
Abstract
The advancement of horizontal drilling and hydraulic fracturing technologies has led to an increased significance of shale gas as a vital energy source. In the realm of oilfield development decisions, production forecast analysis stands as an essential aspect. Despite numerical simulation being a prevalent method for production prediction, its time-consuming nature is ill-suited for expeditious decision-making in oilfield development. Consequently, we present a data-driven model, ASGA-XGBoost, designed for rapid and precise forecasting of shale gas production from horizontally fractured wells. The central premise of ASGA-XGBoost entails the implementation of ASGA to optimize the hyperparameters of the XGBoost model, thereby enhancing its prediction performance. To assess the feasibility of the ASGA-XGBoost model, we employed a dataset comprising 250 samples, acquired by simulating shale gas multistage fractured horizontal well development through the use of CMG commercial numerical simulation software. Furthermore, XGBoost, GA-XGBoost, and ASGA-XGBoost models were trained using the data from the training set and employed to predict the 30-day cumulative gas production utilizing the data from the testing set. The outcomes demonstrate that the ASGA-XGBoost model yields the lowest mean absolute error and offers optimal performance in predicting the 30-day cumulative gas production. Additionally, the mean absolute error of the unoptimized XGBoost model is markedly greater than that of the optimized XGBoost model, indicating that the latter, refined through the application of intelligent optimization algorithms, exhibits superior performance. The insights gleaned from this investigation have the potential to inform the development of strategic plans for shale gas oilfields, ultimately promoting the cost-effective exploitation of this energy resource.
Introduction
Natural gas has emerged as a critical component of the global energy framework due to its high fuel value and low pollution (Barnes and Bosworth, 2015; Najibi et al., 2009; Reymond, 2007). Nevertheless, the world's burgeoning economy has rendered conventional gas reserves insufficient to satisfy societal demands (Abdul et al., 2021; Bhuiyan et al., 2022; Li et al., 2021). Consequently, an increasing number of studies are focusing on the exploration and production of unconventional gas resources (Song et al., 2017; Umbach, 2013; Wang and Lin, 2014). Shale gas, an unconventional gas with substantial global reserves (Guo et al., 2017), was once deemed unfeasible to extract due to its adsorption properties and super-low permeability and porosity (Zhang et al., 2015). Nevertheless, advancements in horizontal well fracturing technology have rendered shale gas extraction achievable (Liang et al., 2012; Lin et al., 2018; Wang et al., 2016). The horizontal wellbore facilitates the positioning of hydraulic fractures in various orientations, significantly enhancing permeability in the wellbore's vicinity and, consequently, bolstering gas production.
Predicting production is a critical aspect of oilfield development decision-making. There exist two primary types of production prediction models: Those driven by physical principles (Hu et al., 2016) and those driven by data (Liu et al., 2014). Physical-driven models can be further divided into analytical models (Cossio et al., 2013) and numerical simulation models (Paul et al., 2019). Analytical models aim to derive solutions based on seepage theory, as demonstrated by Lin et al. (2022), who developed a productivity prediction model for shale gas fractured horizontal wells, taking into account factors such as the fracture network's complexity, stress sensitivity effects, adsorption, and desorption. While analytical models offer rapid computation, their accuracy in predicting production from horizontal wells under complex conditions is limited due to the numerous assumptions involved. In contrast, numerical simulation models have the capacity to simulate intricate seepage situations and estimate production based on a wide range of reservoir data, encompassing geological, and drilling data. Theoretically, the accuracy of these models improves as more comprehensive data is considered. Yuan et al. (2018) established a shale gas discrete fracture network model based on an unstructured vertical bisection grid to predict the production of the shale gas fracturing horizontal well. While numerical simulation models often outperform their analytical counterparts in production prediction, their computational demand can be overwhelming for practical implementation.
In recent years, machine learning has been widely applied in the energy field, such as investment analysis of green energy projects (Hasan et al., 2022), levelized cost analysis (Li et al., 2022), analysis of financial development and open innovation (Alexey et al., 2023), oil production prediction (Cheng and Yang, 2021), and so on. Data-driven models, built by machine learning algorithms, could get the functional relationship between the production and its influencing parameters thanks to a training process based on available data (Mirzaei-Paiaman and Salavati, 2012). In general, data-driven models could be the substitute for physics-driven models. Compared with physics-driven models, data-driven models have no presumed functional relationship, and the functional relationships are obtained from the training data (Kulgaa et al., 2017). Chen et al. (2022) established a productivity prediction model of shale gas horizontal wells by the long short-term memory (LSTM) network. Wang et al. (2022) predicted the production of the shale gas horizontal well by building a deep learning network. Data-driven models offer high prediction accuracy and fast calculation speed, although ensuring optimal hyperparameters for the utilized machine learning algorithm is crucial to their accuracy.
