
Abstract
Mediation analysis is increasingly used in the social sciences. Extension to social network data, however, has proved difficult because statistical network models are formulated at a lower level of analysis (the dyad) than many outcomes of interest. This study introduces a general approach for micro-macro mediation analysis in social networks. The author defines the average mediated micro effect (AMME) as the indirect effect of a network selection process on an individual, group, or organizational outcome through its effect on an intervening network variable. The author shows that the AMME can be nonparametrically identified using a wide range of common statistical network and regression modeling strategies under the assumption of conditional independence among multiple mediators. Nonparametric and parametric algorithms are introduced to generically estimate the AMME in a multitude of research designs. The author illustrates the utility of the method with an applied example using cross-sectional National Longitudinal Study of Adolescent to Adult Health data to examine the friendship selection mechanisms that indirectly shape adolescent school performance through their effect on network structure.
A large methodological literature develops mediation methods for observational and experimental data (Bollen and Stine 1992; Breen, Karlson, and Holm 2013; Imai, Keele, and Tingley 2010; Imai, Keele, and Yamamoto 2010; Karlson, Holm, and Breen 2012; Mackinnon 2008; Mize, Doan, and Long 2019; Pearl 2001; Sobel 1982, 2008). Mediation analysis involves identifying the intervening variables that explain the relationship between an explanatory variable and an outcome. It has gained increasing popularity in the social sciences as recent theoretical advances have provided clarity on the conditions necessary to identify, estimate, and interpret indirect effects (Pearl 2001). These advancements have contributed to a burgeoning body of research that uses mediation analysis to evaluate the mechanisms responsible for social outcomes, such as racial disparities in educational attainment (Zhou 2022), implicit racial biases (Melamed et al. 2019), and poverty (Desmond and Wilmers 2019).
Although social scientists often regard networks as an intervening variable in causal processes (e.g., An, Beauvile, and Rosche 2022; Chetty et al. 2022; DiMaggio and Garip 2012; Pedulla and Pager 2019), mediation methods for social networks are currently underdeveloped. Contemporary methods are limited to comparisons between two models where the same network acts as the dependent variable (Duxbury 2023). 1 Yet sociologists are often interested in how network selection affects individual, group, and organizational outcomes. Structuralist perspectives posit that networks exert contextual effects on social action (Burt 1992; Centola 2015; Coleman 1990; Granovetter 1973; Melamed, Harrell, and Simpson 2018; White 1992). To the extent that distinct selection mechanisms create unique network contexts, network selection is likely to indirectly influence individual, group, and organizational outcomes by altering network structure.
For example, Bearman, Moody, and Stovel (2004) motivated their analysis of adolescent dating networks by arguing that chain-link structures optimize sexually transmitted disease (STD) diffusion. This implies an indirect effect of relational dating norms—in their case, four-cycle avoidance—on individual STD risk and network-level STD diffusion because of a change in network topology. Schaefer, Kornienko, and Fox (2011) motivated their study of depression homophily by arguing that peer depression worsens mental health. Duxbury and Haynie (2020) examined how suspension can decrease school achievement by driving students into academically underperforming peer groups. Padgett and Ansell (1993) classically showed that the Medicis’ navigation into advantageous network positions enabled them to consolidate political power in fifteenth-century Florence. Each of these studies imply an indirect network selection effect on an individual or group outcome via network structure.
Although indirect network selection effects are often implicated in sociology, the lack of mediation methods for social networks has hampered statistical evaluation of indirect network selection effects on higher-order outcomes. 2 The main impediment to micro-macro network mediation analysis is that statistical network models are formulated at a lower level of analysis (the dyad) than the individual, group, and organizational outcomes that researchers often want to study. Because current mediation methods assume multiple models fit to the same unit of analysis, they cannot be used to address questions that implicate indirect effects of network selection processes on outcomes measured on higher level units.
In this study, I develop a general approach for micro-macro mediation analysis in social networks. In the framework, micro processes represent network selection effects that dictate whether two nodes are connected and are captured by the terms in a statistical network model. Here, “macro” structure encompasses all network statistics calculated above the dyad level, including node, subgraph, and global statistics. The approach allows researchers to estimate, test, and interpret the indirect effect of a network selection process on an individual, group, or organizational outcome acting through an intervening network variable.
I begin by outlining prior approaches to mediation analysis in regression. I then discuss three problems in social networks: the unit of analysis problem, interdependence, and posttreatment confounders. Next, I introduce the average mediated micro effect (AMME) and present identification results for the AMME under the assumption of conditional independence among multiple posttreatment confounders. I then introduce parametric and nonparametric algorithms for estimating the AMME. I conclude by providing an example using cross-sectional National Longitudinal Study of Adolescent to Adult Health (Add Health) data. The mediation approach is implemented in the netmediate R package available on the Comprehensive R Archive Network.
Prior Approaches to Mediation Analysis
Following contemporary mediation research (Imai, Keele, and Yamamoto 2010; Pearl 2001; Sobel 2008), I use notation and language common to the potential outcomes framework.
3
Suppose we have a random sample of size n. Let
The indirect effect of
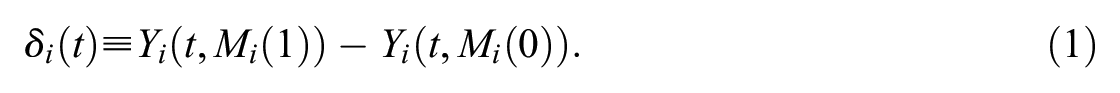
This represents the change in the outcome that can be attributed to a treatment induced change in a mediator when the treatment is held constant and the mediator is changed from
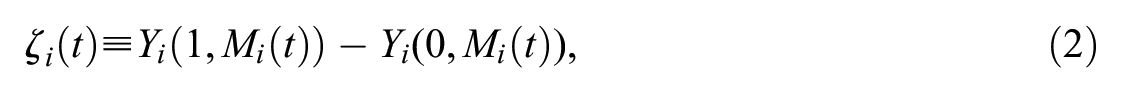
which is the effect of the treatment on the outcome when the treatment is changed from 0 to 1 and the mediator is constant. The sum of the direct and indirect effects equals the total effect:
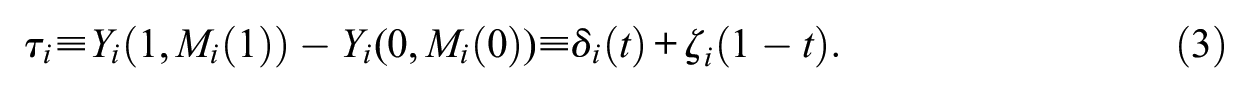
Given the unit-level quantities of interest, we define the population average effect for each quantity:
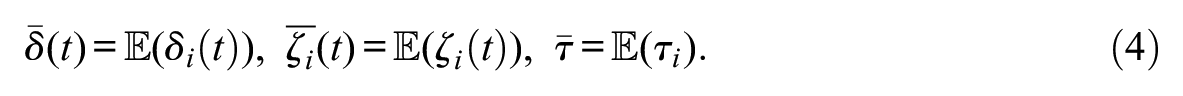
The goal of mediation analysis is to decompose the total effect into direct and indirect effects. The conventional approach involves fitting two linear regressions separately (e.g., Bollen and Stine 1992; Sobel 1982):

and

where
Formally, the sequential ignorability assumption holds that

and

where the notation
Definition of the Problem and Issues with Prior Approaches
The conventional approach to mediation analysis encounters three problems when applied to indirect network selection effects. First, prior approaches assume the mediating variable, outcome, and treatment are measured on the same unit of analysis. Second, current methods assume independent observations. Third, conventional strategies assume no posttreatment confounding. I graphically introduce the direct and indirect pathways I aim to disentangle before elaborating on each problem in the following subsections.
