
Abstract
Traditional machine learning methods are difficult to accurately forecast oil production when development measures change. A method of oil reservoir production prediction based on normalized mutual information and a long short-term memory-based sequence-to-sequence model (Seq2Seq-LSTM) was proposed to forecast reservoir production considering the influence of liquid production and well spacing density. First, the marine sandstone reservoirs in the Y basin were taken as the research object to establish the sample database. Then, the feature selection was carried out according to the normalized mutual information, and liquid production, production time, equivalent well spacing density, fluidity and original formation pressure were determined as input features. Finally, a Seq2Seq-LSTM model was established to forecast reservoir production by learning the interaction from multiple samples and multiple sequences, and mining the relationship between oil production and features. The research showed that the model has a high accuracy of production prediction and can forecast the change of production when the liquid production and well spacing density change, which can provide scientific recommendations to help the oilfield develop and adjust efficiently.
Keywords
Introduction
The development of oil and gas resources has an important impact on a country's energy security and economic development (Ullah et al., 2022). Changing well spacing density and adjusting liquid production are the most popular development measures to control oil production in reservoirs. It is very important for the adjustment and formulation of the reservoir development plan to forecast oil production considering the influence of liquid production and well spacing density. Decline curve analysis (DCA), numerical reservoir simulation, analytical methods and machine learning are widely used to predict the oil and gas production of reservoirs.
DCA is an empirical formula for determining production changes by regression of oil and gas production data, without the help of relevant data on reservoir physical properties. Arps (1945) proposed the simplest empirical DCA method, which has been universally used for conventional reservoirs. Many scholars modified the traditional Arps’ decline model and thus proposed the Power Law Exponential decline model and the Stretched Exponential Decline Model (Ilk et al., 2008; Valko, 2009). The technique of DCA can roughly characterize the variation of reservoir production, but can’t consider the influence of development measures on oil and gas production. Numerical reservoir simulation is to simulate the underground oil and water flow by establishing and solving the reservoir geological and numerical models, and giving the distribution of oil and water at a certain time to predict the reservoir dynamics (Gao et al., 2016; Yang et al., 2021; Zhang and Awotunde, 2016). If the accuracy of numerical simulation to predict production is high, it often needs to invest considerable time and effort. Therefore, it is a formidable task to establish an accurate and practical numerical model. The analytical method uses a lot of assumptions to establish a mathematical model (Liu et al., 2017; Sang et al., 2014; Wang et al., 2020b). Compared with numerical reservoir simulation, the analytical method has the advantage of faster calculation speed, but the simplified model has limited practicability. The oil and gas production of reservoirs is mainly influenced by geological parameters, fluid properties and development measures. It is difficult for traditional methods to accurately forecast oil production because of the complex nonlinear relationship between various factors and production.
After years of development, a large amount of production data has been accumulated in a reservoir, which provides the basis for the application of machine learning (ML). The applicability of ML in various domains of petroleum engineering has attracted extensive attention and interest. Vector autoregression (Zhang and Jia, 2021), support vector regression (Huang et al., 2021; Masoud et al., 2020), random forest (Bhattacharya et al., 2019; Xue et al., 2021) and artificial neural network (Liu et al., 2021b; Negash and Yaw, 2020; Zhang et al., 2016; Zhou et al., 2021b) are used to predict oil and gas production. However, these traditional ML methods do not take into account the trend of production over time and the correlation between the data before and after.
In order to improve prediction accuracy, a deep learning method called long short-term memory (LSTM) network has been popularly used to forecast oil production. Sagheer and Kotb (2018) established a deep LSTM architecture to predict production data from North China Oilfield in China and Cambay Basin Oilfield in India. Wang et al. (2020a) used the production data of waterflooding sandstone reservoirs to establish the production prediction model by the LSTM network, which can predict the production of ultra-high water cut period. Yang and Wang (2020) presented a novel optimization method that integrates the LSTM neural network and dynamic programming to solve the optimization problem of SAGD steam injection volume innovatively. Bao et al. (2020) used ensemble Kalman filter enhanced LSTM to establish a data-driven end-to-end model for forecasting production, which can forecast future water content and oil production by inputting injection rate, bottom hole pressure, previous water content and oil production. Xu et al. (2020) proposed a transfer-LSTM production prediction model of coalbed methane, which combined the idea of transfer learning and the LSTM model. Song et al. (2020) optimized the structure and parameters of the LSTM model by particle swarm optimization algorithm and established the production forecasting model of fractured horizontal wells in volcanic reservoirs. Liu et al. (2020) proposed an LSTM model based on ensemble empirical mode decomposition, which can accurately predict the oil production of wells. Dong et al. (2021) first used well groups with sufficient historical data to train the LSTM model, and then the model combined with transfer learning was applied to the production prediction of the well group with a short development time in the same oilfield. Guo et al. (2021) extracted features by combining convolutional autoencoder and spatial pyramid pooling and established the coalbed methane production prediction model based on LSTM. Rodriguez and Salazar (2022) used LSTM neural network to forecast oil and water production in an oil field exploited through waterflooding, which can change input parameters such as bottom hole pressure or water injection rate to predict production. Zhang et al. (2022) used a temporal convolutional network (TCN) to predict the oil production of a single well in water flooding reservoirs at different water cut stages. Du et al. (2023) established a data-driven production forecasting model for coalbed methane based on Bi-LSTM.
The above models are only are only trained to predict the production of one well or one reservoir, referred to as ‘single-series learning’. In the same oilfield, there is a certain similarity between each well or each reservoir. If the neural network is able to train multiple related time series and samples altogether in one lumped model, it can not only learn the variation of time series, but also learn the relationship between target variable and features from multiple samples and multiple sequences. This neural network is called ‘cross-series learning’, which can simultaneously predict multiple target variables. At present, this neural network model has been applied to forecast weather, temperature and other fields (Castro et al., 2021; Fang et al., 2021; Javier et al., 2021; Zaytar and Amrani, 2016).
In this study, an LSTM-based sequence-to-sequence model (Seq2Seq-LSTM) driven by reservoir spatial-temporal data was proposed to forecast the oil production of reservoirs in response to the limitations of existing machine learning in predicting oil production. The traditional LSTM models cannot forecast production under the influence of well spacing density and liquid production. The Seq2Seq-LSTM network is employed to learn the interaction from multiple samples and multiple sequences and explores the relationship between oil production and features, such as reservoir properties and development measures. The proposed model can accurately forecast the oil production when the liquid production and well spacing density change, which can provide scientific recommendations to help the oilfield develop and adjust efficiently.
Methodology
Modelling steps
In this work, a method of oil reservoir production prediction based on spatial–temporal data and Seq2Seq-LSTM was proposed to forecast reservoir production considering the influence of liquid production and well spacing density. This method follows the flowchart shown in Figure 1. Next, the modelling steps are elaborated based on the flowchart.
Some reservoirs in the target area are selected as samples to collect the historical production data and the parameters of reservoir physical properties, including oil production, liquid production, production time, number and type of development wells, original formation pressure, reservoir thickness, reservoir area, porosity, heterogeneity and fluidity, and extract the time series of relevant parameters of each reservoir. On the one hand, since the reservoirs in the target area are jointly developed by horizontal wells and vertical wells, in order to standardize and quantify different well types, it is essential to convert the horizontal wells into the equivalent number of vertical wells to obtain the equivalent well spacing density. On the other hand, data normalization is carried out to reduce the adverse impact on model training caused by dimensional differences. Normalized mutual information is used to evaluate the correlation between the feature series and oil production series, and features with strong correlations are imported into the model. The data are divided into training set and testing set. Based on the training set, the structure and parameters of the Seq2Seq-LSTM model are defined and optimized by a genetic algorithm (GA). Based on the trained model and testing set, the oil production of reservoirs considering the influence of liquid production and well spacing density is predicted to verify the accuracy of the model.