Intelligent optimization algorithms, such as genetic algorithms (GAs) (Irani et al., 2011) and particle swarm optimization (PSO) (Nasimi et al., 2012), offer feasible approaches to hyperparameter optimization. Irani et al. (2011) established a neural network model coupled with GA to predict permeability. David et al. (2022) predicted the optimal rate of penetration by the multilayer perceptron model optimized by the GA. Li et al. (2022) proposed a PSO-CNN-LSTM model to solve the time-series prediction problems. Massive researches clearly indicate that intelligent optimization algorithms can drastically improve the performance of data-driven models in production prediction. Nonetheless, these algorithms vary in their adaptability to specific data-driven models, requiring further research to explore their suitability for different scenarios.
In this study, a prediction model named ASGA-XGBoost was proposed to predict the 30-day cumulative gas production of the shale gas horizontal fracturing well. In the process, ASGA, an improved GA, was used to search for the optimal hyperparameter combination of the XGBoost model. Compared with the GA-XGBoost model, ASGA-XGBoost has better performance in predicting the 30-day cumulative gas production of the shale gas horizontal fracturing well. The prediction results can provide help for the formulation of a shale gas oilfield development plan, resulting in the economic and effective development of shale gas.
Methodology
XGBoost algorithm
Extreme gradient boosting (XGBoost) is a prominent ensemble algorithm that integrates a vast array of weak learners to generate a strong learner (Chen and Guestrin, 2016). Typically, XGBoost relies on the classification and regression tree (CART) as its fundamental learner, which is well-suited to solve classification and regression problems. Owing to its superior performance, XGBoost has been extensively implemented in the petroleum industry, including sweet spot searching (Tang et al., 2021), dynamometer-card classification (Chris, 2020), and water absorption prediction (Liu et al., 2020).
XGBoost is renowned for its exceptional computation speed and remarkable prediction accuracy. As a supervised machine learning method, XGBoost leverages the input and output parameters of the dataset for modeling purposes. The algorithm functions through a process of incrementally integrating multiple base learners to consistently improve the residual reduction. As illustrated in Figure 1, each base learner is iteratively added to the ensemble, and the output prediction result is determined as mentioned below:

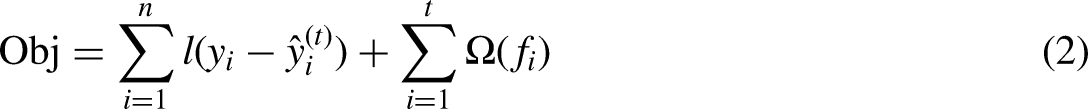
The workflow of the XGBoost algorithm. In the process, each tree is built to fit the residual of the previous tree. The final prediction result is obtained by synthesizing the calculation results of all trees.
XGBoost has ten hyperparameters, including booster, n_estimators, max_depth, min_child_weight, eta, gamma, subsample, colsample_bytree, reg_alpha, and reg_lambda. Booster determines the type of base learner, usually a decision tree, and n_estimators is the number of base learners. For tree booster, max_depth denotes the maximum depth and min_child_weight is the minimum sum of leaf node sample weights. Eta represents the learning rate, which can be decreased to reduce overfitting. gamma indicates the minimum loss function drop for node splitting. subsample decides the proportion of random samples for each base learner. colsample_bytree is the subsample ratio of columns when constructing each tree. reg_alpha represents the L1 regularization term and reg_lambda denotes the L2 regularization term. These ten hyperparameters are key determinants for optimizing the prediction accuracy of XGBoost model. Hence, obtaining optimal hyperparameters is crucial for the XGBoost model's optimal functionality.
ASGA-XGBoost model
In this study, a modified adaptive GA based on the Spearman correlative coefficient (ASGA) was proposed to get the optimal hyperparameters. GA, proposed by John Holland first, is a method for searching for the optimal solution by simulating the natural evolution process (John, 1992). Over the past few decades, GA has extensively found applications in multiple optimization problems (Karen, 2005; Wathiq and Maytham, 2011; Souza et al., 2018). However, GA frequently necessitates numerous iterations to arrive at the most fitting solution, leading to prolonged optimization times. In other words, GA optimization accuracy is typically challenging to sustain within a certain number of iterations. Zhou and Ran (2023) proposed a modified GA based on the Spearman correlative coefficient (SGA) to improve the optimization speed and accuracy. Compared to GA, SGA modifies the crossover and mutation rates’ determination methods. Generally, in GA, each gene has the same crossover and mutation rates, which can prolong the search for the optimal solution. The purpose of SGA is to approach the optimal solution quickly by adjusting the crossover and mutation rates of the genes.
