
Abstract
Subject relative clauses (RCs) have been shown to be acquired earlier, comprehended more accurately, and produced more easily than object RCs by children. While this subject preference is often claimed to be a universal tendency, it has largely been investigated piecemeal and with low-powered experiments. To address these issues, this meta-analysis follows an established and rigorous scientific method to test the generalizability of the subject preference in RC acquisition by evaluating the collective evidence. While the results show a significant crosslinguistic subject preference, there is a large amount of heterogeneity in the data. The manifestation of this subject preference may not be uniform across languages, depending on typological properties such as language headedness, RC headedness, and main clause similarity. The true impact of these features, however, requires research on more typologically diverse languages.
Introduction
Ever since Keenan and Comrie (1977) proposed the Noun Phrase Accessibility Hierarchy to account for the typological generalization on the availability of relativization in different grammatical noun phrase (NP) positions, studies in relative clauses (RCs) have been on a quest to explore to what extent this hierarchy reflects the psychological reality in the acquisition and processing of RCs. Much of the research in child language has focused on whether there is a subject–object asymmetry, that is, an asymmetry in performance and preference between subject RCs (SRCs) and object RCs (ORCs). Simply put, SRCs (1) are generally acquired earlier than ORCs (2).
(1) the apprentice [RC who _ betrayed the master ] (2) the master [RC who the apprentice betrayed _ ]
In corpus studies, this is indicated by the earlier emergence and subsequent mastery of SRCs than ORCs. Cross-sectional experimental studies show that SRCs are interpreted more accurately and quickly, and produced with fewer errors than ORCs. These findings are taken to demonstrate the developmental sequence in children’s acquisition of RCs: patterns that are easier to process are also mastered earlier by children (e.g. Kidd & Bavin, 2002; O’Grady, 2011). This pattern prevails in many languages and beyond child language acquisition (e.g. adult language processing, second language acquisition), leading to the claim that the subject preference is a universal tendency.
This might not always be the case, however. With increasing research on typologically diverse languages, some studies have shown divergent patterns in the RC preference. A crosslinguistic survey by Lau and Tanaka (2021) demonstrated that research on languages with typological differences in RC construction has found that results range from a clear subject preference to a clear object preference, with some studies reporting a lack of evidence for any preference. While varying results may pose challenges for the generalizability of the subject preference, the variable direction of the asymmetry also suggests the presence of multiple factors related to the different typological properties across languages. Here, we briefly review five such factors that have been proposed to account for the asymmetry: resource-based, experience-based, main clause similarity, prominence, and structural effects; however, as explained in section ‘The current study’, the current meta-analysis addresses just two of them due to the limitation of the sample: resource-based and main clause similarity effects.
Resource-based effects are attributed to the working memory resources required to process RCs. Here, we consider what Gibson and Wu (2013) referred to as ‘retrieval cost’, which is associated with retrieving and integrating the information stored in working memory. The retrieval cost can be inferred from the linear distance between the head and the gap in RCs. This determines processing ease, based on the differences in the amount of cognitive load associated with storing the filler-gap information (e.g. Gibson, 1998, 2000; King & Just, 1991; Wanner & Maratsos, 1978). The logic is that engagement in more simultaneous tasks (e.g. storing unresolved dependency until resolved by input while processing other incoming information) requires more resources, resulting in increased processing difficulty. The degree of difficulty is often measured in terms of the length (by linguistic units) of the dependency: The longer the dependency, the greater the cognitive load. One of the typological differences that influences the dependency length is the RC headedness, that is, the relative position of the relativized NP, or the ‘head’ to the RC. Under this account, the subject preference in head-initial RCs, in which the head precedes the RC, is attributed to the shorter filler-gap dependency in SRCs (1) compared to ORCs (2). However, this account predicts an object preference for head-final RCs, in which the head follows the RCs. This is because of a shorter filler-gap dependency in ORCs (4) than in SRCs (3), as shown in the Mandarin examples below.
(3) [RC _ beipan shifu de ] tudi betray master ‘the apprentice who betrayed the master’ (4) [RC tudi beipan_ de] shifu apprentice betray ‘the master who the apprentice betrayed’
The resource-based effects would also predict different results depending on the canonical word order of the language. In SOV languages with head-final RCs, such as Japanese and Korean, SRCs have a longer dependency than ORCs, much like Mandarin. There is, however, another way to characterize the retrieval cost, focusing not on the distance but on where the integration of information of all levels (e.g. semantic, syntactic, etc.) happens, such as the verb. Under this second explanation, Japanese and Korean are predicted to have no subject–object asymmetry (Gibson & Wu, 2013), because the verb, where the NP information is integrated, is right next to the head noun in both types of RCs. Consequently, SOV languages with head-initial RCs, like Persian, are also hypothesized to show no asymmetry (Rahmany et al., 2014). While both versions are referred to as retrieval/integration cost accounts by Gibson and Wu (2013), we call this second type of resource-based effects as those related to integration, and differentiate it from the first type of resource-based effects associated with the distance, as they make different predictions for SOV languages.
The experience-based effects are proposed based on the logic that speakers of a language hear certain patterns more frequently than others, and that this previous experience shapes how they use the language (Ambridge et al., 2015). In the context of child language research, the frequency of certain patterns in child-directed speech helps predict the outcomes in child speech. The frequency discrepancy between SRCs and ORCs is apparent if animacy is taken into account. This is due to the general tendency of SRC heads being animate, and ORC heads being inanimate. Nevertheless, many experimental studies compare SRCs with ORCs, both with animate heads. While such control is necessary for some experimental designs, it creates a situation where the frequent type of SRCs is pitted against the infrequent type of ORCs, in which case a subject preference is not surprising. Previous studies (e.g. Kidd et al., 2007) found that, when animate-headed SRCs are compared to inanimate-headed ORCs, children find both RC types equally easy to interpret.
In a similar vein, the resemblance of RC to canonical word order patterns has been proposed to influence a language’s RC preference (Bever, 1970; Diessel & Tomasello, 2005). We refer to this factor as the main clause similarity effect. In English, for example, SRCs follow the S[VO] pattern, which resembles the canonical SVO word order, while ORCs follow the O[SV] pattern. According to this proposal, the English subject preference stems from the close similarity of SRCs to main clauses. Variations in languages’ canonical word order (language headedness) and RC constituent configuration (RC headedness) determine which type of RC shows main clause similarity. For example, in an SVO language with head-final RC constructions, like in Mandarin, ORCs (instead of SRCs) would enjoy the advantage of word order similarity with main clauses due to their word order [SV]O.
The subject preference is also attributed to the prominence of the subject (e.g. O’Grady, 2011). Because a clause is usually focused on the referent of the subject, the most prominent argument, it is therefore hypothesized that an RC would be easier to be regarded as a restrictor if the referent of the head noun is the subject. 1 In other cases, it would be difficult since the focus of the clause does not align with the referent of the head noun. Other relevant prominence effects that have been explored include topicality (e.g. Mak et al., 2006) and perspective (e.g. MacWhinney, 2005).
Finally, it is also possible to account for the subject preference based on the structural effects. One suggestion is that the subject preference is attributed to the privileged structural position associated with the subject (e.g. Collins, 1994; Hawkins, 2004). While the application of this hypothesis depends on how RCs are structurally derived, subjects are analyzed to be external to VPs and objects inside VPs in many languages, which makes subjects less deeply embedded and more accessible than objects. Another structural account attributes the difficulty associated with ORCs to the intervening element between the head and the gap (e.g. Friedmann et al., 2009). A subject preference is observed because such an intervener is absent in SRCs, but it is possible to manipulate the features of the intervener to reduce the difficulty with ORCs.
