
Abstract
This paper proposes that artificial agents’ underperformance in interpersonal influence situations can be explained by stereotypical perceptions of such agents’ lack of capacity to act and accomplish goals (i.e., agency), triggered by their non-human identity. In two experiments of text-based conversations (N = 305 and 309), the identity of a human advice giver was manipulated to be either a human or a chatbot. The chatbot identity resulted in less perceived agency of the giver, which then mediated the identity’s effects on the advice seeker’s (a) perceived advice effectiveness and (b) intention to follow advice after the conversation, as well as (c) adherence to advice and (d) trouble relief after a week. A positive correlation between perceived agency of the artificial agent and the seeker’s self-efficacy was identified as part of this mediation. In contrast, perceived emotional capacity (i.e., experience), despite a discrepancy between the two identities, had non-significant mediating effects.
Artificial agents (e.g., chatbots) are emerging as an important component of mediated communication (Hancock et al., 2020). Ranging from question-answering, counseling, education, customer-service, to medical and health assistance (Adamopoulou & Moussiades, 2020), many applications of such agents fall into the realm of advice interactions (MacGeorge et al., 2016): They attend to people’s needs, provide support, and oftentimes aim at persuasion and changing behaviors (Flanagin, 2017; Fogg & Fogg, 2003), emulating social influence among people (or more specifically, interpersonal influence; Dillard & Wilson, 2014).
Regarding the effectiveness of such influence, however, artificial agents often underperform. Studies showed that people are less likely to be influenced by artificial agents than humans (Fox et al., 2015), including taking advice (Prahl & Swol, 2017, 2021). Although technological limitations could be a culprit, the underperformance persists even when artificial agents’ behaviors are equivalent to humans, for example, using the same humans or same bots behind the manipulated human versus artificial-agent identities (Fox et al., 2015). Accordingly, developers face a dilemma about disclosing artificial agents’ true identity, as the disclosure can undermine the agents’ influence on users (Mozafari et al., 2020). These phenomena suggest that, beyond behavioral realism and presence (Blascovich et al., 2002), knowing the identity of an artificial agent is sufficient to reduce its influence—as if certain stereotypes exist against them.
The current project investigates the proposition that certain stereotypical perceptions of artificial agents can explain their underperformance in interpersonal influence contexts such as advice interactions. Such perceptions are stereotypical in that they can be triggered by minimal cues of the agents’ identity, independent from technology materiality, and thus different from heuristics associated with technological features and affordances (e.g., Sundar, 2008, 2020). The stereotyping relies on treating artificial agents as a non-human social category (or several categories), and thus also differs from human stereotypes imposed on artificial agents due to anthropomorphic cues of human social categories or roles (e.g., gender stereotypes; Nass et al., 1994). Meanwhile, the stereotypical perceptions focused here differ from stereotypical expectations of artificial agents before interactions (C. Edwards et al., 2016; Spence et al., 2014). Because stereotyping in actual interactions incorporates both prototypical knowledge about a social category and interactional experiences (Operario & Fiske, 2004), stereotypical perceptions during and after interactions are more likely to explain interaction outcomes, such as influence.
To explicate the nature of the stereotypical perceptions, we focus on basic dimensions of person perception. As part of the cognitive substratum of people’s anthropomorphism tendency (Epley et al., 2007), these dimensions likely also organize the perceptions of non-human agents (Kwan & Fiske, 2008). Particularly, we draw on Wegner and Gray’s concept of mind perception and its two dimensions: (a) agency, which refers to people’s perceptions about an entity being a “causal agent” (Wegner, 2002, p. 15) and its abilities to “act and accomplish goals” (Wegner & Gray, 2016, p. 26) such as to plan, to think, to self-control, to communicate, and to act morally; and (b) experience, which captures the perceived ability of an entity to “have an inner life, to have feelings and experiences such as experiencing sadness, joy, anger, and fear” (Wegner & Gray, 2016, p. 26). The two dimensions align with the two-dimension models of social cognition (Abele & Wojciszke, 2014; Fiske et al., 2002, 2007; also see Wiggins, 1979) and does not assume human as the only target of perception, thus facilitating the study of stereotypical perceptions about both human and non-human entities (e.g., H. M. Gray et al., 2007).
The current inquiry, then, boils down to a study of whether artificial agents’ influence in advice interactions is undermined by stereotypical perceptions of lack of agency, lack of experience, or lack of both, compared to humans. While research often attends to artificial agents’ emotional abilities (e.g., Ho et al., 2018; Liu & Sundar, 2018) along with the popular interests in emotional machines, we argue that perceived agency matters more in social influence situations involving these agents. As elaborated later, agency perceptions were identified as important factors in various social influence situations (Brewer et al., 2004; Ridgeway, 2001; Tiedens & Fragale, 2003), and as important antecedents of influence such as trustworthiness or credibility (Mayer et al., 1995; McCroskey & Young, 1981). We also attend to the link between other’s perceived agency and one’s own self-efficacy (Lent & Lopez, 2002) as a downstream mechanism. Since self-efficacy is central to the self-perception of agency (Bandura, 1997), such a self–other link of agency perception may shed light on the negotiation of agency and control between humans and artificial agents (Gibbs et al., 2021; Sundar, 2020) in influence situations.
Below, we first discuss the stereotypical perception of artificial agents and develop our hypotheses, drawing on research of human anthropomorphic perceptions and social influence across several social scientific areas. We also address three questions about the role of self-efficacy, the role of emotion, and the issue of measurement invariance between self-reported perceptions of humans and artificial agents. Next, we report two experiments of dyadic text conversations where participants sought and received sleep advice from a human consultant, who was presented to the advice seeker as either a human or an artificial agent (i.e., the Wizard of Oz approach; e.g., Ho et al., 2018). The manipulation was expected to impact seekers’ influence outcomes reported immediately and after 1 week. The effects were expected to be mediated by the giver’s perceived agency. Implications of the findings were then discussed.
Stereotypical Perceptions of Artificial Agents
People can perceive artificial agents stereotypically. It is well-known that we often “mindlessly” (Nass & Moon, 2000) perceive machines based on mental shortcuts, or heuristics (Sundar, 2008, 2020). For artificial agents, heuristics related to human-likeness can be triggered by very minimal cues (Nass et al., 1993, 1994) due to people’s anthropomorphic tendency to perceive non-human agents with humanlike characteristics (Epley et al., 2007). Some of these heuristics may resemble social stereotyping, since people tend to classify social actors based on apparent similarities (i.e., social categorization, see Dovidio & Gaertner, 2010). As a result, human-like artificial agents may be perceived as quasi-social categories, followed by stereotyping as a heuristic for efficient cognition and social behaviors (van Knippenberg & Dijksterhuis, 2000). Because social categorization only needs minimal cues (Dovidio & Gaertner, 2010), knowing artificial agents’ identity may suffice stereotyping. Previous research hinted at this possibility: For instance, people’s expectations of a partner’s uncertainty, likability, and social presence differed when the partner assumed an artificial-agent identity versus a human identity (Edwards et al., 2016; Spence et al., 2014). Likewise, agents assumed non-human identities often underperform in influence tasks despite equivalent behaviors (Fox et al., 2015).
Although the content of social stereotypes can be myriad and context-dependent, it is organized by a few dimensions (Fiske et al., 2002). Research has converged on various two-dimension models, ranging from the “dominance” and “affiliation” of traits (Wiggins, 1979), to the “agency” and “communion” of person perception (Abele & Wojciszke, 2014), and to the “competence” and “warmth” of social stereotype (Fiske et al., 2002). Similar pairs are also conceived in the study of trustworthiness (“ability” and “benevolence,” Mayer et al., 1995) and credibility (“competence” and “goodwill,” McCroskey & Teven, 1999; McCroskey & Young, 1981). Terminologies aside, the two dimensions are better understood through their adaptive functions that serve the needs of humans as social animals: that is, (a) to recognize each other’s capacity to accomplish goals, and (b) to detect each other’s prosociality (Fiske et al., 2007).
The two dimensions may also organize perceptions (and stereotypical perceptions) of artificial agents. For one thing, the adaptive functions of the two dimensions resonate with the two major motives of people’s anthropomorphism—(a) to understand, control, and predict another agent’s behavior, and (b) to develop social connection (Epley et al., 2007). Meanwhile, the anthropomorphic tendency heavily relies on the self-knowledge about human characteristics (Epley et al., 2007) and thus share the same cognitive substratum of person perception (Kwan & Fiske, 2008). This is especially true if systematic knowledge about the agents is not yet acquired (Epley et al., 2007)—and this is not uncommon for people’s knowledge of artificial agents today.
That said, specific conceptualizations of the two dimensions for person perception may not be directly applicable to artificial agents. For example, “communion” and “agency” of interpersonal perception (or “warmth” and “competence” of social stereotype) often consist of rating a person as “considerate,” “empathetic,” and “friendly,” as well as “competent,” “talented,” and “ambitious” (Abele & Wojciszke, 2014; Fiske et al., 2002). These adjectives can sound strange when describing a machine, since they do not rely on objective criteria but assume certain human-human relational status. To address this issue, we adopt Wagner and Gray’s concepts of agency and experience (Wegner, 2002; Wegner & Gray, 2016). As mentioned before, the two concepts focus on abilities perceivable for both human and non-human agents. These abilities are logical elements of the goal-accomplishing capacity (e.g., the abilities to plan, think, and self-control, Wegner, 2002) and prosociality (e.g., the abilities to experience discrete emotions, which are key to empathy and thereby prosociality, de Waal, 2008). Thus, they may better probe the stereotypical perceptions for artificial agents.
In sum, research suggests people can stereotype artificial agents per the same dimensions of person perception. As discussed below, one of the dimensions, agency, may assume a greater significance in perceiving artificial agents, especially in influence situations.