Direct and Indirect Micro-Macro Pathways
Figure 1 outlines the direct and indirect micro-macro relationships that we seek to disentangle. As above, I use T, M, Y, and X to denote the explanatory variable, mediating variable, outcome variable of interest, and confounding pathways. However, now T represents a micro-level network selection process. By micro-level, I refer to network selection processes that determine whether two nodes are connected, such as reciprocity, triadic closure, or homophily, and that are commonly represented by the parametrized terms in statistical network models, such as the exponential random graph model (ERGM) or stochastic actor-oriented model (SAOM). These processes are often represented by dyadic attributes, but they may also be captured by nodal or contextual variables. For example, in friendship networks, sociality effects refer to node characteristics that determine whether actors are more or less likely to send or receive friendship ties compared with other actors with different attributes (e.g., girls tend to have more friends, on average, than boys) (see Goodreau, Kitts, and Morris 2009; Robins, Elliot, and Pattison 2001). Figure 1 also incorporates the micro-level pretreatment confounders Z that provide alternative network selection mechanisms.
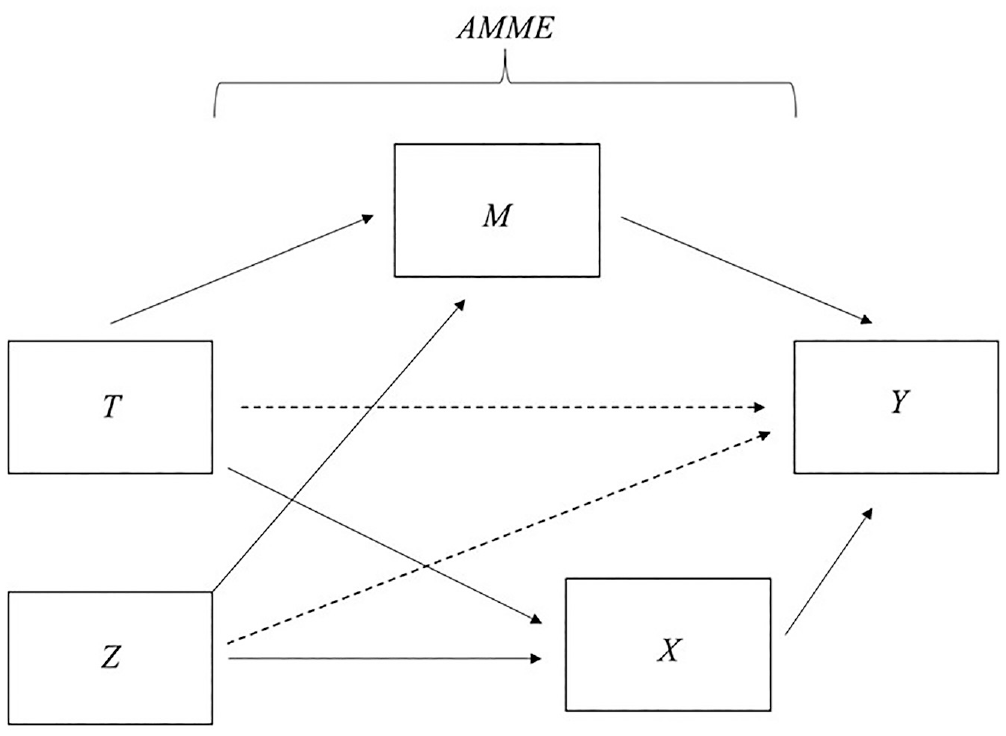
Model of direct and indirect micro-macro network effects.
M represents the macro-level mediating network variable focal to the analysis. M is a node, subgraph, or network-level measure. For example, M may represent a node measure like betweenness centrality, a subgraph measure like community membership, or a global measure like transitivity. Y is the outcome variable measured at the node, subgraph, or network level. In an in-school friendship network, Y may represent a student measure like grade point average (GPA), a group measure such as the percentage of same-race ties within a grade level, or a school measure such as the student-to-teacher ratio. Y and M may be measured on the same unit of analysis or Y may be measured at a lower unit of analysis. This may occur when there is a contextual network effect on a node outcome, such as the effect of in-school friendship network density on student delinquency (Kreager, Rulison, and Moody 2011). X represents a vector of posttreatment confounders, or macro statistics that confound the effect of a mediator on the outcome and that may also be affected by the explanatory network selection process of interest. Posttreatment confounders are the intervening variables not focal to the analysis, and mediators are the intervening variables of substance interest. 6
The research goal is to identify the indirect effect of T on Y acting through M, which I refer to as the AMME. The AMME is captured by the effect of T on Y that arises indirectly because of a change in M. For example, if we are interested in student school performance, we might posit a peer effect of alters’ GPAs on student GPA. A selection process, such as triadic closure, may indirectly affect GPA by increasing or decreasing GPA segregation in the network at large. Our goal would be to identify the indirect effect of triadic closure on student GPA because of a change in peer GPA (see Figure 2).
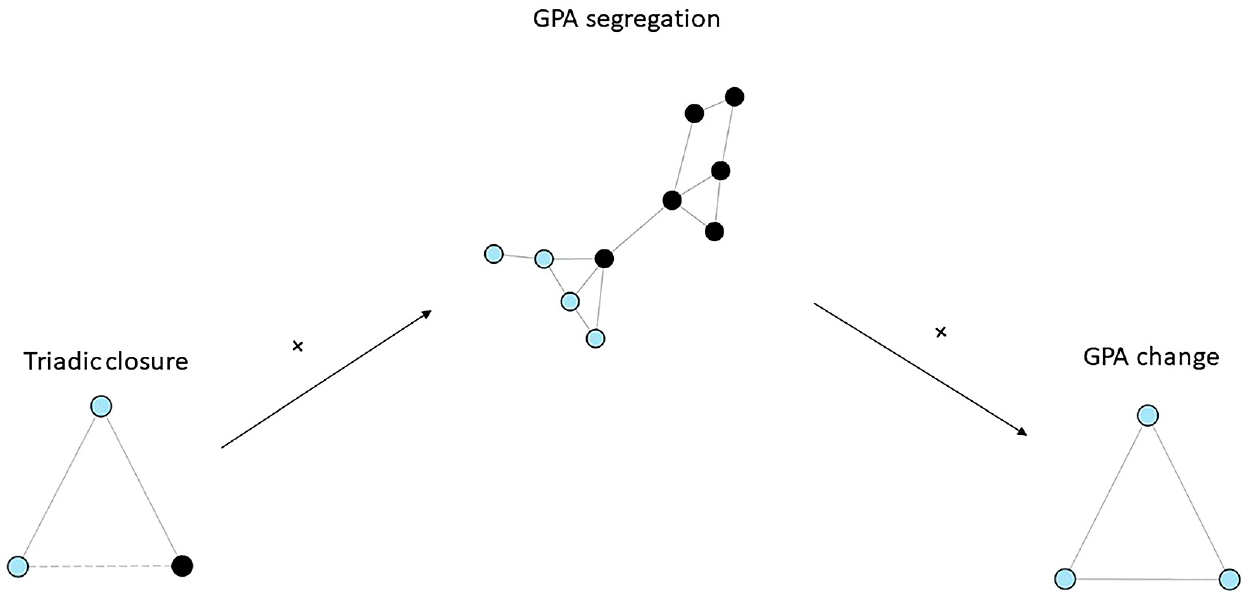
Indirect selection effect of triadic closure on student grade point average (GPA) operating through GPA segregation.