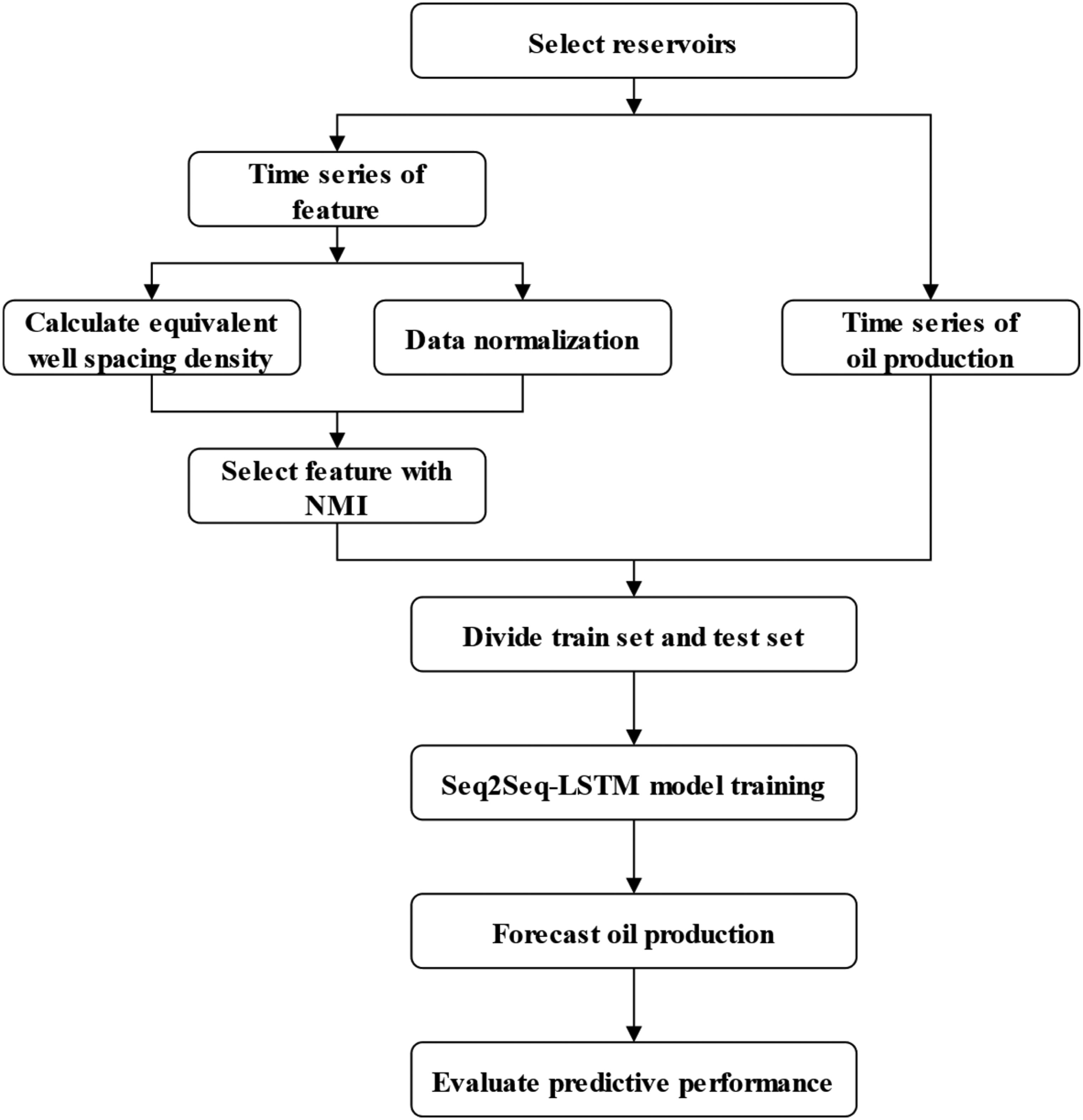
Workflow of the production prediction driven by reservoir spatial–temporal data.
Normalized mutual information
It is very important to select the main features affecting reservoir production, which is helpful to improve the generalization ability and prediction accuracy of the model. The input variable selection is accomplished through normalized mutual information (NMI). NMI is adopted as the similarity measure, as equation (1), which measures how much information, on average, one random variable provides to another (Danon et al., 2006; Liu et al., 2021a; Zhou et al., 2021a). The advantage of NMI is that it can measure the nonlinear relationship between variables.
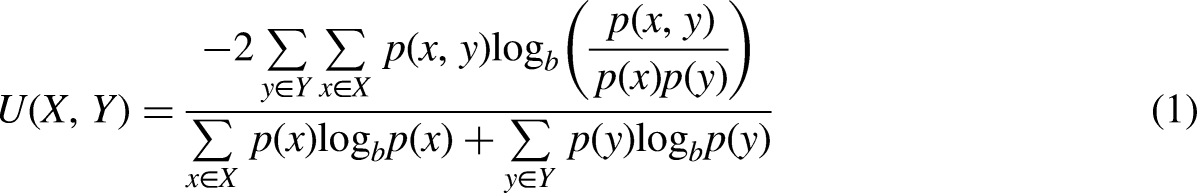
According to the definition of NMI, when U(X, Y) = 0, it shows that X and Y are independent of each other, that is, zero correlation; the larger the value of U(X, Y), the stronger the correlation between X and Y; when U(X, Y) = 1, it shows that X and Y are complete correlation. The value of NMI between each feature and the target is calculated by equation (1), and sorted in descending order. Finally, the first k features are imported into the model.
Long short-term memory
Long short-term memory (LSTM) is a special kind of RNN, capable of learning long-term dependencies (Hochreiter and Schmidhuber, 1997). LSTM is explicitly designed to avoid the long-term dependency problem. LSTM adds a new internal state ct to transmit circular information in linear mode, and then transmits information in nonlinear mode to the external state ht of the hidden layer. Computing processes are demonstrated as






A schematic diagram of the LSTM network is shown in Figure 2. First, the three gates (ft, it, ot) and the candidate value c͂t are calculated by using the output ht−1 at the previous moment and the input xt at the current moment. Next, the cell state ct is updated according to the ‘forget gate’ ft and the ‘input gate’ it. Finally, the internal state ct is processed by the tanh layer and then combined with the ‘output gate’ ot to transmit data messages to the external state ht.