Primacy of Agency in Perceiving Influence-inducing Artificial Agents
When perceiving other humans, people attend more to prosociality (“warmth” or “communion”) than the capacity to act and accomplish goals (“competence” or “agency,” Abele & Wojciszke, 2014). This is because people as conspecifics are generally more certain about each other’s goal-accomplishing capacity, but less certain about if a stranger is prosocial or antisocial—and misjudging the latter can be critical to survival (Abele & Wojciszke, 2014). However, the perception of artificial agents’ capacity to act and accomplish goals may be equally or even more important than its prosociality, because most artificial agents in everyday scenarios are commercialized products, which may be deemed as safe and designed to benefit people. Whether and how they can act and accomplish goals, however, may be less certain.
The attention to the capacity to act and accomplish goals—or agency in Wegner’s (2002) terms—is perhaps more salient when non-human agents can (or are believed to) influence humans. This is not unique to artificial agents. Cultural anthropologists observed that humans interact with many non-human entities such as mythical gods, totems, and talking animals, as well as artificial intelligence, in a form of fetishism such that the entities are perceived as a cause rather than effect of human affairs (Suchman, 2006). Similarly, developmental psychologists found that infants pay more attention to animate objects (i.e., geometric shapes with googly eyes) if the objects appear to facilitate or hinder (i.e., influence) other animate objects (Hamlin et al., 2007). Social psychologists also found that people tend to perceive social groups that can influence them as active entities with goals and means to accomplish the goals (Brewer et al., 2004; Campbell, 1958). Put simply, people’s anthropomorphic perceptions of non-human entities hinges on perceiving them as causal agents (and thereby has mind and will, Wegner, 2002).
Similar evidence exists for artificial agents. Studies using Wegner and Gray’s concepts of agency and experience found that schizophrenia patients tended to over-attribute agency but not experience to robots—and this over-attribution did not occur when the patients perceived human adults (K. Gray et al., 2011; also Raffard et al., 2018). This suggests, deep in our mind, there is a special attention to artificial agents’ goal-accomplishing capacity, potentially triggered by the patients’ exaggerated sense of the robots’ influence on them. Another evidence is that people more quickly lose confidence in the advice of artificial-intelligence algorithms than equally-performing humans, after seeing both of them making mistakes (i.e., “algorithm aversion,” Dietvorst et al., 2015), and thereby less likely to follow artificial agents’ advice (Prahl & Swol, 2017). Further research shows that algorithm aversion does not seem to be explained by people’s emotional reactions (Prahl & Swol, 2017). Instead, making mistakes suggests a lack of goal-accomplishing capacity. Relatedly, algorithm aversion can be reduced when people can share the agency (i.e., modify the decisions, Dietvorst et al., 2018) or see the algorithms improving performance overtime (i.e., demonstrating the ability to learn, Berger et al., 2021).
The above evidence suggests people attend more to agency when perceiving artificial agents, especially when they can or try to influence us. Coincidently, research of human social influence also deems agency perceptions a key factor. Stereotypical perception of artificial agents’ lack of agency, then, may play a role in their underperformance in social influence situations.
Agency Perceptions, Social Influence, and Advice Interactions
Different lines of human social influence research concur in the importance of agency perceptions. For example, research on social status shows that people defer to each other based on performance expectation, or competence, to accomplish shared goals in cooperative situations (Ridgeway, 2001). This judgment is also key to trustworthiness or credibility in both face-to-face and mediated contexts (Mayer et al., 1995; McCroskey & Young, 1981), including that of machines (Sundar, 2008); and trust is an important antecedent of social influence. In less cooperative settings, people can influence each other through demonstrating and perceiving of power, or dominance (Tiedens & Fragale, 2003), which may also indicate the power holder’s capacity to approach goals (Keltner et al., 2003). Beyond dyads, groups induce social influence in terms of conformity. Scholars argue that this form of influence is typically through perceptions of the group as a holistic, categorical entity (Hogg & Abrams, 1988) with shared goals and the means to accomplish goals (Campbell, 1958)—or, in other words, as a “dynamic actor” with various levels of “group efficacy” (Brewer et al., 2004, p. 28).
Moreover, like other aspects of social cognition, agency perceptions can be informed heuristically by existent stereotypes (Operario & Fiske, 2004). Research has consistently found that social identity is sufficient to bias agency perceptions and affect influence in accordance with cultured stereotypes in societies (Fiske et al., 2002; Ridgeway, 2001). Likewise, artificial agents might also underperform relative to humans in social influence situations if these agents are stereotypically perceived as lacking agency—even if they behave the same way as humans. Such stereotypes might have existed. For example, research subjects in the United States tended to believe robots are much less agentic than humans (H. M. Gray et al., 2007).
The preceding logic should also apply to advice interactions, which represent a prevalent context of daily social influence: When people experience difficulties in life, they often disclose the troubles and needs to others and receive advice oriented towards behavioral changes for trouble relief (MacGeorge et al., 2011, 2016). In this context, influence is often evaluated in terms of several outcomes from the advice seeker’s perspective, including (a) perceived advice effectiveness, which suggests a change of the seeker’s appraisal about their troubling problems so as to facilitate coping (Feng & MacGeorge, 2010; MacGeorge et al., 2011; also see Cappella, 2018 for a relevant discussion in persuasion research), (b) intention to follow advice, which is widely studied as an antecedent of volitional behavioral change (Fishbein & Ajzen, 2011), (c) adherence to advice, which is a direct outcome of influence as behavioral change, and (d) trouble relief, which should also reflect the underlying behavioral changes (MacGeorge et al., 2016) especially when the actual behavioral change is hard to observe.
Accordingly, artificial agents’ underperformance induced by their identity, as found in other influence situations (Fox et al., 2015; Mozafari et al., 2020), should also manifest in the above four outcomes in advice interactions. Thus, we first postulate:
H1. Compared to those with an artificial agent identity, advice givers with a human identity will be more influential in terms of the effectiveness (H1a), intention (H1b), adherence (H1c), and trouble relief (H1d).
Moreover, this influence discrepancy can be further attributed to artificial agents’ lack of perceived agency that triggered stereotypically by their identity, given our previous discussions about the salient roles of perceived agency in both human anthropomorphic perceptions and human social influence situations. We thus expect the following mediation effects:
H2. Perceived agency of an advice giver will mediate the effects of the giver’s identity on the influence outcomes, including effectiveness (H2a), intention (H2b), adherence (H2c), and trouble relief (H2d).
While these hypotheses represent our core arguments, three additional questions deserve attention: (a) How does perceived agency of an artificial agent interplay with one’s self-perception of agency? (b) Does the stereotypical perception of artificial agents’ emotional capacity play a similar role? (c) Can we capture people’s perce- ptions of artificial agents and humans with the same self-reported measures of agency and experience? We elaborate on these questions below.
Self–Other Link of Agency Perception in Advice Interactions
In supportive contexts such as advice interactions, a positive self–other link of agency perception (as if a contagion of agency) may serve as a downstream mechanism of perceived agency’s effect on influence. This link involves the enhancement of self-efficacy, which is central to the self-perception of agency (Bandura, 1997) and is critical to volitional behavioral change (Fishbein & Ajzen, 2011) especially in supportive contexts (Cohen & Wills, 1985; MacGeorge et al., 2004). In fact, a positive link between self and other’s perceived agency has been found in related situations of influence. Research shows that self-efficacy can be built from the perception of “other-efficacy” (which is akin to the perceived agency of another person) in supportive relationships such as coach–athlete, advisor–trainee, and counselor–client, and subsequently facilitate advice taking and influence (Lent & Lopez, 2002). Although the mechanism of such a self–other link is not yet clear, it is possible that perceiving the other being capable and agentic signals the other as a capable helper, thus motivating oneself to act accordingly as influence outcomes. It is also possible that being present with a co-acting other, who presumably manifests agency, unconsciously enhances one’s drive to act and perform (Zajonc, 1965), which is then recognized and contributes to one’s own sense of agency.
Such a self–other link of agency perception points to a potential form of the negotiation of agency and control between humans and artificial agents, and a positive link may be particularly relevant in advice interactions. Given the increasing research attention to such negotiations (Gibbs et al., 2021; Sundar, 2020), it is interesting to ask if self-efficacy can be a downstream mechanism, such that the stereotypically perceived lack of agency reduces artificial agents’ influence through not being able to boost advice seekers’ self-efficacy. We thus ask:
RQ1. Does self-efficacy of an advice seeker further mediate the indirect effects of an advice giver’s identity on influence outcomes via perceived agency of the advice giver?
Role of Emotion and Perceived Experience
So far, we do not speculate the other dimension of mind perception—experience—to play a similar role. Admittedly, the capacity to experience emotions is critical to empathy, and thus enable the detection of prosociality in social interactions (Wegner & Gray, 2016; also see Abele & Wojciszke, 2014; de Waal, 2008; Fiske et al., 2002). The communication of emotions, especially in terms of emotional support, can facilitate advice-taking among people (Feng, 2009) and between people and artificial agents (e.g., Ho et al., 2018; Liu & Sundar, 2018).
However, the stereotypical perception about artificial agents’ emotional capacity is different from their actual communication of emotions. Such a stereotype may be washed away by actual interactions quicker than the stereotype about agency because emotions can be more easily detected in interactions. Also, being stereotypically caring and empathic is necessary but not sufficient to be perceived as trustworthy or credible (Mayer et al., 1995; McCroskey & Teven, 1999) in order to induce influence. Therefore, compared to perceived agency, it is less clear if perceived experience of artificial agents can explain the identity-induced influence discrepancy. That said, it is useful to explore if perceived experience functions as a mechanism in parallel to perceived agency, given that they are both dimensions of mind perception. We thus explore the mediating effects of perceived experience in parallel with our H2 and RQ1:
RQ2a. Does perceived experience of the advice giver mediate the effects of the giver’s identity on the influence outcomes?