In this meta-analysis, we set out to evaluate the generalizability of the subject preference in previous studies across languages with different typological properties and research designs. We also evaluate the relative influence of different factors reviewed above to the extent possible within the scope of the study and the nature of the data set, which are explained in the next section. The investigation will shed light on whether a shared mechanism influences the acquisition of different languages, and what its relationship is to language-specific factors.
The current study
This study investigates whether the meta-analysis of cumulative findings points toward a crosslinguistic tendency for a subject preference in child language. We also ask whether variations in this preference can be accounted for by typological differences in relation to the factors we reviewed in section ‘Introduction’. We are particularly interested in the relative influence of multiple factors rather than finding one determining factor.
In the analysis below, we limit our scope to comprehension experiments that use picture selection (sentence–picture matching, picture–sentence matching) or referent (character) selection tasks. In these tasks, children are presented with two or more pictures, from which children choose a correct picture (picture selection) or a correct referent within the picture (referent selection) to match the sentence they hear. Referent selection may also be done using toys as in Brandt et al. (2009). Such paradigms were chosen because they are the most common methodology in the observation of child acquisition of RCs. While each has its own limitations, these tasks are comparatively easier for cross-comparison because by their very nature they present finite response options, making the interpretation of the data of these tasks less noisy and variable than more open-ended tasks (such as elicited production). There are also fundamental differences between the two paradigms. A picture selection task typically requires children to pick a picture that matches the event described by the RC rather than the target referent identified by the RC. This paradigm has been criticized for being infelicitous in testing children’s understanding of the restrictive function of an RC, which is to narrow down to a specific referent, potentially resulting in an over-estimation of a child’s performance (e.g. Adani, 2011; Arnon, 2005; Hu, 2014). Referent selection is then introduced as a remedy by requiring children to identify a referent instead of a picture of the event. Because this method requires reversible events with multiple animate referents, the task demand of the referent selection task is high and the setup of the task might potentially create bias toward certain types of RCs, leading to an under-estimation of children’s RC knowledge. Another improved variant of the referent selection task uses toys instead of pictures, accompanied by a supporting discourse context (Brandt et al., 2009). To be inclusive, we considered all three types of methods in the current meta-analysis, and the nature of tasks is included as a predictor in the analyses to account for the potential task differences.
In addition to the task adopted in the study, we coded the language tested, as well as the typological properties of the language such as language headedness, RC headedness, and main clause similarity to help generate predictions based on the effects reviewed in section ‘Introduction’.
Language headedness refers to the structure of phrases in a language, including verb phrases, noun phrases, and adpositional phrases (Polinsky & Magyar, 2020). Based on their main clause word order, languages are categorized as head-initial or head-final. Languages may not be fully consistent in headedness for all phrasal types; we follow the widespread practice of categorizing languages according to the placement of the verb, as the head, relative to its constituent in verb phrases.
2
English is an example of a head-initial language, while Japanese and Korean are examples of head-final languages. Language headedness also correlates with the structure of RCs. Head-initial languages tend to have head-initial RCs, as shown in the English example (5), and head-final languages tend to have head-final RCs, as shown in the Japanese example (6).
(5) the apprentice [RC who betrayed the master] (6) [RC sisyoo-o uragit-ta] desi master- ‘the apprentice who betrayed the master’
However, as mentioned, not all languages are fully consistent in headedness across phrasal types. For example, Cantonese and Mandarin have a head-initial verb phrase but use head-final RCs. Persian uses head-final verb phrases but uses head-initial RCs. For this reason, we treat RC headedness separately from language headedness.
Based on language headedness and RC headedness, we categorize the languages into four types as summarized in Table 1. We label each variation with the name of a representative language.
The plausible RC constructions.
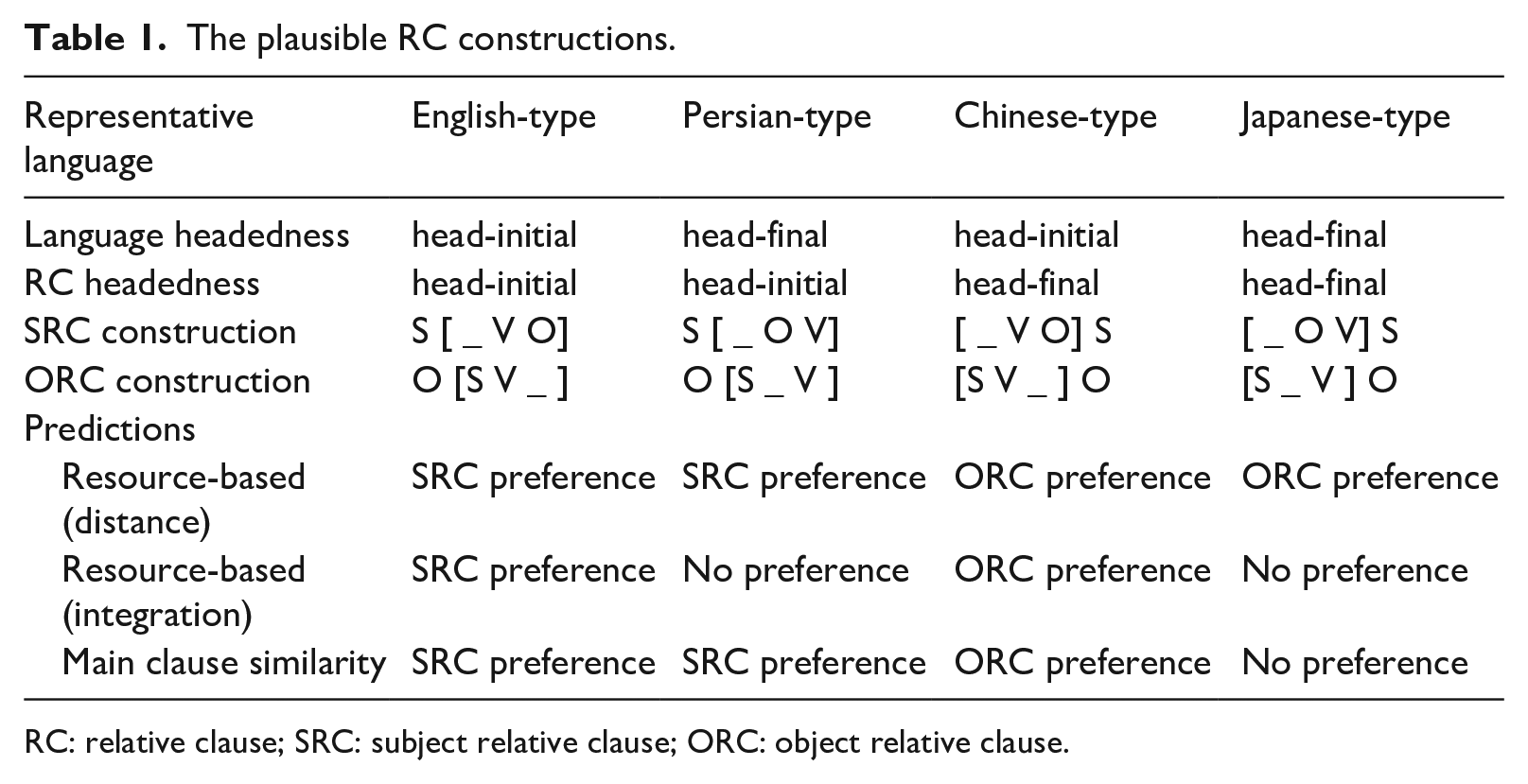
RC: relative clause; SRC: subject relative clause; ORC: object relative clause.