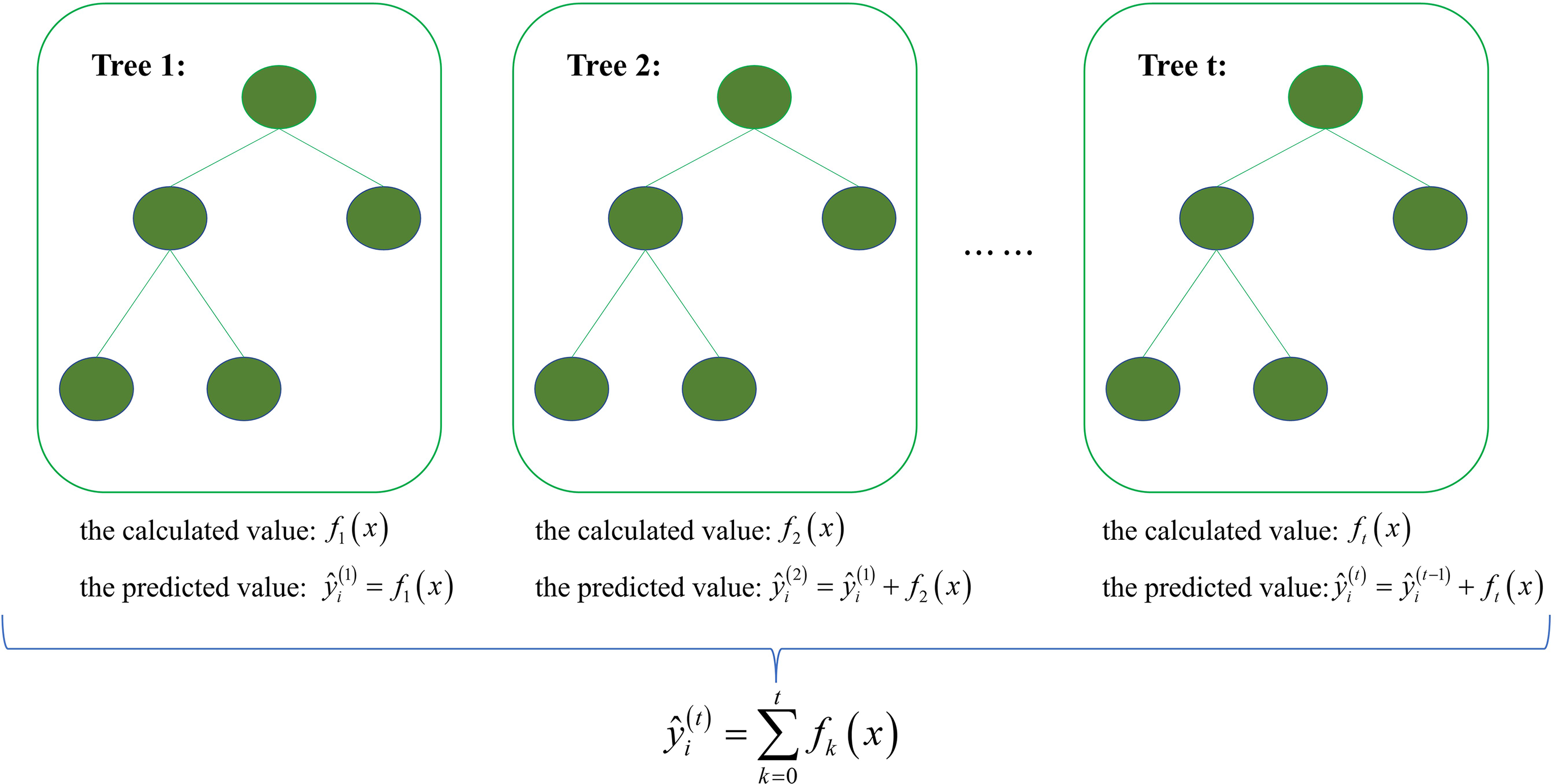
However, SGA necessitates a dataset containing optimized hyperparameters and the optimization objective to determine Spearman correlation coefficients between parameters and objectives, subsequently determining the mutation and crossover rates. In this study, the ten hyperparameters of the XGBoost model constitute the optimized parameters, and the validation error of the XGBoost model becomes the optimization objective. Nonetheless, the absence of datasets containing hyperparameters and validation errors precludes the direct application of SGA to optimize XGBoost's hyperparameters. To address this, a modified SGA, referred to as ASGA, was introduced. ASGA integrates a dataset creation process to calculate Spearman correlation coefficients. Specifically, the new individuals and their corresponding validation errors in each iteration process are added to the dataset to increase the number of data samples. Accordingly, each iteration process necessitates recalculating the Spearman correlation coefficient, and the crossover and mutation rates differ for each step. The incorporation of ASGA helps XGBoost models identify optimal hyperparameters and enhance performance in production prediction. As depicted in Figure 2, the workflow of ASGA-XGBoost is as follows:
The workflow of the ASGA-XGBoost model. There are 7 steps to achieve the ASGA-XGBoost algorithm. Its main idea is getting the best hyperparameters of the XGBoost model through a large number of iterative calculations.
Step 1—Population Initialization. The population consists of a certain number of individuals, also called chromosomes, and each chromosome is composed of some genes. In this study, each gene denotes a hyperparameter of the XGBoost model. In this process, n individuals are obtained by randomly generating the hyperparameters within limits.
