
Abstract
Demand response (DR) is a strategy that encourages customers to adjust their energy usage during periods of peak demand, aiming to enhance the reliability of the power grid and reduce operational costs. The optimal DR scheme utilizes both distribution system operators and consumers within the energy network to achieve optimal results. The integration of renewable energy sources into smart grids poses significant challenges due to their intermittent and unpredictable nature. DR strategies, coupled with reinforcement learning techniques, have emerged as promising approaches to address these challenges and optimize grid operations where traditional methods fail to meet such kind of complex requirements. This article presents a reinforcement learning-based strategy to optimize DR and energy management in smart grids, focusing on battery-photovoltaic integrated systems. The proposed method employs the soft actor-critic with automated adjustment of temperature algorithm to enhance load-shifting flexibility and grid stability. Experimental results, using the CityLearn environment, demonstrate significant reductions in energy costs 3% and 15% compared to rule-based control and soft actor-critic-based strategies, respectively.
Keywords
Introduction
Transforming energy grids to become carbon neutral requires radical changes in how energy is consumed, especially to address the fluctuating nature of wind and solar power generation. An approach to mitigating this challenge is demand response (DR), a strategy that encourages users to shift their energy consumption from low-generation periods to times when energy production is abundant (Siano, 2014). With the growing adoption of renewable energy sources (RES), such as solar and wind, both intrinsically intermittent, DR plays a vital role in balancing energy supply and demand.
DR is most often implemented through buildings. To deal with the uncertainties associated with RES and to prevent grid instability, their integration into existing infrastructure must be handled with care. The complexity of building energy management (BEM) increases due to the need for adaptive load shifting in response to grid signals (Wang and Hong, 2020). Participation in DR programs enables building networks to better control energy usage, reduce operational costs, and buffer the variability introduced by renewable energies (Yang et al., 2022).
Various methods have been proposed to optimize energy consumption in grid-responsive buildings. Rule-based control techniques are frequently used in BEM systems because of their simplicity and ease of implementation (Bay et al., 2022; Ferahtia et al., 2022). Rule-based controllers, however, frequently produced less-than-ideal performance in dynamic environments due to their reliance on static thresholds and inability to adjust to real-time variations in energy demand.
Model predictive control (MPC) has also made notable contributions to both DR and BEM (Mariano-Hernández et al., 2021). Another approach formulates DR as a scheduling problem using mixed-integer linear programming, which requires detailed knowledge of the system dynamics and appliance characteristics (Henggeler Antunes et al., 2022). However, as the number of buildings increases, creating individualized energy models becomes infeasible. The complexity introduced by time-varying variables and building diversity limits the scalability of traditional model-based methods for large-scale DR applications.
With the rapid advancement of machine learning, reinforcement learning (RL) has emerged as a powerful alternative to traditional model-based approaches for solving DR problems, framing them as sequential decision-making tasks (Vázquez-Canteli and Nagy, 2019). Unlike traditional optimization methods, RL doesn’t necessitate pre-existing knowledge of system behavior and can be employed in a model-free way, simplifying its application in real-world scenarios.
In recent years, various RL methods have been proposed and explored for energy management tasks. These include deep Q-networks (Amer et al., 2023), proximal policy optimization algorithm (Schulman et al., 2017), deep deterministic policy gradient (DDPG) off—policy algorithm (Lillicrap et al., 2019), twin delayed DDPG off-policy algorithm (Fujimoto et al., 2018), among others. RL has been successfully implemented in developing several DR programs (Ajagekar and You, 2023; Jin et al., 2022; Kong et al., 2020; Lu and Hong, 2019; Mocanu et al., 2019; Yang et al., 2020). According to Brandi et al. (2022), an RL agent trained offline could achieve comparable cost savings to a model predictive controller (MPC) for an office building, while also requiring significantly less computational time for real-time decision-making.
Despite these advances, single-agent deep RL (DRL) techniques often struggle to effectively capture the interactions between multiple buildings in DR scenarios. As the complexity and dimensionality of the environment increase, scalability becomes a major challenge. In response, multi-agent DRL has recently gained significant interest among power system researchers for their applications in distributed control and energy management within hybrid energy systems and microgrids (Karavas et al., 2015; Zeng et al., 2011). However, in DR scenarios, where energy demand and renewable generation fluctuate widely across daily and seasonal cycles, traditional RL algorithms with static parameters often lack the adaptability required to respond to these fluctuations effectively.
To address these challenges, we propose the use of soft actor-critic with automated adjustment of temperature (SAC-AAT) algorithm (Haarnoja et al., 2019) for optimizing demand response management. SAC-AAT extends the soft actor-critic (SAC) algorithm, a state-of-the-art RL method that performs well in continuous action spaces and environments requiring robust decision-making under uncertainty. The automated adjustment of temperature in SAC-AAT improves adaptability, allowing for more flexible and responsive DR control in environments with fluctuating energy demand and variable renewable energy supply.
Methods
Energy modeling
CityLearn (Vázquez-Canteli et al., 2020) is an OpenAI Gym-based simulation framework for implementing RL algorithms in urban energy management, enabling DR by controlling energy storage across multiple buildings. It uses pre-simulated building data to model hourly energy loads, including cooling, heating, and non-shiftable loads, and provides a standardized platform for benchmarking RL algorithms. The environment can model various types of energy demands, electrical devices, energy storage systems, and electricity sources (Figure 1). The number of buildings can range from a single unit to an extensive district.
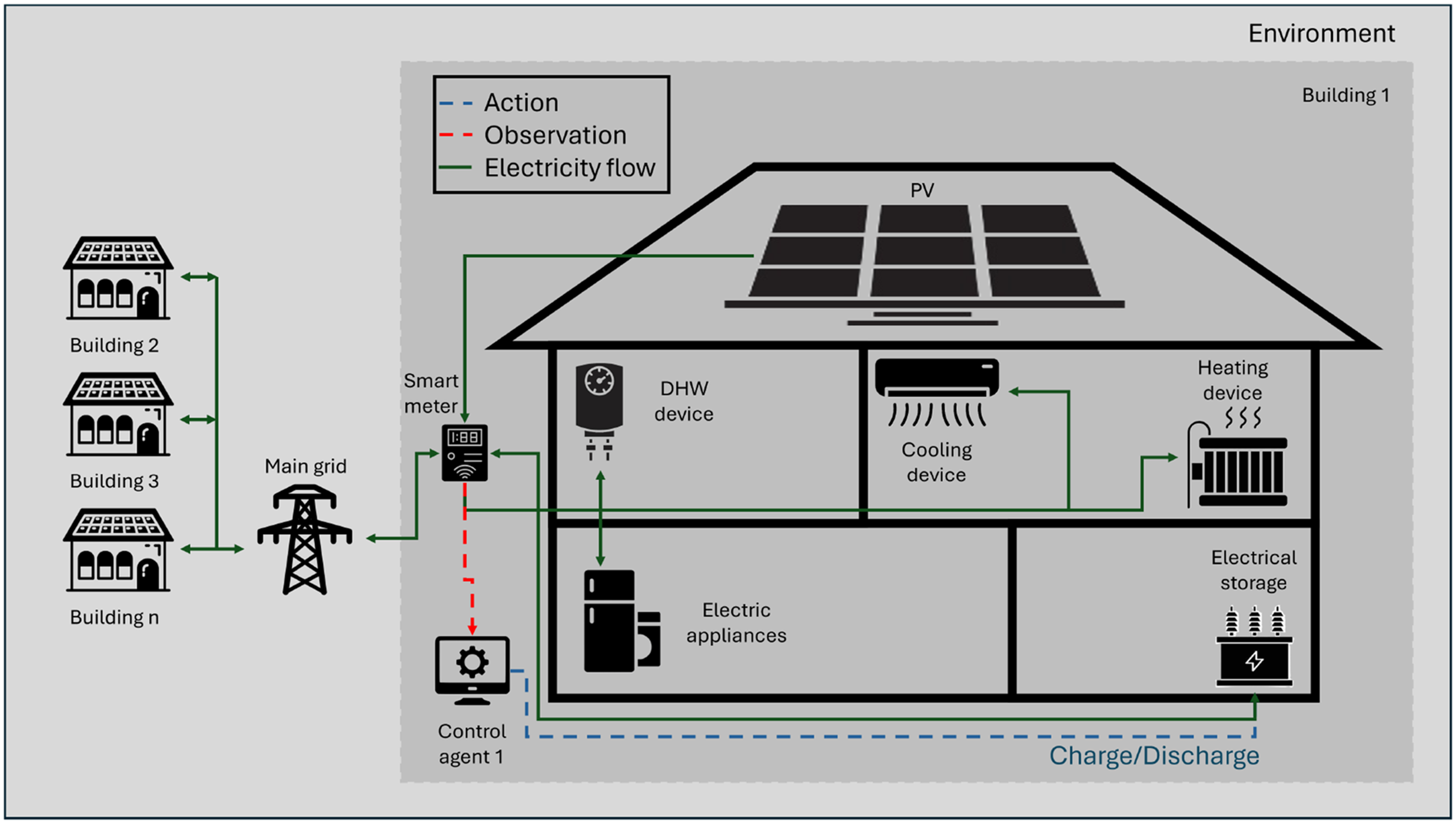
CityLearn proposed energy models.
In this study, all energy demands, including heating, cooling, and electrical appliance usage, are aggregated into a single non-shiftable load. This approach ensures that these demands are treated as essential and must be satisfied immediately. All buildings are equipped with 4 kWp solar panels as a RES, allowing the buildings to generate their own electricity. The system relies exclusively on batteries with a capacity of 6.4 kWh for energy storage, focusing on optimizing charge and discharge cycles to manage demand peaks, enhance renewable energy self-consumption, and maintain grid stability. The electric energy storage system operates dynamically, with charging and discharging power denoted as
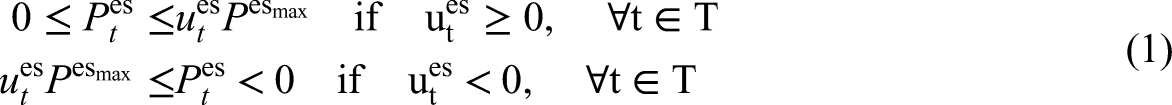
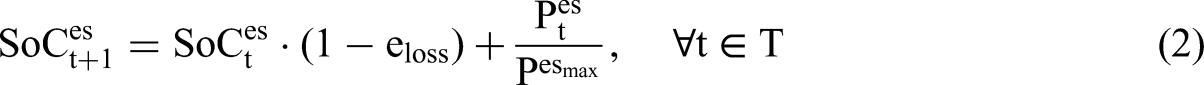
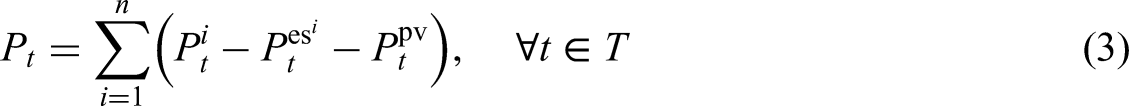
RL formulation: Markov decision process (MDP)
RL is a subfield of machine learning that centers around training an agent to make sequential decisions through direct interaction with a dynamic environment. Unlike supervised learning, where the agent learns from labeled examples, RL operates in a trial-and-error fashion, allowing the agent to explore different strategies and adapt its behavior based on the outcomes of its actions (Figure 2). The DR problem in grid-responsive buildings is formulated as a multi-agent extension of the MDP and is defined by a five-tuple
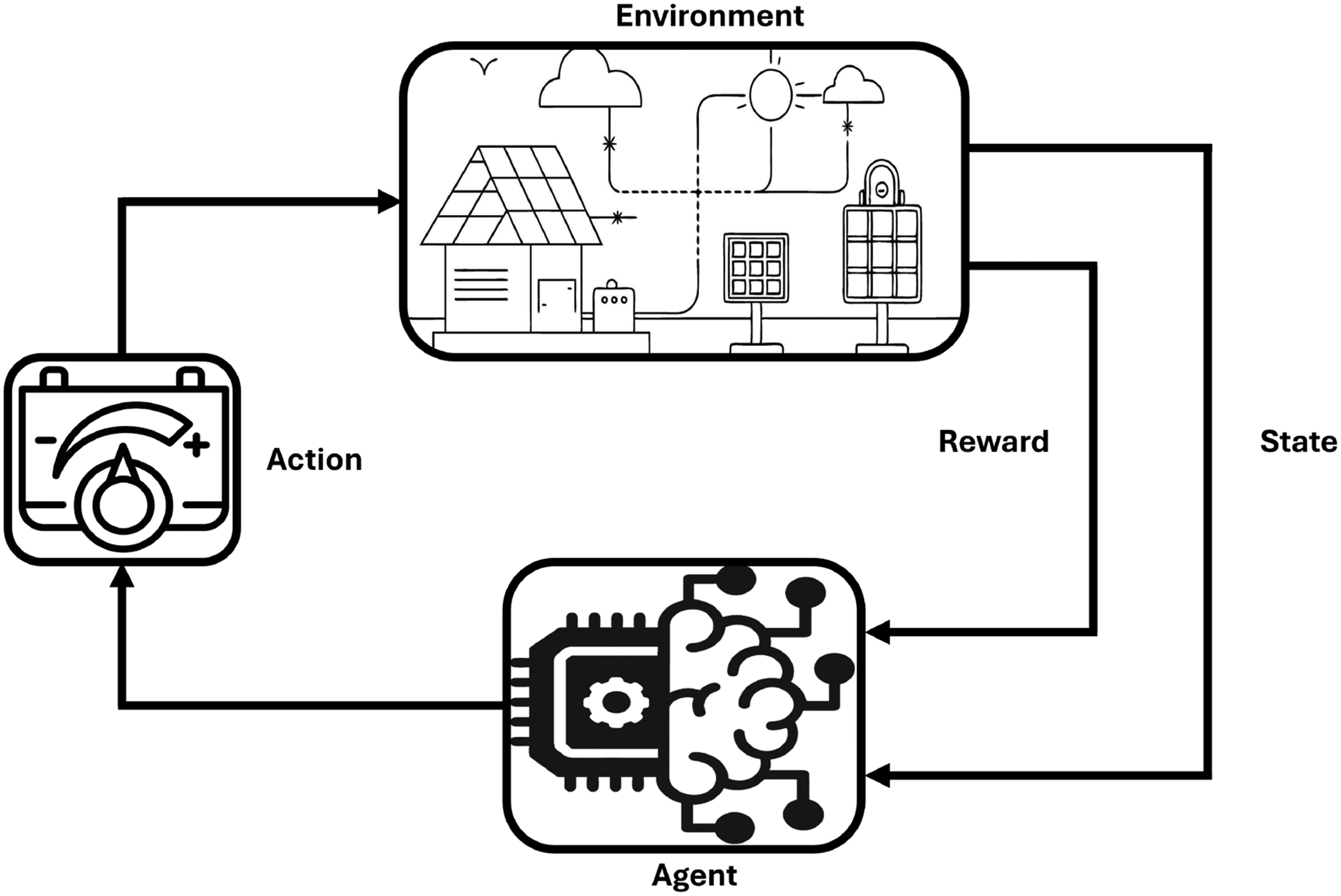
Reinforcement learning control framework for energy system.
In the proposed DR management system, the observable state
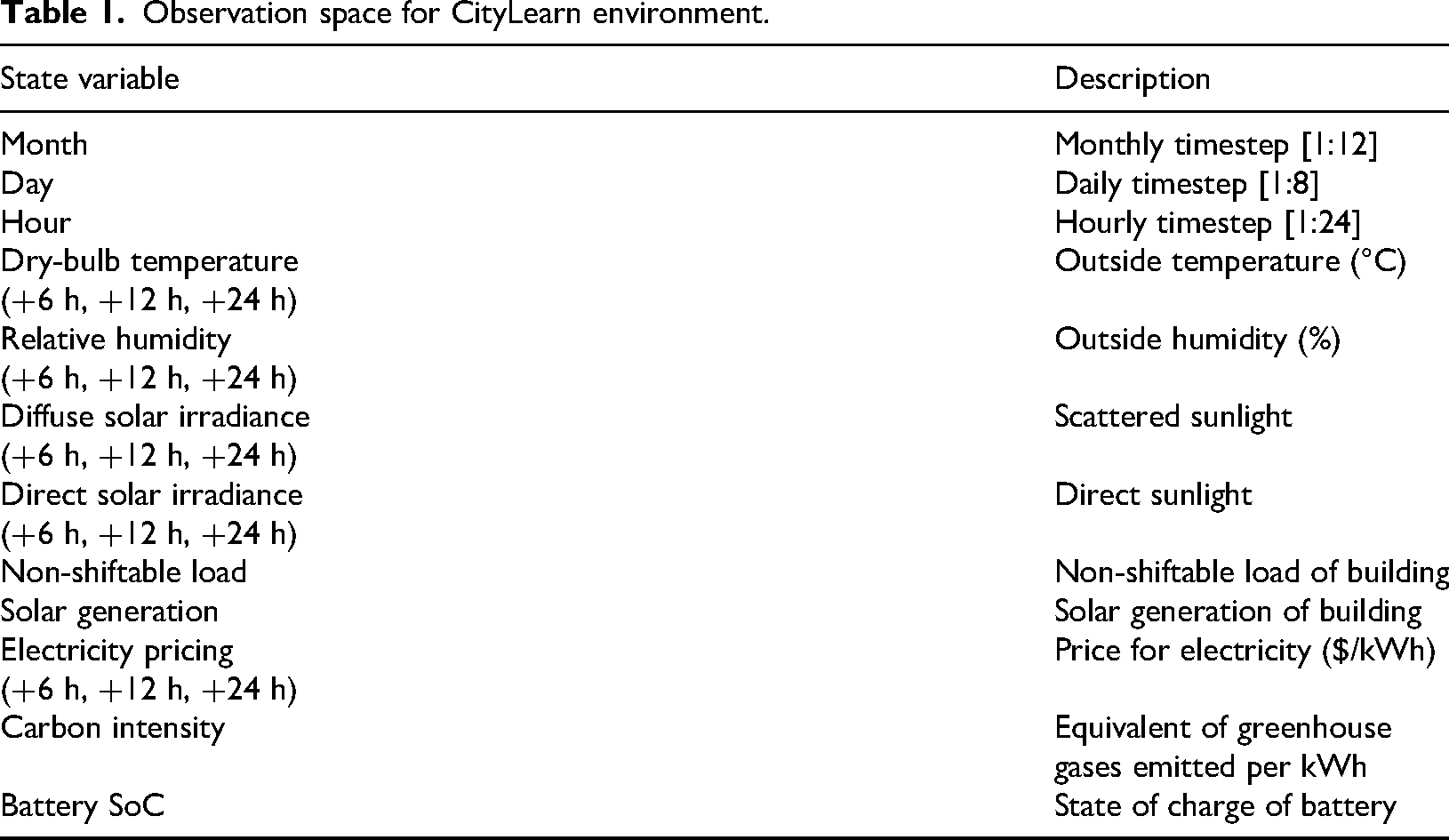
In terms of shared information, the state comprises weather-related variables and their future predictions for 6, 12, and 24-hour intervals. Other shared variables include dynamic electricity prices, carbon intensity emitted during electricity production, and time-related information such as the current hour, day, and month (Table 1). The action space
Observation space for CityLearn environment.
The reward function is designed to minimize electricity costs 

Soft actor-critic (SAC) algorithm with automated adjustment temperature
SAC-AAT is an extension of the SAC, which combines value-based methods, such as Q-learning, as critics with policy-based methods as actors and employs separate networks for the policy and value functions. SAC maximizes the reward while encouraging exploration using an entropy term. The objective function is: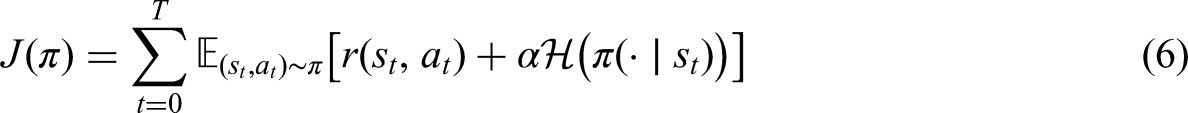


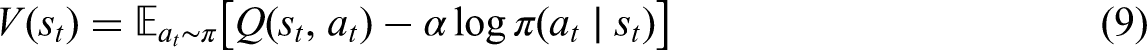
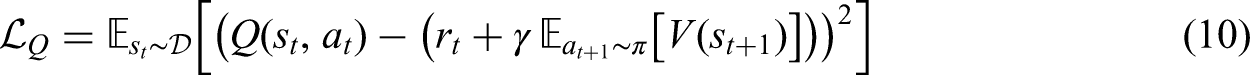
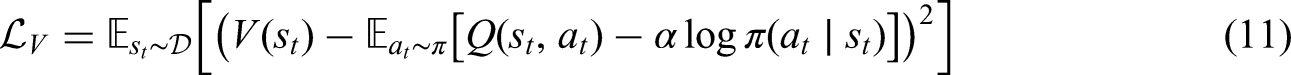
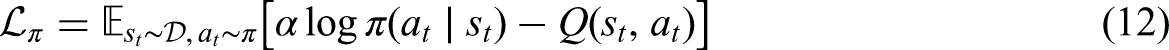
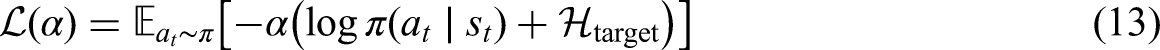

Training SAC-AAT Algorithm.

To ensure the policy maintains the desired level of stochasticity, 
Overall, SAC-AAT enhances SAC by enabling the agent to automatically adjust its level of exploration throughout training, which can lead to better performance without the need for manual tuning of the entropy parameter. The dynamic adjustment of exploration is particularly useful in environments where the optimal level of exploration changes as the agent learns.
SAC-AAT model for DR management
Figure 3 illustrates the system workflow of the SAC-AAT controller, aimed at optimizing energy management in smart buildings by adaptively controlling energy storage. The workflow begins with the environment, where agents interact with buildings. At each time step, for agent
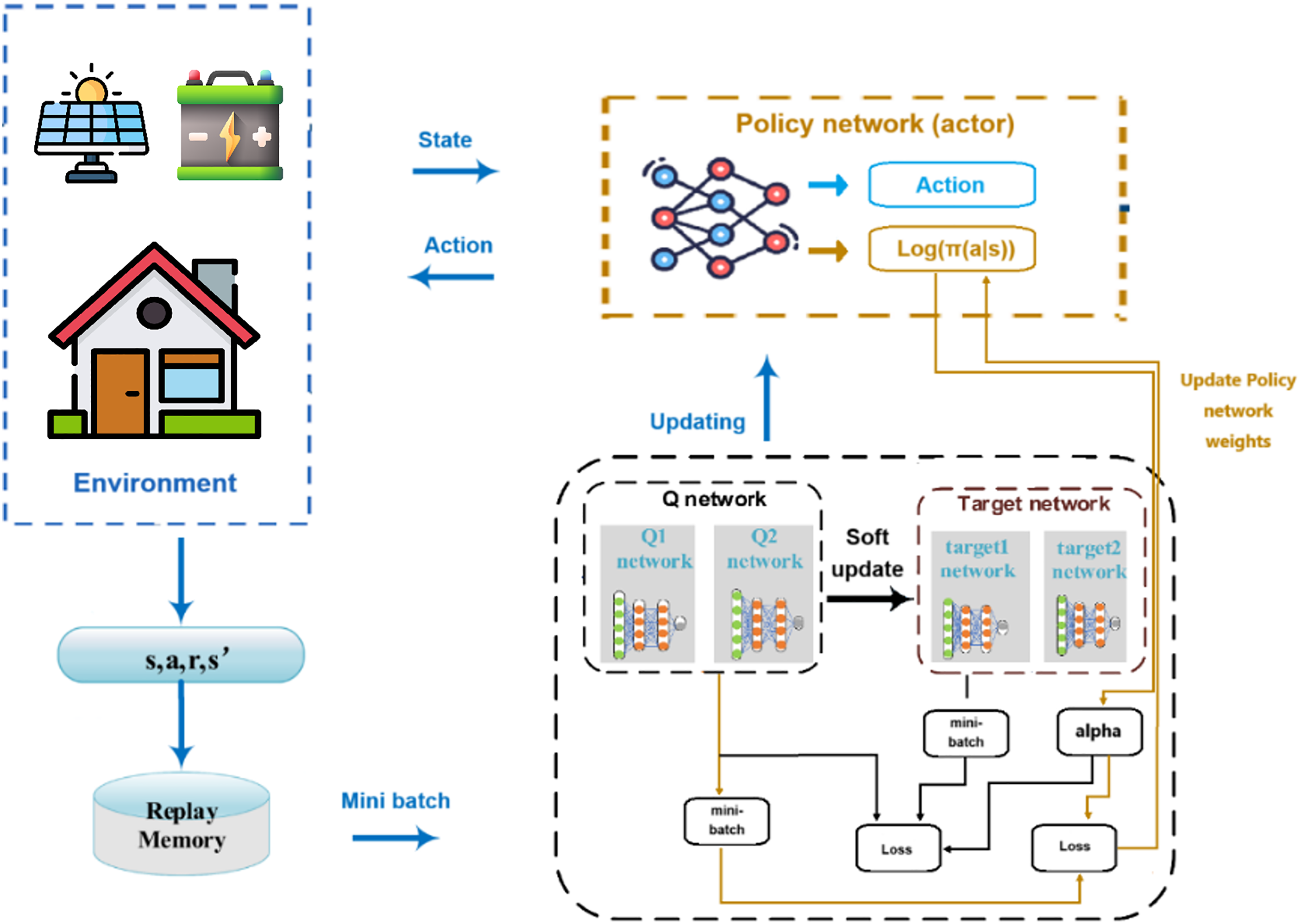
Soft actor-critic with automated adjustment of temperature (SAC-AAT) demand response management model.
The batteries are dynamically charged by storing excess solar energy when generation exceeds demand and discharge by supplying stored energy during peak demand or high-price periods. This adaptive battery control plays a crucial role in optimizing energy management. During peak periods, the system discharges batteries to reduce grid stress and flatten the demand curve. By using stored energy during high-price periods, it minimizes reliance on costly grid electricity. Additionally, batteries store solar energy for later use, reducing wastage and maximizing renewable energy utilization, all of which contribute to maintaining grid stability. Agents receive feedback in the form of rewards based on their performance in reducing energy costs, lowering carbon emissions, flattening demand peaks, and preserving battery health. These rewards guide the agents in refining their policies over time.
The system evaluates predicted energy flows for each building and executes decisions for battery operations in real-time. This dynamic approach not only reduces energy bills for users by leveraging low-cost energy during off-peak hours but also enhances comfort and reliability by ensuring that essential energy demands are always met. For the grid, the system lowers peak demand, reduces the need for costly infrastructure upgrades, enables smoother integration of RES, and improves overall resilience and stability.
Experiments and results
Dataset overview and simulation hyperparameters
This case study explores the development of a controller to manage battery systems in a random two-building setup, integrating DR signals into the control strategy to improve operational efficiency and flexibility. The data utilized in this research is derived from 17 zero net energy (ZNE) single-family homes located in the Sierra Crest ZNE community in Fontana, California. These buildings were part of a study on grid integration within zero net energy communities, conducted under the California Solar Initiative program. The dataset includes comprehensive information on energy demand, solar generation, weather, carbon emissions, and pricing data over the span of one year.
Figure 4 illustrates the energy demand and solar generation for one of the buildings over the course of a year. The data shows how peak demands and variations in renewable energy generation present challenges in balancing supply and demand, highlighting the potential benefits of incorporating battery storage to mitigate these fluctuations. Each timestep in the CityLearn environment corresponds to 1 h. This resolution is suitable for evaluating high-level BEM and demand response strategies. While shorter timesteps would introduce more fluctuations and may require different control architectures, the SAC-AAT controller is designed to operate effectively at the hourly level, as it aligns with the temporal granularity of energy pricing, solar generation patterns, and demand peaks.
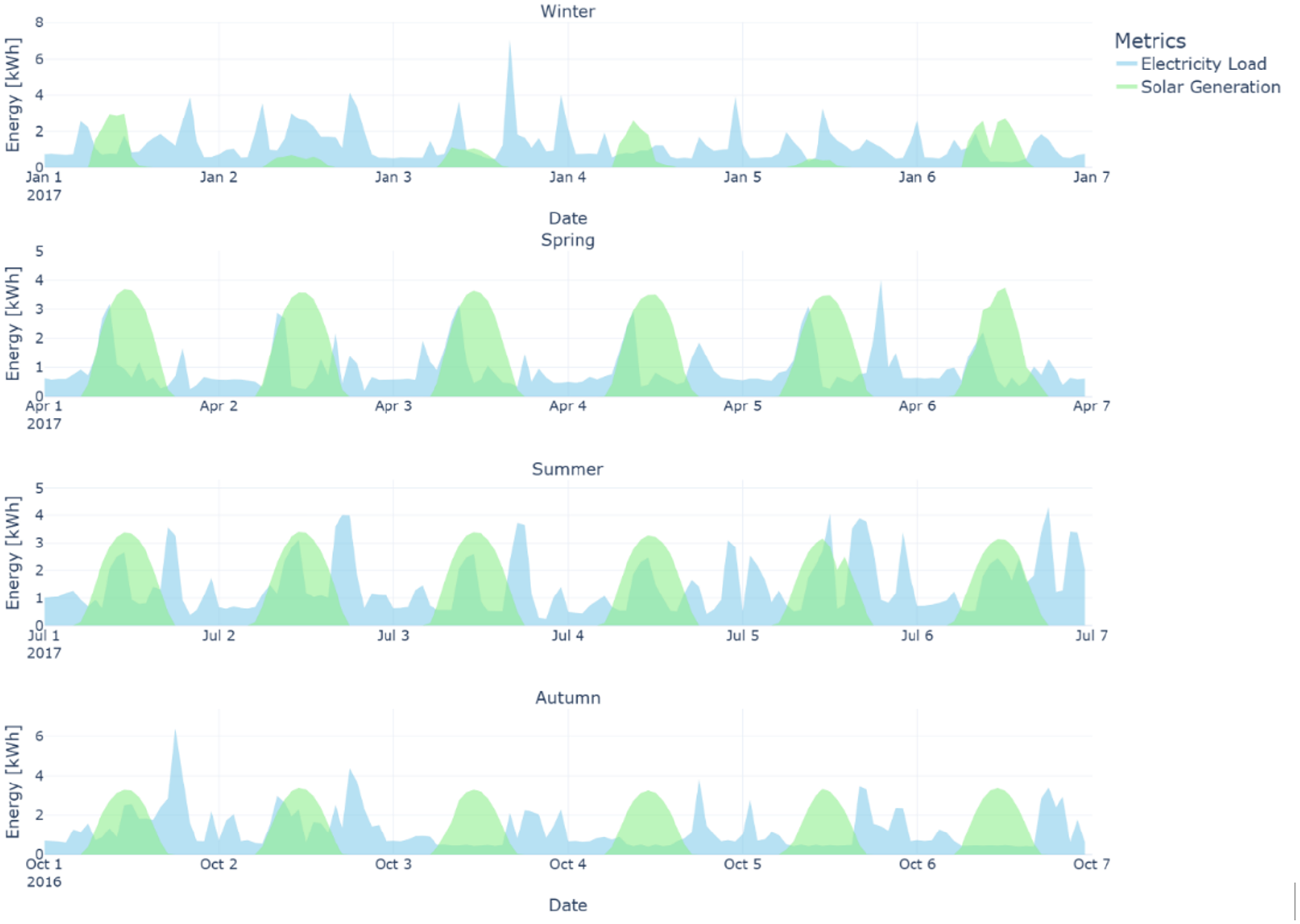
Energy patterns for a representative week in each season.
It is important to note that the CityLearn environment operates on an hourly time resolution. While this limits the ability to capture sub-hourly fluctuations or real-time battery dynamics, it is sufficient for evaluating high-level energy management strategies. The focus of this work is on optimizing long-term energy cost, emissions, and peak demand at the building and district level, rather than real-time control or power electronics behavior.
Multiple simulation runs are conducted to fine-tune the critical parameters for the case study, as the performance of DRL tends to decline when these parameters are altered. Table 2 details the chosen hyperparameters for the SAC-AAT model, aimed at optimizing performance and stability in a continuous control environment.
SAC-AAT-based controller hyperparameters.

SAC-AAT: soft actor-critic with automated adjustment of temperature; NN: neural network.
The discount factor influences the agent’s performance by determining how the agent prioritizes future rewards, thereby improving its learning efficiency. Choosing an appropriate learning rate is also crucial in DRL training. A learning rate that is too small may result in extensive training and the risk of the process getting stuck, while a learning rate that is too large can lead to suboptimal solutions or unstable training. Alpha
Benchmarking and evaluation
Rule-based controllers (RBC) and SAC-based control strategies were implemented to regulate the charging and discharging of electrical energy storage systems across buildings, aiming to minimize electricity costs and mitigate electrical load fluctuations during the considered DR events. The performance of these models is then compared against the SAC-AAT to demonstrate the proposed method’s effectiveness. The first RBC (baseline) optimizes the electrical load of the cluster without considering the participation of buildings in DR events throughout the simulation period. It operates without utilizing battery storage, with electricity demand being fully met by drawing power from the main grid. This baseline method serves as a reference to evaluate the benefits of incorporating energy storage systems and intelligent control strategies. In contrast, the second RBC was developed to meet the requirements of DR events. Unlike the baseline controller, it serves as a reliable benchmark for evaluating the performance of more advanced controllers based on the RL methods. It is a widely used control strategy in various systems, such as HVAC and batteries, due to its simplicity. It operates based on a set of rules expressed as
On the other hand, SAC is a model-free, off-policy reinforcement learning algorithm. Being an off-policy method, it allows for efficient experience reuse and learning with fewer samples, without the need for system modeling. It serves as the backbone for the development and functionality of SAC-AAT. While SAC focuses on maximizing a balance between reward and entropy for efficient exploration and stable learning in environments with continuous action spaces, SAC-AAT extends this framework by incorporating automatic adjustment mechanisms tailored for specific applications. The SAC-based controller is implemented as a decentralized controller. For the experimental settings, we ensure a consistent configuration is applied across all baseline methods as well as the proposed multi-agent actor-critic technique for DR in grid-responsive buildings. The hyperparameters used for the SAC agent are outlined in Table 3.
SAC-based controller hyperparameters.
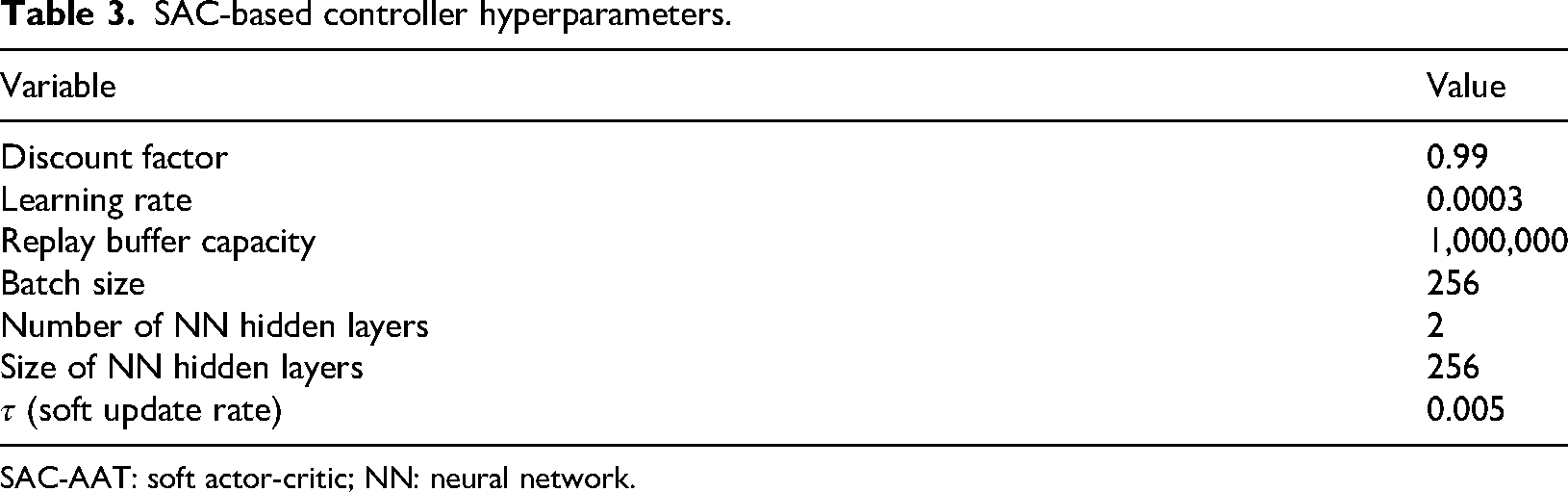
SAC-AAT: soft actor-critic; NN: neural network.
We evaluate the agents’ performance based on their ability to minimize five cost functions that quantify the energy flexibility of the entire district or individual buildings, including factors such as grid stability and the mitigation of fluctuations caused by RES.
Cost is calculated as the total expense for electricity imported by building 
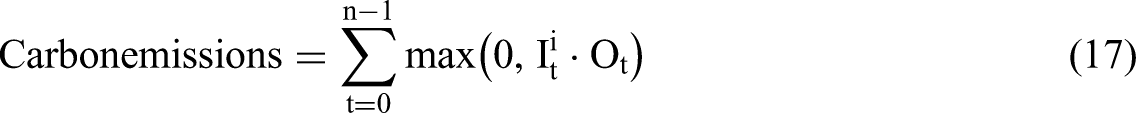

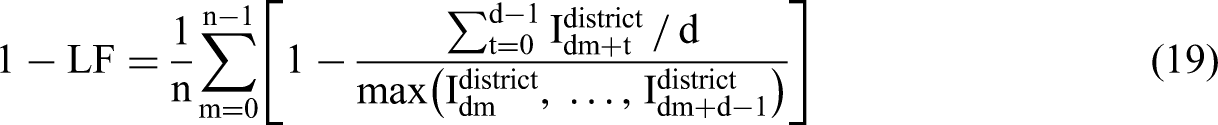

Results and analysis
The main task of the DRL controllers is to optimize energy management in a smart grid environment by dynamically controlling battery energy storage systems, ensuring the smoother integration of RES while maintaining grid stability. Table 4 illustrates the district-level performance of DR controllers across various cost functions during the simulation period. The cost metric represents the total electricity expenses incurred by operating the energy management system. It is a critical measure of economic efficiency, as it directly impacts the financial burden on households, businesses, and utilities. Lowering electricity costs benefits consumers by reducing utility bills and helps businesses achieve cost efficiency, thereby improving profitability. Simultaneously, minimizing emissions contributes to reducing the environmental footprint of energy systems. The SAC-AAT-based controllers achieve the lowest electricity costs. Furthermore, they exhibit the lowest emissions, average daily peak, and ramping over the simulation period, highlighting their effectiveness in load curve shaping and maintaining grid stability. The RBC model exhibits a high
Performance comparison of control strategies.

RBC: rule-based controllers; SAC: soft actor-critic; SAC-AAT: soft actor-critic with automated adjustment of temperature.
Figure 5 compares the performance of control methods (baseline, RBC, SAC, and SAC-AAT) in terms of cost and emissions for individual buildings. The proposed DR controllers achieved the lowest costs and emissions in both buildings. Thanks to its automated temperature adjustment mechanism, the SAC-AAT-based controller dynamically adapts to varying environmental conditions. On the other hand, the RBC achieves lower costs compared to SAC, highlighting its effectiveness in simple predefined scenarios. However, SAC-based controllers balance exploration and exploitation but lack tailored optimizations for specific conditions.
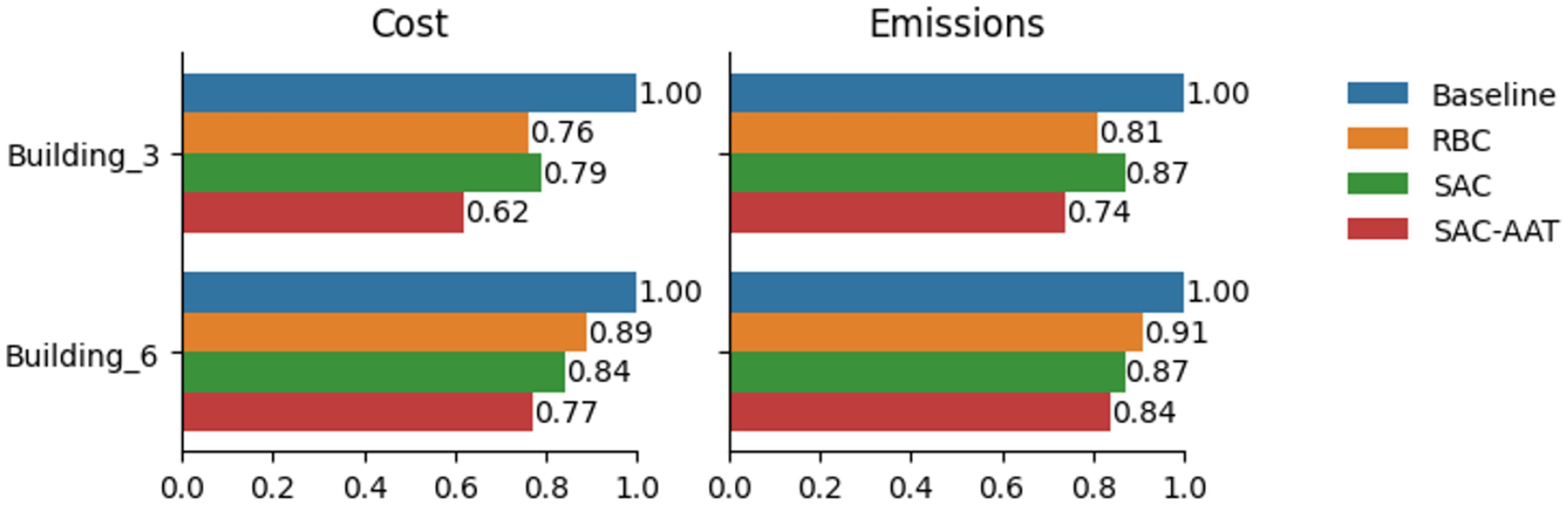
Cost and emissions for Buildings 3 and 6 under each control strategy.
Reducing fluctuations in energy demand is essential for ensuring grid stability, integrating RES, and lowering energy costs. Stable demand profiles minimize stress on the grid, reduce the risk of outages, and enable more efficient use of renewable energy, which is often intermittent. Figure 6 illustrates a comparison of different control strategies at the district level. Specifically, it highlights the impact of two control strategies—RBC and SAC-AAT—on load profiles, using the baseline as a reference. The aggregated load profile produced by the SAC-AAT controller is significantly more uniform than that of the RBC, indicating its superior ability to smooth demand and enhance grid reliability.
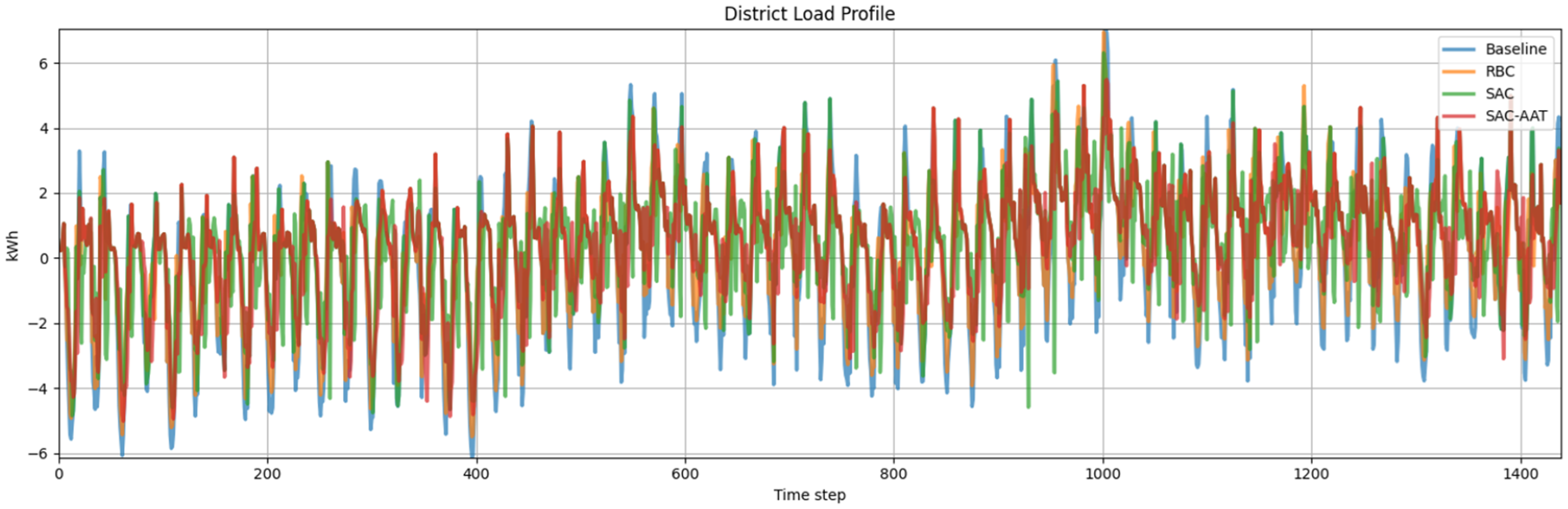
District energy demand under different control methods.
On the other hand, the analysis at a single building level (Figure 7) showed that SAC performs moderately well, reducing variability compared to RBC in Building 6. This highlights that RBC relies on static, predefined rules and lacks the ability to adapt to dynamic changes in the environment.
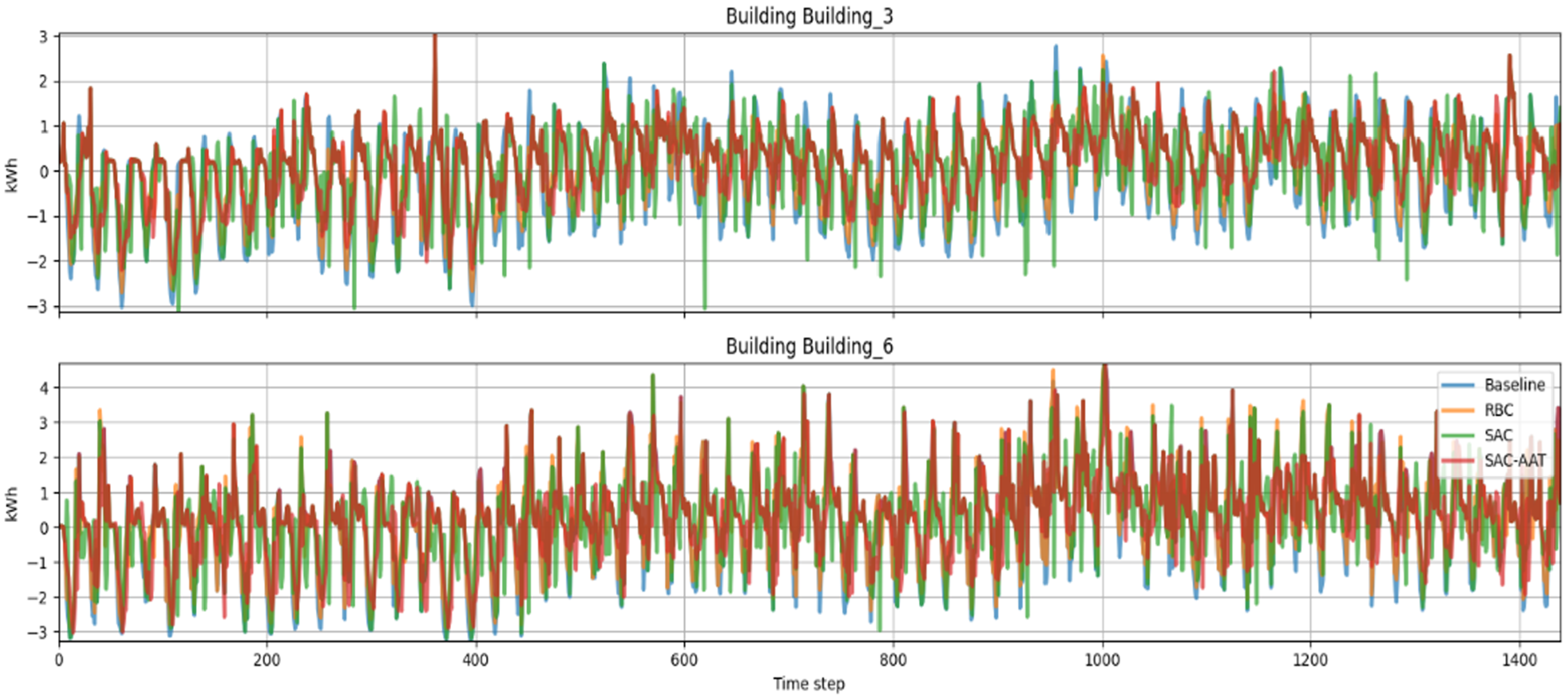
Energy demand profiles for Buildings 3 and 6.
Average daily building loads further validate the above statements (Figure 8). With the SAC-AAT controller, the load curves exhibit smaller fluctuations and tend to follow a more stable consumption pattern.
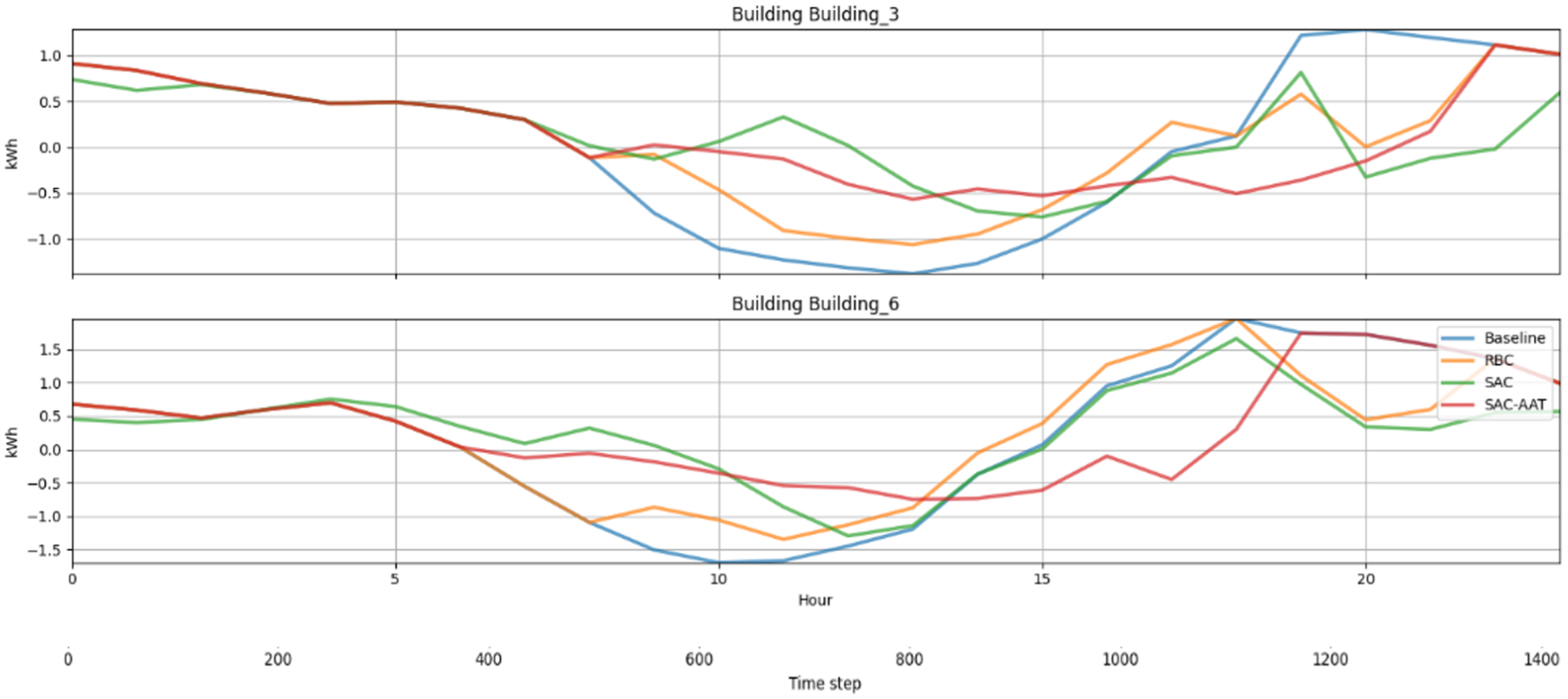
Average daily energy demand in Buildings 3 and 6.
Lastly, Figure 9 illustrates the episodic rewards across 25 episodes, comparing the performance of various control models. Here, each episode corresponds to a full simulation year consisting of 8760 hourly timesteps. The reward serves as a metric for evaluating how well the RL agent is achieving its objective and provides feedback to the agent about the effectiveness of its actions in each state.
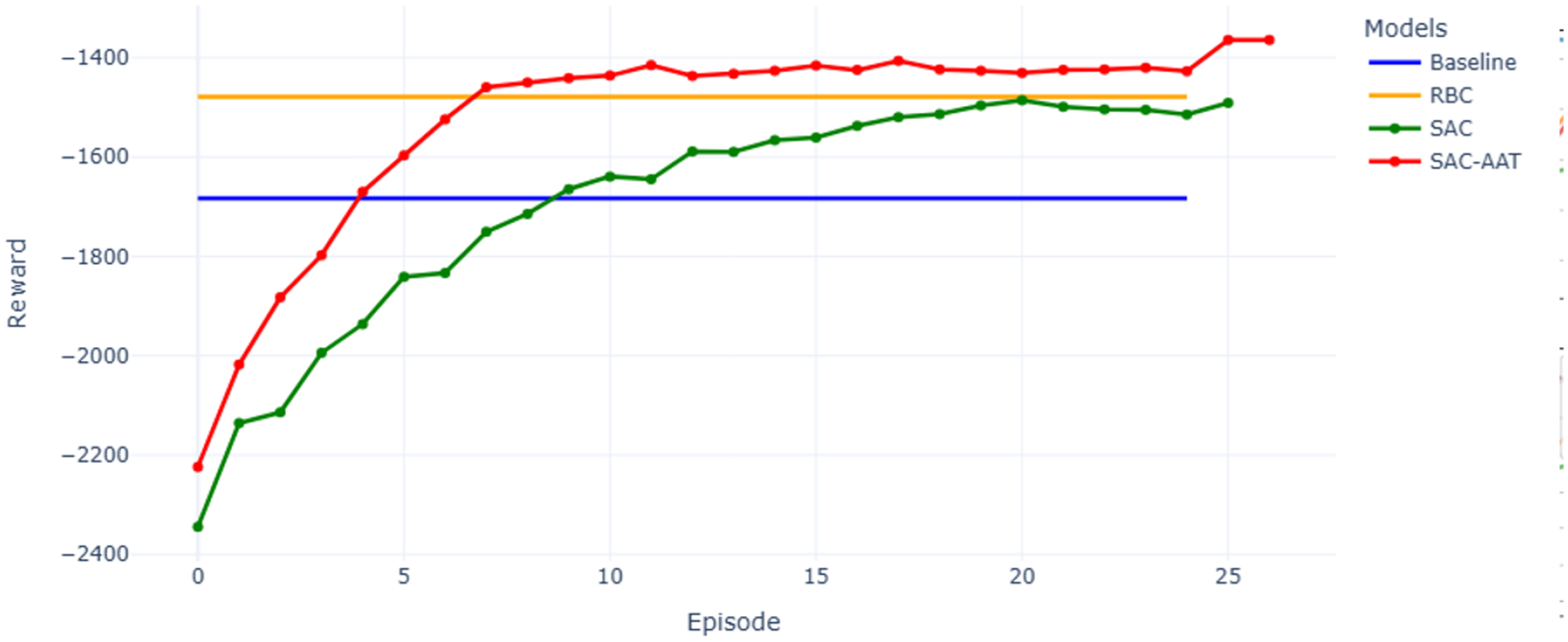
The evolution of episodic cumulative rewards for control methods.
The baseline and RBC models display constant reward values across episodes, as they use fixed, non-learning strategies. RBC initially outperforms baseline, reflecting its rule-based optimization. In contrast, the SAC and SAC-AAT models learn over time. Each episode corresponds to one full simulation year. In the early episodes, RBC achieves better rewards than SAC due to SAC’s exploration phase. However, SAC-AAT exhibits a faster and more stable learning curve, surpassing the Baseline by episode 4 and RBC by episode 7. The faster convergence and higher final reward of SAC-AAT indicate more effective and adaptive energy management, resulting in lower operational costs and improved performance over time. This trend confirms that reinforcement learning models, particularly SAC-AAT, improve with experience and outperform static strategies in long-term deployments.
Discussion and future work
While the proposed SAC-AAT controller demonstrates strong performance in simulated scenarios, several limitations must be acknowledged. Initially, the model has only been validated within the CityLearn simulation environment, utilizing set building data and hourly time intervals. While CityLearn offers a standardized and useful platform for evaluation, it is unable to completely mirror the intricate realities of building-level controls, occupant behavior, or limitations imposed by grid infrastructure. While SAC-AAT includes an automatic adjustment of the temperature parameter to enhance exploration, the technique still requires significant training and hyperparameter optimization. This leads to computational demands that could pose difficulties for systems with limited resources or applications that require real-time performance. Furthermore, the model is based on the assumption that input data is accurate and continuously available, which might not always be the case in real-world scenarios.
Although there are some constraints, the suggested SAC-AAT framework presents encouraging opportunities for practical use in smart grid and BEM systems. By adjusting in real-time to fluctuations in energy prices, demand trends, and renewable generation, SAC-AAT can assist utilities and building managers in minimizing operational expenses and enhancing the self-consumption of renewable energy. In the context of smart buildings, the integration of SAC-AAT into energy management systems could improve comfort, ensure demand fulfillment, and reduce emissions. The algorithm’s compatibility with continuous control tasks makes it suitable for integration with Internet of Things platforms and BMSs. From an economic perspective, reduced electricity bills and improved renewable energy utilization offer strong incentives for adoption. Future research will investigate how to adapt the SAC-AAT controller for different types of buildings and more detailed time intervals. Furthermore, integrating SAC-AAT with other advanced reinforcement learning methods, like attention-driven coordination in multi-agent frameworks or hybrid model-based approaches, could improve its scalability and resilience.
Conclusion
In this study, we explored the SAC-AAT control strategy for DR management in a district-level energy system, comparing the performance against baseline, rule-based and SAC controllers. The results demonstrated that RL models, particularly those enhanced with attention mechanisms, can significantly improve energy demand management, enabling smoother load profiles, reduced peak demand, and minimized emissions. The proposed model, incorporating an attention-inspired mechanism, consistently outperformed all baseline models in terms of cumulative reward, energy cost, and emissions reduction. By adaptively focusing on high-demand periods, the SAC-AAT controller demonstrated improved responsiveness to dynamic energy conditions, enabling more precise and stable demand management. The baseline and RBC models exhibited limited adaptability, with static or rule-based strategies that failed to respond effectively to fluctuations in energy demand. While the RBC approach outperformed baseline by employing a set of predefined rules, its inability to adapt dynamically led to frequent demand peaks and suboptimal utilization in complex environments. Future work could explore additional improvements, such as incorporating more complex DR strategies or extending the model to larger, more diverse building clusters. Overall, this study underscores the value of advanced RL techniques in achieving sustainable and resilient energy management solutions.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Technology Development Program (RS-2025-02312851) funded by the Ministry of SMEs and Startups (MSS, Korea).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.