The resource-based and main clause similarity effects generate different predictions for these languages. As reviewed in section ‘Introduction’, resource-based effects, if based on the distance, generate subject preference for head-initial RCs as used in English and Persian but object preference for head-final RCs used in Japanese and Chinese. 3 If there are resource-based effects related to integration costs, the predictions for head-initial languages are unaffected but head-final languages such as Japanese and Persian are predicted to show no preference. Because the predictions based on resource-based effects are generated based on language headedness and RC headedness, we further investigate the interaction of the two factors. In addition, the similarity of the constituent orders of main clauses and RCs (main clause similarity) was coded as a separate moderator.
This meta-analysis does not address the experience-based, prominence, and structural effects as we were not able to estimate the influence of relevant factors in our models. For example, we coded animacy configuration to address experience-based effects, but, as mentioned previously, most of the comprehension tasks thus far used reversible actions with animate referents and there were not enough data points of studies involving inanimate referents to generate meaningful predictions about animacy. We also coded morphosyntactic alignment to consider prominence effects, but only one study (Gutierrez-Mangado, 2011) met our eligibility criteria and did not contribute meaningful statistics. Finally, we coded the form of the intervener (embedded subject) in ORCs (e.g. number marking, gender marking, pronoun, lexical NP) to consider whether such structural effects modulate the difficulty of ORCs and the degree of subject preference, as proposed by Friedmann et al. (2009). However, these predictors also lacked sufficient variation for meaningful comparisons.
This meta-analysis thus focuses on resource-based and main clause similarity effects. We investigate the relative influence of these factors, considering the possibility that there is no one determining factor for the RC preference, but rather all or some of these different factors cumulatively influence the RC preference in child language acquisition. For example, in the case of English, the clearest results pointing toward a subject preference are expected, while the results may not be as clear cut in Chinese- and Japanese-type languages in which different factors generate different predictions.
Significance of meta-analysis
Meta-analysis is a relatively new methodology for the field of language acquisition. We found only seven such studies in the major journals, such as First Language, Journal of Child Language, Language Acquisition, and Language and Learning Development, with six published between 2020 and 2022. However, we think the field would benefit from greater use of this methodology, which enables us to address a major problem with the current state of the research: the lack of a comprehensive crosslinguistic picture. This lack is largely due to methodological constraints.
First, subject preference has been investigated in a piecemeal fashion, with individual research teams working on one or a few languages and employing different experimental designs, although their methodologies are often similar. In addition, most (psycho)linguistic studies are statistically underpowered (Vasishth & Gelman, 2021; Winter, 2019). This is particularly evident in experimental studies with children, which typically include a small number of trials so as not to overburden the young participants. Child language research also tends to involve a small number of participants, due to the labor-intensive nature of data collection. These practical issues are difficult for individual researchers to avoid. Nevertheless, researchers have collectively tested hundreds or possibly thousands of children with similar methodologies. As Vasishth and Gelman (2021) suggested, meta-analysis offers a way to address the issue of low-powered experiments because it allows us to combine previous efforts and examine the collective evidence by evaluating the summary effect.
There are at least two studies that share a similar goal. Vasishth et al. (2013) conducted a meta-analysis focusing on psycholinguistic research on adult Chinese speakers’ RC preferences in order to explain the mixed observations in Mandarin studies. Lau and Tanaka (2021) synthesized the evidence on RC preferences across different languages and populations, although their review does not qualify as a systematic review or meta-analysis as the data collection methods were not reported and the summary effects were not statistically evaluated.
The current study is distinct from these previous reviews in two aspects. First, the current study engages the literature on child RC acquisition across languages, focusing on comprehension studies that employ very common paradigms (i.e. picture/referent selection tasks). This is different from Vasishth et al. (2013), which focused on research on adult processing in Mandarin, or Lau and Tanaka (2021), which included studies with a wider range of participant populations. Second, as explained in the next section, we employed PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses; Page et al., 2021), a rigorous scientific method for research synthesis that establishes up-to-date meta-analytic protocols. This protocol was not used in Vasishth et al. or Lau and Tanaka’s studies.
We demonstrate the steps for applying meta-analysis to research on language acquisition with the hope of encouraging future researchers to think of it as an option to consolidate studies that share similar interests.
Methods
We followed the procedures described by Cooper (2016), Borenstein et al. (2009), and the guidelines established by PRISMA to conduct the current meta-analysis, focusing on studies using the picture or referent selection task, one of the most widely used methods to test children’s comprehension of RCs.
Search strategy
The first and second authors identified 469 relevant records by searching four databases: Linguistics and Language Behavior Abstracts (LLBA), Education Resources Information Center (ERIC), ProQuest Dissertations & Theses Abstracts & Indexes (A&I), and Web of Science Core Collection through ProQuest. Using Boolean operators ‘AND’ and ‘OR’, the keywords were set so that the search engines would find any paper including ‘relative clause(s)’ as well as one of the following terms specifying the task: ‘picture selection’, ‘sentence-picture matching’, ‘picture-sentence matching’, ‘character selection’, or ‘referent selection’. Of the 469 records, 90 duplicates were removed prior to screening using the ‘Find Duplicates’ function in EndNote X9, leaving 379 records.
Eligibility criteria
Reports meeting the following eligibility criteria were selected during the coding process:
(A) The study includes data from typically developing, neurotypical children with normal hearing. This includes control participants in studies on bilinguals, second language acquisition, clinical populations, and so on.
(B) The report must minimally include the comparison of SRCs and ORCs.
(C) The report must involve a task referred to as ‘sentence-picture matching’, ‘picture-sentence matching’, ‘picture selection’, ‘character selection’, or ‘referent selection’.
(D) The outcome measure(s) must include accuracy. 4
(E) The relevant information on descriptive or inferential statistics are available through the published reports or through publicly available data in online repositories.
Study selection
The first and second authors screened the 379 records based on titles and abstracts and excluded 307 records. Of the 72 reports then sought for retrieval, one was not available. The remaining 71 reports were assessed for eligibility by the first and second authors as well as five research assistants who served as coders. 5 Reports were excluded for the following reasons: did not contain qualified participant groups (n = 31; Criterion A); did not compare SRCs and ORCs (n = 7; Criterion B); did not contain any qualified experiment (n = 1; Criterion C); the relevant statistical information was not available (n = 2, Criterion E). In the end, 30 reports were included in the statistical analysis (section ‘Data analysis’). The 30 reports were further divided into 76 separate studies based on the number of separate statistical tests performed on different participant groups, conditions, languages, and so forth, which were treated as independent studies in subsequent analyses. One study from Abu Bakar et al. (2016) was excluded because we could not calculate the effect size estimate based on the reported descriptive statistics (mean = 100%; SD = 0). The meta-analysis included the remaining 75 studies. This procedure followed the PRISMA flowchart in Figure 1. A list of all reports assessed for eligibility, sorted by inclusion/exclusion criteria, is provided in Supplemental Material 1.