Step 2—Fitness Calculation. Fitness serves as a crucial criterion for selecting desirable individuals for breeding in the subsequent generation. In this study, the fitness is calculated by the validation error of the XGBoost model, where smaller validation errors indicate higher fitness.
Step 3—Selection Operation. The purpose of the selection operation is to inherit the excellent individuals to the next generation. Roulette wheel selection is the most common way to select individuals from the population as parents. In this process, each individual in the population has a probability of being selected, which is associated with fitness. In general, individuals with higher fitness have a greater probability of selection. Moreover, the operation of roulette wheel selection needs to be repeated n times to get n pairs of individuals as parents, which are used to get the next generation via crossover and mutation operation.
Step 4—Calculation of the Crossover and Mutation Rates. Firstly, a dataset including the hyperparameters and training error of the XGBoost model should be established. In the optimization process, the new population obtained in each iteration needs to be put in the dataset.
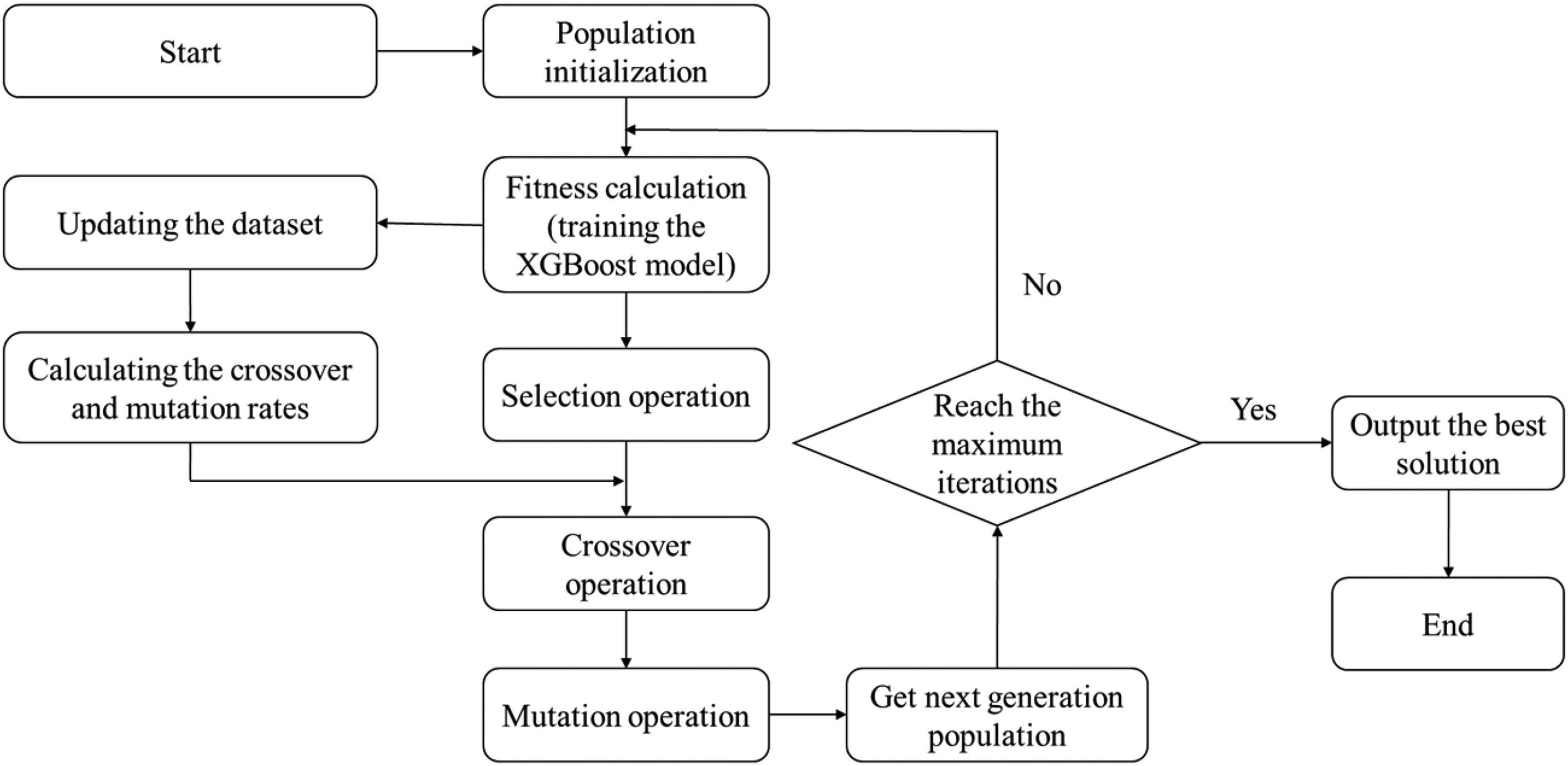
Secondly, the Spearman correlative coefficients between the hyperparameters and the validation error could be calculated. Correlation coefficients, such as Pearson, Kendall, and Spearman, are primarily used to represent the correlation between two parameters. The Pearson correlation coefficient works well only in describing the linear relationship of two continuous variables with a positive distribution. Nevertheless, the relationships between the hyperparameters and the validation error might be nonlinear. Moreover, the Kendall correlation coefficient is usually applied to the rank variables while most hyperparameters are continuous variables. Compared with the two methods, the Spearman correlation coefficient has no requirement for data distribution and variables. Furthermore, it also can indicate correlations between two variables that are linear or even partially non-linear. Therefore, the Spearman correlation coefficient is selected to calculate the correlative coefficients of the hyperparameters and the validation error. The Spearman correlation coefficient can be calculated by:
Thirdly, the crossover and mutation rates could be gotten by the calculated Spearman correlative coefficients. In this study, the gene with a high Spearman correlative coefficient has low crossover and mutation rates so the excellent gene has a greater probability of retention. To achieve this purpose, the crossover and mutation rates could be calculated by:

Step 5—Crossover Operation. The process of crossover operation is to cross one or more genes on two individuals to get a new individual. Based on the calculation crossover rates of Step 4, each gene has a probability to decide whether to be crossed or not. In this step, n new individuals could be obtained by crossing the n pair of individuals selected thanks to the selection operation.
