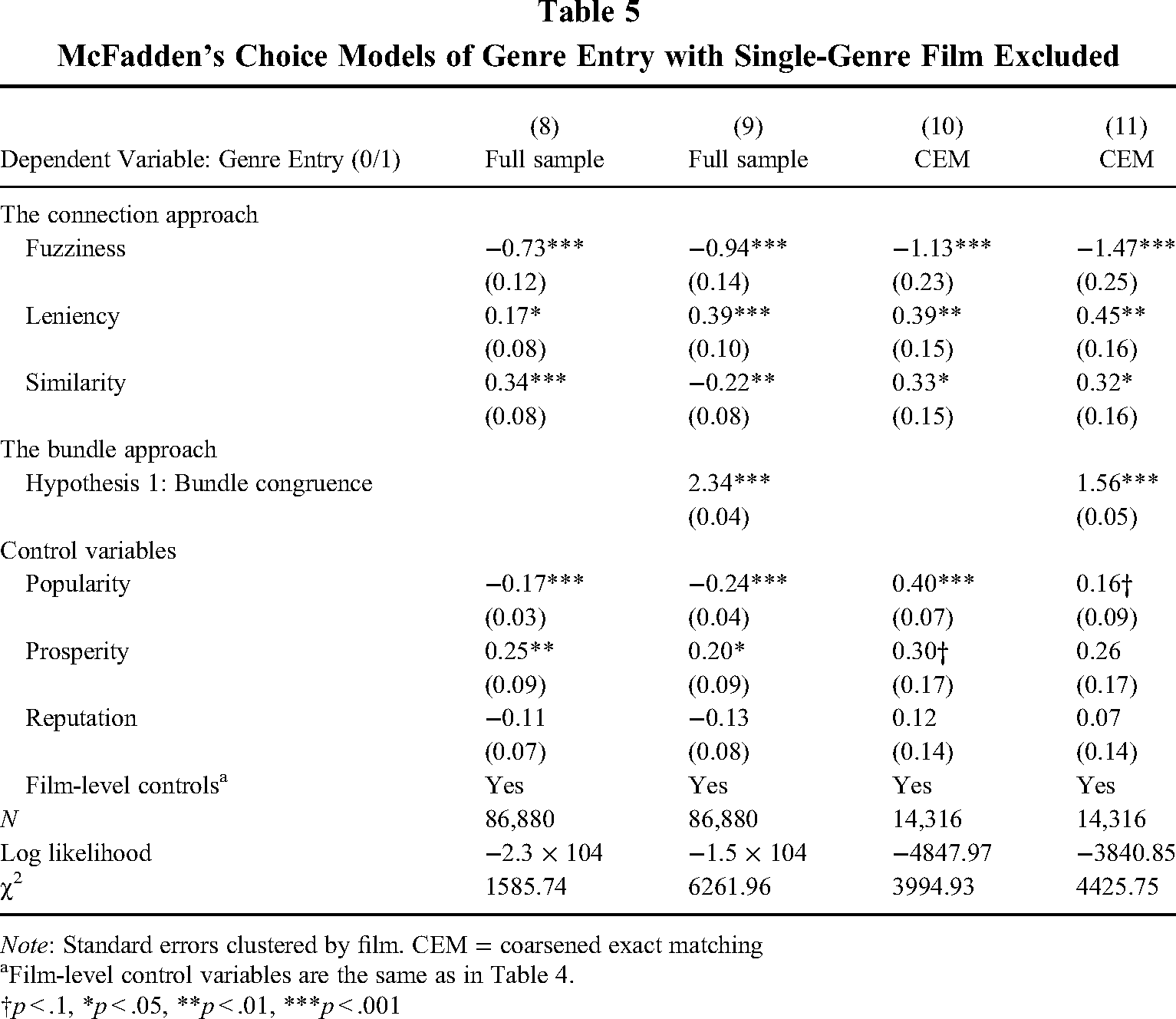
Note: Standard errors clustered by film. CEM = coarsened exact matching
Film-level control variables are the same as in Table 4.
†p < .1, *p < .05, **p < .01, ***p < .001
The second issue also revolves around the validity of bundle congruence. To further prove the idea that genre congruence is meaningful in market participants’ categorization decisions, we listed all highly matched and mismatched category bundles based on the calculation of our algorithm and checked if the results are in tune with our intuition. These bundles are listed in Table 6. The five most matched bundles include horror-thriller, comedy-romance, mystery-thriller, crime-thriller, and biography-documentary, whereas the five most mismatched bundles are documentary-thriller, documentary-horror, animation-horror, documentary-romance, and animation-mystery. We believe that the algorithm-generated bundle congruence measurement coincides with the general audience's perception about the market.