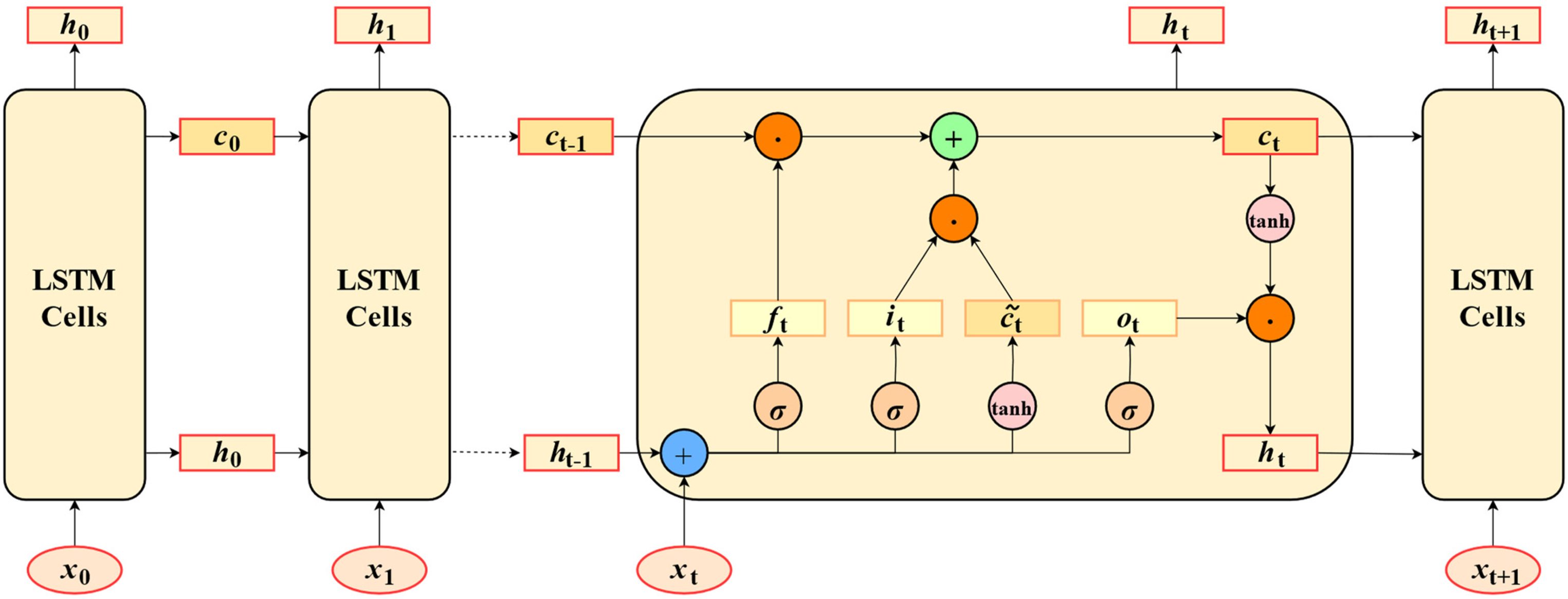
Schematic diagram of long short-term memory (LSTM) network.
LSTM-based sequence-to-sequence model
Seq2Seq-LSTM is an encoder–decoder neural network model composed of two LSTMs, which can realize the conversion from one sequence to another, taking into account the spatial–temporal dependence of multivariate time series data (Du et al., 2018). A schematic diagram of Seq2Seq-LSTM is shown in Figure 3. The model framework includes an encoder and decoder.
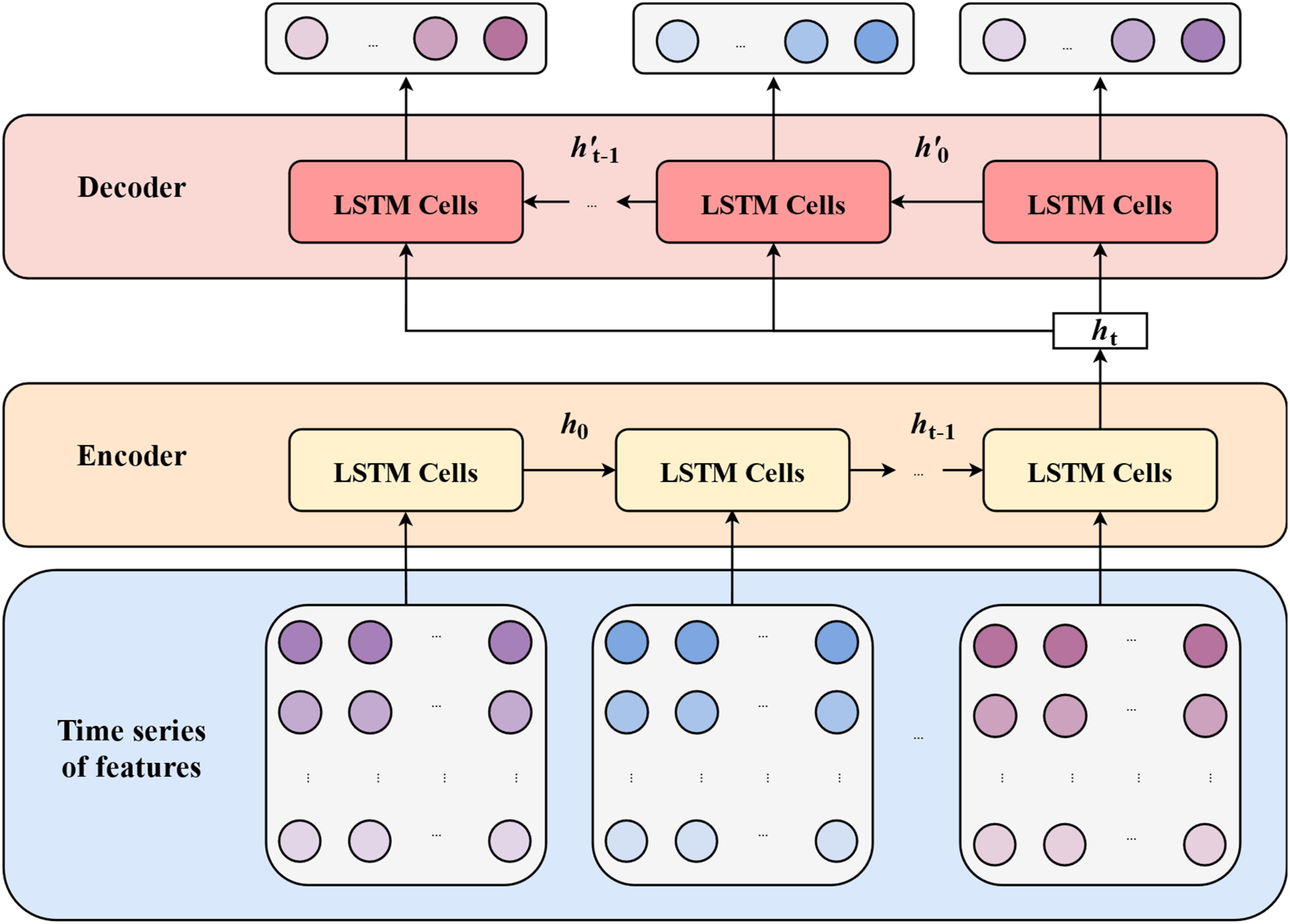
Schematic diagram of long short-term memory-based sequence-to-sequence model (Seq2Seq-LSTM).
The LSTM encoder takes n historical time series X1, X2, …, Xn with length T as imported data for learning and creates the fixed dimension vector u. u is the hidden state of the encoder at the last moment:


When generating the target sequence, the LSTM decoder is used for decoding. At step t of the decoding process, the prefix sequence Y1:(t−1) has been generated.


For the prediction of reservoir production, oil production can be obtained by inputting the sequence of factors. The Seq2Seq-LSTM model driven by spatial-temporal data is to input all reservoir samples at the same time, and then learn the relationship between features and the oil production, so as to input a set of features and output a monthly oil production.
Database establishment
Data pre-processing
The marine sandstone reservoirs in the Y basin are taken as the research object. The structural differences of reservoirs in the Y basin are small, mainly low-amplitude anticline structure, no-fault, and high porosity and permeability. Each reservoir has its own independent oil–water system vertically. The reservoirs are developed by edge water or bottom water drive because of the strong water energy. The development time of these reservoirs is between 4 and 25 years, with complete and accurate historical production data and geological data. Most of the reservoirs are in the ultra-high water cut stage. Development wells in many reservoirs include horizontal wells and vertical wells at the same time. The development measures of these reservoirs are liquid production adjustment and well spacing density adjustment.