Step 6—Mutation Operation. Mutation operation is mainly used for the n new individuals generated by crossover operation. Its purpose is to get a new population by randomly changing the genes of the new individuals. Similarly, each gene has a probability to decide whether to be changed, which is calculated in Step 4. After mutation operation, a population with n new individual could be gotten.
Step 7
Application
Data description
To assess the applicability of this approach, the CMG commercial numerical simulation software was employed to simulate multistage fracturing horizontal well development for shale gas extraction. The resultant data encompassed geological, fracturing, and production parameters. Specifically, six parameters, including porosity, permeability, the number of fracturing sections, the length of the horizontal well, fracture width, and fracture half-length, served as the inputs for the XGBoost model, while the 30-day cumulative gas production constituted the output.
Figure 3 displays the shale gas reservoir, which was established using the CMG commercial numerical simulation software, possessing dimensions of 3000 × 3000 × 100 m. The grid's dimensions measure 200 × 200 × 10, with a spacing of 15 m in the I and J directions and 10 m in the K direction, as indicated in Table 1. The shale gas horizontal well is located in the fifth layer, and perforation produces vertical fractures.
Numerical simulation of the shale gas fracturing horizontal well. There are 10 layers in the reservoir and the horizontal well is located in the fifth layer.
Basic gas-reservoir parameters.

To get the dataset for the XGBoost model, three steps need to be done. Firstly, based on the bounds of the input parameters shown in Table 2, the geological and fracturing parameters were generated randomly by a computer program. Secondly, the cumulative gas production of the horizontal well could be calculated by inputting the geological and fracturing parameters into the established CMG numerical model. Thirdly, the dataset could be gotten by repeating the two steps. In this study, a dataset with 250 groups of samples was obtained. Figure 4 gives the distributions between input parameters and output parameter.
The values of input parameters.
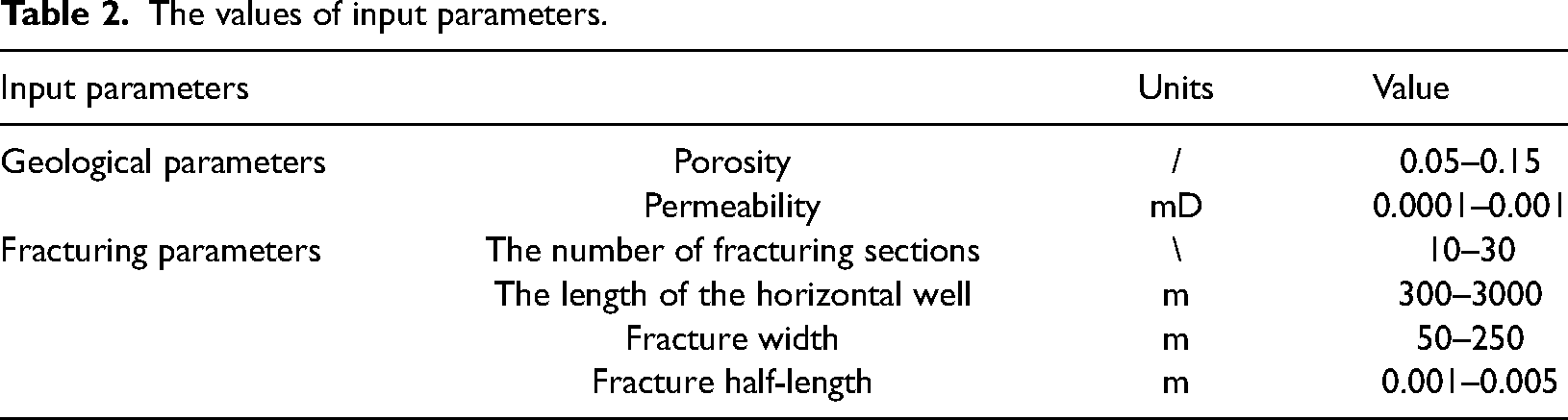
The distribution plots between the input parameters and output parameter. The input parameters are porosity, permeability, the number of fracturing sections, the length of the horizontal well, fracture width, and fracture half-length. The output is the 30-day cumulative gas production.