The 10 Most Matched and Mismatched Category Bundles in Feature Films 2015
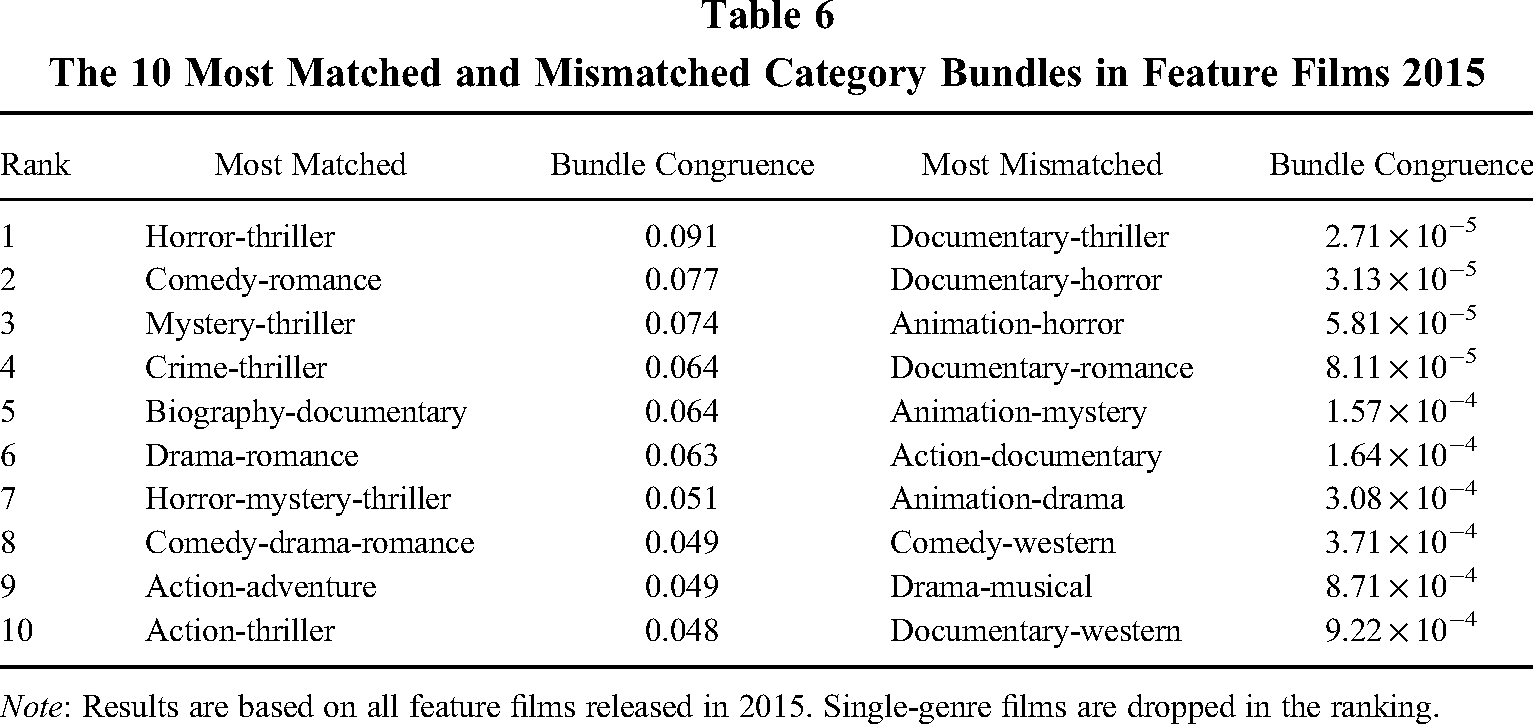
Note: Results are based on all feature films released in 2015. Single-genre films are dropped in the ranking.