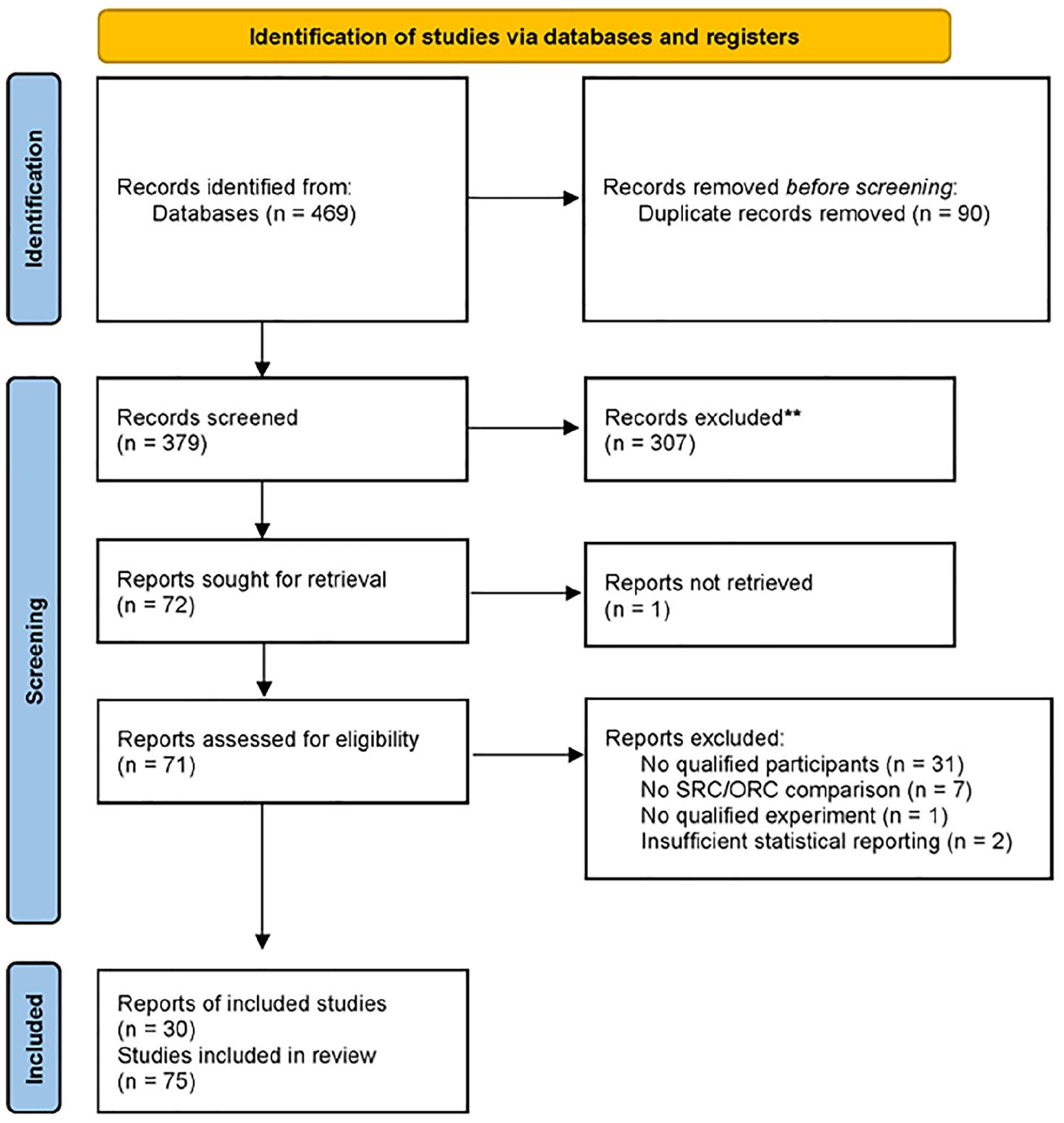
PRISMA Flowchart on Study Selection.
Data extraction
Five coders blind to the purpose of the meta-analysis extracted study characteristics, language characteristics (e.g. language name, language headedness, RC headedness), participant characteristics, and outcome measures (descriptive statistics such as mean accuracy and standard deviation, if any), based on a predefined coding scheme. Each study was coded by at least two coders. Due to technical issues, the second author recoded a subset of the reports. Any inconsistency between coders was resolved through discussion between the first and second authors.
The coding of statistical tests and effect size estimates was done by the second author. The effect sizes on the difference in comprehension between SRCs and ORCs for independent population samples (e.g. age groups and experimental conditions) were extracted and then transformed into d-family effect sizes.
Of the 75 studies included, the effect sizes of 18 studies were estimated based on the effect estimates reported as test statistics in text, including 11 studies reporting the logistic-regression statistics (odds ratio, OR; log odds ratio, LOR) and 7 reporting analysis of variance (ANOVA)-type statistics (F, t, or Z). For the remaining 57 studies, whose effect sizes were not reported or were not usable for data analysis, we extracted descriptive statistics (means, M; standard deviations, SD) and computed effect sizes based on the retrieved information. Out of these 57 studies, 49 of them reported usable M and SD in text or tables, and the values were extracted accordingly. For the remaining eight studies in which no numerical values of M or SD were reported in text or tables, the third author retrieved the M and/or SD values from the graphs (e.g. measuring the length of a bar on a bar graph in terms of the number of pixels). For one report, we retrieved the data from an online repository. The two reports excluded from the meta-analysis due to insufficient statistical reporting (Criterion E) were those we were unable to include despite exhausting all means.
Effect sizes and their variability were estimated for each study by converting the effect estimates to Cohen’s d based on the statistics reported in the study, as described in section ‘Data analysis’.
Data analysis
Effect sizes were standardized to Hedges’ g following the procedures outlined below.
For the studies that used logistic-regression models and reported the effect estimates (ORs or LORs) with their standard errors of the estimates (n = 7), we used the esc package in R (Lüdecke, 2019) to obtain the effect sizes (Cohen’s d) and their variances in Cohen’s d (Vd) (using the convert_or2d function).
For studies that used logistic-regression models and reported the effect estimates (ORs or LORs) without the standard errors of the estimates (n = 4), we estimated Cohen’s d based on the formula in (7) (variance of Cohen’s d to be computed later):
(7)
For studies that used ANOVA-type models, the degree of freedom of the numerator of the F ratio was set as 1 (n = 2), as we focused on the F ratios that compared two conditions only (i.e. SRC and ORC conditions). We converted these F values to t based on the formula in (8).
(8)
Then, together with other studies reporting their effects as t-test statistics (n = 3), the formula in (9) was used, following Formula 7 for Cohen’s dz in Lakens (2013):
(9)
For studies that used Wilcoxon signed-rank tests (n = 2), we used a similar formula as that in (9) to transform it into Cohen’s d, that is, we divided Z by the square root of the sample size to obtain d. Together with those reported t-test statistics, we applied equation (9) to seven studies. In total, the above procedure based on reported effect statistics was applied to 18 studies.
For studies for which we only had descriptive statistics (n = 57; with n = 49 extracted from text and tables and n = 8 extracted from graphs), we computed effect sizes and Cohen’s d from means and SDs using the esc_mean_sd function from the esc package (Lüdecke, 2019).
For effects that lacked the variance estimates of Cohen’s d (Vd) up to this point (n = 11), we computed Vd based on the formula in (10) following Formula 4.28 in Borenstein et al. (2009), where r is the correlation of the dependent variables between the two conditions (SRCs and ORCs) and n is the number of pairs:
(10)
Because none of the included studies reported this correlation, we considered all possible values of r from −1 to + 1 with a step size of 0.01. For each possible value of r, we computed the Vd for every study and conducted a separate meta-analysis. We found that the general patterns of results did not depend on specific r values. For simplicity and to be conservative, in the results to be reported in section ‘Results’, we assumed r = 0. 6
Because Cohen’s d is biased in estimating the population effect size, especially for small sample sizes of less than 20 (Lakens, 2013), we applied Hedges’ correction (Hedges, 1981) to convert the effect size estimates and their variance estimates from Cohen’s d to Hedges’ g based on the formulas in (11) and (12), where the correlation factor is defined as (13):
(11)
(12)
(13)
This procedure resulted in 75 valid effect size estimates (with variability) from 30 reports. We then used the rma.mv function from the metafor package in R (Viechtbauer, 2010) to fit multilevel linear mixed-effects models in our meta-analysis. This function allowed us to take into account both between-studies and within-studies heterogeneity of effects when estimating the overall subject preference and moderator effects. For the meta-analysis on the overall difference in performance between SRCs and ORCs, we fitted the model without inserting any moderators into the rma.mv function. For the meta-analysis on the age effects, task effects, and effects of the typological properties, namely, language headedness (head-initial, head-final), RC headedness (head-initial, head-final), and main clause similarity (subject resemblance, object resemblance, no resemblance), we inserted the respective factors with study-specific labels into the rma.mv as moderators. The R script used for the analysis can be found in Supplemental Material 2.