The 30 bottom water reservoirs in the Y basin are selected as samples to establish the database by sorting out and analysing the static and dynamic data of reservoirs. Sample selection observes the following principles: marine sandstone reservoirs developed by natural energy; same type of drive; similar oil property; accurate reservoir geological data and development data. According to the development experience of reservoirs, the parameters affecting oil production include static feature parameters and dynamic feature parameters. The static feature parameters include original formation pressure, reservoir thickness, reservoir area, porosity, heterogeneity and fluidity. The static feature parameters include production time, liquid production and well spacing density. Collect the above feature parameters and monthly oil production data of these 30 reservoirs from the beginning of development to January 2020. The static feature parameters of some reservoirs are shown in Table 1.
Static feature parameters of reservoirs.
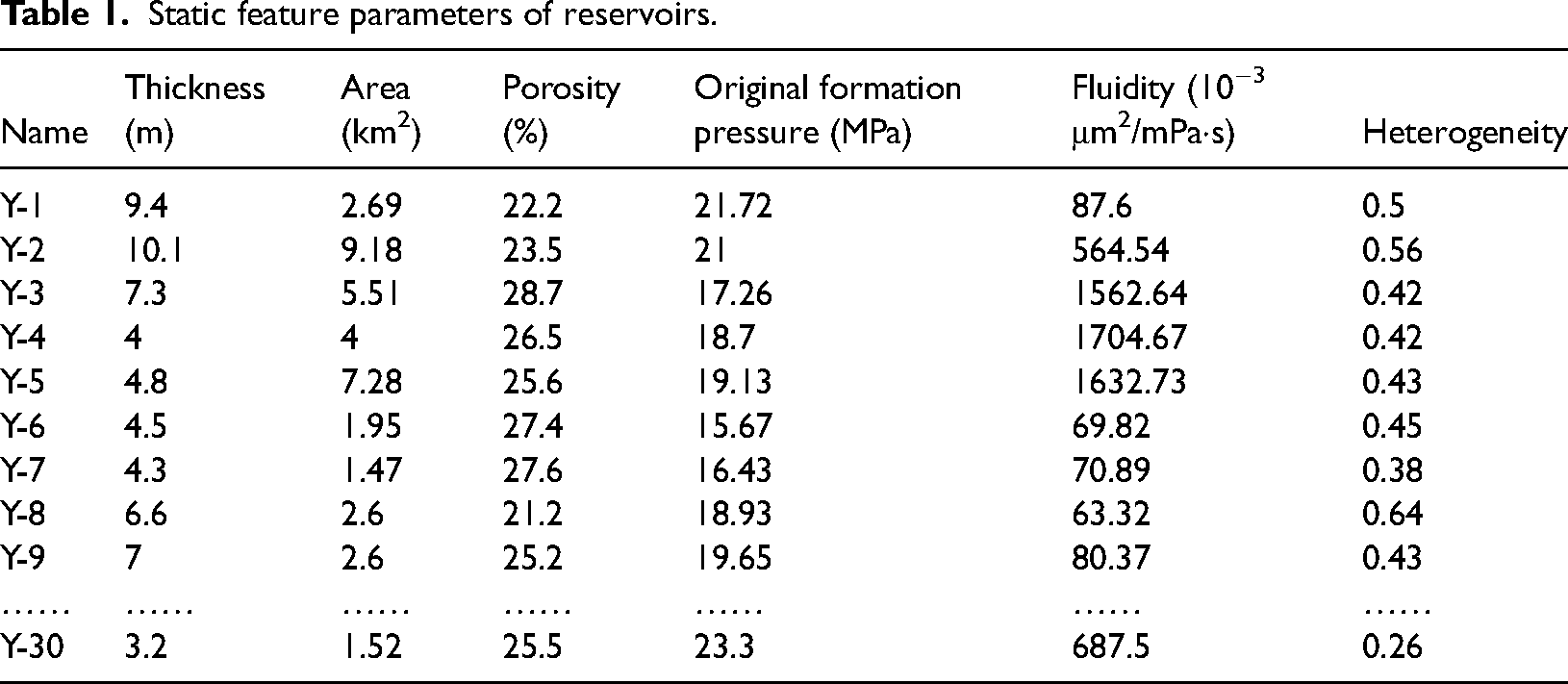
In order to determine the equivalent well spacing density of reservoirs, it is necessary to sort out the type, parameters and production time of each well in the reservoir. The number of different types of wells in the Y-1 reservoir and Y-2 reservoir changes with time, as shown in Figure 4.
Type and number of development wells: (a) Y-1 reservoir; (b) Y-2 reservoir.
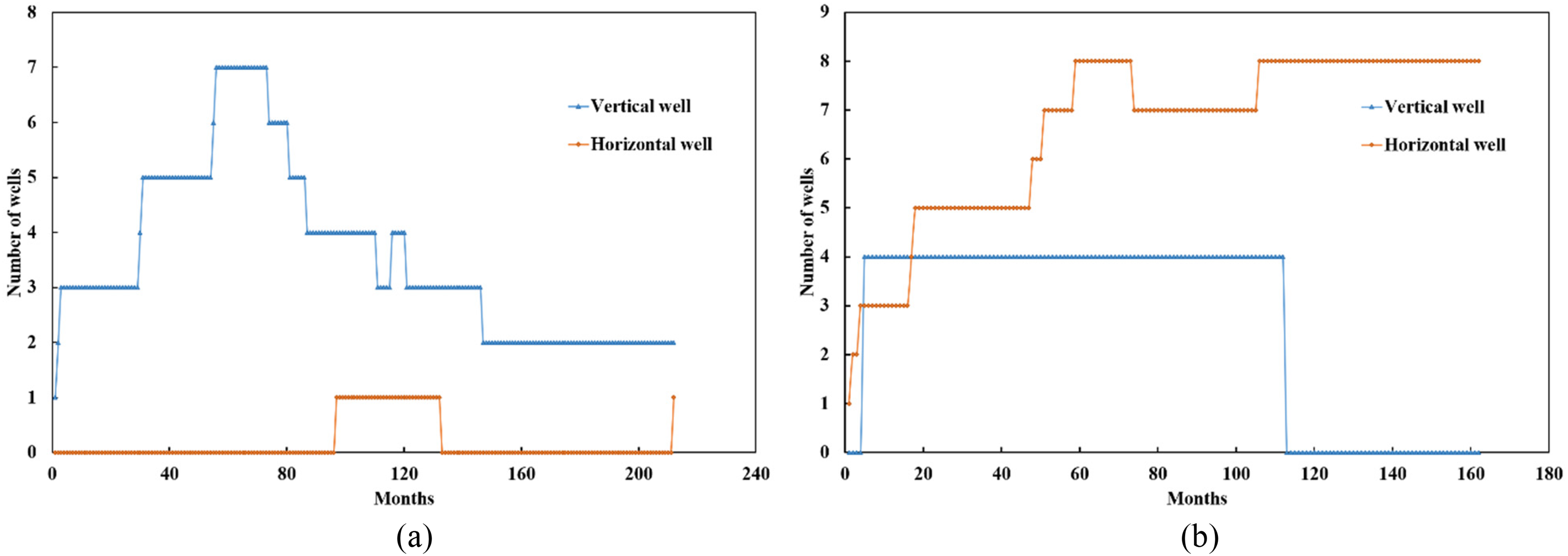
Since the reservoirs in the Y basin are jointly developed by horizontal wells and vertical wells, it is significant to convert the horizontal wells into the equivalent number of vertical wells to obtain the equivalent well spacing density so that different well types can be compared. In this work, the method of converting a horizontal well into vertical wells is based on the same total production and total control area. The equivalent number of vertical wells is calculated by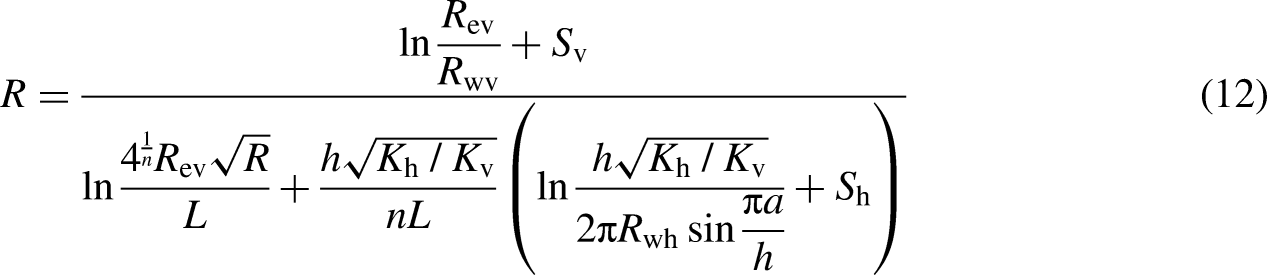
After obtaining the total number of equivalent vertical wells in the target reservoir, the equivalent well spacing density of each reservoir can be calculated, given as follows:
Taking Y-1 and Y-2 reservoirs as examples, the variation of equivalent well spacing density with time is calculated by equations (12) and (13), as shown in Figure 5.