Analysis of the Economic Outcome of Bundle Congruence
Hypothesis 3 argues that a film including highly congruent bundles in its genre list will achieve larger economic returns since it reveals more information about the nature of a product and facilitates audiences in making taste-based decisions. The results are shown in Table 7. Model 12 includes all controls and the number of genres, which is a traditional category-spanning variable. In Model 13, two connection variables, fuzziness and leniency, are added. Model 14 tests the effect of bundle congruence on a film's box office revenues, with all other variables included. Consistent with the early category-spanning literature (Hsu et al., 2009; Zhao, Ishihara, & Lounsbury, 2013; Zuckerman, 1999), Model 12 shows that the number of genres reduces economic returns (p < .001). Nevertheless, Model 13 indicates that after the connection variables are added, the negative effect of category spanning attenuates (p = .089). Meanwhile, both fuzziness and leniency are insignificant in Model 13. We believe that the insignificance of fuzziness and leniency is caused by their high correlation, as their VIFs reach 7.15 and 6.38. In unpresented analyses, when either fuzziness or leniency is dropped from the model, the remaining variable becomes significant, and the negative effects of the number of genres can be reproduced. Our results confirm the argument that category fuzziness and leniency provide additional information regarding categorization decisions (Carnabuci et al., 2015; Pontikes & Barnett, 2015). In Model 14, we further add bundle congruence into the model. Its VIF value is 1.56, suggesting that multicollinearity is unlikely an issue here. In addition, bundle congruence is positively related to box office revenues (p = .026). Hypothesis 3 is thus supported. In terms of economic significance, a one-standard-deviation increase in bundle congruence will lead to a 7% increase in a film's box office revenues. Interestingly, we also find that the negative effects of the number of genres disappear in Model 14, which will be discussed in the next section.
Analysis of the Economic Outcome of Bundle Congruence
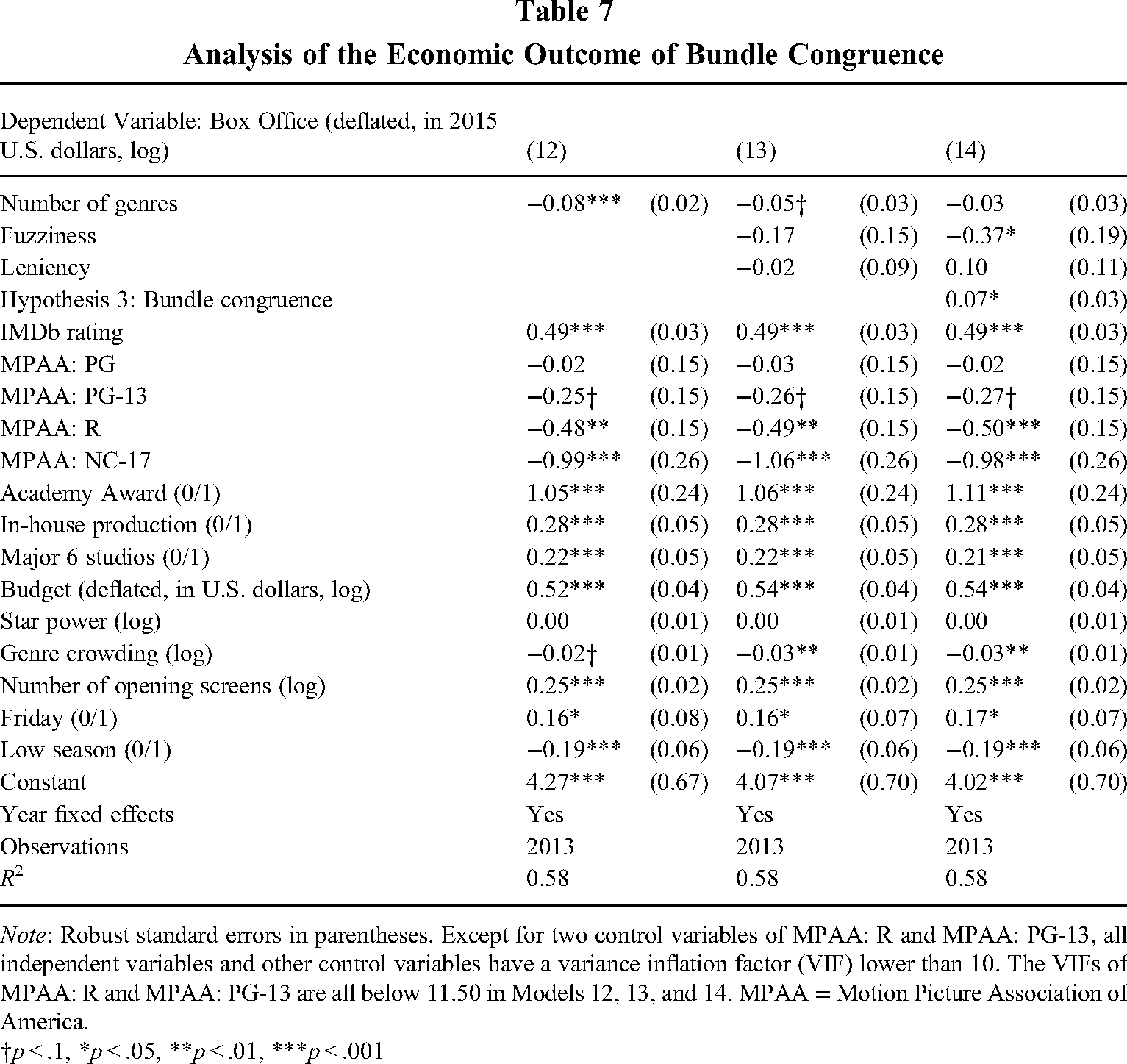
Note: Robust standard errors in parentheses. Except for two control variables of MPAA: R and MPAA: PG-13, all independent variables and other control variables have a variance inflation factor (VIF) lower than 10. The VIFs of MPAA: R and MPAA: PG-13 are all below 11.50 in Models 12, 13, and 14. MPAA = Motion Picture Association of America.