RQ2b. Does self-efficacy of the advice seeker further mediate the indirect effects of the advice giver’s identity on the influence outcomes via perceived experience of the advice giver?
As mentioned before, the actual communication of emotions (i.e., emotional support) is important to advice interactions (Feng, 2009; Ho et al., 2018; Liu & Sundar, 2018). Although it is not a focus of the current study, emotional support may interfere with the stereotypical perception mechanisms. As detailed later, we conducted two studies to address this issue. The first study minimizes emotional support, whereas the second study preserves emotional support and thus serves as a robust test of the mechanism of perceived agency.
Measurement Invariance in Perceptions of Human and Artificial Agent
Studies that involve perceptions of artificial agents often use self-reported measures designed for person perceptions (e.g., Ho et al., 2018; Liu & Sundar, 2018; Prahl & Swol, 2021). However, people’s responses to such measures may not follow the same patterns when artificial agents are the target of perception. Particularly, even though Wegner and Gray’s constructs of agency and experience were conceived for both humans and non-human agents, there is no guarantee that people would respond to every aspect of the concept (e.g., “the agent is capable of planning,” “. . .self-control,” “. . . thought”) with the same weight or same baseline for both humans and artificial agents. A hypothetical example of the weight difference could be that people understand human’s agency mostly based on the ability to control, whereas their understanding of artificial agent’s agency hinges on the ability to plan. Similarly, a hypothetical case of the baseline difference could be that people rate humans generally higher on the ability to control, yet rate artificial agents higher on the ability to plan, and such an item-level difference is not systematic and thus not captured by the overall scale scores.
This methodological issue (often referred to as measurement invariance, see Millsap, 2012; Vandenberg & Lance, 2000) warrants theoretical attention. A recent large-scale examination (Friehs et al., 2022) of the two-dimension stereotype content model (“warmth” and “competence,” Fiske et al., 2002) reveals a substantial lack of measurement invariance across people’s perceptions of different social groups. This is likely also to manifest here in perceiving humans and artificial agents. That said, such a lack of invariance does not necessarily suggest invalidity of the concepts or measurements (Friehs et al., 2022). Rather, any measurement invariance or non-invariance can help to reveal deeper similarities or differences in perceiving humans and artificial agents. Therefore, we raise the final research question:
RQ3. If and how does the measurement structure of agency, and of experience, differ between perceptions of human versus artificial agent?
We conducted two studies to address our hypotheses and questions. Specifically, we examine H1, H2, RQ1, and RQ2 independently in each study. RQ3 requires a larger sample size for the analytical procedure, and we thus combined data from both studies. The study materials and correlational matrices for replicating the analyses can be found in the Supplemental Material and the online repository (https://osf.io/jvqmt)
Study 1
A conversational task was designed to provide advice to participants who reported experience of moderate to severe sleep disturbance (advice seekers). Participants who reported experience of little or minimal sleep disturbance played as advice givers. In other words, these advice givers were semi-confederates whose identity was then manipulated for the seekers. The reason for using such semi-confederates is to maximize the variation of conversational dynamics because heavily scripted communicative moves from trained confederates may reduce the external validity of an interaction study like the current one: In the current study, without allowing more diverse and natural conversations to occur, the identity’s effect may (or may not) work only in the context defined by certain scripted conversations. Our approach of employing such semi-confederates is more stringent, making the tests of the identity effects more conservative against the rich conversation dynamics. Such semi-confederates have been used in studies of interpersonal communication (e.g., Walther et al., 2010).
Methods
Experimental design
The study is a 3 × 2 factorial experiment, including the identity manipulation of advice givers (human-giver, bot-giver, and a control condition where the advice is displayed on a webpage without a conversation) and a method factor of two versions of sleep advice (“wind-down routine” and “turn off electronics”). The usefulness of the sleep advice was pre-tested with a sample of workers from mturk.com). The method factor was included to improve the robustness against specific advice.
Participants
We recruited 589 students (≥18 years old with M = 19.840, SD = 2.227) at a west coast university in the United States. The participants included 78.498% females, and 52.801% Asian, 24.958% Hispanic, 23.939% Caucasian, 2.207% African American, and 4.075% other races or ethnicities. They were compensated with course credits, and the study was exempted from review by the university’s Institutional Review Board. The recruitment size was roughly determined by a stopping rule that the number of seekers who passed the manipulation check (explained later) had to reach 75 in each of the three conditions (human-giver, bot-giver, and control). This was meant to detect a small-to-medium effect of the identity manipulation on influence outcomes (i.e., d = 0.408, based on previous work using desktop computers and subjective outcomes; converted from the average weighted, max-coded r reported in Figure 5 of Fox et al., 2015) at a 95% confidence level with an 80% power.
Role assignment
Before the conversation, participants assumed the advice seeker or advice giver role based on responses to eight questions about their sleep disturbance (Cronbach’s α = .777) adopted from the Diagnosis and Statistical Manual of Mental Disorder Fifth Edition (DSM-V; American Psychiatric Association, 2013; also see Supplemental Material). Participants responded using a 5-level scale, and those who indicated adverse sleep quality beyond the scale’s neutral point in any of the eight questions assumed the seeker role. Otherwise, the participants assumed the giver role. Both givers and seekers were then placed in an online waiting room to be randomly matched with each other. The study retained 360 seekers and randomly assigned 105 to the human-giver condition, 124 to the bot-giver condition, and 131 to the control condition. Accordingly, 229 givers were matched with seekers in the first two conditions. The seekers had higher sleep disturbance scores (i.e., sum of responses to the eight questions, M = 25.128, SD = 5.176) than givers (M = 16.122, SD = 3.592) with t(582.560) = 24.902, p < .001, d = 1.950. Because the level of sleep disturbance may affect the advice’s usefulness and, in turn, the influence outcomes, seekers’ baseline sleep disturbance was statistically controlled in all analyses.
Main conversation task
After the role assignment, participants read role-specific instructions. Advice givers read that they had a healthy sleep pattern and were invited to give sleep advice to a fellow participant who suffered from sleep disturbance. They then read the detailed advice (either “no electronic device” or “having a wind down routine,” see Supplemental Material, Figure S1), followed by conversation instructions to (a) reveal themselves as a “sleep consultant” without disclosing name and personal information (to preserve the identity manipulation), (b) explicitly ask if they can help the seeker regarding sleep quality, (c) offer the advice without engaging in any talk about emotions or emotional support, and (d) speak for at least 10 turns and avoid ending abruptly. Givers were blind to the identity manipulation.
Meanwhile, advice seekers were informed that they might have some sleep issues. In the two conversation conditions, they read that (a) they will talk to a “fellow participant trained” (vs. a “chatbot designed”) “as a sleep health consultant,” and (b) they must chat for at least 10 turns. In the control condition, they were informed that they would be reading a piece of sleep advice.
Then, seekers and givers were randomly paired and directed to a dyadic chatroom (see Supplemental Material, Figure S2). The role-specific instructions were displayed aside as a reminder. For seekers, the instruction mentioned the consultant’s identity (i.e., “a fellow participant” or “a chatbot”), and the chat history displayed the source of each message from the giver as either “sleep consultant” or “sleep bot.” For givers, the chatroom displayed the source of the seeker’s messages as “advice seeker.” After 20 turns in total, the participants could leave the chat. Seekers in the control condition were not paired with givers but instead showed a webpage that contained the same advice (see Supplemental Material, Figure S1). Upon leaving the chatroom or finishing reading the webpage in the control condition, participants were led to a post-conversation survey. After 7 days, the participants were invited to a follow-up survey.
Manipulation check and data exclusion
The post-conversation survey immediately asked the seekers about the giver’s identity. Participants were excluded if they could not recall the identity. This exclusion is justifiable: Since stereotyping requires a minimal knowledge of social identity, any difference among participants could not be attributed to stereotyping if they were unsure about the giver’s identity. In addition, the association between the manipulation and the check result was minor, with χ2(1) = 2.659, p = .103 (see Table S1 in Supplemental Material). The final sample (N = 309) retained 76 (72.380%) seekers in the human-giver condition and 102 (82.258%) in the bot-giver condition, along with 131 in the control condition.
We also assessed if the advice givers (i.e., the semi-confederates) were indeed behavioral equivalent between the two conditions by comparing their linguistic styles measured with Linguistic Inquiry and Word Count (LIWC, Pennebaker et al., 2015). As shown in Supplemental Material, Figure S3, only 1 out of the 93 LIWC categories (i.e., 1.075%) was statistically significant (t[152.290] = −2.357, p = .044). Given the large number of tests, we concluded there was little evidence of behavioral difference in advice givers across the two conditions.
Measurements
The post-conversation survey measured two influence outcomes. Perceived advice effectiveness (M = 3.907, SD = 0.955, Cronbach’s α = .933; adapted from Feng, 2009) was measured by a 5-level semantic differential scale with “effective–ineffective,” “helpful–unhelpful,” “beneficial–not beneficial,” and “adequate–inadequate,” following the prompt “[t]he consultant’s responses were. . .” in the two conversational conditions (and “[t]he sleep advice were. . .” in the control condition). Intention to follow advice (M = 4.029, SD = 0.898, Cronbach’s α = .946; adapted from Fishbein & Ajzen, 2011) was measured as the agreement to “I plan to follow the advice I was given,” “[i]t is my intention to use the advice I was given,” and “I intend to do what I was advised,” on a 5-level scale.
After a week, the follow-up survey measured two additional outcomes (278 out of the 309 seekers in the final sample completed the follow-up study). Adherence to advice was measured by (a) the agreement to the statement “[i]n the past seven days, I followed the sleep advice I was given” with a 5-level scale, and (b) the answer to the question “[h]ow many days in the past seven days did you follow the sleep advice?” The two answers were re-scaled between 0 and 1, and then averaged (M = 0.442, SD = 0.257, r = .776). Participants also answered the same questions about sleep disturbance, and trouble relief was measured as the improvement (i.e., pre-study score minus the post-study score; M = 0.655, SD = 5.456).