Identification Problems in Network Mediation Settings
The first identification problem lies in the unit of analysis. Network selection processes are relational, and thus are captured by treating dyads as the unit of analysis in statistical network models (Butts 2008; Frank and Strauss 1986; Holland and Leinhardt 1981; Krackhardt 1987; Snijders 2001; Stadtfeld, Hollway, and Block 2017). However, many outcome variables of interest represent attributes of the individuals, groups, or organizations nested in social networks. This means the effect of T on M cannot be captured using separate models treating M and Y as outcome variables. The coefficients from such models are not comparable. Approaches that rely on models fit to the same data therefore cannot be used to identify indirect network selection effects.
The second problem relates to posttreatment confounding. Conventional mediation methods assume no posttreatment confounders. This permits the analyst to estimate the indirect effect by increasing the value of the treatment without worrying that an alternative mediator explains the indirect pathway. The assumption of no posttreatment confounding is usually violated in network mediation settings. Changing a treatment value for a selection process necessitates a change in the complete network, and thus a change in multiple network statistics. For example, if we are interested in the indirect effect of triadic closure on GPA acting through peer GPA, we must account for the confounding effect of transitivity because triadic closure necessitates an increase in transitivity. This means the assumption of no posttreatment confounding cannot be supported in many network mediation designs.
The third problem relates to nonindependence. Potential outcomes used in prior approaches are defined as the value obtained by the outcome when the mediator obtains a value implied by a prespecified treatment value. These potential outcomes assume independence among observations. They require that the value of an explanatory variable for an observation can be altered without changing the value of other variables for other observations. Network data violate this assumption because of relational dependencies between data points (for a discussion, see An 2018; VanderWeele and An 2013). For example, GPA segregation in school friendship networks is a function of the joint distribution of GPA and ties. Increasing triadic closure for a randomly chosen dyad thus breaks the covariance between GPA and friendship ties in the network at large. Yet if triadic closure produces GPA segregation, it is because the students who tend to befriend one another through triadic closure tend to have similar GPAs. This means the potential outcomes used to define conventional indirect effects do not adequately capture the relational dependencies of central interest in network mediation analysis. 7
The AMME
With the above problems in mind, I define an indirect network selection effect that capitalizes on the distribution of attributes and network dependencies in the observed data. I then show that the AMME can be nonparametrically identified 8 under the sequential ignorability assumption with multiple conditionally independent posttreatment confounders. This approach assumes that the outcome of interest and micro processes are measured at different units of analysis but that the micro units are “nested in” the macro units, such that the two data sets can be linked by a common identifier.
Micro-Macro Direct, Indirect, and Total Effects
Let i index the unit of analysis for the outcome variable.
The potential value of
Prior micro-macro network methods evaluate the contributions of network selection processes to network structure by comparing observed values to counterfactual conditions where a micro process is set to 0 (Block 2023; Duxbury forthcoming; Huang and Butts 2023; Indlekofer and Brandes 2013; McMillan, Kreager, and Veenstra 2022; Robins, Pattison, and Woolcock 2005). The logic behind this approach is that by “switching off” the contributions of a micro process holding all else constant, the change in a macro statistic can only be attributed to the selection process of interest. Extending this procedure to mediation analysis, I compare the potential outcomes in which a micro process makes no contribution to the potential outcomes expressed in the observed data. The advantage of this approach is that it preserves covariance between the ties and the distribution of node, edge, and dyad attributes in the observed data.10,11
Under this set up, we can define two types of micro-macro indirect effects, one with respect to
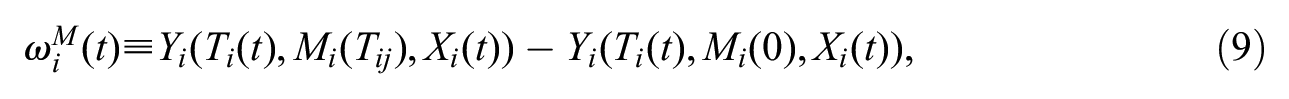
and
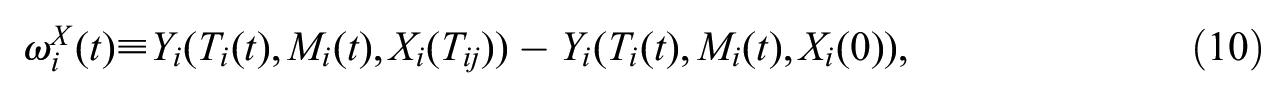
for t = 0,
The indirect effects defined in equations (9) and (10) capture the change in the potential outcome for i due to a broader change in network structure. It compares the observed outcome to the potential outcome that arises when an explanatory selection process makes no contribution. A key utility of this indirect effect is that it captures network spillover. To see this, note that setting
As in the conventional case, I capture the population average effect (i.e., the AMME), as
In some cases, T may exert a direct effect. For example, if T represents student gender, then gender may shape Y indirectly by shaping network structure as well as directly due to gendered expectations about school performance. The unit-level direct effect can be defined as
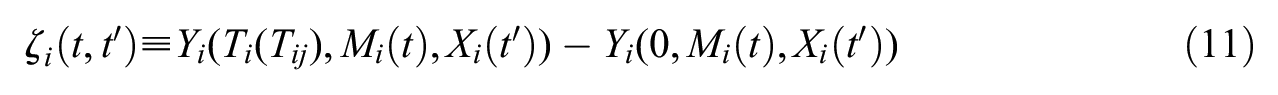
For each t,
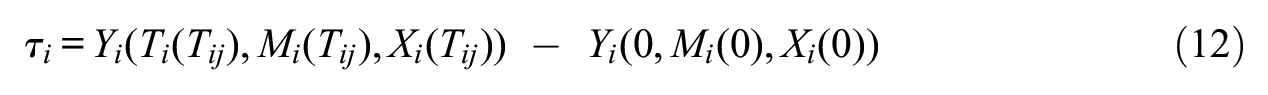
and can be calculated as the sum of the direct and indirect effects. This represents the effect of T on Y operating through all direct and indirect pathways. The percentage explained for direct and indirect effects can be calculated with reference to
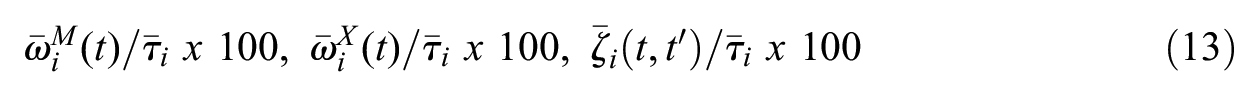
Thus far, I have assumed a continuous outcome variable. I now extend the AMME to binary outcomes. I replace the observed outcome
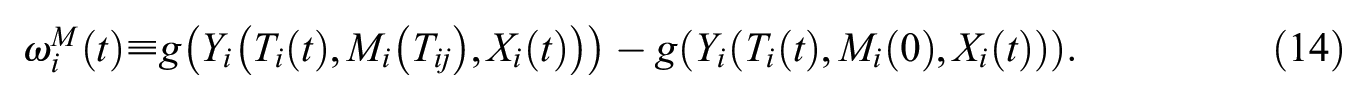
In this case, the AMME is the change in the probability of realizing a positive case of the outcome variable because of the indirect effect of a network selection process operating through an intervening network variable. When
Identification Result
I now demonstrate that the AMME can be nonparametrically identified with the observed data under sequential ignorability with multiple conditionally independent mediators.