†p < .1, *p < .05, **p < .01, ***p < .001
Discussion
Our starting point is that categories are interrelated in the classification system, and both system- and bundle-level interconnectedness will manifest in the category membership of a product. Our particular concern has been the influence of category bundles on audiences’ categorization decisions. Our study is the first to propose that audiences often evaluate categories in a product's description at the bundle level. We develop a new measurement, bundle congruence, to examine to what extent category bundles shape the categorization of feature films and box office success. We have shown that moviegoers are more likely to choose a genre that achieves a higher level of bundle congruence in a film. We also found that the bundle-based mechanism has stronger explanatory power than the connection-based mechanism in predicting the category membership of products. Furthermore, at the product level, a film's overall bundle congruence is positively related to its box office success.
We view our article as a part of “the ontological turn” that Kennedy and Fiss (2013) called for in category research. Instead of treating categories as given and studying how they regulate human behaviors, we view categories as an outcome or accomplishment that is shaped by human behaviors. Within the former stream of research, a rich discussion has ensued to discover how category spanning affects an individual's career path (e.g., Leung, 2014), product success (e.g., Negro et al., 2015; Zuckerman, 1999, 2004), and organizational performance (e.g., Hsu et al., 2009; Ruef & Patterson, 2009). Less known is the latter stream, namely, how the choice of categories is affected by the cognitive proclivity of decision makers, which is an important dependent variable in its own right (Kennedy & Fiss, 2013). We made a conscious decision to pursue the later stream in this article, studying how genres are chosen (or fall out of use) as moviegoers “reproduce” their cognitions of category bundles in movie categorization. Although we do not delve into the organizational implications of category membership (the former stream) in this article we believe that both streams are theoretically indispensable. The former literature concerns how humans create artifacts (categories) to facilitate social interactions, while the latter reveals that human behaviors are restrained by the artifacts (categories) they created.
Theoretical Implications
Our study provides a more nuanced perspective of intercategory relationships and their impact on the categorization process. Scholars have pointed out that the patterns of linkage among the categories determine the usage of categories and shape the audience's perception of products bearing those category labels (e.g., Leung, 2014; Negro et al., 2011; Paolella & Durand, 2016; Wry & Castor, 2017). These scholars do not, however, differentiate various linkages that a category can have with other categories. Without fine-grained analyses of how a category's linkage with other categories is formed in different ways, existing studies fall short of explaining why categories are still chosen regardless of their less lenient or highly fuzzy identities. We address this dilemma by introducing the concept of a category bundle. We prove that audiences group several categories into a bundle to facilitate categorization. Compared with previous literature, our bundle approach is built upon realistic assumptions about audiences. We assume that audiences often possess limited knowledge of the connections of each category with all other categories. They are cognitive misers who tend to “shirk” the burden of scrutinizing each category in a one-by-one manner. Our study is the first to propose that audiences often contemplate categories at the bundle level rather than the category level.