The post-conversation survey asked the seekers in the two conversational conditions regarding the mind perception about the givers, using the scale from K. Gray et al. (2011). Participants responded on a 5-level scale from “not at all” to “extremely,” after the prompt “I think the consultant is capable of. . .” Agency was measured with six items, including “self-control,” “acting morally,” “planning,” “communication,” “memory,” and “thought” (M = 3.515, SD = 0.964, Cronbach’s α = .934). Experience was measured with six items, including “feeling pain,” “feeling pleasure,” “feeling desire,” “feeling fear,” “feeling rage,” and “feeling joy” (M = 2.628, SD = 1.227, Cronbach’s α = .970). Meanwhile, self-efficacy was measured as 5-level responses (“not at all” to “extremely”) to questions: “How confident are you to follow the sleep advice if you wanted to do so?” “How much personal control do you feel you have over following the sleep advice?” “How much do you feel that following the sleep advice is beyond your control?” Responses to the last question did not converge with others (Cronbach’s α = .518 for all three, and .702 when excluding the last one). Thus, we kept the first two questions (M = 3.356, SD = 0.843, r = .541). Table 1 separates the Ms, SDs, and 95% CIs of all composite variables in the three conditions (human, bot, and control). Correlations among all composite variables across conditions can be found in Table S3 of Supplemental Material.
Summaries of Measurements (Scale Mean Scores) Across Conditions.
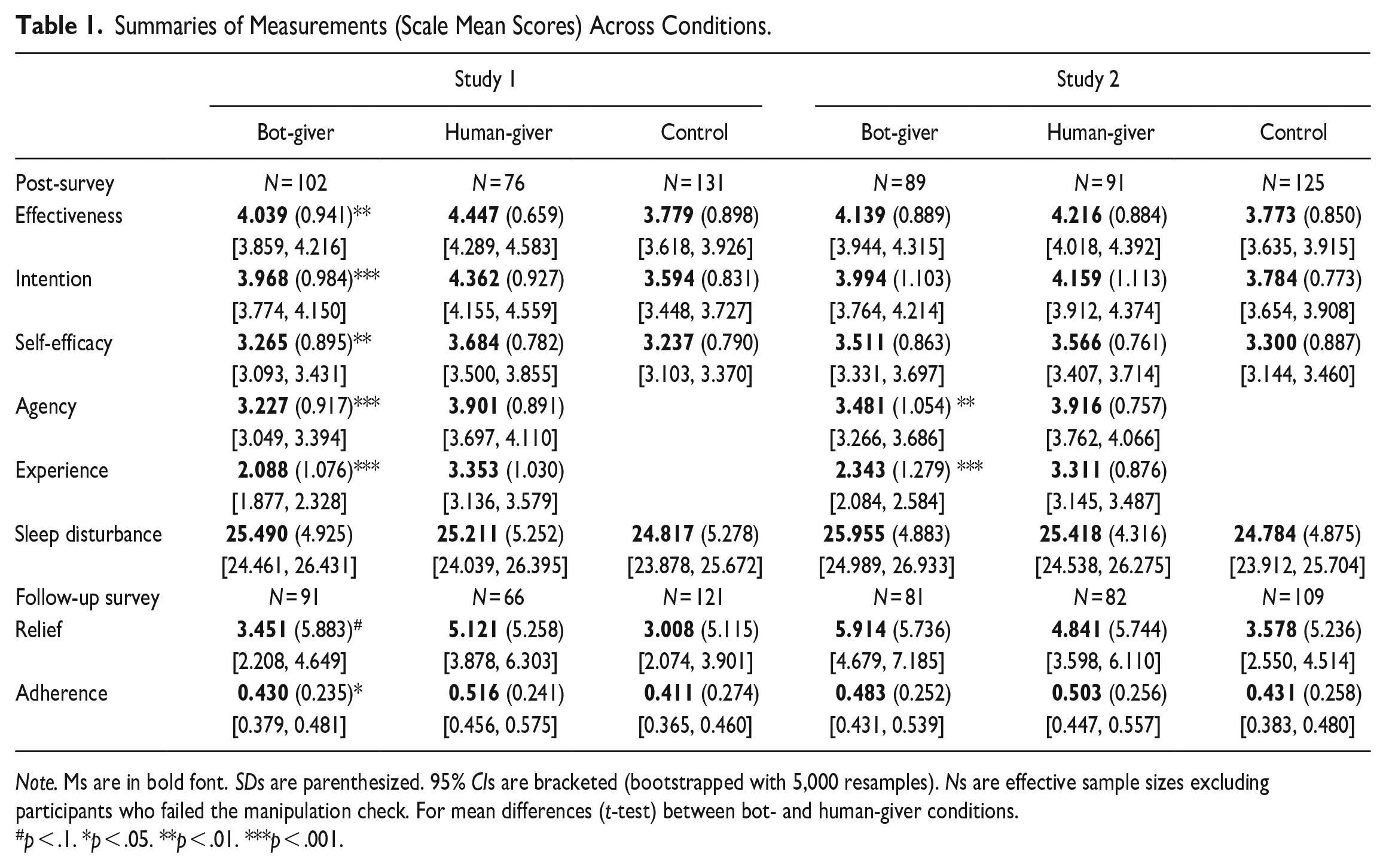
Note. Ms are in bold font. SDs are parenthesized. 95% CIs are bracketed (bootstrapped with 5,000 resamples). Ns are effective sample sizes excluding participants who failed the manipulation check. For mean differences (t-test) between bot- and human-giver conditions.
p < .1. *p < .05. **p < .01. ***p < .001.
Analytical procedure
We used three structural regression models (see Model 1-1–1-3 in Table 2, also Figure 1) to investigate H1, H2, RQ1, and RQ2ab. These models controlled for sleep disturbance score and estimated the identity’ total effects (H1) and indirect effects (H2, RQ1 and 2ab) on the four influence outcomes simultaneously, with robust standard errors and bias-corrected, bootstrapped confidence intervals (with 5,000 resamples).
Summaries of Structural Regression Models for Study 1 and Study 2.
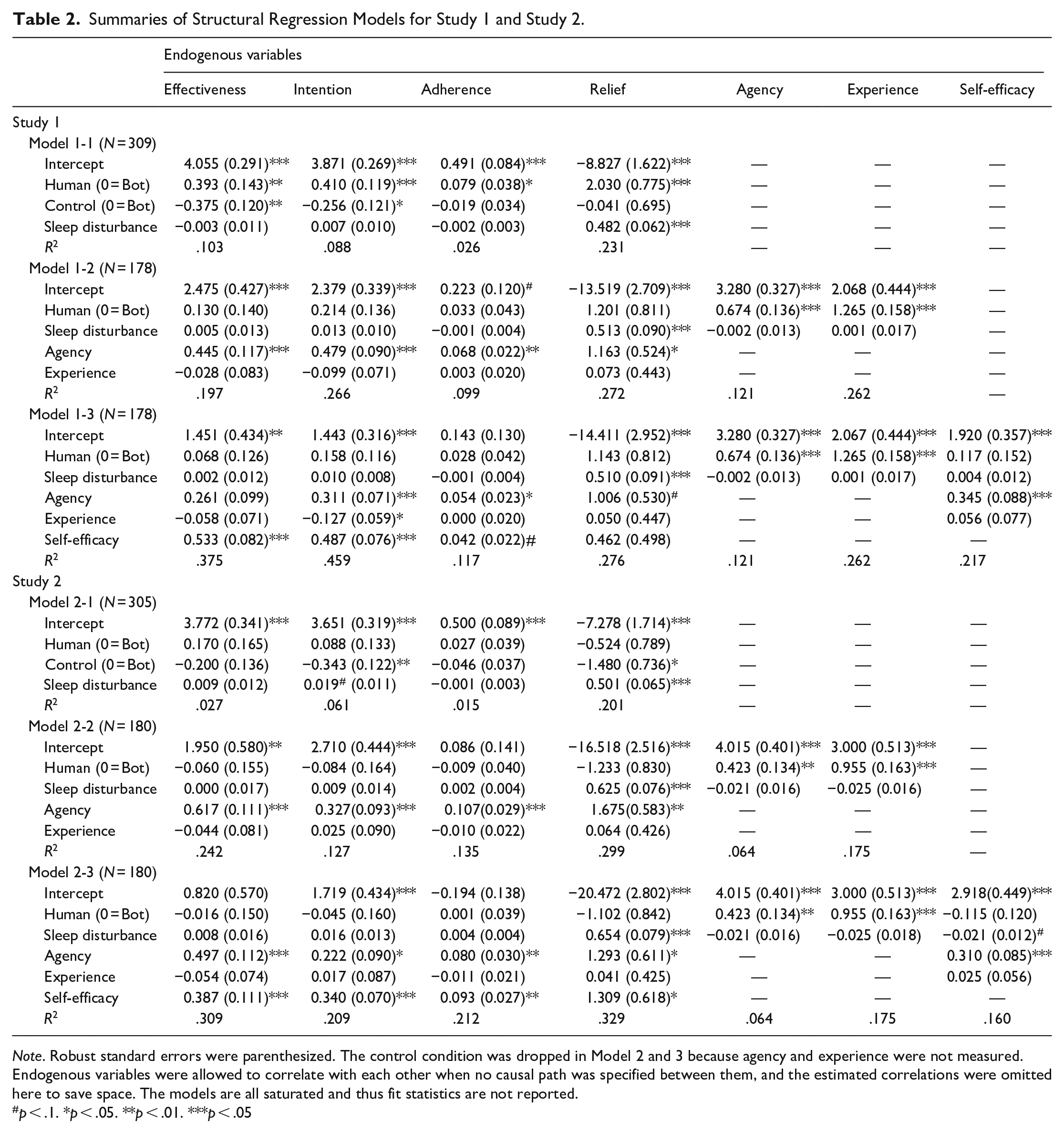
Note. Robust standard errors were parenthesized. The control condition was dropped in Model 2 and 3 because agency and experience were not measured. Endogenous variables were allowed to correlate with each other when no causal path was specified between them, and the estimated correlations were omitted here to save space. The models are all saturated and thus fit statistics are not reported.