Equivalent well spacing density in the reservoir: (a) Y-1 reservoir; (b) Y-2 reservoir.
Data normalization is carried out to reduce the adverse impact on model training caused by differences in parameter units. Z-score standardization is selected in this study. The standardized parameters of this method are determined by
Feature selection based on normalized mutual information
Feature selection based on NMI is used to analyse the effect of each feature on monthly oil production. The results of the NMI of each feature sequence are shown in Figure 6.
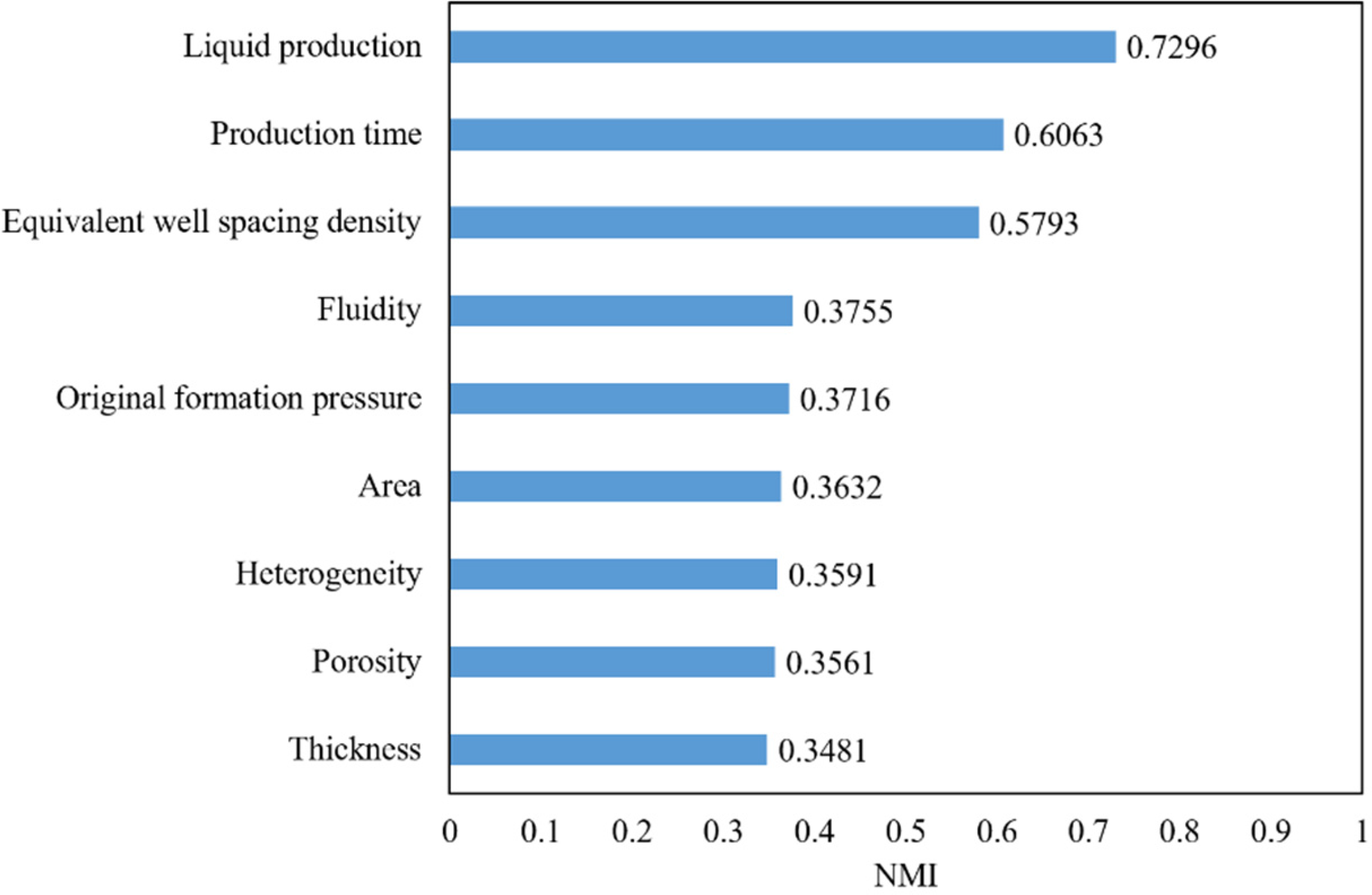
Calculation results of normalized mutual information (NMI).
The larger the value of NMI, the stronger the correlation between feature and oil production. According to the value of NMI from large to small, the correlation between feature and oil production from strong to weak is liquid production > production time > equivalent well spacing density > fluidity > original formation pressure > area > heterogeneity > porosity > thickness.
According to the ranking of NMI calculation results, the first k features are used as import data of the model. In this work, the first five features, which are liquid production, production time, equivalent well spacing density, fluidity, and original formation pressure, are selected as input of the model.
Modelling and application
Model training and structure optimizing
After the feature selection is completed, the prediction model of reservoir production can be established. Firstly, the original time series is divided into a training set and testing set on the basis of the ratio of 8.5:1.5. And then, Adam (Kingma and Ba, 2014) is adopted as a learning algorithm in this study. Adam algorithm can be regarded as the combination of the momentum method and RMSProp algorithm. It not only uses momentum as the parameter update direction, but also can adaptively adjust the learn rate.
Based on the Adam algorithm, the weights of the model are optimized by training the model continuously. Root mean square error (RMSE) is used to characterize the accuracy of the model, and its formula is as follows: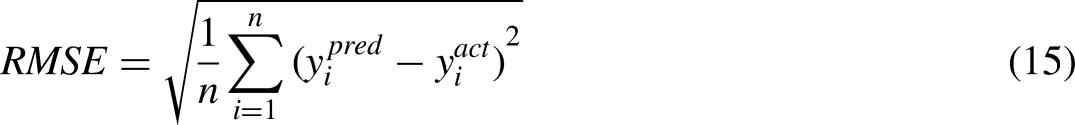
The hyper-parameters of the model are optimized by GA, which uses the random global searching algorithm to simulate the physical process of biological natural evolution, and can select, cross and mutate each individual randomly to search for the optimal solution. In this work, the coefficient of determination (R2) is used as the fitness function of GA.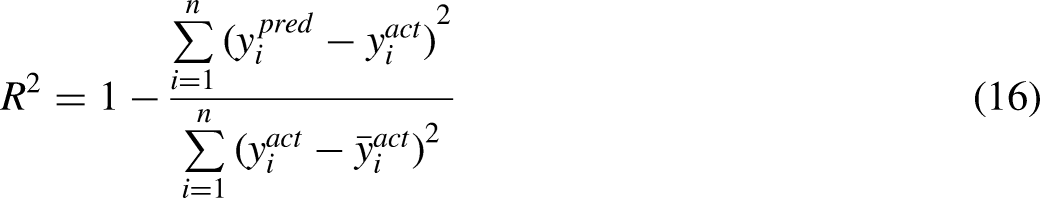
The hyper-parameters of the model include the number of hidden units, fully connected layer, dropout layer, epochs, mini-batch size and initial learn rate. Table 2 shows the ranges of hyper-parameters for models. The optimum hyper-parameters of the proposed model Seq2Seq-LSTM are shown in Table 3, which are optimized by GA.