This article also reconciles the categorical-imperative argument and the persistence of category spanners. Acknowledging the existence of category bundles, we provide an alternative approach through which category spanners appear in the market. Many scholars have endeavored to resolve this conundrum (Alexy & George, 2013; Paolella & Durand, 2016; Zhao et al., 2013). These scholars either claim that category spanning produces some unrecognized benefits (e.g., Hsu, 2006; Tang & Wezel, 2015) or suggest that spanning behaviors are preserved with the concurrent implementation of specific strategies that mitigate the negative effects of spanning (e.g., Zhao et al., 2013). While these arguments undoubtedly apply in many cases, we suggest an alternative explanation in which category spanning might simply embody the bundle structure in product markets. When audiences employ bundle logic in categorization, they assign multiple categories simultaneously. Because in this case the assigned categories are cognitively coherent together, such a “category spanning” will not impose as many cognitive burdens on audiences as has been predicted by previous literature (e.g., Hsu et al., 2009). In Model 14 of Table 7, when we include both category spanning and bundle congruence in the box office regression, the negative relationship between category spanning and performance becomes insignificant. Meanwhile, the positive effects of bundle congruence remain. Our explanation is that when market participants actively bundle categories in their sensemaking of products, the categorical imperative, whose effects stem from market audiences’ cognitive and capability limitations in coping with boundary-crossing objects, may become less of an issue for a product. In other words, when audiences evaluate a product's category profile by bundling categories, at the cognition level, accounting for the number of categories of a product becomes less important.
Third, we also contribute to the stream of free categorization research by pinpointing the premise on which the conditional independence of free categorization holds (Hannan et al., 2019). Using Bayes’s theorem, Hannan et al. (2019) argue that the task of assigning a set of distinct categories to an object follows the law of conditional independence. That is, given that someone has prior knowledge about the categorization system (the features of each category, the priors about all possible category combinations, etc.), the decision to assign category A to an object is independent of the decision to assign category B to the same object. In other words, the probability that the object receives both A and B designations is the product of two separate probabilities in which A or B is used. Hannan et al.’s own experiments indicate that conditional independence does not accurately approximate how people assign categories to objects. Specifically, if an object harmonizes with the descriptions of two categories, categories A and B, its likelihood of receiving both A and B is substantially higher than the likelihood predicted by the property of conditional independence; meanwhile, the actual likelihood that this object receives neither A nor B is much lower than the likelihood predicted (Hannan et al., 2019).
The violations of conditional independence, on the other hand, validate our claim that audiences consider candidate categories using bundle logic. Hannan et al. (2019) believe that the “position” of an object in relation to the categories it is subject to determines the extent to which the conditional independence assumption does not hold. However, Hannan et al. do not theorize the “position” in their framework but rather encourage future work to do so. Our construct of the category bundle addresses this gap properly. A product's bundle congruence, which denotes how well multiple categories fit together as bundles in the product, essentially measures the overall “position” of a product within audiences’ cognitive boundaries. In a category classification system in which congruent bundles are universal, the law of conditional independence will be frequently violated (Hannan et al., 2019). We encourage future work to empirically test this argument.
Practical Implications
Our study also has important managerial implications. We found that after multiple factors that are directly related to the quality of a product (e.g., budget, star power, number of opening screens, and seasonality) have been controlled, a product labeled with highly congruent category bundles still attains higher economic outcomes. Our results indicate that even in an audience-centric market, producers should actively manage the category labels of their product to ensure that their products receive adequate returns. In the feature film market, since moviegoers mostly categorize a film just before or at the beginning of its theatrical release, it is vital for studios to expend their marketing efforts during this stage and target these “early users,” whose categorization decisions will greatly affect general audiences’ moviegoing decisions. In addition, the marketing message delivered to audiences should be consistent, with highly congruent genre elements presented in ads/trailers. In a study of Hollywood movies, Hsu (2006) documented the fact that studios often test different ways of conceptualizing and marketing a film by releasing multiple versions of trailers, each of which corresponds to distinct genres. Although such a strategy can attract as many moviegoers as possible, it is not recommended according to our research, in that the genre elements in trailers are not congruent. Hence, a successful categorization strategy concerns not only sending coherent bundle signals to audiences but also sending the signal at the right time.
Limitations and Future Research
This study is not devoid of its limitations. We argue that audiences unanimously apply bundle logic in their reasoning of product categories, but little is known about the heterogeneity among audiences that may produce divergent category decisions. In a recent work, Chae (2022) found that when producers are responsible for categorization, they base the category boundary of their products on the heterogeneity of the consumer group (e.g., income level and education) they confront. She found that the high purchasing power of consumers reduces producers’ category-spanning behaviors but that the culturally omnivorous preferences of those consumers encourage spanning decisions (Chae, 2022). Linking her findings to this study, one natural extension is to consider the idiosyncrasies of audiences and explore whether audience groups employ the bundle logic differently.