p < .1. *p < .05. **p < .01. ***p < .05
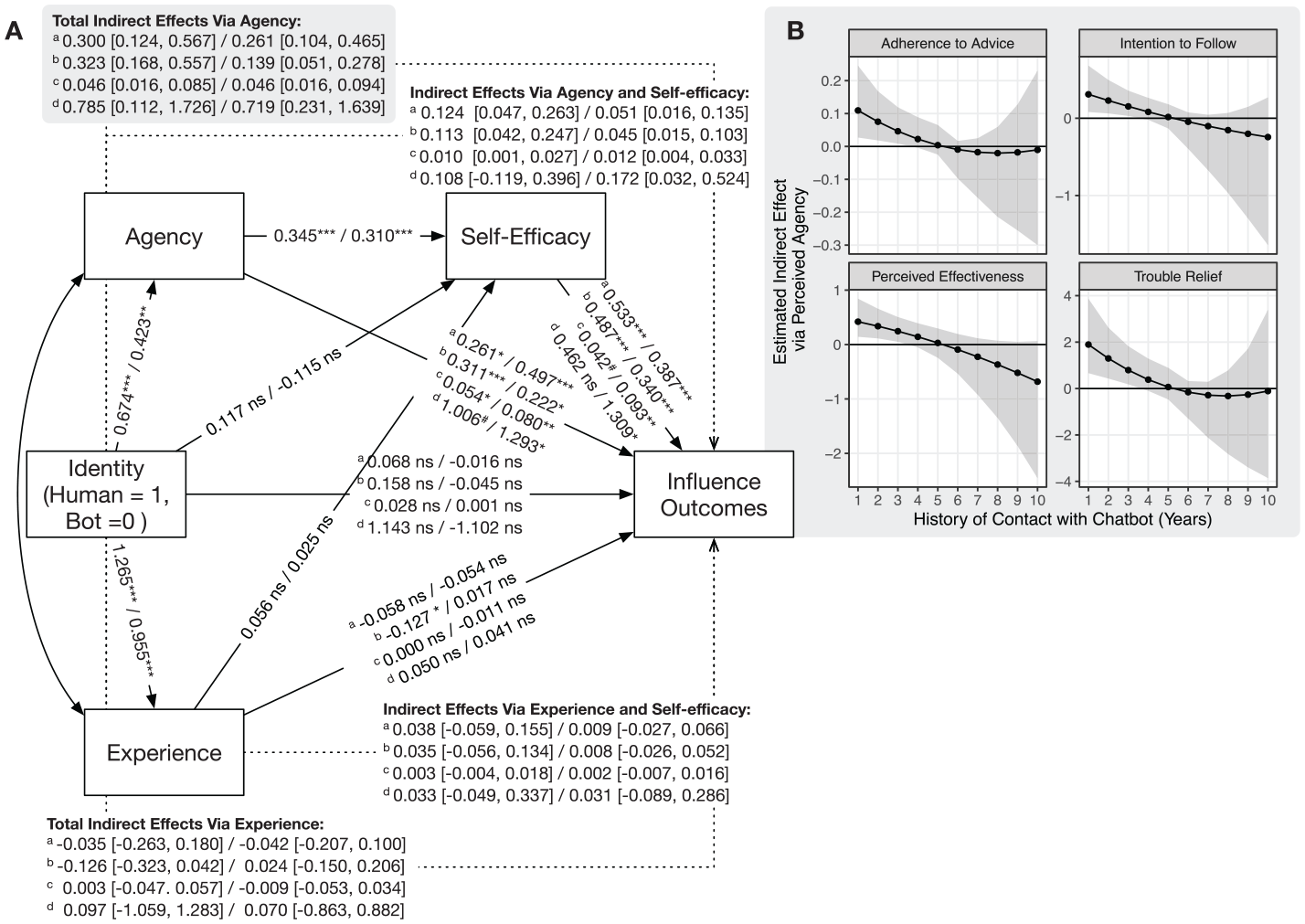
Path diagram of Model 3 for Study 1 and Study 2 (Panel A) and the sensitivity of the total indirect effects of perceived agency against history of contact with chatbots in Study 2 (Panel B).
Results
H1 proposed that human identity would induce greater influence than artificial-agent identity. Our model (Table 2, Model 1-1) shows that advice givers with a human identity, compared to a bot identity, elicited greater perceived advice effectiveness (B = 0.393, 95% CI = [0.112, 0.673], p = .006, η2 = .077) and intention to follow advice (B = 0.410, 95% CI = [0.177, 0.643], p = .001, η2 = .072) after the conversation, as well as adherence to advice (B = 0.079, 95% CI = [0.004, 0.154], p = .038, η2 = .026) and trouble relief (B = 2.030, 95% CI = [0.510, 3.550], p = .009, η2 = .029) after a week. Two-sample t-tests, as reported in Table 1, also reached same conclusions. Thus, H1a, H1b, H1c, and H1d were supported. Compared to the control condition, the bot givers induced more perceived effectiveness and intention to follow advice (so as combining both the bot- and human-giver conditions, see Supplemental Material, Table S4).
H2 predicted that perceived agency would mediate the above effects, whereas RQ2a explores a parallel mediation via experience. Our model (Table 2, Model 1-2) supports such mediation effects of perceived agency on perceived advice effectiveness (0.300, 95% CI = [0.124, 0.567]), intention to follow advice (0.323, 95% CI = [0.168, 0.557]), adherence to advice (0.046, 95% CI = [0.016, 0.085]), and trouble relief (0.784, 95% CI = [0.108, 1.721]), supporting H2a, H2b, H2c, and H2d. With respect to RQ2a, we found non-significant mediation effects via experience on perceived advice effectiveness (−0.035, 95% CI = [−0.263, 0.180]), intention to follow advice (−0.126, 95% CI = [−0.323, 0.042]), adherence to advice (0.003, 95% CI = [−0.047, 0.057]), and trouble relief (0.092, 95% CI = [−1.061, 1.271]). To be clear, the identity manipulation effectively affected both perceived agency and experience: Bot-givers were perceived with less agency (B = −0.674, 95% CI = [−0.942, −0.406], p < .001, η2 = .120) and less experience (B = −1.265, 95% CI = [−1.587, −0.948], p < .001, η2 = 0.262) than human-givers.
Finally, RQ1 asked if the giver’s perceived agency would enhance the seeker’s self-efficacy, which would then further mediate the indirect effects of identity on influence outcomes. RQ2b explores a similar mediation via perceived experience, but it is no longer meaningful given the non-significant results for RQ2a. Our model (Table 2, Model 1-3, also see Figure 1) still estimated all possible mediations via self-efficacy. As expected, the indirect effect of identity–first via perceived agency and then self-efficacy—was 0.124 (95% CI = [0.047, 0.263]) on perceived advice effectiveness, 0.113 (95% CI = [0.042, 0.247]) on intention to follow advice, and 0.010 (95% CI = [0.001, 0.027]) on adherence to advice, although the indirect effect on trouble relief (H3d) was non-significant (0.108, 95% CI = [-0.119, 0.396]).
Discussion
The findings confirmed that perceived agency can explain the underperformance of artificial-agent identity over human identity in advice taking. In contrast, we found no evidence of a comparable role of perceived experience. It is noteworthy that although participants distinguished between a human and an artificial agent more in terms of emotional capacity (η2 = 0.262) than perceived agency (η2 = 0.120), the capacity to act and accomplish goals mattered more on the influence outcomes. At the same time, the findings generally revealed a positive self–other link of agency perception in further explaining the mediation of perceived agency.
Study 2
In Study 1, the provision of emotional support was discouraged. Although emotional support can improve advice taking (Feng 2009), we believe the mechanism related to perceived agency should persist. Study 2 thus encouraged emotional support in the same task to test our hypotheses against the possible interference. Additional measures were also included for further diagnoses and post-hoc analyses.
Methods
Participants
We recruited 605 students (≥18 years old, M = 19.788, SD = 2.261) from the same university. These include 83.082% females, and 48.264% Asian, 27.603% Hispanic, 24.628% Caucasian, 2.479% African American, and 4.528% other races or ethnicities.
Based on the same stopping rule, role assignment procedure, and manipulation check of Study 1, we assigned 128 seekers to the human-giver condition (91 or 71.094% was retained after the manipulation check), 110 to the bot-giver condition (89 or 80.909% retained), and 125 to the control condition. Among the 303 retained participants, 272 completed the follow-up survey (89.769%). The association between the identity manipulation and the manipulation check result was minor, with χ2(1) = 2.583, p = .108 (see Table S1 in Supplemental Material). As for the behavioral equivalence between givers across the two conditions, only 4 out of the 93 LIWC categories (4.301%) were statistically different (.01 < p < .05), and they do not include the significant category found in Study 1 (see Supplemental Material, Figure S4). Considering the possibility of false positive, there was still little evidence of behavioral difference.
Changes of procedure
Study 2 resembles Study 1, except that the givers were encouraged to “offer some emotional support through expressions of sympathy, understanding, or care, before giving advice.” We asked the givers to give emotional support before giving advice in order to maximize advice effectiveness, based on previous work (Feng, 2009).