Results
Study characteristics
The data in the current meta-analysis included 30 reports representing 16 languages: Basque, Cantonese, Danish, English, European Portuguese, Finnish, French, German, Hebrew, Italian, Japanese, Korean, Malay, Mandarin, Persian, and Tagalog. Supplemental Material 1 provides a complete list. We did not include language as a moderator in further analyses as there was only a small number of studies per language to be statistically meaningful.
Overall subject preference
From the model for the subject preference analysis, we found a significant effect of subject preference (summary effect estimate = 0.65, SE = 0.15, 95% CI = [0.37, 0.94], with a positive value indicating subject preference and a negative value object preference; Z = 4.49, p < .0001). However, high heterogeneity across studies, Q(74) = 402.67, p < .0001, suggests the possibility of moderators for explaining the different effects estimated across studies. Figure 2 shows the forest plot of the meta-analysis on the comparison between SRCs and ORCs.
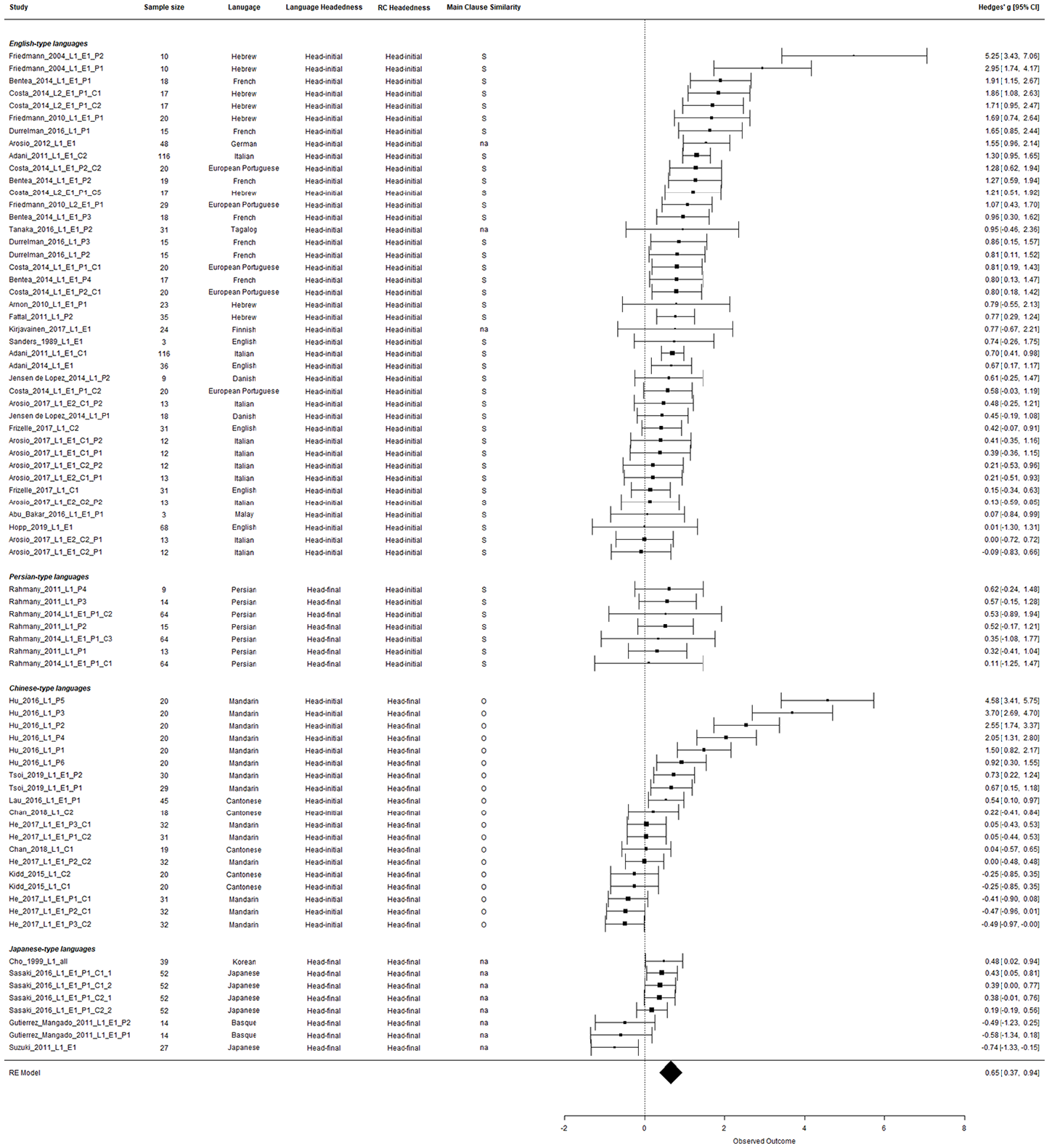
Forest Plot of the Meta-Analysis on the Comparison Between SRCs and ORCs. 7
While most of the studies were on the positive side, suggesting better performance of children on SRCs in general, a number of reports, including Gutierrez-Mangado’s (2011) on Basque, He et al.’s (2017) on Mandarin, and Suzuki’s (2011) on Japanese, did not cross over to the positive side, showing that the children did not perform better on SRCs than ORCs. Others, such as Arosio et al. (2017) on Italian, Hopp et al. (2019) on English, and Chan et al. (2018) on Mandarin, hovered around the zero line.
Publication bias
Figure 3 shows the funnel plot of the data included in the present meta-analysis. If there was no publication bias, the distribution of the effects should be symmetrical around the overall effect estimate (vertical dotted line in Figure 3). In the present analysis, there are several studies located in the lower-right region of the funnel plot, which are subject preference effects with low effect precision, but there are no such studies on the lower-left region. This creates an asymmetry in the funnel plot, which may be a sign of publication bias.
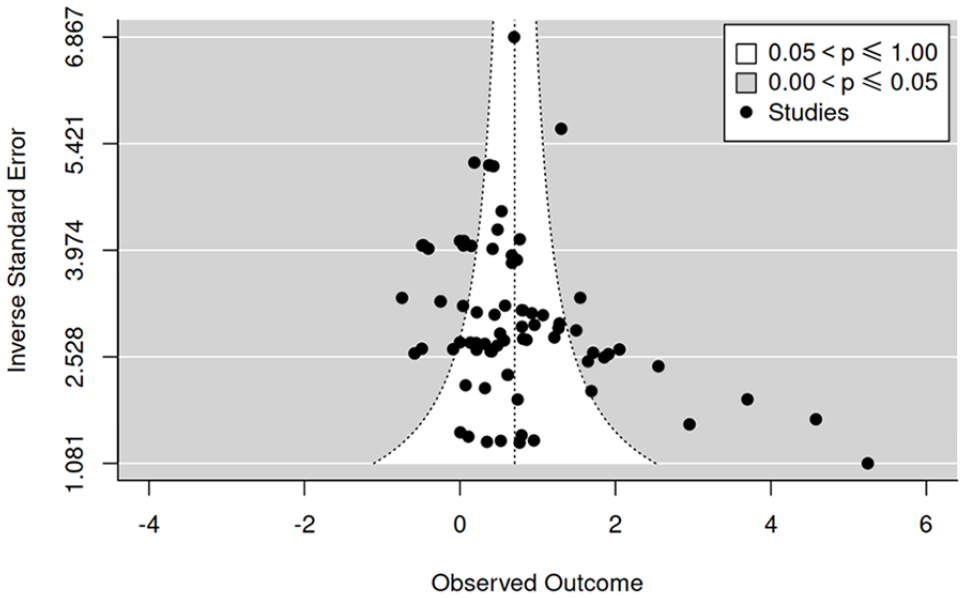
Funnel Plot of All Data Sets.