Ranges of hyper-parameters.

Obtained optimum hyper-parameters of Seq2Seq-LSTM based on GA.

Seq2Seq-LSTM: long short-term memory-based sequence-to-sequence model; GA: genetic algorithm.
Result verification
In this study, two reservoirs (Y-1 and Y-2 reservoirs) from the database are used to validate the proposed Seq2Seq-LSTM model. There is a total of 212 actual monthly oil production of the Y-1 reservoir and 162 actual monthly oil production of the Y-2 reservoir. The original series is divided on the basis of the ratio of 8.5:1.5 to obtain the training set and testing set, and the original oil production series, liquid production series, and equivalent well spacing density series are shown in Figure 7. According to Figure 7, the relationship between oil production, liquid production, and well spacing density can be understood intuitively. In general, the reservoirs developed by natural energy mainly adjust the oil production by changing liquid production and well spacing density. The oil production increased to varying degrees when the well spacing density or liquid production increased. In the Y-1 reservoir, the oil production in the 209th month increased, because the well spacing density and liquid production increased significantly. In the Y-2 reservoir, the oil production in the 113th-month oil production gradually decreased on the whole, because the well spacing density remained unchanged and the liquid production slightly decreased on the whole.
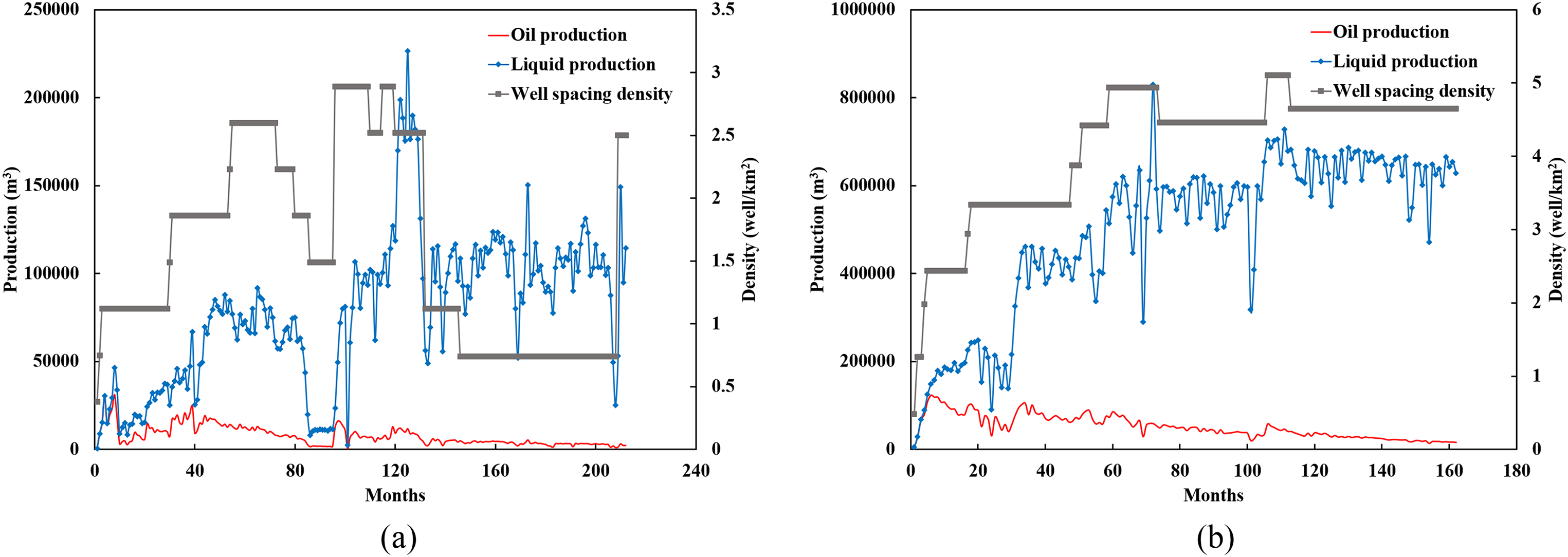
The original oil production, liquid production and equivalent well spacing density: (a) Y-1 reservoir; (b) Y-2 reservoir.
Figure 8 shows the prediction results of the proposed model, in which the actual oil production rate is compared with the predicted values using Seq2Seq-LSTM. It is clear that the oil production calculated by the proposed model is very close to the actual value. The data points of the training set and testing set are basically distributed near the 45° line (the closer to the 45° line, the smaller the deviation between the predicted value and the actual value). Based on the results, the proposed model can accurately reproduce the reservoir development history and better forecast the future monthly oil production of the reservoir.
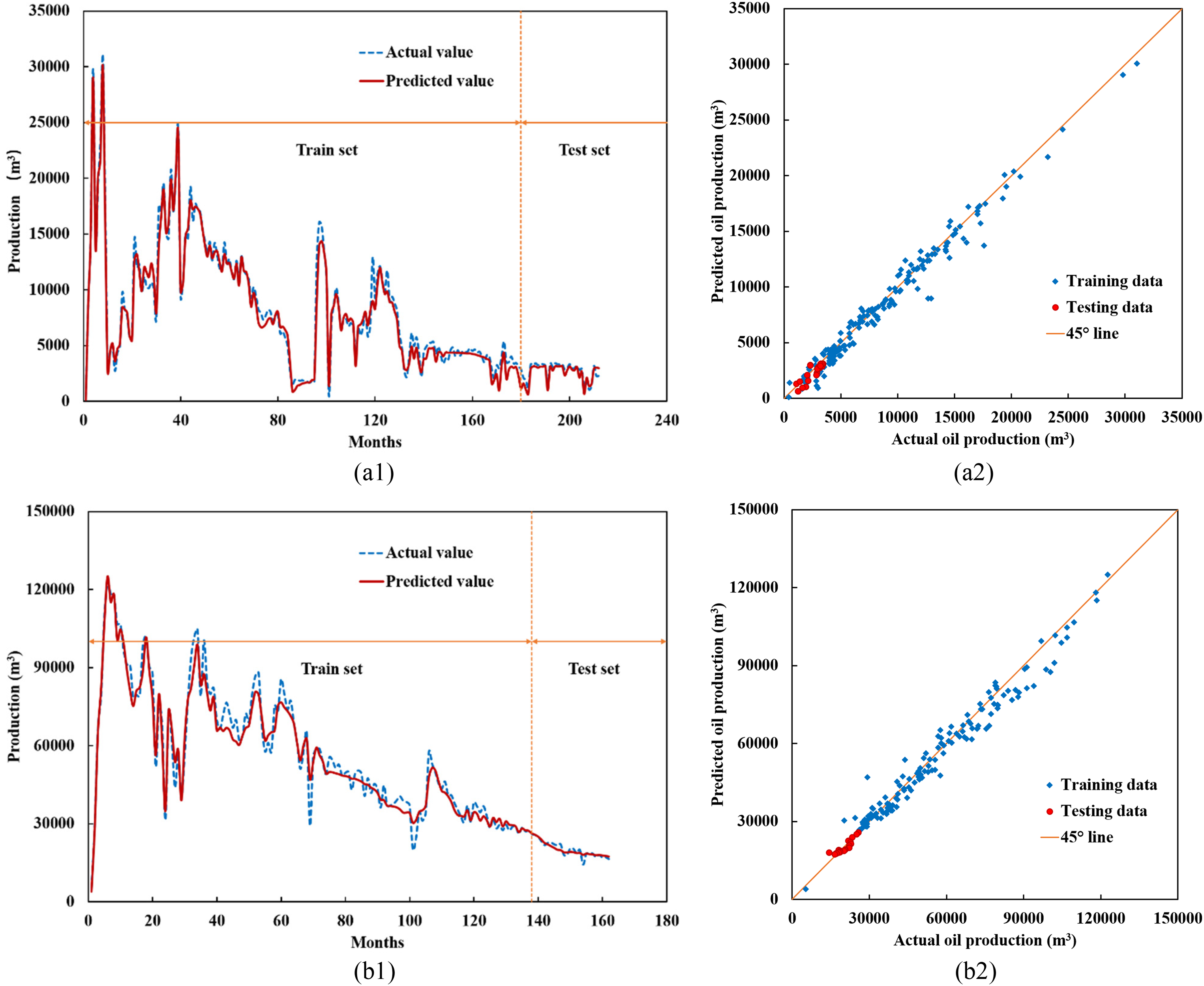
Comparison between actual production and predicted value of long short-term memory-based sequence-to-sequence model (Seq2Seq-LSTM): (a) Y-1 reservoir; (b) Y-2 reservoir.