Key measurements
Using the same measurements from Study 1, we similarly measured perceived advice effectiveness (M = 3.957, SD = 0.994, Cronbach’s α = .940), intention to follow advice (M = 4.012, SD = 0.892, Cronbach’s α = .943), adherence to advice (M = 0.468, SD = 0.256, r = .766), trouble relief (M = 4.654, SD = 5.608), agency (M = 3.701, SD = 0.939, Cronbach’s α = .938), and experience (M = 2.832, SD = 1.194, Cronbach’s α = .967), self-efficacy (M = 3.441, SD = 0.850, r = 0.497), along with sleep disturbance before the study (M = 25.315, SD = 4.727, Cronbach’s α = .723).
Additional measurements
We measured expectancy confirmation (Burgoon & Le Poire, 1993) in the post-conversation survey to diagnose the minor association between the identity manipulation and the manipulation check found in Study 1 (and also Study 2), because we suspect the failure of the check was due to expectation violation. Two items were measured (“[t]he consultant responded in the way I expect most people to respond in this situation” and “. . .engaged in normal conversational behaviors”) with a 5-level scale (“not at all” to “extremely”). The mean score was 3.515 (SD = 1.001, r = .475, N = 238 for all seekers including those who failed the check). We also measured the history of contact with chatbot for a sensitivity analysis of perceived agency’s mediation. If the mediation is indeed due to stereotyping, it may change in accordance with the history of social contact (as in the case of social stereotyping, Pettigrew & Tropp, 2005). In the follow-up survey, we asked participants “[h]ow long have you been using chatbots” with options ranging between 1 and 10 years. The mean was 3.534 (SD = 2.163) for seekers who passed the check, and 3.171 (SD = 1.790) for those who failed—and the difference was non-significant, with t(66.208) = 1.000, p = .321.
Analytical procedure
We used a robust linear regression and estimated marginal means to diagnose the identity manipulation and the manipulation check result, in predicting expectancy confirmation (see Table S6 in Supplemental Material). We used the same structural regression models as in Study 1 (see Model 2-1 – 2-3 in Table 2) to investigate H1, H2, RQ1, and RQ2ab. For the sensitivity analysis, Model 2-2 was modified to include a moderated mediation of perceived agency by history of contact (see Table S7 in Supplemental Material).
For RQ3, we compared a series of confirmatory factor analyses (CFA) to examine configural, metric, and scalar invariance for the measures of perceived agency and experience, following Vandenberg and Lance (2000; also Millsap, 2012) as detailed in the Results section. To ensure the agency and experience measures have discriminant validity and do not cross-load with other measures, each CFA also includes scale items for self-efficacy and three influence outcomes (effectiveness, intention, adherence) and treat sleep disturbance and trouble relief as single-item factors (see Figure 2 for the specification of the final retained CFA). The models were estimated with full-information maximum likelihood and robust statistics. The model fit and comparisons were based on model χ2 and other indices including CFI (>.95), TLI (>.95), RMSEA (<.05), and SRMR (<.05) per conventions (see Kline, 2016). It is noteworthy that we combined Study 1 and Study 2 (N = 358) for a more reliable estimation of these CFAs. That said, the sample size is still not ideal. The analyses thus only provide preliminary information about the measurement invariance of mind perceptions between perceiving human and artificial agents.
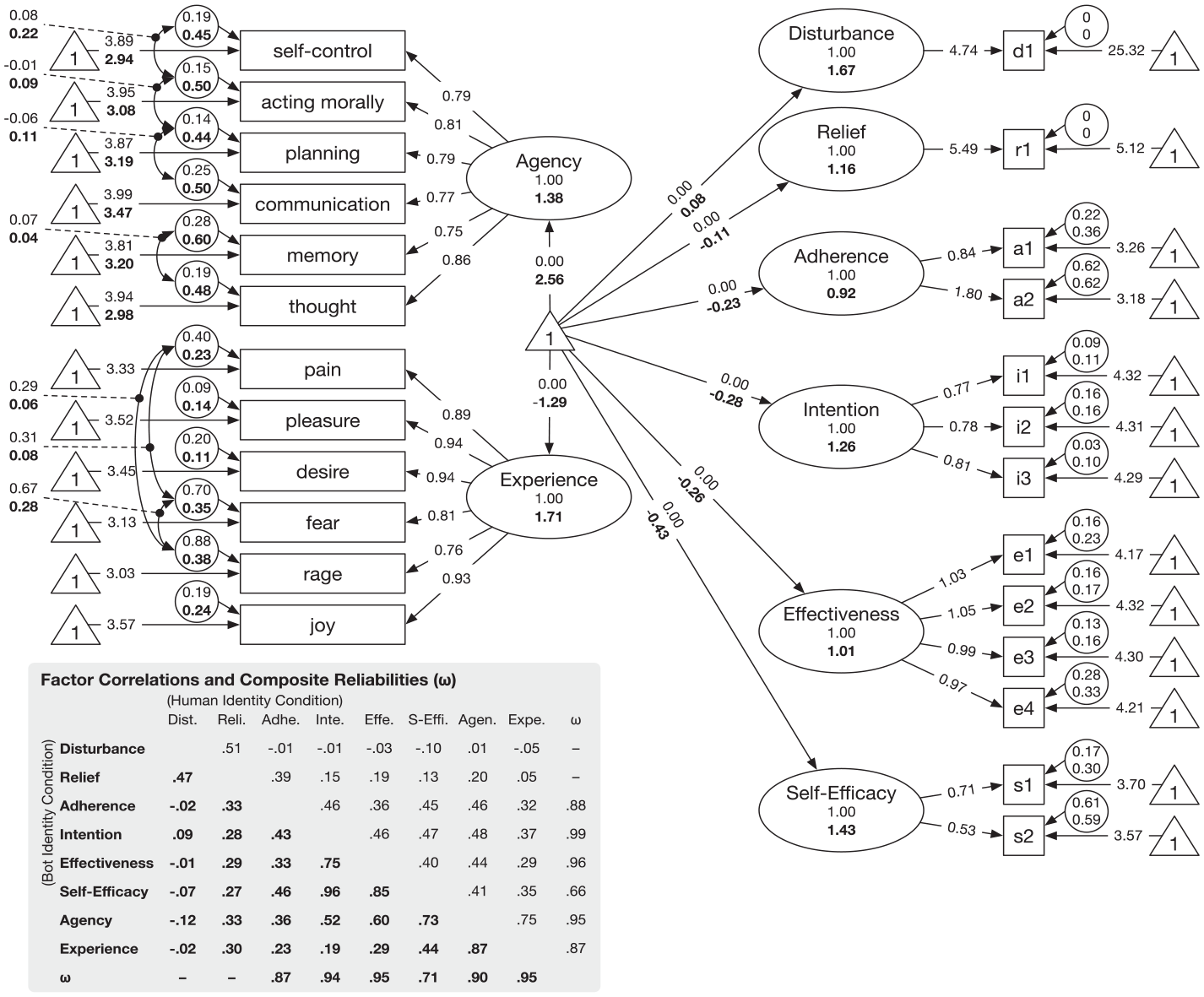
Illustration of the retained partial scalar invariance CFA model (CFA7).
Results
Diagnosis of manipulation check failure
We suspected seekers’ slightly greater failure rate in the human-giver condition was due to expectancy violation. The regression analysis shows that the identity manipulation and the check result had an interaction effect on expectation confirmation (B = 0.951, SE = 0.323, p < .001): Compared with those who passed the check, participants who failed after chatting with perceived human givers reported a lower level of expectedness, whereas those who failed after chatting with perceived bot givers reported a higher level of expectedness (see Table S6 and Figure S4 in Supplemental Material). Using estimated marginal means, we found the difference in expectedness was non-significant between the two conditions for those who passed the check (Mdiff = −0.085, SE = 0.155, p = .581), but significant if we included those who failed the check (Mdiff = 0.390, SE = 0.162, p = .016). Thus, excluding those who failed the check is desirable, as that removes the alternative explanation such that the manipulation could have also triggered expectation violation, in addition to stereotyping.
Total and indirect effects of identity
H1, H2, RQ1, RQ2ab were examined again. First, we found non-significant total effects of the identity manipulation on perceived advice effectiveness (p = .305), intention to follow advice (p = .511), adherence to advice (p = .481), and trouble relief (p = .507), thus H1 was not supported (see Table 2, Model 1). Another model (see Supplemental Material, Table S4) confirms that the control condition, compared with the two conversational conditions in combination, induced less perceived advice effectiveness (B = −0.287, p = .008), intention to follow advice (B = −0.388, p < .001), and trouble relief (B = −1.213, p = .049), along with a marginally significant reduction in adherence to advice (B = −0.060, p = .054). This result rules out the possibility that the non-significant differences between the two conversational conditions were due to ineffective conversations.
The lack of total effect does not preclude mediating mechanisms (MacKinnon, 2008). Thus, we proceeded to estimate whether perceived agency (H2) or experience (RQ2a) might have still played a mediating role. Our model (see Table 2, Model 2) revealed the same patterns in Study 1: Identity had indirect effects via perceived agency on perceived advice effectiveness (0.261, 95% CI = [0.104, 0.465]), intention to follow advice (0.139, 95% CI = [0.051, 0.278]), adherence to advice (0.046, 95% CI = [0.016, 0.092]), and trouble relief (0.709, 95% CI = [0.221, 1.617]), thus supporting H2a, H2b, H2c, and H2d. Also consistent with Study 1, we found non-significant indirect effects of identity via perceived experience on perceived advice effectiveness (−0.042, 95% CI = [−0.207, 0.100]), intention to follow advice (0.024, 95% CI = [−0.150, 0.206]), adherence to advice (−0.009, 95% CI = [−0.053, 0.032]), and trouble relief (0.061, 95% CI = [−0.845, 0.901]). Nevertheless, givers with the bot identity were, again, perceived with both less agency (B = −0.423, 95% CI = [−0.693, −0.154], p = .002, η2 = .054) and experience (B = −0.955, 95% CI = [−1.277, −0.634], p < .001, η2 = .167) than those with a human identity.