Building the productivity prediction model
For the production prediction model established by the XGBoost algorithm, the input has six parameters, including porosity, permeability, the number of fracturing sections, the length of the horizontal well, fracture width, fracture half-length, and the output is the 30-day cumulative gas production. In this study, 80% of the samples from the dataset above were randomly selected as the training set, and the remaining 20% were used as the testing set. The training set was used to train the XGBoost model. In the process, 10% of samples from the training set were used as the validation set to achieve the 10-fold cross-validation, which is beneficial for obtaining a stable and accurate XGBoost model. The validation accuracy could represent the training accuracy of the XGBoost model. To improve the performance of the XGBoost model, ASGA was used to optimize the hyperparameters of the XGBoost model. Furthermore, to test the superiority of ASGA, GA was applied to the hyperparameter optimization and the comparison results are shown in Figure 5. As can be seen, the number of iterations used by ASGA to reach the optimal training accuracy is less than that of GA, and the training accuracy of the XGBoost model optimized by ASGA is 2.28% higher than that of GA. Thus, ASGA has a faster optimization speed and higher accuracy than GA. More precisely, the hyperparameters optimized by ASGA and GA are shown in Table 3.
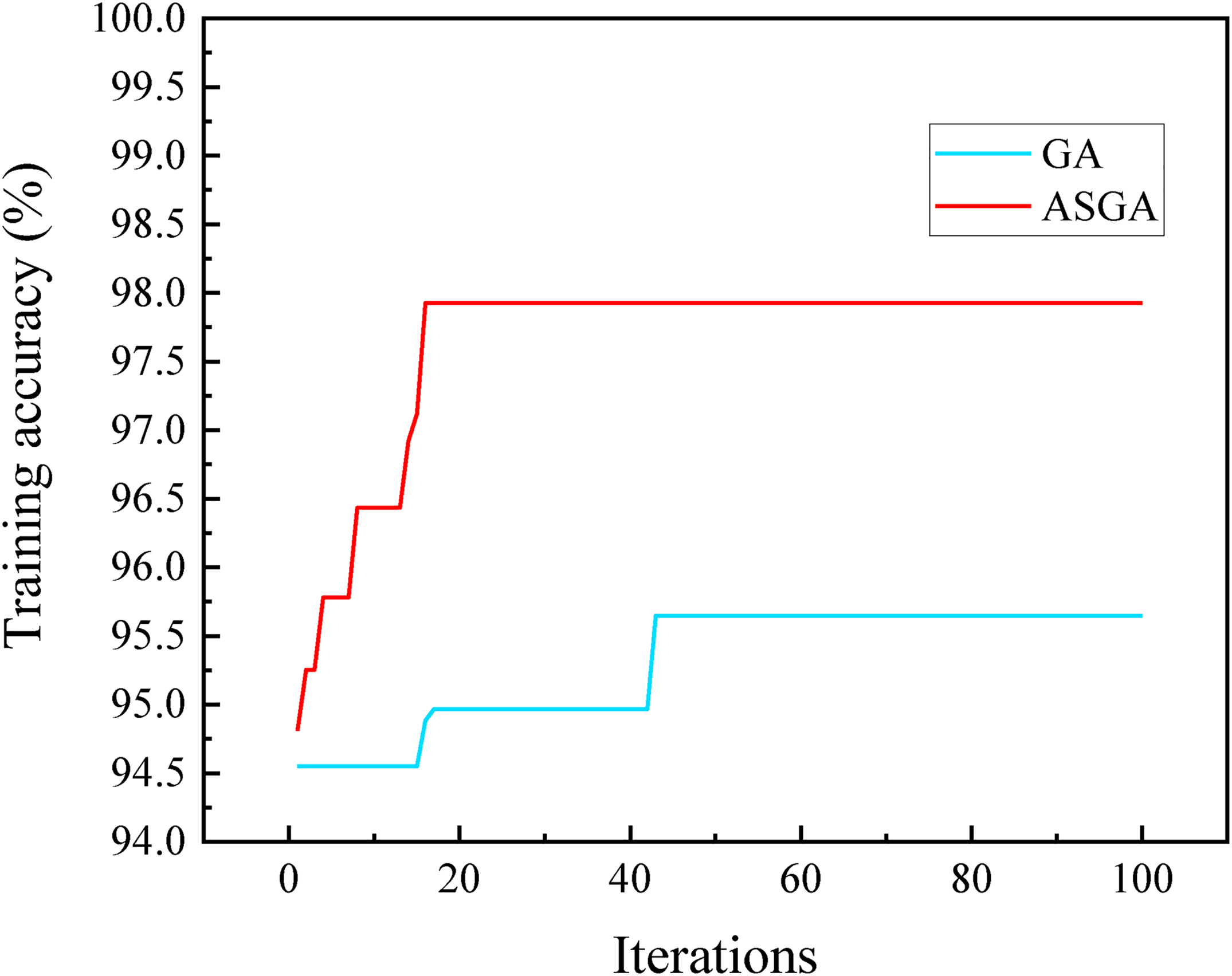
Comparison plots of GA vs. ASGA. The horizontal axis represents the iterations in the optimization process, and the vertical axis denotes the training accuracy of the XGBoost model. The light blue line denotes the optimization process of GA, and the red line represents the optimization process of ASGA.