The predictive performance of Seq2Seq-LSTM is summarized in Table 4. When the coefficient of determination R2 is close to 1, it indicates that the model is accurate. The R2 of the test set in Y-1 and Y-2 reservoirs is 0.829 and 0.814, which means that the predictive performance of the proposed model is superior.
Performance of long short-term memory-based sequence-to-sequence model (Seq2Seq-LSTM) in Y-1 and Y-2 reservoirs.

In order to verify the superiority of the Seq2Seq-LSTM model, the traditional LSTM model is used to predict the oil production of the Y-1 reservoir. The oil production results predicted by the two methods from month 181 to month 212 are shown in Figure 9.
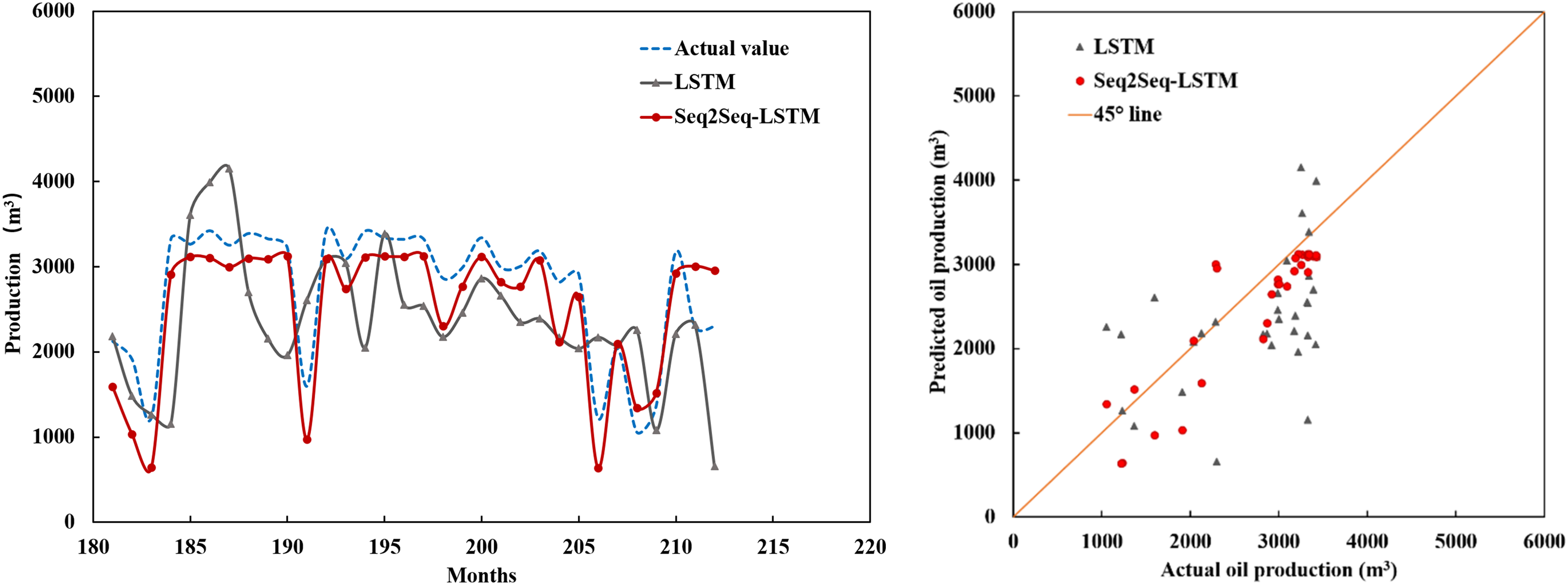
Comparison of prediction results of Seq2Seq-LSTM and LSTM in Y-1 reservoir.
According to the prediction results of the test set in the Y-1 reservoir, the R2 of the LSTM model is 0.235, which is much lower than the 0.829 of the Seq2Seq-LSTM model, indicating that the prediction performance of Seq2Seq-LSTM model is significantly better than that of LSTM model. In the process of oil field production, liquid production and well spacing density are constantly adjusted, which has a great impact on oil production. The Seq2Seq-LSTM model can accurately predict the change in oil production after taking development measures because it learns the influence of liquid production and well spacing density change on oil production. However, the traditional LSTM model can only predict future oil production by relying on past oil production, so it can not reflect the impact of development measures on oil production.
In summary, the monthly oil production of reservoirs predicted by the method based on spatial–temporal data and Seq2Seq-LSTM is similar to the actual value. The advantage of the proposed model is that it can predict the oil production when liquid production and well spacing density of reservoirs change. Since the model learns the variation of oil production and features with time in multiple reservoirs through cross-learning, and explores the relationship between oil production and features, it can accurately predict the corresponding oil production even when liquid production and well spacing density are adjusted, which proves the reliability of the model.
Production prediction under different development measures
After verifying the reliability of the Seq2Seq-LSTM model driven by reservoir spatial-temporal data, taking the Y-2 reservoir as an example, the model is used to forecast the oil production in the next 24 months under different liquid production and well spacing density of reservoirs.
Figure 10 shows the predicted results of monthly oil production under different liquid production. The results show that if the current conditions remain unchanged, the trend of the predicted oil production is consistent with the declining trend of the original oil production. If the liquid production increased, the predicted oil production increased rapidly, then decreased rapidly and finally decreased slowly. If the increase of liquid production is larger, the predicted cumulative oil production is larger, which indicates that the oil production of the reservoir can be improved by increasing liquid production in this development stage. These reservoirs are developed using natural water energy without the need for additional water injection. Therefore, there is no need to consider the economic cost of increasing liquid production. In addition, the liquid production studied did not exceed the maximum liquid production in the history of the reservoir.