We then used the ‘trim and fill’ technique (trimfill[] function from metafor) to evaluate whether there is any need to ‘trim’ and/or ‘fill’ the distribution of effects. Figure 4 shows the funnel plot of the trimmed-and-filled dataset. Using the R0 estimator for trimfil(), seven studies were estimated to be missing on the left side (p = .0039), suggesting a potential publication bias in our dataset. 8
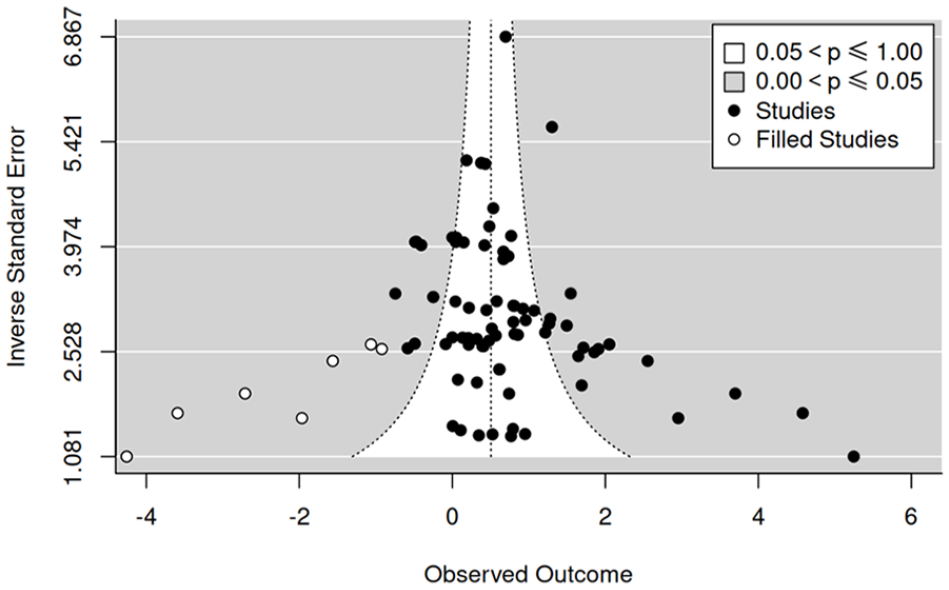
Funnel Plot After the ‘Trim and Fill’ Procedure.
To assess the impact of publication bias on our main finding of subject preference, we analyzed the ‘trimmed-and-filled’ dataset using a mixed-effects meta-analysis model. We found the same pattern of result but a weaker subject preference effect (summary effect estimate = 0.51, SE = 0.13, 95% CI = [0.25, 0.76]; Z = 3.86, p < .0001), suggesting that the overall subject preference is still present after correcting for publication bias. 9
Age effect
Six studies from He et al. (2017) and one study from Hopp et al. (2019) only included information on the age range. The remaining 68 studies provided mean ages, which were included as a moderator to consider age effects. The data represented ages from 32 months (2;8) to 130.46 months (10;10.46). When we statistically controlled for age (assuming all participants were of the same age), there was a significant subject preference (intercept = 0.70, SE = 0.15, 95% CI = [0.40, 1.00]; Z = 4.61, p < .0001). As age increased, the subject preference tended to slightly weaken, but this moderating effect of age on the subject advantage was not significant (slope = −0.00, SE = 0.00, 95% CI = [−0.01, 0.00]; Z = −1.00, p = .32). 10
Task effect
Forty-three studies from 15 reports used a picture selection task and 32 studies from 15 reports used a referent selection task. There was a significant subject preference in both studies that used a picture selection task (summary effect estimate = 0.69, SE = 0.21, 95% CI = [0.29, 1.10]; Z = 3.35, p = .0008) and studies that used a referent selection task (summary effect estimate = 0.62, SE = 0.21, 95% CI = [0.20, 1.04]; Z = 2.87, p = .004). The moderating effect of the task was not significant (summary effect estimate = 0.08, SE = 0.30, 95% CI = [−0.51, 0.66]; Z = 0.25, p = .80).
Among those that used a referent selection task, six studies from three reports (Chan et al., 2018; Kirjavainen et al., 2017; Rahmany et al., 2014) used toys. The remaining 37 studies used a picture referent selection task. Because of the imbalance in the number, we did not include the distinction between picture and toy referent selection tasks in the model, as it would not be statistically informative.
Modulating factors
In order to take language typology into consideration, we coded language headedness, RC headedness, and main clause similarity as possible predictors of the subject preference.
Language headedness
We categorized the languages as head-initial (60 studies) or head-final (15 studies, on Basque, Japanese, Korean, and Persian). For head-initial languages, we found a strong subject preference (summary effect estimate = 0.81, SE = 0.15, 95% CI = [0.50, 1.11]; Z = 5.22, p < .0001). For head-final languages, there was no significant subject preference (summary effect estimate = 0.08, SE = 0.30, 95% CI = [−0.50, 0.66]; Z = 0.27, p = .79). The difference between the two types of language headedness was significant (difference = 0.73, SE = 0.34, 95% CI = [0.07, 1.38]; Z = 2.16, p = .03), with head-initial languages showing a stronger subject preference effect.
RC headedness
We categorized the languages according to the position of the type of RC tested in the study: head-initial RCs (48 studies) or head-final RCs (27 studies, on Basque, Cantonese, Japanese, Korean, Mandarin). 11 There was a statistically significant subject preference for head-initial RCs (summary effect estimate = 0.87, SE = 0.17, 95% CI = [0.53, 1.21]; Z = 4.97, p < .0001) but not for head-final RCs (summary effect estimate = 0.29, SE = 0.23, 95% CI = [−0.16, 0.73]; Z = 1.26, p = .21). The difference between head-initial and head-final RCs was significant (difference = 0.58, SE = 0.29, 95% CI = [0.02, 1.14]; Z = 2.03, p = .04).
Language headedness and RC headedness
We conducted an analysis based on a two-factor model crossing language headedness and RC headedness. The model showed a significant subject preference for English-type languages (head-initial languages with head-initial RCs) (n = 41; summary effect estimate = 0.92, SE = 0.18, 95% CI = [0.56, 1.28]; Z = 5.02, p < .0001). We did not find a significant subject preference for Persian-type languages (head-final languages with head-initial RCs; n = 7, summary effect estimate = 0.42, SE = 0.52, 95% CI = [−0.61, 1.45]; Z = 0.81, p = .42), Chinese-type languages (head-initial languages with head-final RCs; n = 19, summary effect estimate = 0.52, SE = 0.29, 95% CI = [−0.05, 1.09]; Z = 1.80, p = .07), or Japanese-type languages (head-final languages with head-final RCs; n = 8, summary effect estimate = −0.08, SE = 0.36, 95% CI = [−0.80, 0.63]; Z = −0.23, p = .82), though there was a general trend of subject preference across these language types except for Japanese-type languages.