Summary of optimal hyperparameter settings for XGBoosrt model.

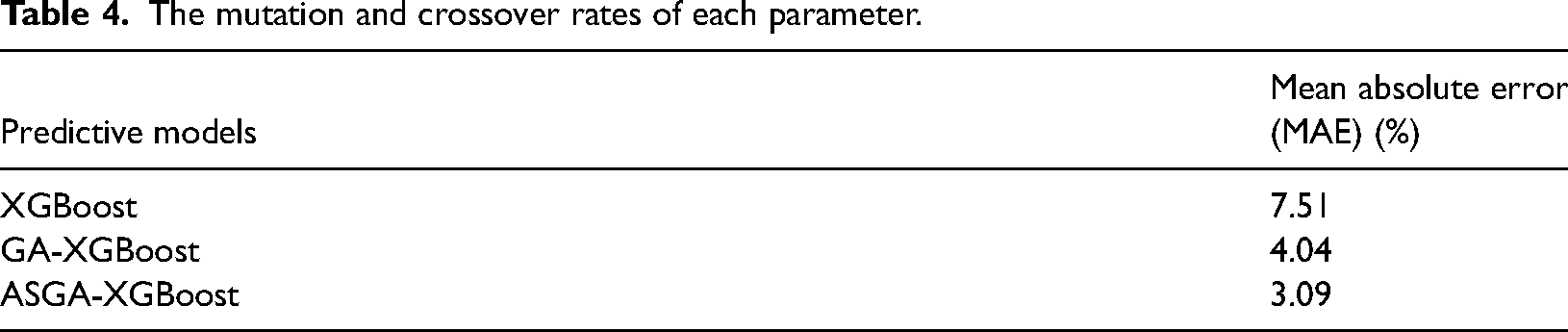
In addition, the samples in the testing set were used to validate the prediction performance of the XGBoost model optimized by ASGA. Moreover, the unoptimized XGBoost model and the XGBoost model optimized by GA were also used to predict the 30-day cumulative gas productions of the samples in the testing set, and the results are shown in Figure 6. As can be seen, the prediction results of the GA-XGBoost and ASGA-XGBoost models are better than that of the XGBoost model. More precisely, mean absolute error (MAE) was calculated to show the performance of the three models, and the result is shown in Table 4. It shows that the MAEs of XGBoost, GA-XGBoost, and ASGA-XGBoost are 7.51%, 4.04%, and 3.09%, respectively. Therefore, ASGA-XGBoost performs best in predicting the 30-day cumulative gas production. Furthermore, it also can be seen that the XGboost models optimized by intelligent optimization algorithms perform better than the XGboost model without optimization.
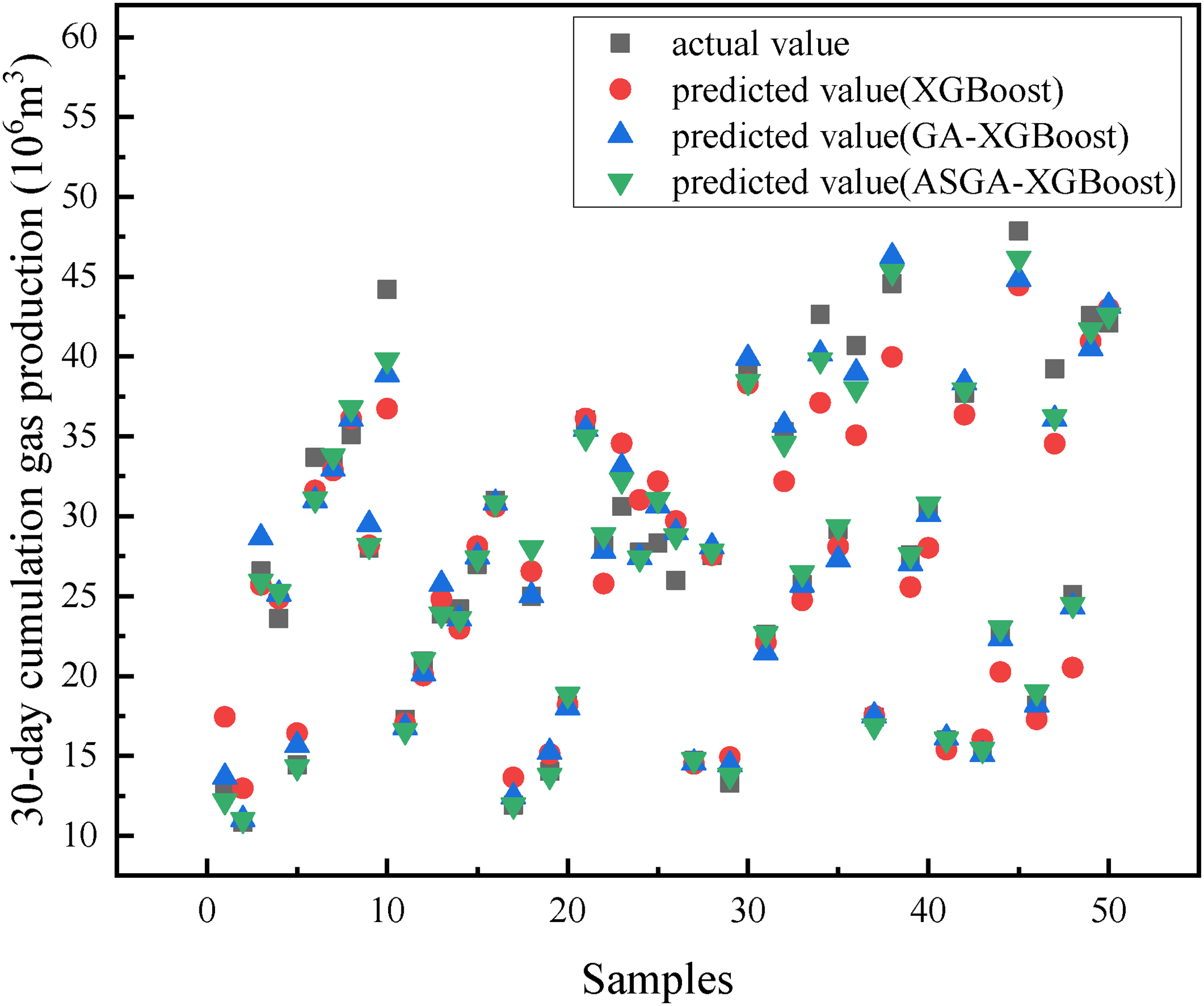
Comparison plots of actual values vs. predicted values for the validation samples. The black points denote the actual values, and the red points represent the values predicted by the XGBoost model. The blue points are the values predicted by the GA-XGBoost model, and the green points denote the values predicted by the ASGA-XGBoost model.
The mutation and crossover rates of each parameter.
Summary and conclusion
In this study, the researchers applied the ASGA-XGBoost model to predict the 30-day cumulative gas production of a shale gas horizontal well. The ASGA algorithm was employed to optimize the hyperparameters of the XGBoost model, leading to improved prediction accuracy. To evaluate the ASGA-XGBoost performance, a dataset was obtained through the establishment of a numerical simulation model of shale gas horizontal well fracturing using the CMG commercial numerical simulation software. Moreover, GA-XGBoost and XGBoost models were also employed in predicting the 30-day cumulative gas production. On the basis of the achieved results, the following conclusions can be drawn:
(1) Compared with GA, ASGA performs better in optimizing the hyperparameters of the XGBoost model. The optimization results show that the number of iteration steps of ASGA used for searching the optimal hyperparameters is less than that of GA, and the optimization accuracy of ASGA is higher than that of GA.
(2) ASGA-XGBoost performs better than GA-XGBoost and XGBoost in predicting the 30-day cumulation gas production. The results show that the MAEs of XGBoost, GA-XGBoost, and XGBoost are 7.51%, 4.04%, and 3.09%, respectively. It also can be seen that the MAE of the XGBoost model that has not been optimized is significantly higher than that of the optimized XGBoost model, which means that the XGboost model optimized by intelligent optimization algorithm performs better than the XGboost model without optimization.
(3) The weakness of this study is that the parameters obtained from numerical simulation are not comprehensive enough. This may limit the application of the ASGA-XGBoost model in the field. Furthermore, it is vital to acknowledge that the Spearman correlation coefficient only presents an approximate depiction of correlation. Such limitations may constrain ASGA's optimization accuracy and subsequently impact the prediction precision of ASGA-XGBoost.
Footnotes
Author contributions
Xin Zhou contributed to the conceptualization, methodology, software, testing, formal analysis, investigation, data curation, experimental studies, writing—original draft preparation, writing—reviewing and editing. Qiquan Ran contributed to the conceptualization, resources, data curation, data acquisition, writing—original draft preparation, writing—reviewing and editing, visualization, supervision, project administration.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by [Key Core Technology Research Projects of PetroChina Company Limited] grant number [2020B-4911]. And the APC was funded by [Research Institute of Petroleum Exploration and Development].