Lastly, we tested if self-efficacy further mediated the indirect effects of identity on influence outcomes via perceived agency, as per RQ1. The findings (see Table 2, Model 2-3 and Figure 1) are consistent with those from Study 1: The indirect effect of identity—via perceived agency and then self-efficacy—was 0.051 (95% CI = [0.016, 0.135]) on perceived advice effectiveness, 0.045 (95% CI = [0.015, 0.103]) on intention to follow advice, 0.012 (95% CI = [0.004, 0.033]) on adherence to advice, and 0.172 (95% CI = [0.032, 0.524]) on trouble relief.
Sensitivity of mediation against the history of contact
If the perceived agency of chatbot was partly derived from stereotypes, participants’ history of contact with chatbots should have affected this perception. Our analysis revealed that history of contact increased perceived agency of chatbot givers (B = 0.139, p = .007) and reduced the difference in perceived agency between chatbot and human givers (B = −0.167, p = .017; see Supplemental Material, Table S7). Moreover, the mediation effects of perceived agency diminished when history of contact increased, typically after 4 years of contact (see Figure 1 Panel B).
Measurement invariance
Seven nested multi-group CFAs were estimated (see Table 3 for model fit indices, and Table S8 in Supplemental Material for all parameter estimates). We started with a configural invariance model where the factor–item structure is identical between the bot-identity and human-identity groups, but all parameters were freed (see CFA 1 in Table 3). The original model (CFA1) does not fit data and was thus improved by correlating some item residuals for the same factors (see notes for CFA 2 in Table 3, also Figure 2). Next, we fitted a metric invariance model (CFA3) by constraining all factor loadings to be equal between the two groups. This model does not significantly differ from the improved configural invariance model (CFA2), with Δχ2(17) = 16.803, p = .468, suggesting no evidence against metric invariance.
Comparisons of Nested CFA Models for Measure Invariance Assessments.
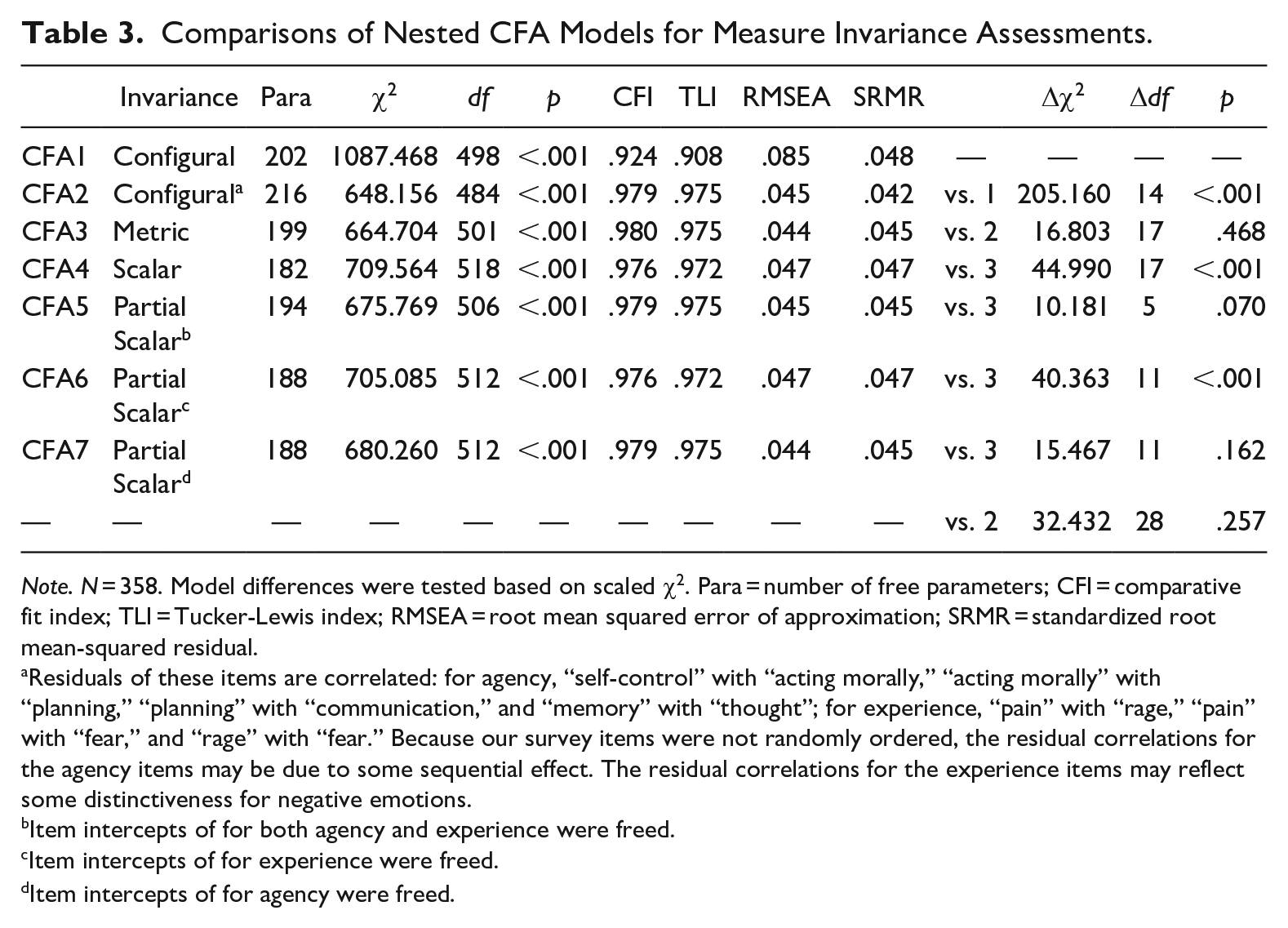
Note. N = 358. Model differences were tested based on scaled χ2. Para = number of free parameters; CFI = comparative fit index; TLI = Tucker-Lewis index; RMSEA = root mean squared error of approximation; SRMR = standardized root mean-squared residual.
Residuals of these items are correlated: for agency, “self-control” with “acting morally,” “acting morally” with “planning,” “planning” with “communication,” and “memory” with “thought”; for experience, “pain” with “rage,” “pain” with “fear,” and “rage” with “fear.” Because our survey items were not randomly ordered, the residual correlations for the agency items may be due to some sequential effect. The residual correlations for the experience items may reflect some distinctiveness for negative emotions.
Item intercepts of for both agency and experience were freed.
Item intercepts of for experience were freed.
Item intercepts of for agency were freed.
Then, we attempted a scalar invariance model by constraining all item intercepts to be equal between the two groups. This time, the model (CFA4) is significantly worse than the metric invariance model (CFA3) with Δχ2(17) = 44.990, p < .001, suggesting some items intercepts differed between the two groups. To identify the differences, we attempted three partial scalar invariance models by freeing all item intercepts for agency and experience (CFA5), for experience only (CFA6), and for agency only (CFA7). Only CFA7 does not significantly deviate from the metric invariance model (CFA3, Δχ2(11) = 15.467, p = .162) and the configural invariance model (CFA2, Δχ2(28) = 32.432, p = .257). CFA7 also fits the data reasonably, with CFI = .979, TLI = .975, RMSEA = .044, and SRMR = .045. Therefore, we retained CFA7 as the final model. We do not further test which specific agency items are different, because that would incur too many significance tests, given our sample’s statistical power.
The final model (CFA7, see Figure 2 for an illustration) reveals several patterns. First, we found no evidence that the giver’s identity changed participants’ response styles to the measures of influence outcomes and self-efficacy (regarding the items factor loadings and intercepts). This is expected, as these measures are about oneself, and people’s understandings of these concepts may not be altered by interaction partner’s identity. Second, we also found no evidence of such a difference for perceived experience (in terms of factor loadings and item intercepts). The model-derived reliabilities of perceived experience for the two identities are also reasonable (ωhuman = .865 and ωbot = .950) and in line with the overall Cronbach’s α (Study 1 = .970, Study 2 = .967) reported before. These together suggest people’s judgments of the emotional capacity for humans and artificial agents are likely comparable and reliable in terms of the other’s abilities to feel “pain,” “pleasure,” “desire,” “fear,” “rage,” and “joy.”
Finally, for perceived agency, CFA7 found no evidence against metric invariance but evidence against scalar invariance. This suggests participants assigned similar weights to “self-control,” “acting morally,” “planning,” “communication,” “memory,” and “thought” when judging human and artificial agent’s agency. However, the intercepts of these judgments differed between the two identities—and the difference was not congruent across these abilities (otherwise, the difference would have been captured by the latent mean). A further look into the intercepts and latent means (see Figure 2) reveals a perplexing picture: The intercepts for all the abilities appear to be lower when givers assumed a bot- rather than human-identity. However, these differences were not absorbed by the latent mean, which is higher for the bot-identity than the human-identity. This pattern suggests some unobserved factors might have existed to change people’s response styles when they were rating the agency of artificial agents instead of humans—although this nature is unclear per our current study design. The counterintuitive pattern of latent mean does not necessary contradict our findings using plain scale scores, since the scores should have absorbed these unobserved factors.
Discussion
Although we did not find a total effect of identity on influence outcomes (unsupported H1a, H1b, H1c, and H1d), findings for the other hypotheses and research questions largely agree with Study 1. The post-hoc analyses also revealed two more nuanced findings: (a) the mechanism of stereotypically perceived agency can diminish as people’s contact with chatbots increases, and (b) there is some deeper difference in people’s perception of agency between humans and artificial agents, as manifested in the lack of scalar invariance for its scale measures. Below, we discuss the general implications of these findings.