Assumption 1: Sequential Ignorability with Multiple Conditionally Independent Mediators
I assume that the following three conditions hold:
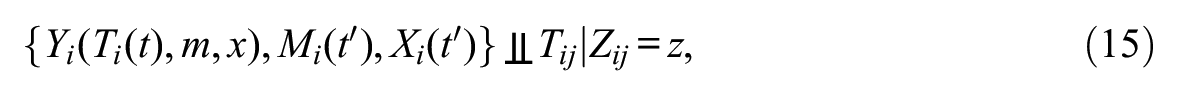
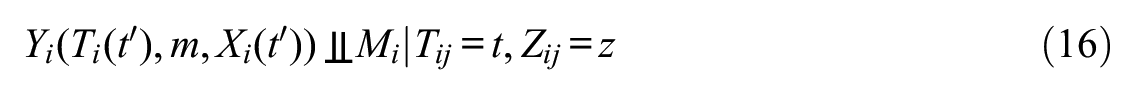
and
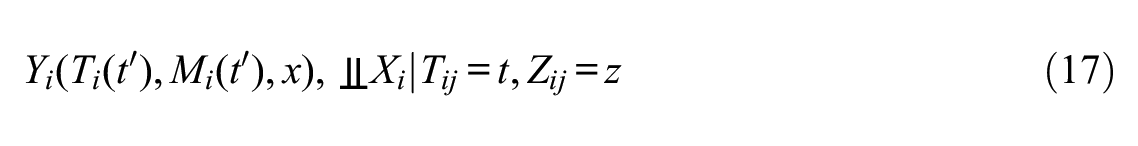
where
This assumption holds conditional independence for (1) the effect of T on M, (2) the effect of M on Y, (3) the effect of X on Y, (4) the effect of T on X, and (5) the effect of T on Y.
The assumption of sequential ignorability is a strong one and can be violated in two common ways. The first is because of unmeasured confounding variables on any pathway. The second is if there is reverse causation, for example, Y has an effect on T. This possibility is common in cross-sectional analyses of peer effects where observed levels of network autocorrelation generically blend processes of selection and influence. Because these possibilities are well studied and occur routinely in network analysis, not just mediation analysis (An 2015a; An et al. 2022; Centola 2010; Shalizi and Thomas 2011; Steglich et al. 2010), I do not belabor the point here. The main takeaway is that sequential ignorability does not hold in research settings where the direction of influence and possibility of omitted variables is not adequately addressed by the modeling strategy chosen by the researcher.
Under sequential ignorability,
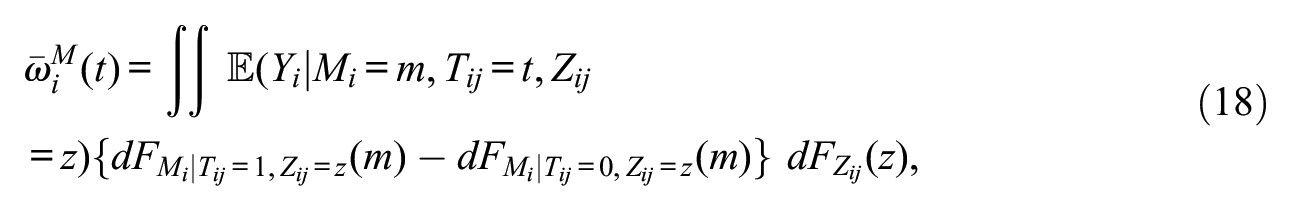
for any t,
Estimation
I now introduce parametric and nonparametric algorithms for estimating the AMME. The procedures build on bootstrap and Monte Carlo algorithms commonly used in computational statistics (Duxbury forthcoming; Imai, Keele, and Yamamoto 2010; King, Tomz, and Wittenberg 2000).
Model Requirements
As in conventional mediation analysis, we require two models to estimate the AMME: a statistical model for a complete network and a statistical model for the outcome of interest. Denote the complete network with A such that

and
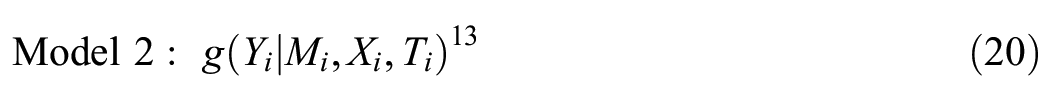
Model 1 is a statistical model for the network A, which may be either binary or valued. A may be a single network, a stacked adjacency matrix of multiple networks, or repeated measures of the same network over time. For example, if model 1 is an ERGM, then
I emphasize again that this approach can accommodate contextual selection effects. For example, consider the case where network selection is modeled using hierarchical ERGM or a meta-regression of lower level network models with contextual covariates (e.g., An 2015b; Schweinberger and Handcock 2015; Slaughter and Koehly 2016; Snijders and Baerveldt 2003). The contextual effects are now captured by model 1. This means the AMME for the contextual effect can be identified under the conditions outlined above. In this instance, the AMME assesses whether the contextual covariate has an indirect effect on an outcome of interest because actors are more likely to select into specific network structures in some social contexts compared with others.
Algorithm
The algorithms proceed under the general logic that the AMME can be estimated using uncertainty in each model to create a distribution of mediating networks and outcome values. In the parametric algorithm, uncertainty is captured by assuming a multivariate normal distribution for the model parameters and using the covariance matrix of the estimator to approximate the variance of the parameter distribution. In the nonparametric algorithm, this is accomplished via bootstrapping. Tables 1 and 2 provide pseudocode for each algorithm.
Algorithm 1: Parametric Estimation Algorithm.

Algorithm 1: Nonparametric Estimation Algorithm.

Parametric Estimation
The parametric estimation algorithm proceeds in four steps. In step 1, fit two models, one of the form
Step 3 contains four subphases. In the first subphase, draw two networks, one using
In step 4, calculate the AMME point estimate with
Nonparametric Estimation
The nonparametric algorithm follows similar logic. It proceeds in three steps. In step 1, the researcher obtains P bootstrap versions of
Simulation
I now provide simulation results to assess the consistency of the algorithmic estimates. Because the AMME relies on realistic distributions of edges and attributes, I initiate the simulation using the Faux Mesa High friendship network (Hunter, Goodreau, and Handcock 2008). The network contains 205 nodes representing high school students and 203 undirected friendship relationships. The simulation broadly entailed generating 1,000 synthetic networks from prespecified coefficients and then estimating the AMME on each network. I first fit a dyad independent ERGM to the Faux Mesa High network that included sex, race, and grade as node sociality effects and as homophily effects (same sex or same race; absolute difference in student grade) and stored the parameter vector. I then used a Metropolis-Hastings algorithm to simulate 1,000 synthetic networks treating the coefficients from the dyad independent ERGM as the “true” generative model parameters.