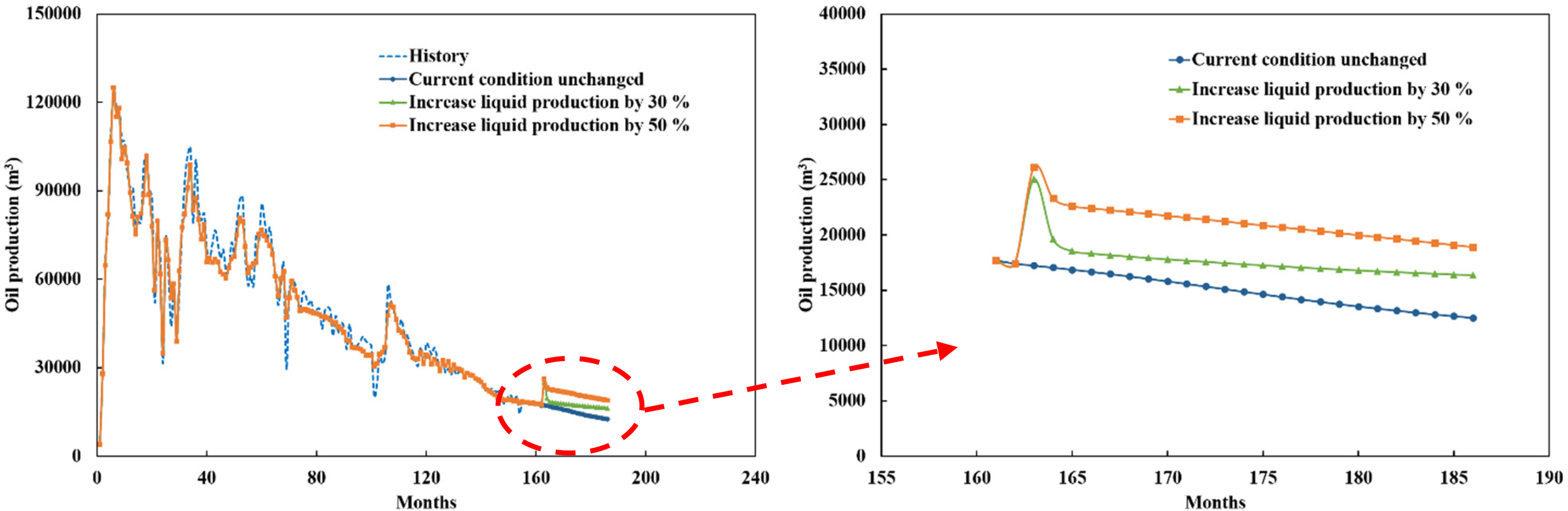
Predicted results of monthly oil production under different liquid production.
Figure 11 shows the predicted results of monthly oil production under different equivalent well spacing densities. The results show that if the equivalent well spacing density increased, the predicted oil production increased rapidly, then decreased slowly. If the number of equivalent vertical wells increases more, the predicted cumulative oil production is larger, which indicates that the oil production of the reservoir can be improved by increasing equivalent well spacing density in this development stage.
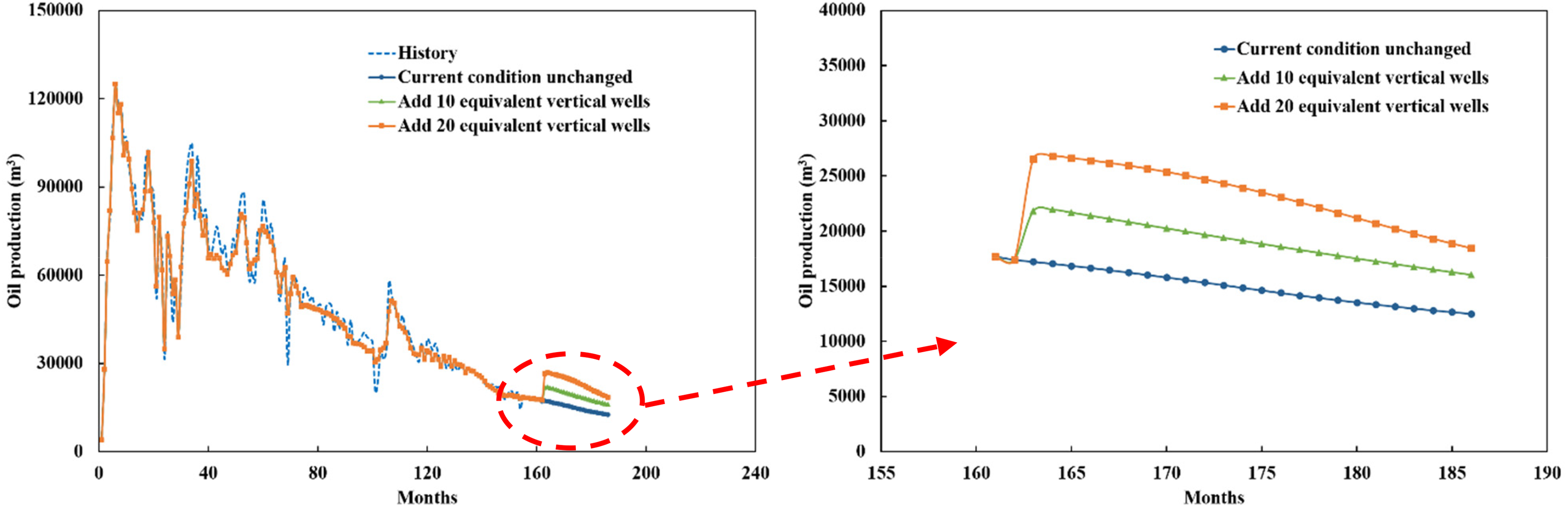
Predicted results of monthly oil production under different equivalent well spacing densities.
Since the Seq2Seq-LSTM model driven by reservoir spatial–temporal data learns the influence of changes in liquid production and well spacing density on oil production, it can accurately predict the oil production of the reservoir after taking development measures. Therefore, the method can be used as an effective way to predict oil production and analyse the remaining potential of reservoirs, which can help to adjust the reservoir development plan.
Conclusions
In this work, we took marine sandstone reservoirs in the Y basin as the research object to establish the sample database. Then, liquid production, production time, equivalent well spacing density, fluidity and original formation pressure were determined as input features according to the normalized mutual information. Finally, a Seq2Seq-LSTM model driven by reservoir spatial-temporal data was established to forecast oil production. By testing the performance of the proposed model on different samples, the following key conclusions are drawn:
A method of oil reservoir production prediction based on normalized mutual information and Seq2Seq-LSTM is proposed to forecast reservoir production considering the influence of liquid production and well spacing density. The Seq2Seq-LSTM model can not only learn the variation of production time series, but also learn the interaction from multiple samples and multiple sequences through cross-learning, and explores the relationship between oil production and every feature. It can be an alternative way for fast and accurate prediction of oil production considering the influence of liquid production and well spacing density in practical application. Two case studies (Y-1 and Y-2 reservoirs) from the database are used to prove the proposed Seq2Seq-LSTM model. The coefficient of determination of the test set in Y-1 and Y-2 reservoirs are calculated to be 0.829 and 0.814, which means that the predictive performance of the proposed model is superior. Meanwhile, compared with the traditional LSTM model, the prediction performance of the proposed model is significantly better than that of the LSTM model. Taking the Y-2 reservoir as an example, the proposed Seq2Seq-LSTM model is used to forecast the oil production in the next 24 months under different liquid production and well spacing density of reservoirs. The experimental results are in good agreement with the experience of the target oilfield. The method can be used as an effective way to predict oil production and analyse the remaining potential of reservoirs, which can help to adjust the reservoir development plan. This study is equivalent to simplifying each reservoir. In order to forecast oil production more accurately, the factors affecting oil production can be considered more comprehensively in future work.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed the following financial support for the research, authorship, and publication of this article: This work received funding support from National Natural Science Foundation of China (51974343).