General Discussion
There are three implications for the study of mediated communication involving artificial agents or agentic machines, regarding (a) the theorization of stereotyping, (b) the importance of agency perception and social influence, and (c) researcher’s anthropomorphism.
Stereotyping of Artificial Agents
The findings support the proposition: Certain stereotypical perceptions of artificial agents can explain their underperformance in influence situations, even if the agents are behaviorally equivalent to humans. The post-hoc finding corroborates this proposition as the stereotyping effect can be reduced by history of contact—mirroring the long-term effect of intergroup contact on social stereotyping and prejudice (Pettigrew & Tropp, 2005). That said, short-term interactions did not eliminate the stereotyping (contrary to some interaction expectations, for example, uncertainty and social presence, A. Edwards et al., 2019), confirming the theoretical relevance of such stereotyping.
The implication, then, is a call for studying and theorizing the stereotyping of artificial agents as a unique phenomenon in its own right. Existent research has touched effects of artificial agents’ identity (e.g., C. Edwards et al., 2016; A. Edwards et al., 2019; Dietvorst et al., 2015; Ho et al., 2018; Prahl & Swol, 2017, 2017; Spence et al., 2014; also see Fox et al., 2015) but have not yet attended fully to the social categorization and stereotyping processes for these agents. For example, research on machine heuristics (see Sundar, 2008) often focuses on those triggered by the materiality of technology (e.g., features and affordances), and only recently starts to address stereotypes of machine in a social-categorial sense (e.g., “AI as symbol,” Sundar, 2020, p. 79). Studies often also subsume the identity of artificial agents as a part of their human-likeness that triggers anthropomorphism (e.g., Ho et al., 2018), including the activation of human stereotypes (e.g., gender stereotypes; Nass et al., 1994). Our findings, however, suggest the stereotyping can be dissociated from technological materiality and human-based stereotypes.
We believe the stereotyping of artificial agents is a fruitful area of research given the vast possibilities of people’s individual and collective sense-making of machines as social constructions (Fulk, 1993; Walther, 1992), which are actively evolving to date (Gambino et al., 2020). Our findings suggest at least two directions: The mediation of mind perception (at least, agency) indicates the relevance of social cognitive processes and a need to cross-examining the stereotyping of such machines with concepts, theories, and findings of human social cognition. At the same time, the finding that history of contact reduced the stereotypical discrepancy in perceived agency and experience between artificial agents and humans, as well as the reduced mediation effect of perceived agency, point to a need to understand the socio-cultural processes that generate and change the stereotypes in societies.
Active View of Machine Agency
The findings revealed a clear role that stereotypically perceived agency (goal-accomplishing capacity) plays in artificial agent’s influence, while we did not expect nor found a comparable role of perceived experience (emotional capacity). Our goal is not to diminish the importance of emotion. Rather, we believe perceived agency and social influence situation, together, make an important venue to address the negotiation of agency and control in human-machine interactions (Gibbs et al., 2021; Sundar, 2020).
This venue represents a more active view of machine agency, in addition to treating machines as a passive medium (Fogg & Fogg, 2003) or passive actors that mainly elicit social reactions (e.g., be applied with human stereotypes, or be reciprocated with intimacy and politeness; see Nass & Moon, 2000). This means research should attend to people’s perceptions of artificial agents as causal agents (Wegner, 2002) with the will and capacity to induce changes in others. This view also highlights social influence (i.e., socially-induced behavioral change) as a key phenomenon underlying research on human-machine interaction, if not communication research in general (Flanagin, 2017). Research should study social influence more explicitly in addition to other relational and cognitive outcomes and consider such influence as an important manifestation and downstream consequence of the negotiation of agency and control.
Our findings also suggest a social–psychological approach to such negotiations: that is, the self-other link of agency perception. This link can be versatile. In supportive contexts (e.g., advice interactions), a positive link may be more relevant as interactants enhance each other’s perceived agency. In other contexts, the link could be negative, revealing status ranking (Ridgeway, 2001) or power moves (Tiedens & Fragale, 2003). Moreover, the link may be subsumed in people’s self-concepts. One possibility is that the perception of machine agency becomes subsumed or assembled into the self-perception of agency (Hoffman & Novak, 2018). Another possibility is the joining of self-perception of agency into the perception of collective agency (or group-efficacy, Brewer et al., 2004) of a group with both human and artificial-agent members, as a part of the psychological group formation processes (Hogg & Abrams, 1988). In all these cases, the self–other link of agency perception is the key.
Caution Against Researcher Anthropomorphism
Our project cautions against simply equating human and artificial agent in research decisions. For example, we could not directly apply concepts of the two-dimensional model of person perception (e.g., Fiske’s “warmth” and “competence”) to perceptions of artificial agents, even though they may share the same cognitive substratum and adaptive functions. We also could not assume the relative importance of the two dimensions to be equal between perceiving people and artificial agents. Even for concepts like agency and experience (Wegner and Gray, 2016), which have counted the comparability between human and non-human agents, people may still not understand them equally for these agents.
We believe the caution against researcher’s anthropomorphism opens research opportunities. Particularly, findings for RQ3 suggest that, although participants agreed on the aspects of agency (e.g., “planning,” “thoughts,” “self-control,” etc.) when judging human and artificial agents (i.e., metric invariance), there was some unknown heterogeneity in the baselines of these judgments (i.e., lack of scalar invariance). In fact, such a lack of scalar invariance (but not metric invariance) is prevalent in studies of perceived warmth and competence across different human social groups (Friehs et al., 2022). In the context of human-machine interaction, the theoretical sources of this lack of scalar invariance warrant future research, as that would shed light on the deeper difference in perceiving agency from humans and artificial agents.
In addition, our use of real humans behind the manipulated identity (i.e., Wizard of Oz approach) may also entail risks of researcher anthropomorphism. We assume artificial agents will emulate and eventually be equivalent to humans, and thus people’s different responses to the identity difference, in the long run, are pure cognitive biases. Relatedly, we did not have to pick prototypes of these agents in the fast-changing landscape of technology today. The preceding assumption is purely analytical, however. The current reality of artificial agents (and may be in the future) suggests their essences and behaviors may fundamentally deviate from humans’ and from each other’s. Then, at least two questions warrant attention from a social cognition perspective. The first is to what extent people believe artificial agents as an essentialist social category or entity (Haslam et al., 2000; Yzerbyt et al., 1998). The second is whether there exists more than one category, and how people distinguish between these categories (e.g., would people distinguish between them per technological features, application contexts, vendors, etc.?).
Limitations
There are several limitations with our studies that warrent discussion. First, we did not examine conversation dynamics, although our findings suggest such dynamics could have played a role. Particularly, the underperformance of artificial agents in Study 1 turned non-significant in Study 2 when emotional support was encouraged. Such a non-significant total effect does not invalidate our argument about perceived agency. Rather, the emotional support must have enabled additional, unobserved causal paths (i.e., inconsistent mediation, MacKinnon, 2008), which then compensated artificial-agent identity’s shortage in perceived agency and subsequently the potential to influence. However, the compensation was not achieved through perceived emotional capacity, because participants in both studies perceived advice givers with a human identity to possess a higher degree of experience. The answers, then, may lie in the conversational dynamics. Future research should examine such dynamics.
Second, our college-student samples consisted predominantly of females (around 80%) and Asians (around 50%), which could have limited the generalizability of our findings (although controlling for gender and the Asian race does not change our results, see Table S9 in Supplemental Material). Future research should examine other populations. Similarly, we only examined a specific context of interpersonal influence (i.e., advice interactions), although our theoretical arguments cover social influence involving artificial agents in general. Validation and adaptation are needed for other social influence situations (e.g., dyadic compliance-gaining and normative influence in groups). In addition, research may examine more theorized types of advice (e.g., advice for task-oriented issues, as well as socio-emotional, personal troubles).
Lastly, we focused on the generic capacities to act and accomplish goals (e.g., think, plan, communicate, act morally, memory, self-control) and to experience emotions (e.g., fear, joy, anger, sad) in light Wegner and Gray’s work on mind perception and the two-dimension models of social cognition. There are other ways to conceive stereotyping, for example, differentially activated social cognitive schemas (e.g., an actor as an object, a person, or a role), or people’s essentialist beliefs about artificial agents as social categories (Haslam et al., 2000; Yzerbyt et al., 1998). Future research should examine these issues.
Conclusion
Many artificial agents today are developed to address our problems and troubles. As we ascribe agency to such agents, they become less a tool or medium but resemble advice givers, whom we encounter in everyday life. Through their “advice,” these agents become a source of social influence. Technologically speaking, they may become as capable as humans in the future. Yet, just like people in different social categories do not influence us equally, the identity of artificial agents will be associated with stereotypical perceptions that curb or exaggerate their influence. The current project sheds some light on such stereotypical perceptions, particularly the perceived capacity to act and accomplish goals. However, as we discussed before, many gaps need to be filled before we can gain a better understanding of how we stereotype artificial agents. Such understandings will help us to envision the future socio-technical landscape of social influence, and how we accept artificial agents as genuine social actors and relationship partners.
Supplemental Material
sj-docx-1-crx-10.1177_00936502221138427 – Supplemental material for Understanding the Influence Discrepancy Between Human and Artificial Agent in Advice Interactions: The Role of Stereotypical Perception of Agency
Supplemental material, sj-docx-1-crx-10.1177_00936502221138427 for Understanding the Influence Discrepancy Between Human and Artificial Agent in Advice Interactions: The Role of Stereotypical Perception of Agency by Wang Liao, Yoo Jung Oh, Bo Feng and Jingwen Zhang in Communication Research
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The first author (WL) gratefully acknowledge the funding from the Society of Hellman Fellows.
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.