Next, I generated a node-level outcome variable using a linear model of the form:
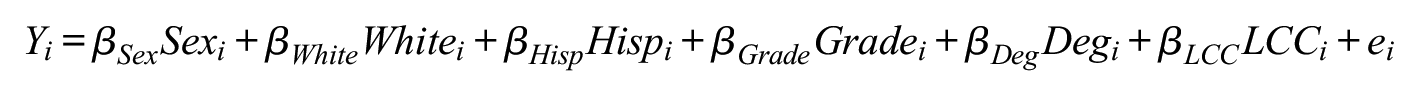
Our primary task is to estimate the AMME with respect to
Beginning with parametric estimation, Figure 3 plots results from the micro-macro mediation analyses with density plots representing sample estimates and dashed vertical lines representing population values. The parametric algorithmic estimates converge to the population value for each effect measure: the AMME with respect to
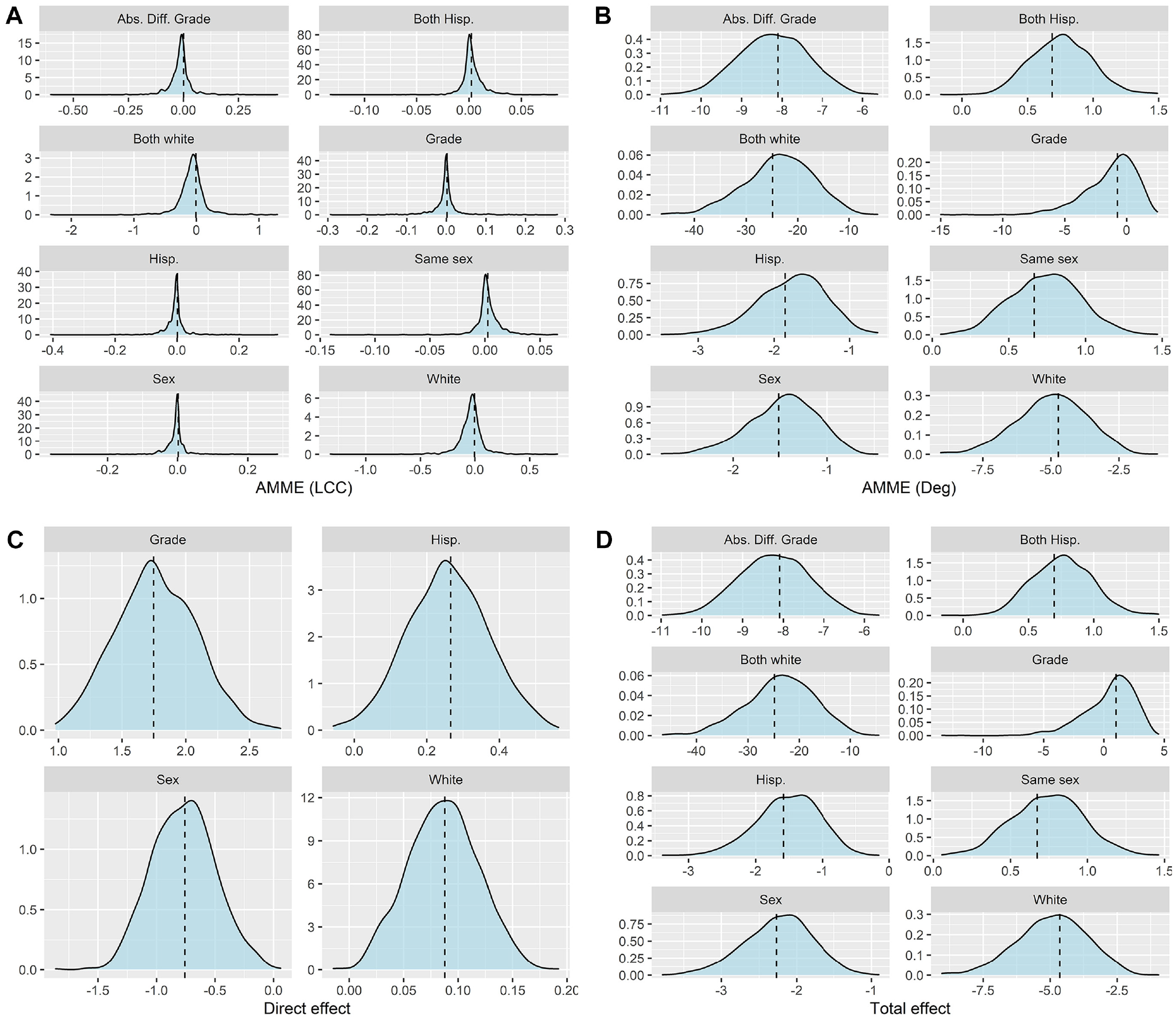
Parametric estimates of (A and B) average mediated micro effects (AMMEs) (N = 16,000), (C) direct effects (N = 4,000), and (D) total effects (N = 8,000).
Turning to nonparametric estimation, results largely align with parametric estimation (see Figure 4). The nonparametric algorithmic estimates converge to the population value for each AMME, direct effect, and total effect. This includes both normally distributed variables as well as the left-skewed total effect and AMME with respect to
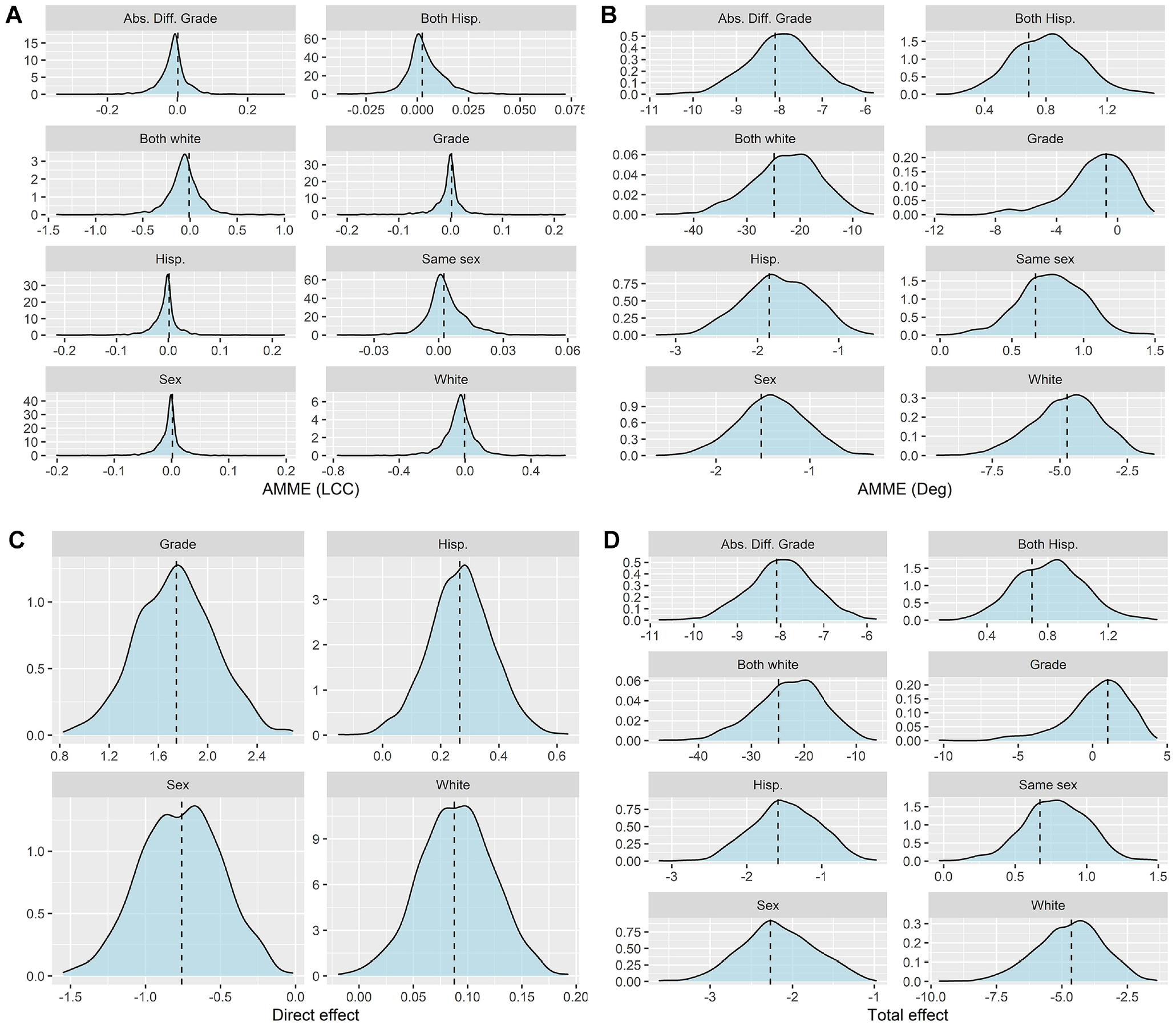
Nonparametric estimates of (A and B) average mediated micro effects (AMMEs) (N = 16,000), (C) direct effects (N = 4,000), and (D) total effects (N = 8,000).
In summary, I introduced a general approach for micro-macro mediation analysis in social network data. The approach can be used to identify, estimate, and interpret the indirect effects of network selection processes on higher-order outcomes acting through network contexts. I now illustrate the utility of the approach in an example analyzing the friendship selection dynamics that indirectly shape adolescent school performance.
Empirical Example: Friendship Selection And School Performance In Adolescent Social Networks
Data
Research on adolescence documents contextual effects of in-school friendship networks. Peer effects shape participation in risky behaviors, mental health, and academic achievement, and overall network cohesion and clustering safeguard against substance use and delinquency (Copeland et al. 2020; Duxbury and Haynie 2020; Haynie 2001; Haynie and Osgood 2006; Kreager et al. 2011; Schaefer et al. 2011). Building on these studies, I examine the network selection mechanisms that indirectly affect adolescent GPA by acting through network structure. The analysis examines in-school friendship data from the largest network collected during the first wave of the Add Health. The network contains 1,167 students enrolled in 7th to 12th grade and 2,293 directed, binary friendship ties.
I conduct a cross-sectional analysis that combines ERGM with a linear network autocorrelation model (LNAM). Networks are modeled as a function of students’ grade, sex, race, parental income, and parental education. 14 I include a mutuality term to account for reciprocity. Because Markov models are usually degenerate (Hunter et al. 2008), I include a geometrically weighted edgewise shared partnership (GWESP) term with a fixed decay parameter of 0.7. All node covariates are included as both sender and receiver effects. I also include a node match term for students’ race, parental education, and gender, and an attribute similarity (absolute difference) term for grade and parental income. 15 The LNAM is formulated at the student level. Student GPA is modeled as a function of race, sex, grade, parental education, and parental income. The mediators of interest are indegree (popularity), outdegree (sociability), betweenness centrality (breadth), and the local clustering coefficient (embeddedness). To capture peer effects, I include a first-order autoregressive parameter that measures similarity between students’ GPAs and alters’ GPAs. I use row normalization such that the measure is the mean GPA among students’ outgoing friendship ties (Leenders 2002). 16
Estimation and Assumptions
Our primary goal is to estimate the total, direct, and indirect effects of each ERGM parameter on student GPA. To do so, I use parametric estimation with 500 Monte Carlo samples for each network selection process. For each iteration, this entails (1) drawing two new parameter vectors on the basis of the ERGM and LNAM estimates; (2) using the simulated ERGM parameter vector to generate two networks, one from the full model and one with the selection mechanism fixed at zero; (3) using the two networks to calculate two unique values of the mediating variable and posttreatment confounders; (4) generating four values of student GPA using the simulated values of the mediating variable, posttreatment confounders, selection mechanisms, and LNAM parameter vector; and (5) calculating the AMME from the resulting output. This process repeats 500 times with each iteration using a new pair of parameter vectors to provide the AMME point estimate.
The plausibility of our estimates depends on the sequential ignorability assumption. The ERGM framework assumes endogeneity among network effects and thus accounts for reverse causality for indirect pathways implicating outdegree, indegree, betweenness centrality, and the local clustering coefficient. 17 However, indirect pathways implicating peer GPA may be violated by simultaneous processes of selection into socially similar peer groups and influence from those groups. We use an approach inspired by An (2015a) to increase the plausibility of sequential ignorability for pathways implicating peer GPA. This entails using peer parental education as an instrument for peer GPA in the LNAM. Because it is unlikely that GPA has an upstream effect on parental education or that students select friends on the basis of parental education, 18 this specification helps us break the feedback loop between GPA selection and influence. 19
Results
Tables 3 and 4 report results from ERGM, LNAM, and micro-macro network mediation analysis. ERGM results reveal positive effects from mutuality and GWESP, indicating that students are more likely to nominate other students as friends if it reciprocates an incoming friendship or if the two students share a third mutual affiliate (Table 3). Students are also more likely to form friendships if they are the same sex, same race, or in a similar grade. The only significant sociality effect is the receiver effect for parental income, indicating that parental income is positively associated with incoming friendship nominations. LNAM results reveal positive effects from indegree and peer GPA (Table 4). The negative coefficient for outdegree, however, indicates that students who nominate many other students as friends tend to have lower GPAs. The local clustering coefficient and betweenness centrality are both nonsignificant. The positive coefficient for sex indicates that girls tend to have higher GPAs than boys. Similarly, Asian students tend to have higher GPAs than black students, and white students tend to have lower GPAs than black students. Students whose parents completed college tend to have higher GPAs than students whose parents did not complete high school.
ERGM and Micro-Macro Network Mediation Results.
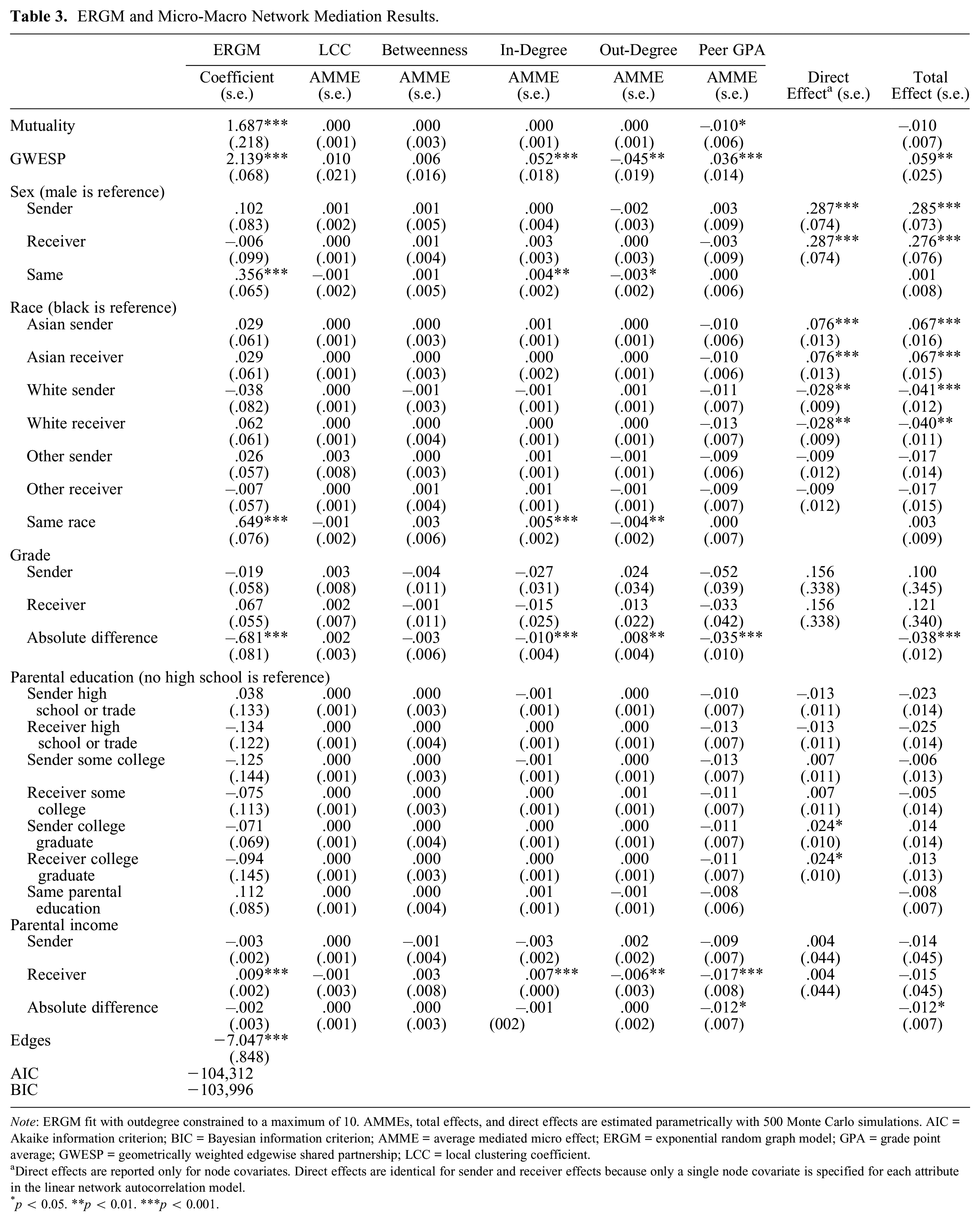
Note: ERGM fit with outdegree constrained to a maximum of 10. AMMEs, total effects, and direct effects are estimated parametrically with 500 Monte Carlo simulations. AIC = Akaike information criterion; BIC = Bayesian information criterion; AMME = average mediated micro effect; ERGM = exponential random graph model; GPA = grade point average; GWESP = geometrically weighted edgewise shared partnership; LCC = local clustering coefficient.
Direct effects are reported only for node covariates. Direct effects are identical for sender and receiver effects because only a single node covariate is specified for each attribute in the linear network autocorrelation model.
p < 0.05. **p < 0.01. ***p < 0.001.
Network Autocorrelation Model of Student GPA.
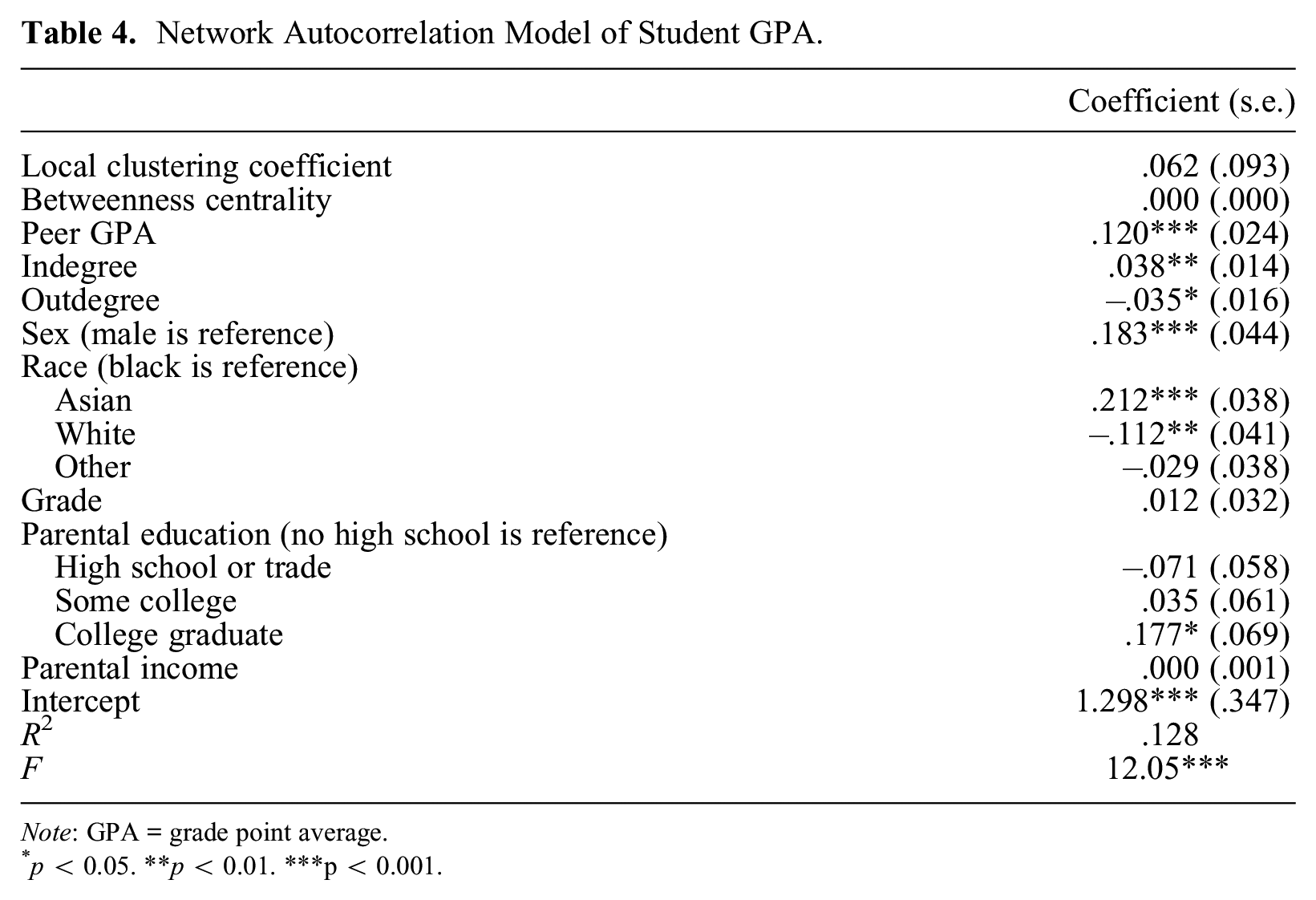
Note: GPA = grade point average.
p < 0.05. **p < 0.01. ***p < 0.001.
Table 3 shows direct, indirect, and total effects from micro-macro network mediation analysis. The direction and significance of all direct effects align with LNAM coefficients. The direct effect of sex is 0.287, meaning that female students’ mean GPA should decrease by 0.287 in the absence of the direct effect of sex. With a mean GPA of 2.63, this effect can account for 10.91 percent of the observed mean GPA. Similarly, the direct effects of Asian, white, and parental college education can explain 2.88 percent (0.076/2.63 = 0.029), −1.06 percent (0.028/2.63 = 0.011), and 0.91 percent (0.024/2.63 = 0.009) of the mean GPA, respectively.