The difference between head-initial RCs and head-final RCs was not significant within head-initial languages (difference = 0.40, SE = 0.34, 95% CI = [−0.27, 1.07]; Z = 1.18, p = .24) or head-final languages (difference = 0.51, SE = 0.64, 95% CI = [−0.74, 1.76]; Z = 0.79, p = .43). The difference between head-initial and head-final languages was also not significant within languages with head-initial RCs (difference = 0.50, SE = 0.56, 95% CI = [−0.59, 1.59]; Z = 0.90, p = .37) or languages with head-final RCs (difference = 0.60, SE = 0.46, 95% CI = [−0.31, 1.51]; Z = 1.30, p = .19).
Main clause similarity
We categorized the languages based on whether word order in either SRCs or ORCs resembled word order in main clauses. Cantonese and Mandarin were categorized in the Object Resemblance group, in which ORCs resemble main clauses (19 studies). Basque, Finnish, German, Japanese, Korean, and Tagalog were categorized as the No Resemblance group (11 studies), as neither SRCs nor ORCs in these languages resemble the word order of the main clause. The remaining 45 studies were categorized in the Subject Resemblance group, in which SRCs resemble main clauses.
There was a strong subject preference for languages with Subject Resemblance (summary effect estimate = 0.83, SE = 0.19, 95% CI = [0.45, 1.21]; Z = 4.28, p < .0001). There was a trend, despite the lack of statistical significance, toward subject preference in the Object Resemblance (summary effect estimate = 0.52, SE = 0.31, 95% CI = [−0.08, 1.12]; Z = 1.70, p = .09) and No Resemblance groups (summary effect estimate = 0.33, SE = 0.31, 95% CI = [−0.28, 0.95]; Z = 1.06, p = .29). We did not find any significant difference in subject preference between the Subject Resemblance and No Resemblance groups (difference = 0.50, SE = 0.37, 95% CI = [−0.23, 1.22]; Z = 1.34, p = .18), between the Object Resemblance and No Resemblance groups (difference = 0.19, SE = 0.44, 95% CI = [−0.67, 1.05]; Z = 0.42, p = .67), or between the Subject Resemblance and Object Resemblance groups (difference = 0.31, SE = 0.36, 95% CI = [−0.40, 1.02]; Z = 0.85, p = .39).
Discussion
The meta-analysis of 75 studies from 30 reports of 16 languages shows that there is indeed a statistically meaningful subject preference crosslinguistically in children’s comprehension of RCs. This effect persists even after correcting for publication bias, controlling for participants’ ages, and across tasks. However, depending on the typological properties, such as language headedness, RC headedness, and main clause similarity, the subject preference does not uniformly manifest as a statistically significant preference. Table 2 summarizes the results.
Summary of results (positive summary effect estimates indicate subject preference and negative values indicate object preference).
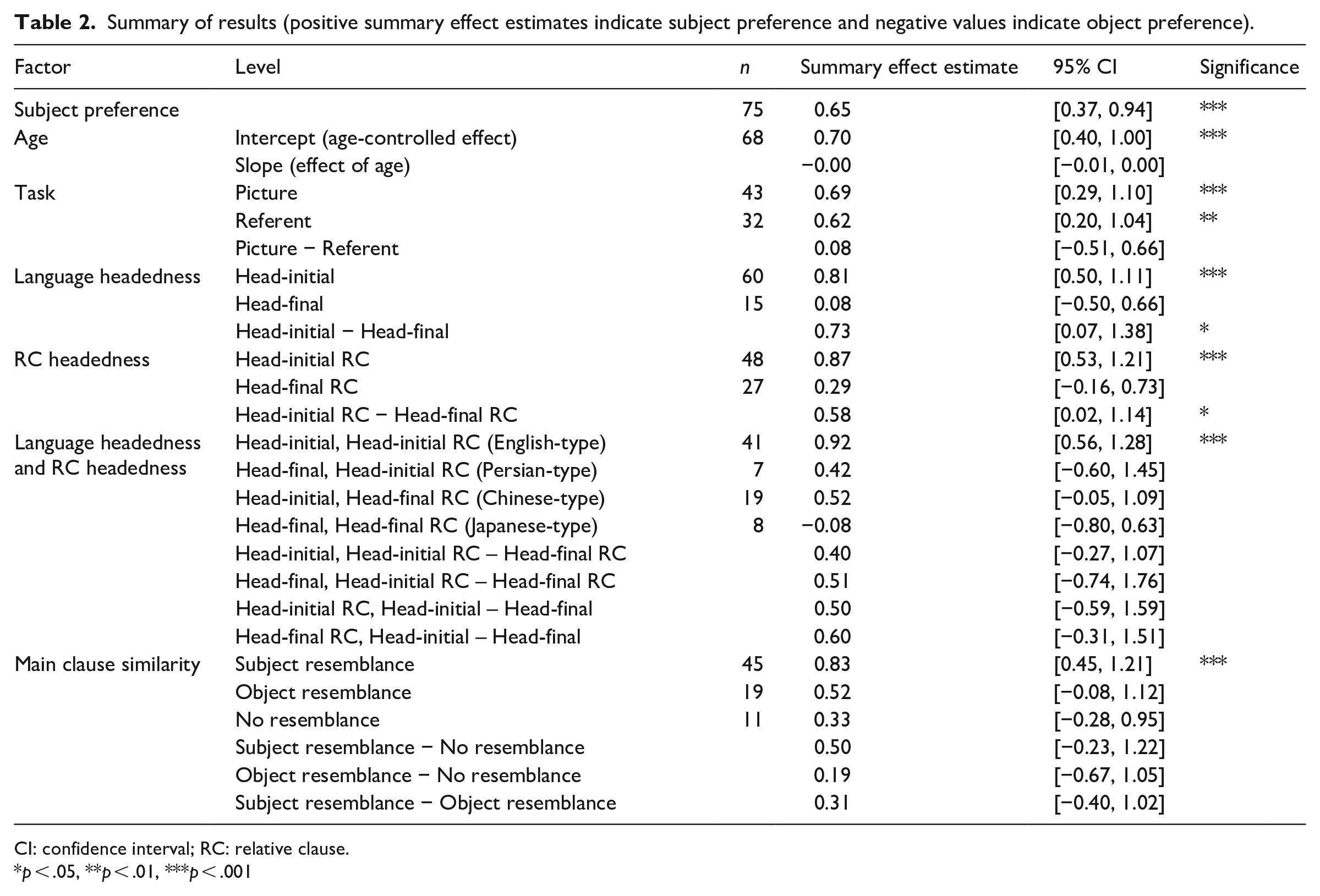
CI: confidence interval; RC: relative clause.
p < .05, **p < .01, ***p < .001
Head-initial languages exhibit a robust and statistically significant subject preference, while this effect lacks significance in head-final languages. Furthermore, a strong and statistically significant subject preference emerges in head-initial RCs, whereas a milder and non-significant trend toward a subject preference is observed in head-final RCs. Moreover, when both language headedness and RC headedness are crossed, a statistically significant subject preference is evident in English-type languages. In contrast, Persian-type and Chinese-type languages display a general, non-significant trend toward a subject preference, and Japanese-type languages exhibit a weak and non-significant trend toward an object preference. Our findings also reveal a statistically significant subject preference in languages where SRCs resemble main clauses. However, in other cases, a weaker and non-significant trend toward a subject preference is observed. Altogether, our results do not align with any of the scenarios predicted in Table 1, revisited in Table 3.
Summary of results.