Second, we examine our arguments in a field with an established category system so that we curb the confounding effects of the transition of a category system (Navis & Glynn, 2010; Ruef & Patterson, 2009) on category decisions. Our findings can be generalized to any context with a mature category system and audiences who actively participate in the categorization of products. However, we do not yet know to what extent turbulent environments (e.g., shifting category systems, contesting categories, and declining categories) will distract audiences from using bundle logic. For example, Granqvist and Ritvala’s (2016) case study on functional-foods and nanotechnology categories suggests that in different stages of market category development, audiences iterate and update their knowledge, perception, and goals of the category, which should impact their categorization behaviors. Therefore, a potentially fruitful avenue for future researchers is to examine whether audiences can still group categories into bundles in less stable contexts.
Finally, a relevant point is that our article regards category bundles as given and explores their effects in categorization without considering how these bundles come into being in the first place. How does a category bundle emerge in the field? Is it based on the semantic similarities between categories or created to accomplish specific goals (Durand & Boulongne, 2017; Durand & Paolella, 2013)? Navis and Glynn (2010) studied the U.S. satellite radio market over its initial years and found that entrepreneurs shifted their identify claims, linguistic framing, and positioning strategy along with the legitimization of the new category. Future research can also use longitudinal data to investigate the emergence and institutionalization of category bundles and the evolving attitudes of market participants throughout the process.
Conclusion
In this study, we have argued and shown that audiences tend to process categories in bundles in the sensemaking of a product. We define a novel concept of bundle congruence to measure the “fit” of category bundles. Our empirical tests suggest that a category's bundle congruence in a product improves the chance that the focal category is used to describe the product. Our results contribute to the growing research on the interconnections of category systems and the multiplicity of market participants in product categorization. We also offer a solution to the contradiction between the prediction of the categorical-imperative argument and the fact that category spanning is ubiquitous in markets. At the practical level, our research is relevant to producers who would like to utilize audiences’ tendency to bundle categories to maximize economic returns.
Footnotes
Acknowledgments
We gratefully acknowledge associate editor Sali Li and two anonymous reviewers for their insightful comments during the review process. We would like to thank Elizabeth Pontikes and Ming Leung for their thoughtful comments. Early versions of this manuscript were presented at the 2020 Academy of Management annual meeting, 2020 Organizational and Management Theory Division Junior Faculty Consortium, Strategic Management Society 40th annual conference, and 2020 British Academy of Management Conference. We sincerely thank seminar participants for their helpful comments. The first author thanks the funding support from the University of Manitoba. The second author thanks the research grant awarded by the University Grants Committee, Hong Kong (GRF CityU 11505420), and the financial support offered by the City University of Hong Kong (No. 9380109).
Notes
Appendix A
Appendix B
This section provides an illustration of how we calculate the congruence of a bundle (Congruence B ) using a hypothetical setting. We assume that only 10 films were released in the past 5 years. Table B1 presents the 10 films.
Assuming that we consider a bundle of three genres (action, adventure, and drama). We use Equation 1 to calculate the congruence of a bundle. Because we are considering three genres, k = 3; seven of the films include at least one genre of the bundle (action, adventure, and drama); hence m = 7. The number of genres that belong to the action-adventure-drama bundle across all films is listed in Table B1. We calculate the congruence using the following formula:
This suggests that the congruence of the hypothetical bundle—action, adventure, and drama—is 0.214.
In other cases, when we calculate the congruence of adventure, animation, and documentary using the information in Table B1, the value will be 0. The reason is that not any two of the three genres have ever appeared together across all films. Similarly, if we consider the congruence of animation and family, the value will reach 1, as they appear simultaneously in their only appearance in the market (Film D).
The congruence index we adopted is more reliable than the traditional pairwise indices (e.g., Pearson's coefficient; Jaccard, Dice, and Sørensen similarity) used in the previous organization theory articles (e.g., Wry & Lounsbury, 2013; Zuckerman, 2004) in that it captures the “congruence” of a set involving more than two elements (Arita, 2017; Baselga, 2013), which is in line with our core argument that multiple categories may form a bundle.
Appendix C
For Hypothesis 3, we estimate the following equation: