
Abstract
Identifying subsurface resource analogs from mature subsurface datasets is vital for developing new prospects due to often initial limited or absent information. Traditional methods for selecting these analogs, executed by domain experts, face challenges due to subsurface dataset's high complexity, noise, and dimensionality. This article aims to simplify this process by introducing an objective geostatistics-based machine learning workflow for analog selection.
Our innovative workflow offers a systematic and unbiased solution, incorporating a new dissimilarity metric and scoring metrics, group consistency, and pairwise similarity scores. These elements effectively account for spatial and multivariate data relationships, measuring similarities within and between groups in reduced dimensional spaces. Our workflow begins with multidimensional scaling from inferential machine learning, utilizing our dissimilarity metric to obtain data representations in a reduced dimensional space. Following this, density-based spatial clustering of applications with noise identifies analog clusters and spatial analogs in the reduced space. Then, our scoring metrics assist in quantifying and identifying analogous data samples, while providing useful diagnostics for resource exploration.
We demonstrate the efficacy of this workflow with wells from the Duvernay Formation and a test scenario incorporating various well types common in unconventional reservoirs, including infill, outlier, sparse, and centered wells. Through this application, we successfully identified and grouped analog clusters of test well samples based on geological properties and cumulative gas production, showcasing the potential of our proposed workflow for practical use in the field.
Introduction
Analog selection is one of the most arduous tasks related to subsurface resource modeling, essential for groundwater, mineral mining, and hydrocarbon extraction. This is because subsurface datasets are generally highly dimensional (include many features), sampled from complicated heterogeneous and nonstationary phenomenon, and often with biased and extremely sparse sample coverage, combined with the imposition of physics, engineering, and geological constraints (Pyrcz and Deutsch, 2014; Tan et al., 2014). Analogs are comparable scale-dependent systems with similar characteristics and properties to support less well-constrained study intervals. Analog datasets for subsurface resource models include well cores and logs, drill holes cores, drill cuttings, seismic and other forms of remotes sensing and production such as fluid flow rates and run-of-mine mineral grades (Howell et al., 2014; Gravey et al., 2019; Bouayad et al., 2020; Prior et al., 2021). The similarity between these systems is predicated on predefined geological and engineering exploitation attributes. Information types extracted from subsurface resource analogs are the prediction of reservoir univariate, multivariance, and spatial distributions, for example, petrophysical features (e.g., permeability, porosity, and fluid saturations), geological features (depositional style, alteration style, sediment provenance, and structural framework). Thus, subsurface resource analog selection, the choice of what analog to use across various scales and study intervals, is important to constrain subsurface resource model input univariate, multivariate, and spatial distributions. Although there are numerous uses of analogs in the subsurface, a couple prominent ones are the use of production data from existing wells as analogs for future wells to generate a type-curve for well hydrocarbon production over time during prospect evaluation and field estimation (Sidle and Lee, 2010; Rodríguez et al., 2014; Sun and Pollitt, 2022), and mining mineral deposit analogs help identify new prospecting targets (Prior et al., 2021). Accurate subsurface resource analog selection is crucial because an inappropriate analog can lead to erroneous information to populate models and become a source of imprecise and inaccurate subsurface uncertainty model predictions.
Decision making for subsurface resource development is supported by subsurface models constructed by an interdisciplinary team of engineers, geologists, and geophysicists that analyze and integrate all available data types. Poor development decisions result in, for example, drilled oil, gas, and water dry holes, the need for additional wells, and waste rock being sent to the mill. Subsurface resource modeling is characterized by features with multiple nonstationary populations that account for the subsurface system's spatial settings. That is, a multivariate, spatiotemporal model based on high-dimensional spatial data. Subsurface datasets are specific examples of big data, given their characterization by data volume, feature variety, sampling velocity, and data veracity (Mohammadpoor and Torabi, 2020). Subsurface data types are from various sources, with their own coverage and scale, and are typically sparsely sampled, uncertain, and incomplete. Usually, when we have a dataset with one or two predictor features (model inputs) and response features (model outputs) to perform inferential analysis that supports predictive modeling, the conventional approach is to apply multivariate analyses or modeling to achieve this objective.
We propose an innovative geostatistics and machine learning-based analog identification workflow that integrates the subsurface dataset's multidimensional predictor feature and spatial location information. The proposed workflow computes the input dissimilarity matrix using a novel combined spatially modified Euclidean and Mahalanobis distance measure to obtain a space of lower dimensionality (LD) via metric multidimensional scaling (MDS) to mitigate the curse of dimensionality while improving interpretability while adaptively integrating spatial and multivariate information. To address the issue of multiple nonstationary populations and repeatability, kriging of the features and clustering analysis is performed using DBSCAN to identify subgroups in the LD space to maximize information extraction. Lastly, for inferential statistical analysis in the LD space, we introduce new metrics, group consistency score (GCS), and pairwise similarity scores (PSS) for ranking and interpretation purposes. Our proposed workflow addresses the subsurface's multivariate spatial problem of analog selection by providing a robust and generalizable framework for spatial analog identification to support inferential analyses and decision making in highly dimensional datasets.
The background section comprehensively accounts for previous work and linkages on high-dimensional data, data science, and geostatistical concepts. The methodology section details the computation of spatial, multivariate dissimilarity metric with spatial weights for MDS dimensionality reduction, cluster analysis in the reduced dimensionality space via DBSCAN, and mapping in low-dimensional space with ordinary kriging. Furthermore, the section delineates the identification of subsurface resource analogs coupled with GCS and PSS rankings. The results and discussion section describes the oil and gas datasets in high- and low-dimensional spaces, limitations, and the considerations of our proposed workflow. Lastly, we explore the accuracy and validity of the proposed subsurface analog resource workflow concerning well types commonly found and drilled in unconventional reservoirs.
Background
Challenges of high-dimensional data
As the number of predictor features increases, there are new challenges related to working in high-dimensional space, known as the curse of dimensionality. The curse of dimensionality makes it difficult to train and build machine learning models and to find analogs in the subsurface due to challenged data visualization, distance concentration, sparse data sampling and coverage, and feature multicollinearity. Visualization refers to performing an ocular inspection of data and models, such as checking for data outliers, distribution modes, and local model prediction bias. Visualization beyond three dimensions requires significant projection and is quite limited. Distance concentration is the loss in sensitivity in distance measures, often stated as a distance-based loss. This is mathematically described as the distance variances between randomly selected data pairs. It follows that the difference between the maximum and minimum data pair distances goes to
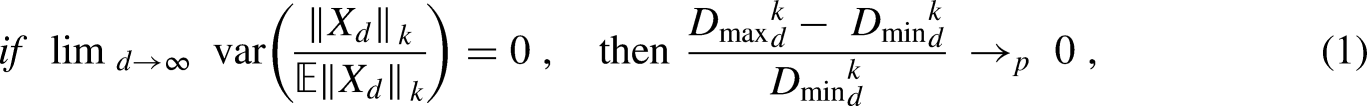
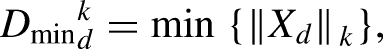
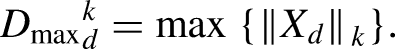
Data sparsity refers to the coverage and sampling limitations in high-dimensional space. Coverage suggests that if the data samples cover
On account of the curse of dimensionality, analog selection quality may be reduced, resulting in subsurface model inference and prediction error, and suboptimal decision making. Due to its direct monetary implication, representative information extraction from analog workflows is critical during subsurface resource exploitation planning and development. Goode (2002) demonstrated that the lack of a robust and generalizable framework or methodology for accurately obtaining reliable information during inferential analysis costs the petroleum industry approximately
Appropriately using subsurface resource analogs is critical during resource evaluation and reserve estimation (Hodgin and Harrell, 2006; Sidle and Lee, 2010). Despite being an important component, most assessments are made qualitatively, relying exclusively on human expertise, experience, and limited statistical approaches. As a result, analog workflows are subjective, lack reproducibility, and inhibit the establishment of robust best practices. Many attempts have been made over the years to develop quantitative analog methods for either hydrocarbon wells or reservoirs using a variety of reservoir and geological features. For example, close-ology, a scale-dependent strategy used for play evaluation and field development options that employ the qualities and attributes of adjacent wells, reservoirs, or field data as a viable substitute (Cook, 2009; Sun and Wan, 2002). When information is minimal for a drill site, close-ology is often implemented. However, this omits important heterogeneity, spatial continuity, nonstationary trends and regions, domain expertise, and secondary information.
Heterogeneity is the variation quality in petrophysical rock features such as permeability with location. For oil, gas, or water reservoir characterization, heterogeneity specifically applies to variability that affects flow through the porous rock matrix. For subsurface resource modeling, heterogeneity measures are commonly applied to identify analogs. That is, reservoirs with similar heterogeneity metrics should flow similarly (Reese, 1996; Jensen et al., 2000; Fitch et al., 2015). Prevalent examples of such heterogeneity measures in the subsurface are the coefficient of variation of permeability, Dykstra-Parsons, and Lorenz coefficients (Lorenz, 1905; Dykstra and Parsons, 1950; Jensen et al., 2000). However, the heterogeneity estimates from these methods disregard the spatial organization of the feature under consideration and are restricted to univariate analysis only (Jensen et al., 2000; Fitch et al., 2015).
Data science
Dromgoole and Speers (1997) pioneered efforts to describe reservoir analogs and complexity for North Sea fields using a field scoring method. This is based on geological complexity and descriptive reservoir features based on high-level interpretations. Bygdevoll (2007) presented a more structured approach, the reservoir complexity index, which assigns analog parameters based on objective parameters and subjective judgment. Data science methods may apply a more general quantitative score based on distance-based dissimilarity, which defines the dissimilarity between pairs of samples through a distance metric. A distance metric exists if it satisfies the conditions of symmetry equation (2), non-negativity equation (3), identification equation (4), definiteness equation (5), and triangle inequality equation (6). For any points (samples in our case),




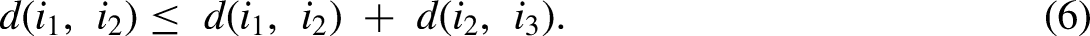
There are various methods for nonlinear dimensionality reduction, such as t-distributed stochastic neighborhood embedding (t-SNE) by van der Maaten and Hinton (2008), uniform manifold approximation and projection (UMAP) by McInnes et al. (2018), and MDS by Torgerson (1952). Although UMAP and t-SNE have been found to outperform MDS as they preserve more of the local structure within the data, both methods do not perform well with sparse and incomplete data (Wang et al., 2021). In addition, Scheidt and Caers (2009) demonstrate that MDS, as a dimensionality reduction method, retains the data's intrinsic structure. Further, Tan et al. (2014) showed that MDS could quantify an uncertainty space.
MDS is a nonlinear dimensionality reduction technique that preserves the measure of dissimilarity between pairs of data points by projecting multidimensional data into a lower dimensional space (Kruskal, 1964; Cox and Cox, 2008). Several variations include nonmetric MDS, which uses an iterative approach applicable to ordinal data, and metric MDS, a nonlinear dimensionality reduction method for multivariate datasets that relies on the Euclidean distance function, dissimilarity metrics, or L2 norm. Assuming a distance matrix,
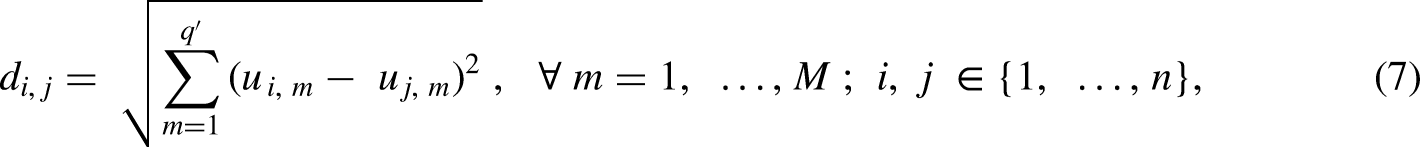
Cluster analysis is a powerful inferential machine learning method for finding groups in datasets for analog selection. A challenge with common clustering algorithms for cluster analysis, such as k-means clustering, is the predetermination of the number of clusters and other assumptions, such as equal group frequency and convex, spherical groups (Olukoga and Feng, 2022). Density-based spatial clustering of applications with noise (DBSCAN) offers a clustering method without predetermining the number of clusters and the ability to model unequal group frequencies and nonconvex groups (Ester et al., 1996; Schubert et al., 2017). DBSCAN is a hierarchical, bottom-up, agglomerative clustering method that grows clusters over connected patterns using a maximal set of density-connected points. Where sufficient density to form a cluster is defined as having a minimal number of samples within the local neighborhood, which is represented by the model hyperparameters radius,
Geostatistics
Due to subsurface data sparsity, geostatistical concepts are important pre-requisites to understanding subsurface resource analog selection concerning spatial prediction and modeling, that is, spatial continuity modeling with variograms and kriging for spatial estimates with uncertainty. Stationarity is a scale-dependent decision that implies the metric of interest is invariant under translation over a spatial interval. The variogram is a two-point spatial statistic that describes a spatial dataset's degree of spatial variability for any lag vector, direction, and distance, along with an indicator of the maximum distance with spatial dependency, known as the variogram range. Variogram-based modeling is the process of fitting a continuous function to an experimental variogram; therefore, through the integration of spatial structures such as geometric anisotropy, nugget effect, and nonstationary trend, variogram-based modeling quantifies spatial correlation to form predictions to augment sparsely sampled spatial models. Under the assumption of mean, variance, and variogram stationarity, a variogram is defined as
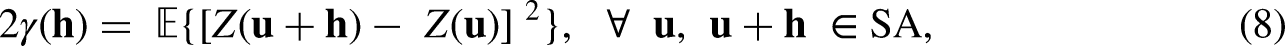
The relationship between stationary covariance,

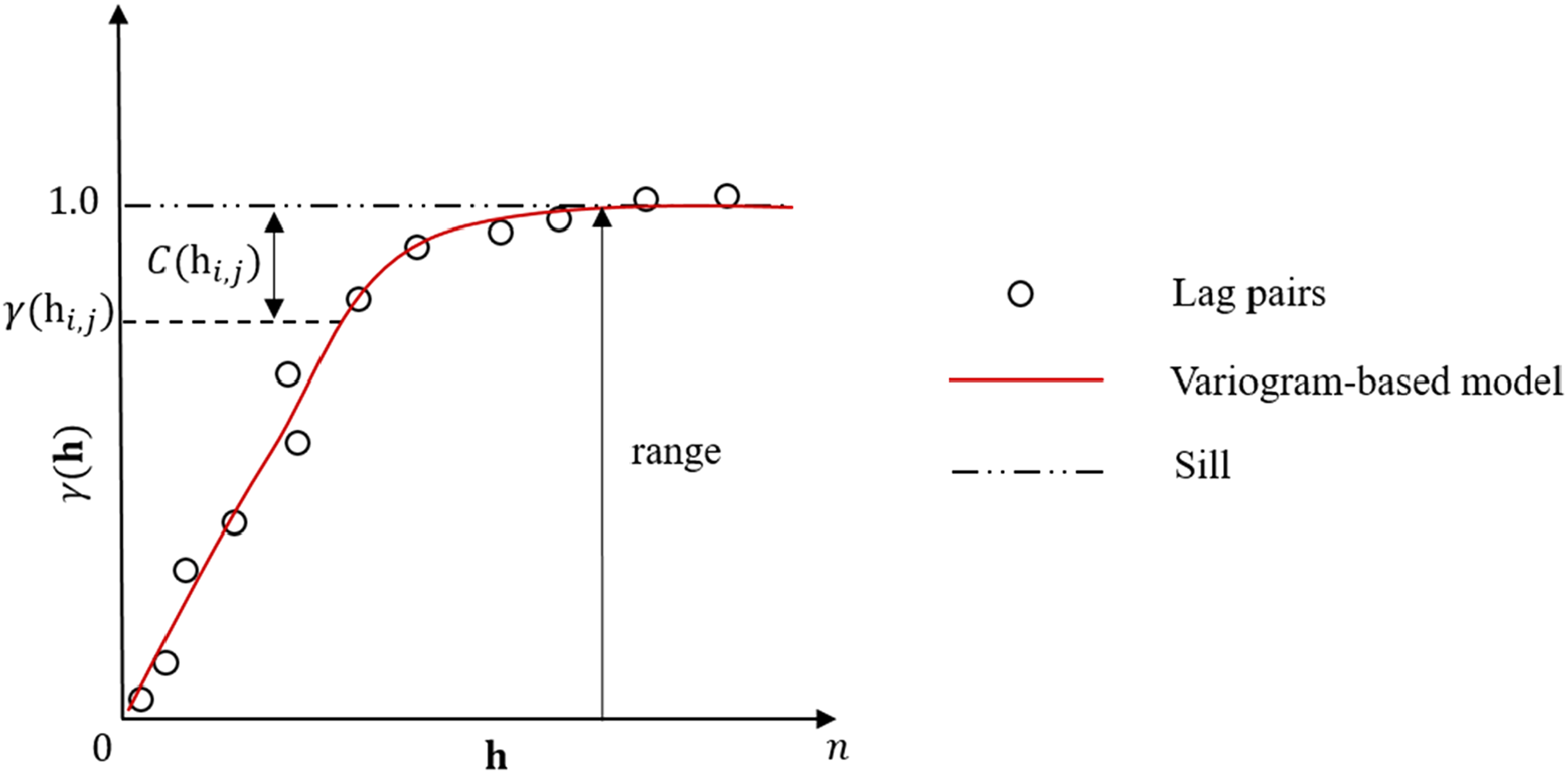
Semivariogram schematic for the normal standardized scores of the feature of interest,
Kriging is a spatial statistical method for estimating a feature at an unsampled location using available data in the study area and the inferred variogram modeling (Krige, 1951; Matheron, 1962). The kriging methods, for example, simple kriging, ordinary kriging, and universal kriging, are differentiated by their associated decision of stationarity. Ordinary kriging is commonly applied for spatial interpolation and prediction problems in the subsurface due to the flexibility to estimate with a nonstationary mean (Khazaz et al., 2015) and is an unbiased spatial estimator because the data weights add up to one and constrain the estimator while minimizing error variance (Matheron, 1962; Journel and Huijbregts, 1976; Pyrcz and Deutsch, 2014).
Methodology
Our proposed subsurface resource, spatial multivariate analog identification workflow, includes the following steps:
Calculate and model the variogram of the standardized feature of interest, Determine the spatial weights from the standardized response feature. Compute the dissimilarity matrix input, Perform metric MDS on Determine the variogram model and kriged estimates for the response in Euclidean space. Perform ordinary kriging on each feature of interest, Z, in the LD space. Create a trend map for all predictor features based on the kriging estimates in step (6). Perform cluster analysis via DBSCAN in the LD space to identify analog clusters. Identify the centroid of each analog cluster and assign it as a spatial analog in the LD space. Finalize the workflow and evaluate the proposed ranking and interpretation metrics, GCS and PSS, for data samples in the LD space.
The first step of our proposed workflow for subsurface resource analog identification is to calculate and model the variogram to obtain
Next, the novel dissimilarity metric is calculated that applies the variogram to adaptively weight the spatial and multivariate feature contributions into the dissimilarity matrix,

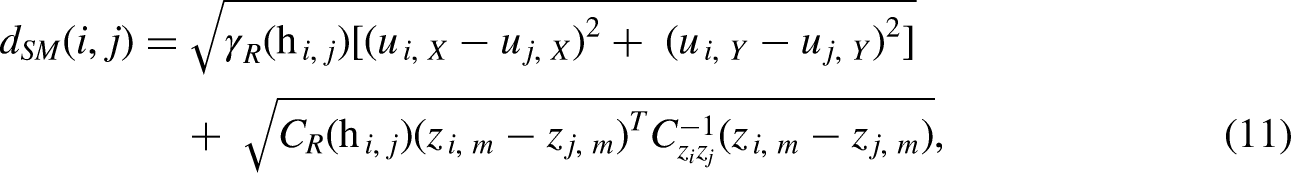
Modifying the work of de Leeuw and Pruzansky (1978) on weighted Euclidean distance, we propose the novel use of the response features’ semivariogram as the weight to account for spatial contributions applicable only to the location vector,
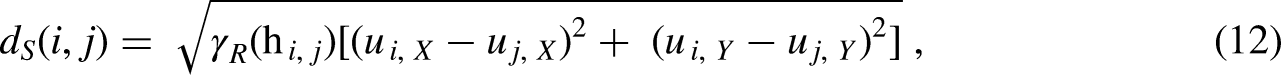
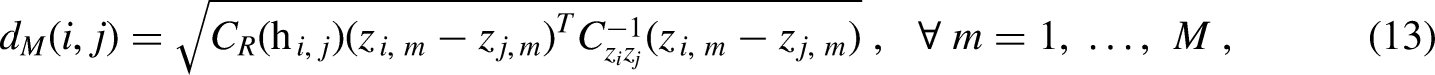
Equation (11) shows that the proposed spatial multivariate dissimilarity metric has two end-member cases that result in scenarios where either the spatial dissimilarity metric or multivariate dissimilarity metric suffices for the dissimilarity matrix,
Next, ordinary kriging is performed on each Z, that is, all predictors and the response features in the LD space to obtain their respective kriged estimates,
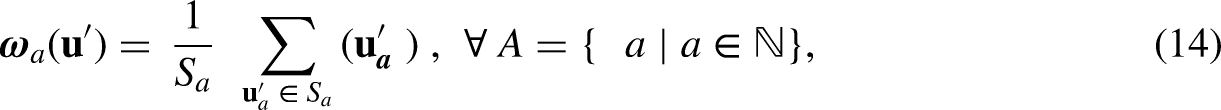
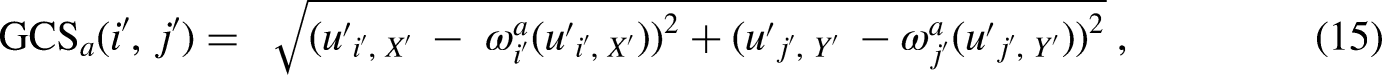
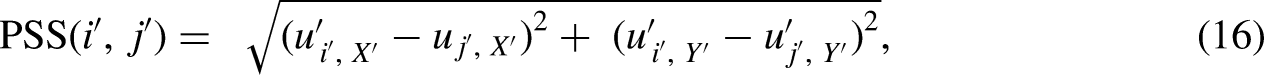
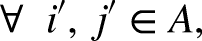
Lastly, to enhance the clarity of the proposed workflow, a roadmap of the major steps involved is shown in Figure 2 using spatial datasets, which may be geological or geophysical data as input. However, note that standardization is needed when using quantitative predictors, and dummy coding is imperative with qualitative predictors in this workflow.
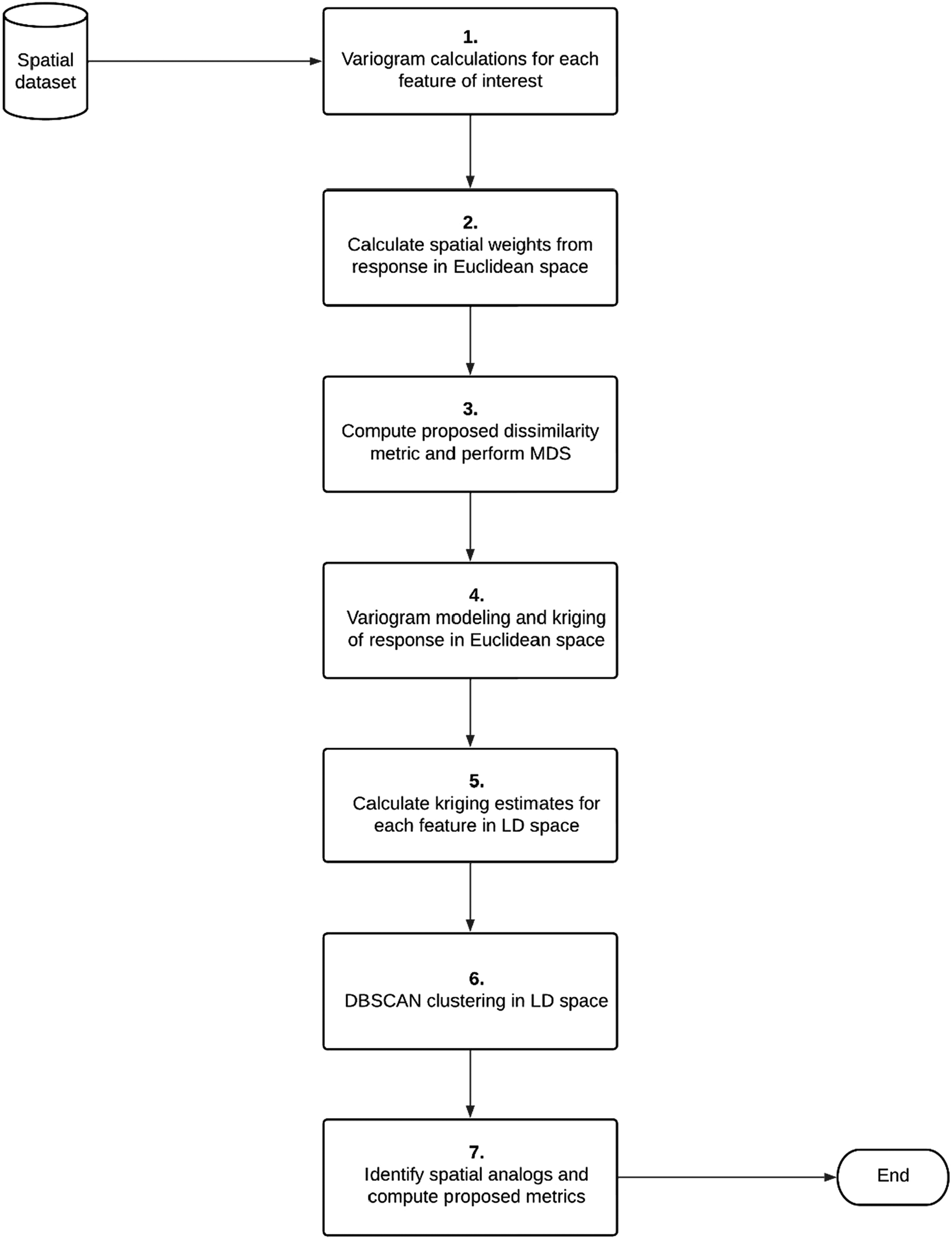
Our proposed geostatistics-based machine learning workflow for spatial multivariate analog identification of subsurface resources.
Results and discussion
Our proposed workflow is demonstrated for two applications in an oil and gas dataset from the South Kaybob field in the Duvernay Formation. The Duvernay Formation was deposited in a subequatorial epicontinental seaway in the late Devonian–Frasnian time, corresponding to the maximum transgression of the late Devonian Sea into the Western Canadian craton (Figure 3). There exists a series of sub-basins deposits of shale from west to east because of the paleo-lows that include shale in a basin and slope environment. Moreover, mineralogy changes in the west-to-east direction; for instance, the contents of silica and quartz are larger in the west than in the east region. On the contrary, the east region contains larger carbonate and clay content. The formation produces across the entire gas, condensate, and oil windows between 2000 and 3700 m depth. Finally, the predominant hydrocarbon production comes from the western shale basin, specifically from the Kaybob region (Salazar et al., 2023). The first application is an introduction that analyzes a subsurface dataset curated after feature selection and has a sample size of
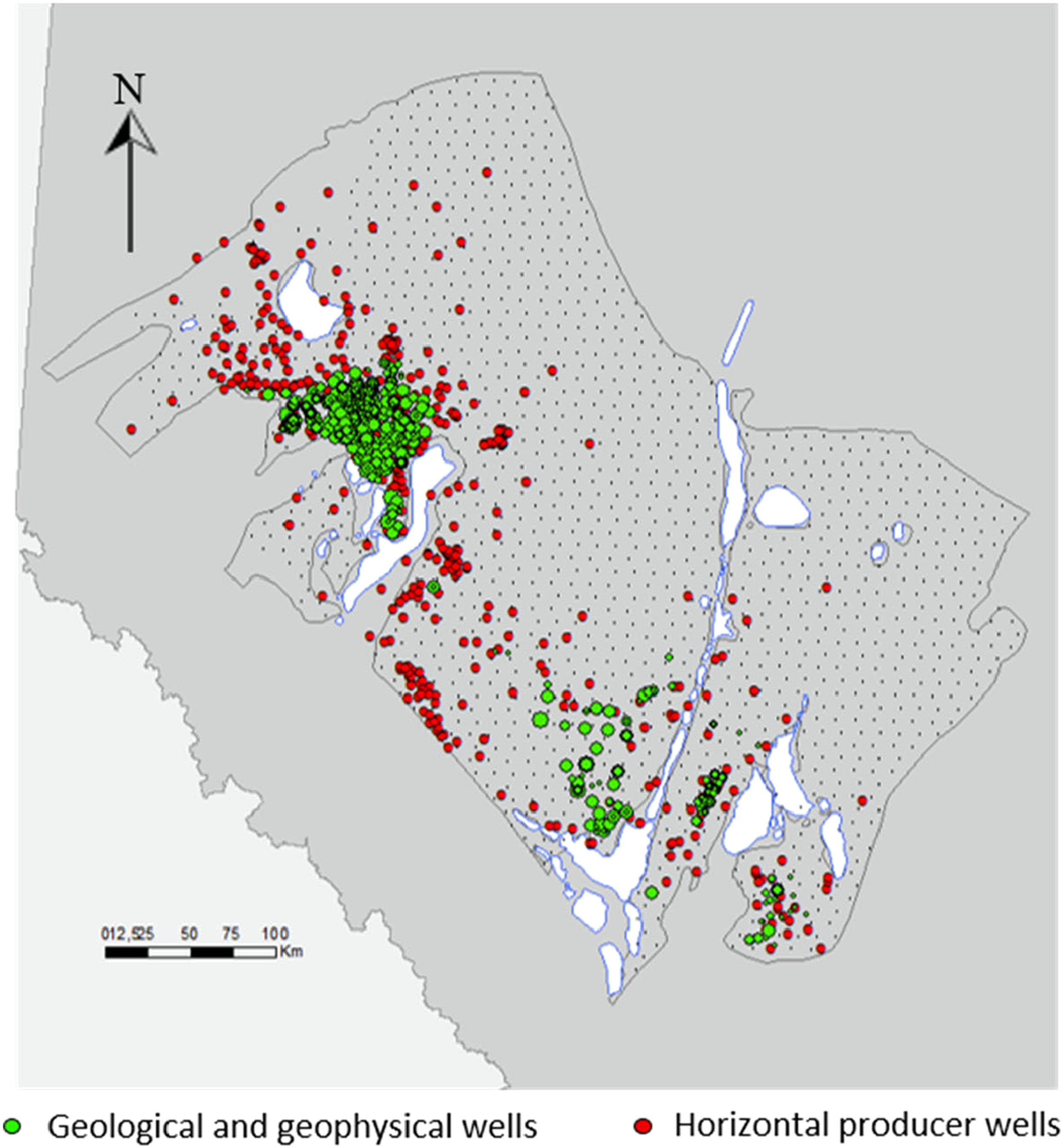
Input from the geological and geophysical wells colored in red, alongside horizontal producers colored in green within the Duvernay Formation.
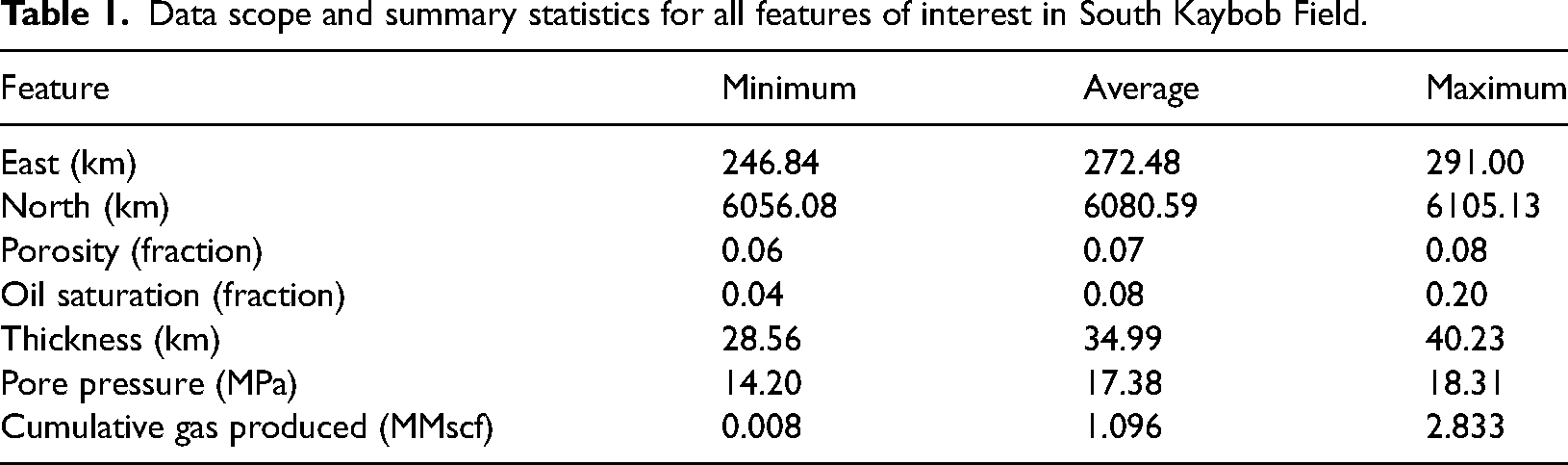
Data scope and summary statistics for all features of interest in South Kaybob Field.
Workflow demonstration
Variogram modeling is performed on the response feature, standardized gas cumulative production, to determine the semivariogram and quantify spatial continuity along the major direction in Euclidean space as
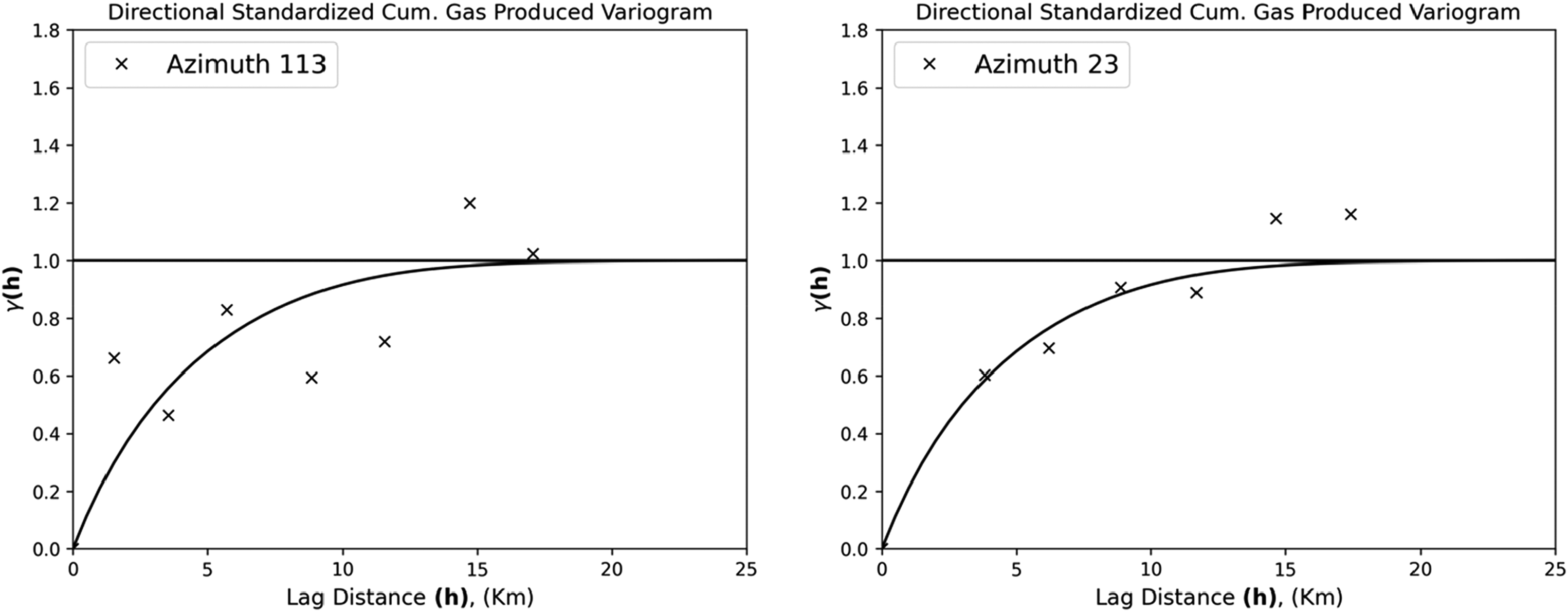
Variogram model of standardized cumulative gas production in Euclidean space. Left: the major direction of spatial continuity and right: minor direction of spatial continuity.
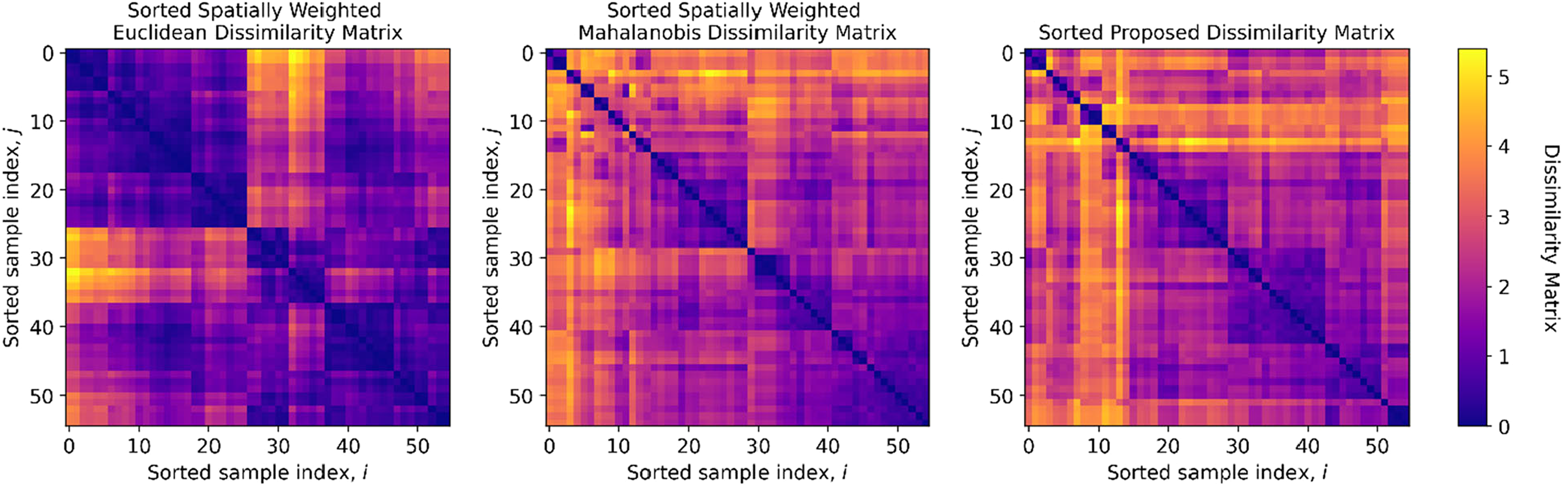
Sorted dissimilarity matrices. Left: proportion of dissimilarity matrix attributed to spatial contribution from Euclidean space. Center: proportion of dissimilarity matrix stemming from all predictors in the multivariate feature space. Right: combined dissimilarity matrix proposed to account for both spatial and multivariate feature space contributions.
Using our proposed spatial multivariate dissimilarity matrix, metric MDS projects the samples to a reduced dimensionality with
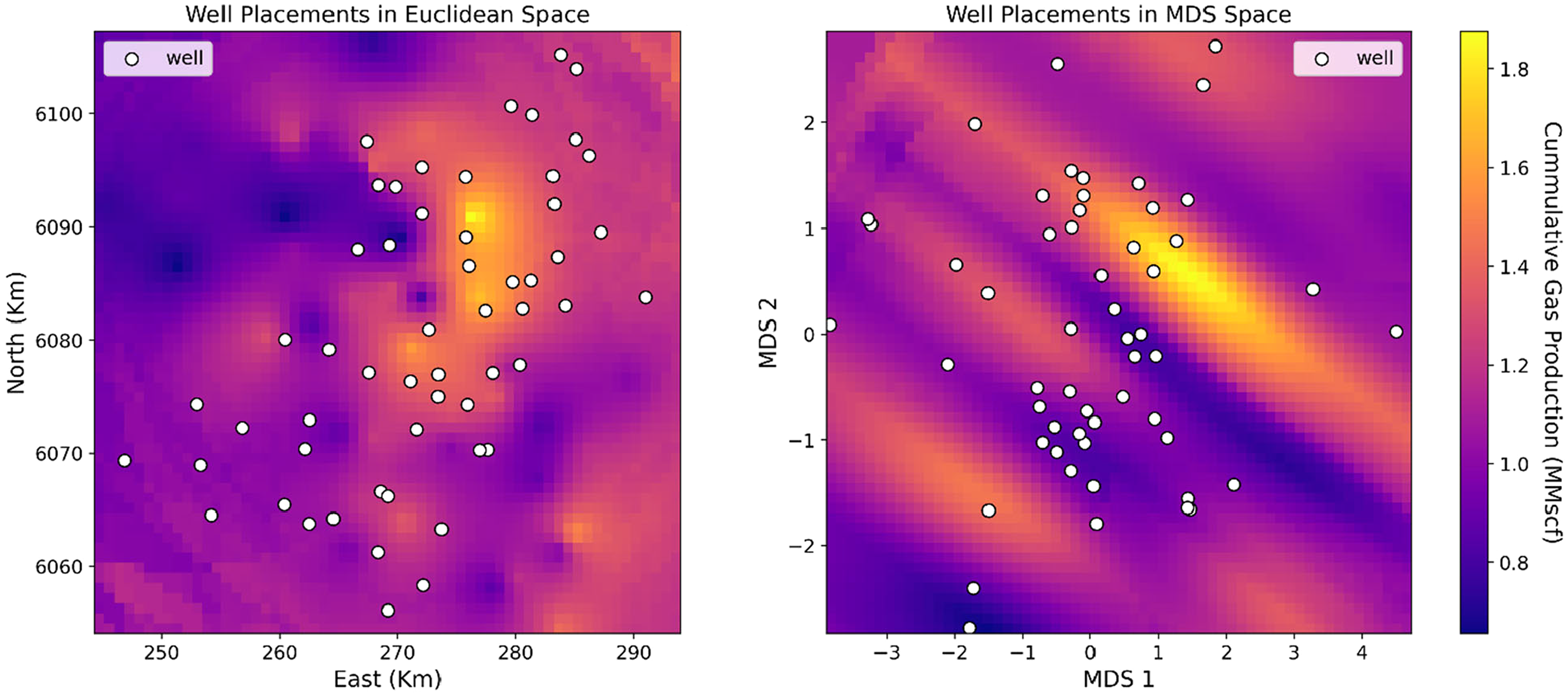
Kriged cumulative gas production maps with data samples. Left: Euclidean space and right: multidimensional scaling (MDS) space of reduced dimensionality.
The direction of spatial continuity for each predictor feature in Table 2, variogram modeling, and ordinary kriging estimates for all predictors in the MDS space are applied to calculate feature trend maps. For example, the trend map in Figure 7 shows porosity has an increasing north-western trend similar to gas production while oil saturation, thickness, and pore pressure have a decreasing north-eastern trend.
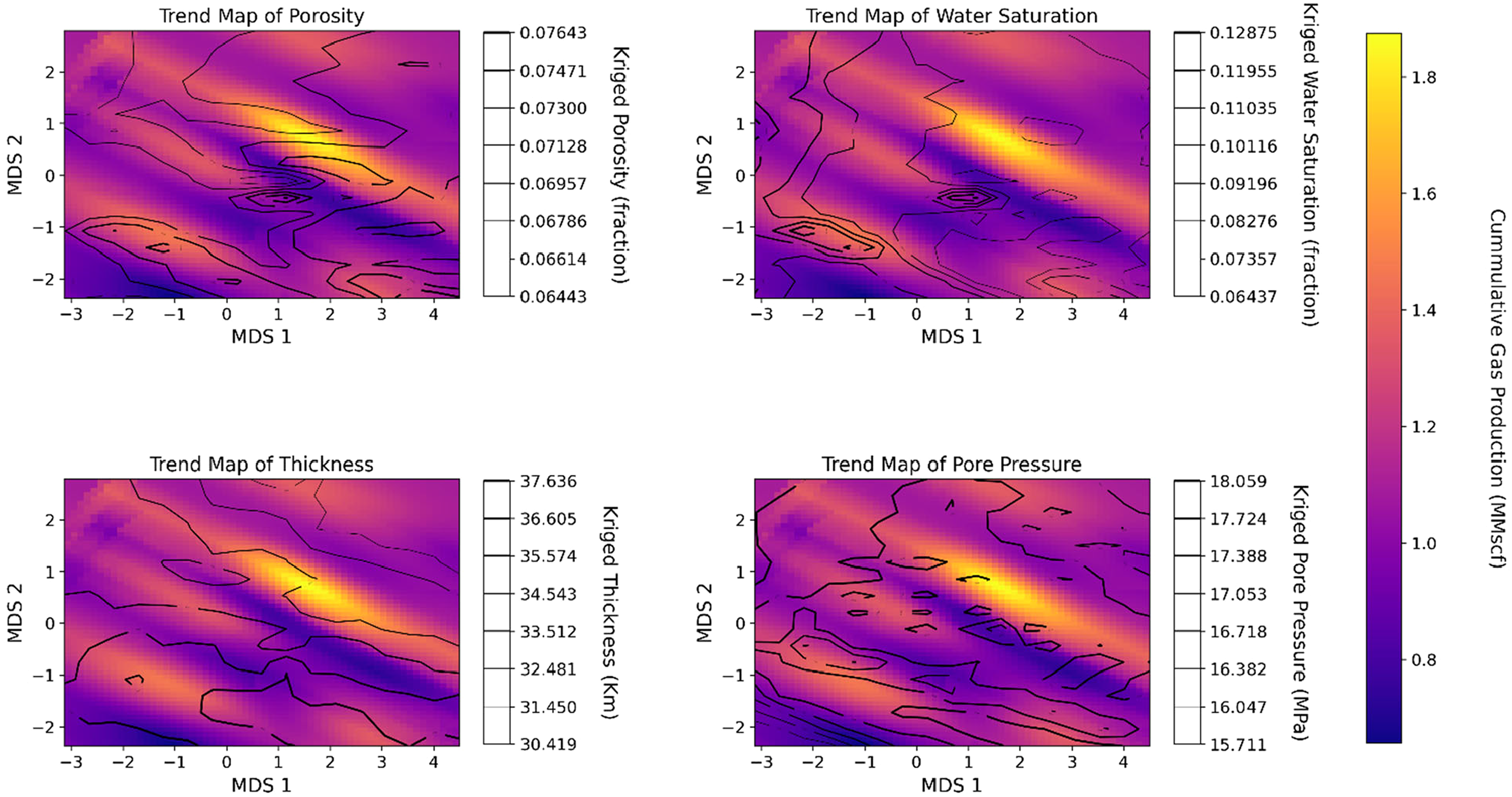
Trend map of kriged estimates for all predictors in MDS space as contour lines for productivity exploration and diagnostics, where increasing line width indicates an increase in magnitude and vice versa. This is underlaid by the map of kriged gas production estimates in the MDS space to extract information from two bivariate distributions. MDS: multidimensional scaling.
Direction of major spatial continuity and ranges for each predictor for variogram modeling in the MDS space.

MDS: multidimensional scaling.
Combining all predictor trends with the cumulative gas production trend, possible new well locations and well diagnostics are identified, such as samples or regions with high or low productivity.
Next, the average intersample distance between well samples determined by the nearest neighbor (elbow method) using normalized MDS projections is 0.059. However, since the data is clustered on a small scale, as shown in the elbow plot from Figure 8, it is inadequate to use the intersample distance as the radius parameter,
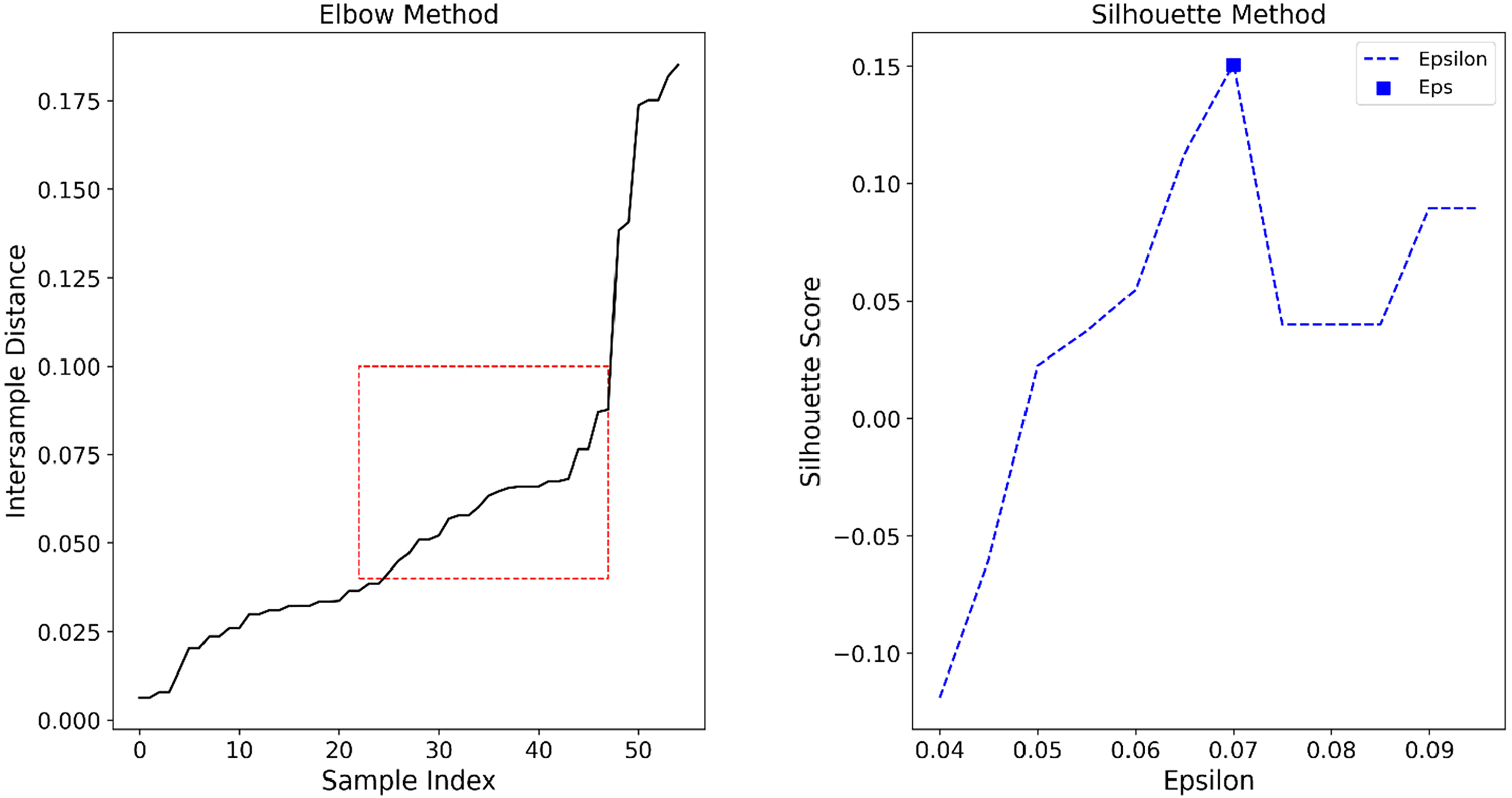
DBSCAN tuning to find optimal parameters in MDS space. Left:
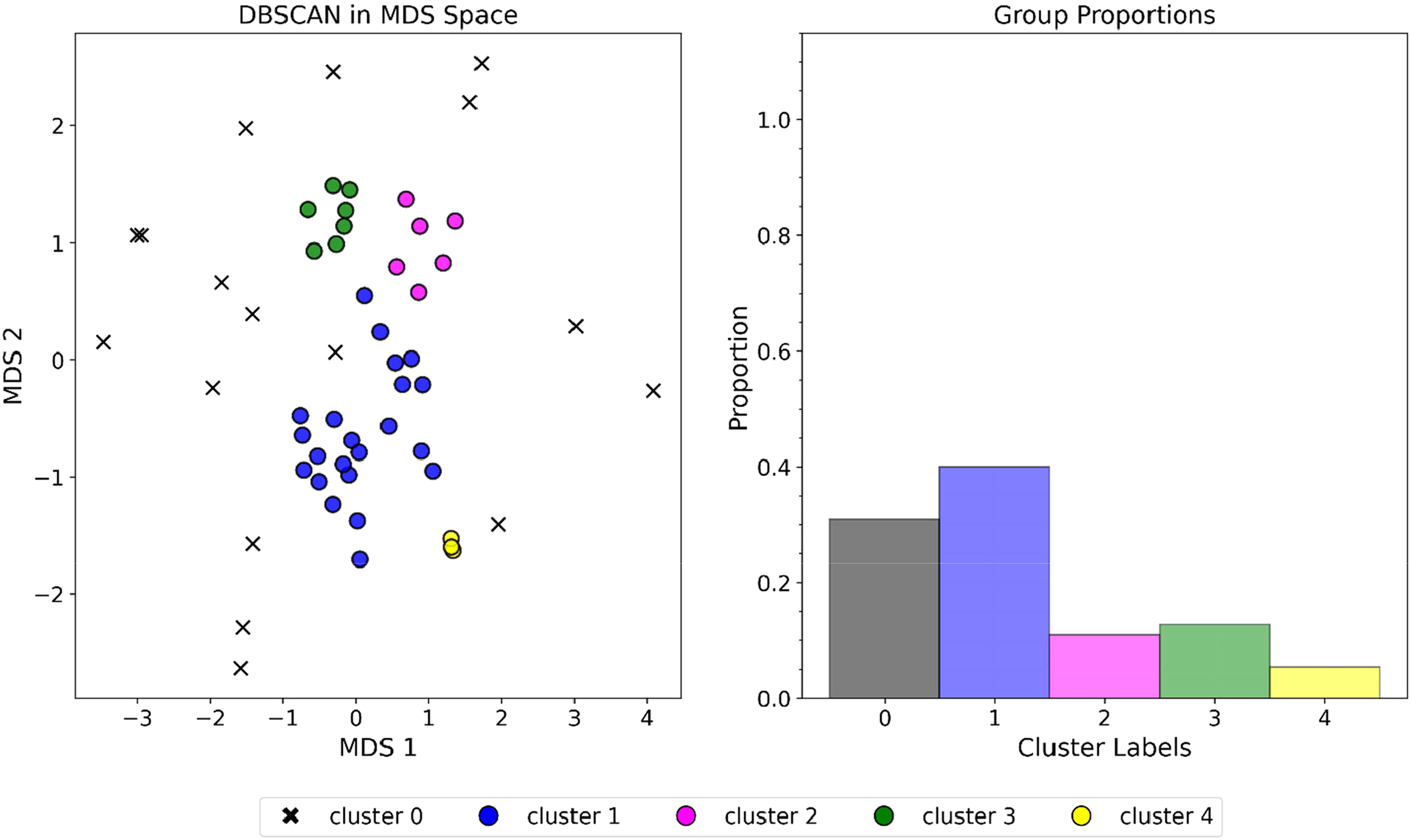
Cluster assignments with DBSCAN in MDS space. Left to right, DBSCAN identification of 4 clusters and cluster proportions. Where cluster 0 represents the DBSCAN outlier label in the MDS space. MDS: multidimensional scaling.
The four combined spatial multivariate clusters identified by DBSCAN indicate that wells within a cluster make a good pool via its respective spatial analogs in the MDS space. Centroid values are assigned to illustrate the separation of analog clusters in Figure 10 to communicate these spatial analogs in the MDS space. For example, observing the MDS space, cluster 1 belongs to a region of wells with relatively low production, while clusters 2 and 3 are in regions of high cumulative gas production, and cluster 4 is in the moderately low production region. Lastly, the cluster labels are used to color-code the well samples by index in the Euclidean space for inferential geological and geophysical well typing.
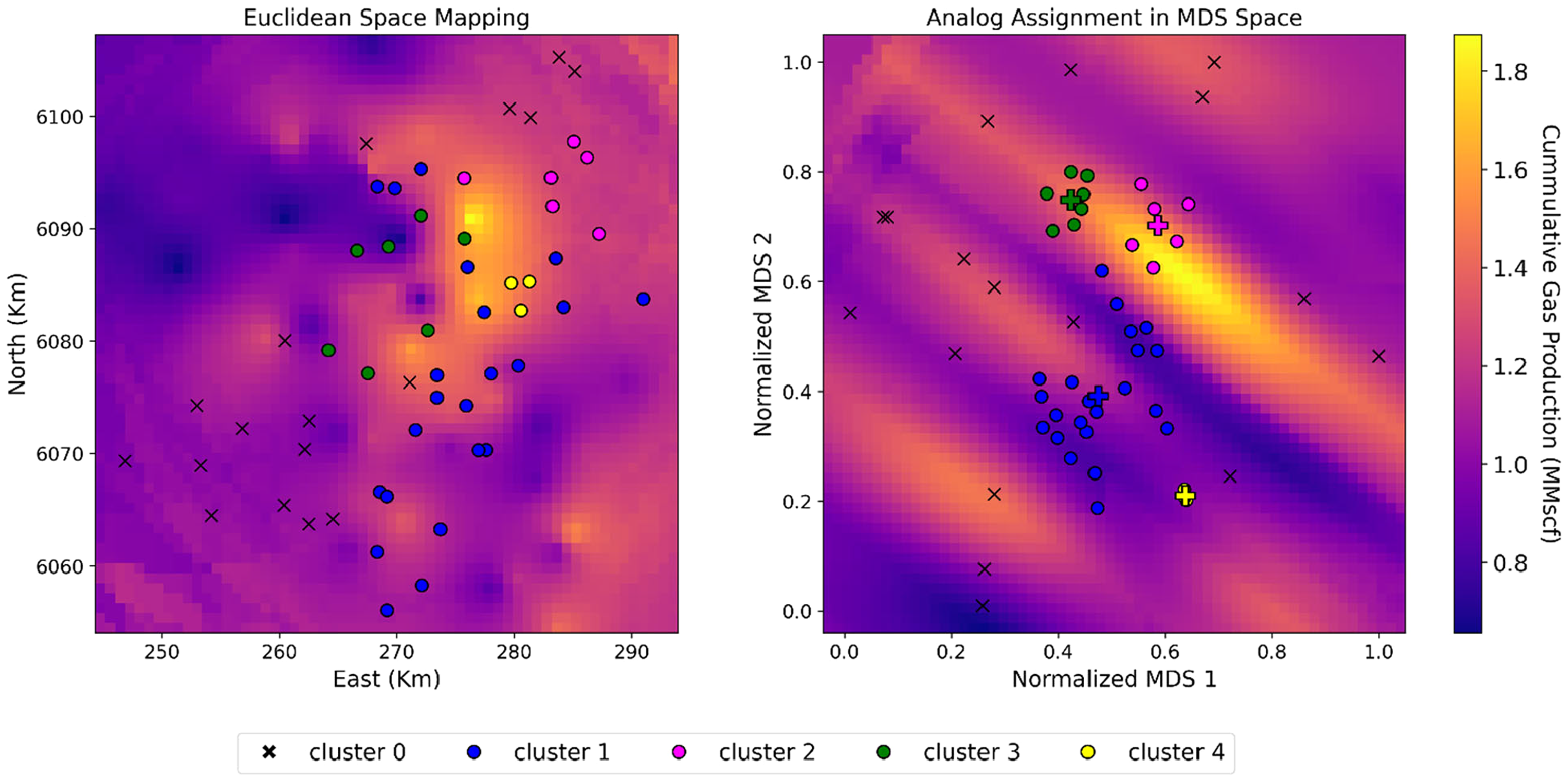
Kriged cumulative gas production maps with data samples. Left: Euclidean space. Right: MDS space of reduced dimensionality with cluster 0 representing the DBSCAN outlier label. Where the cross markers and cluster 0 respectively represent the spatial analogs and DBSCAN outlier label from MDS space. MDS: multidimensional scaling.
Case study with end member test wells
The demonstrated workflow is repeated with extreme cases of samples added in, representing four test wells typically encountered in oil and gas reservoirs: infill, outlier, centered, and sparse wells to ascertain efficacy and stress-test end member wells. In subsequent mentions, these wells are denoted by the letters i, o, c, and s. The proposed workflow is compared to existing methods for analog selection, such as close-ology and multivariate analysis, which computes
Similarly, the spatial continuity in the MDS space for cumulative gas produced is characterized by a major and minor range of
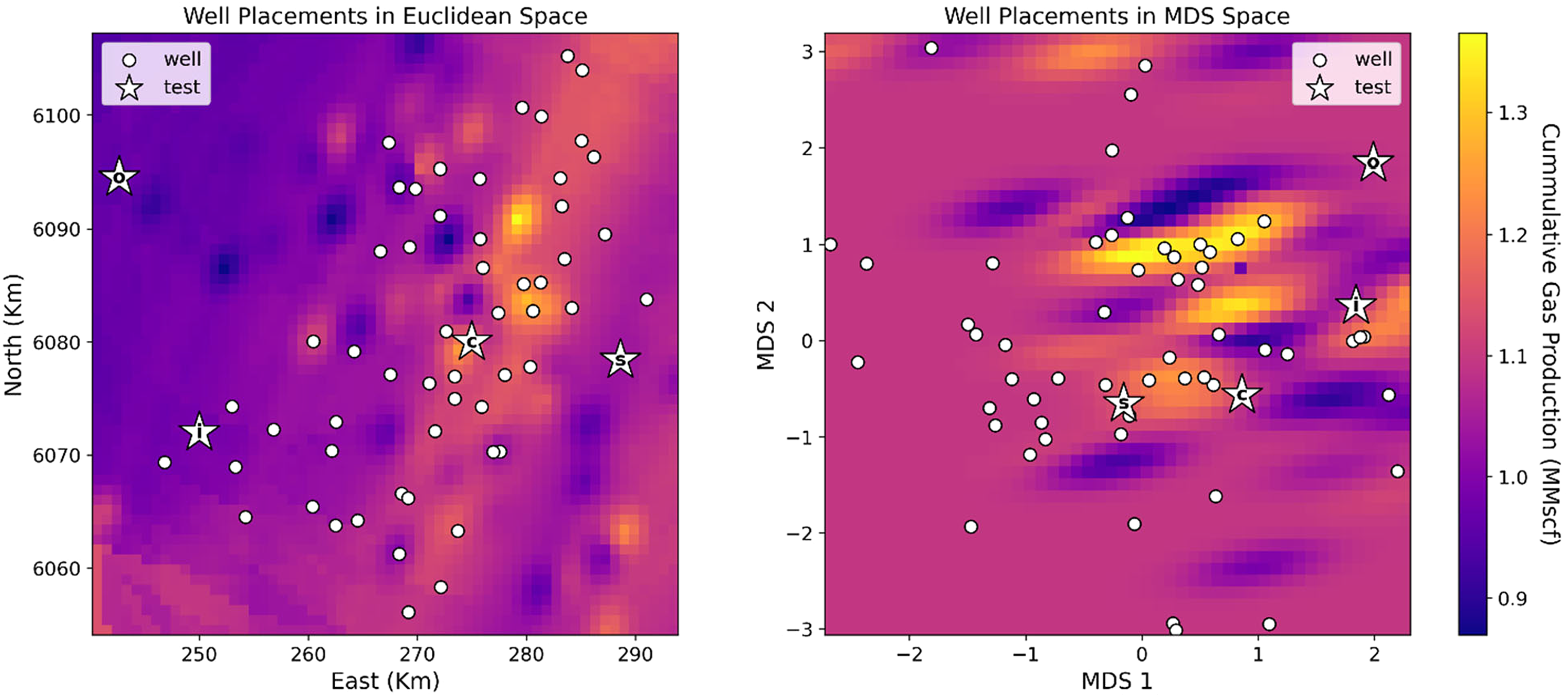
Kriged cumulative gas production maps with data samples, including the 4 test wells. Left: Euclidean space. Right: MDS space of reduced dimensionality. Where the annotated stars i, o, c, and s are the infill, outlier, centered, and sparse test wells, respectively. MDS: multidimensional scaling.
Optimally tuned DBSCAN hyperparameters

MDS: multidimensional scaling.
Using the optimally tuned DBSCAN parameters, four clusters are identified in the close-ology case. In comparison, 2 and 4 clusters were found in the multivariate analysis and our proposed cases, respectively, in Figure 12. However, since DBSCAN clustering is only performed in Euclidean space for the close-ology case using X, Y, it is not possible to generate a map in the MDS space unlike the multivariate and proposed cases with a mappable MDS space.
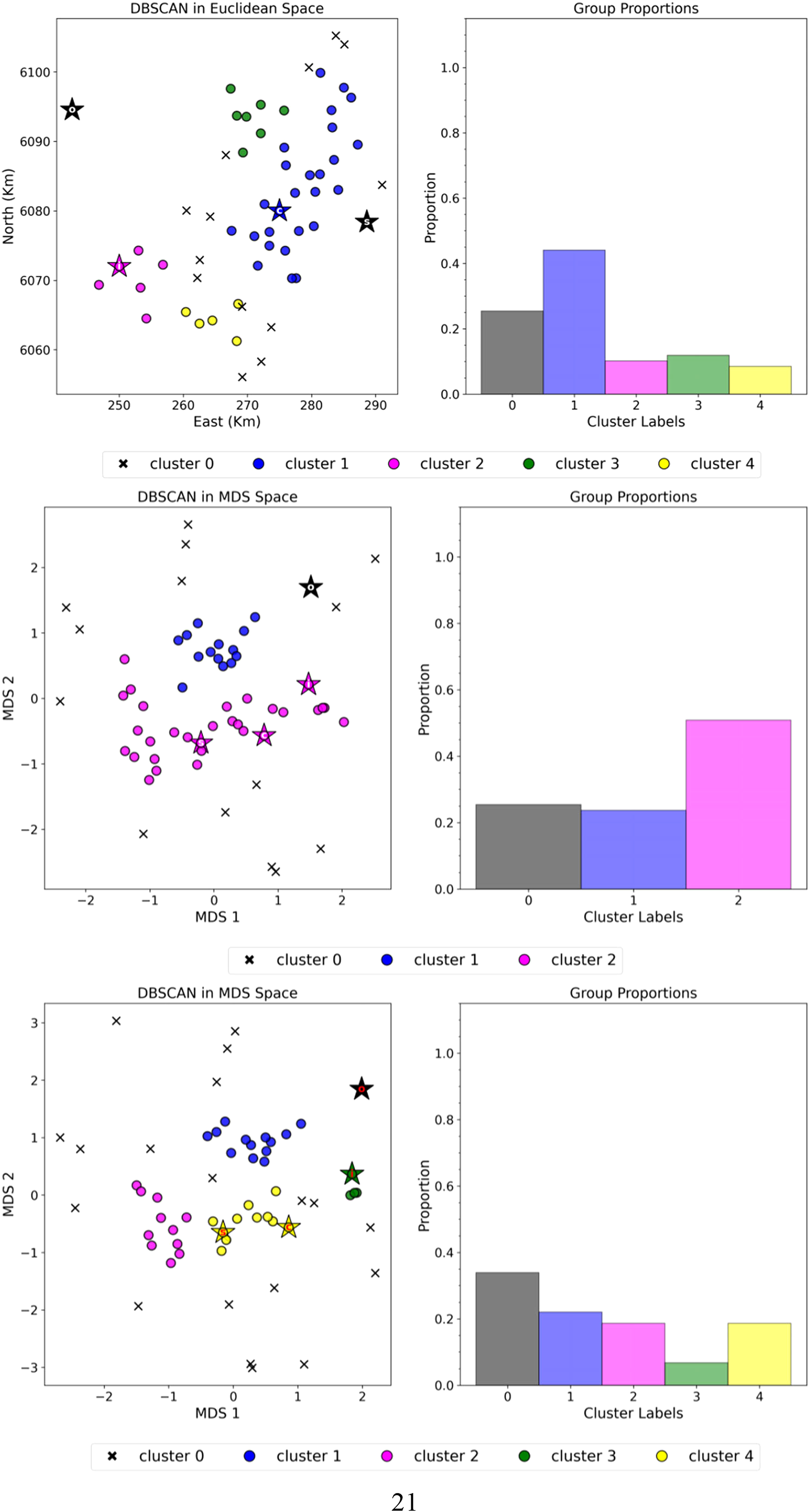
DBSCAN clustering results for the three cases. Top: Close-ology case using classical Euclidean dissimilarity metric for
When metric MDS is computed with different dissimilarity matrix inputs, different LD projections are obtained for the multivariate analysis and proposed cases shown in Figure 13. For these individual cases, 2 and 4 spatial analogs are identified in the MDS space, and their analog clusters are used to color code all well samples by index in the Euclidean space for inferential geological and geophysical typing. For the multivariate case in the MDS space in Figure 13, wells in cluster 1 belong to a variable region of relatively low to medium production and a select few in the high production zones. Meanwhile, wells in cluster 2 are in regions of medium cumulative gas production. For the proposed case in the MDS space, wells in cluster 1 belong to regions of high gas production, cluster 2 in a relatively low gas production region, and clusters 3 and 4 in moderately high production regions.
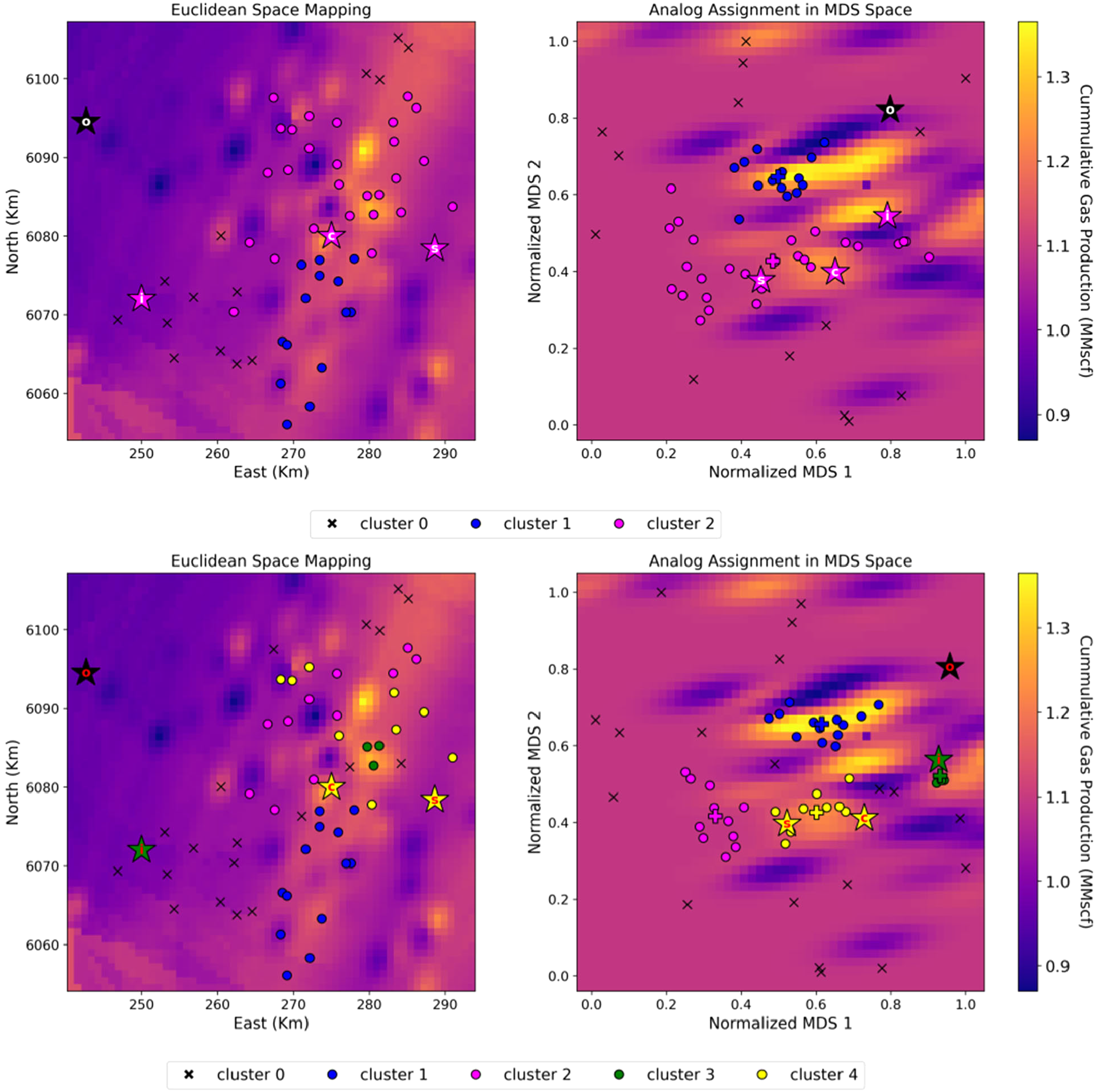
Kriged cumulative gas production maps in Euclidean and MDS spaces with data samples color-coded by cluster labels determined in MDS space. Top: Multivariate case. Bottom: proposed case. Where the cross marker represents the spatial analog in each analog cluster. MDS: multidimensional scaling.
The GCS between each test well and its corresponding spatial analog is determined as 0.0848 for the sparse well in cluster 4, 0.1278 for the centered well in cluster 4, 0.0420 for the infill well in cluster 3, and 0.5270 for the outlier well in cluster 0. Similarly, the PSS between the spatial analog for each analog cluster and the
Pairwise similarity score between the four test wells and the spatial analog of each cluster.

Conclusions
We introduce a novel workflow for spatial, multivariate analog selection applicable to subsurface resources utilizing geostatistical and machine learning techniques. Our innovative workflow provides a reliable alternative to traditional expert-driven and statistical analog identification workflows, addressing challenges such as the curse of dimensionality, objectivity, repeatability, and accounting for spatial context. The proposed workflow integrates a hybrid dissimilarity metric that simultaneously accounts for both spatial and multivariate contributions of the data and inferential machine learning for dimensionality reduction to flexibly mitigate the curse of dimensionality to cluster analog groups. With the proposed workflow, subsurface resource analogs are identified using this robust and generalizable framework to support inferential analyses and decision making in highly dimensional spatial datasets. The proposed workflow provides an unbiased, repeatable alternative to support conventional expert-driven workflows in contrast to existing methodologies such as close-ology and multivariate analysis. Our workflow requires sufficient data for reliable variogram and density-based clustering model inferences, along with associated assumptions such as stationarity of the variance, variogram, and clustering scale. Nonetheless, this study paves the way for future research, offering a framework that can be optimized and adapted to various datasets, ultimately contributing to developing advanced analog selection tools.
Footnotes
Acknowledgements
The authors sincerely appreciate Equinor and the Digital Reservoir Characterization Technology (DIRECT) consortium's industry partners at the Hildebrand Department of Petroleum and Geosystems Engineering, University of Texas at Austin. We acknowledge Equinor for granting permission to use the dataset presented here.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the DIRECT consortium's industry partners at the Hildebrand Department of Petroleum and Geosystems Engineering, University of Texas at Austin.
Research data
The data used for demonstration in this article is private and cannot be shared due to restrictons. However, a well-documented workflow using a synthetic subsurface dataset showing the applicability of our workflow is publicly available on the corresponding author's GitHub Repository: ![]() . No Equinor proprietary data is within the GitHub repository.
. No Equinor proprietary data is within the GitHub repository.