Turning to indirect effects, the AMMEs are nonsignificant for all selection processes when operating through betweenness centrality or the local clustering coefficient. This reflects the nonsignificant effects of the local clustering coefficient and betweenness centrality in LNAM (Table 4). 20 The AMMEs for GWESP indicate that triadic closure has a positive indirect effect on student GPA by increasing students’ indegree (0.052) and peer GPA (0.036), but these positive effects are partly offset by increases in outdegree, which have a negative effect on student GPA (AMME = −0.045). The total effect captures the contributions of triadic closure to GPA operating through all indirect pathways. The total effect is 0.059 and can explain roughly 2.2 percent of the observed mean GPA (0.059/2.63 = 0.022). In other words, the GPA benefits of network selection through triadic closure in the observed network are comparable with the direct effect of being Asian compared with being black (0.059 vs. 0.067).
In contrast to GWESP, mutuality indirect effects are nonsignificant for both indegree and outdegree. The only significant mutuality indirect effect operates through peer GPA, where the AMME is −0.010. As a result, the total effect of mutuality is nonsignificant. Thus, although selection through triadic closure has positive indirect effects by increasing peer GPA, selection through reciprocity has a small negative indirect effect by decreasing peer GPA.
Formal analyses of the AMME also reveal how homophily can positively or negatively affect academic achievement. Race and sex homophily both have positive indirect effects on GPA by increasing indegree, but they have competing negative indirect effects through outdegree. Consequently, the total effects of both selection processes are nonsignificant. Grade similarity has a negative total effect on student GPA acting through all indirect pathways. Roughly 92.1 percent of the negative total effect is explained by relatively lower peer GPA among friendships between students in similar grade levels (−0.035/−0.038 = 0.921); the remaining portion of the total effect results from indirect effects of grade similarity operating through indegree and outdegree. Operating through all indirect pathways, the negative effect of network selection through grade similarity is comparable with the negative direct effect of being white compared with being black in the studied network (−0.038 vs. −0.041).
The indirect effects of parental income are also noteworthy. Although the parental income direct and total effects are nonsignificant, parental income has negative indirect receiver effects on student GPA by reducing peer GPA and outdegree. Although it is perhaps surprising for a receiver effect to shape outdegree, the relationship makes sense once we recognize it as network spillover. In the absence of a positive receiver effect, students less frequently nominate high parental income students as friends, decreasing the outdegree among students who would otherwise connect to high-income alters. Each of these indirect effects are partly offset by the positive receiver effect of parental income on indegree. Parental income similarity is also associated with decreases in GPA because of decreases in peer GPA. This likely reflects income segregation that concentrates relatively low academic achievement among low-income student peer groups.
In summary, micro-macro network mediation analyses reveal several interesting results about the selection processes that shape student GPA. Tendencies to form friends through triadic closure are associated with GPA increases because of increases in indegree and peer GPA that are partly offset by increases in outdegree. Weaker indirect effects were detected from mutuality and sex and race homophily operating through peer GPA, indegree, and outdegree. Parental income and grade similarity are both associated with indirect reductions in GPA because of decreases in peer GPA. Parental income also has significant indirect effects on student GPA by decreasing peer GPA that are partly offset by increases in indegree; most other node covariates only have direct effects on GPA but no indirect effect. Collectively, these results illustrate how the proposed approach can be used to evaluate how network selection processes indirectly shape student outcomes by altering social network structure.
Discussion
Social scientists are often interested in how networks act as an intervening mechanism in causal processes (e.g., Bearman et al. 2004; Chetty et al. 2022; DiMaggio and Garip 2012; Pedulla and Pager 2019), but researchers have been limited in their ability to statistically evaluate indirect network selection effects on individual, group, and organizational outcomes because of a lack of formal methods for micro-macro network mediation analysis. This study proposed a general methodological approach for evaluating indirect network selection effects with multiple conditionally independent posttreatment confounders. The AMME can be identified under sequential ignorability in a broad range of modeling frameworks. The approach thus provides a new tool for statistically evaluating indirect selection effects on outcome variables measured on the individuals, groups, and organizations nested in social networks.
The sequential ignorability assumption is crucial for mediation analysis. The stringency of this assumption, however, is pronounced in analyses of peer effects due to simultaneous selection and influence processes. Some modeling approaches are explicitly designed to grapple with this problem (Snijders et al. 2007; Steglich et al. 2010). However, researchers will likely have difficulty disentangling selection from influence in some empirical settings. One promising direction for future work is to develop sensitivity analyses for micro-macro network mediation. Although the sequential ignorability assumption is untestable, researchers can assess the sensitivity of indirect effect estimates to violations of sequential ignorability in some mediation frameworks (Cheng et al. 2018; Imai, Keele, and Tingley 2010; Zhou 2022). Extending sensitivity analysis to the micro-macro network mediation approach described here will help researchers evaluate how strong the violation of sequential ignorability would have to be to alter estimates of indirect network selection effects.
Another strategy to address sequential ignorability is randomization. Although I focused on observational research designs due to their common occurrence in sociology, a growing body of research conducts experiments that randomly assign actors to network locations (e.g., Melamed et al. 2018). In some instances, researchers randomize at the dyadic level, for example, by assigning nodes to either similar or dissimilar alters (Centola 2010). The proposed approach can be used in this type of experimental design. In such cases, sequential ignorability is partly supported by randomization and the researcher’s primary task is to ensure there is no omitted variable on the pathway from mediator to outcome.
Researchers have many options for disentangling the order of selection and influence mechanisms in observational research settings. One of the most powerful tools for parsing selection and influence dynamics is the SAOM (Steglich et al. 2010), which allows researchers to model the coevolution of network selection and influence processes in longitudinal network data. Outside the SAOM framework, researchers can use lagged predictor variables when modeling network selection to ensure selection dynamics are temporally prior to changes in network structure. An instrumental variable may also be available to break the feedback loop between selection and influence (e.g., An 2015a).
Researchers may be interested in estimating multiple indirect selection effects in a single analysis. In these cases, the risk for type 1 error rates increases. The nonparametric algorithm partly safeguards against type 1 error rates by resampling with replacement, but parametric estimates may be vulnerable. One possible solution is to use Bayesian estimation techniques to seed the parametric algorithm. This would involve estimating models in a Bayesian framework and then using random draws from the posterior distribution in each algorithmic call.
A promising direction for further work is to consider multiple causally connected posttreatment confounders. The approach introduced here assumes conditional independence among posttreatment pathways, but it may be possible for a posttreatment variable to intervene on the causal path from micro mechanism to outcome through a second posttreatment variable (Imai and Yamamoto 2013). Future work should examine under what conditions the micro-macro network approach can accommodate posttreatment causal relationships.
In summary, I introduced a general methodological approach for evaluating indirect network selection effects on higher-order outcomes in social network data. The AMME can be identified and estimated with common regression and network models. It is broadly relevant for researchers interested in assessing the network selection processes that contribute to individual, group, and organizational outcomes by altering network structure. The approach thus offers a new tool for researchers to examine the indirect network selection effects that are often theoretically implied but rarely empirically tested in social networks research.
Footnotes
Appendix: Derivation of AMME Identification
The derivation is an extension of theorem 1 in Imai, Keele, and Yamamoto (2010) and the derivation for multiple conditionally independent mediators provided by Imai and Yamamoto (2013). I show that the sequential ignorability results reported in prior studies apply even when examining different units of analysis. I consider the identification of
for all t, t
Using equations (15) and (16), we can write
Finally, equation (A8) implies
Substituting this expression into the definition of
Acknowledgements
I thank David Melamed, Ken Bollen, Per Block, Ken Frank, Santiago Olivella, Christian Steglich for helpful comments.