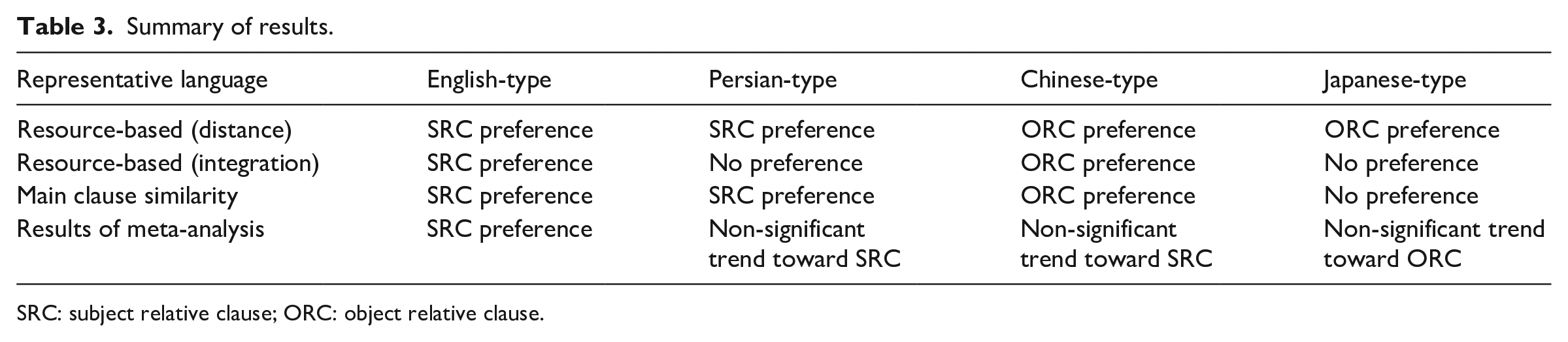
SRC: subject relative clause; ORC: object relative clause.
Taking all factors into account, neither resource-based nor main clause similarity effects singularly determine the RC preference. Instead, they might interact with each other, either strengthening the subject preference or attenuating it. Generally, a subject preference is present in head-initial languages, head-initial RCs, and languages with SRCs resembling the word order of main clauses. When all three typological properties align to support a subject preference, as seen in English-type languages, a robust subject preference emerges. In other instances, there is no definitive subject preference. In most cases, however, a weaker, non-significant trend toward a subject preference persists. The only exception arises in the case of Japanese-type languages, where a non-significant trend toward an object preference emerges when considering both language headedness and RC headedness. 12 It is crucial to note that no strong object preference emerges in any configuration, at least not to a degree comparable to the observed subject preference, even in Mandarin, for which an object preference is predicted from resource-based and main clause similarity effects. All these together seem to suggest a default preference for SRCs. Given the different typological properties of RCs across languages, various factors come into play and exert their particular influences on children’s comprehension of RCs. These factors also modulate the degree of difficulty of SRCs and ORCs during acquisition, resulting in the observed pattern across the four types of languages in our meta-analysis.
That said, we want to be cautious in interpreting the non-significant trend toward subject or object preference. It is not clear whether the lack of significance is a true reflection of a weak effect or a reflection of the lack of representative data for sufficient statistical power to show the true picture. This is not an issue that could be solved by sophisticated statistical tools, as it is due to the lack of linguistic diversity in the research field, also suggested by Kidd and Garcia (2022). As reported in section ‘Modulating factors’, the typological properties represented in our data are heavily biased toward head-initial languages, head-initial RCs, and languages with SRCs resembling the word order of main clauses. Further, we could not test other relevant typological properties (e.g. morphosyntactic alignment) because of the extremely small sample available. Consequently, while this meta-analysis offers a broad-strokes picture of the current scholarship, the meta-analysis approach cannot make up for missing pieces due to the lack of linguistic diversity in the field.
There are other limitations to this study. First, the modulating factors included in the study are not exhaustive. For instance, our results demonstrated that the subject preference was evident irrespective of whether the picture-selection or referent-selection task was employed. However, we were unable to statistically compare toy-based tasks with picture-based tasks due to the limited sample size. Other factors have been suggested to play a role in child RC acquisition, such as NP animacy, and givenness. Some of these were originally coded in our study but were not included in this article due to the imbalance in the sample size, resulting in unreliable statistical comparisons. These factors should be explored in the future.
The alignment between statistical analysis and reporting also warrants attention. As explained in section ‘Data extraction’, we had to invest considerable effort to acquire the necessary statistical information for meta-analysis in certain reports, as this information was not readily accessible within the reports. In some cases, this is because the target participants are a control group, but in other cases, it was because the study did not report sufficient descriptive or inferential statistical information. Further, in some cases, we had to assume a value of correlation in the performance between the SRC and ORC conditions before we could estimate the variance of effects (Vd). In order to encourage future meta-analyses, we strongly recommend researchers to not only report the effect estimates but also report the uncertainty associated with the effect estimates when reporting inferential statistics. For instance, when reporting a coefficient estimate from a regression model, it would be helpful to also report the standard error of the estimate or the 95% confidence interval associated with the estimate. For multiple measurements taken from within-subjects designs, it would be helpful to report the pairwise correlations for all measurements across participants in addition to the traditional results from, for example, t-tests or ANOVA. These additional values are readily available in many common statistics programs (e.g. jamovi, JASP, R, SPSS). It should be easy for researchers to generate them and include them in their manuscripts. They can also include further information in Appendices and Supplemental Materials to facilitate future cumulative analyses.
Our meta-analysis included theses and dissertations, with the majority of the included reports being published journal articles. Consequently, there existed publication bias within our meta-analysis, although the overall subject preference persisted after accounting for this bias. Publication bias is a common occurrence in most meta-analysis datasets, as studies with null results often face challenges in being published. The inclusion of unpublished results could potentially alter the landscape; however, the field currently lacks established archiving conventions. At the time of the study selection, we did a cursory search on LingBuzz, PsyArXiv, and Open Science Framework preprints, but were not able to find any relevant information. We hope that archiving preprints and publishing null results will become the main practices in the field.
Conclusion
Looking at the big picture, there is an overall subject preference crosslinguistically, at least according to the current scholarship in the field. Nonetheless, the manifestation of this subject preference may not be uniform across languages, depending on typological properties such as language headedness, RC headedness, and main clause similarity. The present meta-analysis suggests that these typological properties interact with each other, strengthening or weakening a subject preference. A robust subject preference is found in head-initial languages, head-initial RCs, or languages with SRCs resembling main clauses. Conversely, a weaker, non-significant trend toward subject or object preference is observable in head-final languages, head-final RCs, or languages with SRCs not resembling main clauses. Neither resource-based nor main clause similarity effects considered in the study satisfactorily account for these results. That said, the lack of samples that represent the latter group of languages prevents the meta-analysis from fully revealing the true influence of these modulating factors on RC preference. Hence, we urge researchers in the field to actively contribute to the diversification of linguistic research.
Supplemental Material
sj-pdf-1-fla-10.1177_01427237241226734 – Supplemental material for On the universality of the subject preference in the acquisition of relative clauses across languages
Supplemental material, sj-pdf-1-fla-10.1177_01427237241226734 for On the universality of the subject preference in the acquisition of relative clauses across languages by Nozomi Tanaka, Elaine Lau and Alan L. F. Lee in First Language
Footnotes
Acknowledgements
We thank Alina Matthews, Kent Meinert, Jacob Owens, Jacob Schmitt, and Daniel Swanson for their help with coding, Laurie Durand for her editorial support, and two anonymous reviewers for their insightful comments and suggestions on the manuscript.
Author contributions
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The publication of this article is supported by the resources provided to the first author by the Hamilton Lugar School of Global and International Studies at Indiana University Bloomington.
Supplemental material
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.